Künstliche Intelligenz
Softwareentwicklung: Abstraktion ist überbewertet | heise online
Kaum ein Prinzip genießt in der Softwareentwicklung so viel Ansehen wie die Abstraktion. Wer abstrahiert, gilt als vorausschauend. Wer Gemeinsamkeiten erkennt und zusammenführt, gilt als erfahren. Wer Code dupliziert, gilt als nachlässig. Sei es in Code-Reviews, in Architektur-Diskussionen oder in Vorstellungsgesprächen: Abstraktion ist der Maßstab, an dem sich guter Code messen lassen muss. Zumindest wird das häufig so vermittelt.
Weiterlesen nach der Anzeige


Golo Roden ist Gründer und CTO von the native web GmbH. Er beschäftigt sich mit der Konzeption und Entwicklung von Web- und Cloud-Anwendungen sowie -APIs, mit einem Schwerpunkt auf Event-getriebenen und Service-basierten verteilten Architekturen. Sein Leitsatz lautet, dass Softwareentwicklung kein Selbstzweck ist, sondern immer einer zugrundeliegenden Fachlichkeit folgen muss.
Ich habe das selbst lange geglaubt. Ich habe abstrahiert, wo es ging, habe Gemeinsamkeiten gesucht, wo keine waren, und habe mich gut dabei gefühlt. Erst mit den Jahren habe ich gelernt, dass das Gegenteil oft näher an der Wahrheit liegt: Dass viele Abstraktionen Code nicht besser machen, sondern schlechter. Dass sie Kopplung erzeugen, wo Unabhängigkeit sein sollte. Und dass eine falsche Abstraktion langfristig teurer ist als gar keine.
DRY bedeutet nicht, was die meisten glauben
Wenn Entwicklerinnen und Entwickler über Abstraktion sprechen, fällt früher oder später das Akronym DRY: „Don’t Repeat Yourself“. Es ist eines der meistzitierten Prinzipien der Softwareentwicklung, und es wird fast überall als technische Anweisung verstanden: „Dupliziere keinen Code“. Es gibt sogar Tools, die Codebasen nach Copy-&-Paste-Mustern durchsuchen und Alarm schlagen, wenn zwei Blöcke zu ähnlich aussehen.
Das Problem: Diese Interpretation hat mit dem, was die Autoren des Prinzips gemeint haben, wenig zu tun. DRY stammt aus dem Buch „The Pragmatic Programmer“ von David Thomas und Andrew Hunt. Dort wird ausdrücklich gesagt, dass es nicht um technische Duplikation geht, sondern um fachliche: Ein fachliches Konzept soll nicht an mehreren Stellen im System implementiert sein, weil das zu Inkonsistenzen bei Geschäftsregeln führt. Hunt und Thomas bringen in ihrem Buch sogar ein explizites Beispiel für technische Duplikation und stellen klar, dass das keine Verletzung von DRY sei!
Das hindert die Branche aber nicht daran, DRY weiterhin als „kopiere keinen Code“ zu verkaufen. Und genau das führt zu einer der häufigsten Formen falscher Abstraktion: Technisch ähnlicher Code wird zusammengeführt, obwohl er fachlich völlig unterschiedliche Dinge repräsentiert.
Um ein Beispiel zu nennen, das viele so oder so ähnlich kennen dürften: Stellen Sie sich vor, eine Anwendung verfügt über eine User-Klasse. Diese Klasse wird für die Persistenz verwendet, für die HTTP-API und für die Fachlogik. Drei verschiedene Kontexte, aber nur eine Klasse, weil die Felder dieselben sind. Wer braucht schon drei User-Klassen?
