Künstliche Intelligenz
OpenAI verdreifacht Rechenleistung und Umsatz
Der ChatGPT-Entwickler OpenAI hat im vergangenen Jahr seinen Jahresumsatz mehr als verdreifacht und dabei die 20-Milliarden-Dollar-Marke geknackt. Im Jahr 2024 lag der Umsatz des Unternehmens noch bei sechs Milliarden US-Dollar. Diese Zahlen nannte Sarah Friar, Finanzchefin von OpenAI, am Sonntag in einem Blogbeitrag.
Weiterlesen nach der Anzeige
Vor allem die Erweiterung der Rechenkapazitäten befeuerte das Umsatzwachstum. So stieg auch die verfügbare Rechenleistung von OpenAI im Jahresvergleich um das Dreifache bzw. von 2023 bis 2025 um das 9,5-Fache: von 0,2 Gigawatt (GW) im Jahr 2023 über 0,6 GW im Jahr 2024 auf rund 1,9 GW im abgelaufenen Jahr. Sowohl die Zahlen für die wöchentlich aktiven Nutzer als auch für die täglich aktiven Nutzer erreichten weiterhin Rekordhöhen, so Friar.
„Investitionen in Rechenleistung ermöglichen Spitzenforschung und bahnbrechende Fortschritte bei der Modellkapazität. Leistungsfähigere Modelle ermöglichen bessere Produkte und eine breitere Akzeptanz der OpenAI-Plattform. Die Akzeptanz treibt den Umsatz an, und der Umsatz finanziert die nächste Welle von Rechenleistung und Innovation. Der Zyklus verstärkt sich“, umriss Friar die Erfolgsformel.
ChatGPT mit Werbung
Doch was nach einer uneingeschränkten Erfolgsgeschichte klingt, offenbart bei genauerem Hinsehen einige Fallstricke. So kündigte OpenAI Ende vergangener Woche an, ab dieser Woche Werbung in seinem KI-Chatbot ChatGPT testen zu wollen, um mehr Einnahmen aus ChatGPT zu generieren und auf diese Weise die hohen Kosten für die KI-Entwicklung zu stemmen. Erste Experimente mit diesem neuen Finanzierungsmodell sollen zunächst auf die Vereinigten Staaten beschränkt bleiben.
Die Finanzierung durch Werbung stellt eine deutliche Kursänderung durch OpenAI dar. Noch im Oktober 2024 hatte OpenAI CEO Sam Altman seine persönliche Ablehnung von Werbung bekräftigt. Aber Hinweise auf ein Umdenken gab es schon länger. Anfang Dezember 2025 rief Altman bei OpenAI aufgrund des wachsenden Konkurrenzdrucks „Alarmstufe Rot“ aus. Seitenprojekte wie die Arbeit an Werbung sollten demnach erst einmal verschoben werden. Doch angesichts der Milliardenverluste des Unternehmens kam es wohl zu dem erneuten Schwenk.
Zugang zu Rechenleistung
Die nächste Entwicklungsstufe werde über Abonnements und Werbung hinausgehen, kündigte Friar an. Mit dem Einzug von KI in die wissenschaftliche Forschung, die Arzneimittelentwicklung, Energiesysteme und Finanzmodellierung entstünden neue Wirtschaftsmodelle. „Lizenzierung, IP-basierte Vereinbarungen und ergebnisorientierte Preisgestaltung werden sich die geschaffene Wertschöpfung teilen“, so die OpenAI-Finanzchefin.
Weiterlesen nach der Anzeige
Entscheidend für die künftige Entwicklung sei der Zugang zu Rechenleistung. „Rechenleistung ist die knappste Ressource in der KI“, so Friar. „Der Zugang zu Rechenleistung entscheidet darüber, wer skalieren kann.“ OpenAI bewältige dies, indem es die Bilanz „schlank“ hält, Partnerschaften eingeht, anstatt zu kaufen, und Verträge mit Flexibilität über Anbieter und Hardwaretypen hinweg strukturiert.
Fokus auf praktischer Umsetzung
Die Produktplattform von OpenAI umfasst derzeit Text, Bilder, Sprache, Code und APIs. „Die nächste Phase sind Agenten und Workflow-Automatisierung, die kontinuierlich laufen, den Kontext über einen längeren Zeitraum hinweg übertragen und toolübergreifend Maßnahmen ergreifen“, wagte Friar einen Blick voraus. Für Einzelpersonen bedeute dies KI, die Projekte verwaltet, Pläne koordiniert und Aufgaben ausführt; für Organisationen werde sie zu einer Betriebsebene für Wissensarbeit.
Für das laufende Jahr 2026 werde OpenAI den Fokus auf „die praktische Umsetzung“ legen, kündigte Friar an. Große und unmittelbare Chancen liägen demnach insbesondere in den Bereichen Gesundheit, Wissenschaft und Wirtschaft. „Die Infrastruktur erweitert das, was wir leisten können. Innovation erweitert das, was [künstliche] Intelligenz leisten kann. Die Einführung erweitert den Kreis derjenigen, die sie nutzen können. Die Einnahmen finanzieren den nächsten Sprung. Auf diese Weise skaliert [künstliche] Intelligenz und wird zur Grundlage der Weltwirtschaft.“
(akn)











