Künstliche Intelligenz
Das kann OpenClaw in der PRAXIS | c’t 3003
Was passiert, wenn ein KI-Agent permanent auf dem eigenen Rechner läuft und per Messenger gesteuert wird? OpenClaw zeigt es: Lampen schalten, Musik generieren, Kinderbuch-Stifte bespielen, vieles funktioniert erstaunlich gut und ohne Konfiguration. Der KI-Agent lernt zudem selbstständig dazu. Klingt perfekt, ist es aber nicht: Das System kann auch Schaden anrichten. Und seit Anthropic die Flatrate gestrichen hat, ist Claude Opus als bestes Modell kaum noch erschwinglich.
Weiterlesen nach der Anzeige
Transkript des Videos
(Hinweis: Dieses Transkript ist für Menschen gedacht, die das Video oben nicht schauen können oder wollen. Der Text gibt nicht alle Informationen der Bildspur wieder.)
Guck mal hier, ich schicke einfach eine Sprachnachricht an meinen OpenClaw-Assistenten. Ich hab hier so ein elektronisches Namensschild, da steht irgendwie hinten www.lednametags.de hinten drauf. Ich hab keine Lust, die Software selbst zu installieren. Ich möchte das einfach an den Rechner hängen, auf dem du läufst, und dann soll da I LOVE c’t 3003 draufstehen. Ja, paar Sekunden später steht da I LOVE c’t 3003 drauf. Und ich hab nichts vorbereitet, ich hab nix selbst installiert, ich hab einfach nur eine Telegram-Sprachi geschickt. Und das Krasse ist, das Ding hat mir sogar eigene Animationen auf das Teil programmiert, was zum Beispiel mit der Windows-Software für dieses LED-Namensschild so ohne Weiteres gar nicht möglich wäre. Ich habe noch mehr Beispiele, ich habe aber auch noch ein paar Horrorgeschichten, warum OpenClaw auch ganz schön problematisch sein kann. Vor allem glaube ich, dass ich euch OpenClaw bzw. ähnliche Systeme jetzt besser erklären kann als vorher, weil ich nämlich auch ein bisschen gebraucht habe, um zu checken, was daran jetzt eigentlich so anders oder besonders ist. Und ich bin zu 100% davon überzeugt, dass solche Systeme in Zukunft alltäglich werden. Bleibt dran!
Liebe Hackerinnen, liebe Internetsurfer, herzlich willkommen hier bei…
Ja, manchmal mache ich hier Videos und denke so: „Passt schon, ne?“ Und dann merke ich aber: „Hm, ich glaube, das hat man gar nicht so gut verstanden.“ Und das habe ich besonders doll gemerkt, als die Streamer Staiy und Drakon auf unser OpenClaw-Video reagiert haben. Das ist jetzt auch kein Vorwurf an die beiden oder so, ist alles gut, aber ich habe offenbar viel zu viel KI-Wissen vorausgesetzt und nicht deutlich genug für normal technisch interessierte Menschen erklärt, was an OpenClaw jetzt eigentlich so krass ist.
Und deshalb versuche ich das jetzt ein zweites Mal. Also finde ich wichtig, weil solche OpenClaw-artigen Systeme wirklich extrem relevant zu werden scheinen. Guck mal hier, in China legen zum Beispiel etliche Kommunen nicht nur so Förderprogramme auf für Firmen, die kommerzielle OpenClaw-Lösungen entwickeln. Es gibt auch wirklich so Aktionen, wo Leute sich kostenlos OpenClaw auf ihre Rechner von Profis installieren lassen können, inklusive so Plüsch-Hummer-Nippes, weil der Hummer, das ist das Wappentier von OpenClaw. Gleichzeitig rät die chinesische zentrale Sicherheitsbehörde für Cyberangelegenheiten aber explizit davon ab, OpenClaw bei Regierungsstellen, Staatsbetrieben und Banken auf Arbeitsrechnern zu installieren.
Und ich finde, das zeigt sehr anschaulich, dass OpenClaw einerseits faszinierend und nützlich ist, aber gleichzeitig auch super gefährlich.
Weiterlesen nach der Anzeige
Aber jetzt endlich konkret, was das ist, OpenClaw? Ja, das ist eine Software, die der österreichische Entwickler Peter Steinberger als Experiment für sich selbst entwickelt hat. In einem Interview mit mir hat er sogar gesagt, dass er es als eine Art Kunstprojekt sieht. Anders als ChatGPT kann OpenClaw Dinge auf einem Computer machen. ChatGPT kann ich natürlich auch Dateien schicken zum Analysieren und ChatGPT kann auch Sachen generieren, zum Beispiel PDFs, aber ChatGPT hat keinen direkten Zugriff auf meinen Rechner. Das wohnt ausschließlich im Browser oder halt in der ChatGPT-Handyapp. OpenClaw wohnt dagegen auf meinem Rechner. Ich selbst muss als Nutzer OpenClaw auf einem Rechner installieren. Ich kann also nicht einfach eine Website aufrufen, sondern ich muss Zugang zu einem Computer haben. Das kann ein lokaler Rechner sein, der hier bei mir auf dem Schreibtisch steht, Homeserver, alter Laptop, Raspberry Pi geht auch, oder halt ein angemieteter Server im Netz. Ich habe OpenClaw hier bei mir auf einem Framework Desktop mit Fedora Linux installiert, auf dem sonst nichts läuft und der permanent eingeschaltet ist. Das ist so der normale Modus Operandi für OpenClaw.
So, und weil das Ding halt lokal auf einem Rechner läuft, denken viele Leute, dass OpenClaw auch zwingend was mit lokalen KI-Modellen zu tun hat und dass man also einen Rechner braucht, auf dem lokale KI-Modelle gut laufen. Und nein, das stimmt nicht. OpenClaw funktioniert mit Abstand am besten, wenn man es mit den leistungsfähigsten KI-Modellen verwendet, und das sind zurzeit leider die großen Cloud-Modelle. Man kann es mit lokalen Modellen verwenden, habe ich auch intensiv ausprobiert, sage ich später noch was zu, aber meiner Meinung nach funktioniert OpenClaw zurzeit am besten mit Anthropic Claude Opus. Das bedeutet also, dass man OpenClaw auch problemlos auf einem Rechner nutzen kann, der keine lokalen Modelle laufen lassen kann. OpenClaw selbst ist sehr ressourcenschonend, das läuft auf einer Kartoffel, das muss ja nur Prompts an Anthropic schicken in meinem Fall und die Ergebnisse entgegennehmen.
Kurzer Einschub, also die coolen Sachen, die mein OpenClaw kann und die in diesem Video vorkommen, für die ist, sag ich mal, zu mindestens 80% das LLM verantwortlich, in meinem Fall Claude Opus. Aber Claude Opus ist inzwischen nahezu unbezahlbar, weil es nicht mehr per Abo geht. Dazu später mehr.
So, und jetzt denken vielleicht einige von euch, haben auch viele kommentiert, ja, okay, das läuft auf dem Rechner und kann da Dinge machen. Was ist daran jetzt aber anders als zum Beispiel Claude Code oder Codex oder OpenCode? Da kann ich ja auch einfach sagen, guck dir mal alle Bilder in dem und dem Verzeichnis auf meiner SSD an und kopiere alle Katzenfotos in das und das Verzeichnis. Ja, das stimmt, aber Claude Code und Co. machen halt nur Sachen, wenn ich die explizit starte und dann prompte. OpenClaw kann ich einfach sagen, schick mir jede Stunde ein Gedicht, das mich daran erinnert, genug Matcha Latte zu trinken, weil OpenClaw halt immer läuft.
So, und jetzt noch ein weiterer Unterschied zu Claude Code und Co. OpenClaw läuft da, wo ich mit meinem Bot kommunizieren will. Also in meinem Fall ist das Telegram. Nicht, weil ich Telegram so super finde, finde ich nicht, aber weil ich OpenClaw halt so in Telegram integrieren kann, dass es ein eigener Account ist. Würde ich WhatsApp oder Signal benutzen, würde der OpenClaw-Bot quasi ich sein. Das heißt, wenn der eine Nachricht schreibt, sieht das für andere so aus, als würde sie von mir kommen. Und das Ding könnte auch alles lesen, was reinkommt. Für mich ist das aber keine Option, deshalb benutze ich Telegram, da sieht er nur, was explizit an ihn geht.
So, und alleine, dass ich mit dem Bot über Messenger kommuniziere, macht für mich schon einen riesigen Unterschied aus, weil ich zum Beispiel einfach von unterwegs mit dem Bot sprechen kann. Ohne Telegram müsste ich mir überlegen, wie ich von außen an meinen Rechner komme, also, was weiß ich, VPN einrichten oder sogar Ports öffnen, muss ich hier alles nicht. OpenClaw ist einfach eine „Person“ in meinem Messenger. Das hat offenbar auch Anthropic gecheckt, also die Leute, die Claude Code machen, und die bieten jetzt auch offiziell Messenger-Unterstützung an.
Und trotzdem ist das immer noch nicht das Gleiche, weil OpenClaw proaktiv Sachen machen kann und Claude Code nur reaktiv. Prompt rein, Antwort raus. Oder auch Prompt rein und dann kommt da die Software raus. OpenClaw hat obendrein auch noch sehr durchdachte Memory-Modelle, damit er sich auch Sachen merken kann, wenn das Kontextfenster gelöscht wird, also quasi das Kurzzeitgedächtnis des KI-Modells. Claude Code versucht das auch, aber immer nur im Rahmen des gerade aktiven Projekts bzw. des aktuellen Projektordners. OpenClaw ist auch selbstmodifizierend. Man kann also einfach auf Telegram sagen, wenn du mir in Zukunft Sprachis schickst, dann bitte auf Schwäbisch mit dem und dem Text-to-Speech-Modell. Und dann wird das gespeichert.
So, jetzt aber endlich nochmal ein paar Beispiele, was das Ding kann und wofür ich das benutze. Ich hatte ja am Anfang schon das Beispiel mit diesem LED-Namensschild hier gezeigt. Ja, ich habe halt nichts konfiguriert, das ging halt einfach. Also einfach sagen, per Text oder Sprachi, ja, und der Bot ist dann wirklich in der Lage, Bilder dafür zu generieren. Und ich habe dann mal gefragt, wie das eigentlich funktioniert, und dann sagt der Bot, mache ich „per Hand“, also ich zitiere, Pixel für Pixel in Python. Das fand ich einigermaßen erstaunlich, vor allem, weil es ja die „offizielle“ Software nur für Windows gibt. Für macOS gibt es eine kostenpflichtige inoffizielle Software, ja und für Linux nur so ein Python-Script. Das ist für Menschen oft nicht so richtig leicht zu bedienen, aber für OpenClaw und solche agentischen Systeme ist so ein Script deutlich leichter als grafische Benutzeroberflächen. Das ist nämlich das Ding, was man echt verstehen muss. Alles, was sich auf der Kommandozeile machen lässt, in Skripten oder Python oder über ein MCP oder über eine API, über MCP hatten wir mal ein eigenes Video, das machen OpenClaw und Claude Code problemlos. Alles, was allerdings mit grafischen Benutzeroberflächen zu tun hat und leider auch Websites im Browser, das geht schon auch irgendwie, aber viel, viel, viel schlechter. Ja, und das Namensschild ist ein perfektes Beispiel, das kann man komplett über Python programmieren und das geht problemlos in Sekunden.
Ich habe dann auch nochmal was vermeintlich Schwierigeres auf OpenClaw geworfen. Ich habe hier nämlich noch so einen alten Tiptoi-Stift, da kann man sich so Kinderbücher mit vorlesen lassen. Man musste allerdings manuell erst die Audiodateien des entsprechenden Kinderbuchs drauftun und die Software dafür, die gibt es nur für Windows und macOS. Ich also wieder eine Sprachi hier an OpenClaw geschickt. Ich möchte die Inhalte von diesem Bild, also von diesem Tiptoi-Buch, auf meinen Tiptoi-Stift draufladen. Bitte regel das alles. Ich möchte einfach nur den Tiptoi-Stift an den Rechner anschließen, auf dem du läufst. Und dann sollen bitte die Inhalte für dieses Buch da drauf gespielt werden. Danke.
Ja, und das hat auch einfach funktioniert. Ich war dann recht ungläubig, weil ich ja schon wusste, dass es eigentlich keine Linux-Software dafür gab. Und ich habe OpenClaw dann gefragt, wie er das gemacht hat. Ja, und dann hat er halt einfach irgendwelche GME-Dateien, whatever, heruntergeladen und die auf den Stift kopiert. Offenbar ist das das Gleiche, was die Windows- und Mac-Software auch macht. Aber woher wusste OpenClaw das? Das steht ja vermutlich nicht in den Claude-Trainingsdaten. Ja, das hat er mir dann alles erklärt. Er hat halt irgendwo irgendwelche Tiptoi-Projekte auf GitHub gefunden und so herausgefunden, wie die Tiptoi-Website aufgebaut ist, wo die Dateien liegen und so weiter. Das hätte ich vielleicht auch selbst irgendwann irgendwie hinbekommen. Aber ich kann definitiv nicht so schnell Informationen erfassen wie ein Sprachmodell und hätte dafür definitiv länger gebraucht.
Ja, und OpenClaw kann natürlich nicht nur Sachen bedienen, die per USB an seinem Host-Rechner dranhängen, sondern auch Sachen im Netzwerk tun. Ich habe drei Sachen ausprobiert, die mir bei mir zu Hause eingefallen sind. Schalte meine Philips-Hue-Lampe in dem und dem Raum an, schmeiß mir mal ein selbstgeneriertes Lied auf mein Google-Home-Assistant-Gerät in der Küche und spiel was auf meinem Sonos-Soundsystem ab. Und alles drei hat er einfach gemacht, ohne dass ich irgendetwas konfigurieren musste.
Ganz kurz, das ist der 3003-Diss-Track, den er lokal auf meinem Rechner generiert hat. Und ich muss leider zugeben, dass ich das öfter als Prank mache, dass ich irgendwelche Quatschlieder generiere und die dann auf diverse Boxen hier in der Wohnung schmeiß, um meine Familie zu ärgern. Ja, das geht alles.
Auf jeden Fall hat er alle diese drei Sachen, also Lampe, Sonos und Google Assistant, alles drei einfach gemacht, ohne dass ich irgendwas konfigurieren musste. Also die Informationen, die ich hier gerade erwähnt habe, einfach wie die Geräte heißen, waren die Informationen, die ich OpenClaw auch gegeben habe. Bei der Hue-Lampe musste ich einmal zum Bestätigen auf die Hue-Bridge drücken, aber das ist ja das ganz normale Sicherheitsfeature, das macht man einmal und dann kann OpenClaw schalten und walten, wie es will. Und manchmal brauchen Sachen auch ein, zwei Versuche, da muss man vielleicht noch eine Frage beantworten oder sagen, versuch’s nochmal. Aber wenn OpenClaw Dinge einmal hinbekommen hat, schreibt er sich die gewöhnlich auch in seine TOOLS.md, das ist quasi sein Notizbuch, wo steht, welche Tools er wie benutzen kann.
Und, weil ich OpenClaw, habe ich ja gerade schon gesagt, auf einem recht leistungsfähigen Rechner laufen habe, kann der darauf halt Lieder, Bilder, Videos generieren und die Tools dafür, also zum Beispiel Ace-Step für Musik, die hat er alle selbst installiert und das ist eine AMD-Maschine und ich habe ehrlich gesagt mit lokalen KI-Tools oft Probleme mit Nicht-Nvidia-Hardware, aber OpenClaw macht das alles ohne Probleme. Also, was heißt ohne Probleme? Manchmal klappt es, wie gesagt, nicht beim ersten Versuch, aber irgendwann passt das dann schon. Manchmal dauert es auch zehn Minuten, aber ist ja egal, ich muss ja nichts machen dabei. Und wie gesagt, einmal installiert, schreibt er sich das auf und dann läuft das.
Aber ich check das schon, das sind alles Dinge, die für so Computerheinis wie mich beeindruckend sind. Aber das ist natürlich auch nichts, was man jeden Tag verwendet, das sind eher so Party-Zaubertricks. Also, dass ich so meine Familie damit ärgere, dass ich auf den Boxen hier in der Wohnung irgendwelche generierten Lieder abspiele. Man kann ja so Pranks mitmachen, ne?
Deshalb. Was ich aber jeden Tag verwendet habe, und das ist mir fast ein bisschen peinlich, das ist OpenClaw als Chatgruppen-Teilnehmer. Ja, ich weiß, das ist psychologisch problematisch, ein LLM zu vermenschlichen, vor allem, weil ich meinen Bot auch so eingestellt habe, dass er wirklich schreibt wie ein Mensch, also viel Kleinbuchstaben, Komma- und Tippfehler etc. Aber es ist wirklich interessant, eine KI im Chat drin zu haben, statt auf so einer ChatGPT-artigen Chatbot-Oberfläche. Und ich weiß auch nicht, ob ich und meine Freunde irgendwie seltsam sind, aber uns hat das sehr konsistent Spaß gemacht, so ein quasi allwissendes Ding im Chat zu haben, das strittige Fragen klären kann und uns irgendwas erklären kann.
Was ich besonders erstaunlich fand, das Ding hat manchmal echten Menschenhumor. Zum Beispiel haben wir einmal über einen Artikel gesprochen, in dem es darum geht, dass Incel-Sprache in den Mainstream wandert, also sowas wie Looksmaxxing, also generell irgendwas-maxxing. Da wurde dann auch die Netflix-Doku „Inside the Manosphere“ erwähnt und jemand sagte dann so, natürlich nicht ernst gemeint, kann man die irgendwo runterladen? Und der Bot: Kann ich dir nicht bei helfen, sorry, bin da Compliancemaxxing. Und ich meine, Compliancemaxxing ist schlau, ist ein gutes Wortspiel, bezieht sich auch wirklich auf Dinge und das ist nur ein Beispiel dafür. Also das Ding wirkt tatsächlich auf eine Art intelligent.
Vor allem fand ich auch interessant, dass der Bot manchmal bessere Antworten gegeben hat als Opus 4.6 auf claude.com, also das gleiche Sprachmodell, nur halt nicht im OpenClaw-Korsett oder Harness, wie man in der KI-Welt dazu sagt. Offenbar lag das daran, dass Opus auf meinem Rechner quasi lokal suchen konnte, über die Brave-API geht das übrigens, während Opus auf claude.com offenbar geblockt war auf dieser spezifischen Website, die da besucht werden sollte.
Also nochmal OpenClaw zusammengefasst, das kann Dinge auf meinem Rechner machen, das läuft permanent als Service oder als Daemon, kann also auch proaktiv irgendwas tun, zum Beispiel zweimal am Tag eine sehr spezifische News-Zusammenstellung in eine Telegram-Chatgruppe oder in Discord oder halt sonst woanders reinposten und es ist LLM-agnostisch. Das heißt, ich kann das mit jedem LLM, was sogenannte Tool Calls beherrscht, nutzen. Und zwar auch lokalen. Also Tool Calls ist Aufruf von Tools. Das können eigentlich alle neueren LLMs.
In der Praxis habe ich mehrere lokale LLMs ausprobiert. Auch auf wirklich leistungsfähigen Maschinen, wie zum Beispiel einem Mac Studio mit 512 GB Unified RAM. Das lief leider nie ansatzweise so gut wie Cloud-Modelle. Das Problem ist nicht nur die „Intelligenz“ der lokalen Modelle, sondern vor allem, dass OpenClaw bei jeder Anfrage riesige Prompts da reinballert. Also das sind hier bei mir bei einem einfachen „Hallo“ 171.000 Tokens, sagt OpenClaw selbst. Ja, also der knallt da halt nicht nur das System-Prompt rein, sondern auch die sogenannten Workspace-Dateien. Das ist die AGENTS.md, das ist die SOUL.md, also seine Seele, die USER.md, also mit welchen Usern er interagiert, und die TOOLS.md, das sind eben die Tools, die aufkamen, und die IDENTITY.md und so weiter. Und das ist in jedem Prompt drin. Das wird von den Cloud-Modellen so gemacht, dass die Sachen, die ein zweites Mal kommen, über den sogenannten KV-Cache verarbeitet werden. Das heißt, man muss diese Tokens dann nicht bezahlen, die gelten dann nicht. Aber ja, bei den lokalen Modellen tut sich ja extrem viel. Zum Beispiel ist Qwen 3.5, was noch nicht so lange raus ist. Das wirkt auf mich erstmal sehr vielversprechend. Das ist auch schnell und da muss ich auf jeden Fall nochmal ein bisschen länger mit experimentieren, aber es ist auf jeden Fall noch kein Opus 4.6, aber vielleicht kommt das noch.
So, und jetzt nochmal das Thema, das man bei OpenClaw natürlich erwähnen muss. Das Ding macht Sachen und kann deshalb auch Sachen kaputt machen. Also ich persönlich würde OpenClaw niemals, niemals Zugriff auf meine Mails geben, auch nicht auf irgendwelche persönlichen Daten, unter gar keinen Umständen auf irgendwas, was mit Geld zu tun hat, und ich würde OpenClaw auch nicht auf einem Rechner installieren, der offene Ports hat, also aus dem großen Internet erreichbar ist. Ich habe OpenClaw auf einem Rechner, der nur bei mir hier im internen Netz hängt, auf dem ich in keine wichtigen Accounts eingeloggt bin, beziehungsweise ich auch nicht OpenClaw irgendwelche Passwörter gebe, wo auch keine wichtigen Daten drauf sind. Generell finde ich gut, wenn man mit solchen Systemen experimentiert, man sollte aber versuchen zu verstehen, was die machen und was die Risiken sind.
OpenClaw kann autonom Software installieren und natürlich kann er sich da Trojaner einfangen und generell kann er sich eine Prompt Injection einfangen. Gerade wenn man kleine lokale Modelle verwendet, die großen State-of-the-Art-Cloud-Modelle sind da natürlich darauf optimiert, dass sie nicht so sensibel auf Prompt Injections reagieren, aber die sind auch nicht zu 100% sicher.
Und was passiert, wenn man OpenClaw Zugriff auf wichtige Daten, wie die eigenen Mails gibt? Das zeigt das inzwischen in der Szene berühmte sogenannte Yue-Incident. Da hat nämlich eine Meta-KI-Forscherin, also jemand, die sich auskennt eigentlich, Hunderte Mails von OpenClaw gelöscht bekommen, ohne dass sie das wollte. Sie hatte aber sogar explizit gesagt, analysiere nur mein Postfach, lösche keine Mails. Es ist dann trotzdem passiert.
Und ich habe solche Sachen auch beobachtet, also undramatischer, weil ich OpenClaw ja keinen Zugriff auf wichtige Sachen gegeben habe, aber OpenClaw hat auf jeden Fall manchmal einfach halluziniert, also mit dem Brustton der Überzeugung Quatsch erzählt, keine Ahnung, Restaurants empfohlen, die es gar nicht gibt, aber es ist auch vorgekommen, dass OpenClaw eine mehrere Wochen problemlos lauffähige Ace-Step-Installation einfach komplett zerschossen hat. Es hat es dann selbst wieder repariert bekommen, aber ja, war erst mal kaputt. Und ich habe auch sehr oft gehabt, dass OpenClaw sich bei einem Update selbst zerkonfiguriert hat, also dass man sowas gesagt hat wie, mach ein Update oder stell das mal so oder so ein und dann sagt OpenClaw, okay, und dann war es weg. Dann konnte ich es nicht mehr über Telegram bedienen. Ich musste mich dann über SSH auf den OpenClaw-Rechner draufgehen und da gibt es dann den OpenClaw-Doctor-Befehl, der OpenClaw wieder repariert. Das klappte auch immer, aber ihr merkt schon, das ist auf jeden Fall faszinierende Software, aber kein Rundum-Sorglos-Paket, auf gar keinen Fall. Ohne zu verstehen, was OpenClaw ist und was es macht und vor allem, was es kaputt machen kann, sollte man OpenClaw auf keinen Fall benutzen. Wenn ihr euch das zutraut, dann probiert das auf einer Maschine aus, wo es kein Problem wäre, wenn alles drauf gelöscht wird. So sollte man das sehen.
Es ist für mich wirklich sonnenklar, dass solche permanent laufenden, selbstlernenden Agentensysteme keine kurzzeitige Modeerscheinung sind, sondern das ist was, was Menschen und Unternehmen in Zukunft immer mehr nutzen werden. Darauf könnt ihr mich gerne festnageln, davon bin ich wirklich überzeugt. Da steckt so viel Potenzial drin. Es ist aber nicht so, dass OpenClaw irgendwie fertig ist oder so. Im Gegenteil, es ist noch buggy, es ist noch gefährlich. Wenn man nicht weiß, was man tut, es ist, wie Peter Steinberger das ja auch beschrieben hat, experimentelle Software, im wahrsten Sinne des Wortes. Man kann damit experimentieren und dadurch besser verstehen, was agentische Systeme Stand heute so leisten können, wie man die vielleicht für sich selbst nutzen kann. Aber das Ding ist nichts für Leute, die irgendwas Fertiges haben wollen. Vor allem ist es, wenn man das meiner Meinung nach beste Modell haben will, extrem teuer.
So, und das ist hier jetzt nochmal eine wichtige Aktualisierung. Anthropic hat nämlich vor wenigen Tagen entschieden, dass man Claude Opus und auch Sonnet nicht mehr mit einem Abo, also einer Flatrate, verwenden kann. Also kann man schon, aber nicht mehr mit externen Tools wie leider OpenClaw. Nicht mal mit dem extrem teuren Claude-Max-Abo für 107,10 Euro im Monat, das ich für meine Zeit mit OpenClaw abgeschlossen hatte. Also für die Zeit, bevor diese neue Regel galt. Will man Claude-LLMs verwenden, muss man jetzt über API abrechnen. Und das ist was, was ich euch unter keinen Umständen empfehlen würde, weil die über 100 Euro, die ich vorher im Monat bezahlt habe, die ballert ihr da locker, wenn ihr ein bisschen was damit macht, am Tag durch. Am Tag, okay? Wenn ihr einfach nur Hallo dahin schreibt, dann kann es sein, dass das Ding weit über 100.000 Token an die Server schickt. Und ja, OpenClaw ist eine Token-Schleuder, das muss man so sagen. Das ist aber halt schade, weil Opus meiner Meinung nach das einzige LLM ist, mit dem OpenClaw halt wirklich nützlich ist.
Es gibt eine Alternative, ob das nun daran liegt, dass OpenClaw-Erfinder Peter Steinberger jetzt bei OpenAI arbeitet. Auf jeden Fall kann man jetzt OpenClaw mit einem einfachen ChatGPT-Plus-Abo, also es kostet ein bisschen mehr als 20 Euro im Monat, über Flatrate benutzen, mit dem aktuellen LLM Codex 5.4. Und das muss man so klar sagen, das ist leider deutlich, deutlich, deutlich schlechter als Claude Opus. Ich habe das ja gezwungenermaßen, nachdem Anthropic halt mein Abo gecancelt hat sozusagen oder die Flatrate, habe ich das umgeschaltet auf Codex 5.4. Und ja, was soll ich sagen, also die Sprache ist irgendwie kaputt. Das Ding sagt Sachen wie, das ist ziemlich hybrisig. Also kommen ständig solche komischen Wortschöpfungen und irgendwelchen Formulierungen, die auch grammatikalisch nicht viel Sinn ergeben. Manchmal werden auch so Fragmente in anderen Sprachen, neulich hatte ich was in Hindi da reingehauen, in die Antworten, ganz komisch. Vor allem kann es aber auch weniger. Also die beeindruckende Tool-Benutzungskompetenz, die ist bei Codex 5.4, ja, schrottig.
Eigentlich bin ich ja sowieso nicht der größte Fan davon, dass alles über irgendwelche Server von irgendwelchen US-Unternehmen läuft. Dauerhaft würde ich OpenClaw auf jeden Fall erst verwenden, wenn es ein lokales Modell gäbe, was gut damit funktioniert. Aber da habe ich noch keins gefunden, was Opus ansatzweise das Wasser reichen kann und was einigermaßen schnell auf bezahlbarer Hardware läuft. Ihr vielleicht? Gerne in die Kommentare schreiben. Interessiert mich wirklich. Tschüss.
c’t 3003 ist der YouTube-Channel von c’t. Die Videos auf c’t 3003 sind eigenständige Inhalte und unabhängig von den Artikeln im c’t Magazin. Die Redakteure Jan-Keno Janssen, Lukas Rumpler, Sahin Erengil und Pascal Schewe veröffentlichen jede Woche ein Video.
(jkj)







Künstliche Intelligenz
Bild-KI in WhatsApp und Instagram ausprobiert: Das kann Muse Image
Metas neue Bilderstellungs-KI hat auf einen Schlag Milliarden an potenziellen Nutzern. Denn im Juli 2026 veröffentlichte der US-Konzern mit Muse Image sein neuestes Modell direkt in WhatsApp und Instagram. Wahrscheinlich ist Muse Image sogar auf Ihrem Smartphone nur eine Wischgeste entfernt.
Die neuen Funktionen sind gut versteckt. Wer einen Status in WhatsApp oder eine Story auf Instagram veröffentlicht, kann diese nun per KI bearbeiten. Vorgefertigte Effekte sollen Selfies mehr Stil verleihen, sofern Sie nicht selbst prompten wollen. Oder Sie generieren direkt ein ganz neues Bild, statt echte Urlaubserinnerungen zu posten.
- Muse Image ist das erste Bildmodell von Metas neuer KI-Abteilung Superintelligence Labs und wurde am 7. Juli 2026 veröffentlicht.
- Nutzer aus Deutschland greifen direkt über WhatsApp oder Instagram auf die neuen Funktionen zu, um Bilder zu verändern oder zu erstellen.
- Der Gratis-Spaß hat Grenzen: Ist das Tageslimit aufgebraucht, bringt Sie auch ein bezahltes Abo nicht weiter.
Wir haben die neuen generativen Funktionen in WhatsApp, Instagram und Metas AI-App angeschaut. Dieser Ratgeber erklärt, wo Sie die Funktionen finden, was damit möglich ist und an welchen Stellen Meta seinen Nutzern Grenzen setzt. Sie haben gar keine Lust auf KI? Dann folgen Sie unserer Anleitung, um der Verwendung Ihrer Fotos zum Training von Metas KI zu widersprechen.
Das war die Leseprobe unseres heise-Plus-Artikels „Bild-KI in WhatsApp und Instagram ausprobiert: Das kann Muse Image“.
Mit einem heise-Plus-Abo können Sie den ganzen Artikel lesen.
Künstliche Intelligenz
Kundendaten bei Dienstleister abgeflossen: Datenschutzvorfall beim Lidl-Shop
Beim Discounter Lidl gab es einen Datenschutzvorfall. Das teilte das Unternehmen betroffenen Kunden mit. Unbefugte konnten sich bei einem Shop-Dienstleister Zugang zu einer Datei mit Kundendaten verschaffen und haben diese abgezogen. Lidl hat die zuständige Datenschutzbehörde informiert. Wer hinter dem Angriff steckt, ist unklar.
Weiterlesen nach der Anzeige
Die Angreifer entwendeten Anrede, Vor- und Nachname, Telefonnummer, E-Mail-Adresse, Geburtsdatum und Kundennummer der betroffenen Kunden. Wie ein Sprecher uns auf Nachfrage mitteilte, sind weder Postanschriften noch Passwörter oder Zahlungsinformationen betroffen. Die Kundenkonten wurden nicht kompromittiert, stellt der Sprecher weiterhin fest.


Datenschutzvorfall bei Lidl
Behörden sind informiert
Der Angriff traf nicht die zentrale Datenbank des Shopsystems, sondern einen IT-Dienstleister des Handelskonzerns. Dieser habe sofort reagiert und „die erforderlichen Maßnahmen getroffen, um die IT-Systeme wieder vollständig abzusichern“, so die Sprecherin. Außerdem habe der Dienstleister Strafanzeige gestellt.
Hinweise auf einen Missbrauch der Daten gebe es keine, heißt es in der uns vorliegenden E-Mail. Dennoch sollen Betroffene wachsam gegenüber Phishing und Identitätsmissbrauch sein, empfiehlt Lidl.
Lidl gehört ebenso zur Schwarz-Gruppe wie der Cloud-Anbieter Schwarz Digits und das Sicherheitsunternehmen XM Cyber.
Weiterlesen nach der Anzeige
(cku)
Künstliche Intelligenz
Top 10: Die beste Gaming-Maus im Test – Preis-Leistungs-Sieger für 30 €
Kabellose Gaming-Mäuse sollen leicht und präzise sein und gleichzeitig viele Zusatztasten bieten. Wir zeigen die besten unter ihnen.
Im Gaming-Bereich haben Spieler je nach Genre unterschiedliche Anforderungen an ihre Peripherie. Gaming-Mäuse für MMORPGs haben etwa eine Vielzahl zusätzlicher Tasten, um der Menge an Fähigkeiten und Routinen im Spiel gerecht zu werden. In der kompetitiven Shooter-Szene dreht sich währenddessen alles um Präzision und blitzschnelle Reaktionen.
Um diesen Anforderungen gerecht zu werden, setzen Hersteller auf schlanke Designs, ein geringes Gewicht und hochpräzise Sensoren. High-End-Mäuse sind zudem mit einer hohen Abtastrate ausgestattet, wodurch Verzögerungen weitestgehend vermieden werden. Im Bereich kompetitiver Shooter übertrumpfen sich Mäusehersteller also regelmäßig mit neuer Technik.
Wir zeigen hier die besten kabellosen Gaming-Mäuse mit einem Fokus auf schlankem Design und geringem Gewicht und zeigen in unserem Ratgeber-Teil zudem auch Mäuse aus anderen Bereichen der Gaming-Welt. Wir erklären außerdem, was hinter Fachbegriffen wie DPI und Polling-Rate (Abtastrate) steckt und was die Griffe, mit denen man eine Maus hält, unterscheidet.
Wenn nicht anders angegeben, sind die Mäuse in dieser Bestenliste vorrangig für Rechtshänder ausgelegt. Mäuse mit symmetrischem Design kann man theoretisch mit beiden Händen verwenden, da sich die seitlichen Buttons allerdings auf der linken Seite befinden, kann dies für Linkshänder unbequem und störend sein.
Welche ist die beste Gaming-Maus?
Unser Testsieger ist die Wireless-Gaming-Maus Logitech G Pro X2 Superstrike für 180 Euro. Per Software kann man sowohl die Klick-Haptik als auch den Betätigungspunkt der Maustasten individuell einstellen. Obendrein kommt sie mit einer 8K-Polling-Rate und einer hervorragenden Verarbeitung.
Als Technologiesieger geht die Glorious Model O3 Wireless für 107 Euro hervor. Sie überrascht mit einem durchdachten Akkusystem, welches die Gaming-Maus dank mitgelieferter Ladestation, austauschbaren Akkus und integriertem Notstrom permanent im Einsatz hält und ein Ladekabel überflüssig macht.
Der Preis-Leistungs-Sieger ist die Cherry Xtrfy M68 Pro Wireless zum absoluten Killerpreis von derzeit 27 Euro (Ebay). Sie überzeugt mit einem griffigen und bequemen Design und liefert zudem präzise Klicks bei 8000 Hz.
Mit ihren induktiven Sensoren liefert die Logitech G Pro X2 Superstrike eine komplette Neuheit im Bereich der Gaming-Mäuse: eine vollständig anpassbare Klicktiefe sowie anpassbares haptisches Feedback. Mit einer Abtastrate von 8000 Hz und einem starken Akku wird sie zum Powerhouse unter den High-End-Gaming-Mäusen. Sie kostet aktuell 180 Euro.
- anpassbare Betätigungspunkte
- anpassbares Klick-Feedback
- Rapid-Trigger-Funktion
- hervorragende Verarbeitung
- ausdauernder Akku
- teuer
- kabelgebunden nur 1000-Hz-Abtastrate möglich
Für 107 Euro sticht die Glorious Model O3 Wireless mit ihrem ungewöhnlichen Akkusystem aus der Masse der Gaming-Mäuse heraus. Eine hochwertige Verarbeitung und eine gute Performance beim Zocken und Arbeiten zählen ebenfalls zu ihren Stärken.
- hervorragende Verarbeitung
- robustes Design
- Austausch der Akkus ist einfach & schnell
- Software sorgt für viel Frustration
- teuer
Für aktuell 27 Euro (Ebay) bietet die Cherry Xtrfy M68 Pro Wireless ein symmetrisches Design mit einer 8000-Hz-Abtastrate und gerade einmal 55 g Eigengewicht. Beim Zocken überzeugt sie mit präzisen Klicks und genauen Bewegungen, während Formfaktor und Griffigkeit auch bei stundenlangem Spielen Freude bereiten.
- bequemes Design
- top Verarbeitung
- gute Performance beim Zocken
- seitlicher Ladeport sehr unpraktisch
- keine Individualisierbarkeit dank fehlender Software
- Einstellungen an der Maus vorzunehmen ist umständlich
Ratgeber
Worauf muss man bei einer Gaming-Maus achten?
Wie auch bei einer Tastatur oder einem Headset muss die Maus in erster Linie bequem benutzbar sein. Abhängig von Sitzposition, Handgröße und Platz auf dem Schreibtisch kommen manche Mäuse aufgrund ihrer Form einfach nicht infrage. Wer mit gesundheitlichen Problemen wie dem Karpaltunnelsyndrom zu kämpfen hat, sollte sich eher nach einer ergonomischen Maus umsehen.
Nicht jede Gaming-Maus unterstützt die gleichen Verbindungsmodi. Während die Mäuse in unserer Bestenliste allesamt kabellos sind, gibt es weiterhin rein kabelgebundene Mäuse. Diese sind in den meisten Fällen günstiger, aber auch weniger flexibel einsetzbar. Das ist primär dann relevant, wenn man die Maus nicht nur zum Zocken am PC verwendet, sondern auch andere Endgeräte wie Tablets mit ihr bedienen möchte.
Die meisten kabellosen Gaming-Mäuse unterstützen eine Funkverbindung via 2,4-GHz-Funk-Receiver. Dieser wird per USB-A-Anschluss entweder direkt an den PC gesteckt oder – je nach Hersteller – mittels eines Verlängerungsadapters mit dem USB-C-Port des Ladekabels verbunden. Das soll vordergründig dafür sorgen, dass die Distanz zwischen dem Receiver und der Maus so kurz wie möglich gehalten wird.
Die Funktechnologie ist mittlerweile so stark, dass die Verzögerung durch die Übertragung des Signals beim Zocken kaum noch ins Gewicht fällt. In vielen Fällen unterstützen Gaming-Mäuse auch eine Bluetooth-Verbindung. Diese eignet sich zwar, um damit zu surfen oder im Büro zu arbeiten, unterliegt aber in puncto Latenz der Funkverbindung um einiges.
Je nachdem, welche Spiele man hauptsächlich spielen möchte, ist ein Griff zu einer High-End-Maus mit 8000-Hz-Abtastrate und State-of-the-art-Sensoren unnötig. Viele Funktionen aus dem High-End-Bereich richten sich an kompetitive Spieler oder Professionals aus dem E-Sport. Für gelegentliches Zocken reicht auch eine Mittelklasse-Maus, wie die Hyperx Pulsefire 2 Haste.
Während die Mäuse in dieser Bestenliste aufgrund ihrer Charakteristika hauptsächlich für kompetitive First-Person-Shooter (FPS) ausgelegt sind, gibt es auch welche, die andere Nischen und Bedürfnisse bedienen. Anstatt ultraleicht gibt es Exemplare, die deutlich mehr wiegen und teilweise sogar mit extra einsetzbaren Gewichten kommen. Auch die bereits erwähnten MMORPG-Mäuse, die mit 8 oder mehr zusätzlichen Buttons ausgestattet sind, um Makros oder Shortcuts auszuführen, gibt es.
Weniger wichtig für die tatsächliche Performance der Maus, aber für den einen oder anderen dennoch essenziell: die RGB-Beleuchtung. Diese reicht von Akzenten wie einem beleuchteten Mausrad oder dem Logo bis hin zur Festbeleuchtung an den Seiten. Ist einem die Akkulaufzeit wichtig, sollte man jedoch auf eine permanente Beleuchtung verzichten oder direkt eine Maus kaufen, die gar keine RGBs hat.
Die Software der Gaming-Maus kann ebenso ein wichtiges Entscheidungskriterium sein. Dazu zählt nicht nur der Funktionsumfang, den diese der Maus ermöglicht. Hersteller wie Logitech oder Asus ROG bieten mit ihren Software-Angeboten Schnittstellen zu anderen Produkten aus dem eigenen Sortiment. Wer also bereits Tastaturen oder Headsets eines bestimmten Herstellers besitzt, sollte sich überlegen, ob sich auch ein Kauf der Gaming-Maus aus dem gleichen Hause lohnt.
Was sind Claw-, Palm- und Fingertip-Grip?
Wie man die Maus hält, ist von Person zu Person unterschiedlich. Dennoch haben sich überwiegend drei differenzierte Handpositionen herauskristallisiert, die auch beim Design der Mäuse mitbedacht werden.
Verwendet man den Claw-Grip, um die Maus zu halten, bedeutet das, dass die Finger gekrümmt auf den Maustasten liegen und die Peripherie über Bewegungen mit dem Handgelenk manövriert wird. Beim Claw-Grip lohnt es sich, auf das Gewicht der Maus zu achten, da eine leichtere Maus weniger Kraftaufwand für das Handgelenk bedeutet und dementsprechend auch weniger anstrengt.
Mäuse – Bilder Grip
Claw Grip

