Künstliche Intelligenz
.NET 10 Release Candidate 1: Nachschlag für Entity Framework Core
Nach Microsofts Plan sollte .NET 10.0 zum Ende der Preview-Phase vor dem frisch erschienenen Release Candidate 1 eigentlich „Feature Complete“ sein und die beiden Release-Candidate-Versionen sollten nur der Qualitätsverbesserung dienen. Das trifft laut Ankündigung auf Laufzeitumgebung, SDK, Sprachcompiler (C#, F#, Visual Basic .NET) und WPF auch zu. Wie schon in der Vergangenheit gibt es aber auch Teile von .NET, die noch signifikante neue Funktionen in Release Candidate 1 nachliefern. Dieses Mal betrifft es insbesondere Entity Framework Core und ASP.NET Core sowie MAUI.
Erste Version von Visual Studio 2026
.NET 10.0 Release Candidate 1 steht auf der .NET-Downloadseite bereit. Wie bei früheren Versionen besitzt der Release Candidate 1 eine Go-Live-Lizenz: Entwicklerinnen und Entwickler können die Version produktiv einsetzen und erhalten offiziellen Support von Microsoft. Gleichwohl müssen sie noch mit Änderungen rechnen bis zum Erscheinungstermin, der für den 11. November 2025 angekündigt ist.

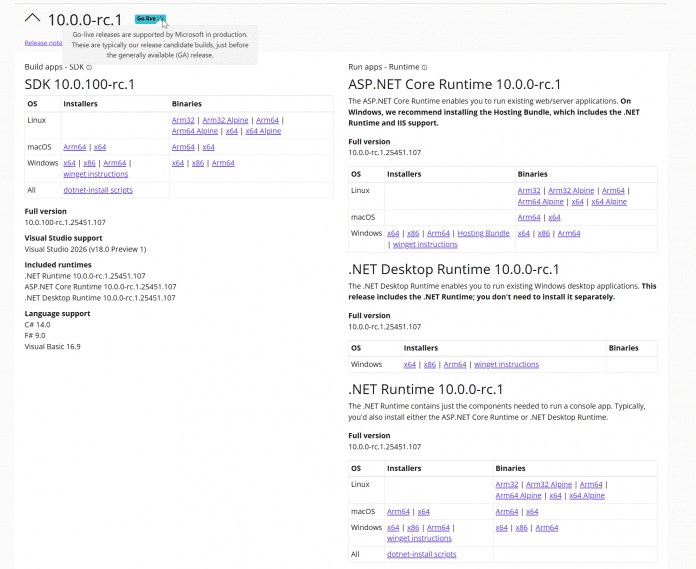
.NET 10.0 Release Candidate 1 hat das Go-Live-Label.
Von Visual Studio 2022 gab es parallel ein Bugfixing-Update von Version 17.14.13 auf 17.14.14. Das Kompilieren einer .NET 10.0-Anwendung gelingt aber nur, wenn man 17.14.14 Preview 1.0 oder die erste Vorschauversion von Visual Studio 2026 (alias „18.0.0 Insiders“) verwendet. Die 2026er Version bietet neben noch mehr KI-Integration auch ein neues Look and Feel im Fluent Design mit zahlreichen neuen Themes wie Icy Mint, Cool Breeze, Mango Paradise und Spicy Red.

Zwischen den Themes in Visual Studio 2026 kann man schnell im Menü Tools/Theme umschalten.
Zudem soll Visual Studio 2026 laut einem Blogbeitrag von Microsoft schneller sein. Bei der Installation fällt ein Detail positiv auf: Visual Studio 2026 fragt, ob man eine Konfiguration (Workloads, individuelle Komponenten, Erweiterungen und Einstellungen) aus einer auf dem Rechner vorhandenen Visual-Studio-2022-Installation oder einer .vsconfig-Datei übernehmen möchte (siehe die folgende Abbildung). Schon Visual Studio 2022 konnte bei der Installation .vsconfig-Dateien verwenden, aber nur beim Starten der IDE-Installation per Kommandozeile (Parameter --config).
Visual Studio 2026 bietet – im Gegensatz zu den beiden 2022er Versionen – auch die Installation des .NET-10.0-SDK als „Individual Component“ an. In den älteren Versionen muss man das .NET-SDK manuell von der Downloadseite installieren.

