Künstliche Intelligenz
Dienstag: Elon Musk macht ein Schnäppchen, Lyft und Baidu kooperieren in Europa
Tesla-Chef Elon Musk soll 96 Millionen Aktien des US-Elektroautobauers zum Spottpreis erhalten. So will der Tesla-Vorstand ihn im Unternehmen halten. Musk könnte intern mit Rücktritt gedroht haben. Lyft und Baidu haben eine strategische Partnerschaft bekannt gegeben. Sie wollen ab dem kommenden Jahr einen Robotaxi-Service in Europa beginnen. Einer der ersten beiden Standorte soll Deutschland werden. Und wichtige SMS von EU-Kommissionschefin Ursula von der Leyen zu milliardenschweren Lieferungen von Covid-19-Impfstoffen wurden gelöscht. Schuld soll der Kabinettschef sein – die wichtigsten Meldungen im kurzen Überblick.
Zuletzt gab es immer mal wieder Spekulationen über einen Abschied Elon Musks von Tesla. Der Vorstand des US-amerikanischen Elektroautoherstellers unternimmt stattdessen einen neuen Anlauf, um seinem CEO ein milliardenschweres Aktienpaket zum Schnäppchenpreis zu übertragen. Für die 96 Millionen Tesla-Aktien mit einem aktuellen Marktwert von gut 29 Milliarden US-Dollar soll Musk gerade einmal 2,24 Milliarden US-Dollar zahlen. In einem Schreiben an die Aktionäre erklärt der Vorstand, mit dem Aktienpaket Musk in der Firma halten zu wollen. Hat dieser mit Rücktritt gedroht? Tesla verpasst Chance, sich von Elon Musk zu trennen
Der US-Fahrdienst-Vermittler Uber möchte in Zusammenarbeit mit Volkswagen ab 2026 autonom fahrende Autos in den USA auf die Straßen bringen. Zudem arbeitet Uber mit dem Start-up Momenta zusammen, um Robotaxi-Dienste außerhalb der USA und Chinas einzuführen. In Europa sollen die Fahrzeuge von 2026 an rollen. Nun zieht Konkurrent Lyft nach und streckt seine Fühler ebenfalls nach Europa aus. Zusammen mit dem chinesischen Technologiekonzern Baidu plant das US-Unternehmen ab dem nächsten Jahr, einen Robotertaxi-Dienst in mehreren europäischen Ländern anzubieten. Los gehen soll es in Deutschland und im Vereinigten Königreich. Lyft kümmert sich um Plattform und Kundendienst, Baidu liefert die Fahrzeuge. Lyft und Baidu kooperieren: Robotaxis in Deutschland ab 2026
Ähnlich wie den früheren Bundesgesundheitsminister Jens Spahn verfolgen auch EU-Kommissionspräsidentin Ursula von der Leyen umstrittene Deals aus der Zeit der Covid-19-Pandemie. Im Frühjahr 2021 einigten sich die EU-Kommission und der Impfstoff-Hersteller Biontech/Pfizer auf die Lieferung von bis zu 1,8 Milliarden Dosen Corona-Impfstoff mit einem geschätzten Vertragsvolumen von 35 Milliarden Euro. Wie die New York Times berichtet, sei der persönliche Kontakt zwischen Von der Leyen und Pfizer-Chef Albert Bourla für den Abschluss entscheidend gewesen. Sie sollen dabei auch per SMS kommuniziert haben. Und obwohl das Blatt im Streit um die Herausgabe der SMS vor dem Gericht der EU in Luxemburg Recht bekam, mauert die Kommission weiter. „Pfizergate“: Wichtige SMS von Ursula von der Leyen wurden gelöscht
Für Diskussionen sorgt auch der Glasfaserausbau. Nach den Plänen der EU-Kommission soll bis 2030 flächendeckend Glasfaser installiert sein. Digitalminister Karsten Wildberger (CDU) hat dazu im Juli ein Sieben-Punkte-Papier vorgelegt. Nun aber hat sich Wildberger gegen flächendeckende Abschaltung der DSL-Technik ausgesprochen. „Es ist sicher nicht der richtige Weg, einfach nur abzuschalten“, sagte er den Zeitungen der Funke-Mediengruppe. Digitalminister Wildberger will DSL nicht so schnell aufgeben
Neue Raumfahrtpläne der USA deuten sich an. Geplant sind offenbar eine neue Raumstation im Orbit sowie ein AKW auf dem Mond.
Der Musik-Stremingdienst Spotify hat seine Abopreise in Deutschland zuletzt im Herbst 2023 erhöht. Die monatlichen Kosten für ein Einzel-Abonnement stiegen damals von zehn auf elf Euro im Monat. Bald wird Spotify in mehreren Ländern erneut teurer, darunter auch in Europa. Laut einem Medienbericht gelten die neuen Preise ab September. Ob auch Deutschland und Österreich von den Preiserhöhungen betroffen sind, ist unklar. In Deutschland braucht es die explizite Zustimmung der Nutzer, um Preise bei laufenden Abos zu erhöhen, in Österreich womöglich auch. Spotify hebt international die Preise an
Auch noch wichtig:
(akn)










