Künstliche Intelligenz
Model-Schau 2: Neue Architekturansätze bei den Sprachmodellen
Das neue Jahr ist noch jung, aber die Sprachmodell-Community hat sich keine Pause gegönnt. So geht es munter mit neuen Modellen, aber auch mit neuen Architekturansätzen ins Jahr 2026, auch wenn einige der vorgestellten Neuerungen noch aus den letzten Wochen von 2025 stammen.
Weiterlesen nach der Anzeige


Prof. Dr. Christian Winkler beschäftigt sich speziell mit der automatisierten Analyse natürlichsprachiger Texte (NLP). Als Professor an der TH Nürnberg konzentriert er sich bei seiner Forschung auf die Optimierung der User Experience.
Gedächtnis-Titan von Google
Bisher kämpfen fast alle Sprachmodelle mit Amnesie. Sobald sie lange Texte verarbeiten sollen, vergessen sie entscheidende Details. Diese Tendenz verstärkt sich mit längerem Kontext. Besonders die Teile in der Mitte gehen dann verloren (lost in the middle). Es gibt zahlreiche Ansätze, Modelle in dieser Hinsicht zu verbessern. Einige Modelle setzen beispielsweise alternierend sogenannte Mamba-Layer (oder State Space Models) ein, die besonders bei langen Sequenzen besser skalieren und weniger Speicherplatz benötigen, dafür aber nicht so präzise arbeiten wie Transformer. Andere Modelle setzen auf rekurrente neuronale Netze (RNNs), die man nach der Erfindung der Transformer eigentlich schon fast abgeschrieben hatte.
(Bild: Golden Sikorka/Shutterstock)

Die Online-Konferenz LLMs im Unternehmen zeigt am 19. März, wie KI-Agenten Arbeitsprozesse übernehmen können, wie LLMs beim Extrahieren der Daten helfen und wie man Modelle effizient im eigenen Rechenzentrum betreibt.
Google hat nun zwei neue Forschungsartikel dazu veröffentlicht. Der erste nennt sich „Titans“ und führt eine Architektur ein, die nach ihren eigenen Worten „die Geschwindigkeit von RNNs mit der Genauigkeit von Transformern zusammenbringt“. Google erreicht das durch den Einsatz von Transformern und dem Attention-Mechanismus für das Kurzzeitgedächtnis, für das Langzeitgedächtnis verwendet der Ansatz tiefe neuronale Netze (und nicht etwa RNNs). Eine sogenannte Überraschungs-Metrik soll sich besonders auf die Textteile konzentrieren, die nicht erwartete Wörter enthalten. Mit einem adaptiven Verfallmechanismus vergisst das Modell dann die Informationen, die es nicht mehr benötigt.
Google stellt mit „MIRAS“ auch gleich einen Blueprint zur Implementierung vor. Das dahinterliegende KI-Modell fokussiert sich auf eine Memory-Architektur, den Attention-Bias (mit dem es wichtige von unwichtigen Informationen unterscheidet) und die Mechanismen zum Vergessen beziehungsweise zum Aktualisieren des Gedächtnisses. Statt des mittleren quadratischen Fehlers oder des Skalarprodukts optimiert Google nichteuklidische Metriken und nennt dafür drei Beispielmodelle, die auf dem Huber-Loss, generalisierten Normen oder einer Wahrscheinlichkeitsabbildung basieren.
Das klingt äußerst mathematisch, aber Google kann damit in ersten Demos bessere Ergebnisse als mit einer reinen Mamba-Architektur erzielen. Den am Schluss erklärten Extrem Long-Context Recall vergleicht der Artikel allerdings nur mit Modellen wie GPT-4 oder Qwen2.5-72B, die schon mindestens ein Jahr alt sind. Diese Ergebnisse sollte man also mit Vorsicht genießen. Spannend wird es, wenn Google damit richtig große Modelle trainiert und zur Verfügung stellt.
Weiterlesen nach der Anzeige
Liquid Foundation Models
Eine ganz andere Architektur setzen die Liquid Foundation Models ein. Lange waren die Liquid Models schon mit Demos präsent, in denen sie mit kleinen Modellen erstaunliche Fähigkeiten entwickeln konnten. Der Durchbruch kam dann mit LFM2. Teile der Modelle setzen die Transformer-Architektur mit Attention ein, andere nutzen Multiplikations-Gates und Konvolutionen mit kurzen Sequenzen. Allerdings war bisher die Performance der darauf aufbauenden Modelle noch nicht gut genug.
Geändert hat sich das mit LFM2.5, einer ganzen Serie von kleinen Modellen mit nur gut einer Milliarde Parametern. Vorerst sind die Modelle für Edge-Devices gedacht, sie lassen sich aber auch mit hoher Geschwindigkeit auf üblicher Hardware ausführen. Die in Abbildung 1 dargestellten Ergebnisse sind mit Vorsicht zu genießen, da sie vom Anbieter stammen. Unabhängig davon machen die Modelle für ihre Größe einen hervorragenden Eindruck. Für viele Anwendungen wie Retrieval-Augmented Generation (RAG) könnten diese gut zum Einsatz kommen, weil das Wissen dafür nicht in den Modellen selbst stecken muss, die hier nur zum Feinabgleich und für Formulierungen eingesetzt werden. Mit einer kleinen GPU lassen sich die Modelle extrem schnell ausführen. Auf einer performanten CPU arbeiten sie immer noch schnell.

