Künstliche Intelligenz
KanDDDinsky 2025: Eindrücke von Europas DDD-Community-Konferenz
Vergangene Woche waren mein Kollege Rendani und ich im Berliner nhow Hotel, zusammen mit rund 250 bis 300 anderen Menschen, die unsere Leidenschaft für Domain-Driven Design (DDD), Event Sourcing und durchdachte Softwarearchitektur teilen. Auf der KanDDDinsky 2025 war unsere erste Teilnahme an dieser Konferenz – nicht nur als Besucher, sondern als Sponsoren und Aussteller für die von uns entwickelte Datenbank EventSourcingDB.
Weiterlesen nach der Anzeige
Ein anderes Konferenzformat
Was uns sofort ins Auge fiel, war die Herangehensweise an die Zeitplanung. Statt des typischen Konferenzformats mit einheitlichen Session-Längen schufen die Organisatoren eine Puzzle-artige Agenda, die 50-minütige Vorträge mit 120-minütigen Hands-on-Workshops kombinierte. Die Sessions liefen in vier parallelen Tracks.


Golo Roden ist Gründer und CTO von the native web GmbH. Er beschäftigt sich mit der Konzeption und Entwicklung von Web- und Cloud-Anwendungen sowie -APIs, mit einem Schwerpunkt auf Event-getriebenen und Service-basierten verteilten Architekturen. Sein Leitsatz lautet, dass Softwareentwicklung kein Selbstzweck ist, sondern immer einer zugrundeliegenden Fachlichkeit folgen muss.
Dieses Format eröffnet interessante Wahlmöglichkeiten für die Teilnehmerinnen und Teilnehmer. Theoretisch ließ sich zwar zwischen Sessions wechseln, praktisch sah die Sache jedoch anders aus. Einen zweistündigen Workshop auf halbem Weg zu verlassen, um einen Vortrag mitzunehmen, ergibt nur bedingt Sinn – auch wenn wir beobachteten, dass einige Teilnehmer sich leise zur Halbzeit aus Vorträgen verabschiedeten, um eine andere Session zu besuchen. Eine elegante Lösung, die sowohl tiefgehende Einblicke als auch schnellen Wissensaustausch ermöglicht – etwas, das uns in dieser Form auf anderen Konferenzen bisher nicht begegnet ist.
Ebenso durchdacht war die viertägige Struktur: Workshops am Dienstag (21. Oktober), die Hauptkonferenz am Mittwoch und Donnerstag (22.-23. Oktober) und ein Open Space am Freitag (24. Oktober). Diese Progression von fokussiertem Lernen über breite Exploration bis hin zu Community-getriebener Konversation zeigt, wie sorgfältig die Organisatoren darüber nachgedacht haben, wie Menschen tatsächlich mit Konferenzen interagieren möchten.
Die Content-Landschaft
Weiterlesen nach der Anzeige
Die Bandbreite der Themen auf der zweitägigen Agenda war beeindruckend. Der Mittwoch startete mit einer interaktiven Keynote zur Modellierung in Software- und menschlichen Systemen, während der Donnerstag Vorträge von Ian Coopers „The Emissary“ bis hin zu Eric Evans höchstpersönlich über „AI and Tackling Complexity“ bot. Die Klassiker waren natürlich vertreten – CQRS, Event Sourcing, DDD-Pattern – standen aber gleichberechtigt neben Sessions zu Wardley Mapping, kollaborativer Modellierung, hexagonaler Architektur und Organisationsdesign.
Über beide Tage hinweg kristallisierten sich mehrere Themen heraus. Vor allem die Schnittstelle von KI und DDD ließ sich kaum ignorieren: Rinat Abdullins „When DDD Met AI: Practical Stories from Enterprise Trenches“, Eric Evans über die Bewältigung von Komplexität mit KI und Hila Fox‘ Diskussion sozio-technischer Systeme im KI-Zeitalter – alle deuteten auf eine Community hin, die sich aktiv damit auseinandersetzt, wie diese Welten aufeinanderprallen. Der Hands-on-Workshop „Epic Systems Design: Surviving Complexity“ von Jacqui und Steven Read fand am Donnerstag statt, ebenso wie eine reflektierende Session unter dem Titel „Over 20 Years of DDD – What We Know, What We Do, What Needs to Change“, quasi eine Meta-Konversation über die Praxis selbst.
Besonders interessant fanden wir, wie natürlich dabei KI ihren Weg in den Diskurs fand. Sessions wie Marco Heimeshoffs „Hybrid Intelligence“ und die verschiedenen KI-fokussierten Vorträge wurden nicht als Neuheiten behandelt, sondern als natürliche Erweiterungen der Kernthemen der Community. Das passt perfekt zu unserer Arbeit an eventsourcing.ai, wo wir thematisieren, wie KI und Event-getriebene Architekturen einander sinnvoll ergänzen können. Die Vorteile Event-getriebener Architekturen für KI-Anwendungen – Nachvollziehbarkeit, Time-Travel-Debugging, deterministische Replays – werden anscheinend zunehmend offensichtlich.
Die Closing Keynote am Donnerstag von Alberto Brandolini über „DDD Lessons from ProductLand“ rundete die Hauptkonferenztage ab: Eine der Koryphäen der Community reflektierte darüber, wie sich DDD-Erkenntnisse jenseits der reinen Softwareentwicklung anwenden lassen.
Die Konferenz fand vollständig auf Englisch statt, was ihren international geprägten Charakter widerspiegelt. Die Teilnehmer kamen hauptsächlich aus Europa – Deutschland, Österreich, Italien und darüber hinaus – und bildeten eine diverse, aber kohärente Community. Dass Inklusion den Organisatoren wichtig ist, zeigte sich sowohl im Speaker-Lineup als auch in der Art, wie die Veranstaltung strukturiert war.
Die größere Erkenntnis
Vielleicht war unsere wichtigste Einsicht aus diesen Tagen gar nicht technischer Natur – es ging um die Community selbst. Manchmal hört man die Einschätzung, DDD, CQRS und Event Sourcing seien Nischeninteressen, die von einer kleinen Gruppe Enthusiasten in isolierten Ecken praktiziert würden.
Die KanDDDinsky widerlegte diese Wahrnehmung eindrücklich. Ja, diese Ansätze sind nicht das, was alle machen. Sie sind nicht der Standard, der mit jedem Framework ausgeliefert oder in jedem Bootcamp gelehrt wird. Aber sie sind auch keineswegs exotisch. Wenn man sich in diesem pink getönten Konferenzraum umsah und Hunderte von Menschen aus zahllosen Unternehmen und Ländern beobachtete, wurde die Realität offensichtlich: Dies ist eine substanzielle, wachsende Community mit handfester Erfahrung im Bau von Produktivsystemen.
Die Gespräche, die wir führten, waren dabei alles andere als theoretisch: Menschen lösen konkrete Probleme mit diesen Pattern. Sie ringen mit echten Trade-offs, teilen ihre Erfahrungen aus dem Alltag und lernen aus den Erfolgen und Misserfolgen der anderen. Dies ist ein ausgereifter Praxisbereich, keine experimentelle Spielwiese.
Für uns hat diese Bestätigung Gewicht. Wir bauen EventSourcingDB, weil wir überzeugt sind, dass Event Sourcing und CQRS erstklassige Tooling-Unterstützung verdienen. Die Größe und das Engagement dieser Community zu erleben, bestätigt uns darin, dass echte Nachfrage nach Tools besteht, die diese Pattern zugänglicher machen.
Ausblick
Die beiden Konferenztage setzten einen starken Akzent, wobei der Open Space am Freitag noch bevorstand, um die Gespräche in einem offeneren Format fortzuführen. Die Mischung aus Vorträgen und Workshops schuf natürliche Rhythmen – intensive Lernsessions, gefolgt von Networking und Zeit zum Verdauen. Die Location funktionierte einwandfrei, die Organisation lief reibungslos, und die Community war einladend.
Wir verarbeiten noch immer all das, was wir gelernt haben, und all die Menschen, die wir kennengelernt haben. Das ist das Zeichen einer guten Konferenz – wenn man mit mehr Fragen als Antworten nach Hause fährt und mehr Kontakte geknüpft hat, als man sofort nachverfolgen kann.
Die KanDDDinsky 2025 hat uns einen Einblick in diese Zukunft gegeben, und sie sieht vielversprechend aus: dicht, erfüllt und summend vor Ideen – genau so, wie wir es mögen. Wir freuen uns bereits darauf, diese Gespräche fortzusetzen und zu beobachten, wie diese Community die nächste Generation Event-getriebener Systeme prägt.
(rme)












