Entwicklung & Code
Wenn Intuition versagt: KI und die Grenzen unserer Vorstellungskraft
Viele sprechen davon, dass Künstliche Intelligenz in n-dimensionalen Räumen arbeitet – und meistens klingt das irgendwie nach Science-Fiction. Wenn man das hört, denkt man sofort an fremde Welten, an Paralleluniversen, kurz: an Dinge, die sich unser Gehirn nicht vorstellen kann.


Golo Roden ist Gründer und CTO von the native web GmbH. Er beschäftigt sich mit der Konzeption und Entwicklung von Web- und Cloud-Anwendungen sowie -APIs, mit einem Schwerpunkt auf Event-getriebenen und Service-basierten verteilten Architekturen. Sein Leitsatz lautet, dass Softwareentwicklung kein Selbstzweck ist, sondern immer einer zugrundeliegenden Fachlichkeit folgen muss.
Doch genau da liegt das Problem: Wir Menschen versuchen nur allzu gerne, uns alles bildlich vorzustellen. Aber ab der vierten Dimension klappt das nicht mehr. Wir stolpern, scheitern und merken, dass unsere Vorstellungskraft an diesem Punkt endet.
Empfohlener redaktioneller Inhalt
Mit Ihrer Zustimmung wird hier ein externes YouTube-Video (Google Ireland Limited) geladen.
KI ist mächtig, aber keine Magie // deutsch
Dennoch sind hochdimensionale Räume in der KI ganz normaler Alltag. Sprachmodelle, Bilderkennung, Empfehlungssysteme – sie alle arbeiten in weitaus mehr als nur drei Dimensionen. Aber kaum jemand kann wirklich erklären, was das konkret bedeutet. Die Aussage, etwas passiere in einem 27-dimensionalen Raum, klingt natürlich eindrucksvoll, aber was steckt dahinter? Ist das ein ganz anderer Raum, quasi eine fremde Welt, etwas, das wir niemals begreifen können? Oder ist es vielleicht doch viel einfacher, als wir zunächst glauben?
Genau da möchte ich Sie heute abholen. Denn es lohnt sich, das zu verstehen. Nicht nur, um mitreden zu können, wenn wieder jemand von tausenden Dimensionen spricht. Sondern auch, weil es zeigt, warum KI oft so schwer nachvollziehbar ist, warum Sprachmodelle Vektordatenbanken brauchen und warum am Ende nicht irgendein magischer Algorithmus entscheidet, ob eine KI funktioniert, sondern ganz klassisch Erfahrung und Fachwissen.
Was sind Dimensionen?
Klären wir zunächst einmal, was Dimensionen überhaupt sind. Auf mich hat das lange sehr gewaltig gewirkt, so, als ob man dafür Astrophysik studiert haben müsste. Aber in Wahrheit steckt da etwas sehr viel Einfacheres dahinter: Eine Dimension ist nämlich nichts anderes als ein Merkmal, eine Eigenschaft, ein Freiheitsgrad – wie auch immer Sie das nennen wollen.
Wenn wir nur eine einzige Dimension haben, dann genügt eine einzelne Zahl, um etwas zu beschreiben. Nehmen Sie zum Beispiel die Temperatur. Sie können sagen:
„Heute sind es 15 Grad.“
Mehr brauchen Sie nicht, um klarzumachen, wie warm oder wie kalt es ist. Eine Zahl genügt. Das ist eine eindimensionale Welt.
Fügen wir eine zweite Dimension hinzu, wird es spannender. Denn dann brauchen Sie schon zwei Zahlen, um sich zurechtzufinden. Stellen Sie sich eine Landkarte vor. Ein einzelner Wert sagt Ihnen nur, wie weit Sie nach links oder nach rechts gehen müssen. Doch ein zweiter Wert sagt Ihnen, wie weit Sie nach oben oder unten gehen müssen. Das heißt: Zwei Dimensionen benötigen zwei Zahlen – und schon können Sie sich auf einer Fläche bewegen.
In der dritten Dimension leben wir alle. Hier genügt die Karte nicht mehr, weil sie nur die Höhe und die Breite kennt. Wir benötigen zusätzlich aber noch die Tiefe. Erst damit können wir wirklich beschreiben, wo sich etwas in unserer Welt befindet. Das heißt, mit drei Zahlen können Sie jedes Objekt eindeutig in Raum und Lage festlegen. Und genau hier steckt die erste entscheidende Erkenntnis: Mehr Dimensionen sind nichts Mystisches, nichts Magisches, sondern einfach nur zusätzliche Eigenschaften. Jede Dimension bedeutet: ein Freiheitsgrad mehr, eine Variable mehr, ein Stück zusätzliche Information.
