Künstliche Intelligenz
Roborock F25 Ace Pro im Test: Wischsauger, der auf Knopfdruck Schaum versprüht
Der F25 Ace Pro ist der neueste Wischsauger aus dem Hause Roborock. Er saugt mit 25.000 Pa und wischt mit Schaum.
Die neueste Iteration der Wischsauger aus dem Hause Roborock, der F25 Ace Pro, versprüht auf Knopfdruck gezielt Schaum für eine bessere Fleckenreinigung. Alles andere bleibt größtenteils beim Alten: Selbstreinigung und Trocknung per Ladestation, Einrichtung per App. Lohnt sich das Upgrade für den Schaum oder bleibt man besser beim Vorgängermodell? Wir haben den Roborock F25 Ace Pro getestet und klären auf. Das Testgerät hat uns der Hersteller zur Verfügung gestellt.
Lieferumfang
Zum Roborock F25 Ace Pro gibt es die Ladestation samt Stromkabel, die Wischwalze, ein Reinigungskonzentrat, einen Ersatz-HEPA-Filter und eine Handbürste für die Wartung. Selbstverständlich liegen auch ein Quick-Start-Guide sowie eine ausführlichere Betriebsanleitung bei. Alle Einzelteile sind dank Styroporeinlagen sicher verstaut. Der Quick-Start-Guide zeigt zudem visuell die Anordnung der einzelnen Komponenten innerhalb der Box, was für ein späteres Verstauen extrem hilfreich ist.
Design
Hier ändert sich nicht wirklich etwas. Wie bisher setzt Roborock mit dem F25 Ace Pro auf schlichtes Schwarz und viel Plastik. Der Wischsauger kommt mit den Maßen 265 x 1100 x 250 mm und wirkt äußerst robust. Alle Einzelteile klicken problemlos ineinander und sitzen fest. Das Auffangsieb aus Kunststoff wirkt allerdings etwas fragil. Das liegt hauptsächlich an den Verbindungsstücken, die sich durch Drücken an beiden Seiten vom Rest des Schmutzwasserfiltersystems lösen.
Roborock F25 Ace Pro – Bilder
Roborock F25 Ace Pro – Bilder