Künstliche Intelligenz
Nvidia übernimmt den Open-Source-Anbieter SchedMD
Der US-Chip-Konzern Nvdia hat SchedMD übernommen, den führenden Entwickler der Software Slurm, einem Open-Source-Workload-Managementsystem für High-Performance-Computing (HPC) und künstliche Intelligenz (KI). Nvidia erhofft sich davon, sein Open-Source-Software-Ökosystem zu stärken und KI-Innovationen für Forscher, Entwickler und Unternehmen voranzutreiben. Das teilte das Unternehmen am Montag mit. Zugleich kündigte Nvidia an, Slurm weiterhin als quelloffene, herstellerneutrale Software entwickeln und vertreiben zu wollen. Zu den finanziellen Bedingungen der Übernahme machte das Unternehmen keine Angaben.
Weiterlesen nach der Anzeige
Nvidia arbeitet nach eigenen Angaben seit über einem Jahrzehnt mit SchedMD zusammen und wird „weiterhin in die Entwicklung von Slurm investieren, um sicherzustellen, dass es der führende Open-Source-Scheduler für HPC und KI bleibt“. HPC- und KI-Workloads umfassen komplexe Berechnungen, bei denen auf Clustern parallele Aufgaben ausgeführt werden, die eine Warteschlangenbildung, Planung und Zuweisung von Rechenressourcen erfordern. Da HPC- und KI-Cluster immer größer und leistungsfähiger werden, ist eine effiziente Ressourcennutzung von entscheidender Bedeutung, schreibt Nvidia.
Slurm-Software in zahlreichen Supercomputern
SchedMD bietet eine solche Software, die bei der Planung großer Rechenaufgaben hilft. Diese können einen großen Teil der Serverkapazität eines Rechenzentrums beanspruchen. Nach Angaben von Nvidia wird die SchedMD-Software Slurm „als führender Workload-Manager in Bezug auf Skalierbarkeit, Durchsatz und komplexes Richtlinienmanagement“ aktuell in mehr als der Hälfte der Top-10- und Top-100-Systeme der Top-500-Liste der Supercomputer eingesetzt. Das mache Slurm zum Teil der kritischen Infrastruktur, die für generative KI erforderlich ist und von Entwicklern von Grundlagenmodellen und KI-Entwicklern zur Verwaltung der Anforderungen an das Modelltraining und die Inferenz verwendet wird. Entwickler und Unternehmen können kostenlos auf Slurm zugreifen, während SchedMD sein Geld mit Engineering- und Wartungsunterstützung verdient.
SchedMD wurde 2010 in Livermore, im US-Bundesstaat Kalifornien, gegründet. Derzeit beschäftigt das Unternehmen 40 Mitarbeitende. Zu den Kunden zählen unter anderem das Cloud-Infrastrukturunternehmen CoreWeave und das Barcelona Supercomputing Center.
„Wir freuen uns sehr über die Zusammenarbeit mit Nvidia, da diese Übernahme die entscheidende Rolle von Slurm in den anspruchsvollsten HPC- und KI-Umgebungen der Welt bestätigt“, wird Danny Auble, CEO von SchedMD, in der Nvidia-Mitteilung zitiert. Und weiter: „Das fundierte Fachwissen und die Investitionen von Nvidia im Bereich des beschleunigten Rechnens werden die Entwicklung von Slurm – das weiterhin als Open Source verfügbar sein wird – vorantreiben, um den Anforderungen der nächsten Generation von KI und Supercomputing gerecht zu werden.“
Weiterlesen nach der Anzeige
(akn)
Künstliche Intelligenz
Snapmaker U1 im Test: Der beste mehrfarbige 3D-Drucker spart 80 % Filament
Der Snapmaker U1 hat vier Druckköpfe, die er flink wechseln kann. So gelingen farbige Drucke ohne Spülvorgang – das geht viel schneller und ist günstiger als bei Materialwechselsystemen.
Snapmaker ist vor allem in der Maker-Szene ein Begriff: Das Unternehmen konnte in der Vergangenheit mit 3-in-1-Geräten punkten, die beispielsweise CNC-Fräse, Laser & 3D-Drucker miteinander kombinieren. Der neueste Coup ist ein reiner 3D-Drucker, aber ein besonderer: Der Snapmaker U1 hat gleich vier Druckköpfe und ein System, das an einen Werkzeug-Wechsler aus dem CNC-Bereich erinnert. Die Kickstarter-Kampagne war erfolgreich, wer mitgemacht hat, hat seinen Drucker inzwischen bekommen – und nun steht die Markteinführung des Geräts bevor. Wir haben vom Hersteller ein Testgerät zur Verfügung gestellt bekommen und konnten den U1 zwei Wochen ausführlich testen.
Aufbau & Einrichtung
