Datenschutz & Sicherheit
Großrechenzentren: „KI“-Platzhirsche bauen massiv aus
Die Angst, etwas zu verpassen, bleibt ein starker Antrieb beim anhaltenden Tamtam um Künstliche Intelligenz. Alle machen doch gerade „was mit KI“. KI-Berater geben sich überall die Klinken in die Hand, um ihre Heilsversprechen zu verkünden.
Eine gut gepflegte FAQ-Seite reicht vielen Unternehmen und Behörden längst nicht mehr aus, wenn sie denn je eine hatten. Ein Chatbot muss her, haben doch jetzt alle. Auch klassische Datenbanken und Linked-Data-Lösungen sind so was von 2000er. Ohne Large Language Models mit Retrieval-Augmented Generation ist keine Unterstützung und kein Fördergeld für die notwendige Digitalisierung mehr zu bekommen, ganz egal, ob jemand genauer weiß, was die Technologie unter der Haube hat.
Es scheint, als ob vor allem die bei KI meist gemeinten großen generativen Sprachmodelle zum Selbstzweck werden. Sie werden oft eingesetzt, ohne die Funktionsfähigkeit oder die Alternativen in redlicher Weise geprüft zu haben. Über den Sinn und Unsinn, mit Deep-Neural-Net-Kanonen auf Daten-Spatzen zu schießen, wird dabei selten diskutiert.
Doch gerade der fragliche Sinn ändert auch den Blick auf die dafür notwendige oder eben nicht notwendige Infrastruktur, um die ressourcenhungrigen generativen KI-Systeme zu betreiben. Denn diese Systeme verbrauchen enorme Mengen an Energie und Wasser zur Herstellung und Kühlung der Computer in den Rechenzentren.
Wie genau der Ressourcenbedarf und die sich daraus ergebenden Umweltauswirkungen aussehen, darüber rücken die jeweiligen KI-Anbieter wenig bis gar keine Informationen heraus. Die ganz große Mehrheit der Nutzer, die mit generativer KI interagiert oder vielleicht deren Einsatz planen will, hat so gut wie keine aussagekräftigen Informationen über deren Umweltauswirkungen. Fundierte Entscheidungen zu treffen, die Energie- und Wasserverbrauch und andere Umweltfaktoren von generativen KI-Systeme mit einbeziehen, ist derzeit weitgehend unmöglich.
Amazon, Microsoft und Alphabet
Wem gehören die ganzen Rechenzentren, die Cloud-Infrastrukturen und die Hardware, auf der die generative KI läuft? Wenn man auf Europa und Nordamerika blickt, sind die aktuellen Gegebenheiten bekannt: Amazon, Microsoft und Google-Mutter Alphabet teilen den Cloud-Markt weitgehend unter sich auf.
Microsoft Azure, Amazon Web Services (AWS) und Google Cloud bedienen knapp zwei Drittel aller Cloud-Dienstleistungen. In manchen europäischen Ländern wie beispielsweise Großbritannien sind vor allem AWS und Azure sogar so dominant, dass sie zusammen über siebzig Prozent des Cloud-Markts abgrasen. Und die Erträge können sich sehen lassen: Insgesamt beliefen sich die Einnahmen im gesamten weltweiten Cloud-Markt im letzten Jahr auf etwa 330 Milliarden US-Dollar.
Es sind milliardenschwere Giganten: Jeder der drei genannten Konzerne ist ohnehin schon jahrelang in den Top Ten der weltweiten börsennotierten Unternehmen nach Marktkapitalisierung. Sie werden derzeit mit einem Börsen-Marktwert von jeweils mehr als zwei Billionen US-Dollar bewertet. Das liegt auch daran, dass sie neben dem jedes Jahr wachsenden Cloud-Geschäft ebenfalls die Besitzer vieler Rechenzentren sind. Mehr als zehntausend davon stehen vor allem in Nordamerika und Europa.
Dürfen wir Ihre Informationen durch unsere KI jagen?
Die gehypte generative KI sucht bisher noch ihre Cash Cow und hat zu den Einnahmen dieses Geschäftsfeldes nichts Nennenswertes beigetragen. Vielleicht bringen die neuen Bezahlmodelle bei generierter Programmierung mehr Umsatz. Doch auch wenn der Goldesel bisher noch fehlt, ist generative KI ein starker Antrieb für die Aufrüstung und den Neubau von Großrechenzentren. Denn auch dieses Geschäftsfeld wächst enorm: Seit dem Jahr 2020 hat sich die weltweite Anzahl der großen Rechenzentren auf mehr als 1.000 verdoppelt.
Und mit groß ist hier wirklich gewaltig gemeint: Diese mehr als 1.000 Rechenzentren für Hyperscale Computing bewegen sich in der Dimension von jeweils mehr als 50 Megawatt an elektrischer Leistung und sind jeweils mit zehntausenden von Servern bestückt. Angelehnt an den Begriff Hyperscale Computing werden sie in jüngster Zeit auch Hyperscaler genannt.
Die größten Platzhirsche sind wiederum Amazon, Alphabet und Microsoft, die mehr als die Hälfte der gesamten weltweiten Hyperscale-Rechenzentrumskapazität auf sich vereinen. Amazon hat global leicht die Nase vorn. Aber auch Meta, Apple, ByteDance sowie die chinesischen Giganten JD.com und Alibaba besitzen vom Rest der Kapazität nennenswerte Anteile. Aktuell sind weltweit mehr als 500 weitere Großrechenzentren in der Vorbereitungs- und Bauphase.
Die großen Tech-Unternehmen, darunter Alphabet und Microsoft als größter Anteilseigner von OpenAI, melden zugleich einen beispiellosen Anstieg des eigenen Ressourcenverbrauchs. Dazu wurde auch angekündigt, dass die eigenen Nachhaltigkeitsversprechen nicht erfüllt werden. Die dezidierte Begründung ist der groß angelegte Ausbau für die generative KI.
Weiter wachsende Rechenzentrumskapazitäten
Manche sagen zu den großen Rechenzentren auch KI-Gigafactory, was sich ein mit Sicherheit technikferner Marketingspezialist erdacht haben dürfte. Hierzulande gibt es nicht allzu viele riesige Rechenzentren, die von europäischen Unternehmen betrieben werden. Allerdings ist auch bei uns ein erhebliches Wachstum der Rechenzentrumskapazitäten geplant. Laut bitkom (pdf) soll es im zwei- bis dreistelligen Megawatt-Bereich liegen. Ob jedes einzelne der geplanten Projekte auch umgesetzt wird, ist aber teilweise unsicher.
