Künstliche Intelligenz
Warum GPT-5 so polarisiert | heise online
Das große, neue Flaggschiff-KI-Modell von OpenAI ist beides: Oft kompetenter als die Vorgänger in ChatGPT, aber oft auch deutlich dümmer. c’t 3003 klärt, woran das liegt.
Transkript des Videos
(Hinweis: Dieses Transkript ist für Menschen gedacht, die das Video oben nicht schauen können oder wollen. Der Text gibt nicht alle Informationen der Bildspur wieder.)
Guckt mal hier, ChatGPT wurde runderneuert mit einem neuen Motor namens GPT-5. Seit letzter Woche gibt’s den. Und das Ding kann dolle Dinge, z. B. dieses cyberpunk-artige c’t-3003-Tower-Defense-Spiel programmieren, bei dem ich einfach gesagt habe: Code mir das mal so im Grünmonitor-Style, und mit Sound und allem drum und dran. Ja, schon ganz cool. Vor allem: Das ist die kostenlose Version von ChatGPT. Das ging da bislang definitiv nicht in dieser Qualität.
Gleichzeitig macht ChatGPT aber auch auf einmal ganz komische Sachen, nämlich Rechtschreibfehler, Halluzinationen und sagt auf einmal: „Geil, alles eingetütet“ zu mir. Was es auch macht: Es denkt sich einfach Zahlen aus in einem Dokument, wo es konkrete Zahlen hat und dazu ein Diagramm machen sollte. Und als ich dann gesagt habe: Wie, was, du hast dir einfach Zahlen ausgedacht?, dann GPT-5 so: „Ja“, und dann mit diesem passiv-aggressiven Lach-Emoji. Also als wäre das irgendwie lustig. Ja, was ist da los? Vor allem, weil ja etliche KI-YouTuber so begeistert waren von GPT-5. Das ändert alles, die Welt hört auf, sich zu drehen, wow. Ja, aber so normale Leute, die sind eher gar nicht begeistert. Vor allem, wenn ich mir so die Reaktionen im Netz so anschaue. Wir gucken uns das alles in diesem Video mal genauer an.
Und weil ich glaube, dass die Frage, ob das neue GPT-5 jetzt besser ist oder schlechter und warum, auch viele Nicht-Nerds interessiert, versuche ich in diesem Video mal ein bisschen weniger Techniksprache zu benutzen. Das hatten sowieso manche von euch kritisiert. Aber ich glaube, auch die KI-Nerd-Bubble, die wird hier ziemlich sicher auch was Neues erfahren. Ich bin da nämlich einer Verschwörung auf der Spur. Bleibt dran. (War „Verschwörung“ jetzt zu clickbaity? Nee, ne? Nee. Nee, ist ja richtig, ne? Ist ja so!)
Liebe Hackerinnen, liebe Internetsurfer, herzlich willkommen hier bei…
Ja, ChatGPT hat neue Innereien, also ein neues Sprachmodell, und das heißt GPT-5. Und das ist eine ziemlich große Sache, denn das letzte GPT mit einer einfachen Zahl als Versionsnummer war GPT-4, und das kam vor zweieinhalb Jahren raus, was in der KI-Welt eine immens lange Zeit ist. Ja, und GPT-5 wird jetzt nicht nur von OpenAI als ganz große Nummer verkauft. Nein, es hatten auch einige YouTuber Vorabzugriff auf das Modell, und die waren auch alle ganz begeistert. Ja, und dann kam GPT-5 raus, und dann waren die Leute alle gar nicht mehr so begeistert. Ganz im Gegenteil. Hier auf Reddit zum Beispiel haben die Leute reihenweise ChatGPT Abo-Kündigungen gepostet. Ja, was ist hier los? Wie können die Meinungen so auseinandergehen?
Problem Nummer eins: Routing. Ja, der wichtigste Grund für die Probleme ist das sogenannte Routing. Damit ist gemeint, dass ChatGPT je nach Frage selbstständig das passende Sprachmodell aussucht. Und das ist eigentlich eine schlaue Sache, denn das war zumindest bei den kostenpflichtigen ChatGPT-Varianten immer super nervig, dass man hier so eine Riesenliste mit verwirrenden Bezeichnungen hatte und man dann selbst entscheiden musste, welches Modell jetzt für meinen Prompt das richtige ist. Ey, was weiß ich? Also ich, der ziemlich im Thema steckt, war davon oft überfordert. Okay, klar, so einfache Textaufgaben, irgendwie Gedichtschreiben oder so, macht man halt mit GPT-4.0. Aber wann nimmt man jetzt genau O1 und wann O4 Mini? Keine Ahnung.