Visual Studio 2026 bietet bei der Installation die Übernahme bestehender Konfigurationen an.
Entity Framework Core nutzt den Spaltentyp JSON
Entity Framework Core unterstützt ab Release Candidate 1 die beiden neuen Spaltentypen JSON und VECTOR, die es in Microsoft SQL Server 2025 (derzeit in der Preview-Phase und der Cloudvariante SQL Azure gibt. JSON hat Entity Framework Core auch bisher schon verwendet, um beispielsweise eine Liste primitiver Datentypen wie List auf eine einzige Tabellenspalte abzubilden – außer bei PostgreSQL, das nativ solche Mengen beherrscht – oder beim Speichern sogenannter Owned Types. Bisher kam dazu aber in der Datenbanktabelle der Spaltentyp nvarchar(max) in Verbindung mit der SQL-Funktion OPENJSON() zum Einsatz.
Nun verwendet Entity Framework Core hier den neuen nativen Spaltentyp JSON, sofern eine SQL-Server-Version angesprochen wird, die ihn beherrscht. Zudem muss man Entity Framework Core mitteilen, dass das Zielsystem JSON-Spalten kennt. Das geschieht durch Aufruf von UseSqlAzure() statt UseSqlServer() beim Zugriff auf eine Cloud-Datenbank. Beim lokalen Microsoft SQL Server muss man den Kompatibilitätslevel auf 170 setzen:
builder.UseSqlServer(connstring, x => x.UseCompatibilityLevel(170));
Neu in Entity Framework Core 10.0 Release Candidate 1 ist, dass Complex Types auch ein JSON-Mapping anbieten. Complex Types hat Microsoft in Entity Framework Core 8.0 als bessere Alternative zu Owned Types eingeführt und in Version 9.0 erweitert, aber in Complex Types wurde bisher kein JSON-Mapping angeboten, sondern sie wurden auf Spalten in der zum übergeordneten Objekttyp gehörenden Tabelle abgebildet. Daher waren sie bisher nur für 1:1-Beziehungen, nicht aber für 1:N-Beziehungen möglich. Das ändert sich in Entity Framework Core-Version 10.0: Hier ist der Aufruf ToJson() bei komplexen Typen im 1:1- und 1:N-Mapping möglich:
modelBuilder.Entity(x =>
{
x.ComplexProperty(p => p.Address, p=>p.ToJson()); // 1:1-Mapping. NEU: p=>p.ToJson()
x.ComplexProperty(p => p.ManagementSet, p => p.ToJson()); // NEU: 1:N mit p=>p.ToJson()
}
Laut den Release Notes kommt es dabei in Release Candidate 1 aber noch zu Problemen und man soll mit dem Praxiseinsatz auf Release Candidate 2 warten. Im Schnelltest zeigte sich, dass beim JSON-Mapping der komplexen Typen unter anderem das Gruppieren mit GroupBy() und die komplette Aktualisierung des komplexen Typen mit ExecuteUpdate() in Release Candidate 1 zu Laufzeitfehlern führen.
Einsatz von Vektoren
Als zweiten neuen SQL Server-Datentyp können Entwicklerinnen und Entwickler ab Release Candidate 1 Microsoft.Data.SqlTypes.SqlVector aus dem NuGet-Paket „Microsoft.Data.SqlClient“ (ab Version 6.1) beim objektrelationalen Mapping mit Entity Framework Core 10.0 verwenden. Ebenso gibt es eine neue EF-Core-Methode EF.Functions.VectorDistance() für die SQL-Funktion VECTOR_DISTANCE(). Bisher existierte für beides ein eigenständiges NuGet-Paket EFCore.SqlServer.VectorSearch. Allerdings kann man in Entity Framework Core 10.0 in LINQ-Abfragen noch nicht die SQL Server-Funktion VECTOR_SEARCH() nutzen.
Die Dokumentation enthält ein Codebeispiel für Vektordaten:
public class Blog
{
// ...
[Column(TypeName = "vector(1536)")]
public SqlVector Embedding { get; set; }
}
…
IEmbeddingGenerator> embeddingGenerator = /* Set up your preferred embedding generator */;
var embedding = await embeddingGenerator.GenerateVectorAsync("Some text to be vectorized");
context.Blogs.Add(new Blog
{
Name = "Some blog",
Embedding = new SqlVector(embedding)
});
await context.SaveChangesAsync();
…
var sqlVector = new SqlVector(await embeddingGenerator.GenerateVectorAsync("Some user query to be vectorized"));
var topSimilarBlogs = context.Blogs
.OrderBy(b => EF.Functions.VectorDistance("cosine", b.Embedding, sqlVector))
.Take(3)
.ToListAsync();
Mehr Optionen für Parametermengen
Bei einem Thema probiert Entity Framework Core seit Jahren verschiedene Strategien: die Übergabe von Parametermengen von .NET an das Datenbankmanagementsystem, beispielsweise um passende Datensätze zu einer Liste von Orten zu suchen:
List destinations = new List { "Berlin", "New York", "Paris" };
var flights = ctx.Flights
.Where(f => destinations.Contains(f.Destination))
.Take(5).ToList();
Entity Framework Core-Versionen 1.0 bis 7.0 haben die Werte aus der Menge [code]destinations[/code] einzeln als statische Werte übergeben:
SELECT TOP(@p) [f].[FlightNo], [f].[Airline], [f].[Departure], [f].[Destination], [f].[FlightDate], [f].[FreeSeats], [f].[Memo], [f].[NonSmokingFlight], [f].[Pilot_PersonID], [f].[Seats], [f].[Timestamp]
