Künstliche Intelligenz
Abgespeckt: Apple schickt dünnes iPhone Air ins Rennen – eSIM only
Das „iPhone 17 Air“ ist offiziell: Apple hat am Dienstagabend eine neue, besonders dünne iPhone-Modellvariante vorgestellt, sie heißt nur iPhone Air. Es ist zugleich das erste komplett neue iPhone seit mehreren Jahren und löst das bisherige Plus-Modell im Line-up ab. Mit einer Bildschirmdiagonale von 6,5 Zoll (2736 × 1260 Pixel, Bildwiederholrate bis zu 120 Hz) liegt das Air zwischen dem Standard-iPhone (6,3 Zoll) und dem 6,9-Zoll-Max-Modell, die der Hersteller parallel als iPhone 17, 17 Pro und 17 Pro Max frisch aufgelegt hat.
Durch die Dicke von 5,6 Millimetern soll sich das iPhone Air abheben, nicht nur von anderen iPhones, sondern ebenso vom Konkurrenten Samsung Galaxy S25 Edge, das 5,8 Millimeter dünn ist. Schlanker sind nur noch einzelne, teure Android-Foldables im aufgeklappten Zustand. Als Material für den Gehäuserahmen des iPhone Air kommt Titan zum Einsatz, für Vorder- wie Rückseite setzt der Hersteller weiterhin auf Glas („Ceramic Shield“). Das Gewicht beziffert Apple mit 165 Gramm.

Apple
)
Funkchips kommen nun von Apple – Mobilfunk wie WLAN
Die dünne Bauweise führt zwangsläufig zu Kompromissen: Das iPhone Air hat auf der Rückseite nur eine einzelne Hauptkamera mit 48-Megapixel-Sensor und den üblichen Funktionen wie mehreren virtuellen Brennweiten sowie einem 2x-Zoom mit 12 Megapixeln. Tele und Ultraweitwinkel bleiben den anderen Modellen vorbehalten – ebenso wie Makromodus und ProRAW-Support. 4K-Videoaufnahmen sind möglich, aber nur bis zu 60 fps.
Wie die anderen iPhone-17-Modelle bietet auch das Air eine „Center Stage“-Frontkamera, die dem Betrachter folgen und den Bildausschnitt anpassen kann. Die biometrische Authentifizierung erfolgt über die Gesichtserkennung Face ID.
Im Innern steckt ein A19-Pro-Chip mit 6-Kern-CPU und 5-Kern-GPU. Zum Einsatz kommt auch ein angeblich schnelleres, aber sparsam arbeitendes hauseigenes Mobilfunkmodem „C1X“ – eine Weiterentwicklung des mit dem iPhone 16e im Frühjahr vorgestellten C1-Basebands. Ein anderes Funkmodul trägt nun ebenfalls – erstmals – ein Apple-Logo: Auch der WLAN- und Bluetooth-Chip „N1“ ist eine Eigenentwicklung, betonte das Unternehmen. Er unterstützt WLAN 7, Bluetooth 6 und Thread. Das Chip-Trio mache das Modell zum „bislang energieeffizientesten iPhone“. Eine Satellitenverbindung wird in Mobilfunklöchern für die SOS-Funktion unterstützt, Messaging ist darüber in Europa bislang aber bisher nicht möglich. Ein Ultrabreitbandchip der 2. Generation ist mit an Bord, ebenso wie Support für Dual-Frequenz-GPS.
Auf einen SIM-Kartenslot verzichtet das iPhone Air, der Mobilfunkzugang erfolgt rein per eSIM. Das gilt auch für die Modelle, die Apple in Europa auf den Markt bringen wird. Dual SIM respektive Dual eSIM – der Parallelbetrieb von zwei Leitungen – wird wohlgemerkt unterstützt.
MagSafe-Batterie-Pack als Accessoire
Der Akku hält angeblich „den ganzen Tag“ durch, konkretere Angaben lieferte Apple bei der Keynote nicht. Bei reiner Videowiedergabe soll das Smartphone bis zu 27 Stunden durchhalten – drei Stunden weniger als das iPhone 17. Kurzerhand präsentierte der Hersteller gleich ein Accessoire: eine neue, schlankere MagSafe-Batterie, die sich auf der Rückseite aufsetzen und optional dazukaufen lässt.
Laden lässt sich das iPhone Air per USB-C, MagSafe, Qi und Qi2. Für die Datenübertragung unterstützt der USB-C-Port allerdings nur lahme USB-2-Geschwindigkeit. Ebenso wie die anderen aktuellen iPhones ist das Air nach IP68 gegen Wasser und Staub geschützt.
Apple iPhone Air: Preise und Verfügbarkeit
Das iPhone Air gibt es in den Farben Schwarz, Weiß, Gold und Himmelblau, es kostet mit 256 GByte Speicherplatz 1200 Euro (in den USA 1000 US-Dollar plus Steuer). Für größere Kapazitäten mit 512 GByte und 1 TByte bittet Apple wie üblich kräftig zur Kasse, diese kosten 1450 respektive 1700 Euro.
Für die „iPhone Air MagSafe Batterie“ veranschlagt der Hersteller weitere 115 Euro. Die Vorbestellung ist ab dem 12. September möglich, der Verkaufsstart folgt am Freitag, dem 19. September – auch in Deutschland.
Während das Basis-iPhone sowie das Pro- und Pro-Max-Modell stets klar ihre Käufer fanden, hatte Apple mit der vierten Modellvariante bislang ein wenig glückliches Händchen: Das im Jahr 2020 neu eingeführte, sehr kompakte iPhone mini stieß zwar auf viel Begeisterung, aber ganz offensichtlich auf wenig Nachfrage. Schon zwei Jahre später stocherte Apple mit dem größeren Plus-Modell in die ganz andere Richtung, das sich preislich zwischen Basis-iPhone und den Pro-Modellen einsortierte. Ein iPhone 17 Plus hat Apple nicht angekündigt, das Air tritt nun an dessen Stelle und muss unter Beweis stellen, ob es letztlich mehr Käufer findet.
(lbe)