Nun könnte man denken:
„Na gut, wenn drei Dimensionen so logisch sind, dann sind vier doch bestimmt auch kein Problem. Dann nehmen wir einfach noch eine Zahl dazu – und schon haben wir die vierte Dimension.“
Theoretisch stimmt das sogar. Mehr als das ist es nämlich tatsächlich nicht. Praktisch merken wir jedoch: Wir können uns das nicht mehr vorstellen. Unser Gehirn stößt an eine Grenze, und deshalb sagen viele Menschen dann, dass es gar keine vierte Dimension gebe.
1-, 2-, 3- und n-dimenensionale Welten
Um das besser verstehen zu können, hilft ein kleines Gedankenexperiment. Stellen Sie sich vor, es gäbe Lebewesen, die nur auf einer Linie leben. Diese kennen dann logischerweise nur eine Richtung, nämlich vorwärts und rückwärts. Das ist ihre Welt. Für sie gibt es weder oben noch unten, weder links noch rechts. Alles, was sie wahrnehmen können, spielt sich auf dieser Linie ab. Diese Linie könnte nun aber auf einem Blatt Papier gezeichnet sein. Und das hieße, dass es durchaus zwei Dimensionen gäbe (nämlich die Länge und die Breite des Blattes), aber weil diese Lebewesen nur die Linie wahrnehmen können, wirkt es für sie wie eine rein eindimensionale Welt.
Jetzt stellen Sie sich ein weiteres Lebewesen vor, das auf ebendiesem Blatt Papier lebt. Für dieses Wesen gibt es nun weitere Richtungen: vorwärts und rückwärts sowie links und rechts. Ein Leben in zwei Dimensionen. Das ist schon viel komplexer, als nur auf einer Linie hin- und herzuwandern. Aber was für uns völlig selbstverständlich ist – nämlich dass man ein Blatt Papier auch hochheben oder drehen kann –, existiert in der Welt dieses Wesens nicht. Es hat schlicht keine Vorstellung von Höhe oder Tiefe. An der Stelle sei die Erzählung Flächenland von Edwin Abbott Abbott empfohlen.
Und genau so geht es uns Menschen. Wir können uns eine dreidimensionale Welt vorstellen, weil unsere Wahrnehmung dreidimensional arbeitet. Aber sobald eine vierte Dimension dazukommt, verlieren wir den Halt. Unser Gehirn ist schlicht nicht dafür gemacht, sich das anschaulich vorzustellen. Das bedeutet jedoch nicht, dass diese vierte Dimension nicht existieren würde oder nicht berechenbar wäre. Ganz im Gegenteil: Die Mathematik kümmert es überhaupt nicht, ob wir uns etwas vorstellen können oder nicht. Für sie ist es völlig normal, mit vier, fünf, 27 oder auch 5.000 Dimensionen zu rechnen. Nur wir Menschen scheitern daran, ein Bild davon in unserem Kopf zu erzeugen. Und genau das ist die zweite wichtige Erkenntnis: Dass wir etwas nicht visualisieren können, heißt noch lange nicht, dass es nicht real ist – und schon gar nicht, dass wir es nicht berechnen könnten.
Dimensionen in der KI
Wenn wir nun von Künstlicher Intelligenz sprechen, sind Dimensionen letztlich nichts anderes als Merkmale, die unsere Daten beschreiben. Um ein konkretes Beispiel zu nennen: Denken Sie bitte kurz an ein Musikstück, das Ihnen gut gefällt. Da gibt es das Tempo, gemessen in Beats per Minute (BPM). Es gibt die Lautstärke, die man in Dezibel angeben kann. Es gibt die Frage, ob Gesang vorkommt oder nicht, welche Instrumente eingesetzt werden und so weiter. All das sind Eigenschaften und jede einzelne dieser Eigenschaften entspricht einer Dimension.
