Entwicklung & Code
Die vier Apokalyptischen Reiter der Aufwandsschätzung von Cloud-Legacy-Projekten
Viele ältere Anwendungen profitieren deutlich von einer Modernisierung zu einer Cloud‑Native‑Architektur. Dieser Ansatz löst bestehende Probleme durch neue Technologien, bietet Entwicklerinnen und Entwicklern eine moderne Arbeitsumgebung und eröffnet neue Absatzchancen als Software‑as‑a‑Service. Verschiedenen Studien zufolge ist Modernisierung bei einer Mehrheit der Unternehmen unvermeidlich, weil deren Altanwendungen geschäftskritisch sind (siehe Lünendonk: Unternehmen ringen mit der IT-Modernisierung und Thinkwise: Legacy-Modernisierung – Warnsignale ernst nehmen). Daher wächst das Interesse, bestehende Kernsysteme zu modernisieren und fit für die Cloud zu machen.
Weiterlesen nach der Anzeige


Thomas Zühlke ist Cloud-Architekt bei adesso SE mit fast 20 Jahren Berufserfahrung, davon die letzten neun Jahre ausschließlich im Cloud-Umfeld. Er berät Kunden bei der Adaption der Azure Cloud, erstellt Roadmaps, entwirft Migrationsstrategie und Modernisierungskonzepte. Trotz vorwiegender Konzeptionsarbeit begeistert er sich weiterhin für die technische Umsetzung der entworfenen Lösungen.
Die DOAG Cloud Native Community (DCNC) vernetzt Interessierte und Anwender aus Deutschland, Österreich und der Schweiz für den Informations- und Erfahrungsaustausch zu Themen rund um Cloud Native. Gemeinsam organisieren sie überregionale Veranstaltungen wie die CloudLand („Das Cloud Native Festival“), die sich wichtigen Themen widmet: AI & ML, DevOps, Compute / Storage / Network, Data & BI, Security & Compliance, Public Cloud, Architecture, Organization & Culture, Customer Stories, Sovereign Cloud und Cloud-native Software Engineering.
Im Rahmen der Cloud Native Kolumne beleuchten Expertinnen und Experten aus der Community regelmäßig die verschiedensten Trends und Aspekte Cloud-nativer Softwareentwicklung und -bereitstellung.
Vorbereitung: Konzeptionsphase
Einer Modernisierung geht meist ein Konzept voraus. Dieses analysiert alte und neue Anforderungen und beschreibt, wie sie umgesetzt werden sollen. Es benennt betriebliche Anpassungen und konzipiert neue Teamstrukturen. Auf dieser Basis erstellt das Unternehmen Schulungspläne für die beteiligten Mitarbeitenden. Alle Änderungen fließen in eine Roadmap ein, die sowohl verpflichtende als auch optionale Schritte mit ihren jeweiligen Kosten abbildet.
Frühe Aufwandsschätzung
Oft ist schon vor dem Modernisierungskonzept eine erste Aufwandsschätzung nötig, etwa für die Budgetplanung. Diese Schätzung ist schwierig, weil Anwendungen komplex sind und sich konkrete Änderungen erst nach einer Analyse bestimmen lassen. Manchmal stehen mehrere Systeme zur Auswahl. Dann müssen Architektinnen und Architekten den geeignetsten Kandidaten identifizieren und eine grobe Kostenschätzung für die kommenden Jahre entwickeln. Unternehmen erwarten in dieser Phase häufig eine schnelle Einschätzung mit nachvollziehbaren Zahlen – quasi ein fundiertes Bauchgefühl.
Weiterlesen nach der Anzeige
Zur Veranschaulichung dient ein reales Beispielprojekt. Das Produkt läuft seit acht Jahren und umfasst ein Team aus einem Frontend-Entwickler, einem Backend-Entwickler und einem Architekten, die sich um die Weiterentwicklung kümmern – alle in Vollzeit. Pro Jahr entstehen rund 600 Personentage an Aufwand; über acht Jahre summiert sich das auf 4800 Personentage. Das Team war zu Beginn möglicherweise größer, dieser Effekt ist über die lange Laufzeit jedoch vernachlässigbar. Der Projektleiter bzw. Product Owner ist in dieser Betrachtung nicht enthalten, da der Fokus für die Berechnung auf den Entwicklungsaufwänden liegen soll.
Aufwandsschätzung Reifegrad 1 – Faustformel
Erfahrungen der vergangenen Jahre zeigen im Allgemeinen, dass für eine minimale Modernisierung und Cloud‑Readiness etwa 10 bis 30 Prozent der ursprünglichen Entwicklungskosten anfallen. Dieser Aufwand umfasst Änderungen an Konfigurationen, den Austausch einzelner Komponenten durch höherwertige Dienste sowie die Anpassung von Querschnittsthemen. Er gilt nicht für reine Lift‑and‑Shift‑Szenarien oder vollständige Neuimplementierungen, da jene deutlich weniger beziehungsweise diese erheblich mehr Aufwand erfordern.
Die Berechnungen setzen voraus, dass das bestehende Team die Modernisierung eigenständig durchführt – ohne externe Unterstützung und zusätzlichen Schulungsbedarf. Für das Beispielprodukt ergibt sich ein Aufwand zwischen 480 und 1440 Personentagen. Diese Spanne ist groß, insbesondere bei älteren Produkten. Je länger ein System läuft, desto größer ist der Anteil der Wartungsphase, die keine neuen Funktionen schafft und dadurch die ursprünglichen Entwicklungsaufwände verwässert. Zudem bleibt unklar, welche Softwareteile konkret angepasst oder modernisiert werden müssen. Der nächste Abschnitt zeigt, wie sich diese Werte genauer herleiten lassen, und nennt die wichtigsten Kostentreiber.
Aufwandsschätzung Reifegrad 2 – Entwickleraufwände
Mehrere Studien haben untersucht, wie sich Ressourcen im Lebenszyklus eines Softwareprojekts verteilen. Sie zeigen ähnliche Ergebnisse, setzen jedoch unterschiedliche Schwerpunkte. Ein bekanntes Beispiel ist „The Staged Model of the Software Lifecycle: A New Perspective on Software Evolution“.
