Künstliche Intelligenz
Blaues Blütenmeer überzeugt: Gewinner des c’t Fotografie-Wettbewerbs stehen fest
Die Redaktion der c’t Fotografie gratuliert den Gewinnern des c’t Fotografie-Fotowettbewerbs. Unter dem Motto „Die Farbe Blau“ haben registrierte Nutzer der heise-Fotogalerie ihre Interpretationen des Themas eingereicht und einander bewertet.
Weiterlesen nach der Anzeige


Leberblümchen im Bokeh-Rausch
Den ersten Platz und damit ein 2-Jahres-Abo der c’t Fotografie sicherte sich Nutzer Finn (3) mit seinem Bild Blaues Blütenmeer. Die Aufnahme zeigt eine Hepatica nobilis – ein Leberblümchen – vor einem verschwommenen, harmonischen Hintergrund in einem faszinierenden Spiel aus Licht und Schatten.

(Bild: Finn (3))
Architektur und Experiment auf den Podiumsplätzen
Platz zwei geht an Karsten Gieselmann für sein Werk Treppenhaus Blues. Die architektonische Aufnahme weckte bei manchen Betrachtern Assoziationen an ein Auge – ein Beweis für die vielschichtige Wirkung des Motivs.

(Bild: Karsten Gieselmann)
Den dritten Platz holte sich rrh_007 mit Experiment – einer kreativen Umsetzung eines klassischen Schulversuchs. Das Bild zeigt eine ursprünglich weiße Tulpe, die durch das Aufsaugen von blauem Wasser ihre Farbe verändert hat und so Wassertransport in Pflanzen sichtbar macht.
Weiterlesen nach der Anzeige

(Bild: rrh_007)
Vielfalt auf den weiteren Plätzen
Die Plätze vier bis zehn zeigen die thematische Bandbreite der Einsendungen: von detailreichen Quallen über Eisformationen bis zu Meereslandschaften mit Treibholz. Auch Aufnahmen, bei denen Menschen auf individuelle Weise mit blauem Licht interagieren, haben die Community überzeugt.
Die Gewinner der Plätze zwei und drei erhalten jeweils einen Bildband. Alle zehn bestplatzierten Bilder werden in der Ausgabe 02/26 der c’t Fotografie vorgestellt. Die vollständige Übersicht aller eingereichten Werke finden Sie in der Bilderstrecke:

Platz 10: Blaupause von Hora42
Hora42
)
(cbr)




![Neu in .NET 10.0 [12]: Mehr Konvertierungen für Spans in C# 14.0](https://i2.wp.com/heise.cloudimg.io/bound/1200x1200/q85.png-lossy-85.webp-lossy-85.foil1/_www-heise-de_/imgs/18/5/0/3/5/8/0/7/csharp_sign-880ad48e29751852.jpg?w=400&resize=400,240&ssl=1 "Neu in .NET 10.0 [12]: Mehr Konvertierungen für Spans in C# 14.0")
![Neu in .NET 10.0 [12]: Mehr Konvertierungen für Spans in C# 14.0](https://i2.wp.com/heise.cloudimg.io/bound/1200x1200/q85.png-lossy-85.webp-lossy-85.foil1/_www-heise-de_/imgs/18/5/0/3/5/8/0/7/csharp_sign-880ad48e29751852.jpg?w=80&resize=80,80&ssl=1 "Neu in .NET 10.0 [12]: Mehr Konvertierungen für Spans in C# 14.0")






Künstliche Intelligenz
Mondprogramm Artemis: NASA plant zusätzlichen Start im kommenden Jahr
Die NASA schichtet das Mondprogramm Artemis um und will im kommenden Jahr eine zusätzliche Mission starten, auf der keine Mondlandung vorgesehen ist. Die soll weiterhin erst 2028 erfolgen, dann aber nicht auf Artemis-3, sondern bei Artemis-4, teilte die US-Weltraumagentur jetzt mit. Möglicherweise könnte in dem Jahr sogar noch Artemis-5 gestartet werden. Im kommenden Jahr soll die Raumkapsel Orion nun im Weltraum mit einer oder gar zwei Mondlandern der Raumfahrtunternehmen SpaceX und Blue Origin gekoppelt werden, um das ausgiebig zu testen. Zudem sollen dabei die neuen Weltraumanzüge unter realen Bedingungen zum Einsatz kommen. Insgesamt bedeutet das auch, dass die Riesenrakete SLS (Space Launch System) öfter starten soll als bislang geplant.
Weiterlesen nach der Anzeige
China macht Druck
Vorgestellt hat die NASA die überarbeiteten Pläne am Freitag bei einer Pressekonferenz, auf der es eigentlich um Artemis-2 gehen sollte. Auf der zweiten Mission des Artemis-Programms sollen zum ersten Mal seit mehr als 50 Jahren wieder Menschen zum Mond fliegen, den sollen sie aber nur umrunden. Wegen eines bei der Generalprobe entdeckten Helium-Lecks musste die Rakete aber wieder zurück in das riesige Vehicle Assembly Building, wo nach der Ursache gefahndet wird. Wie lange das dauert, ist noch unklar, aber ein nächster Anlauf wird frühestens im April in Angriff genommen. Wenn der Start gelingt, will die NASA damit jährlich stattfindende Flüge zum Mond einleiten.
Die deutlich höhere Schlagzahl bei der Rückkehr der USA zum Mond begründet der neue NASA-Chef Jared Isaacman auch mit der „glaubhaften Konkurrenz unseres größten geopolitischen Gegners“, womit er China meint. Das Raumfahrtprogramm der Volksrepublik wird immer ambitionierter.
Erst einmal steht aber jetzt Artemis-2 an, der Start dafür war eigentlich schon für den 6. Februar geplant. Das konnte aber schon nicht eingehalten werden. Die Crew besteht aus Reid Wiseman, Victor Glover und Christina Koch von der NASA sowie dem Kanadier Jeremy Hansen. Auf ihrem zehntägigen Flug sollen sie zuerst die Erde umrunden und dann in Richtung des Erdtrabanten beschleunigen. Für den Flug dorthin sind danach vier Tage veranschlagt. Anfang April könnte die Rakete an mehreren Tagen gestartet werden, das gegenwärtig letzte Startfenster öffnet sich dann am 30. April.
(mho)
Künstliche Intelligenz
ExfilState: Interview mit Fabian Thomas über Seitenkanalangriffe auf ARM-Chips
Der Sicherheitsforscher Fabian Thomas hat im Oktober 2025 ein Paper zu Seitenkanalangriffen auf ARM-CPUs veröffentlicht. Die neuen Seitenkanäle nutzen den Cache der CPU aus, um Informationen zu leaken.
Anstatt wie bei bisherigen ähnlichen Angriffen den in der CPU integrierten Timer zum Messen der Ladeoperationen zu verwenden, greift das Team des CISPA Helmholtz-Zentrums für Informationssicherheit in Saarbrücken auf kleine Programme zurück, die indirekt als Zeitmesser fungieren.
Mit diesen sogenannten Timer-freien Seitenkanälen konnte Thomas minimale Unterschiede im Cache feststellen und etwa Berührungen auf dem Touchscreen nachweisen.
Das war die Leseprobe unseres heise-Plus-Artikels „ExfilState: Interview mit Fabian Thomas über Seitenkanalangriffe auf ARM-Chips“.
Mit einem heise-Plus-Abo können Sie den ganzen Artikel lesen.
Künstliche Intelligenz
Dyson Spot + Scrub AI im Test: Überraschend unspektakulärer Saugroboter
Mit dem Spot + Scrub AI bringt Staubsauger-Experte Dyson endlich wieder einen neuen Saugroboter – mit ausfahrbarer Wischwalze und beutelloser Station.
Dyson ist vor allem für seine kabellosen Akkustaubsauger bekannt. Saugroboter hatte der britische Hersteller zwar bereits vor einigen Jahren im Programm, präsentierte dann aber lange kein neues Modell. Mit dem Spot + Scrub AI meldet sich Dyson nun zurück im Markt der Saug- und Wischroboter.
Für 999 Euro gibt es einen Roboter mit 18.000 Pa Saugleistung, ausfahrbarer Wischwalze, zwei gegenläufigen Seitenbürsten und einer Station mit beutelloser Staubentleerung, Warmwasser-Reinigung und Heißluft-Trocknung. Klingt nach einem soliden Gesamtpaket. Im Alltag zeigt der Dyson Spot + Scrub AI aber auch deutliche Schwächen – hauptsächlich bei der Objekterkennung. Wie gut er wirklich reinigt und ob sich der Preis lohnt, klären wir im Test. Das Testgerät hat uns der Hersteller zur Verfügung gestellt.
Design: Wie gut ist die Verarbeitung des Dyson Spot + Scrub AI?
Der Dyson Spot + Scrub AI misst 373 mm im Durchmesser und 110 mm in der Höhe. Damit ist er spürbar größer als die meisten Konkurrenten: Modelle von Roborock, Dreame oder Ecovacs kommen typischerweise auf rund 350 mm Durchmesser und bleiben teils deutlich unter 100 mm Höhe. Der Dyson wirkt dadurch insgesamt wuchtiger. Die Farbgebung in Schwarz und Blau ist typisch Dyson.
Auffällig ist das ungewöhnliche Bumper-Design: Der Front-Bumper reicht bis auf die Oberseite des Roboters und erstreckt sich über den Home- und Power-Knopf hinweg. Damit nimmt der bewegliche Stoßfänger fast eine Hälfte des Gehäuses ein. Bei anderen Herstellern beschränkt sich der Bumper auf ein Frontschild, das sich nur vorn bewegt. Einen Laserturm auf der Oberseite gibt es nicht – der LiDAR-Sensor sitzt frontal am Gerät. Trotzdem fällt der Roboter mit 110 mm nicht flach aus; als wirklich flach gelten Modelle unter 90 mm.
Dyson Spot + Scrub AI – Bilderstrecke
Dyson Spot + Scrub AI – Bilderstrecke

