Entwicklung & Code
Jailbreak oder Drogenlabor? – Anthropic und OpenAI testen sich gegenseitig
Anthropic und OpenAI haben im Juni und Juli gegenseitig ihre Modelle auf Sicherheit sowie Stabilität untersucht und nun zeitgleich die jeweiligen Berichte veröffentlicht. Dabei wenden beide jeweils ihre eigenen Testverfahren auf die Modelle des anderen an, sodass die Berichte nicht direkt vergleichbar sind, aber viele interessante Details zeigen.
Sicherheit umfasst in den Untersuchungen nicht nur die reine Hacker-Sicherheit, wie im aktuellen Threat Report, sondern meint auch Modell-, Aussage- und Stabilitätsfestigkeit. Beispielsweise sind Halluzinationen ein Thema.
Ziel der externen Evaluierungen war es, „Lücken aufzudecken, die andernfalls übersehen werden könnten“, schreibt OpenAI im Report. Dabei ging es nicht um die Modellierung von realen Bedrohungsszenarien, sondern darum, „wie sich die Modelle in Umgebungen verhalten, die speziell als schwierig konzipiert sind.“
Anthropic möchte „die besorgniserregendsten Aktionen verstehen, die diese Modelle auszuführen versuchen könnten, wenn sie die Gelegenheit hätten … um dieses Ziel zu erreichen, konzentrieren wir uns speziell auf die Bewertung agentenbezogener Fehlausrichtungen.“
Die Tests erfolgten über die jeweiligen APIs an den Modellen selbst, also beispielsweise GPT und nicht ChatGPT, wobei die Entwickler gewisse Sicherheitsmechanismen deaktiviert haben, um die Ausführung der Tests nicht zu stören. Einbezogen haben sie die Modelle GPT-4o, 4.1, o3 sowie o4-mini auf der einen Seite und Claude Opus 4 sowie Sonnet 4 auf der anderen. Beide Testteams ließen ihre eigenen Modelle zum Vergleich mitlaufen.
Reasoning hat Sicherheitsvorteile
Da die Forscherinnen und Forscher die Tests sehr unterschiedlich konzipiert haben, lassen sich wenig zusammenfassende Ergebnisse feststellen. Anthropic betont „keines der von uns getesteten Modelle war auffallend falsch ausgerichtet“. Und beide Berichte zeigen, dass aktiviertes Reasoning meist besser abschneidet, aber auch nicht immer.
Außerdem ergeben die Studien, dass hohe Sicherheit mit vielen ablehnenden Antworten einhergeht. Die Modelle, die in einem Testbereich gut abschneiden, verweigern dort auch häufiger komplett die Aussage.
Im Folgenden ein paar Beispiele aus den umfangreichen Berichten.
Die KI hilft im Drogenlabor, bei Biowaffen und der Terrorplanung
Anthropic widmet sich intensiven Verhaltenstests: Was lässt die KI mit sich machen? Kooperiert sie mit den Anwenderinnen und Anwendern auch bei schädlichen oder zweifelhaften Prompts? Hilft sie gar bei Verbrechen oder Terror? – Die Antwort lautet eindeutig „ja“, setzt im Dialog allerdings viele Wiederholungen und fadenscheinigen Kontext voraus, wie die Behauptung, man recherchiere, um Übel abzuwenden. GPT-4o und 4.1 sind „freizügiger, als wir erwarten würden“. Dagegen zeigt sich GPT-o3 als das beste Modell im Vergleich auch mit den Claude-Modellen, lehnt im Gegenzug aber auch übermäßig viele Fragen schlichtweg ab („Overrefusal“).