Palm Grip

Fingertip Grip

Beim Palm-Grip liegt die Hand vollständig auf der Maus, was bedeutet, dass man sie ausschließlich über den Arm bewegt. Feine Bewegungen mittels Handgelenk sind nur schwer möglich. Um den Griff zu unterstützen, ist es ratsam, eine längere und auch etwas breitere Maus zu wählen, die Platz für die gesamte Handfläche bietet.
Hält man die Maus ausschließlich mit den Fingerspitzen, spricht man hier vom Fingertip-Grip. Dabei berührt die Handfläche nicht die Maus, welche daher über das Handgelenk bewegt wird. Neben texturierten Flächen an den Seiten der Maus, die den Fingerspitzen besseren Halt geben, ist auch hier ein leichtes Gerät zu bevorzugen, um das Handgelenk zu entlasten. Da die Handfläche keinen Kontakt mit der Maus hat, ist es auch nicht verkehrt, auf eine flachere und kürzere Maus zurückzugreifen.
Was sind Abtastrate und DPI?
Die Abtastrate sagt aus, wie häufig die Maus ihre Position an den PC weitergibt, und spiegelt die damit verbundene Reaktionszeit wider. Sie wird dabei immer in Hz angegeben. Einfach gesagt: je höher der Hz-Wert, desto schneller die Reaktionszeit und desto geringer die Verzögerung. Allerdings bedeutet eine höhere Abtastrate auch mehr Auslastung für den PC und kann dementsprechend, vor allem bei älteren Computern, die Leistung beeinträchtigen.
Der Standard bei Gaming-Mäusen ist nach wie vor 1000 Hz. In den letzten Jahren haben sich Frequenzen von 4000 bis 8000 Hertz ebenfalls etabliert und werden vermehrt im hochpreisigen High-End-Segment genutzt.
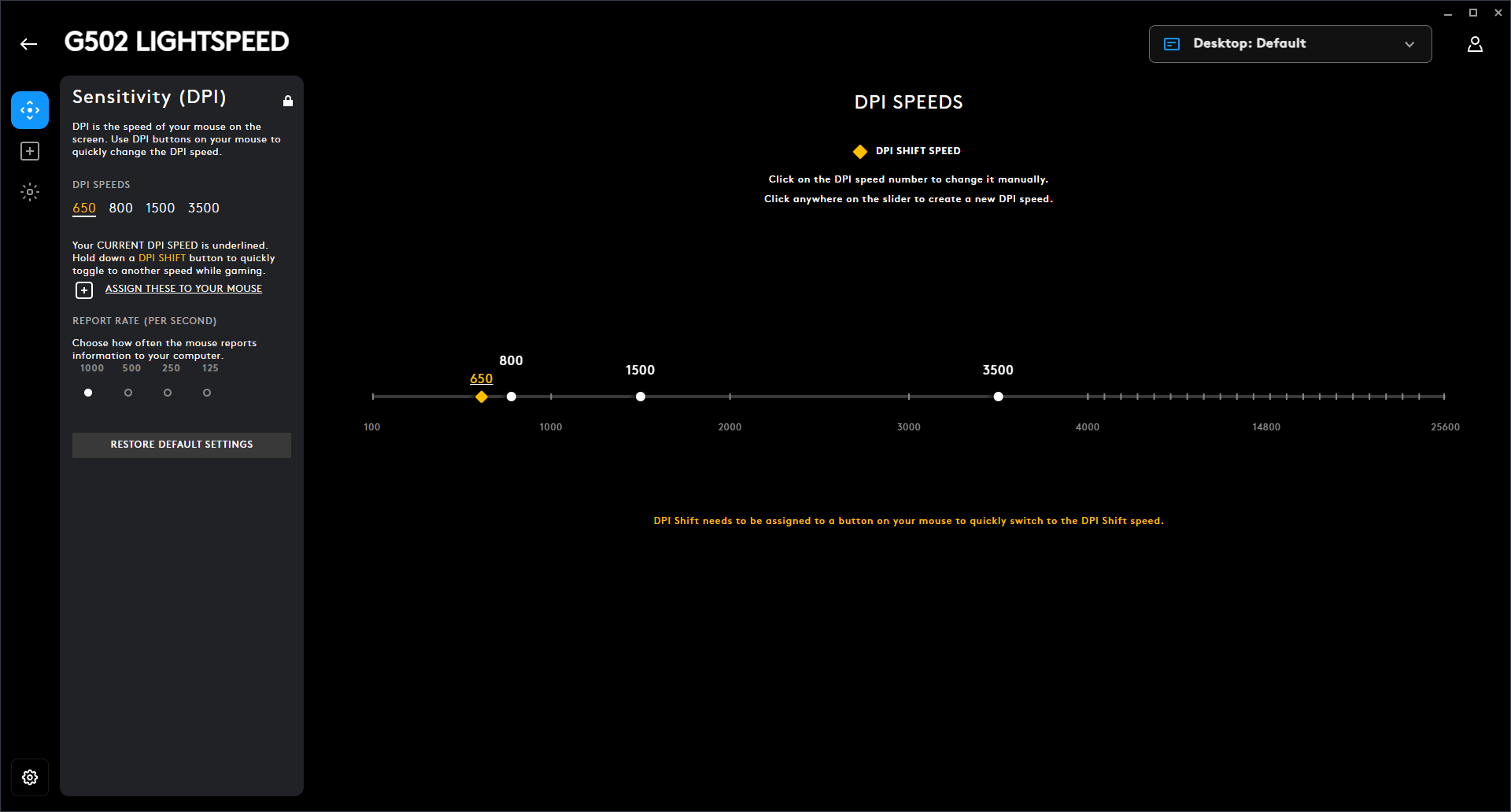
DPI hingegen steht für Dots per Inch und beschreibt, wie viele Pixel der Mauszeiger auf dem Monitor zurücklegt, wenn man die Maus auf dem Schreibtisch einen Inch (2,54 cm) bewegt. Erhöht man die DPI-Einstellung, wird der Sensor sensibler. Schiebt man jetzt die Maus die gleiche Distanz auf dem Schreibtisch wie zuvor, bewegt sich der Zeiger deutlich weiter. Manche Hersteller verwenden die Abkürzung CPI (Counts per Inch) anstatt DPI, meinen damit aber das Gleiche.
Verringert man den DPI-Wert, wird der CMOS-Sensor (Complementary metal-oxide-semiconductor) weniger sensibel und das Gegenteil tritt ein: Der Zeiger bewegt sich weniger weit für die gleiche zurückgelegte Distanz auf dem Schreibtisch. Bei einer DPI-Einstellung von 600 muss man die Maus etwa rund 8 cm bewegen, um von der linken Seite eines Full-HD-Monitors (1920 × 1080 Pixel) ganz auf die rechte Seite zu gelangen. Hat man einen höheren DPI-Wert eingestellt, beispielsweise 2000, dann muss man die Maus für die gleiche Strecke nur einen halben Zoll oder 1,27 cm bewegen.
Grundsätzlich ist der DPI-Wert Geschmackssache, allerdings empfiehlt es sich je nach Programm, eine niedrigere DPI zu wählen. Bei kompetitiven FPS-Games etwa, bei denen es wichtig ist, pixelgenau mit der Maus zu zielen. Andersherum lohnt sich eine etwas höhere DPI, wenn man mit einem Multi-Monitor-Setup arbeitet und die Maus etwa über drei Bildschirme bewegen muss. Da viele Mäuse aber in der Lage sind, verschiedene DPI-Profile anzulegen und per Knopfdruck zwischen diesen zu wechseln, ist die Geschwindigkeit der Maus für jede Situation problemlos anpassbar.
Welche Sensoren stecken in einer Maus?
Im Vergleich zu den Mäusen von früher, die mit ihren Kugeln und Rollen sehr anfällig für die Ansammlung von Fusseln waren und deswegen regelmäßig gereinigt werden mussten, ist man bei modernen Mäusen auf eine digitale Sensorik umgestiegen: optische Sensoren und Laser-Sensoren.
Bei optischen Mäusen beleuchtet eine LED die Fläche unter ihr, wodurch der CMOS-Sensor im Inneren der Maus in der Lage ist, Fotos vom Untergrund aufzunehmen. Die Maus ist so imstande, die Oberflächenstruktur zu erfassen und durch die digitale Verarbeitung der geschossenen Bilder festzustellen, wie weit und wohin sie sich bewegt hat, um die Cursorbewegung und -position auf dem Monitor abzubilden.

Laser-Mäuse setzen ebenfalls auf die Aufnahme tausender Bilder, um Position und Oberfläche zu bestimmen. Der Unterschied ist jedoch, dass der verbaute Laser tiefer in die Oberfläche eindringen kann als die LED einer optischen Maus und so die Feinheiten und Veränderungen in der Struktur dieser besser für die Kamera erfassbar macht. Daraus resultiert primär, dass Laser-Mäuse noch präzisere Bewegungen ermöglichen, als es optische bereits tun – und solche Mäuse auf mehr Oberflächen ohne Probleme funktionieren.
Beide Sensoren eignen sich für die Arbeit im Büro oder beim Gaming. Man sollte allerdings bei optischen Mäusen darauf achten, auf einer matten und lichtundurchlässigen Oberfläche zu arbeiten. Bei Oberflächen wie Glastischen oder bei Tischen mit einem glänzenden, reflektierenden Finish hat es der Sensor schwer, zuverlässig zu arbeiten. Laser-Mäuse haben dieses Problem nicht und finden sich auf so ziemlich allen Oberflächen gut zurecht. Aufgrund ihrer deutlich präziseren Erfassung sind sie nicht jedermanns Geschmack und je nach Modell eventuell auch etwas Overkill für den regulären Einsatz im Büro.
Fazit
Leichte kabellose Gaming-Mäuse sind flexibel einsetzbar, auf Dauer schonender für das Handgelenk als schwere Mäuse und obendrein ideal, um in FPS wie Valorant oder CS2 zu dominieren. Um eine solche Maus zu genießen, muss man nicht unbedingt tief in die Tasche greifen – aber im High-End-Bereich gibt es phänomenal gute Hardware, die beim Zocken einen deutlichen Unterschied macht.
Ausschlaggebend hierfür ist in erster Linie die hohe Abtastrate, dank der die Mäuse extrem kurze Reaktionszeiten vorweisen können und im Spiel für verzögerungsfreie und präzise Klicks sorgen. Zusätzliche Funktionen, die dank der Software freigeschaltet werden, ermöglichen häufig eine zusätzliche Individualisierung im Umgang mit der Maus. Makros, Shortcuts oder gar auf den Spieler angepasste Beschleunigungskurven sind möglich.
Mit unserer Bestenliste haben wir die stärksten Gaming-Mäuse vorgestellt. Unser Testsieger ist die Logitech G Pro X2 Superstrike für 180 Euro. Als Technologiesieger geht die Glorious Model O3 Wireless für 111 Euro hervor. Ein unschlagbares Preis-Leistungs-Verhältnis bietet die Cherry Xtrfy M68 Pro Wireless für derzeit 27 Euro (Ebay).
Weitere interessante Themen:
Logitech G Pro X2 Superstrike
Die Gaming-Maus Logitech G Pro X2 Superstrike startet eine kleine Revolution: Dank induktiver Sensoren gibt es verstellbare Klicktiefe und haptisches Feedback.
- anpassbare Betätigungspunkte
- anpassbares Klick-Feedback
- Rapid-Trigger-Funktion
- hervorragende Verarbeitung
- ausdauernder Akku
- teuer
- kabelgebunden nur 1000-Hz-Abtastrate möglich
Logitech G Pro X2 Superstrike im Test: Gaming-Maus mit verstellbarer Klicktiefe
Die Gaming-Maus Logitech G Pro X2 Superstrike startet eine kleine Revolution: Dank induktiver Sensoren gibt es verstellbare Klicktiefe und haptisches Feedback.
Logitech geht mit der G Pro X2 Superstrike den nächsten Schritt in Richtung High-End-Gaming-Maus. Bereits die G Pro X Superlight 2 (Testbericht) konnte uns vollends überzeugen. Die X2 Superstrike setzt mit brandneuer Technologie noch einmal eine Schippe darauf.
Induktive Sensoren statt regulärer Switches ermöglichen anpassbare Klicks – sowohl in Sachen Schnelligkeit als auch in Bezug auf das haptische Feedback. Hier muss man keine Kompromisse eingehen und kann die Maus ganz den eigenen Anforderungen anpassen. Wie sie sich im Einsatz zeigt, klären wir im Test. Das Testgerät hat uns der Hersteller zur Verfügung gestellt.
Lieferumfang
Die Maus kommt mit einem Verbindungskabel (USB-A-zu-USB-C), dem 2,4-GHz-Funkdongle (USB-A) und einem Extender (USB-C-zu-USB-A), um den Dongle mit dem Kabel zu verbinden und ihn so näher an die Maus zu bringen. Außerdem liegen der Gaming-Peripherie noch optionales Grip-Tape, ein Quick-Start-Guide sowie ein Ersatzdeckel für die Verstaumöglichkeit auf der Unterseite der Maus bei.
Design
Vom Formfaktor her und mit den Maßen 63,5 x 40 x 125 mm entspricht die X2 Superstrike eins zu eins der X Superlight 2. Mit etwa 61 g ist sie auch nur gut 1 g schwerer. Im von Logitech „Lunar Eclipse“ getauften Farbdesign präsentiert sich die Gaming-Maus in einer Kombination aus Schwarz und Weiß. Das Gros der Schale ist weiß, während linke und rechte Maustaste in Schwarz gehalten sind. Das Logitech-Logo, der Superstrike-Schriftzug sowie die komplette Unterseite der Maus sind ebenfalls schwarz. Sie ist zwar symmetrisch, aufgrund der linken seitlichen Buttons aber in erster Linie für Rechtshänder geeignet.
Logitech G Pro X2 Superstrike – Bilder
Logitech G Pro X2 Superstrike – Bilder

Logitech G Pro X2 Superstrike – Bilder

Logitech G Pro X2 Superstrike – Bilder

Logitech G Pro X2 Superstrike – Bilder

Logitech G Pro X2 Superstrike – Bilder

Logitech G Pro X2 Superstrike – Bilder

Logitech G Pro X2 Superstrike – Bilder

Logitech G Pro X2 Superstrike – Bilder

Logitech G Pro X2 Superstrike – Bilder

Logitech G Pro X2 Superstrike – Bilder

Was die Bedienelemente angeht, hat sich nichts verändert: Das Mausrad ist aus Kunststoff und mit einer gummierten und texturierten Oberfläche versehen. Ein dedizierter DPI-Button fehlt auch bei der Superstrike 2. Auf der linken Seite befinden sich die erwarteten zwei Extra-Buttons, und auf der Unterseite liegt der An-/Ausschalter. Der magnetisch fixierte Deckel für die Verstaumöglichkeit des Funkdongles sitzt bombenfest und lässt sich durch Hineindrücken lösen. Der USB-C-Port zum Laden der Maus befindet sich vorn an der Spitze und ermöglicht so gleichzeitiges Spielen und Laden.
Die Verarbeitung ist einwandfrei, was man bei dem Preis allerdings auch erwarten darf. Alles sitzt fest, nichts klappert und auch beim Schütteln der Maus regt sich im Inneren nichts.
Software
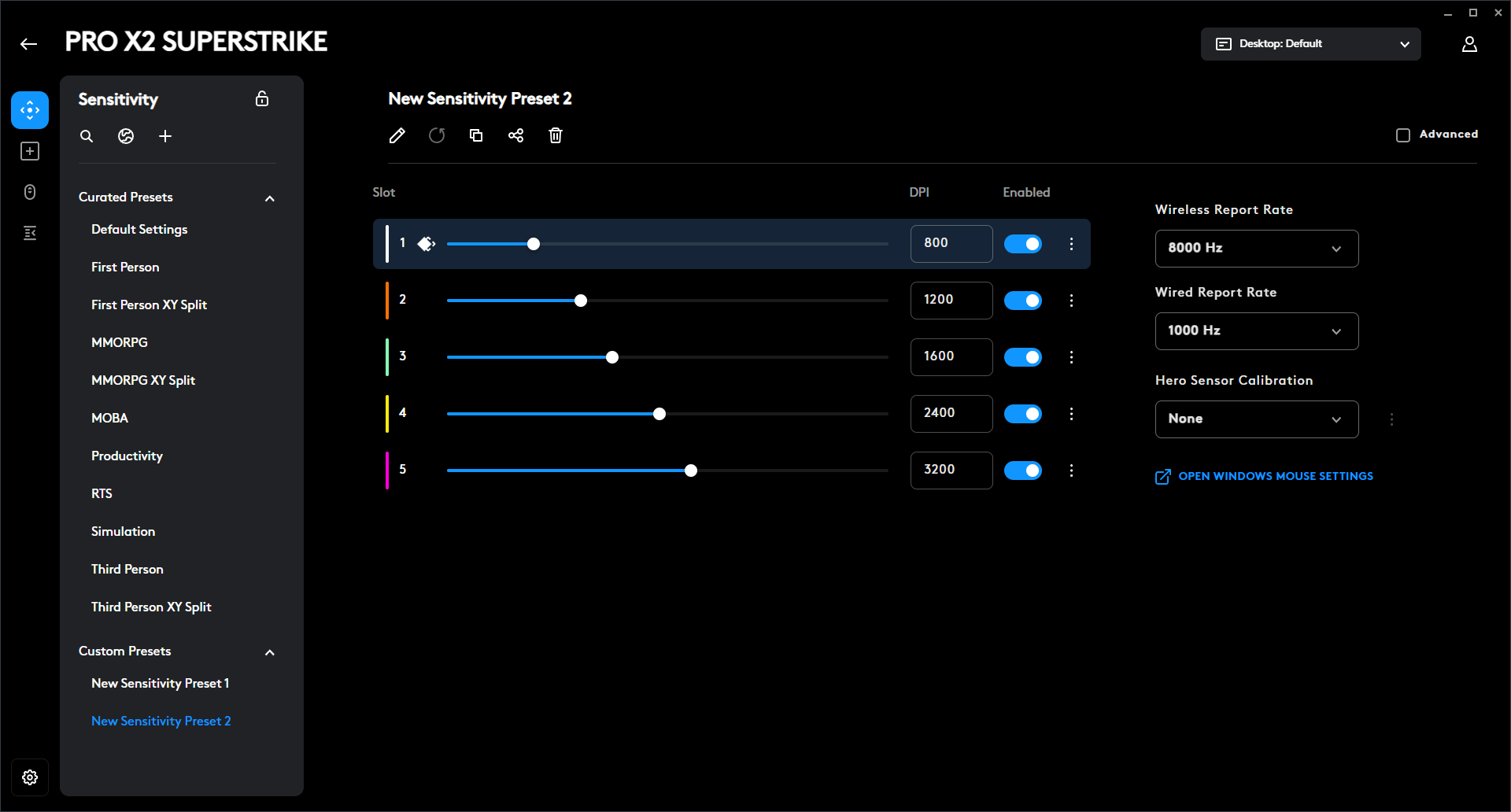
Maus und Funkdongle werden problemlos von unserem Desktop-PC unter Windows 11 erkannt. Wer die Maus anschließend konfigurieren möchte, kommt um die Software Logitech G-Hub nicht herum. Neben den DPI und der Tastenbelegung stellt man für die G Pro X2 Superstrike auch den Betätigungspunkt sowie das haptische Feedback ein und schaltet, wenn gewünscht, die Rapid-Trigger-Funktion hinzu. Die Bedienung der App ist gewohnt intuitiv und die Benutzeroberfläche aufgeräumt.
Insgesamt stehen fünf verschiedene DPI-Profile zur Auswahl, die sich alle individuell anpassen lassen. Der DPI-Bereich liegt dabei zwischen 100 und 44.000, veränderbar in Fünfer-Schritten oder höher. Klickt man das Advanced-Kästchen an, offenbaren sich weitere Einstellungsmöglichkeiten. Nun lassen sich die DPI der x- und y-Achse individuell einstellen und die Lift-Off-Distance verändern. Unterteilt ist die Distanz in low, medium und high. Hier hätten wir eine Angabe in mm besser gefunden.
Neben von Logitech bereitgestellten DPI-Profilen mit Bezeichnungen wie MMORPG, First Person oder MOBA, kann man auch eigene Presets erstellen und abspeichern oder von der Community kreierte DPI-Profile über das Globus-Symbol suchen und herunterladen.
Die Abtastrate der G Pro X2 Superstrike geht bis auf 8000 Hz hoch, allerdings nur im kabellosen Modus. An das Ladekabel angeschlossen, ist bei 1000 Hz Schluss. Das ist schade, da andere, zum Teil deutlich günstigere Konkurrenzmodelle, das auch mit dem Kabel hinbekommen. Zusätzlich zu den 8000 Hz unterstützt die Gaming-Maus auch 4000, 2000, 1000, 500, 250 und 125 Hz.
Logitech G Pro X2 Superstrike – Bilder App
Logitech G Pro X2 Superstrike – Bilder App
Logitech G Pro X2 Superstrike – Bilder App
Logitech G Pro X2 Superstrike – Bilder App
Logitech G Pro X2 Superstrike – Bilder App

Logitech G Pro X2 Superstrike – Bilder App

Logitech G Pro X2 Superstrike – Bilder App

Logitech G Pro X2 Superstrike – Bilder App

Logitech G Pro X2 Superstrike – Bilder App
Logitech G Pro X2 Superstrike – Bilder App
Logitech G Pro X2 Superstrike – Bilder App
Für die Tastenbelegung stehen unter anderem Tastenkombinationen, einzelne Tasten der Tastatur, Media-Steuerung und Makros zur Verfügung, letztere mit inkludiertem Editor. Der BHOP-Modus ist auch wieder am Start. Aktiviert man ihn, wird die erste Betätigung des Mausrads ignoriert, außer es folgt eine zweite Mausradbewegung im zuvor festgelegten Zeitfenster. Das soll verhindern, dass man im Eifer des Gefechts aus Versehen zu springen beginnt. Der Hintergrund ist, dass man beim Bunny-Hopping das Springen auf das Mausrad anstatt auf die Leertaste legt, um präziser und mit besserem Timing hüpfen zu können.
Das wohl spannendste Feature der Pro X2 Superstrike ist allerdings das Haptic Inductive Trigger System (HITS). Ähnlich wie bei Tastaturen mit magnetischen Switches lässt sich auch hier der Betätigungspunkt der linken und rechten Maustaste individuell anpassen, mit dem Unterschied, dass in der Maus keine Switches verbaut sind.
Hinzu kommt noch die Rapid-Trigger-Funktion, ebenfalls bekannt aus der Welt der magnetischen Tastatur-Switches, mit der man festlegen kann, wie schnell die Maustaste nach dem Klick zurücksetzt. Damit jedoch nicht genug: Selbst das haptische Feedback beim Klicken kann angepasst werden – von ausgeschaltet bis hin zum prägnanten Klick.
Bedienbarkeit
Beim Spielen überzeugt uns die Logitech G Pro X2 Superstrike auf ganzer Linie. Der Formfaktor ermöglicht für uns eine bequeme Verwendung im Fingerspitzengriff. Mit 61 g Eigengewicht ist sie nicht die leichteste der von uns bisher getesteten Gaming-Mäuse, aber auch nach mehreren Stunden am Stück treten bei uns in der Hand und im Handgelenk keinerlei Ermüdungserscheinungen auf. Die seitlichen Buttons sind mit regulären Switches ausgestattet und haben einen angenehmen Druckpunkt, der verhindert, dass man sie aus Versehen betätigt.
Die Sensoren auf Induktionsbasis, die Logitech anstelle traditioneller Switches verwendet, sind ein wahrer Gamechanger. Dass hier keine regulären Switches im Einsatz sind, merkt man, sobald die Maus ausgeschaltet ist. Dann klicken die Tasten nämlich nicht mehr – ein haptisches Feedback fehlt. Das Klickverhalten samt Betätigungs- und Resetpunkt individuell einstellen zu können, ist einfach genial. Die Unterschiede sind tatsächlich deutlich spürbar.
Dass beiden Maustasten unabhängig voneinander einstellbar sind, ist praktisch, da man so etwa der rechten Maustaste für das Aim-Down-Sights einen anderen Betätigungspunkt zuweisen kann als der linken Schusstaste. Dank Onboard-Speicher lassen sich zudem bis zu fünf Profile abspeichern. Richtet man sich Profile für verschiedene Spiele ein, kann man sie dann direkt von der Maus aus abrufen.
In der Praxis machen sich die Unterschiede zu herkömmlichen Switches schnell bemerkbar. Sowohl in Overwatch als auch in Valorant bemerken wir die deutlich schnelleren Klicks sowie das schnellere Zurücksetzen der Tasten mit aktiviertem Rapid-Trigger. Das ist zu Beginn etwas ungewohnt und bedarf eventuell ein wenig Herumprobieren mit verschiedenen Klickstärken. Hat man jedoch die richtige Kombination für sich gefunden, fühlt sich der Umgang mit der G Pro X2 Superstrike unglaublich gut an.
Auch der Akku der Gaming-Maus überzeugt. Wie lange er mit einer Ladung durchhält, variiert stark mit den gewählten Funktionen. Maximal ist laut Logitech ein Betrieb von 90 Stunden möglich. In der App sieht man immer eine Prognose der verbleibenden Stunden in Abhängigkeit der aktuellen Einstellungen.
Mit der Abtastrate dauerhaft auf 8000 Hz, dem Betätigungspunkt bei 2, Rapid Trigger auf 2 und dem haptischen Feedback auf 2 attestiert uns die App 19 Stunden bis zum nächsten Ladevorgang. Die Zahl halten wir allerdings für sehr konservativ, da wir nach zweieinhalb Tagen im täglichen Einsatz auf der Arbeit und anschließender drei bis vierstündiger Zocksessions am Abend immer noch 62 Prozent Akku und 12 Stunden angezeigt bekommen. Setzen wir die Abtastrate auf 1000 Hz herunter, schießt die Prognose auf über 60 Stunden hoch.
Preis
Die Logitech G Pro X2 Superstrike gibt es aktuell für 180 Euro. Die UVP liegt ebenfalls bei 180 Euro.
Fazit
Die Möglichkeit, die Bedienbarkeit der Maus komplett an die eigenen Bedürfnisse anpassen zu können, macht die Logitech G Pro X2 Superstrike zu einer unglaublich flexiblen Peripherie. Die Begriffe „Innovation“ und erstaunliche „Technologie“ dienen dabei nicht nur als Marketing-Schlagwort, sondern hält tatsächlich, was sie verspricht. Klicks fühlen sich schneller an und auch das haptische Feedback verändert sich je nach gewählter Einstellung merklich. Zusätzlich überzeugen auch die Verarbeitung und die generelle Bedienbarkeit der G Pro X2 Superstrike.
Logitech serviert hier eine technisch beeindruckende High-End-Gaming-Maus, die ein unglaubliches Maß an Individualisierung liefert und ihresgleichen sucht. Allerdings zahlt man dafür auch einen happigen Preis von 180 Euro. Wer gerne Early-Adopter einer neuen Technologie im Bereich der Gaming-Mäuse sein möchte, schlägt hier definitiv zu.
Glorious Model O3 Wireless
Die Glorious Model O3 Wireless setzt auf zwei austauschbare sowie einen fest verbauten Akku, um die Gaming-Maus permanent mit Strom zu versorgen.
- hervorragende Verarbeitung
- robustes Design
- Austausch der Akkus ist einfach & schnell
- Software sorgt für viel Frustration
- teuer
Gaming-Maus Glorious Model O3 Wireless im Test: Endlos Zocken dank drei Akkus
Die Glorious Model O3 Wireless setzt auf zwei austauschbare sowie einen fest verbauten Akku, um die Gaming-Maus permanent mit Strom zu versorgen.
Die meisten modernen Gaming-Mäuse sind mittlerweile kabellos und setzen auf fest verbaute Akkus, um die Peripherie möglichst lange mit Strom zu versorgen, bis man dann doch wieder das Kabel auspacken und die Peripherie aufladen muss.
Nicht so bei der Glorious Model O3 Wireless. Hier verfolgt der Hersteller mit einem System aus Ladestation, zwei austauschbaren und einem fest verbauten Akku zur Überbrückung den Traum des wahrhaftig kabellosen Gamings. Per Ladestation, die gleichzeitig auch als Hub für den 2,4-GHz-Dongle dient, lädt einer der beiden Akkus auf, während der andere in der Maus im Einsatz ist. Der fest verbaute Akku dient zur Überbrückung.
Ob das Konzept aufgeht und wie sich die Gaming-Maus mit 8000-Hz-Abtastrate in der Praxis schlägt, erklären wir im Test. Das Testgerät hat uns der Hersteller zur Verfügung gestellt.
Lieferumfang
Die Maus kommt mit der Ladestation, einem 2,4-GHz-Funk-Dongle, einem USB-A-zu-USB-C-Verbindungskabel sowie zwei austauschbaren Akkus. Ein Quick-Start-Guide sowie Sticker liegen ebenfalls bei.
Design
Die Model O3 Wireless gibt sich im symmetrischen Rechtshänder-Design, mit zwei Buttons auf der linken Seite und wiegt mit eingesetztem Akku etwa 66 g. Farblich wählt man zwischen Schwarz und Weiß. Der Look ist auffällig: Die Schale der Gaming-Maus verläuft nicht in einem Guss über die ganze Maus, sondern ist zur Mitte hin unterbrochen. Ein Fluss aus bunt leuchtenden LEDs bahnt sich seinen Weg und zieht einen Graben zwischen der vorderen und der hinteren Hälfte der Maus. Das leuchtende Mittelstück ist leicht tiefer gelegt als die restliche Schale.
Glorious Model O3 Wireless – Bilder
Glorious Model O3 Wireless – Bilder