Es gliedert den Lebenszyklus in folgende Phasen (siehe Abbildung unten):
- Initial Development
- Evolution
- Servicing
- Phase‑Out
- Close‑Down
Das Modell unterscheidet zwischen aktiver (Evolution) und passiver Wartung (Servicing). Aktive Wartung gilt als Entwicklungsaufwand, da sie Erweiterungen durch neue Features, regulatorische Anforderungen oder Mandantenanpassungen umfasst. Passive Wartung betrifft ausschließlich erhaltende Maßnahmen wie Bugfixes oder Bibliotheksupdates und fließt nicht in die Modernisierungskosten ein. Weitergehende Informationen zu Modellen, die unter anderem auch die mit der Zeit steigenden Wartungskosten berücksichtigen, finden sich in: How much does software development cost? In-depth guide for 2025; Lebenszyklus-Kosten von IT Produkten und IT Project Outsourcing In 2025 – A Comprehensive Guide.
Aus der Erfahrung haben sich folgende, in der Abbildung hervorgehobenen Werte bewährt:
- Initial Development ≈ 15 Prozent
- Evolution ≈ 25 Prozent
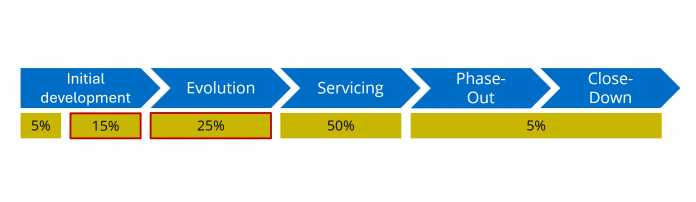
Verteilung von Aufwänden auf die Phasen des Software-Lebenszyklus
Die Phasen Phase‑Out, Close‑Down und Servicing bleiben unberücksichtigt, da sie keine relevante Entwicklungstätigkeit enthalten. Der Entwicklungsanteil der Software beträgt (inklusive etwa 5 Prozent für die zu Beginn häufig erhöhte Lernkurve und eventuell benötigte Proof-of-Concepts) somit 40 Prozent von 4800 Personentagen, also 1920 Personentage. Davon entfallen 10 bis 30 Prozent auf die Modernisierung, also 192 bis 576 Personentage. Diese Werte sind realistisch, doch bleibt die Bandbreite groß. Um sie zu verfeinern, müssen die größten Aufwandstreiber identifiziert werden.
(Bild: cloudland.org)

Vom 19. bis 22. Mai 2026 finden Interessierte beim Cloud Native Festival CloudLand ein prall gefülltes Line-up mit mehr als 200 Highlights – darunter die beiden neuen Themenbereiche „Open Source“ und „Platform Engineering“. Besucherinnen und Besucher erwartet eine bunte Mischung überwiegend interaktiver Sessions, Hands-ons und Workshops, begleitet von einem umfassenden Rahmenprogramm, das zum aktiven Mitmachen einlädt.
Tickets für das Festival und Unterkünfte im Heide Park Soltau lassen sich über die Festival-Homepage buchen.
Aufwandsschätzung Reifegrad 3 – Apokalyptische Reiter
Je gründlicher die Analyse einer Modernisierung, desto genauer wird die Schätzung. Für eine solide Näherung genügt es, die zentralen Aufwandstreiber zu erkennen und zu prüfen, ob sie im Projekt relevant sind. Einige Basisbausteine müssen bei jeder Modernisierung angepasst werden, etwa CI/CD‑Pipelines oder Logging‑Mechanismen. Solche Arbeiten lassen sich pauschal mit rund 5 Prozent der Entwicklungsaufwände veranschlagen.
Daneben existieren optionale Basisbausteine, die den Aufwand erheblich steigern können. Diese entscheidenden Faktoren werden sinnbildlich als apokalyptische Reiter bezeichnet. Jeder dieser vier Treiber kann mit etwa 5 Prozent der Entwickleraufwände bewertet werden:
Architektur der Geschäftslogik
Häufig erfolgt eine Umstellung auf Microservices oder Self‑Contained Systems. Dadurch entstehen neue System‑Schnitte, Kommunikationswege und Skalierungsmechanismen, während die Business‑Logik selbst unverändert bleibt.
Architektur des Speicherkonzepts
Ein Wechsel von relationalen Datenbanken zu Dokumenten‑ oder Graphenmodellen oder die Einführung von Event Sourcing/CQRS erfordert umfassende Anpassungen an Persistenz, Migration und Nachrichtenverarbeitung.
Mandantenkonzept
SaaS‑Lösungen verlangen Multi‑Tenant‑Fähigkeit. Altanwendungen nutzen häufig getrennte Installationen je Mandant und sind nicht auf zentrale Datenhaltung oder gemeinsame Berechtigungsmodelle ausgelegt.
Authentifizierung und Autorisierung (AuthN/AuthZ)
Viele Systeme verwenden noch eine eigene Benutzerverwaltung oder veraltete Identity‑Provider. Die Migration zu Cloud‑Providern (z. B. Azure Entra ID) sowie die Einführung verschlüsselter Kommunikation und zentraler Token‑Validierung erhöhen den Aufwand deutlich.
Selten umfasst die Modernisierung zusätzlich ein Redesign des GUI‑Konzepts oder den Wechsel zu einem neuen Frontend‑Framework. Auch dafür kann ein pauschaler Mehraufwand von 5 Prozent angesetzt werden. Darüber hinaus entstehen gelegentlich parallele Projekte für Infrastruktur und Governance (Landing Zones), um die modernisierte Lösung sicher betreiben zu können.
Im Beispielprojekt greifen drei dieser Reiter: die Umstellung auf Microservices (+ 5 %), die Einführung eines Mandantenkonzepts (+ 5 %) und die Modernisierung des Security‑Konzepts (+ 5 %). Zusammen mit der Basisanpassung ergibt sich ein Gesamtaufwand von 20 Prozent der 1920 Entwicklungs‑Personentage, also etwa 384 Personentage.