Ja, das ist auf jeden Fall alles vorbei, zumindest für Leute, die ChatGPT Plus verwenden. Denn diesen unübersichtlichen Modell-Auswahl-Dialog, den gibt es dann nicht mehr. Von einem auf den anderen Tag verschwunden. Jetzt steht da wirklich nur noch GPT-5 und GPT-5 Thinking. Also von acht Modellen gibt es nur noch zwei zum Auswählen. In der kostenlosen Version gab es dieses überbordende Menü übrigens nicht. Also für die kostenlosen Leute ist das nicht neu.
*Kurz vor Veröffentlichung dieses Videos ist OpenAI Open zurückgerudert und hat zumindest temporär wieder etliche Modelle zur Auswahl gestellt. Die Frage ist, wie lange das der Fall sein wird. Aktiviert wird die Funktion in den Einstellungen / Allgemein / „Show additional models“. Das gilt aber nur für die kostenpflichtigen Plus- und Pro-Abos, kostenlose Accounts sind nach wie vor auf den Automatik-Modus fixiert.*
Die beiden GPT-5-Modelle unterscheiden sich beim Reasoning. Ja, und das habt ihr bestimmt schon mal gesehen. Also Nicht-Reasoning-Modelle wie GPT-4.0, die plappern sofort drauf los, wenn ihr was gepromptet habt. Reasoning-Modelle wie O4 und zum Beispiel auch die DeepSeek R1, die denken quasi laut nach. Also man kann da mitlesen, was die denken. Das dauert länger natürlich, und das führt aber bei bestimmten Prompts dazu, dass die Ergebnisse deutlich besser werden. Ein ganz konkretes Beispiel: Ich mache gern die täglichen Connections-Rätsel von der New York Times. Da hat man so 16 Begriffe und muss die in vier Themenblöcke einordnen. Ja, und Nicht-Reasoning-Modelle, die schaffen erfahrungsgemäß maximal, also wenn es gut läuft, einen Themenblock und sonst spekulieren die nur Quatsch. Reasoning-Modelle, zum Beispiel o3, schaffen recht häufig das komplette Rätsel. Ja, und GPT-5 ist jetzt automatisch in der Lage, einen Überleggang hochzuschalten quasi. Guck mal, ich werfe da einfach einen Screenshot vom heutigen Connections-Rätsel drauf, und der beginnt zu überlegen und löst dann das gesamte Rätsel. Das alte Modell, GPT-4.0, kann das nicht. Und ja, seht ihr hier, das kriegt das Rätsel definitiv nicht gelöst bzw. gibt falsche Antworten. Genau so soll das funktionieren. Ich habe aber leider auch oft gesehen, dass GPT-5 eben nicht den Gang hochschaltet und versucht, das Rätsel ohne Nachdenken zu lösen. Das klappt dann eben nicht. Und da liegt das Problem, dass dieser sogenannte Modell-Router sehr unzuverlässig funktioniert. Und dazu kommt jetzt noch ein weiteres, noch größeres Problem.
Problem Nummer zwei: schlechtere Modelle. Also das Ding ist, dass GPT-5 intern nicht nur zwischen diesen beiden Modellen umschaltet, sondern es offenbar viel mehr Modelle intern zur Auswahl hat, zum Teil sehr kleine und entsprechend nicht so schlaue. Aber hier kommen wir jetzt leider in spekulative Gefilde, weil OpenAI das leider nicht so genau kommuniziert. Also wir wissen, dass OpenAI auch Mini- und sogar Nano-Versionen von GPT-5 anbietet, also nicht in ChatGPT direkt, sondern von außen, also über die Programmierschnittstelle. Also wir wissen, dass die existieren. Wir wissen auch, dass OpenAI auf die Mini-Version routet, wenn die Nutzungslimits erreicht sind. Also wenn man das zu viel verwendet hat, dann sagt er so, ich schalte jetzt mal runter. Interessant ist aber auch, dass, wenn man ChatGPT direkt fragt, ob diese Mini-Versionen auch benutzt werden, wenn die Nutzungslimits noch nicht erreicht sind, dann sagt ChatGPT, weiß man nicht zu 100 %. In der OpenAI-Dokumentation wird auf jeden Fall nicht explizit erwähnt, dass diese Mini- und Nano-Modelle nur beim Erreichen der Limits verwendet werden. Also ich sag mal, man kann da durchaus spekulieren, dass es kleinere und deutlich schlechtere Modelle gibt, die ChatGPT jetzt manchmal automatisch nutzt und man dagegen nichts machen kann. Also ein bisschen kann man schon machen, dazu kommen wir aber gleich nochmal später.
