Entwicklung & Code
Was Whatsapp und Signal verraten, trotz Verschlüsselung
Signal und Whatsapp verschlüsseln Nachrichten Ende-zu-Ende, was bedeutet, dass sie auf der gesamten Reise von Sender zu Empfänger verschlüsselt bleiben. Das gilt für die Inhalte. Doch andere Informationen lassen sich mit etwas Aufwand durchaus ernten; auf der IT-Sicherheitsmesse DEFCON 2025 haben am Sonntag (Ortszeit) die österreichischen Sicherheitsforscher Gabriel Gegenhuber und Maximilian Günther ihre Sidechannel- und Protokoll-Angriffe vorgestellt.
Wie sich zeigt, verraten Zustellbestätigungen Signals und Whatsapps einiges über die eingesetzten Endgeräte und deren Zustand. Zustellbestätigungen sind nicht zu verwechseln mit Lesebestätigungen, die jeder Nutzer in den Einstellungen seiner App abschalten kann. Die Zustellbestätigungen sind unabdingbar für den Dienst, damit dieser sich nicht endlos müht, bereits zugestellte Nachrichten zuzustellen.

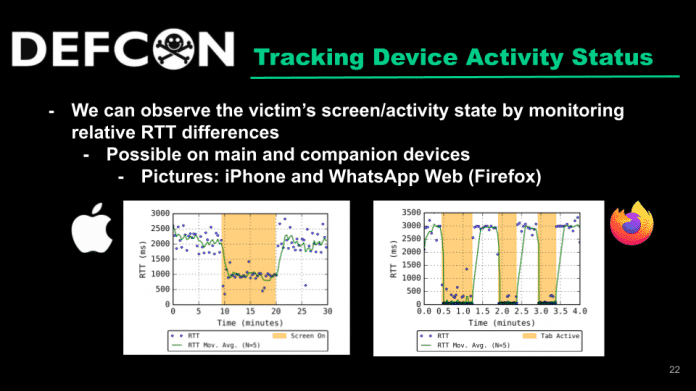
Vortragsfolie
(Bild: Universität Wien/SBA Research)
Allein schon die Laufzeit (Round-trip Time, RTT) der Zustellbestätigung lässt mehr Rückschlüsse zu, als der Laie annehmen würde. Dauert es sehr lange, ist das Gerät offline. Doch schon Schwankungen im Sekundenbereich verraten den Zustand des Empfangsgerätes: Am schnellsten geht es, wenn die App gerade im Vordergrund ist, also wahrscheinlich benutzt wird. Langsamer geht es, wenn sie nicht im Vordergrund ist, und noch langsamer, wenn der Bildschirm aus oder der Browsertab inaktiv ist.
Diese Streuung ist noch dazu je nach Endgerätemodell, Verbindungsmethode (LAN, WLAN oder Mobilfunk) und Zustand (wird mit dem Handy gerade telefoniert oder nicht) unterschiedlich. Dem nicht genug: Die Übermittlung der Bestätigungen ist für unterschiedliche Geräteklassen unterschiedlich implementiert. So werden die Zustellbestätigungen für Whatsapp und Signal von Smartphone-Apps (Android, iOS) einzeln übermittelt, bei den Desktop-Varianten der Dienste allerdings in Gruppen – und bei Whatsapp für MacOS in gestürzter Reihenfolge.
Rückschlüsse auf Aufenthaltsort
Angreifer können sich durch Daten aus Testserien mit eigenen Geräten Datenbanken anlegen, um später von Angriffszielen gewonnene Daten abgleichen zu können. Damit ließe sich auf einen Blick sagen, was für Geräte unter einem Whatsapp- oder Signal-Konto genutzt werden und in welchem Zustand sie sich wahrscheinlich gerade befinden. Das lässt weitere Rückschlüsse zu: Ist beispielsweise ein bestimmtes Desktopgerät oder eine bestimmte Browserinstanz regelmäßig zu Bürozeiten online, kann bei eintreffenden Zustellbestätigungen unter Umständen auf den Aufenthaltsort des Zieles geschlossen werden. Umgekehrt lassen Zustellbestätigungen von einem meist nur Abends oder am Wochenende genutzten Desktoprechner auf den Aufenthalt zu Hause schließen.
Die Anzahl der unter einem Konto registrierten Geräte ist sogar noch einfacher festzustellen: Die Schlüsselserver von Whatsapp und Signal vergeben fortlaufende Nummern, wobei 0 respektive 1 das „Hauptgerät“ anzeigt. Höhere Nummern sind zusätzliche Geräte, sodass der Angreifer auch danach unterscheiden kann.
Heimliche Nachrichtenflut
Für den Erkenntnisgewinn sind allerdings Serien von Zustellbestätigungen erforderlich. Eine einzelne Messung sagt höchstens aus, ob das Gerät online ist. Würde es dem Opfer nicht auffallen, von einer Lawine an Nachrichten eingedeckt zu werden? Nein, denn es ist möglich, speziell strukturierte Nachrichten an Teilnehmer von Whatsapp und Signal zu schicken, die zwar Zustellbestätigungen auslösen, am Endgerät aber nicht angezeigt werden. Dafür haben die Forscher alternative Implementierungen der Anwendungen genutzt.
Also kann ein Angreifer eine lange Serie stiller „Pings“ an ein Ziel schicken, von dem er lediglich die Telefonnummer oder den Nutzernamen kennt, ohne dass es auffällt. Die Signal-Infrastruktur hat immerhin eine Begrenzung auf eine Nachricht alle zwei Sekunden eingebaut, bei Whatsapp konnten die Österreicher gar kein Rate Limiting ausmachen. Die Observation ist damit engmaschig über lange Zeiträume hinweg möglich.
Somit kann aus der Ferne eruiert werden, auf wie vielen Endgeräte ein Opfer sein Whatsapp- oder Signal-Konto nutzt, mit welchen Arten von Geräten und Betriebssystemen, zu welchen Uhrzeiten, und in welchem Betriebszustand diese gerade sind, samt Übertragungsmethode und vielleicht Aufenthaltsort. Das ermöglicht digitales Stalking ebenso wie die Auswahl von Malware für einen gezielten Angriff über einen anderen Kanal; zudem können die Informationen dabei helfen, einen körperlichen Überfall genau dann durchzuführen, wenn das Zielgerät entsperrt ist, was insbesondere Sicherheitsbehörden und Geheimdiensten hilft.












