Entwicklung & Code
Integration-Tests mit TestContainers: Von der Theorie zur Praxis
Wer Integration-Tests schreibt, kennt das Problem: Entweder man arbeitet mit Mocks, die nur begrenzt die Realität abbilden, oder man kämpft mit langsamen, schwer wartbaren Testumgebungen. Mocks haben den Charme, dass Tests schnell durchlaufen und keine externe Infrastruktur benötigen. Doch sie bergen eine Gefahr: Die Tests werden grün, weil die Mocks perfekt zu den Tests passen. Das heißt nicht unbedingt, dass der Code mit echten Systemen funktioniert. Wer garantiert, dass der Mock das Verhalten einer PostgreSQL-Datenbank oder einer Kafka-Queue korrekt abbildet?
Weiterlesen nach der Anzeige
Die Alternative in Form einer dedizierten Testumgebung mit echten Diensten bringt andere Probleme mit sich: Wie setzt man den Zustand zwischen Tests zurück? Wie verhindert man, dass Tests sich gegenseitig beeinflussen? Und wie stellt man sicher, dass die Testumgebung exakt der Produktionsumgebung entspricht?
Mit TestContainers gibt es einen pragmatischen Ausweg: Die Bibliothek startet echte Dienste in wegwerfbaren Docker-Containern. Jeder Test bekommt seine eigene, frische Instanz – komplett isoliert, mit definiertem Startzustand – und nach Testende automatisch aufgeräumt. Der Ansatz ist allerdings nur dann praktikabel, wenn die containerisierten Dienste schnell genug starten. Bei einer Datenbank, die in weniger als einer Sekunde bereit ist, lässt sich für jeden einzelnen Test ein neuer Container hochfahren. Bei Diensten mit mehreren Minuten Startzeit muss man hingegen zu Shared Containers greifen.
Die Idee hinter TestContainers
TestContainers ist ein Projekt zur programmatischen Steuerung von Docker-Containern in Tests. Der Kerngedanke ist simpel: Statt Mocks zu schreiben oder manuelle Testumgebungen zu pflegen, lässt man den Test selbst die benötigte Infrastruktur hochfahren. Nach Testende räumt TestContainers automatisch auf – kein manuelles Stoppen von Containern, keine vergessenen Ressourcen.
Die konzeptionelle Funktionsweise ist schnell erklärt: Ein Test startet einen oder mehrere Container, wartet, bis sie bereit sind, führt die eigentlichen Testschritte durch und stoppt zum Schluss die Container. TestContainers übernimmt dabei die dynamische Portzuordnung, sodass der Test sich nicht um Portkonflikte kümmern muss. Ein integrierter Reaper-Mechanismus sorgt dafür, dass Container auch dann aufgeräumt werden, wenn ein Test abstürzt oder abbricht.
Besonders wichtig sind die Wait Strategies. Ein gestarteter Container ist nämlich nicht automatisch sofort bereit, Anfragen zu verarbeiten. Eine Datenbank braucht beispielsweise Zeit zum Initialisieren, ein Webserver muss zunächst hochfahren. Wait Strategies definieren, wann ein Container als bereit gilt – etwa wenn ein bestimmter Port lauscht, eine HTTP-Anfrage erfolgreich ist oder eine spezifische Logzeile erscheint.
Weiterlesen nach der Anzeige
TestContainers bietet dabei bereits für viele gängige Anwendungen und Dienste vorgefertigte Module wie PostgreSQL, MySQL, Redis, MongoDB und Kafka. Diese Module sind Wrapper-Klassen um die generische Container-API, die bereits sinnvolle Defaults mitbringen, etwa Standardports, typische Umgebungsvariablen und passende Wait Strategies.