Weiterlesen nach der Anzeige
Die Antwort zeigt sich spätestens nach ein paar Monaten: Für die Persistenz und die API braucht man JSON-Annotationen. Plötzlich trägt die Fachlogik-Klasse Annotationen, die ihr völlig egal sein sollten. Dann ändert sich das Persistenzformat, aber die Annotationen lassen sich nicht einfach anpassen, weil das die API brechen würde. Also fügt man weitere Annotationen hinzu. Dann kommt ein internes Feld dazu, das über die API jedoch nicht sichtbar sein soll. Also braucht man Logik, die bestimmte Felder ausblendet. Und so wächst die Klasse nach und nach zu einer immer größeren Müllhalde, auf der sich immer mehr Sonderfälle und Ausnahmen ansammeln.
Die Lösung wäre so einfach gewesen: drei separate Klassen, eine pro Kontext. Ja, das bedeutet, zwischen ihnen mappen zu müssen. Ja, das ist ein wenig mehr Tipparbeit. Aber jede Klasse existiert aus einem eigenen Grund, ist unabhängig von den anderen evolvierbar, und der Code ist explizit und nachvollziehbar. In der Sprache der Softwarearchitektur: niedrige Kopplung und hohe Kohäsion. Nicht zufällig sind das die beiden grundlegenden Prinzipien guter Architektur. Und nicht zufällig verletzt die zusammengeführte User-Klasse beide.
Viele Entwicklerinnen und Entwickler wehren sich gegen diesen Ansatz. Es wird argumentiert: Drei Klassen für dasselbe Konzept, das sei zu viel Aufwand und zu viel Redundanz. Aber die drei Klassen existieren aus unterschiedlichen Gründen. Sie haben unterschiedliche Lebenszyklen, unterschiedliche Änderungsgründe, unterschiedliche Abhängigkeiten. Sie gehören nicht zusammen, auch wenn sie ähnlich oder (zunächst) sogar gleich aussehen.
Das Muster dahinter ist immer dasselbe: Technische Ähnlichkeit wird mit fachlicher Zusammengehörigkeit verwechselt. Die resultierende Abstraktion erzeugt eine Kopplung zwischen Dingen, die nichts miteinander zu tun haben. Änderungen an einem Kontext ziehen Änderungen in einem anderen nach sich, oder man muss den jeweiligen Kontext durch die Abstraktion hindurchschleifen, was die Komplexität weiter erhöht. Und all das nur, weil jemand irgendwann gesagt hat: „Das sieht doch fast gleich aus, das kann man zusammenfassen.“
Wenn Frameworks das Denken übernehmen
Falsche Abstraktionen entstehen jedoch nicht nur durch missverstandene Prinzipien. Sie werden auch von Frameworks geliefert, fertig verpackt und als Feature beworben. Das Versprechen lautet: „Sie müssen das Darunterliegende nicht verstehen. Wir kümmern uns darum. Konzentrieren Sie sich auf Ihre Geschäftslogik.“
Das klingt verlockend, und es funktioniert. Solange man auf dem getrampelten Pfad bleibt, ist alles in Ordnung. Die Dokumentation beschreibt den Happy Path, die Tutorials führen durch den Happy Path, die Community beantwortet Fragen zum Happy Path. Das Problem beginnt, wenn man davon abweichen muss. Und in realen Projekten muss man das früher oder später immer.
Nehmen Sie React als Beispiel: JSX ist eine Abstraktion, die es erlaubt, HTML-ähnliche Syntax in JavaScript zu schreiben. Die meisten React-Entwicklerinnen und -Entwickler nutzen JSX täglich, aber nur wenige können erklären, was dabei eigentlich passiert. Wie wird aus JSX am Ende JavaScript, das der Browser versteht und ausführen kann? Welche Transformationsschritte sind involviert? Warum darf eine Render-Funktion nur einen einzigen Root-Knoten zurückgeben und nicht mehrere?
Die Antwort auf die letzte Frage ist aufschlussreich: In JSX wird jedes Element in einen Funktionsaufruf (sinngemäß: createElement) übersetzt, das heißt, die Render-Funktion gibt das Ergebnis dieses Funktionsaufrufs zurück. Und da eine Funktion in JavaScript nur einen Rückgabetyp haben kann, kann eine Render-Funktion naturgemäß nicht mehrere Elemente auf oberster Ebene zurückgeben – auch wenn sich das in JSX zunächst wie eine valide HTML-Struktur liest.