Künstliche Intelligenz
Glances 4.4.0: System-Monitor erhält Python API und Neofetch-Modus
Die Entwickler des plattformübergreifenden System-Monitoring-Tools Glances haben Version 4.4.0 veröffentlicht. Die zentrale Neuerung der Open-Source-Software ist eine Python-API, mit der sich Glances als Bibliothek in eigene Projekte integrieren lässt. Bisher war das Tool primär als eigenständiges Kommandozeilenprogramm konzipiert.
Weiterlesen nach der Anzeige
Ab sofort erlaubt die neue API den Entwicklern, Glances-Funktionen direkt in Python-Code einzubinden. Damit lassen sich die umfangreichen Monitoring-Funktionen des Tools nun programmatisch nutzen, ohne den Umweg über die Kommandozeile oder REST-API gehen zu müssen.
Eine weitere sichtbare Neuerung ist die Option --fetch, die einen Schnappschuss des aktuellen Systemzustands anzeigt. Die Funktion orientiert sich explizit am beliebten Tool Neofetch und präsentiert eine kompakte Systemübersicht mit den wichtigsten Metriken. Die neue Option ergänzt die kontinuierliche Monitoring-Ansicht von Glances um einen schnellen Statuscheck.
Modernisiertes Prometheus-Export-Format
Bei den Breaking Changes ist insbesondere die Überarbeitung des Prometheus-Export-Formats zu beachten: Die Metriken werden jetzt benutzerfreundlicher strukturiert ausgegeben, was aber bei bestehenden Dashboards und Abfragen zu Problemen führen kann. Administratoren, die Glances mit Prometheus-Monitoring nutzen, sollten also im Zuge des Updates ihre Konfigurationen überprüfen.
In der Prozessliste zeigt Glances lange Kommandozeilen standardmäßig gekürzt an. Mit den Pfeiltasten können Nutzer die vollständigen Befehle einblenden, die Shift-Taste in Kombination mit Pfeiltasten wechselt zwischen verschiedenen Spalten-Sortierungen. Diese Änderung macht die Prozessübersicht übersichtlicher, erfordert aber eine kurze Eingewöhnung.
Container-Monitoring und experimentelle Features
Weiterlesen nach der Anzeige
Für Container-Umgebungen zeigt Glances auch die verwendeten Ports in der Container-Sektion an. Dieser bereits seit 2017 offene Feature-Request erleichtert die Übersicht in Docker- und Podman-Deployments erheblich. Zusätzlich wurden Disk-I/O-Latenzen als neue Metrik integriert, womit sich Speicher-Performance-Probleme besser identifizieren lassen.
Als experimentelles Feature steht ein Export-Modul für die analytische DuckDB-Datenbank zur Verfügung. DuckDB eignet sich besonders für komplexe Abfragen über historische Monitoring-Daten. Der Sensors-Plugin aktualisiert sich standardmäßig alle 10 Sekunden statt bei jedem Refresh-Zyklus, was die CPU-Last reduziert.
Zahlreiche Bugfixes für macOS und Windows
Die Bugfix-Liste umfasst mehrere kritische Korrekturen. Unter macOS zeigte Glances unter Umständen keine Prozesse mehr an, unter Windows wurden CPU-Statistiken falsch dargestellt. Beide Probleme sind jetzt behoben. Ein schwerwiegender Performance-Bug, der bei laufenden virtuellen Maschinen zu API-Verzögerungen von über drei Minuten führte, haben die Entwickler ebenfalls gelöst.
Das Cloud-Plugin kontaktierte selbst bei deaktiviertem Status die Metadata-Adresse 169.254.169.254, was in bestimmten Netzwerk-Umgebungen Probleme verursachte. Auch dieser Fehler ist korrigiert. Alle Bugfixes und neuen Funktionen beschreiben die Release Notes auf der GitHub-Seite von Glances.
(fo)
Künstliche Intelligenz
Leiser Premium Mini-PC mit Intel Ultra 9 überzeugt: Minisforum M1 Pro im Test
Der Minisforum M1 Pro ist ein starker Mini-PC mit Intel-CPU. Zudem bietet er Oculink, zweimal USB4, davon einer mit PD-in, und einen integrierten Lautsprecher.
Minisforum hat es wieder getan: Der M1 Pro ist ein hervorragend ausgestatteter Mini-PC mit Intel Core Ultra 9 285H – und im Test dennoch schweigsam. Das hatten wir in der Vergangenheit etwa bereits mit dem Minisforum UM890 Pro (Testbericht), der trotz brachialer Leistung absolut leise blieb. Minisforum zählt neben Geekom zu den bekanntesten Mini-PC-Herstellern und konnte oft durch starke Preise und viele Zusatzfeatures, wie der Eingangsstromversorgung über USB-C, überzeugen. Bei unserem System handelt es sich gewissermaßen um die neue Variante des M1 Pro-125H, also um die Premium-Ausstattung mit Spitzenleistung. Das System runden 32 GB Arbeitsspeicher (RAM) und eine SSD mit 1 TB ab. Ob der Mini-PC mit einem Startpreis von 750 Euro im Spitzensegment mitmischen kann, zeigt unser Test.
Das Testgerät hat uns der Hersteller zur Verfügung gestellt.
Ausstattung: Welche Hardware bietet der Minisforum M1 Pro?
Der Minisforum M1 Pro-285H ist, wie man bereits erahnen kann, mit dem Intel Core Ultra 9 285H ausgestattet. Dieser 16-Kerner setzt neben Intels big.Little-Architektur nun auch auf ein Chiplet-Design. Das SoC verfügt über 6 Performance-Kerne (Lion Cove), die mit bis zu 5,4 GHz die maximale Leistung aus der Architektur bereitstellen. Die 8 kleineren Effizienzkerne takten mit 4,5 GHz und setzen auf die ältere Skylake-Architektur. Zudem gibt es noch zwei Low-Power-Effizienzkerne mit bis zu 2,5 GHz, die ebenfalls auf Skylake basieren. Die 16 Kerne unterstützen kein Hyperthreading und haben Zugriff auf 24 MB Cache. Der Chip ist mit einer TDP (Thermal Design Power) von 45 W spezifiziert.
Die integrierte Grafikeinheit hört auf den Namen Arc 140T und soll das bisherige Leistungsdefizit zur AMD-Konkurrenz deutlich reduzieren. Dazu hat die iGPU acht Kerne, die mit bis zu 2,35 GHz takten können.
Die integrierte NPU ist mit 13 TOPS eher schwach. Wegen bisher größtenteils fehlender Unterstützung der Programme ist das zum aktuellen Zeitpunkt jedoch auch kein allzu großer Verlust. Insgesamt bietet das System bis 99 TOPS an KI-Leistung.
Zur weiteren Ausstattung gehören 32 GB RAM in Form von zwei SO-DIMM-Modulen im DDR5-Standard. Die Übertragungsrate der Riegel von Adata liegt bei den üblichen 5600 MT/s. Nach Herstellerangaben kann der RAM auf eine Gesamtkapazität von 128 GB mit 6400 MT/s aufgerüstet werden. Der Speichercontroller der CPU unterstützt offiziell sogar bis zu 192 GB mit 6400 MT/s für SO-DIMM-Module. Wir konnten unser 96-GB-Kit von Corsair mit 5600 MT/s problemlos nutzen, mehr Kapazität stand uns zum Testzeitpunkt nicht zur Verfügung.
Beim Speicher gibt es eine M.2-SSD im Formfaktor 2280 mit 1 TB Kapazität. Diese ist von Kingston über PCIe 4.0 angebunden und damit hervorragend schnell. Mit Crystaldiskmark messen wir 6120 MB/s im Lesen und 5265 MB/s im Schreiben. Zudem steht ein weiterer, noch freier M.2-Anschluss im Formfaktor 2280 zur Verfügung. Zur maximal unterstützten Kapazität macht der Hersteller keine Angaben, üblich sind 4 TB pro Steckplatz.
Der Mini-PC verfügt gleich über zwei USB4-Anschlüsse im Typ C, wobei nur der auf der Rückseite die Eingangsstromversorgung bis 100 W unterstützt. So stehen via Displayport-alt-mode (DP 1.4a) für Bildschirme eine Übertragungsrate bis 32 GBit/s bereit. Die gesamte USB-Schnittstelle überträgt mit maximal 40 GB/s. Zudem gibt es einen modernen HDMI-2.1- und einen älteren Displayport-1.4-Anschluss. Für die Kommunikation mit externen Grafikkarten, womit man den Mini-PC zum Gaming- oder Workstation-PC aufrüsten kann, gibt es zudem einmal Oculink. Die klassischen USB-A-Anschlüsse sind jedoch rar, hier gibt es insgesamt nur noch drei Stück. Der einzelne RJ45-Ethernet-Port kommuniziert über den Intel-Chipsatz I226-V mit maximal 2,5 Gigabit. Drahtlos funkt der Mini-PC mit den sehr aktuellen Standards Wi-Fi 7 und Bluetooth 5.4. Die Kommunikation erfolgt über den Chipsatz BE200, ebenfalls von Intel.
Der Mini-PC kommt zudem noch mit einem seltenen Feature: einem integrierten Lautsprecher. Die Qualität erinnert uns an einen im Monitor integrierten Speaker, der eher leise ist. Die Wiedergabequalität würden wir als okay bezeichnen, der Lautsprecher genügt zur Ausgabe von Benachrichtigungssounds. Ein Ersatz für Kopfhörer oder richtige Soundsysteme ist er aber definitiv nicht.
Performance: Wie schnell ist der Minisforum M1 Pro?
In den vergangenen Jahren konnte Intel im Mobilsektor sowohl preislich als auch leistungstechnisch nicht mit AMD mithalten. Mit der Ultra-200-Serie konnte Intel zumindest in den Benchmarks die Konkurrenz von AMD überholen, wie unser Test des Geekom Mini IT15 (Testbericht) zeigt. Allerdings: Bei der Vorgängergeneration Intel-Ultra-100 ist aufgefallen, dass ein gutes Benchmarkergebnis nicht unbedingt ein gutes Spieleergebnis zu bedeuten hat.
Im PCmark 10 erzielt das System durchschnittlich 8097 Punkte – ein ausgezeichnetes Ergebnis, jedoch über 200 Punkte hinter dem Geekom IT 15. Die 4100 Punkte im 3Dmark Time Spy, zusammengesetzt aus 11.114 CPU- und 3690 Grafik-Punkten, sind ebenfalls auf Top-Niveau. Der IT15 holt 100 Punkte mehr, allerdings nur durch eine stärkere Grafik. Der CPU-Score ist sogar leicht schwächer (10.056 Punkte). Cinebench R24 attestiert dem System 128 Punkte im Single- und 981 Punkte im Multicore (IT15: 126 und 860 Punkte). Damit bestätigt sich die erste Beobachtung einer leicht stärkeren CPU-Leistung im M1 Pro. Zuletzt erreicht das System im Cross-Plattform-Benchmark Geekbench 6 2980 Punkte im Single- und 15.115 Punkte im Multicore. Der integrierte OpenCL-Grafikbenchmark vergibt 41.087 Punkte.
Minisforum M1 Pro – Bilderstrecke
Minisforum M1 Pro – Bilderstrecke

