Apps & Mobile Entwicklung
Mehr Personalisierung: Gemini soll Abos aus Apps von Drittanbietern unterstützen

Google will Gemini offenbar stärker mit externen Diensten verknüpfen. Hinweise aus einer Vorabversion deuten auf neue Optionen der Personalisierung hin, über die der KI-Assistent künftig kontextbezogene persönliche Daten aus verschiedenen Quellen und Drittanbieter-Apps in die Antworten einbeziehen können soll.
Gemini soll auch externe Dienste für Antworten nutzen können
Die Hinweise darauf stammen laut TestingCatalog aus einer noch nicht öffentlich freigeschalteten Gemini-Version. Zu den entdeckten Neuerungen zählt demnach die Einbindung kostenpflichtiger Abonnements und der damit verbundenen Dienste in die Antwortgenerierung des KI-Modells von Google. Künftig könnte Gemini bevorzugt Informationen aus anderen bezahlten Angeboten heranziehen, um Antworten zu erstellen.
Ein neuer Hinweistext soll Nutzer darüber informieren, dass Gemini kostenpflichtige Abonnements priorisieren kann, um bessere Ergebnisse zu liefern. Ähnliche Formulierungen finden sich bereits in den Einstellungen von Gemini, bislang allerdings ausschließlich für Googles eigene Dienste. Die Platzierung innerhalb des betreffenden App-Bereichs könnte laut dem Bericht als Hinweis darauf gewertet werden, dass Google die Funktion künftig auch für Anwendungen von Drittanbietern öffnen könnte.
Überraschend wäre ein solcher Schritt nicht. Erst vor wenigen Tagen hatte Google nach der Einführung der sogenannten Konnektoren die Integration des Design-Dienstes Canva breiter verfügbar gemacht. Solche Schnittstellen ermöglichen Gemini den direkten Zugriff auf Inhalte und Daten aus externen Anwendungen und erweitern die Einsatzmöglichkeiten des KI-Modells deutlich.
Mehr Kontrolle über Nutzung externer Apps
Eine weitere entdeckte Funktion könnte noch einen Schritt weiter gehen. Nutzer könnten künftig nachvollziehen und verwalten, welche kontextbezogenen Informationen Gemini aus verbundenen Anwendungen verwenden darf. Darauf deutet eine bereits vorhandene, derzeit jedoch noch funktionslose Schaltfläche hin, die offenbar auf eine künftige Verwaltungsoberfläche verweist.
TestingCatalog vermutet dahinter eine App-spezifische Steuerung, über die sich für jede Anwendung einzeln festlegen lässt, welche Informationen Gemini für die Antworten berücksichtigen darf. Damit würde Google zugleich einen vergleichsweise transparenten Ansatz verfolgen, auch mit Blick auf den Datenschutz. Nutzer könnten einzelne Anwendungen dann auch gezielt von der Datennutzung ausschließen.
Das Große wird erkennbar
Die Entdeckungen fügen sich in eine größere Strategie ein, die sich bereits an anderer Stelle abzeichnet. So soll Google auch für NotebookLM zusätzliche persönliche Kontexte und Erinnerungsfunktionen planen. Der nun sichtbar werdende personalisierte Ansatz würde damit nicht allein den Gemini-Chatbot betreffen, sondern auch weitere KI-Produkte von Google.