FROM [Operation].[Flight] AS [f]
WHERE [f].[NonSmokingFlight] = CAST(1 AS bit) AND [f].[FlightDate] > GETDATE() AND [f].[FreeSeats] > CAST(0 AS smallint) AND [f].[Destination] IN (N'Berlin', N'New York', N'Paris')
Das sorgte jedoch im Datenbankmanagementsystem für viele verschiedene Ausführungspläne.
Seit Version 8.0 übergibt Entity Framework Core die Liste als ein JSON-Array, das im SQL-Befehl mit OPENJSON() aufgeteilt wird:
SELECT TOP(@p) [f].[FlightNo], [f].[Airline], [f].[Departure], [f].[Destination], [f].[FlightDate], [f].[FreeSeats], [f].[Memo], [f].[NonSmokingFlight], [f].[Pilot_PersonID], [f].[Seats], [f].[Timestamp]
FROM [Operation].[Flight] AS [f]
WHERE [f].[NonSmokingFlight] = CAST(1 AS bit) AND [f].[FlightDate] > GETDATE() AND [f].[FreeSeats] > CAST(0 AS smallint) AND [f].[Destination] IN (
SELECT [d].[value]
FROM OPENJSON(@destinations) WITH ([value] nvarchar(30) '$') AS [d]
)
Das erschwerte dem Datenbankmanagementsystem die Optimierung der Ausführungspläne, da es die Zahl der Parameter nicht mehr kannte.
Seit Version 9.0 ist es möglich, über die Funktion EF.Constant() oder den globalen Aufruf TranslateParameterizedCollectionsToConstants() in der Kontextklasse in OnConfiguring() zum alten Verhalten zurückzukehren:
var flights1 = ctx.Flights
.Where(f => EF.Constant(destinations).Contains(f.Destination))
.Take(5).ToList();
Beim geänderten Standard konnten Entwicklerinnen und Entwickler im Einzelfall mit EF.Parameter() anschließend das JSON-Array übergeben.
Nun in Entity Framework Core 10.0 hat Microsoft abermals einen neuen Standard implementiert, nämlich die einzelne Übergabe der Werte als eigene Parameter:
SELECT TOP(@p) [f].[FlightNo], [f].[Airline], [f].[Departure], [f].[Destination], [f].[FlightDate], [f].[FreeSeats], [f].[Memo], [f].[NonSmokingFlight], [f].[Pilot_PersonID], [f].[Seats], [f].[Timestamp]
FROM [Operation].[Flight] AS [f]
WHERE [f].[NonSmokingFlight] = CAST(1 AS bit) AND [f].[FlightDate] > GETDATE() AND [f].[FreeSeats] > CAST(0 AS smallint) AND [f].[Destination] IN (@destinations1, @destinations2, @destinations3)
Das geschieht im obigen Beispiel mit drei Werten. Entity Framework Core arbeitet aber auch noch bei 1000 Werten auf diese Weise, wie ein Schnelltest zeigte.
Man kann das alte Verhalten mit EF.Constant() und EF.Parameter() erzwingen, da die optimale Strategie auch davon abhängt, wie stark die Zahl der Werte zur Laufzeit variiert. Die globale Änderung des Standards erfolgt mit
UseParameterizedCollectionMode(ParameterTranslationMode.Constant). Erlaubt sind die Werte: Constant, Parameter und MultipleParameters. Die erst in Version 9.0 eingeführte Methode TranslateParameterizedCollectionsToConstants() existiert noch, aber sie ist als [Obsolete] markiert.
Verbesserungen bei ASP.NET Core
ASP.NET Core führt in Release Candidate 1 neue Metriken für ASP.NET Core Identity zum Überwachen der Benutzerverwaltung ein, beispielsweise aspnetcore.identity.user.create.duration, aspnetcore.identity.sign_in.sign_ins und aspnetcore.identity.sign_in.two_factor_clients_forgotten.
Der Persistent Component State in Blazor soll nun auch beim Einsatz der Enhanced Navigation beim statischen Server-Side-Rendering funktionieren
Um Instanzen von Klassen und Records in Blazor zu validieren, die Microsoft schon in der Preview-Phase von .NET 10.0 verbessert hatte, gibt es drei weitere Neuerungen:
- Validierungsannotationen können auch für Typen und nicht nur wie bisher für Properties definiert werden.
- Die neue Annotation
[SkipValidation]schließt Typen und Properties von der Validierung aus. - Ebenso werden alle mit
[JsonIgnore]annotierten Properties nicht mehr validiert.
Zudem gibt es nochmals einige kleinere Verbesserungen für die OpenAPI-Schema-Generierung, wie in den Release Notes beschrieben ist.
Kleine Verbesserungen bei MAUI
Auch bei .NET MAUI gibt es neue Metriken für die Überwachung der Layout-Performance:
layout.measure_count,layout.measure_duration,layout.arrange_countundlayout.arrange_duration.
Das Steuerelement WebViewInitializing() und WebViewInitialized(), um die Initialisierung anzupassen. Vergleichbare Ereignisse gab es zuvor im Steuerelement BlazorWebViewInitializing() und BlazorWebViewInitialized()). Das Steuerelement IsRefreshEnabled zusätzlich zu IsEnabled.
Dark Mode bei Windows Forms
Das Windows-Forms-Teams schreibt in den Release Notes, dass der in .NET 9.0 eingeführte Dark Mode nicht mehr als experimentell gekennzeichnet ist. Gleichzeitig heißt es dort aber auch, dass die Arbeit am Dark Mode weitergehen wird.