Künstliche Intelligenz
Fedora Linux 43: Adieu X11, Hallo WebUI
Zwar ist Fedora um weitreichende Umbauten an der Linux-Distribution nie verlegen, doch haben die beiden signifikanten Änderungen zur jetzt veröffentlichten Version 43 weiteren Vorlauf benötigt und im Falle der entfernten X11-Unterstützung in Gnome zu internen Diskussionen geführt. Mit Fedora Linux 43 ist die Gnome-Session ab jetzt nur noch mit Wayland als Display-Protokoll verfügbar – ein optionales Paket zum Nachrüsten einer X11-Session gibt es nicht mehr. Denn Gnome und seine Komponenten sind hier nun ganz ohne X11 kompiliert – eine Möglichkeit dieser Desktop-Umgebung ab Gnome Version 47. Die Reduktion auf Wayland sollte zunächst auch den Display-Manager GDM zur Anmeldung betreffen, welcher ohne X11-Unterstützung auch keine anderen, zusätzlichen installierten Desktop-Umgebungen mit diesem Protokoll mehr starten könnte. So wie Ubuntu verzichtete Fedora deshalb auf den letzten Schritt und belässt X11 bis Fedora 49 in GDM, damit Anwender mit mehreren installierten Desktops neben Gnome vorerst nicht auf einen anderen Display-Manager wie LightDM ausweichen müssen.
Weiterlesen nach der Anzeige
Anaconda in neuem Gewand
Der Installer Fedoras, genannt Anaconda, fiel immer schon mit einer ungewöhnlichen Benutzerführung auf, die keine linearen Menüs präsentiert, sondern Untermenüs für die einzelnen Schritte wie Partitionierung, Benutzerkonto sowie Netzwerkverbindungen zeigt. Zuletzt bekam Anaconda in Fedora 26 mit dem alternativen Partitionierer Blivet eine größere Ergänzung, die fortgeschrittenen Anwendern detaillierte Einstellungen beim Anlegen neuer Partitionen bot. Jetzt zieht Fedora mit dem neuen Installer WebUI die lange bekannten Probleme der Anaconda-Oberfläche glatt. WebUI basiert auf HTML, Javascript sowie Python und setzt ein lineares, intuitiveres Frontend vor Anaconda, das den gewohnten Installationswegen anderer Linux-Distributionen ähnlicher ist.

