Entwicklung & Code
Databricks legt Genie Code vor: Ein KI-Agent soll Datenteams die Arbeit abnehmen
Databricks hat mit Genie Code einen KI-Agenten vorgestellt, der die Arbeit von Datenteams grundlegend verändern soll. Statt Entwicklern lediglich beim Schreiben von Code zu assistieren, übernimmt der Agent der Ankündigung zufolge eigenständig komplexe Aufgaben: den Aufbau von Datenpipelines, die Fehlerbehebung in Produktionssystemen, die Erstellung von Dashboards und die Wartung laufender Systeme. Laut Ali Ghodsi, Mitbegründer und CEO von Databricks, weist Genie Code den Weg hin zu „agentenbasierter Datenarbeit“.
Weiterlesen nach der Anzeige

![]()
Am 7. und 8. Oktober 2026 lädt die data2day Data Scientists, Data Engineers und Data Teams zur mittlerweile 13. Auflage der Konferenz ein. Bis zum 15. April können Expertinnen und Experten beim Call for Proposals noch ihre Vorschläge für Talks und Workshops einreichen.
Was Genie Code leisten soll
Genie Code ergänzt laut Ankündigung im Databricks-Blog die bestehende Genie-Produktfamilie, mit der Nutzer bereits per Chat-Interface auf ihre Unternehmensdaten zugreifen können. Im Vergleich mit herkömmlichen Coding-Agenten soll sich Genie Code vor allem durch seine tiefe Integration in die unternehmenseigene Dateninfrastruktur auszeichnen. Über den Unity Catalog von Databricks greift der Agent auf Metadaten, Datenherkunft, Nutzungsmuster und Governance-Richtlinien zu. Herkömmliche Coding-Agenten scheitern laut Databricks häufig an Datenaufgaben, weil ihnen genau dieser Kontext fehlt.
Genie Code ist dabei kein einzelnes Sprachmodell, sondern ein agentenbasiertes System, das Aufgaben über mehrere Modelle und Werkzeuge hinweg verteilt. Je nach Anforderung wählt das System der Ankündigung zufolge automatisch das passende Modell aus – ob proprietäres Frontier-Modell, Open-Source-Modell oder ein auf Databricks gehostetes Custom-Modell.
Die Funktionen erstrecken sich über den gesamten Daten- und ML-Lebenszyklus: Der Agent soll vollständige Machine-Learning-Workflows abwickeln können – vom Feature-Engineering über das Training und den Vergleich mehrerer Modelltypen bis hin zum Deployment auf Databricks Model Serving. Experimente werden dabei in MLflow protokolliert. Im Bereich Data Engineering erstellt Genie Code laut Hersteller produktionsreife Spark-Pipelines, berücksichtigt Unterschiede zwischen Staging- und Produktionsumgebungen und wendet automatisch Datenqualitätsprüfungen an. Darüber hinaus soll der Agent Dashboards mit wiederverwendbaren semantischen Definitionen generieren und mehrstufige Aufgaben autonom planen und ausführen können.
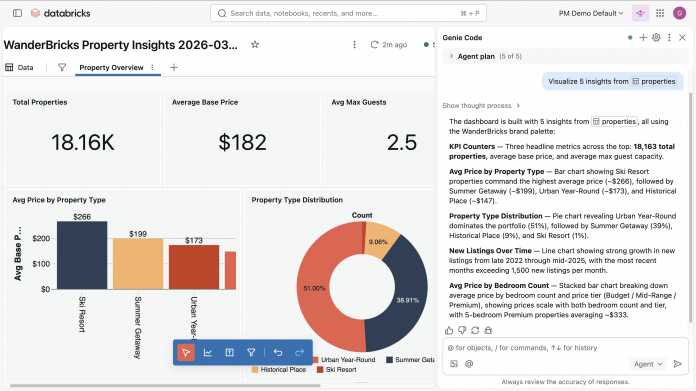
Genie Code soll Visualisierungen erstellen, Filter konfigurieren und Dashboard-Layouts organisieren – mit wiederverwendbaren semantischen Definitionen.
(Bild: Databricks)
Ein weiterer Aspekt ist die proaktive Überwachung: Genie Code soll Lakeflow-Pipelines und KI-Modelle im Hintergrund überwachen, Fehler triagieren und Anomalien untersuchen, bevor ein Mensch eingreifen muss. Sogenannte „Background Agents“ Agents“, die diese Überwachung dauerhaft im Hintergrund übernehmen, sind laut Databricks allerdings noch nicht verfügbar – sollen aber bald nachgereicht werden.
Weiterlesen nach der Anzeige
Der Agent verfügt über einen persistenten Speicher, der interne Anweisungen auf Basis vergangener Interaktionen und Coding-Präferenzen automatisch aktualisiert. So soll er mit der Zeit „besser werden“.
Übernahme von Quotient AI
Parallel zur Vorstellung von Genie Code gab Databricks die Übernahme von Quotient AI bekannt. Das Unternehmen ist auf die Bewertung und das verstärkende Lernen für KI-Agenten spezialisiert und war zuvor bereits an der Qualitätsverbesserung für GitHub Copilot beteiligt. Durch die Integration soll eine kontinuierliche Leistungsüberwachung direkt in Genie Code eingebettet werden: Quotient misst laut Databricks die Antwortqualität, erkennt Regressionen frühzeitig und lokalisiert Fehler – und speist diese Erkenntnisse in einen Verbesserungsprozess ein.
Lesen Sie auch
Verfügbarkeit und Erweiterbarkeit
Genie Code ist laut Databricks ab sofort allgemein verfügbar und direkt in Databricks-Workspaces integriert – in Notebooks, im SQL-Editor und im Lakeflow-Pipelines-Editor. Eine aufwendige Konfiguration sei nicht erforderlich.
Der Agent lässt sich über drei Wege erweitern: Über das Model Context Protocol (MCP) kann Genie Code mit externen Tools wie Jira, Confluence oder GitHub interagieren. Über sogenannte Agent Skills lassen sich domänenspezifische Fähigkeiten definieren, etwa für den Umgang mit personenbezogenen Daten oder unternehmensspezifische Validierungsframeworks. Und über den persistenten Speicher lernt der Agent aus vergangenen Interaktionen und passt sich an die Arbeitsweise des jeweiligen Teams an.
Die neuen Funktionen von Databricks reihen sich in einen branchenweiten Trend ein. Nahezu alle großen Anbieter setzen inzwischen auf agentenbasierte KI-Systeme, die komplexe Aufgaben autonom lösen sollen. Doch wie weit die tatsächlichen Fähigkeiten reichen, ist umstritten – insbesondere auch im Hinblick auf nicht-funktionale Anforderungen.
(map)