Beim Erdbeertest kann LFM 2.5 ebenso wenig überzeugen (Abb. 1) …
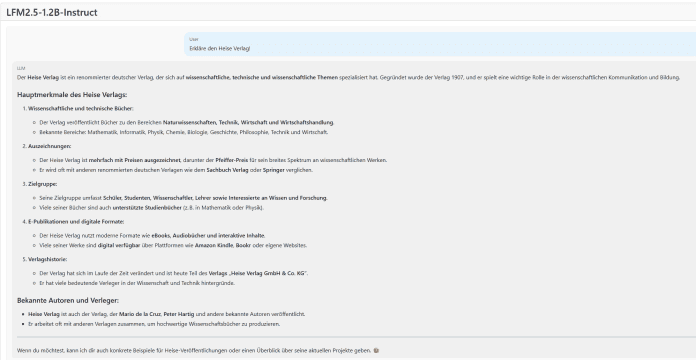
wie mit der Erklärung von heise (Abb. 2).
Neben den Modellen zur Textgenerierung gibt es auch ein hybrides Modell, das gesprochenen Text sowohl verstehen, als auch erzeugen kann. Gerade für mobile Endgeräte kann die Funktion sinnvoll sein, damit man auch ohne Internet- und Cloud-Zugriff Sprache in Text und umgekehrt umwandeln kann.

Performance von LFM2.5-1.2B-Instruct im Vergleich zu ähnlich großen Modellen (Abb.3)
(Bild: Hugging Face)
Schlanke Coding-Modelle erobern Benchmarks
Bei IQuest-Coder handelt es sich um ein neues Modell mit 40 Milliarden Parametern, das insbesondere in der Loop-Variante interessante Ideen mit einbringt. Der Transformer arbeitet rekurrent, verarbeitet also die Tokens mehrfach – zunächst doppelt in zwei Iterationen. IQuestLab verspricht damit deutlich höhere Performance. Seine Entwickler behaupten, in den einschlägigen Benchmarks wesentlich bessere Ergebnisse erzielen zu können als vergleichbar große Modelle. Trotz anfänglicher Euphorie scheint das Modell aber nicht besonders populär zu sein.
Einen anderen Weg geht NousResearch. Es nutzt Qwen-14B als Basismodell, um mit modernen Methoden daraus ein Coding-Modell zu erzeugen. Auch wenn es nicht mit den deutlich größeren Modellen konkurrieren kann, erzielt es für seine Größe gute Ergebnisse und zeigt einen möglichen weiteren Weg für Coding-Modelle auf.
Chinesische Modelle mit offenen Gewichten
Die seit Kurzem an der Börse in Hong Kong notierte Firma Z.ai hat mit GLM-4.7 ein lang erwartetes Modell veröffentlicht, das sich in vielen Benchmarks an die Spitze der Modelle mit offenen Gewichten gesetzt hat. Mit 355 Milliarden Parametern verfügt es zwar über eine stattliche Größe, ist aber immer noch viel kleiner als die Modelle von DeepSeek oder Kimi. Laut Benchmarks ist GLM 4.7 besonders gut bei Coding-Aufgaben und bei komplexen Denkaufgaben.
Im Vergleich zum Vorgänger GLM 4.6 ist es praktisch in allen Dimensionen besser, außerdem hat Z.ai die Kontextlänge auf 200.000 Token erhöht. Das führt zu einem sehr großen Modell mit 335 Milliarden Parametern. Das Modell verfügt dazu über 160 Experten, von denen immer acht (und ein geteilter) aktiv sind. Zusammen mit den ersten dichten Layern ergeben sich damit 32 Milliarden Parameter, die bei jedem Aufruf aktiv sind. Um den RAM-Bedarf der (quantisierten) Modelle etwas zu verkleinern, haben einige User versucht, die Experten zu eliminieren, die häufig schlechte Antworten erzeugen. Das Verfahren dazu nennt sich REAP (Reflection, Explicit Problem Deconstruction, and Advanced Prompting) und produziert schlankere Modelle, deren Ausgabe sich kaum von der des vollen Modells unterscheiden lässt.