Die Galerie zeigt einige Windows-Forms-Steuerelemente im Dark Mode.
Ausblick auf die stabile Version
Vor der für November angekündigten Veröffentlichung von .NET 10.0 ist noch ein weiterer Release Candidate im Oktober geplant. Als Erscheinungstermin für die stabile Version hat Microsoft den 11. November 2025 verkündet. iX, dpunkt.verlag und www.IT-Visions.de präsentieren .NET 10.0 am 18. November im eintägigen Online-Event betterCode() .NET.
(rme)









Künstliche Intelligenz
Softwareentwicklung: Debugger? Nein, danke! | heise online
Ich benutze seit vielen Jahren keinen Debugger mehr. Stattdessen füge ich console.log oder fmt.Println an den Stellen in meinen Code ein, wo ich es für sinnvoll erachte. Dafür werde ich oft belächelt und gelegentlich kritisiert, weil das vermeintlich kein „richtiges“ Fehlersuchen wäre.
Weiterlesen nach der Anzeige

Golo Roden ist Gründer und CTO von the native web GmbH. Er beschäftigt sich mit der Konzeption und Entwicklung von Web- und Cloud-Anwendungen sowie -APIs, mit einem Schwerpunkt auf Event-getriebenen und Service-basierten verteilten Architekturen. Sein Leitsatz lautet, dass Softwareentwicklung kein Selbstzweck ist, sondern immer einer zugrundeliegenden Fachlichkeit folgen muss.
Ich habe jedoch meine Gründe, und die sind – aus meiner Sicht – durchaus gut. Am Ende des Tages bin nämlich oft ich derjenige, der gefragt oder gerufen wird, wenn anderen Entwicklern (trotz Debugger) die Ideen ausgehen. Und ich finde den Fehler dann in der Regel nach einer Weile. Nicht weil ich keinen Debugger benutze, sondern weil letztlich die Methodik entscheidet und nicht das Tool.
Fangen wir damit an, was mir vorgeworfen wird. Da heißt es oft:
„Ach, du benutzt console.log? Wie niedlich!“
Oder:
„Das ist doch kein richtiges Debugging!“
Oder:
Weiterlesen nach der Anzeige
„Den Typen sollte man niemals wichtigen Code schreiben lassen, das ist kein richtiger Entwickler, der benutzt ja noch nicht mal einen Debugger!“
Die implizite Annahme dahinter ist immer: Ein guter Entwickler muss einen Debugger beherrschen. Interessanterweise ist das allerdings stark von der Community abhängig, in der man sich bewegt. In der Go- und in der JavaScript-Community beispielsweise sind fmt.Println beziehungsweise console.log völlig normal und akzeptiert. Niemand guckt einen da schräg an. In der Java- oder C#-Welt hingegen wird der Einsatz eines Debuggers oft als Pflicht angesehen. Das zeigt bereits: Es gibt nicht die eine richtige Art zu debuggen. Das ist stark davon abhängig, in welchem Ökosystem man sich bewegt.
Set-up-Aufwand und fehlende Übung
Warum benutze ich nun keinen Debugger? Dafür habe ich vier konkrete Gründe. Erstens: Der Set-up-Aufwand. Einen Debugger zu starten, zu attachen und zu konfigurieren kann je nach Set-up des Projekts (auf das man eventuell gar keinen Einfluss hat) sehr aufwendig sein. Besonders in fremden Projekten, wo man nicht genau weiß, wie die Infrastruktur aufgebaut ist, verliert man unter Umständen sehr schnell viel Zeit. Zeit, die man eigentlich für etwas anderes bräuchte, nämlich um den Fehler zu finden. Stattdessen konfiguriert man zunächst eine halbe Stunde lang Tools und ärgert sich, dass es nicht so funktioniert, wie man sich das vorstellt.
Empfohlener redaktioneller Inhalt
Mit Ihrer Zustimmung wird hier ein externes YouTube-Video (Google Ireland Limited) geladen.
Debugger? Nein, Danke! // deutsch
Zweitens: Die fehlende Übung. Wenn man viele Tests schreibt – und das sollte man tun –, erübrigen sich die einfachen Fälle. Die landen gar nicht erst auf dem Tisch, weil die Tests sie bereits abfangen. Was übrig bleibt, sind die schwierigen Fälle. Die gibt es jedoch gar nicht so oft. Vielleicht alle paar Wochen einmal, vielleicht alle paar Monate. Deswegen fehlt dann die Übung mit dem Debugger. Man ist aus der Routine raus, und wenn man ihn dann braucht, steht man da und muss sich erst wieder zurechtfinden. Man weiß dann oft gar nicht mehr so richtig, wie das funktioniert, wo welche Buttons sind, und so weiter. Genau das verstärkt natürlich auch den ersten Punkt, weil man wieder von vorn anfängt, um herauszufinden, wie man ihn überhaupt startet und attached.
Timing-Verzerrung bei nebenläufigen Systemen