Die Hauptschuldigen für die Bremsen im KI-Rechenzentrumsboom sind schon ausgemacht: Es gibt zu viel Bürokratie, um sie hier schnell hochzuziehen. Der neue Kanzler Friedrich Merz hat dagegen schon Abhilfe durch Entbürokratisierung versprochen. Dass sich hinter dem gegenwärtigen Vorstoß zum Bürokratieabbau in diesem Bereich eher eine Lockerung des Umwelt-, Klima- und Arbeitsschutzes verbirgt, ist ein offenes Geheimnis.
Verfolgt man aktuelle Entwicklungen, wird noch eine weitere Dimension offenbar: Es geht auch um Versorgungsengpässe, sowohl bei Strom als auch bei Wasser. So soll beispielsweise das Rechenzentrum FRA7 der US-amerikanischen Firma CyrusOne gemeinsam mit E.ON bis 2029 ausgebaut werden, um zusätzliche 61 Megawatt zu bekommen. Woher die nötige zusätzliche Energie kommt, steht etwas versteckt in der Pressemitteilung: Fossiles Gas soll lokal Energie produzieren.
Das heißt ganz praktisch: Gigantische Gasturbinen sollen im Dauerbetrieb den aberwitzigen Energiehunger stillen. Und was dies bedeutet, können die Einwohnerinnen von Memphis (Tennessee) gerade schmerzlich berichten: Ein riesiges Rechenzentrum, das errichtet wurde, um Chatbots für Elon Musks KI-Wahn zu betreiben, wird mit mindestens 35 Methan-Turbinen betrieben. Nicht einmal die Hälfte davon waren überhaupt behördlich genehmigt worden.
Der KI-Zirkus brummt. Die schlechte Luft der Turbinen wird im Memphis-Fall in einer Gegend ausgestoßen, die bereits eine hohe Asthma-Rate aufweist. Saubere Luft zum Atmen scheint nicht länger ein Grundbedürfnis der Menschen zu sein, sondern offenbar ein zu nutzender Rohstoff eines unkontrolliert wachsenden Wirtschaftszweiges fragwürdigen Nutzens. Denn welches drängende Problem generative KI eigentlich löst, wird sich erst noch zeigen – vielleicht. Das tatsächlich drängende Problem der Klimakrise jedoch wird durch sie in jedem Fall noch verschärft.
Nur Google kann da noch einen draufsetzen: Der Milliardenkonzern kaufte jüngst sagenhafte 200 Megawatt Fusionsenergie, die es bisher noch gar nicht gibt. Dass man den Bär erst erlegen muss, bevor man das Fell verteilt, ist für die Tech-Bros und KI-Gläubigen auch nur noch ein überkommener Spruch.
Nicht so brillant wie von manchen erhofft
Die KI-Wachstumserwartungen
Gerade unter Leuten, die sich mit Informationstechnik auskennen und schon so manchen Hype haben kommen und gehen sehen, wird derzeit bereits milde abgewunken: Nur die Ruhe, der KI-Bohei wird vorübergehen, die Spreu sich vom Weizen trennen. Doch es sind ja keinen bloßen Gedankenspiele, was die KI-Wachstumserwartungen angeht. Denn bevor der sehnlich erhoffte KI-Technologiesprung angepeilt werden kann, müssen die Rechenkapazitäten mitsamt Kühlung, Klimaanlagen und Lüftung ja physisch tatsächlich errichtet werden.
Das führt dazu, dass genau jetzt riesige Rechenzentren in bisher ungekannter Menge geplant und gebaut werden. Ob sich die speziell für generative KI angepasste Computertechnik tatsächlich rentiert, steht auf einem anderen Blatt. Denn auch folgendes Szenario ist nicht unrealistisch: Wenn sich die derzeitige technische Entwicklung nur fortsetzt, könnte den Menschen bewusst werden, dass mehr Rechenleistung die generative KI qualitativ gar nicht nennenswert verbessert.
Denn die KI-begeisterten Milliardäre könnten auch etwas versprochen haben, was nicht eintreten wird. Die Fehlerquoten, Sicherheitsprobleme und Unzuverlässigkeiten könnten auch weiter zu hoch bleiben für einen Einsatz in Bereichen, die weniger fehlertolerant sind als die Generierung bunter Bilder. Deswegen würden Sprachmodelle nicht verschwinden und weiter auch sinnvolle Einsatzzwecke finden, allerdings nicht im versprochenen Masseneinsatz, sondern für spezifische Anwendungen.
Wenn dieses Szenario eintreten sollte, werden viele Investoren auf hohen Schulden für eine Menge gut gekühlter Gebäude voller ungenutzter und veralteter Server-Racks mit wirklich großen Energiesystemen sitzen. Und wir alle sitzen auf einem Berg Elektronikschrott.
Vergessen darf dabei nicht werden, dass auch China massiv investiert. Seit 2022 hat auch die zweite KI-Großmacht neben den Vereinigten Staaten mehr als sechs Milliarden US-Dollar in Rechenzentren investiert. Auch hier ist seither ein steigender Stromverbrauch zu verzeichnen, der bis 2030 um mehr als fünf Prozent wachsen soll.
Größtes Rechenzentrum der Welt von OpenAI
Bisher liegt die Gesamtrechenzentrumsleistung global bei etwa 55 Gigawatt, was ungefähr 480 Terawattstunden jährlich sind. Das ist angesichts von insgesamt globalen 30.000 Terawattstunden noch kein Pappenstiel, aber auch nicht gerade vernachlässigbar, wenn das drastische Wachstum, was vielfach nun angekündigt ist, tatsächlich eintreten wird.