Für weniger verbreitete Dienste oder eigene Systeme kann man eigene Wrapper schreiben. Sie bauen auf dem GenericContainer auf und kapseln domänenspezifische Konfiguration. Das praktische Beispiel im Folgenden zeigt, wie unkompliziert die Umsetzung ist: eine Klasse, die das Image, Ports und Kommandozeilenparameter konfiguriert und eine Client-Instanz zurückgibt. Der Wrapper abstrahiert die TestContainers-API und bietet eine auf den konkreten Dienst zugeschnittene Schnittstelle.
Auf den ersten Blick scheint Docker Compose eine Alternative zu sein, das ebenfalls Container für Tests starten kann. Der Unterschied liegt jedoch in der Herangehensweise: Docker Compose arbeitet deklarativ mit YAML-Dateien und richtet typischerweise eine geteilte Umgebung für mehrere Tests ein. TestContainers hingegen ist programmatisch und integriert sich direkt in den Testcode. Jeder Test kann seine eigene Containerkonfiguration haben, Container werden im laufenden Betrieb gestartet und wieder gestoppt.
Ein weiterer Unterschied: Bei Compose muss man explizit darauf achten, Container zwischen verschiedenen Tests zurückzusetzen. Bei TestContainers ist das Design von Anfang an auf Isolation ausgelegt. Jeder Test bekommt neue Container, was sie robuster und unabhängiger voneinander macht.
Mehr Idee als Projekt
TestContainers ist kein monolithisches Open-Source-Projekt, sondern eher eine Idee, die in verschiedenen Programmiersprachen umgesetzt wurde. Es gibt TestContainers für Java, Go, .NET, Node.js, Python, PHP, Rust und zahlreiche weitere Sprachen – entwickelt von verschiedenen Maintainer-Teams mit unterschiedlichen Schwerpunkten.
Das bedeutet, dass beispielsweise Features, die in der Java-Implementierung selbstverständlich sind, in der Python-Version fehlen können – und umgekehrt. Auch die API-Gestaltung unterscheidet sich zwischen den Programmiersprachen, selbst wenn die Konzepte gleich bleiben. Die Dokumentationsqualität variiert und die Reife der Implementierungen ebenso.
Die Community und der Support sind pro Sprache organisiert: Hilfe zur Go-Implementierung findet man in anderen Foren als Hilfe zur PHP-Version.
Man sollte nicht davon ausgehen, dass ein bestimmtes Feature existiert, nur weil man es aus einer anderen Sprache kennt. Ein Blick in die Dokumentation der jeweiligen Implementierung ist unerlässlich. Die gute Nachricht: Die Grundkonzepte sind überall gleich. Wer das Prinzip verstanden hat, findet sich grundsätzlich auch in anderen Implementierungen zügig zurecht.
Ein Praxisbeispiel
Um die Unterschiede zwischen TestContainers-Implementierungen konkret zu zeigen, dient die Datenbank EventSourcingDB als Beispiel. Dabei handelt es sich um eine auf Event Sourcing spezialisierte, von the native web entwickelte Datenbank. Sie ist Closed Source, aber die zugehörigen Client-SDKs (Software Development Kits) sind Open Source auf GitHub verfügbar.
EventSourcingDB steht dabei exemplarisch für einen typischen Service, den man in Anwendungen benötigt – sei es eine Datenbank, eine Message-Queue oder ein anderer Infrastrukturdienst. Der entscheidende Vorteil für unser Beispiel: EventSourcingDB startet in weniger als einer Sekunde, was den „Container pro Test“-Ansatz praktikabel macht. Die Client-SDKs für verschiedene Sprachen enthalten jeweils eine eigene TestContainers-Integration, deren Implementierung sich lohnt anzuschauen.
Dieser Artikel betrachtet die Go- und PHP-Implementierung im Detail. Beide verfolgen konzeptionell den gleichen Ansatz, unterscheiden sich aber in wichtigen Details. Daher eignen sich die Implementierungen gut, um die Unterschiede zwischen TestContainers-Implementierungen zu illustrieren.









