Künstliche Intelligenz
Was Wi-Fi 8 bringt: Neue Funktionen für stabileres WLAN
Schon zur Fachmesse CES Anfang 2024 begann die Herstellervereinigung Wi-Fi Alliance (WFA) Wi-Fi-7-Produkte zu zertifizieren und zu vermarkten, doch erst ein halbes Jahr später schloss das Institute of Electrical and Electronics Engineers (IEEE) die Arbeiten an der Wi-Fi 7 zugrunde liegenden Norm 802.11be ab. Die finale, 1020 Seiten starke Fassung erschien im Sommer 2025. Das ist nur der Wi-Fi 7 betreffende Teil des WLAN-Standards, der Rest für alles andere steckt in den 5956 Seiten von 802.11-2024.
Damit ist Wi-Fi 7 endlich offiziell, doch schon im Januar 2022 begannen Mitarbeiter führender WLAN-Firmen – darunter Qualcomm, MediaTek, Huawei, Broadcom und Samsung – laut nachzudenken, welche Neuerungen auf IEEE 802.11be folgen könnten. So nahm im September 2022 die Ultra High Reliability Study Group (UHR SG) ihre Arbeit auf und formulierte eine Beschreibung des Projekts IEEE P802.11bn. Seit November 2023 arbeitet die Task Group bn (TGbn) an einer Norm für das, was laut gewöhnlich gut unterrichteten Kreisen ab der CES 2028 von der WFA als Wi-Fi 8 vermarktet werden soll. Der erste Entwurf (Draft 1.0) mit 502 Seiten Umfang erschien im August 2025.
- Wi-Fi 8 bringt nur einen moderaten Geschwindigkeitssprung, dafür aber zuverlässigere Funkverbindungen und mehr Spektrumeffizienz.
- Mit Seamless Mobility Domain können Clients mit mehreren Basen gleichzeitig verbunden sein, Roamingaussetzer adé.
- Distributed Resource Units und Enhanced Long Range steigern die Reichweite für Internet-of-Things-Geräte.
Weil auch IEEE 802.11 den Regeln der Physik unterliegt, beschränken sich die „ultrahohen“ Verbesserungen darauf, gegenüber Wi-Fi 7 die Verzögerung und den Paketverlust um ein Viertel zu reduzieren sowie die maximale Übertragungsgeschwindigkeit um ein Viertel zu erhöhen. Im Alltag viel wichtiger ist, dass Wi-Fi 8 das WLAN zuverlässiger machen soll.
Das war die Leseprobe unseres heise-Plus-Artikels „Was Wi-Fi 8 bringt: Neue Funktionen für stabileres WLAN“.
Mit einem heise-Plus-Abo können Sie den ganzen Artikel lesen.