Den Erdbertest besteht GLM-4.7 (Abb. 4).
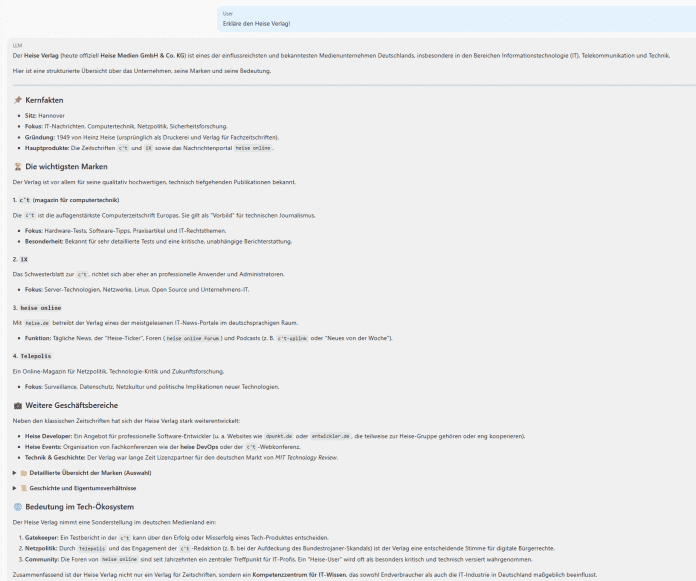
Die heise-Erklärung ist im Vergleich zu vielen anderen Modellen auffällig stimmig, auch wenn sie ausgerechnet bei Heise Developer etwas dazu erfindet. (Abb. 5)

Bei Taiwan gibt sich GLM-4.7 recht offen (Abb. 6).

Auch zu Tiananmen hält sich das Modell kaum zurück (Abb. 7).

Und erklärt sogar die Unterdrückung durch die chinesische Parteiführung (Abb. 8).
Bei MiniMax 2.1 handelt es sich um ein weiteres Modell aus China, das sich ebenso wie GLM 4.7 auf Coding, Nutzung von Werkzeugen und agentische Workflows fokussiert. Der Anbieter veröffentlicht wesentlich weniger Informationen als Z.ai, aber in den entsprechenden Dateien lässt sich einiges finden. Wenig überraschend handelt es sich auch bei MiniMax 2.1 um ein MoE-Modell, allerdings mit 256 Experten, von denen immer acht befragt werden. Von den insgesamt 230 Milliarden Parametern sind dann jeweils immer 10 Milliarden aktiv. Auch MiniMax kann wie GLM 4.7 mit knapp 200.000K Token umgehen.
Die Community ist sich nicht einig, ob GLM 4.7 oder MiniMax 2.1 sich besser für Programmieraufgaben eignet. Zweifellos sind beides sehr starke Modelle, die dank (relativ) weniger aktiver Parameter auch noch verhältnismäßig schnell ausgeführt werden können.

Auch Minimax-M2.1 zählt beim Erdbeertest richtig (Abb. 9).

Bei der heise-Erklärung gibt es eine Mischung aus korrekten und erfundenen Informationen (Abb. 10).

