Entwicklung & Code
Typesense 30.0: Open-Source-Suchmaschine mit globalen Kuratierungsregeln
Die Entwickler der Open-Source-Suchmaschine Typesense haben Version 30.0 veröffentlicht. Das Update bringt grundlegende API-Änderungen für Synonyme und Kuratierungsregeln (Curation Rules) sowie neue Features wie Maximale Marginale Relevanz (Maximum Marginal Relevance, MMR) zur Diversifizierung von Suchergebnissen. Die bisher sammlungsspezifischen Synonyme und Kuratierungsregeln sind nun globale Ressourcen, die zwischen Sammlungen (Collections) geteilt werden können.
Weiterlesen nach der Anzeige
Administratoren müssen vor dem Update auf Version 30.0 einen Snapshot anlegen, da die neue Version eine automatische Migration durchführt. Dabei werden bestehende sammlungsspezifische Synonyme und Überschreibungen (Overrides) in globale Synonym-Sets und Kuratierungs-Sets überführt. Die API-Endpunkte ändern sich dabei von /collections/{collection}/synonyms/* zu /synonym_sets/* und von /collections/{collection}/overrides/* zu /curation_sets/*. Bestehende Suchanfragen funktionieren nach der Migration weiter, für Lese- und Schreibzugriffe auf die neuen Sets müssen Entwickler ihre Anwendungen jedoch an die neuen Endpunkte anpassen.
Diversifizierung mit MMR
Ein zentrales neues Feature ist die Diversifizierung von Suchergebnissen per MMR. Der Algorithmus diversifiziert die obersten 250 Treffer basierend auf einer vordefinierten Ähnlichkeitsmetrik (Similarity-Metric). Die MMR-Formel berücksichtigt dabei sowohl die Relevanz eines Dokuments zur Suchanfrage als auch dessen Ähnlichkeit zu bereits ausgewählten Ergebnissen. Der Lambda-Parameter steuert die Balance zwischen Relevanz und Diversität, wobei der Standardwert 0,5 beträgt. Administratoren können MMR über Curation Sets mit verschiedenen Ähnlichkeitsmetriken wie Jaccard für Arrays oder Vector Distance für Embeddings konfigurieren.
Die globale Struktur von Synonymen und Kuratierungsregeln reduziert Redundanzen, da diese Ressourcen nicht mehr für jede Sammlung separat angelegt werden müssen. Dies führt zu geringerem Speicherbedarf und potenziell besseren Cache-Hits bei der Wiederverwendung. Synonym-Sets unterstützen sowohl One-way- als auch Multi-way-Synonyme und können sprachspezifisch konfiguriert werden. In Kuratierungsregeln lassen sich nun auch Synonyme und Stemming verwenden, außerdem unterstützen sie MMR-Diversifizierung sowie dynamisches Filtern und Sortieren.
Erweiterte JOIN-Funktionen und Cloud-Integration
Version 30.0 erweitert die JOIN-Features deutlich. Der facet_by-Parameter unterstützt nun referenzierte Felder aus verknüpften Sammlungen, etwa facet_by=$Customers(product_price). Entwickler können mit include_fields die Anzahl verknüpfter Dokumente abrufen sowie Sortierung und Limits auf verknüpfte Felder anwenden. Neu ist auch die cascade_delete: false-Option, die verhindert, dass referenzierte Dokumente automatisch gelöscht werden, wenn alle Referenzen entfernt wurden. Diese Option erfordert async_reference: true im Schema.
Weiterlesen nach der Anzeige
Für die Suche in natürlicher Sprache (Natural Language Search) und Auto-Embedding unterstützt Typesense 30.0 nun OpenAI-Modelle von Azure sowie GCP Service Account Authentication. Dies ermöglicht die Integration in Cloud-Umgebungen mit Azure- und Google-Cloud-Modellen. Für die vektorbasierte Bildsuche stehen neue CLIP Multilingual Models zur Verfügung, die mehrsprachige Ähnlichkeitssuche (Similarity) in Bildern ermöglichen. Der neue IPv6-Support erlaubt Binding und Serving über IPv6-Adressen, was die Integration in moderne Dual-Stack- und IPv6-only-Netzwerke erleichtert.
Performance-Verbesserungen und Bugfixes
Zu den Verbesserungen gehören ein truncate-Parameter für String-Felder zur besseren Suche mit einem exakten Treffer (Exact Match) bei langen Strings sowie group_max_candidates für exakte found-Werte bei group_by-Operationen. Die Synonym-Matching-Logik wurde verbessert und sortiert Ergebnisse nun nach Match-Qualität. Ein Transliterator-Pool beschleunigt die Tokenisierung für kyrillische und chinesische Zeichen. Die Vereinigungssuche (Union Search) unterstützt nun group_by, pinned_hits und ein remove_duplicates-Flag.
Version 30.0 behebt zahlreiche Fehler, darunter Probleme mit Analytik-IDs bei unterschiedlichen filter_by– und analytics_tag-Parametern sowie feldspezifische Token-Separatoren im Highlighting. Pagination-Parameter werden nun korrekt an die Vereinigungssuche übergeben, und Deadlocks bei asynchronen Referenzen wurden beseitigt. Das Highlighting wurde so angepasst, dass bei Phrasensuchen (Phrase Queries) nur noch exakte Treffer markiert werden und bei der Suche in natürlicher Sprache die tatsächliche Abfrage (Query) hervorgehoben wird.
Details zur neuen Version finden sich in den Release Notes auf GitHub.
(fo)