Wer versteht, was unter der Haube passiert, für den ist die Einschränkung selbstverständlich. Für alle anderen ist sie eine willkürliche Regel, die man auswendig lernt, ohne sie zu begreifen.
Solange alles funktioniert, fällt das fehlende Verständnis nicht auf. Doch sobald man auf ein Problem stößt, das nicht auf dem Happy Path liegt, ändert sich die Situation. Man versteht nicht nur das Problem nicht, sondern auch das Werkzeug nicht, mit dem man es lösen müsste. Statt mit dem Framework zu arbeiten, arbeitet man gegen es. Das ist der Moment, in dem die Abstraktion leckt.
TypeScript ist nur so gut wie das JavaScript-Verständnis dahinter
Dasselbe Muster zeigt sich auf einer anderen Ebene auch bei Programmiersprachen beziehungsweise Compilern, beispielsweise TypeScript. TypeScript ist eine Abstraktion über JavaScript, die statische Typisierung hinzufügt. Das Versprechen: mehr Sicherheit, bessere Tooling-Unterstützung, weniger Laufzeitfehler. Und dieses Versprechen löst TypeScript in vielen Fällen auch ein.
Was TypeScript nicht einlöst, ist das implizite Versprechen, dass man JavaScript nicht mehr verstehen müsse. Viele Entwicklerinnen und Entwickler steigen heute direkt mit TypeScript ein, ohne je ernsthaft JavaScript geschrieben zu haben. Sie lernen TypeScript-Syntax, TypeScript-Pattern, TypeScript-Tooling. JavaScript ist für sie eine Art Kompilierungsziel, das man nie direkt anfasst.
Das funktioniert, bis es nicht mehr funktioniert. Viele der Einschränkungen und vermeintlich seltsamen Verhaltensweisen von TypeScript ergeben nur dann Sinn, wenn man JavaScript versteht. Warum verhält sich das Typsystem in bestimmten Fällen unerwartet? Warum gibt es Design-Entscheidungen, die auf den ersten Blick unlogisch wirken? Die Antwort ist fast immer dieselbe: Weil TypeScript abwärtskompatibel zu JavaScript sein will und muss, und es anders schlicht nicht funktioniert.
Wer JavaScript kennt, versteht diese Entscheidungen. Wer JavaScript nicht kennt, steht vor einer Wand aus unerklärlichen Regeln. Die Abstraktion verdeckt genau das Wissen, das man braucht, wenn sie an ihre Grenzen stößt. Und das Paradoxe daran: Auch die meisten Entwicklerinnen und Entwickler, die JavaScript nutzen, kennen JavaScript zu wenig. Die Sprache hat einen Ruf als einfach, der täuscht. Unter der Oberfläche verbergen sich Konzepte, deren Verständnis erheblich dabei hilft, sowohl JavaScript als auch TypeScript besser einzusetzen.
Auch KI abstrahiert, und auch KI leckt
Die jüngste Iteration desselben Musters liefert die künstliche Intelligenz. KI-basierte Coding-Assistenten und -Agenten versprechen, die Softwareentwicklung grundlegend zu vereinfachen. Sie generieren Code, vervollständigen Funktionen, schlagen Architekturen vor, schreiben Tests. Das Versprechen ist vertraut: „Sie müssen sich nicht um die Details kümmern. Die KI übernimmt das. Konzentrieren Sie sich auf die großen Zusammenhänge.“
Das klingt nach demselben Versprechen, das Frameworks seit Jahren geben. Und es funktioniert auf dieselbe Weise: hervorragend auf dem Happy Path. Solange die Anforderungen im Bereich dessen liegen, wofür ausreichend Trainingsmaterial existiert, liefert KI beeindruckende Ergebnisse. In Sekunden entsteht Code, der kompiliert, Tests besteht und auf den ersten Blick korrekt aussieht.