Künstliche Intelligenz
KI und Urheberrechte: EU-Abgeordnete wollen Abkürzung nehmen
Unter welchen Voraussetzungen ist das Training von KI-Modellen mit urheberrechtlich geschützten Inhalten zulässig? Während die Frage derzeit in ganz Europa Gerichte beschäftigt, schaffen die Anbieter längst technologische Fakten. Doch die Überarbeitung der 2019 auf den Weg gebrachten und umstrittenen DSM-Richtlinie, mit der eine Ausnahme für KI-Training in die Urheberrechtslage hineingeschrieben wurde, wird noch auf sich warten lassen. Der Zeitplan der EU-Kommission sieht vor, dass 2026 geprüft wird, welcher Handlungsbedarf besteht – und dann gegebenenfalls Reformvorschläge in den langen EU-Verhandlungsprozess eingebracht werden. Anfang August sollen externe Beratungsfirmen der EU-Kommission für ihren Evaluationsbericht die notwendigen Grundlagen zuliefern – anschließend würde diese die sorgfältig auswerten und dann mögliche Gesetzesänderungen vorschlagen.
Weiterlesen nach der Anzeige
Aus Sicht der Abgeordneten im Europaparlament ist das aber erstens viel zu spät und zweitens die derzeitige Lage kein Zustand, der so bleiben kann. Kommende Woche wird daher im Plenum am Straßburger Sitz der Volksvertretung aller 450 Millionen EU-Bürger über einen sogenannten Initiativbericht des deutschen CDU-Rechtspolitikers Axel Voss abgestimmt – der eine Vielzahl Vorschläge enthält, was jetzt besonders dringend zu tun wäre. Es gehe um eine „pragmatische Lösung“ zwischen KI-Anbietern und Urhebern, sagt Axel Voss.
Einer der wesentlichen Kernpunkte des Vorschlags: In Zukunft soll es klare Standards geben, wie die Anbieter signalisieren können, was mit urheberrechtlich geschützten Inhalten möglich ist. Die sogenannte Text-and-Data-Mining-Schranke für das Urheberrecht gilt nämlich nur, wenn die Urheber nicht maschinenlesbar widersprochen haben. „Für ein Businessmodell die TDM-Ausnahme zu nutzen, um daraus ein Konkurrenzprodukt zu erstellen, war niemals die Idee des Gesetzes“, sagt Axel Voss.
Vorgaben für Maschinenlesbarkeit zentral
Doch um diesen Punkt, die Maschinenlesbarkeit, drehen sich viele der juristischen Streitigkeiten: Wie, in welchem Format und mit welchen Signalen genau kann eine Nutzung erlaubt oder verweigert werden? Der Bericht, der im Januar schon im Rechtsausschuss von Politikern aller Parteien, mit Ausnahme des rechten Randes einstimmig gefasst wurde, sieht hier klare Vorgaben vor. Es solle eine Verantwortung für jeden geben, seine Werke zu kennzeichnen, unter welchen Bedingungen diese sodann für KI-Training nutzbar seien, erklärt Voss.
„Wenn wir die Text-und-Data-Mining-Regelung einfach abschaffen würden, dann würden alle KI-Modelle in Europa in eine ganz tiefe Rechtsunsicherheit fallen“, warnt der SPD-Abgeordnete Tiemo Wölken. Aber da, wo die Urheberrechtsrichtlinie zu kurz fasse, etwa bei Transparenz und Vergütung, da brauche es einen zusätzlichen Rahmen.
Treuhänder könnte Nutzung prüfen
Weiterlesen nach der Anzeige
Um herauszufinden, wie Werke genutzt wurden, braucht es aber eine Möglichkeit, die tatsächliche Nutzung durch Anbieter wie OpenAI, Anthropic, Suno, ForestLabs oder Mistral auch nachzuvollziehen. Die Abgeordneten des Rechtsausschusses sehen hier sowohl technische Möglichkeiten wie etwa das Watermarking, aber auch die eines unabhängigen und unparteiischen Treuhänders wie etwa das Amt der Europäischen Union für geistiges Eigentum (EUIPO). Der könnte dann für die Urheber die Angaben der KI-Betreiber prüfen, ohne dass ein direkter Einblick gewährt werden müsste.