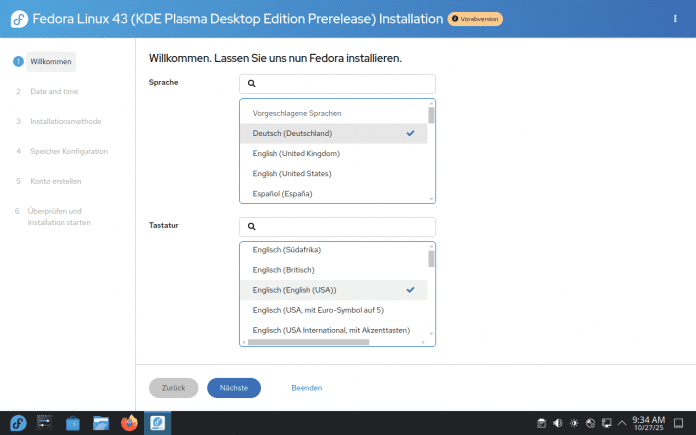
Diese Oberfläche zur Installation war schon in der Gnome-Ausgabe von Fedora 42 zu sehen. Nun ist der neue, lineare Installer auch der Standard in der KDE-Version und den anderen Fedora-Spins geworden.
(Bild: Screenshot David Wolski)
Mit einer neuen Option zur Reinstallation kann WebUI das System außerdem über ein bestehendes erneut installieren, behält dabei aber die bereits vorhandenen Daten in den Home-Verzeichnissen. Sein Debüt hatte der neue Installer, der seit Fedora 37 in Entwicklung ist, schon in der vorherigen Ausgabe. Allerdings nur in der Gnome-Version Fedoras, während jetzt der neue Installer auch bei KDE Plasma und den Fedora-Spins der Standard ist. Kleine Unterschiede gibt es dabei im Installer der Gnome-Ausgabe: Die Erstellung des ersten Benutzerkontos erfolgt in Gnome nach dem ersten Boot des installierten Systems, bei den anderen Fedora-Ausgaben gleich in der WebUI. In den kommenden Ausgaben wird WebUI auch die Server-Ausgabe, die Netzwerk-Installationsmedien und die Immutable-Ausgaben installieren und das bisherige GTK4-Frontend für Anacoda ab Fedora 46 komplett ersetzen. Der Aufbau als App mit Web-Techniken soll überdies die Installation Fedora in Cloud-Instanzen über Remote-Verbindungen im Browser erleichtern.
Boot-Partition und initiale Ramdisk
Einfacher ist auch die automatische Partitionierung geworden, bei welcher Fedora von Haus ein btrfs-Volumes mit dem Home-Verzeichnis als Subvolumes anlegt, mit einer aktivierten Komprimierung per Zstandard und sehr niedriger Kompressionsstufe. Dieses Verfahren soll keinen Speicherplatz sparen, sondern die Schreibvorgänge für Flash-Datenträger messbar reduzieren. Im EFI-Modus verlangt Fedora nun stets nach einem Datenträger mit GPT als Partitionstabelle und akzeptiert keinen Master Boot Record mehr. Diese Kombination ist zwar seitens der EI-Spezifikation möglich, machte in der Praxis mit UEFI-Implementierungen verschiedener Hersteller immer wieder Probleme. Wer Fedora einige Versionen schon per Paketmanager DNF auf neue Ausgaben aktualisiert hat, kennt in vielen Fällen auch die Fehlermeldung über eine zu kleine /boot-Partition beim Entpacken neuer Kernel-Pakete. Die separate Boot-Partition dehnt Fedora deshalb bei Neuinstallation auf 2 GByte aus, um größere initiale Ramdisk, die weiterhin experimentellen Unified Kernel Images (UKIs) und mehr Firmware aufnehmen zu können. Für initiale Ramdisks nutzt Fedora nicht mehr den Packer XZ, sondern Zstandard, um einen Neustart ein paar Sekunden schneller absolvieren zu können. Das Paketformat aktualisiert Fedora auf RPM 6.0, das mehrere Signaturen pro Paket erlaubt, die Verwaltung der OpenPGP-Schlüssel aus Repositorys vereinfacht und lokal gebaute, eigene RPM-Paket automatisch signieren kann.