Roborock F25 Ace Pro – Bilder

Roborock F25 Ace Pro – Bilder

Roborock F25 Ace Pro – Bilder

Roborock F25 Ace Pro – Bilder

Roborock F25 Ace Pro – Bilder

Roborock F25 Ace Pro – Bilder

Roborock F25 Ace Pro – Bilder

Roborock F25 Ace Pro – Bilder

Roborock F25 Ace Pro – Bilder

Roborock F25 Ace Pro – Bilder

Roborock F25 Ace Pro – Bilder

Roborock F25 Ace Pro – Bilder

Roborock F25 Ace Pro – Bilder

Roborock F25 Ace Pro – Bilder

Die Ladestation ist kompakt und ebenfalls in unspektakulärem Schwarz gehalten. Das Stromkabel ist hingegen grau und bricht mit der sonst sehr einheitlichen Optik. Auch hier wirkt alles top verarbeitet.
Einrichtung
Die Einrichtung des Wischsaugers ist gewohnt einfach und schnell erledigt. Für die erste Inbetriebnahme muss man sämtliche Schutzfolien vom Gehäuse entfernen, die Wischwalze anbringen und den Griff in die dafür vorgesehene Öffnung stecken, bis er einrastet. Anschließend stellt man den F25 Ace Pro an die angeschlossene Ladestation, um den Akku aufzuladen. Zeitgleich kann die Koppelung mit der Roborock-App starten. Hinter dem Schmutzwassertank ist ein QR-Code versteckt, den man mit der Roborock-App einscannt, anschließend verbindet das Gerät mit dem heimischen WLAN. Etwaige anstehende Firmware-Updates können jetzt gestartet werden.
Für den ersten Einsatz steht zum Schluss noch das Auffüllen des Frischwassertanks und des Reinigungsmittelfachs an. Alles in allem ist die Einrichtung auch beim F25 Ace Pro super schnell und einfach erledigt.
Steuerung
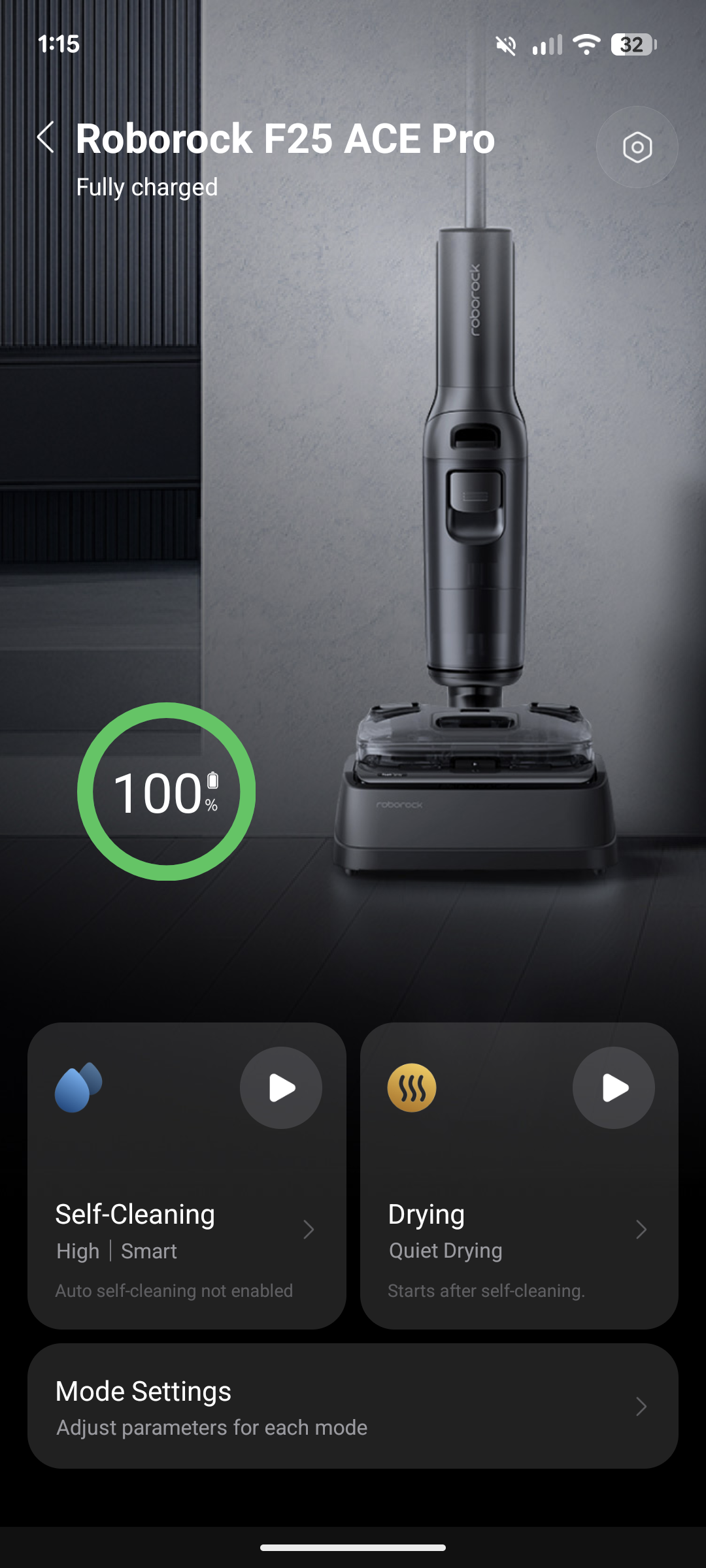
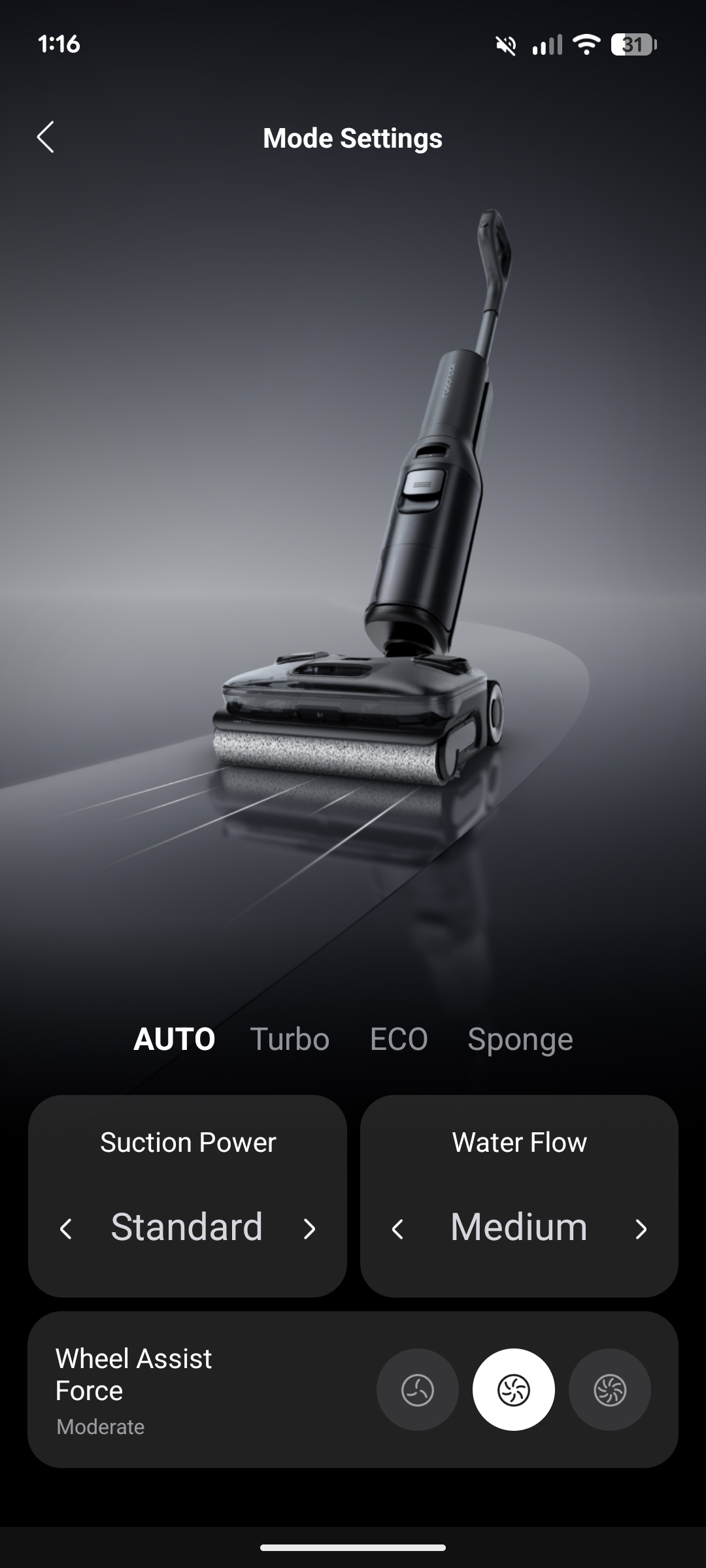
Die Steuerung per App funktioniert erneut super. Man wechselt schnell zwischen den einzelnen Modi hin und her, justiert die Saugstärke und Wassermenge oder passt die Stärke der motorisierten Räder an. Auch die anschließende Selbstreinigung und Trocknung startet man bequem per App. Selbstverständlich steuert sich der Wischsauger auch über die Knöpfe am Gerät selbst.
Das LCD gibt Aufschluss über den gerade aktiven Modus sowie den derzeitigen Akkustand, wobei die Prozentanzeige der App aufschlussreicher ist als die Batterieanzeige auf dem Display.
