Entwicklung & Code
Testing Unleashed: Wie Tester Vertrauen in Softwareteams aufbauen
In dieser Folge sprechen Richard Seidl und Katja Obring (alias: Kat) darüber, wie agile Teams die Qualität des gesamten Produkts steigern. Sie zeichnen die Rolle des Testers nach – vom Fehlerfinder zum Moderator, der Risiken, Daten und Empathie in die tägliche Arbeit einbringt.
Eine Geschichte über einen Check-out, der auf alten Telefonen fehlgeschlagen ist, zeigt, warum Zugänglichkeit und Leistung in den Sprint gehören und nicht ans Ende. Sie sprechen auch darüber, was es zu automatisieren und zu erforschen gilt, wie man scharfe Metriken festlegt und wie Pairing und kleine Experimente Gewohnheiten ändern.
„So I think the first step is always trying to understand who you are talking to, trying to understand what matters to them, what do they really care about. Bad quality is something that hurts the business, but how does it hurt this particular person? What is the impact on this person or on the team that this person works with?“ – Kat Obring
Dieser Podcast betrachtet alles, was auf Softwarequalität einzahlt: von Agilität, KI, Testautomatisierung, bis hin zu Architektur- oder Code-Reviews und Prozessoptimierungen. Alles mit dem Ziel, bessere Software zu entwickeln und die Teams zu stärken. Frei nach dem Podcast-Motto: Better Teams. Better Software. Better World.
Richard Seidl spricht dabei mit internationalen Gästen über modernes Software Engineering und wie Testing und Qualität im Alltag gelebt werden können.
Die aktuelle Ausgabe ist auch auf Richard Seidls Blog verfügbar: „Wie Tester Vertrauen in Software-Teams aufbauen – Kat Obring“ und steht auf YouTube bereit.
(mdo)












Entwicklung & Code
Infrastructure-as-Code: Die neue Plattform formae soll Terraform & Co. ablösen
Das Unternehmen Platform Engineering Labs kündigt formae als neue Infrastructure-as-Code-Plattform (IaC) an. Der offiziellen Verlautbarung zufolge soll sie die Einschränkungen („fundamentale Unzulänglichkeiten“) von Tools wie Terraform reformieren und einen grundlegend neuen Weg beschreiten: Die unter der FSL-Lizenz (Fair Source) veröffentlichte quelloffene Software verspricht, bestehende Cloud-Infrastrukturen automatisch zu erkennen und in verwaltbaren Code zu überführen. Damit sei formae die erste IaC-Plattform, die sich nicht auf einen idealisierten Plan stütze, sondern von der Realität ausgehe, wie Pavlo Baron, Mitgründer und CEO von Platform Engineering Labs, erklärt.
Weiterlesen nach der Anzeige
Automatische Infrastruktur-Erkennung als Kernfunktion
Während Terraform und vergleichbare IaC-Werkzeuge auf manuell erstellten Konfigurationsdateien basieren, soll formae automatisch die gesamte bestehende Cloud-Infrastruktur einer Organisation erfassen und in Code überführen – unabhängig davon, wie diese ursprünglich erstellt wurde. Die Plattform arbeitet mit sogenannten „formas“, versionierten Code-Artefakten, die sowohl temporär als auch dauerhaft gespeichert werden können. Laut dem Entwicklungsteam eliminiert dieser Ansatz das Problem der State-Dateien, die bei Terraform häufig zu Inkonsistenzen zwischen dem geplanten und dem tatsächlichen Zustand der Infrastruktur führen.
Die neue Plattform soll dabei nicht nur einfach die Komplexität vom Development zum Betrieb hin verlagern, sondern tatsächlich die kognitive Belastung sowohl für Entwicklungs- als auch für Betriebsteams reduzieren. Dazu trägt Platform Engineering Labs zufolge eine Agent-basierte Architektur bei, die Änderungs- und Zustandsverwaltung von den Clients entkoppelt. Auf diese Weise sei eine sorgfältige, asynchrone Annäherung an den erklärten Zielzustand möglich. Um zudem das Risiko verminderter Zuverlässigkeit bei Infrastrukturänderungen gering zu halten, setzt formae auf Patch-basierte Updates, die sich präzise und inkrementell mit minimalem Ausmaß durchführen lassen.