Fazit: Eine gute Schätzung ersetzt kein Konzept – aber sie zeigt, wo sich Aufwand wirklich lohnt
Die Kombination aus Entwicklungsaufwandsanalyse und Bewertung einzelner Änderungsbausteine liefert eine ausreichend präzise Schätzung. Da genaue Prozentwerte schwer festzulegen sind, empfiehlt sich eine Unterteilung in Fünf‑Prozent‑Schritte, sofern keine detaillierteren Informationen vorliegen. Eine Schätzung bleibt jedoch stets eine Annäherung.
Vor jeder Modernisierung ist deshalb ein detailliertes Konzept unverzichtbar. Es identifiziert obligatorische und optionale Änderungen, bewertet deren Aufwand und legt einen konkreten Umsetzungsplan fest. Fehlt dieses Konzept, scheitert die Modernisierung oft schon vor dem Projektstart.
(map)











Entwicklung & Code
comments_outline_white
Weiterlesen nach der Anzeige
Im Herbst 2025 erschien mit dem OpenJDK 25 die aktuelle Version, für die viele Hersteller einen Long-Term-Support (LTS) anbieten. Viele Unternehmen nutzen solche Releases als Stabilitätsanker für Migrationen und langfristige Planung. Java 26 ist dagegen wieder ein reguläres Halbjahres-Release und damit ein Schritt in einer kontinuierlichen Evolution der Plattform: Sprache, Runtime und Standardbibliothek werden systematisch modernisiert, ohne die Stabilität und Abwärtskompatibilität zu gefährden, für die Java seit Jahrzehnten bekannt ist.

Falk Sippach ist bei der embarc Software Consulting GmbH als Softwarearchitekt, Berater und Trainer tätig. Seit über 15 Jahren begleitet er vorwiegend agile Softwareentwicklungsprojekte im Java-Umfeld. Als aktives Mitglied der Java-Community gibt er sein Wissen gerne in Artikeln und Blogbeiträgen sowie als Referent auf Konferenzen weiter.
Ein kleines Release mit strategischer Bedeutung
Insgesamt enthält Java 26 zehn JEPs (JDK Enhancement Proposals). Ein Teil davon setzt bekannte Entwicklungen fort, etwa bei Pattern Matching, Structured Concurrency oder der Vector API. Andere Änderungen betreffen die Performance der JVM, neue Netzwerkprotokolle oder Verbesserungen im Security-Stack. Hinzu kommen einige Aufräumarbeiten im JDK, etwa die endgültige Entfernung der alten Applet-API.
Auch wenn Java 26 auf den ersten Blick unspektakulär wirkt, ist seine strategische Bedeutung nicht zu unterschätzen. Einige der Änderungen bereiten die Plattform auf größere Entwicklungen vor, die in den kommenden Jahren anstehen. Dazu gehören insbesondere Project Valhalla mit den Value Types, eine stärkere Integrität des Objektmodells unter dem Leitgedanken „Integrity by Default“ sowie die Optimierungen für moderne Hardware, KI- und Cloud-Workloads.
HTTP/3 Unterstützung im Java HTTP Client
Der in Java 11 eingeführte java.net.http.HttpClient hat sich in den vergangenen Jahren zum Standardwerkzeug für HTTP-Kommunikation in Java-Anwendungen entwickelt. Mit Java 26 unterstützt diese API nun auch HTTP/3 (JEP 517). HTTP/3 setzt nicht mehr auf TCP, sondern auf QUIC, einem UDP-basierten Transportprotokoll. Dadurch ergeben sich mehrere Vorteile gegenüber HTTP/1.1 und HTTP/2:
Weiterlesen nach der Anzeige
- geringere Latenz beim Verbindungsaufbau,
- bessere Performance bei Paketverlust,
- kein Head-of-Line-Blocking zwischen parallelen Streams und
- stabilere Verbindungen bei Netzwechsel, etwa bei mobilen Clients.
Gerade in Cloud-Umgebungen oder bei global verteilten Anwendungen kann HTTP/3 spürbare Vorteile bringen. Für Entwicklerinnen und Entwickler bleibt die Nutzung der API dagegen weitgehend unverändert. Die gewünschte HTTP-Version können sie einfach beim Erstellen des Clients angeben:
HttpClient client = HttpClient.newBuilder()
.version(HttpClient.Version.HTTP_3)
.build();
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create("
.GET()
.build();
HttpResponse response =
client.send(request, HttpResponse.BodyHandlers.ofString());
System.out.println(response.body());
Lazy Constants: Initialisierung von Konstanten erst bei Bedarf
Mit JEP 526 bringt Java 26 eine weitere Iteration der sogenannten Lazy Constants. Das Feature war bereits in Java 25 unter dem Namen Stable Values enthalten und erscheint nun als zweite Preview mit einer überarbeiteten API. Die Idee dahinter ist einfach: Konstanten sollen erst dann berechnet werden, wenn die Anwendung sie benötigt. Bisher erzeugt die JVM final-Felder im Rahmen der Klasseninitialisierung. Das ist effizient, wenn die Anwendung die Werte verwendet, kostet aber Zeit beim Start. In der Praxis können aufwendig zu erzeugende Objekte enthalten sein, die eine Anwendung möglicherweise nie oder erst viel später benötigt. Darum ist es sinnvoll, sie auch erst später zu initialisieren. Ein typisches Beispiel sind vorbereitete reguläre Ausdrücke oder Lookup-Strukturen:
static final Map PATTERNS = Map.of(
"email", Pattern.compile("..."),
"phone", Pattern.compile("..."),
"zip", Pattern.compile("...")
);
Beim Laden der Klasse werden hier alle Patterns sofort kompiliert – unabhängig davon, ob sie später verwendet werden oder nicht. Eine solche Initialisierung selbst lazy umzusetzen, ist schwierig. Sie muss Thread-sicher sein und darf gleichzeitig möglichst wenig Synchronisations-Overhead erzeugen. Ein klassischer Ansatz wäre das sogenannte Double-Checked Locking:
private volatile Logger logger;
Logger logger() {
if (logger == null) {
synchronized (this) {
if (logger == null) {
logger = Logger.create(OrderController.class);
}
}
}
return logger;
}
Solche Konstrukte sind nicht nur fehleranfällig, sondern vor allem schwer lesbar und führen schnell zu subtilen Nebenläufigkeitsproblemen. Lazy Constants lösen dieses Problem direkt auf Plattformebene:
private final LazyConstant logger = LazyConstant.of(() -> Logger.create(OrderController.class));
void submitOrder(User user) {
logger.get().info("order started");
}
Die JVM übernimmt die Thread-sichere Initialisierung beim ersten Zugriff, sodass Entwicklerinnen und Entwickler keine eigenen Synchronisationsmechanismen implementieren müssen. Die JVM hat zudem die Möglichkeit, Optimierungen vorzunehmen. Das kann zudem in späteren Java-Releases zu Performanceverbesserungen führen.