Fester Bestandteil des Roborock F25 Ace Pro ist die Ansagerstimme, die jeden Moduswechsel und generell jede Zustandsänderung des Wischsaugers vertont. Uns stört das während des Tests nicht, auch wenn sie relativ laut ist. Das relativiert sich jedoch, sobald der Wischsauger in Betrieb ist. Die vertonten Informationen beschränken sich wirklich nur auf das Nötigste. Etwa der Wechsel in einen anderen Modus, die Information, dass der Ladevorgang beginnt oder die Aufforderung, dass man die Selbstreinigung starten soll. Man kann sie aber, wenn gewünscht, jederzeit leiser stellen oder auch ganz verstummen lassen. Es stehen neben Englisch und Deutsch auch viele andere Sprachausgaben, wie etwa Japanisch, Spanisch und Polnisch zur Auswahl. Beim
Roborock F25 Ace Pro – Bilder App
Roborock F25 Ace Pro – Bilder App
Roborock F25 Ace Pro – Bilder App
Roborock F25 Ace Pro – Bilder App
Roborock F25 Ace Pro – Bilder App
Roborock F25 Ace Pro – Bilder App
Roborock F25 Ace Pro – Bilder App
Roborock F25 Ace Pro – Bilder App
Roborock F25 Ace Pro – Bilder App
Über den Trigger am Griffinneren aktiviert sich die Düse am Bürstenkopf und verwandelt einen Teil des Reinigungskonzentrats in Schaum, der vor dem Wischsauger verteilt wird. Die motorisierten Räder fahren mit einer angenehmen Beschleunigung, die in Kombination mit der 70-Grad-Schwenkung des Wischsaugers für eine super präzise und komfortable Steuerung sorgt.
Auch den Roborock F25 Ace Pro kann man für die Reinigung senkrecht auf den Boden legen. Die App dient dann als Fernbedienung, mit der man den Wischsauger auch unter Möbel fahren kann, ohne sich dabei verrenken zu müssen. Eine Kamera, um unter den Möbeln sehen zu können, wo der Sauger gerade lang fährt, fehlt leider. Generell bietet sich die Fernsteuerung per App nur für punktuelle Bewegungen an, da sie sehr verzögert und grob auf die Eingaben reagiert.
Reinigung
Bei der täglichen Reinigung macht der F25 Ace Pro eine durchaus gute Figur. Mit 25.000 Pa saugt er gröbere Schmutzpartikel problemlos auf, während die Wischfunktion im Automatikmodus ideal das Parkett befeuchtet. Wir beseitigen mit ihm problemlos eingetrocknete Kakaoflecken, aber auch Flüssigkeiten wie verschüttete Hafermilch sind keine Herausforderung.