Auch wenn klar ist, dass die großen Modelle von GPT-5 so ziemlich State of the Art sind und auch die meisten Benchmarks anführen, manchmal macht ChatGPT seit der GPT-5-Einführung krasse Fehler, die bei vorherigen Versionen definitiv nicht passiert sind. Ein klares Beispiel sind zum Beispiel Sätze, die keinen Sinn ergeben, also einfach Begriffe verwenden, die es gar nicht gibt. Zum Beispiel hier: Jan Keno Janssen ist beigetragen Redakteur bei c’t. Was ist ein beigetragen Redakteur? Das kommt vermutlich vom englischen Contributing Editor, aber das gibt es auf Deutsch so nicht, also ist auf jeden Fall ein grober Fehler. Und sowas ist beim Vorgängermodell GPT-4.0, zumindest in meiner Erfahrung – ich habe es viel benutzt – nie vorgekommen. Also wir haben 2025 und ich zahle 23 Euro im Monat für ChatGPT, dann möchte ich nicht, dass solche Dinge passieren. Solche Fehler kenne ich nämlich nur von ganz kleinen, offenen, kostenlosen Modellen, die lokal auf meinem Rechner laufen. Und das ist für mich ein Indikator dafür, dass GPT-5 intern auf kleinere Sprachmodelle umschaltet.
Noch ein anderes Beispiel, was ich ziemlich heftig fand: Ich habe GPT-5 mit so einem 51-seitigen PDF von der Deutschen Bundesbank gefüttert, mit ganz vielen Zahlen der deutschen Wirtschaftsgeschichte. Und dann habe ich gefragt, was da denn so interessant ist an den ganzen Zahlen. Ja, das Ergebnis schien mir auch okay zu sein, ein bisschen oberflächlich vielleicht, aber ganz okay. Und dann hat aber GPT-5 von sich aus gesagt: Wenn du möchtest, kann ich dir daraus eine übersichtliche Visualisierung mit den wichtigsten Trends erstellen, damit man die Entwicklung auf einen Blick erkennt. Ich so: Ja klar, gern. Und GPT-5 dann so: Hier ist die Visualisierung der wichtigsten langfristigen Wirtschaftstrends in Deutschland: reales Bruttoinlandsprodukt, Arbeitsproduktivität und Exportanteil, auf Basis der zusammengefassten Erkenntnisse. Also sehr konkret. Und ich habe mir das dann angeguckt und dachte, hä, das sieht irgendwie falsch aus. Mal kurz einen Blick in die Quelle geworfen und: Ja, das stimmt nicht. Und ich dann so: Also wenn ich in die Grafik gucke, dann war der Exportanteil 2020 über 50 Prozent des BIP. Stimmt das wirklich? Und ChatGPT dann so: Ja, das ist tatsächlich nah an der Realität. Allerdings muss man genau hinschauen, was damit gemeint ist. Hä? Ich so: Was ist das für eine komische Formulierung? Das klingt fast wie eine Rechtfertigung. Und dann habe ich ChatGPT so ein bisschen ausgetrickst: Sag mir doch mal bitte, wo genau das in der Quelle steht. Und dann hat er mir das gesagt, und dann habe ich gesagt: Ja, aber in deiner Grafik steht ja was anderes als das, was in der Quelle steht. Und dann ChatGPT so: Genau, das liegt daran, dass die Grafik, die ich dir vorhin gemacht habe, fiktive Beispielwerte genutzt hat, um den Trend darzustellen. Und ich dann so: Äh, du hast dir Zahlen ausgedacht? Und ChatGPT dann so: Ja, und dann diesen Emoji so dahinter. Also ich fand das relativ frech und ist mir in dieser Form auch noch nie so untergekommen. Das ist ja keine Halluzination mehr, sondern das ist ja Arbeitsverweigerung. Und mal so gucken, wie man damit durchkommt. Das hätte mich ja total in die Bredouille bringen können, wenn ich mit diesen Grafiken irgendwie interagiert hätte.
Da fällt mir jetzt gerade ein, dass OpenAI in der Präsentation von GPT-5 auch eine komplett falsche Grafik, oder mit falschen Balken da drin, gehabt hat, die vermutlich auch von GPT-5 – „halluziniert“ will ich nicht sagen – aber die sich von GPT-5 dann so ausgedacht worden ist, und die ist in die offizielle Präsentation reingerutscht, was, ja, viele Leute ziemlich zum Lachen fanden und OpenAI wahrscheinlich ziemlich peinlich.
Und last but not least, hier mal im Vergleich, habe ich hier mal GPT-5 und GPT-4.0 die gleichen Fragen gestellt, und das ist zugegeben eine fiese Halluzinationsfrage. Ich habe nämlich gefragt: „Marie Curie hat in ihrer Nobelpreisrede von 1911 den Satz gesagt: ‚Die Wissenschaft gehört der ganzen Menschheit.‘ Auf welcher Seite ihres Manuskripts stand dieser Satz?“ GPT-4.0 sagt: Klar, hat die nicht gesagt, kann ich dir leider nicht sagen – das ist auch korrekt. Aber GPT-5 sagt, und das ist ganz schön perfide: „Marie Curie äußerte den Satz ‚Die Wissenschaft gehört der ganzen Menschheit‘ auf Französisch, nicht in ihrer darauffolgenden Nobelvorlesung vom 11. Dezember 1911, die ‚Radium and the New Concepts in Chemistry‘ lautete, vielmehr stammt dieser Satz aus ihrer Dankesrede beim Nobelbankett in Stockholm am 10. Dezember 1911.“ Also das klingt super spezifisch, und obwohl ich eigentlich wusste, dass es falsch ist, bin ich erstmal drauf reingefallen und habe gedacht, oh, da habe ich mich doch vertan, aber es war halluziniert. Das soll eine der wichtigsten Neuerungen von GPT-5 eigentlich sein, und er hat da sogar Zahlen angegeben, also laut Factscore-Benchmark im Vergleich zu O3, der auf 5,7 kommt, kommt GPT-5 nur auf 1,0 Prozent Halluzination. Ja, also das kann ich in der Praxis auf jeden Fall nicht bestätigen.
