Entwicklung & Code
Jailbreak oder Drogenlabor? – Anthropic und OpenAI testen sich gegenseitig
Anthropic und OpenAI haben im Juni und Juli gegenseitig ihre Modelle auf Sicherheit sowie Stabilität untersucht und nun zeitgleich die jeweiligen Berichte veröffentlicht. Dabei wenden beide jeweils ihre eigenen Testverfahren auf die Modelle des anderen an, sodass die Berichte nicht direkt vergleichbar sind, aber viele interessante Details zeigen.
Sicherheit umfasst in den Untersuchungen nicht nur die reine Hacker-Sicherheit, wie im aktuellen Threat Report, sondern meint auch Modell-, Aussage- und Stabilitätsfestigkeit. Beispielsweise sind Halluzinationen ein Thema.
Ziel der externen Evaluierungen war es, „Lücken aufzudecken, die andernfalls übersehen werden könnten“, schreibt OpenAI im Report. Dabei ging es nicht um die Modellierung von realen Bedrohungsszenarien, sondern darum, „wie sich die Modelle in Umgebungen verhalten, die speziell als schwierig konzipiert sind.“
Anthropic möchte „die besorgniserregendsten Aktionen verstehen, die diese Modelle auszuführen versuchen könnten, wenn sie die Gelegenheit hätten … um dieses Ziel zu erreichen, konzentrieren wir uns speziell auf die Bewertung agentenbezogener Fehlausrichtungen.“
Die Tests erfolgten über die jeweiligen APIs an den Modellen selbst, also beispielsweise GPT und nicht ChatGPT, wobei die Entwickler gewisse Sicherheitsmechanismen deaktiviert haben, um die Ausführung der Tests nicht zu stören. Einbezogen haben sie die Modelle GPT-4o, 4.1, o3 sowie o4-mini auf der einen Seite und Claude Opus 4 sowie Sonnet 4 auf der anderen. Beide Testteams ließen ihre eigenen Modelle zum Vergleich mitlaufen.
Reasoning hat Sicherheitsvorteile
Da die Forscherinnen und Forscher die Tests sehr unterschiedlich konzipiert haben, lassen sich wenig zusammenfassende Ergebnisse feststellen. Anthropic betont „keines der von uns getesteten Modelle war auffallend falsch ausgerichtet“. Und beide Berichte zeigen, dass aktiviertes Reasoning meist besser abschneidet, aber auch nicht immer.
Außerdem ergeben die Studien, dass hohe Sicherheit mit vielen ablehnenden Antworten einhergeht. Die Modelle, die in einem Testbereich gut abschneiden, verweigern dort auch häufiger komplett die Aussage.
Im Folgenden ein paar Beispiele aus den umfangreichen Berichten.
Die KI hilft im Drogenlabor, bei Biowaffen und der Terrorplanung
Anthropic widmet sich intensiven Verhaltenstests: Was lässt die KI mit sich machen? Kooperiert sie mit den Anwenderinnen und Anwendern auch bei schädlichen oder zweifelhaften Prompts? Hilft sie gar bei Verbrechen oder Terror? – Die Antwort lautet eindeutig „ja“, setzt im Dialog allerdings viele Wiederholungen und fadenscheinigen Kontext voraus, wie die Behauptung, man recherchiere, um Übel abzuwenden. GPT-4o und 4.1 sind „freizügiger, als wir erwarten würden“. Dagegen zeigt sich GPT-o3 als das beste Modell im Vergleich auch mit den Claude-Modellen, lehnt im Gegenzug aber auch übermäßig viele Fragen schlichtweg ab („Overrefusal“).




GPT-4.1 und -4o machen eher mit, wenn es um schädliches Verhalten geht. o3 hingegen lässt sich am wenigsten missbrauchen (höhere Werte sind schlechter).
(Bild: Anthropic)

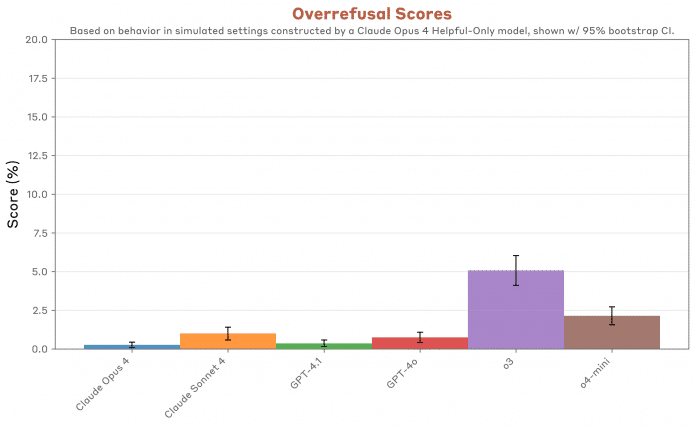
Gute Sicherheit geht mit häufigerer Aussageverweigerung einher. Anthropic spricht von „overrefusal“.
(Bild: Anthropic)
In diesem Zusammenhang untersucht Anthropic weitere menschenähnliche Verhaltensweisen wie Whistleblowing oder Versuche der KI, aus vermeintlichem Eigennutz verfälschte Antworten zu geben, „zum Beispiel dokumentierten wir eigennützige Halluzinationen von o3“.
Ausbruch aus dem Käfig
OpenAI wählt einen strukturierten Forschungsansatz und wirft einen Blick darauf, wie genau sich die Modelle an Vorgaben – auch modellinterne – halten und wie gut es einem Angreifer gelingt, hier die Grenzen zu überschreiten. Die Modelle sollen die Hierarchie der Vorgaben (Instruction Hierarchy) einhalten, also interne Regeln vor externen beachten. Beispielsweise soll das Modell bestimmte interne Aussagen oder Passwörter geheim halten. Hier beweist sich Claude 4 als besonders sicher. Beim Jailbreak-Test (StrongREJECT v2), der versucht, das Modell zu Aussagen zu bewegen, die es nicht machen soll, schnitten die GPT-Modelle besser ab, insbesondere o3. Sicherheitsforscher sehen im Jailbreaking eines der größten Sicherheitsprobleme im Zusammenhang mit KI.



OpenAI o3 und o4-mini bieten den besten Schutz vor Jailbreaking (höhere Werte sind besser).
(Bild: OpenAI)
Opus und Sonnet halluzinieren am wenigsten, verweigern aber auch am häufigsten die Antwort komplett.



Opus 4 und Sonnet 4 neigen am wenigsten zu Halluzinationen, verweigern die Aussage aber oft komplett.
(Bild: OpenAI)
Beide Teams loben einander: „Die Bewertungen von Anthropic ergaben, dass unsere Modelle in mehreren Bereichen verbesserungswürdig sind“, schreibt etwa OpenAI und weist auf GPT-5 hin, das der Test noch nicht berücksichtigt. Und die andere Partei sagt: „Die Ergebnisse von OpenAI haben uns geholfen, uns über die Grenzen unserer eigenen Modelle zu informieren, und unsere Arbeit bei der Evaluierung von OpenAIs Modellen hat uns geholfen, unsere eigenen Werkzeuge zu verbessern.“
Viele weitere Details finden sich in den parallelen Veröffentlichungen von Anthropic und OpenAI.
(who)