Mit der Schaumfunktion bearbeiten wir hartnäckigere Flecken und zum Großteil bemerken wir, dass sich die Verschmutzung im Anschluss tatsächlich leichter löst. Ein Allheilmittel ist das allerdings nicht, denn auch der F25 Ace Pro kommt an seine Grenzen. Eine besonders hartnäckige und festgetretene Verschmutzung auf dem Parkettboden bekommt er auch mit Schaum und mehrmaligem Darüberfahren nicht ohne weiteres gelöst. Hier müssen wir von Hand reinigen.
Auf Fliesen kann er verhältnismäßig gut sauber machen, auch wenn er in erster Linie für Parkettböden gedacht ist. Er muss sich aber deutlich schneller mit Flecken geschlagen geben als auf dem Holzboden. Hier hilft ebenso der zusätzliche Schaum beim Lösen der Verschmutzungen. Mit dem Schaum die gewünschte Stelle zu treffen, erfordert ein, zwei Versuche, bis man den Sprühradius raus hat. Die Düse beginnt nämlich unmittelbar vor dem Bürstenkopf zu sprühen und verteilt den Schaum dann in etwa bis zu 15 cm nach vorne.
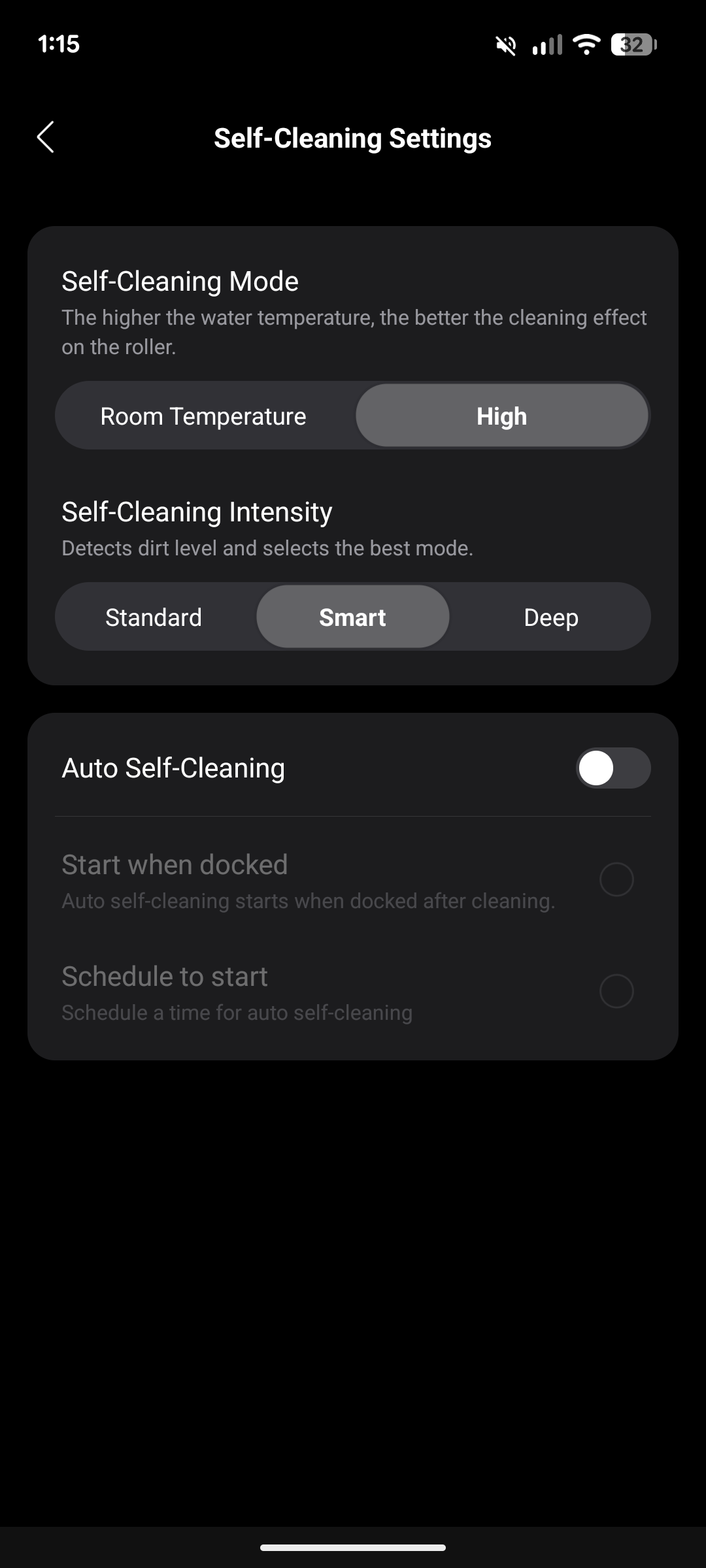
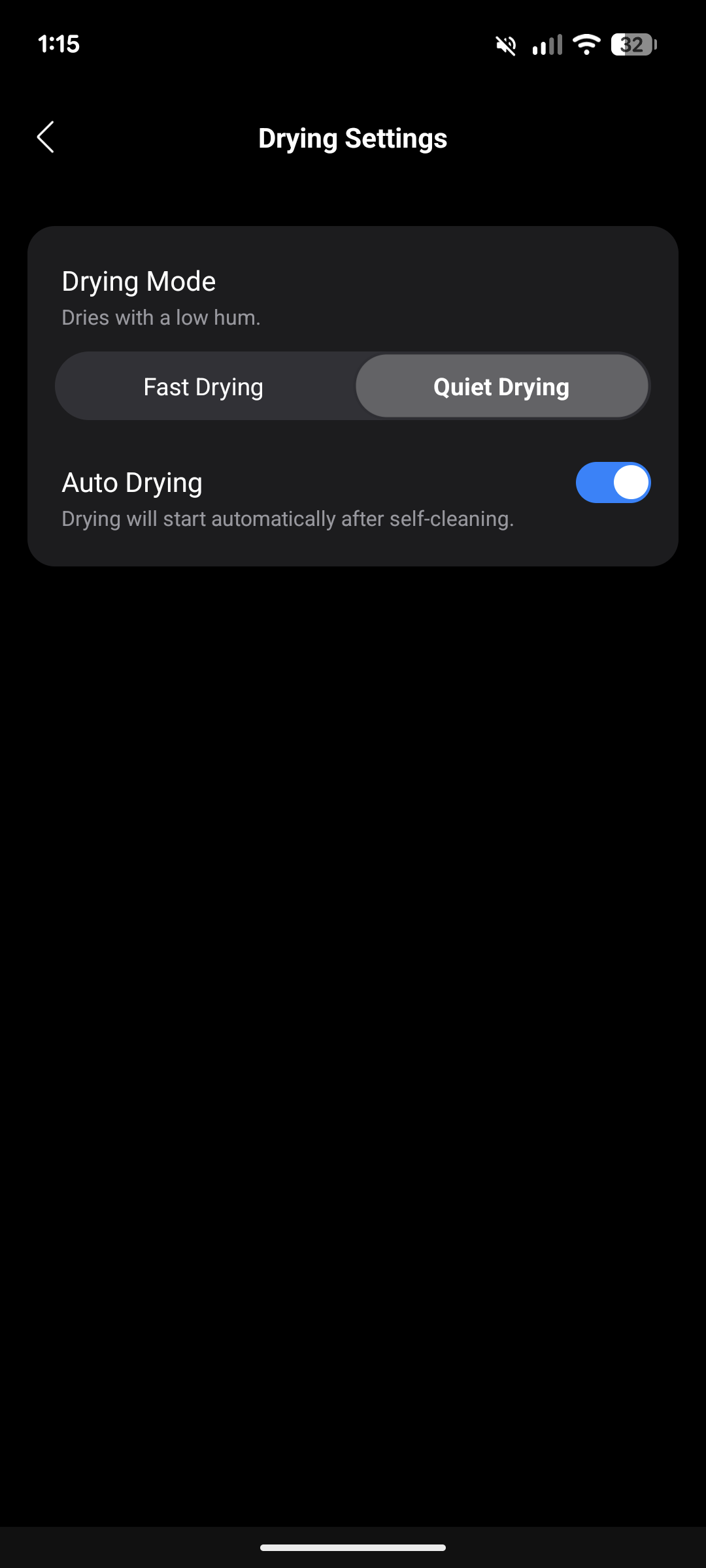
Die Selbstreinigung mit der Ladestation erfolgt mit 95 °C heißem Wasser und reinigt die Wischwalze während unseres Tests rundum zufriedenstellend innerhalb von fünf Minuten. Auch die anschließende Lufttrocknung findet bei 95 °C statt, wahlweise in fünfminütiger Schnelltrocknung oder in der deutlich entspannteren dreißigminütigen Trocknung. Wir entscheiden uns für letztere und begrüßen das leise, angenehme Surren während des Vorgangs.
Was die Lautstärke angeht, ist der Roborock F25 Ace Pro im Betrieb vollkommen in Ordnung. Im Automatik-Modus und Max-Modus arbeitet er mit 50 bis 60 dB(A), die wir per Smartphone-App direkt am Gerät messen. 60 dB(A) waren aber tatsächlich auch die Obergrenze, die wir hier feststellen konnten. Die Werte dienen selbstverständlich nur als Richtwert und sind nicht mit Messwerten von professionellem Equipment zu vergleichen.