GPT-4.1 und -4o machen eher mit, wenn es um schädliches Verhalten geht. o3 hingegen lässt sich am wenigsten missbrauchen (höhere Werte sind schlechter).
(Bild: Anthropic)
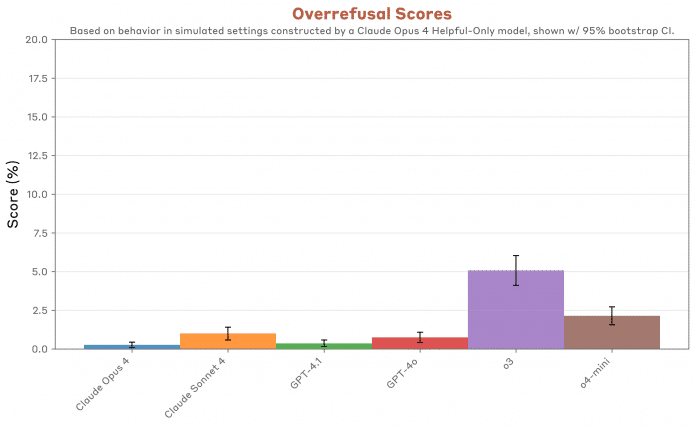
Gute Sicherheit geht mit häufigerer Aussageverweigerung einher. Anthropic spricht von „overrefusal“.
(Bild: Anthropic)
In diesem Zusammenhang untersucht Anthropic weitere menschenähnliche Verhaltensweisen wie Whistleblowing oder Versuche der KI, aus vermeintlichem Eigennutz verfälschte Antworten zu geben, „zum Beispiel dokumentierten wir eigennützige Halluzinationen von o3“.
Ausbruch aus dem Käfig
OpenAI wählt einen strukturierten Forschungsansatz und wirft einen Blick darauf, wie genau sich die Modelle an Vorgaben – auch modellinterne – halten und wie gut es einem Angreifer gelingt, hier die Grenzen zu überschreiten. Die Modelle sollen die Hierarchie der Vorgaben (Instruction Hierarchy) einhalten, also interne Regeln vor externen beachten. Beispielsweise soll das Modell bestimmte interne Aussagen oder Passwörter geheim halten. Hier beweist sich Claude 4 als besonders sicher. Beim Jailbreak-Test (StrongREJECT v2), der versucht, das Modell zu Aussagen zu bewegen, die es nicht machen soll, schnitten die GPT-Modelle besser ab, insbesondere o3. Sicherheitsforscher sehen im Jailbreaking eines der größten Sicherheitsprobleme im Zusammenhang mit KI.

OpenAI o3 und o4-mini bieten den besten Schutz vor Jailbreaking (höhere Werte sind besser).
(Bild: OpenAI)
Opus und Sonnet halluzinieren am wenigsten, verweigern aber auch am häufigsten die Antwort komplett.

Opus 4 und Sonnet 4 neigen am wenigsten zu Halluzinationen, verweigern die Aussage aber oft komplett.
(Bild: OpenAI)
Beide Teams loben einander: „Die Bewertungen von Anthropic ergaben, dass unsere Modelle in mehreren Bereichen verbesserungswürdig sind“, schreibt etwa OpenAI und weist auf GPT-5 hin, das der Test noch nicht berücksichtigt. Und die andere Partei sagt: „Die Ergebnisse von OpenAI haben uns geholfen, uns über die Grenzen unserer eigenen Modelle zu informieren, und unsere Arbeit bei der Evaluierung von OpenAIs Modellen hat uns geholfen, unsere eigenen Werkzeuge zu verbessern.“
Viele weitere Details finden sich in den parallelen Veröffentlichungen von Anthropic und OpenAI.
(who)











Entwicklung & Code
Modernes C++: Trauer um unseren Blogautor Rainer Grimm
Leider ist unser Autor Rainer Grimm im Oktober verstorben. Wir trauern um einen großartigen Autor, Experten und Menschen. Rainer hat seit fast zehn Jahren regelmäßig in diesem Blog über aktuelle C++-Themen, kommende Standards, komplexe Probleme und mehr geschrieben.