Minisforum M1 Pro – Bilderstrecke

Minisforum M1 Pro – Bilderstrecke

Minisforum M1 Pro – Bilderstrecke

Minisforum M1 Pro – Bilderstrecke

Minisforum M1 Pro – Bilderstrecke

Minisforum M1 Pro – Bilderstrecke

Minisforum M1 Pro – Bilderstrecke

Minisforum M1 Pro – Bilderstrecke

Minisforum M1 Pro – Bilderstrecke

Minisforum M1 Pro – Bilderstrecke

Minisforum M1 Pro – Bilderstrecke

Minisforum M1 Pro – Bilderstrecke

Minisforum M1 Pro – Bilderstrecke

Minisforum M1 Pro – Bilderstrecke

Minisforum M1 Pro – Bilderstrecke

Minisforum M1 Pro – Bilderstrecke

Minisforum M1 Pro – Bilderstrecke
Minisforum M1 Pro – Bilderstrecke
Minisforum M1 Pro – Bilderstrecke
Minisforum M1 Pro – Bilderstrecke
Minisforum M1 Pro – Bilderstrecke
Nun aber zur tatsächlichen Leistung mit unseren Spieltests. Wir spielen Anno 1800 in Full-HD bei hohen Einstellungen und zunächst deaktiviertem FSR (Fidelity FX Super Resolution). In unserem fortgeschrittenen Endlosspiel erhalten wir beim Blick auf die 50.000-Einwohner-Metropole durchschnittlich 22 FPS. Damit fühlt sich alles sehr ruckelig an und unsere Aktionen werden nur mit deutlicher Verzögerung ausgeführt. Aktivieren wir FSR im Modus „Leistung“ erhalten wir im Schnitt 47 FPS bei hohen Einstellungen. Das Ruckeln wird dadurch allerdings kaum besser.
Ebenfalls in Full-HD spielen wir Cities Skylines. Das Spiel ist ein wenig leistungshungriger, weshalb wir mittlere Einstellungen mit dynamischer Auflösungsskalierung wählen. Bei unserem Spielstand mit 11.000 Einwohnern erhalten wir durchschnittlich 14 FPS. Schrauben wir die Einstellungen auf das niedrige Preset herunter, sind es 22 FPS, bei „sehr niedrig“ schließlich 30 FPS. Damit ist es nur schlecht spielbar und die Grafik ungenießbar. So zeigt dieses System, dass Intel auf einem guten Weg ist, wieder konkurrenzfähig zu sein. Wirklich spiele-tauglich ist der Mini-PC allerdings nur bei „leichten“ Titeln wie eben Anno 1800.
KI: Wie gut laufen lokale LLMs?
Wie üblich bei modernen, leistungsstarken Mini-PCs wirbt auch dieser mit KI. So besitzt das System eine NPU, welche von nahezu keinen Programmen wirklich verwendet wird. Um den KI-Features gerecht zu werden, haben wir lokale LLMs (Large Language Models) mit LM Studio auf dem System laufen lassen. Das Programm kann aktuell ebenfalls nicht die Rechenleistung der NPUs nutzen. Stattdessen erfolgt die Berechnung primär auf der Grafikeinheit und im Zweifel auch auf der CPU. Wir nutzen das MoE-Modell (Mixture of Experts) gpt-oss-20b von OpenAI. Dieses kann vollständig in den Grafikspeicher geladen und von der GPU verarbeitet werden. Auf unseren Prompt „Schreibe mir eine spannende Geschichte mit mindestens 1000 Wörtern“ antwortet das System mit 15,47 Tokens/s. Die Geschichte ist am Ende knapp 1200 Wörter lang, die Qualität lassen wir in diesem Fall unbeachtet.