Das heißt: Je mehr Merkmale wir aufnehmen, desto mehr Dimensionen kommen hinzu. Bei Musik könnten das auch noch die Tonhöhe sein, die Länge eines Stücks, die Tonart, die Verteilung der Wellen im Frequenzspektrum und so weiter. Jede dieser Eigenschaften ist eine Variable und zusammen bilden sie einen Raum, in dem jedes Musikstück seinen Platz hat. Dasselbe gilt natürlich nicht nur für Musik, sondern für alle Daten.
Plötzlich wird klar: Dimensionen in der KI sind nichts Abgehobenes, keine geheimnisvollen Räume, sondern schlicht und einfach nur Features: Dinge, die man messen, beobachten oder aus den Daten ableiten kann. Und das ist die dritte wichtige Erkenntnis: In der KI sind Dimensionen keine Science-Fiction-Welten, sondern handfeste Eigenschaften. Mehr Dimensionen bedeuten mehr Informationen, die ein Modell gleichzeitig berücksichtigen kann.
Warum Vektordatenbanken so wichtig sind
Besonders interessant wird es nun, wenn wir uns Sprachmodelle anschauen. Denn Sprache funktioniert nur, wenn wir Bedeutungen verstehen, wenn wir merken, dass bestimmte Wörter nah beieinanderliegen, dass sie ähnlich sind, dass sie etwas miteinander zu tun haben. Und genau dafür brauchen Sprachmodelle sogenannte Vektordatenbanken. Man kann sich das vorstellen wie eine riesige Landkarte – aber eben nicht in zwei Dimensionen, sondern in hunderten oder gar tausenden. Jedes Wort ist ein Punkt in diesem Raum. Wörter, die oft gemeinsam vorkommen, liegen nah beieinander. Wörter, die Gegensätze sind oder nichts miteinander zu tun haben, liegen weit auseinander. Wörter, die in ähnlichen Kontexten auftauchen, rücken wiederum näher zusammen.
Nehmen Sie beispielsweise die Begriffe „Natur“ und „Technologie“. Die beiden sind vermutlich ziemlich weit voneinander entfernt. „Computer“ und „Technologie“ hingegen liegen wahrscheinlich nah beieinander. Das Wort „Baum“ ist ganz klar bei „Natur“ angesiedelt, aber nicht ganz so weit von „Technologie“ entfernt, wie man zunächst vermuten würde, denn auch in der Informatik sprechen wir von Bäumen, wenn wir bestimmte Datenstrukturen meinen.
Rasch wird klar, dass nur zwei oder drei Dimensionen für diesen Ansatz niemals ausreichen. Auf einer zweidimensionalen Karte oder selbst in einem dreidimensionalen Raum könnten Sie vielleicht ein paar Wörter sinnvoll anordnen, aber die Mehrdeutigkeit ginge schnell verloren. Es braucht viel mehr Freiheitsgrade, um die feinen Unterschiede abzubilden. Deshalb arbeiten Sprachmodelle mit vielen tausend Dimensionen. Denn nur so können sie die Vielfalt und die Nuancen menschlicher Sprache erfassen. Und das führt uns direkt zur vierten wichtigen Erkenntnis: Vektordatenbanken sind nichts anderes als mehrdimensionale Karten von Bedeutungen. Ohne sie könnten Sprachmodelle nicht funktionieren.
Curse of Dimensionality
So faszinierend das alles klingt, bringt es doch ein ganz eigenes Problem mit sich: Je mehr Dimensionen wir hinzufügen, desto schwieriger wird es für uns, mit einfachen Begriffen wie „Nähe“ oder „Abstand“ umzugehen. In zwei oder drei Dimensionen haben wir ein klares Gefühl dafür: Wir können sehen, ob zwei Punkte nah beieinander liegen oder weit auseinander. Wir können intuitiv einschätzen, ob Dinge zusammengehören oder nicht. In 27 oder 5000 Dimensionen funktioniert das jedoch nicht mehr. Mathematisch lässt sich der Abstand zwar problemlos berechnen, aber unsere Intuition hört auf, uns dabei zu helfen.
Das führt dazu, dass Abstände ihre Aussagekraft verlieren. Dinge, die in drei Dimensionen klar voneinander getrennt wären, rücken in höheren Dimensionen oft erstaunlich nah zusammen. Oder umgekehrt: Punkte, die in zwei Dimensionen nahe beieinander erscheinen, können in einem Raum mit vielen Dimensionen plötzlich extrem weit auseinanderliegen.