Die aktuelle Preview bringt eine im Vergleich zum ersten Entwurf deutlich vereinfachte API. Niedrigstufige Methoden wie orElseSet() oder trySet() sind nicht mehr enthalten. Stattdessen konzentriert sich die API nun auf Fabrikmethoden, die den Inhalt über eine Berechnungsfunktion erzeugen. Zusätzlich soll der von StableValue zu LazyConstant geänderte Name den Zweck klarer beschreiben: einen konstanten Wert, der erst bei Bedarf erzeugt wird. Gerade in Cloud- und Microservice-Architekturen kann das Vorteile bringen. Anwendungen starten schneller, unnötige Objektallokationen werden vermieden und der Speicherbedarf in der frühen Laufphase einer Anwendung sinkt.
JVM-Optimierungen für moderne Workloads
Neben neuen APIs enthält Java 26 mehrere Verbesserungen in der Laufzeitumgebung. Sie zielen vor allem auf zwei typische Anforderungen moderner Anwendungen ab: hoher Durchsatz bei paralleler Last und schnelleres Startverhalten in Cloudumgebungen.
Mehr Durchsatz im G1 Garbage Collector
Der Garbage Collector (GC) G1 ist seit vielen Jahren der Standard-GC der JVM. Seine Stärke liegt in relativ stabilen Pausenzeiten bei gleichzeitig gutem Durchsatz. In Systemen mit vielen CPU-Kernen stieß G1 jedoch bislang an interne Skalierungsgrenzen, weil bestimmte Operationen stark synchronisiert waren. Mit JEP 522 reduziert Java 26 gezielt diese Synchronisationspunkte. Dadurch entsteht weniger Lock Contention im Garbage Collector, und die Parallelisierung lässt sich besser nutzen. Besonders profitieren davon Anwendungen mit vielen Threads und hoher Objektallokation – etwa hoch parallele Backend-Systeme oder datenintensive Batch-Workloads.
Ahead-of-Time Object Caching
Ein weiterer Schritt in Richtung schnellerer Starts ist JEP 516. Dahinter verbirgt sich ein Mechanismus, der es erlaubt, bestimmte Objekte bereits im Voraus zu erzeugen und wiederzuverwenden. Typische Kandidaten dafür sind:
- Lookup-Tabellen,
- Konfigurationsstrukturen,
- Metadatenobjekte und
- häufig verwendete String- oder Datenstrukturen.
Statt diese Strukturen bei jedem Start neu aufzubauen, können sie vorbereitet und beim Start direkt wiederverwendet werden. Das reduziert die Initialisierungsarbeit und verkürzt die Warm-up-Phase einer Anwendung. Ein wichtiger Unterschied zu früheren Ansätzen ist, dass dieses Ahead-of-Time Object Caching nun unabhängig vom verwendeten Garbage Collector funktioniert. Dadurch lässt sich die Optimierung mit unterschiedlichen GC-Konfigurationen kombinieren. Gerade in containerisierten Umgebungen kann das relevant sein. Anwendungen starten schneller, Auto-Scaling reagiert effizienter und der Ressourcenbedarf während der Startphase sinkt.
PEM Encodings im JDK
Mit JEP 524 verbessert Java 26 in der zweiten Preview den Umgang mit kryptografischen Schlüsseln und Zertifikaten. Das JDK erhält eine native Unterstützung für PEM-kodierte kryptografische Objekte.
PEM („Privacy-Enhanced Mail“) ist ein textbasiertes Format zur Darstellung von Zertifikaten und Schlüsseln, das in vielen Bereichen zum Einsatz kommt, etwa für X.509-Zertifikate, Public und Private Keys oder Certificate Signing Requests. Eine typische PEM-Datei sieht folgendermaßen aus:
-----BEGIN PUBLIC KEY-----
MFkwEwYHKoZIzj0CAQYIKoZIzj0DAQcDQgAEi/kRGOL7wCPTN4KJ2ppeSt5UYB6u
cPjjuKDtFTXbguOIFDdZ65O/8HTUqS/sVzRF+dg7H3/tkQ/36KdtuADbwQ==
-----END PUBLIC KEY-----
Obwohl dieses Format im TLS- und Cloud-Umfeld weitverbreitet ist, war die direkte Unterstützung im JDK bislang begrenzt. Entwickler und Entwicklerinnen mussten häufig auf Drittbibliotheken zurückgreifen oder eigene Parser implementieren. Die neue API übernimmt zentrale Aufgaben wie das Einlesen von PEM-Daten, das Entfernen der Header und Footer sowie das Base64-Decoding. Dadurch lassen sich Zertifikate und Schlüssel direkt mit Bordmitteln des JDK verarbeiten. Gerade in aktuellen Deployment-Szenarien tauchen PEM-Dateien häufig auf, etwa in Kubernetes-Secrets, TLS-Konfigurationen, ACME-/Let’s-Encrypt-Integrationen oder mTLS-Set-ups zwischen Services. Die native Unterstützung reduziert Boilerplate-Code und verringert die Abhängigkeit von externen Security-Bibliotheken.
Aufräumarbeiten im JDK
Zur Evolution einer Plattform gehört nicht nur das Hinzufügen neuer Funktionen, sondern auch das konsequente Entfernen überholter Technologien und das Korrigieren von Fehlverhalten. Java 26 enthält zwei Änderungen, die auf den ersten Blick unspektakulär wirken, aber eine klare strategische Richtung zeigen.