Desktops: Fedora in vielen Varianten
Weiterlesen nach der Anzeige
Der Kernel ist in Version 6.17, wie bei Fedora zu erwarten, auch hier wieder sehr jung. Im Laufe des Unterstützungszeitraums bis Dezember 2026 werden die Entwickler auch mindestens noch die kommende Kernel-Version 6.18 nachschieben. Die GNU-Toolchain hat Fedora auf Gcc 15.2 und Glibc 2.42 gehievt. Python-Entwickler bekommen den Interpreter in Version 3.14 vorinstalliert, das wieder einige Methoden als veraltet markiert oder bereits entfernt hat. Zur Abwärtskompatibilität gibt es weiterhin Python 3.13 in den Paketquellen. Wie immer gibt es Fedora auch mit anderen Desktops als mit Gnome 49 und KDE Plasma 6.5 in den Hauptversionen.
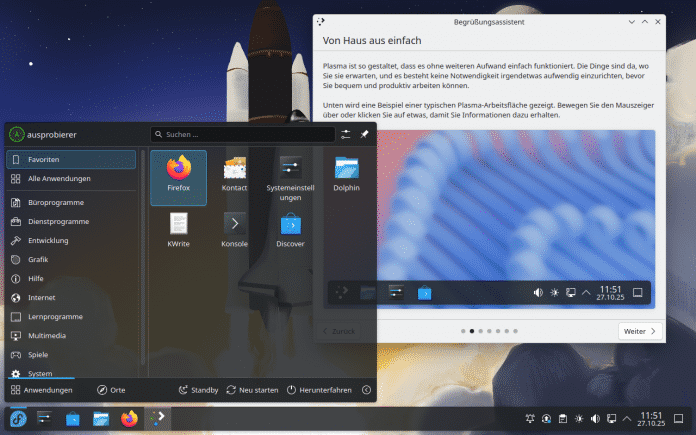
Seit Fedora 42 ist die KDE-Ausgabe, nun mit Plasma 6.5 ausgestattet, zur Hauptausgabe neben Gnome befördert. Automatischer Theme-Wechsel und abgerundete Kanten sind die Highlights dieser Plasma-Version.
(Bild: Screenshot David Wolski)
Installierbare Live-Systeme gibt es als „Spins“ auch wieder mit den schlankeren Arbeitsumgebungen von XFCE, LXQT, LXDE und Mate. Zudem gibt als Alternative zu Gnome auch das von Linux Mint bekannte Cinnamon, Budgie und auch schon eine Vorabversion des neuen Rust-Desktops Cosmic, der aktuell von System76 entwickelt wird. Auch diese Versionen liegen nicht nur für die x86-64Architektur vor, sondern auch für ARM.
Der aktuelle Stand der wichtigsten Unix- und Linux-Distributionen:
(dmk)
Künstliche Intelligenz
KanDDDinsky 2025: Eindrücke von Europas DDD-Community-Konferenz
Vergangene Woche waren mein Kollege Rendani und ich im Berliner nhow Hotel, zusammen mit rund 250 bis 300 anderen Menschen, die unsere Leidenschaft für Domain-Driven Design (DDD), Event Sourcing und durchdachte Softwarearchitektur teilen. Auf der KanDDDinsky 2025 war unsere erste Teilnahme an dieser Konferenz – nicht nur als Besucher, sondern als Sponsoren und Aussteller für die von uns entwickelte Datenbank EventSourcingDB.
Weiterlesen nach der Anzeige
Ein anderes Konferenzformat
Was uns sofort ins Auge fiel, war die Herangehensweise an die Zeitplanung. Statt des typischen Konferenzformats mit einheitlichen Session-Längen schufen die Organisatoren eine Puzzle-artige Agenda, die 50-minütige Vorträge mit 120-minütigen Hands-on-Workshops kombinierte. Die Sessions liefen in vier parallelen Tracks.