Entwicklung & Code
.NET 11.0 Preview 5 vereinfacht das statische serverseitige Rendering in Blazor
Die fünfte Vorschauversion der kommenden .NET-Version 11.0 ist gestern Abend erschienen. Parallel dazu gab es auch die Version 11904.113 der für .NET 11.0 notwendigen Insiders-Variante von Visual Studio 2026. Alternativ ist eine Arbeit mit Visual Studio Code und dem im SDK mitgelieferten Kommandozeilencompiler möglich.
Weiterlesen nach der Anzeige

Dr. Holger Schwichtenberg hat Fachbücher zu .NET 10.0, C# 14.0, Blazor 10.0 und Entity Framework Core 10.0 veröffentlicht. Er arbeitet als Berater und Trainer bei www.IT-Visions.de.
(Bild: King / stock.adobe.com)

Das ist neu in .NET 11.0: Dr. Holger Schwichtenberg und weitere Experten präsentieren am 17. November 2026 auf der Online-Konferenz betterCode() .NET 11.0 die Änderungen für Entwicklerinnen und Entwickler in .NET SDK, C# 15.0 und mehr. Bis zur Veröffentlichung des Programms sind vergünstigte Blind-Bird-Tickets verfügbar.
Sortieren und Paging beim bei Blazor Static SSR
Bei dem in .NET 8.0 eingeführten statischen serverseitigen Rendering (Blazor Static SSR), das als eine Ablösung für ASP.NET Core MVC und ASP.NET Core Razor Pages verstanden werden kann, funktioniert das Tabellensteuerelement QuickGrid, das Microsoft im NuGet-Paket Microsoft.AspNetCore.Components.QuickGrid liefert, bisher nur eingeschränkt. Lediglich bei den interaktiven Varianten Blazor Server und Blazor WebAssembly sowie Blazor Hybrid stehen alle Funktionen des QuickGrid-Steuerelements zur Verfügung.
Seit Blazor 11.0 Preview 5 ist es möglich, dass das QuickGrid-Steuerelement auch in statisch serverseitig gerenderten Blazor-Seiten sortieren und blättern kann. Wenn das Grid nicht interaktiv ist, werden die sortierbaren Spaltenüberschriften und die Seitennavigation als erweiterte HTML-Formulare gerendert, die ihren Zustand über URL-Abfrageparameter (Query String) übertragen. Lädt eine Nutzerin oder ein Nutzer die Seite neu oder kopiert die URL und öffnet sie erneut, bleiben Sortierung und aktuelle Seite erhalten. Dadurch lassen sich diese Zustände einfach per URL teilen oder als Lesezeichen speichern.
Lesen Sie auch
Im Schnelltest zeigte sich: In Zusammenarbeit mit Entity Framework Core als Datenquelle mit Paging in der Datenbank erzeugt das Blättern einen Laufzeitfehler: „InvalidOperationException: A second operation was started on this context instance before a previous operation completed. This is usually caused by different threads concurrently using the same instance of DbContext.“
Weiterlesen nach der Anzeige
Das folgende Beispiel funktioniert aktuell nur korrekt, wenn es immer alle Datensätze lädt und das Paging im RAM ausführt via
private List
@page "/QuickGridSSR"
@using Microsoft.AspNetCore.Components.QuickGrid
@using Microsoft.EntityFrameworkCore
@inject IDbContextFactory DbFactory
@implements IAsyncDisposable
QuickGrid SSR
p.FlightNo)" Title="FlugNr" Sortable="true" />
p.Departure)" Title="Abflugort" Sortable="true">
p.Destination)" Title="Zielort" Sortable="true">
p.FlightDate)" Title="Datum" Format="dd.MM.yyyy" Sortable="true" />
p.FreeSeats)" Title="Freie Plätze" />
flightSet => context.Flights;
protected override void OnInitialized()
{
context = DbFactory.CreateDbContext();
}
// IAsyncDisposable implementieren, um den DbContext korrekt zu verwerfen, wenn die Komponente nicht mehr benötigt wird
public async ValueTask DisposeAsync()
{
if (context != null)
{
await context.DisposeAsync();
}
}
}
Listing: QuickGrid mit Blazor Static SSR mit Zugriff auf eine Datenbank via Entity Framework Core