Maßgeblich für eine zeitnahe faire Vergütung sei, dass gute kollektivrechtliche Einigungen erzielt würden, sind sich der Sozialdemokrat Wölken und der Christdemokrat Voss einig. Sprich: Anbieter und Verwertungsgesellschaften müssten für die konkreten Fragen eine Lösung herbeiführen. Doch das scheint derzeit in weiter Ferne zu liegen – und die KI-Anbieter haben nicht nur viel Wagniskapital, sondern auch jede Menge Geduld, da der Druck auf sie überschaubar ist.
Europaabgeordnete: KI-Kannibalisierung bedroht Nachrichtenmedien
Wie groß der Druck auf die Urheberseite ist, zeigt sich an einem anderen Punkt: durch die KI-Zusammenfassungen bei Suchmaschinen und die Suchnutzung von KI-Chatbots verändern sich die Nutzerströme immer stärker weg von klassischen Medienanbietern. Aus Nutzerlieferanten werden Sackgassen, mit Informationen jener, die nun abgeschnitten werden. „Auf dem Spiel steht nichts Geringeres als die Lebensfähigkeit von Nachrichtenmedien“, sagt der SPD-Europaabgeordnete Tiemo Wölken. Eine Klarstellung, dass Leistungsschutzrechte für Presse auch für KI-Nutzung gelte, ist dabei nur eine der Forderungen.
Wölken verlangt von der EU-Kommission zudem, mit höchster Priorität zu prüfen, ob Chatbots und KI-Elemente in Suchmaschinen den Anforderungen von Digital Markets Act und Digital Services Act unterliegen würden und ist sich dabei mit Axel Voss einig: Er sehe die Gefahr, dass auch die Berichterstattung über das tagtägliche Geschehen immer stärker durch KI-Lösungen intransparent und womöglich interessengeleitet gesteuert werde. „Wir können es uns nicht leisten, jahrelang an Gesetzen zu tüfteln“, warnt der CDU-Politiker, der den Bericht federführend verantwortet hat.
Welche Folgen der Voss-Bericht tatsächlich haben kann, bleibt offen. Denn anders als auf nationaler Ebene kann das Europaparlament Gesetze nicht allein auf den Weg bringen – das Anfangsvorschlagsrecht liegt bei der EU-Kommission, die sich dann mit Parlament und dem Rat der Mitgliedstaaten einigen muss. Dieser Prozess dauert selbst im kürzestmöglichen Fall mehrere Monate. Und könnte damit schon mit der regulären DSM-Überarbeitungsmöglichkeit zeitlich zusammenfallen.
(mho)
Künstliche Intelligenz
#TGIQF: Das Quiz um Festplatten, SSDs und Co.
Heutzutage fallen sie meist nur noch dann auf, wenn sie mal wieder beim Laptop-Kauf zu knapp kalkuliert wurden und voll sind: die Massenspeicher. Früher dominierten Festplatten den Markt, seit den mittleren 2000ern sind SSDs der Storage der Wahl – Aufgrund der fehlenden mechanischen Teile sind sie robuster und zudem in der Regel schneller als die auf rotierenden Scheiben basierenden herkömmlichen HDDs.
Weiterlesen nach der Anzeige
Dabei markiert 2026 das Jahr der Festplatte: jetzt nicht im chinesischen Kalender, sondern im Jubiläum. IBM brachte im Jahr 1956 das erste Computersystem mit Festplatte auf den Markt. Dazu erwarb der IT-Konzern am 4. März 1956 von dem chinesisch-amerikanischen Ingenieur An Wang das Patent zur „magnetischen Pulssteuerungsvorrichtung“, was entscheidend für die Magnetkernspeicherentwicklung war.