Der Snapmaker U1 kommt gut verpackt in einem stabilen Karton in die Redaktion. Im Inneren befindet sich der zum größten Teil vormontierte 3D-Drucker. Im Vergleich zum Aufbau eines aktuellen Bambu-Lab-Druckers muss man hier etwas mehr Arbeit reinstecken, bis das erste Druckmodell im Bauraum liegt: Wir haben ungefähr drei Stunden zwischen dem Öffnen des Kartons und dem Start des ersten Drucks gebraucht. Die Endmontage besteht vor allem aus dem Zusammensetzen und Verschrauben der Filament-Führungen, dem Einsetzen der Druckköpfe und dem Entfernen der Transportsicherungen. Die Schritte sind gut dokumentiert und auch von Anfängern hinzubekommen. Mehr dazu zeigt die folgende Fotostrecke.
Der U1 hat einen XY-Core-Aufbau, bei dem sich der Druckkopf auf der X- und auf der Y-Achse auf einer festen Höhe bewegt, das Druckbett stellt die Z-Achse dar und fährt im Laufe des Drucks Schicht für Schicht nach unten. Der Druckbereich beträgt 27 Zentimeter in alle Richtungen, ist also minimal größer als bei den meisten anderen Druckern (Bambu Lab A1, P1S, P2S, X1C: 25,6 Zentimeter).
Die Filamentspulen sitzen außen am Gehäuse, jeweils zwei auf einer Seite. Das Filament wird durch einen Antrieb von der Spule über den PTFE-Schlauch bogenförmig ins Gehäuse des Druckers geführt – deswegen stehen vier Schläuche oben über dem U1 ab. Dieser Aufbau ist funktional, hat aber ein paar Nachteile. Zum Einen wird die Filament-Spule auf eine Spindel gesteckt, statt auf Rollen zu laufen wie bei den Materialwechsel-Systemen von Anycubic, Bambu & Co. – als das mitgelieferte Filament aufgebraucht war, haben wir den ersten Haken dieses Aufbaus entdeckt: Die Spulen des bei uns in der Redaktion beliebten, günstigen Jayo-Filaments haben einen anderen Innendurchmesser und lassen sich nicht aufstecken. Die Lösung war das Drucken eines Adapters – muss man wissen, und gegebenenfalls braucht es eben ein paar Adapter für die unterschiedlichen Filament-Hersteller.
Außerdem stört es uns, dass das Filament wie beim günstigen Bambu A1 Mini mit seinem AMS Lite nicht abgedeckt ist, statt in einer geschlossenen Box vor Staub und Luftfeuchtigkeit geschützt zu sein. Zu guter Letzt ist das Gehäuse des U1 oben offen – da nützen auch die hochwertige Echtglastür an der Vorderseite und das Kunststoff-Fenster auf der Rückseite nichts. Staub rieselt von oben aufs Druckbett, das man vor jedem Druck einmal abwischen sollte, und ohne Abdeckung bleibt das Drucken von aufwendigeren Filamenten verwehrt.
Gegen Aufpreis lassen sich diese Haken geradebiegen. Für 160 Euro gibt es eine Abdeckung für den U1, die oben auf das Gerät gesetzt wird und einen geschlossenen Bauraum nachrüstet; für 130 Euro gibt es vier geschlossene Filament-Boxen. Zum Testzeitpunkt war die Abdeckung leider noch nicht lieferbar, weswegen wir unsere Tests auf leichter zu druckende Filamente wie PLA, TPU und PETG beschränkt haben. Irgendwie wäre es uns lieber gewesen, wenn der U1 gleich mit der Abdeckung ausgeliefert worden wäre – 860 Euro für einen 3D-Drucker, der in dieser Ausführung vor allem PLA druckt, wirkt im Vergleich zu den 360 Euro für einen Bambu A1 mit Vierfach-Materialwechsler unverhältnismäßig. Dass das aber zu einfach gedacht ist, zeigt der Test – denn der Snapmaker hat anderen Stärken.
Filament & Materialien
Mangels Gehäuse-Deckel haben wir uns im Test bislang auf das Drucken von PLA , TPU und PETG beschränkt. Mit der optionalen Abdeckung kann der Snapmaker U1 aber erheblich mehr: Sein Druckbett erreicht 100 Grad, die Düsen sogar 300 Grad. Damit sind auch ABS oder ASA, PET und PA möglich.
Bambu Lab hat mit seinem AMS den mehrfarbigen 3D-Druck salonfähig gemacht – und günstig in der Anschaffung. Dabei befinden sich im Materialwechsler vier Spulen, die je nach Bedarf die gleiche Düse füttern. Beim Farb- oder Materialwechsel wird das alte Filament abgeschnitten, das neue zugeführt und vorgeschoben. Die Mischfarbe dazwischen wird als sogenanntes Poop aus dem Drucker ausgeworfen.
Snapmaker zündet mit dem Materialwechselsystem des U1 nun die nächste Stufe. Im hinteren Bereich des Druckers sitzen vier Druckköpfe, jeweils bestehend aus Hot-End, Extruder und Nozzle. Je nach gewünschter Farbe bzw. nach gewünschtem Material fährt der bewegliche Teil des Druckkopfes nach hinten und holt sich über einen raffinierten Mechanismus die jeweils gerade nötige „andere Hälfte“, in der verschiedene Farben oder Materialien direkt auf ihren Einsatz warten. Dadurch entfällt der bei bisherigen Materialwechslern nötige Spülvorgang der Düse – und damit viel Zeit und vor allem Materialverschwendung.