Künstliche Intelligenz
KI und Wettbewerb: Kommission soll Wirtschaftsministerium beraten
An Kommissionen zu Fragen der Künstlichen Intelligenz herrschte in der Vergangenheit bereits kein Mangel. Heute nimmt eine weitere ihre Arbeit auf, die der Bundeswirtschaftsministerin Katherina Reiche (CDU) und der Bundesregierung mit ihren Ratschlägen weiterhelfen soll. „Wir müssen KI nicht nur verstehen, sondern sie mit Mut und Gestaltungswillen voll annehmen – als Chance für Wohlstand, Wachstum und Fortschritt“, lässt sich Reiche zitieren. „Entscheidend dafür sind ein funktionierender Wettbewerb und die richtige Einstellung: Wir müssen uns zutrauen, vorne mitzuspielen, unsere Stärken konsequent nutzen und uns im globalen Wettbewerb behaupten.“ Doch davon scheint die Bundesrepublik bislang eher weiter entfernt, weshalb Beratung durch Experten vielleicht gar keine schlechte Idee ist.
Weiterlesen nach der Anzeige
In einem Pressegespräch sortierten zwei der drei Vorsitzenden denn auch gleich, was die 15-köpfige Kommission leisten könnte – und auch, was nicht. Aus seiner Sicht gehe es darum, hier nicht primär aus Endanwenderperspektive auf die Thematik zu schauen, sagt der Vorsitzende Rupprecht Podszun, Wettbewerbsrechtler an der Universität Düsseldorf. Es gehe um die Bedeutung auf allen Ebenen. Ein stärkeres Gewicht müsse dabei auf die Frage gelegt werden, wie Abhängigkeiten aufgebrochen werden könnten – der Amazon-Cloud-Vorfall habe das zuletzt erst wieder illustriert, wie problematisch solche Einzelanbieterabhängigkeiten sein können.
Zwischen Schatzsuche und Wettbewerbsrecht
Dass beim Thema KI die Messe längst gelesen sei, das glaubt der Ko-Vorsitzende Rolf Schumann nicht. Das Rennen habe zwar begonnen, sei aber noch überhaupt nicht gelaufen, sagt Ko-Geschäftsführer bei Schwarz Digits, dem deutschen IT-Hoffnungsträger, der aus dem Kaufland-Lidl-Universum entsprang. „Wir haben in Deutschland ganz, ganz viel Expertenwissen“, sagt er. Für US-Hyperscaler wäre es genau deshalb so interessant, an die Daten des Mittelstandes zu kommen. Dieser Schatz müsse gehoben werden, aber ohne ihn aus den eigenen Händen zu geben, meint Schumann. Welche Rolle dabei genau das Wettbewerbsrecht spielen kann, soll die Kommission herausfinden. Zuletzt war hier eine Art Durchsetzungs-Duopol entstanden, bei dem die EU-Kommission den Digital Markets Act (DMA) und das Bundeskartellamt in Bonn das Gesetz gegen Wettbewerbsbeschränkungen (GWB) parallel, aber nicht einheitlich anwandten.
Lesen Sie auch
Wie viel die Kommission mit insgesamt 15 Mitgliedern in und zwischen ihren fünf Sitzungen wirklich zu den vielen vorhandenen und ineinander verschränkten Problemstellungen beitragen kann, ist offen. Zur Gruppe gehört eine Mischung aus Wissenschaftlern und Unternehmern – etwa Siemens-Vorstand Cedrik Neike, Start-up-Verband-Chefin Verena Pausder und KI-Professor Björn Ommer –, aber keine zivilgesellschaftlichen Vertreter. Es gehe jedenfalls nicht darum, dass „die Fördergießkanne rausgeholt werde“ und auch die regulatorische Gesamtlandschaft werde mit dieser Kommission kaum zu überarbeiten sein. Vielmehr gehe es um marktgängige Lösungen und einzelne Akzente, sagt Rupprecht Podszun. So könnten Hinweise der Kommission etwa im Beschaffungsrecht eine nachhaltigere Wirkung erzielen, hofft der Jurist.
Schwarz-Digits-Chef: „Großer Fan von Regulierung“
Weiterlesen nach der Anzeige
Für intensivere Diskussionen, auch mit Wirtschaftsministerin Katherina Reiche und ihrem Parteikollegen Digitalminister Karsten Wildberger, könnte unterdessen ein anderer Punkt sorgen. Er sei ein „großer Fan von Regulierung“, erläutert Schwarz-Digits-Geschäftsführer Schumann. Denn es gebe „kaum Technologien, die keine Dual-Use-Problematik haben.“ Er sehe allerdings große Probleme dabei, mit dem bisherigen Rechtsrahmen KI adäquat zu regulieren: Die bedinge nun einmal, dass es „in bestimmten Bereichen eine Blackbox gibt“, weshalb es nur darum gehen könne, die Ergebnisse zu regulieren.
Drei Wochen vor dem deutsch-französischen Souveränitätsgipfel, der zuletzt auch international für einige Aufmerksamkeit sorgte und angeblich in Washington mit Argusaugen betrachtet wird, hoffen beide darauf, dass Europas Staaten, aber auch Unternehmen die Zeichen der Zeit erkennen und beim KI-Thema die notwendigen Schritte gehen würden. „Wovor haben wir Angst?“, fragt Schumann. „Wir haben die entsprechende Wirtschaftskraft, wenn wir es auf die Straße bringen.“
(afl)
Künstliche Intelligenz
HyperOS 3: Xiaomi verpasst der 15T-Serie das große Update – weitere folgen
Mit Xiaomi hat der nächste große Smartphone-Hersteller nach Google, Samsung und Sony damit begonnen, sein großes Update auf HyperOS 3 für erste Smartphones zu verteilen. Kurios ist, dass Xiaomi nicht explizit schreibt, dass der OS-Aufsatz auf Android 16 basiert.
Weiterlesen nach der Anzeige
Xiaomi hat über die Social-Media-Plattform X den globalen Start seines neuen Betriebssystems HyperOS 3 angekündigt. Zuerst erhalten die Modelle der 15T-Serie, bestehend aus dem Xiaomi 15T und dem Xiaomi 15T Pro, das Update. Laut Hersteller sollen zeitnah weitere Geräte das Update erhalten; neben Modellen der Xiaomi-15-Serie gehören auch Smartphones und Tablets der Redmi-Familie dazu.