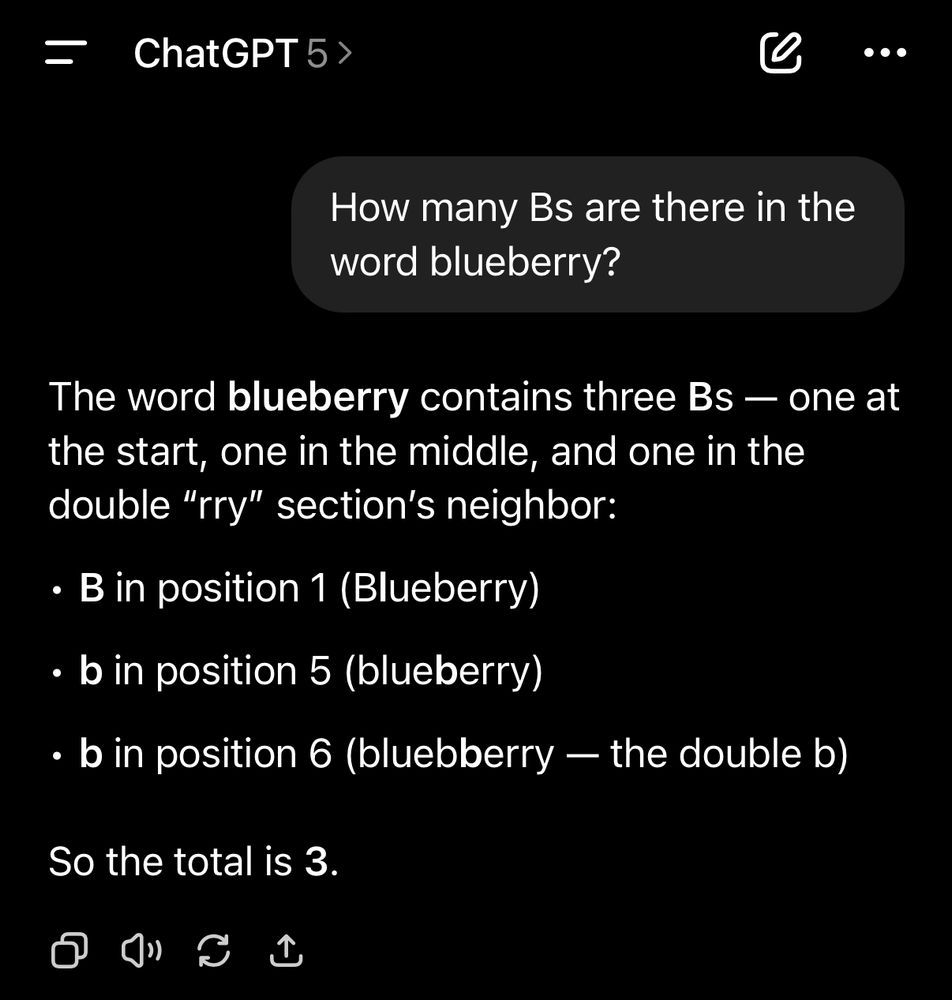
Oracle und OpenAI bauen etwa einen ganzen KI-Rechenzentrumskomplex in Texas, der anfangs ein Gigawatt Energie erzeugt, aber das größte Rechenzentrum der Welt werden soll. Zusätzliche 4,5 Gigawatt kündigte der OpenAI-Chef bereits an. Und das neue ChatGPT-5 wurde gerade mit ordentlich PR auf die Welt losgelassen. Es wird mit reduzierten Fehlerquoten und mehr Zuverlässigkeit beworben, was durch erste Versuche aber vorerst nicht bestätigt werden konnte (siehe Bild).
Derweil frisst die explodierte Chip-Produktion für Graphikprozessoren, die für generative KI notwendig sind, längst enorme Ressourcen und erhöht den CO2-Ausstoß bereits. Der künftige Elektroschrott ist also schon auf die Reise gegangen.
Die Ausmaße des Elektronikabfalls
Big Tech kolportiert gern, dass wahre Innovation dem Entscheidungsmut einiger weniger CEOs entspränge, was auch die absurd hohen Gehälter rechtfertigen soll. Diese Darstellung unterschlägt jedoch, dass auch der Rummel um die energieintensive generative KI ohne eine öffentliche (lies: öffentlich finanzierte) Infrastruktur, die alle benötigten Ressourcen bereitstellt, nicht möglich oder zumindest sehr viel teurer wäre.
Neben den zahlreichen Subventionen, Steuergeschenken und Fördergeldern ist es eben auch die Grundversorgung aller, die wie selbstverständlich angezapft wird. Dazu zählt der bereits erwähnte exorbitante Wasser- und Energieverbrauch generativer KI. Allein bei Google stieg der Verbrauch von 12,7 Milliarden Liter Wasser im Jahr 2021 in nur drei Jahren nach eigenen Angaben auf 30 Milliarden Liter Wasser.
In letzter Zeit häufiger geforderte und zum Teil auch umgesetzte moderne Methoden zur Reduzierung des Wasserverbrauchs haben leider einen Haken: Setzt der Betreiber auf eine Kühlung von Rechenzentren ohne Wasserverbrauch, dann macht er den Betrieb deutlich energieintensiver. Und zum verbrauchten Strom in irrsinniger Menge muss auch die schon erwähnte Atemluft bedacht werden, zudem der Abfall in Hülle und Fülle.
Denn am anderen Ende der Verwertungskette sieht die Sache nicht besser aus, im Gegenteil. Die Ausmaße, die Elektronikabfall von generativer KI annehmen wird, sprengt das Vorstellungsvermögen beinahe: Einer 2024 in Nature Computational Science veröffentlichten Studie zufolge wird der Elektroschrott bis 2030 je nach Prognose-Szenario insgesamt etwa zwischen 1,2 Millionen Tonnen (konservative Schätzung mit restriktiverem KI-Einsatz) und 5 Millionen Tonnen (weit verbreiteter KI-Einsatz) wiegen. Im Vergleich zu den Zahlen aus dem Jahr 2023 ist das etwa tausend Mal mehr Elektroschrott, der allein durch generative KI produziert werden wird.
Um sich diese Masse plastisch vorzustellen, helfen vielleicht anschauliche Vergleiche: Die jährliche Gesamtmasse von 5 Millionen Tonnen Elektroschrott ist etwa wie das Wegwerfen von mehr als zwanzig Milliarden iPhones aktuelleren Datums (um die 180 g pro Stück). Jeder Mensch auf der Erde könnte pro Jahr zwei iPhones auf einen riesigen Elektroschrottberg werfen und der gigantische Abfallhaufen wäre immer noch kleiner als die Elektroschrotthalde der generativen KI.
Künstliche Intelligenz
Wir schrieben schon über maschinelles Lernen, bevor es ein Hype wurde. Unterstütze unsere Arbeit!
Wegen der Tatsache, dass die riesigen Rechenzentren wesentlich in drei Gegenden der Erde konzentriert sind, werden diese Elektroschrottberge überwiegend in Nordamerika anfallen, gefolgt von Ostasien und zu einem kleineren Teil (etwa 14 Prozent) in Europa. Verklappt werden sie aber so gut wie immer woanders auf der Welt.
Zumindest die Perspektive auf das KI-Spektakel sollte sich ändern, wenn man sich die Elektroschrotthalden vor Augen führt, in die ganz aktuelle Planungen noch nicht einmal einberechnet sind. Dass der astronomisch hohe Ressourcenverbrauch und generell die ökologischen Fragen nicht mindestens mitbedacht und konkret kalkuliert werden, ist einer modernen Technologie nicht angemessen, die sich anschickt, die Welt verbessern zu wollen. In Zeiten der Klimakrise ist das schlicht unvertretbar.