Die IaC-Plattform formae verspricht eine Vereinheitlichung aller Ressourcen für Infrastructure-as-Code.
(Bild: Platform Engineering Labs)
IaC-Markt: Terraform unter Druck
Die Ankündigung von formae erfolgt in einer Zeit, in der der IaC-Markt in Bewegung ist. Terraform-Hersteller HashiCorp – seit dem Frühjahr 2025 ein Teil von IBM – hatte 2023 seine Lizenzierung von der Mozilla Public License (MPL) auf die umstrittene Business Source License (BSL) umgestellt. Darauf reagierte die Community mit dem Open-Source-Fork OpenTofu, der inzwischen unter der Schirmherrschaft der Cloud Native Computing Foundation steht und zudem von einer wachsenden Zahl von Unternehmen Unterstützung erfährt.
Weiterlesen nach der Anzeige
Unterdessen arbeitet HashiCorp an neuen Funktionen für Terraform, darunter die Integration mit Ansible und erweiterte Such- und Import-Möglichkeiten für bestehende Cloud-Ressourcen. Die jüngsten Entwicklungen deuten darauf hin, dass HashiCorp den Fokus vermehrt auf KI-Integration legt, etwa durch das interne Projekt „Infragraph“, das als vollständiges Infrastruktur-Inventar für das KI-Training dienen soll.
Verfügbarkeit und Community
Mit formae strebt Platform Engineering Labs eine Vereinheitlichung aller Ressourcen für Infrastructure-as-Code an, unabhängig davon, ob diese über Patches mit minimalem Auswirkungsradius, Terraform, OpenTofu, Pulumi, ClickOps oder Legacy-Skripte erstellt wurden. Die Plattform soll die Grundlage für ein offenes und erweiterbares Ökosystem schaffen.
formae ist ab sofort auf GitHub verfügbar. Community-Diskussionen finden auf Discord statt. Die FSL-Lizenz habe Platform Engineering Labs gewählt, um Entwicklerinnen und Entwicklern zunächst alle Möglichkeiten offenzuhalten, sich intensiv und uneingeschränkt mit der Software auseinanderzusetzen – auch eigene Beiträge dazu zu leisten – und gleichzeitig ein nachhaltiges kommerzielles Modell zu ermöglichen.
(map)
Entwicklung & Code
Python-Webframework: Django-Developer nutzen zunehmend HTMX und Alpine.js
Die Django Software Foundation und das Team hinter der Python-Entwicklungsumgebung JetBrains PyCharm haben die Ergebnisse zur Umfrage „State of Django 2025“ veröffentlicht. Weltweit haben gut 4600 Entwicklerinnen und Entwickler teilgenommen, die Django verwenden – ein Open-Source-Webframework für die Programmiersprache Python. Die Studie zeigt die Trends und Tools im Django-Ökosystem: React und jQuery erweisen sich als die beliebtesten JavaScript-Bibliotheken, doch HTMX und Alpine.js holen auf und auch die KI-Verwendung nimmt zu.
Weiterlesen nach der Anzeige
(Bild: jaboy/123rf.com)

Call for Proposals für die enterJS 2026 am 16. und 17. Juni in Mannheim: Die Veranstalter suchen nach Vorträgen und Workshops rund um JavaScript und TypeScript, Frameworks, Tools und Bibliotheken, Security, UX und mehr. Vergünstigte Blind-Bird-Tickets sind bis zum Programmstart erhältlich.
Django-Developer nutzen zunehmend KI
Während laut der Studie knapp 80 Prozent der befragten Developer weiterhin die offizielle Dokumentation unter djangoproject.com als ihre Lernquelle nutzen, sind KI-Tools mit 38 Prozent auf dem Vormarsch und haben sowohl Blogs (33 Prozent) als auch Bücher (22 Prozent) überholt.