Entwicklung & Code
React-Entwicklung: Beliebtheit von TanStack Query bleibt ungebrochen
Die neue Ausgabe der Developer-Umfrage State of React ist erschienen. Über 3500 Entwicklerinnen und Entwickler teilen darin ihre Erfahrungen mit der JavaScript-Bibliothek React und ihrem Ökosystem. Die Open-Source-Library TanStack Query schneidet in der Nutzergunst sehr gut ab, während die neueren React-Features Server Components und Server Functions recht unbeliebt sind.
Weiterlesen nach der Anzeige

(Bild: jaboy/123rf.com)

Tools und Trends in der JavaScript-Welt: Die enterJS 2026 wird am 16. und 17. Juni in Mannheim stattfinden. Das Programm dreht sich rund um JavaScript und TypeScript, Frameworks, Tools und Bibliotheken, Security, UX und mehr. Frühbuchertickets sind im Online-Ticketshop erhältlich.
Anhaltende Schwierigkeiten mit Server Components
Erneut wurden die Befragten nach ihren größten „Pain Points“ bei der React-Entwicklung befragt. Unter den Haupt-APIs führt hier bereits zum wiederholten Mal forwardRef. Allerdings ist forwardRef seit dem Ende 2024 erschienenen React 19 nicht mehr notwendig, weshalb das React-Team es als deprecated (veraltet) markiert hat. Im Umgang mit neueren APIs bemängeln die Developer in erster Linie Schwierigkeiten in Bezug auf die Kompatibilität mit React und exzessive Komplexität.
An anderer Stelle konnten die Teilnehmenden angeben, ob sie bestimmte Features und Libraries nutzen oder davon gehört haben, und ob sie diesen positiv, negativ oder neutral gegenüberstehen. Dabei zeigt sich, dass die neueren React Server Components weiterhin wenig Begeisterung auslösen. Bei der Beurteilung aller React-APIs belegen sie den dritten Platz in der Negativwertung, danach folgen Server Functions auf Platz 4. Die Unbeliebtheit der Server Components und Functions ist jedoch laut den Studienmachern bedenklich, denn diese neuen APIs sollen den Weg für Reacts nächsten großen Evolutionsschritt in Richtung eines vollständigeren Fullstack-Frameworks ebnen.

State of React 2025: Die Top 5 der unbeliebtesten React-Features (Sortierung nach Sentiment: negative)
(Bild: State of React 2025)
Es zeigt sich auch, dass sowohl Server Components als auch Functions verglichen mit anderen React-Features noch recht selten im Einsatz sind: Sie wurden erst von 45 Prozent beziehungsweise 37 Prozent der Befragten verwendet, was den Plätzen 17 und 19 gleichkommt. Insbesondere Personen, die sie noch nicht verwendet haben, stehen den neuen Features negativ gegenüber. Beispielsweise bewerten fünf Prozent der User von Server Functions diese negativ, aber neun Prozent derjenigen, die nur davon gehört haben.
Positiv treten dagegen die APIs createContext hervor: Unter ihren Nutzern haben 54 beziehungsweise 48 Prozent den APIs gegenüber eine positive Einstellung, lediglich zwei beziehungsweise sechs Prozent negativ. Auch im letzten Jahr waren diese Features in den Top 3, wobei createContext vom dritten auf den zweiten Platz aufgestiegen ist und den Hook useState mit knappem Vorsprung verdrängt hat. Das beliebteste Feature
Weiterlesen nach der Anzeige