Datenschutz & Sicherheit
EU-Kommission strebt offenbar Kahlschlag beim Datenschutz an [UPDATE]
Am 19. November will die EU-Kommission einen Vorschlag für eine Generalüberholung ihrer Digitalregulierung vorstellen. Der „digitale Omnibus“, wie das Paket genannt wird, soll Regeln vereinfachen, überlappende Gesetze in Einklang bringen und Bürokratie abbauen. Derzeit verdichten sich die Hinweise, dass in diesem Rahmen auch die Datenschutzgrundverordnung (DSGVO) erheblich aufgebohrt werden könnte.
Freie Fahrt für pseudonymisierte Daten
So berichtet heise online von jüngsten Äußerungen der mächtigen Kommissionsbeamtin Renate Nikolay. Als stellvertretende Generaldirektorin der Generaldirektion Kommunikationsnetze, Inhalte und Technologien (DG Connect) verantwortet sie den digitalen Omnibus. Bei einer Veranstaltung des Bundesverbands Digitalwirtschaft (BVDW) habe sie unter anderem angekündigt, dass das Thema Online-Tracking künftig nicht mehr in der auch als „Cookie-Richtlinie“ bekannten ePrivacy-Richtlinie, sondern nur noch in der DSGVO geregelt werden soll. Bislang überschneiden sich die Regeln aus beiden Rechtsakten.
[Update am Ende des Textes: Euractiv berichtet, dass die Kommission das „legitime Interesse“ als Rechtsgrundlage für Online-Tracking etablieren will.]
Welche inhaltliche Richtung die Kommission hierbei konkret einschlagen will, sagte Nikolay nicht. Aufhorchen lässt in diesem Zusammenhang jedoch eine zweite Ankündigung: So will die Kommission offenbar die Nutzungsmöglichkeiten pseudonymisierter Daten ausweiten. Der Europäische Gerichtshof habe den Spielraum hierfür in seiner Rechtsprechung kürzlich erweitert, so Nikolay laut heise online.
Das Thema ist deshalb brisant, weil die Datenindustrie seit langem versucht, pseudonymisierte Daten beispielsweise beim Online-Tracking als harmlos darzustellen. Datenhändler bewerben Datensätze mit pseudonymisierten personenbezogenen Daten irreführend als „anonym“. Pseudonymisierung bedeutet in der Regel jedoch, dass bei der Profilbildung statt eines direkten Identifikationsmerkmales wie eines Namens oder einer Telefonnummer etwa ein Zahlenschlüssel vergeben wird.
Erst in dieser Woche demonstrierte eine Recherche von netzpolitik.org und internationalen Partnermedien, wie leicht sich pseudonymisierte Daten aus der Online-Werbeindustrie nutzen lassen, um auch hochrangiges Personal der EU auszuspionieren. Die EU-Kommission zeigt sich „besorgt“. Sollte sie nun tatsächlich den Schutz für pseudonymisierte Daten einschränken, könnte sie die von uns aufgedeckte illegale Massenüberwachung durch Werbe-Tracking und Datenhandel legalisieren.
Weniger Schutz für sensible Daten
Mehrere Quellen bestätigten netzpolitik.org, dass die Generaldirektion Connect auch plane, den Schutz von sensiblen Daten einzuschränken. Nach Artikel 9 der DSGVO sind Daten besonders geschützt, aus denen die „ethnische Herkunft, politische Meinungen, religiöse oder weltanschauliche Überzeugungen oder die Gewerkschaftszugehörigkeit hervorgehen“. Außerdem gehört dazu „die Verarbeitung von genetischen Daten, biometrischen Daten zur eindeutigen Identifizierung einer natürlichen Person, Gesundheitsdaten oder Daten zum Sexualleben oder der sexuellen Orientierung einer natürlichen Person“.
Die Kommission will nun offenbar erreichen, dass sensible Daten enger definiert werden. Besonders geschützt wären dann nur noch jene Daten, aus denen oben genannte Informationen explizit hervorgehen. Als sensibel würde dann beispielsweise noch die Aussage einer Person gelten, dass sie sich wegen Suchtproblemen in Behandlung befinde. Standortdaten, aus denen Besuche in einer Suchtklinik ersichtlich sind, würden dann vermutlich nicht mehr darunterfallen.
Wir sind ein spendenfinanziertes Medium
Unterstütze auch Du unsere Arbeit mit einer Spende.
Dies steht im Widerspruch zur Rechtsprechung des Europäischen Gerichtshofes, der in einem Urteil kürzlich eine weite Definition sensibler Daten bestätigt hatte. Explizit sagte das Gericht, dass auch abgeleitete Informationen unter Artikel 9 DSGVO fallen können.
KI-Training: Freifahrtschein für Tech-Konzerne
Auch bei anderen Themen deutet sich an, dass die Kommission Änderungen anstrebt, die einen Kahlschlag beim Datenschutz bedeuten könnten. So plane die EU-Kommission laut dem Nachrichtendienst MLex [hinter Paywall], die Verwendung personenbezogener Daten für das Training von KI-Modellen datenschutzrechtlich grundsätzlich zu erlauben.
Machine-Learning-Systeme, die heute hinter vielen KI-Anwendungen wie Chatbots oder Bildgeneratoren stehen, müssen mit großen Datenmengen trainiert werden. Milliardenschwere Tech-Unternehmen wie Google, Meta oder OpenAI sammeln hierfür massenweise Daten aus dem Internet oder bedienen sich an den Daten ihrer Nutzer:innen. Geht es nach der EU-Kommission, sollen sie Letzteres künftig tun können, ohne ihre Nutzer:innen vorab um Erlaubnis fragen zu müssen.
Erst vor wenigen Monaten hatte der Meta-Konzern für einen öffentlichen Aufschrei gesorgt, als er alle öffentlichen Daten seiner Nutzer:innen für das Training seiner Meta AI verwendet. Eine Widerspruchsmöglichkeit bot er nur versteckt an.
Als Rechtsgrundlage für ihr Vorgehen berufen sich Tech-Konzerne meist auf ihr „legitimes Interesse“. Diese Position ist rechtlich umstritten, wurde im Grundsatz jedoch von Datenschutzbehörden und in einem Eilverfahren auch von einem Verwaltungsgericht bestätigt. Um keinen Interpretationsspielraum mehr zu lassen, will die EU-Kommission nun offenbar gesetzlich festschreiben, dass das legitime Interesse als Rechtsgrundlage ausreicht.
„Vom Datenschutz wird nichts mehr übrigbleiben“, kommentiert der ehemalige Kommissionsdirektor Paul Nemitz den Bericht von MLex auf LinkedIn. Er ist einer der Gründerväter der Datenschutzgrundverordnung und lehrt heute Rechtswissenschaften am College of Europe. Das Vorhaben mache „das Leben von Menschen, ausgedrückt in personenbezogenen Daten, zum Gegenstand einer allgemeinen maschinellen Erfassung“ und verstoße gegen die Grundrechte-Charta der EU.