Dyson Spot + Scrub AI – Bilderstrecke

Dyson Spot + Scrub AI – Bilderstrecke

Dyson Spot + Scrub AI – Bilderstrecke

Dyson Spot + Scrub AI – Bilderstrecke

Dyson Spot + Scrub AI – Bilderstrecke

Dyson Spot + Scrub AI – Bilderstrecke

Dyson Spot + Scrub AI – Bilderstrecke

Dyson Spot + Scrub AI – Bilderstrecke

Dyson Spot + Scrub AI – Bilderstrecke

Dyson Spot + Scrub AI – Bilderstrecke

Dyson Spot + Scrub AI – Bilderstrecke

Dyson Spot + Scrub AI – Bilderstrecke

Dyson Spot + Scrub AI – Bilderstrecke

Dyson Spot + Scrub AI – Bilderstrecke

Dyson Spot + Scrub AI – Bilderstrecke

Dyson Spot + Scrub AI – Bilderstrecke

Dyson Spot + Scrub AI – Bilderstrecke

Dyson Spot + Scrub AI – Bilderstrecke

Dyson Spot + Scrub AI – Bilderstrecke

Dyson Spot + Scrub AI – Bilderstrecke

Dyson Spot + Scrub AI – Bilderstrecke

Dyson Spot + Scrub AI – Bilderstrecke

Dyson Spot + Scrub AI – Bilderstrecke

Dyson Spot + Scrub AI – Bilderstrecke

Dyson Spot + Scrub AI – Bilderstrecke

Dyson Spot + Scrub AI – Bilderstrecke

Dyson Spot + Scrub AI – Bilderstrecke

Dyson Spot + Scrub AI – Bilderstrecke

Dyson Spot + Scrub AI – Bilderstrecke

Dyson Spot + Scrub AI – Bilderstrecke

Dyson Spot + Scrub AI – Bilderstrecke

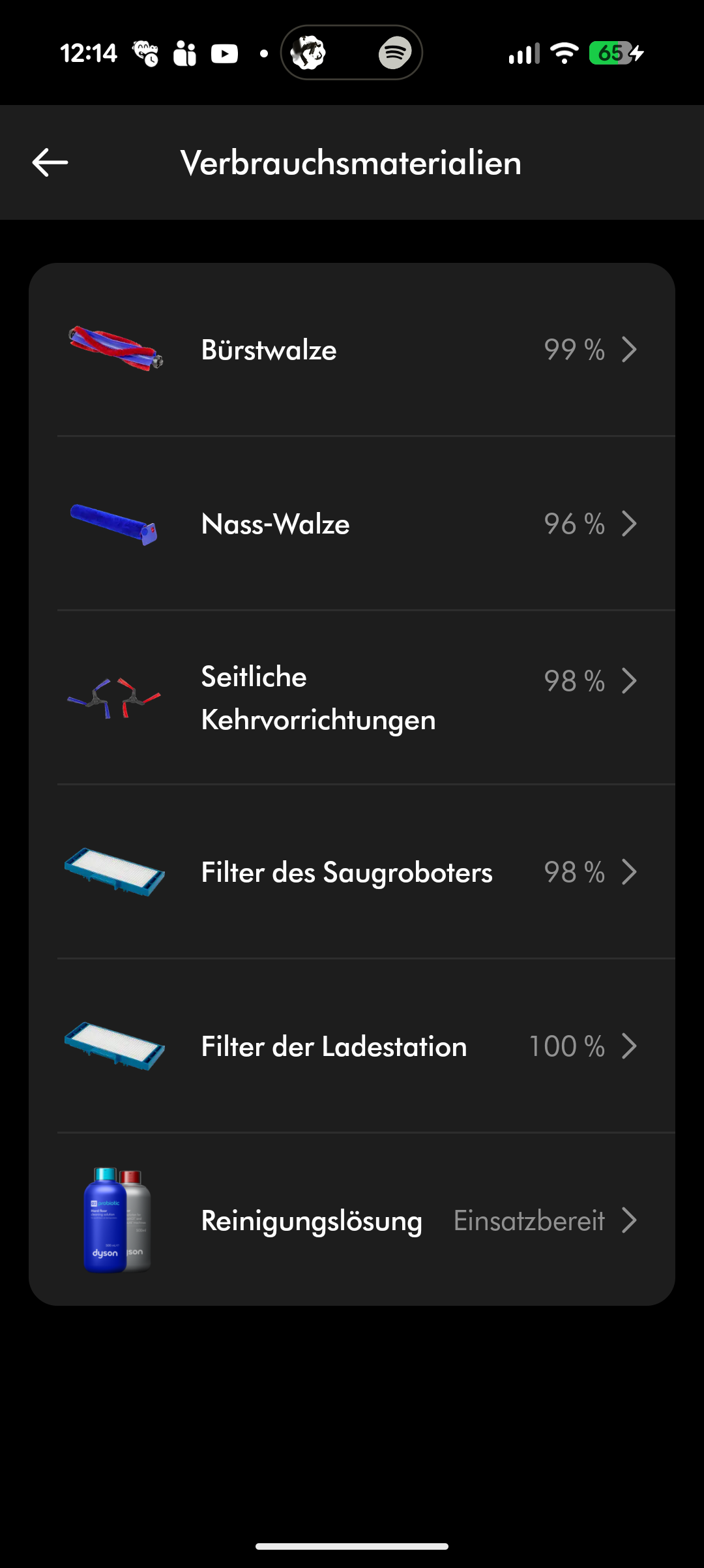
Der Roboter wartet mit durchdachten Details auf. Der Staubbehälter rastet per Druckmechanismus ein: Einmaliges Drücken entriegelt ihn, erneutes Drücken lässt ihn wieder einrasten. Hinten sitzt der durchsichtige Frischwasserbehälter, aus dem der Roboter während der Fahrt die Wischwalze mit Wasser versorgt. Leider lässt sich dieser Tank nicht entnehmen und auch nicht über die App per Pumpe entleeren – zumindest finden wir keine entsprechende Funktion. Darunter befindet sich der ebenfalls durchsichtige Schmutztank, der entnehmbar ist, aber grundsätzlich von der Station sauber gehalten wird. Eine regelmäßige Reinigung von Hand empfiehlt sich zur Beseitigung von Rückständen dennoch.
Die Wischwalze lässt sich durch einen pfiffigen Mechanismus entriegeln und kann über eine Führungsschiene entnommen werden. Zur Reinigung von Hand und einem späteren Austausch der Walze bei Abnutzung ist das sinnvoll und gut gelöst. Auch andere Teile des Roboters lassen sich mit kleinen Hebeln und Knöpfen recht intuitiv herausnehmen und warten.
Die Station misst 440 × 455 × 508 mm und gehört damit zu den eher breiten Vertretern. Zum Vergleich: Die Station des Ecovacs X9 Pro Omni kommt auf nur 338 × 500 × 459 mm. Aufgebaut ist sie aber smart. Der Dyson-typische zylindrische Staubbehälter verfügt über einen hochklappbaren Handgriff mit integriertem Schiebeknopf. Über diesen öffnet sich am Boden eine Klappe zum Entleeren. Allerdings ist dieser Knopf sehr streng zu bedienen – hier wäre ein leichtgängigerer Mechanismus wünschenswert. Das Fassungsvermögen für Staub beträgt 3 Liter.
Einrichtung: Wie schnell ist der Dyson Spot + Scrub AI betriebsbereit?
Die Einrichtung des Dyson Spot + Scrub AI verläuft wie bei den meisten Saugrobotern. Station aufstellen, anschließen, Frischwasser einfüllen, Roboter platzieren und über die MyDyson-App koppeln. Die App führt Schritt für Schritt durch den Prozess und erklärt alles gut verständlich. Wer dennoch Hilfe braucht, kann den telefonischen Concierge-Service von Dyson nutzen. Ein Mitarbeiter leitet dann persönlich durch die Einrichtung – ein Top-Service, den kaum ein anderer Hersteller bietet.
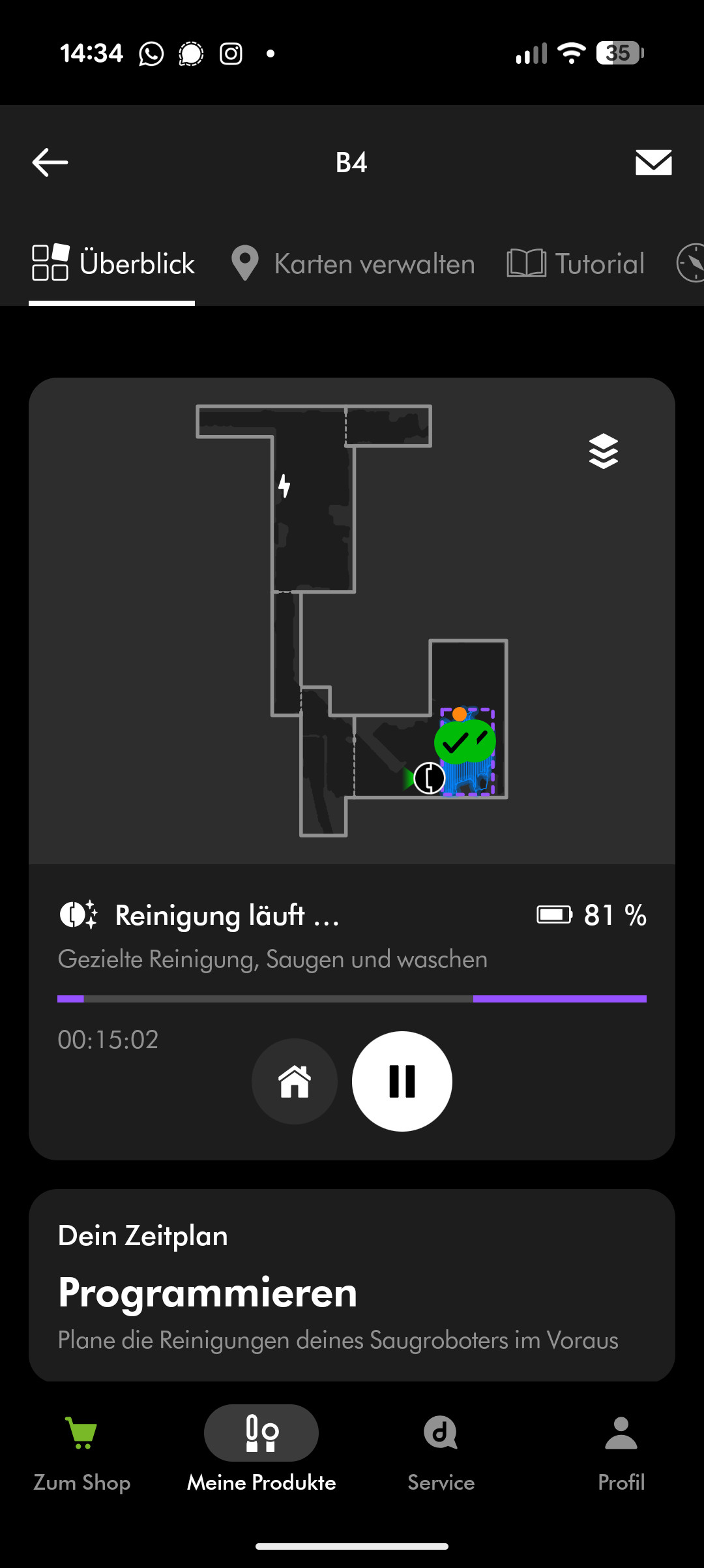
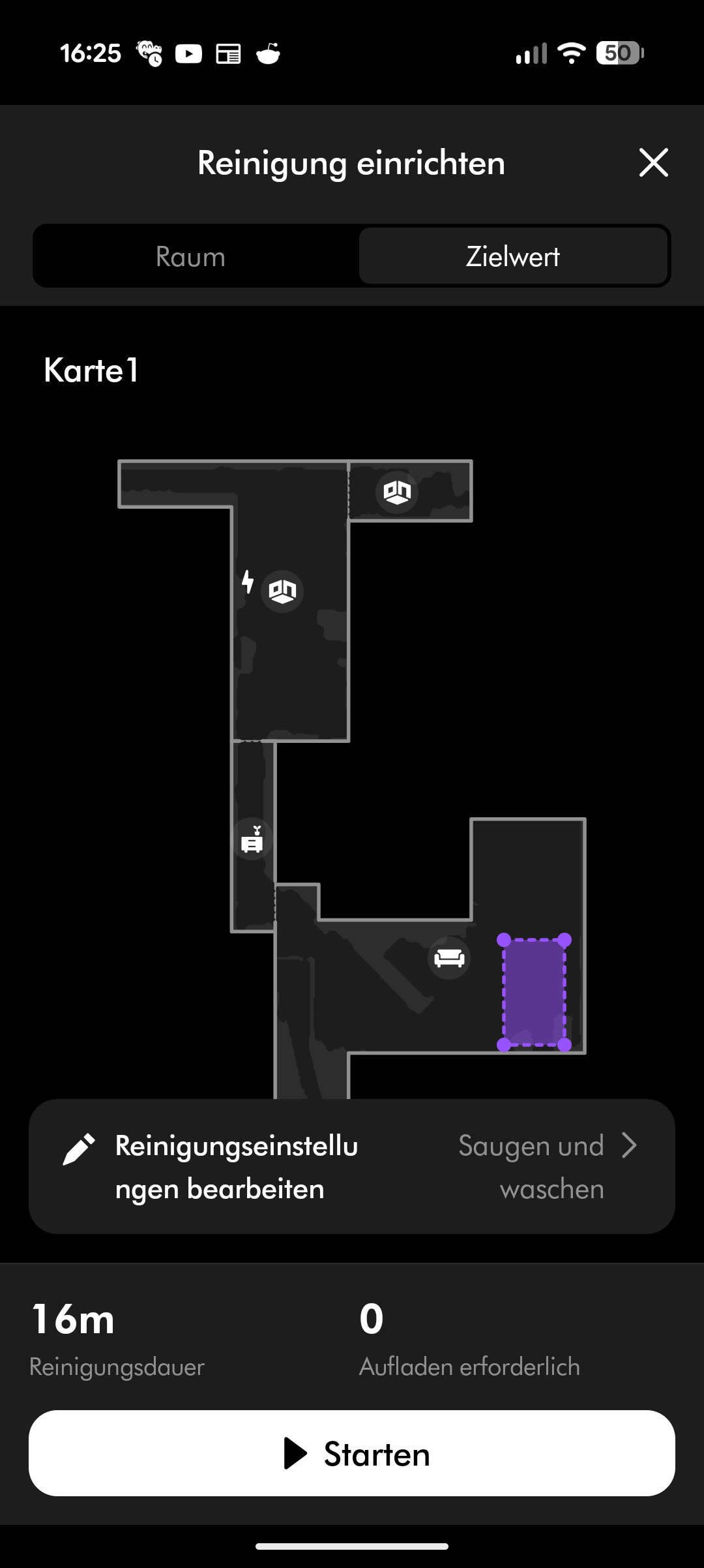
Die MyDyson-App selbst ist recht schick und übersichtlich gestaltet. Allerdings wirken manche Features etwas eigen und stellenweise rudimentär. Saugkraft und Wischleistung anzupassen, erfordert jeweils einen Klick mehr als bei der Konkurrenz. Der Roboter schätzt bei Auswahl einer Zone oder eines Raums die voraussichtliche Reinigungszeit und Quadratmeterzahl – eine nette Funktion, die aber nicht immer akkurat arbeitet. Im Test gab es teils deutliche Abweichungen, insbesondere wenn der Roboter an einzelnen Stellen erhöhtes Schmutzaufkommen feststellte und diese Bereiche nachbehandelte.
Dyson Spot + Scrub AI – App & Einrichtung
Dyson Spot + Scrub AI – App & Einrichtung
Dyson Spot + Scrub AI – App & Einrichtung