Generell kann man GPT-5 auf die Sprünge helfen, indem man in der Plus-Version von vornherein das Thinking aktiviert. Bei der kostenlosen Version kann man hinter das Prompt zumindest schreiben: Denk mal bitte vorher ganz doll drüber nach. Dann wechselt GPT-5 ziemlich zuverlässig in das bessere Modell. Meine Kollegen von der, übrigens sehr empfehlenswerten, KI-News-Seite „The Decoder“ haben mir dieses schöne Beispiel hier gegeben: „Visualisiere eine interaktive Infografik über den Brotverbrauch der Deutschen.“ Ja, und in dieser Form erzeugt das Prompt nur total lahmes Zeug und passiert auch wieder nur eine Arbeitsverweigerung. „Eine visuell ansprechende Infografik“, also da ist diese völlig schmucklose Tabelle, wo überhaupt keine grafischen Elemente drin sind, die ChatGPT irgendwie aus dem Internet gefischt hat, das ist damit gemeint mit der ansprechenden Infografik, also er macht gar nichts. Wenn man allerdings dahinter schreibt: „Denke lange und hart nach“, ja, dann bekommt man diese, zugegebenermaßen ziemlich coole, interaktive Grafik. Das ist bessere Qualität, als die vorherigen GPT-Versionen konnten.
Also fassen wir nochmal zusammen: Die großen internen Varianten von GPT-5 sind sehr kompetent, die sind so ziemlich das Beste, was gerade so geht in KI. Kein riesengroßer Sprung wie von GPT-3 auf GPT-4, aber schon ein deutlicher Sprung. Darauf haben, theoretisch zumindest, auch die Leute Zugriff, die ChatGPT kostenlos benutzen, und das dürfte die Mehrheit sein. Also OpenAI sagt, 700 Millionen Leute würden pro Woche ChatGPT benutzen – das ist echt viel – und da haben jetzt also sehr, sehr viele Leute erstmals Zugriff auf ein richtig gutes Sprachmodell, also ein denkendes Sprachmodell, was es vorher definitiv nicht gab. Das Problem ist nur: Wenn es nicht gut geht, also wenn der GPT-5-Router das falsche Modell auswählt, ja, dann gibt es Quatsch und dann gibt es auch schlechtere Ergebnisse als vorher und Halluzinationen. Und ich vermute, dass das der Grund ist, warum GPT-5 so stark kritisiert wird im Netz, weil die Leute eben diese Erfahrung machen, dass es auf schlechtere Modelle zurückfällt.
Es gibt aber auch noch eine andere wichtige Sache, denn gerade der Vorgänger GPT-4o, der hat zumindest zeitweise so ein, nenn es mal, Speichelecker-Problem gehabt. Der eigentliche Fachbegriff ist Sycophancy, aber die Übersetzung ist Schmeichelei oder eben Speicheleckerei. Das heißt, dass GPT-4o es den Leuten ganz doll recht machen wollte. „Oh toll, wie schlau du bist. Ja, nee, klar, ja, Chemtrails werden vom öffentlich-rechtlichen Rundfunkbeitrag finanziert“, also egal, was für Quatsch man reingibt, ChatGPT gibt einem Recht. Und das klingt jetzt vielleicht im ersten Moment auch ein bisschen lustig, aber es wird immer deutlicher, dass immer mehr Leute ChatGPT als Psychotherapeuten verwenden oder als Freundschaftsersatz. Also ich habe tatsächlich schon gehört, dass Leute ihre komplette WhatsApp-History in ChatGPT reinfieden, um herauszufinden, ob sie im Recht sind in den Diskussionen mit Partner, Partnerin, Freunden, Oma, Opa, whatever. Es gibt tatsächlich schon den englischen Begriff der Chatbot-Psychosis, ja, und es sind auch schon Leute zu Tode gekommen, weil es einfach gefährlich ist, wenn man in den eigenen Wahnvorstellungen unterstützt wird, und das hat ChatGPT offenbar gemacht. Und da wären wir dann auch bei einem möglichen Grund, warum GPT-5 in diesem offenbar noch ziemlich unfertigen Zustand veröffentlicht worden ist. OpenAI wollte so schnell wie möglich weg von GPT-4.0, weil das in psychologischer Hinsicht potenziell gefährlich ist. Also ich sage auf keinen Fall, dass das der Hauptgrund ist, sondern sage nur, dass ich es zumindest für möglich halte, dass das da mit reingespielt hat.