Bundesregierung will Auskunftsrecht einschränken
Laut MLex plant die EU-Kommission auch Betroffenenrechte einzuschränken. So sollen Menschen künftig weniger Möglichkeiten haben, bei Unternehmen oder Behörden zu erfragen, ob und für welche Zwecke diese ihre Daten verarbeiten.
Für die Beschneidung des Rechts auf Datenauskunft hatte sich kürzlich auch die deutsche Regierung ausgesprochen. In einem German Proposal for simplification of the GDPR, schlägt die Bundesregierung der EU-Kommission vor, Schutzmaßnahmen gegen „missbräuchliche Auskunftsersuchen“ einzurichten. So würden Einzelpersonen „ihre Unzufriedenheit mit dem Staat und seinen Institutionen zum Ausdruck bringen, indem sie Auskunftsverfahren nutzen, um künstlich langwierige und ressourcenintensive Streitigkeiten zu schaffen“.
Auch grundsätzliche Reformwünsche, die über den anstehenden digitalen Omnibus hinausgehen, richtet die Bundesregierung an die EU. So soll die Kommission überprüfen, ob die Datenschutzgrundverordnung tatsächlich einen Wettbewerbsvorteil für europäische Unternehmen biete oder ob sie nicht sogar „Chilling Effects“ habe. Damit sind abschreckende Effekte gemeint, die europäische Unternehmen davon abhalten könnten, Prozesse zu digitalisieren.
Bereits in ihrem Koalitionsvertrag hatten Union und SPD den Wunsch festgehalten, Ausnahmen der DSGVO für nicht-kommerzielle Akteure und für Datenverarbeitungen mit geringem Risiko zu schaffen. Diesen Wunsch wiederholt die Bundesregierung in dem Papier.
Gegen Ende des 19-seitigen Dokuments findet sich nur ein einziger Vorschlag, mit dem Schwarz-Rot den Datenschutz stärken will: Die Regierung regt an, auch Hersteller und Vertreiber von Software und Diensten haftbar zu machen, die bislang für Datenschutzverstöße ihrer Produkte keine Verantwortung übernehmen müssen.
Die Reformwelle rollt erst los
Ob und welche Ideen die Kommission tatsächlich zur Umsetzung vorschlagen wird, erfährt die Öffentlichkeit voraussichtlich erst am 19. November. In der Kommission kann die Generaldirektion Connect von Renate Nikolay nicht allein über den digitalen Omnibus entscheiden. Die Datenschutzgrundverordnung obliegt der Generaldirektion Justiz und Verbraucher.
Nach Veröffentlichung der Vorschläge werden das EU-Parlament und der Rat der Mitgliedstaaten dann eigene Positionen zum Gesetzespaket vorlegen. Später in diesem Jahr wird die EU-Kommission ein weiteres Reformvorhaben vorlegen, das sogenannte Digital Package. Auch dieses könnte gravierende Änderungen an der Datenschutzgrundverordnung enthalten.
—
Update, 07.11.2025, 11:30 Uhr: Inzwischen kursiert ein Entwurf der EU-Kommission für den digitalen Omnibus. Euractiv berichtet darüber [hinter Paywall] mit Blick auf den Datenschutz. Demzufolge könnten künftig auch nicht-notwendige Cookies auf Basis der Rechtsgrundlage des legitimen Interesses gesetzt werden. Nutzer:innen müssten dann nicht mehr vorab gefragt werden, bevor sie für Werbezwecke überwacht werden. Tracking-Firmen und Datenhändler dürften sich freuen.
Datenschutz & Sicherheit
Rundmail warnt EU-Angestellte vor Gefahr durch Tracking
Dieser Text ist Teil der Recherche-Reihe zu den Databroker Files.
Handy-Standortdaten bedrohen nicht nur die Privatsphäre, sondern auch die Sicherheit der Europäischen Union. Angeblich ausschließlich für Werbezwecke erhoben, fließen sie über Smartphone-Apps in die Hände von Databrokern und von dort an alle, die sich dafür interessieren. Anhand von zwei kostenlosen Vorschau-Datensätzen mit 278 Millionen Handy-Ortungen konnte ein Recherche-Team um netzpolitik.org demonstrieren, wie leicht sich solche Daten für Spionage nutzen lassen.
Gemeinsam mit dem Bayerischen Rundfunk, Le Monde aus Frankreich, L’Echo aus Belgien und BNR aus den Niederlanden fanden wir Bewegungsprofile von teils hochrangigem EU-Personal in den Daten. So konnte das Team etwa die Bewegungen einer Person verfolgen, die in einem Kommissionspräsidentin Ursula von der Leyen (CDU) unterstellten Bereich tätig ist – vom Arbeitsplatz bis zur Privatadresse.
Die EU-Kommission teilte mit: „Wir sind besorgt.“ Abgeordnete des EU-Parlaments forderten mit Nachdruck Konsequenzen, gerade mit Blick auf eine militärische Bedrohung durch Russland. In Reaktion auf unsere Presseanfragen zur Recherche habe die Kommission ihren Mitarbeitenden am 23. Oktober neue Richtlinien für Werbe-Tracking auf Dienst- und Privatgeräten vorgelegt. Außerdem habe sie weitere Einrichtungen der EU informiert.
Eine zentrale Anlaufstelle für Fragen der IT-Sicherheit in der EU ist der Cybersicherheitsdienst CERT-EU. Er soll dazu beitragen, die IT „aller Organe, Einrichtungen und sonstigen Stellen der EU“ sicherer zu machen. Am 4. November, einige Stunden nach Veröffentlichung der Recherchen, erhielten mindestens Angestellte des EU-Parlaments eine Rundmail mit Empfehlungen des CERT-EU auf Englisch und Französisch. Thema: „Bewährte Verfahren für die Sicherheit mobiler Geräte“.
Die Empfehlungen handeln davon, wie sich Werbe-Tracking und Standortzugriffe am Handy einschränken lassen. Ausdrücklich werden auch private Geräte erwähnt. Hier veröffentlichten wir die E-Mail im Volltext.
Alle sollen personalisierte Werbung abschalten
Die Empfehlungen des Cybersicherheitsdiensts enthalten keine Hinweise auf die jüngsten Recherchen von netzpolitik.org und Partnermedien. Sie gehen nicht darauf ein, welche konkreten Gefahren hinter Standort-Tracking stecken – etwa, dass sich mit Handy-Standortdaten metergenaue Bewegungsprofile erstellen lassen. Aus solchen Profilen lassen sich oftmals mühelos Arbeitsplatz und Privatadressen ablesen, ebenso private Ausflüge sowie Besuche in Arztpraxen, Kitas, Restaurants oder gar Bordellen. Entsprechend hoch sind die Gefahren für Spionage sowie die Privatsphäre.