Entwicklung & Code
CNCF standardisiert KI-Infrastruktur mit neuem Kubernetes-Programm
Für viele Unternehmen lautet die zentrale Frage nicht mehr, ob sie künstliche Intelligenz einsetzen, sondern wie sie diese verantwortungsvoll und nachhaltig integrieren. Bislang bremsen fragmentierte, nicht standardisierte Insellösungen und meist teure proprietäre KI-Stacks die Einführung noch. Besonders für Organisationen, die auf Datensouveränität, Compliance und langfristige finanzielle Stabilität setzen, stellt die unkoordinierte KI-Infrastruktur ein erhebliches Risiko dar – in Hybrid-Cloud-Umgebungen ebenso wie On-Premises.
Weiterlesen nach der Anzeige
Mit der im Rahmen der KubeCon + CloudNativeCon North America 2025 offiziell freigegebenen Version 1.0 des „Kubernetes AI Conformance“-Programms will die Cloud Native Computing Foundation (CNCF) nun Ordnung in die zersplitterte KI-Landschaft bringen. Das Programm geht dabei über eine Zertifizierung hinaus – es ist als eine weltweit getragene Open-Source-Initiative angelegt, die einen gemeinsamen technischen Standard für KI-Infrastrukturen schaffen soll. „Insbesondere für europäische Unternehmen liefert sie den Rahmen, um KI sicher und skalierbar einzusetzen“, erklärt Mario Fahlandt, der bei der CNCF unter anderem als Co-Chair der Technical Advisory Group (TAG) Operational Resilience sowie der Special Interest Group (SIG) Contributor Experience für Kubernetes aktiv ist. „Die Initiative definiert eine klare, zukunftssichere Roadmap, die Workload‑Portabilität, technische Konsistenz und digitale Souveränität gewährleistet.“
Technische Standards versus Prozess‑Frameworks
Während der KI-Markt durch eine Vielzahl an Zertifizierungen geprägt ist, müssen Entscheidungsträger klar zwischen technischen und organisatorischen Standards unterscheiden. Einige Anbieter konzentrieren sich auf Management- und Governance-Frameworks wie ISO 42001. Dieser internationale Standard legt Anforderungen für den Aufbau eines KI-Managementsystems (AIMS) fest. Er unterstützt Unternehmen dabei, Risiken, ethische Fragen, Datenschutz und regulatorische Vorgaben zu steuern. Außerdem bewertet er, ob interne Prozesse eine verantwortungsvolle Entwicklung und Bereitstellung von KI sicherstellen.
Das neue CNCF‑Programm „Kubernetes AI Conformance“ hebt sich grundlegend von Governance-Standards ab. Es fungiert primär als technischer Implementierungsstandard und legt dazu fest, welche Fähigkeiten, APIs und Konfigurationen ein Kubernetes-Cluster benötigt, um KI‑ und ML‑Workloads zuverlässig und effizient auszuführen. Damit zielt die CNCF-Konformität auf eine garantierte technische Portabilität ab, die auch zu weniger Abhängigkeit von einzelnen Herstellern beiträgt. Sie stellt sicher, dass Unternehmen ihre KI-Anwendungen künftig auf jeder konformen Plattform betreiben können – in der Public Cloud, im eigenen Rechenzentrum oder an Edge-Standorten. Diese Portabilität bildet die Grundlage digitaler und damit auch datengetriebener Souveränität.
Die Entwicklung des Standards treibt innerhalb des Kubernetes-Projekts eine neu gebildete Arbeitsgruppe voran, die durch die Special Interest Groups Architecture und Testing unterstützt wird. Seit der KubeCon Europe im Frühjahr 2025 hat die Gruppe zunächst zentrale technische Säulen definiert, die die besonderen Anforderungen von KI‑Workloads berücksichtigen. „Darauf aufbauend entstand ein verbindlicher Anforderungskatalog, den jede Plattform erfüllen muss, um als Kubernetes-AI-konform zu gelten“, erläutert Fahlandt.