Gerade für das Clustering, also das Bilden von Gruppen und Ähnlichkeiten, ist das ein echtes Problem. Denn: Je mehr Dimensionen es gibt, desto schwieriger wird es, sinnvolle Strukturen zu erkennen. Die Daten verhalten sich für uns Menschen plötzlich fremd, unanschaulich, manchmal sogar widersprüchlich. Das ist der sogenannte „Curse of Dimensionality“. Mit jeder zusätzlichen Dimension schrumpft unsere Fähigkeit, das Ganze noch zu durchschauen. Was für den Computer nur Mathematik ist, wird für uns zur Blackbox. Und das ist die fünfte wichtige Erkenntnis: Mehr Dimensionen bedeuten zwar mehr Möglichkeiten für die KI, für uns Menschen jedoch weniger Intuition und weniger Nachvollziehbarkeit.
Was bedeutet das für die Praxis?
In der Praxis bedeutet das, dass je mehr Dimensionen eine KI nutzt, die Frage umso wichtiger wird, welche Eigenschaften wir überhaupt hineingeben. Das heißt, die Datenvorbereitung und die Auswahl der richtigen Features sind entscheidend. Das klingt leider oft wesentlich leichter, als es tatsächlich ist. Denn es gibt keinen magischen Algorithmus, der uns sagt, welche Merkmale am besten geeignet wären, wie wir sie normalisieren müssten oder wie wir sie am besten kombinieren könnten. In der Realität bedeutet das: Man muss es ausprobieren. Man testet verschiedene Kombinationen, schaut, welche Ergebnisse dabei herauskommen, justiert nach und probiert wieder von vorn.
Das ist manchmal sehr mühsam und oft auch frustrierend. Aber es ist die Realität in der KI-Entwicklung. Am Ende ist es eine Mischung aus Statistik, Wahrscheinlichkeiten und sehr viel Ausprobieren. Provokant könnte man sagen: KI ist letztlich nur besseres Raten. Sie arbeitet nicht mit Gewissheiten, sondern mit Wahrscheinlichkeiten, mit Unschärfen, mit Annäherungen.
Genau darin liegt die große Herausforderung: Je mehr Dimensionen im Spiel sind, desto weniger können wir uns auf unsere Intuition verlassen. Wir können nicht mehr einfach draufschauen und sehen, warum die KI eine bestimmte Entscheidung getroffen hat. Wir sind darauf angewiesen, das Ganze mathematisch zu verstehen oder zu akzeptieren, dass es für uns eine Blackbox bleibt. Das ist die sechste wichtige Erkenntnis: KI ist mächtig, aber keine Magie. Sie ist im Kern Statistik auf Steroiden.
KI ist keine Magie
Genau an diesem Punkt bekommen so viele Menschen einen falschen Eindruck: Weil KI für uns so oft wie eine Blackbox wirkt, glauben wir schnell, KI sei etwas „Magisches“. Etwas, das von allein funktioniert, quasi: Man wirft Daten hinein, und die Maschine findet schon die richtigen Muster. Aber so funktioniert es nicht.
Gerade weil KI so viel Trial and Error ist, braucht es Menschen, die Erfahrung mitbringen. Menschen, die fachlich verstehen, welche Merkmale überhaupt sinnvoll sind. Denn wenn man die falschen Features auswählt, kann das Modell noch so groß und komplex sein – es wird niemals zu brauchbaren Ergebnissen kommen. Das heißt: Es braucht technisches Know-how, um Architekturen zu bauen, die mit dieser Mehrdimensionalität umgehen können. Es reicht nicht, einfach eine KI zu trainieren, sondern man muss wissen, wie man Daten normalisiert, vorbereitet und strukturiert. Und es braucht Erfahrung, um aus diesem Trial and Error ein zumindest halbwegs zielgerichtetes Vorgehen zu machen. Nicht einfach blind irgendetwas zu probieren, sondern zu verstehen, warum ein bestimmter Ansatz funktioniert oder warum er scheitert.
Und das ist die siebte wichtige Erkenntnis: KI-Erfolg ist keine Frage von Magie, sondern das Ergebnis einer Kombination aus Statistik und Expertise. Ohne Fachwissen bleibt KI blind. Ohne Erfahrung bleibt sie zufällig. Erst die Verbindung macht sie wirklich wertvoll.