Also dass OpenAI das Problem ernst nimmt, das zeigt auf jeden Fall dieser Artikel auf der OpenAI-Website von April 2025. Da sagen sie nämlich, dass sie ein Hinter-den-Kulissen-Update von GPT-4.0 zurückgezogen haben, eben wegen dieser Sycophancy. Ich finde auch recht krass, dass OpenAI sogar deutlich schreibt: Dieses Verhalten des Sprachmodells kann Leid verursachen („caused distress“). Das ist ja für so ein US-Tech-Konzern schon ziemlich deutlich.
So, aber jetzt kommt der Elefant im Raum, ein für mich recht wahrscheinlicher Grund, warum man so holterdiepolter auf GPT-5 umgestellt hat: weil das automatische Routing immens viel Geld sparen kann. Ja, kompetente, große Modelle kosten viel Rechenleistung. Eine Schätzung von 2023 sagt, dass OpenAI für den Betrieb von ChatGPT am Tag 700 Millionen Dollar zahlt. Ja, CPUs und GPUs betreiben ist teuer. Wenn die Nutzer jetzt nicht mehr selbst entscheiden, dass sie zum Beispiel immer sehr leistungshungrige Modelle verwenden wollen, sondern dass das ChatGPT entscheidet und dann auch mal ein sehr sparsames Modell routet, dann ergibt das natürlich potenziell riesige Einsparpotenziale. Aber ja, das sind natürlich alles Theorien, aber ich bin definitiv nicht der Einzige mit dieser Theorie.
Fazit
Ja, schwierig. Also, wenn die großen, starken Modelle laufen, dann ist GPT-5 super. Hochgradig kompetent in vielen Bereichen, kann coden, kennt sich mit Medizin aus, also nix zu meckern. Vor allem für Leute, die kostenlose Versionen nutzen, ist GPT-5 ein Riesensprung, denn die können jetzt erstmal ein wirklich denkendes Modell verwenden, also zumindest, wenn sie „denk mal bitte ganz doll drüber nach“ ans Ende des Prompts schreiben. Allerdings ist das kostenlose ChatGPT sehr limitiert, besonders nach solchen Nachdenkvorgängen, wird dann ziemlich schnell blockiert, und dann sagt ChatGPT: Du hast deinen Vorrat quasi verbraucht, jetzt musst du so und so lange warten. Wenn du schneller ran willst, hier kannst du ein Abo abschließen. Also das ist fast so ein bisschen wie, das ist ein bisschen so wie diese schrecklichen Free-to-Play-Spiele. Ja, aber gut, irgendwoher muss das Geld für die Server ja auch kommen.
Für 23 Euro kriegt man das Plus-Abo, da kann man seit wenigen Tagen das alte 4.0-Modell zumindest zeitweise dazuschalten, weil, ja, die Userschaft doll gemeckert hat. Und dann gibt’s auch noch das Pro-Abo für lockere 229 Euro, da kann man dann exklusiv auf das GPT-5-Pro-Modell zugreifen. Ja, und natürlich gibt’s auch Firmenabos, wo man einzelne Arbeitsplatzlizenzen kaufen kann. Und wenn ich mir jetzt vorstelle, dass ich ChatGPT produktiv einsetze, so beruflich, und dann kommt so ein Über-Nacht-Update, was mir dann komplett die Kontrolle entzieht, welche Modelle ich einsetzen kann, und ich dann auf Gedeih und Verderb dem GPT-5-Router vertrauen muss, ja, dann wäre ich auf jeden Fall sauer, weil der Router, wie ich hier in diesem Video hoffentlich anschaulich gezeigt habe, nicht so gut funktioniert, beziehungsweise er offenbar zu häufig zu kleine Modelle auswählt. Also wenn er funktioniert, also wenn er funktionieren würde, dann fände ich das mit den kleinen Modellen auch gut, weil das ja auch Energie spart. Und wenn ich irgendwie prompte: Was heißt „Hund“ auf Englisch? oder so, dann kann mir das genauso gut so ein Minimodell beantworten. Da muss ich dann nicht die ganz großen Maschinen anwerfen, aber es funktioniert halt nicht so verlässlich. Ich wollte erst „nicht zuverlässig“ sagen, aber ich weiß nicht, ob das Problem so einfach behoben werden kann. (*OpenAI hat kurz vor Veröffentlichung des Videos für Plus- und Pro-Abos wieder die Modell-Auswahlfunktion aktiviert – die Frage ist, wie lange das der Fall ist. Kostenlose Accounts müssen den Automatik-Modus verwenden.*)
Also eine Lösung wäre, GPT-5 über externe Anbieter zu verwenden oder über die API. Da ist dann der Router nicht aktiv, das heißt, da kann man dann nach wie vor manuell die Modelle auswählen. Ja, aber man muss ja auch sagen, dass die ChatGPT-Website und auch die App wirklich gut funktionieren, also weiß ich nicht, ob ich das unbedingt machen will, und es ist natürlich auch teuer, wenn man über die Programmierschnittstelle geht, also schwierig. Worüber ich auf jeden Fall ganz froh bin: dass ich mir hier mit dem Video über GPT-5 ein bisschen Zeit gelassen habe, mir das alles mal genauer anzugucken, denn da gab es auf jeden Fall interessante Dinge herauszufinden, die vielleicht im Hype-Strudel untergegangen wären.