Wer nur wenige Farbwechsel durchführt, wird den Unterschied kaum bemerken. Wer etwa eine Frontplatte aus schwarzem Kunststoff druckt, in der eine Beschriftung aus weißem Kunststoff vorgesehen ist, kommt mit wenigen Materialwechseln in den obersten zwei, drei Schichten aus. Wer hingegen ein mehrfarbiges Benchy druckt, erlebt einen Unterschied wie Tag und Nacht. Wir haben das Boot mit gleichen Farbeinstellungen auf einem Bambu P1S gedruckt. Der Drucker hat für das gut 11 Gramm schwere Boot über 20 Stunden Druckzeit benötigt und insgesamt über 300 Gramm Filament verbraucht – davon gut 30 Gramm für den Prime Tower und über 260 Gramm für die Spülvorgänge. Diese 260 Gramm werden als Poop ausgeworfen. Der Snapmaker U1 hat für das gleiche Modell keine 3,5 Stunden gebraucht und insgesamt knapp 34 Gramm Filament – also fast 90 Prozent weniger Material und über 90 Prozent weniger Druckzeit. Freilich ist das Benchy mit seinen vielen schiefen Ebenen hier ein besonders fieses Beispiel, weil es über 500 Farbwechsel benötigt, aber genau hier spielt der U1 seine Stärken perfekt aus.
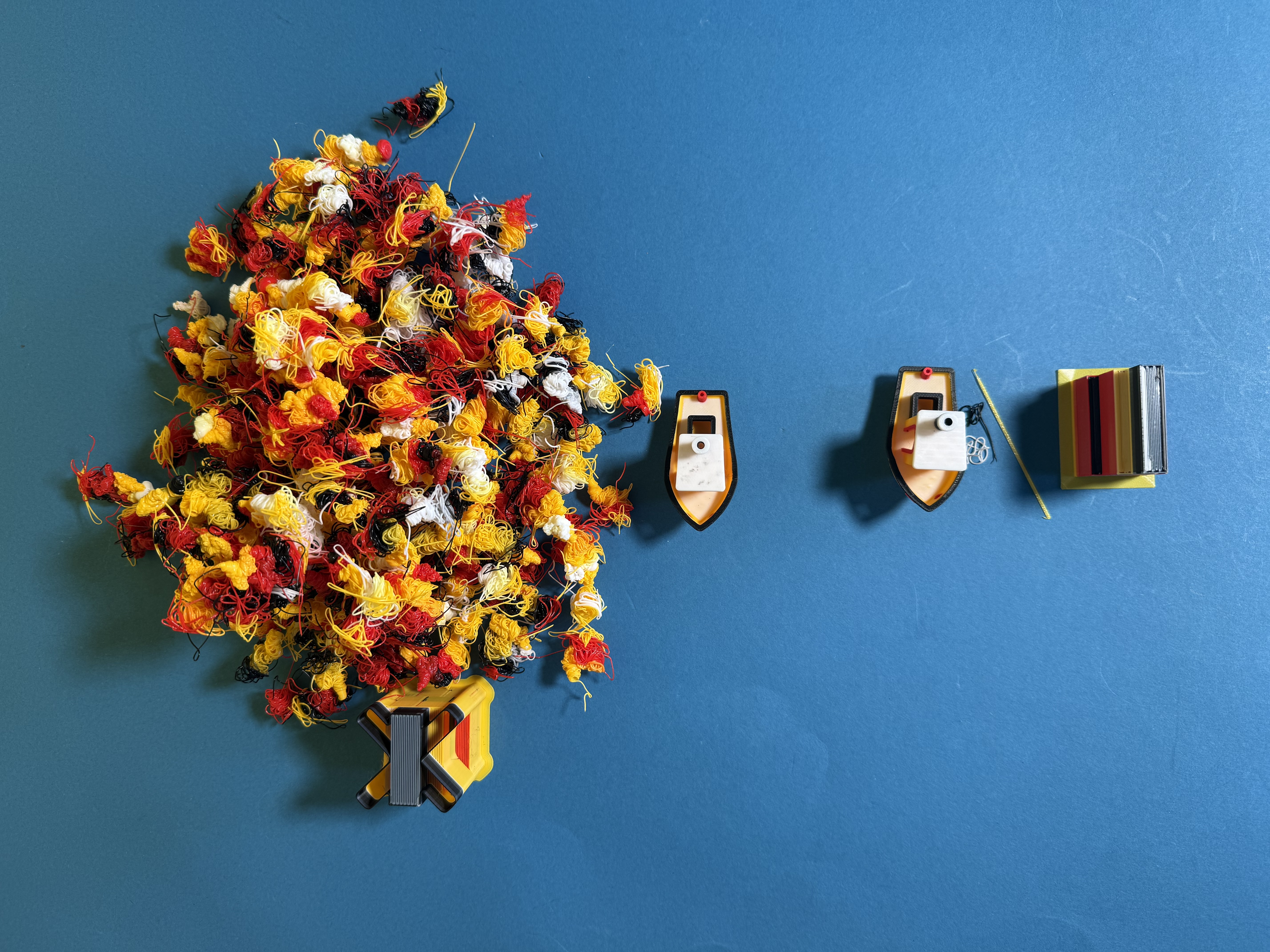
Eine Sache lieben wir in der Praxis an Multi-Material-Systemen wie Bambus AMS besonders: Die Filamentrollen lassen sich jederzeit – ohne die Nozzle aufheizen zu müssen – entnehmen und austauschen. Diesen Komfort nimmt man schnell für selbstverständlich. Beim U1 funktioniert das so nicht. Damit der Farbwechsel so schnell passieren kann, sitzt das Filament wie beim „klassischen“ Drucker ohne Materialwechsler in der Nozzle fest. Wer das Filament tauschen möchte, muss über das Touchscreen-Display des Druckers die zu wechselnden Filamente auswählen. Immerhin: Der Drucker macht dann seinen Job, wenn man ein paar Minuten später wieder auftaucht, kann man die Filamente entnehmen. Außer TPU – das gummiartige Material lässt sich nicht automatisch entfernen, man muss es von Hand aus dem Antrieb ziehen und währenddessen beim Drucker stehen.
Noch eine wichtige Ergänzung: Mit dem Nozzle-Wechsler kann man natürlich nicht nur verschiedene Farben des gleichen Materials, sondern auch verschiedene Materialien drucken – etwa PETG als Support für PLA oder andersherum. Da diese beiden Kunststoffe nicht gut aufeinander halten, lassen sich Stützstrukturen so viel einfacher entfernen.
Druckbild & Geschwindigkeit
Als Erstes legen wir die vier mitgelieferten Filament-Rollen in Gelb, Rot, Weiß und Schwarz ein und drucken einen kleinen, vierfarbigen Drachen, der fertig gesliced im Speicher des Druckers hinterlegt ist. Es macht viel Spaß, dem flotten Drucker bei der Arbeit zuzusehen. Vor allem der Wechsel des Werkzeugkopfes ist klasse und erinnert an die allerersten Drucke, bei denen man stundenlang vor dem Gerät saß und es bei der Arbeit beobachtet hat.
Wir testen unsere typischen Drucke, den Spiderman, das Sliding-Puzzle, das Benchy, ein Test-Pattern – und sind begeistert. Der Snapmaker U1 druckt schnell und die Ergebnisse sehen hervorragend aus. Eine Kleinigkeit trennt ihn dann aber doch noch von der Perfektion: Wir drucken alle drei Versionen des Sliding Puzzles. Bei besonders präzisen Druckern wie vielen Modellen von Bambu Lab lässt sich die Variante mit dem geringsten Abstand perfekt verwenden, die mit dem größten Abstand fällt fast auseinander, wenn man sie anhebt.
Bei besonders unpräzisen Druckern wie dem Sceoan Windstorm S1 ist auch die Version mit dem größten Abstand ein massiver Block geschmolzener Kunststoff und absolut unbeweglich. Der Snapmaker liegt im gehobenen Mittelfeld: Die 0,15-mm-Ausführung bewegt sich nicht, die anderen beiden funktionieren. Wir schieben den Grund dafür auf die Wechsel-Mechanik der Werkzeugköpfe. Auch unsere Testdrucke in TPU und PETG können sich sehen lassen, wobei TPU auch auf dem Snapmaker einfach ein nerviges Material ist, das diverse Sonderbehandlung benötigt – und es keinen Spaß macht, die Modelle hinterher vom Druckbett abzulösen.
Snapmaker U1: Einsatz & Ergebnisse
Sliding Puzzle: In grün hat’s der Bambu P1S gedruckt, in gelb der Snapmaker U1, in der Ausführung mit 0,15 mm Abstand zwischen den beweglichen Teilen. Der Bambu-Druck funktioniert wie aus dem Bilderbuch, der Snapmaker-Druck ist festgebacken. Der Fairness halber: Mit 0,2 mm Abstand funktioniert das Sliding Puzzle auch beim Snapmaker wie eine Eins.