Weiterlesen nach der Anzeige
Effizientes Management von Beschleunigern im KI-Training
KI‑Trainingsjobs setzen umfassende Hardware‑Ressourcen voraus und benötigen meist teure, häufig zudem knapp verfügbare GPUs. In nicht standardisierten Umgebungen ergeben sich daraus zwei Kernprobleme:
- Ressourcenfragmentierung: Wertvoller GPU‑Speicher bleibt ungenutzt.
- Topologie‑Blindheit: Das Scheduling ist nicht für Multi‑GPU‑Workloads optimiert.
Beide Aspekte tragen zur Überprovisionierung und steigenden Kosten bei.
Eine CNCF‑konforme Plattform muss daher die Kubernetes-API für Dynamic Resource Allocation (DRA) unterstützen. Seit Kubernetes-Version 1.34 gilt DRA als stabil und ermöglicht es, komplexe Hardware-Ressourcen flexibel anzufordern und zu teilen. Ähnlich dem PersistentVolumeClaim‑Modell für Speicher können Nutzerinnen und Nutzer gezielt Ressourcen aus definierten Geräteklassen anfordern. Kubernetes übernimmt dabei automatisch das Scheduling und die Platzierung aller Workloads.
Erweiterte Ingress‑Funktionen für KI-Inferenz
KI‑Inferenz‑Workloads – also KI-Modelle im Betrieb – unterscheiden sich stark von typischen, zustandslosen Webanwendungen. Sie laufen meist länger, beanspruchen viele Ressourcen und speichern Zustände. Standard‑Load‑Balancer sind für deren Lastverteilung ungeeignet. Das CNCF‑Konformitätsprogramm verlangt daher die Unterstützung der Kubernetes Gateway API und ihrer Erweiterungen für modellbewusstes Routing (model‑aware routing).
Die Gateway API Inference Extension, ein offizielles Kubernetes‑Projekt, erweitert Standard-Gateways zu spezialisierten Inference‑Gateways. Damit lassen sich Routing und Load Balancing gezielt für KI‑Workloads optimieren. Unterstützte Funktionen sind unter anderem gewichtete Verkehrsaufteilung (weighted traffic splitting) und Header‑basiertes Routing, das etwa für OpenAI-Protokoll‐Header relevant ist.
Zeitplanung und Orchestrierung von KI‑Workloads
Verteilte KI-Trainingsjobs bestehen aus mehreren Komponenten, die gleichzeitig starten müssen. Plant der Scheduler Pods einzeln ein, kann es zu Deadlocks kommen: Ein Job bleibt hängen, weil einige Pods keine Ressourcen finden, andere aber bereits Ressourcen blockieren. Eine Kubernetes-Plattform muss mindestens eine All‑or‑Nothing‑Scheduling‑Lösung unterstützen, beispielsweise Kueue oder Volcano. So starten verteilte KI‑Workloads nur, wenn alle zugehörigen Pods gleichzeitig platziert werden können.
Ist ein Cluster‑Autoscaler aktiv, soll er Knotengruppen mit bestimmten Beschleunigertypen je nach Bedarf automatisch vergrößern oder verkleinern. Ebenso muss der HorizontalPodAutoscaler Beschleuniger‑Pods korrekt skalieren und dabei auch benutzerdefinierte Metriken berücksichtigen, die für KI‑ und ML‑Workloads relevant sind.
Überwachung und Metriken
Moderne KI‑Workloads und spezialisierte Hardware erzeugen neue Lücken im Monitoring. Noch fehlt ein einheitlicher Standard, um Beschleuniger-Metriken zu erfassen – viele Teams verfügen daher nicht über geeignete Werkzeuge, um Infrastrukturprobleme schnell zu analysieren.
Jede CNCF‑konforme Plattform muss daher künftig eine Anwendung installieren können, die Leistungsmetriken für alle unterstützten Beschleunigertypen – etwa Auslastung oder Speichernutzung – über einen standardisierten Endpunkt verfügbar macht. Zusätzlich ist ein Überwachungssystem erforderlich, das Metriken automatisch erfasst und verarbeitet, wenn Workloads sie im Standardformat (z. B. Prometheus‑Expositionsformat) bereitstellen.