Apps & Mobile Entwicklung
Tensordyne: KI-Start-up will mit TDN Math Nvidias Dominanz brechen
Das in Kalifornien und München ansässige KI-Start-up Tensordyne schickt sich an, mit einer eigens entwickelten logarithmische Zahlen- und Rechenarchitektur für KI-Inferenz sowie entsprechender eigener Hardware den Markt aufzurollen. Tensordyne wirbt mit vielfach höherer Leistung und niedrigerem Verbrauch im Vergleich zu Nvidia.
Gegründet im Jahr 2017
Tensordyne wurde 2017 unter dem Namen Recogni gegründet. Das Unternehmen konzentrierte sich von Beginn an auf die Entwicklung energieeffizienter KI-Hardware und spezieller Chiparchitekturen, die komplexe KI-Berechnungen mit geringerem Energieverbrauch ermöglichen sollten. In den folgenden Jahren entwickelte Recogni eigene Technologien für KI-Inferenz und konnte umfangreiche Investitionen einholen, um die Forschungs- und Entwicklungsaktivitäten in den USA und Europa auszubauen.
Im Jahr 2024 erfolgte die Umbenennung in Tensordyne, verbunden mit einer strategischen Neuausrichtung vom reinen Chipentwickler hin zum Anbieter kompletter KI-Inferenzsysteme für Rechenzentren. Heute entwickelt das Unternehmen nicht nur eigene Prozessoren, sondern auch die zugehörige Hardware, Software und mathematische Grundlagen, um leistungsstarke und energieeffiziente KI-Lösungen bereitzustellen. Mit Standorten in Sunnyvale (Kalifornien) und München positioniert sich Tensordyne als innovativer Anbieter im Markt für KI-Infrastruktur. Passend dazu hat das Unternehmen jetzt den Tape-out und eigenen „TDN72 Inference Pod“ sowie das erste Rack-System angekündigt.

TDN Math sei der große Vorteil von Tensordyne
Die „DNA“ von Tensordyne ist in der eigens entwickelten logarithmischen Zahlen- und Rechenarchitektur für KI-Inferenz zu finden, vom Unternehmen „TDN Math“ oder „Logarithmic Mathematics“ genannt. Die Grundidee besteht darin, Zahlen nicht wie üblich im Floating-Point-Format (FP16, FP8 usw.) darzustellen, sondern in einer logarithmischen Form. Dadurch können viele Multiplikationen durch wesentlich einfachere Additionen ersetzt werden. Mathematisch basiert das auf der Eigenschaft:
log(A×B)=log(A)+log(B)
Da KI-Modelle den Großteil ihrer Rechenleistung für Matrixmultiplikationen benötigen, können spezialisierte Chips mit logarithmischer Mathematik deutlich weniger Transistoren für Recheneinheiten benötigen. Der frei werdende Chipplatz kann stattdessen für mehr Speicher (SRAM), zusätzliche Tensor-Einheiten oder schnellere Datenverbindungen genutzt werden. Laut Tensordyne führt das zu höherer Energieeffizienz und besserer Ausnutzung der Hardware im Vergleich zu etablierten Lösungen.
Der eigentliche technische Knackpunkt ist jedoch die Addition. Während Multiplikationen im logarithmischen Raum einfach werden, sind Additionen dort deutlich komplizierter. Nach Angaben des Unternehmens liegt die eigentliche Innovation in einer sehr effizienten und präzisen Umwandlung bzw. Behandlung dieser Operationen, sodass die Vorteile des logarithmischen Rechnens erhalten bleiben. Genau diese Verfahren sind Teil des proprietären Know-hows von Tensordyne. Das Unternehmen gibt an, damit eine Genauigkeit von über 99,9 Prozent gegenüber den ursprünglichen KI-Modellen zu erreichen und gleichzeitig den Energieverbrauch sowie die Chipfläche gegenüber herkömmlichen FP8-/FP16-Lösungen zu reduzieren.
TDN72 Inference Pod and Rack System
Die Plattform von Tensordyne besteht neben der TDN Math aus dem TDN AIP (Artificial Intelligence Processor) sowie dem TDN Link (Any-to-Any Scale-Up Interconnect) und lässt sich im „TDN72 Inference Pod and Rack System“ zusammenführen. Dabei handelt es sich um einen Inference Pod mit 72 Chips pro Compute-Tray, der es mit Nvidias NVL72 auf Basis von Grace Blackwell aufnehmen und dabei gleichzeitig deutlich weniger Energie verbrauchen soll. Vier TDN72 Pods ergeben dabei ein vollständiges „Tensordyne Napier“-Rack, das im Vergleich zu Nvidia beworben wird mit:
- 17 Mal mehr Tokens pro Watt
- 13 Mal mehr Tokens pro Sekunde
- Bis zu 33 Millionen USD mehr Jahresumsatz pro Rack
Tensordyne argumentiert, dass die KI-Branche vor einem grundlegenden Infrastrukturwandel stehe. Da die Nachfrage nach KI-Inferenz stark wachse, würden Hyperscaler und Cloud-Anbieter dieses Jahr voraussichtlich mehr als 700 Milliarden US-Dollar in Infrastruktur investieren. Bestehende Systeme würden Betreiber jedoch weiterhin zu Kompromissen zwischen Geschwindigkeit, Packungsdichte und Betriebskosten zwingen.