Golo Roden ist Gründer und CTO von the native web GmbH. Er beschäftigt sich mit der Konzeption und Entwicklung von Web- und Cloud-Anwendungen sowie -APIs, mit einem Schwerpunkt auf Event-getriebenen und Service-basierten verteilten Architekturen. Sein Leitsatz lautet, dass Softwareentwicklung kein Selbstzweck ist, sondern immer einer zugrundeliegenden Fachlichkeit folgen muss.
Dieses Format eröffnet interessante Wahlmöglichkeiten für die Teilnehmerinnen und Teilnehmer. Theoretisch ließ sich zwar zwischen Sessions wechseln, praktisch sah die Sache jedoch anders aus. Einen zweistündigen Workshop auf halbem Weg zu verlassen, um einen Vortrag mitzunehmen, ergibt nur bedingt Sinn – auch wenn wir beobachteten, dass einige Teilnehmer sich leise zur Halbzeit aus Vorträgen verabschiedeten, um eine andere Session zu besuchen. Eine elegante Lösung, die sowohl tiefgehende Einblicke als auch schnellen Wissensaustausch ermöglicht – etwas, das uns in dieser Form auf anderen Konferenzen bisher nicht begegnet ist.
Ebenso durchdacht war die viertägige Struktur: Workshops am Dienstag (21. Oktober), die Hauptkonferenz am Mittwoch und Donnerstag (22.-23. Oktober) und ein Open Space am Freitag (24. Oktober). Diese Progression von fokussiertem Lernen über breite Exploration bis hin zu Community-getriebener Konversation zeigt, wie sorgfältig die Organisatoren darüber nachgedacht haben, wie Menschen tatsächlich mit Konferenzen interagieren möchten.
Die Content-Landschaft
Weiterlesen nach der Anzeige
Die Bandbreite der Themen auf der zweitägigen Agenda war beeindruckend. Der Mittwoch startete mit einer interaktiven Keynote zur Modellierung in Software- und menschlichen Systemen, während der Donnerstag Vorträge von Ian Coopers „The Emissary“ bis hin zu Eric Evans höchstpersönlich über „AI and Tackling Complexity“ bot. Die Klassiker waren natürlich vertreten – CQRS, Event Sourcing, DDD-Pattern – standen aber gleichberechtigt neben Sessions zu Wardley Mapping, kollaborativer Modellierung, hexagonaler Architektur und Organisationsdesign.
Über beide Tage hinweg kristallisierten sich mehrere Themen heraus. Vor allem die Schnittstelle von KI und DDD ließ sich kaum ignorieren: Rinat Abdullins „When DDD Met AI: Practical Stories from Enterprise Trenches“, Eric Evans über die Bewältigung von Komplexität mit KI und Hila Fox‘ Diskussion sozio-technischer Systeme im KI-Zeitalter – alle deuteten auf eine Community hin, die sich aktiv damit auseinandersetzt, wie diese Welten aufeinanderprallen. Der Hands-on-Workshop „Epic Systems Design: Surviving Complexity“ von Jacqui und Steven Read fand am Donnerstag statt, ebenso wie eine reflektierende Session unter dem Titel „Over 20 Years of DDD – What We Know, What We Do, What Needs to Change“, quasi eine Meta-Konversation über die Praxis selbst.
Besonders interessant fanden wir, wie natürlich dabei KI ihren Weg in den Diskurs fand. Sessions wie Marco Heimeshoffs „Hybrid Intelligence“ und die verschiedenen KI-fokussierten Vorträge wurden nicht als Neuheiten behandelt, sondern als natürliche Erweiterungen der Kernthemen der Community. Das passt perfekt zu unserer Arbeit an eventsourcing.ai, wo wir thematisieren, wie KI und Event-getriebene Architekturen einander sinnvoll ergänzen können. Die Vorteile Event-getriebener Architekturen für KI-Anwendungen – Nachvollziehbarkeit, Time-Travel-Debugging, deterministische Replays – werden anscheinend zunehmend offensichtlich.
Die Closing Keynote am Donnerstag von Alberto Brandolini über „DDD Lessons from ProductLand“ rundete die Hauptkonferenztage ab: Eine der Koryphäen der Community reflektierte darüber, wie sich DDD-Erkenntnisse jenseits der reinen Softwareentwicklung anwenden lassen.
Die Konferenz fand vollständig auf Englisch statt, was ihren international geprägten Charakter widerspiegelt. Die Teilnehmer kamen hauptsächlich aus Europa – Deutschland, Österreich, Italien und darüber hinaus – und bildeten eine diverse, aber kohärente Community. Dass Inklusion den Organisatoren wichtig ist, zeigte sich sowohl im Speaker-Lineup als auch in der Art, wie die Veranstaltung strukturiert war.
Die größere Erkenntnis
Vielleicht war unsere wichtigste Einsicht aus diesen Tagen gar nicht technischer Natur – es ging um die Community selbst. Manchmal hört man die Einschätzung, DDD, CQRS und Event Sourcing seien Nischeninteressen, die von einer kleinen Gruppe Enthusiasten in isolierten Ecken praktiziert würden.
Die KanDDDinsky widerlegte diese Wahrnehmung eindrücklich. Ja, diese Ansätze sind nicht das, was alle machen. Sie sind nicht der Standard, der mit jedem Framework ausgeliefert oder in jedem Bootcamp gelehrt wird. Aber sie sind auch keineswegs exotisch. Wenn man sich in diesem pink getönten Konferenzraum umsah und Hunderte von Menschen aus zahllosen Unternehmen und Ländern beobachtete, wurde die Realität offensichtlich: Dies ist eine substanzielle, wachsende Community mit handfester Erfahrung im Bau von Produktivsystemen.
Die Gespräche, die wir führten, waren dabei alles andere als theoretisch: Menschen lösen konkrete Probleme mit diesen Pattern. Sie ringen mit echten Trade-offs, teilen ihre Erfahrungen aus dem Alltag und lernen aus den Erfolgen und Misserfolgen der anderen. Dies ist ein ausgereifter Praxisbereich, keine experimentelle Spielwiese.