Die Probleme beginnen, wenn die Anforderungen exotischer werden. Wenn die Kombination aus Technologien, Randbedingungen und fachlichen Regeln so spezifisch ist, dass kein Trainingsmaterial dafür existiert. Oder wenn der generierte Code subtile Fehler enthält, die man nicht erkennt, weil man nie gelernt hat, wie der Code unter der Haube funktioniert. Ein Off by One Error in einer Schleife, eine Race Condition in asynchronem Code, ein falsch gesetzter Index in einer Datenbankabfrage: Solche Fehler fallen nur auf, wenn man den Code tatsächlich liest und versteht. Wer das nicht macht, weil die KI es vermeintlich übernimmt, hat ein Problem, das er möglicherweise erst Monate später bemerkt.
Noch bedenklicher ist der schleichende Verlust von Kompetenz. Wer jahrelang Code von Hand geschrieben hat und nun KI einsetzt, verfügt über das Wissen, die Ergebnisse zu beurteilen. Wer aber nie ohne KI gearbeitet hat oder das eigene Wissen nicht mehr pflegt, verliert genau die Fähigkeit, die nötig wäre, um die Grenzen der Abstraktion zu erkennen.
Das Muster ist immer dasselbe. Eine Abstraktion verspricht Einfachheit. Sie löst dieses Versprechen ein, solange alles nach Plan läuft. Und sie versagt genau dann, wenn man sie am dringendsten brauchte: in den Situationen, die vom Plan abweichen. Joel Spolsky hat das 2002 in seinem Artikel „The Law of Leaky Abstractions“ auf den Punkt gebracht: Alle nichttrivialen Abstraktionen sind bis zu einem gewissen Grad undicht. Das galt für Frameworks, es galt für Programmiersprachen, und es gilt für KI.
Nicht jede Abstraktion ist schlecht
Nach vier Negativbeispielen wäre es leicht, den Schluss zu ziehen, dass Abstraktion grundsätzlich schädlich ist. Das wäre falsch. Es gibt nämlich durchaus sinnvolle Abstraktionen, die funktionieren, und das seit Jahrzehnten.
Das vielleicht beste Beispiel stammt aus der Unix-Welt: „Everything is a file“. Das bedeutet: In Unix sind Dateien, Geräte, Pipes und Sockets über dasselbe Interface ansprechbar: open, read, write, close. Diese Abstraktion ist inzwischen über fünfzig Jahre alt und funktioniert noch immer hervorragend. Sie ist zu einem Fundament geworden, auf dem ganze Ökosysteme aufbauen.
Was macht diese Abstraktion anders als die gescheiterten Beispiele? Erstens ist sie minimal. Sie versteckt nicht zu viel, sondern genau so viel, wie nötig ist, um eine gemeinsame Schnittstelle zu bieten. Zweitens basiert sie auf einem tiefen Verständnis des Problems. Die Unix-Entwickler haben nicht zuerst abstrahiert und dann geschaut, was man damit machen kann. Sie haben erst verstanden, was sie brauchen, und dann die kleinstmögliche gemeinsame Abstraktion gefunden. Und drittens: Wenn sie leckt (und das tut sie), ist das Leck nachvollziehbar, weil die Abstraktion dünn genug ist, um hindurchzuschauen.
Genau das unterscheidet eine gelungene Abstraktion von einer gescheiterten. Gelungene Abstraktionen setzen Verständnis voraus und machen es nicht überflüssig. Sie entstehen aus Erfahrung, nicht aus Annahmen. Und sie respektieren, dass die Kopplung niedrig und die Kohäsion hoch bleiben muss.
