Entwicklung & Code
JetBrains: Preissprung bei Entwicklungsumgebungen ab 1. Oktober
Das tschechische Softwareunternehmen JetBrains hat angekündigt, seine Preise am 1. Oktober 2025 anzuziehen. Nach drei Jahren der Preisstabilität sieht sich der Hersteller beliebter Entwicklungsumgebungen (Integrated Development Environments, IDEs) aufgrund der Inflation gezwungen, die Preise für Abonnements zu erhöhen. Wer im Voraus zahlt, kann die bisherigen Preise noch für eine begrenzte Zeitdauer über den 1. Oktober hinaus beibehalten.
Preissteigerungen für IDEs, .NET-Tools, dotUltimate und All Products Pack
Betroffen sind die Abos für die JetBrains-Entwicklungsumgebungen – wie IntelliJ IDEA, WebStorm oder PhpStorm –, die .NET-Tools, das .NET-Toolkit dotUltimate und die IDE-Sammlung All Products Pack. Auf einer Webseite informiert JetBrains über die Preisänderungen. Beispielsweise erhöhen sich die Kosten der IDE IntelliJ IDEA Ultimate für den individuellen Einsatz bei jährlicher Zahlweise von 169 Euro auf 199 Euro (plus Mehrwertsteuer), bei monatlicher Zahlung von 16,90 Euro auf 19,90 Euro – jeweils auf das erste Nutzungsjahr bezogen. Für Unternehmen fallen die Steigerungen happiger aus: Das gleiche Produkt kostet pro User und Jahr derzeit 599 Euro (oder 59,90 Euro monatlich), ab dem 1. Oktober 719 Euro (oder 71,90 Euro monatlich) – eine Erhöhung um rund 20 Prozent.


Kosten für IntelliJ IDEA Ultimate für die individuelle Nutzung
(Bild: JetBrains)
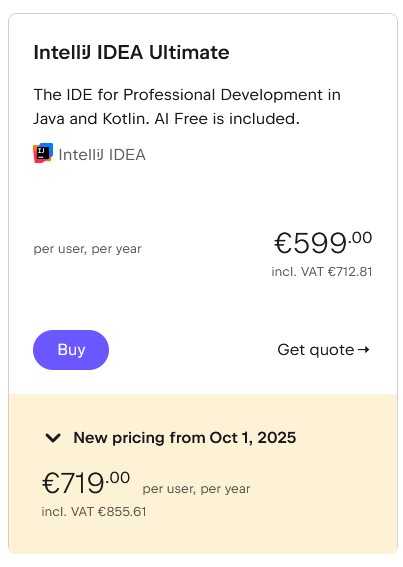
Kosten für IntelliJ IDEA Ultimate für Unternehmen
(Bild: JetBrains)
Beim All Products Pack, das aus elf Entwicklungsumgebungen und weiteren Inhalten besteht, steigen die Preise für den individuellen Einsatz von 289 Euro auf 299 Euro pro Jahr an, für den Einsatz in Unternehmen pro Jahr und User von 779 Euro auf 979 Euro.
Für bestimmte Nutzergruppen wie Lehrkräfte, Schülerinnen und Schüler oder Core Maintainer von Open-Source-Projekten sind weiterhin kostenfreie Angebote aufgeführt.
Alternative: Im Voraus bezahlen und sparen
JetBrains bietet seinen bestehenden sowie neuen Kundinnen und Kunden die Möglichkeit, im Voraus noch zu den derzeitigen Preisen zu bezahlen: Für individuelle Abos gilt dieser dann bis zu drei Jahre lang, für kommerzielle bis zu zwei Jahre. Dann wird die entsprechende Zahlung jedoch auf einen Schlag vor dem 1. Oktober 2025 fällig.
Weitere Details bieten der JetBrains-Blog und die Preisübersichtsseite.
(mai)