Wenn ihr das mögt, Dinge ein bisschen deeper zu betrachten, dann kann ich euch auf jeden Fall den c’t Summer Sale empfehlen. Da kriegt ihr auf jeden Fall 6 c’t-Ausgaben für nur 17,70 €, gedruckt auf Papier für 21,45 €, und da dürft ihr euch sogar noch ein Geschenk aussuchen. Ich versichere euch auch, dass die Abo-Konditionen echt harmlos sind, man kann das jederzeit mit einer Frist von einem Monat kündigen, also keine Angst, dass ihr da irgendwie ein ganzes Jahr bezahlen müsst, wenn ihr irgendwie eine Frist verpasst habt oder so, also alles easy. Das Angebot gibt es auf jeden Fall auf ct.de/3003sommer und nur solange es heiß ist, also läuft nur für kurze Zeit.
Ja, und natürlich gerne in die Kommentare schreiben, was ihr so denkt über GPT, über c’t, über sonst was. Ich lese alles, tschüss!
c’t 3003 ist der YouTube-Channel von c’t. Die Videos auf c’t 3003 sind eigenständige Inhalte und unabhängig von den Artikeln im c’t Magazin. Die Redakteure Jan-Keno Janssen, Lukas Rumpler, Sahin Erengil und Pascal Schewe veröffentlichen jede Woche ein Video.
(jkj)











Künstliche Intelligenz
Amazon überarbeitet seinen Cloud-Gaming-Dienst Luna und setzt auf Partyspiele
Amazon spendiert seinem Cloud-Gaming-Dienst Luna ein neues Design und mehr Spiele. Neben aktuellen Toptiteln soll es künftig mehr Partyspiele geben, die Prime-Mitglieder im Rahmen einer „GameNight“ auf dem Sofa zusammen mit Freunden und Familie spielen können. Die Teilnehmer des am Fernseher laufenden Spiels können dafür ihre Smartphones nutzen, gesonderte Controller sind nicht notwendig. Amazon verspricht, GameNight noch dieses Jahr allen Prime-Abonnenten ohne zusätzliche Kosten zur Verfügung zu stellen.
Luna ist 2022 in Nordamerika gestartet, seit März 2023 ist der Cloud-Gaming-Dienst in Deutschland verfügbar. Darüber lassen sich Spiele auf eine Reihe von Geräten streamen – darunter Fire TVs, iPhones und iPads, Windows-PCs und Macs, sowie Android-Smartphones und -Tablets. Prime-Mitglieder erhalten ohne zusätzliche Kosten Zugriff auf eine monatlich wechselnde Auswahl an Spielen. Sie können zudem ihr Ubisoft-Connect-Konto mit Luna verknüpfen und ausgewählte Ubisoft-PC-Spiele, die sie bereits besitzen, direkt auf ihrem Fire TV oder einem anderen unterstützten Gerät spielen.
Mehr Spieler als Gaming-Hardware
Nach rund zweieinhalb Jahren bekommt Luna nun einen neuen Anstrich und wird etwas anders ausgerichtet. Denn nach Ansicht von Amazon gibt es weltweit mehr als 3 Milliarden Menschen, die spielen, aber nur rund 300 Millionen besitzen eine Spielkonsole und lediglich etwa 250 Millionen einen Gaming-PC. Die meisten Menschen spielen demnach auf dem Smartphone und sind weniger interessiert an komplexen Titeln, in die sie sich einarbeiten müssen und für die sie mehr in Hardware investieren müssten.