Dyson Spot + Scrub AI – App & Einrichtung
Dyson Spot + Scrub AI – App & Einrichtung
Dyson Spot + Scrub AI – App & Einrichtung
Dyson Spot + Scrub AI – App & Einrichtung
Dyson Spot + Scrub AI – App & Einrichtung
Dyson Spot + Scrub AI – App & Einrichtung
Dyson Spot + Scrub AI – App & Einrichtung
Dyson Spot + Scrub AI – App & Einrichtung
Dyson Spot + Scrub AI – App & Einrichtung
Dyson Spot + Scrub AI – App & Einrichtung

Dyson Spot + Scrub AI – App & Einrichtung
Dyson Spot + Scrub AI – App & Einrichtung

Dyson Spot + Scrub AI – App & Einrichtung

Dyson Spot + Scrub AI – App & Einrichtung

Dyson Spot + Scrub AI – App & Einrichtung
Dyson Spot + Scrub AI – App & Einrichtung
Dyson Spot + Scrub AI – App & Einrichtung

Dyson Spot + Scrub AI – App & Einrichtung
Dyson Spot + Scrub AI – App & Einrichtung

Dyson Spot + Scrub AI – App & Einrichtung
Dyson Spot + Scrub AI – App & Einrichtung
Dyson Spot + Scrub AI – App & Einrichtung
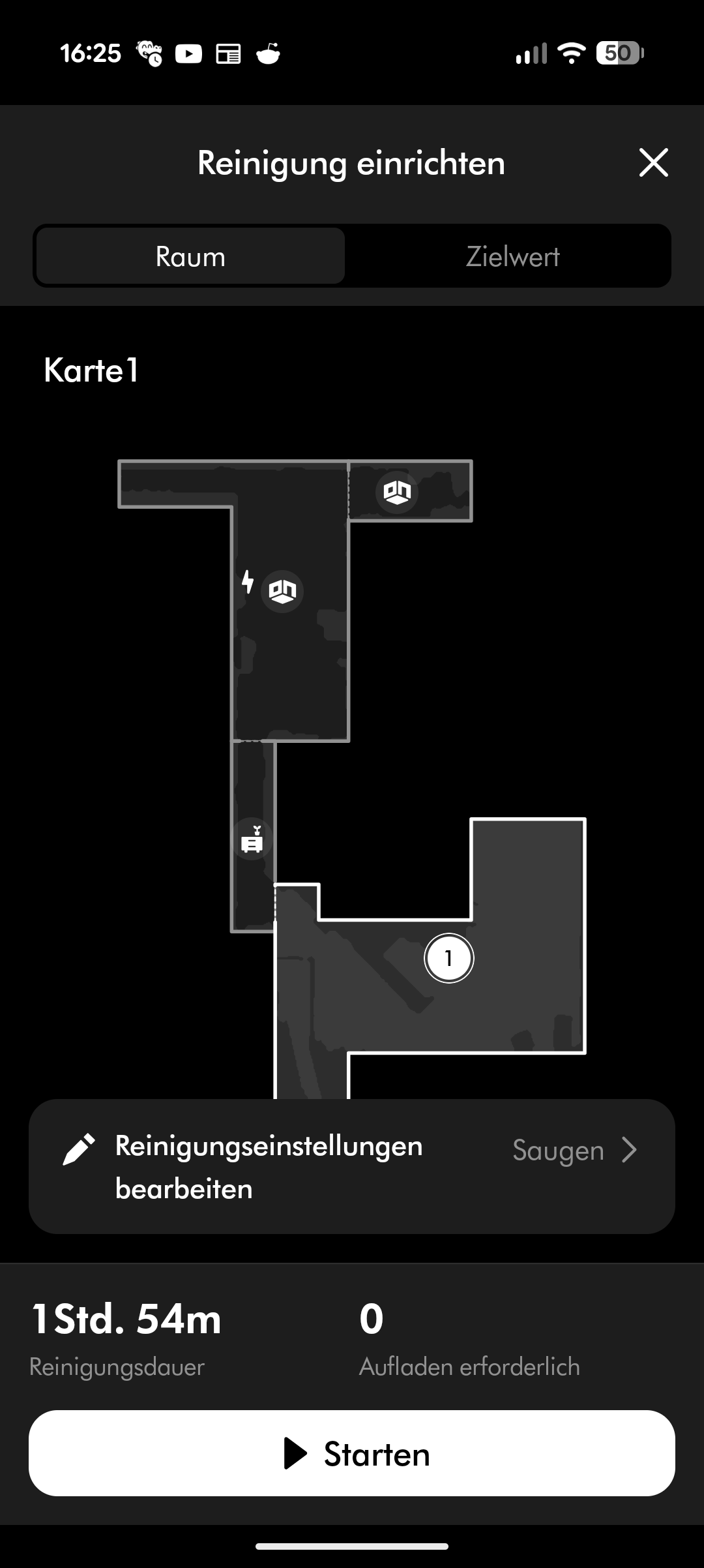
Dyson Spot + Scrub AI – App & Einrichtung
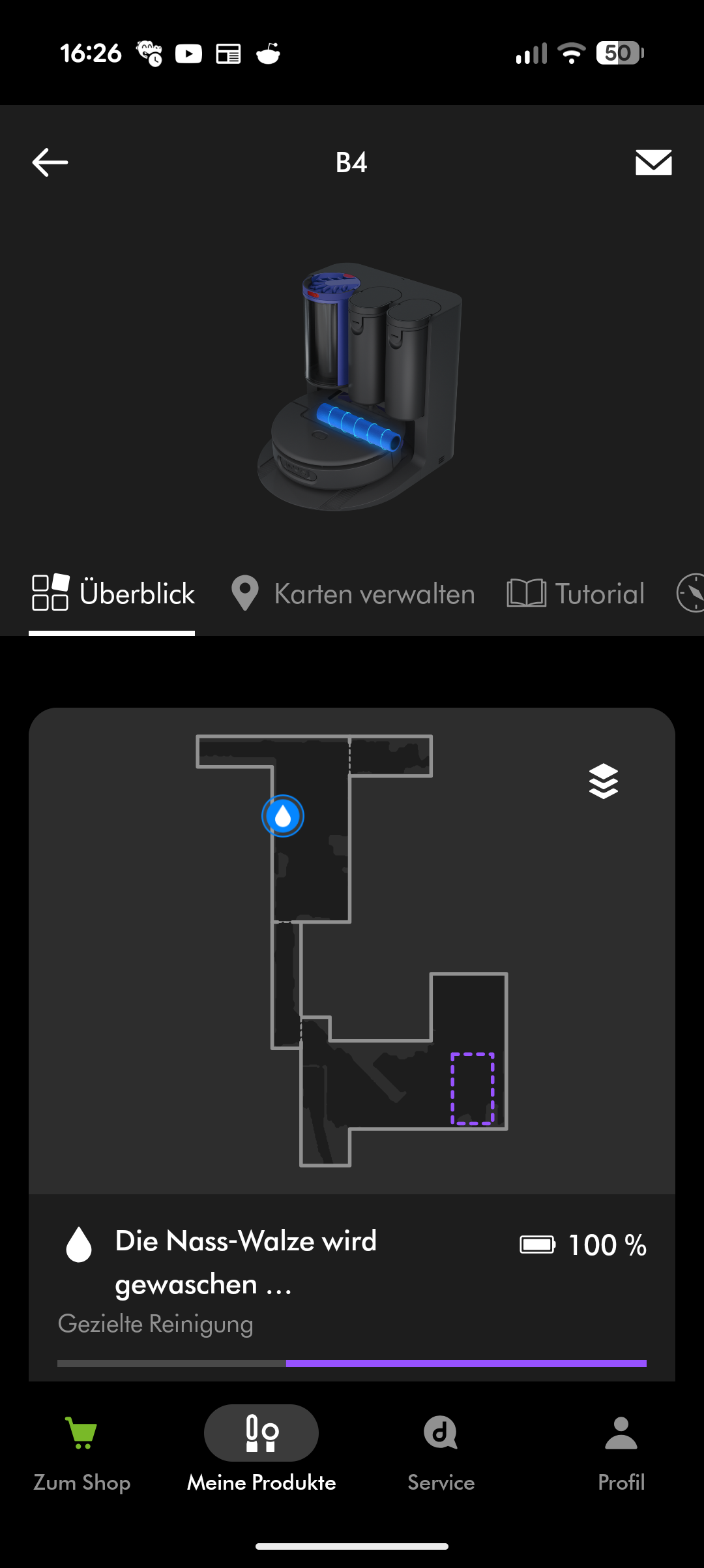
Dyson Spot + Scrub AI – App & Einrichtung
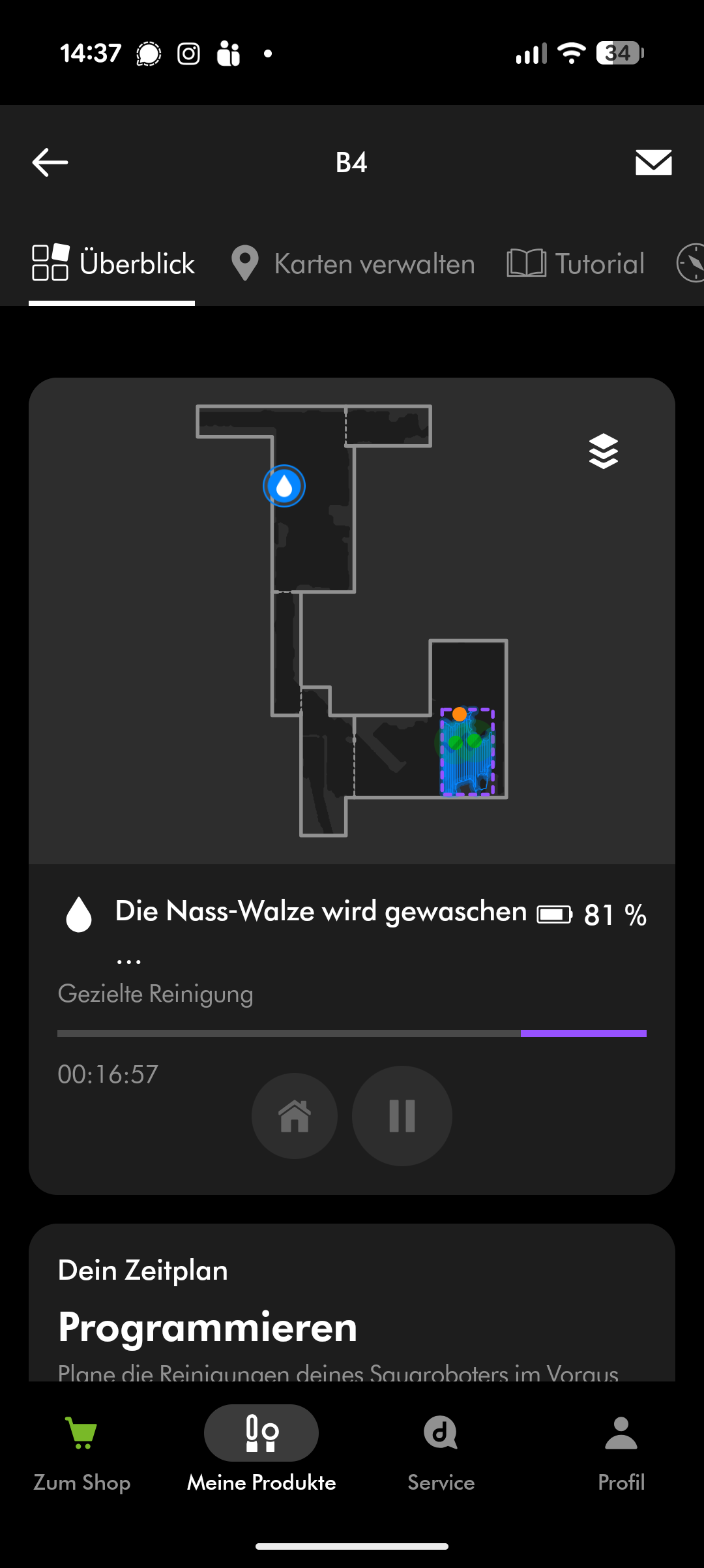
Dyson Spot + Scrub AI – App & Einrichtung
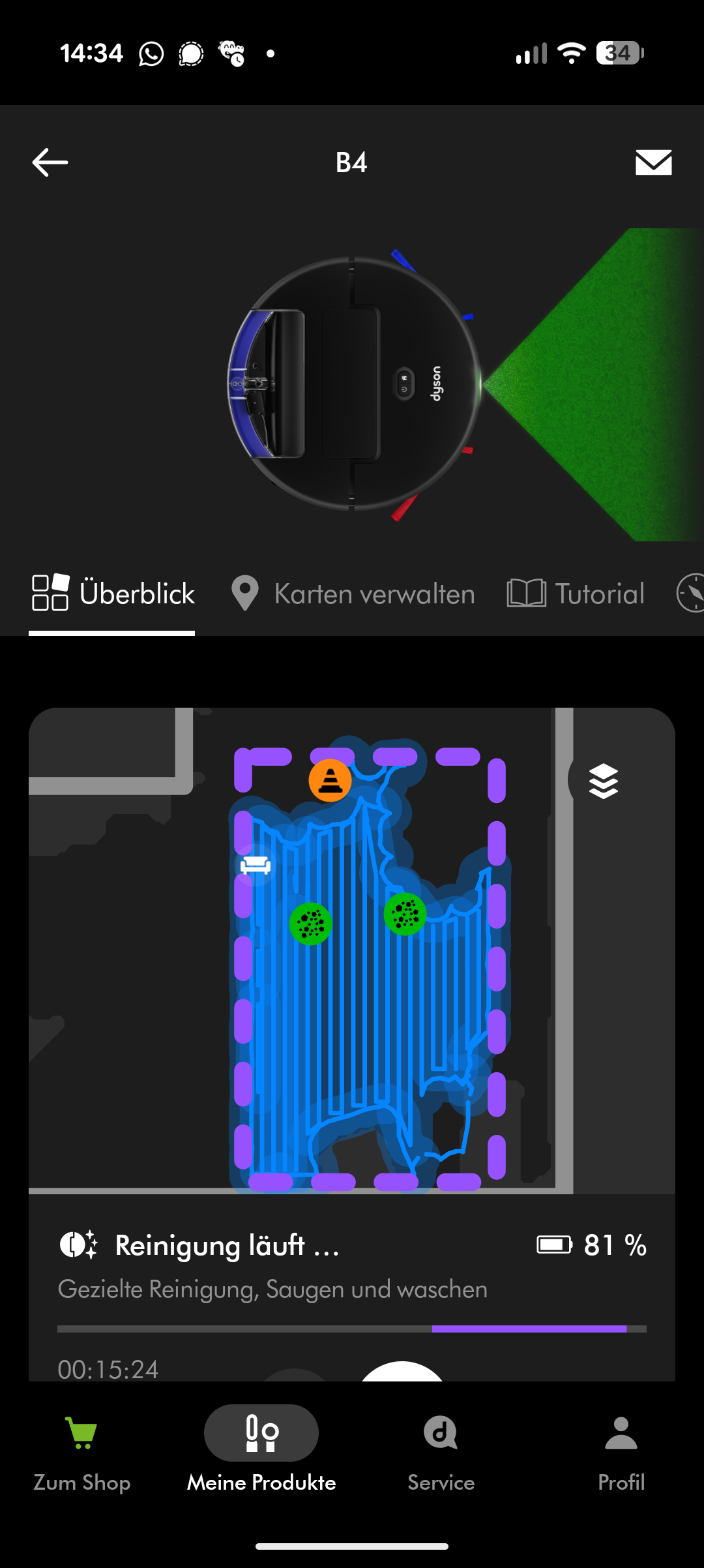
Dyson Spot + Scrub AI – App & Einrichtung
Dyson Spot + Scrub AI – App & Einrichtung
Dyson Spot + Scrub AI – App & Einrichtung
Dyson Spot + Scrub AI – App & Einrichtung
Dyson Spot + Scrub AI – App & Einrichtung
Dyson Spot + Scrub AI – App & Einrichtung
Dyson Spot + Scrub AI – App & Einrichtung
Dyson Spot + Scrub AI – App & Einrichtung
Dyson Spot + Scrub AI – App & Einrichtung
Dyson Spot + Scrub AI – App & Einrichtung
Dyson Spot + Scrub AI – App & Einrichtung
Dyson Spot + Scrub AI – App & Einrichtung