Das JEP 504 entfernt die Applet-API endgültig aus dem JDK. Applets waren in den 1990er-Jahren ein zentrales Versprechen der Java-Plattform: Java-Code sollte direkt im Browser laufen und so interaktive Webanwendungen ermöglichen. Diese Zeit ist längst vorbei. Moderne Browser unterstützen keine NPAPI-Plug-ins mehr, Sicherheitsanforderungen sind deutlich gestiegen und Webanwendungen basieren heute auf völlig anderen Architekturen – etwa JavaScript-Frameworks, REST-APIs oder Single-Page-Applications. Die Applet-API ist bereits seit mehreren Java-Versionen als „deprecated for removal“ markiert und verschwindet nun endgültig aus dem JDK. Für aktuelle Anwendungen hat diese Änderung praktisch keine Auswirkungen.
Deutlich weitreichender ist JEP 500: „Prepare to Make Final Mean Final“. In der Java-Sprache garantiert das Schlüsselwort final, dass ein Feld nach der Konstruktion nicht mehr verändert werden kann. In der Praxis ließ sich diese Einschränkung jedoch über Reflection oder Low-Level-APIs wie Unsafe umgehen. Viele Frameworks – insbesondere Serialisierungsbibliotheken – nutzten diese Möglichkeit, um Objekte ohne Aufruf des Konstruktors zu erzeugen oder Felder direkt zu manipulieren. Das Vorgehen kann jedoch wichtige Validierungsregeln (Invarianten) eines Objekts verletzen.
Als Beispiel dient folgende Java-Klasse mit Preconditions:
public class Adult {
private final Instant birthdate;
public Adult(Instant birthdate) {
this.birthdate = birthdate;
if (isYoungerThan18(birthdate)) {
throw new IllegalArgumentException("Not 18 yet");
}
}
}
Wird ein Objekt dieser Klasse beispielsweise per Reflection erzeugt, kann eine Anwendung birthdate setzen, ohne dass die Validierung im Konstruktor ausgeführt wird. Das Ergebnis ist ein Objekt in einem ungültigen Zustand. JEP 500 bereitet daher den Weg für ein strengeres Integritätsmodell. Ziel ist es, dass final künftig standardmäßig tatsächlich die Unveränderlichkeit garantiert. Unsichere Zugriffe auf solche Felder sollen eingeschränkt werden, während Übergangsmechanismen über JVM-Parameter weiterhin Kompatibilität mit bestehendem Code ermöglichen. Diese Entwicklung ist Teil eines größeren Trends unter dem Stichwort „Integrity by Default“. Die Plattform bewegt sich weg von einem Modell, in dem Frameworks beliebig tief in das Objektmodell eingreifen können, und hin zu einem Ansatz, der Invarianten stärker schützt und bei dem das Verhalten von Objekten verlässlicher bleibt.
Während die bisher beschriebenen JEPs hauptsächlich neue Themen umfassten, gibt es wie bei jedem JDK-Release einige langlaufende Preview- und Inkubator-Features. Dazu zählen die Primitive Types in Patterns (mittlerweile in der vierten Fassung), die Structured Concurrency (sechste Preview) und die Vector API (zum elften Mal als Inkubator-Feature).
Pattern Matching über primitive Typen
Seit Java 21 entwickelt sich Pattern Matching schrittweise zu einem zentralen Sprachkonzept. Ziel ist es, komplexe Typprüfungen und Fallunterscheidungen einfacher und sicherer auszudrücken. Gemeinsam mit Records und Sealed Classes lassen sich damit Strukturen ähnlich wie algebraische Datentypen modellieren, wodurch viele ungültige Zustände bereits auf Typebene ausgeschlossen werden können. Nach Type Patterns, Pattern Matching im switch, Record Patterns und Unnamed Patterns sind Primitive Type Patterns der nächste Schritt in der Entwicklung von Java hin zum datenorientierten Paradigma. Das Feature tauchte erstmals bereits in Java 23 auf und erscheint in Java 26 mit JEP 530 als vierte Preview. Inhaltlich hat sich gegenüber dem letzten Release wenig geändert – das OpenJDK-Team sammelt weiterhin Feedback, bevor es die Funktion finalisiert.
Pattern Matching erlaubt es, Datenstrukturen mit einem Muster zu vergleichen und gleichzeitig Teile daraus zu extrahieren. Ein Pattern kombiniert dabei eine Bedingung („passt dieser Typ oder Wertebereich?“) mit Variablen, in die passende Werte gebunden werden. Während dieses Konzept bisher nur für Referenztypen galt, erweitert Java 26 es auf primitive Datentypen und erlaubt es, primitive und Referenztypen austauschbar im Pattern Matching-Kontext zu verwenden. Das folgende Beispiel zeigt, wie man ein int verlustfrei in einen byte konvertiert:
private static String checkByte(int value) {
if (value instanceof byte b) {
return "byte b = " + b;
} else {
return "kein byte: " + value;
}
}
System.out.println(checkByte(127)); // byte b = 127
System.out.println(checkByte(128)); // kein byte: 128
Neben den vereinfachten, verlustfreien Konvertierungen schärft das aktuelle JEP vor allem die Dominanzregeln im switch weiter. Sie stellen sicher, dass kein case unerreichbar ist, weil ein vorheriges Pattern bereits alle möglichen Werte abdeckt. Der Compiler erkennt solche Situationen inzwischen zuverlässiger und meldet sie als Fehler. Zusammen mit den bereits eingeführten Pattern-Typen ist das ein wichtiger Schritt hin zu einer konsistenteren und deklarativeren Sprache. Entwicklerinnen und Entwickler können Datenstrukturen direkt auswerten, Boilerplate-Code reduzieren und komplexe Fallunterscheidungen klarer formulieren. Weitere Mustertypen wie Array Patterns oder die Dekonstruktion beliebiger Klassen (nicht nur Records) sollen in zukünftigen OpenJDK-Releases folgen.
Die Structured Concurrency reift weiter
Die Einführung von Virtual Threads in Java 21 hat die Nebenläufigkeit in Java deutlich vereinfacht. Doch diese schlanken Threads allein lösen noch nicht alle strukturellen Probleme paralleler Programme. Wie werden mehrere Aufgaben gemeinsam orchestriert? Was passiert, wenn eine Teilaufgabe fehlschlägt? Und wie stellt man sicher, dass keine Hintergrund-Tasks unkontrolliert weiterlaufen? Genau hier setzt die Structured-Concurrency-API an. Das Feature kam ebenfalls erstmals als Preview in Java 21 und erscheint in Java 26 mit JEP 525 in der sechsten Preview. Nachdem es in Java 25 größere Änderungen an der API gab, dient die aktuelle Iteration vor allem dazu, weitere Erfahrungen aus der Praxis zu sammeln und das API-Design zu stabilisieren.