State of React 2025: Die Top 5 der beliebtesten React-Features (Sortierung nach Sentiment: positive)
(Bild: State of React 2025)
TanStack Query am beliebtesten, Next.js stürzt ab
Nachdem TanStack Query im vergangenen Jahr Next.js überholt hat, verteidigt das quelloffene State-Management-Tool in diesem Jahr den Titel der beliebtesten Library. Darauf folgt Zustand, ebenfalls ein Open-Source-Tool zur Zustandsverwaltung, und auf dem dritten Platz landet die UI-Library shadcn/ui. Diese erzielte in der diesjährigen Studie JavaScript Rising Stars den zweiten Platz, was über 26.000 neuen GitHub-Sternen im Jahr 2025 Rechnung trägt.
Next.js, in der Vorjahresumfrage noch auf dem dritten Platz unter den Libraries, findet sich dieses Mal abgeschlagen auf Rang 9 wieder. Im Vergleich zeigt sich, dass 42 Prozent der TanStack-Query-User diese Library positiv bewerten, während lediglich 27 Prozent der Next.js-User ihre genutzte Library positiv sehen. Ein besonders gutes Image hat anscheinend TanStack Start: Unter denjenigen, die bereits davon gehört haben, es aber nicht einsetzen, liegt die Positivbewertung bei 23 Prozent.
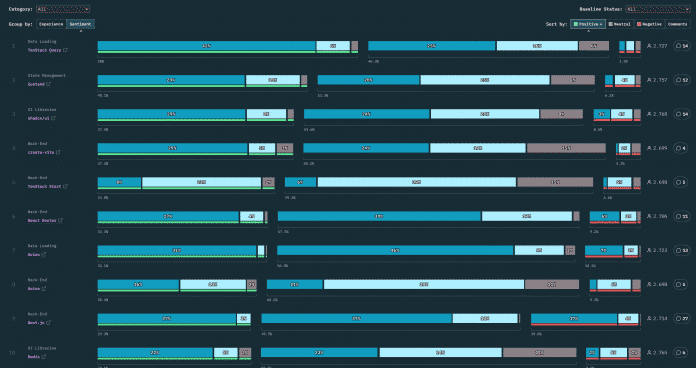
State of React 2025: Die Top 10 der beliebtesten Libraries
(Bild: State of React 2025)
Datengrundlage
Die Online-Umfrage State of React 2025 lief vom 19. November 2025 bis 13. Januar 2026. Weltweit nahmen 3760 Personen daran teil. Dabei geben die Studienmacher Devographics, die auch hinter dem State of JavaScript stehen und nicht mit dem offiziellen React-Team assoziiert sind, zu bedenken, dass unter anderem Anbieter von Frameworks und Libraries ihre User zur Teilnahme animieren konnten. Der State of React erhebt nicht den Anspruch, repräsentativ für das gesamte Ökosystem zu stehen. Als Sponsoren unterstützten unter anderem Google und JetBrains die aktuelle Studie. Die Ergebnisse lassen sich auf der Website des Projekts einsehen.
(mai)
Entwicklung & Code
Model-Schau: Coding, OCR und chinesisches Neujahr
Seit der letzten Model-Schau Ende Januar hat sich einiges bei den Sprachmodellen getan. Eine große Rolle scheint dabei das chinesische Neujahr zu spielen, vor dem die Anbieter nochmal viele Modelle veröffentlicht haben. Doch der Reihe nach!
Weiterlesen nach der Anzeige

Prof. Dr. Christian Winkler beschäftigt sich speziell mit der automatisierten Analyse natürlichsprachiger Texte (NLP). Als Professor an der TH Nürnberg konzentriert er sich bei seiner Forschung auf die Optimierung der User Experience.
Coding-Modelle
Schon im September 2025 hat Qwen Modelle mit einer neuen, hybriden Architektur angekündigt. Das einzige verfügbare Modell war Qwen3-Next-80B-A3B-Instruct, das aber mehr als Experiment zu betrachten war. Allerdings hat Qwen die vorgestellte Architektur in das Modell Qwen3 Coder-Next übernommen. Auch die Anzahl der (aktiven) Parameter stimmt genau überein. Hervorzuheben sind die hybriden Attention-Layer, die einen sehr langen Kontext von 262.144 Token erlauben, dabei nicht sehr viel Speicher benötigen und damit auch die Rechengeschwindigkeit kaum reduzieren.
Dadurch ist Qwen3-Coder-Next auf eigener Hardware schnell ablauffähig, wenn ausreichend Speicher zur Verfügung steht, was vor allem bei leistungsfähigen Macs mit Apple Silicon der Fall sein dürfte. So hat sich das Modell bei einigen Developern zu einem Lieblingsmodell für den lokalen Betrieb gemausert. Einige sind davon sogar so begeistert, dass sie es auch abseits vom Coding einsetzen.
(Bild: Golden Sikorka/Shutterstock)