Dyson Spot + Scrub AI – App & Einrichtung
Dyson Spot + Scrub AI – App & Einrichtung
Dyson Spot + Scrub AI – App & Einrichtung
Dyson Spot + Scrub AI – App & Einrichtung
Dyson Spot + Scrub AI – App & Einrichtung
Dyson Spot + Scrub AI – App & Einrichtung
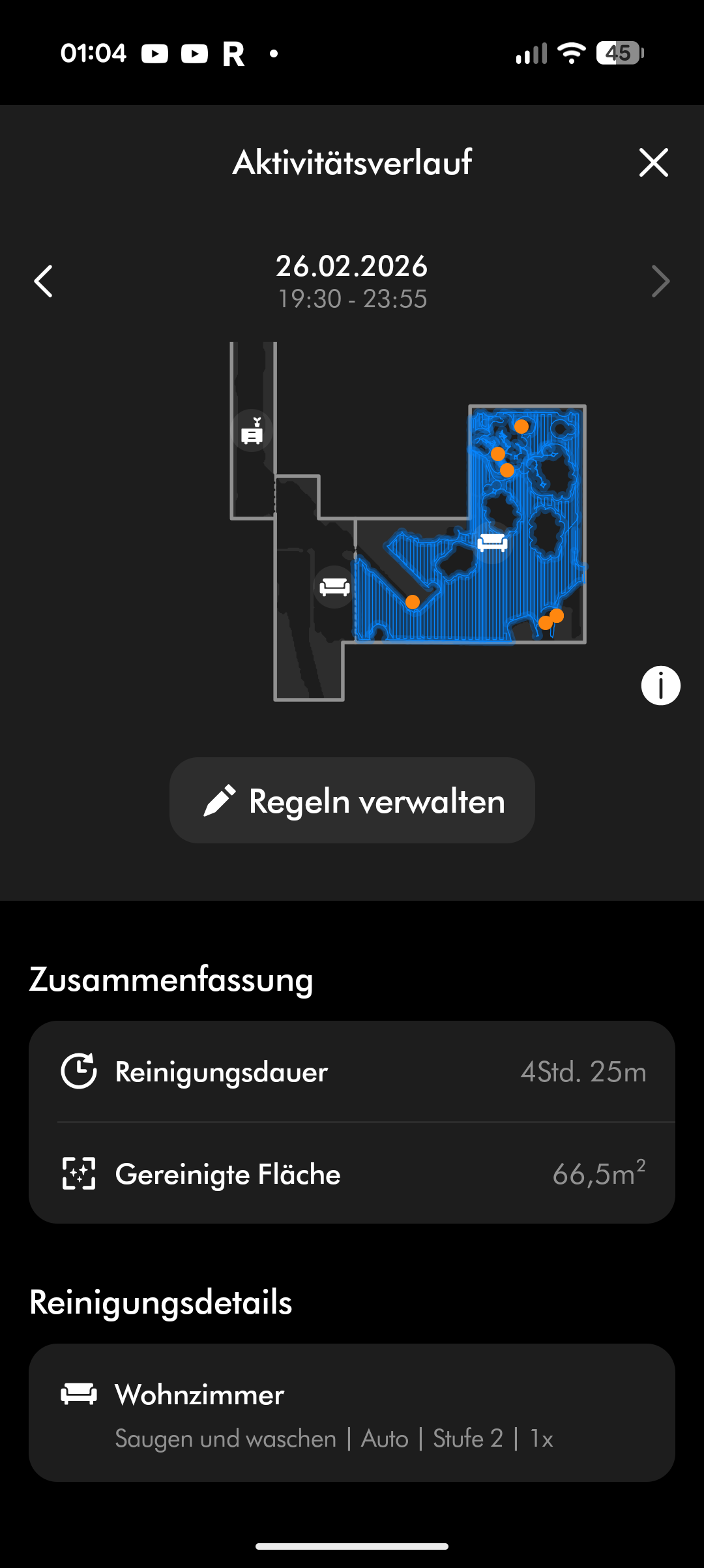
Dyson Spot + Scrub AI – App & Einrichtung
Dyson Spot + Scrub AI – App & Einrichtung
Dyson Spot + Scrub AI – App & Einrichtung
Dyson Spot + Scrub AI – App & Einrichtung
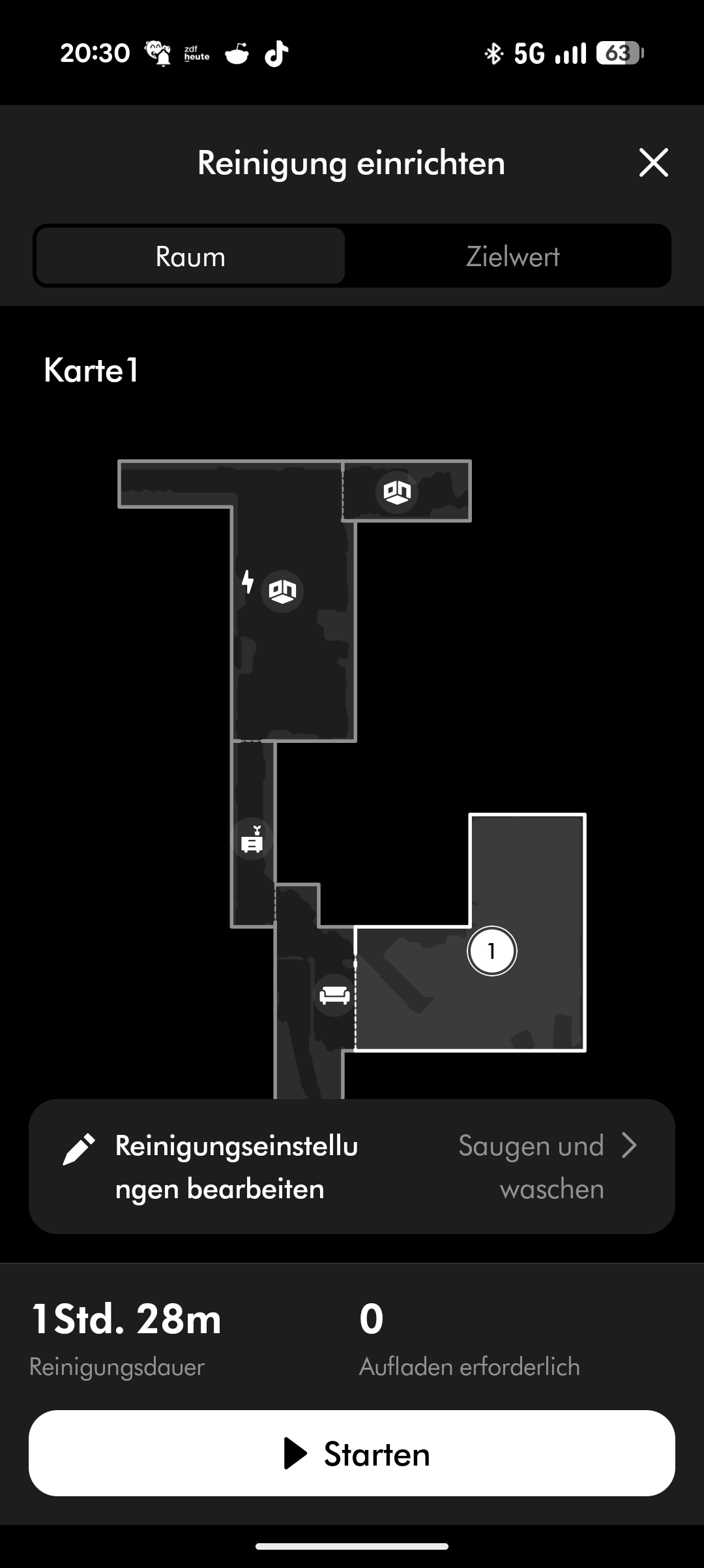
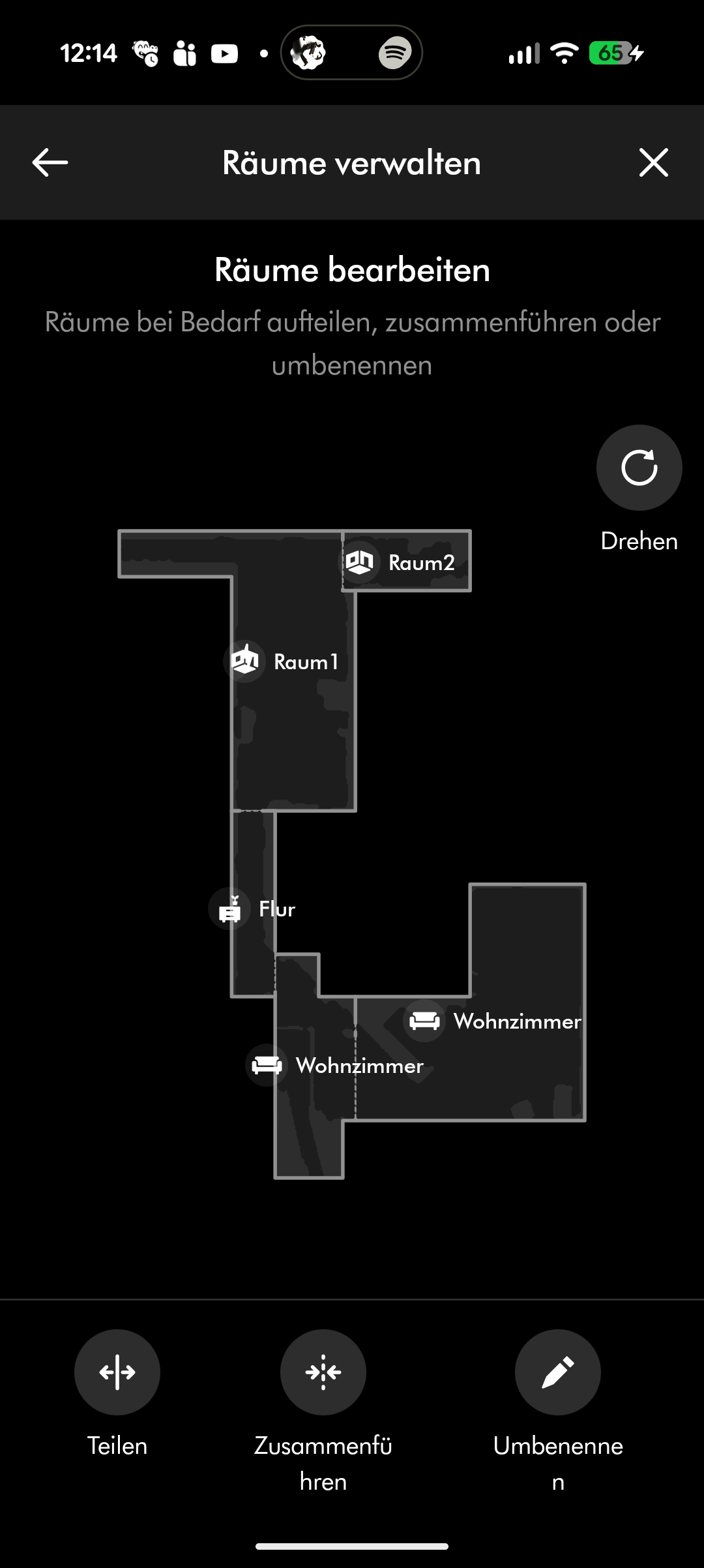
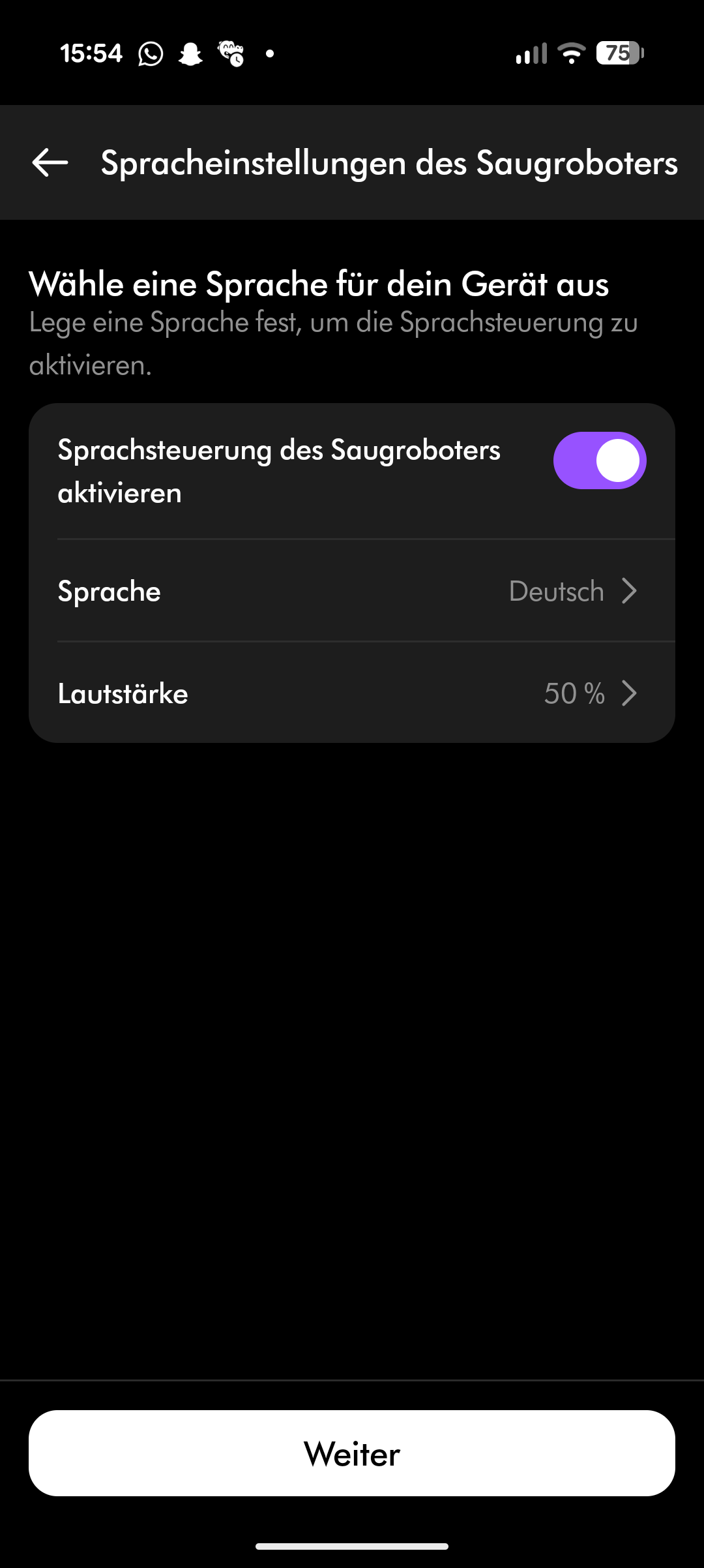
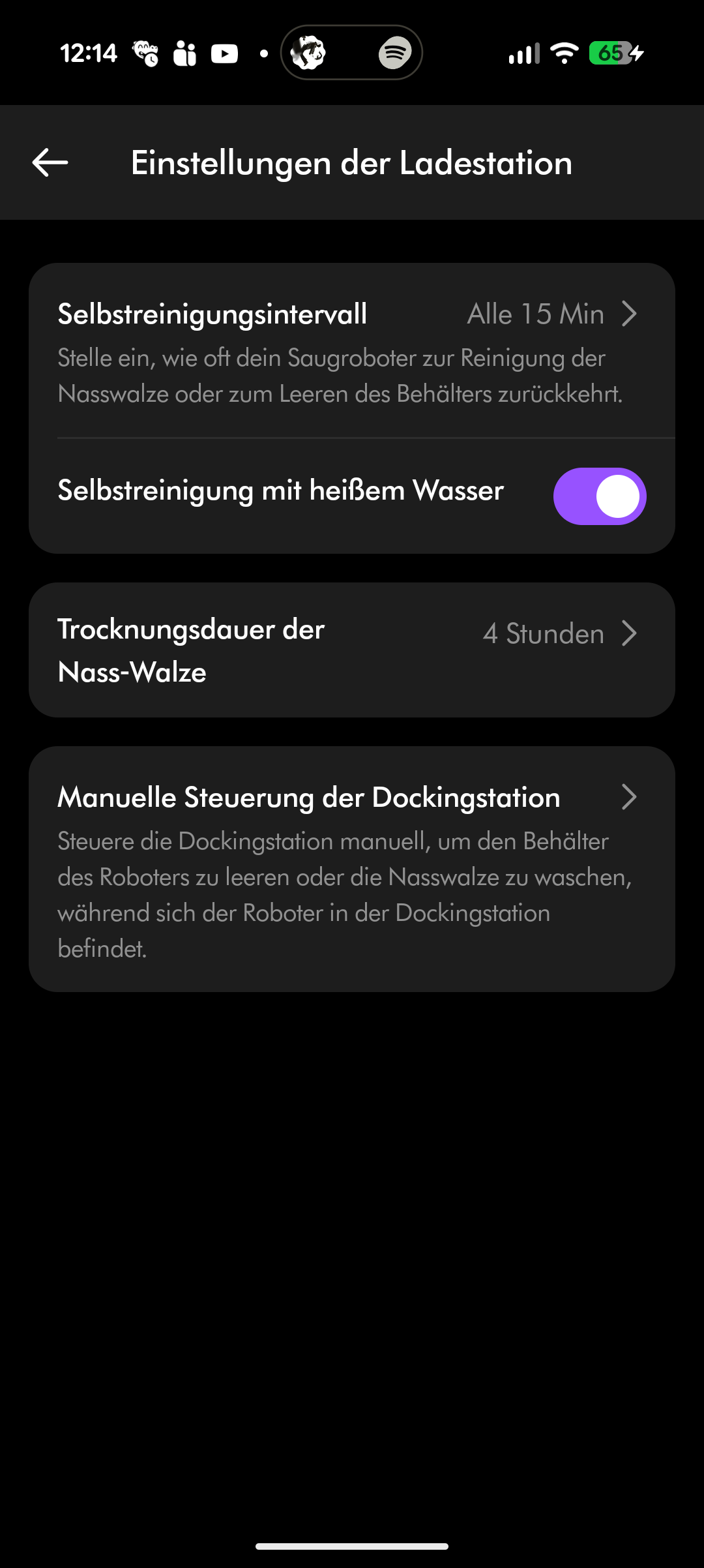
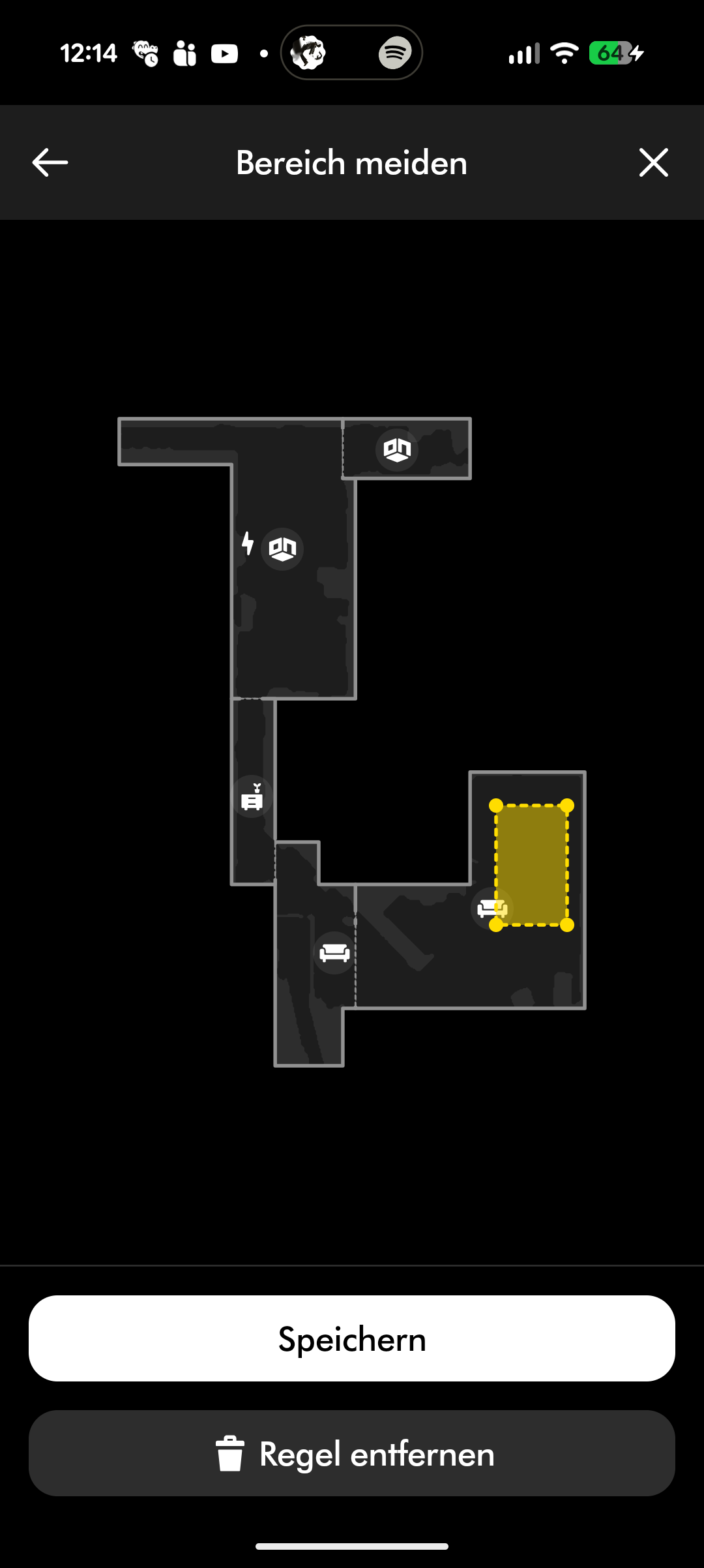
Der Spot + Scrub AI unterstützt Amazon Alexa, Apple Siri und Google Assistant. Reinigungszeiten lassen sich programmieren, Zonen und Sperrzonen einrichten und virtuelle Wände setzen. Die Teppicherkennung hebt den Wischaufsatz automatisch an. All das funktioniert zuverlässig, auch wenn die App insgesamt nicht ganz an den Funktionsumfang von Roborock oder Dreame heranreicht.
Navigation: Wie gut erkennt der Dyson Spot + Scrub AI Hindernisse?
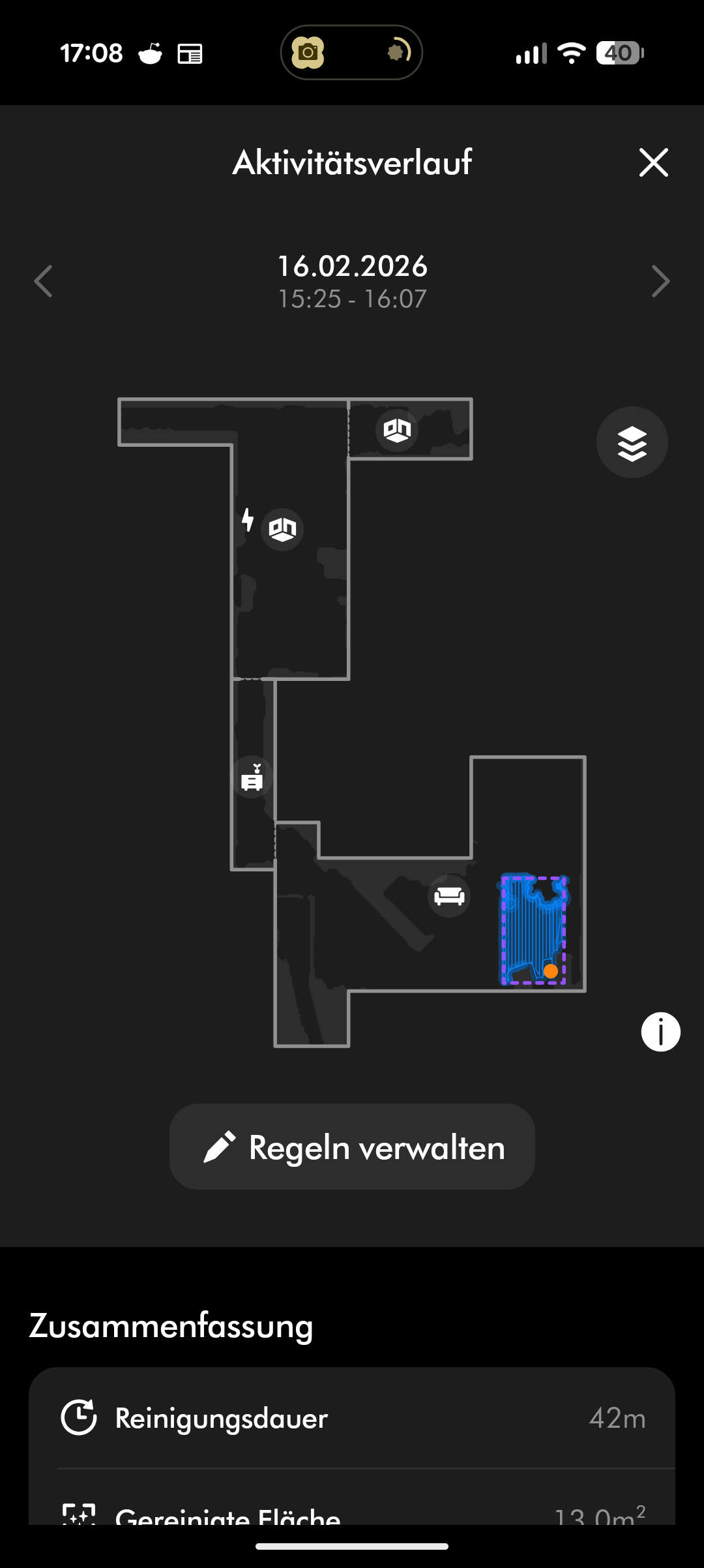