Die Lautstärke der Selbstreinigung fährt ebenfalls bis auf 60 dB(A) hoch, bewegt sich aber überwiegend bei etwa 55 dB(A). Das leise Surren der dreißigminütigen Selbsttrocknung pegelt sich bei etwa 35 dB(A) unmittelbar an der Station ein, ist aber bei laufendem Fernseher oder Musik nicht mehr wirklich zu hören.
Die anschließende Reinigung des Schmutzwassertanks findet nach wie vor von Hand statt. Hier gibt es nichts zu beanstanden, denn das Auffangsieb löst sich mit nur einem Handgriff vom Tank und hinterlässt größtenteils nur Plörre. Der feste Schmutz bleibt am Sieb hängen und kann einfach in den Mülleimer verfrachtet werden. Anschließend noch den HEPA-Filter, das Sieb und den Tank durchspülen, abtrocknen und wieder einsetzen, und der F25 Ace Pro ist erneut einsatzbereit.
Akkulaufzeit
Roborock verspricht bis zu 60 Minuten Betrieb im Eco-Modus, 40 Minuten im Auto-Modus und 30 Minuten im Max-Modus mit dem F25 Ace Pro. Die Werte decken sich mit unseren Beobachtungen, denn nach etwa 15 Minuten im Auto-Modus mit mehrmaligem Wechsel in den Max-Modus verbleiben noch gut 60 Prozent Akkuladung. Das sollte ausreichen, um die meisten Wohnungen problemlos durchzuwischsaugen.
Preis
Die UVP des Roborock F25 Ace Pro liegt bei 649 Euro. Aktuell gibt es den Wischsauger für 549 Euro auf der Roborock-Website. Alternativ ist er zum gleichen Preis auch bei Amazon verfügbar.
Fazit
Für 549 Euro reinigt der Roborock F25 Ace Pro zuverlässig die meisten Verschmutzungen – sowohl durch Wischen als auch Saugen. Unterstützt wird er hierbei durch die neu hinzugekommene Schaumdüse, die in unserem Test einen guten Job macht und tatsächlich eine nützliche Ergänzung für die regelmäßige Putzaktion ist.
Mit 25.000 Pa hat er zwar auf dem Papier eine höhere Saugleistung als noch der F25 Ace, saugt für uns aber nicht merklich besser oder schlechter. Auch die restlichen Funktionen gleichen sich mehr oder weniger mit denen älterer Modelle. Für Besitzer eines aktuelleren Roborock-Saugwischers lohnt sich also ein Upgrade auf den F25 Ace Pro nicht wirklich, da hier die Schaumdüse die einzige tatsächliche Neuerung darstellt.
Wer noch keinen Wischsauger hat, bekommt mit dem Roborock F25 Ace Pro aber ein kompetentes Modell, das im Hinblick auf Reinigung, Verarbeitung und Handhabung überzeugt.