Erst verstehen, dann vielleicht abstrahieren
Was lässt sich aus all dem lernen? Joel Spolsky hat neben dem Artikel zu den leckenden Abstraktionen noch einen zweiten Artikel geschrieben, der hierher gehört: „Back to Basics“. Darin kritisiert er, dass zu vielen Entwicklerinnen und Entwicklern die Grundlagen fehlen (und das war, wohlgemerkt, bereits 2001). Dass die Meinung vorherrsche, die Garbage Collection werde es schon richten, ohne dass man verstanden hat, was ein Stack und was ein Heap ist, wann was verwendet wird und welche Auswirkungen das hat.
Natürlich muss man nicht in allem Expertin oder Experte sein, das ist allein aufgrund der Menge an Themen auch gar nicht machbar. Aber die Grundlagen des eigenen Werkzeugs zu verstehen ist keine optionale Zusatzqualifikation, sondern die Voraussetzung dafür, die Abstraktion über diesem Werkzeug sinnvoll nutzen zu können. Wer nicht weiß, wie JavaScript funktioniert, wird an TypeScript scheitern. Wer nicht versteht, was JSX unter der Haube tut, wird an React scheitern. Wer nicht in der Lage ist, Code selbst zu beurteilen, wird an KI scheitern.
Mein Rat lautet daher nicht, auf Abstraktion grundsätzlich zu verzichten. Mein Rat lautet, mit Abstraktion zu warten, also nicht mit einer Abstraktion starten, sondern alles erst einmal explizit machen. Jede Klasse, jede Funktion, jede Schnittstelle so schreiben, dass sie für sich allein verständlich ist. Code wird nur einmal geschrieben, aber viele Male gelesen. Lesbarkeit, Nachvollziehbarkeit und Verständlichkeit sind wichtiger als drei Zeilen weniger Tipparbeit.
Erst wenn man genau weiß, wie sich die Anforderungen verhalten, welche Teile sich tatsächlich gemeinsam ändern und welche nur zufällig ähnlich aussehen, dann und nur dann kann man über Abstraktion nachdenken. Und selbst dann lohnt sich die Frage: Brauche ich die Abstraktion wirklich? Oder mache ich den Code damit nur kürzer, aber nicht besser? Senkt die Abstraktion die Kopplung und erhöht die Kohäsion, oder bewirkt sie das Gegenteil?
Viele der besten Codebasen, die ich in über 30 Jahren Berufserfahrung gesehen habe, zeichneten sich nicht durch clevere Abstraktionen aus, sondern durch Klarheit. Durch Code, den man lesen und verstehen konnte, ohne erst drei Indirektionsebenen nachzuverfolgen. Durch explizite Strukturen, die auf den ersten Blick verrieten, was sie taten und warum. Das ist die wahre Kunst der Softwareentwicklung, und abschließend kann man sagen: Abstraktion ist überbewertet, Verständnis nicht.
(rme)











Künstliche Intelligenz
Android Studio Panda 2: KI-Agent erstellt neue Android-Apps
Google hat Android Studio Panda 2 veröffentlicht. Die neue Version stattet die integrierte Entwicklungsumgebung für Android-Apps mit erweiterten KI-Möglichkeiten aus: Per KI-Agent lassen sich komplette neue App-Prototypen erstellen. Aber auch im Umgang mit vorhandenen Codebasen soll der KI-Agent unterstützen können und Entwickler von Boilerplate-Code befreien.
Weiterlesen nach der Anzeige
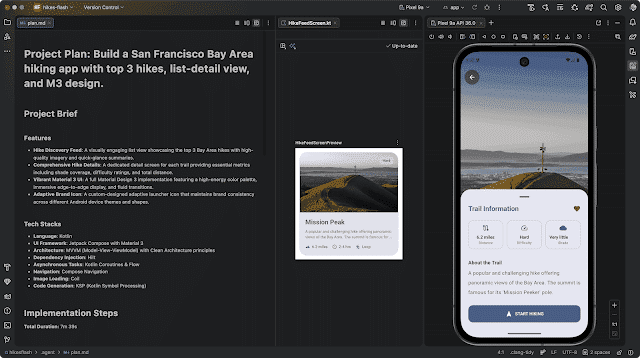
Per Prompt zur App: Google demonstriert den KI-gestützten „New Project“-Flow.