Glorious Model O3 Wireless – Bilder

Glorious Model O3 Wireless – Bilder

Glorious Model O3 Wireless – Bilder

Glorious Model O3 Wireless – Bilder

Glorious Model O3 Wireless – Bilder

Glorious Model O3 Wireless – Bilder

Glorious Model O3 Wireless – Bilder

Glorious Model O3 Wireless – Bilder

Glorious Model O3 Wireless – Bilder

Glorious Model O3 Wireless – Bilder

Glorious Model O3 Wireless – Bilder

Glorious Model O3 Wireless – Bilder

Glorious Model O3 Wireless – Bilder

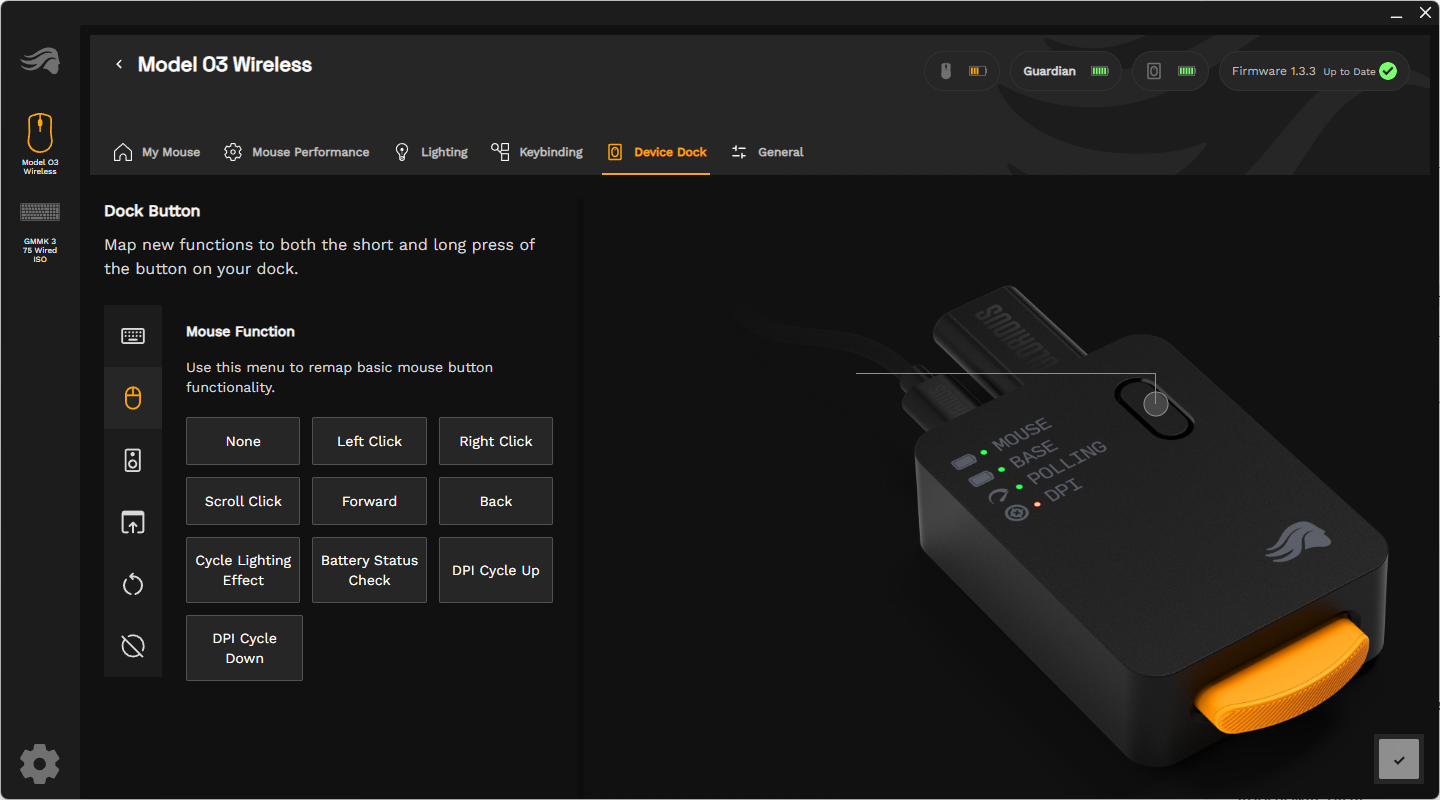
Das ist aber nicht der einzige Blickfang der Model O3 Wireless, denn am hinteren Ende der Maus sitzt der orangefarbene Akku, dessen texturiertes Endstück prominent heraussticht. Möchte man ihn zum Austausch lösen, muss man ihn in die Maus drücken. Während ein Akku im Einsatz ist, lädt der zweite bereits in der Ladestation.
Diese fungiert zeitgleich auch als Hub für den Funk-Dongle. Alternativ kann man den Dongle auch direkt an einen USB-A-Port des PCs stecken. Nebst Ladefunktion bietet die Station auch einen Überblick zum Akkustand der Maus, des Ersatzakkus in der Station, der derzeitigen Abtastrate sowie der aktuellen DPI – farblich kodiert via LEDs.
Software
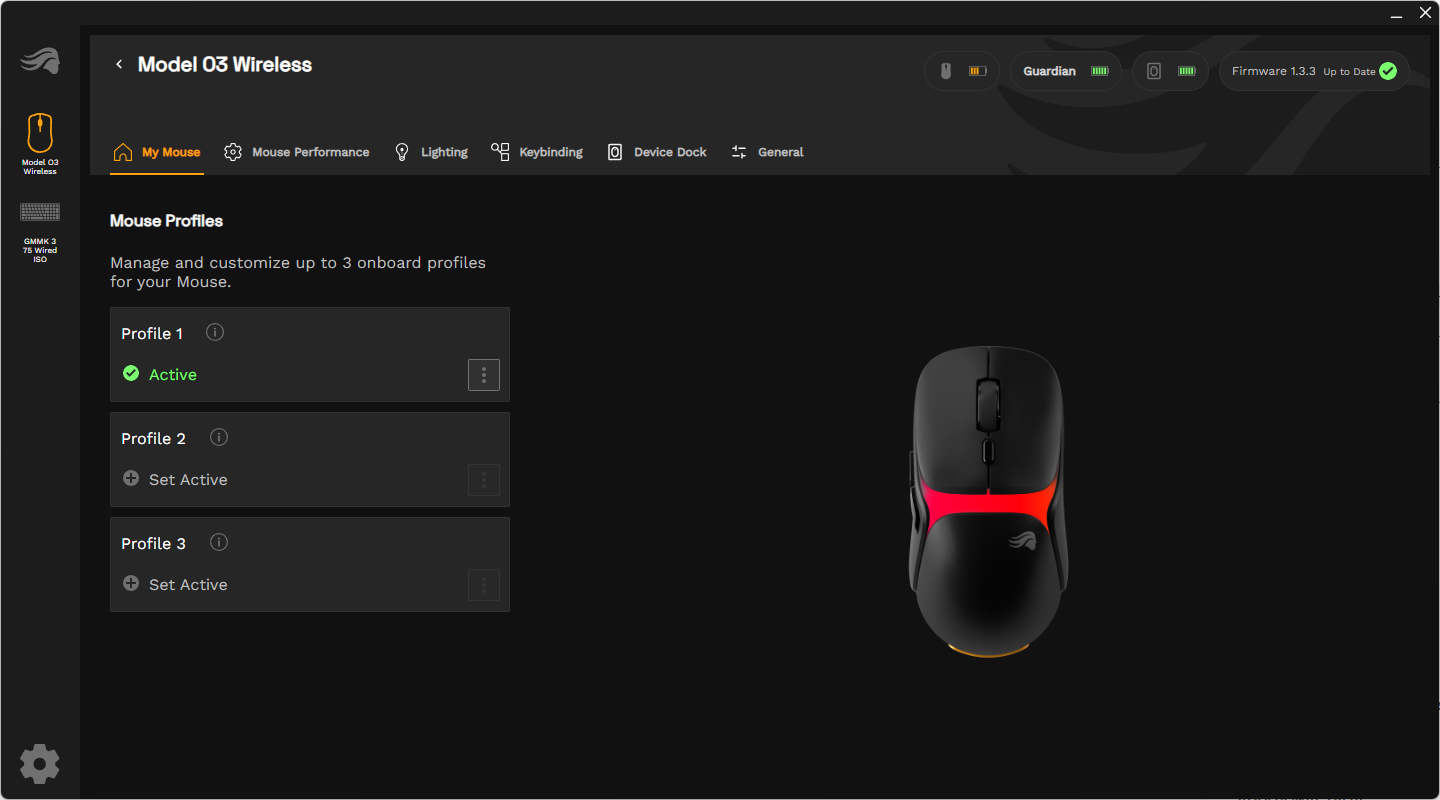
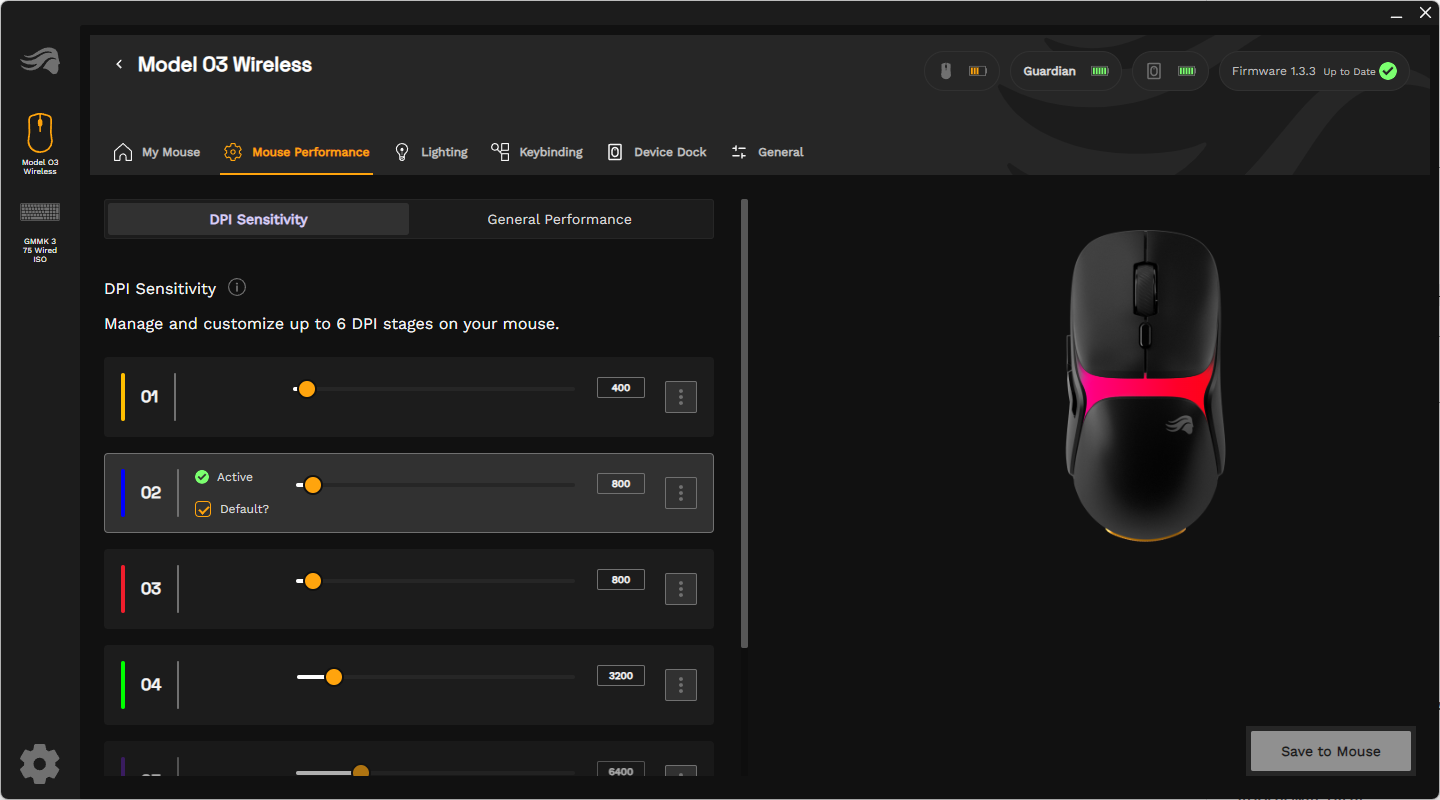
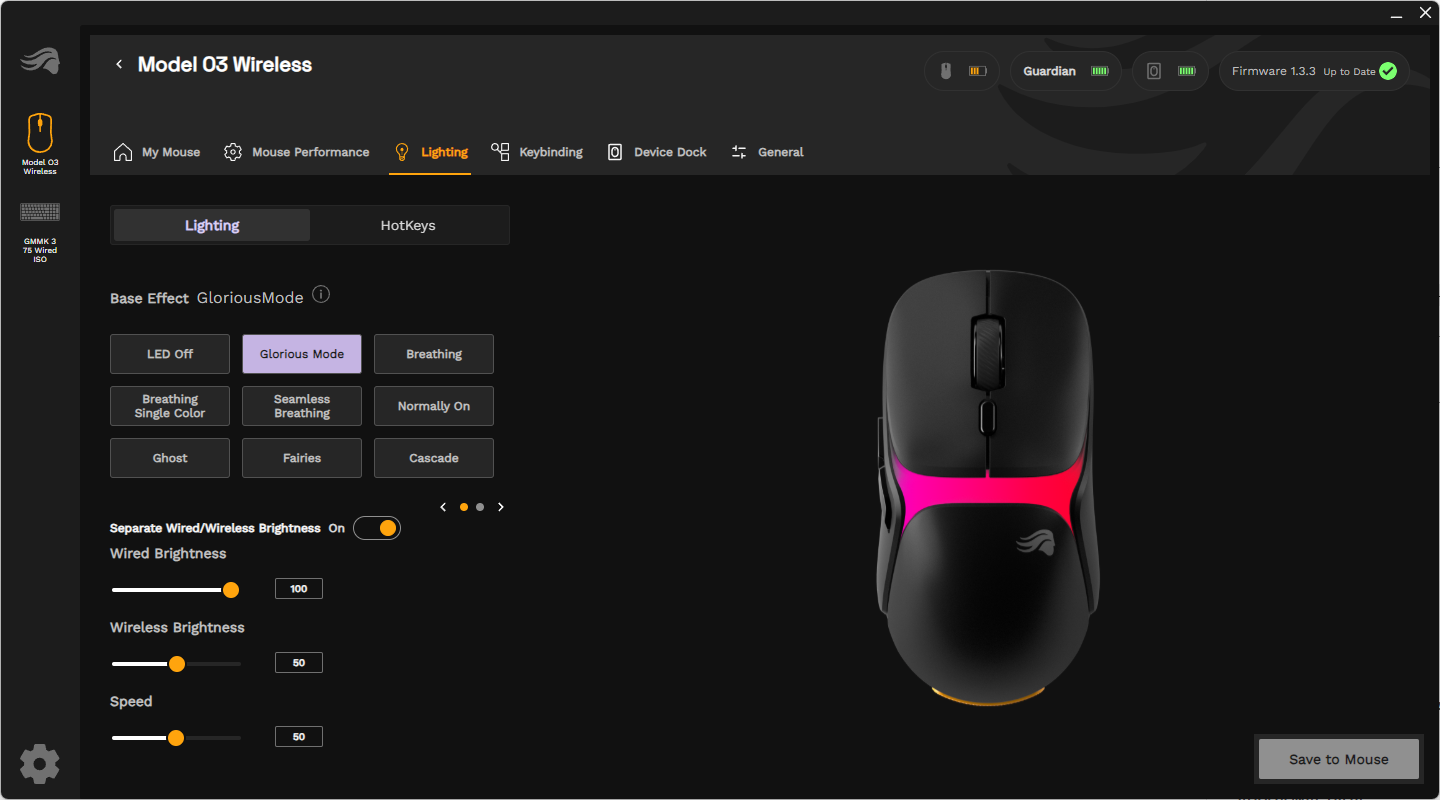
Die Maus arbeitet mit der App Glorious Core. Bis zu drei Profile mit unterschiedlichen Einstellungen lassen sich auf der Maus abspeichern. Sechs unterschiedliche DPI-Werte, farblich kodiert, können nach Belieben eingerichtet werden. Die Maus unterstützt dabei 50 bis 30.000 DPI.
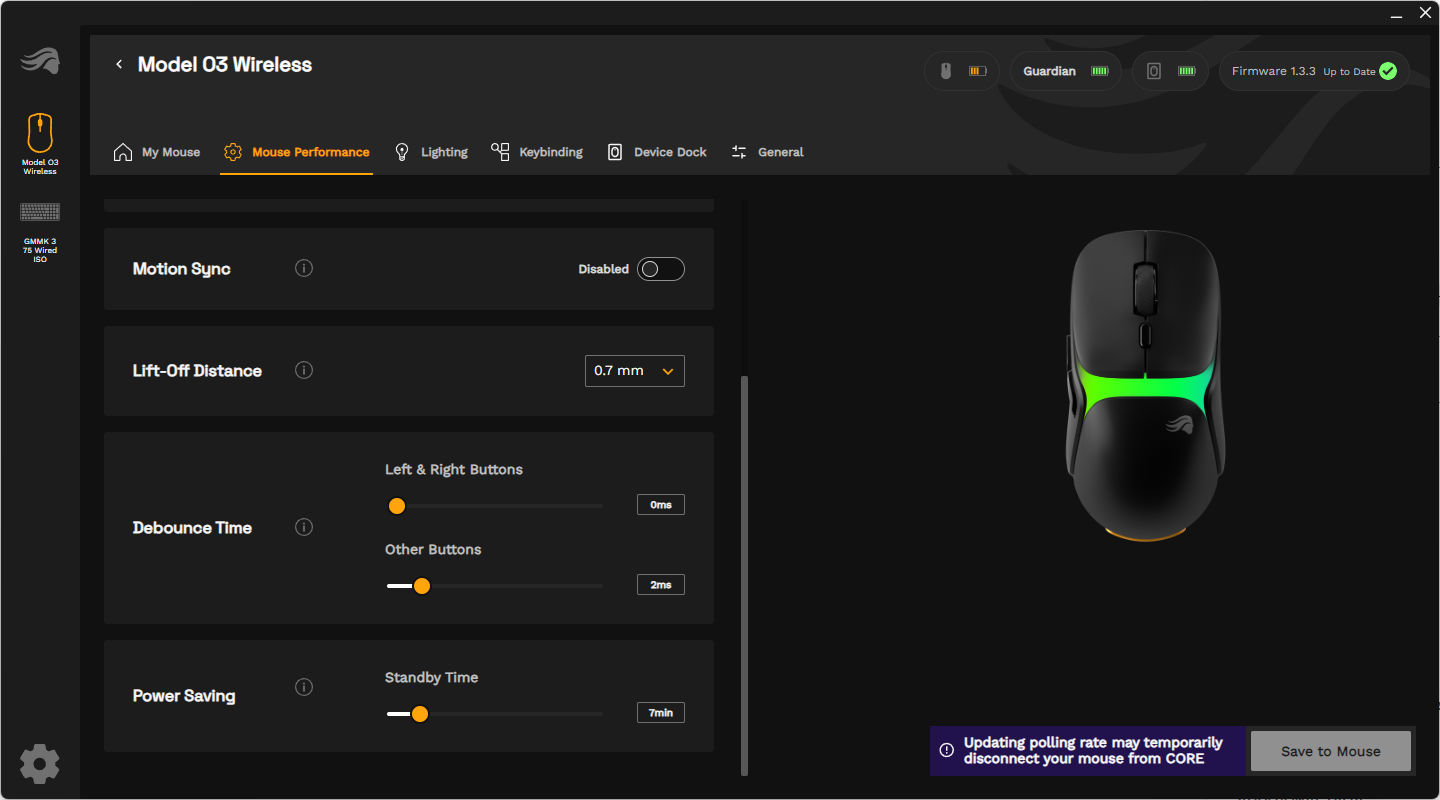
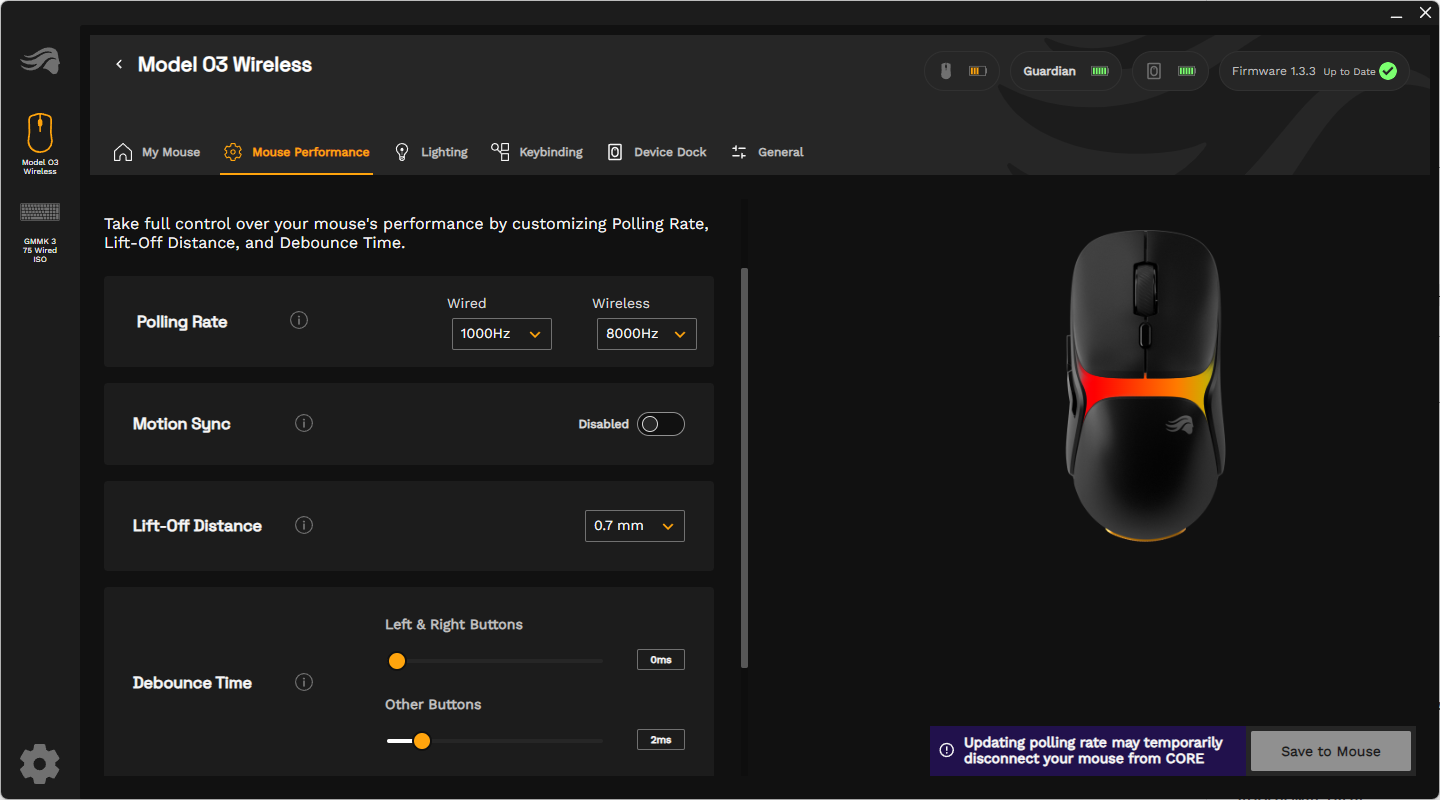
Abtastrate, Motion Sync, Lift-Off-Distance und Debounce Time kann man ebenfalls anpassen. Im kabelgebundenen Modus sind maximal 1000 Hz möglich, kabellos kann die Model O3 Wireless auf eine Abtastrate von bis zu 8000 Hz zugreifen. Die Lift-Off-Distance, also bis zu welcher Höhe beim Anheben der Maus der Sensor noch Bewegungen registriert, gibt es in den Settings 0,7, 1,0 und 2,0 mm. Die Debounce-Time stellt man für die linke und rechte Maustaste kombiniert und für die restlichen Buttons der Peripherie separat ein.
Glorious Core bietet 11 unterschiedliche vordefinierte Beleuchtungseffekte für die Model O3 Wireless. Die Einstellungsmöglichkeiten beschränken sich hier auf die Helligkeit und Geschwindigkeit der Effekte. Für die Tastenbelegung der Maus und des Ladedocks stehen die üblichen Verdächtigen zur Auswahl: Tastatureingaben, Maus-Funktionen, Mediensteuerung und Windows-Funktionen. Einen integrierten Makro-Editor gibt es nicht.
Glorious Model O3 Wireless – Bilder App
Glorious Model O3 Wireless – Bilder App
Glorious Model O3 Wireless – Bilder App
Glorious Model O3 Wireless – Bilder App
Glorious Model O3 Wireless – Bilder App
Glorious Model O3 Wireless – Bilder App
Glorious Model O3 Wireless – Bilder App
Glorious Model O3 Wireless – Bilder App
Glorious Model O3 Wireless – Bilder App
Glorious Model O3 Wireless – Bilder App
Glorious Model O3 Wireless – Bilder App
Leider ist die Software eine der größten Schwächen der Gaming-Maus, da sie oft die vorgenommenen und abgespeicherten Einstellungen nicht übernimmt. Das passierte etwa beim Versuch, die Tastenbelegung der seitlichen Buttons zu ändern. Erst nachdem wir die Tasten komplett zurücksetzen und die gewünschte Funktion erneut auf die Taste legen, spielt die Maus mit.
Auch beim Ändern der Abtastrate streikt Glorious Core manchmal. Man wird zwar gewarnt, dass die App beim Umstellen der Abtastrate die Verbindung zur Maus kurzzeitig verlieren kann, dass die Maus dabei dann aber die Einstellungen nicht übernimmt, darf einfach nicht sein. In unserem Fall müssen wir das Programm dann komplett beenden und neu starten, um die Abtastrate erfolgreich anzupassen.
Bedienbarkeit
Die Frustrationen mit der Software ausgeklammert, macht die Model O3 Wireless einen soliden Eindruck auf dem Mauspad. Beim Zocken mit Fingerspitzengriff manövriert sich die Maus angenehm über den Schreibtisch. Die unkonventionelle Form der Schale und der hinten leicht herausragende Akku stören uns nicht, da die Handinnenfläche in unserem Fall die Maus nicht berührt. Verwendet man hier einen anderen Griff, kann es sein, dass man sich an die Form gewöhnen muss. Durch den Akku verschiebt sich der Schwerpunkt der Maus nach hinten, was uns beim Zocken aber nicht sonderlich gestört hat.
Die Model O3 Wireless arbeitet mit optischen Switches und dem BAMF-3.0-Sensor, welcher auf dem Pixart PAW 3950 aufbaut. Er hat eine maximale Geschwindigkeit von 750 IPS und eine maximale Beschleunigung von 50 g. Die Klicks fühlen sich angenehm und präzise an. Auch die Bewegungen der Maus machen einen flüssigen Eindruck. Am PC verwenden wir die Peripherie im 2,4-GHz-Funkmodus und haben während des Testzeitraums keinerlei Verbindungseinbrüche oder spürbare Verzögerungen – sowohl beim Arbeiten als auch beim Zocken.
Was die Glorious Model O3 Wireless jedoch besonders macht, ist das ausgeklügelte Akkusystem. Die Maus hat nicht nur zwei austauschbare Akkus, sondern auch die sogenannte Guardian Battery. Diese ist fest verbaut und liefert der Maus bis zu 10 Stunden Strom, wenn kein Akku in ihr steckt. Der Sinn dahinter ist, dass beim Austauschen der Akkus die Maus nicht ausgeht und so die Verbindung zum PC trennt. Das gewährleistet einen reibungslosen Austausch und sofortiges Weiterzocken ohne Verzögerungen.
In der Praxis funktioniert diese Lösung hervorragend. Der Austausch der Akkus geht mit zwei Handgriffen unheimlich schnell vonstatten und die Maus ist sofort einsatzbereit. Während der vollgeladene Akku die Maus mit Strom versorgt, wird der leere Akku parallel im Dock aufgeladen. Die Maus signalisiert im Übrigen mittels rotem Aufleuchten der LEDs, dass der Akku zur Neige geht und ausgetauscht werden sollte.
Akku
Offiziell gibt Glorious für die Model O3 Wireless eine Einsatzzeit von bis zu 71 Stunden im 2,4-GHz-Modus an. Theoretisch ist die Ausdauer jedoch irrelevant, da man permanent einen vollgeladenen Akku zum Austausch zur Verfügung hat. Während des Testzeitraums hält ein Akku bei einer Mischung aus 1000- und 8000-Hz-Abtastrate und Beleuchtung bei 50 Prozent Helligkeit im Schnitt etwa 5 Stunden durch, bis die Maus uns per rot leuchtenden LEDs zum Austauschen animiert.
Das ist im Vergleich zu Mäusen mit fest verbauten Akkus natürlich extrem kurz, relativiert sich aber durch den einfachen und schnellen Austausch und macht die Kabelverbindung von der Maus zum PC komplett überflüssig.
Preis
Die Glorious Model O3 Wireless hat eine UVP von 170 Euro. In Schwarz gibt es sie momentan für knapp 107 Euro. In Weiß gibt es sie aktuell für 111 Euro.
Fazit
Die Glorious Model O3 Wireless wirbelt den Markt der kabellosen Gaming-Mäuse mit einem komplett neuen Ansatz auf: Anstatt die fest verbaute Batterie aufzumotzen, arbeitet die Peripherie mit austauschbaren Akkus und ermöglicht so mehr oder weniger permanent kabelloses Zocken. Die Umsetzung ist gelungen, denn der Austausch der Akkus geht reibungslos und schnell vonstatten.
Auch die Verarbeitung und das Handling der Maus im täglichen Einsatz überzeugen uns. Leider drückt Glorious Core, die Software der Maus, den sonst sehr positiven Eindruck. Einstellungen werden vermeintlich gespeichert, aber nicht von der Maus übernommen. Nur durch mehrmaliges Resetten und erneutes Einrichten der Einstellungen werden diese anerkannt. Das darf bei einer so hochpreisigen Maus einfach nicht sein.
Das ist schade, denn die Glorious Model O3 Wireless macht ansonsten einen für uns hervorragenden Job. Hier kann man nur hoffen, dass die Benutzerfreundlichkeit mit zukünftigen Software-Updates deutlich verbessert wird.
Cherry Xtrfy M68 Pro 8K Wireless
Die Cherry Xtrfy M68 Pro Wireless bietet ein flaches, symmetrisches Design mit einer 8000-Hz-Abtastrate und kommt ohne App.
- bequemes Design
- top Verarbeitung
- gute Performance beim Zocken
- seitlicher Ladeport sehr unpraktisch
- keine Individualisierbarkeit dank fehlender Software
- Einstellungen an der Maus vorzunehmen ist umständlich
Cherry Xtrfy M68 Pro Wireless im Test: Gaming-Maus mit 8000 Hz, 55 g & ohne App
Die Cherry Xtrfy M68 Pro Wireless bietet ein flaches, symmetrisches Design mit einer 8000-Hz-Abtastrate und kommt ohne App.
Die Xtrfy M68 Pro Wireless ist die aktuellste Iteration der Cherry-Maus und speziell für Gaming ausgelegt. Mit einer Abtastrate von 8000 Hz, einem Gewicht von gerade mal 55 g und einem kompakten, abgerundeten Design bringt sie Präzision und Bedienkomfort auf das Mauspad. Der Verzicht auf eine dedizierte App bietet sowohl Vorteile als auch Nachteile. Wir klären im Test auf. Das Testgerät hat uns der Hersteller zur Verfügung gestellt.
Lieferumfang
Die Cherry Xtrfy M68 Pro Wireless kommt ungewöhnlicherweise mit zwei 1,8-m-langen USB-A-zu-USB-C-Verbindungskabeln. Eines ist für den 2,4-GHz-Funkdongle gedacht und ein weiteres dient dazu, die Maus zu laden. Nebst der Anleitung und dem Datenblatt liegen zudem ein paar zusätzliche Maus-Skates bei.
Design
Die Cherry Xtrfy M68 Pro Wireless gibt es sowohl in Schwarz als auch in Weiß. Auffällig sind die nach vorn hin stark abflachenden Tasten der 55 g leichten Gaming-Maus, die ihr die Maße 61 × 39,5 × 123,3 mm spendieren. Das flachere Design hat zur Folge, dass der USB-C-Ladeport, der sich bei den meisten Gaming-Mäusen heutzutage an der Schnauze befindet, bei der M68 Pro Wireless auf der rechten Seite platziert ist. Warum diese Designentscheidung nicht optimal ist, dazu später mehr.
Cherry Xtrfy M68 Pro Wireless – Bilder
Cherry Xtrfy M68 Pro Wireless – Bilder

Cherry Xtrfy M68 Pro Wireless – Bilder

Cherry Xtrfy M68 Pro Wireless – Bilder

Cherry Xtrfy M68 Pro Wireless – Bilder

Cherry Xtrfy M68 Pro Wireless – Bilder

Cherry Xtrfy M68 Pro Wireless – Bilder

Cherry Xtrfy M68 Pro Wireless – Bilder

Cherry Xtrfy M68 Pro Wireless – Bilder

Cherry Xtrfy M68 Pro Wireless – Bilder

Cherry Xtrfy M68 Pro Wireless – Bilder

Cherry Xtrfy M68 Pro Wireless – Bilder

Cherry Xtrfy M68 Pro Wireless – Bilder

Über eine kleine LED vorne links an der Peripherie gibt die M68 Pro Wireless farblich kodiert Informationen wie den aktuellen Akkustand, die DPI oder die Polling-Rate (Abtastrate) wieder. Erwartungsgemäß befinden sich auf der linken Seite der symmetrischen Maus zwei zusätzliche Tasten. Auch wenn der Formfaktor symmetrisch ist, handelt es sich aufgrund der Button-Platzierung bei den meisten symmetrischen Mäusen trotz alledem um Rechtshändergeräte.
Über einen Schalter auf der Unterseite der Peripherie schaltet man die Gaming-Maus ein und wechselt zwischen verschiedenen Einstellungsmenüs. Ein zusätzlicher Button dient dazu, die Einstellungen der Maus zu verändern.
Die Verarbeitung ist einwandfrei, und die Maus fühlt sich trotz des geringen Gewichts robust an. Im Inneren der M68 Pro Wireless klappert zudem nichts, während die Gewichtsverteilung optimal zur Mitte hin austariert wurde. Das macht sich primär beim Anheben bemerkbar.
Einrichtung & Software
Die Cherry Xtrfy M68 Pro Wireless verzichtet vollkommen auf den Einsatz einer Software. Zum einen macht das die Einrichtung der Gaming-Maus super einfach, da man sie ohne Weiteres sofort einsetzen kann, zum anderen verliert sie dadurch einiges an Individualisierbarkeit.
Sämtliche Einstellungen bezüglich DPI, Abtastrate und Co. müssen über die Buttons der Maus konfiguriert werden. Dazu dient der bereits erwähnte Schalter auf der Unterseite der Maus in Kombination mit dem daneben gelegenen Button. Mit dem Switch wechselt man zwischen CPI (Counts per Inch, meist gleichbedeutend mit DPI), Polling-Rate und Debounce Time. Hier kommt die mitgelieferte Anleitung zum Tragen. Da das grafische Interface einer App fehlt, um Informationen zu vermitteln, muss man sich zudem voll und ganz auf die LED der Maus verlassen.

Insgesamt gibt es acht verschiedene DPI-Profile (400, 800, 1200, 1600, 3200, 4000, 7200, 26.000), zwischen denen man wechseln kann. Die Polling-Rate ist standardmäßig auf 1000 Hz eingestellt, lässt sich aber auf bis zu 8000 Hz erhöhen und auf 125 Hz senken. Zudem stehen noch Abstufungen von 250 Hz, 500 Hz und 4000 Hz zur Verfügung. Kabelgebunden sind maximal 1000 Hz möglich.
Debounce Time, Motion Sync und Lift-Off-Distance lassen sich ebenfalls konfigurieren – allesamt durch Wechseln in das DT-Menü via des Schalters. Die geringstmögliche Verzögerung bei der Debounce Time beträgt 2 ms und kann, wenn gewünscht, auf 4 ms, 8 ms oder 12 ms erhöht werden. Die Lift-Off-Distance kann man nur zwischen 1 mm und 2 mm wechseln, andere Mäuse bieten hier teilweise noch 0,7 mm an. Motion Sync schaltet man ganz simpel ein oder aus.
Die Maus ermöglicht zudem, die Sensor-Performance etwas anzupassen. Dafür stehen drei Sensormodi zur Verfügung: Pro-Gaming-Mode für die beste Leistung und den höchsten Stromverbrauch, Standard-Gaming-Mode für ausbalancierte Leistung und Stromverbrauch und der Low-Power-Mode, der einen geringeren Stromverbrauch priorisiert und dafür die Leistung des Sensors zurückschraubt.
In einer Welt, in der mehr und mehr Gaming-Mäuse auf Web-Apps umsteigen oder diese zusätzlich zu den traditionellen Desktop-Apps anbieten, wirkt der vollständige Verzicht auf eine App-Lösung hier unnötig einschränkend. Die Konfigurationen gelingen zwar auch rein über die Buttons der Maus relativ reibungslos, wir müssen aber jedes Mal die Anleitung zurate ziehen, um uns die richtige Button-Kombination ins Gedächtnis zu rufen. Der Verzicht auf eine App bedeutet zudem, dass man Buttons nicht neu belegen kann.
Bedienbarkeit
Beim Zocken fühlt sich die Cherry Xtrfy M68 Pro Wireless ausgesprochen gut an: Die Klicks sind crisp, präzise und die Maus bietet eine gute Griffigkeit. Cherry verwendet den Pixart-PAW-3395-Sensor, der eine Geschwindigkeit von 650 IPS und eine Beschleunigung von 50 g unterstützt. Die 2,4-GHz-Verbindung bleibt während unseres Tests dauerhaft stabil und ohne merkbare Verzögerungen. Wir verwenden Mäuse im Fingerspitzengriff und kommen mit der M68 Pro Wireless super klar. Auch nach mehreren Stunden in Overwatch bedient sich die Peripherie ausgesprochen angenehm.
Die seitlichen Buttons fühlen sich hervorragend an und benötigen eine für uns optimale Betätigungskraft. Auch das Mausrad steuert sich gut, allerdings wünschen wir uns hier eine etwas bessere Texturierung der Oberfläche.
Wirklich störend ist der seitlich angebrachte Ladeport der Maus. Er wird von einem Gummistopfen verdeckt, den man mühselig aus der Maus pfriemeln muss. Hat man das Ladekabel angeschlossen, kommt direkt das nächste Ärgernis: Aufgrund der seitlichen Positionierung stößt man vorn mit der Maus permanent mit dem Kabel zusammen, wodurch die Mausbewegungen enorm beeinträchtigt werden. Bei entspannteren Singleplayer-Spielen mag das nicht ganz so tragisch sein, bei kompetitiven Online-Games ist man so aber klar im Nachteil.
Akku
Im Inneren der Gaming-Maus steckt ein 350-mAh-Akku, für den Cherry bis zu 90 Stunden Laufzeit pro Ladung verspricht. Wie lange der Akku bei einem Daheim am Ende tatsächlich durchhält, hängt vor allem davon ab, mit welcher Abtastrate man die Maus verwendet und ob für welchen Sensor-Modus man sich entscheidet. Wir verwenden die Maus sowohl tagsüber für die Arbeit (1000 Hz, Standard-Gaming-Mode) als auch am Abend zum Zocken (8000 Hz, Pro-Gaming-Mode) und kommen so auf etwas weniger als drei Tage, bevor wir die Maus ans Ladekabel hängen müssen. Für eine vollständige Ladung benötigt die Peripherie zwei Stunden.
Preis
Die UVP der Cherry Xtrfy M68 Pro Wireless liegt bei 140 Euro. Aktuell gibt es das schwarze Modell bereits für 27 Euro (Ebay). In Weiß kostet sie momentan knapp 60 Euro.
Fazit
Die Cherry Xtrfy M68 Pro Wireless überzeugt uns im Test mit ihrer Performance beim Spielen, gestützt durch ein schlankes und angenehmes Design sowie den kompetenten Sensor, der für präzise Bewegungen sorgt. So kommen auch nach mehreren Stunden des Spielens weder Frust noch Ermüdungserscheinungen auf.
Während die fehlende Software zwar für einen reibungslosen Plug-and-play-Einsatz sorgt, vermissen wir vor allem eine unkomplizierte Konfiguration der Maus, die bei der M68 Pro Wireless ausschließlich über die Buttons am Gerät selbst vorzunehmen ist. Sehr frustrierend ist zudem auch der seitlich und damit sehr ungünstig platzierte Ladeport. Dieser sorgt dafür, dass das Ladekabel regelmäßig beim Spielen gegen die Maus stößt und so die Bewegungsfreiheit beeinträchtigt.
Für die nächste Iteration der Maus wünschen wir uns hier definitiv eine Verbesserung. So können wir die Gaming-Maus nur bedingt empfehlen.
Asus ROG Harpe II Ace
Die Gaming-Maus Asus ROG Harpe II Ace spricht mit ihrem Design und ihren Funktionen in erster Linie Zocker an, die die eigene Performance optimieren möchten.
- 8000-Hz-Abtastrate, mit und ohne Kabel
- Mit 48 g extrem leicht
- keine Installation nötig dank Web-App
- sinnvolle Funktionen, um Performance zu verbessern
Asus ROG Harpe II Ace im Test: Gaming-Maus für Zocker mit hohen Ansprüchen
Die Gaming-Maus Asus ROG Harpe II Ace spricht mit ihrem Design und ihren Funktionen in erster Linie Zocker an, die die eigene Performance optimieren möchten.
Mit der Harpe II Ace liefert Asus ROG eine Gaming-Maus, die vor allem kompetitive Gaming-Enthusiasten ansprechen soll. Mit einer Abtastrate von bis zu 8000 Hz, ultraleichten 48 g Eigengewicht, bis zu 42.000 DPI und diversen Feintuning-Optionen per Web-App überzeugt die Peripherie auf den ersten Blick. Ob sie auch im Dauereinsatz durchhält, zeigen wir in unserem Test.
Das Testgerät hat uns der Hersteller zur Verfügung gestellt.
Lieferumfang
Zur Asus ROG Harpe II Ace gibt es ein USB‑A‑zu‑USB‑C‑Verbindungskabel, den 2,4-GHz-Funk-Receiver sowie den dazugehörigen Verlängerungsadapter. Neben einem Quick-Guide liegt dem Paket außerdem noch ein Set an Stickern bei sowie eine ausführlichere Bedienungsanleitung. Auch ein Set an zusätzlichen Maus-Skates sowie das Grip-Tape dürfen hier nicht fehlen.
Außer mit dem Funkmodus ist die ROG Harpe II Ace noch in der Lage, sich per Bluetooth kabellos mit den Endgeräten zu verbinden.
Design
Die Asus ROG Harpe II Ace ist in Schwarz oder Weiß erhältlich. Neben dem ROG-Schriftzug auf der linken Seite und dem Ace-Schriftzug auf der rechten prangt auf dem Mausrücken das Logo der Marke. Farbe spendiert der Maus das mit RGB-LEDs ausgestattete Mausrad. Farben sowie Effekte stellt man mittels der Web-App ein. Das Mausrad selbst ist mit schräg verlaufenden Rillen texturiert, die Halt bieten beim Scrollen.
Asus Rog Harpe II Ace – Bilder
Asus Rog Harpe II Ace – Bilder