(Bild: Rainer Grimm)
Im Oktober 2023 hatte Rainer die Diagnose erhalten, dass er an Amyotropher Lateralsklerose (ALS) leidet, einer schweren und unheilbaren neurologischen Erkrankung, die zu Muskellähmung führt. In seinem englischen Blog „My ALS Journey“ schrieb Rainer offen über seine Krankheit. Noch Anfang September lautete die Überschrift „I feel good“.
Bis zum Schluss war sein Ziel, über die Krankheit zu informieren und die Forschung indirekt zu unterstützen, um Ansatzpunkte für Therapien zu finden. Außerdem sammelte er immer wieder Geld für die ALS-Forschung, unter anderem durch spezielle Aktionen beim Verkauf seiner Bücher und durch einen Spendenlauf.
Experte für C++
Als Experte schrieb er über C++ und andere IT-Themen. Neben seinem regelmäßigen Blog verfasste er zahlreiche Artikel und sieben Bücher. Ein achtes Buch hatte er in Arbeit. Zusätzlich arbeitete er als Trainer und trat auf zahlreichen Konferenzen auf.
Seinen Blog schrieb er bis zum Schluss regelmäßig und hat in den vergangenen Monaten die wichtigsten Neuerungen von C++26 vorgestellt. „Modernes C++“ erschien lange Zeit wöchentlich. Nach dem Fortschreiten seiner Krankheit wechselte er auf einen Zweiwochentakt. Er konnte dabei bereits nicht mehr tippen, sondern diktierte die Texte, und seine Ehefrau Beatrix Jaud-Grimm half bei der Korrektur. Bis zum Ende hielt er Onlinevorträge und war als Trainer aktiv.
Geboren wurde Rainer am 26. Juni 1966. Nach seiner Ausbildung zum Krankenpfleger und Rettungssanitäter holte er das Abitur nach und studierte Mathematik. Er arbeitete anschließend als Softwarearchitekt bei der Tübinger Firma Science + Computing. 2016 hatte er zusammen mit seiner Ehefrau ein Schulungsunternehmen für C++ gegründet.
Leidenschaft für den Laufsport
Rainer war nicht nur IT-Experte, sondern auch leidenschaftlicher Läufer und Trainer beim TV Rottenburg. Er hat an vielen Meisterschaften teilgenommen und als junger Mann zweimal den Ironman absolviert. Noch im September hatte er einen Spendenlauf für die ALS-Forschung organisiert.
Anfang Oktober 2025 erkrankte Rainer an einer schweren Lungenentzündung. Er entschied sich bewusst gegen lebenserhaltenden Maßnahmen, die eine Dauerbeatmung bedeutet hätten und ihm die Möglichkeit zu sprechen genommen hätten.
Rainer starb am 6. Oktober im Kreis seiner Familie. Er hinterlässt seine Ehefrau Beatrix, die ihn während seiner Krankheit aufopfernd gepflegt hat, und zwei Kinder.
(rme)
Entwicklung & Code
Die Produktwerker: Anforderungen wirksam kommunizieren als Product Owner
Anforderungen zu formulieren, gehört zum Alltag jeder Produktrolle. Doch obwohl viele Product Owner viel Zeit und Sorgfalt in ihre User Stories und Akzeptanzkriterien stecken, kommt am Ende oft etwas anderes heraus als gedacht. Warum ist das so – und was lässt sich daran ändern?
Klare Kommunikation für wirksame Produktentwicklung
In der aktuellen Folge des Podcasts „Die Produktwerker“ sprechen Tim Klein und Oliver Winter darüber, worauf es bei der Kommunikation von Anforderungen wirklich ankommt. Dabei geht es weniger um Tools oder Templates – sondern um die Frage, wie Sprache, Haltung und Kontext darüber entscheiden, ob Teams und Stakeholder das Gleiche verstehen, wenn sie über ein Feature oder ein Problem sprechen.
Die beiden Gastgeber greifen damit ein alltägliches, aber oft unterschätztes Thema auf – und geben zahlreiche Impulse für mehr Klarheit, bessere Zusammenarbeit und letztlich wirksamere Produktentwicklung. Eine Folge, deren Inhalte Product Ownern in ihrer täglichen Arbeit sofort weiterhelfen werden.
(Bild: deagreez/123rf.com)