Für uns hat diese Bestätigung Gewicht. Wir bauen EventSourcingDB, weil wir überzeugt sind, dass Event Sourcing und CQRS erstklassige Tooling-Unterstützung verdienen. Die Größe und das Engagement dieser Community zu erleben, bestätigt uns darin, dass echte Nachfrage nach Tools besteht, die diese Pattern zugänglicher machen.
Ausblick
Die beiden Konferenztage setzten einen starken Akzent, wobei der Open Space am Freitag noch bevorstand, um die Gespräche in einem offeneren Format fortzuführen. Die Mischung aus Vorträgen und Workshops schuf natürliche Rhythmen – intensive Lernsessions, gefolgt von Networking und Zeit zum Verdauen. Die Location funktionierte einwandfrei, die Organisation lief reibungslos, und die Community war einladend.
Wir verarbeiten noch immer all das, was wir gelernt haben, und all die Menschen, die wir kennengelernt haben. Das ist das Zeichen einer guten Konferenz – wenn man mit mehr Fragen als Antworten nach Hause fährt und mehr Kontakte geknüpft hat, als man sofort nachverfolgen kann.
Die KanDDDinsky 2025 hat uns einen Einblick in diese Zukunft gegeben, und sie sieht vielversprechend aus: dicht, erfüllt und summend vor Ideen – genau so, wie wir es mögen. Wir freuen uns bereits darauf, diese Gespräche fortzusetzen und zu beobachten, wie diese Community die nächste Generation Event-getriebener Systeme prägt.
(rme)
Künstliche Intelligenz
Firefox integriert verschlüsselte Direktsuche in Adressleiste
Mozilla arbeitet an einer Funktion für Firefox, die Suchergebnisse künftig direkt in der Adressleiste anzeigen soll – Nutzer umgehen damit die klassische Suchmaschinen-Ergebnisseite. Das soll Anwendern nicht nur Zeit sparen, sondern gleichzeitig deren Unabhängigkeit von zentralisierten Suchmaschinen stärken. Dafür muss man jedoch gesponsorte Ergebnisse in Kauf nehmen.
Weiterlesen nach der Anzeige
Ein paar Eingaben weniger
Während herkömmliche Suchvorschläge in Browsern lediglich Vorschläge für Suchanfragen liefern, die dann zur Ergebnisseite der Suchmaschine führen, zeigt Firefox künftig direkt relevante Antworten an. Das können etwa Flugstatus-Informationen, Website-Adressen oder lokale Geschäftsempfehlungen sein. Mozilla argumentiert, dass Browser-Adressleisten heute größtenteils nur als Umweg zu Suchmaschinen dienen – das sei gut für die Anbieter von letzteren, aber nicht die Anwender.
Die technische Herausforderung lag für Mozilla im Datenschutz: Ein früherer Versuch der Funktion scheiterte: Mozilla konnte keinen Weg finden, bei dem das Unternehmen selbst nicht erfahren würde, wer wonach sucht. Anbieter von Suchmaschinen hätten ein Interesse an genau diesen Daten der Nutzer – Mozilla aber nicht.
Die jetzt entwickelte Architektur nutzt das Verschlüsselungsprotokoll Oblivious HTTP (OHTTP), an dessen Entwicklung Mozilla beteiligt war. Das Verfahren trennt systematisch die Kenntnis über die Identität des Nutzers von der Kenntnis über den Suchinhalt: Wenn Firefox eine Suchanfrage stellt, wird diese per OHTTP verschlüsselt und an einen Relay-Server geschickt, den der US-Cloud-Anbieter Fastly betreibt. Dieser Relay-Server kann die IP-Adresse des Nutzers sehen, aber nicht den verschlüsselten Suchtext.
Drei-Parteien-Modell verhindert Zuordnung
Der Relay-Server leitet die verschlüsselte Anfrage an Mozilla-Server weiter, wo sie entschlüsselt wird. Mozilla kann den Suchtext lesen, kennt aber nicht die IP-Adresse des Absenders. Anschließend kann Mozilla direkt eine Antwort liefern oder diese von spezialisierten Suchdiensten abrufen. Keine einzelne Partei kann eine Suchanfrage einer bestimmten Person zuordnen, das zumindest ist der Plan.
Weiterlesen nach der Anzeige
Firefox wird weiterhin traditionelle Suchvorschläge für alle Anfragen anzeigen und Direktergebnisse nur dann einblenden, wenn eine hohe Übereinstimmung mit der vermuteten Nutzerabsicht besteht. Ähnlich wie bei Suchmaschinen können manche dieser Ergebnisse gesponsert sein, um Firefox zu finanzieren. Allerdings betont Mozilla, dass weder das Unternehmen noch der Sponsor erfahren wird, wem die Ergebnisse angezeigt werden – und nur bei hoher Relevanz werden gesponserte Inhalte überhaupt ausgespielt.
Lesen Sie auch
Zunächst nur in den USA verfügbar
Die Einführung erfolgt zunächst ausschließlich in den Vereinigten Staaten, da Mozilla laut Ankündigung die Funktion im großen Maßstab testen muss. Das System erfordert ausreichende Serverkapazitäten und eine geografisch verteilte Infrastruktur, um keine spürbaren Latenzen zu verursachen. Eine Ausweitung auf andere Regionen soll auf Basis der gesammelten Erfahrungen evaluiert werden – entsprechend gibt es noch keine Angaben zu einer Verfügbarkeit in Deutschland.
Da sich die Funktion noch in der Entwicklung befindet, wird sie erst im Laufe des kommenden Jahres schrittweise eingeführt. Nutzer können die Funktion in den Firefox-Einstellungen unter „Suche“ durch Deaktivieren der Option „Vorschläge während der Eingabe abrufen“ abstellen. Wer die Funktion bereits vor der Verfügbarkeit in den Einstellungen deaktivieren möchte, kann über about:config den Parameter browser.urlbar.quicksuggest.online.enabled auf false setzen.
(fo)

