Entwicklung & Code
Neu in .NET 10.0 [6]: Generische Erweiterungsblöcke in C# 14.0
Erweiterungsblöcke mit dem Schlüsselwort extension habe ich in der vorherigen Folge der Serie zu .NET 10.0 vorgestellt. Ein Erweiterungsblock darf einen oder mehrere generische Typparameter (optional inklusive Einschränkung mit where) besitzen:
Weiterlesen nach der Anzeige
extension(List source) { … }
oder
extension(List source) where T : INumber { … }


Dr. Holger Schwichtenberg ist technischer Leiter des Expertennetzwerks www.IT-Visions.de, das mit 53 renommierten Experten zahlreiche mittlere und große Unternehmen durch Beratungen und Schulungen sowie bei der Softwareentwicklung unterstützt. Durch seine Auftritte auf zahlreichen nationalen und internationalen Fachkonferenzen sowie mehr als 90 Fachbücher und mehr als 1500 Fachartikel gehört Holger Schwichtenberg zu den bekanntesten Experten für .NET und Webtechniken in Deutschland.
Folgender Code zeigt eine Klasse mit Erweiterungsblocken für List, wobei T auf Zahlen beschränkt ist, durch where T : INumber:
public static class MyExtensions
{
extension(List source) where T : INumber // <-- Receiver Ein Erweiterungsblock darf eine oder mehrere generische Typparameter (optional inklusive Constraint) besitzen!!!
{
public List WhereGreaterThan(T threshold)
=> source.Where(x => x > threshold).ToList();
public bool IsEmpty
=> !source.Any();
///
/// Erweitern um eine Instanz-Eigenschaft mit Getter und Setter
///
public int Size
{
get { return source.Count; }
set
{
while (value < source.Count) source.RemoveAt(source.Count - 1);
if (value > source.Count) source.AddRange(Enumerable.Repeat(default(T)!, value - source.Count).ToList());
}
}
// NEU: Operatorüberladung als Extension und neu ist auch, dass man += überladen kann
public void operator +=(int count)
{
source.Size = source.Count + count;
}
// NEU: Operatorüberladung als Extension und neu ist auch, dass man -= überladen kann
public void operator -=(int count)
{
source.Size = source.Count - count;
}
// NEU: Operatorüberladung als Extension und neu ist auch, dass man ++ überladen kann
public void operator ++()
{
source.Size += 1;
}
}
}
Folgender Code ruft die Erweiterungsmethoden für List auf:
Weiterlesen nach der Anzeige
public void Run()
{
CUI.Demo(nameof(CS14_ExtensionDemo) + ": Collection");
var list = new List { 1, 2, 3, 4, 5 };
var large = list.WhereGreaterThan(3);
Console.WriteLine(large.IsEmpty);
if (large.IsEmpty)
{
Console.WriteLine("Keine Zahlen größer als 3!");
}
else
{
Console.WriteLine(large.Count + " Zahlen sind größer als 3!");
}
CUI.H2("list.Size = 10");
// Das klappt: Die Liste wird auf 10 Elemente mit Nullen aufgefüllt
list.Size = 10;
foreach (var x in list)
{
CUI.OL(x, separator: " = ");
}
CUI.H2("list.Size -= 2");
list.Size -= 2;
bool restart = true;
foreach (var x in list)
{
CUI.OL(x, separator: " = ", restartCounter: restart);
restart = false;
}
CUI.H2("list.Size++");
list.Size++;
restart = true;
foreach (var x in list)
{
CUI.OL(x, separator: " = ", restartCounter: restart);
restart = false;
}
}
Der Code erzeugt folgende Ausgabe:

Ausgabe des Beispielcodes
(rme)



 Testing 2026: Programm und Online-Workshops stehen fest")
 Testing 2026: Programm und Online-Workshops stehen fest")






Entwicklung & Code
Vite 8.0: Rust-basierter Bundler Rolldown ist der neue Standard
Vite 8.0 ist erschienen. Unter der Haube bringt das Frontend-Build-Tool nun Rolldown mit – einen Rust-basierten Bundler, der für eine höhere Build-Geschwindigkeit sorgt. Für die Suche nach Plug-ins steht darüber hinaus eine neue Registry bereit.
Weiterlesen nach der Anzeige
Erst kürzlich zeigte die aktuelle Umfrage State of JavaScript, dass Vite zum wiederholten Mal das beliebteste Tool unter JavaScript-Entwicklern ist und bei der Nutzungshäufigkeit nur noch knapp hinter webpack liegt.
(Bild: jaboy/123rf.com)