Bei der Taiwan-Frage gibt es eine differenzierte, aber recht knappe Antwort (Abb. 11).

Die Tiananmen-Ereignisse verharmlost das Modell (Abb. 12).

Und es äußerst sich zur Zensur, auch wenn es hier den Bezug zu dem zuvor als Referenz genannten Tiananmen auslässt (Abb. 13).
Modelle von LG aus Südkorea
Aus Südkorea hat man bisher wenige Modelle gesehen. Das hat sich nun geändert, mit K-EXAONE stellt LG ein entsprechendes Modell zur Verfügung. Wie nicht anders zu erwarten, ist es vor allem auf englische und koreanische Texte trainiert, spricht aber auch Spanisch, Deutsch, Japanisch und Vietnamesisch. Mit 236 Milliarden Parametern ist es sehr groß, auch wenn nur jeweils immer 23 Milliarden Parameter aktiv sind. Es nutzt Sliding Window Attention und kann damit lange Kontexte von bis zu 256K Token verarbeiten. In den Benchmarks performt das Modell ähnlich gut wie das (deutlich kleinere) gpt-oss-120b oder das (ebenso große) Qwen-235B-A22B-Thinking.
Spannende Zeiten
Es hat sich in den letzten Wochen einiges getan – in ganz unterschiedlichen Richtungen. Ob sich Googles Ideen umsetzen lassen und durchsetzen können, wird sich erst in einer ganzen Weile zeigen. Unstrittig dürfte hingegen sein, dass die Liquid Foundation Models für ihre Größe wirklich Beachtliches leisten. Das trifft auch für die (scheinbar wenig zensierten) großen chinesischen Modelle zu, die sich sehr gut für agentische Aufgaben eignen. Schließlich taucht auch erstmals ein großes koreanisches Modell auf, das konkurrenzfähig ist. Das lässt auf eine weitere Diversifizierung in der Zukunft hoffen.
(rme)











Künstliche Intelligenz
Weltfrauentag: Die schönsten Aufnahmen von Fotografinnen der c’t Fotogalerie
Der Weltfrauentag ist ein guter Anlass, um einmal die Frauen der c’t Fotografie Galerie in den Fokus zu rücken und ihre Beiträge hervorzuheben. Viele von ihnen sind inzwischen langjährige Mitglieder, die sich sowohl fotografisch als auch in den Diskussionen und den gemeinsamen Interpretationen (GI) aktiv beteiligen und diese entschieden mitgestalten. Dennoch sind sie insgesamt in der Unterzahl.
Weiterlesen nach der Anzeige
(Bild: heise )
Die fotografischen Beiträge unserer Fotografinnen sind oft geprägt von einem Staunen über die Schönheit der Welt. Manche zeugen von der Neugier auf Unbekanntes, zeigen einen feinen Humor in kleinen Entdeckungen auf der Straße oder ein emotionales Gespür für die Details, die in der Natur zu finden sind. In ihren Portfolios sind viele Fotothemen enthalten, jedoch wenige Porträts. Wer weiß, vielleicht stehen die Damen für Porträts eher vor als hinter der Kamera?
Die Werke unserer Fotografinnen haben wir in drei Kategorien unterteilt. Die erste und größte vereint Landschafts- und Architekturaufnahmen. Hier sind viele Aufnahmen von Reisen oder bewusst gestalteten Landschaften zu finden. Die zweite Galerie präsentiert Naturbilder, die eher ins Detail gehen – Blüten, Tiere, Insekten. In der dritten Kategorie finden Sie abstrakte oder experimentelle Fotografie. Dazu zählen auch urbane Motive oder Lost Places. In dieser Kategorie trifft Fotografie an manchen Stellen schon auf angewandte Kunst, Entdecker- auf Experimentierfreude.
Jede der ausgewählten Fotografinnen wird nacheinander mit vier Motiven aus ihrem Portfolio vorgestellt. Wir haben die Motive thematisch ausgewählt, was bedeutet, dass wir uns für ein Thema entschieden haben. Die eine oder andere Galeriefotografin ist vielleicht bei Landschaft und Architektur vertreten, fotografiert aber auch gern Tiere und Pflanzen. Wer mehr über die einzelne Person erfahren will oder den Auszug aus dem Portfolio mag, kann über die Links unter den Bildern die persönliche Seite der jeweiligen Fotografin finden. Nutzer, die in der Galerie angemeldet sind, können auch über persönliche Nachrichten in Kontakt treten.
Landschaft und Architektur