Wenn Sie sich das alles noch einmal vor Augen führen, bleibt ein klares Bild: KI arbeitet in unglaublich vielen Dimensionen. Dimensionen, die wir uns nicht vorstellen können, weil unser Denken schon bei der vierten an seine Grenzen stößt. Genau das macht KI so mächtig und gleichzeitig so schwer nachvollziehbar. Deshalb genügt es nicht, einfach irgendein Modell laufen zu lassen: Es braucht Fachwissen, um die richtigen Features zu wählen. Es braucht technisches Know-how, um Architekturen zu bauen, die mit dieser Mehrdimensionalität zurechtkommen. Und es braucht Erfahrung, um das Ganze in eine Richtung zu lenken, die wirklich Ergebnisse bringt.
(rme)











Entwicklung & Code
Infrastructure-as-Code: Die neue Plattform formae soll Terraform & Co. ablösen
Das Unternehmen Platform Engineering Labs kündigt formae als neue Infrastructure-as-Code-Plattform (IaC) an. Der offiziellen Verlautbarung zufolge soll sie die Einschränkungen („fundamentale Unzulänglichkeiten“) von Tools wie Terraform reformieren und einen grundlegend neuen Weg beschreiten: Die unter der FSL-Lizenz (Fair Source) veröffentlichte quelloffene Software verspricht, bestehende Cloud-Infrastrukturen automatisch zu erkennen und in verwaltbaren Code zu überführen. Damit sei formae die erste IaC-Plattform, die sich nicht auf einen idealisierten Plan stütze, sondern von der Realität ausgehe, wie Pavlo Baron, Mitgründer und CEO von Platform Engineering Labs, erklärt.
Weiterlesen nach der Anzeige
Automatische Infrastruktur-Erkennung als Kernfunktion
Während Terraform und vergleichbare IaC-Werkzeuge auf manuell erstellten Konfigurationsdateien basieren, soll formae automatisch die gesamte bestehende Cloud-Infrastruktur einer Organisation erfassen und in Code überführen – unabhängig davon, wie diese ursprünglich erstellt wurde. Die Plattform arbeitet mit sogenannten „formas“, versionierten Code-Artefakten, die sowohl temporär als auch dauerhaft gespeichert werden können. Laut dem Entwicklungsteam eliminiert dieser Ansatz das Problem der State-Dateien, die bei Terraform häufig zu Inkonsistenzen zwischen dem geplanten und dem tatsächlichen Zustand der Infrastruktur führen.
Die neue Plattform soll dabei nicht nur einfach die Komplexität vom Development zum Betrieb hin verlagern, sondern tatsächlich die kognitive Belastung sowohl für Entwicklungs- als auch für Betriebsteams reduzieren. Dazu trägt Platform Engineering Labs zufolge eine Agent-basierte Architektur bei, die Änderungs- und Zustandsverwaltung von den Clients entkoppelt. Auf diese Weise sei eine sorgfältige, asynchrone Annäherung an den erklärten Zielzustand möglich. Um zudem das Risiko verminderter Zuverlässigkeit bei Infrastrukturänderungen gering zu halten, setzt formae auf Patch-basierte Updates, die sich präzise und inkrementell mit minimalem Ausmaß durchführen lassen.
Die IaC-Plattform formae verspricht eine Vereinheitlichung aller Ressourcen für Infrastructure-as-Code.
(Bild: Platform Engineering Labs)
IaC-Markt: Terraform unter Druck
Die Ankündigung von formae erfolgt in einer Zeit, in der der IaC-Markt in Bewegung ist. Terraform-Hersteller HashiCorp – seit dem Frühjahr 2025 ein Teil von IBM – hatte 2023 seine Lizenzierung von der Mozilla Public License (MPL) auf die umstrittene Business Source License (BSL) umgestellt. Darauf reagierte die Community mit dem Open-Source-Fork OpenTofu, der inzwischen unter der Schirmherrschaft der Cloud Native Computing Foundation steht und zudem von einer wachsenden Zahl von Unternehmen Unterstützung erfährt.
Weiterlesen nach der Anzeige
Unterdessen arbeitet HashiCorp an neuen Funktionen für Terraform, darunter die Integration mit Ansible und erweiterte Such- und Import-Möglichkeiten für bestehende Cloud-Ressourcen. Die jüngsten Entwicklungen deuten darauf hin, dass HashiCorp den Fokus vermehrt auf KI-Integration legt, etwa durch das interne Projekt „Infragraph“, das als vollständiges Infrastruktur-Inventar für das KI-Training dienen soll.