The State of Django 2025: Django-Entwicklerinnen und -Entwickler informieren sich vorrangig mittels der offiziellen Dokumentation.
In der Entwicklung mit Django sind KI-Tools ebenfalls beliebt, insbesondere für Aufgaben wie Autovervollständigung, Codegenerierung und das Schreiben von Boilerplate-Code. Beispielsweise nutzen 69 Prozent der Befragten ChatGPT und 34 Prozent GitHub Copilot. Wie die Studienmacher vermuten, wird sich im nächsten Jahr eine noch stärkere KI-Nutzung zeigen.
JavaScript: React und jQuery an der Spitze, HTMX und Alpine.js im Aufwind
Weiterlesen nach der Anzeige
In Kombination mit Django kommen wie bereits in den Vorjahren am häufigsten die JavaScript-Bibliotheken React und jQuery zum Einsatz. Allerdings zeigt sich ein deutlicher Anstieg in der Nutzung von HTMX und Alpine.js, die beide den Ansatz serverseitiger Templates verfolgen. Seit 2021 hat HTMX von fünf auf 24 Prozent zugelegt, Alpine.js von drei auf 14 Prozent. Das anstehende Release Django 6.0 wird offiziellen Support für Template Partials bieten, was die Kombination mit HTMX und Alpine.js als gangbare Alternative offenbar weiter festigen wird.
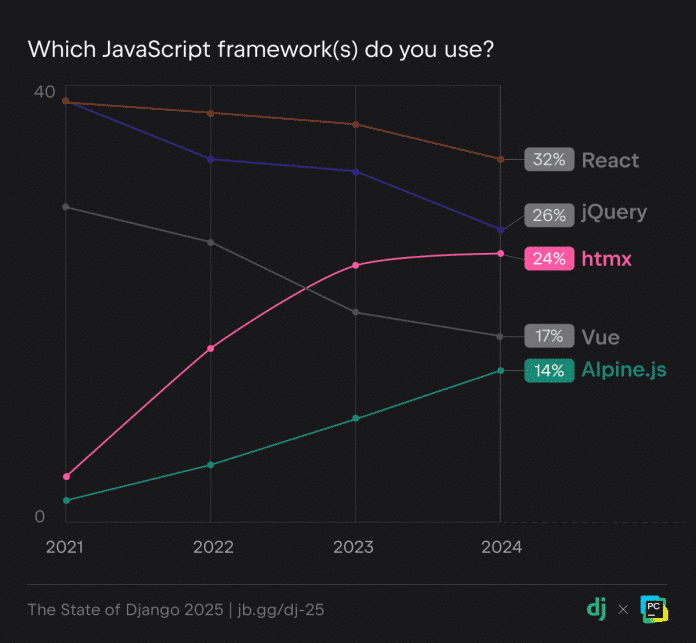
The State of Django 2025: Diese JavaScript-Frameworks nutzen Django-Developer.
Zu den weiteren Funden der Studie zählt, dass Django-Developer tendenziell sehr erfahren sind: Knapp ein Drittel arbeitet bereits mindestens elf Jahre mit dem Framework. Zudem kommt Django hauptsächlich beruflich zum Einsatz. Diese und weitere Ergebnisse präsentiert der JetBrains-Blog.
20 Jahre Django – mit inklusiver Community
Bei Django handelt es sich um ein High-Level-Webframework für die Programmiersprache Python, mit Fokus auf Schnelligkeit, Sicherheit und Skalierbarkeit. Am 13. Juli 2025 hat Django bereits sein zwanzigjähriges Jubiläum gefeiert. Wie das Django-Team in dem Zuge ankündigte, sind auch in Zukunft viele Releases mit mehreren Jahren Support sowie Tausende neue Packages im Django-Ökosystem zu erwarten – in einer großen, inklusiven Online-Community.
Auch die Python Software Foundation, die hinter der Programmiersprache steht, legt Wert auf eine vielfältige Entwicklergemeinschaft. Erst kürzlich wurde bekannt, dass sie einen Antrag auf Fördergelder der US-Regierung aufgrund von Anti-DEI-Vorgaben (Diversity, Equity and Inclusion) zurückgezogen hat.
(mai)
Entwicklung & Code
Python Software Foundation: Chancengleichheit wichtiger als US-Fördergelder
Die Python Software Foundation (PSF) hat einen Anfang des Jahres gestellten Antrag auf Fördergelder der US-Regierung zurückgezogen.Konkret hatte die PSF bei der National Science Foundation der US-Regierung 1,5 Millionen US-Dollar Fördergelder nach dem Safety, Security, and Privacy of Open-Source Ecosystems (Safe-OSE) beantragt. Das Programm soll die Sicherheit in Open-Source-Ökosystemen stärken und gegen Angriffe schützen.
Weiterlesen nach der Anzeige
Nach einigen Monaten wurde der Antrag offenbar für die Förderung empfohlen. Laut des PSF-Blogs sind nur 36 Prozent, also gut ein Drittel, aller Erstanträge erfolgreich.
Inakzeptable Bedingungen für die Förderung
Die anfängliche Freude wich allerdings schnell ernsten Bedenken, als die Stiftung die Bedingungen für die Förderung zugesandt bekam.
Konkret fand sich darin die Aussage, dass geförderte Organisationen „keine Programme durchführen und während der Laufzeit dieser finanziellen Unterstützung auch keine Programme durchführen werden, die DEI oder eine diskriminierende Gleichstellungsideologie fördern oder unterstützen, die gegen die Bundesgesetze gegen Diskriminierung verstößt“.
Trumps Kampf gegen DEI
DEI steht für Diversity, Equity and Inclusion, also Vielfalt, Gerechtigkeit und Inklusion. Es geht vor allem darum, unterrepräsentierte Gruppen zu fördern. Kurz nach dem Start seiner zweiten Amtszeit hat US-Präsident Donald Trump in seinem Kampf gegen „Wokeness“ die DEI-Programme massiv eingeschränkt. In der Ankündigung auf der offiziellen Seite des Weißen Hauses ist von „illegalen und unmoralischen Diskriminierungsprogrammen“ die Rede, die von der Biden-Administration erzwungen worden seien.
Die Bedingungen für die Förderungen inklusive der Anti-DEI-Vorgaben gelten nicht nur für die Security-Bemühungen, sondern für die gesamte Arbeit der geförderten Organisationen.
Weiterlesen nach der Anzeige
Widerspruch zur Mission der PSF
Die Python Software Foundation hat die Chancengleichheit in ihrem offiziellen Mission-Statement verankert. Darin heißt es „Die Mission der Python Software Foundation besteht darin, die Programmiersprache Python zu fördern, zu schützen und weiterzuentwickeln sowie das Wachstum einer vielfältigen und internationalen Gemeinschaft von Python-Programmierern zu unterstützen und zu erleichtern.“
(Bild: Python Software Foundation)
![]()
Der Autor der Programmiersprache Python Guido van Rossum hat am 6. März 2001 die Python Software Foundation als US-amerikanischen Non-Profit-Organistion gegründet.
Die PSF kümmert sich um die Weiterentwicklung von Python und verwaltet zudem den Paketmanager Python Package Index (PyPI). Letzterer ist ebenso wie der JavaScript-Paketmanager npm immer wieder Ziel von Supply-Chain-Angriffen.
Laut des Blogbeitrags hat die PSF keinen Weg gefunden, die Fördergelder zu erhalten und gleichzeitig an der Mission festzuhalten. Da sie zu dem Schluss gekommen sei, dass sie die Gelder nicht annehmen kann, ohne ihre eigene Mission zu verraten.
Die PSF ist nicht die erste Organisation, die ihren Fördergeldantrag wegen der Bedingungen zurückzieht. Im Juni war die in Deutschland wenig bekannte Organisation The Carpentries denselben Schritt gegangen. The Carpentries bietet Trainings für Softwareentwicklung und Data Science an, und stellt alle Schulungsmaterialien unter der Creative-Commons-Lizenz bereit.
Die Gelder der National Science Foundation wären nicht die erste finanzielle Unterstützung für die Python Software Foundation zur Förderung der Sicherheit gewesen. Im Juni 2022 hatte die Open Source Security Foundation (OpenSSF), die unter dem Dach der Linux Foundation steht, die PSF mit 400.000 US-Dollar unterstützt.
(rme)