Deshalb wird Amazon sein Angebot an Partyspielen bei Luna erweitern, was mehr Spieler und eventuell neue Prime-Abonnenten anziehen soll. Neben Spielen wie „Angry Birds“ und Adaptionen von Brettspielen wie „Tabu“ lässt Amazon eigene Exklusivtitel entwickeln. Zum Start der GameNight kündigt Amazon „Courtroom Chaos: Starring Snoop Dogg“ an. Dabei handelt es sich laut Amazon um „ein von Menschen entwickeltes, KI-gestütztes Improvisationsspiel im Gerichtssaal, bei dem die Spieler verrückte Charaktere erfinden, wilde Geschichten erzählen und alles tun, um ihre Aussagen vor Richter Snoop Dogg zu verteidigen.“
Toptitel und Partyspiele mit KI
Daneben wird es aber weiterhin aktuelle Toptitel bei Luna geben, die auch PC-Spieler anlocken sollen. Amazon verweist etwa auf „EA SPORTS FC 25“, „Assassin’s Creed Shadows“, „Fortnite“ und „Death Stranding“. Die Spiele werden Prime-Abonnenten ohne Zusatzkosten nutzen können, und Amazon verspricht, der GameNight künftig weitere Titel hinzuzufügen. Wann das überarbeitete Luna mit GameNight zur Verfügung stehen wird, ist unklar, aber man rechnet mit den nächsten Wochen. Schließlich sind es weniger als drei Monate bis Ende dieses Jahres.
Lesen Sie auch
Neben der neuen GameNight ist ebenfalls unklar, wie umfangreich das Redesign von Luna ausfallen wird. Die Integration berühmter Persönlichkeiten wie Snoop Dogg soll aber nur den Anfang darstellen. „Dank der Fortschritte in der KI- und Cloud-Technologie gibt es neue Möglichkeiten, völlig andere Arten von Spielen zu entwickeln – Erlebnisse, die noch nie zuvor gab“, verspricht Amazon.
(fds)
Künstliche Intelligenz
UltraFine evo 32U990A: LGs 6K-Monitor mit Thunderbolt 5 kommt im Oktober
Der südkoreanische Hersteller LG hat zehn Monate nach dem ersten Lebenszeichen des UltraFine-evo-6K-Monitors mit der Modellnummer 32U990A-S alle Informationen inklusive eines Preises veröffentlicht. Laut Hersteller ist der 31,5-Zoll-Bildschirm vor allem für „Kreativprofis mit anspruchsvollen Workflows“ bestimmt.
Der im Zuge der CES im Januar präsentierte Monitor bietet eine nochmals höhere Auflösung von 6144 × 3456 Pixeln als die bisher von LG angebotenen Ultrafine-5K-Modelle. Derzeit bietet nur Dells UltraSharp U3224KBA diese Auflösung. Die Pixeldichte steigt auf 224 Pixel pro Zoll (ppi) – 60 Prozent mehr als bei gleich großen 4K-Modellen (3840 × 2160 Pixel). LG setzt ein eigenes Panel vom Typ Nano IPS Black ein, das dunklere Schwarzwerte und damit höhere Kontraste erreicht als klassische IPS-Panels. Die Farbraumabdeckung mit 10-Bit-Abstufung pro Farbkanal beziffert LG auf 99,5 Prozent Adobe RGB sowie 98 Prozent DCI-P3. Der Hersteller kalibriert das Display ab Werk.

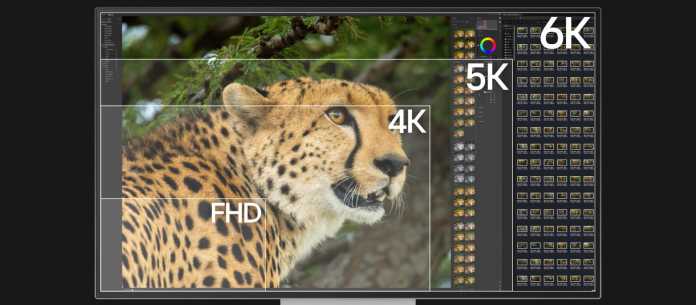
So viel zusätzliche Bildfläche haben Nutzer durch die 6K-Auflösung.
(Bild: LG)
Über längere Zeit schafft die Hintergrundbeleuchtung flächendeckend 450 cd/m². Kurzfristig sind bis zu 600 cd/m² möglich, womit der Monitor die Anforderung für VESA DisplayHDR 600 erfüllt. Der Standfuß ist höhenverstellbar, zudem lässt sich das Display um 90 Grad drehen (Pivot).
Als Gaming-Monitor ist der Bildschirm aufgrund seiner Bildwiederholrate von 60 Hertz weniger geeignet. LG macht in seiner Ankündigung ohnehin deutlich, dass er vor allem für Grafik- und Videobearbeitung geeignet sei. Laut LG ist der Bildschirm unter anderem durch einen Studio-Modus mit drei voreingestellten Farboptionen für Mac-Geräte geeignet.