Drittens: Die Timing-Verzerrung. Das ist für mich ein wichtiger Punkt, der viel zu oft ignoriert wird. Ein Debugger und dort insbesondere der Einsatz von Breakpoints verzerren nämlich das Zeitverhalten der Anwendung dramatisch. Ich habe vor vielen Jahren einmal in einem Projekt mit hunderten parallel laufenden Threads gearbeitet. Da war es praktisch unmöglich, mit einem Debugger etwas ausfindig zu machen. Warum? Weil jeder Breakpoint zum einen das Zeitverhalten komplett verändert hat. Hielt man einen Thread an, liefen die anderen weiter, und auf einmal hatte man ein völlig anderes Timing, und dann war der Fehler unter Umständen plötzlich weg. Oder es tauchten neue Fehler auf. Zum anderen hatte man bei zwei Läufen sowieso nie denselben Stand, weil Threads nebenläufig sind und das Scheduling von ihnen nicht deterministisch ist. Das heißt, hier kam es sehr darauf an, nachvollziehen zu können, welcher Thread etwas macht, was dann bei einem anderen Thread etwas verursacht. Das geht nur, indem man Code liest, sich Dinge notiert und vor allem, indem man sehr viel über den Code nachdenkt. Ein Debugger hilft einem da tatsächlich überhaupt nicht weiter, im Gegenteil: Er macht die Sache eigentlich nur schlimmer.
Viertens – und das ist aus meiner Sicht der wichtigste Punkt überhaupt: Der Debugger nimmt einem nicht das Denken ab. Die eigentliche Arbeit ist nämlich vor allem das Nachvollziehen und Nachdenken darüber, wie es zu einer bestimmten Situation überhaupt gekommen ist. Das kann ein Debugger naturgemäß nicht. Er ist nur ein Werkzeug. Er zeigt, was passiert ist, aber nicht warum. Man sieht die Werte in den Variablen, man sieht, welche Funktionen gerade aufgerufen werden, aber man versteht nicht die Kausalkette, wie es überhaupt dazu gekommen ist. Genau dieses Warum ist die Arbeit, die man als Entwicklerin oder als Entwickler leisten muss. Und das ist leider das, was vielen häufig schwerfällt.
Systematisches Denken als Kernkompetenz
Genau das ist der springende Punkt: Was wirklich zählt, ist systematisches Denken. Die Kernkompetenz beim Debuggen ist nämlich nicht, einen Debugger bedienen zu können. Die Kernkompetenz ist, Fehler systematisch eingrenzen zu können. Durch logisches Schlussfolgern die Zahl der Optionen, die als Ursache infrage kommen, immer weiter zu reduzieren. Und genau das macht der Mensch, nicht das Tool. Der Debugger kann einem zeigen, wie der Stand der Dinge ist, aber er kann einem nicht sagen, was sein sollte und warum es anders ist als erwartet.
Ich möchte dazu ein konkretes Beispiel geben, das zeigt, was ich meine. Vor einer Weile hatten wir bei einem Kunden ein Problem mit asynchronem Rendering in einer React-App. Keiner von uns wusste, dass an besagter Stelle etwas Asynchrones passierte; es war uns einfach nicht bewusst. Nachdem dann zwei Entwickler daran schon mehrere Stunden gesucht hatten, haben sie mich gefragt, ob ich einmal mit nach dem Fehler schauen könne. Beide hatten mit dem Debugger gearbeitet, hatten sich die Komponenten-Hierarchie angeschaut, hatten sich die Props angeschaut, hatten alles Mögliche gemacht. Ich habe es durch das Verwenden von console.log, das Beobachten des Verhaltens, Lesen des Codes und Nachdenken geschafft, den Fehler nach und nach immer weiter einzugrenzen. Und nach einer knappen Stunde blieb nur noch eine Möglichkeit als Ursache übrig: Diese und jene Zeile musste anscheinend asynchron verarbeitet werden, es war die einzig mögliche Erklärung, wie es zu dem gezeigten Verhalten kommen konnte.
Dann haben wir in die Dokumentation von React geschaut, und genau so war es dann auch. Natürlich hätte man das auch am Anfang nachschauen können, nur kam niemand auf die Idee, ausgerechnet an dieser Stelle zu suchen. Die Lektion dabei ist: Der Debugger hat das Problem offensichtlich nicht gelöst. Sondern: Das systematische Eingrenzen hat es am Ende gebracht. Eben die Frage:
„Wo könnte das Problem liegen?“
und dann Schritt für Schritt, nach und nach, alle Möglichkeiten bis auf eine ausschließen.
Warum console.log funktioniert: Observability-Mindset
Wenn wir damit jetzt zu der Erkenntnis gekommen sind, dass systematisches Denken wichtiger ist als das Tool, stellt sich natürlich die Frage: Was ist dann an console.log oder fmt.Println eigentlich vermeintlich so falsch? Oder andersherum gefragt: Warum funktioniert das so gut? Dafür gibt es tatsächlich drei ausgezeichnete Gründe.
Erstens: das Observability-Mindset. Im Grunde macht man nämlich Observability im Kleinen. In Production hat man oft auch keinen Debugger – nur Logging, Tracing, Metrics. Wer gewohnt ist, durch gezieltes Logging zu debuggen, denkt automatisch in die Richtung:
„Was muss ich wissen, um das System zu verstehen?“
Man überlegt sich: An welcher Stelle brauche ich welche Informationen? Was ist relevant? Was hilft mir weiter? Das ist eine wertvolle Fähigkeit, gerade für moderne verteilte Systeme, bei denen man nicht mehr mit einem Debugger arbeiten kann, weil die einzelnen Services auf verschiedenen Maschinen laufen.
Reproduzierbarkeit und bewusstes Denken
Zweitens: Reproduzierbarkeit und Dokumentation. Mit Logs hat man eine dauerhafte Spur. Man kann den Code laufen lassen, die Ausgabe analysieren, den Code erneut laufen lassen, die Ausgaben vergleichen. Man sieht:
„Ah, beim ersten Mal war der Wert hier 42, beim zweiten Mal ist er aber 43, da muss irgendwo ein Zähler sein, der nicht zurückgesetzt wird.“
Mit einem Debugger ist das oft sehr viel flüchtiger. Man klickt sich durch, sieht etwas, aber hat es nicht festgehalten. Beim nächsten Durchlauf muss man sich dann wieder durchklicken, und wenn man nicht aufgepasst hat, weiß man gar nicht mehr so genau, was man beim letzten Mal eigentlich gesehen hat.
Drittens: Bewusstes Denken wird erzwungen. Man muss sich überlegen: Was will ich eigentlich wissen? Wo könnte das Problem liegen? Welche Variablen sind relevant? An welcher Stelle im Code muss ich schauen? All das fördert systematisches Denken. Gerade für weniger erfahrene Entwicklerinnen und Entwickler kann ein Debugger dann nämlich schnell ein schlechtes Hilfsmittel werden: Sie setzen dann einen Breakpoint, schauen sich Variablen an, klicken sich durch den Call-Stack, verstehen aber nicht den größeren Zusammenhang. Sie sehen zwar Daten, aber sie verstehen nicht, was sie bedeuten. Durch bewusstes Logging muss man sich diese Fragen aber stellen. Man muss sich überlegen, was relevant ist. Das ist eine wertvolle Übung.
Die Praxis bestätigt die Methodik
Jetzt kommt eine Beobachtung aus der Praxis, die das Ganze noch unterstreicht: Ich bin, wie eingangs bereits erwähnt, in Kundenprojekten oft derjenige, der gefragt wird, wenn anderen die Ideen ausgehen. Die Leute kommen zu mir und sagen:
„Golo, wir suchen jetzt seit Tagen nach der Ursache für diesen Bug, wir finden ihn einfach nicht, kannst du mal draufschauen?“
Trotz Debugger finden sie den Fehler nicht. Ich finde ihn dann über kurz oder lang – ohne Debugger. Warum? Weil die Methodik entscheidet, nicht das Tool. Genau das können leider viel zu viele Entwicklerinnen und Entwickler nicht allzu gut: systematisch eingrenzen und logisch schlussfolgern. Die verlassen sich darauf, dass der Debugger ihnen die Antwort quasi auf dem Silbertablett präsentieren wird. So funktioniert das jedoch nicht. Der Debugger ist nur ein Werkzeug, das einem Daten zeigt. Die Interpretation dessen, also das Verstehen, das logische Schlussfolgern, das muss man selbst machen.
Ich will es aber auch nicht so darstellen, als wären Debugger per se schlecht oder als ob man sie nie benutzen sollte. Das wäre unseriös, und das wäre auch falsch. Es gibt durchaus Situationen, in denen ein Debugger legitim und sinnvoll ist. Zum Beispiel beim Verstehen von fremdem Code, den man noch gar nicht kennt. Man steigt in ein neues Projekt ein, und da kann ein Debugger natürlich helfen, schnell einen Überblick zu bekommen, im Sinne von:
„Ah, diese Funktion ruft jene auf, die ruft wiederum diese andere auf.“
Oder bei sehr komplexen Objektgraphen, die man visualisieren möchte. Wenn man eine verschachtelte Datenstruktur hat, die man sich in einer schönen Baumansicht anschauen will, ist ein Debugger praktisch. Aber auch hier gilt: Der Debugger ersetzt nicht das Denken. Er ist ein Hilfsmittel, mehr nicht. Es geht mir also, um das noch einmal zu betonen, nicht darum, Debugger an sich zu verteufeln. Sondern es geht mir darum, zu sagen: Bloß weil jemand keinen Debugger verwendet, macht das sie oder ihn nicht zu einem schlechten Developer. Unter Umständen bewirkt es das genaue Gegenteil.
Die Methodik macht den Unterschied
Das heißt: Nicht das Tool macht gute Developer aus, sondern die Methodik macht es. Systematisches Eingrenzen, logisches Denken, die Fähigkeit, eine Kausalkette nachzuvollziehen – das sind die Fähigkeiten, die zählen. Nur weil jemand keinen Debugger benutzt, ist sie oder er nicht schlecht oder falsch aufgehoben in der Entwicklung. Im Gegenteil: Wer ohne Debugger auskommt, hat oft die bessere Methodik, weil sie oder er sich nicht auf ein Tool verlässt, sondern auf das eigene Denken.
Mein Rat daher: Probieren Sie es einmal aus. Versuchen Sie beim nächsten Problem einmal, bewusst ohne Debugger auszukommen. Setzen Sie bewusst console.log oder fmt.Println ein, grenzen Sie systematisch ein und denken Sie nach. Stellen Sie sich die Frage: Was könnte die Ursache sein? Wie kann ich das überprüfen? Was schließe ich damit aus? Das wird vermutlich anstrengend, weil man es vielleicht nicht so geübt ist, so zu arbeiten. Je öfter man das macht, desto überraschter wird man aber sein, wie gut das funktioniert. Und irgendwann wird man merken, dass man auf einmal viel bewusster über seinen Code nachdenkt.
(rme)
Künstliche Intelligenz
Marktübersicht: Ethernet-Switches mit Ports für 2,5 und 5 GBit/s