Sicherheit und Ressourcentrennung
Beschleuniger wie GPUs sind gemeinsam genutzte Ressourcen. Fehlt eine strikte Isolierung auf Kernel‑ und API-Ebene, können Container‑Workloads gegenseitig auf Daten oder Prozesse zugreifen und so Sicherheitsrisiken in Multi‑Tenant‑Umgebungen verursachen. Eine CNCF‑konforme Plattform muss daher den Zugriff auf Beschleuniger klar trennen und über Frameworks wie Dynamic Resource Allocation (DRA) oder Geräte-Plug-ins kontrollieren. Nur so lassen sich Workloads isolieren und unerlaubte Zugriffe oder Beeinträchtigungen verhindern.
Unterstützung für Operatoren
KI-Frameworks wie Ray oder Kubeflow sind verteilte Systeme, die auf Kubernetes als Operatoren laufen. Eine Plattform benötigt dafür eine stabile Basis, um zu verhindern, dass instabile Webhooks, CRD‑Verwaltung (Custom Resource Definition) oder eine unzuverlässige API-Server-Struktur dazu führen, dass Operatoren ausfallen und die gesamte KI-Plattform zum Stillstand kommt.
Eine CNCF-konforme Umgebung muss mindestens einen komplexen KI-Operator (etwa Ray oder Kubeflow) installieren und ausführen können. Sie muss nachweisen, dass Operator‑Pods, Webhooks und die Reconciliation der Custom Resources stabil und vollständig funktionieren.
Ein internationaler, Community‑getriebener Standard mit europäischer Beteiligung
Das Kubernetes-AI-Conformance‑Programm der CNCF schafft auf Basis der von der Arbeitsgruppe WG AI Conformance definierten Säulen einen stabilen, offenen und zukunftssicheren Standard für KI-Infrastrukturen. Plattformen, die auf den offenen Upstream-APIs basieren, eröffnen insbesondere auch europäischen Unternehmen die Chance, ihre KI-Strategien portabel und souverän umzusetzen – von der Public Cloud bis zum sicheren On‑Premises‑Rechenzentrum. „Verschiedene Anbieter‑Plattformen sind bereits ‚Kubernetes AI Conformant‘ für die Kubernetes-Versionen 1.33 und 1.34“, sagt Fahlandt. Dazu zählen auch Plattformen europäischer Anbieter wie Gardener, Giant Swarm, Kubermatic und SUSE.
Weitere Anforderungen werden laufend entwickelt und im Community‑Prozess diskutiert. Die CNCF lädt alle Interessierten ein, sich aktiv an dem offenen Standard zu beteiligen. Weitergehende Informationen rund um das Programm finden sich in der offiziellen Ankündigung im CNCF-Blog.
(map)
Entwicklung & Code
fish 4.2.0: Mehrzeilige Befehle und UTF-8 als Standard
Die Entwickler der Shell fish haben Version 4.2.0 veröffentlicht. Zu den wichtigsten Neuerungen zählen mehrzeilige Befehle in der verlaufsbasierten Autovervollständigung sowie grundlegende Änderungen bei der Zeichenkodierung.
Weiterlesen nach der Anzeige
Die Autovervollständigung auf Basis der Befehlshistorie schlägt nun auch mehrzeilige Kommandos vor – eine Funktion, die bei komplexeren Shell-Skripten oder verschachtelten Befehlen für viele Nutzer im Alltag praktisch ist. Zudem wurden Probleme beim Löschen mehrzeiliger transienter Prompts behoben: Wenn ein solcher Prompt mehr Zeilen umfasst als der finale Prompt, wird er jetzt korrekt entfernt.
Ein weiteres praktisches Feature betrifft die Terminal-Konfiguration: Anwender können jetzt den Titel des Terminal-Tabs getrennt vom Fenstertitel setzen, indem sie die Funktion fish_tab_title definieren – gut für den Überblick. Bei sehr langen Kommandozeilen blendet fish außerdem den Teil des mehrzeiligen Prompts aus, der aufgrund der Bildlaufposition nicht mehr sichtbar ist. Das verhindert doppelte Zeilen nach dem Neuzeichnen.