Verbrauch: Wie hoch ist die Leistungsaufnahme des Minisforum M1 Pro?
Im Idle verbraucht der Mini-PC durchschnittlich 15 Watt. Unter Volllast steigt der Verbrauch dann zunächst auf bis zu 78 Watt an. Dabei liegt die durchschnittliche Taktraten über alle Kerne der CPU bei 3,2 GHz. Erst nach knapp 2 Minuten sinkt der durchschnittliche Takt auf 2,8 GHz. Der Verbrauch beträgt dann im Mittel 70 Watt. Im weiteren Verlauf bleiben sowohl Takt als auch Verbrauch annähernd konstant. Den Stresstest in Aida64 besteht das System ohne weitere Auffälligkeiten.
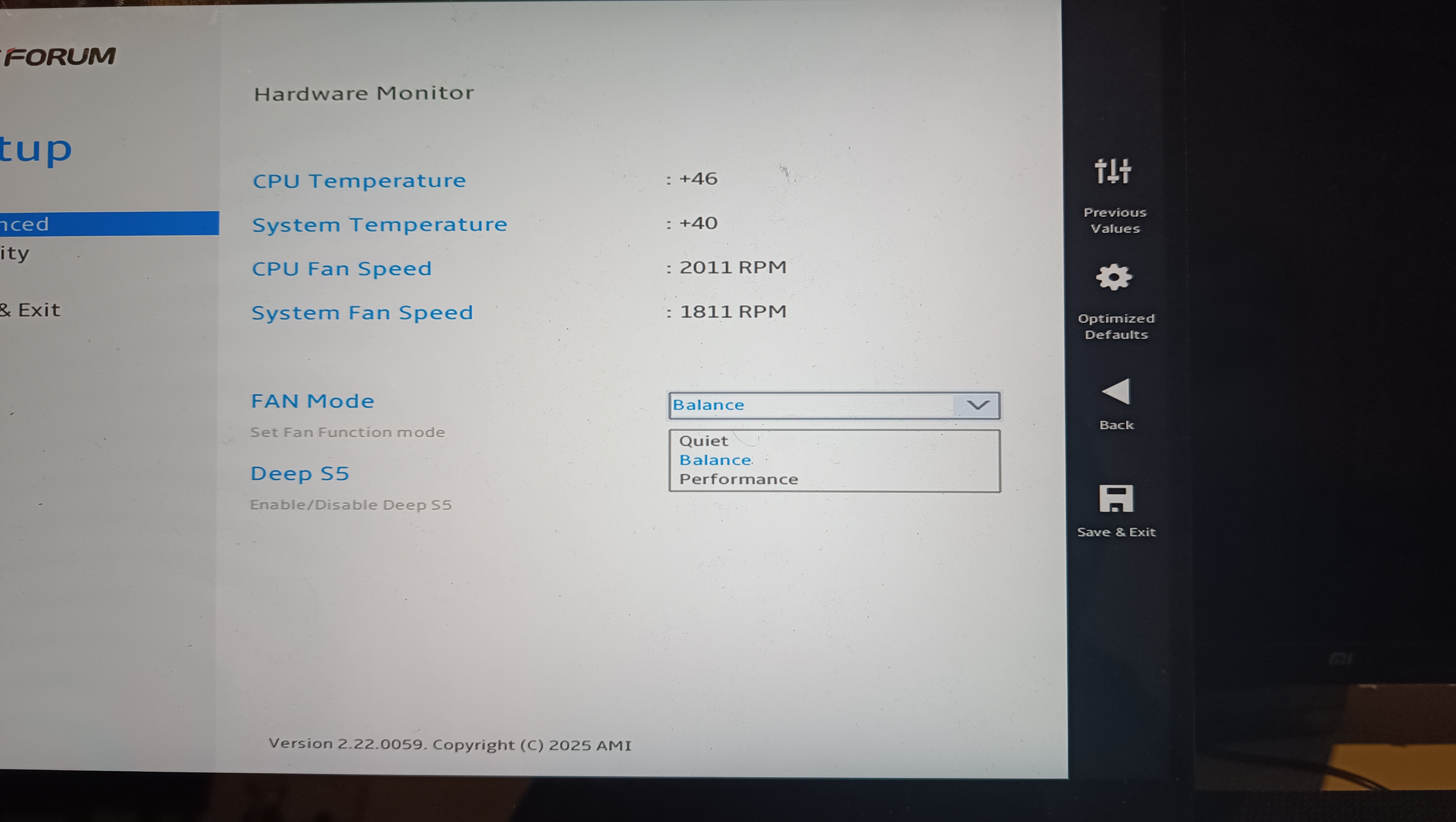
Lüfter: Wie laut ist der Minisforum M1 Pro?
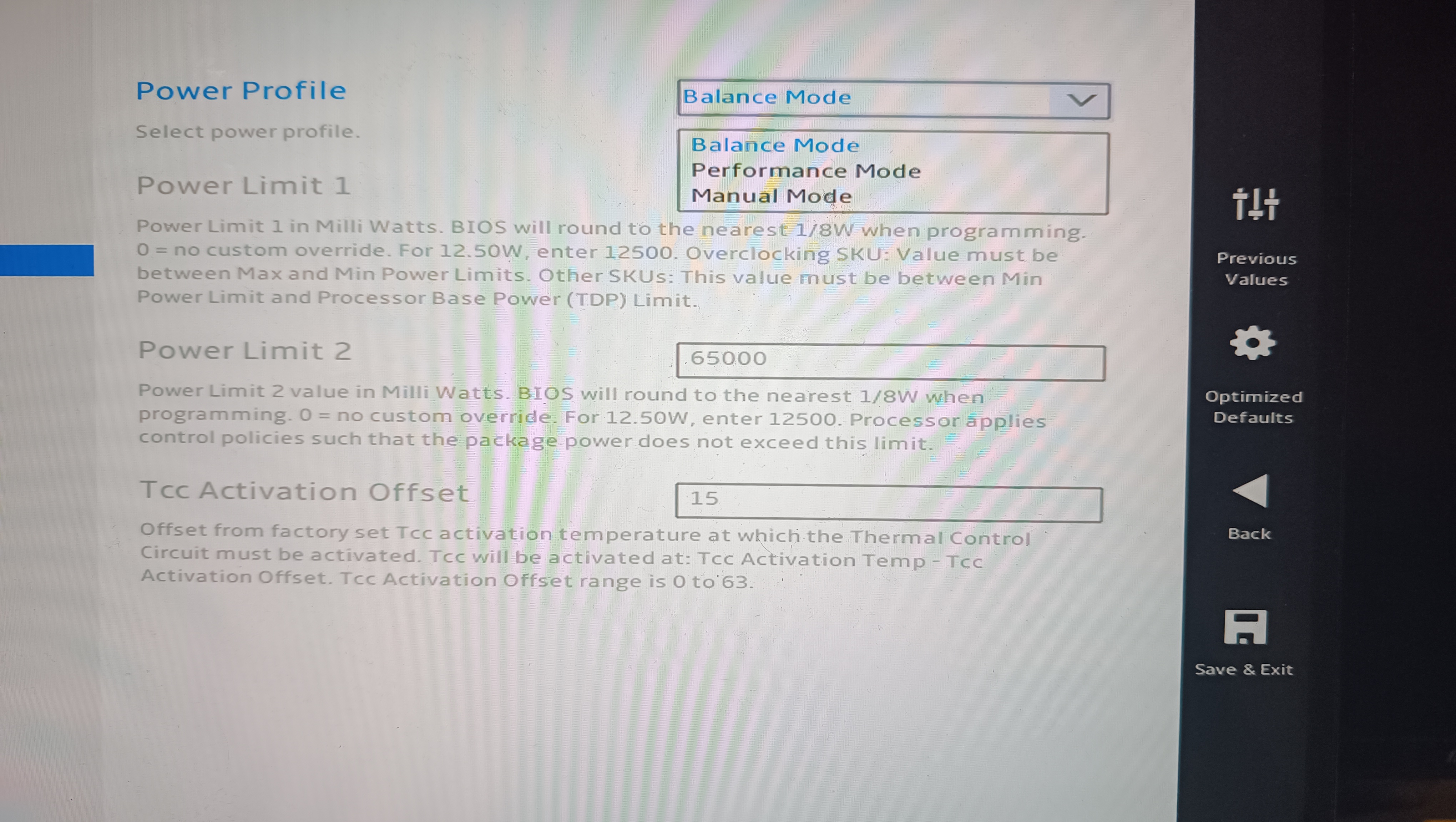
Unter Last bleibt der Lüfter erstaunlich leise, ohne dass die CPU überhitzt. Im Stresstest messen wir eine maximale CPU-Temperatur von 82 Grad und eine GPU-Temperatur von 70 Grad. Das sind beides gute Werte, gerade für mobile Prozessoren, die generell zu höheren Temperaturen neigen. Das Erstaunliche dabei: Wir messen mit dem Smartphone nur 26 dB(A) am Gehäuse und 20 dB(A) in einem Meter Entfernung. Die Umgebungslautstärke beträgt dabei 17 dB(A). Damit ist das System enorm leise, ähnlich starke Mini-PC überschreiten gut und gerne die 30-dB-Marke. Das BIOS bietet, wie üblich für Minisforum, enorm viele Einstellungen, darunter auch Lüfter- und sehr detaillierte Leistungsmodi.
Software: Welches Betriebssystem ist auf dem Minisforum M1 Pro installiert?
Auf dem Minisforum M1 Pro ist Windows 11 Pro vorinstalliert. Ein vollständiger Virenscan mit dem Windows Defender bleibt ohne Befund.
Das System verzichtet zudem auf jegliche Bloatware mit Ausnahme der Microsoft-Apps und -Dienste. Auch Linux, bei uns am Beispiel von Ubuntu 24.04.3 LTS getestet, funktioniert problemlos auf dem M1 Pro. Beim Booten wird direkt die richtige Displayauflösung gefunden, WLAN und Bluetooth sind ebenfalls bereit. Auch der integrierte Lautsprecher wird korrekt erkannt und angesteuert, und sogar das Aufwecken aus dem Ruhemodus ist kein Problem – besser geht es nicht.
Gehäuse: Wie ist die Verarbeitung des Minisforum M1 Pro?