„Thank God It’s Quiz Friday!“ Jeden Freitag gibts ein neues Quiz aus den Themenbereichen IT, Technik, Entertainment oder Nerd-Wissen:
Auf den heimischen Schreibtisch schwappte die Technologie erst in den 1980ern mit Aufkommen von IBM-PC, Apple Macintosh, Commodore Amiga und Atari ST., bei den beiden letzteren zu Anfang noch als sündhaft teure Zusatzausstattung.
Mit den 2000ern lösten Flash-Speicher allmählich die Festplatten ab: SSDs machten kompaktere Mobilrechner möglich. Die Flash-Technologie befindet sich auch in Tablets und Smartphones – hier allerdings fest verbaut. Aber was bedeutet SSD nochmal? Das und vieles anderes wollen wir von Ihnen wissen in unserem kleinen Quiz-Einstieg ins sonnige Wochenende.
In der heiseshow stellte Moderatorin Anna Bicker auch in dieser Woche der fest installierten Crew Dr. Volker Zota und Malte Kirchner Fragen: Sie rotierten um die spitzfindigen Fragen und waren nicht ganz speichersicher, hatten aber auch keinen Totalausfall. PS: Ja, es lautet wirklich Billion.
Sie können in Ruhe in 10 Fragen maximal 100 Punkte erreichen. Die Punktzahl kann gern im Forum mit anderen Mitspielern verglichen werden. Halten Sie sich dabei aber bitte mit Spoilern zurück, um anderen Teilnehmern nicht die Freude am Quiz zu verhageln. Lob und Kritik sind wie immer gern gelesen.
Weiterlesen nach der Anzeige
Bleiben Sie zudem auf dem Laufenden und erfahren Sie das Neueste aus der IT-Welt: Folgen Sie uns bei Mastodon, auf Facebook oder Instagram. Und schauen Sie auch gern beim Redaktionsbot Botti vorbei.
Und falls Sie Ideen für eigene Quizze haben, schreiben Sie einfach eine Mail an den Quizmaster, aka Herr der fiesen Fragen.
(mawi)
Künstliche Intelligenz
Großbritannien verbrennt so wenig Kohle wie zuletzt zu Lebzeiten von Shakespeare
In Großbritannien wurde im vergangenen Jahr so wenig Kohle verbrannt wie zuletzt im Jahr 1600, also zu Lebzeiten von William Shakespeare. Das ist das Ergebnis einer Untersuchung des Klima-Portals Carbon Brief, laut der im Vereinigten Königreich im vergangenen Jahr weniger als eine Million Tonnen Kohle verbrannt wurde. Dieser Wert wurde demnach erstmals unter Königin Elizabeth I. erreicht, als ein Holzmangel zu einer „Energiekrise“ geführt hatte. Der Kohleverbrauch im vergangenen Jahr lag demnach 56 Prozent unter dem Wert von 2024, 97 Prozent unter dem von 2015 und 99,6 Prozent unter dem absoluten Höchstwert aus dem Jahr 1956. Einen großen Anteil hatte die Abschaltung des letzten britischen Kohlekraftwerks im Herbst 2024.
Weiterlesen nach der Anzeige
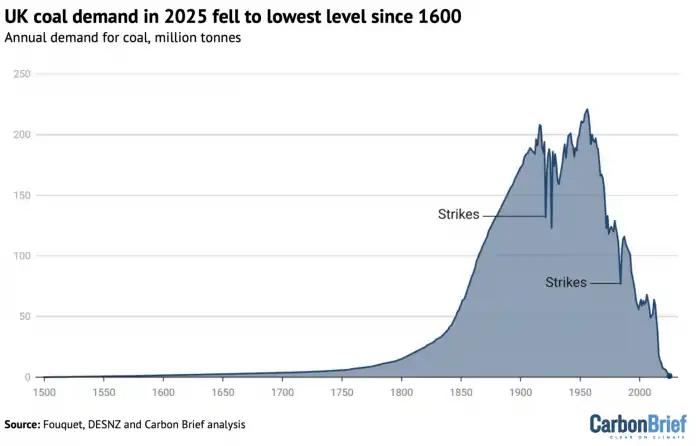
Zeitlicher Verlauf des britischen Kohleverbrauchs
(Bild: Carbon Brief)
Weil auch der Verbrauch von Erdgas leicht um 1,5 Prozent gefallen ist, sind die britischen Treibhausgasemissionen insgesamt um 2,4 Prozent gesunken und damit auf einem Niveau angekommen, das zuletzt vor 150 Jahren erreicht wurde, schreibt Carbon Brief. Erstmals wurde damit sogar wieder das Emissionstief aus dem Jahr 1926 unterschritten: Damals hat ein tagelanger Generalstreik das öffentliche Leben lahmgelegt. Insgesamt stoße das Vereinigte Königreich jetzt so viele Emissionen aus, wie zuletzt unter Queen Victoria im 19. Jahrhundert. Die britischen Emissionen liegen damit 54 Prozent unter dem Niveau von 1990 – obwohl die Wirtschaftsleistung seitdem fast doppelt so groß geworden ist. Der leicht verringerte Verbrauch von Erdgas hatte insgesamt den größten Anteil an dem jüngsten Abfall der Emissionen, der Rest geht vorwiegend auf die verringerte Kohleverbrennung und Rückgänge in der Stahlindustrie zurück.
Die Entwicklung in Großbritannien ist auch deshalb besonders interessant, weil das Land als Ursprungsland der Industriellen Revolution jahrhundertelang besonders stark von Kohleenergie abhängig und Vorreiter bei der Nutzung gewesen ist. Die ersten Dampfmaschinen, die etwa ab Anfang des 18. Jahrhunderts eingesetzt wurden, um Wasser aus Minen zu pumpen, wurden mit Kohle betrieben. Durch Verbesserungen an der Technik stieg die Nachfrage nach den Maschinen, damit stiegen dann auch der Kohleverbrauch und die CO₂-Emissionen. Die Schließung des letzten britischen Kohlekraftwerks in Ratcliffe-on-Soar nahe Nottingham war deshalb auch von besonderer Bedeutung. Deutschland ist dagegen lange nicht so weit, mehrere Kraftwerke sollen hierzulande noch über zehn Jahre lang laufen. Hier wurden 2024 über 90 Millionen Tonnen Kohle gefördert.
(mho)