UTF-8 jetzt vorausgesetzt
Eine grundlegende Änderung betrifft die Zeichenkodierung: fish geht jetzt immer von UTF-8 aus, selbst wenn das System kein UTF-8-Locale konfiguriert hat. Eingabebytes, die kein gültiges UTF-8 darstellen, werden weiterhin korrekt verarbeitet – Dateipfade mit veralteten Kodierungen lassen sich also nach wie vor verwenden, werden aber möglicherweise anders auf der Kommandozeile dargestellt. Auf Systemen ohne Multi-Byte-Locale verzichtet fish künftig auf ASCII-Ersatzzeichen für Unicode-Symbole wie das Auslassungszeichen.
Die Mausbedienung wurde flexibler: fish deaktiviert nicht mehr zwangsweise die Mauserfassung (DECSET/DECRST 1000), sodass Nutzer per Mausklick den Cursor bewegen oder Vervollständigungsvorschläge auswählen können. Die Tastenkombination alt-p fügt zudem kein überflüssiges Leerzeichen mehr zur Kommandozeile hinzu.
Standalone-Build nun Standard
Weiterlesen nach der Anzeige
Für Distributoren und Entwickler ist relevant, dass der Standalone-Build-Modus jetzt standardmäßig aktiv ist. Die Dateien in $CMAKE_INSTALL_PREFIX/share/fish werden künftig nicht mehr verwendet – mit Ausnahme der HTML-Dokumentation. Dadurch brechen künftige Updates laufende Shells nicht mehr ab, wenn sich interne Hilfsfunktionen geändert haben. Die Datendateien werden vorerst redundant installiert, um bereits laufende Shells zu schützen. Die minimale unterstützte Rust-Version wurde auf 1.85 geändert.
Release-Tags und Quellcode-Archive sind nun wieder GPG-signiert. Die Dokumentation in den Release-Paketen wird jetzt mit der aktuellen Sphinx-Version erstellt, wodurch die vorgenerierten Man-Pages OSC-8-Hyperlinks enthalten. Die Sphinx-Abhängigkeit ist jetzt in pyproject.toml spezifiziert, wodurch Nutzer uv für den Dokumentations-Build einsetzen können.
Plattform-spezifische Verbesserungen
Unter macOS setzt fish als Login-Shell die Variable MANPATH nun korrekt, wenn diese bereits in der Umgebung vorhanden war. Ein Windows-spezifisches Problem, bei dem die webbasierte Konfiguration nicht startete, wurde ebenfalls behoben. Für MSYS2 gibt es einen Workaround für Konsole und WezTerm, der verhindert, dass diese das falsche Arbeitsverzeichnis beim Öffnen neuer Tabs verwenden.
Im Rahmen der Version 4.0, die im Februar 2025 erschien, hatten die fish-Entwickler den Kerncode von C++ nach Rust portiert. Release 4.2.0 behebt mehrere Regressionen aus den Vorgängerversionen 4.0.0 und 4.1.0, darunter Probleme mit der webbasierten Konfiguration unter Python 3.9, falsche Terminal-Modi bei bestimmten Kommandos und Fehler beim Speichern universeller Variablen unter MSYS2. Auch VTE-basierte Terminals zeigen beim Ändern der Fenstergröße wieder das korrekte Verhalten.
Schließlich wurden auch die Übersetzungen erweitert: Neben den bereits vorhandenen Sprachen ist nun Chinesisch (Taiwan) mit an Bord, zudem wurden die französischen Übersetzungen ergänzt. Die Release Notes auf GitHub listen alle Änderungen detailliert auf. Für Linux stehen Standalone-Binaries für verschiedene CPU-Architekturen bereit, macOS-Pakete können über Homebrew bezogen werden. Windows-10- und -11-Nutzer müssen das Windows Subsystem for Linux (WSL) heranziehen, darüber hinaus lässt sich fish mit Cygwin und MSYS2 verwenden.
(fo)
Entwicklung & Code
Schadsoftware weiter aktiv: GlassWorm erneut in Open-VSX-Paketen gefunden