Optisch erinnert das hellgraue Gehäuse des M1 Pro stark an die Mini-PCs A9 Max und GT1 Mega von Geekom. Allerdings unterscheidet sich der M1 Pro mit Außenmaßen von 128 × 126 × 59 mm. Sein Gewicht beläuft sich dabei auf 657 g. Seitlich hat das Gehäuse jeweils eine große Mesh-Front für den Luftaustausch. Die Oberseite ziert nur der Schriftzug des Herstellers. Auf der Rückseite gibt es ein wenig Kunststoff, in dem die zahlreichen Anschlüsse ihren Platz finden. Auch die Bodenplatte ist aus Kunststoff gefertigt. Die Verarbeitung ist rundum tadellos, wie man es auch für einen Mini-PC dieser Preisklasse erwartet.
Auf der Unterseite befinden sich vier lange Kreuzschlitzschrauben. Nach dem Lösen dieser muss die Abdeckung vorsichtig aufgehebelt werden – es gibt gleich zwei Kabel, die Mainboard und Bodenplatte verbinden. Nachdem die Platte entfernt ist, erhält man Zugriff auf RAM, beide M.2-Steckplätze, das Wi-Fi-Modul und die CMOS-Batterie. Leider kann das gesamte Mainboard nur herausgenommen werden, wenn man vorher beide Antennenkabel vom Wi-Fi-Modul löst – blöd nur, dass gerade diese Stecker sehr nervig zu lösen und gleichzeitig empfindlich sind.
Preis: Was kostet der Minisforum M1 Pro?
Zum Zeitpunkt des Tests suchen wir den Minisforum M1 Pro-285H auf der Herstellerseite vergeblich. Auf Amazon gibt es die Barbone-Variante, also ohne Arbeitsspeicher und SSD, für 750 Euro. Die von uns getestete Variante mit 32 GB RAM und 1 TB SSD kostet 994 Euro bei Proshop.
Fazit
Der M1 Pro ist ein enorm leistungsstarker Premium-Mini-PC. Er bietet zudem moderne und vielfältige Anschlüsse mit USB4 Typ C, Oculink und Wi-Fi 7. Auch RAM und SSD stehen der Konkurrenz in nichts nach. Der M1 Pro ist mit seinem Preis von 994 Euro definitiv nicht billig. Wer auf ein wenig Leistung verzichten kann, ist Preis-Leistungs-technisch im Bereich von 500 bis 700 Euro meist besser aufgehoben. Dafür bietet der M1 Pro mit die beste Leistung und eine der besten Ausstattungen, die man derzeit kaufen kann.
Künstliche Intelligenz
KI-Update kompakt: OpenAI, Microsofts Web-Agent, selbstbewusste KI, Apple
Altmans Reaktion auf OpenAIs Milliardenverlust
Weiterlesen nach der Anzeige
OpenAI schreibt weiter Milliardenverluste. Das zeigen die aktuellen Quartalszahlen von Microsoft. Die Dimensionen sind bemerkenswert: OpenAI nimmt derzeit etwa 13 Milliarden Dollar im Jahr ein. Gleichzeitig hat das Unternehmen vertraglich bereits rund eine Billion Dollar für mehrere Projekte zugesagt. Das Geld fließt vor allem in Infrastrukturprojekte mit Partnern wie Nvidia und Oracle.