Nach Angaben des Unternehmens wurde das Napier-System speziell entwickelt, um diese Zielkonflikte aufzulösen. Durch die gemeinsame Optimierung von Mathematik, Prozessorarchitektur, Speicher und Netzwerk soll hohe Inferenz-Geschwindigkeiten mit deutlich besserer Energie- und Kosteneffizienz als bei Nvidia kombiniert werden.
Tensordyne Napier kommt 288 KI-Prozessoren
Tensordyne Napier ist ein Rack, das wiederum aus vier TDN72 Pods besteht, in denen jeweils 72 Tensordyne Napier AI-Prozessoren zum Einsatz kommen. Der Chip wird in 3 nm bei TSMC (N3P) gefertigt, weist 138 Milliarden Transistoren auf und ist mit 300 Watt TDP spezifiziert. Jeder AI-Prozessor kommt mit 256 MB SRAM (40 TB/s) und 144 GB HBM3e (4,7 TB/s) und soll damit eine Rechenleistung von 2,1 PFLOPS für Dense FP8 erreichen. Ein Compute-Tray im TDN72 Pod nimmt neun Napier-Chips für dann 2,3 GB SRAM und 1,3 TB HBM3e auf. Verbaut ist außerdem ein Intel Xeon für die Runtime API, zudem sind 8 TB NVMe SSD und zweimal 200 Gbit/s Ethernet als Front I/O an Bord. Für den Scale-up im Rack mit vier Pods setzt Tensordyne auf den eigenen TDN Link mit 1 TB/s bidirektionaler Bandbreite.
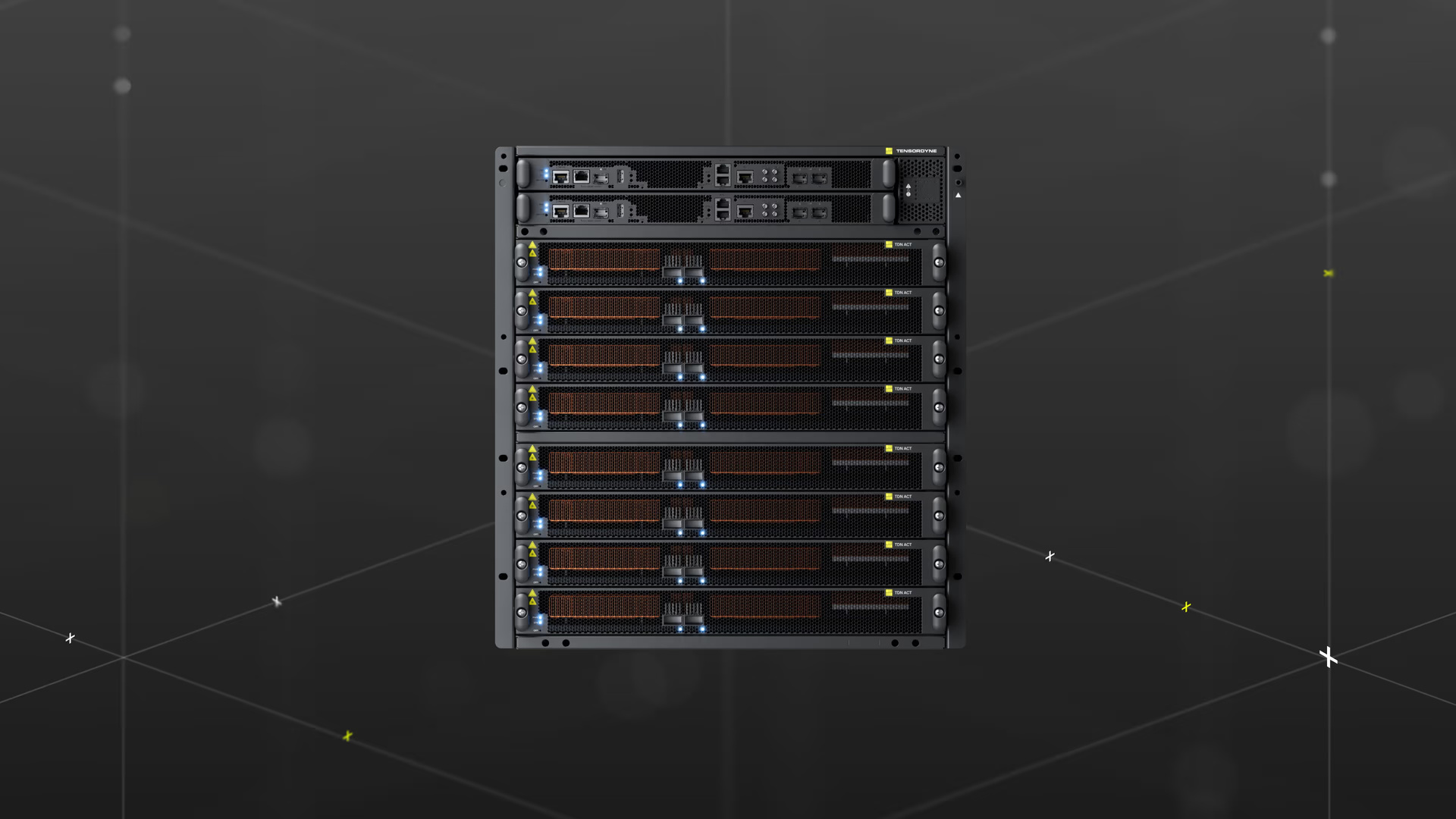