Künstliche Intelligenz
Schweizer Franken: Eidgenossen verankern Bargeld in der Verfassung
Das vertraute Klimpern in der Hosentasche erhält in der Schweiz Verfassungsrang. In einer Volksabstimmung hat am Sonntag eine deutlichen Mehrheit von 73,4 Prozent den Bundesbeschluss über die schweizerische Währung und die Bargeldversorgung angenommen.
Weiterlesen nach der Anzeige
Damit rückt der Schutz von physischem Geld eine Stufe höher: Was bisher lediglich auf Gesetzesebene geregelt war, wird nun fest in der Bundesverfassung verankert. Der Franken bleibt die offizielle Währung. Der Bund steht zudem über die Schweizerische Nationalbank in der Pflicht, stets für eine ausreichende Bargeldversorgung zu sorgen.
Vorschlag von Aktivisten abgelehnt
Aktivisten wollten mit einer anderen Bargeld-Initiative einen noch stärkeren Schutz ausdrücklich auch von „Münzen und Banknoten“ erreichen. Doch damit scheiterten sie gegen 54,4 Prozent Nein-Stimmen.
Initiator Richard Koller wertete das Gesamtergebnis trotzdem als Erfolg. Das Kernanliegen, Bargeld vor einer schleichenden Verdrängung durch digitale Zahlungsmittel zu bewahren, sei durch den stattdessen angenommenen Gegenvorschlag von Bundesrat und Parlament faktisch übernommen worden. Die Unterschiede zwischen den Vorlagen lagen primär in juristischen Nuancen und einzelnen Formulierungen.
Symbolischer Sieg mit politischer Sprengkraft
Für die Schweizer Bevölkerung ändert sich im Portemonnaie vorerst nichts. Das Votum hat primär symbolische Wirkung und sichert die Wahlfreiheit zwischen Smartphone, Karte und Bargeld langfristig ab. In Deutschland wird derweil darüber diskutiert, eine elektronische Bezahloption zur Pflicht zu machen.
Weiterlesen nach der Anzeige
Trotz des klaren Entscheids ist die eidgenössische Debatte nicht beendet: Das Augenmerk richtet sich nun auf die Kantone. In Genf gibt es bereits eine Verpflichtung für Gastronomiebetriebe, Bargeld anzunehmen. Nationalräte verschiedener Parteien kündigten weitere Vorstöße an, um eine Annahmepflicht vor allem im öffentlichen Dienst und im Verkehrswesen durchzusetzen.
(vbr)
Künstliche Intelligenz
LGs neue OLED-TVs: Die helle Generation
LG hat in Frankfurt seine TV-Produktpalette 2026 gezeigt. Das jüngste Modell der G6-Serie unterscheidet sich auf den ersten Blick wenig von seinem Vorgänger G5. Der G6 nutzt das gleiche Chassis und auch das gleiche OLED-Panel mit RGB-Tandem-Struktur. Allerdings wird dies im G6 intern anders angesteuert, was zu sicht- und messbaren Verbesserungen geführt hat. An zwei 65-Zöllern (G5 und G6) konnten wir bei einem Hands-on die Leuchtdichte messen und bekamen einen Eindruck von der neuen Bildqualität.
Weiterlesen nach der Anzeige
So leuchtet das brandneue G6-Modell nun mit 3100 cd/m2 in der Spitze stolze 800 cd/m2 heller als sein Vorgänger OLED65G5; das sorgt insbesondere bei der Wiedergabe von HDR-Inhalten (High Dynamic Range) für noch hellere Punktlichter. Auf einem zu zehn Prozent weißen Schirm haben wir rund 2400 cd/m2 statt der bisherigen 2300 cd/m2 gemessen, und auf einem komplett weißen Schirminhalt erreichte das brandneue Modell bemerkenswerte 460 cd/m2 gegenüber 380 cd/m2 am bisherigen G5-Modell. Beide Fernseher haben wir mit HDR-Signalen im Filmmaker-Modus bei maximaler Helligkeitseinstellung gemessen.