Entwicklung & Code
Open Source statt kostenpflichtig: Alpha-Version von Vite+ steht bereit
Vite+ Alpha ist erschienen – quelloffen unter MIT-Lizenz. Der Hersteller VoidZero, der auch das quelloffene JavaScript-Build-Tool Vite entwickelt, hatte Vite+ im letzten Jahr zunächst als für Unternehmen kostenpflichtiges Angebot angekündigt. Bei Vite+ handelt es sich um ein Kommandozeilentool, das eine einheitliche Toolchain für die Webentwicklung bieten soll.
Weiterlesen nach der Anzeige
Vite+ auch für Unternehmen Open Source
Wie VoidZero angibt, hat es sich entgegen der ersten Ankündigung im Oktober 2025 für die vollständige Open-Source-Veröffentlichung von Vite+ entschieden. Zunächst sollte Vite+ für größere Unternehmen kostenpflichtig sein, dagegen für individuelle Entwicklerinnen und Entwickler, Open-Source-Projekte sowie kleine Unternehmen kostenfrei. Der Hersteller begründet diesen Richtungswechsel unter anderem mit der ermüdenden Debatte darüber, welche Features kostenfrei und welche kostenpflichtig sein sollten. Auch Feedback von der Community spielte in die Entscheidung hinein.

(Bild: jaboy/123rf.com)

Tools und Trends in der JavaScript-Welt: Die enterJS 2026 wird am 16. und 17. Juni in Mannheim stattfinden. Das Programm dreht sich rund um JavaScript und TypeScript, Frameworks, Tools und Bibliotheken, Security, UX und mehr. Frühbuchertickets sind im Online-Ticketshop erhältlich.
Vite+: Einheitliche Toolchain für Web Developer
Laut Evan You, dem Entwickler von Vue.js und Vite sowie Gründer von VoidZero, haben sich im JavaScript-Umfeld die Tooling-Komplexität und die Performance für Unternehmen zu Flaschenhälsen entwickelt. An dieser Stelle soll Vite+ als einheitliche Toolchain Abhilfe schaffen, mit dem Ziel, Webentwicklung leichtgewichtiger, einfacher und schneller zu gestalten.
Vite+ ist ein Kommandozeileninterface, das die Technologien Vite, Vitest, Oxlint, Oxfmt, Rolldown, tsdown sowie den neuen Task Runner namens Vite Task kombiniert. Damit soll es das Erstellen von Webprojekten vollständig abdecken – inklusive Testing, Linting, Formatierung und Verwaltung von Runtime und Paketmanager. Zum Konfigurieren aller Tools dient eine einzige vite.config.ts-Datei im Root des Projekts.
In Vite+ können Entwicklerinnen und Entwickler Befehle wie vp env zum Verwalten von Node.js – global oder je Projekt –, vp install zum Installieren von Dependencies, vp check für das Linting mit Oxlint, das Formatieren von Code mit Oxfmt und das Type-Checking mit tsgo oder vp build für das Erstellen von Produktions-Builds mit Rolldown und Oxc verwenden.
Weiterlesen nach der Anzeige
Wie VoidZero ausführt, funktionieren alle diese Befehle out-of-the-box nahtlos miteinander und sind mit allen Frameworks im Vite-Ökosystem kompatibel, beispielsweise React, Vue oder Svelte. Die Migration auf Vite+ soll am einfachsten funktionieren, wenn Entwickler bereits die kürzlich erschienene Version Vite 8.0 verwenden.
Alle weiteren Details zum Alpha-Release von Vite+ sind im VoidZero-Blog zu finden.
(mai)
Entwicklung & Code
Vite 8.0: Rust-basierter Bundler Rolldown ist der neue Standard
Vite 8.0 ist erschienen. Unter der Haube bringt das Frontend-Build-Tool nun Rolldown mit – einen Rust-basierten Bundler, der für eine höhere Build-Geschwindigkeit sorgt. Für die Suche nach Plug-ins steht darüber hinaus eine neue Registry bereit.
Weiterlesen nach der Anzeige
Erst kürzlich zeigte die aktuelle Umfrage State of JavaScript, dass Vite zum wiederholten Mal das beliebteste Tool unter JavaScript-Entwicklern ist und bei der Nutzungshäufigkeit nur noch knapp hinter webpack liegt.
(Bild: jaboy/123rf.com)