Mehrfarbig und beweglich: Die Präzision des U1 ist für die allermeisten Drucke ausreichend hoch.

Rot Snapmaker, Grün Bambu P1S: Vor allem bei den Überhängen ab 50 Grad sieht’s beim Bambu noch etwas besser aus, …

… wie man hier sehen kann, …

… das Gesamtergebnis des Tests ist überdurchschnittlich gut.

Wenn man den Prime Tower weglässt, spart man zwar noch etwas Filament, aber das lohnt sich nicht – denn dadurch, dass die Düsen teilweise unter Temperatur auf ihren nächsten Einsatz warten, wollen sie zwingend abgestriffen werden. Ansonsten bleiben überschüssige Filament-Reste unschön am Modell hängen.

Das mehrfarbige Benchy sieht klasse aus.

Fotos drucken in 3D: Das CMYK-Lithophane im Hintergrund …

… wird mit Hintergrundbeleuchtung zu einem echten Farbfoto.
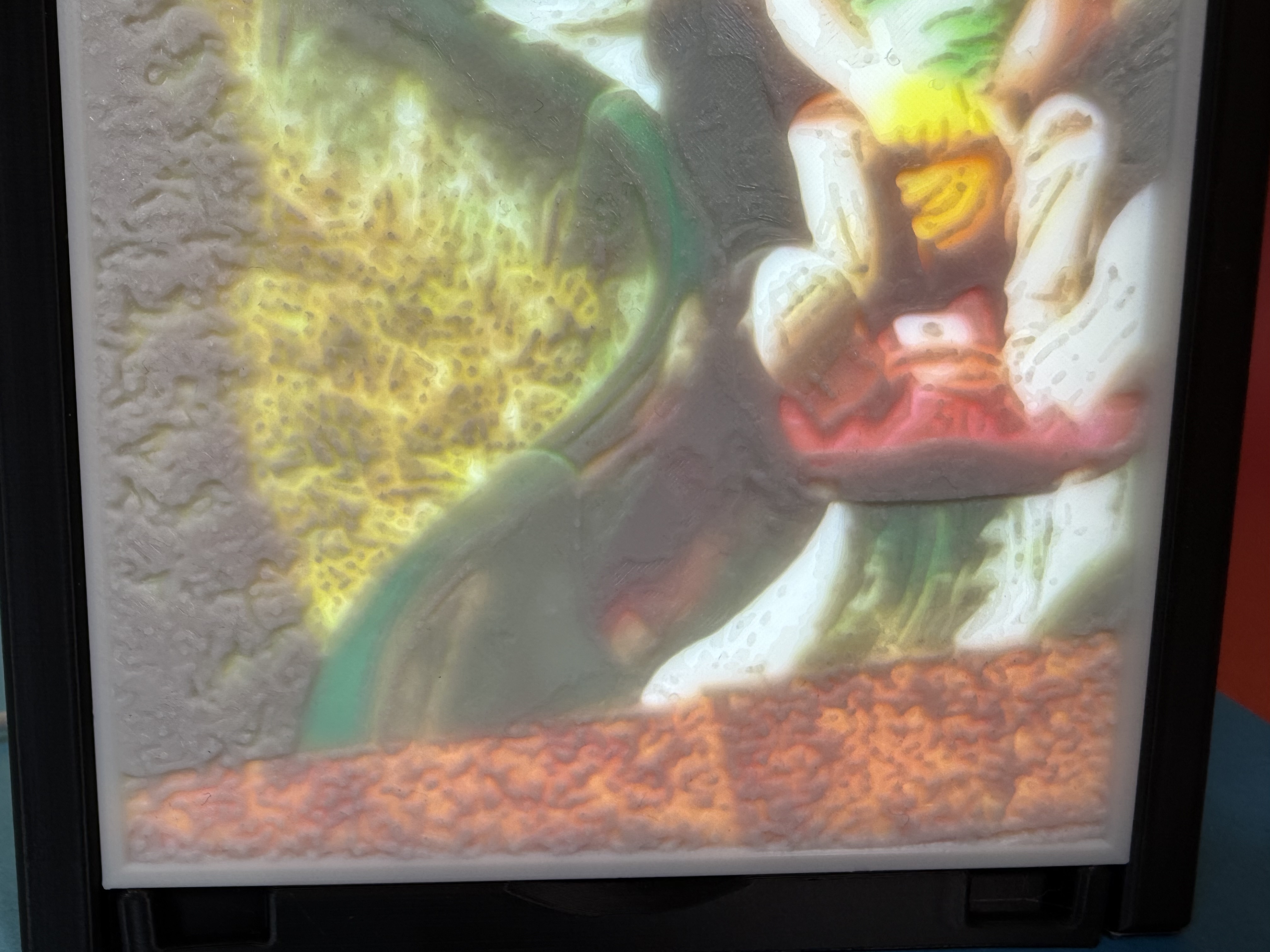
Dank Kamera und Licht kann man auch von unterwegs per Slicer-Software oder Handy-App einen Blick auf den Stand der Dinge werfen.