So geht Produktmanagement: Auf der Online-Konferenz Product Owner Day von dpunkt.verlag und iX am 13. November 2025 kannst du deinen Methodenkoffer erweitern und dich von den Good Practices anderer Unternehmen inspirieren lassen.
Die aktuelle Ausgabe des Podcasts steht auch im Blog der Produktwerker bereit: „Anforderungen wirksam kommunizieren als Product Owner„.
(mai)
Entwicklung & Code
Visual Studio Code 1.105 erweitert KI-Chat um vollqualifizierte Tool-Namen
Mit der September-2025-Version von Visual Studio Code führt Microsoft eine Reihe von Neuerungen ein, darunter erweiterte Chat-Funktionen und vollqualifizierte Tool-Namen sowie einen MCP-Marktplatz. Entwicklerinnen und Entwickler erhalten zudem neue Möglichkeiten zur KI-gestützten Konfliktlösung und verbesserte Authentifizierungsoptionen.
Chat-System erhält umfangreiche Neuerungen
Das Chat-System von Visual Studio Code 1.105 führt vollqualifizierte Tool-Namen ein, um Konflikte zwischen integrierten Tools und solchen von MCP-Servern oder Extensions zu vermeiden. Die Namen der Tools verweisen nun unmittelbar auf den MCP-Server, die Erweiterung oder die Werkzeugsammlung, zu der sie gehören. Statt codebase verwenden Entwickler nun search/codebase, statt list_issues nutzen sie github/github-mcp-server/list_issues. Laut Microsoft hilft dies auch beim Auffinden fehlender Extensions oder MCP-Server.

Eine Code Action unterstützt bei der Migration zu den qualifizierten Tool-Namen.
(Bild: Microsoft)
Für benutzerdefinierte Modelle hat Microsoft die Edit-Tools verbessert und einen Lernmechanismus zur Auswahl optimaler Tool-Sets eingeführt. Bei OpenAI-kompatiblen Modellen lässt sich die Liste der Edit-Tools über die Einstellung github.copilot.chat.customOAIModels konfigurieren. Die Unterstützung für verschachtelte AGENTS.md-Dateien in Unterordnern des Arbeitsbereichs ist als experimentelle Funktion verfügbar. Dies ermöglicht spezifischere Kontexte und Anweisungen für verschiedene Codebereiche, etwa unterschiedliche Vorgaben für Frontend- und Backend-Code. Die Funktion lässt sich über die Einstellung chat.useNestedAgentsMdFiles aktivieren.
Benachrichtigungen des Betriebssystems informieren nun über eingehende Chat-Antworten, wenn das VS Code-Fenster nicht im Fokus steht. Die Benachrichtigung enthält eine Vorschau der Antwort und bringt bei Auswahl den Chat-Input in den Fokus. Das Verhalten steuert die Einstellung chat.notifyWindowOnResponseReceived. In Visual Studio Code 1.105 stehen zudem neue LLMs zur Verfügung: GPT-5-Codex von OpenAI, optimiert für agentisches Coding, und Claude Sonnet 4.5 von Anthropic für Coding und Real-World-Agenten. Die Auswahl erfolgt über den Modell-Picker im Chat.
MCP-Marktplatz als Vorschau-Feature
Die neue Version des kostenlosen Code-Editors stellt erstmals einen MCP-Marktplatz in der Extensions-Ansicht bereit, der das Durchsuchen und Installieren von MCP-Servern direkt im Editor ermöglicht. Der Marktplatz nutzt die GitHub MCP Registry als Datenquelle. Entwickler können MCP-Server über den @mcp-Filter, die Dropdown-Auswahl „MCP Servers“ oder die direkte Namenssuche finden. Die Funktion ist standardmäßig deaktiviert und lässt sich über chat.mcp.gallery.enabled aktivieren. Laut Microsoft befindet sich das Feature noch in der Vorschau-Phase – etwaige Unzulänglichkeiten beim Verwenden seien daher nicht auszuschließen.
Beim Senden von Chat-Nachrichten starten MCP-Server nun automatisch. VS Code vermeidet in diesem Fall störende Dialoge und zeigt stattdessen Indikatoren im Chat an, wenn ein Server Aufmerksamkeit benötigt. Die Einstellung chat.mcp.autostart steuert das Verhalten.
Verbessert hat das VS-Code-Entwicklungsteam zudem die Darstellung von MCP-Ressourcen aus Tools: Der Editor fügt standardmäßig eine Vorschau des Ressourceninhalts hinzu und gibt Anweisungen zum Abrufen vollständiger Inhalte, was die Modell-Performance bei der Tool-Nutzung steigern soll. Darüber hinaus wurden einige MCP-Spezifikations-Updates implementiert: SEP-973 ermöglicht benutzerdefinierten Icons für Server, Ressourcen und Tools. SEP-1034 erlaubt Standard-Werte bei der Elicitation-Nutzung.
Weitere Verbesserungen für Entwickler
Visual Studio Code 1.105 führt KI-gestützte Lösung von Merge-Konflikten ein. Bei Dateien mit Git-Merge-Konflikt-Markierungen erscheint eine neue Aktion in der unteren rechten Editor-Ecke, die den Chat öffnet und einen agentischen Ablauf mit Merge-Base und Änderungen beider Branches als Kontext startet.
Das runTests-Tool im Chat unterstützt nun Test-Code-Coverage-Berichte an den Agenten, was die Generierung und Verifikation von Tests ermöglicht, die den gesamten Code abdecken. Für lang laufende Tasks zeigt VS Code OS-Benachrichtigungen bei Abschluss an, wenn das Fenster nicht im Fokus steht. Die Einstellung task.notifyWindowOnTaskCompletion steuert dieses Verhalten.
Alle weiteren Informationen zu Visual Studio Code 1.105 lassen sich dem Ankündigungsbeitrag entnehmen.
Lesen Sie auch
Python in Visual Studio Code: Verbesserungen für Python Environments
Nicht nur den Sourcecode-Editor selbst, sondern auch die Python-Erweiterungen hat Microsoft mit einem Update versehen. Im Oktober-Release (während bei Visual Studio Code der Vormonat namensgebend ist, richtet sich die Python-Erweiterung nach dem aktuellen) widmet sich das Entwicklungsteam insbesondere den Verbesserungen der Erweiterung Python Environments. Das Update verspricht unter anderem verbesserte Leistung und Zuverlässigkeit bei der Arbeit mit Conda-Umgebungen – Code lässt sich nun direkt ohne conda run starten. Auch gelegentlich auftretende Abstürze beim Ausführen von Python-Dateien, die input() verwenden, wurden korrigiert. Die Erweiterung aktualisiert nun auch automatisch die Umgebungsmanager beim Erweitern von Baumknoten, sodass die Umgebungsliste ohne weitere Maßnahmen auf dem neuesten Stand bleibt.
Weitere Informationen zu den Updates für Python in VS Code liefert ein Beitrag auf Microsofts Entwicklerblog.
(map)