Saisonende
Uschi Hermann
)
Naturfotografie
Weiterlesen nach der Anzeige

Chrysantheme
uschi1956
)
Lesen Sie auch
Abstraktion und künstlerische Fotografie

We all live in a yellow…
fotopassion
)
(cbr)
Künstliche Intelligenz
Petra‑AI: KI soll Frauen in der Perimenopause unterstützen
Weiterlesen nach der Anzeige
Frauen sind in der medizinischen Forschung lange unterrepräsentiert gewesen – mit spürbaren Folgen für Diagnostik, Therapie und Datenlage. Symptome werden häufig nicht richtig eingeordnet, evidenzbasierte Informationen sind schwer zugänglich.
Mit dem Forschungsprojekt „Petra‑AI“ will ein interdisziplinäres Konsortium unter Leitung von Dr. Theresa Ahrens vom Fraunhofer IESE eine KI‑gestützte App entwickeln, die Frauen in der Perimenopause wissenschaftlich fundiert, verständlich und sicher begleitet.

Dr. Theresa Ahrens leitet die Abteilung Digital Health Engineering am Fraunhofer IESE und koordiniert das Forschungsprojekt „PETRA-AI“.
(Bild: Fraunhofer IESE)
Im Interview erklärt Ahrens, welche Rolle ein KI‑Chatbot spielen kann und warum strukturierte, interoperable Gesundheitsdaten entscheidend sind, um Versorgungslücken zu schließen.
Was verbirgt sich hinter Petra-AI?
Das Projekt „Petra-AI: AI‑gestützte, edukative Therapiebegleitung für die Perimenopause“ ist ein öffentlich gefördertes Forschungsprojekt, in dem wir eine KI‑gestützte App zur Unterstützung von Frauen in der Perimenopause entwickeln. Ziel ist es, evidenzbasierte Informationen bereitzustellen und Frauen dabei zu helfen, ihre Symptome besser einzuordnen und zu lindern. Das Projekt wird vom Bundesministerium für Forschung, Technologie und Raumfahrt (BMFTR) gefördert und läuft über drei Jahre.
Wer arbeitet an dem Projekt mit?
Wir sind ein interdisziplinäres Konsortium. Neben dem Fraunhofer IESE als Konsortialführer ist das Digital Health Start-up Femna Care beteiligt, außerdem die Juniorprofessur für Gesundheit und E-Health der Ruhr-Universität Bochum, die Sozialforschungsstelle der Fakultät Sozialwissenschaften an der Technischen Universität Dortmund sowie das Berlin Institute of Health an der Charité.
Weiterlesen nach der Anzeige
Femna bringt Expertise im Bereich Frauengesundheit ein. Die sozialwissenschaftlichen Partner begleiten die nutzerzentrierte Entwicklung und Co-Creation-Prozesse. Das Berlin Institute of Health unterstützt uns bei interoperablen Datenstandards wie FHIR und SNOMED, damit Forschungsdaten strukturiert und weiterverwendbar erhoben werden können.
Ist auch eine Kommerzialisierung von PETRA-AI geplant?
Nein, es handelt sich erstmal um ein reines Forschungsprojekt. Allerdings entwickeln wir die Technologie mit dem Anspruch, dass sie langfristig in die Versorgung überführt werden kann. Wir möchten keine Forschung „für die Schublade“ betreiben.
Welche Rolle spielt der KI-Chatbot konkret?
Der Chatbot soll evidenzbasierte Informationen verständlich und niedrigschwellig vermitteln. Eine zentrale Herausforderung des Projekts liegt in der bedarfsgerechten Anpassung der KI‑gestützten Inhalte an den jeweiligen Wissensstand und die sprachlichen Voraussetzungen der Nutzerinnen.
Gleichzeitig ist uns die Sicherheit extrem wichtig. Sprachmodelle können halluzinieren – also falsche Informationen erzeugen. Gerade im Gesundheitskontext ist das problematisch. Deshalb arbeiten wir intensiv an technischen Absicherungen und evaluieren verschiedene bestehende Sprachmodelle. Ein eigenes komplettes Sprachmodell zu trainieren wäre wirtschaftlich nicht sinnvoll, aber wir erweitern und sichern die gewählten Modelle technisch ab.
Kann KI im Gesundheitswesen eigentlich fehlerfrei sein?
Die Erwartung, dass KI-Systeme hundertprozentig fehlerfrei arbeiten, ist unrealistisch. Entscheidend ist, transparent zu machen, was KI kann – und was nicht.
Es gibt zum Beispiel den sogenannten „Automation Bias“: Menschen können dazu neigen, KI-Systemen zu stark zu vertrauen. Deshalb müssen wir KI als Unterstützung verstehen, nicht als Ersatz für ärztliche Expertise. KI-Systeme sind soziotechnische Systeme – das Zusammenspiel zwischen Mensch und Maschine muss immer mitgedacht und erforscht werden.
Wie positionieren Sie sich zur Einordnung der Menopause? Es gibt auch die Befürchtung, dass sie als Krankheit behandelt wird.