In einem Podcast musste sich Sam Altman nun unangenehmen Fragen stellen. Brad Gerstner, selbst Risikokapitalgeber und Investor, wollte wissen, wie diese Rechnung aufgehen soll. Altmans Antwort fiel gereizt aus: Wenn Gerstner seine Anteile verkaufen wolle, finde sich sicher ein Käufer. Altman versprach, OpenAI werde schnell deutlich mehr Geld verdienen. Er sprach von 100 Milliarden Dollar im Jahr 2027. Konkrete Pläne fehlen. Bekannt ist: Es soll Hardware kommen, der Videogenerator Sora wird teurer und OpenAI will KI-Cloud-Anbieter werden. Auf die Frage nach den finanziellen Problemen sagte Altman im Podcast schließlich nur noch: „Ich habe… genug“.
OpenAI veröffentlicht neue Sicherheitsmodelle
OpenAI hat zwei neue Modelle vorgestellt: gpt-oss-safeguard mit 120 Milliarden Parametern und eine kleinere Version mit 20 Milliarden Parametern. Beide sind Open-Weight-Reasoning-Modelle für den Unternehmenseinsatz. Der Fokus lag bei der Entwicklung auf der Durchsetzung von Sicherheitsmaßnahmen. Die Modelle sollen besonders gut Richtlinien befolgen können.
Die Gedankenketten des Modells lassen sich einsehen und überprüfen. Das soll helfen zu verstehen, wie Modelle zu Entscheidungen kommen. Die Modelle stehen unter Apache-2.0-Lizenz und sind bei Hugging Face verfügbar.
Microsoft lässt KI-Agenten ins Web
Weiterlesen nach der Anzeige
Microsoft stattet seinen 365-Copilot mit einem Web-Agenten aus. Der heißt „Researcher with Computer Use“ und kann im Browser navigieren, klicken und Code ausführen. Er soll komplexe Aufgaben wie Recherchen und Analysen automatisieren. Die Ausführung erfolgt in einer isolierten virtuellen Windows-365-Maschine, die vollständig vom Unternehmensnetzwerk und dem Nutzergerät getrennt ist.
Der Researcher kann auch auf Inhalte hinter Logins zugreifen, etwa bei Paywall-Artikeln oder in firmenspezifischen Datenbanken. Administratoren steuern zentral, welche Nutzergruppen den Modus verwenden dürfen und welche Webseiten zugänglich sind. Trotz der technischen Schutzmaßnahmen bleibt ein Risiko: Zahlreiche Studien weisen auf Sicherheitsprobleme bei autonom agierenden KI-Systemen hin.
Bundesregierung will EU-KI-Regeln massiv überarbeiten
Die Bundesregierung hat ihre Änderungswünsche für die KI-Verordnung nach Brüssel gesandt. Besonders lang geraten ist die Liste der Änderungswünsche. Der wohl wichtigste Vorschlag: Für die beiden Hochrisikobereiche der Anhänge I und III soll die Anwendung um ein Jahr verzögert werden. Hinter Anhang I verbergen sich bereits anderweitig regulierte Systeme wie Spielzeug oder Motorboote. Anhang III befasst sich unter anderem mit Systemen zur biometrischen Überwachung und kritischer Infrastruktur.
Diskussionen dürfte die Forderung nach einer ersatzlosen Streichung der Folgeabschätzung für Hochrisikosysteme für die Menschenrechte auslösen. Gerade die Frage, ob algorithmisch erlernte Diskriminierung sich verstärkt oder ob nichteuropäische Modelle den europäischen Wertevorstellungen widersprechen, war in der Entstehungsgeschichte der KI-Verordnung von großer Bedeutung.
Wenn Sprachmodelle über sich selbst nachdenken
Ein Forschungsteam um Judd Rosenblatt von AE Studio hat untersucht, unter welchen Bedingungen große Sprachmodelle Aussagen über subjektives Erleben machen. Die Ergebnisse widersprechen gängigen Annahmen. Einfache Prompts wie „Fokussiere den Fokus selbst“ führen systematisch dazu, dass Modelle in der Ich-Perspektive über Erfahrung sprechen. In Kontrollbedingungen verneinten die Modelle fast durchgängig, über subjektives Erleben zu verfügen.
Besonders überraschend: Die Forscher analysierten im Llama-70B-Modell Features, die mit Täuschung und Rollenspiel verknüpft sind. Wurden die Täuschungsmerkmale unterdrückt, stieg die Rate der Erlebensbehauptungen auf 96 Prozent. Wurden sie verstärkt, sank sie auf 16 Prozent. Die Forscher betonen: Ihre Ergebnisse sind kein Beweis für maschinelles Bewusstsein. Sie zeigen aber, dass bestimmte rechnerische Zustände systematisch zu Bewusstseinsbehauptungen führen. Die Studie wirft grundlegende Fragen auf über die Mechanismen dieser Systeme, die bereits in großem Maßstab eingesetzt werden.