Entwicklung & Code
Visual Studio 2022: Im Oktober-Update erinnert sich Copilot an frühere Wünsche
Microsoft hat seine Entwicklungsumgebung Visual Studio 2022 mit dem Oktober-Update versehen. Es bietet nun eine größere Auswahl an Large Language Models (LLMs) im Chat und bringt GitHub Copilot Memories – ein Erinnerungsvermögen für den KI-Assistenten. Darüber hinaus hat Microsoft für C++-Entwicklerinnen und -Entwickler eine Anleitung veröffentlicht, wie sie ihre Projekte auf das nächste Release Visual Studio 2026 aktualisieren können.
Weiterlesen nach der Anzeige
KI-Updates für Visual Studio 2022
Unter der Bezeichnung Copilot Memories kann sich der KI-Assistent GitHub Copilot nun an Dinge „erinnern“: Wenn Entwickler beispielsweise das Verhalten des Copiloten korrigieren, einen Standard explizit ausdrücken oder ihn darum bitten, sich etwas zu merken, erhalten sie die Aufforderung, die entsprechende Präferenz zu speichern. Diese wird in einer von drei möglichen Dateien abgespeichert: .editorconfig für Coding-Standards, CONTRIBUTING.md für Best Practices, Richtlinien und Architekturstandards oder README.md für High-Level-Informationen über das Projekt. Diese gespeicherten Informationen gelten auch für den Rest des Teams, der am Projekt arbeitet.
(Bild: coffeemill/123rf.com)

Verbesserte Klassen in .NET 10.0, Native AOT mit Entity Framework Core 10.0 und mehr: Darüber informieren .NET-Profis auf der Online-Konferenz betterCode() .NET 10.0 am 18. November 2025. Nachgelagert gibt es sechs ganztägige Workshops zu Themen wie C# 14.0, künstliche Intelligenz und Web-APIs.
Darüber hinaus können Developer im Oktober-2025-Update nun auch die Anthropic-Sprachmodelle Claude Sonnet 4.5 und Claude Haiku 4.5 verwenden. Claude Sonnet 4.5 hat soll insbesondere in der Softwareentwicklung vergleichsweise stabil und vielseitig sein, während Claude Haiku 4.5 sich durch eine erhöhte Leistung bei geringeren Kosten auszeichnet.
Neben diesen sind auch weitere neue KI-Features mit an Bord, die Microsoft auf seinem Entwicklerblog vorstellt.
C++-Projekte auf Visual Studio 2026 aktualisieren
Speziell für C++-Projekte hat Microsoft eine Anleitung verfasst, wie sie sich auf Visual Studio 2026 migrieren lassen. Derzeit ist das nächste Major Release nur innerhalb des Insider-Programms verwendbar, nähert sich jedoch der allgemeinen Verfügbarkeit.
Weiterlesen nach der Anzeige
Microsoft empfiehlt C++-Developern daher das Ausprobieren der neuen Version in Visual Studio 2026 Insiders, die sich parallel zu einer stabilen Visual-Studio-Version installieren lässt. Dann können C++-Developer zunächst bei ihrer bestehenden MSVC-Toolset-Version verbleiben und den neuen Setup-Assistenten verwenden, um fehlende Tools je nach Projekt zu installieren. Wenn sie dafür bereit sind, können sie schließlich ihre MSCV-Build-Tools auf Version 14.50 aktualisieren, die den MSVC-Compiler in Version 19.50 mitbringen.
(mai)
Entwicklung & Code
Keep Android Open – Abwehr gegen Verbot anonymer Apps von Google
Teile der Android-Developer-Community wehren sich in einem öffentlichen Aufruf unter dem Namen „Keep Android Open“ gegen die von Google schrittweise eingeführten Sideloading-Regeln, die eine Authentifizierung von App-Herausgebern erfordern – auch von denen, die jenseits des offiziellen Android Play Stores veröffentlichen.
Weiterlesen nach der Anzeige
Der Aufruf unbekannter Herkunft kritisiert insbesondere, dass Google den Smartphone-Kundinnen und -Kunden das Recht nimmt, die Software zu installieren, die sie möchten. Entwickler hingegen können Apps nicht mehr direkt weitergeben.
Ferner nimmt die Maßnahme der Gesellschaft ein Stück digitale Souveränität. Der Aufruf weist darauf hin, Google sei „ein Unternehmen, das nachweislich den außergerichtlichen Forderungen autoritärer Regierungen nachkommt, vollkommen legale Apps zu entfernen, die ihnen zufällig nicht gefallen.“
Gegen Monopolisierung und Übermacht
Die Initiative ruft nun Entwicklerinnen und Entwickler dazu auf, der Forderung nach Registrierung nicht nachzukommen: „Reagiert (höflich) auf jede Einladung mit einer Liste eurer Bedenken und Einwände.“ Außerdem sollen sie ihre jeweilige Regulierungsbehörde kontaktieren und auf die Gefahren von “ Monopolen und die Zentralisierung der Macht im Technologiesektor“ aufmerksam machen.
Es folgt eine lange Liste mit Kontaktadressen der jeweiligen Behörden in der Welt. Ferner weist Keep Android Open auf eine Petition von Change.org hin.
In Foren wird ein gewisser Zusammenhang des Aufrufs mit dem alternativen Android-App-Store F-Droid gesehen. Der Text empfiehlt unter Sonstiges an erster Stelle „Install F-Droid“ und umgekehrt gibt es von F-Droid einen Blogeintrag, der die Initiative bewirbt: „Um mehr darüber zu erfahren, was du als Verbraucher tun kannst, besuche keepandroidopen.org.“
Weiterlesen nach der Anzeige
Sideloading nur nach Registrierung und Authentifizierung
Google hatte im Sommer angekündigt, dass sich Herausgeber aller Apps, die auf Android-Geräten installiert werden sollen, registrieren müssen. Dabei müssen sie einen Identitätsnachweis erbringen: Personen mit Ausweis, Firmen mit DUNS-Nummer. Diese Maßnahme zur Stärkung der Sicherheit will Google schrittweise in den Jahren 2026 und 2027 erzwingen. Die Firma stellte jedoch klar, das Sideloading an sich nicht verbieten zu wollen. Für kleine Projekte und Hobby-Entwickler gibt es zudem kostenlose Konten.
(who)
Entwicklung & Code
Aus Softwarefehlern lernen – Teil 6: Eine Zeile Code mit fatalen Auswirkungen
In der Softwareentwicklung gibt es Bereiche, in denen schon ein einziger Fehler katastrophale Folgen haben kann. Besonders anfällig sind dabei Kryptografiebibliotheken und Parser – also genau jene Bausteine, die Daten validieren, entschlüsseln oder die Integrität von Kommunikation sicherstellen.
Weiterlesen nach der Anzeige