Fedora Linux 43: Adieu X11, Hallo WebUI

Diese Idee machte ihn mit 27 zum jüngsten Selfmade-Milliardär der Welt

Query Groups: Google zeigt SEOs, wonach die Audience sucht

Der ultimative Guide für eine unvergessliche Customer Experience

Adobe Firefly Boards › PAGE online
eine gute Nachricht ist")
Relatable, relevant, viral? Wer heute auf Social Media zum Vorbild wird – und warum das für Marken (k)eine gute Nachricht ist
-
 UX/UI & Webdesignvor 2 Monaten
UX/UI & Webdesignvor 2 MonatenDer ultimative Guide für eine unvergessliche Customer Experience
-
 UX/UI & Webdesignvor 2 Monaten
UX/UI & Webdesignvor 2 MonatenAdobe Firefly Boards › PAGE online
-
eine gute Nachricht ist") Social Mediavor 2 Monaten
Social Mediavor 2 MonatenRelatable, relevant, viral? Wer heute auf Social Media zum Vorbild wird – und warum das für Marken (k)eine gute Nachricht ist
-

 Entwicklung & Codevor 2 Monaten
Entwicklung & Codevor 2 MonatenPosit stellt Positron vor: Neue IDE für Data Science mit Python und R
-

 UX/UI & Webdesignvor 1 Woche
UX/UI & Webdesignvor 1 WocheIllustrierte Reise nach New York City › PAGE online
-

 Entwicklung & Codevor 2 Monaten
Entwicklung & Codevor 2 MonatenEventSourcingDB 1.1 bietet flexiblere Konsistenzsteuerung und signierte Events
-

 UX/UI & Webdesignvor 1 Monat
UX/UI & Webdesignvor 1 MonatFake It Untlil You Make It? Trifft diese Kampagne den Nerv der Zeit? › PAGE online
-

 Apps & Mobile Entwicklungvor 2 Monaten
Apps & Mobile Entwicklungvor 2 MonatenGalaxy Tab S10 Lite: Günstiger Einstieg in Samsungs Premium-Tablets