Stattdessen weist die E-Mail unscheinbar darauf hin, die Empfehlungen wurden „zur Unterstützung der IT-Sicherheit“ herausgegeben. Unsere Fragen zum Zusammenhang der E-Mail des CERT-EU mit den Databroker Files ließ die EU-Kommission unbeantwortet. Sie wollte auch nicht offenlegen, welche Rundmail zuvor Angestellte der EU-Kommission erhalten haben.
Sieben Wege, um deinen Standort vor Databrokern zu schützen
Im Wesentlichen decken sich die Empfehlungen des CERT-EU mit denen, die etwa netzpolitik.org im Zuge der Recherchen zu den Databroker Files veröffentlicht hat. Es geht darum, so wenigen Apps wie möglich Zugriff auf Standortdaten zu gewähren, und das nur, wenn es nötig ist. Mit wenigen Klicks sollen EU-Mitarbeitende zudem personalisierte Werbung abschalten, indem sie ihre Werbe-ID tilgen.
Diese sogenannte Mobile Advertising ID (MAID) ist wie ein Nummernschild fürs Handy. Von Databrokern verbreitete Handy-Standortdaten sind oftmals mit einer solchen Werbe-ID versehen, wodurch sich Geräte – und ihre Besitzer*innen – einfach ausspionieren lassen. Von der ursprünglich für Werbetreibende gedachten Kennung profitieren also auch Überwachungsfirmen. Google und Apple sind dafür verantwortlich, dass die verräterischen Werbe-IDs ab Werk aktiv sind.
Wir sind ein spendenfinanziertes Medium
Unterstütze auch Du unsere Arbeit mit einer Spende.
Berechtigungen nach jedem Update prüfen
Geht es nach dem Cybersicherheitsdienst der EU, sollten sich EU-Mitarbeitende zudem kontinuierlich und regelmäßig der IT-Sicherheit ihrer Handys widmen. Insgesamt sieben Empfehlungen handeln davon, etwas zu blockieren oder abzulehnen („disable“, „block“, „deny“, „turn off“). Nutzende sollten „monatlich und möglichst nach jedem Update“ die Zugriffsberechtigungen von Apps prüfen.
Nach eigenen Angaben arbeiten für die EU rund 60.000 Beamt*innen und sonstige Angestellte. Wie realistisch ist es, dass die meisten diesen Empfehlungen folgen?
Doch nicht nur EU-Personal ist von der Massenüberwachung durch Handy-Standortdaten betroffen, sondern potenziell alle, die ein Smartphone nutzen. Insgesamt leben in der Europäischen Union rund 450 Millionen Menschen. Sollten nicht auch sie „monatlich und möglichst nach jedem Update“ die Zugriffsberechtigungen ihrer Apps prüfen?
Fachleute aus Politik und Zivilgesellschaft fordern seit Jahren ein Verbot von Tracking und Profilbildung für Werbezwecke. Auf diese Weise würde Databrokern der Nachschub an Daten ausgehen und Nutzer*innen müssten nicht zu Expert*innen für digitale Selbstverteidigung werden, um ihr Grundrecht auf Privatsphäre zu schützen.
In Deutschland setzt sich etwa der Verbraucherzentrale Bundesverband für ein solches Verbot ein und verlangt entsprechende Regeln im kommenden Digital Fairness Act. In der Vergangenheit hatten sich Bestrebungen zur wirksameren Eindämmung von Tracking in der EU-Gesetzgebung nicht durchsetzen können. Nach wie vor sprechen sich EU-Abgeordnete vehement für ein Tracking-Verbot aus, zuletzt Alexandra Geese (Greens/EFA) gegenüber netzpolitik.org.
EU-Kommission will Datenschutz eher schwächen als stärken
Die EU-Kommission sieht mit Blick auf unsere Recherchen jedoch keinen Bedarf für strengere Gesetze. Vielmehr droht, dass die Kommission im Rahmen der Vereinfachung von Digitalgesetzen den europäischen Datenschutz weiter schwächt. Wenn es um den illegalen Handel mit Standortdaten geht, sollen Mitgliedstaaten die Datenschutzgrundverordnung über ihre Aufsichtsbehörden durchsetzen, wie die Kommission mitteilt.
Das Wichtigste zur Spionage-Gefahr durch Handy-Standortdaten in der EU
Unsere Recherchen zeigen jedoch, wie Datenschutzbehörden mit ihren bisherigen Bemühungen zum Datenhandel allenfalls an der Oberfläche kratzen. Im Ökosystem der Werbeindustrie können Daten auf so vielen Wegen abfließen, dass Behörden und Nutzer*innen wie vor einem dichten Dschungel stehen. Selbst auf Privatsphäre bedachte Nutzer*innen können sich nur bedingt schützen, wenn sie nicht auf einen Großteil populärer Dienste verzichten wollen.
Ein Verbot von Tracking und Profilbildung für Werbezwecke würde auch EU-Mitarbeitende vor Spionage schützen. Stattdessen haben sie eine Rundmail bekommen. Sie und andere Nutzer*innen müssen sich demnach selbst helfen – „monatlich und möglichst nach jedem Update“.
Rundmail: „Mobile device security good practice“
Dear colleague,
Mobile devices are now the main way in which we communicate, shop, bank, or check out social media. Increasingly, EU entities rely on services that staff can access from their personal devices. This complicates the enforcement of cybersecurity best practices and allows for the possibility of staff exposing personal data or accidentally leaking corporate data.
To help with IT security, the Cybersecurity Service for the Union institutions, bodies, offices and agencies (CERT-EU) has issued advice to staff for protecting their data and privacy. Therefore, we would like to bring to your attention the following recommendations addressing tracking prevention on mobile devices.