Tools und Trends in der JavaScript-Welt: Die enterJS 2026 wird am 16. und 17. Juni in Mannheim stattfinden. Das Programm dreht sich rund um JavaScript und TypeScript, Frameworks, Tools und Bibliotheken, Security, UX und mehr. Frühbuchertickets sind im Online-Ticketshop erhältlich.
Rolldown ersetzt Rollup und esbuild
Vite startete einst mit den beiden Bundlern esbuild und Rollup. Dabei kam esbuild während der Entwicklung zum Einsatz, Rollup für optimierte Produktions-Builds. Mit Vite 8.0 erfolgt nun der Wechsel zu Rolldown als einheitlichem Bundler, der die beiden Vorgänger ablöst. Hierbei soll es sich um die bedeutendste Änderung seit Vite 2.0 handeln.
Rolldown stammt ebenso wie Vite aus dem Hause VoidZero. Der Bundler besitzt eine Rollup-kompatible API, basiert auf der Programmiersprache Rust und soll 10- bis 30-mal schnellere Builds ermöglichen. Beispielsweise seien die Produktions-Build-Zeiten während der Beta-Phase von rolldown-vite bei Mercedes-Benz.io um 38 Prozent gesunken, bei der Newsletter-Plattform Beehiiv sogar um 64 Prozent.
Eine weitere Neuerung ist die Website registry.vite.dev, ein durchsuchbares Verzeichnis von Plug-ins für Vite, Rolldown und Rollup. Als Datenquelle dienen npm und die von Plug-in-Autoren hinterlegten Metadaten. Diese Daten werden täglich aktualisiert. Plug-in-Autoren können zusätzliche Metadaten hinterlegen, indem sie das Feld compatiblePackages in der JSON-Datei des Pakets hinzufügen.
Weiterlesen nach der Anzeige
Update auf das neue Release
Der Umstieg auf Vite 8.0 soll für die meisten Entwicklerinnen und Entwickler problemlos vonstattengehen. Für komplexe Projekte empfiehlt das Vite-Team jedoch eine schrittweise Migration: zuerst den Wechsel vom vite-Package zum rolldown-vite-Package in Vite 7, und erst anschließend den Wechsel zu Vite 8. Auf diese Weise lässt sich einfacher feststellen, ob mögliche Schwierigkeiten vom neuen Bundler herrühren. Weitere Hinweise finden Entwickler in der Migrationsanleitung.
Wie das Vite-Team einräumt, ist die Installationsgröße von Vite 8 etwa 15 MB größer als Vite 7. Das liegt hauptsächlich daran, dass lightningcss nun keine optionale Dependency mehr ist und dass die Rolldown-Binärdatei größer ist als esbuild und Rollup. Eine Verringerung der Installationsgröße steht jedoch auf dem Plan.
Alle weiteren Details zu Vite 8.0 finden sich im Vite-Blog und im Changelog.
(mai)
Entwicklung & Code
Databricks legt Genie Code vor: Ein KI-Agent soll Datenteams die Arbeit abnehmen
Databricks hat mit Genie Code einen KI-Agenten vorgestellt, der die Arbeit von Datenteams grundlegend verändern soll. Statt Entwicklern lediglich beim Schreiben von Code zu assistieren, übernimmt der Agent der Ankündigung zufolge eigenständig komplexe Aufgaben: den Aufbau von Datenpipelines, die Fehlerbehebung in Produktionssystemen, die Erstellung von Dashboards und die Wartung laufender Systeme. Laut Ali Ghodsi, Mitbegründer und CEO von Databricks, weist Genie Code den Weg hin zu „agentenbasierter Datenarbeit“.
Weiterlesen nach der Anzeige
![]()
Am 7. und 8. Oktober 2026 lädt die data2day Data Scientists, Data Engineers und Data Teams zur mittlerweile 13. Auflage der Konferenz ein. Bis zum 15. April können Expertinnen und Experten beim Call for Proposals noch ihre Vorschläge für Talks und Workshops einreichen.
Was Genie Code leisten soll
Genie Code ergänzt laut Ankündigung im Databricks-Blog die bestehende Genie-Produktfamilie, mit der Nutzer bereits per Chat-Interface auf ihre Unternehmensdaten zugreifen können. Im Vergleich mit herkömmlichen Coding-Agenten soll sich Genie Code vor allem durch seine tiefe Integration in die unternehmenseigene Dateninfrastruktur auszeichnen. Über den Unity Catalog von Databricks greift der Agent auf Metadaten, Datenherkunft, Nutzungsmuster und Governance-Richtlinien zu. Herkömmliche Coding-Agenten scheitern laut Databricks häufig an Datenaufgaben, weil ihnen genau dieser Kontext fehlt.