Die Druckköpfe halten magnetisch …

… und der Wechsel dauert zwischen fünf und sieben Sekunden.

Das fest integrierte Display hat eine hohe Auflösung, die Bedienung lässt keine Wünsche offen. Viele Nutzer wünschen sich eine neigbare Halterung, aber wir sind zufrieden.

Noch einmal zum Vergleich: So sieht es hinter dem Bambu P1S aus, nachdem er das vierfarbige Benchy gedruckt hat, …

… und so sieht es beim Snapmaker aus.

Der Snappy ist flott, allerdings ist uns in der Praxis aufgefallen, dass die zeitliche Schätzung von Software und Slicer häufig sehr optimistisch ist – in der Praxis braucht der Snapmaker U1 oft spürbar länger, als es die Software berechnet hat.
Dadurch, dass das Gehäuse oben offen ist, wirkt der U1 lauter als viele andere Drucker in diesem Preissegment. Solange das Druckbett im oberen Bereich unterwegs ist, macht unser U1 beim Verfahren der Nozzle beim Absehnken und Anheben des Druckbetts deutlich hörbare knallende Geräusche, die leiser werden, je höher der Drucker bereits gedruckt hat. Es gibt ein paar schnarrende Bewegungsgeräusche, die bei anderen Druckern leiser sind und etwas weniger unangenehm klingen. Aber insgesamt ist das Gerät weder besonders laut noch besonders nervig.
Software & App
Wer Bambu Lab aufgrund des geschlossenen Öko-Systems ablehnt, könnte hier genau richtig sein: Auf dem Snapmaker U1 läuft Klipper, der mitgelieferte Slicer nennt sich Snapmaker Orca – genau, er basiert auf dem Orca Slicer. Der Drucker lässt sich komplett offline einrichten, soll dann auch nicht nach Hause telefonieren. Alternativ gibt es einen Cloud-Service, über den man dann wie bei Bambu von überall aus per App & Computer den Status und das Live-Bild aus dem Druckraum einsehen sowie neue Drucke starten kann.
Als unser Snapmaker U1 ankam, hat genau dieser Cloud-Service nicht funktioniert. Reddit-Beiträgen zufolge waren die Snapmaker-Server überfordert, weil zu viele der neuen Geräte gleichzeitig ausgeliefert und in Betrieb genommen wurden. Die gute Nachricht: So konnten wir direkt den gut funktionierenden lokalen Modus testen, zwei Tage später lief dann auch der Cloud-Service ohne Probleme – seitdem durchgehend. Zwar behauptet der Slicer gelegentlich, dass der Drucker offline wäre, aber wenn man dann einmal die Filament-Farben anklickt, geht alles wieder.
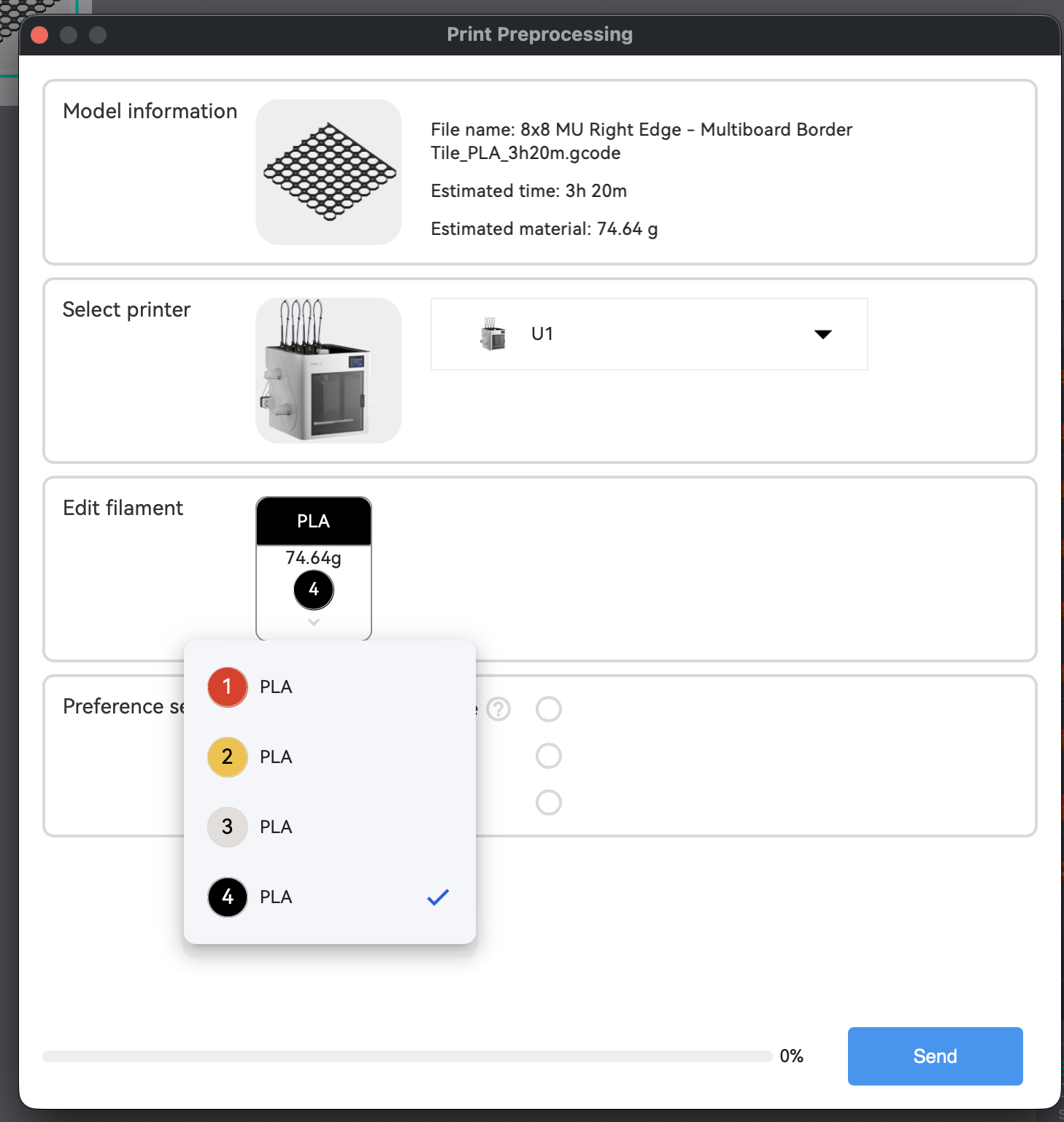
Vieles wirkt nicht ganz so rund und nicht ganz so „aus einer Hand“ wie bei Bambu Lab, wenn beispielsweise beim Starten eines Drucks aus der Slicer-Software ein Warnhinweis kommt, dass der Dateiname der urprünglichen STL-Datei keine Sonderzeichen wie # enthalten dürfen, weil es ansonsten zu Problemen kommen kann. Aber das Zuweisen von Farben und Filamenten funktioniert hier wie dort einwandfrei.
Preis & Alternativen
Der Snapmaker U1 kostet aktuell 869 Euro. Wer auch ABS, ASA & Co. drucken möchte, sollte sich überlegen, direkt die optionale Abdeckung mitzubestellen, was den Preis auf ziemlich exakt 1000 Euro treibt.
Wer einfach nur drucken möchte, kann das deutlich günstiger haben. Der kleinere und nicht geschlossene Bambu Lab A1 Mini (Testbericht) kostet 189 Euro, mit Materialwechsler AMS Lite 299 Euro. Der etwa gleich große A1 kommt auf 259 respektive 369 Euro. Geschlossene Geräte, die eben auch ABS, ASA & Co. verarbeiten können, wie der Centauri Carbon von Elegoo (Testbericht) kosten als einfarbiger Drucker unter 300 Euro. Geschlossene Farbdrucker wie der Bambu P1S oder der neue P2S kosten mit Materialwechsler 599 respektive 750 Euro. Im direkten Vergleich ist der Snapmaker also kein Schnäppchen.
Fazit
Der Snapmaker U1 ist aktuell der beste mehrfarbige 3D-Drucker. Wer vor allem farbig druckt, sollte sich den U1 unbedingt ansehen. Zum Aufpreis können wir nur sagen: Shut up and take my money. Wer viel farbig druckt – und dabei eben mehr machen möchte als eine einfarbige Beschriftung auf einem andersfarbigen Untergrund aufzutragen – kommt am Snapmaker U1 nicht vorbei. Bis zu 90% Zeit- und Filament-Ersparnis – echt und gemessen – sprechen eine deutliche Sprache, auch wenn das Benchy natürlich besonders gemein ist.
Schade finden wir vor allem, dass der Deckel nicht standardmäßig im Lieferumfang enthalten ist. Ansonsten gibt es hier und dort Kleinigkeiten, die man sicherlich besser machen könnte – aber unterm Strich ist der Snapmaker U1 ein genialer 3D-Drucker.
Künstliche Intelligenz
Vodafone Stiftung: Wirksame Altersverifikation für Social Media gefordert
Die Vodafone Stiftung hat eine Handreichung mit zehn Handlungsempfehlungen für Politik, Bildungsakteure und Plattformbetreiber herausgegeben. Die wichtigsten Forderungen in Bezug auf die treibenden Debatten dieses Jahres: eine „verpflichtende, wirksame und datensparsame Altersverifikation für risikobehaftete Plattformen“ und ein Smartphone-Verbot mindestens bis zum Ende der Sekundarstufe I in Schulen.
Weiterlesen nach der Anzeige
Die zehn Empfehlungen leitet die Stiftung unter anderem aus ihrer diesjährigen Jugendstudie „Zwischen Bildschirmzeit und Selbstregulation“ ab, in der die befragten Jugendlichen deutlich machten, dass sie gerne weniger Social-Media-Angebote nutzen würden und sich dabei auch mehr Unterstützung erhofften. Damit spielt die Stiftung den Ball nun Richtung derer, die Rahmenbedingungen für Internet- und Bildungsangebote verändern können.