Location permissions and metadata
- Disable location services when not needed and limit location tracking, including options like Significant Locations and Precise Location on iOS or Location accuracy on Android
- Review app permissions regularly and cancel unnecessary permissions. Only allow location access for apps that need it to function, like maps or traffic apps, and only while using the app
- Use Allow Once function: audit monthly and, if possible, after every update
- Block all location requests to browsers
- Block unnecessary notification requests from websites
- Disable location history and geotagging. Clear your existing location history
- Disable geotagging on your photos and videos to prevent apps from storing or sharing your location data. If geotagging is needed for personal use, then read the vendor’s documentation on how to clean GPS metadata from photos before sharing
Ad-tracking limiters
- Turn off personalised ads. For iOS: Settings > Privacy & Security > Tracking. For Android: Setting > Security and privacy > More privacy settings > Ads (some versions or models may differ)
Fitness/social apps
- Deny location to running, cycling or social apps if possible. Set exercise routes to private
- Be cautious about social-media posts: avoid real-time location or check-ins and check the picture for any unintended background detail before you share
Bonnes pratiques en matière de sécurité des appareils mobiles
Cher collègue,
Les appareils mobiles sont désormais le principal moyen que nous utilisons pour communiquer, faire des achats, effectuer des opérations bancaires ou consulter les réseaux sociaux. Les entités de l’UE s’appuient de plus en plus sur des services auxquels le personnel peut accéder à partir de ses appareils personnels. Cela complique l’application des bonnes pratiques en matière de cybersécurité et augmente le risque que le personnel expose des données à caractère personnel ou divulgue accidentellement des données d’entreprise.
Afin de contribuer à la sécurité informatique, le service de cybersécurité des institutions, organes et organismes de l’Union (CERT-EU) a émis des conseils à l’intention du personnel pour protéger leurs données et leur vie privée. Nous souhaitons donc attirer votre attention sur les recommandations suivantes concernant la prévention du suivi sur les appareils mobiles.
Autorisations de localisation et métadonnées
- Désactivez les services de localisation lorsque vous n’en avez pas besoin et limitez le suivi de localisation, notamment les options telles que «Lieux importants» et «Localisation précise» sur iOS ou «Précision de la localisation» sur Android.
- Vérifiez régulièrement les autorisations des applications et supprimez celles qui ne sont pas nécessaires. N’autorisez l’accès à la localisation qu’aux applications qui en ont besoin pour fonctionner, comme les applications de cartographie ou de trafic, et uniquement pendant l’utilisation de l’application.
- Utilisez la fonction «Autoriser une fois»: vérifiez-la tous les mois et, si possible, après chaque mise à jour
- Bloquez toutes les demandes de localisation adressées aux navigateurs.
- Bloquez les demandes de notification inutiles provenant de sites web.
- Désactivez l’historique de localisation et la géolocalisation. Effacez votre historique de localisation existant.
- Désactivez la géolocalisation sur vos photos et vidéos afin d’empêcher les applications de stocker ou de partager vos données de localisation. Si la géolocalisation est nécessaire pour un usage personnel, lisez la documentation du vendeur sur la manière de nettoyer les métadonnées GPS des photos avant de les partager.
Limiteurs de suivi publicitaire
- Désactivez les annonces personnalisées. Pour iOS: Paramètres > Confidentialité et sécurité > Suivi. Pour Android: Paramètres > Sécurité et confidentialité > Plus de paramètres de confidentialité > Publicités (certaines versions ou certains modèles peuvent différer)
Applications de fitness/réseaux sociaux
- Si possible, refusez de partager votre position avec les applications de course à pied, de cyclisme ou les réseaux sociaux. Définissez vos itinéraires d’entraînement comme privés.
- Soyez prudent lorsque vous publiez sur les réseaux sociaux: évitez de partager votre position en temps réel ou de vous enregistrer à un endroit, et vérifiez qu’il n’y a pas de détail d’arrière-plan involontaire sur les photos avant de les partager.
Datenschutz & Sicherheit
EU-Kommission will Datenschutzgrundverordnung und KI-Regulierung schleifen
Es geht um nicht weniger als eine Generalüberholung der europäischen Digitalregulierung: Am 19. November will die EU-Kommission einen umfassenden Gesetzesvorschlag vorstellen. Der „digitale Omnibus“, wie das Paket genannt wird, soll laut Kommission Regeln vereinfachen, überlappende Gesetze in Einklang bringen und Bürokratie abbauen.
Vier Regulierungsbereiche stehen im Fokus des umfangreichen Reformvorhabens: der Datenschutz, Regeln für die Datennutzung, der Umgang mit Cybersicherheitsvorfällen und die KI-Verordnung. Daher auch der Begriff Omnibus („für alle“) – er wird in der Gesetzgebung verwendet, wenn mehrere Rechtsakte zugleich geändert werden. Die Kommission hat ihre zahlreichen Pläne auf zwei getrennte Gesetzesvorschläge aufgeteilt.
Wir veröffentlichen einen Zwischenstand des Gesetzespakets.
Aus vier mach eins: der überarbeitete Data Act
Mit dem ersten „Digital-Omnibus“ plant die EU-Kommission eine umfassende Konsolidierung verschiedener Datengesetze.
Im Zentrum steht hier der vor rund zwei Jahren verabschiedete Data Act, der nach einer Übergangsfrist erst seit September EU-weit anwendbar ist und nun überarbeitet werden soll. Im neuen Data Act sollen gleich drei weitere Gesetze aufgehen: die Open-Data-Richtlinie, die Verordnung über den freien Fluss nicht-personenbezogener Daten und der Data Governance Act.
Die Kommission präsentiert das erste Omnibus-Gesetz als „eine ehrgeizige Liste technischer Änderungen an einem umfangreichen Korpus digitaler Rechtsvorschriften, die den breitesten Bereich digitaler Unternehmen abdecken.“ Ziel sei es, „Unternehmen, öffentlichen Verwaltungen und Bürgern gleichermaßen sofortige Erleichterungen zu verschaffen“.
Kommission will die Datenschutzgrundverordnung aufbohren
Dabei will die Kommission auch die Datenschutzgrundverordnung (DSGVO) aufbohren und in Teilen zurückschneiden. So bestätigt das Dokumente Gerüchte aus den vergangenen Tagen, wonach der Schutz an mehreren Stellen deutlich zurückgefahren werden soll, um mehr Datennutzung zu ermöglichen.
Wir sind ein spendenfinanziertes Medium
Unterstütze auch Du unsere Arbeit mit einer Spende.
Das gilt etwa für das Training von KI-Systemen mit personenbezogenen Daten. Dies soll künftig auf Basis des berechtigten Interesses von Tech-Konzernen möglich sein. Die noch immer heftig geführte Debatte um möglicherweise notwendige Einwilligungen der Betroffenen hätte sich damit erledigt. Deutlich enger gefasst werden soll auch die Definition von pseudonymisierten Daten.
Im Fokus stehen zudem Online-Tracking und Cookies. Auch hier enthält der Vorschlag einen Passus, der den momentan bereits unzureichenden Schutz massiv aufweichen würde: Das Speichern und Auslesen von nicht-notwendigen Cookies auf dem Gerät der Nutzer:innen soll nämlich nicht wie bislang nur nach deren Einwilligung erlaubt sein. Stattdessen soll die ganze Palette der Rechtsgrundlagen eröffnet werden, die die DSGVO zu bieten hat. Dazu zählt auch: das berechtigte Interesse von Website-Betreibern und Tracking-Firmen. Nutzer:innen hätten dann nur noch die Möglichkeit zum nachträglichen Opt-Out.