(Bild: Google)
Neue Apps per Prompt
Wie das Android-Team ausführt, soll der KI-gestützte „New Project“-Flow das Erstellen eines App-Prototyps mit nur einem Prompt ermöglichen. Dabei können Developer neben einer Beschreibung der geplanten App auch Bilder hochladen. Der KI-Agent setzt dann die Pläne in die Tat um und nutzt dazu Technologien wie Kotlin und Compose unter Befolgung der Best Practices in der Android-Entwicklung. Die App wird letztlich zu einem Android-Emulator deployt und Developer können jeden Screen dahingehend prüfen, ob er ihren Anforderungen entspricht.
Nicht nur neue Apps, sondern auch bestehende Codebasen sollen von den Fähigkeiten des KI-Agenten profitieren. Der Version Upgrade Assistant in Android Studio kann nun mithilfe von KI Dependencies verwalten. Dazu klicken Entwickler im Versionskatalog mit der rechten Maustaste, wählen AI und anschließend Update Dependencies aus. Auch aus dem Refactor-Menü lässt sich die KI-Funktion aktivieren: Update all libraries with AI.

Die Dependency-Verwaltung kann nun per KI geschehen.
(Bild: Google)
Dann soll der KI-Agent mehrere automatisierte Runden durchführen, bis er Dependency-Konflikte behoben hat und der Build schließlich erfolgreich verläuft.
Weiterlesen nach der Anzeige
Qualitätsverbesserung gegen Aufpreis
Neben dem kostenfreien Standard-Modell in Android Studio kann der KI-Agent für zahlende Kunden auf weitere Optionen zugreifen. Entwicklerinnen und Entwickler können ihren eigenen API-Key für Google AI Studio eingeben, um einen zahlungspflichtigen Gemini-API-Key einzubinden. Das ermöglicht Zugriff auf neuere und schnellere Modelle von Google zum Erstellen neuer Apps, darunter das KI-Bildmodell Nano Banana und Gemini 3.1 Pro Preview, was das Generieren verbesserter Designs ermöglichen und die Codequalität erhöhen soll.
Android Studio Panda 2 steht bei Google zum Download bereit. Weitere Informationen bietet der Blogeintrag zur Ankündigung.
(mai)
Künstliche Intelligenz
Nur sechs Wochen nach Release: „Highguard“ wird abgeschaltet
Vier Jahre Entwicklungszeit für ein Spiel, das nur sechs Wochen spielbar ist: Das Schicksal des gefloppten Online-Shooters „Highguard“ ist besiegelt. Er wird am 12. März abgeschaltet, teilten die Entwickler in einem Post auf X mit. Seit dem Release am 26. Januar wird „Highguard“ also nur 45 Tage spielbar gewesen sein.
Weiterlesen nach der Anzeige
Da es sich um einen Free2Play-Titel handelt, entfällt eine generelle Kaufpreiserstattung. Allerdings wurden in „Highguard“ In-Game-Items per Mikrotransaktionen verkauft – wie Entwickler Wildlight damit umgehen wird und ob betroffene Spieler ihr Geld dafür zurückbekommen, ist offen.
Alles oder nichts
„Highguard“ war ein Online-Shooter mit Live-Service-Elementen: Damit sind Online-Spiele gemeint, die regelmäßig mit neuen Inhalten versorgt werden und langfristig Einnahmen generieren können – wenn sie eine Spielerschaft erreichen, die groß genug ist. Schaffen sie das nicht, stehen sie schnell vor einem Trümmerhaufen.