Genie Code ist dabei kein einzelnes Sprachmodell, sondern ein agentenbasiertes System, das Aufgaben über mehrere Modelle und Werkzeuge hinweg verteilt. Je nach Anforderung wählt das System der Ankündigung zufolge automatisch das passende Modell aus – ob proprietäres Frontier-Modell, Open-Source-Modell oder ein auf Databricks gehostetes Custom-Modell.
Die Funktionen erstrecken sich über den gesamten Daten- und ML-Lebenszyklus: Der Agent soll vollständige Machine-Learning-Workflows abwickeln können – vom Feature-Engineering über das Training und den Vergleich mehrerer Modelltypen bis hin zum Deployment auf Databricks Model Serving. Experimente werden dabei in MLflow protokolliert. Im Bereich Data Engineering erstellt Genie Code laut Hersteller produktionsreife Spark-Pipelines, berücksichtigt Unterschiede zwischen Staging- und Produktionsumgebungen und wendet automatisch Datenqualitätsprüfungen an. Darüber hinaus soll der Agent Dashboards mit wiederverwendbaren semantischen Definitionen generieren und mehrstufige Aufgaben autonom planen und ausführen können.
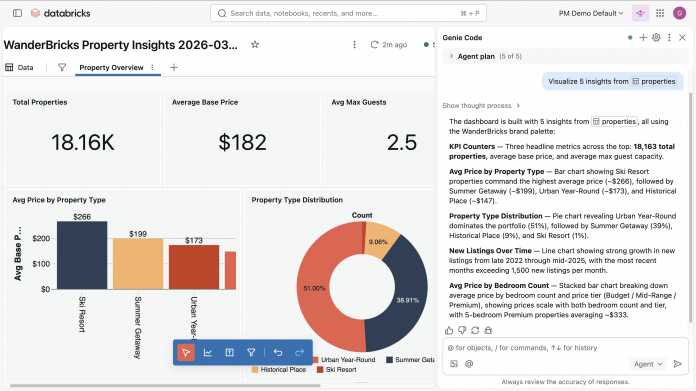
Genie Code soll Visualisierungen erstellen, Filter konfigurieren und Dashboard-Layouts organisieren – mit wiederverwendbaren semantischen Definitionen.
(Bild: Databricks)
Ein weiterer Aspekt ist die proaktive Überwachung: Genie Code soll Lakeflow-Pipelines und KI-Modelle im Hintergrund überwachen, Fehler triagieren und Anomalien untersuchen, bevor ein Mensch eingreifen muss. Sogenannte „Background Agents“ Agents“, die diese Überwachung dauerhaft im Hintergrund übernehmen, sind laut Databricks allerdings noch nicht verfügbar – sollen aber bald nachgereicht werden.
Weiterlesen nach der Anzeige
Der Agent verfügt über einen persistenten Speicher, der interne Anweisungen auf Basis vergangener Interaktionen und Coding-Präferenzen automatisch aktualisiert. So soll er mit der Zeit „besser werden“.
Übernahme von Quotient AI
Parallel zur Vorstellung von Genie Code gab Databricks die Übernahme von Quotient AI bekannt. Das Unternehmen ist auf die Bewertung und das verstärkende Lernen für KI-Agenten spezialisiert und war zuvor bereits an der Qualitätsverbesserung für GitHub Copilot beteiligt. Durch die Integration soll eine kontinuierliche Leistungsüberwachung direkt in Genie Code eingebettet werden: Quotient misst laut Databricks die Antwortqualität, erkennt Regressionen frühzeitig und lokalisiert Fehler – und speist diese Erkenntnisse in einen Verbesserungsprozess ein.
Lesen Sie auch
Verfügbarkeit und Erweiterbarkeit
Genie Code ist laut Databricks ab sofort allgemein verfügbar und direkt in Databricks-Workspaces integriert – in Notebooks, im SQL-Editor und im Lakeflow-Pipelines-Editor. Eine aufwendige Konfiguration sei nicht erforderlich.
Der Agent lässt sich über drei Wege erweitern: Über das Model Context Protocol (MCP) kann Genie Code mit externen Tools wie Jira, Confluence oder GitHub interagieren. Über sogenannte Agent Skills lassen sich domänenspezifische Fähigkeiten definieren, etwa für den Umgang mit personenbezogenen Daten oder unternehmensspezifische Validierungsframeworks. Und über den persistenten Speicher lernt der Agent aus vergangenen Interaktionen und passt sich an die Arbeitsweise des jeweiligen Teams an.
Die neuen Funktionen von Databricks reihen sich in einen branchenweiten Trend ein. Nahezu alle großen Anbieter setzen inzwischen auf agentenbasierte KI-Systeme, die komplexe Aufgaben autonom lösen sollen. Doch wie weit die tatsächlichen Fähigkeiten reichen, ist umstritten – insbesondere auch im Hinblick auf nicht-funktionale Anforderungen.
(map)