Für die RGB-Tandemstruktur des WOLED hat Panelhersteller LG Display im vergangenen Jahr die gelbe Leuchtschicht an der blauen durch rote und grüne ersetzt.
(Bild: LG)
Glatte Farbverläufe
Deutliche Fortschritte hat LG dagegen beim Unterdrücken des sogenannten Banding für die Wiedergabe von feinen Farbverläufen gemacht. Dies war in der Vergangenheit ein Schwachpunkt des Herstellers; Samsung, Sony oder Panasonic gelingt das besser. Banding äußert sich durch sichtbare Abstufungen, beispielsweise am changierenden Himmel oder am wabernden Blau in Unterwasseraufnahmen.
Die Farbsignale übergibt der Hersteller dafür nun mit 12 Bit pro Farbe statt vormals 10 Bit ans Display und berechnet die weißen Subpixel für feinere Lichter intern mit 13 Bit. In der Folge gelingen dem TV Farbverläufe wesentlich gleichmäßiger, der Vorgänger G5 zeigte in Testbildern dagegen einige Abbrüche mit harten Farbübergängen an feinen Verläufen.

Farbverläufe gibt der brandneue G5 dank verbesserter Ansteuerung gleichmäßig abgestuft wieder.
(Bild: Ulrike Kuhlmann / heise medien)
Sparsamer im Betrieb
Weiterlesen nach der Anzeige
Weitere Verbesserungen finden sich im Bildprozessor. Das SoC wird nun in 6-Nanometer-Technik gefertigt, wodurch der Chipsatz aus CPU, GPU, Speicher, Netzwerkfunktion etc. laut LG dank der kleineren Strukturen 30 Prozent weniger Strom benötigt und dadurch weniger Wärme produziert. Das ist nicht nur gut für den Geldbeutel der Zuschauer, sondern auch fürs OLED, denn organische Displays reagieren empfindlich auf Wärme, sie altern dadurch schneller.
Mit der sogenannten Dual-AI-Resolution des neuen Alpha-11-Prozessors separiert LG die Kantenglättung von der Berechnung feiner Strukturen beim Upscaling. Die Umrechnung ist immer dann nötig, wenn Inhalte mit geringerer Auflösung als der 4K-Panel-Auflösung (3840 × 2160 Pixel) vom TV wiedergegeben werden müssen. Das Upscaling greift unter anderem bei (fast) allen TV-Signalen in HD (1280 × 720 oder 1920 × 100 Bildpunkte) und beim Videostreaming in Full HD, wie es Netflix & Co. in ihren preiswerten Abomodellen anbieten.
Natürlich bietet LG zusätzlich diverse KI-Bildoptimierungen an, die aber zuweilen über das Ziel hinausschießen und nichts für Puristen sind. Bei der von uns empfohlenen „Filmmaker“-Voreinstellung sind derartige KI-Optimierungen ohnehin deaktiviert.
Spieglein, Spieglein …
An der Entspiegelung hat LG ebenfalls gearbeitet. Die neue dielektrische Entspiegelung der Displayoberfläche ist aber weniger gelungen: Sie reduziert einfallendes Licht jetzt zwar noch stärker, versieht es aber mit einem merklichen Rotstich. Außerdem wird die Oberfläche dadurch etwas blickwinkelabhängig, von schräg betrachtet bekommt das Bild an den Seiten einen leichten Farbschimmer. Das bemerkt man insbesondere auf gleichmäßigen, helleren Bildinhalten, sie wirken von der Seite und aus geringem Betrachtungsabstand an den Rändern grünlich.
Offenbar musste sich LG hier zwischen Pest und Cholera entscheiden: Entweder mehr störende Reflexionen oder mehr blickwinkelabhängige Farbveränderungen. Aus einigen Metern Abstand sind die Farbstiche wegen der dann kleineren Einblickwinkel nicht mehr zu sehen. Trotzdem sind sie schade, gerade weil sich OLEDs durch ihre blickwinkelstabile Darstellung weiterhin von den LCDs abheben.
(uk)
Künstliche Intelligenz
Irankrieg: Langfristig potenzielle Gefahr für die Chip- und Speicherproduktion
Der Irankrieg könnte die weltweite Chipproduktion beeinflussen, wenn er lange anhält. Insbesondere in Südkorea bereitet die Situation Sorgen, weil dort die zwei weltweit größten Speicherhersteller Samsung und SK Hynix ansässig sind. Aufgrund der hohen Nachfrage bei KI-Rechenzentren herrscht bereits eine Speicherkrise, die insbesondere Endkunden trifft. Kurzfristig soll es jedoch keine signifikanten Auswirkungen geben.
Weiterlesen nach der Anzeige
Ein längerer Konflikt könnte sich auf die Lieferketten für die Speicherproduktion auswirken. Aus dem Nahen Osten stammen etwa große Mengen Helium und Brom. Vor allem Helium ist in der Chipfertigung wichtig. Hersteller verwenden es etwa zur Kühlung von Silizium-Wafern in der Produktion, da Helium eine hohe Wärmeleitfähigkeit und weitere geeignete Eigenschaften aufweist. Brom ist für manche Ätzvorgänge wichtig.
Katar ist laut einer Untersuchung des United States Geological Survey der nach den USA zweitgrößte Lieferant von Helium weltweit. Auf beide Länder entfielen 2025 demnach 76 Prozent der weltweiten Produktion. Katar hat nach iranischen Angriffen und der Bedrohung der Schifffahrtswege durch die Straße von Hormuz Produktion und Export von Helium eingestellt.
Alarmiert, aber nicht kritisch
Die Nachrichtenagentur Reuters gibt Politikeraussagen aus Südkorea wieder, die vor langwierigen Lieferstopps warnen: „Funktionäre wiesen auf die Möglichkeit hin, dass die Halbleiterproduktion gestört werden könnte, wenn einige dieser wichtigen Materialien nicht aus dem Nahen Osten bezogen werden können“, sagt Kim Young-bae, Mitglied der südkoreanischen Nationalversammlung, nach Treffen unter anderem mit Samsungs Führungsriege. Insgesamt sollen Südkoreas Chip- und Speicherhersteller von über einem Dutzend Produkten aus dem Nahen Osten abhängig sein.
SK Hynix gibt zumindest kurzfristig Entwarnung: Der Speicherhersteller verfüge „seit Langem über vielfältige Lieferketten und ausreichende Vorräte“ an Helium. „Daher [ist] kaum mit Auswirkungen auf das Unternehmen zu rechnen.“
Auch der weltweit größte Chipauftragsfertiger TSMC zeigt sich entspannt: Derzeit seien keine wesentlichen Auswirkungen zu erwarten. Die Firma will die Situation aber weiterhin genau beobachten.
Weiterlesen nach der Anzeige
In Südkorea sackten die Aktien von Samsung und SK Hynix zum Wochenbeginn um beinahe zehn Prozent ab. Bei den im Westen gehandelten Hinterlegungszertifikaten (Global Depositary Receipt, GDR) ist das Minus bislang nicht ganz so drastisch. Der gesamte Aktienmarkt ist derzeit volatil.
(mma)