Ethernet-Standards sind unerbittlich: 100 Meter und nicht mehr darf die maximale Länge eines Segments betragen. Möchte man von Gigabit-Ethernet auf 10GE wechseln, sind diese 100 Meter allerdings Wunschdenken – die oft noch übliche Verkabelung von 5e und 6 gibt die Länge nämlich kaum her. Während Switches aber etwa alle fünf Jahre ausgetauscht werden, ist die Verkabelung auf 10 bis 15 Jahre ausgelegt. Weil sie oft schon beim Bau der Gebäude verlegt wird, sind die technischen Eigenschaften damit im wahrsten Sinne des Wortes zementiert.
Deshalb sind Techniken gefragt, die vorhandene passive Infrastrukturen bestmöglich ausnutzen. Sofern es sich nicht um Neubauten der letzten fünf Jahre handelt, bestehen sie zu 90 Prozent aus Twisted-Pair-Kabeln der Kategorien 5e und 6 (Cat5e und Cat6), die für Gigabit-Ethernet ausgelegt sind.
- NBASE-T-Switches stellen Ethernet-Ports mit Übertragungsraten von 2,5 und 5 GBit/s bereit. Am häufigsten werden Access-Points angeschlossen, immer öfter aber auch NAS und Videoendpunkte.
- Die meisten Switches unterstützen 24 oder 48 Ports auf einer Höheneinheit im 19-Zoll-Rack oder in einem modularen Chassis. Nahezu immer lassen sich die kompakten Chassis zu einem Stack verbinden. Unterschiede gibt es bei den Uplink-Ports.
- Der nach langer Entwicklungszeit verabschiedete PoE-Standard 802.3bt (Power over Ethernet) definiert 90 bis 100 Watt pro Port, womit sich WiFi-7-Access-Points, Kameras und auch kleine Industrie-PCs mit Strom versorgen lassen.
- Die größten Unterschiede gibt es bei den Deployment- und Managementtools: Trotz klarem Trend in die Cloud stellen die meisten Hersteller auch Tools für den lokalen Betrieb bereit. Bereits eingesetzte Managementwerkzeuge bilden daher eines der wichtigsten Entscheidungskriterien für neue Switches.
Wie also eine neue Generation von Switches einführen, ohne die Verkabelung zu erneuern? Der Gedanke liegt nahe, Zwischenschritte bei der Übertragungsrate einzuführen, statt einen Sprung um den Faktor 10 zu wagen. Das funktioniert je nach deren Qualität mit den bereits verlegten Kupferkabeln. Da die Entfernung vom Endgerät zum Switch selten 100 Meter beträgt, sind höhere Übertragungsraten vor allem dann möglich, wenn die Entfernung sinkt.
Das war die Leseprobe unseres heise-Plus-Artikels „Marktübersicht: Ethernet-Switches mit Ports für 2,5 und 5 GBit/s“.
Mit einem heise-Plus-Abo können Sie den ganzen Artikel lesen.
Künstliche Intelligenz
Mercedes-Benz: Gewinn sackt um rund 50 Prozent ab
Der Gewinn von Mercedes-Benz ist in den ersten neun Monaten um die Hälfte zurückgegangen. Das Konzernergebnis sackte im Vergleich zum Vorjahreszeitraum um 50,3 Prozent von 7,80 Milliarden Euro auf 3,87 Milliarden Euro ab, wie der Konzern mitteilte. Als Gründe dafür wurden unter anderem Zölle, geringere Absatzzahlen und Aufwendungen für Effizienzmaßnahmen angegeben.
Weiterlesen nach der Anzeige
Einklang mit der Prognose
Vorstandschef Ola Källenius sagte, die Quartalsergebnisse stünden im Einklang mit der Prognose für das Gesamtjahr. Das Konzernergebnis gab im dritten Quartal im Vergleich zum Vorjahreszeitraum um fast 31 Prozent von 1,71 Milliarden Euro auf 1,19 Milliarden Euro nach. Der Umsatz sank um 6,9 Prozent auf 32,14 Milliarden Euro.
Um die Profitabilität wieder zu steigern, hatte der Vorstand im Februar ein Sparprogramm angekündigt: Die Produktionskosten sollen bis 2027 um zehn Prozent sinken, ebenso die Fixkosten. Auch die Materialkosten sollen gesenkt werden. Mit dem Gesamtbetriebsrat vereinbarte Mercedes ein Paket mit Abfindungsprogramm für Beschäftigte in indirekten Bereichen. Laut dem Management hat das Sparprogramm einen Umfang von rund 5 Milliarden Euro im Vergleich zu früheren internen Planungen.
Entlassungen in Deutschland
Das bereinigte Ergebnis vor Zinsen und Steuern (Ebit) des Konzerns betrug im dritten Quartal 2 Milliarden Euro nach 2,5 Milliarden Euro im Vorjahreszeitraum. Das Konzern-Ebit sei um Sondereffekte in Höhe von insgesamt 1,34 Milliarden Euro bereinigt worden, teilte der Hersteller weiter mit. 876 Millionen Euro davon entfalle auf den Personalabbau in Deutschland sowie auf Sparbemühungen im Ausland. Wie viele Menschen in Deutschland das Unternehmen verließen, wurde nicht mitgeteilt.
Schwache Geschäfte in China und den USA hatten Mercedes-Benz erneut ein Absatzminus eingebracht. Von Juli bis September wurden 525.300 Pkw und Vans abgesetzt. Das sind zwölf Prozent weniger als im Vorjahreszeitraum. In den ersten neun Monaten des Jahres steht bei Mercedes für Pkw und Vans nun insgesamt ein Minus von neun Prozent auf rund 1,6 Millionen Fahrzeuge in den Büchern. Bereits 2024 war der Absatz der Schwaben angesichts der Krise in der Autoindustrie um vier Prozent auf knapp 2,4 Millionen gesunken.
Weiterlesen nach der Anzeige
Mehr zur Marke Mercedes-Benz
(mfz)
 auch in Weiß erhältlich")
Acer: Radeon RX 9060 XT und RX 9070 (XT) auch in Weiß erhältlich