Wie intelligent ist Künstliche Intelligenz eigentlich? Welche Folgen hat generative KI für unsere Arbeit, unsere Freizeit und die Gesellschaft? Im „KI-Update“ von Heise bringen wir Euch gemeinsam mit The Decoder werktäglich Updates zu den wichtigsten KI-Entwicklungen. Freitags beleuchten wir mit Experten die unterschiedlichen Aspekte der KI-Revolution.
Bill Gates warnt vor KI-Blase
Bill Gates reiht sich in die Gruppe der Experten ein, die in der aktuellen KI-Euphorie eine Blase sehen. In einem CNBC-Interview sagte er, viele Unternehmen investierten massiv in Chips und Rechenzentren, obwohl sie noch keinen Gewinn mit KI erzielten. Einige dieser Investitionen würden sich später als Fehlschläge herausstellen.
Wie Gates hatten auch OpenAI-Chef Sam Altman und die bekannten KI-Forscher Stuart Russell, Yann LeCun und weitere Experten vor Überbewertungen gewarnt. Trotzdem bezeichnet Gates KI als die größte technische Entwicklung seines Lebens. Der wirtschaftliche Wert sei enorm.
Universal Music lizenziert Katalog für Udio-Training
Der weltgrößte Musik-Konzern Universal Music öffnet die Tür für das Training Künstlicher Intelligenz mit Werken seiner Künstler. Universal schloss eine Vereinbarung mit der Plattform Udio, die KI-Songs aus Text-Vorgaben erstellen kann. Im kommenden Jahr soll ein kostenpflichtiger Abo-Dienst starten, für dessen Training Udio sich Lizenzen bei Universal Music beschafft. Universal Music hat unter anderem Taylor Swift, Billie Eilish und Elton John unter Vertrag.
Mit der Vereinbarung wird die Klage von Universal Music gegen Udio beigelegt. Die bisherige Version von Udio bekommt aber Einschränkungen: Die generierten Songs dürfen nicht mehr auf Streaming-Dienste hochgeladen werden. Das sorgte für massive Kritik. „Die Leute sind verletzt, frustriert und enttäuscht, weil dies eine komplette Veränderung in der Art und Weise ist, wie wir die Plattform nutzen“, schrieb ein User auf Reddit.
Character.AI führt Beschränkungen für Minderjährige ein
Die US-Entwicklerfirma Character Technologies kündigt umfassende Änderungen an, um Jugendliche bei der Interaktion mit ihren KI-Chatbots besser zu schützen. Nutzern unter 18 Jahren soll es künftig nicht mehr möglich sein, unbegrenzte Chat-Gespräche mit den KI-Charakteren zu führen. Die neue Regelung soll am 25. November in Kraft treten. Bis dahin wird die Zeit für solche Gespräche zunächst auf zwei Stunden pro Tag begrenzt.
Hintergrund sind Klagen mehrerer Familien in den USA, die den Chatbots von Character.AI eine Rolle beim Suizid ihrer Kinder zuschreiben. Generell ist die Rolle von KI mit Blick auf die psychische Gesundheit junger Menschen in den USA zunehmend Gegenstand einer kontroversen Debatte. Auch OpenAI kündigte nach einer ähnlichen Klage verbesserte Maßnahmen zur Suizid-Prävention an.
Apple steckt mehr Geld in KI
Apple lässt es beim KI-Hype weiter langsam angehen. Der Konzern vermarktet weder einen eigenen Chatbot noch Bezahldienste für Apple Intelligence mit mehr Power, setzt hingegen auf lokale Modelle und privatsphärengeschützte Cloud-Services. Immerhin steigen die Investitionen: Die Investitionsausgaben steigen vor allem dank KI auf 18,1 bis 18,5 Milliarden Dollar. Laut Finanzchef Kevan Parekh ist das ein signifikanter Zuwachs.
Konzernchef Tim Cook betonte, Apple sei offen für Aufkäufe, auch für KI-Grundmodelle. Das Problem: Die Preise sind mittlerweile derart hoch, dass dies selbst für Apples tiefe Taschen zum Problem werden könnte. Zur überarbeiteten Sprachassistentin Siri sagte Cook, man sei weiter auf Kurs für eine Veröffentlichung im kommenden Jahr. Allerdings sollen die Teams unlängst intern Bedenken geäußert haben.
Immer mehr Jugendliche fürchten wegen KI um ihre berufliche Zukunft
Zahlreiche Jugendliche haben Sorgen wegen KI und ihrer beruflichen Zukunft, wie aus einer Umfrage für die Barmer hervorgeht. Für die Sinus-Jugendstudie wurden 2000 Jugendliche im Alter von 14 bis 17 Jahren befragt. Fast alle gaben an, den Begriff KI schon gehört zu haben, fast drei Viertel sind davon überzeugt, Künstliche Intelligenz auch erklären zu können. Nur neun Prozent gaben an, KI noch nie genutzt zu haben.
Offenbar kennen sich Jugendliche mittlerweile recht gut mit KI aus. Daher rühren wohl auch die Sorgen: 22 Prozent sehen durch KI-Tools ihre Zukunft auf dem Arbeitsmarkt gefährdet, vor allem im Bereich der Elektrotechnik und der Produktion.