Das TDN-Rack könne dabei Tokens standardmäßig ausliefern, sodass ein Modell die gesamte Inferenz (Prefill und Decode) auf derselben Infrastruktur ausführt und Tokens sequenziell erzeugt, oder sogenannte „disaggregated Inference“ ausführen, also diese Schritte systemisch trennen, sodass Prefill und Decode auf unterschiedlichen Trays laufen. Beim Prefill verarbeitet ein KI-Modell den gesamten eingegebenen Prompt auf einmal und erstellt dabei den Kontext (z. B. Key-Value-Cache), der alle bisherigen Informationen enthält; das ist rechenintensiv, passiert aber nur einmal. Beim Decode wird anschließend die Antwort Token für Token generiert, wobei das Modell jeweils auf den gespeicherten Kontext zugreift, wodurch jeder einzelne Generationsschritt effizienter ist, aber viele Wiederholungen nötig sind.
Erste Systeme ab Mitte 2027
Nachdem jetzt der Tape-out der eigenen Hardware erfolgreich war, sollen gegen Ende dieses Jahres die Chips in den eigenen Laboren getestet und validiert werden. Mitte des nächsten Jahres sei laut Tensordyne mit der Verfügbarkeit von fertigen Systemen zu rechnen, sodass bis dahin auch mit entsprechend neuerer Konkurrenz von (unter anderem) Amazon, AMD, Cerebras, Google oder Nvidia gerechnet werden muss.
Apps & Mobile Entwicklung
Paket-Manager für Windows, macOS & Linux: Devolutions verbessert mit UniGetUI 2026.2.1 den Datenschutz