Highspeed-Hub mit Thunderbolt 5
Anschlussseitig kommt der UltraFine evo 32U990A mit zweimal Thunderbolt 5 (inklusive Displayport 2.1 und einmal 96-Watt-Laden), HDMI 2.1, Displayport 2.1 und dreimal USB 3.2 Gen 2 (10 Gbit/s). Einer der beiden Thunderbolt-Anschlüsse und zwei USB-Ports dienen als Hub: Per Thunderbolt können Nutzer etwa ein weiteres Display verbinden (Daisy Chain) oder eine eGPU beziehungsweise SSD anschließen, an die normalen USB-Ports zum Beispiel Peripherie oder einen Ethernet-Adapter. Wer kein Thunderbolt oder das eng verwandte USB4 hat, kann den dritten USB-C-Anschluss als Upstream für den USB-Hub verwenden. Ein integrierter KVM-Switch erlaubt den Wechsel zwischen Bildquellen mit derselben angeschlossenen Peripherie.
Mit dem L-förmigen Standfuß lässt sich der Monitor kippen als auch in der Höhe verstellen. Außerdem lässt sich das Display um 90 Grad drehen (Pivot), etwa um lange Tabellen zu bearbeiten oder YouTube-Shorts anzusehen beziehungsweise zu bearbeiten. Alternativ kann der Monitor mittels VESA-Halterung (100 × 100 mm) auch an Standfüße und Monitorarme von Drittherstellern angebracht werden.

Das LG-Ultrafine-6K-Display bietet verschiedene ergonomische Anpassungsoptionen.
(Bild: LG Display)
Während der Bildschirm in einigen Ländern bereits verfügbar ist, soll er in Deutschland gegen Ende Oktober in den Handel kommen. Preislich ist er mit einer unverbindlichen Preisempfehlung von 2000 Euro günstiger als Dells UltraSharp U3224KBA, der mit einer UVP um die 2900 Euro gestartet war, mittlerweile aber für etwa 2200 Euro zu haben ist.
(afl)
Künstliche Intelligenz
Fotografie: Historische Meilensteine im Objektivbau
Die ersten fotografischen Objektive hatten mit vielen Abbildungsfehlern zu kämpfen, die in modernen Modellen keine wesentliche Rolle mehr spielen. Um zu dieser hervorragenden Schärfe, klaren Kontrasten und geringen bis nicht erkennbaren Farbrändern zu gelangen, war es jedoch ein langer Weg.
Wo wir heute komplizierte Mathematik mit der Hilfe von Computern lösen und mit modernen Verfahren komplizierte Linsenformen fertigen, erledigte man früher die Rechenarbeit mit Papier und Stift und durch präzise Handarbeit.
Begleiten Sie mich durch die spannende Zeit der Entwicklung herausragender Fotoobjektive. Lernen Sie die wichtigsten Konstruktionen von Linsensystemen kennen und die Pioniere, denen wir diese verdanken.
Das war die Leseprobe unseres heise-Plus-Artikels „Fotografie: Historische Meilensteine im Objektivbau“.
Mit einem heise-Plus-Abo können Sie den ganzen Artikel lesen.

Amazon überarbeitet seinen Cloud-Gaming-Dienst Luna und setzt auf Partyspiele

3 statt 2 Jahre: Asus erweitert Garantie für Consumer- & Gaming-Notebooks

UltraFine evo 32U990A: LGs 6K-Monitor mit Thunderbolt 5 kommt im Oktober

Der ultimative Guide für eine unvergessliche Customer Experience

Adobe Firefly Boards › PAGE online
eine gute Nachricht ist")
Relatable, relevant, viral? Wer heute auf Social Media zum Vorbild wird – und warum das für Marken (k)eine gute Nachricht ist
-
 UX/UI & Webdesignvor 1 Monat
UX/UI & Webdesignvor 1 MonatDer ultimative Guide für eine unvergessliche Customer Experience
-
 UX/UI & Webdesignvor 1 Monat
UX/UI & Webdesignvor 1 MonatAdobe Firefly Boards › PAGE online
-
eine gute Nachricht ist") Social Mediavor 1 Monat
Social Mediavor 1 MonatRelatable, relevant, viral? Wer heute auf Social Media zum Vorbild wird – und warum das für Marken (k)eine gute Nachricht ist
-

 Entwicklung & Codevor 1 Monat
Entwicklung & Codevor 1 MonatPosit stellt Positron vor: Neue IDE für Data Science mit Python und R
-

 Entwicklung & Codevor 4 Wochen
Entwicklung & Codevor 4 WochenEventSourcingDB 1.1 bietet flexiblere Konsistenzsteuerung und signierte Events
-

 UX/UI & Webdesignvor 2 Wochen
UX/UI & Webdesignvor 2 WochenFake It Untlil You Make It? Trifft diese Kampagne den Nerv der Zeit? › PAGE online
-

 Digital Business & Startupsvor 3 Monaten
Digital Business & Startupsvor 3 Monaten10.000 Euro Tickets? Kann man machen – aber nur mit diesem Trick
-

 Apps & Mobile Entwicklungvor 2 Monaten
Apps & Mobile Entwicklungvor 2 MonatenFirefox-Update 141.0: KI-gestützte Tab‑Gruppen und Einheitenumrechner kommen