Tools und Trends in der JavaScript-Welt: Die enterJS 2026 wird am 16. und 17. Juni in Mannheim stattfinden. Das Programm dreht sich rund um JavaScript und TypeScript, Frameworks, Tools und Bibliotheken, Security, UX und mehr. Frühbuchertickets sind im Online-Ticketshop erhältlich.
Rolldown ersetzt Rollup und esbuild
Vite startete einst mit den beiden Bundlern esbuild und Rollup. Dabei kam esbuild während der Entwicklung zum Einsatz, Rollup für optimierte Produktions-Builds. Mit Vite 8.0 erfolgt nun der Wechsel zu Rolldown als einheitlichem Bundler, der die beiden Vorgänger ablöst. Hierbei soll es sich um die bedeutendste Änderung seit Vite 2.0 handeln.
Rolldown stammt ebenso wie Vite aus dem Hause VoidZero. Der Bundler besitzt eine Rollup-kompatible API, basiert auf der Programmiersprache Rust und soll 10- bis 30-mal schnellere Builds ermöglichen. Beispielsweise seien die Produktions-Build-Zeiten während der Beta-Phase von rolldown-vite bei Mercedes-Benz.io um 38 Prozent gesunken, bei der Newsletter-Plattform Beehiiv sogar um 64 Prozent.
Eine weitere Neuerung ist die Website registry.vite.dev, ein durchsuchbares Verzeichnis von Plug-ins für Vite, Rolldown und Rollup. Als Datenquelle dienen npm und die von Plug-in-Autoren hinterlegten Metadaten. Diese Daten werden täglich aktualisiert. Plug-in-Autoren können zusätzliche Metadaten hinterlegen, indem sie das Feld compatiblePackages in der JSON-Datei des Pakets hinzufügen.
Weiterlesen nach der Anzeige
Update auf das neue Release
Der Umstieg auf Vite 8.0 soll für die meisten Entwicklerinnen und Entwickler problemlos vonstattengehen. Für komplexe Projekte empfiehlt das Vite-Team jedoch eine schrittweise Migration: zuerst den Wechsel vom vite-Package zum rolldown-vite-Package in Vite 7, und erst anschließend den Wechsel zu Vite 8. Auf diese Weise lässt sich einfacher feststellen, ob mögliche Schwierigkeiten vom neuen Bundler herrühren. Weitere Hinweise finden Entwickler in der Migrationsanleitung.
Wie das Vite-Team einräumt, ist die Installationsgröße von Vite 8 etwa 15 MB größer als Vite 7. Das liegt hauptsächlich daran, dass lightningcss nun keine optionale Dependency mehr ist und dass die Rolldown-Binärdatei größer ist als esbuild und Rollup. Eine Verringerung der Installationsgröße steht jedoch auf dem Plan.
Alle weiteren Details zu Vite 8.0 finden sich im Vite-Blog und im Changelog.
(mai)
Entwicklung & Code
Databricks legt Genie Code vor: Ein KI-Agent soll Datenteams die Arbeit abnehmen
Databricks hat mit Genie Code einen KI-Agenten vorgestellt, der die Arbeit von Datenteams grundlegend verändern soll. Statt Entwicklern lediglich beim Schreiben von Code zu assistieren, übernimmt der Agent der Ankündigung zufolge eigenständig komplexe Aufgaben: den Aufbau von Datenpipelines, die Fehlerbehebung in Produktionssystemen, die Erstellung von Dashboards und die Wartung laufender Systeme. Laut Ali Ghodsi, Mitbegründer und CEO von Databricks, weist Genie Code den Weg hin zu „agentenbasierter Datenarbeit“.
Weiterlesen nach der Anzeige
![]()
Am 7. und 8. Oktober 2026 lädt die data2day Data Scientists, Data Engineers und Data Teams zur mittlerweile 13. Auflage der Konferenz ein. Bis zum 15. April können Expertinnen und Experten beim Call for Proposals noch ihre Vorschläge für Talks und Workshops einreichen.
Was Genie Code leisten soll
Genie Code ergänzt laut Ankündigung im Databricks-Blog die bestehende Genie-Produktfamilie, mit der Nutzer bereits per Chat-Interface auf ihre Unternehmensdaten zugreifen können. Im Vergleich mit herkömmlichen Coding-Agenten soll sich Genie Code vor allem durch seine tiefe Integration in die unternehmenseigene Dateninfrastruktur auszeichnen. Über den Unity Catalog von Databricks greift der Agent auf Metadaten, Datenherkunft, Nutzungsmuster und Governance-Richtlinien zu. Herkömmliche Coding-Agenten scheitern laut Databricks häufig an Datenaufgaben, weil ihnen genau dieser Kontext fehlt.
Genie Code ist dabei kein einzelnes Sprachmodell, sondern ein agentenbasiertes System, das Aufgaben über mehrere Modelle und Werkzeuge hinweg verteilt. Je nach Anforderung wählt das System der Ankündigung zufolge automatisch das passende Modell aus – ob proprietäres Frontier-Modell, Open-Source-Modell oder ein auf Databricks gehostetes Custom-Modell.