Verfügbarkeit und Community
Mit formae strebt Platform Engineering Labs eine Vereinheitlichung aller Ressourcen für Infrastructure-as-Code an, unabhängig davon, ob diese über Patches mit minimalem Auswirkungsradius, Terraform, OpenTofu, Pulumi, ClickOps oder Legacy-Skripte erstellt wurden. Die Plattform soll die Grundlage für ein offenes und erweiterbares Ökosystem schaffen.
formae ist ab sofort auf GitHub verfügbar. Community-Diskussionen finden auf Discord statt. Die FSL-Lizenz habe Platform Engineering Labs gewählt, um Entwicklerinnen und Entwicklern zunächst alle Möglichkeiten offenzuhalten, sich intensiv und uneingeschränkt mit der Software auseinanderzusetzen – auch eigene Beiträge dazu zu leisten – und gleichzeitig ein nachhaltiges kommerzielles Modell zu ermöglichen.
(map)
Entwicklung & Code
Python-Webframework: Django-Developer nutzen zunehmend HTMX und Alpine.js
Die Django Software Foundation und das Team hinter der Python-Entwicklungsumgebung JetBrains PyCharm haben die Ergebnisse zur Umfrage „State of Django 2025“ veröffentlicht. Weltweit haben gut 4600 Entwicklerinnen und Entwickler teilgenommen, die Django verwenden – ein Open-Source-Webframework für die Programmiersprache Python. Die Studie zeigt die Trends und Tools im Django-Ökosystem: React und jQuery erweisen sich als die beliebtesten JavaScript-Bibliotheken, doch HTMX und Alpine.js holen auf und auch die KI-Verwendung nimmt zu.
Weiterlesen nach der Anzeige
(Bild: jaboy/123rf.com)

Call for Proposals für die enterJS 2026 am 16. und 17. Juni in Mannheim: Die Veranstalter suchen nach Vorträgen und Workshops rund um JavaScript und TypeScript, Frameworks, Tools und Bibliotheken, Security, UX und mehr. Vergünstigte Blind-Bird-Tickets sind bis zum Programmstart erhältlich.
Django-Developer nutzen zunehmend KI
Während laut der Studie knapp 80 Prozent der befragten Developer weiterhin die offizielle Dokumentation unter djangoproject.com als ihre Lernquelle nutzen, sind KI-Tools mit 38 Prozent auf dem Vormarsch und haben sowohl Blogs (33 Prozent) als auch Bücher (22 Prozent) überholt.

The State of Django 2025: Django-Entwicklerinnen und -Entwickler informieren sich vorrangig mittels der offiziellen Dokumentation.
In der Entwicklung mit Django sind KI-Tools ebenfalls beliebt, insbesondere für Aufgaben wie Autovervollständigung, Codegenerierung und das Schreiben von Boilerplate-Code. Beispielsweise nutzen 69 Prozent der Befragten ChatGPT und 34 Prozent GitHub Copilot. Wie die Studienmacher vermuten, wird sich im nächsten Jahr eine noch stärkere KI-Nutzung zeigen.
JavaScript: React und jQuery an der Spitze, HTMX und Alpine.js im Aufwind
Weiterlesen nach der Anzeige
In Kombination mit Django kommen wie bereits in den Vorjahren am häufigsten die JavaScript-Bibliotheken React und jQuery zum Einsatz. Allerdings zeigt sich ein deutlicher Anstieg in der Nutzung von HTMX und Alpine.js, die beide den Ansatz serverseitiger Templates verfolgen. Seit 2021 hat HTMX von fünf auf 24 Prozent zugelegt, Alpine.js von drei auf 14 Prozent. Das anstehende Release Django 6.0 wird offiziellen Support für Template Partials bieten, was die Kombination mit HTMX und Alpine.js als gangbare Alternative offenbar weiter festigen wird.