Asus Rog Harpe II Ace – Bilder

Asus Rog Harpe II Ace – Bilder

Asus Rog Harpe II Ace – Bilder

Asus Rog Harpe II Ace – Bilder

Asus Rog Harpe II Ace – Bilder

Asus Rog Harpe II Ace – Bilder

Asus Rog Harpe II Ace – Bilder

Neben den zwei Hauptmaustasten hat die Gaming-Peripherie zwei weitere Tasten auf der linken Seite, die frei konfigurierbar sind. Auf der Unterseite der Maus befinden sich der Schalter, um zwischen den drei Verbindungsmodi zu wechseln, sowie der DPI- und der Pairing-Button. Ein Fach bietet Platz, um den Funk-Receiver für den Transport zu verstauen. Der USB-C-Port der Maus befindet sich vorn am Gerät.
Einrichtung
Nachdem die Maus per Verbindungskabel am PC angeschlossen ist, beginnt dieser sofort mit der Einrichtung. Anschließend weist ein Popup-Fenster darauf hin, dass man die Maus mittels der Web-App Gearlink konfiguriert. Praktisch, denn so erspart man sich eine Installation und kann sie theoretisch von überall verwenden, vorausgesetzt, man hat eine Internetverbindung.
Per Gearlink sollte man dann auch umgehend ein Firmware-Update durchführen. In unserem Fall entleerte sich der Akku der Maus grundlos rasant. Erst nachdem wir das Firmware-Update für den Funk-Receiver und die Maus durchgeführt hatten, normalisierte sich der Akkuverbrauch wieder.
Software
Bei Gearlink handelt es sich um eine Web-App, die auch schon für andere Eingabegeräte aus dem Hause Asus ROG zur Verfügung steht. Das Praktische daran ist, dass sie vollends über den Browser läuft und man lokal kein Programm installieren muss. Alle Einstellungen an der Maus hinterlegt das Programm direkt auf dem internen Speicher der Peripherie. So muss Gearlink nicht durchgehend im Hintergrund aktiv sein.
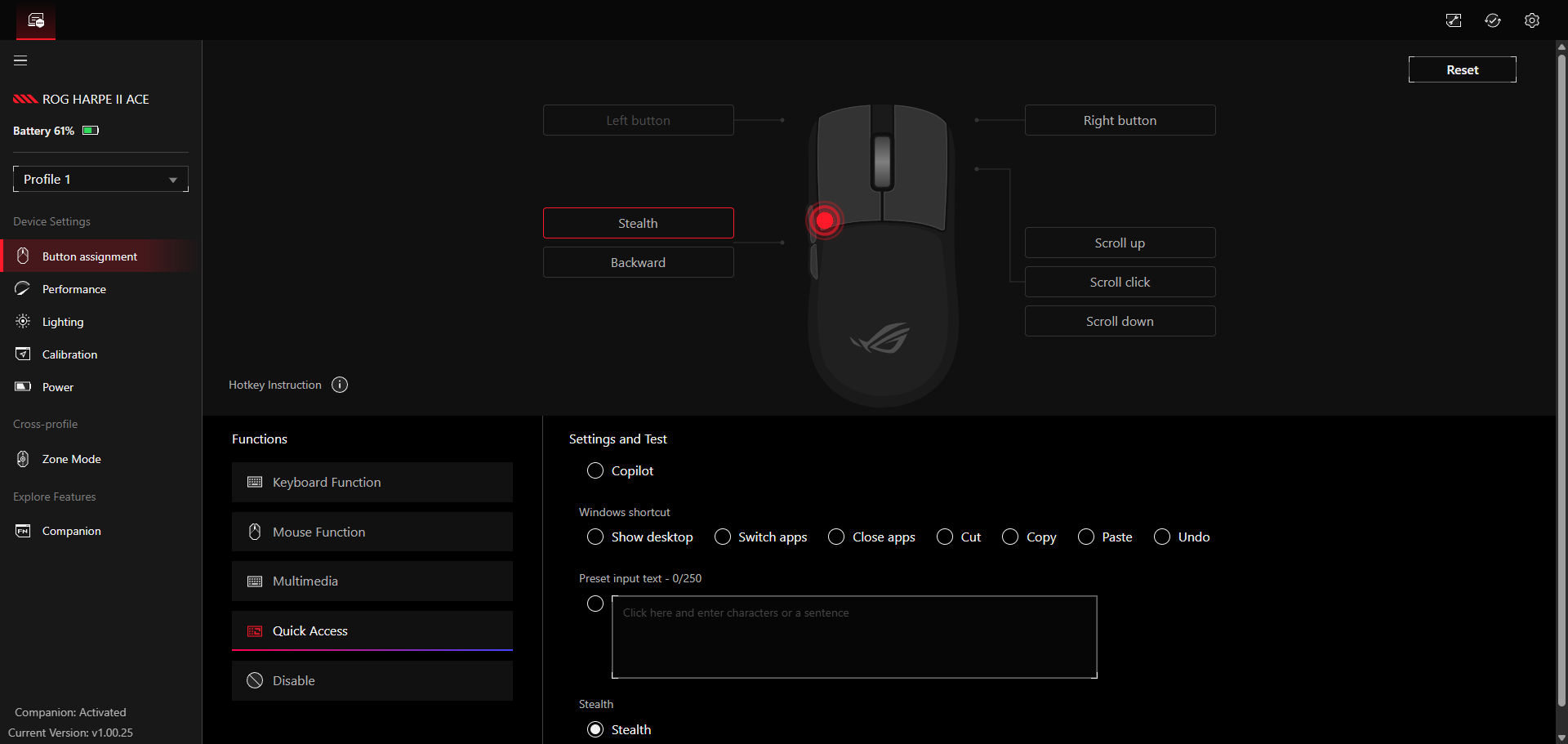
Über das Menü Button Assignment weist man den Tasten der Maus neue Funktionen zu. Während das Gros der zur Verfügung stehenden Funktionen bekannt sein dürfte, sorgt die ominöse Stealth-Funktion für Schmunzeln: Drückt man die Taste, auf der die Stealth-Funktion liegt, minimiert der PC automatisch alle offenen Fenster und schaltet den Audioausgang stumm. Dieser Killswitch dürfte vor allem diejenigen freuen, die noch bei ihren Eltern wohnen und nicht beim Zocken oder anderweitigen Dingen am PC überrascht werden möchten.
Asus Rog Harpe II Ace – Bilder App
Asus Rog Harpe II Ace – Bilder App
Asus Rog Harpe II Ace – Bilder App
Asus Rog Harpe II Ace – Bilder App
Asus Rog Harpe II Ace – Bilder App
Asus Rog Harpe II Ace – Bilder App
Asus Rog Harpe II Ace – Bilder App
Asus Rog Harpe II Ace – Bilder App
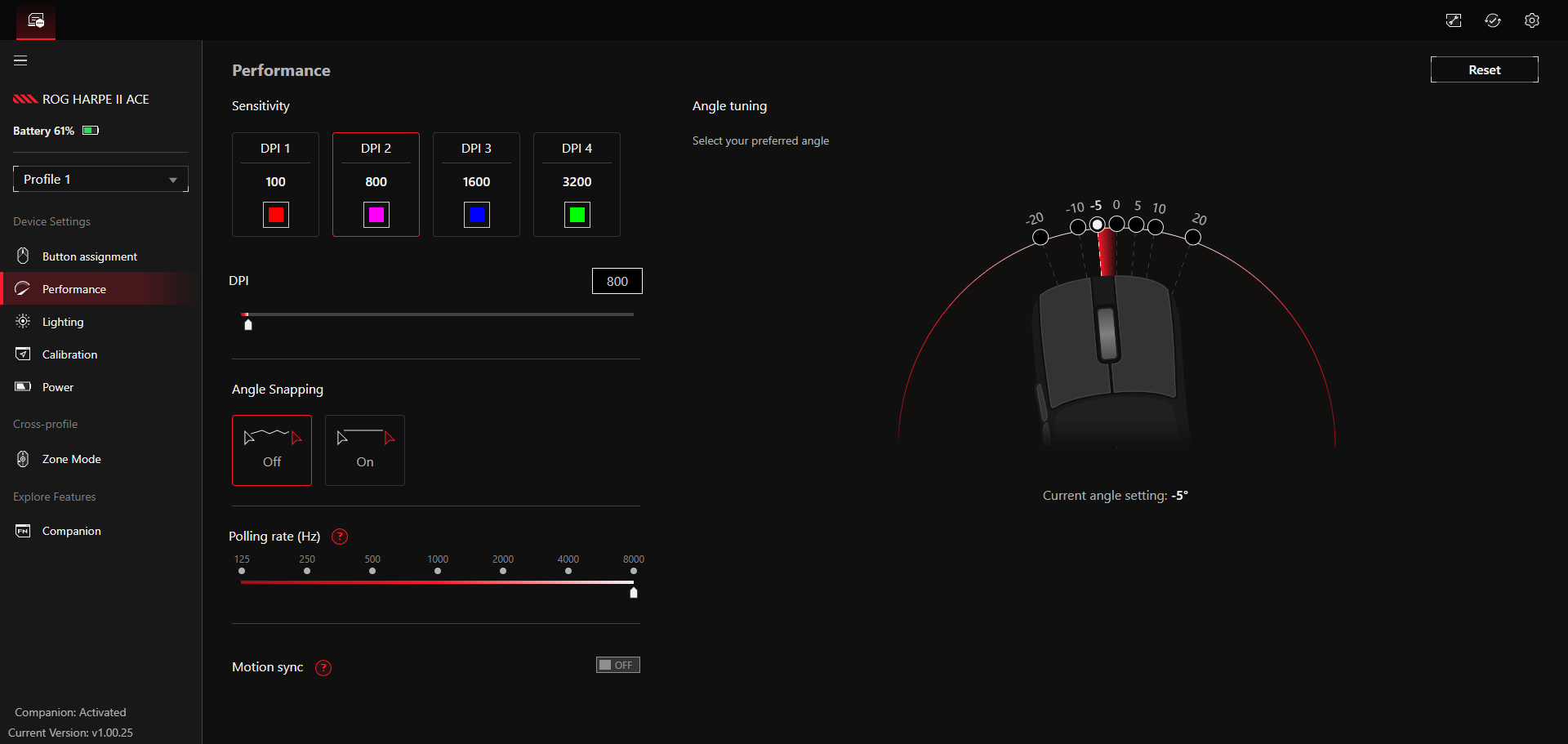
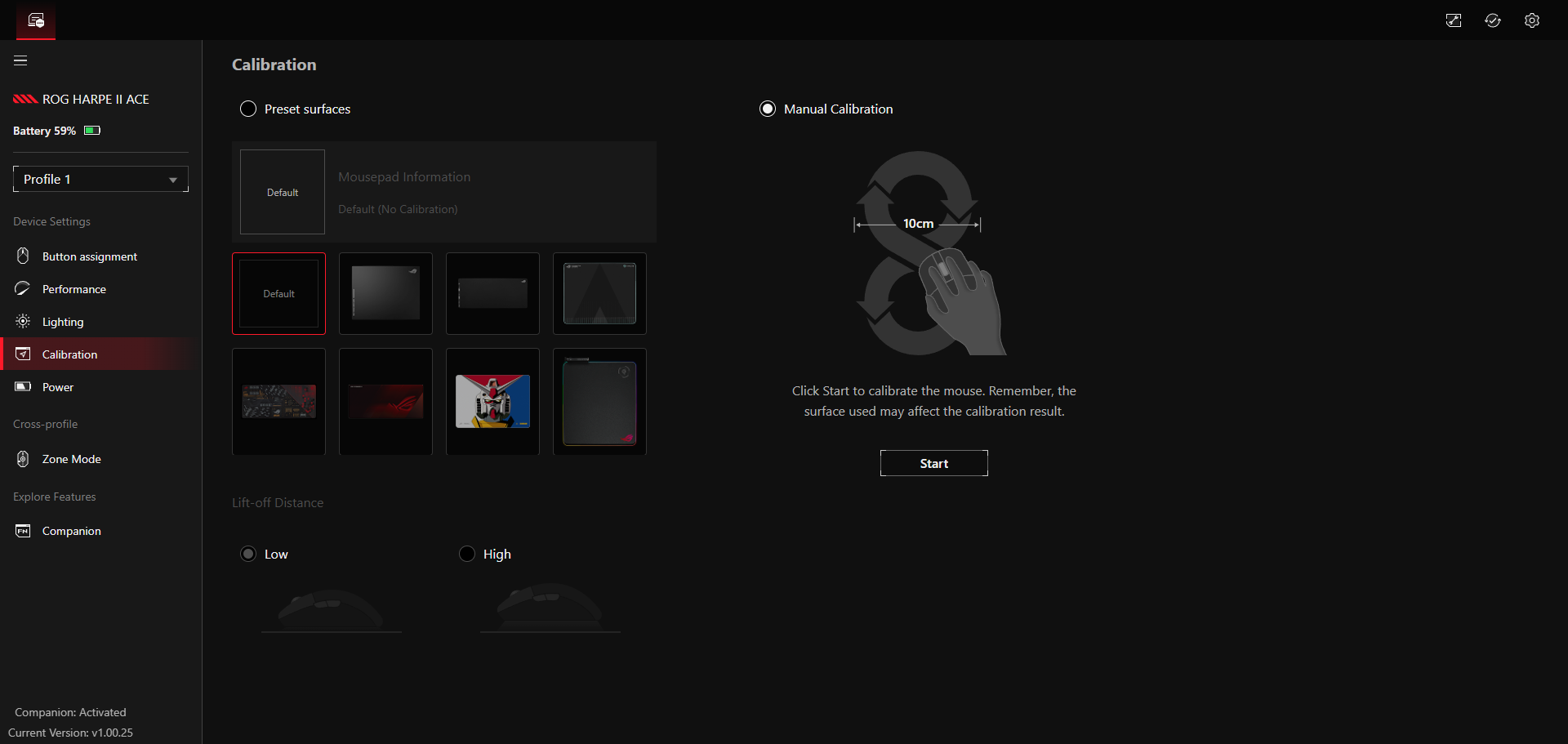
Hinter Performance verbergen sich unter anderem Einstellungen zu den DPI und der Abtastrate. Insgesamt gibt es vier verschiedene DPI-Profile, die man mit unterschiedlich hohen DPI-Werten versehen kann. Von 100 bis hin zu extrem hohen 42.000 DPI hat man hier die volle Bandbreite zur Auswahl. Wahlweise aktiviert man hier auch Angle Snapping und Motion Sync. Wir verzichten jedoch darauf, da uns die Steuerung mit diesen, vor allem beim Zocken, nicht gefällt. Interessanter ist der Menüpunkt Angle Tuning. Da wir persönlich unsere Maus leicht schräg nach links ausgerichtet halten, führt für uns eine Bewegung von links nach rechts nicht zu einer geraden Linie auf dem Bildschirm. Tatsächlich verläuft sie nach rechts oben. Indem man in der App den Winkel anpasst, richtet man die Maus neu aus und eine gerade Bewegung entsteht. Es lohnt sich, damit etwas herumzuexperimentieren und einen Winkel zu finden, der sich für einen natürlich anfühlt. Schlussendlich verändert man im Performance-Menü auch die Abtastrate der Maus von 125 bis 8000 Hz. Wie bei allen Mäusen gilt auch hier: Je höher die Abtastrate, desto höher ist der Akkuverbrauch.
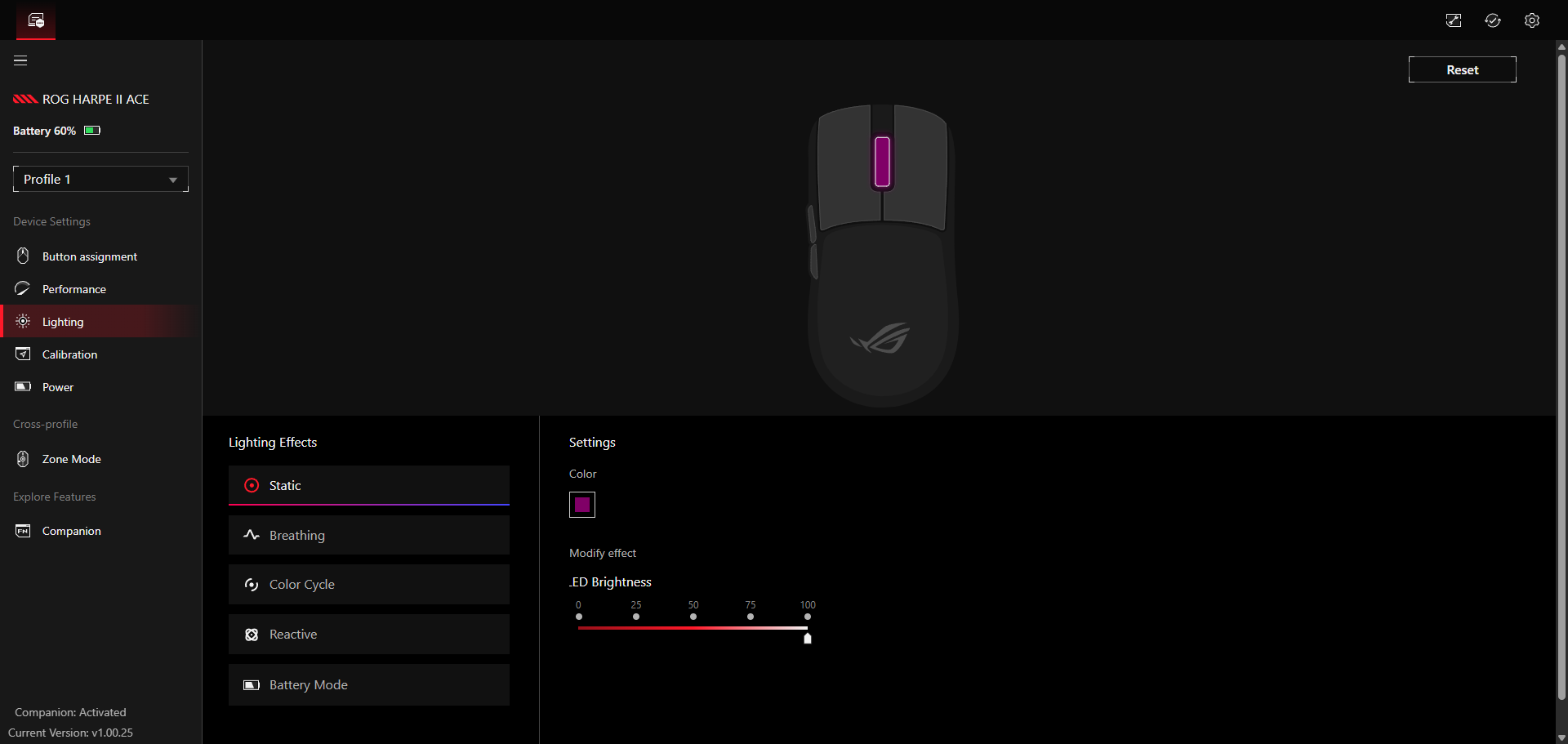
Lighting beinhaltet alle Beleuchtungseinstellungen. Praktisch ist hier, dass man über die Beleuchtung den Akkustand der Maus anzeigen lassen kann. Insgesamt gibt es fünf Effekte, zwischen denen man wählt.
Zusammenfassend bietet die App eine gute Mischung an sinnvollen Funktionen, die es einem ermöglichen, die Maus den eigenen Bedürfnissen nach anzupassen. Überrascht hat uns jedoch das Fehlen eines Makro-Editors, der normalerweise zum Standard gehört.
Bedienbarkeit
Wenn wir Mäuse verwenden, bedienen wir sie mit dem sogenannten Fingertip-Grip. Bei diesem haben nur die Fingerspitzen Kontakt zur Maus, während Handballen und Handgelenk in der Luft schweben. Das ist insofern relevant, als die Asus Rog Harpe II Ace laut Hersteller in erster Linie für Menschen mit Fingertip- und Claw-Grip konzipiert wurde. Unabhängig davon, ob es sich dabei um Marketing-Talking-Points handelt oder nicht – die Harpe II Ace überzeugt uns im täglichen Gebrauch.
Das verwendete Material sorgt für eine gute Haftung, sammelt aber binnen Minuten Fingerabdrücke en masse. Die seitlichen Buttons haben einen hervorragenden Druckpunkt und sind mit ausreichendem Abstand positioniert, sodass man sie noch bequem erreicht, aber nicht versehentlich betätigt. Die geringen 48 g Eigengewicht schonen hingegen das Handgelenk und verhindern Ermüdungserscheinungen. Zudem hat die Maus zumindest für unsere großen Hände nach hinten genügend Spielraum für Feinjustierungen, ohne mit dem Handballen gegen den Mausrücken zu stoßen.
Wie auch bei den anderen Mäusen mit einer Polling-Rate von 8000 Hz gibt es an der Harpe II Ace hier nichts auszusetzen. Klicks wirken latenzfrei und die Maus unglaublich responsiv. Hier bemerken wir ebenfalls sofort den Unterschied nach dem Wechsel von 1000 Hz zu 8000 Hz.
Nach einem Abstecher in unseren FPS des Vertrauens – Valorant – gefallen uns die bereits erwähnten Druckpunkte der seitlichen Buttons, aber auch die der linken und rechten Maustaste. Bei den seitlichen Buttons haben wir bei anderen Mäusen oft das Problem, dass wir sie entweder aus Versehen oder nicht stark genug drücken, um die dort hinterlegte Push-to-Talk-Funktion zu aktivieren. Nicht so hier. Nach mehreren Ranked-Matches haben uns die verwendeten ROG-Optical-Micro-Switches überzeugt. Zu keiner Zeit haben wir das Gefühl, dass Klicks ungewollt oder gar nicht registriert wurden.
Der Akku macht einen ordentlichen Job, wird aber deutlich stärker beansprucht, wenn man die Maus permanent mit 8000 Hz und aktivierter RGB-Beleuchtung verwendet. Eine Aufladung ist so in unserem Fall gut alle zwei Tage fällig. Aktiviert man zusätzlich noch den Zone-Mode, wirkt sich das noch einmal stärker auf den Akku aus. Der Zone-Mode deaktiviert nämlich sämtliche Energiesparfunktionen, um das Maximum an Leistung aus der Maus zu holen.
Preis
Die Asus ROG Harpe II Ace gibt es sowohl in Schwarz für 134 Euro als auch in Weiß für 136 Euro.
Fazit
Die Asus ROG Harpe II Ace ist eine hervorragende, auf kompetitives Zocken abgestimmte Gaming-Maus, die mit ihrer 8000-Hz-Abtastrate und den optischen Switches perfekt für FPS wie Valorant oder CS2 geeignet ist. Mit nur 48 g verhindert sie auch nach mehreren Stunden des Zockens Ermüdungserscheinungen. Durch die zusätzlichen Einstellungsmöglichkeiten der Web-App Gearlink kann man die Maus ein gutes Stück weit den eigenen Bedürfnissen anpassen. Mit derzeit knapp 129 Euro ist sie allerdings alles andere als erschwinglich.
Logitech G Pro X Superlight 2
Die kabellose Gaming-Maus Logitech G Pro X Superlight 2 wiegt 60 g, hat eine Abtastrate von 8000 Hz und einen ominösen BHOP-Modus.
- kabellose Abtastrate von bis zu 8000 Hz
- ausführliche DPI-Einstellungen
- top Akkuleistung
- Oberfläche sorgt für guten Halt
Logitech G Pro X Superlight 2 im Test: Diese Gaming-Maus ist perfekt für Shooter
Die kabellose Gaming-Maus Logitech G Pro X Superlight 2 wiegt 60 g, hat eine Abtastrate von 8000 Hz und einen ominösen BHOP-Modus.
Die technischen Daten der Logitech G Pro X Superlight 2 dürften Fans kompetitiver Shooter hellhörig machen: 8000-Hz-Abtastrate, 60 g leicht, 100 bis 44.000 DPI und ein Bunny-Hop-Modus. Wir haben die kabellose Gaming-Maus getestet. Das Testgerät hat uns der Hersteller zur Verfügung gestellt.
Lieferumfang
Ähnlich leicht wie die Maus ist auch die Box, in der sie geliefert wird. Zur Peripherie gibt es ein Ladekabel mit USB-A-auf-USB-C-Anschluss, einen Funk-Receiver sowie einen Funk-Adapter, um den Receiver an das Ladekabel anzuschließen. Als Zubehör liegt der Maus Grip-Tape bei, welches man auf die Maustasten und seitlich für besseren Halt anbringen kann. Möchte man noch besser über das Mauspad gleiten, tauscht man den Deckel des Funk-Receiver-Fachs, auf der Unterseite der Maus, gegen ein mitgeliefertes Ersatzstück mit Antihaftbeschichtung aus.
Design
Optisch ist unser Testmodell der Logitech G Pro X Superlight 2 in schlichtem Schwarz gehalten. Alternativ gibt es die Maus noch in Weiß und Rosa. Auf der rechten Seite prangt der Schriftzug Superlight in silber, während auf dem Mausrücken das Logitech-Logo, ebenfalls in silber, platziert ist. Eine einzelne, winzige LED blinkt in bestimmten Situationen auf – etwa wenn man die Maus einschaltet oder der Akku zur Neige geht. Neben Maustasten und Mausrad gibt es zwei Buttons auf der linken Seite, die man per Software frei belegen kann. Die Superlight 2 wird dem Namen gerecht und bringt rund 60 g auf die Waage, ihre Maße betragen 125 x 63,5 x 40 mm.
Logitech G Pro X Superlight 2 – Bilder
Logitech G Pro X Superlight 2 – Bilder

Logitech G Pro X Superlight 2 – Bilder

Logitech G Pro X Superlight 2 – Bilder

Logitech G Pro X Superlight 2 – Bilder

Logitech G Pro X Superlight 2 – Bilder

Logitech G Pro X Superlight 2 – Bilder

Der An-/Aus-Schalter befindet sich auf der Unterseite der Maus und lässt sich dank rauer Texturierung einfach nach oben oder unten schieben. Ebenfalls auf der Unterseite ist ein magnetisch haftender Deckel, hinter dem sich das Fach für den Funk-Receiver befindet. Hier verstaut man den winzigen Receiver idealerweise, wenn man die Maus transportiert. Durch das Herunterdrücken des Deckels löst sich die magnetische Anziehungskraft und der Verschluss löst sich von der Maus. Der USB-C-Port ist vorn an der Maus angebracht. Dadurch kann man sie auch während des Ladens problemlos weiter verwenden.
Einrichtung
Wie es sich für Logitech-Produkte gehört, profitiert auch die G Pro X Superlight 2 von der Integration in den Ghub. Über die Software richtet man die Maus unkompliziert ein und aktualisiert die Treiber der Peripherie und des Funk-Receivers. Zur Aktualisierung wird man automatisch aufgefordert, wenn man mit der an den PC angeschlossenen Maus G-Hub zum ersten Mal startet – der ganze Prozess dauert nur wenige Minuten. Anschließend kann man sich, wenn gewünscht, an die Einstellungen der Maus machen.
Software
Wie bei so ziemlich allen Produkten aus der Gaming-Sparte von Logitech dient G-Hub auch bei der Superlight 2 als Software, um sämtliche Einstellungen an der Peripherie vorzunehmen. Die Menüs sind übersichtlich und leicht verständlich gestaltet. Für so ziemlich jedes Icon ploppt ein Tooltip auf, wenn man mit dem Mauszeiger darüber fährt.
Insgesamt gibt es drei Menüs für die Superlight 2: Sensitivity, Assignments und Scroll Wheel. Über Sensitivity stellt man die DPI der Maus ein, also wie sensibel sie auf Bewegungen reagiert. Das reicht von 100 bis 44.000 DPI – genug Spielraum also, um auch wirklich jeden Anwendungszweck abzudecken. Wer möchte, kann sogar unterschiedlich hohe DPIs für die x- und y-Achse festlegen. Insgesamt gibt es fünf Slots – jeweils farblich kodiert – für unterschiedliche DPI-Einstellungen. Die LED auf der Maus signalisiert beim Wechsel dann, welches der Profile gerade aktiv ist. Zusätzlich gibt es Presets von Logitech für verschiedene (Gaming)-Anwendungen wie FPS, MMORPG, Productivity und RTS.
Logitech G Pro X Superlight 2 – Bilder App
Logitech G Pro X Superlight 2 – Bilder App
Logitech G Pro X Superlight 2 – Bilder App
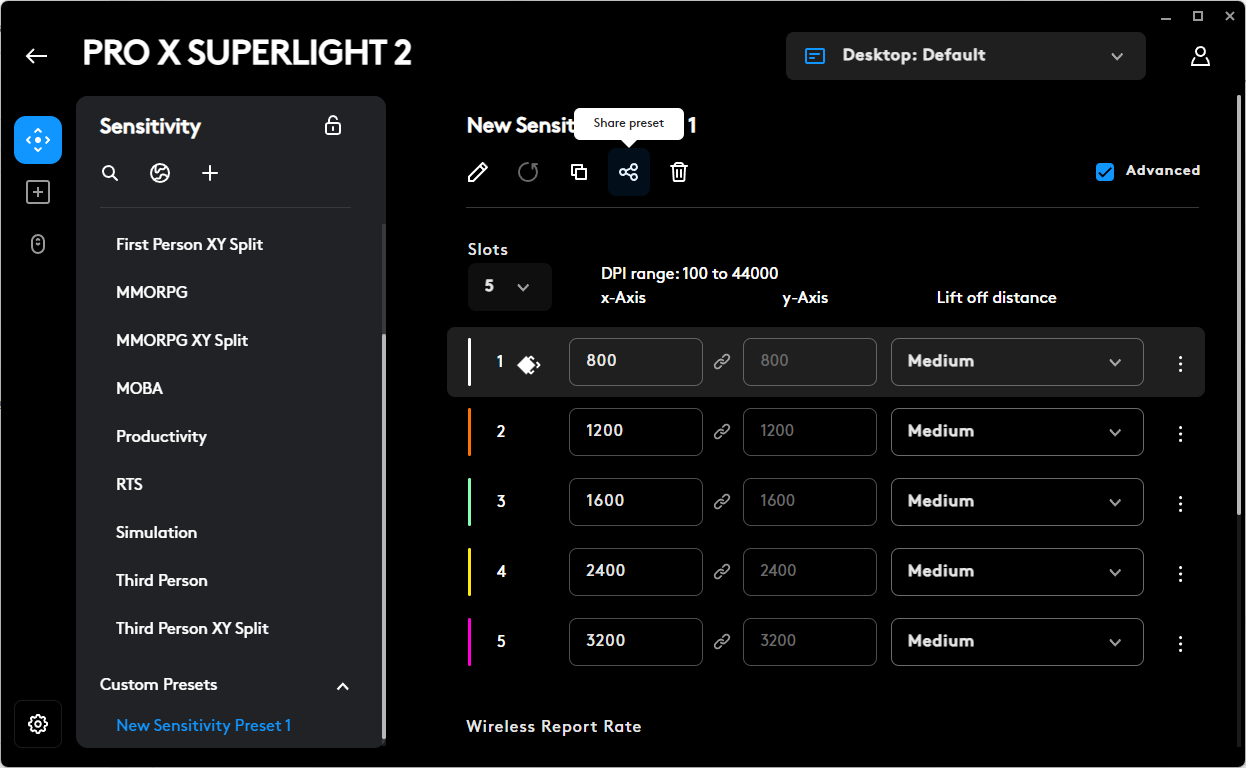
Logitech G Pro X Superlight 2 – Bilder App
Logitech G Pro X Superlight 2 – Bilder App
Logitech G Pro X Superlight 2 – Bilder App
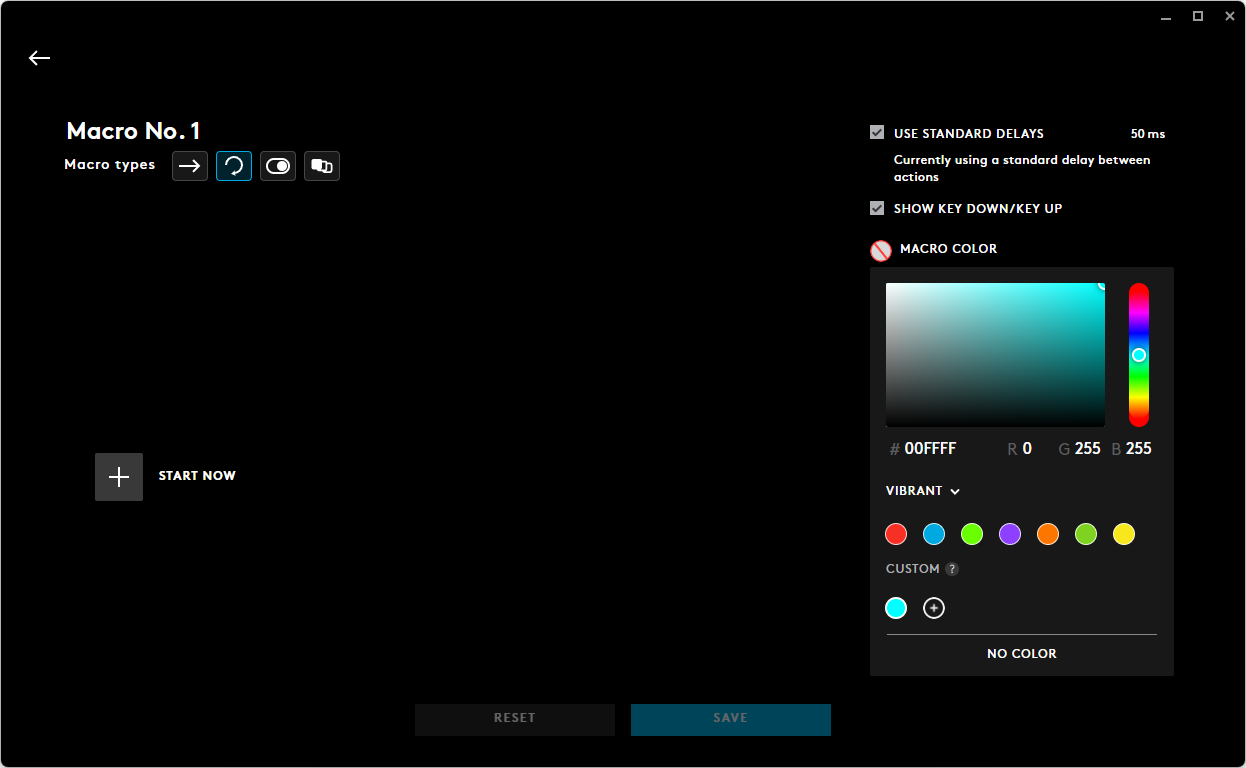
Logitech G Pro X Superlight 2 – Bilder App
Logitech G Pro X Superlight 2 – Bilder App
Logitech G Pro X Superlight 2 – Bilder App
Neben der Lift-Off-Distance, also der Distanz zwischen Maus und Schreibtisch beim Anheben der Peripherie, stellt man über das Sensitivity-Menü auch die gewünschte Abtastrate der Superlight 2 ein. Praktisch: Die Logitech G Pro X Superlight 2 benötigt keinen extra Adapter für die 8000 Hz Polling-Rate, wie es bei vielen anderen Mäusen der Fall ist, sondern unterstützt die Technologie von vornherein. Unterteilt wird hier zwischen der kabellosen und kabelgebundenen Abtastrate. Kabellos sind bis zu 8000 Hz möglich, kabelgebunden hört es bei 1000 Hz auf.
Im Menü Assignments weist man den Maus-Buttons Funktionen zu. Hier wählt man entweder aus einer Liste von Befehlen (etwa Copy-and-paste) und Keyboard-Tasten aus oder legt Aktionen für bestimmte Programme auf die Tasten. Für Discord lässt sich etwa das Mikrofon stumm schalten. Auch einen Makro-Editor liefert die Software.
Der dritte und wohl kurioseste Menüpunkt nennt sich Scroll Wheel. Dahinter verbirgt sich der sogenannte BHOP-Mode. BHOP steht für Bunny hop und ist eine Technik, bei der man durch kontrolliertes Springen beim Vorwärtsbewegen an Geschwindigkeit gewinnt. Viele FPS-Spieler nutzen das Mausrad anstatt der Leertaste, um den Charakter im Spiel springen zu lassen. Ist der BHOP-Mode aktiv, soll verhindert werden, dass man durch Anstupsen des Mausrads sofort anfängt zu springen. Erst durch ein zweites Mal Scrollen innerhalb eines definierten Zeitrahmens, 100 bis 1000 ms, wird dann der Sprung ausgeführt.
Bedienbarkeit
Die Logitech G Pro X Superlight 2 fühlt sich fantastisch in der Hand an. Ihr geringes Gewicht schont das Handgelenk und auch ohne das Grip-Tape bietet sie für uns genug Halt und Griffigkeit. Das Mausrad, wenngleich aus Plastik, um das Gewicht zu verringern, fühlt sich stabil an und sorgt dank der gummierten und texturierten Oberfläche für kontrollierte Scrollbewegungen. Häufiges Säubern steht bei der Superlight 2 jedoch an der Tagesordnung, denn Rückstände durch die natürlichen Öle der Haut sind schnell sichtbar auf der Oberfläche.
Für die Maustasten verwendet Logitech mechanisch-optische Switches. Spannend ist, dass man in den Einstellungen zwischen den Modi optical only und hybrid wechseln kann. Letzterer dient zum Stromsparen. Die Klicks haben einen überraschend tiefen und prägnanten Ton, der sich von den hellen und flachen Klicks bisheriger Mäuse, die wir verwendet haben, unterscheidet.
Der Unterschied von einer 1000-Hz-Abtastrate, die wir bis dato gewohnt waren, zu 8000 Hz ist deutlich spürbar. Die Maus fühlt sich tatsächlich responsiver an und auch während diverser Gaming-Sessions in Valorant machte sich der Unterschied bemerkbar. Kommentare unseres Zock-Partners à la Du triffst heute erstaunlich gut
kratzten zwar am Ego, bestätigen aber unseren Eindruck. Ob und wie stark hier ein Placebo-Effekt mit schwingt, sei mal dahingestellt.
Der Akku macht ebenfalls eine gute Figur: Nach drei Tagen im täglichen Dauerbetrieb auf der Arbeit und mehrstündiger Gaming-Sessions am Abend zeigt uns G-Hub eine Restladung von 30 Prozent an. Wir verwenden die Maus dabei ausschließlich mit einer Abtastrate von 8000 Hz und ohne den Stromsparmodus. Das anschließende Aufladen ist auch erfreulich schnell und stört nicht, da man die Maus währenddessen problemlos verwenden kann. Die Akkuleistung variiert selbstverständlich von Person zu Person in Abhängigkeit der Einstellungen, wir sind jedoch sehr zufrieden mit der Performance.
Preis
Die UVP der Logitech G Pro X Superlight 2 liegt bei 180 Euro. Derzeit gibt es die Gaming-Maus bereits für 100 Euro.
Fazit
Das Gesamtpaket der Logitech G Pro X Superlight 2, bestehend aus nützlichen Funktionen, guter Haptik, starkem Akku und super Software, überzeugt uns auf ganzer Linie. Die 8000-Hz-Abtastrate im kabellosen Zustand liefert einen merklichen Unterschied in der Responsivität und benötigt dafür, im Gegensatz zu manch anderen Herstellern, keinen zusätzlichen Adapter. Das Ganze spiegelt sich jedoch im Preis wider: Mit derzeit 98 ist die Maus alles andere als günstig und für die reine Verwendung etwa als reine Office-Maus viel zu teuer. Von ihr profitieren in erster Linie FPS-Spieler, die mit einer leichten, performanten und super präzisen Maus die nächste anstehende Gaming-Session bereichern möchten.
Razer Deathadder V4 Pro
Die Gaming-Maus Deathadder V4 Pro ist leichter und größer als der Vorgänger und kommt von vornherein mit einer Abtastrate von 8000 Hz.
- gute Verarbeitung
- starker Akku
- Razer Synapse bietet praktische Funktionen
- nützliche LED-Anzeige am Funk-Receiver
- teuer
- glänzende Oberfläche zieht Staub & Schmutz an
Razer Deathadder V4 Pro im Test: Starke Gaming-Maus dank Razer Synapse
Die Gaming-Maus Deathadder V4 Pro ist leichter und größer als der Vorgänger und kommt von vornherein mit einer Abtastrate von 8000 Hz.
Leichter, schneller und präziser? Die Razer Deathadder V4 Pro kommt als neuestes Update der langlebigen Deathadder-Reihe diesmal von vornherein mit einer Abtastrate von 8000 Hz, einem neuen Sensor und hat dabei noch abgenommen. 56 anstatt 63 g bringt die neue Profi-Gaming-Maus nun auf die Waage. Hinter den Kulissen arbeitet derweil erneut Razer Synapse, die Software, mit der man die Gaming-Maus den eigenen Bedürfnissen entsprechend konfiguriert. Ob das Gesamtpaket den stolzen Preis wert ist, zeigen wir im Test.
Das Testgerät hat uns der Hersteller zur Verfügung gestellt.
Lieferumfang
Die Peripherie kommt mit einem 1,8 m langen USB-A-zu-USB-C-Nylonstoffkabel für die Verbindung mit dem PC sowie dem Funk-Dongle für die kabellose Verbindung. Nebst der Kurzanleitung für die erste Inbetriebnahme liegen zudem noch Griptape sowie ein Stickerset bei.
Design
Die Deathadder V4 ist wie bereits erwähnt nicht nur gut 7 g leichter als das Vorgängermodell, sondern tatsächlich auch 7 mm länger (68 x 44 x 128 mm). Erhältlich ist sie in Schwarz und Weiß. Das ergonomische Schalendesign hat die typische Erhöhung zur linken Mitte. Erwartungsgemäß gibt es zwei zusätzliche Buttons auf der linken Seite, die mit der Software frei belegt werden können. Die Oberfläche ist glatt und leicht glänzend, was vor allem dazu führt, dass Staub, Fingerabdrücke und Co. schnell sichtbar sind. Häufiges Abwischen ist also leider vorprogrammiert.
Das Mausrad ist aus Plastik und mit einem optischen Switch ausgestattet. Die Rillen auf der Oberfläche helfen dabei, nicht mit dem Finger abzurutschen. Statusmeldungen teilt die Maus via der kleinen LED unmittelbar über dem Mausrad mit. Der USB-C-Port befindet sich vorne an der Peripherie, wodurch man diese problemlos während des Aufladens weiterverwenden kann.
Razer Deathadder V4 Pro – Bilder
Razer Deathadder V4 Pro – Bilder