Das vorherige Listing zur Laufzeit (Seite 1)
Vereinfachte Session-Handhabung
Blazor Static SSR unterstützt seit der Einführung in .NET 8.0 die in ASP.NET Core verfügbaren serverseitigen Sessions (Cookie .AspNetCore.Session mit Session-ID, Speicherung der Daten im RAM oder einem persistenten Speicher) zur Datenübergabe zwischen Seiten. Bisher mussten Entwicklerinnen und Entwickler dafür das Session-Objekt im HttpContext-Objekt verwenden und komplexe Objekte selbst per JSON serialisieren:
@inject IHttpContextAccessor HttpContextAccessor
…
var HttpContext = HttpContextAccessor.HttpContext;
var json = System.Text.Json.JsonSerializer.Serialize(regForm);
HttpContext.Session.SetString("Formulardaten", json);
beziehungsweise
BO.RegistrationData daten =
System.Text.Json.JsonSerializer.Deserialize(
HttpContext.Session.GetString("Formulardaten") ?? string.Empty);
In .NET 11.0 Preview 5 hat Microsoft nun die Annotation [SupplyParameterFromSession] eingeführt, die die Handhabung von Session-Variablen genauso einfach macht wie von Query-String-Parametern [SupplyParameterFromQuery], Form-Daten [SupplyParameterFromForm] und TempData-Werten [SupplyParameterFromTempData], wobei letztere Annotation erst in .NET 11.0 Preview 4 eingeführt wurde.
Entwicklerinnen und Entwickler annotieren in einer Seite eine oder mehrere Properties mit der Annotation [SupplyParameterFromSession]. Dabei sind einfache und komplexe Datentypen möglich, während [SupplyParameterFromTempData] auch in Preview 5 weiterhin nur mit einfachen Datentypen funktioniert:
[SupplyParameterFromSession]
public string Message { get; set; }
[SupplyParameterFromSession]
public BO.RegistrationData RegData { get; set; }
Session-Werte werden dabei automatisch mit System.Text.Json in JSON serialisiert.
Analoge Properties deklarieren Entwicklerinnen und Entwickler in den Folgeseiten und können dann auf die Werte ohne weiteres Zutun zugreifen. Voraussetzung ist wie bisher, dass in der Startseite die Sessions aktiviert wurden:
builder.Services.AddDistributedMemoryCache();
builder.Services.AddSession();
…
app.UseSession();
Entwicklung & Code
OpenProject 17.5 führt projektbezogene IDs ein
Mit OpenProject 17.5 können Anwender erstmals zwischen zwei Arten von Kennungen für ihre Arbeitspakete wählen: einer fortlaufenden Nummerierung über die gesamte Installation oder projektbezogenen Kennungen. Vor allem große Organisationen und Teams, die von Atlassian Jira umsteigen, sollen davon profitieren. Daneben erweitert die Version die Möglichkeiten zur Anpassung agiler Backlogs und bringt kleinere Verbesserungen für Dokumentation und Besprechungsplanung.
Weiterlesen nach der Anzeige
OpenProject ist eine quelloffene Anwendung für Projektmanagement und Zusammenarbeit. Die Software unterstützt klassische und agile Projektmethoden und bietet unter anderem Aufgaben- und Ressourcenverwaltung, Gantt-Diagramme, Scrum-Backlogs sowie Funktionen für Dokumentation und Team-Arbeit. Sie läuft wahlweise als Cloud-Dienst oder im Eigenbetrieb.
Projektbezug direkt in der Kennung
Die wichtigste Neuerung von OpenProject 17.5 sind projektspezifische Arbeitspaket-Kennungen, die zunächst als Beta vorliegen. Bislang vergab OpenProject die IDs ausschließlich über eine globale Nummernfolge für die gesamte Installation. Ein Arbeitspaket erhielt etwa die Kennung „#2385“ – unabhängig davon, zu welchem Projekt es gehörte.
Künftig können Administratoren stattdessen projektbezogene Kennungen aktivieren. Diese ergänzen die ID um ein Projektkürzel und orientieren sich damit an einem Schema, das viele Anwender bereits von Jira kennen. Aus einer generischen Nummer wird so eine Kennung wie „ERP-2385“ oder „APP-4711“. Zu welchem Projekt ein Arbeitspaket gehört, lässt sich auf diese Weise sofort erkennen – das erleichtert die Orientierung in Umgebungen mit vielen Projekten.
Bestehende IDs bleiben gültig