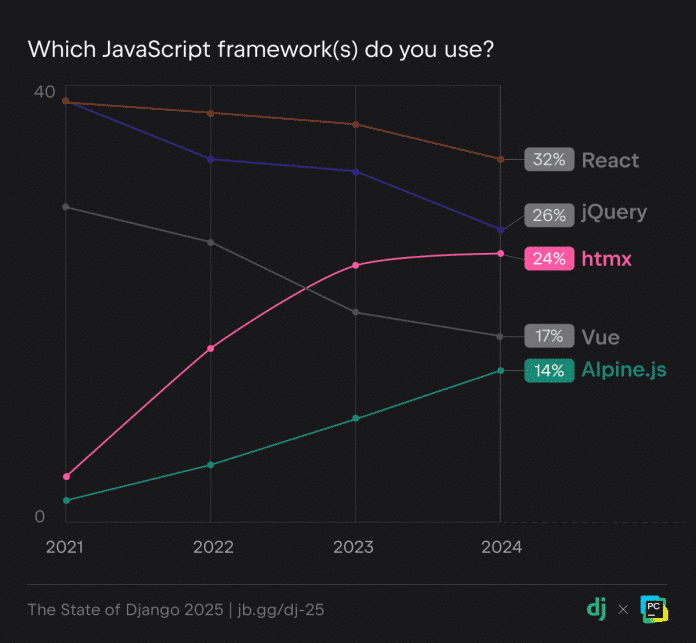
The State of Django 2025: Diese JavaScript-Frameworks nutzen Django-Developer.
Zu den weiteren Funden der Studie zählt, dass Django-Developer tendenziell sehr erfahren sind: Knapp ein Drittel arbeitet bereits mindestens elf Jahre mit dem Framework. Zudem kommt Django hauptsächlich beruflich zum Einsatz. Diese und weitere Ergebnisse präsentiert der JetBrains-Blog.
20 Jahre Django – mit inklusiver Community
Bei Django handelt es sich um ein High-Level-Webframework für die Programmiersprache Python, mit Fokus auf Schnelligkeit, Sicherheit und Skalierbarkeit. Am 13. Juli 2025 hat Django bereits sein zwanzigjähriges Jubiläum gefeiert. Wie das Django-Team in dem Zuge ankündigte, sind auch in Zukunft viele Releases mit mehreren Jahren Support sowie Tausende neue Packages im Django-Ökosystem zu erwarten – in einer großen, inklusiven Online-Community.
Auch die Python Software Foundation, die hinter der Programmiersprache steht, legt Wert auf eine vielfältige Entwicklergemeinschaft. Erst kürzlich wurde bekannt, dass sie einen Antrag auf Fördergelder der US-Regierung aufgrund von Anti-DEI-Vorgaben (Diversity, Equity and Inclusion) zurückgezogen hat.
(mai)
Entwicklung & Code
Python Software Foundation: Chancengleichheit wichtiger als US-Fördergelder
Die Python Software Foundation (PSF) hat einen Anfang des Jahres gestellten Antrag auf Fördergelder der US-Regierung zurückgezogen.Konkret hatte die PSF bei der National Science Foundation der US-Regierung 1,5 Millionen US-Dollar Fördergelder nach dem Safety, Security, and Privacy of Open-Source Ecosystems (Safe-OSE) beantragt. Das Programm soll die Sicherheit in Open-Source-Ökosystemen stärken und gegen Angriffe schützen.
Weiterlesen nach der Anzeige
Nach einigen Monaten wurde der Antrag offenbar für die Förderung empfohlen. Laut des PSF-Blogs sind nur 36 Prozent, also gut ein Drittel, aller Erstanträge erfolgreich.
Inakzeptable Bedingungen für die Förderung
Die anfängliche Freude wich allerdings schnell ernsten Bedenken, als die Stiftung die Bedingungen für die Förderung zugesandt bekam.
Konkret fand sich darin die Aussage, dass geförderte Organisationen „keine Programme durchführen und während der Laufzeit dieser finanziellen Unterstützung auch keine Programme durchführen werden, die DEI oder eine diskriminierende Gleichstellungsideologie fördern oder unterstützen, die gegen die Bundesgesetze gegen Diskriminierung verstößt“.
Trumps Kampf gegen DEI
DEI steht für Diversity, Equity and Inclusion, also Vielfalt, Gerechtigkeit und Inklusion. Es geht vor allem darum, unterrepräsentierte Gruppen zu fördern. Kurz nach dem Start seiner zweiten Amtszeit hat US-Präsident Donald Trump in seinem Kampf gegen „Wokeness“ die DEI-Programme massiv eingeschränkt. In der Ankündigung auf der offiziellen Seite des Weißen Hauses ist von „illegalen und unmoralischen Diskriminierungsprogrammen“ die Rede, die von der Biden-Administration erzwungen worden seien.