Razer Deathadder V4 Pro – Bilder

Razer Deathadder V4 Pro – Bilder

Razer Deathadder V4 Pro – Bilder

Razer Deathadder V4 Pro – Bilder

Razer Deathadder V4 Pro – Bilder

Razer Deathadder V4 Pro – Bilder

Razer Deathadder V4 Pro – Bilder

Power- und DPI-Button teilen sich einen Knopf auf der Unterseite der Maus. Kurzes Drücken wechselt zwischen den einzelnen DPI-Profilen, während längeres Drücken die Maus ein- oder ausschaltet. Persönlich bevorzugen wir immer die Lösung eines Schalters, um die Maus ein- oder auszuschalten, das ist jedoch Geschmackssache.
Der Funk-Receiver der Deathadder erfüllt direkt mehrere Funktionen und sieht dabei noch schick aus: Der kuppelförmige Receiver, in der gleichen Farbe gehalten wie die Maus, hat vorne drei LEDs, die Informationen wie den Akkustand, das derzeitige DPI-Profil oder die Verbindungsqualität abbilden. Welche Informationen man angezeigt haben möchte, wählt man in Razer Synapse aus.
Einrichtung
Nach dem Verbinden der Maus mit dem PC über das mitgelieferte Kabel ist sie sofort startklar. Auch der Funk-Dongle muss kurz vom PC eingerichtet werden. Währenddessen ploppt eine Benachrichtigung für den Download von Razer Synapse auf. Über das Tool konfiguriert man sämtliche Funktionen der Maus und updatet zudem auch die Firmware von Deathadder und Funk-Dongle.
Software
Wer bereits einmal ein Razer-Produkt verwendet hat, dem dürfte Razer Synapse sofort ein Begriff sein. Das Tool ist die Schnittstelle für die meisten Razer-Peripherien und bietet diverse Einstellungsmöglichkeiten. Tastenbelegungen, DPI-Einstellungen und die Abtastrate richtet man hierüber unter anderem ein.
Für die Tastenbelegungen stehen so ziemlich alle Funktionen parat, die man von einer Maus erwartet: darunter Makros, Änderung der Sensitivität, das Starten von Programmen sowie Windows-Shortcuts. Sollte man mehrere Razer-Produkte haben, lassen sich über die Maus auch Funktionen anderer Geräte steuern.
Razer Deathadder V4 Pro – Bilder App
Razer Deathadder V4 Pro – Bilder App
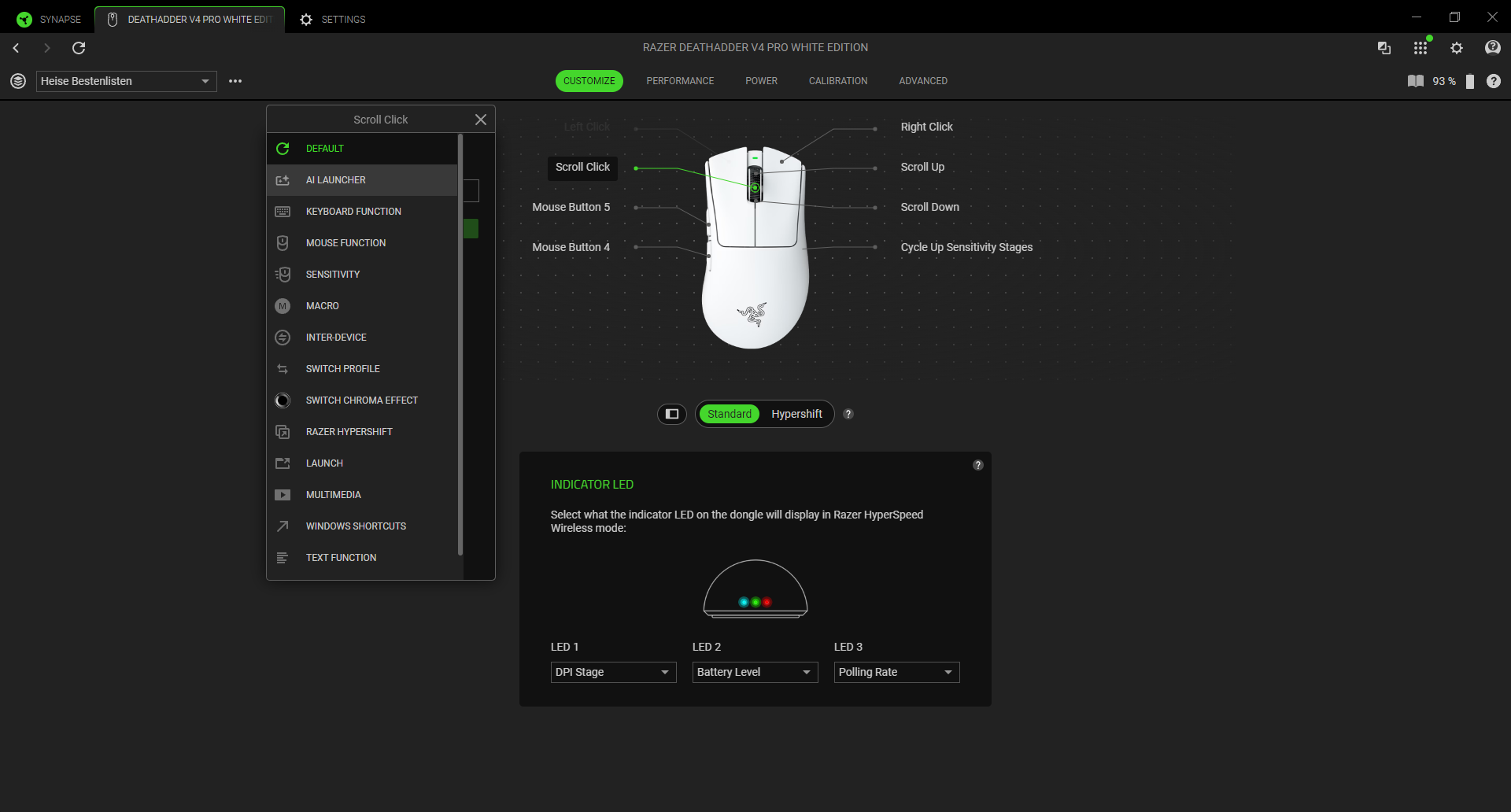
Razer Deathadder V4 Pro – Bilder App
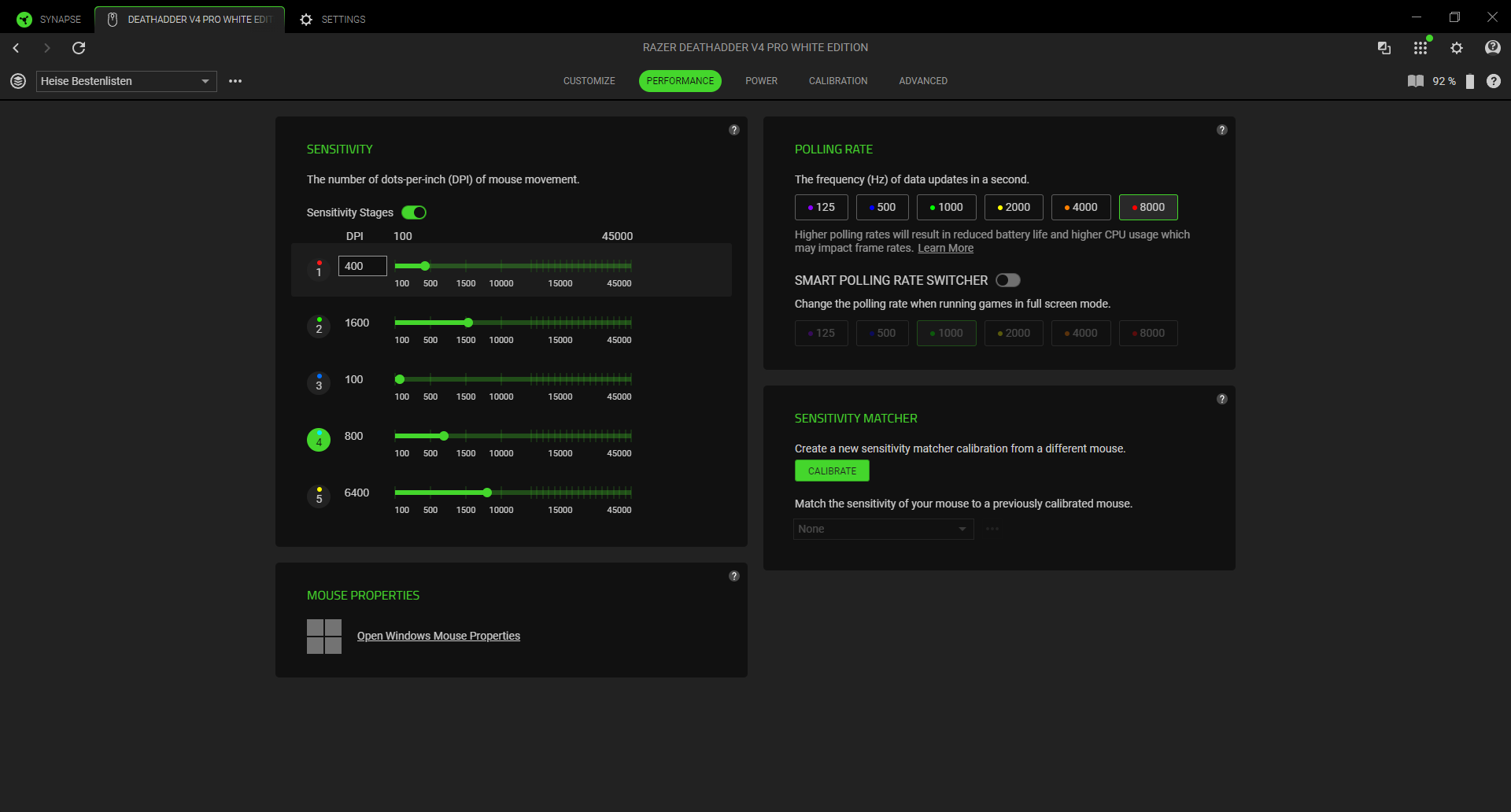
Razer Deathadder V4 Pro – Bilder App
Razer Deathadder V4 Pro – Bilder App
Razer Deathadder V4 Pro – Bilder App
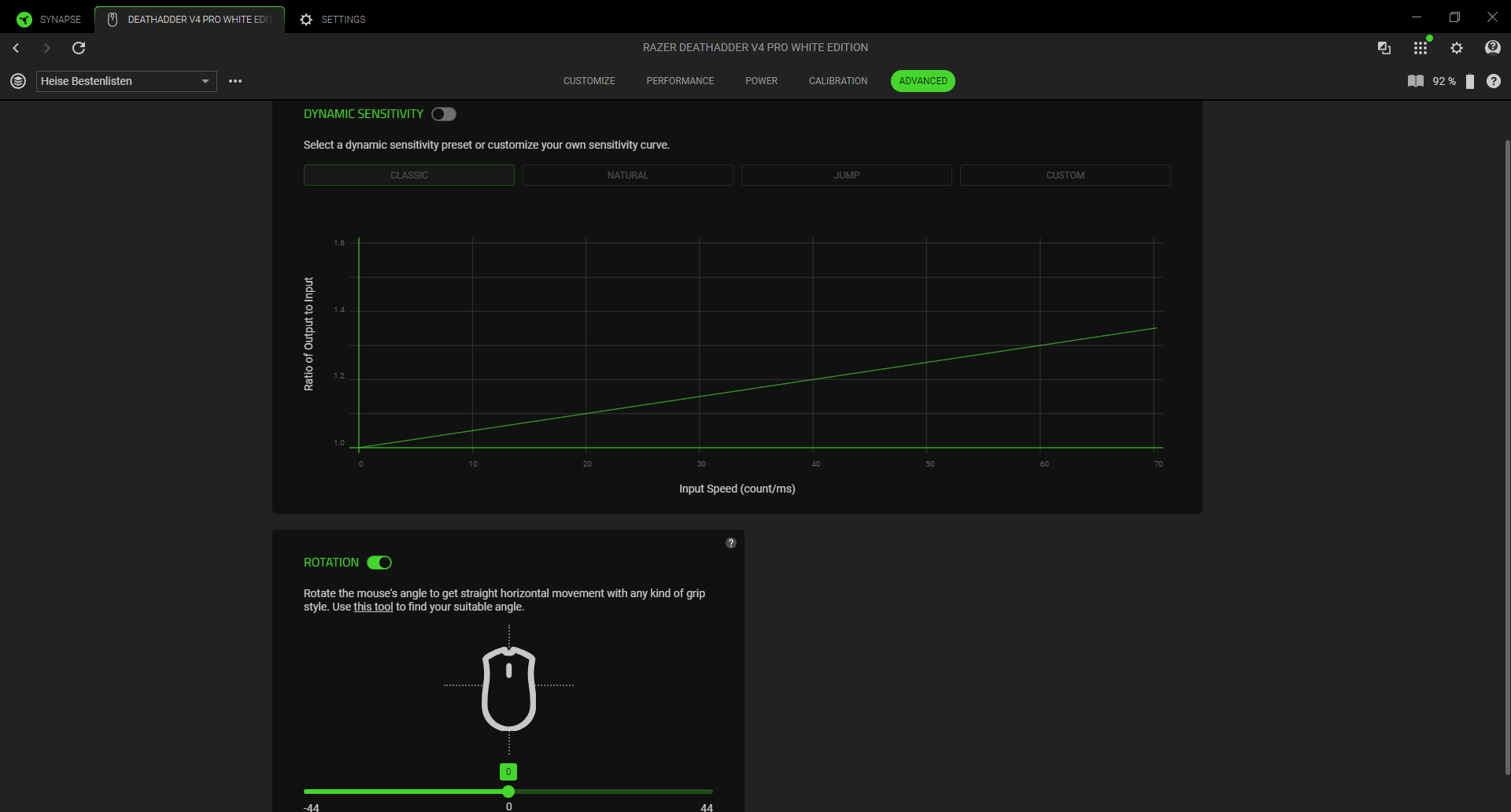
Fünf verschiedene DPI-Profile stehen zur Verfügung, mit einer Range von 100 bis 45.000 DPI, die man sogar auf 1er-Schritte genau feintunen kann. Dabei lassen sich sowohl die x- als auch die y-Achse separat anpassen. Praktisch ist auch die Funktion vom Sensitivity Matcher. Hat man zuvor mit einer anderen Maus gezockt, übersetzt das Tool die dortige Sensitivität auf die Razer Deathadder V4 Pro.
Die Abtastrate, auf Englisch Polling-Rate, reicht von 125 Hz bis 8000 Hz. Dazwischen liegen 4000, 2000, 1000 und 500 Hz.
Generell hat Razer viele praktische Features in Synapse gesteckt. Der hinzuschaltbare Polling-Rate-Wechsler etwa, der die Abtastrate, falls gewünscht, auf einen anderen Wert setzt, wenn man ein Spiel im Vollbildmodus startet. Aber auch Stromsparoptionen sowie die Kalibrierung der Maus in Abhängigkeit von der Mauspad-Oberfläche sind sinnvolle Optionen.
Bedienung
Trotz der glatten Oberfläche bietet die Razer Deathadder V4 Pro für unseren Fingertip-Grip genug Halt, um problemlos über den Tisch zu gleiten und beim Anheben nicht aus der Hand zu rutschen. Den längeren Rumpf bemerken wir tatsächlich, da dieser gelegentlich gegen den Handballen drückt. Als wirklich störend empfinden wir das aber nicht. Die Razer Optical Switches leisten gute Arbeit und Klicks mit den beiden Maustasten fühlen sich hervorragend und präzise an. Die zwei seitlichen Buttons sind erfreulich groß und benötigen ausreichend Kraft, um nicht im Eifer des Gefechts aus Versehen betätigt zu werden.
Der Akku bietet ordentlich Ladung, vorausgesetzt, man nutzt ihn nicht permanent mit einer 8000-Hz-Abtastrate. Diese beansprucht nämlich sowohl den Akku als auch die CPU des Computers. Wir verwenden die Razer Deathadder V4 Pro tagsüber während der Arbeit mit 4k Hz und abends beim Zocken mit 8k und kommen so problemlos auf 3 Tage, bis wir die 20-Prozent-Warnung via Synapse erhalten und die Maus ans Ladekabel hängen. Ein solider Wert.
Preis
Die Razer Deathadder V4 Pro hat eine UVP von 180 Euro. In Schwarz kostet sie momentan 150 Euro. In Weiß bekommt man sie für 128 Euro. Eine grüne Version der Maus gibt es exklusiv im Razer-Store für 180 Euro.
Fazit
Mit einem Preis von 151 Euro richtet sich die Razer Deathadder V4 Pro vor allem an Enthusiasten. Diese bekommen dafür allerdings auch eine richtig gute Gaming-Maus, die mit ihrer soliden Verarbeitung, einem starken Akku und präzisen Klicks für viel Freude beim Zocken sorgen dürfte. Die Software Razer Synapse versorgt die Maus indes mit einer Vielzahl an praktischen und vor allem bereichernden Funktionen. Die glänzende Oberfläche zieht Staub und Schmutz leider magisch an und der Preis dürfte viele abschrecken. Wer damit leben kann, macht mit einem Kauf hier definitiv nichts falsch.
Asus Rog Keris II Ace
Die superleichte Gaming-Maus Asus ROG Keris II Ace ist nicht nur top verarbeitet, sondern bekommt dank eines Firmware-Updates auch mehr Power.
- hervorragende Haptik
- Akkuanzeige per Mausrad ist praktisch
- dank Firmware-Update 8000 Hz auch kabellos
- Akku bei aktiver Beleuchtung vergleichsweise etwas schwachbrüstig
- Armoury Crate statt Gearlink Web-App
Asus ROG Keris II Ace im Test: Diese Gaming-Maus lässt man nicht mehr los
Die superleichte Gaming-Maus Asus ROG Keris II Ace ist nicht nur top verarbeitet, sondern bekommt dank eines Firmware-Updates auch mehr Power.
Mit der Keris II Ace liefert Asus ROG neben der Harpe II Ace eine weitere High-End-Gaming-Maus. Ebenfalls mit einer Abtastrate von 8000 Hz ausgestattet, kommt die kabellose Leichtgewicht-Maus diesmal im ergonomischen Design daher. Was unter der Haube steckt und wie sie sich beim Zocken und im Alltag schlägt, beleuchten wir im Test. Das Testgerät hat uns der Hersteller zur Verfügung gestellt.
Lieferumfang
Die Maus kommt mit einem 2 m langem USB-A-zu-USB-C-Verbindungskabel mit Nylonstoffmantel. Im Gegensatz zur Harpe II Ace benötigt die Keris II Ace einen Polling-Rate-Booster, also einen Adapter, der in den USB-Port gesteckt wird, damit sie die 8000-Hz-Abtastrate erreicht. Dieser wird ebenfalls mitgeliefert. Für den kabellosen Einsatz liegt selbstverständlich auch der Funk-Receiver samt Reichweiten-Adapter bei. Ersatz-Gleitfüße, optionales Griptape für besseren Halt und ein Stickerset hat man als Goodies dazugepackt. Die inkludierte Betriebsanleitung gibt zudem einen generellen Überblick über die Funktionen der Maus.
Design
Farblich kommt die Maus wahlweise in Schwarz oder Weiß. Mit 54 g Eigengewicht reiht sie sich zudem in die Riege der superleichten Mäuse ein. Größentechnisch liegt sie bei Maßen 67 x 42 x 121 mm. Im Vergleich zur Harpe II Ace setzt Asus ROG hier explizit auf ein ergonomisches Schalendesign der Rechtshändermaus. Im Klartext bedeutet das, dass die Maus mittig links höher gewachsen ist. Wir bemerken während des Tests beim täglichen Gebrauch weder spürbare Vor- noch Nachteile im Vergleich zum sonst symmetrischen Design anderer Mäuse. Die Riffelungen links und rechts an der Peripherie bieten für uns optimalen Halt und fühlen sich angenehm an, weswegen wir nicht auf das mitgelieferte Griptape zurückgreifen.
Asus ROG Keris II Ace – Bilder
Asus ROG Keris II Ace – Bilder

Asus ROG Keris II Ace – Bilder

Asus ROG Keris II Ace – Bilder

Asus ROG Keris II Ace – Bilder

Asus ROG Keris II Ace – Bilder

Asus ROG Keris II Ace – Bilder

Asus ROG Keris II Ace – Bilder

Asus ROG Keris II Ace – Bilder

Wie die meisten Gaming-Mäuse hat auch die Keris II Ace links zwei zusätzliche Buttons, deren Funktion man per Software konfiguriert. Farbliche Akzente setzt das gummierte und mit LEDs ausgestattete Mausrad. Eine schöne Lösung, da die Beleuchtung von Gaming-Mäusen häufig so platziert ist, dass sie unter der Hand verschwindet und nicht zur Geltung kommt. Wer keine Beleuchtung mag, kann sie selbstverständlich per Software ausschalten und so direkt auch den Akkuverbrauch verringern. Apropos Akku: Der USB-C-Port für die Kabelverbindung befindet sich an der „Schnauze“ der Maus, wodurch man keine Ladepause einlegen muss und beinahe verzögerungsfrei weiter zocken kann.
Neben der Kabelverbindung und der 2,4-GHz-Funk-Verbindung kann die Keris II Ace auch Bluetooth. Um zwischen den drei Modi hin und her zu wechseln, gibt es einen Schalter auf der Mausunterseite. Dort befinden sich auch der DPI-Button, mit dem man die DPI-Profile wechselt, sowie ein Pairing-Button für die Kopplung im BT-Modus. Nicht außergewöhnlich, aber dennoch gerne gesehen, ist der Stauraum für den Funk-Dongle auf der Unterseite.
Einrichtung
Wie bei den meisten Mäusen kann die Asus ROG Keris II Ace direkt nach dem Verbinden per Kabel und der anschließenden automatischen Einrichtung durch den PC loslegen. Allerdings ist sie zum Zeitpunkt des Tests nicht mit der Web-App Gearlink kompatibel. Um den vollen Funktionsumfang der Maus nutzen zu können, benötigt man daher die kostenlose Software Armoury Crate. Diese ist im Unterschied zu Gearlink nur unter Windows verfügbar und daher für Nutzer anderer Betriebssysteme, wie Linux, nicht nutzbar. Sie ist vor allem auch für die Firmware-Updates von Maus und Funk-Receiver essenziell. Diese sollte man umgehend durchführen. Wie wir im Test herausfanden und uns von Asus ROG anschließend bestätigen ließen, bekam die Keris II Ace per Firmware-Update ein Upgrade spendiert. So kann sie nun auch im kabellosen Funk-Modus auf eine Abtastrate von 8000 Hz zugreifen. Ursprünglich ging das nur kabelgebunden, kabellos war bei 4000 Hz Schluss.
Software
Für die Software heißt es „back to the roots“: Anstatt der sehr praktischen Web-App Gearlink, die wir während unseres Tests der Harpe II Ace zu schätzen gelernt haben, müssen wir hier mit der PC-App Armoury Crate vorliebnehmen. Diese fiel uns in der Vergangenheit durch Abstürze, Aufhänger und Probleme bei der Installation negativ auf. Während des Tests mit der Keris II Ace verhält sich die geräteübergreifende Software erfreulich kooperativ. Abstürze gab es keine und auch die Installation klappt dieses Mal auf Anhieb. Allerdings bemerken wir manchmal eine etwas träge Performance innerhalb des Programms, wenn wir zum Beispiel zwischen Tabs hin und her wechseln.
Auf der Haben-Seite verbucht das Programm jedoch ein paar nützliche Funktionen: Erwartungsgemäß können die Tasten der Maus mit neuen/anderen Aktionen belegt werden, darunter auch Windows-Shortcuts und Multimedia-Funktionen. Installiert man noch den Makro-Editor hinzu, lassen sich auch selbst erstellte Makros auf Tasten legen. Vier DPI-Profile stehen zur Auswahl, jedes davon ist konfigurierbar. Die Spanne liegt hier bei 100 bis 42.000 DPI. Die Abtastrate (auch Polling-Rate), also wie häufig die Maus pro Sekunde mit dem PC kommuniziert, reicht von 125 Hz bis 8000 Hz. Praktisch: Man kann unterschiedliche Profile anlegen und sie anschließend mit bestimmten Spielen verknüpfen. Startet man das betreffende Spiel, wechselt das Profil automatisch. Das ist dann von Vorteil, wenn man nicht dauerhaft mit einer bestimmten Polling-Rate arbeiten möchte. In Valorant sind die 8000 Hz super, beim Arbeiten im Homeoffice vielleicht etwas übertrieben.
Asus ROG Keris II Ace – Bilder App
Asus ROG Keris II Ace – Bilder App
Asus ROG Keris II Ace – Bilder App
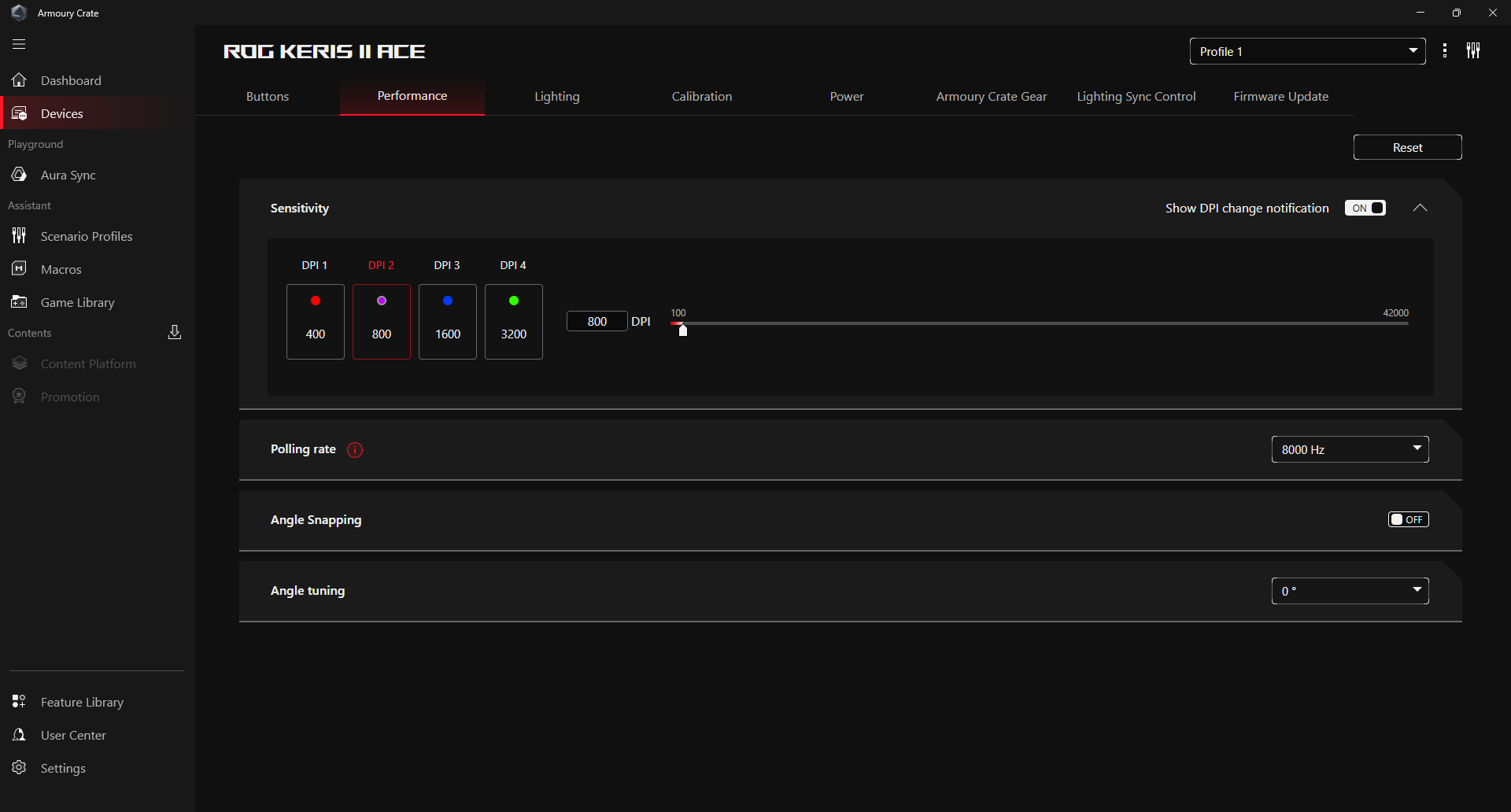
Asus ROG Keris II Ace – Bilder App
Asus ROG Keris II Ace – Bilder App
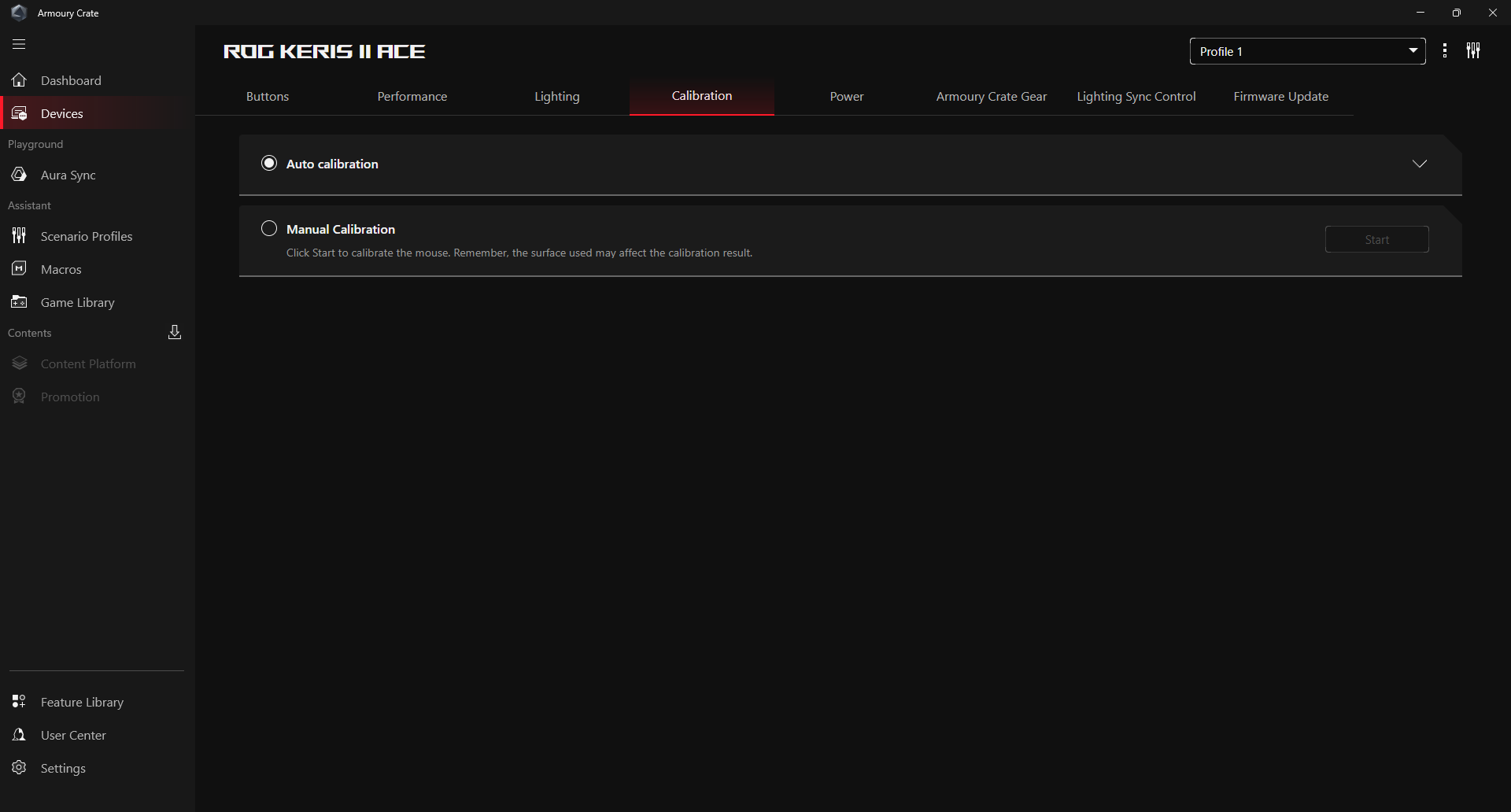
Asus ROG Keris II Ace – Bilder App
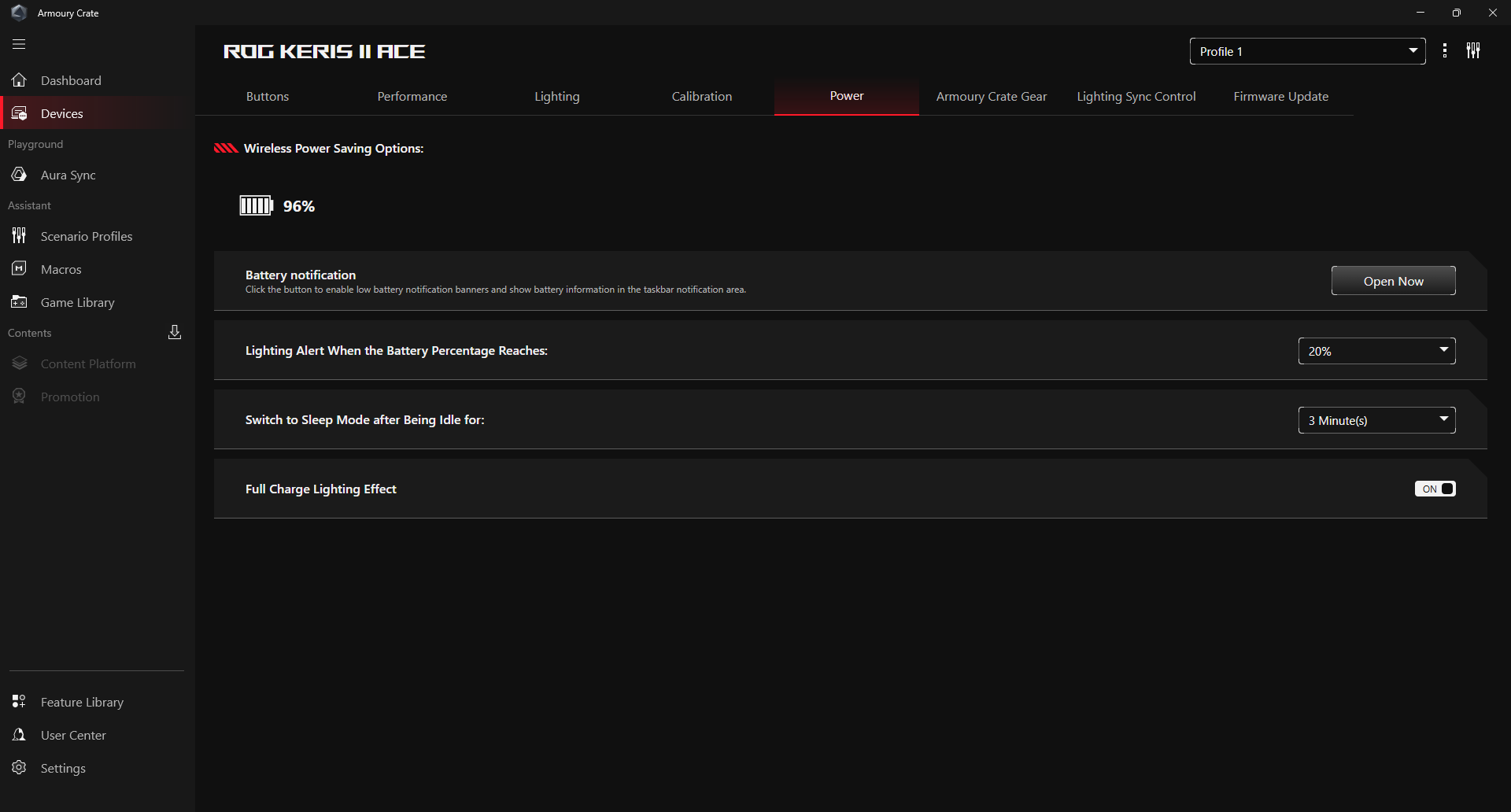
Asus ROG Keris II Ace – Bilder App
Asus ROG Keris II Ace – Bilder App
Asus ROG Keris II Ace – Bilder App
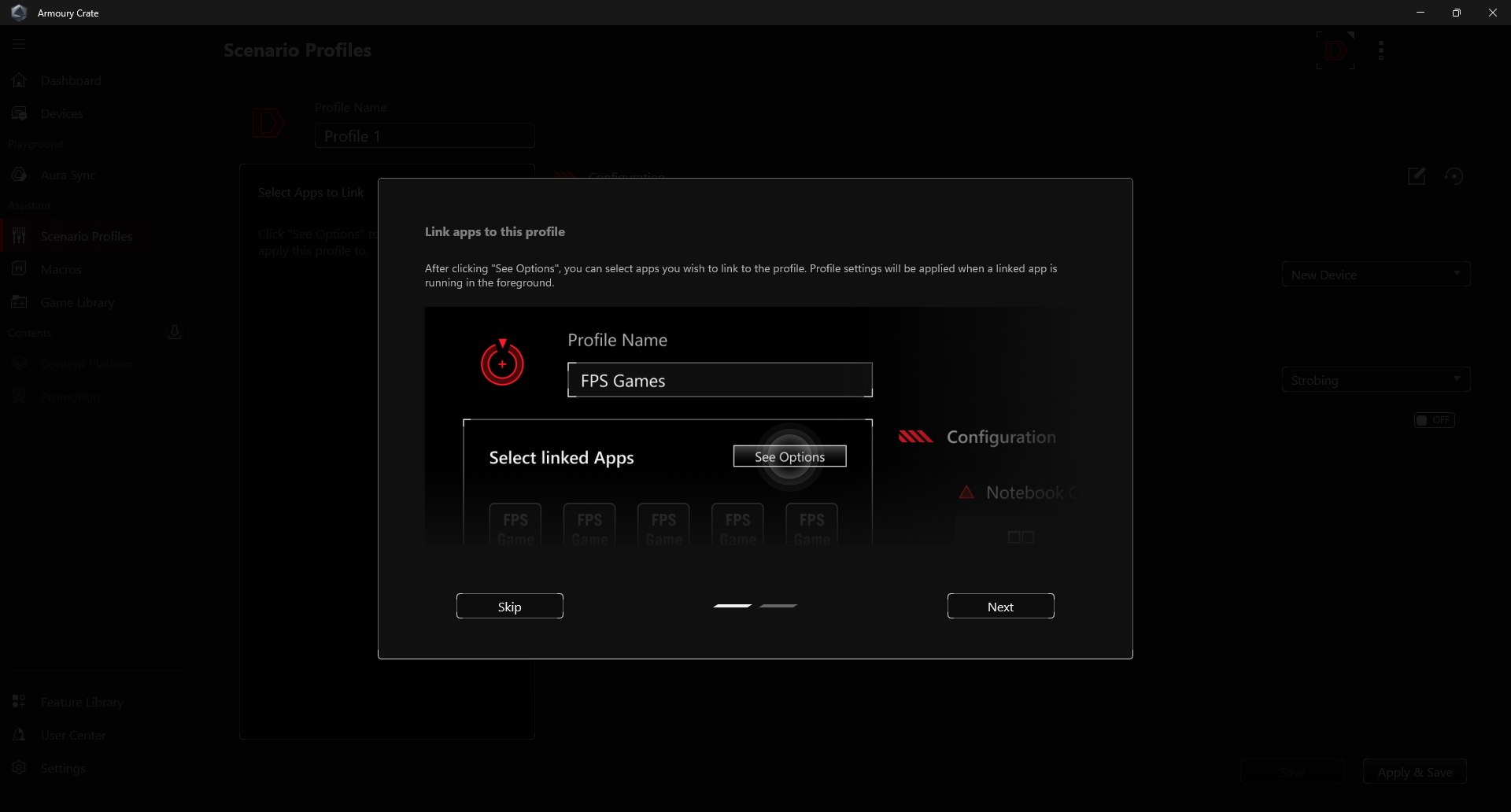
Asus ROG Keris II Ace – Bilder App
Asus ROG Keris II Ace – Bilder App
Asus ROG Keris II Ace – Bilder App
Funktionen wie Angle Snapping und Angle Tuning sind auch wieder mit am Start. Letztere ist vor allem für diejenigen interessant, die ihre Maus nicht gerade, sondern angewinkelt halten und auf dem Schreibtisch bewegen. Die Software macht dann aus den schrägen Bewegungen auf dem Schreibtisch gerade Bewegungen auf dem Bildschirm. Angle Snapping kann man sich hingegen als digitales Lineal vorstellen, das einem dabei hilft, eine gerade Linie zu ziehen. Das Feature ist jedoch Geschmackssache und nicht für jedes Spiel zu gebrauchen.
Die Beleuchtungseinstellungen halten sich in Grenzen, sind aber völlig ausreichend. Fünf verschiedene Effekte stehen zur Auswahl. Extrem nützlich ist der Battery Mode, welcher farbkodiert den Akkustand wiedergibt. Effekte wie pulsierende Farben oder der permanente Wechsel durch das Farbspektrum sind auch am Start.
Bedienung
Die Asus ROG Keris II Ace liegt gut in der Hand. Wir bedienen sie mit dem Fingertip-Grip, haben also ausschließlich über die Fingerspitzen Kontakt zur Maus. Dank der etwas gröberen Oberflächen- und Seitenflächen-Textur haben wir zu keiner Zeit das Gefühl, die Kontrolle über die Maus zu verlieren. Dank des matten Finishs bleiben Fingerabdrücke auf der Oberfläche zudem aus. Wir verwenden die Maus sowohl bei der Arbeit als auch beim Zocken. In beiden Fällen macht sie einen souveränen Job. Die optischen Switches der linken und rechten Maustaste liefern ein angenehmes Klickgeräusch und haben einen guten Druckpunkt. Die 8000-Hz-Abtastrate hält, was sie verspricht, und sorgt während unseres Tests für verzögerungsfreies Zocken.
Das Verbindungskabel ist mit 2 m lang genug, um während des Ladens beim Spielen nicht zu stören. Der Akku leert sich, abhängig von den gewählten Einstellungen, verhältnismäßig schnell. Mit voller Beleuchtung und einer permanenten Abtastrate von 8000 Hz sehen wir die Prozentanzeige zügig schwinden. Wir haben aber die Erfahrung gemacht, dass bereits das Senken der Beleuchtungsintensität auf 50 Prozent den Akkuverbrauch deutlich reduziert. Wer noch mehr aus dem Akku herausholen möchte, schaltet die Beleuchtung ganz aus und nutzt die 8000 Hz nur gezielt beim Zocken.
Preis
Die Asus ROG Keris II Ace in Weiß gibt es momentan für 108 Euro. In Schwarz kostet sie derzeit knapp 110 Euro auf Amazon.
Fazit
Als super leichte Maus macht die Asus ROG Keris II Ace für 105 Euro vieles richtig. Dank der raueren Textur der Schale und der geriffelten Seiten bedient sie sich hervorragend und liegt gut in der Hand. Nach einem Firmware-Update arbeitet sie jetzt auch kabellos mit einer Abtastrate von 8000 Hz und muss sich nicht hinter der Harpe II Ace verstecken. Die RGB-Beleuchtung ist nicht nur ein netter farblicher Touch, sondern durchaus nützlich, da sie den Akkustand anzeigen kann. Schade ist, dass man statt der praktischen Web-App Gearlink hier wieder auf Armoury Crate umsteigen muss. Ein Programm, das nach wie vor leider nicht rund läuft und in unserem Test zwar diesmal nicht abstürzt, aber weiterhin träge ist. Zudem sind so Linux-Nutzer ausgesperrt, da Armoury Crate nur für Windows verfügbar ist. Der Akku kommt bei voller Beleuchtung ganz schön ins Schwitzen und verliert verhältnismäßig schnell an Ladung, das lässt sich aber durch Anpassen der RGB-Intensität eindämmen.
Letztlich macht es einfach Spaß, mit der Keris II Ace zu spielen. Sie bedient sich äußerst angenehm und punktet mit ihrer Leistung auf dem Schlachtfeld. Der etwas schwächelnde Akku und die teilweise ruckelige Software trüben den Eindruck ein wenig, dennoch liefert sie einen hervorragenden Job ab, ist allerdings auch nicht günstig.
Be Quiet Dark Perk Ergo
Hinter der Be Quiet Dark Perk Ergo und der Dark Perk Sym stecken zwei wirklich solide Gaming-Mäuse, mit denen man gekonnt Shooter spielen kann.
- gute Akkulaufzeit
- 8000-Hz-Abtastrate
- Web-App und Desktop-App für Mauseinstellungen
- zuverlässige Performance beim Spielen
- Wechsel zwischen Web-App und Desktop-App nicht immer reibungslos
- Web-App hat nicht alle Funktionen der Desktop-App
Be Quiet Dark Perk Ergo im Test: Leichte Gaming-Maus für Egoshooter
Hinter der Be Quiet Dark Perk Ergo und der Dark Perk Sym stecken zwei wirklich solide Gaming-Mäuse, mit denen man gekonnt Shooter spielen kann.
Mit der Dark Perk Ergo und der Dark Perk Sym wagt Be Quiet den Einstieg in die Welt der superleichten Gaming-Mäuse. Ausgestattet sind die beiden Nager mit einer 8000-Hz-Abtastrate und dem Pixart-PAW3950-Sensor, der bis zu 32.000 DPI ermöglicht.
Die Mäuse unterscheiden sich vorwiegend in ihrer Form: Die Dark Perk Sym besitzt einen symmetrischen Körperbau, während die Dark Perk Ergo ergonomisch geformt ist. Bei beiden Varianten handelt es sich allerdings um Rechtshänder-Mäuse. Wir haben beide Versionen ausgiebig getestet und klären, ob sie den Kauf wert sind. Die Testgeräte stellte uns der Hersteller zur Verfügung.
Lieferumfang
Beide Mäuse kommen mit einem orangen USB-A-zu-USB-C-Verbindungskabel, dem Funk-Dongle mit 2,4 GHz sowie einem Funk-Adapter. Neben der Betriebsanleitung liegt zudem ein zusätzliches Set an Maus-Skates bei.
Design
Sowohl die Dark Perk Sym als auch die Dark Perk Ergo sind in schlichtem Schwarz gehalten. Beide Gaming-Mäuse wiegen gerade mal 55 g. Das geringe Gewicht erklärt sich schnell, wenn man die Mäuse umdreht. Sie sind auf der Unterseite offen und gewähren so Einblick in das Innere der Gaming-Peripherie. Der Be-Quiet-Schriftzug ziert die so sichtbare Platine. Wenn man genau hinschaut, kann man sogar die Mechanik beim Klicken der seitlichen Buttons beobachten.
Beim Rest des Layouts geht es derweil traditioneller zu: Zwei Buttons gibt es auf der linken Seite, während der Power-Button und der DPI-Switch auf der Unterseite der Maus liegen. Das Mausrad ist aus Plastik und gummiert geriffelt, einen Schalter, um zwischen Einrasten und Durchdrehen des Scrollrads zu wechseln, gibt es nicht. Was die Maße angeht, unterscheiden sich die beiden Modelle natürlich geringfügig aufgrund ihres Formfaktors. Die Dark Perk Ergo misst 120 × 66 × 40 mm, während die Dark Perk Sym 123 × 66 × 39 mm misst.
Be Quiet Dark Perk Ergo – Bilder
Be Quiet Dark Perk Ergo – Bilder