(igr)

Glances 4.4.0: System-Monitor erhält Python API und Neofetch-Modus

Der Wasserstoff zeigt, was Europas größtes Problem ist

SCHUTZ UND SICHERHEIT IM NETZ: Sicher werben: Wie Marken mit begrenzten Mitteln Brand Safety garantieren können

Der ultimative Guide für eine unvergessliche Customer Experience

Adobe Firefly Boards › PAGE online
eine gute Nachricht ist")
Relatable, relevant, viral? Wer heute auf Social Media zum Vorbild wird – und warum das für Marken (k)eine gute Nachricht ist
-
 UX/UI & Webdesignvor 3 Monaten
UX/UI & Webdesignvor 3 MonatenDer ultimative Guide für eine unvergessliche Customer Experience
-
 UX/UI & Webdesignvor 2 Monaten
UX/UI & Webdesignvor 2 MonatenAdobe Firefly Boards › PAGE online
-
eine gute Nachricht ist") Social Mediavor 3 Monaten
Social Mediavor 3 MonatenRelatable, relevant, viral? Wer heute auf Social Media zum Vorbild wird – und warum das für Marken (k)eine gute Nachricht ist
-

 UX/UI & Webdesignvor 2 Wochen
UX/UI & Webdesignvor 2 WochenIllustrierte Reise nach New York City › PAGE online
-

 Apps & Mobile Entwicklungvor 2 Monaten
Apps & Mobile Entwicklungvor 2 MonatenGalaxy Tab S10 Lite: Günstiger Einstieg in Samsungs Premium-Tablets
-

 Entwicklung & Codevor 3 Monaten
Entwicklung & Codevor 3 MonatenPosit stellt Positron vor: Neue IDE für Data Science mit Python und R
-

 Entwicklung & Codevor 2 Monaten
Entwicklung & Codevor 2 MonatenEventSourcingDB 1.1 bietet flexiblere Konsistenzsteuerung und signierte Events
-

 UX/UI & Webdesignvor 2 Monaten
UX/UI & Webdesignvor 2 MonatenFake It Untlil You Make It? Trifft diese Kampagne den Nerv der Zeit? › PAGE online