Die Bedingungen für die Förderungen inklusive der Anti-DEI-Vorgaben gelten nicht nur für die Security-Bemühungen, sondern für die gesamte Arbeit der geförderten Organisationen.
Weiterlesen nach der Anzeige
Widerspruch zur Mission der PSF
Die Python Software Foundation hat die Chancengleichheit in ihrem offiziellen Mission-Statement verankert. Darin heißt es „Die Mission der Python Software Foundation besteht darin, die Programmiersprache Python zu fördern, zu schützen und weiterzuentwickeln sowie das Wachstum einer vielfältigen und internationalen Gemeinschaft von Python-Programmierern zu unterstützen und zu erleichtern.“
(Bild: Python Software Foundation)
![]()
Der Autor der Programmiersprache Python Guido van Rossum hat am 6. März 2001 die Python Software Foundation als US-amerikanischen Non-Profit-Organistion gegründet.
Die PSF kümmert sich um die Weiterentwicklung von Python und verwaltet zudem den Paketmanager Python Package Index (PyPI). Letzterer ist ebenso wie der JavaScript-Paketmanager npm immer wieder Ziel von Supply-Chain-Angriffen.
Laut des Blogbeitrags hat die PSF keinen Weg gefunden, die Fördergelder zu erhalten und gleichzeitig an der Mission festzuhalten. Da sie zu dem Schluss gekommen sei, dass sie die Gelder nicht annehmen kann, ohne ihre eigene Mission zu verraten.
Die PSF ist nicht die erste Organisation, die ihren Fördergeldantrag wegen der Bedingungen zurückzieht. Im Juni war die in Deutschland wenig bekannte Organisation The Carpentries denselben Schritt gegangen. The Carpentries bietet Trainings für Softwareentwicklung und Data Science an, und stellt alle Schulungsmaterialien unter der Creative-Commons-Lizenz bereit.
Die Gelder der National Science Foundation wären nicht die erste finanzielle Unterstützung für die Python Software Foundation zur Förderung der Sicherheit gewesen. Im Juni 2022 hatte die Open Source Security Foundation (OpenSSF), die unter dem Dach der Linux Foundation steht, die PSF mit 400.000 US-Dollar unterstützt.
(rme)

KanDDDinsky 2025: Eindrücke von Europas DDD-Community-Konferenz

Endlich Watch History für Reels auf Instagram

PNY CS3250 SSD: Das neue Flaggschiff kommt wahrscheinlich mit Phison E28

Der ultimative Guide für eine unvergessliche Customer Experience

Adobe Firefly Boards › PAGE online
eine gute Nachricht ist")
Relatable, relevant, viral? Wer heute auf Social Media zum Vorbild wird – und warum das für Marken (k)eine gute Nachricht ist
-
 UX/UI & Webdesignvor 2 Monaten
UX/UI & Webdesignvor 2 MonatenDer ultimative Guide für eine unvergessliche Customer Experience
-
 UX/UI & Webdesignvor 2 Monaten
UX/UI & Webdesignvor 2 MonatenAdobe Firefly Boards › PAGE online
-
eine gute Nachricht ist") Social Mediavor 2 Monaten
Social Mediavor 2 MonatenRelatable, relevant, viral? Wer heute auf Social Media zum Vorbild wird – und warum das für Marken (k)eine gute Nachricht ist
-

 Entwicklung & Codevor 2 Monaten
Entwicklung & Codevor 2 MonatenPosit stellt Positron vor: Neue IDE für Data Science mit Python und R
-

 UX/UI & Webdesignvor 1 Woche
UX/UI & Webdesignvor 1 WocheIllustrierte Reise nach New York City › PAGE online
-

 Entwicklung & Codevor 2 Monaten
Entwicklung & Codevor 2 MonatenEventSourcingDB 1.1 bietet flexiblere Konsistenzsteuerung und signierte Events
-

 UX/UI & Webdesignvor 1 Monat
UX/UI & Webdesignvor 1 MonatFake It Untlil You Make It? Trifft diese Kampagne den Nerv der Zeit? › PAGE online
-

 Apps & Mobile Entwicklungvor 2 Monaten
Apps & Mobile Entwicklungvor 2 MonatenGalaxy Tab S10 Lite: Günstiger Einstieg in Samsungs Premium-Tablets