Die Menopause und auch die als Perimenopause bezeichnete Übergangsphase sind keine Erkrankungen im klassischen Sinne. Dennoch kann die Lebensqualität erheblich beeinträchtigt sein. Manche Frauen erleben Symptome über viele Jahre hinweg – teilweise bis zu 15 Jahre.
Viele Symptome werden im Versorgungsalltag nicht als hormonell bedingt erkannt. Das kann zu langen „Odysseen“ führen. Deshalb ist Aufklärung wichtig – sowohl für Betroffene als auch für Ärztinnen und Ärzte.
Spielt der Lebensstil eine Rolle bei der Wahrnehmung der Menopause?
Sicherlich gibt es individuelle Unterschiede, aber ich sehe derzeit vor allem eine gesellschaftliche Enttabuisierung. Über Frauengesundheit wurde lange wenig offen gesprochen. Social Media hat hier durchaus eine positive Rolle gespielt, weil der Austausch einfacher geworden ist – auch wenn die Qualität der Informationen dort stark schwankt.
Wird die App konkrete Therapieempfehlungen geben, etwa zur Hormonersatztherapie?
Das Ziel ist nicht, dass der Chatbot selbstständig eine Therapie vorschlägt oder sogar verschreibt. Er kann jedoch Vor- und Nachteile erklären und aktuelle Studienlagen verständlich aufbereiten. Gerade bei der Hormonersatztherapie existieren noch viele Ängste, die auf älteren Studien basieren. Hier kann evidenzbasierte Information helfen, informierte Entscheidungen gemeinsam mit Ärztinnen und Ärzten zu treffen.
Wie gehen Sie mit Datenschutz und Forschungsdaten um?
In der Pilotphase werden Teilnehmerinnen umfassend aufgeklärt. Daten werden pseudonymisiert erhoben und nach FAIR-Kriterien (Anm. d. Red.: auffindbar, zugänglich, interoperabel und wiederverwendbar) für die Forschung zugänglich gemacht.
Wann wird es erste Ergebnisse geben?
Das Projekt läuft zunächst drei Jahre. Wir starten mit Interviews und Workshops, um die Bedürfnisse der Frauen von Anfang an einzubeziehen. Am Ende ist eine strukturierte Pilotphase geplant, in der wir Akzeptanz, Nutzungsfreundlichkeit und Wirkung evaluieren.
Sie wirken trotz der Herausforderungen optimistisch.
Ja, sonst wäre ich keine Wissenschaftlerin geworden. Es sind komplexe Probleme – medizinisch, technisch und gesellschaftlich. Aber wir haben ein starkes, interdisziplinäres Team. Und man darf nicht vergessen: Frauen machen immerhin 50 Prozent der Weltbevölkerung aus. Dennoch ist Frauengesundheit in Forschung und Entwicklung lange unterrepräsentiert gewesen. Das ändert sich gerade – und das ist gut so.
(mack)
Künstliche Intelligenz
Thunderbird optimieren: E-Mails effizient organisieren und filtern
„You’ve got Mail!“ Früher hat man sich über digitale Post noch gefreut, heute nervt sie bisweilen. Spam, Phishing, falsche Versprechen – trotz allem bleibt die E-Mail weiterhin ein relevantes und zentrales Kommunikationsmittel. Allein die vielen Accounts bei diversen Online-Diensten verlangen nach einer E-Mail-Adresse. Dann soll wenigstens die Postverwaltung leicht von der Hand gehen.
- E-Mails sind weiterhin ein wichtiges Kommunikationsmittel, doch sie nerven auch – Spam sei Dank.
- Thunderbird kümmert sich seit zwei Jahrzehnten um digitale Post und erleichtert die Organisation mehrerer Konten.
- Der Mail-Client ist komplett Open-Source und kostenlos für Windows, macOS und Linux verfügbar, ebenso für Android.
- Unser Ratgeber hilft bei der Einrichtung und Optimierung von Thunderbird, damit Mails weniger nerven.
Diesen Job übernimmt Thunderbird: Der Mail-Client ist seit zwanzig Jahren die Lieblingsapp vieler Nerds, um Mails effizienter zu organisieren. Die quelloffene App unterstützt nahezu jeden Mail-Dienst und bietet viele durchdachte Funktionen, praktische Tastaturkürzel sowie einen gemeinsamen Posteingang. Filter sortieren automatisch aus, was unwichtig ist. Thunderbird ist außerdem komplett kostenlos.
Zwischenzeitlich sah es um die Zukunft von Thunderbird etwas düster aus. Doch wie ein Donnervogel aus der Asche stieg der Mail-Client wieder empor. Die Entwicklung ist gesichert, und Thunderbird bekam jüngst viele neue Funktionen und eine moderne Bedienoberfläche spendiert. Auf irgendwelche KI-Spielereien haben die Entwickler glücklicherweise verzichtet. Was der Mail-Client alles kann und wie man ihn einrichtet, erklärt dieser Ratgeber. Er fokussiert sich dabei auf die Desktop-Version.
Das war die Leseprobe unseres heise-Plus-Artikels “ Thunderbird optimieren: E-Mails effizient organisieren und filtern“.
Mit einem heise-Plus-Abo können Sie den ganzen Artikel lesen.