Softwareentwicklung: Debugger? Nein, danke! | heise online

Sächsisches Polizeigesetz: Polizeiwunschliste auf Mehrheitssuche

Der ultimative Guide für eine unvergessliche Customer Experience

Adobe Firefly Boards › PAGE online
eine gute Nachricht ist")
Relatable, relevant, viral? Wer heute auf Social Media zum Vorbild wird – und warum das für Marken (k)eine gute Nachricht ist
-
 UX/UI & Webdesignvor 2 Monaten
UX/UI & Webdesignvor 2 MonatenDer ultimative Guide für eine unvergessliche Customer Experience
-
 UX/UI & Webdesignvor 2 Monaten
UX/UI & Webdesignvor 2 MonatenAdobe Firefly Boards › PAGE online
-
eine gute Nachricht ist") Social Mediavor 2 Monaten
Social Mediavor 2 MonatenRelatable, relevant, viral? Wer heute auf Social Media zum Vorbild wird – und warum das für Marken (k)eine gute Nachricht ist
-

 UX/UI & Webdesignvor 2 Wochen
UX/UI & Webdesignvor 2 WochenIllustrierte Reise nach New York City › PAGE online
-

 Entwicklung & Codevor 2 Monaten
Entwicklung & Codevor 2 MonatenPosit stellt Positron vor: Neue IDE für Data Science mit Python und R
-

 Entwicklung & Codevor 2 Monaten
Entwicklung & Codevor 2 MonatenEventSourcingDB 1.1 bietet flexiblere Konsistenzsteuerung und signierte Events
-

 UX/UI & Webdesignvor 1 Monat
UX/UI & Webdesignvor 1 MonatFake It Untlil You Make It? Trifft diese Kampagne den Nerv der Zeit? › PAGE online
-

 Apps & Mobile Entwicklungvor 2 Monaten
Apps & Mobile Entwicklungvor 2 MonatenGalaxy Tab S10 Lite: Günstiger Einstieg in Samsungs Premium-Tablets