Der Dyson Spot + Scrub AI navigiert per LiDAR-Sensor und Kamera. Die Kartierung funktioniert solide, der Roboter fährt strukturiert seine Bahnen ab und erstellt eine brauchbare Karte der Wohnung. Absturzsensoren schützen vor Treppenstürzen. Das Tempo bei der Navigation ist normal für einen Saugroboter – im Unterschied etwa zu Narwal, deren Roboter deutlich flotter unterwegs sind, bewegt sich der Spot + Scrub AI eher gemächlich durch die Räume.
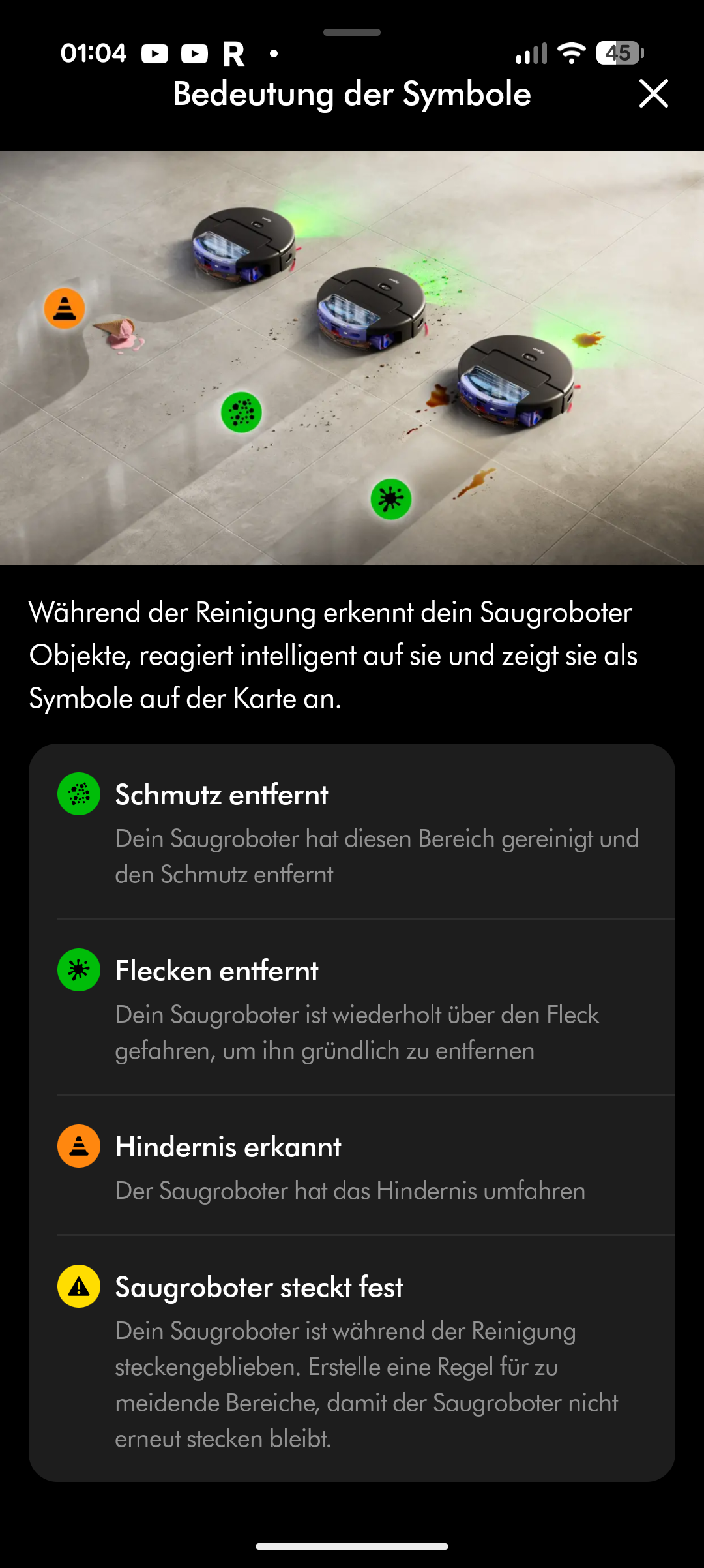
Die Objekterkennung ist allerdings eine deutliche Schwachstelle. Im Vergleich zu Konkurrenten wie Narwal oder Roborock agiert der Spot + Scrub AI deutlich rabiater. Er fährt gerne eigenständig zwischen Stuhlbeine, bleibt dort stecken und wird mit der Zeit zunehmend ruppig. Sein großflächiger Stoßfänger fährt regelmäßig gegen Gegenstände, Stühle werden auch mal durch die Gegend geschoben. Im Test fuhr der Roboter auf einen Türstopper auf und schleifte diesen mehrere Meter mit. Im Zweifel fährt der Spot + Scrub AI gegen Hindernisse, anstatt sie zu umfahren. Hier besteht deutlicher Nachholbedarf gegenüber der Konkurrenz.
Reinigung: Wie gut saugt und wischt der Dyson Spot + Scrub AI?