UniGetUI 2026.2.1 bringt neben zahlreichen Fehlerkorrekturen und Stabilitätsverbesserungen auch neue Funktionen sowie Anpassungen beim Datenschutz mit sich. Zu den Neuerungen zählen unter anderem eine erweiterte Exportfunktion für Logdateien und ein neuer Operationszähler zur besseren Übersicht laufender Paketvorgänge.
Fehlerprotokolle lassen sich leicht anonymisieren
In der neuen Version kann UniGetUI nun Benutzernamen automatisch aus exportierten Logdateien entfernen. Dadurch lassen sich Fehlerprotokolle einfacher mit Entwicklern oder dem Support-Team teilen, ohne persönliche Informationen offenzulegen. Gleichzeitig soll diese Funktion den Datenschutz innerhalb der Anwendung verbessern.
Darüber hinaus haben die Entwickler einen neuen Operationszähler integriert. Dieser soll Anwendern einen besseren Überblick über laufende Paketoperationen verschaffen und auf einen Blick zeigen, welche Installations-, Aktualisierungs- oder Deinstallationsvorgänge derzeit noch aktiv sind. Nach erfolgreichen Updates öffnet UniGetUI zudem künftig standardmäßig die Release Notes, sodass Nutzer schneller über neue Funktionen, Verbesserungen und Fehlerbehebungen informiert werden. Zusätzlich wurden die Diagnosewerkzeuge erweitert, was die Fehlersuche vereinfachen und aussagekräftigere Informationen für Support-Anfragen liefern soll.
Auch Zuverlässigkeit verbessert
Bei den Verbesserungen lag der Schwerpunkt dieses Mal vor allem auf der Stabilität. Besonderes Augenmerk galt dem Update-Prozess. So wurden unter anderem Probleme bei der Paketsuche, der Aktualisierung von Paketen sowie beim Abruf von Metadaten behoben. Auch an der Benutzeroberfläche wurden verschiedene Fehler korrigiert.
Eine genaue Auflistung aller Änderungen und Verbesserungen bieten die Release Notes.
Ab sofort verfügbar
Das Update auf UniGetUI 2026.2.1 kann wahlweise über die integrierte Aktualisierungsfunktion des Paketmanagers angestoßen oder als vollständige Datei auf der Projektseite bei GitHub heruntergeladen werden. Alternativ lässt sich die neue Version auch wie gewohnt bequem über den Link am Ende dieser Meldung aus dem Download-Bereich von ComputerBase beziehen.
Downloads
-

4,7 Sterne
UniGetUI ist eine grafische Oberfläche für die Windows-Paketmanager Winget, Chocolatey und Scoop.
Apps & Mobile Entwicklung
Jonsbo D33: Micro-ATX-Gehäuse bekommt „eSport-Tech-Vibe“

Eigentlich ist das Jonsbo D33 ein edel anmutendes Micro-ATX-Gehäuse. Das Marketing müht sich allerdings, daraus viel mehr zu machen Es überschlägt sich fast dabei, dem Frontgutter, wahlweise in Alu-Optik oder aus Holz, eine größere Bedeutung zuzumessen.
Das D33 wird in Weiß und Schwarz jeweils mit Aluoptik- oder Holzgitter an der Front produziert. Soweit, so normal für ein Gehäuse des 2026er-Jahrgangs, wo diese Optik, vielleicht abgesehen vom eingefassten I/O-Panel, regelmäßig auftaucht. Lange Linien entlang der Front bieten sich schließlich an.
Bei Jonsbo muss daraus mehr werden. Ein „von Technologie inspiriertes Gitter-Frontpanel“ besitze das Modell, verrät die Produktseite, dessen „gestaffelte Linie und Facettendesign einen e-Sport-Tech-Vibe“ hervorrufen sollen. Mehr noch: „Eleganz und Leidenschaft“ sollen darin aufeinanderprallen. Wohlgemerkt: In einem Gehäuse mit relativ funktionaler, modellabhängig optisch veredelten Gitterfront. Vollendet wird die Beschreibung durch den 2026 obligatorischen Hinweis auf „KI-Produktivität“ und „hochbelastendes 3A-Gaming“, für die das Gehäuse genug Kühlung liefern soll.
-