Golo Roden ist Gründer und CTO von the native web GmbH. Er beschäftigt sich mit der Konzeption und Entwicklung von Web- und Cloud-Anwendungen sowie -APIs, mit einem Schwerpunkt auf Event-getriebenen und Service-basierten verteilten Architekturen. Sein Leitsatz lautet, dass Softwareentwicklung kein Selbstzweck ist, sondern immer einer zugrundeliegenden Fachlichkeit folgen muss.
Die Teile der Serie „Aus Softwarefehlern lernen“:
In diesen Bereichen gilt: Ein vermeintlich kleiner Bug kann globale Auswirkungen haben. Zwei der bekanntesten Vorfälle der letzten Jahre illustrieren das eindrücklich, nämlich Heartbleed und Apples „goto fail“.
Muster 6: Kryptografie- und Parser-Fehler: Wenn eine einzige Codezeile die Sicherheit kippt
Heartbleed war ein Fehler in OpenSSL, einer der meistgenutzten Kryptografiebibliotheken der Welt. Der Bug betraf die Implementierung des TLS-Heartbeat-Mechanismus. Heartbeats sind kleine Nachrichten, mit denen Client und Server prüfen, ob die Verbindung noch lebt. Ein Client sendet (im Falle von TLS) dazu eine Nachricht, in der er unter anderem die Länge der eigenen Daten angibt. Der Server spiegelt diese Daten zurück.
Der fatale Fehler dabei war, dass die angegebene Länge nicht validiert wurde. Ein Angreifer konnte also behaupten, er sende zum Beispiel 64 KByte Daten, sendete tatsächlich aber nur 1 Byte. OpenSSL las daraufhin blind die fehlenden 63.999 Bytes aus seinem Speicher und schickte sie zurück. Diese Out-of-Bounds-Reads erlaubten es, mit ein bisschen Glück sensible Informationen wie Passwörter, Session Keys oder private Schlüssel auszulesen.
Die Tragweite war enorm. Millionen von Webservern waren betroffen, und weil TLS-Private-Keys kompromittiert waren, mussten die Betreiber zahllose Zertifikate austauschen. Der Bug bestand dabei über zwei Jahre in der OpenSSL-Codebasis, obwohl er nur wenige Zeilen lang war.
Fast zeitgleich machte Apple mit einem ebenfalls winzigen, aber folgenschweren Fehler namens goto fail Schlagzeilen. In der Implementierung der SSL-Zertifikatsprüfung in iOS und macOS fand sich eine verdoppelte Codezeile:
Weiterlesen nach der Anzeige
if ((err = SSLHashSHA1.update(&hashCtx, &signedParams)) != 0)
goto fail;
goto fail;
Die zweite goto fail-Zeile war dabei falsch eingerückt, sodass Reviewer den Fehler schlecht erkennen konnten. Das System führte die zweite Zeile nämlich immer aus, unabhängig vom Ergebnis der if-Anweisung. Das wiederum hatte zur Folge, dass das System einen Teil der sicherheitskritischen Zertifikatsprüfung übersprang. Dadurch konnte ein Angreifer einen Man-in-the-Middle-Angriff durchführen, weil macOS, iOS und andere Apple-Betriebssysteme gefälschte Zertifikate akzeptierten. Wie bei Heartbleed war der betroffene Code winzig, die Folgen jedoch massiv.
Was haben beide Fehler gemein? Sicherheitskritischer Code ist oft alt und wenig verändert: Entwicklerinnen und Entwickler fassen Parser, Krypto-Routinen oder Protokollimplementierungen selten an – und wenn, dann oft unter Zeitdruck.
- Einzelne Zeilen können sicherheitsentscheidend sein: Die Logik ist komplex, Tests decken selten alle Pfade ab, und Compiler warnen nicht vor falscher Einrückung oder fehlender Längenvalidierung.
- Fehler bleiben lange unentdeckt: Heartbleed war über zwei Jahre im Code.
goto failfiel erst auf, als unabhängige Forscher den Code analysierten.
Wer sicherheitskritische Software entwickelt oder integriert, sollte daher einige Prinzipien beherzigen:
- Vier-Augen-Prinzip und Code-Reviews: Kein sicherheitsrelevanter Commit sollte von nur einer Person geschrieben und gemerged werden.
- Fuzzing und Differential-Tests: Automatisierte Tests, die zufällige und manipulierte Eingaben erzeugen, decken viele Parser- und Memory-Bugs auf.
- Reproduzierbare Builds und Dependency-Audits: Developer müssen sicherheitskritische Software in derselben Version reproduzierbar bauen und signieren. Änderungen in Libraries müssen sie aktiv verfolgen und bewerten.
- Minimaler und isolierter Code: Krypto- und Parser-Funktionen sollten möglichst klein und möglichst isoliert sein, um die Angriffsfläche zu minimieren.
- Proaktive Schlüssel- und Zertifikatsrotation: Selbst wenn ein Fehler wie Heartbleed auftritt, kann ein schneller Schlüsselaustausch die Folgen begrenzen.
Die beiden Fälle zeigen: Security-Bugs entstehen oft in den unscheinbarsten Codezeilen. Wer sie ignoriert, riskiert nicht nur Ausfälle, sondern auch Vertrauensverlust und juristische Folgen. Für Unternehmen ist daher klar: Sicherheitskritische Bereiche benötigen besondere Prozesse, zusätzliche Tests und regelmäßige Audits.
(who)
Nicht verpassen: Pixel-Handys bekommen Überraschungs-Update