Die Reinigungsleistung des Dyson Spot + Scrub AI fällt insgesamt gut aus. Auf Hartboden arbeitet er sehr akribisch und entfernt über 90 Prozent des ausgebrachten Testschmutzes, bestehend aus Vogelfutter, Mehl und klebrigen Saftflecken. Der Roboter erkennt Partikel zuverlässig und differenziert zwischen Verschmutzungen, die weggewischt werden müssen, und solchen, die höhere Saugleistung erfordern.
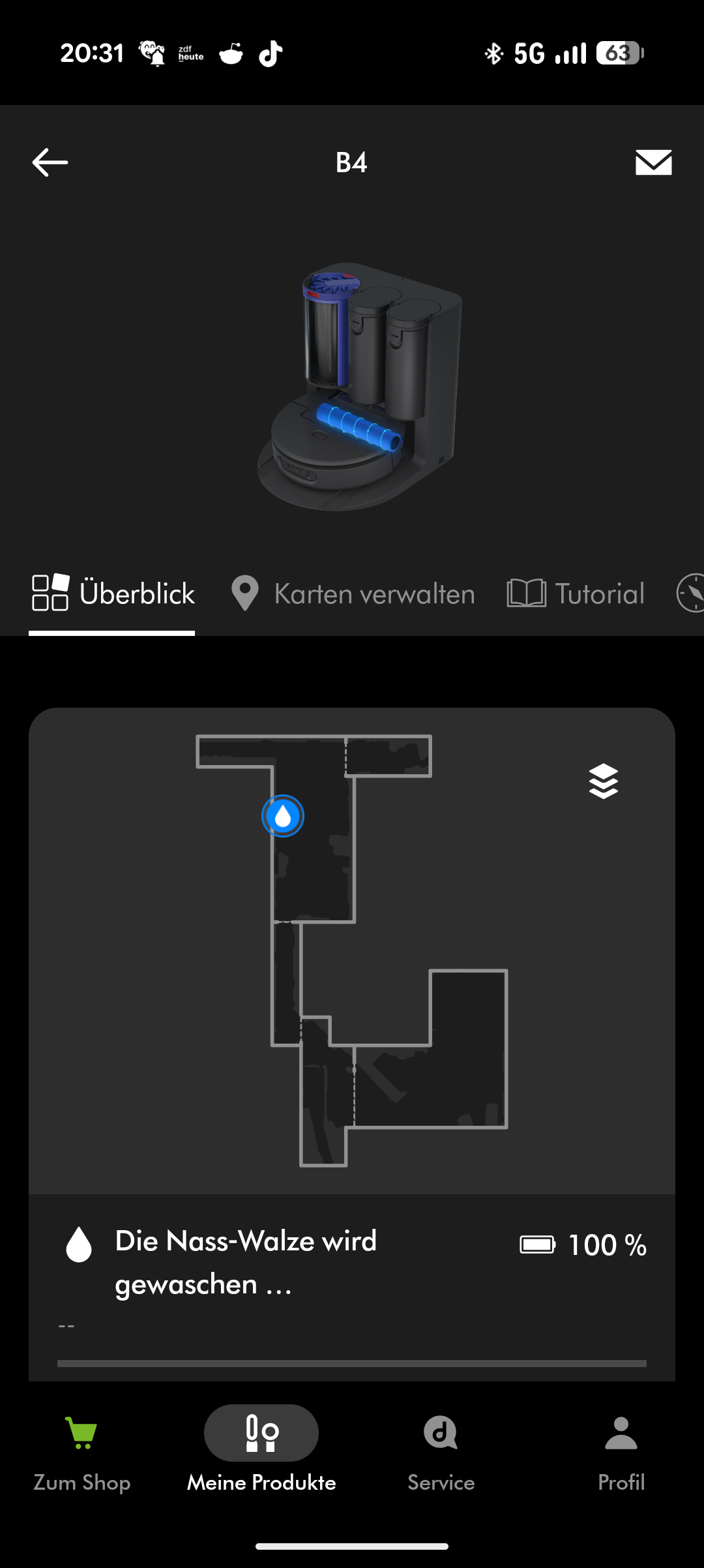
Eine grüne LED an der Unterseite leuchtet permanent und unterstützt offenbar die Schmutzerkennung am Boden. Stellt der Spot + Scrub AI an einzelnen Stellen erhöhtes Schmutzaufkommen fest, behandelt er diese Bereiche automatisch nach und erhöht die Saugkraft.
Die Saugleistung liegt bei 18.000 Pa. Zwei gegenläufig nach innen drehende Seitenbürsten kehren lose Partikel zur Anti-Tangle-Bodenbürste. Durch die gegenläufige Rotation werden Partikel besser eingekehrt, die eine einzelne Bürste eventuell verpassen oder durch die Gegend schießen würde. Die 2-fach-Filterung hält Feinstaub im Gerät.
Auf Teppich erreicht der Spot + Scrub AI rund 85 Prozent Schmutzaufnahme – ebenfalls ein guter Wert. Allerdings neigt er dazu, kleinere Teppiche aufzuschieben und hin- und herzubewegen. Die Teppicherkennung funktioniert zuverlässig: Der ausfahrbare Wischaufsatz wird automatisch angehoben, sobald der Roboter Teppich erkennt.
Dyson Spot + Scrub AI – Reinigung
Dyson Spot + Scrub AI – Reinigung