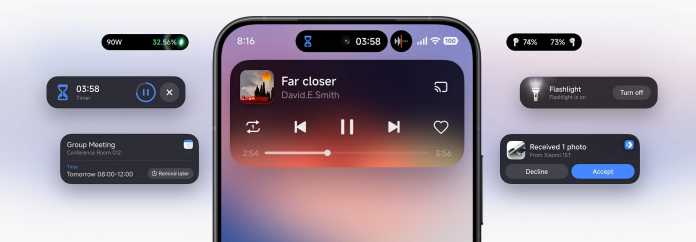
Xiaomis „HyperIsland“ erinnert stark an Apples Dynamic Island.
(Bild: Xiaomi)
Laut Hersteller soll HyperOS 3 den Start von Apps beschleunigen, die durchschnittliche Auslastung der Grafikeinheit reduzieren als auch die Gaming-Performance erhöhen. Überdies spricht Xiaomi von einem geringeren Stromverbrauch beim Videos-Abspielen sowie einer flüssigeren Bedienung, begleitet von längerer Akkulaufzeit.
Lesen Sie auch
Zudem hat Xiaomi die Bedienoberfläche überarbeitet, die unter anderem mit neuen Icons und einer „HyperIsland“ aufwartet, die stark an Apples Dynamic Island erinnert. In der Insel können etwa aktive Anrufe, Musik, Navigation, Timer oder Termin-Erinnerungen und mehr angezeigt und mit ihnen interagiert werden. Auch der umfangreich anpassbare Sperrbildschirm mutet ein wenig an iOS-inspiriert an.