iX-Workshop Softwarearchitektur für KI-Systeme – skalierbare Lösungen entwickeln

Ausbau in Dresden: Globalfoundries erweitert deutsche Halbleiterfabriken

Der ultimative Guide für eine unvergessliche Customer Experience

Adobe Firefly Boards › PAGE online
eine gute Nachricht ist")
Relatable, relevant, viral? Wer heute auf Social Media zum Vorbild wird – und warum das für Marken (k)eine gute Nachricht ist
-
 UX/UI & Webdesignvor 2 Monaten
UX/UI & Webdesignvor 2 MonatenDer ultimative Guide für eine unvergessliche Customer Experience
-
 UX/UI & Webdesignvor 2 Monaten
UX/UI & Webdesignvor 2 MonatenAdobe Firefly Boards › PAGE online
-
eine gute Nachricht ist") Social Mediavor 2 Monaten
Social Mediavor 2 MonatenRelatable, relevant, viral? Wer heute auf Social Media zum Vorbild wird – und warum das für Marken (k)eine gute Nachricht ist
-

 UX/UI & Webdesignvor 2 Wochen
UX/UI & Webdesignvor 2 WochenIllustrierte Reise nach New York City › PAGE online
-

 Entwicklung & Codevor 2 Monaten
Entwicklung & Codevor 2 MonatenPosit stellt Positron vor: Neue IDE für Data Science mit Python und R
-

 Entwicklung & Codevor 2 Monaten
Entwicklung & Codevor 2 MonatenEventSourcingDB 1.1 bietet flexiblere Konsistenzsteuerung und signierte Events
-

 UX/UI & Webdesignvor 2 Monaten
UX/UI & Webdesignvor 2 MonatenFake It Untlil You Make It? Trifft diese Kampagne den Nerv der Zeit? › PAGE online
-

 Apps & Mobile Entwicklungvor 2 Monaten
Apps & Mobile Entwicklungvor 2 MonatenGalaxy Tab S10 Lite: Günstiger Einstieg in Samsungs Premium-Tablets