Klassische Java-Anwendungen starten parallele Aufgaben häufig über ExecutorService und Future:
ExecutorService executor = Executors.newFixedThreadPool(2);
Future user = executor.submit(() -> loadUser());
Future> orders = executor.submit(() -> loadOrders());
String userResult = user.get();
List orderResult = orders.get();
Dieses Modell bringt einige Nachteile mit sich: Die Fehlerbehandlung ist fragmentiert, Tasks können weiterlaufen, obwohl andere bereits fehlgeschlagen sind, und die Lebensdauer der Aufgaben ist nicht klar an einen Scope gebunden. Structured Concurrency verfolgt einen anderen Ansatz: Parallele Aufgaben werden innerhalb eines gemeinsamen Lebenszyklus gestartet und verwaltet. Ähnlich wie bei try-with-resources ist damit klar definiert, wann Tasks beginnen und wann sie garantiert beendet sind:
try (var scope = StructuredTaskScope.open()) {
Subtask user = scope.fork(() -> loadUser());
Subtask> orders = scope.fork(() -> loadOrders());
scope.join(); // Join subtasks, propagating exceptions
return new UserSummary(user.get(), orders.get());
}
Alle gestarteten Tasks gehören hier zu einem gemeinsamen Scope. Schlägt eine Aufgabe fehl, werden die anderen automatisch abgebrochen. Nach Verlassen des try-Blocks ist garantiert, dass keine Tasks weiterlaufen. Ein wichtiger Bestandteil des Konzepts ist die zentrale Fehlerbehandlung. Statt Exceptions einzelner Tasks separat zu behandeln, führt join() die Fehler des Scopes zusammen. Wenn ein Task fehlschlägt, löst join() eine StructuredTaskScope.FailedException aus, die die ursprüngliche Exception der fehlgeschlagenen Subtask kapselt. Gleichzeitig werden verbleibende Tasks abgebrochen.
Sogenannte Joiner definieren, wie Ergebnisse der Subtasks kombiniert und wie Fehler oder Zeitüberschreitungen behandelt werden sollen. Häufig verwendete Strategien sind bereits als Fabrikmethoden vorhanden, etwa Joiner.awaitAllSuccessfulOrThrow() (Default-Joiner) oder Joiner.anySuccessfulOrThrow(). Außerdem kann man einfach eigene Joiner implementieren. Java 26 führt zudem den Callback onTimeout() ein. Damit können Anwendungen entscheiden, wie sie mit Zeitüberschreitungen umgehen – etwa indem sie nur die bis dahin erfolgreichen Ergebnisse zurückgeben.
Ihre volle Stärke entfaltet die Structured Concurrency in Kombination mit Virtual Threads. Jede Aufgabe kann ohne komplexes Thread-Pool-Management in einem eigenen Virtual Thread laufen. Das ermöglicht ein Programmiermodell, das synchron wirkt, intern aber stark parallel skaliert. Gerade in Backend-Architekturen eignet sich dieser Ansatz für typische Muster wie parallele Serviceaufrufe, Datenaggregation oder Fan-Out/Fan-In-Strukturen. Structured Concurrency verbindet eine hohe Skalierbarkeit mit einem deutlich verständlicheren Programmiermodell für nebenläufige Anwendungen. Komplizierte und fehleranfällige Alternativen wie reaktive Programmierbibliotheken oder manuelle Thread-Verwaltung werden damit überflüssig.
Vector API: SIMD für Java
Ein weiteres langfristiges Performance-Projekt setzt Java 26 mit JEP 529 fort: die Vector API. Sie erscheint inzwischen zum elften Mal im Inkubator-Status und gehört damit zu den langlebigsten experimentellen Features der letzten Jahre.
Ziel der Vector API ist es, SIMD-Instruktionen (Single Instruction, Multiple Data) aktueller CPUs direkt aus Java heraus nutzbar zu machen. Dabei lassen sich mehrere Werte in einem einzigen CPU-Befehl parallel verarbeiten. Diese Technik spielt eine wichtige Rolle in Bereichen wie numerischen Simulationen, Bildverarbeitung, Signalverarbeitung oder Machine-Learning-Algorithmen. Ein einfacher Vergleich zeigt den Unterschied. Ohne Vector API erfolgt die Verarbeitung der Werte in einer Schleife:
void scalarComputation(float[] a, float[] b, float[] c) {
for (int i = 0; i < a.length; i++) {
c[i] = (a[i] * a[i] + b[i] * b[i]) * -1.0f;
}
}
Mit der Vector API lassen sich mehrere Werte gleichzeitig berechnen:
Listing 11: SIMD-Instruktionen mit Vector-API
```java
static final VectorSpecies SPECIES = FloatVector.SPECIES_PREFERRED;
void vectorComputation(float[] a, float[] b, float[] c) {
int i = 0;
int upperBound = SPECIES.loopBound(a.length);
for (; i < upperBound; i += SPECIES.length()) {
// FloatVector va, vb, vc;
var va = FloatVector.fromArray(SPECIES, a, i);
var vb = FloatVector.fromArray(SPECIES, b, i);
var vc = va.mul(va)
.add(vb.mul(vb))
.neg();
vc.intoArray(c, i);
}
for (; i < a.length; i++) {
c[i] = (a[i] * a[i] + b[i] * b[i]) * -1.0f;
}
}
Die Breite der Operation hängt von der CPU ab – beispielsweise 128 oder 256 Bit. Der JIT-Compiler kann diese Operationen direkt auf die SIMD-Instruktionen der jeweiligen Hardware abbilden. Die Vector API ist strategisch wichtig für datenintensive Anwendungen, etwa für Vektorberechnungen in Datenbanken, Embedding-Vergleiche in KI-Systemen oder andere numerische Workloads. Allerdings wartet sie noch auf eine wichtige Grundlage: Project Valhalla und die geplanten Value Types. Erst mit einem kompakteren Speicherlayout für Werte kann die API ihr volles Potenzial entfalten. Auch wenn die Vector API weiterhin im Inkubator bleibt, zeigt ihre kontinuierliche Weiterentwicklung deutlich, wohin sich die Plattform bewegt: Java soll aktuelle Hardware effizient ausnutzen können und auch für stark daten- und rechenintensive Anwendungen wie KI konkurrenzfähig bleiben.