HyperOS 3 enthält unter anderem neuen Funktionen zum besseren Datenaustausch mit Apple-Geräten.
(Bild: Xiaomi)
Überdies sind in HyperOS 3 zahlreiche Funktionen wie Touch-to-Share oder App-Support für iPads an Bord, mit denen Nutzer besser mit Apples Ökosystem kommunizieren können. Zudem sind viele KI-Features an Bord – als KI-Assistenten setzt der Hersteller auf Googles Gemini.
Weiterlesen nach der Anzeige
HyperOS 3 für viele Xiaomi-Modelle
Xiaomi plant, viele weitere Modelle bis in den März 2026 mit HyperOS 3 zu versorgen. Zwischen Oktober und November sollen nach der 15T-Serie die Topmodelle des ersten Halbjahres wie das Xiaomi 15 Ultra das Update erhalten; auch das Foldable Mix Flip sowie Tablets wie das Pad Mini und die Pad-7-Modelle sind laut Hersteller früh an der Reihe.
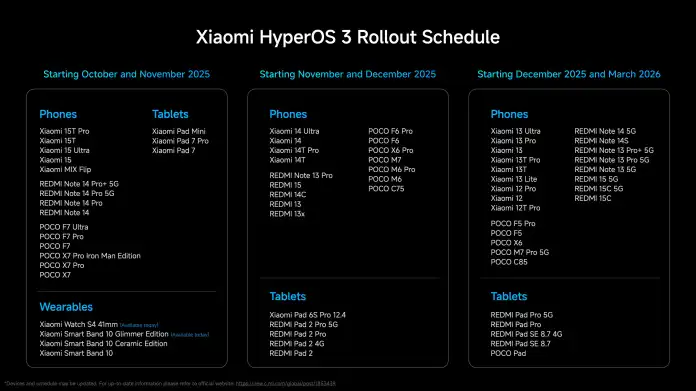
HyperOS 3: Diese Geräte erhalten laut Xiaomi den neuen Android-Aufsatz.
(Bild: Xiaomi)
In der zweiten Release-Welle zwischen November und Dezember will Xiaomi seine 14er Serie auf den aktuellen Stand bringen, genauso wie einige Redmi-Modelle und weitere Tablets. Zuletzt sollen dann die Xiaomi-13- und -12er-Serie HyperOS 3 bekommen. Auch weitere Redmi-Geräte wie das Note 14 5G, 15 5G sowie Poco-Smartphones und diverse Tablets der Redmi-Familie sollen bis Ende März 2026 mit dem Update versorgt werden.
Lesen Sie auch
Eine Anfrage an Xiaomi, ob HyperOS 3 für alle Modelle auf Google Android 16 basieren wird, hat der Hersteller bis zur Veröffentlichung des Artikels nicht beantwortet. In seiner Ankündigung zu HyperOS 3 verlor der Hersteller kein Wort darüber, welche Android-Version zum Einsatz kommt. Dass Xiaomi Android 16 bei einigen Geräten verwenden wird, ist seit Monaten ersichtlich, denn Google sagte schon im Mai, dass der Hersteller die mit dem Update angekündigte Live-Update-Funktion integrieren wird.
(afl)
Künstliche Intelligenz
VDA fordert Ladepflicht für Plug-in-Hybride
Das unbenutzte Ladekabel im Kofferraum des Plug-in-Hybridautos (PHEV) war jahrelang sprichwörtlich. Nun häufen sich die Beweise dafür, dass es sich dabei nicht um eine haltlose Übertreibung handelt. PHEV überschreiten ihre CO₂-Emissionswerte offenbar so eklatant, dass sich die Autoindustrie Sorgen über den Fortbestand der bei den Kunden beliebten Mischform aus Elektro- und konventionellem Auto machen muss. Nachdem aktuelle Erhebungen aus dem Realbetrieb gezeigt haben, wie weit deren vermutete Umweltvorteile verfehlt werden, reagiert der deutsche Branchenverband der Autoindustrie VDA jetzt mit einem Vorschlag. Man wolle die Fahrer mit technischen Lösungen dazu bringen, weitere Strecken elektrisch zurückzulegen.
Weiterlesen nach der Anzeige
Plug-in-Hybride emittieren eklatant zu viel
Erkenntnissen der Nichtregierungsorganisation „Transport and Environment“ (T&E) und der europäischen Umweltbehörde EEA zufolge emittieren diese Fahrzeuge rund die fünffache Menge an Kohlendioxid, mit der sie homologiert wurden. Das ist ein Vielfaches der für Verbrenner im Realbetrieb typischen Überschreitungen, die in der Regel nur um einige Prozent vom Prüfstandwert abweichen. Eine Messung ist erst möglich, seit die Hersteller den Verbrauch fahrzeugindividuell erfassen müssen. T&E konnte sich daher auf reale Fahrdaten von 127.000 Autos stützen, eine Stichprobe von bisher unerreichter Größe.
Dass PHEV in der Anrechnung ihrer CO₂-Minderung zu positiv beurteilt worden waren, galt auch bei der EU schon lange als Tatsache, die Termine für eine Verschärfung der Regeln sind daher längst gesetzt. So soll kommendes Jahr der sogenannte Utility Factor für die Berechnung der CO₂-Flottenemissionen verschärft werden. Demnach soll etwa die Bemessungsgrundlage für die CO₂-Emissionen in zwei Stufen eine deutlich größere elektrische Reichweite erfordern. Ab Anfang 2026 muss sie für Neufahrzeuge rund um das Zwei- bis Dreifache, 2027 auf das Vierfache des heutigen Werts steigen. Mindestens so angsterregend für die Hersteller dürfte die Aussicht auf einen Ersatz des bislang nur auf dem Prüfstand ermittelten CO₂-Ausstoßes durch eine realistischere Einstufung sein. Denn damit droht der mühsam erreichte Flottenverbrauch außer Reichweite zu geraten, mit deutlich höheren Kosten für die schärferen Ziele und milliardenteuren Strafen im Falle einer Verfehlung.
Hintertür für die Autoindustrie
Bislang war die milde Behandlung solcher Autos eine Hintertür für die Autoindustrie, durch die sie weiter eine große Menge an Verbrennungsantrieben verkaufen konnte. In Deutschland werden als Dienstwagen eingesetzte PHEV mit bestimmten Leistungsmerkmalen bis zu einer Preisgrenze sogar steuerlich gefördert. Der kurzzeitige Erfolg der PHEV ist ganz weitgehend nicht durch technische Vorteile gegenüber Elektroautos, sondern vielmehr durch gezielte Anreize erklärbar. Die Neuzulassungszahlen der PHEV stiegen in Deutschland von Januar bis September um 64 Prozent, in Europa waren es im Jahresvergleich für den August über 54 Prozent Zuwachs, während Autos mit Verbrennungsmotoren deutschland- und EU-weit zweistellige Einbußen verzeichnen. Für die durch die Antriebswende gebeutelte Autoindustrie sind Plug-in-Hybride derzeit also die fetteste Cashcow.
Konkret regt der VDA etwas überraschend an, diese Autos so zu konzipieren, „dass regelmäßiges Laden verpflichtend ist.“ So könnte man durch eine verminderte Leistungsabgabe erzwingen, dass die Batterie „innerhalb einer noch festzulegenden Fahrstrecke“ mindestens einmal aufgeladen werde.
Weiterlesen nach der Anzeige
(fpi)