Die Stiftung erklärt, dass sich Heranwachsende weiterhin in einem „aufgeladenen Spannungsfeld von Chancen und Belastungen durch soziale Medien“ befinden. Sie seien auch „durchaus aufgeklärt und selbstkritisch“, was ihr Social-Media-Verhalten an Chancen und Risiken mit sich bringe und hätten sich bereits selbst Techniken für einen kompetenten Umgang mit Online-Angeboten angeeignet. Das reiche aber nicht aus, wie die Jugendstudie deutlich gemacht habe. Deshalb brauche es nun eine Politik, „die gleichermaßen auf Stärkung der Fähigkeiten zur Selbstregulation, Hilfsangebote und gesetzlichen Schutz setzt.“
Der Stiftung zufolge suchen Jugendliche eher im Schulleben als im eigenen Elternhaus Unterstützung, wenn sie Probleme mit ihrem Nutzungsverhalten oder Online-Phänomenen feststellen. Das sei auch – anders als bei anderen Bildungsthemen – unabhängig von der sozioökonomischen Herkunft der Jugendlichen ausgeprägt. Die Stiftung rät deshalb dazu, Angebote für alle Jugendlichen zu machen und sich nicht auf gruppenspezifische Ansätze wie etwa das Startchancenprogramm zu fokussieren.
Demnach fordert die Stiftung, dass folgende zehn Punkte von Politik, Bildungsakteuren und Plattformbetreibern umgesetzt werden:
1. eine verpflichtende, wirksame und datensparsame Altersverifikation für risikobehaftete Plattformen.
Weiterlesen nach der Anzeige
Anbieter solcher Plattformen hätten sich bisher einem wirksamen System zum Nachweis des Alters bei der Einrichtung eines Kontos verweigert. Dementsprechend müsste es ein staatlich verantwortetes Tool geben, welches auch die Zustimmung der Eltern bei unter 16-Jährigen einfordert und das Anbieter verpflichtend integrieren sollen.
2. ein Verbot manipulativer und süchtig machender Designelemente wie etwa Endlos-Scrollen, variable Belohnungssysteme oder aggressive Push-Benachrichtigungen.
Dies müsse auf Social-Media-Plattformen zumindest bei Konten für Minderjährige gelten. Stattdessen sollten Wohlbefindens-orientierte Designstandards entwickelt werden.
3. die Einführung verpflichtender und unabhängiger Risiko-Audits für Social-Media-Plattformen, die regelmäßig den Einfluss auf Kinder und Jugendliche bewerten.
Die Ergebnisse müssten vollständig veröffentlicht werden und in die Gestaltung von Algorithmen, Inhalten und Sicherheitsmechanismen nachweislich einfließen. Das Ziel: „Accountability by Design“.
4. die verbindliche Integration von Social-Media-Kompetenz in schulische Medienbildung spätestens ab der Sekundarstufe I – mit klaren curricularen Vorgaben, regelmäßigen Projekten und dialogorientierten Formaten.
5. die Unterstützung von Schulen für eine angemessene Digital- und Medienkompetenzvermittlung.
Derzeit verfügten Schulen nicht über ausreichende personelle Ressourcen. Es bedürfe daher „eines rechtskreisübergreifenden Zusammenwirkens aller verfügbaren öffentlichen Einrichtungen, von der Jugendhilfe über die Medienanstalten bis hin zu den öffentlichen Kultureinrichtungen, um auf örtlicher und regionaler Ebene ein ausreichendes Medienkompetenzprogramm für die Kinder und Jugendlichen in dieser Region auf die Beine stellen zu können.“
6. die Einbindung von Zivilgesellschaft und Wirtschaft in die Erarbeitung der Medienbildung, um deren Ressourcen zu aktivieren und koordiniert den Bildungsorten zur Verfügung zu stellen.
Die Kooperation mit außerschulischen Lernorten müsse demnach verstärkt werden und der Ausbau des geschlossenen Ganztags biete die Möglichkeit, am Nachmittag pädagogisch sinnvolle Angebote zu machen.
7. die Förderung evidenzbasierter Methoden, Programme und Tools zur Unterstützung der Entwicklung von Selbststeuerung und -regulation für Jugendliche durch Politik, Wissenschaft und Bildungswirtschaft.
8. ein Smartphone-Verbot bis zum Ende der Sekundarstufe I in Klassenräumen und Unterrichtsstunden.
Auch für Pausen spreche viel dafür, Smartphones nicht zur Benutzung zuzulassen, erklärt die Stiftung. Handys seien, soweit sie nicht als Instrument in Formaten zur Medienkompetenz benötigt werden, „vorrangig eine Quelle der Ablenkung und zum Teil auch der Umgehung von Lernschritten. Die allermeisten digitalen Lerntools sind didaktisch sinnvoller auf Tablets oder Laptops zu nutzen.“
9. der systematische Ausbau der Elternarbeit zur Medienerziehung „durch niedrigschwellige, digitale und schulisch angebundene Angebote.“
Die Kompetenz, das Selbstvertrauen, aber auch die Verantwortungsbereitschaft der Eltern, ihre Kinder auf einem guten Weg durch die Social-Media-Welt zu begleiten, müssen massiv gestärkt werden.
10. die Beteiligung von Kindern und Jugendlichen als verbindlicher Bestandteil bei der Erarbeitung und Festlegung digitaler Kompetenzen und Regeln an den Schulen.
Die Handlungsempfehlungen der Vodafone Stiftung erinnern an die Leitlinien für die sichere Internetnutzung für Kinder im Vereinigten Königreich. Auch dort wurden effektive Altersverifikationen und sichere Feeds gefordert. Australien hat mittlerweile ein Mindestalter von 16 Jahren für Social Media durchgesetzt.
(kbe)