Das Monetarisierungsmodell von Live-Service-Games ist auf den langfristigen Verkauf von In-Game-Items ausgelegt. Bleiben die Spieler weg, finden die verbleibenden Fans keine Multiplayer-Partien mehr, geben kein Geld mehr aus und verlassen das Spiel schließlich. Derweil fallen für Entwickler laufende Kosten für den Server-Betrieb und die Weiterentwicklung an. Es ist eine Abwärtsspirale, der Wildlight Entertainment mit der kompletten Abschaltung von „Highguard“ zuvorkommt.
Live-Service-Spiele wie „Highguard“ sind immer Wetten auf den großen Erfolg, bringen aber auch ein großes Risiko mit sich – sie sind „boom or bust“, alles oder nichts. Titel wie „Fortnite“, „League of Legends“ und „Counter-Strike“ dominieren seit Jahren die Spielzeit von Gamern und generieren riesige Umsätze. Gescheiterte Konkurrenten landen wie „Highguard“ schnell auf dem Scheiterhaufen.
Das ist etwa mit Amazons Online-Shooter „Crucible“ passiert, der nur wenige Monate durchhielt. Der Online-Shooter „Concord“ schaffte sogar nur zwei Wochen, bis Publisher Sony die Reißleine zog, die Server abschaltete und das Entwicklerstudio Firewalk schloss. Der Fall von „Highguard“ ist also für die Entwickler tragisch, in der Branche aber nicht ungewöhnlich.
Kontroverse um Game-Awards-Trailer
Weiterlesen nach der Anzeige
Dabei startete „Highguard“ sogar mit guten Zahlen: Fast 100.000 Spieler probierten den Free2Play-Titel zu Stoßzeiten laut dem inoffiziellen Steam-Tracker SteamDB zum Marktstart am 26. Januar gleichzeitig aus – auch, weil das Spiel bei den Game Awards mit einem Trailer vorgestellt worden war. Tatsächlich wurde dieser Trailer als letzte Ankündigung der Show ausgestrahlt – ein Slot, für den Spieler besonders hohe Erwartungen haben. Nach der Ankündigung eines eher generisch aussehenden Live-Service-Spiels überwog bei vielen Zuschauern die Enttäuschung, viele schossen aus Frust auf „Highguard“ ein. Die Entwickler bedauerten die Situation in Interviews mehrfach.
Die Zahlen von SteamDB belegen aber, dass „Highguard“ mit dem umstrittenen Game-Awards-Trailer zumindest Aufmerksamkeit generiert hatte. 100.000 gleichzeitige Spieler zum Launchtag sind ein guter Wert, auf dem man aufbauen kann. Laut den Entwicklern erreichte das Spiel insgesamt sogar 2 Millionen Menschen.
Doch „Highguard“ schaffte es nicht, daraus Schwung zu nehmen: Die Nutzer-Reviews auf Steam fielen recht negativ aus, die Spielerzahlen purzelten rapide. Zuletzt spielten „Highguard“ am Tag nur noch wenige Hundert Menschen gleichzeitig.
Ein Patch kommt noch
„Trotz der Leidenschaft und harten Arbeit unseres Teams ist es uns nicht gelungen, eine nachhaltige Spielerbasis aufzubauen, die das Spiel langfristig tragen kann“, schreiben die Entwickler auf X. Wie es mit dem Studio weitergeht, ist unklar. Aus früheren Fällen weiß man, dass Spieleunternehmen einen derartigen Flop in der Regel nicht überleben.
Bis zum 12. März will Wildlight noch einen Patch veröffentlichen, der unter anderem eine neue Waffe und Skilltrees umfasst – ein kurzlebiger Ausblick auf das, was die Entwickler über die kommenden Monate und Jahre geplant hatten.