Der Mitte Oktober entdeckte Supply-Chain-Angriff über die Marktplätze von Visual Studio Code geht offenbar weiter: Auf dem Open-VSX-Marktplatz der Eclipse Foundation sind drei weitere Pakete mit GlassWorm aufgetaucht.
Weiterlesen nach der Anzeige
Die Pakete setzen auf dieselben Verschleierungstechniken und nutzen dieselben Angriffsmuster wie die im Oktober gefundenen Packages. Kurz nach dem Bekanntwerden des Angriffs hatte die Eclipse Foundation ihn offiziell als abgeschlossen erklärt und zusätzliche Sicherheitsmaßnahmen angekündigt.
Die drei Anfang November gefundenen Pakete ai-driven-dev.ai-driven-dev, adhamu.history-in-sublime-merge und yasuyuky.transient-emacs kommen laut dem Security-Unternehmen Koi gemeinsam auf knapp 10.000 Downloads.
Wiederum setzt der Angriff auf die Solana-Blockchain und verwendet Folgen von Unicode-Zeichen, die viele Editoren nicht anzeigen. Auch auf GitHub finden sich Hinweise auf Schadsoftware mit denselben Mustern.
Der unsichtbare Glaswurm
Den Namen GlassWorm hatte Koi der Schadsoftware im Oktober gegeben, da sie zum einen im Editor unsichtbar ist und sich zum anderen selbst vermehren soll – ähnlich wie die im September auf npm gefundene Schadsoftware Shai Hulud.
Allerdings vermehrt der GlassWorm sich nicht eigenständig, sondern greift lediglich Credentials unter anderem zu GitHub ab, die die Angreifer vermutlich mit KI-Unterstützung nutzen, um die Schadsoftware zu verteilen.
Die Malware enthält nicht nur wie üblich verschleierten Code, sondern setzt auf Unicode-Zeichen, die im Editor nicht sinnvoll darstellbar sind – und daher oft überhaupt nicht dargestellt werden. Dafür verwendet sie Folgen von Unicode-Variantenselektoren. Das Resultat ist für menschliche Reviewer unsichtbar. Diff-Betrachter und ähnliche Tools zeigen die eigentlichen Unterschiede ebenfalls nicht an, weisen aber darauf hin, dass Unterschiede bestehen. Hinzu kommt, dass ein kleines Codestück sichtbar sein muss, um den restlichen, versteckten Code zu dekodieren und auszuführen.
Weiterlesen nach der Anzeige
Blockchain für die C2-Infrastruktur
Dank der Solana-Blockchain ist die Infrastruktur für die Command-and-Control-Server resilient gegen das Abschalten einzelner Server. Die Schadsoftware besorgt sich über die öffentliche Blockchain Links im Base64-Format auf den Payload mit der eigentlichen Schadsoftware.
Auf die Weise können die Angreifer jederzeit den C2-Server austauschen und die neue Adresse über die Blockchain veröffentlichen.
Auch auf GitHub aktiv
Der GlassWorm ist laut dem Koi-Blog nun auch auf GitHub aufgetaucht. Maintainer haben gemeldet, dass ihre Repositories vermutlich KI-generierte, auf den ersten Blick zum Projekt passende und legitime Commits erhalten haben, die Code mit den Angriffsmustern von GlassWorm enthalten, der ebenfalls unsichtbar ist.
Im Blogbeitrag heißt es, dass die Commits auf GitHub Private Use Areas nutzen, also für den eigenen Gebrauch ausgewiesene Unicode-Zeichen. Damit soll der Code ebenfalls unsichtbar werden, was wir aber in eigenen Versuchen nicht nachvollziehen konnten.
Russische Gruppe hinter den Angriffen vermutet
Laut dem Koi-Blog haben die Angreifer nach einem Tipp eines Security-Forschers, der anonym bleiben will, einen Endpunkt auf ihrem Server ungesichert gelassen. Koi hat die Lücke genutzt, um Daten auszulesen.
Dort fanden sie Informationen zu den vom Angriff betroffenen Unternehmen und Organisationen, darunter eine staatliche Einrichtung aus dem Nahen Osten.