Nach Angaben des Herstellers funktionieren bestehende numerische IDs und Verweise auch nach einer Umstellung weiter. Alte Links, Lesezeichen und Referenzen sollen weiterhin auf die jeweiligen Arbeitspakete zeigen. Die Wahl zwischen numerischen und projektspezifischen Kennungen gilt allerdings für die gesamte Installation und damit für alle Projekte.
Ein wesentlicher Grund für die neuen Kennungen sind Migrationen von Jira. Unternehmen können ihre bisherigen Jira-Issue-Keys beibehalten, wenn sie ihre Projekte nach OpenProject übertragen. So lassen sich etablierte Namenskonventionen und Referenzen in Dokumentationen, Integrationen oder Automatisierungen weiternutzen. Der Jira-Migrator übernimmt jetzt zusätzlich Fälligkeitstermine sowie geschätzte und verbleibende Arbeitsstunden.
Weiterlesen nach der Anzeige
Mehr Kontrolle über Backlogs
Auch die agilen Planungsfunktionen hat OpenProject ausgebaut. Administratoren können nun einzelne Arbeitspakettypen gezielt aus Backlogs ausschließen. So sehen Teams bei der Sprint-Planung nur die Aufgaben, die für sie tatsächlich relevant sind.
Zudem hat OpenProject die Sprint- und Kartenansichten überarbeitet. Informationen wie übergeordnete Arbeitspakete, Prioritäten, Story Points, Zuständigkeiten und der Sprint-Status lassen sich dadurch schneller erfassen.
Kleinere Neuerungen bei Dokumentation und Meetings
Weitere Änderungen betreffen die Dokumentation und Besprechungsplanung. Verweise auf Arbeitspakete lassen sich nun direkt in den Fließtext einbetten. In Eingabefeldern auf Basis des CKEditor reichert OpenProject solche Verweise schon während der Eingabe mit Zusatzinformationen an.
Wiederkehrende Besprechungen unterstützen außerdem neue monatliche Muster wie den ersten Montag oder den letzten Freitag eines Monats. Ändert sich ein Termin, fasst das System mehrere Änderungen in einer Benachrichtigung zusammen und reduziert so die Zahl der E-Mails.
Die Cloud-Anwendungen von OpenProject erhalten das Update seit dem 10. Juni 2026 automatisch; für selbst betriebene Instanzen stehen Anleitungen für Paket- und Docker-Installationen bereit. Alle Details listet OpenProject in den Release Notes zu Version 17.5 auf.
Lesen Sie auch
Siehe auch:
(fo)
Entwicklung & Code
uBlock Origin: Die letzten Chrome-Workarounds fallen
Google entfernt in Chromium nun auch die letzten internen Schalter, mit denen sich Erweiterungen auf Basis von Manifest V2 (MV2) bislang noch am Leben halten ließen. Wie aus einer Mitteilung des Chrome-Teams an die W3C WebExtensions Community Group hervorgeht, hat Chromium 150 das Flag kExtensionManifestV2Disabled verloren. Mit Chromium 151 sollen die Optionen ExtensionManifestV2Unsupported, ExtensionManifestV2Availability und voraussichtlich AllowLegacyMV2Extensions folgen. Damit verlieren auch die bekannten Umgehungslösungen, mit denen sich die klassische Vollversion des Werbe- und Inhaltsblockers uBlock Origin in Chrome erzwingen ließ, schrittweise ihre technische Grundlage.
Weiterlesen nach der Anzeige
Was hinter Manifest V2 und V3 steckt
Manifest V2 und sein Nachfolger Manifest V3 (MV3) beschreiben, welche Schnittstellen Browser-Erweiterungen nutzen dürfen. Die klassische Version von uBlock Origin basiert weiterhin auf MV2. Google startete den Übergang zu MV3 in Chrome ab Oktober 2024 schrittweise und schloss ihn mit Chrome 138 im Juli 2025 endgültig ab, wodurch die Vollversion von uBlock Origin für Chrome-Nutzer offiziell nicht mehr verfügbar ist.
Kern der Umstellung ist der Ersatz der mächtigen webRequest-API durch das eingeschränktere declarativeNetRequest-Modell, was Google mit Sicherheits-, Stabilitäts- und Performancevorteilen begründet. Für MV3 existiert mit uBlock Origin Lite eine eigenständige, bewusst funktionsreduzierte Variante des Blockers; sie stößt jedoch an die Grenzen bei den Filterregeln in declarativeNetRequest und bietet nicht die dynamischen Filterfähigkeiten der Vollversion.
Vom Policy-Ende zur Abschaltung im Code