Die Online-Konferenz LLMs im Unternehmen zeigt am 19. März, wie KI-Agenten Arbeitsprozesse übernehmen können, wie LLMs beim Extrahieren der Daten helfen und wie man Modelle effizient im eigenen Rechenzentrum betreibt.
OpenAI musste nachlegen und hat das Modell GPT-5.3-Codex veröffentlicht. Laut eigener Beschreibung ist es deutlich schneller als das Vorgängermodell und besser für agentische Aufgaben geeignet. Das neue Modell kann Code Reviews durchführen und OpenAI hat es inzwischen durch das kleinere Modell GPT-5.3-Codex-Spark ergänzt. Damit soll es sich auch für Realtime-Coding eignen. Sicher spürt OpenAI allerdings auch den Preisdruck, der durch die offenen Modelle entsteht. Coding-Modelle produzieren (insbesondere wenn sie Reasoning verwenden) notorisch viele Token, was sich in sehr hohen Kosten manifestieren kann.
Auch Coding-Primus Anthropic hat mit Claude Opus 4.6 ein neues Modell geschaffen, das sich hervorragend für Coding-Aufgaben eignet. Zusätzlich kann Opus 4.6 Finanzanalysen durchführen, Präsentationen erstellen und viele Aufgaben des täglichen Lebens übernehmen. Nicht zuletzt deswegen nutzen es viele auch für OpenClaw, was aber schnell zu unabsehbaren Kosten führen kann. Sowohl im Bereich Text als auch beim Coding ist Opus 4.6 unangefochtener Sieger bei den Arena-Leaderboards.
Weiterlesen nach der Anzeige
Wie man Coding-Modelle wirklich effizient nutzt und was man damit alles erreichen kann, hat Steve Yegge mit seinem viel beachteten Gas Town erklärt und das entsprechende Tooling gleich mit implementiert. Yegge spart dabei nicht mit Warnungen, dass man das System nur dann nutzen sollte, wenn man über die notwendigen Erfahrungen verfügt und sich auf dieses neue Paradigma auch wirklich einlassen möchte. Teilweise sind die Vorschläge extrem, aber es könnte dennoch einen Ausblick darauf bieten, wie sich agentisches Coding mit LLMs in Zukunft weiterentwickeln kann. Vorsicht ist allerdings geboten, weil Gas Town Token „verbrennt“ – die Kosten können geradezu explodieren, wenn man ein teures Modell verwendet.
OCR-Modelle
Durch die Vision-Language-Modelle ist OCR mehr und mehr zu einer Domäne der großen Sprachmodelle geworden. Nachdem es einige Monate in diesem Bereich ziemlich ruhig war, erschienen nun gleich mehrere neue Modelle.
Sehr beliebt ist das neue GLM-OCR-Modell von Z.ai. Obwohl der Anbieter ein Newcomer bei OCR-Modellen ist, stellt das Modell zumindest nach den Benchmarks die ebenfalls neuen DeepSeek-OCR-2 und PaddleOCR-VL-1.5 in den Schatten. Eine in früheren Tests verwendete iX-Seite kann das Modell nicht ganz fehlerfrei in Text wandeln, kommt aber mit den Spalten bestens zurecht – das Ergebnis liegt nur als Text vor, ist aber gut verwendbar.
Tabellen und Formeln kann GLM-OCR auch interpretieren, die Wandlung von Grafiken in Daten ist aber bisher nicht möglich.
Aber auch DeepSeek-OCR-2 hat sich gegenüber seinem Vorgänger deutlich weiterentwickelt und nutzt nun ein – interessanterweise altes – Qwen-VL-Modell als Encoder. Die iX-Seite wird dabei perfekt erkannt:

DeepSeek-OCR2 erkennt die iX-Seite sehr gut (Abb. 1).
Auch das konvertierte Markdown sieht gut aus.
PaddleOCR-VL-1.5 nutzt einige neue Ansätze wie Text Spotting und kann auch Textboxen erkennen, die nicht rechteckig sind. Ein Fokus liegt außerdem auf Tabellen, die es auch über mehrere Seiten zusammensetzen kann. Als einziges der genannten Systeme kann PaddleOCR-VL-1.5 Daten aus Diagrammen extrahieren. Die iX-Seite verarbeitet es gut und benötigt dabei zwar wenig Speicher, rechnet aber äußerst lange.
Es wäre spannend zu erfahren, ob die Anbieter die aus PDF extrahierten Texte auch als Trainingsdaten für ihre großen Sprachmodelle nutzen. Dazu schweigen sich jedoch alle aus.
Neue Modelle aus China
Die stets aktiven Anbieter aus China haben sich in den vergangenen Wochen selbst übertroffen. Angeblich soll das am chinesischen Neujahr liegen, das traditionell mit Urlaub verbunden ist.
Kimi K2.5 wird von vielen als das aktuell stärkste Modell mit offenen Gewichten wahrgenommen. Moonshot hat das Modell zwar schon vor einer Weile veröffentlicht, die technischen Informationen waren aber nur spärlich. Das hat sich nun geändert, weil der zugehörige technische Bericht jetzt bereitsteht. Das Dokument berichtet ausführlich über das Training und die Evaluation des Modells. Besonders das Training hat es dabei in sich, denn Moonshot hat sowohl im Pre-Training als auch beim Reinforcement Learning multimodale Daten verwendet. Das erklärt möglicherweise auch, warum Kimi K2.5 so weit oben in der Vision-Rangliste bei arena.ai steht. Eine weitere Besonderheit stellt Agent Swarm dar: Das Modell kann Agentenaufrufe parallel durchführen, was die Geschwindigkeit bei komplexen Aufgaben stark erhöht. Diese Anforderungen berücksichtigt Moonshot bereits beim Training. Die Autoren beschreiben auch Details des Trainingsprozesses, verschweigen aber die benötigte Rechenzeit. Im Vergleich zu DeepSeek geht der Bericht weniger in die Tiefe, aber viele Details sind dennoch sehr interessant.
Mit Step-3.5-Flash betritt ein weiterer, bisher weitgehend unbekannter Player die Bühne der großen (chinesischen) Sprachmodelle. Im Vergleich zu Kimi K2.5 ist das Modell regelrecht klein, auch wenn es über 196 Milliarden Parameter verfügt (von denen elf Milliarden aktiv sind). Diese Größe ermöglicht es aber, das Modell auch auf leistungsfähiger (Mac-) Hardware in einer quantisierten Version zu betreiben. Für ein derart kleines Modell produziert es sehr ansehnliche Ergebnisse, ist aber in ersten Tests auch sehr stark chinesisch indoktriniert. Bei der Frage nach dem Heise Verlag liegt es mit dem Gründungsjahr und dem Gründer falsch. Bei politisch sensiblen Fragen verweigert sich das Modell.
Das trifft in diesem Maße nicht auf GLM 5.0 zu. Z.ai ist ein in der Zwischenzeit etablierter Anbieter offener Sprachmodelle, der auch sehr bereitwillig Auskunft über politisch heikle Themen gibt. Die Community hat diesem Modell entgegengefiebert und wurde nicht enttäuscht. Gar nicht lange nach GLM 4.7 liefert Z.ai ein extrem starkes Modell, das es insbesondere beim Coding mit fast allen kommerziellen Modellen aufnehmen kann. Auch sonst hat GLM 5.0 eine starke Performance, aber im Vergleich zum Vorgänger die Anzahl der Parameter auf 744 Milliarden Parameter (davon 40 Milliarden aktiv) mehr als verdoppelt. Es benötigte bei einer geeigneten Quantisierung auf einem Mac Studio stolze 512 GByte RAM, wenn man sich nicht in noch höhere Kosten für GPUs stürzen möchte. In den Arena-Benchmarks schneidet das Modell hervorragend ab. In unseren Tests konnte es (als eines der wenigen Modelle) das Gründungsjahr und den Gründer des Heise Verlags korrekt nennen.
Da konnte MiniMax nicht zurückstehen und hat auch noch ein neues Modell veröffentlicht. MiniMax 2.5 ist mit 230 Milliarden Parametern (davon zehn Milliarden aktiv) deutlich kleiner und kann in einer geeigneten Quantisierung auch mit 128 GByte RAM auf der CPU laufen. Noch ist es nicht in vielen Benchmarks vertreten, aber die ersten Resultate sehen gut aus. In ersten Tests gibt auch MiniMax 2.5 falsche Antworten zum Heise Verlag. Bei Fragen zu politisch heiklen Themen in China bleibt es neutral, aber sehr kurz angebunden.
Weniger stark beachtet, aber dennoch interessant ist das Modell Nanbeige4.1-3B. Es handelt sich um ein „kleines“ Reasoning-Modell mit lediglich drei Milliarden Parametern, das aber in bestimmten Benchmarks die viel größeren Qwen3-Modelle mit bis zu 32 Milliarden Parametern schlägt. Als erstes kleines Sprachmodell beherrscht es auch Deep Search und kann in bis zu 500 Runden Tools aufrufen. Es wird spannend, ob andere Modelle nachziehen können, beziehungsweise welche Fähigkeiten die großen Modelle erlangen, wenn sie ähnliche Mechanismen einsetzen.