Wichtiger Baustein in der langfristigen Entwicklung
Java 26 ist kein spektakuläres Feature-Release, aber ein wichtiges Puzzlestück in der langfristigen Weiterentwicklung der Plattform. Viele Änderungen wirken auf den ersten Blick klein, bereiten jedoch größere Entwicklungen vor. Eine der wichtigsten Baustellen bleibt Project Valhalla, das mit Value Types das Typsystem von Java grundlegend erweitert. Value Types versprechen kompaktere Datenstrukturen ohne Objekt-Header, bessere Cache-Lokalität und weniger Druck auf den Garbage Collector. Gerade für numerische Anwendungen, Datenverarbeitung oder KI-nahe Workloads wird das erhebliche Performancegewinne bringen. Jüngsten Gerüchten zufolge könnten Value Classes bereits im Sommer 2026 in das OpenJDK-Projekt einfließen und mit Java 28 im März 2027 erstmals als Preview-Feature erscheinen.
Parallel dazu entwickelt sich das Sicherheits- und Integritätsmodell der Plattform weiter. Unter dem Leitgedanken „Integrity by Default“ gibt es Einschränkungen für Mechanismen, die Objektinvarianten über Reflection oder unsichere APIs umgehen können. Ziel ist ein stabileres und besser optimierbares Objektmodell. Die Neuerungen in Java 26 zeigen eine klare Richtung: Die Plattform wird systematisch moderner – von der Sprache über das Nebenläufigkeitsmodell bis hin zur Runtime und den Netzwerkprotokollen. Dabei bleibt Java seinem bewährten Ansatz treu, größere Veränderungen schrittweise einzuführen und möglichst abwärtskompatibel zu bleiben.
Neben den vorgestellten zehn JEPs enthält Java 26 zahlreiche kleinere Verbesserungen. Details dazu finden sich in den Release-Notes. Änderungen an der Java-Klassenbibliothek lassen sich zudem sehr übersichtlich im Java Almanac nachvollziehen, der die Unterschiede zwischen den JDK-Versionen auflistet. Und auch ein Blick nach vorn lohnt sich: Im JEP-Index unter Draft and submitted JEPs sammeln sich bereits zahlreiche Ideen für kommende Java-Versionen.
(rme)
Entwicklung & Code
Programmiersprache C++26: Reflexion zur Kompilierungszeit
Im heutigen Beitrag meines C++-Blogs möchte ich über C++26 und eine der wahrscheinlich wirkungsvollsten Funktionen schreiben, die dem Arbeitsentwurf hinzugefügt wurden. Auch wenn C++26 noch ein paar Wochen bis zur offiziellen Fertigstellung braucht, wissen wir seit dem WG21-Sommertreffen im Juni 2025, was in C++26 enthalten sein wird.
Weiterlesen nach der Anzeige

Andreas Fertig ist erfahrener C++-Trainer und Berater, der weltweit Präsenz- sowie Remote-Kurse anbietet. Er engagiert sich im C++-Standardisierungskomitee und spricht regelmäßig auf internationalen Konferenzen. Mit C++ Insights ( hat er ein international anerkanntes Tool entwickelt, das C++-Programmierenden hilft, C++ noch besser zu verstehen.
Der neue Standard wird viele spannende Verbesserungen bringen, aber die wahrscheinlich größte Veränderung ist die Reflexion (Reflection) zur Kompilierungszeit! In Sofia hat das Standardisierungs-Komitee sieben Reflection-Papiere für C++26 angenommen:
- P1306R5: Expansion statements
- P2996R13: Reflection for C++26
- P3096R12: Function parameter reflection in reflection for C++26
- P3293R3: Splicing a base class subobject
- P3394R4: Annotations for reflection
- P3491R3: define_static_{string,object,array}
- P3560R2: Error handling in reflection
Die verlinkten Beiträge bieten genügend theoretischen Lesestoff.
Kommen wir zur Praxis
Die wichtigste Frage ist: Was kannst du mit dieser neuen Funktion machen? Einige haben bereits ihre Ideen veröffentlicht.
Steve Downey hat ein Beispiel, das eine JSON-Zeichenkette zur Kompilierungszeit analysiert und daraus C++-Objekte erstellt. Der direkte Link zum Compiler Explorer lautet godbolt.org/z/YsEK418K6.
Weiterlesen nach der Anzeige
Das zweite Beispiel stammt von Jason Turner und ermöglicht es, Bindungen zu anderen Sprachen zu generieren. Der direkte Link zum Compiler Explorer lautet godbolt.org/z/6Y17EG984.
Ich finde beide Beispiele prima, aber will auch ein eigenes zeigen. Das Problem, das ich jahrelang zu lösen versucht habe und das auch in verschiedenen Schulungen und sogar in meinem eigenen Buch Programming with C++20 – Concepts, Coroutines, Ranges, and more auftaucht. Ich musste die bittere Pille schlucken, einen nicht so tollen Code zu zeigen.
Reflexion, Reflexion an der Wand, was kann ich mit dir alles machen?
Ich rede von Enums und nicht davon, wie man ein Enum in einen String konvertiert und umgekehrt. Der Code dafür ist übrigens in den oben verlinkten Beiträgen zu finden.
Nein, ich hab mindestens noch ein anderes Problem mit Enums: Iteration. Wie oft wollte ich schon über ein enum iterieren. Es gibt Lösungen, die meist makrobasiert und mit vielen Regeln sind. Zum Beispiel nur aufeinanderfolgende Zahlen und ein letztes Mitglied namens Last oder MAX. Aber was ist, wenn es Lücken in einem enum gibt? Wie
enum class Color { Transparent, Red = 2, Green, Blue = 8, Yellow };
Genau, dann greift die Regel, dass nicht aufeinanderfolgende Nummerierungen nicht erlaubt sind.