Dyson Spot + Scrub AI – Reinigung

Dyson Spot + Scrub AI – Reinigung

Dyson Spot + Scrub AI – Reinigung

Dyson Spot + Scrub AI – Reinigung

Dyson Spot + Scrub AI – Reinigung

Dyson Spot + Scrub AI – Reinigung

Dyson Spot + Scrub AI – Reinigung

Dyson Spot + Scrub AI – Reinigung

Dyson Spot + Scrub AI – Reinigung

Dyson Spot + Scrub AI – Reinigung

Dyson Spot + Scrub AI – Reinigung

Dyson Spot + Scrub AI – Reinigung

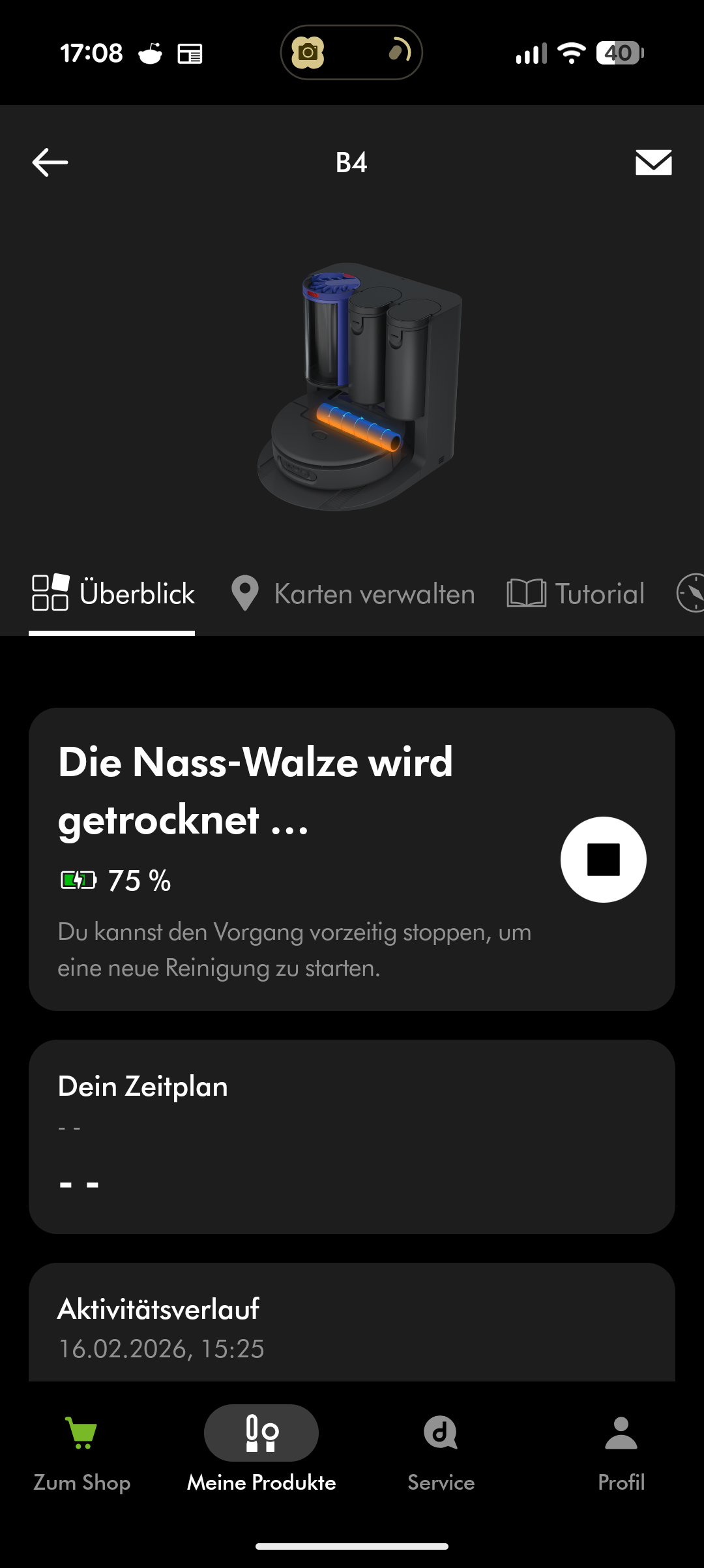
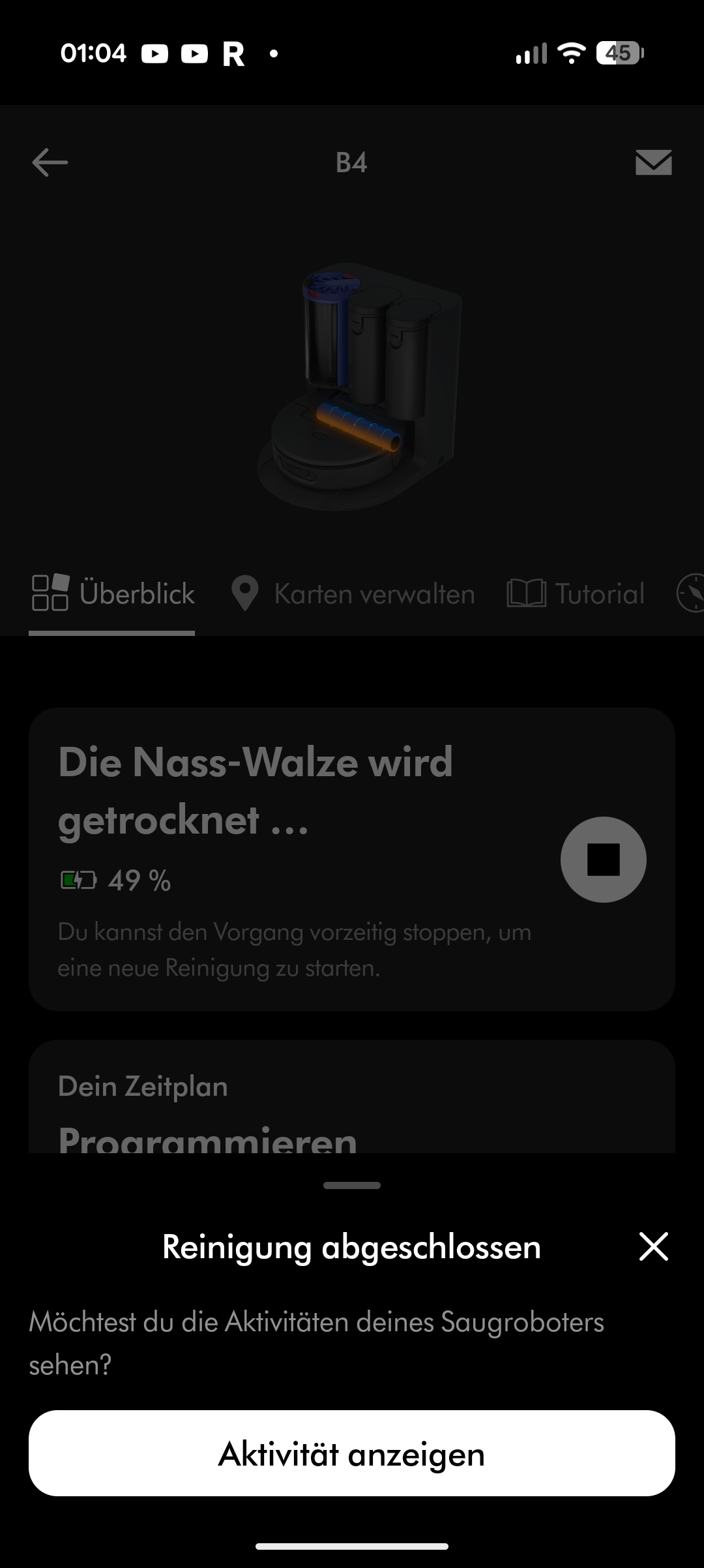
Beim Wischen versorgt sich der Roboter während der Fahrt automatisch aus dem nicht entnehmbaren Frischwasserbehälter. Er kehrt regelmäßig zur Station zurück, wo die Wischwalze mit Warmwasser gereinigt wird. Am Ende des Reinigungsvorgangs trocknet die Station die Walze mit Heißluft. Der Frischwasserbehälter des Roboters wird von der Station automatisch nachgefüllt. Ein Abpumpen des Restwassers aus dem Roboter scheint nicht möglich – zumindest fanden wir diese Option weder in der App noch am Gerät.
Drei Reinigungsmodi stehen zur Wahl: Saugen, Wischen oder beides gleichzeitig. Im kombinierten Modus zeigt der Spot + Scrub AI seine Stärke: Er erkennt unterschiedliche Verschmutzungsarten und passt sein Verhalten an. Klebrige Flecken werden gewischt, lose Partikel stärker gesaugt. Das Ergebnis auf Hartboden überzeugt. Bei hartnäckig eingetrocknetem Schmutz braucht es aber gelegentlich einen zweiten Durchgang.
Auf Volllast erreicht der Dyson Spot + Scrub AI eine Lautstärke von knapp 59 dB(A). Das ist akzeptabel, aber nicht leise.
Einen Wermutstropfen gibt es bei den Geräuschen: Die Frischwasserpumpe, der beidseitige Ausfahrmechanismus der Wischwalze und deren Drehbewegung erzeugen eine Geräuschkulisse, die etwas schrill und quäkig klingt. Das wirkt nicht so hochwertig, wie man es von Dyson erwarten würde – es erinnert eher an Kinderspielzeug.
Akkulaufzeit: Wie lange arbeitet der Dyson Spot + Scrub AI?
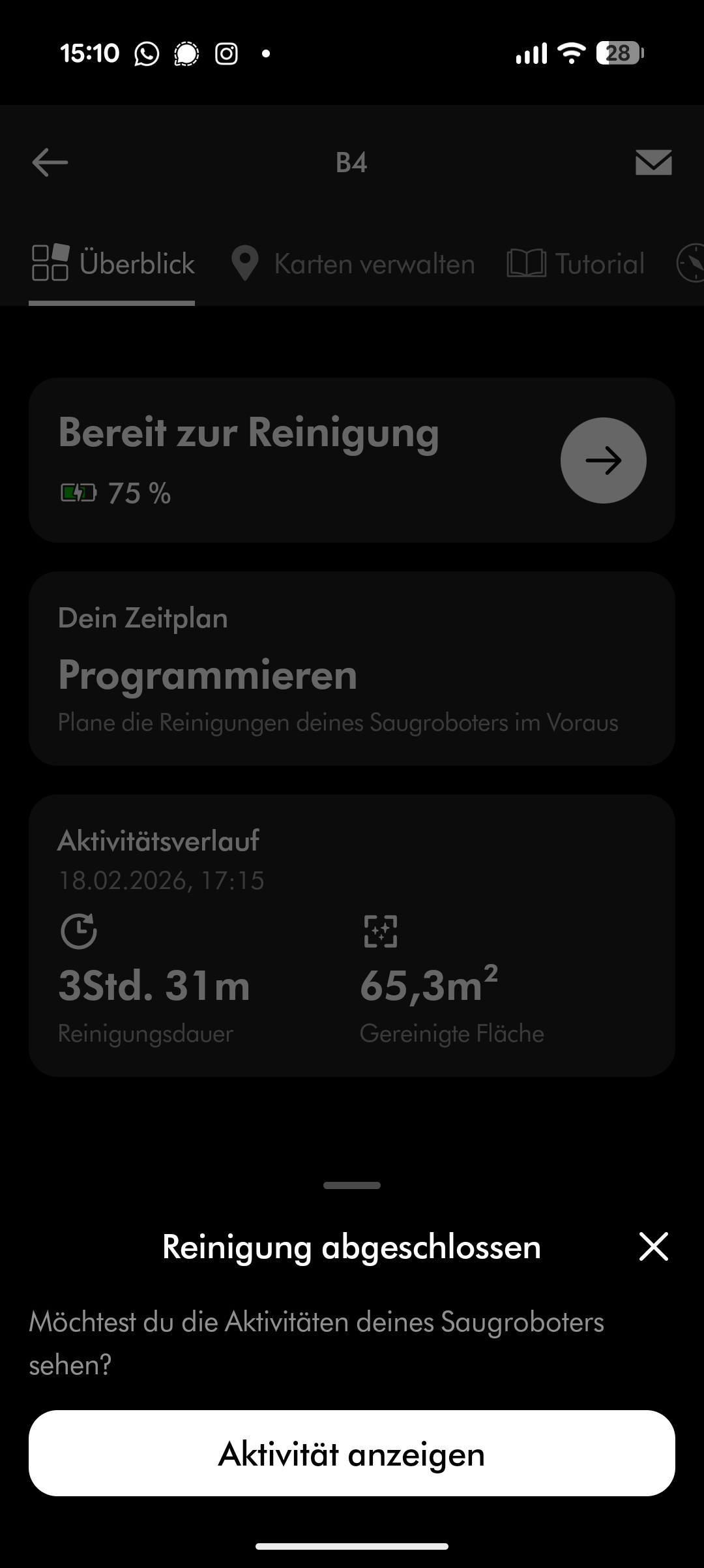
Der 5,0-Ah-Akku des Dyson Spot + Scrub AI soll laut Hersteller bis zu 200 Minuten durchhalten. Im Praxistest fällt die Laufzeit allerdings deutlich kürzer aus. Bei Standardeinstellungen – Saugstufe auf Auto, Wischen auf Stufe 2 von 3 und einfache Saugbahnen – verbraucht der Roboter in 25 Minuten über 31 Prozent Akku.
Für unseren Testraum von knapp 60 Quadratmetern benötigt er zwischen dreieinhalb und viereinhalb Stunden. Das liegt daran, dass er regelmäßig zur Station zurückkehrt, um die Wischwalze zu reinigen und den Staubbehälter zu entleeren. Die Ladedauer beträgt rund 3 Stunden. Für größere Wohnungen muss der Spot + Scrub AI zwischenladen, was die Gesamtreinigungszeit weiter verlängert. Die Akkulaufzeit ist damit eher mager und gehört nicht zu den Stärken des Roboters.
Preis: Was kostet der Dyson Spot + Scrub AI?
Der Dyson Spot + Scrub AI kostet aktuell kurz nach Marktstart 999 Euro. Für einen Dyson ist das gar nicht so teuer – kabellose Akkusauger des Herstellers kosten teils ähnlich viel. Im Vergleich zur Konkurrenz ist der Preis fair, aber nicht besonders günstig. Modelle von Roborock oder Dreame bieten teils bessere Objekterkennung und ähnliche Reinigungsleistung für ähnliche Kosten. Der Preis dürfte mit der Zeit noch etwas fallen.