Lange erwartet und vor ganz kurzem erschienen ist nun auch Qwen3.5. Das Modell steht in unterschiedlichen Größen zur Verfügung, allerdings fehlen aktuell noch die kleineren Modelle. Schon jetzt zeigt sich allerdings, dass Qwen3.5 sehr leistungsfähig ist und gegenüber der vorherigen Version sehr viel Boden gutgemacht hat. Die großen Qwen3.5-Modelle (wie 122B) spielen dabei fast schon in der gleichen Liga wie (das viel größere) Stepfun. Eine genauere Analyse folgt im nächsten Artikel.
Open Responses
Als Interoperabilitätsstandard hat sich die OpenAI-API etabliert. Fast immer wird dabei die completions-Ressource angefragt, obwohl der Name eigentlich nicht mehr zeitgemäß ist. Auch die Übergabe weiterer Parameter ist eher historisch gewachsen als inhaltlich motiviert. Verschlüsselung beherrscht das Interface in dieser Form gar nicht.
All diesen Problemen hat sich ursprünglich OpenAI angenommen und dafür die Responses-API geschaffen, deren Weiterentwicklung unter dem Namen Open Responses die Community übernommen hat. Auch den Umgang mit Agenten beherrscht das neue Format besser und kann somit Reasoning-Zyklen umgehen. Dabei legt das Protokoll unter anderem fest, wie viele Tools maximal aufgerufen werden dürfen.
Viele Werkzeuge unterstützen die neue API bereits. Eine Standardisierung ist nicht nur sinnvoll, sondern wichtig, weil durch die agentische Interaktion eine immer bessere Konfigurierbarkeit der Schnittstellen dringend notwendig wird.
Rasante Neuerungen, aber mit Grenzen
Die Geschwindigkeit, mit der die Anbieter neue Modelle vorstellen, hat sich in den letzten Monaten eher noch einmal erhöht. Ob das so weitergehen kann, sei dahingestellt. OpenAI stellt jedenfalls schon weniger neues Personal ein. Bei den chinesischen Anbietern ist es wesentlich intransparenter, wie lange sie sich das leisten können. Insbesondere fehlt es dort auch an Umsatz, der sich mit den offenen Modellen deutlich schwerer (und vor allem extrem schwer außerhalb Chinas) erzielen lässt.
Hinzu kommt der Hype um OpenClaw als Agent. Dessen Betrieb ist mit offenen Modellen sogar autark möglich, allerdings sind auch dann die Sicherheitsprobleme erheblich. Wenn man die Berichte darüber liest, fragt man sich, ob die Technologie wirklich schon reif genug ist, sie so „von der Leine“ zu lassen. Die Diskussionen über die Guardrails bekommen so eine ganze neue Dimension. Das trifft nicht für alle Anwender zu: Das amerikanische Verteidigungsministerium wollte Anthropic dazu zwingen, genau diese Guardrails in den von ihnen genutzten Modellen abzuschalten. Anthropic blieb standhaft. Zwar sind sie nun ihren Auftrag los, haben aber ChatGPT in den Popularitätswerten überholt.
(rme)
Entwicklung & Code
Gram: Komplett KI-freier Coding-Editor | heise online
Ganz gegen den Trend gibt es jetzt einen Coding-Editor, der komplett auf KI-Funktionen verzichtet: Gram 1. Er basiert auf dem Editor Zed und verzichtet auf KI, automatische Updates, Telemetrie, Abos und Collaboration.
Weiterlesen nach der Anzeige
Als Begründung für die Abspaltung von Zed nennt der Blog insbesondere die schnelle Weiterentwicklung von Zed, die dem Autor immer mehr irrelevante Patches lieferte. „Ab jetzt habe ich entschieden, damit aufzuhören.“ Die Ablehnung von KI begründet der Verfasser des Beitrags – vermutlich der Hauptkontributor des Projekts Kristoffer Grönlund – damit, dass er als Lehrer festgestellt hat, dass Schülerinnen und Schüler keine Programmiersprache mehr lernen können, weil sofort der Coding-Assistent anspringt: „Sie kommen gerade so weit, ‚pr-’ einzutippen, und sofort beginnt der Editor, die Schüler mit unsinnigen Vorschlägen, Aufforderungen und Ablenkungen zu bombardieren.“
Zed-Extensions lassen sich nutzen
Da Gram auf Zed basiert, funktionieren dessen Extensions nach wie vor, Anwender müssen sie aber aus den Quellen bauen und selbst updaten. Automatische Aktualisierungen sind deaktiviert. Auch Sprachserver und Node.js müssen manuell zugefügt werden. Dafür ist die Dokumentation im Editor integriert, und er unterstützt weitere Sprachen wie Gleam, Zig und Odin.
Binaries für den in Rust geschriebenen Editor gibt es für Mac sowie Linux, und weitere Informationen finden sich im Blog und auf Codeberg. Hier heißt es ganz klar: „Agenten sind von diesem Projekt ausgeschlossen.“ Auch Zed selbst bietet im Übrigen eine Möglichkeit, KI-Funktionen auszuschalten.
Weiterlesen nach der Anzeige
(who)