Folgender Code zeigt einen Ansatz, der anderen Sprachen wie C# ähnelt, in denen das Iterieren der enum-Werte ohne weitere Umstände möglich ist:
// #A
template
requires std::is_enum_v
constexpr inline auto num_enumerators_of{
std::meta::enumerators_of(^^E).size()};
// #B
template
requires std::is_enum_v
consteval auto get_enum_values()
{
std::array> res;
template for(size_t i{}; constexpr auto& e : std::define_static_array(
std::meta::enumerators_of(^^E)))
{
res[i++] = [:e:];
}
return res;
}
Ich habe in #A eine Hilfsvariable erstellt, einfach weil es für sich schon hilfreich ist, die Anzahl der Werte in einem enum zu ermitteln.
Die Implementierung für die Aufgabe selbst befindet sich dann in #B. Du kannst dir eine andere Implementierung ausdenken, die für größere Enums besser geeignet ist, aber diese hier ist schön kurz und bündig.
Die Utility-Funktion sieht in Aktion nicht besonders aus, und man merkt nicht, dass im Hintergrund eine Reflexion stattfindet:
for(const auto e : get_enum_values()) {
std::print("{} ", std::to_underlying(e));
}
std::println();
Wie du siehst, gibt #B den stark typisierten Enum-Wert zurück. Deshalb ist std::to_underlying erforderlich, wenn der Wert mit std::print verwendet wird. Das ist eine Designentscheidung: Der Code bleibt so lange wie möglich stark typisiert.
Es gibt noch weitere Designüberlegungen, beispielsweise ob get_enum_values auch eine Variable sein sollte, da sie für jeden Typ konstant ist.
An dieser Stelle werde ich nicht alle neuen Teile erklären, da ich nur zeigen möchte, was mit C++26 möglich ist.
Den vollständigen Code zum Experimentieren findest du im Compiler Explorer.
P.S.: Falls du dich fragst, ob die Implementierung von #B für ein leeres enum, welches ein std::array der Größe Null ergibt, korrekt ist, lautet die Antwort: Ja, der Code ist korrekt. Einer der Vorteile von std::array ist, dass es einen Sonderfall für den Fall der Größe Null gibt. Ein Array im C-Stil wäre nicht gültig.
(rme)
Entwicklung & Code
Software Testing: Effektives Testreporting ohne Overhead
In dieser Folge spricht Richard Seidl mit Matthias Groß über Testreporting und dessen Umsetzung im Projektalltag. Im Fokus steht eine pragmatische Herangehensweise: Statt überladener Dashboards setzt Matthias Groß auf eine klare 3×3-Matrix und automatisierte Datenaufbereitung mit Python und Excel.
Weiterlesen nach der Anzeige
Die beiden beleuchten, wie Testreporting nicht nur den Status sichtbar macht, sondern auch als Führungsinstrument genutzt werden kann. Das Gespräch zeigt, wie wichtig Zieldefinition, Datenqualität und flexible Sichten sind. Besonders spannend sind die Einblicke zu KI-Experimenten im Reporting und die ehrlichen Reflexionen darüber, was wirklich zählt.
Matthias Groß ist Partner der TestGilde GmbH und seit 2007 als Berater für Softwarequalitätssicherung und Testmanagement tätig. Seine Schwerpunkte liegen im operativen Testmanagement, der Einführung und Weiterentwicklung von Testmanagementstrukturen sowie der Betreuung kundenspezifischer Testservices. Er engagiert sich zudem an der Dualen Hochschule Baden-Württemberg, ist Mitgründer der Testcommunity The TestLänd und Mitglied des Programmkomitees des QS-Tags.
Software Testing im Gespräch
Bei diesem Format dreht sich alles um Softwarequalität: Ob Testautomatisierung, Qualität in agilen Projekten, Testdaten oder Testteams – Richard Seidl und seine Gäste schauen sich Dinge an, die mehr Qualität in die Softwareentwicklung bringen.
Die aktuelle Ausgabe ist auch auf Richard Seidls Blog verfügbar: „Effektives Testreporting ohne Overhead – Matthias Groß“.
Weiterlesen nach der Anzeige
(mai)

Dieses Google Maps-Update macht das Verlaufen unmöglich

Framework: Gas Town orchestriert Coding-Agenten nach Kubernetes-Vorbild

Super High IOPS SSD: Kioxias schnelle HBM-Erweiterung startet Ende 2026

Schnelles Boot statt Bus und Bahn: Was sich von London und New York lernen lässt

Community Management und Zielgruppen-Analyse: Die besten Insights aus Blog und Podcast

Community Management zwischen Reichweite und Verantwortung
-
 Künstliche Intelligenzvor 3 Monaten
Künstliche Intelligenzvor 3 MonatenSchnelles Boot statt Bus und Bahn: Was sich von London und New York lernen lässt
-
 Social Mediavor 2 Wochen
Social Mediavor 2 WochenCommunity Management und Zielgruppen-Analyse: Die besten Insights aus Blog und Podcast
-
 Social Mediavor 1 Monat
Social Mediavor 1 MonatCommunity Management zwischen Reichweite und Verantwortung
-
Künstliche Intelligenzvor 4 Wochen
Top 10: Die beste kabellose Überwachungskamera im Test – Akku, WLAN, LTE & Solar
-

 Social Mediavor 3 Monaten
Social Mediavor 3 MonatenDie meistgehörten Gastfolgen 2025 im Feed & Fudder Podcast – Social Media, Recruiting und Karriere-Insights
-

 UX/UI & Webdesignvor 2 Monaten
UX/UI & Webdesignvor 2 MonatenEindrucksvolle neue Identity für White Ribbon › PAGE online
-

 Künstliche Intelligenzvor 2 Monaten
Künstliche Intelligenzvor 2 MonatenAumovio: neue Displaykonzepte und Zentralrechner mit NXP‑Prozessor
-

 Künstliche Intelligenzvor 3 Monaten
Künstliche Intelligenzvor 3 MonatenÜber 220 m³ Fläche: Neuer Satellit von AST SpaceMobile ist noch größer