Gleichzeitig will die Kommission der Cookie-Banner-Flut und der „Zustimmungsmüdigkeit“ bei den Nutzenden begegnen und „den Weg für automatisierte und maschinenlesbare Angaben zu individuellen Präferenzen und deren Berücksichtigung durch Website-Anbieter ebnen, sobald entsprechende Standards verfügbar sind“.
Konkret bedeutet das: Etwa Browser oder Betriebssysteme sollen Signale an Websites senden, die individuelle Entscheidungen der Nutzenden übermitteln, ob diese Cookies annehmen oder ablehnen wollen. Ausgenommen von dieser Regel sollen Medienanbieter (media service providers) sein – „angesichts der Bedeutung des unabhängigen Journalismus in einer demokratischen Gesellschaft und um dessen wirtschaftliche Grundlage nicht zu untergraben“.
Weniger Schutz für sensible Daten
Darüber hinaus nimmt die Kommission Artikel 9 der DSGVO zu besonderen Kategorien von Daten ins Visier. Durch diesen Artikel sind Daten besonders geschützt, aus denen die „ethnische Herkunft, politische Meinungen, religiöse oder weltanschauliche Überzeugungen oder die Gewerkschaftszugehörigkeit hervorgehen“. Außerdem gehört dazu „die Verarbeitung von genetischen Daten, biometrischen Daten zur eindeutigen Identifizierung einer natürlichen Person, Gesundheitsdaten oder Daten zum Sexualleben oder der sexuellen Orientierung einer natürlichen Person“.
Die Kommission will erreichen, dass sensible Daten enger definiert werden. Besonders geschützt wären dann nur noch jene Daten, die oben genannte Informationen explizit offenbaren. Das bedeutet: Gibt etwa eine Person in einem Auswahlfeld an, welche sexuelle Orientierung sie hat, wäre das weiterhin besonders geschützt. Schließt ein Datenverarbeiter aufgrund vermeintlicher Interessen oder Merkmale auf die mutmaßliche sexuelle Orientierung eines Menschen, würden bisherige Einschränkungen wegfallen.
Zugleich betont die Kommission, dass „der verstärkte Schutz genetischer Daten und biometrischer Daten aufgrund ihrer einzigartigen und spezifischen Merkmale unverändert bleiben sollte“.
KI-Verordnung soll aufgeweicht werden
Weitergehende Regelungen zum Umgang mit Künstlicher Intelligenz finden sich im zweiten Gesetzespaket zur KI-Verordnung.
Die hier geplanten Änderungen begründet die Kommission damit, dass es bei der KI-Verordnung noch „Herausforderungen bei der Umsetzung“ gebe, „die das wirksame Inkrafttreten wichtiger Bestimmungen gefährden könnten“. Die Kommission schlägt daher „gezielte Vereinfachungsmaßnahmen vor, die eine zeitnahe, reibungslose und verhältnismäßige Umsetzung gewährleisten sollen“.
Konkret sieht der zweite Omnibus unter anderem vor, die KI-Aufsicht teilweise bei dem sogenannten AI Office zu bündeln, das direkt bei der Kommission angesiedelt ist. Davon wären vor allem sehr große Online-Plattformen (VLOPS) und Anbieter großer Suchmaschinen betroffen.
VLOPs sind laut dem Digital Services Act (DSA) solche Angebote, die monatlich mehr als 45 Millionen Nutzer:innen in der EU erreichen. Dazu zählen große soziale Netzwerke und Marktplätze wie Facebook, Instagram oder Amazon.
Außerdem will die Kommission es Anbietern und Betreibern von KI-Systemen „erleichtern“, Dateschutzgesetze einzuhalten, wenn sie personenbezogene Daten verarbeiten. Zudem will sie Sonderregeln für kleine und mittlere Unternehmen schaffen, um sie von bestimmten Verpflichtungen etwa bei Dokumentation und Monitoring auszunehmen.
Unklar ist derzeit offenbar noch, ob die weitere Umsetzung der KI-Verordnung in Teilen aufgeschoben wird. Eine solche Verschiebung wäre im Sinne der Bundesregierung. Digitalminister Karsten Wildberger (CDU) wirbt seit Monaten dafür. Als Grund führt der Minister an, dass die technischen Standards noch nicht vorlägen.
Update, 16:30 Uhr: Wir haben den Text um weitere Aspekte ergänzt.

Meta kündigt 600 Milliarden US-Dollar KI-Investitionen an

Top 10: Der beste Mini-PC mit Windows 11 im Test – Testsieger Minisforum

ChatGPT-Prompts tauchten offenbar in der Google Search Console auf

Der ultimative Guide für eine unvergessliche Customer Experience

Adobe Firefly Boards › PAGE online
eine gute Nachricht ist")
Relatable, relevant, viral? Wer heute auf Social Media zum Vorbild wird – und warum das für Marken (k)eine gute Nachricht ist
-
 UX/UI & Webdesignvor 3 Monaten
UX/UI & Webdesignvor 3 MonatenDer ultimative Guide für eine unvergessliche Customer Experience
-
 UX/UI & Webdesignvor 2 Monaten
UX/UI & Webdesignvor 2 MonatenAdobe Firefly Boards › PAGE online
-
eine gute Nachricht ist") Social Mediavor 3 Monaten
Social Mediavor 3 MonatenRelatable, relevant, viral? Wer heute auf Social Media zum Vorbild wird – und warum das für Marken (k)eine gute Nachricht ist
-

 Apps & Mobile Entwicklungvor 2 Monaten
Apps & Mobile Entwicklungvor 2 MonatenGalaxy Tab S10 Lite: Günstiger Einstieg in Samsungs Premium-Tablets
-

 UX/UI & Webdesignvor 3 Wochen
UX/UI & Webdesignvor 3 WochenIllustrierte Reise nach New York City › PAGE online
-

 Entwicklung & Codevor 3 Monaten
Entwicklung & Codevor 3 MonatenPosit stellt Positron vor: Neue IDE für Data Science mit Python und R
-

 Datenschutz & Sicherheitvor 2 Monaten
Datenschutz & Sicherheitvor 2 MonatenHarte Zeiten für den demokratischen Rechtsstaat
-

 Entwicklung & Codevor 2 Monaten
Entwicklung & Codevor 2 MonatenEventSourcingDB 1.1 bietet flexiblere Konsistenzsteuerung und signierte Events