Die jetzt diskutierten Änderungen markieren das Ende eines mehrstufigen Abschaltprozesses. In einem ersten Schritt hatte Google den klassischen MV2-Erweiterungen bereits den offiziellen Boden entzogen: Laut der Chrome-Dokumentation zur MV2-Abschaltung ist Chrome 138 die letzte Version, die MV2-Erweiterungen in Verbindung mit der Enterprise-Richtlinie ExtensionManifestV2Availability unterstützt. Mit Chrome 139 wurde diese Richtlinie entfernt. Die Policy war primär für verwaltete Unternehmensumgebungen gedacht, wurde aber auch von technisch versierten Anwendern genutzt, um die Nutzung älterer Erweiterungen über den ursprünglich vorgesehenen Zeitraum hinaus zu verlängern.
Genau auf dieser offiziellen Richtlinie beruhte die häufig als „Registry-Hack“ bezeichnete Umgehungslösung. Unter Windows ließ sich ExtensionManifestV2Availability über Gruppenrichtlinien oder Registry-Einträge setzen und die Abschaltung von MV2 so zeitweise aufschieben. Google hatte diese Möglichkeit jedoch von Anfang an als befristete Übergangsmaßnahme beschrieben: Unternehmen, die die Policy nutzten, erhielten laut Chrome-Entwicklerblog ein zusätzliches Jahr bis Juni 2025 zur Migration. Mit dem Wegfall der Richtlinie ab Chrome 139 verlor dieser Weg seine Grundlage.
Die nun an die WebExtensions Community Group gemeldeten Schritte setzen tiefer an: Statt nur die Verfügbarkeit über Policies zu steuern, entfernt das Chrome-Team die zugrunde liegenden Feature-Flags und Codepfade. Begleitend nennen Google-Entwickler in der Diskussion technische Komplexität, technische Schulden und Sicherheitsrisiken – darunter MV2-spezifische Bugs – als Gründe für die Entfernung der MV2-Unterstützung.
Weiterlesen nach der Anzeige
Wo die Vollversion noch läuft
An der Plattformfrage selbst ändert sich nichts: Die klassische Version von uBlock Origin wird vom Entwickler weiterhin als MV2-Erweiterung gepflegt, eine vollwertige MV3-Portierung existiert nicht. Für Chromium-basierte Browser verweist das Projekt stattdessen auf uBlock Origin Lite. Wer den vollen Funktionsumfang behalten will, ist laut Projektangaben auf Browser angewiesen, die MV2 weiterhin zulassen.
Die Vollversion läuft weiterhin auf Firefox und auf Brave. Mozilla unterstützt MV2 und MV3 ausdrücklich parallel. Die Erweiterungen für Firefox sind von der Chrome-Abschaltung nicht betroffen, der Browser behält die blockierende webRequest-API, wie auch eine Übersicht zur MV3-Auswirkung festhält. Brave wiederum unterstützt MV2 browser-seitig prinzipiell (force-enabled): Laut Brave-Blog hostet Brave gezielt vier Extensions (AdGuard, NoScript, uBlock Origin, uMatrix) selbst.
Bei den übrigen Chromium-Browsern ist der Stand uneinheitlich. Opera unterstützt nach eigenen Angaben weiterhin bestehende Manifest‑V2‑Erweiterungen und will das so lange wie möglich fortsetzen. Bei Edge ist die Lage weiterhin uneinheitlich: Microsoft dokumentiert die Abschaffung von Manifest V2, hat aber die konkrete Zeitlinie lange offen gelassen; ob und wie lange uBlock Origin in voller Version unterstützt bleibt, ist damit nicht eindeutig festgelegt. Ob und wie lange weitere Browser-Projekte eigene Kompatibilitätslösungen aufrechterhalten, dürfte davon abhängen, in welchem Umfang sie bereit sind, von Googles Chromium-Basis abzuweichen und die entsprechenden Komponenten selbst weiterzupflegen – so wie es Brave mit seinen hartkodierten Ausnahmen vormacht.
Welche Optionen Nutzern bleiben
Für Nutzer markiert die Entfernung der MV2-Flags in Chromium 150 und 151 damit die letzte Phase einer seit Jahren laufenden Umstellung. Während Google die alte Erweiterungsplattform endgültig auslaufen lässt, bleiben im Wesentlichen drei Alternativen: der Wechsel auf MV3-Alternativen wie uBlock Origin Lite, der Umstieg auf Brave mit seiner weiterhin aktiven MV2-Unterstützung oder der Wechsel zu Firefox mit eigenem Plattformmodell und voller webRequest-Unterstützung.
(fo)