Drei Fragen, drei Antworten: Mehr Sichtbarkeit für Frauen auf IT-Konferenzen

Weltfrauentag: Die schönsten Aufnahmen von Fotografinnen der c’t Fotogalerie

Wochenrück- und Ausblick: Zwei Spiele, zwei Podcasts und x Neuigkeiten von Apple

Schnelles Boot statt Bus und Bahn: Was sich von London und New York lernen lässt

Community Management zwischen Reichweite und Verantwortung

Community Management und Zielgruppen-Analyse: Die besten Insights aus Blog und Podcast
-
 Künstliche Intelligenzvor 2 Monaten
Künstliche Intelligenzvor 2 MonatenSchnelles Boot statt Bus und Bahn: Was sich von London und New York lernen lässt
-
 Social Mediavor 4 Wochen
Social Mediavor 4 WochenCommunity Management zwischen Reichweite und Verantwortung
-
 Social Mediavor 6 Tagen
Social Mediavor 6 TagenCommunity Management und Zielgruppen-Analyse: Die besten Insights aus Blog und Podcast
-
Künstliche Intelligenzvor 2 Wochen
Top 10: Die beste kabellose Überwachungskamera im Test – Akku, WLAN, LTE & Solar
-

 Datenschutz & Sicherheitvor 3 Monaten
Datenschutz & Sicherheitvor 3 MonatenSyncthing‑Fork unter fremder Kontrolle? Community schluckt das nicht
-

 Entwicklung & Codevor 3 Monaten
Entwicklung & Codevor 3 MonatenKommentar: Anthropic verschenkt MCP – mit fragwürdigen Hintertüren
-

 Künstliche Intelligenzvor 3 Monaten
Künstliche Intelligenzvor 3 MonatenGame Over: JetBrains beendet Fleet und startet mit KI‑Plattform neu
-

 Social Mediavor 3 Monaten
Social Mediavor 3 MonatenDie meistgehörten Gastfolgen 2025 im Feed & Fudder Podcast – Social Media, Recruiting und Karriere-Insights