Die Funktionen erstrecken sich über den gesamten Daten- und ML-Lebenszyklus: Der Agent soll vollständige Machine-Learning-Workflows abwickeln können – vom Feature-Engineering über das Training und den Vergleich mehrerer Modelltypen bis hin zum Deployment auf Databricks Model Serving. Experimente werden dabei in MLflow protokolliert. Im Bereich Data Engineering erstellt Genie Code laut Hersteller produktionsreife Spark-Pipelines, berücksichtigt Unterschiede zwischen Staging- und Produktionsumgebungen und wendet automatisch Datenqualitätsprüfungen an. Darüber hinaus soll der Agent Dashboards mit wiederverwendbaren semantischen Definitionen generieren und mehrstufige Aufgaben autonom planen und ausführen können.
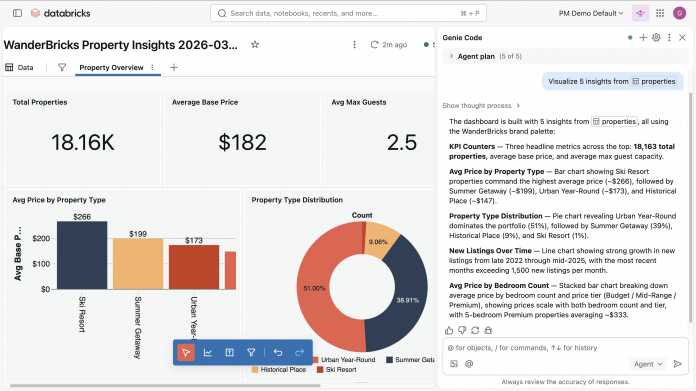
Genie Code soll Visualisierungen erstellen, Filter konfigurieren und Dashboard-Layouts organisieren – mit wiederverwendbaren semantischen Definitionen.
(Bild: Databricks)
Ein weiterer Aspekt ist die proaktive Überwachung: Genie Code soll Lakeflow-Pipelines und KI-Modelle im Hintergrund überwachen, Fehler triagieren und Anomalien untersuchen, bevor ein Mensch eingreifen muss. Sogenannte „Background Agents“ Agents“, die diese Überwachung dauerhaft im Hintergrund übernehmen, sind laut Databricks allerdings noch nicht verfügbar – sollen aber bald nachgereicht werden.
Weiterlesen nach der Anzeige
Der Agent verfügt über einen persistenten Speicher, der interne Anweisungen auf Basis vergangener Interaktionen und Coding-Präferenzen automatisch aktualisiert. So soll er mit der Zeit „besser werden“.
Übernahme von Quotient AI
Parallel zur Vorstellung von Genie Code gab Databricks die Übernahme von Quotient AI bekannt. Das Unternehmen ist auf die Bewertung und das verstärkende Lernen für KI-Agenten spezialisiert und war zuvor bereits an der Qualitätsverbesserung für GitHub Copilot beteiligt. Durch die Integration soll eine kontinuierliche Leistungsüberwachung direkt in Genie Code eingebettet werden: Quotient misst laut Databricks die Antwortqualität, erkennt Regressionen frühzeitig und lokalisiert Fehler – und speist diese Erkenntnisse in einen Verbesserungsprozess ein.
Lesen Sie auch
Verfügbarkeit und Erweiterbarkeit
Genie Code ist laut Databricks ab sofort allgemein verfügbar und direkt in Databricks-Workspaces integriert – in Notebooks, im SQL-Editor und im Lakeflow-Pipelines-Editor. Eine aufwendige Konfiguration sei nicht erforderlich.
Der Agent lässt sich über drei Wege erweitern: Über das Model Context Protocol (MCP) kann Genie Code mit externen Tools wie Jira, Confluence oder GitHub interagieren. Über sogenannte Agent Skills lassen sich domänenspezifische Fähigkeiten definieren, etwa für den Umgang mit personenbezogenen Daten oder unternehmensspezifische Validierungsframeworks. Und über den persistenten Speicher lernt der Agent aus vergangenen Interaktionen und passt sich an die Arbeitsweise des jeweiligen Teams an.
Die neuen Funktionen von Databricks reihen sich in einen branchenweiten Trend ein. Nahezu alle großen Anbieter setzen inzwischen auf agentenbasierte KI-Systeme, die komplexe Aufgaben autonom lösen sollen. Doch wie weit die tatsächlichen Fähigkeiten reichen, ist umstritten – insbesondere auch im Hinblick auf nicht-funktionale Anforderungen.
(map)
Entwicklung & Code
Neu in .NET 10.0 [14]: Starten einzelner C#-Dateien unter Linux und macOS
In meinem vorangegangenen Beitrag in dieser Serie zu .NET 10 habe ich beschrieben, wie man eine C#-Datei als File-based App unter Windows startet. Das geht auch unter Linux und macOS – sogar ohne dotnet voranstellen zu müssen.
Weiterlesen nach der Anzeige
Dr. Holger Schwichtenberg ist technischer Leiter des Expertennetzwerks www.IT-Visions.de, das mit 53 renommierten Experten zahlreiche mittlere und große Unternehmen durch Beratungen und Schulungen sowie bei der Softwareentwicklung unterstützt. Durch seine Auftritte auf zahlreichen nationalen und internationalen Fachkonferenzen sowie mehr als 90 Fachbücher und mehr als 1500 Fachartikel gehört Holger Schwichtenberg zu den bekanntesten Experten für .NET und Webtechniken in Deutschland.
Dazu verwendet man eine sogenannte Hash-Bang-Zeile oder Shebang-Zeile am Anfang der C#-Datei:
#!/usr/bin/env dotnet
Folgender Kommandozeilenbefehl sorgt dafür, dass die Datei ausführbar ist:
chmod +x Dateiname.cs
Ein Start ist dann ohne Erwähnung von „dotnet“ möglich:
Weiterlesen nach der Anzeige
./Dateiname.cs
Es ist unter Linux und macOS nicht einmal notwendig, dass die Datei auf .cs endet:

Unter Linux lässt sich eine C#-Datei ohne Erwähnung von dotnet starten (Abb. 1).
Ein solch direkter Start einer einzelnen C#-Datei, ohne „dotnet“ davor zu schreiben, ist unter Windows jedoch nicht möglich.
(rme)

Marktforscher: Speicherkrise hält bis mindestens Ende 2027 an

Motorola Signature im Test: Dünnes Top-Smartphone mit hervorragender Kamera

Top 10: Die besten Saugroboter im Test – Roborock vor Ecovacs, Eufy & Dyson

Schnelles Boot statt Bus und Bahn: Was sich von London und New York lernen lässt

Community Management und Zielgruppen-Analyse: Die besten Insights aus Blog und Podcast

Community Management zwischen Reichweite und Verantwortung
-
 Künstliche Intelligenzvor 2 Monaten
Künstliche Intelligenzvor 2 MonatenSchnelles Boot statt Bus und Bahn: Was sich von London und New York lernen lässt
-
 Social Mediavor 2 Wochen
Social Mediavor 2 WochenCommunity Management und Zielgruppen-Analyse: Die besten Insights aus Blog und Podcast
-
 Social Mediavor 1 Monat
Social Mediavor 1 MonatCommunity Management zwischen Reichweite und Verantwortung
-
Künstliche Intelligenzvor 3 Wochen
Top 10: Die beste kabellose Überwachungskamera im Test – Akku, WLAN, LTE & Solar
-

 Künstliche Intelligenzvor 3 Monaten
Künstliche Intelligenzvor 3 MonatenDigital Health: „Den meisten ist nicht klar, wie existenziell IT‑Sicherheit ist“
-

 Social Mediavor 3 Monaten
Social Mediavor 3 MonatenDie meistgehörten Gastfolgen 2025 im Feed & Fudder Podcast – Social Media, Recruiting und Karriere-Insights
-

 UX/UI & Webdesignvor 1 Monat
UX/UI & Webdesignvor 1 MonatEindrucksvolle neue Identity für White Ribbon › PAGE online
-

 Künstliche Intelligenzvor 3 Monaten
Künstliche Intelligenzvor 3 MonatenEMEC vereint Gezeitenkraft, Batteriespeicher und H₂-Produktion in einer Anlage