Debatte um mögliche Entlastung nach Ende des Tankrabatts

Abstand zu Anthropic zu groß: OpenAI erwägt Preissenkung, um Kundenzahl zu erhöhen

Was kommt nach dem Kapitalismus? Die Antworten eines Startup-Gründers

Mähroboter ohne Begrenzungsdraht für Gärten mit bis zu 300 m²

iPhone Fold Leak: Apple spart sich wohl iPad‑Multitasking

JBL Bar 1300MK2 im Test: Soundbar mit Dolby Atmos, starkem Bass und Akku‑Rears
-
 Apps & Mobile Entwicklungvor 3 Monaten
Apps & Mobile Entwicklungvor 3 MonatenMähroboter ohne Begrenzungsdraht für Gärten mit bis zu 300 m²
-
 Künstliche Intelligenzvor 3 Monaten
Künstliche Intelligenzvor 3 MonateniPhone Fold Leak: Apple spart sich wohl iPad‑Multitasking
-
Künstliche Intelligenzvor 3 Monaten
JBL Bar 1300MK2 im Test: Soundbar mit Dolby Atmos, starkem Bass und Akku‑Rears
-

 Künstliche Intelligenzvor 3 Monaten
Künstliche Intelligenzvor 3 MonatenOscars 2026: Was die heise‑Leser anders entschieden hätten
-

 Social Mediavor 3 Monaten
Social Mediavor 3 MonatenVon Kennzeichnung bis Plattformpflichten: Was die EU-Regeln für Influencer Marketing bedeuten – Katy Link im AllSocial Interview
-

 Künstliche Intelligenzvor 3 Monaten
Künstliche Intelligenzvor 3 MonatenEmpfehlungsalgorithmen bei TikTok erklärt: Die Maschine hinter dem Endlos‑Feed
-
Künstliche Intelligenzvor 3 Monaten
Top 10: Die besten Wireless‑Adapter für Carplay im Test – iPhone kabellos nutzen
-

 Künstliche Intelligenzvor 2 Monaten
Künstliche Intelligenzvor 2 MonatenWeitere Entlassungswelle bei Disney: Bis zu 1000 Mitarbeiter betroffen