Be Quiet Dark Perk Ergo – Bilder

Be Quiet Dark Perk Ergo – Bilder

Be Quiet Dark Perk Ergo – Bilder

Be Quiet Dark Perk Ergo – Bilder

Be Quiet Dark Perk Ergo – Bilder

Be Quiet Dark Perk Ergo – Bilder

Be Quiet Dark Perk Ergo – Bilder

Eine richtige Beleuchtung hat die Maus nicht. Lediglich eine kleine LED über den seitlichen Buttons, die beim DPI-Wechsel farblich kodiert signalisiert, welches Profil gerade aktiv ist. Generell wirken beide Mäuse sehr schlicht und stechen optisch kaum hervor. Die Verarbeitung ist einwandfrei, wenngleich wir etwas Angst hätten, die Maus aufgrund der offenen Unterseite fallen zu lassen.
Einrichtung & Software
Die Einrichtung erfolgt problemlos per Anschluss via des Verbindungskabels direkt an die Maus oder per 2,4-GHz-Dongle. Anschließend sollte man entweder das IO Center als Desktop-App herunterladen oder die Web-App im Browser aufrufen. Für etwaige Firmware-Updates muss man sowohl Maus als auch Dongle parallel an den PC anschließen. Leider können Einstellungen wie die Klickgeschwindigkeit und die Maussensitivität zum Testzeitpunkt nur über das Betriebssystem oder die Desktop-App angepasst werden, weswegen man in diesen Fällen um eine Installation der App nicht herumkommt.
Die Web-App funktioniert bis auf eine Ausnahme reibungslos. Der Wechsel zwischen der Desktop-App und der Browser-Version gelingt nicht immer sofort. Häufig muss die PC-App vorher beendet und/oder die Browser-App neu geladen werden, damit die Maus im Browser konfigurierbar ist (Stand: Launch-Version beider Apps).
Be Quiet Dark Perk Ergo – Bilder App
Be Quiet Dark Perk Ergo – Bilder App
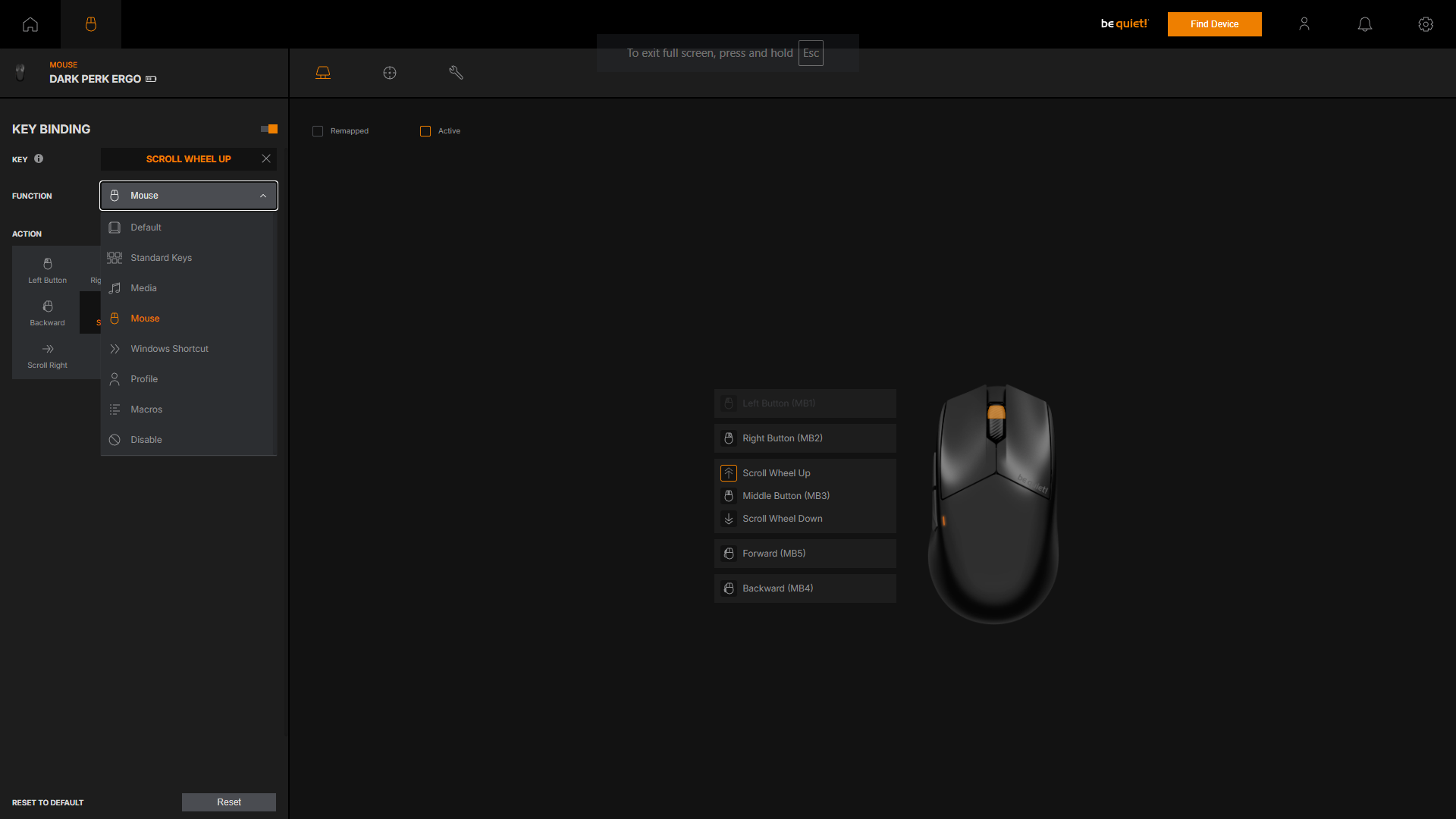
Be Quiet Dark Perk Ergo – Bilder App
Be Quiet Dark Perk Ergo – Bilder App
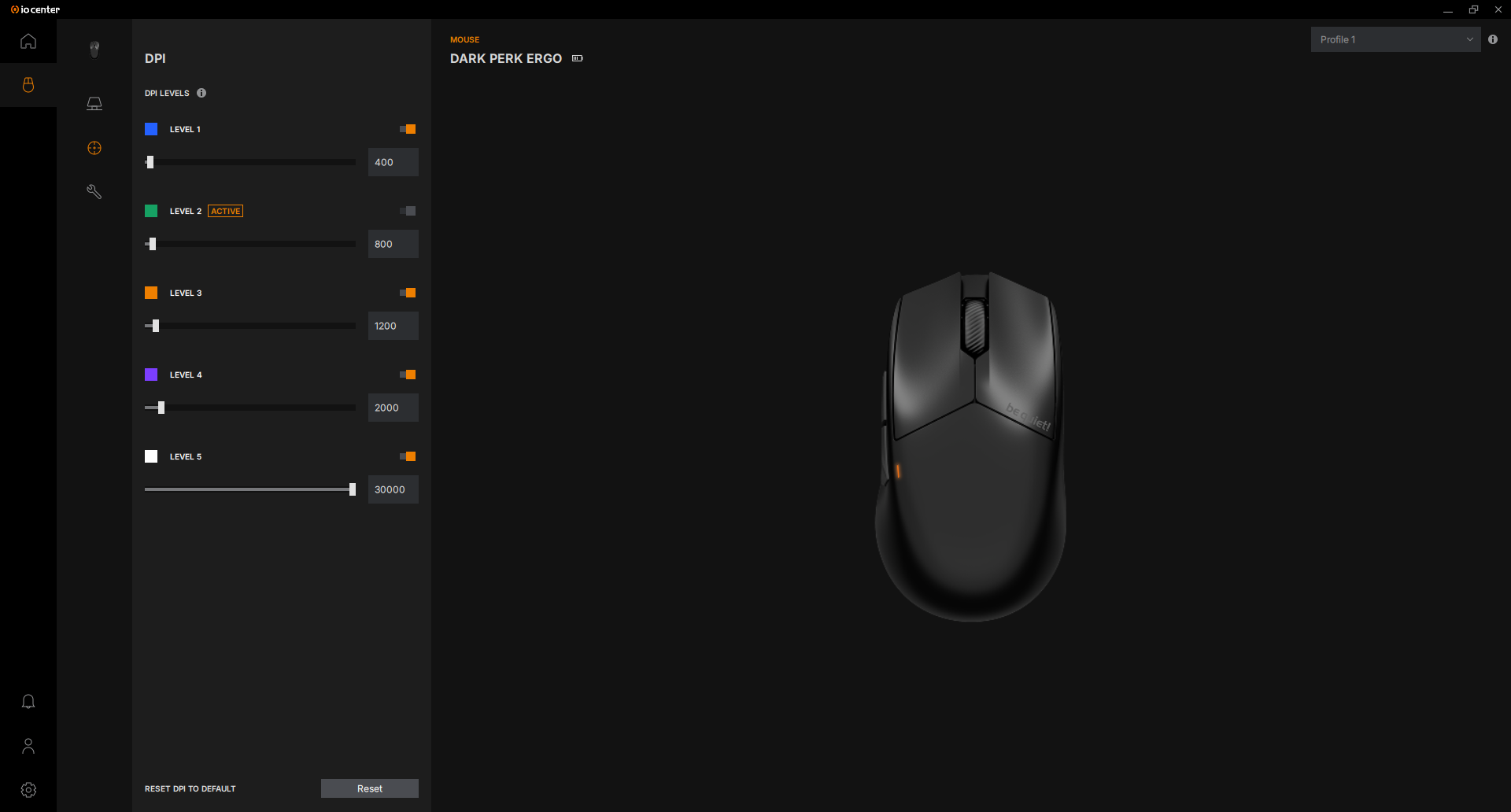
Be Quiet Dark Perk Ergo – Bilder App
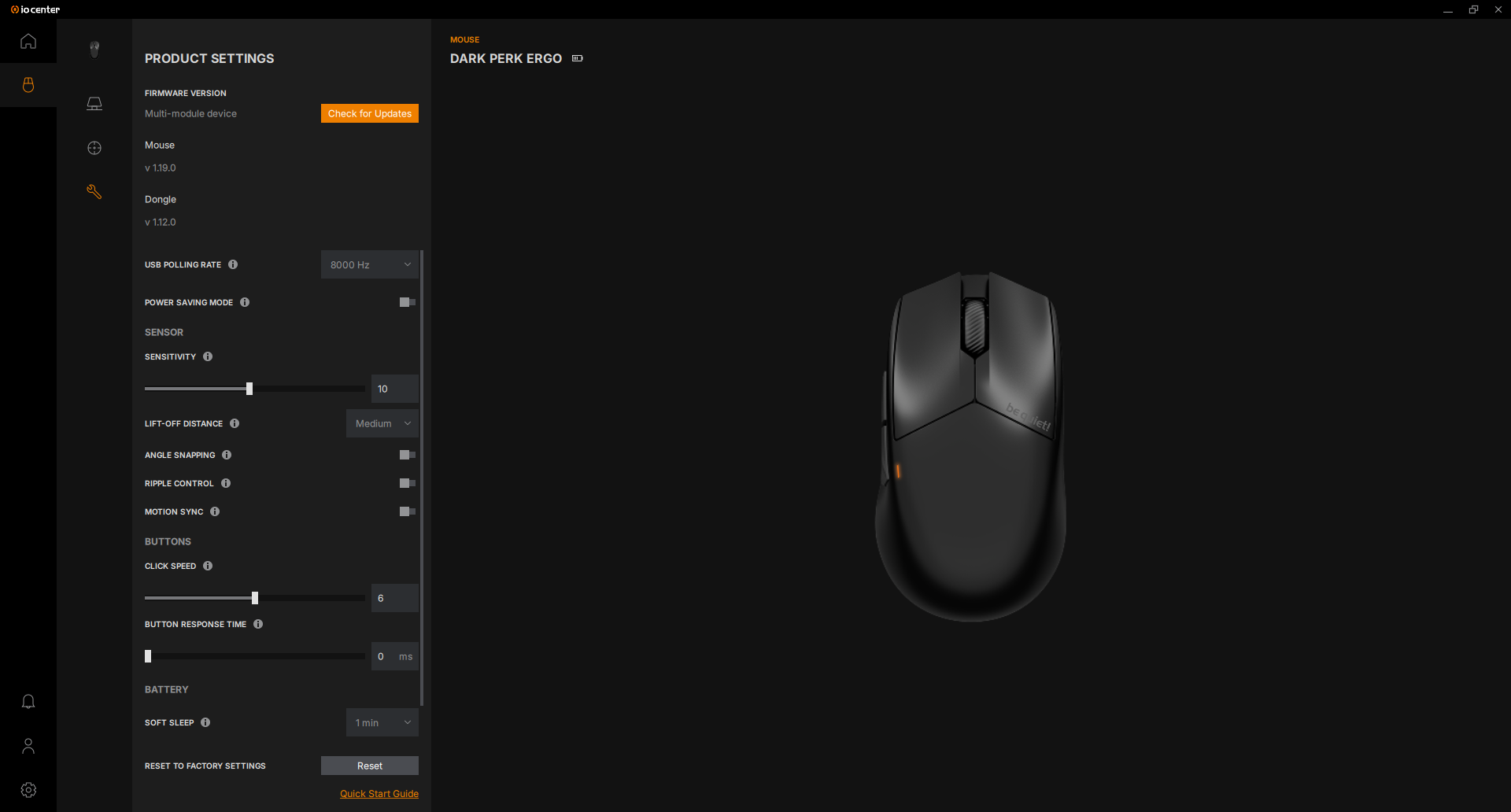
Be Quiet Dark Perk Ergo – Bilder App
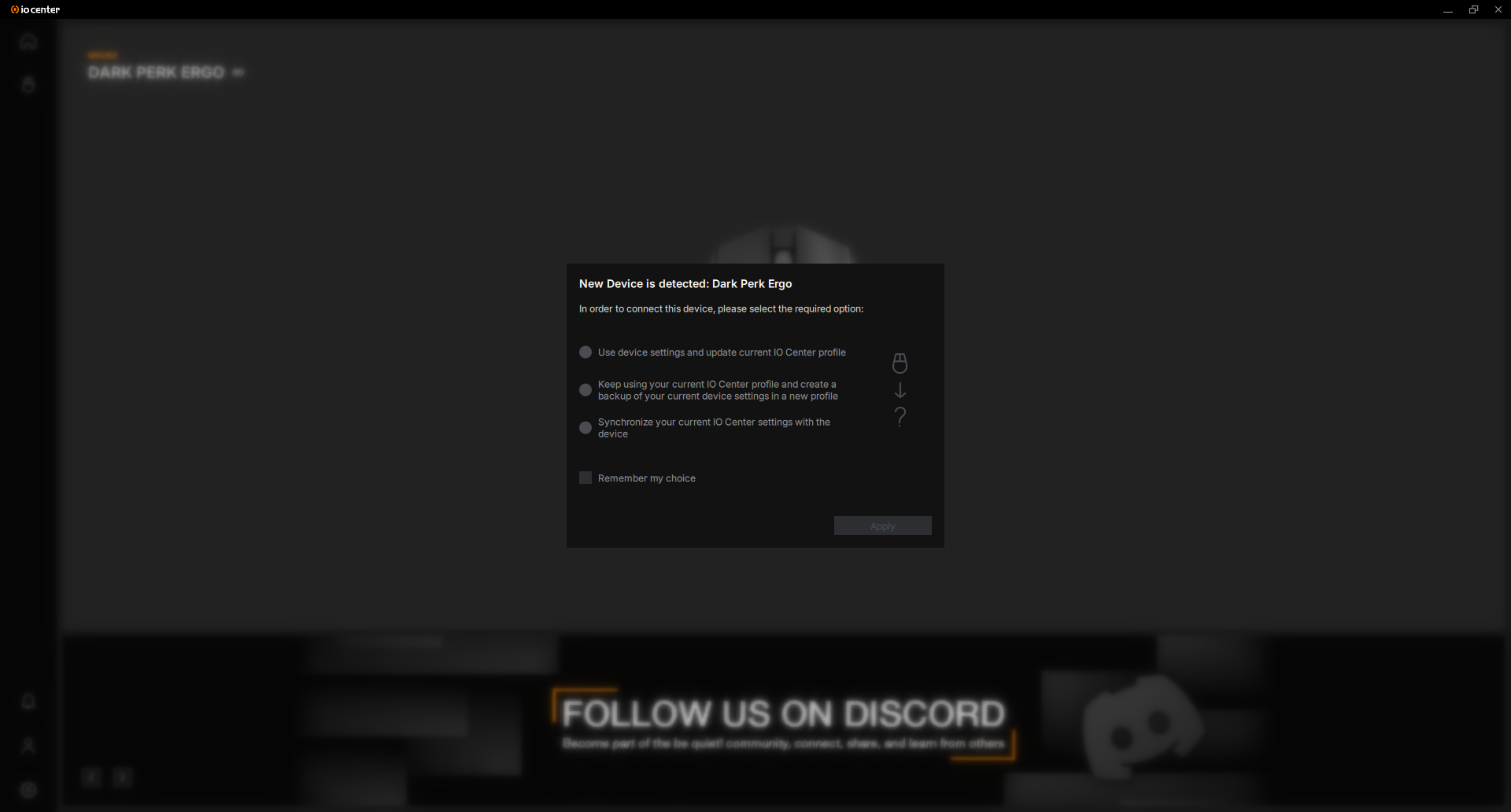
Die Einstellungsmöglichkeiten decken sich zum Großteil mit denen anderer Hersteller. Maustasten lassen sich mit verschiedenen Funktionen neu belegen, die fünf DPI-Profile mit unterschiedlichen Werten den eigenen Bedürfnissen anpassen – allerdings nicht kleiner als in fünfziger Schritten. Der verbaute Pixart-PAW3950-Sensor ermöglicht hier bis zu 32.000 DPI.
Spannend bei den Maustasten-Einstellungen ist, dass man auch das Verhalten des Klicks bestimmen kann. Ein einfacher Klick kann so wahlweise als Doppelklick ausgelesen werden. Alternativ kann man eine Aktion so lange ausführen lassen, wie man die Taste gedrückt hält. Mit der Auto-Fire-Einstellung richtet man hingegen ein, wie viele Klicks pro Sekunde (bis zu 50) bei gedrückter Maustaste auslösen.
Weitere Einstellungsmöglichkeiten beinhalten die Abtastrate (125 – 8000 Hz), Stromsparmodus inklusive Sleep-Timer sowie die Lift-Off-Distance. Auch Angle Snapping, Ripple Control und Motion Sync sind wie bei anderen Gaming-Mäusen am Start. Etwas außergewöhnlicher ist da schon die Möglichkeit, die Klickgeschwindigkeit sowie die Klickverzögerung einzustellen.
Bedienbarkeit
Im Praxistest kommen wir mit beiden Mäusen problemlos klar. Sowohl in täglichen Arbeitsszenarien als auch beim Spielen am Abend. Unser Mausgriff ist zwischen Fingertip- und Claw-Grip angesiedelt. Wir können beide Mäuse so einwandfrei bedienen, bevorzugen bei einer Gaming-Maus aber generell eine symmetrische Form. Die Omron-Optical-D2FP-FN2-Switches liefern einen zufriedenstellenden Betätigungspunkt und erfordern eine für uns ideale Betätigungskraft, um ungewollte Auslöser zu vermeiden.
Für uns sind auch die seitlichen Buttons immer ein wichtiges Kriterium bei der Wahl der Maus, da wir hier die Push-to-Talk-Funktion für den Voice-Chat im Spiel legen. Tatsächlich unterscheiden sich die beiden Modelle hier etwas voneinander. Nicht nur klingen die Klicks unterschiedlich (etwas heller bei der Sym) sondern auch die Buttons haben eine leicht andere Form. Bei der Sym sind sie etwas schmaler und der hintere Button ist etwas länger gezogen. Bei beiden Modellen klicken die seitlichen Tasten super zufriedenstellend, wobei wir generell die etwas breitere Variante der Dark Perk Ergo bevorzugen.
Beim Spielen verwenden wir überwiegend eine Abtastrate von 8000 Hz, tagsüber während der Arbeit hingegen hauptsächlich 1000 Hz. Sowohl kabelgebunden als auch kabellos wirken unsere Inputs präzise und ohne spürbare Verzögerungen. Das Gehäuse beider Mäuse ist aus ABS-Plastik und liegt hervorragend in der Hand. Auch wenn optionales Grip-Tape im Lieferumfang grundsätzlich auch bei den Be Quiet Dark Perk eine nette Dreingabe gewesen wäre, vermissen wir hier keine texturierten Seitenteile – trotz der glatten Oberfläche bieten beide Mäuse exzellenten Halt.
Der Akku macht während des Testzeitraums ebenfalls eine gute Figur. Wie bereits erwähnt, wechseln wir nur für unsere Gaming-Sessions auf eine Abtastrate von 8000 Hz und nutzen beide Mäuse im Alltag mit 1000 Hz. Damit erreicht man zwar nicht die maximal angegebenen 110 Stunden Laufzeit (bei 1000 Hz), kommt bei gemischter Nutzung jedoch problemlos auf etwa zwei bis drei Tage, bevor die Mäuse wieder ans Ladekabel müssen. Bei ausschließlicher Nutzung mit einer Abtastrate von 1000 Hz halten sie deutlich länger durch.
Preis
Die UVP der Be Quiet Dark Perk Ergo und Dark Perk Sym liegt bei 110 Euro. Die Dark Perk Ergo gibt es momentan für 89 Euro zu kaufen. Für die Dark Perk Sym zahlt man aktuell ebenfalls etwa 89 Euro.
Fazit
Mit der Dark Perk Ergo und der Dark Perk Sym steigt Be Quiet vielversprechend in den Markt der Gaming-Mäuse ein. Beide Exemplare überzeugen mit einer soliden Verarbeitung, einer guten Haptik und präzisen und verzögerungsfreien Klicks. Die Kombination aus Web-App und Desktop-App ist praktisch, läuft allerdings bisher nicht vollkommen rund. Nichts, was ein zukünftiges Firmware-Update nicht lösen könnte.
Als Neueinsteiger auf dem Markt bieten die beiden Mäuse von Be Quiet aber wenig Neues, für das sich ein Umstieg lohnen würde. Wer aktuell auf der Suche nach einer neuen High-End-Gaming-Maus ist, macht mit einem Kauf der Dark Perk Sym oder Dark Perk Ergo jedoch wenig falsch.
Logitech G305X Superlight
Leicht, kompakt und mit einer beeindruckenden Akkulaufzeit: Die Gaming-Maus Logitech G305 X Superlight liefert ab – und das für unter 100 Euro.
- beeindruckende Akkulaufzeit
- mit 61 g angenehm leicht
- knackige & präzise Klicks
- Logitech G-Hub als kompetente Software
- 8000 Hz nur via separat erhältlichem Dongle
Gaming-Maus Logitech G305 X Superlight im Test: Ewig zocken mit einer Akkuladung
Leicht, kompakt und mit einer beeindruckenden Akkulaufzeit: Die Gaming-Maus Logitech G305 X Superlight liefert ab – und das für unter 100 Euro.
Die Logitech G305 X Superlight stellt ein Update der beliebten G305 dar. Trotz 61 statt 99 Gramm Gewicht, RGB-Beleuchtung und mehr DPI bleibt der Formfaktor gleich. Bis zu 130 Stunden Laufzeit pro Ladung schreibt Logitech dem Akku zu. Wir haben die Gaming-Maus für 80 Euro getestet und verraten, ob sich der Kauf lohnt. Das Testgerät hat uns der Hersteller zur Verfügung gestellt.
Lieferumfang
Die Logitech G305 X Superlight kommt mit 2,4-GHz-USB-A-Funkdongle und einem USB-C-zu-USB-A-Verbindungskabel.
Design
Die Bauform der 61 g schweren Logitech G305 X Superlight ist vollkommen symmetrisch und mit Maßen von 63,9 × 38,2 × 117,3 mm relativ kompakt. Sie folgt dem typischen Layout von Rechtshändermäusen, mit zwei Buttons auf der linken Seite der Peripherie. Unter dem Mausrad befindet sich der DPI-Button, welcher von einem milchigen Kunststoffstreifen umschlossen ist. Hier scheint die RGB-Beleuchtung der kleinen Maus dezent hindurch.
Auf der Unterseite der Peripherie befinden sich An-/Aus-Schalter sowie der Modus-Button, um zwischen der Funk- und der Bluetooth-Verbindung zu wechseln. Außerdem verstaut man hier den 2,4-GHz-Funkdongle. Vorne an der Maus liegt der USB-C-Port, um sie per Kabel zu laden. Dadurch kann man sie auch problemlos während des Ladens kabelgebunden verwenden. Unser Testgerät ist weiß, es gibt aber auch eine schwarze Variante der G305 X Superlight.
Trotz des geringen Gewichts und des kleinen Formfaktors wirkt die Logitech G305 X Superlight recht robust. Im Inneren klappert nichts, am Gehäuse wackelt oder knarzt nichts, und in der Hand fühlt sie sich ausgesprochen griffig an.
Logitech G305X Lightspeed – Bilder
Logitech G305X Lightspeed – Bilder

Logitech G305X Lightspeed – Bilder

Logitech G305X Lightspeed – Bilder

Logitech G305X Lightspeed – Bilder

Logitech G305X Lightspeed – Bilder

Logitech G305X Lightspeed – Bilder

Logitech G305X Lightspeed – Bilder

Logitech G305X Lightspeed – Bilder

Logitech G305X Lightspeed – Bilder

Logitech G305X Lightspeed – Bilder

Logitech G305X Lightspeed – Bilder

Software
Wie für alle Logitech-Gaming-Produkte kommt auch bei der G305 X Superlight die Software G-Hub zum Einsatz. Die App bietet fünf verschiedene DPI-Profile, ermöglicht es, die Tastenbelegung der Maus zu verändern sowie die Beleuchtung der LEDs anzupassen. Zudem findet der BHOP-Modus erneut Einzug, dazu später mehr.
Die Einrichtung ist binnen weniger Sekunden erledigt. Die Software erkennt die Peripherie sofort und gewährt Zugriff auf die Einstellungen. Die fünf DPI-Profile lassen sich wahlweise sowohl auf der x- als auch auf der y-Achse konfigurieren. Wer das nicht braucht, kann den DPI-Wert auch ganz regulär für beide Achsen gleichzeitig festlegen. Die DPI-Spanne liegt hier zwischen 100 und 44.000 und ist sogar in Einser-Schritten veränderbar. Logitech liefert zudem auch DPI-Presets für verschiedene Szenarien und Spielgenres.
Logitech G305X Lightspeed – Bilder App
Logitech G305X Lightspeed – Bilder App
Logitech G305X Lightspeed – Bilder App
Logitech G305X Lightspeed – Bilder App
Logitech G305X Lightspeed – Bilder App
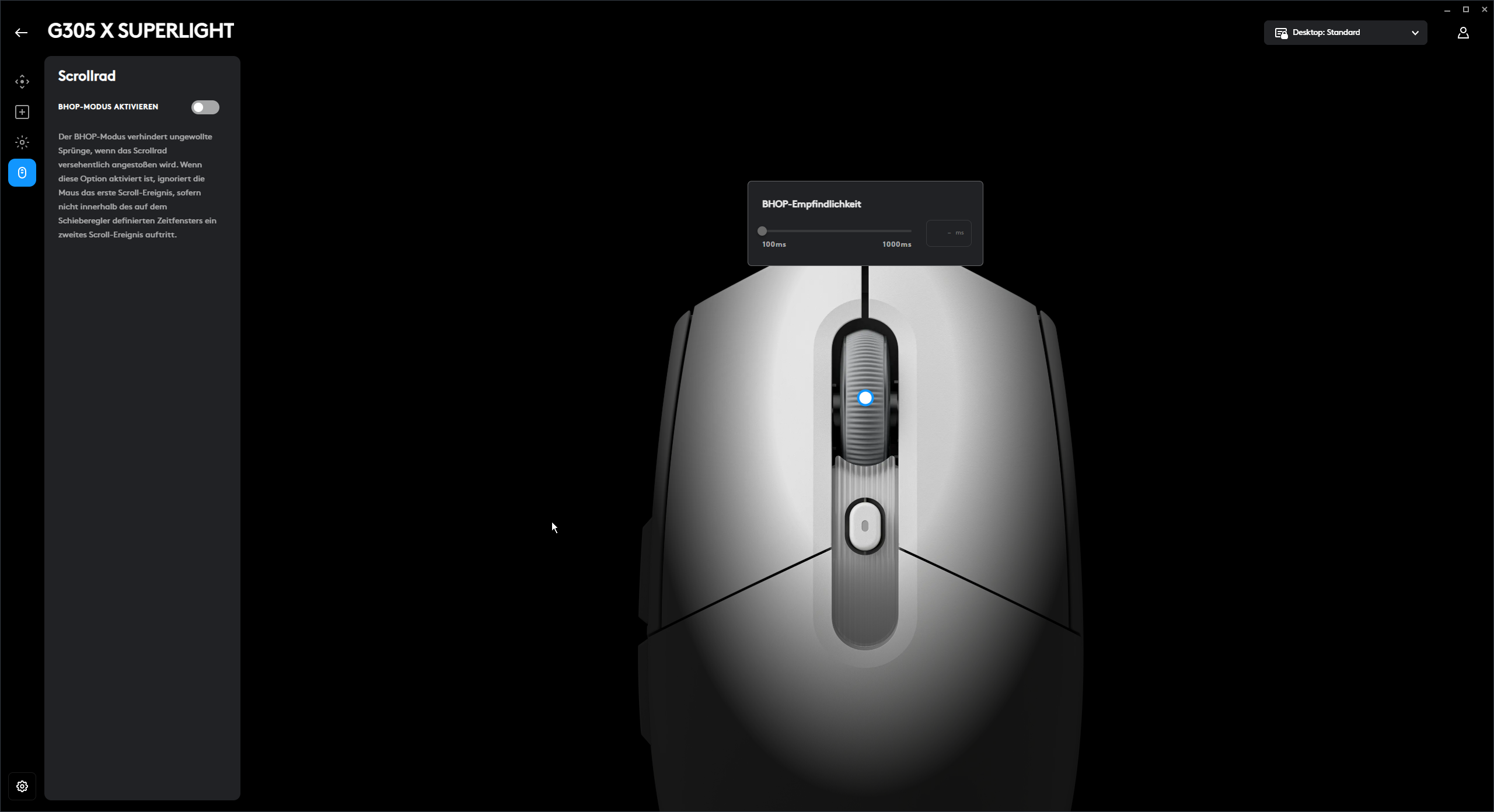
Logitech G305X Lightspeed – Bilder App