Hinweise auf iPad-Versionen von Pixelmator Pro, Motion und MainStage

Adobe Firefly 5: Neue KI-Modelle schneiden Videos und komponieren Musik

Glasfaser: Digitalminister bringt alle an einen Tisch

Der ultimative Guide für eine unvergessliche Customer Experience

Adobe Firefly Boards › PAGE online
eine gute Nachricht ist")
Relatable, relevant, viral? Wer heute auf Social Media zum Vorbild wird – und warum das für Marken (k)eine gute Nachricht ist
-
 UX/UI & Webdesignvor 2 Monaten
UX/UI & Webdesignvor 2 MonatenDer ultimative Guide für eine unvergessliche Customer Experience
-
 UX/UI & Webdesignvor 2 Monaten
UX/UI & Webdesignvor 2 MonatenAdobe Firefly Boards › PAGE online
-
eine gute Nachricht ist") Social Mediavor 2 Monaten
Social Mediavor 2 MonatenRelatable, relevant, viral? Wer heute auf Social Media zum Vorbild wird – und warum das für Marken (k)eine gute Nachricht ist
-

 UX/UI & Webdesignvor 2 Wochen
UX/UI & Webdesignvor 2 WochenIllustrierte Reise nach New York City › PAGE online
-

 Entwicklung & Codevor 2 Monaten
Entwicklung & Codevor 2 MonatenPosit stellt Positron vor: Neue IDE für Data Science mit Python und R
-

 Entwicklung & Codevor 2 Monaten
Entwicklung & Codevor 2 MonatenEventSourcingDB 1.1 bietet flexiblere Konsistenzsteuerung und signierte Events
-

 UX/UI & Webdesignvor 1 Monat
UX/UI & Webdesignvor 1 MonatFake It Untlil You Make It? Trifft diese Kampagne den Nerv der Zeit? › PAGE online
-

 Apps & Mobile Entwicklungvor 2 Monaten
Apps & Mobile Entwicklungvor 2 MonatenGalaxy Tab S10 Lite: Günstiger Einstieg in Samsungs Premium-Tablets