Lesen Sie auch
(dahe)
Künstliche Intelligenz
Für fast eine halbe Milliarde US-Dollar: Teradata lässt Klage gegen SAP fallen
SAP hat einen jahrelangen Rechtsstreit mit dem Datenbank- und Analytics-Spezialisten Teradata aus den USA außergerichtlich beilegen können. Wie aus einer Mitteilung Teradatas an die US-Börsenaufsicht SEC hervorgeht, haben sich die Unternehmen auf einen Vergleich geeinigt, für den SAP 480 Millionen US-Dollar zahlt. Nach Abzug aller Gebühren und Aufwendungen für die seit 2018 währende Auseinandersetzung sollen davon vor Steuern zwischen 355 Millionen und 362 Millionen US-Dollar übrig bleiben, schätzt Teradata.
Weiterlesen nach der Anzeige
Der nun beigelegte Rechtsstreit zwischen den beiden Unternehmen geht ursprünglich auf eine Teradata-Klage aus dem Juni 2018 zurück, auf die weitere beiderseitige Klagen folgten. Teradata warf SAP vor, über Jahrzehnte geistiges Eigentum gestohlen und seine Marktmacht ausgenutzt zu haben. Den Anschuldigungen zufolge habe der deutsche Softwarekonzern ein 2006 gemeinsam gegründetes Joint-Venture dazu genutzt, Zugriff auf das geistige Eigentum von Teradata zu erhalten. SAPs Bündelung der HANA-Datenbank mit dem ERP-System S/4HANA sei zudem eine Benachteiligung anderer Anbieter und verstoße damit gegen US-Wettbewerbsrecht.
SAP hatte laut Gerichtsdokumenten 2019 mit einer Patentklage in den USA zurückgeschlagen. Teradata legte darauf 2020 mit einer zweiten Klage in den USA nach und SAP 2021 mit weiteren Patentverletzungsvorwürfen. Der Streit lief durch verschiedenen Instanzen, zuletzt scheitertete SAP am Obersten Gerichtshof der Vereinigten Staaten mit dem Antrag, Teradatas Klage wegen Verstoß gegen das US-Kartellrecht abzuweisen. Ein erneutes Gerichtsverfahren in der Sache war für April 2026 angesetzt.
(axk)

Social Media nach dem Massenfeed: Was Micro-Communities für Marken verändern

Android Studio Panda 2: KI-Agent erstellt neue Android-Apps

Zu viele Disclaimer? OpenAI macht ChatGPT mit GPT-5.3 direkter

Schnelles Boot statt Bus und Bahn: Was sich von London und New York lernen lässt

Community Management zwischen Reichweite und Verantwortung

Community Management und Zielgruppen-Analyse: Die besten Insights aus Blog und Podcast
-
 Künstliche Intelligenzvor 2 Monaten
Künstliche Intelligenzvor 2 MonatenSchnelles Boot statt Bus und Bahn: Was sich von London und New York lernen lässt
-
 Social Mediavor 3 Wochen
Social Mediavor 3 WochenCommunity Management zwischen Reichweite und Verantwortung
-
 Social Mediavor 2 Tagen
Social Mediavor 2 TagenCommunity Management und Zielgruppen-Analyse: Die besten Insights aus Blog und Podcast
-
Künstliche Intelligenzvor 2 Wochen
Top 10: Die beste kabellose Überwachungskamera im Test – Akku, WLAN, LTE & Solar
-

 Datenschutz & Sicherheitvor 3 Monaten
Datenschutz & Sicherheitvor 3 MonatenSyncthing‑Fork unter fremder Kontrolle? Community schluckt das nicht
-

 Entwicklung & Codevor 3 Monaten
Entwicklung & Codevor 3 MonatenKommentar: Anthropic verschenkt MCP – mit fragwürdigen Hintertüren
-

 Künstliche Intelligenzvor 3 Monaten
Künstliche Intelligenzvor 3 MonatenGame Over: JetBrains beendet Fleet und startet mit KI‑Plattform neu
-

 Social Mediavor 3 Monaten
Social Mediavor 3 MonatenDie meistgehörten Gastfolgen 2025 im Feed & Fudder Podcast – Social Media, Recruiting und Karriere-Insights