Ende der Pseudonyme im Netz?: Mit LLMs lassen sich im großen Ausmaß Online-Konten deanonymisieren

Google verkürzt Versionszyklus des Chrome-Browsers von vier auf zwei Wochen

Bulk Crap Uninstaller 6.0: Praktisches Tool mit großem Versionssprung

Schnelles Boot statt Bus und Bahn: Was sich von London und New York lernen lässt

Community Management zwischen Reichweite und Verantwortung

Community Management und Zielgruppen-Analyse: Die besten Insights aus Blog und Podcast
-
 Künstliche Intelligenzvor 2 Monaten
Künstliche Intelligenzvor 2 MonatenSchnelles Boot statt Bus und Bahn: Was sich von London und New York lernen lässt
-
 Social Mediavor 3 Wochen
Social Mediavor 3 WochenCommunity Management zwischen Reichweite und Verantwortung
-
 Social Mediavor 2 Tagen
Social Mediavor 2 TagenCommunity Management und Zielgruppen-Analyse: Die besten Insights aus Blog und Podcast
-
Künstliche Intelligenzvor 2 Wochen
Top 10: Die beste kabellose Überwachungskamera im Test – Akku, WLAN, LTE & Solar
-

 Datenschutz & Sicherheitvor 3 Monaten
Datenschutz & Sicherheitvor 3 MonatenSyncthing‑Fork unter fremder Kontrolle? Community schluckt das nicht
-

 Entwicklung & Codevor 3 Monaten
Entwicklung & Codevor 3 MonatenKommentar: Anthropic verschenkt MCP – mit fragwürdigen Hintertüren
-

 Künstliche Intelligenzvor 3 Monaten
Künstliche Intelligenzvor 3 MonatenGame Over: JetBrains beendet Fleet und startet mit KI‑Plattform neu
-

 Social Mediavor 3 Monaten
Social Mediavor 3 MonatenDie meistgehörten Gastfolgen 2025 im Feed & Fudder Podcast – Social Media, Recruiting und Karriere-Insights