-

 UX/UI & Webdesignvor 2 Monaten
UX/UI & Webdesignvor 2 MonatenIllustrierte Reise nach New York City › PAGE online
-

 Künstliche Intelligenzvor 2 Monaten
Künstliche Intelligenzvor 2 MonatenAus Softwarefehlern lernen – Teil 3: Eine Marssonde gerät außer Kontrolle
-
Künstliche Intelligenzvor 2 Monaten
Top 10: Die beste kabellose Überwachungskamera im Test
-

 UX/UI & Webdesignvor 3 Monaten
UX/UI & Webdesignvor 3 MonatenFake It Untlil You Make It? Trifft diese Kampagne den Nerv der Zeit? › PAGE online
-

 UX/UI & Webdesignvor 2 Monaten
UX/UI & Webdesignvor 2 MonatenSK Rapid Wien erneuert visuelle Identität
-

 Entwicklung & Codevor 4 Wochen
Entwicklung & Codevor 4 WochenKommandozeile adé: Praktische, grafische Git-Verwaltung für den Mac
-

 Künstliche Intelligenzvor 2 Monaten
Künstliche Intelligenzvor 2 MonatenNeue PC-Spiele im November 2025: „Anno 117: Pax Romana“
-

 Künstliche Intelligenzvor 2 Monaten
Künstliche Intelligenzvor 2 MonatenDonnerstag: Deutsches Flugtaxi-Start-up am Ende, KI-Rechenzentren mit ARM-Chips