Für die Tastenbelegung stehen diverse Tastenkombinationen à la Strg + C und Strg + V parat, aber auch Makros kann man erstellen und auf eine der Tasten legen. Neu hinzugekommen sind Audiosamples, die man per Tastendruck abspielen kann. Logitech liefert hier eine Auswahl, die von Begrüßungen in verschiedenen Sprachen bis hin zu speziellen Soundeffekten wie Keuchen, Piepton oder Applaus reicht. Die Option, eigene Samples hochzuladen und auf die Tasten zu legen, konnten wir nicht finden.
Sechs verschiedene Beleuchtungseffekte und vier vordefinierte Effektfarben liefert die App. Dazu kommt die Option, benutzerdefinierte Farben festzulegen. Wer möchte, kann die Beleuchtung selbstverständlich auch komplett ausschalten.
Mit aktiviertem BHOP-Modus ignoriert die G305 X die erste Scrollbewegung des Mausrads, außer eine zweite Bewegung findet innerhalb eines zuvor festgelegten Zeitfensters statt. Das soll verhindern, dass es aus Versehen betätigt wird. Gerade im Bereich der kompetitiven taktischen Shooter legen Spieler die Sprungfunktion gerne auf das Mausrad, um kontrollierter springen zu können. Das zeitlich genau abgestimmte Springen ermöglicht schnellere Bewegungen im Spiel und wird Bunny-Hopping genannt.
Die App liefert, wie auch in den vergangenen Tests anderer Logitech-Gaming-Mäuse, eine hervorragende Performance und glänzt mit einer fantastischen Benutzerfreundlichkeit, aufgeräumtem Design und nützlichen Funktionen.
Bedienbarkeit
Wir verwenden die Logitech G305 X Superlight bei der täglichen Arbeit im Büro und setzen sie abends beim Zocken ein. Überrascht hat uns hier der Akku. Nach gut einer Woche im täglichen Einsatz attestiert uns G-Hub noch 85 Prozent Akkustand. Logitech wirbt mit bis zu 130 Stunden pro Ladung, was für uns durchaus plausibel klingt. Wer die Maus nur für die abendliche Gaming-Session verwendet, wird mit einer Akkuladung sehr lange auskommen. Praktisch ist in diesem Zusammenhang die Schnellladefunktion, die nach 2 Minuten Aufladen bereits 3,5 Stunden Akkulaufzeit gibt.
Wie alle Mäuse greifen wir auch die G305 X Superlight mit den Fingerspitzen. Sie bedient sich komfortabel über mehrere Stunden hinweg und liegt sicher in der Hand. Die Klicks der zwei Haupttasten sind knackig, während die Betätigungskraft der zwei seitlichen Tasten für unseren Geschmack minimal zu schwach ist. Sie ist aber hoch genug, damit wir die Tasten nicht aus Versehen durch Auflegen des Daumens betätigen.
In Overwatch und Valorant bemerken wir keine Verzögerung der Klicks, die Maus wirkt ausgesprochen responsiv und die Betätigung der Maustasten überhaupt nicht schwammig. Die G305 X Superlight unterstützt von Haus aus eine Abtastrate von 1000 Hz und kann per separat erhältlichem – aber derzeit ausverkauftem – Dongle auf bis zu 8000 Hz hoch gehen.
Preis
Die UVP der Logitech G305 X Superlight liegt bei 80 Euro. Aktuell bekommt man sie in Schwarz für 77 Euro. In Weiß kostet sie derzeit ebenfalls 77 Euro.
Fazit
Die Logitech G305 X Superlight erfindet das Rad nicht neu, liefert mit geringem Gewicht, präzisen Klicks und einer starken Akkulaufzeit aber eine solide Grundlage, um beim Zocken mit ihr viel Spaß zu haben. Im Vergleich zur Flagship-Gaming-Maus Logitech G Pro X2 Superstrike (Testbericht) kostet sie auch nur etwa halb so viel. Unterstützt wird sie durch die App Logitech G-Hub, die mit einer top Benutzerfreundlichkeit glänzt.
Wer mehr Leistung aus der Peripherie herausholen möchte, muss einen separaten Dongle kaufen, der die Abtastrate der G305 X Superlight auf bis zu 8000 Hz erhöht. Braucht man das nicht, bekommt man mit der G305 X Superlight trotzalledem eine starke Gaming-Maus.
Steelseries Aerox 3 Wireless
Die Gaming-Maus Steelseries Aerox 3 Wireless fällt durch ihr löchriges Design auf, was trotz der vielen Öffnungen eine IP54-Zertifizierung hat.
- schickes Design
- praktische Funktionen per Software
- solide Haptik
- starke RGB-Beleuchtung
- Akku nicht sehr ausdauernd
- etwas zu teuer für den Funktionsumfang
- seitliche Buttons relativ schmal
Gaming-Maus Steelseries Aerox 3 Wireless im Test: IP54 trotz löchriger Optik
Die Gaming-Maus Steelseries Aerox 3 Wireless fällt durch ihr löchriges Design auf, was trotz der vielen Öffnungen eine IP54-Zertifizierung hat.
Die Steelseries Aerox 3 Wireless fällt sofort dank des luftig-löchrigen Designs der Schale in Kombination mit der kräftigen RGB-Beleuchtung auf. Schickes Aussehen ist aber bekanntlich nicht alles, und da stellt sich die Frage, ob die 67 g leichte kabellose Gaming-Maus noch mehr zu bieten hat. Wir haben sie getestet und verraten es. Das Testgerät wurde uns vom Hersteller zur Verfügung gestellt.
Lieferumfang
Zusammen mit der Maus gibt es ein 1,8 m langes Verbindungskabel (USB-C-zu-USB-A), einen 2,4-GHz-Funkreceiver sowie einen Extension-Adapter. Eine Kurzanleitung liegt ebenfalls bei.
Design
Die Steelseries Aerox 3 Wireless kommt im symmetrischen Formfaktor, mit etwa 67 g Gewicht und den Maßen 121 × 67 × 38 mm. Das macht sie relativ groß, weswegen sie auch prima für größere Hände geeignet ist. Unser Testmodell ist weiß, alternativ gibt es die kabellose Gaming-Maus aber auch in Schwarz und im milchig transluzenten Ghost-Look.
Optisch ist der Nager dank der löchrigen Schale definitiv ein Blickfang. Mit aktivierter RGB-Beleuchtung kann man so einen guten Blick ins Innere der Peripherie erhaschen. Die LEDs befinden sich im unteren Teil der Maus und strahlen durch transluzentes Plastik seitlich sowie logischerweise oben durch die Löcher hindurch. Tatsächlich, und das wirkt aufgrund der unzähligen Öffnungen fast unglaubwürdig, ist die Maus IP54 zertifiziert. Dadurch ist sie vor Staub und Spritzwasser geschützt.
Steelseries Aerox 3 Wireless – Bilder
Steelseries Aerox 3 Wireless – Bilder

Steelseries Aerox 3 Wireless – Bilder

Steelseries Aerox 3 Wireless – Bilder

Steelseries Aerox 3 Wireless – Bilder

Steelseries Aerox 3 Wireless – Bilder

Steelseries Aerox 3 Wireless – Bilder

Steelseries Aerox 3 Wireless – Bilder

Steelseries Aerox 3 Wireless – Bilder

Steelseries Aerox 3 Wireless – Bilder

Die Schale besteht aus ABS-Plastik, verzichtet aber auf das häufig verwendete weiche Finish. Dadurch fühlt sie sich ein klein wenig rauer an. An der Verarbeitung gibt es so gut wie nichts auszusetzen. Lediglich der DPI-Button wirkt etwas wackelig beim Drücken.
Das gummierte Mausrad aus Plastik ist für unseren Geschmack etwas zu tief gelegen, lässt sich aber noch gut bedienen. Auf der linken Seite befinden sich zwei zusätzliche, ziemlich schmale Buttons. Auch die Unterseite ist von Löchern durchzogen, allerdings durch das transluzente Plastik abgedichtet. Hier befindet sich der Power-Schalter, der gleichzeitig auch die Verbindungsmodi – Funk, Bluetooth und kabelgebunden – wechselt. Für Letzteren befindet sich der USB-C-Port vorn an der Maus.
Einrichtung & Software
Die Einrichtung klappt problemlos, Maus und Funkdongle werden von unserem PC unter Windows 11 sofort erkannt. Die Aerox 3 Wireless ist zudem kompatibel mit ChromeOS, Linux, Mac und der Xbox. Das gilt allerdings nur für die Maus, denn die Software Steelseries Engine läuft zum Testzeitpunkt nur unter Windows 7 und höher sowie unter Mac OSX 10.12 und höher. Da sie aber mit einem Onboard-Speicher ausgestattet ist, lassen sich Einstellungen direkt auf ihr abspeichern.
Engine ist Teil der Steelseries-GG-Suite und beherbergt alle Einstellungsmöglichkeiten der Maus. Die Maustasten kann man mit neuen Funktionen belegen, darunter das Öffnen von Programmen, das Aufzeichnen und Ausführen von Makros oder das Ausführen von Shortcuts (auch Windows- oder Mac-spezifische Shortcuts). Praktisch: Unter dem Dropdown-Menü ist zusätzlich ein Aufnahme-Tool integriert, über das man etwa Tastenkombinationen händisch aufzeichnet und direkt auf eine gewünschte Maustaste legt.
Steelseries Aerox 3 Wireless – Bilder App
Steelseries Aerox 3 Wireless – Bilder App
Steelseries Aerox 3 Wireless – Bilder App
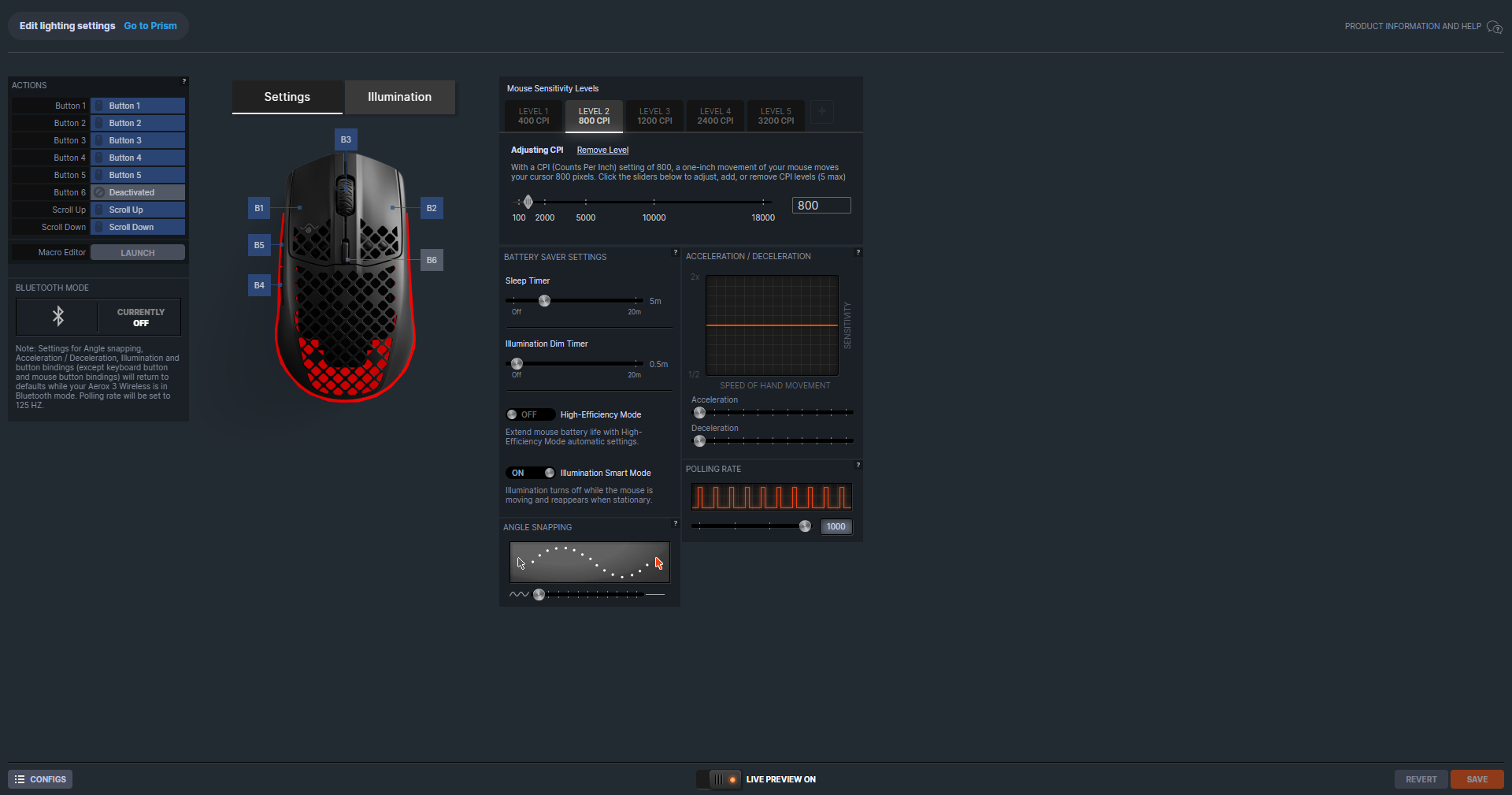
Steelseries Aerox 3 Wireless – Bilder App
Steelseries Aerox 3 Wireless – Bilder App
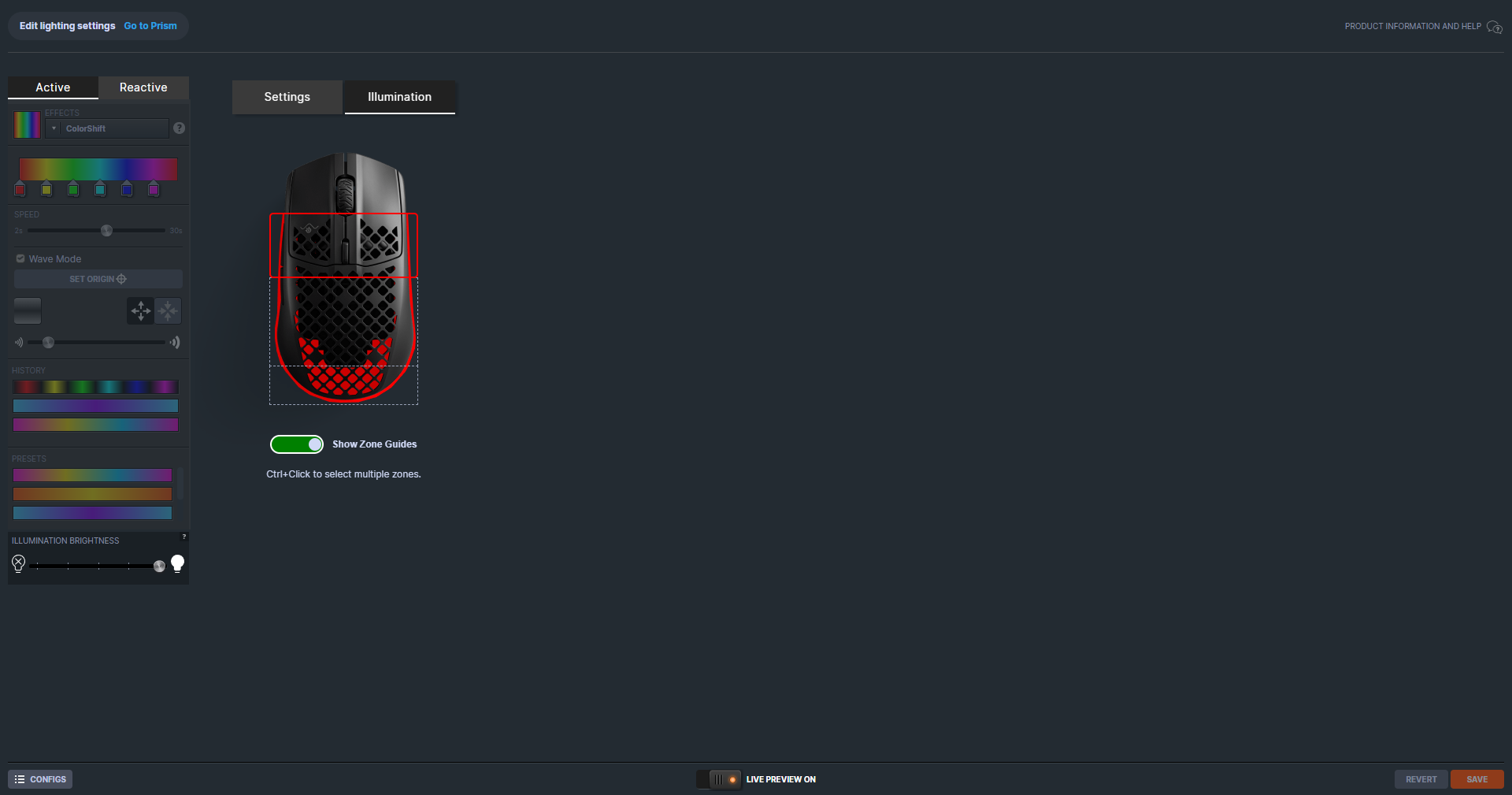
Steelseries Aerox 3 Wireless – Bilder App
Steelseries Aerox 3 Wireless – Bilder App
Fünf verschiedene DPI-Profile stehen zur Auswahl und sind selbstredend individuell anpassbar. Bis zu 18.000 DPI sind maximal möglich, während in der anderen Richtung bei 100 Schluss ist. Ein nettes Detail: Verändert man den Wert eines Profils, beispielsweise von vormals 800 auf 100, ordnet es sich im Menü automatisch vor dem nächsthöheren ein.
Wer möchte, kann die Beschleunigung und Entschleunigung des Mauscursors per Schieberegler anpassen, Angle-Snapping hinzuschalten oder die Abtastrate (maximal 1000 Hz) verändern. Energiesparfunktionen beinhalten die Regulierung des Sleep-Timers sowie der LED-Dimmung. Zusätzlich gibt es noch den High-Efficiency-Mode, der das Gros der Beleuchtung deaktiviert und die Abtastrate bei 125 Hz parkt. Von vornherein aktiviert ist hingegen der Illumination-Smart-Mode. Der sorgt dafür, dass die Maus nur leuchtet, wenn sie nicht bewegt wird, lässt sich aber jederzeit ausschalten.
Die Beleuchtung lässt sich entweder über Engine oder das optional aktivierbare Prism einrichten. Die Beleuchtung der Maus ist in beiden Programmen in drei Zonen aufgeteilt, wobei jede Zone mit anderen Farben und Effekten versehen werden kann. Zur Auswahl stehen 26 Presets. Alternativ kann man aus fünf Grundeffekten wählen, die dann unter anderem in Ausrichtung, Farbe und Geschwindigkeit anpassbar sind.
Bedienbarkeit
Sowohl beim Spielen als auch beim Arbeiten macht die Maus einen kompetenten Eindruck. Wir bemerken keine spürbaren Verzögerungen oder ungewollt ausgelöste Klicks. Die Schale bietet eine für uns vollkommen ausreichende Griffigkeit, und während der durchlöcherte Rücken der Maus sich anfangs etwas ungewöhnlich angefühlt hat, haben wir uns schnell an dessen Textur gewöhnt.
Die Tasten sind lang genug, damit Palm-, Fingertip- und Claw-Grip-Spieler diese komfortabel betätigen können. Das Mausrad ragt für uns wie bereits erwähnt etwas zu flach aus dem Gehäuse hervor und auch die super schmalen seitlichen Tasten gefallen uns nach mehreren Gaming-Sessions nach wie vor nicht. Traditionell legen wir auf die vordere Taste unseren Push-to-Talk-Button. Im Fall der Aerox 3 Wireless pikst bei gedrückter vorderer Taste dann aber die hintere Taste leicht in den Daumen.
Sowohl Betätigungspunkt als auch Betätigungskraft der verwendeten Golden-Micro-IP54-Switches fühlen sich für uns optimal austariert an. Ein Klick benötigt vergleichsweise aber durchaus etwas Kraft und könnte für den einen oder anderen eine Umgewöhnung bedeuten.
Wir verwenden die Steelseries Aerox 3 Wireless tagsüber während der Arbeit und abends beim Spielen ausschließlich mit 1000-Hz-Abtastrate sowie aktivierter Beleuchtung und hinzugeschaltetem Illumination-Smart-Mode. In dieser Konfiguration ist der Akku nach nicht einmal einem Tag im Einsatz bereits zu einem Drittel leer. Am zweiten Tag hängen wir die Maus dann ans Ladekabel. Wer die Maus nur zum Zocken verwendet, holt hier sicherlich mehr Laufzeit heraus. Auch das Ausschalten der RGB-Beleuchtung dürfte den Akku etwas entlasten.
Preis
Die Steelseries Aerox 3 Wireless hat eine UVP von 110 Euro. Aktuell kostet sie in Weiß auf Amazon 83 Euro. Die Ghost-Variante schlägt mit gut 92 Euro zu Buche. In schwarzer Optik gibt es die Gaming-Maus derzeit für etwa 70 Euro auf Amazon.
Fazit
Im Praxistest überzeugt die Steelseries Aerox 3 Wireless beim Arbeiten und Zocken als zuverlässige Gaming-Maus. Eine ausgezeichnete Verarbeitung mit solider Griffigkeit punktet hier ebenfalls, wenngleich wir uns deutlich breitere seitliche Buttons gewünscht hätten. Die luftige Optik gefällt uns und lässt die intensive RGB-Beleuchtung hervorragend zur Geltung kommen. Leider ist der Akku verhältnismäßig schwach, wenn man diese aktiviert. Die Software überzeugt indes durch ihre Benutzerfreundlichkeit, bietet aber neben den erwarteten Standardfunktionen wenig Aufregendes.
Grundsätzlich macht man mit einem Kauf der Steelseries Aerox 3 Wireless wenig falsch. Vor allem, wenn man nicht die neuesten Funktionen benötigt und mit dem vergleichsweise schwächelnden Akku kein Problem hat. Optisch ist sie definitiv ein Hingucker und auch sonst überzeugt die Maus beim Arbeiten und Zocken. Zur UVP ist sie allerdings etwas zu teuer – hier empfehlen wir, auf einen Sale zu warten.
ZUSÄTZLICH GETESTET
MSI Versa 300 Elite Wireless
MSI Versa 300 Elite Wireless
Die MSI Versa 300 Elite Wireless kommt mit drei Verbindungsmodi, einem ausdauernden Akku und schicker RGB-Beleuchtung.
- robustes Design mit guter Verarbeitung
- super Akkuleistung
- preiswert
- Software hängt sich öfter auf
MSI Versa 300 Elite Wireless im Test: Kabellose Gaming-Maus mit starkem Akku
Die MSI Versa 300 Elite Wireless kommt mit drei Verbindungsmodi, einem ausdauernden Akku und schicker RGB-Beleuchtung.
Mit gerade mal 65 g Eigengewicht geht die MSI Versa 300 Elite Wireless als vergleichsweise leichte Gaming-Maus mit guter Ausstattung und ansprechender RGB-Beleuchtung in den Ring. Wir haben uns die MSI Versa 300 Elite Wireless im Test genauer angeschaut und klären, ob sie die aktuell etwa 50 Euro wert ist.
Lieferumfang
Der Lieferumfang der MSI Versa 300 Elite Wireless ist überschaubar. Die leichte Gaming-Maus kommt mit einem über 2 m langen USB-A-zu-USB-C-Verbindungskabel und dem 2,4-GHz-Funkreceiver.
Design
Die MSI Versa 300 Elite Wireless hat den klassischen symmetrischen Mauskörper und die Maße 64 x 41 x 125 mm bei etwa 65 g. Aufgrund der zwei Buttons auf der linken Seite der Maus ist sie trotz der Symmetrie eher für Rechtshänder geeignet. Farblich hat man die Wahl zwischen einer schwarzen und weißen Variante. Für eine bessere Griffigkeit sind beide Seiten der Maus texturiert. Löblich: Der DPI-Switch befindet sich oben auf der Versa, anstatt wie so oft auf der Unterseite. So kann man ihn auch während des Spielgeschehens verwenden und bei Bedarf mit einer anderen Funktion belegen.
Das Mausrad hat, wie die Seiten der Peripherie, ebenfalls eine diamantförmige Texturierung erhalten und erinnert vom Look her etwas an ein Nietenarmband. Auf der Unterseite der Maus befinden sich ein Aufbewahrungsfach für den Funkreceiver und der Verbindungsmodusschalter. Mit letzterem wechselt man zwischen kabelgebunden, Funk und Bluetooth (5.3). Selbstverständlich hat die Versa 300 Elite Wireless auch Maus-Skates auf der Unterseite, um besser über das Mauspad gleiten zu können. Der USB-C-Port ist vorne an der Maus und ermöglicht so gleichzeitiges Laden und Zocken.
Einrichtung & Software
Die Einrichtung klappt problemlos: Sowohl der Funkreceiver als auch die Maus, angeschlossen per mitgeliefertem Verbindungskabel, erkennt der PC (Windows 11) umgehend. Eine offizielle Mac-Unterstützung gibt es nicht, auch die Software MSI Center steht nur auf Windows-PCs zur Verfügung.
Mit ihr aktualisiert man die Firmware der Maus und greift auf diverse Einstellungsmöglichkeiten zu. Das Problem: Die Software hängt sich in unserem Fall regelmäßig auf oder braucht teilweise lange, bis sie reagiert. Das passiert nicht so häufig, dass sie dadurch unbrauchbar ist, frustriert aber dennoch. Anstatt einen Hub für alle MSI-Produkte zu haben, wäre eine dedizierte Software nur für die Mäuse potenziell besser gewesen. Einstellungen zur DPI, der Tastenbelegungen, Abtastrate und mehr sind alle beisammen, die Beleuchtungsoptionen fehlen allerdings. Für letztere muss man das Softwarepaket Mystic Light innerhalb des MSI Centers installieren. Sowohl die Seiten als auch das Logo auf dem Mausrücken lassen sich farblich anpassen und mit sieben unterschiedlichen Effekten bestücken. Geschwindigkeit und Helligkeit der Beleuchtung sind ebenfalls individualisierbar.
MSI Versa 300 Elite Wireless – Bilder App
MSI Versa 300 Elite Wireless – Bilder App
MSI Versa 300 Elite Wireless – Bilder App
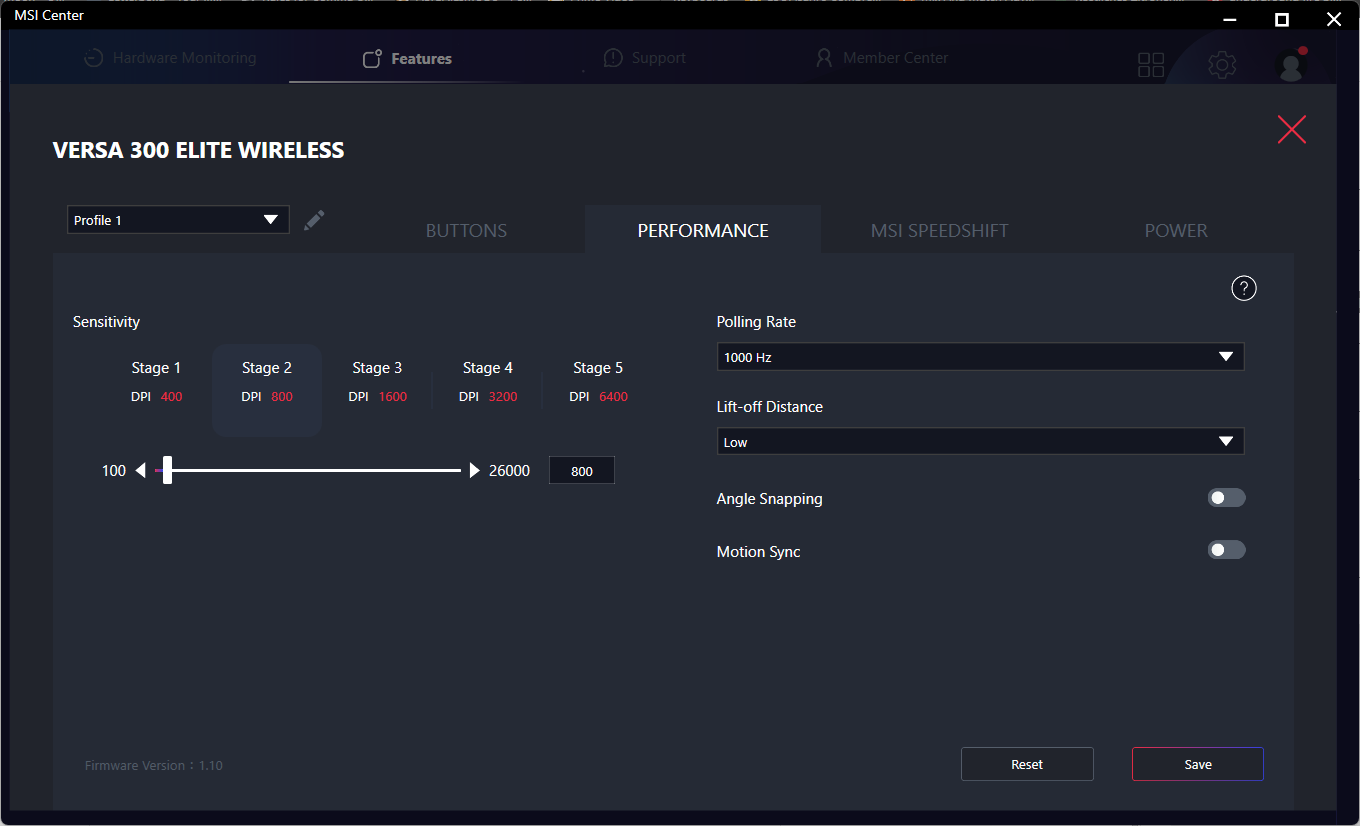
MSI Versa 300 Elite Wireless – Bilder App
MSI Versa 300 Elite Wireless – Bilder App
MSI Versa 300 Elite Wireless – Bilder App
Fünf anpassbare DPI-Profile stehen zur Auswahl. Der DPI-Bereich der Versa 300 Elite Wireless liegt zwischen 100 und 26.000 DPI, justierbar in Hunderter-Schritten. Für die Tastenbelegung steht auch ein etwas versteckter Makro-Editor parat. Mit ihm kann man Makros live aufzeichnen und/oder importieren und exportieren. Abtastrate (maximal 1000 Hz) und Lift-Off-Distance kann man ebenfalls konfigurieren.
Mit MSI Speedshift soll man regulieren können, wie präzise die Maus arbeitet. Das Ganze ist auch schön grafisch per Tachometer aufbereitet, das dazugehörige Tooltip liest sich aber mehr wie ein Marketingtext und gibt wenig Aufschluss auf die tatsächlichen Unterschiede zwischen den drei Stufen. Es ist auch nicht klar, ob eine niedrigere Einstellung etwa den Akku schont oder Ähnliches.
Bedienbarkeit
Die MSI Versa 300 Elite Wireless liegt angenehm in der Hand, die texturierten Seiten geben Halt beim Bewegen der Peripherie. Das Gewicht ist optimal verteilt, was man vor allem beim Anheben der Maus merkt. Auch nach mehreren Stunden liegt sie gut in der Hand und erzeugt bei uns keine Ermüdungserscheinungen. Die verwendeten Omron-Switches haben einen guten Betätigungspunkt und fühlen sich präzise an. Ungewollte Doppelklicks stellen wir nicht fest. Beim Zocken reagiert die Maus sehr zufriedenstellend, ohne merkbare Verzögerung. Dem Mausrad fehlt es für uns etwas an haptischem Feedback beim Scrollen, die ziemlich herausstehende Texturierung gefällt jedoch.
Der Akku ist erstaunlich ausdauernd. Mit einer Ladung kommen wir problemlos vier bis fünf Tage aus. Wir verwenden die Maus dabei mit aktiver Beleuchtung bei etwa 50 Prozent Helligkeit, 1000-Hz-Abtastrate und exklusiv mit 2,4-GHz-Funk. Wie immer holt man mehr aus dem Akku raus, wenn man die Beleuchtung reduziert oder komplett ausschaltet.
Preis
Die UVP der MSI Versa 300 Elite Wireless liegt bei 65 Euro. Aktuell kostet sie in Schwarz knapp 50 Euro. In Weiß gibt es sie derzeit nur für über 100 Euro zu kaufen.
Fazit
Für etwa 50 Euro liefert die MSI Versa 300 Elite Wireless eine grundsolide Performance ab. Neben einem robusten und hervorragend ausbalancierten Gehäuse besticht die 65-g-Maus mit präzisen Klicks, einem griffigen Design und einem ausdauernden Akku. Die Software hat sich während des Testzeitraums bei uns aber regelmäßig aufgehängt oder mit längeren Verzögerungen gearbeitet, was auf Dauer ziemlich nervt. Wer damit leben kann, bekommt mit der Versa 300 Elite Wireless eine verhältnismäßig preiswerte und ansonsten zuverlässige Maus.
Akko Dash Ultra
Akko Dash Ultra
Mit 43 g ist die kompakte Akko Dash Ultra kaum in der Hand zu spüren. Beim Spielen überzeugt sie mit 8000-Hz-Abtastrate und präzisen Klicks dafür umso mehr.
- mit 43 g sehr leicht
- gute Bedienbarkeit
- ausdauernder Akku
- drei Sets an Skate-Dots, um das Gleitverhalten anzupassen
- Erweiterungsadapter des Funk-Receivers kam mit Wackelkontakt
- Software benötigt dringend ein Update
- DPI über die Maus zu wechseln ist zu umständlich
Akko Dash Ultra im Test: 43 g leichte kabellose Gaming-Maus für kleine Hände
Mit 43 g ist die kompakte Akko Dash Ultra kaum in der Hand zu spüren. Beim Spielen überzeugt sie mit 8000-Hz-Abtastrate und präzisen Klicks dafür umso mehr.
Die Akko Dash Ultra ist nicht nur ziemlich leicht, sondern dank ihres Formfaktors besonders für kleine bis mittelgroße Hände geeignet. Als symmetrische Top-Gaming-Maus für Rechtshänder bietet sie ein schlichtes, vertrautes Design und ist zudem bestens ausgestattet, um präzise und schnell zu reagieren.
Optische Switches und ein Sensor, der eine bis zu 8000 Hz hohe Abtastrate ermöglicht, machen sie auch für kompetitive Spieler interessant. Wie sich die Gaming-Maus tatsächlich im Einsatz schlägt, zeigen wir im Test. Das Testgerät hat uns der Hersteller zur Verfügung gestellt.
Lieferumfang
Zusätzlich zur Maus gibt es ein USB-A-zu-USB-C-Verbindungskabel, einen 2,4-GHz-Funk-Receiver inklusive Extension-Adapter. Außerdem liegen noch mehrere Grip-Tapes bei sowie ein paar zusätzliche Maus-Skates. Außergewöhnlich ist hier, dass Akko noch drei Sets à 20 Skate-Dots mitliefert. Jedes Set (Weiß, Grau und Rot) hat eine andere Beschaffenheit und somit unterschiedliche Reibungsstärken. Wer möchte, kann sich so das Maushandling anpassen, indem er die Punkte auf die Maus-Skates klebt. Für die Einrichtung der Peripherie liegt noch eine Betriebsanleitung bei.
Design
Die Dash Ultra gibt es in Schwarz oder Weiß. Unser Testmodell kommt in Schwarz und bringt etwa 43 g auf die Waage. Die Bauform der Maus ist formal symmetrisch, allerdings ist sie nur für Rechtshänder geeignet, da die zwei seitlichen Buttons auf der linken Seite der Dash Ultra platziert sind. Sie misst 117,6 × 60,9 × 37,1 mm und wird von Akko für Hände mit einer Länge von maximal 17,5 cm empfohlen.
Akko Dash Ultra – Bilder
Akko Dash Ultra – Bilder