Hier gibt’s das Nothing Phone 4a Pro direkt deutlich günstiger

Elektroauto Kia EV2: Basismodell ab 26.600 Euro

AWS S3: Account Regional Namespaces machen Bucketsquatting den Garaus

Schnelles Boot statt Bus und Bahn: Was sich von London und New York lernen lässt

Community Management und Zielgruppen-Analyse: Die besten Insights aus Blog und Podcast

Community Management zwischen Reichweite und Verantwortung
-
 Künstliche Intelligenzvor 3 Monaten
Künstliche Intelligenzvor 3 MonatenSchnelles Boot statt Bus und Bahn: Was sich von London und New York lernen lässt
-
 Social Mediavor 2 Wochen
Social Mediavor 2 WochenCommunity Management und Zielgruppen-Analyse: Die besten Insights aus Blog und Podcast
-
 Social Mediavor 1 Monat
Social Mediavor 1 MonatCommunity Management zwischen Reichweite und Verantwortung
-
Künstliche Intelligenzvor 4 Wochen
Top 10: Die beste kabellose Überwachungskamera im Test – Akku, WLAN, LTE & Solar
-

 Social Mediavor 3 Monaten
Social Mediavor 3 MonatenDie meistgehörten Gastfolgen 2025 im Feed & Fudder Podcast – Social Media, Recruiting und Karriere-Insights
-

 UX/UI & Webdesignvor 2 Monaten
UX/UI & Webdesignvor 2 MonatenEindrucksvolle neue Identity für White Ribbon › PAGE online
-

 Künstliche Intelligenzvor 2 Monaten
Künstliche Intelligenzvor 2 MonatenAumovio: neue Displaykonzepte und Zentralrechner mit NXP‑Prozessor
-

 Künstliche Intelligenzvor 3 Monaten
Künstliche Intelligenzvor 3 MonatenÜber 220 m³ Fläche: Neuer Satellit von AST SpaceMobile ist noch größer