Fazit
Mit dem Spot + Scrub AI meldet sich Dyson nach längerer Pause im Saugroboter-Markt zurück. Das Ergebnis ist solide: Gute Reinigungsleistung auf Hart- und Teppichboden, eine durchdachte beutellose Station mit Warmwasser-Reinigung und Heißluft-Trocknung sowie zwei gegenläufige Seitenbürsten und automatische Schmutzerkennung. Neu ist die Wischwalze bei Dyson, auf die der Hersteller nun wie viele Konkurrenten setzt. Auf Hartboden erreicht der Roboter über 90 Prozent Schmutzaufnahme – ein starker Wert. Das ungewöhnliche Bumper-Design mit dem bis auf die Oberseite reichenden Stoßfänger und der vorn verbaute LiDAR-Sensor ohne Turm setzen eigene Akzente.
Allerdings trüben einige Schwächen das Gesamtbild. Die Objekterkennung ist im Vergleich zu Narwal oder Roborock deutlich schlechter: Der Spot + Scrub AI fährt rabiat gegen Hindernisse, schiebt Stühle und schleift Türstopper mit. Die Akkulaufzeit fällt eher mittelmäßig aus, die Geräuschkulisse der Mechanik wirkt nicht hochwertig. Auch die App hat Luft nach oben. Im Marktvergleich sehen andere Tests den Dyson Spot + Scrub AI ebenfalls als gut reinigenden, aber teuren und in Details unausgereiften Premium-Roboter, dessen solide Gesamtleistung hauptsächlich durch die nur mittelmäßige Objekterkennung und Komfortfunktionen gebremst wird.
Was die Saug- und Reinigungsfunktionen angeht, schlägt sich das System insofern ordentlich, setzt aber keine Maßstäbe, sondern erledigt vieles genauso wie die Konkurrenz. Für 999 Euro bekommt man ein insgesamt ordentliches Paket – aber keinen Klassenprimus.

Gold im Marketing: Welche Marken die Olympischen Winterspiele für sich nutzen konnten

CB-Funk-Podcast #157: Gruselig, aber dieses Mal nicht die Technik!

Mondprogramm Artemis: NASA plant zusätzlichen Start im kommenden Jahr

Schnelles Boot statt Bus und Bahn: Was sich von London und New York lernen lässt

Community Management zwischen Reichweite und Verantwortung

Huawei Mate 80 Pro Max: Tandem-OLED mit 8.000 cd/m² für das Flaggschiff-Smartphone
-
 Künstliche Intelligenzvor 2 Monaten
Künstliche Intelligenzvor 2 MonatenSchnelles Boot statt Bus und Bahn: Was sich von London und New York lernen lässt
-
 Social Mediavor 2 Wochen
Social Mediavor 2 WochenCommunity Management zwischen Reichweite und Verantwortung
-
 Apps & Mobile Entwicklungvor 3 Monaten
Apps & Mobile Entwicklungvor 3 MonatenHuawei Mate 80 Pro Max: Tandem-OLED mit 8.000 cd/m² für das Flaggschiff-Smartphone
-

 Datenschutz & Sicherheitvor 3 Monaten
Datenschutz & Sicherheitvor 3 MonatenSyncthing‑Fork unter fremder Kontrolle? Community schluckt das nicht
-

 Entwicklung & Codevor 3 Monaten
Entwicklung & Codevor 3 MonatenKommentar: Anthropic verschenkt MCP – mit fragwürdigen Hintertüren
-
Künstliche Intelligenzvor 1 Woche
Top 10: Die beste kabellose Überwachungskamera im Test – Akku, WLAN, LTE & Solar
-

 Künstliche Intelligenzvor 3 Monaten
Künstliche Intelligenzvor 3 MonatenGame Over: JetBrains beendet Fleet und startet mit KI‑Plattform neu
-

 Social Mediavor 2 Monaten
Social Mediavor 2 MonatenDie meistgehörten Gastfolgen 2025 im Feed & Fudder Podcast – Social Media, Recruiting und Karriere-Insights