KI-Hackathon und Exit-Strategien: RISE in STARTUPLAND fokussiert auf Innovation & Wachstum

YouTube DMs kommen in Deutschland zurück

Speicherknappheit beim M3 Ultra: Apple deckelt Mac Studio bei 256 GB statt 512 GB RAM

Schnelles Boot statt Bus und Bahn: Was sich von London und New York lernen lässt

Community Management zwischen Reichweite und Verantwortung

Community Management und Zielgruppen-Analyse: Die besten Insights aus Blog und Podcast
-
 Künstliche Intelligenzvor 2 Monaten
Künstliche Intelligenzvor 2 MonatenSchnelles Boot statt Bus und Bahn: Was sich von London und New York lernen lässt
-
 Social Mediavor 3 Wochen
Social Mediavor 3 WochenCommunity Management zwischen Reichweite und Verantwortung
-
 Social Mediavor 4 Tagen
Social Mediavor 4 TagenCommunity Management und Zielgruppen-Analyse: Die besten Insights aus Blog und Podcast
-
Künstliche Intelligenzvor 2 Wochen
Top 10: Die beste kabellose Überwachungskamera im Test – Akku, WLAN, LTE & Solar
-

 Datenschutz & Sicherheitvor 3 Monaten
Datenschutz & Sicherheitvor 3 MonatenSyncthing‑Fork unter fremder Kontrolle? Community schluckt das nicht
-

 Entwicklung & Codevor 3 Monaten
Entwicklung & Codevor 3 MonatenKommentar: Anthropic verschenkt MCP – mit fragwürdigen Hintertüren
-

 Künstliche Intelligenzvor 3 Monaten
Künstliche Intelligenzvor 3 MonatenGame Over: JetBrains beendet Fleet und startet mit KI‑Plattform neu
-

 Social Mediavor 3 Monaten
Social Mediavor 3 MonatenDie meistgehörten Gastfolgen 2025 im Feed & Fudder Podcast – Social Media, Recruiting und Karriere-Insights