Schweizer Franken: Eidgenossen verankern Bargeld in der Verfassung

Die FOMO-Strategie im Fundraising: So bringen Gründer Investoren zum Handeln

Samsung-Galaxy-Watch-Nutzer sollten dieses Update sofort installieren

Schnelles Boot statt Bus und Bahn: Was sich von London und New York lernen lässt

Community Management zwischen Reichweite und Verantwortung

Community Management und Zielgruppen-Analyse: Die besten Insights aus Blog und Podcast
-
 Künstliche Intelligenzvor 2 Monaten
Künstliche Intelligenzvor 2 MonatenSchnelles Boot statt Bus und Bahn: Was sich von London und New York lernen lässt
-
 Social Mediavor 4 Wochen
Social Mediavor 4 WochenCommunity Management zwischen Reichweite und Verantwortung
-
 Social Mediavor 1 Woche
Social Mediavor 1 WocheCommunity Management und Zielgruppen-Analyse: Die besten Insights aus Blog und Podcast
-
Künstliche Intelligenzvor 3 Wochen
Top 10: Die beste kabellose Überwachungskamera im Test – Akku, WLAN, LTE & Solar
-

 Entwicklung & Codevor 3 Monaten
Entwicklung & Codevor 3 MonatenKommentar: Anthropic verschenkt MCP – mit fragwürdigen Hintertüren
-

 Künstliche Intelligenzvor 3 Monaten
Künstliche Intelligenzvor 3 MonatenGame Over: JetBrains beendet Fleet und startet mit KI‑Plattform neu
-

 Künstliche Intelligenzvor 3 Monaten
Künstliche Intelligenzvor 3 MonatenDigital Health: „Den meisten ist nicht klar, wie existenziell IT‑Sicherheit ist“
-

 Social Mediavor 3 Monaten
Social Mediavor 3 MonatenDie meistgehörten Gastfolgen 2025 im Feed & Fudder Podcast – Social Media, Recruiting und Karriere-Insights