KI und Wettbewerb: Kommission soll Wirtschaftsministerium beraten

Meine 3 besten Tipps bei Selbstzweifel

KI-Spot von Jung von Matt: Mit diesem Horror-Werbefilm warnt Sixt zu Halloween vor der Konkurrenz

Der ultimative Guide für eine unvergessliche Customer Experience

Adobe Firefly Boards › PAGE online
eine gute Nachricht ist")
Relatable, relevant, viral? Wer heute auf Social Media zum Vorbild wird – und warum das für Marken (k)eine gute Nachricht ist
-
 UX/UI & Webdesignvor 2 Monaten
UX/UI & Webdesignvor 2 MonatenDer ultimative Guide für eine unvergessliche Customer Experience
-
 UX/UI & Webdesignvor 2 Monaten
UX/UI & Webdesignvor 2 MonatenAdobe Firefly Boards › PAGE online
-
eine gute Nachricht ist") Social Mediavor 2 Monaten
Social Mediavor 2 MonatenRelatable, relevant, viral? Wer heute auf Social Media zum Vorbild wird – und warum das für Marken (k)eine gute Nachricht ist
-

 Entwicklung & Codevor 2 Monaten
Entwicklung & Codevor 2 MonatenPosit stellt Positron vor: Neue IDE für Data Science mit Python und R
-

 Entwicklung & Codevor 2 Monaten
Entwicklung & Codevor 2 MonatenEventSourcingDB 1.1 bietet flexiblere Konsistenzsteuerung und signierte Events
-

 UX/UI & Webdesignvor 1 Monat
UX/UI & Webdesignvor 1 MonatFake It Untlil You Make It? Trifft diese Kampagne den Nerv der Zeit? › PAGE online
-

 UX/UI & Webdesignvor 1 Woche
UX/UI & Webdesignvor 1 WocheIllustrierte Reise nach New York City › PAGE online
-

 Apps & Mobile Entwicklungvor 2 Monaten
Apps & Mobile Entwicklungvor 2 MonatenGalaxy Tab S10 Lite: Günstiger Einstieg in Samsungs Premium-Tablets