Akko Dash Ultra – Bilder

Akko Dash Ultra – Bilder

Akko Dash Ultra – Bilder

Akko Dash Ultra – Bilder

Akko Dash Ultra – Bilder

Akko Dash Ultra – Bilder

Die Oberfläche hat ein mattes Finish, mit Ausnahme des spiegelnden Kunststoffelements. Dieses flankiert das Mausrad. Über dem Mausrad ruht eine LED, die für Statusmeldungen der Maus zuständig ist. Die Unterseite der Peripherie ist teilweise offen und erlaubt einen Blick auf die Platine des Nagers. Zusätzlich zum Verbindungsmodusschalter befindet sich hier noch der Bluetooth-Pairing-Button. Der USB-C-Port der Maus befindet sich vorn an der Schnauze, wodurch man sie problemlos während des Aufladens weiterverwenden kann.
Das Design ist schlicht, die Verarbeitung einwandfrei. Die Dash Ultra ist ausgesprochen leicht, fühlt sich aber nicht billig an, da alles fest sitzt und die Maus sauber verarbeitet ist.
Einrichtung & Software
Die Erstinbetriebnahme klappt problemlos, die Maus und der Funk-Receiver werden von unserem Windows-11-PC nach der Einrichtung sofort erkannt. Die Verbindung zwischen Maus und Funk-Receiver gelingt ebenso reibungslos.
Der Verlängerungsadapter für den Funk-Receiver hat allerdings ein Problem. In unserem Fall lag ein Wackelkontakt vor. Ist der Dongle mit dem Adapter verbunden, reichen bereits kleinste Bewegungen des Kabels, um die Verbindung zu unterbrechen. Direkt am USB-Port des PCs angeschlossen, funktioniert der Receiver jedoch einwandfrei. Ob das ein genereller Konstruktionsfehler ist oder wir nur ein Montagsmodell erwischt haben, ist unklar.
Mit dem Akko Gaming Hub konfiguriert man die Peripherie und aktualisiert deren Firmware. Die App bietet Möglichkeiten, die Tasten der Maus mit anderen Funktionen zu belegen, die Leistung der Dash Ultra zu konfigurieren und hat einen Makro-Editor an Bord. Dass die Software noch das ein oder andere Update vertragen könnte, kristallisiert sich für uns schnell heraus: Beim Versuch, die Funktion „DPI verringern“ auf eine der beiden seitlichen Tasten zu legen, stürzt beim anschließenden Drücken der Taste jedes Mal die Maus ab. Das ist aber tatsächlich die einzige Funktion, bei der das passiert.
Akko Dash Ultra – Bilder App
Akko Dash Ultra – Bilder
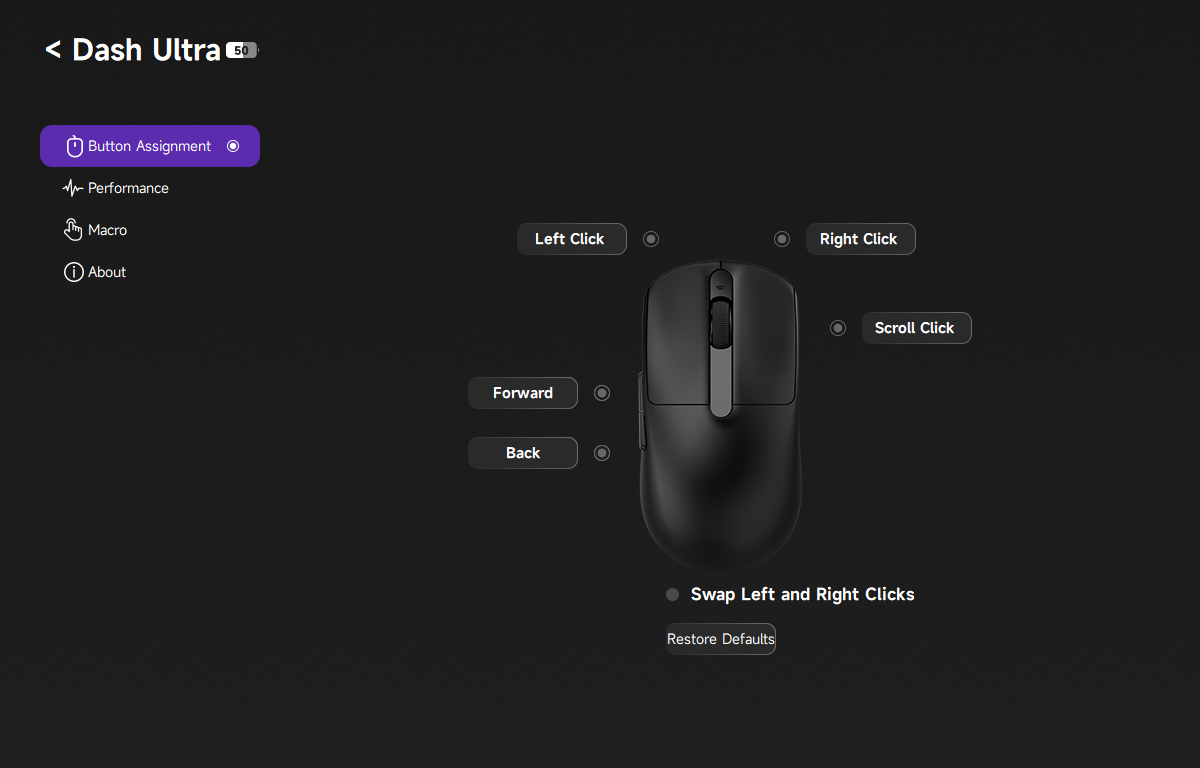
Akko Dash Ultra – Bilder
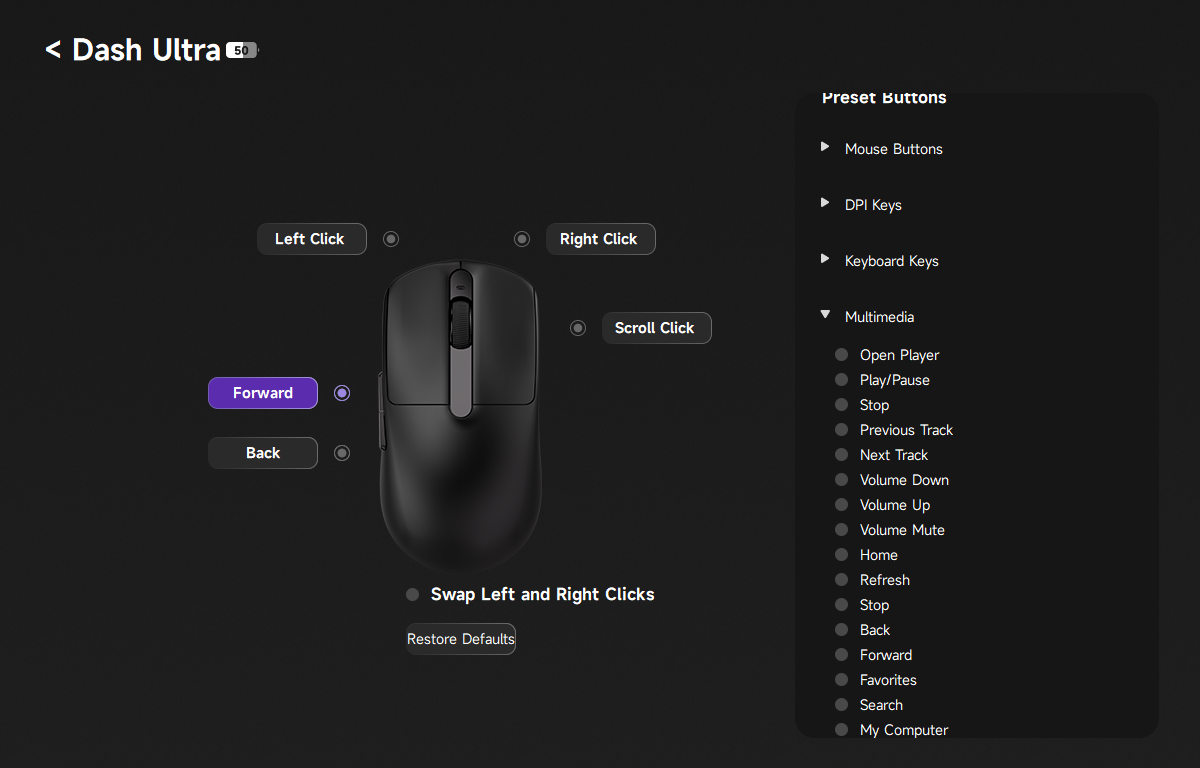
Akko Dash Ultra – Bilder
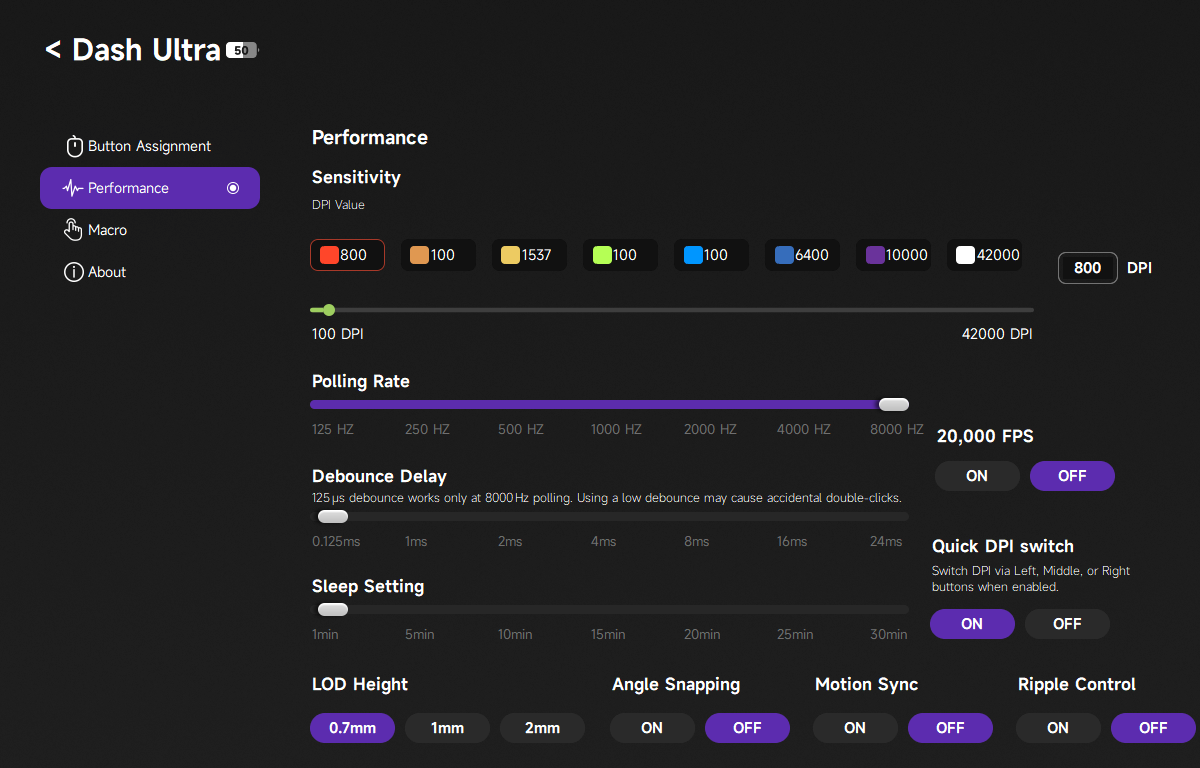
Akko Dash Ultra – Bilder
Akko Dash Ultra – Bilder
Insgesamt acht verschiedene DPI-Profile gibt es, deren Werte man wahlweise sogar in Einer-Schritten verändern kann. 100 DPI sind hierbei der niedrigste und 42.000 DPI der höchste Wert – was sehr hoch ist. Da ein physischer DPI-Schalter an der Maus fehlt, kann man den Quick-DPI-Switch per Software hinzuschalten. Durch gleichzeitiges Drücken der linken, rechten und mittleren Maustaste für drei Sekunden wechselt das DPI-Profil dann in ein höheres. Das Ganze ist äußerst umständlich, auf Dauer wechselt man das am besten manuell über die Software.
Bis auf 8000 Hz lässt sich die Abtastrate der Dash Ultra hochschrauben und mit den üblichen Abständen auf bis zu 125 Hz heruntersetzen. Den Debounce Delay kann man bei 8000 Hz sogar auf 0,125 ms heruntersetzen und generell auf bis zu 24 ms erhöhen. Die Verzögerung soll vor allem verhindern, dass ungewollte Doppelklicks entstehen. Je niedriger die Verzögerung eingestellt ist, desto schneller werden Klicks hintereinander registriert.
Standard-Features wie Motion Sync, Ripple Control und Angle Snapping stehen ebenfalls zur Verfügung. Für die Lift-Off-Distance wählt man zwischen 0,7 mm, 1 mm und 2 mm. Die Funktion ist vor allem für diejenigen interessant, die ihre Maus regelmäßig zum Bewegen hochheben, anstatt sie durchgehend über das Mauspad zu fahren.
Bedienbarkeit
Mit etwa 20 cm Länge befindet sich unsere Hand jenseits der empfohlenen Maximalgröße von 17,5 cm. Im Alltag kommen wir mit der Maus im Fingerspitzengriff trotzdem problemlos zurecht. Um sie bequem mit dem Handflächengriff zu nutzen, ist sie aber definitiv zu klein für uns.
Die Klicks fühlen sich sehr weich an, was nicht zuletzt den Omron-Optical-Switches zu verdanken ist, die in der Dash Ultra verbaut sind. In Kombination mit dem Pixart-PAW3950-Sensor der Maus liefern sie beim Zocken präzise und schnelle Aktivierungen. Persönlich bevorzugen wir Klicks, die etwas mehr Betätigungskraft benötigen, das ist aber immer Geschmackssache. Fest steht, dass sich die Dash Ultra hier mit ihren 8000 Hz sowohl kabellos als auch kabelgebunden im Einsatz für uns bewährt hat.
Auch ohne das optionale Grip-Tape liegt sie sicher in der Hand und dank des geringen Gewichts treten selbst nach mehreren Stunden des Overwatch-Competitive-Grinds keinerlei Ermüdungserscheinungen auf. Der 300-mAh-Akku spielt hier ebenfalls mit: Er liefert der Maus genügend Strom, um mehrere Tage mit ihr zocken zu können. In unserem Testzeitraum verwenden wir die Dash Ultra sowohl tagsüber für die Arbeit (4000 Hz) als auch am Abend zum Spielen (8000 Hz) und kommen so im Schnitt auf etwas weniger als drei Tage, bevor wir sie bei 20 Prozent ans Ladekabel hängen.
Wer hier für die Arbeit auf die deutlich sinnvolleren stromsparenden 1000 Hz geht oder die Dash Ultra generell nur daheim zum Zocken verwendet, holt noch mehr Laufzeit pro Ladung heraus.
Preis
Die Akko Dash Ultra mit Omron-Optical-Switches kostet derzeit sowohl in Weiß als auch in Schwarz etwa 71 Euro. Wer sich hingegen für die hauseigenen Akko-Custom-Optical-Switches entscheidet, bekommt die Maus bereits für 64 Euro.
Fazit
Mit der Akko Dash Ultra bekommt man eine kompetente Gaming-Maus, die auf dem Mauspad mit präzisen Klicks, einem leichten Gewicht und ausdauerndem Akku überzeugen kann. Aufgrund ihrer Größe ist die symmetrische Maus am ehesten für kleine bis mittelgroße Hände geeignet. Beim Spielen macht sie eine gute Figur und überzeugt mit Präzision und Reaktionsschnelligkeit.
Getrübt wird das Ganze leider durch den Erweiterungsadapter mit Wackelkontakt. Hier wünschen wir uns definitiv eine bessere Qualitätskontrolle. Ist der Funkdongle direkt am USB-Port des PCs angeschlossen, funktioniert die Maus jedoch einwandfrei. Ein Update der Software ist ebenfalls nötig, da wir es während unseres Tests geschafft haben, durch eine Veränderung der Tastenbelegung (DPI-verringern-Funktion) die Maus zum Abstürzen zu bringen.
Die Akko Dash Ultra liefert eine gute Performance, zeigt bei der Qualitätskontrolle und der Software aber noch Verbesserungspotenzial. Insgesamt bietet sie dennoch ein stimmiges Gesamtpaket für preisbewusste Spieler.
Cherry Xtrfy M8 Wireless
Cherry Xtrfy M8 Wireless
Die Cherry Xtrfy M8 Wireless ist eine absolut minimalistische Gaming-Maus und verzichtet auf alles, was die Performance nicht verbessert.
- geringes Gewicht von 55 g
- flache, komfortable Form
- gute Akkulaufzeit
- keine Software für Einstellungsanpassung
- maximal 1000 Hz Abtastrate
Cherry Xtrfy M8 Wireless im Test: Gaming-Maus für Sparfüchse kostet 30 Euro
Die Cherry Xtrfy M8 Wireless ist eine absolut minimalistische Gaming-Maus und verzichtet auf alles, was die Performance nicht verbessert.
Die Cherry Xtrfy M8 Wireless ist von Grund auf fürs Gaming entwickelt, verzichtet aber auf Features wie eine RGB-Beleuchtung. Stattdessen hat die Maus ein extra flaches Design, wiegt nur 55 g und ist zudem auch noch preiswert. Das kompakte und leichte Design soll Ermüdungserscheinungen verhindern – das haben wir getestet.
Lieferumfang
Die M8 Wireless kommt in einer kompakten und ansehnlichen Box. Neben der Maus gibt es den Funk-Receiver, ein super flexibles USB-A-auf-USB-C-Kabel, sowie einen Adapter von USB-A-in auf USB-C-in, um den Receiver dank des Kabels näher an die Maus zu bringen. Zudem gibt es ein weiteres Set der Gleitfüße aus PTFE, einen Xtrfy-Sticker und einen Quick-Start-Guide – auf den unnötigen Papierkram verzichtet man hier.
Einrichtung
Für die Einrichtung der M8 Wireless gibt es keine App. Stattdessen sind alle Einstellungen über die Knöpfe auf der Unterseite zu erreichen und zudem im Quick-Start-Guide ausführlich beschrieben. Fürs Erste können wir die Maus direkt per Kabel oder über Receiver mit dem PC verbinden und den Schieber auf der Unterseite aus der „Off“-Position bewegen. Anschließend blinkt die seitliche LED in einer Farbe, worüber sich der aktuelle Akkustand abliest.
Design
Optisch setzt die Maus im „Retro“-Design auf verschiedene Grautöne. Zusätzlich sind die Seitentasten und die Ränder des Mausrads in Orange gehalten. Die Optik erinnert ein wenig an das typische Noctua-Farbschema. Alternativ gibt es die Peripherie noch in Hellblau mit rosa Akzenten („Frosty Mint“), Lila mit rosa und hellblauen Akzenten („Frosty Purple“) sowie in Schwarz und Weiß, jeweils auch mit hellblauen Akzenten. Das Gehäuse ist vollständig aus Kunststoff gefertigt und hochwertig verarbeitet. Wir können nach über zwei Jahren Einsatz keinerlei optische Alterung erkennen. Aufgrund ihrer symmetrischen Form eignet sie sich theoretisch auch für Linkshänder – die beiden Seitentasten auf der linken Seite sind dann aber nicht mehr komfortabel nutzbar. Der Ladeanschluss befindet sich im Vergleich zu den meisten kabellosen Mäusen nicht vorne, sondern seitlich rechts am hinteren Teil der Maus. Er ist weit in das Gehäuse eingelassen und mit einer Abdeckung aus Gummi geschützt. Diese lässt sich meist nur mit Hilfswerkzeug, wie etwa einem SIM-Tool oder spitzem Stift, entfernen. Wir können zum Laden auch kein alternatives Kabel finden, das in die Aussparung passt. Die Abdeckung ist bei uns, wie zu erwarten bei einem losen Kleinteil, vor Kurzem im Umzug endgültig verloren gegangen. Es wird mehrfach darauf hingewiesen, dass die Maus nur direkt an einem Computer geladen werden darf und nicht an einem USB-Netzteil. Womöglich hat Cherry hier an einer Sicherheitsschaltung gespart, um das Gewicht weiter zu reduzieren. Wir haben darauf verzichtet, das Leben unserer Maus aufs Spiel zu setzen.
Cherry Xtrfy M8 Wireless – Bilder
Cherry Xtrfy M8 Wireless – Bilder

Cherry Xtrfy M8 Wireless – Bilder

Cherry Xtrfy M8 Wireless – Bilder

Cherry Xtrfy M8 Wireless – Bilder

Cherry Xtrfy M8 Wireless – Bilder

Cherry Xtrfy M8 Wireless – Bilder

Cherry Xtrfy M8 Wireless – Bilder

Cherry Xtrfy M8 Wireless – Bilder

Cherry Xtrfy M8 Wireless – Bilder

Cherry Xtrfy M8 Wireless – Bilder

Cherry Xtrfy M8 Wireless – Bilder

Cherry Xtrfy M8 Wireless – Bilder

Cherry Xtrfy M8 Wireless – Bilder

Cherry Xtrfy M8 Wireless – Bilder

Cherry Xtrfy M8 Wireless – Bilder

Cherry Xtrfy M8 Wireless – Bilder

Cherry Xtrfy M8 Wireless – Bilder

Cherry Xtrfy M8 Wireless – Bilder

Cherry Xtrfy M8 Wireless – Bilder

Cherry Xtrfy M8 Wireless – Bilder

Cherry Xtrfy M8 Wireless – Bilder

Cherry Xtrfy M8 Wireless – Bilder

Cherry Xtrfy M8 Wireless – Bilder

Cherry Xtrfy M8 Wireless – Bilder

Cherry Xtrfy M8 Wireless – Bilder

Mit dem flachen Design und kompakten Abmessungen eignet sich die Maus vor allem für Spieler mit Claw- oder Fingertip-Grip. Wir können mit der M8 auch trotz größerer Hände problemlos im Palm-Grip spielen und arbeiten. Das liegt vor allem an den weit nach unten reichenden Haupttasten. Die Maus misst 118 × 60,5 × 38,5 mm und bringt dabei nur 55 g auf die Waage. Damit erfüllt sie die Anforderungen an eine kompakte Gaming-Maus bestens.
Software
Wie bereits erwähnt, gibt es keine Software, über die die Maus konfiguriert wird. Stattdessen schieben wir den Schalter auf der Unterseite in die Stellung zur entsprechenden Einstellung. Diese sind „CPI“, für die DPI, „PR“ für Polling Rate (Abtastungsrate) und „DT“ für die Debounce Time (Entprellungszeit der Tasten). Die verfügbaren Werte können mit dem Taster auf der Unterseite durchgeschaltet werden, die LED gibt hier entsprechend ein farbliches Feedback. Die Lift-Off-Distanz und Motion-Sync lassen sich über verschiedene Kombinationen der Seiten-, Haupt- und Mausradtasten durchschalten. Diese müssen jeweils für mindestens drei Sekunden gehalten werden, womit ein ungewolltes Verstellen nicht passieren sollte. Wir hatten hiermit in über zwei Jahren Nutzung nie Probleme. So gibt es auch ohne Software alle wichtigen Einstellungen, aber eben auch nicht mehr. Man muss sich hier mit festen Schritten der DPI zwischen 400 und 26.000 und 125, 500 oder 1000 Hz Abtastrate zufrieden geben. Letzteres ist für den ein oder anderen Enthusiasten eventuell schon etwas zu gering. Gerade höherpreisige Modelle wie etwa die Logitech G Pro X Superlight 2 funken mit bis zu 8000 Hz. Zum Thema Firmware-Updates: Diese können direkt von der Cherry-Website heruntergeladen werden, das letzte ist allerdings aus 2022. Wir haben jedoch keinerlei Bugs oder Auffälligkeiten erlebt, die demnach ein Update erfordern würden.
Bedienbarkeit
Die Cherry Xtrfy M8 Wireless liegt super in der Hand und und durch das niedrige Gewicht können wir problemlos mehrere Stunden ohne Ermüdung im Handgelenk zocken. Die Haupttasten haben einen deutlichen Druckpunkt und fühlen sich ebenfalls hochwertig an. Auch nach über 2 Jahren Einsatz können wir hier keine Verschlechterung feststellen. Das Scrollrad hat im Vergleich zu anderen Mäusen viel Widerstand. Vor allem der Mittelklick im Mausrad ist eher schwergängig, wird dadurch aber auch nie versehentlich, etwa beim Bunnyhopping, betätigt. Wir haben dazu in Valorant das Springen auf das Mausrad gelegt und hatten davon einen sehr positiven Eindruck. Durch eine neue Maus schleicht sich gerne der Placebo-Effekt ein, dass man auf einmal viel besser spielt und viel mehr Schüsse trifft. Das Gefühl hatten wir hier auch, langfristig gesehen ist unser Spielniveau allerdings nahezu gleich geblieben. Am Ende liegt es eben immer noch primär am Spieler und nicht an der Hardware. Für uns liegt die hintere Seitentaste für unsere großen Hände eher suboptimal. Wir haben daher meist nur die vordere Seitentaste, etwa zum Zoomen des Zielfernrohrs, genutzt. Die Tasten können dabei einfach im jeweiligen Spiel in den Optionen gemappt werden, allgemeine Funktionen wie Copy oder Paste sind wegen der fehlenden Software nicht möglich.
Der Akku macht auch eine gute Figur. Wir mussten die Maus bei gelegentlichen Gaming-Sessions und viel alltäglicher Nutzung nur alle paar Wochen laden – die versprochenen 75 Stunden sind mit 1000 Hz Abtastrate allerdings nicht drin. Falls der Akku während einer Session aufgibt, kann man die Maus auch mit angestecktem Ladekabel ohne große Einschränkungen nutzen. Das USB-Kabel ist leicht, flexibel und ziemlich lang. Auch wenn der Ladeport eher ungewöhnlich platziert ist, fällt das Kabel beim Gaming kaum auf. Cherry bewirbt eine Ladezeit von zwei Stunden auf 100 Prozent, was wir in der Praxis bestätigen können.
Preis
Die Cherry Xtrfy M8 Wireless gibt es aktuell am günstigsten für 28 Euro in der Farbe Frosty Mint. In Weiß ist sie mit knapp 32 Euro etwas teurer. Die UVP liegt bei 70 Euro.
Fazit
Die Cherry Xtrfy M8 Wireless ist eine waschechte Gaming-Maus, die auf alles Unnötige verzichtet. Trotzdem vermissen wir in unserem Test keinerlei Funktionen oder Einstellungen. Als größtes Manko sehen wir die Abtastrate von nur 1000 Hz. Hier liefert die Konkurrenz oft schon 8000 Hz. Das sorgt insgesamt für ein noch reaktionsschnelleres Erlebnis, kostet dann aber auch deutlich mehr Geld. Nichtsdestotrotz kann uns die M8 Wireless überzeugen und ist auch nach über zwei Jahren Nutzung ein treuer Begleiter beim Gaming und im Alltag. Für derzeit 28 Euro ist sie eine gute Lösung für budgetorientierte Gamer, die auf das ein oder andere Extra verzichten können.
Razer Deathadder V3 Hyperspeed
Razer Deathadder V3 Hyperspeed
Die Razer Deathadder V3 Hyperspeed schlängelt sich mit nur 55 g über den Schreibtisch. Ob sie außer mit ihrer Leichtigkeit auch sonst überzeugen kann, zeigt der Test.
- anpassbare Mausbeschleunigung
- DPI individuell anpassbar für X- und Y-Achse
- ergonomisch geformt
- glatte Oberfläche fühlt sich erstaunlich gut an
- Verbindungskabel sehr kurz
- 8000-Hz-Abtastrate nur durch separaten Dongle möglich
Razer Deathadder V3 Hyperspeed im Test
Die Razer Deathadder V3 Hyperspeed schlängelt sich mit nur 55 g über den Schreibtisch. Ob sie außer mit ihrer Leichtigkeit auch sonst überzeugen kann, zeigt der Test.
Als Leichtgewicht-Gaming-Maus wird die Razer Deathadder V3 Hyperspeed vor allem als E-Sports-Maus vermarktet. Sie passt mit ihrem schlichten Design aber auch hervorragend ins Büro oder das heimische Arbeitszimmer. Mit ihrer individuell anpassbaren Mausbeschleunigung, einer Abtastrate von 1000 Hz und DPI-Profilen, bei denen man horizontale und vertikale DPI getrennt voneinander bestimmen kann, bringt sie einiges an Potenzial mit. Im Test zeigen wir, ob das Gesamtpaket überzeugt.
Lieferumfang
Die Razer Deathadder V3 Hyperspeed kommt mit einem USB-A-auf-USB-C-Verbindungskabel, einem 2,4-GHz-Funk-Dongle und einem Wireless-Extender. Der Packung liegen außerdem eine Betriebsanleitung sowie ein paar Sticker bei. Lobenswert: Die Verpackung besteht zum Großteil aus Pappe.
Einrichtung
Die Funktionen der Razer Deathadder V3 Hyperspeed richtet man mit der Software Razer Synapse ein, welche es kostenlos zum Download auf der Razer-Website gibt. Sie funktioniert theoretisch auch ohne diese, man verzichtet dann aber auf die Möglichkeit, die DPI-Settings der Maus feiner zu justieren und die Tasten neu zu belegen.
Design
Die Deathadder V3 Hyperspeed ist für Rechtshänder geformt, kommt ganz in Schwarz daher und ohne RGB-Beleuchtung. Mit offiziellen 55 g (53,5 g auf unserer Waage) ist sie wahrlich ein Fliegengewicht und ein großer Unterschied zur gut 60 g schwereren Logitech-Maus, die der Tester sonst im Alltag verwendet. Beworben wird sie mit einer „Smooth-Touch-Texture“, was im Endeffekt bedeutet, dass sie eine glatte Oberfläche ohne Texturierung hat. Auch Grip-Tapes an den Seiten fehlen, die sonst besseren Halt geben würden. Trotz alledem fühlt sie sich erstaunlich gut an und gibt wider Erwarten genügend Halt.
Razer Deathadder V3 Hyperspeed – Bilder
Razer Deathadder V3 Hyperspeed – Bilder

Razer Deathadder V3 Hyperspeed – Bilder

Razer Deathadder V3 Hyperspeed – Bilder

Razer Deathadder V3 Hyperspeed – Bilder

Razer Deathadder V3 Hyperspeed – Bilder

Razer Deathadder V3 Hyperspeed – Bilder

Razer Deathadder V3 Hyperspeed – Bilder

Razer Deathadder V3 Hyperspeed – Bilder

Razer Deathadder V3 Hyperspeed – Bilder

Razer Deathadder V3 Hyperspeed – Bilder

Razer Deathadder V3 Hyperspeed – Bilder

Razer Deathadder V3 Hyperspeed – Bilder

Razer Deathadder V3 Hyperspeed – Bilder

Neben den zwei Maustasten verfügt die Razer Deathadder V3 Hyperspeed über zwei seitlich angebrachte Buttons, ein Mausrad mit genoppter Oberfläche und einen DPI bzw. An-/Aus-Knopf auf der Unterseite. Warum man diesen nicht oben auf der Maus angebracht hat, ist uns ein Rätsel, da man so jedes Mal die Maus umdrehen muss, um zwischen den DPI-Profilen zu wechseln. Ebenfalls auf der Unterseite befindet sich eine Aussparung, in der der Funk-Dongle Platz findet, wenn er gerade nicht am PC steckt. Das Verbindungskabel steckt man vorn an die Maus über einen USB-C-Port.
Im Inneren der Maus befindet sich der optische Sensor Razer Focus X 26k, welcher bis zu 26.000 DPI unterstützt – keine Seltenheit unter Gaming-Mäusen. Für die Tasten verwendet man optische Maus-Switches.
Software
Razer Synapse ist die Schaltzentrale für sämtliche Funktionen der Deathadder V3 Hyperspeed. Darunter befinden sich DPI-Profile, anpassbare Tastenbelegung, Veränderung der Abtastrate und mehr.
Spannend sind die Optionen, die sich hinter dem Menüpunkt „Advanced“ verstecken. Hier stellt man wahlweise eine dynamische Beschleunigung ein, die man entweder mittels Presets wählt oder für die man direkt eine eigene Kurve erstellt. Das Preset „Jump“ ist etwa für jemanden interessant, der mit einer niedrigen DPI zockt. Durch eine schnelle Bewegung mit der Maus erhöhen sich kurzfristig die DPI und man ist so schneller in der Lage zu reagieren, wenn man etwa von hinten angeschossen wird. Aktiviert man das Feature, wird allerdings der Akku schneller leer.
Razer Deathadder V3 Hyperspeed – Bilder App
Razer Deathadder V3 Hyperspeed – Bilder App
Razer Deathadder V3 Hyperspeed – Bilder App
Razer Deathadder V3 Hyperspeed – Bilder App
Razer Deathadder V3 Hyperspeed – Bilder App
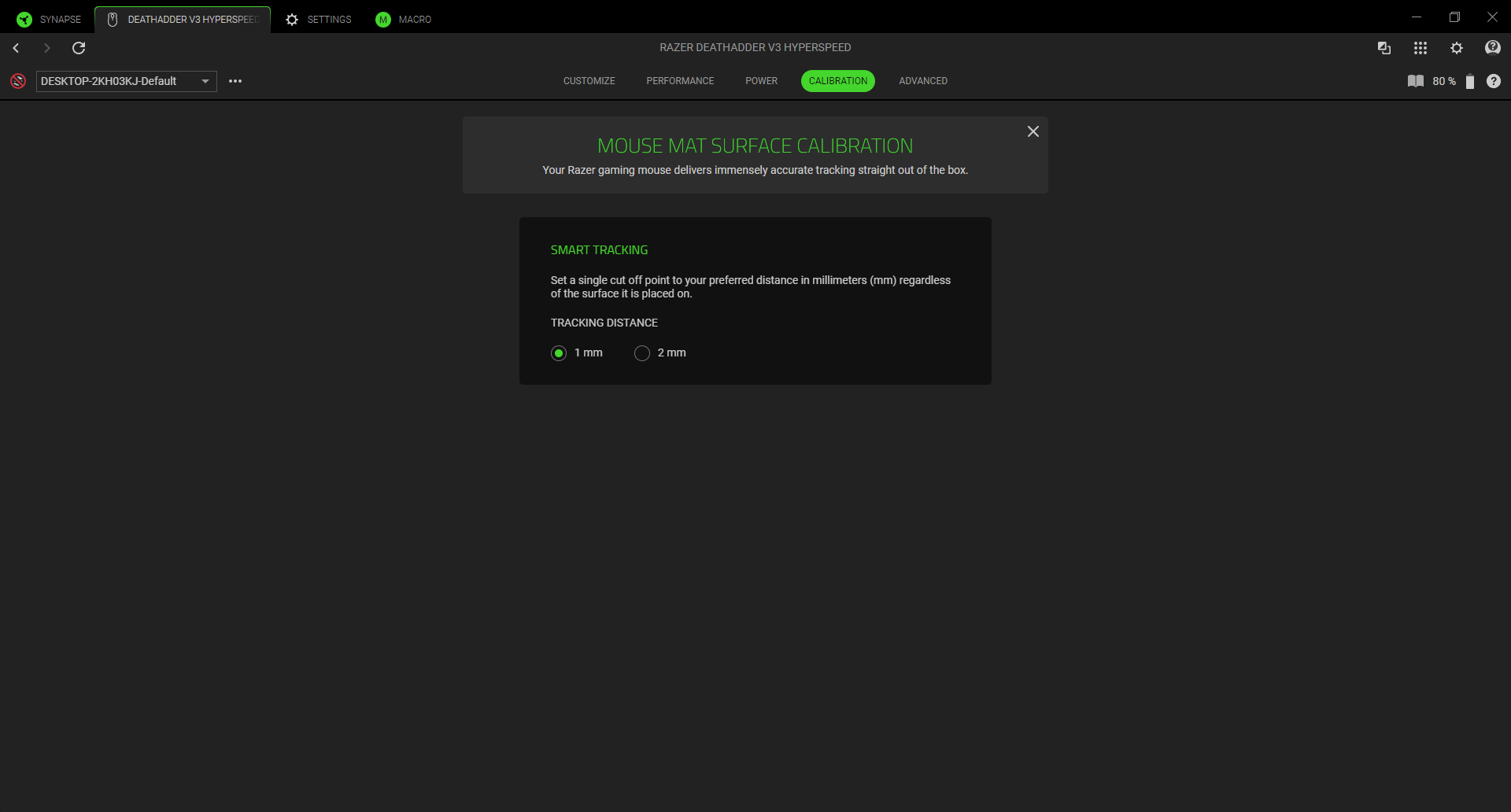
Razer Deathadder V3 Hyperspeed – Bilder App
Bei den DPI-Profilen überrascht die Option, unterschiedliche Werte für horizontale (X-Achse) und vertikale Bewegungen (Y-Achse) festzulegen. Insgesamt gibt es fünf verschiedene Profile, die nach eigenen Wünschen anpassbar sind und zwischen denen man wechseln kann.
Sinnvoll sind auch die Stromspar-Einstellungen der Razer Deathadder V3 Hyperspeed. Hier legt man fest, ab wann die Maus in den Schlafmodus geht, wenn sie nicht benutzt wird, und ab wie viel Prozent Akkuspeicher sie in den Low-Power-Modus wechselt. Dieser reduziert unter anderem die Sensorbeschleunigung der Maus, um Strom zu sparen.
Bedienbarkeit
Sowohl Arbeiten als auch Zocken lässt sich mit der Razer Deathadder V3 Hyperspeed hervorragend. Bewegt man seine Mäuse hauptsächlich mit dem Handgelenk, darf man sich umso mehr über das geringe Gewicht freuen, da dies – zumindest für unseren Tester – zu einer spürbaren Entlastung ebendieses beitrug. Der Unterschied wird einem vor allem dann bewusst, wenn man anschließend wieder zu einer schwereren Maus wechselt.
Sehr unpraktisch ist, dass das mitgelieferte Verbindungskabel äußerst kurz ist, wodurch es je nach Setup schwierig wird, die Maus mit angeschlossenem Kabel komfortabel zu bedienen. Mit einem Laptop ist das Ganze kein Problem. Hat man jedoch einen Desktop-PC, der womöglich auch noch auf dem Boden und nicht auf dem Tisch steht, dürfte das Kabel deutlich zu kurz sein, um die Maus daran angeschlossen weiterhin zu verwenden.
Mit einer Abtastrate von bis zu 1000 Hz bedient die Deathadder V3 Hyperspeed den Standard unter kabellosen Gaming-Mäusen. Über den separat erhältlichen Razer Hyperpolling Wireless Dongle für 35 Euro ist sie außerdem in der Lage, kabellos 8000 Hz zu unterstützen.
Preis
Die Razer Deathadder V3 Hyperspeed gibt es aktuell für 66 Euro.
Fazit
Die Razer Deathadder V3 Hyperspeed überzeugt mit ihren 55 g in vielerlei Hinsicht. Nützliche Features wie die variable Mausbeschleunigung unterstützen einen beim Gaming, während der Stromsparmodus dafür sorgt, dass man auch unterwegs so lange wie möglich etwas von der Maus hat. Weitere Funktionen wie die individuelle Belegung der einzelnen Tasten und die Möglichkeit, die DPI auf zwei Achsen unterschiedlich einzustellen, runden den Funktionsumfang der Deathadder V3 Hyperspeed ab. Dank ihres geringen Gewichts steuert sie sich zudem deutlich angenehmer mit dem Handgelenk, als es schwerere Mäuse tun.
Während sie sowohl kabellos als auch kabelgebunden einsetzbar ist, sorgt das mitgelieferte Verbindungskabel bei den meisten PC-Setups für Frust, da es viel zu kurz ist, um die Deathadder V3 Hyperspeed weiterhin zu nutzen. Schade ist auch, dass man nur über einen separat erhältlichen Dongle auf die 8000-Hz-Abtastrate zugreifen kann.
Als kompetente Gaming-Maus der Leichtgewichtsklasse besticht die Razer Deathadder V3 Hyperspeed allerdings da, wo es drauf ankommt – beim Zocken. Wer zuvor mit schwereren Mäusen gearbeitet hat, muss sich eventuell zuerst umgewöhnen, hat anschließend jedoch eine hervorragende Peripherie auf dem Schreibtisch, die nur wenige Wünsche offenlässt.

Gemeinsame Kollektion: BVG und Uniqlo machen Berliner Nahverkehr tragbar

Bild-KI in WhatsApp und Instagram ausprobiert: Das kann Muse Image

Neues Bundespolizeigesetz: Der Bundestag hat das Zeitalter der automatisierten Überwachung eingeläutet

„Don’t Starve Elsewhere“: Survival‑Hit kehrt nach zehn Jahren zurück

xTool P3 im Test: CO₂-Laser mit 80 Watt schneidet und graviert auch Acryl

Weitere Entlassungswelle bei Disney: Bis zu 1000 Mitarbeiter betroffen
-
 Künstliche Intelligenzvor 3 Monaten
Künstliche Intelligenzvor 3 Monaten„Don’t Starve Elsewhere“: Survival‑Hit kehrt nach zehn Jahren zurück
-
Künstliche Intelligenzvor 3 Monaten
xTool P3 im Test: CO₂-Laser mit 80 Watt schneidet und graviert auch Acryl
-
 Künstliche Intelligenzvor 3 Monaten
Künstliche Intelligenzvor 3 MonatenWeitere Entlassungswelle bei Disney: Bis zu 1000 Mitarbeiter betroffen
-

 Apps & Mobile Entwicklungvor 3 Monaten
Apps & Mobile Entwicklungvor 3 MonatenMega-GPUs für Nvidia, AMD & Co: TSMC zeigt CoWoS-Package mit >11.600 mm² & 24 × HBM5E
-

 Social Mediavor 2 Monaten
Social Mediavor 2 MonatenMetas neuer Creative Setup Workflow: Was sich wirklich ändert – und warum das nicht nur eine UI-Frage ist!
-

 UX/UI & Webdesignvor 4 Tagen
UX/UI & Webdesignvor 4 TagenRegional & mit Gefühl: Identity für Klimafonds Baden-Württemberg › PAGE online
-

 Künstliche Intelligenzvor 3 Monaten
Künstliche Intelligenzvor 3 MonatenApple‑Geräte mit Microsoft Intune verwalten – zweiteiliges Live-Webinar
-

 Entwicklung & Codevor 2 Monaten
Entwicklung & Codevor 2 MonatenKommentar: Das Ende der SaaS-Gelddruckmaschine