„Voices of Humanity“: Kurzfilm von 27KM würdigt Helfende in Krisengebieten

Apple: Der M5 ist bereit für iPad Pro, MacBook Pro und Vision Pro

Julie Joliat’s Kalender 2026 › PAGE online

Der ultimative Guide für eine unvergessliche Customer Experience

Adobe Firefly Boards › PAGE online
eine gute Nachricht ist")
Relatable, relevant, viral? Wer heute auf Social Media zum Vorbild wird – und warum das für Marken (k)eine gute Nachricht ist
-
 UX/UI & Webdesignvor 2 Monaten
UX/UI & Webdesignvor 2 MonatenDer ultimative Guide für eine unvergessliche Customer Experience
-
 UX/UI & Webdesignvor 1 Monat
UX/UI & Webdesignvor 1 MonatAdobe Firefly Boards › PAGE online
-
eine gute Nachricht ist") Social Mediavor 2 Monaten
Social Mediavor 2 MonatenRelatable, relevant, viral? Wer heute auf Social Media zum Vorbild wird – und warum das für Marken (k)eine gute Nachricht ist
-

 Entwicklung & Codevor 2 Monaten
Entwicklung & Codevor 2 MonatenPosit stellt Positron vor: Neue IDE für Data Science mit Python und R
-

 Entwicklung & Codevor 1 Monat
Entwicklung & Codevor 1 MonatEventSourcingDB 1.1 bietet flexiblere Konsistenzsteuerung und signierte Events
-

 UX/UI & Webdesignvor 4 Wochen
UX/UI & Webdesignvor 4 WochenFake It Untlil You Make It? Trifft diese Kampagne den Nerv der Zeit? › PAGE online
-

 Apps & Mobile Entwicklungvor 3 Monaten
Apps & Mobile Entwicklungvor 3 MonatenFirefox-Update 141.0: KI-gestützte Tab‑Gruppen und Einheitenumrechner kommen
-

 Online Marketing & SEOvor 3 Monaten
Online Marketing & SEOvor 3 MonatenSo baut Googles NotebookLM aus deinen Notizen KI‑Diashows