Die Daten enthalten russische Texte und einen Verweis auf RedExt.
(Bild: Koi)
Interessanterweise waren laut Koi auch Keylogger-Daten des Angreifers in den Daten zu finden. Aus ihnen lässt sich unter anderem ablesen, dass die Angreifer Russisch sprechen und das Command-and-Control-Framework RedExt verwenden.
Koi hat die Informationen an die Strafverfolgungsbehörden weitergegeben, um die Opfer zu informieren und gegen die Angreifer vorzugehen.
(rme)

Mähroboter für 360 Euro: Roboup Raccoon 2 SE für kleine Gärten im Test

PlayStation 5: Sony nennt Verkaufszahl von 84,2 Millionen Konsolen

Top 10: Der beste Mini-Beamer mit Akku im Test – schon ab 250 Euro gut
-

 UX/UI & Webdesignvor 3 Monaten
UX/UI & Webdesignvor 3 MonatenDer ultimative Guide für eine unvergessliche Customer Experience
-

 UX/UI & Webdesignvor 2 Monaten
UX/UI & Webdesignvor 2 MonatenAdobe Firefly Boards › PAGE online
-

 Apps & Mobile Entwicklungvor 3 Monaten
Apps & Mobile Entwicklungvor 3 MonatenGalaxy Tab S10 Lite: Günstiger Einstieg in Samsungs Premium-Tablets
-
eine gute Nachricht ist")
eine gute Nachricht ist") Social Mediavor 3 Monaten
Social Mediavor 3 MonatenRelatable, relevant, viral? Wer heute auf Social Media zum Vorbild wird – und warum das für Marken (k)eine gute Nachricht ist
-

 UX/UI & Webdesignvor 4 Wochen
UX/UI & Webdesignvor 4 WochenIllustrierte Reise nach New York City › PAGE online
-

 Datenschutz & Sicherheitvor 2 Monaten
Datenschutz & Sicherheitvor 2 MonatenHarte Zeiten für den demokratischen Rechtsstaat
-

 Entwicklung & Codevor 3 Monaten
Entwicklung & Codevor 3 MonatenPosit stellt Positron vor: Neue IDE für Data Science mit Python und R
-

 Entwicklung & Codevor 2 Monaten
Entwicklung & Codevor 2 MonatenEventSourcingDB 1.1 bietet flexiblere Konsistenzsteuerung und signierte Events