Jonsbo D33 (Bild: Jonsbo)
Bild 1 von 7
Layout und Aufbau
Lüfter liefert Jonsbo nicht mit. Montiert werden können sie im Format 120 Millimeter an der Oberseite in einer Halterung, die auch einen 360-mm-Radiator aufnimmt, im Heck, am Boden sowie hinter der Front. Eine Besonderheit der Halterung ist, dass sie zwischen Lüfter und Wärmetauscher montiert werden muss. An der Vorderseite können auch 140-mm-Lüfter eingesetzt werden, was jedoch die Nutzung eines SFX-Netzteils voraussetzt. Mit ATX-Stromspender schrumpft die Lüfterbreite auf 120 Millimeter – denn das Netzteil befindet sich hinter der Front.
Das D33 bringt auf gut 40 Liter Volumen auch besonders hohe Kühler und lange Grafikkarten unter, Größenbeschränkungen gibt es nur in der Theorie. Festplatten werden in einer Halterung hinter das Mainboard gesetzt, die zwei Laufwerke aufnimmt. Im Innenraum kann außerdem das DS916 Secondary Screen Display montiert werden, das die Anzeige von Systemdaten, Bildern und Co erlaubt.
Preis und Verfügbarkeit
Im Handel sind bereits drei Varianten des D33 gelistet. In Schwarz und Weiß kostet der Tower in der Basisvariante rund 85 Euro, in Weiß mit Holz sind es knapp 100 Euro.


Tensordyne: KI-Start-up will mit TDN Math Nvidias Dominanz brechen

+++ STARTUPLAND +++ Super Early Bird +++ Robotik +++ Candis +++ Anthropic +++ Mario Götze +++
Ambush Marketing at its best: Levi’s wird mit verhülltem Stadionlogo zum WM-Werbestar

JBL Bar 1300MK2 im Test: Soundbar mit Dolby Atmos, starkem Bass und Akku‑Rears

Oscars 2026: Was die heise‑Leser anders entschieden hätten

Empfehlungsalgorithmen bei TikTok erklärt: Die Maschine hinter dem Endlos‑Feed
-
Künstliche Intelligenzvor 3 Monaten
JBL Bar 1300MK2 im Test: Soundbar mit Dolby Atmos, starkem Bass und Akku‑Rears
-
 Künstliche Intelligenzvor 3 Monaten
Künstliche Intelligenzvor 3 MonatenOscars 2026: Was die heise‑Leser anders entschieden hätten
-
 Künstliche Intelligenzvor 3 Monaten
Künstliche Intelligenzvor 3 MonatenEmpfehlungsalgorithmen bei TikTok erklärt: Die Maschine hinter dem Endlos‑Feed
-

 Social Mediavor 3 Monaten
Social Mediavor 3 MonatenVon Kennzeichnung bis Plattformpflichten: Was die EU-Regeln für Influencer Marketing bedeuten – Katy Link im AllSocial Interview
-

 Künstliche Intelligenzvor 2 Monaten
Künstliche Intelligenzvor 2 Monaten„Don’t Starve Elsewhere“: Survival‑Hit kehrt nach zehn Jahren zurück
-

 Künstliche Intelligenzvor 2 Monaten
Künstliche Intelligenzvor 2 MonateniX-Workshop Angriffsziel lokales AD − Schwachstellen finden und beheben
-

 Künstliche Intelligenzvor 2 Monaten
Künstliche Intelligenzvor 2 MonatenWeitere Entlassungswelle bei Disney: Bis zu 1000 Mitarbeiter betroffen
-

 Künstliche Intelligenzvor 2 Monaten
Künstliche Intelligenzvor 2 MonatenKine‑Exakta: Die erste Spiegelreflexkamera fürs Kleinbild
