Künstliche Intelligenz
Test: Roborock Qrevo Curv 2 Flow – Saugroboter mit kurioser Station & Wischwalze
Der Roborock Qrevo Curv 2 Flow ist der erste Saugroboter des Herstellers mit einer Wischwalze statt klassischer Wischmopps.
Roborock strukturiert sein Sortiment klar: Die Saros-Reihe bildet die absolute Spitze, die Qrevo-Modelle markieren den Einstieg in die Oberklasse. Der Hersteller setzt dabei zum Teil auf experimentelle Ansätze. Genau so einer steckt im Qrevo Curv 2 Flow: eine Wischwalze statt klassischer Wischmopps. Die soll während der Fahrt permanent abgestreift und mit Frischwasser beträufelt werden, sodass sie stets sauber und feucht bleibt. Der Roboter muss dadurch seltener zur Station zurückkehren. Gleichzeitig soll die Walze verhindern, dass grobe Verschmutzungen auf dem Boden verschmiert werden – ein typisches Problem herkömmlicher Roboter, die auf Mopps setzen.
Den Curv 2 gibt es in mehreren Varianten: als CurvX, 2 Pro und Curv 5A1. Die Wischwalze bleibt dabei dem Flow vorbehalten. Das Stationsdesign teilen sich alle Modelle. Preislich steigt der Qrevo Curv 2 Flow mit 899 Euro ein – deutlich günstiger als der Vorgänger, der seinerzeit über 1000 Euro kostete, und weit unter dem Saros 20 für fast 1500 Euro. Was der Roborock Qrevo Curv 2 Flow im Alltag leistet, zeigt unser Test. Das Testgerät hat uns der Hersteller zur Verfügung gestellt.
Design: Wie gut ist die Verarbeitung des Roborock Qrevo Curv 2 Flow?
Der Roboter selbst misst 353 mm im Durchmesser bei einer Höhe von 119 mm und ist in Weiß gehalten. An der Unterseite sitzen zwei gegenläufig rotierende Seitenbürsten mit Anti-Tangle-Funktion sowie die Duo-Divide-Hauptbürste. Die ausfahrbare Spira-Flow-Wischwalze ersetzt die bei anderen Modellen üblichen Wischmopps.
Roborock Qrevo Curv 2 Flow – Bilderstrecke
Roborock Qrevo Curv 2 Flow – Bilderstrecke

Roborock Qrevo Curv 2 Flow – Bilderstrecke

Roborock Qrevo Curv 2 Flow – Bilderstrecke

Roborock Qrevo Curv 2 Flow – Bilderstrecke

Roborock Qrevo Curv 2 Flow – Bilderstrecke

Roborock Qrevo Curv 2 Flow – Bilderstrecke

Roborock Qrevo Curv 2 Flow – Bilderstrecke

Roborock Qrevo Curv 2 Flow – Bilderstrecke

Roborock Qrevo Curv 2 Flow – Bilderstrecke

Roborock Qrevo Curv 2 Flow – Bilderstrecke

Roborock Qrevo Curv 2 Flow – Bilderstrecke

Roborock Qrevo Curv 2 Flow – Bilderstrecke

Roborock Qrevo Curv 2 Flow – Bilderstrecke

Roborock Qrevo Curv 2 Flow – Bilderstrecke

Roborock Qrevo Curv 2 Flow – Bilderstrecke

Roborock Qrevo Curv 2 Flow – Bilderstrecke

Roborock Qrevo Curv 2 Flow – Bilderstrecke

Roborock Qrevo Curv 2 Flow – Bilderstrecke

Roborock Qrevo Curv 2 Flow – Bilderstrecke

Roborock Qrevo Curv 2 Flow – Bilderstrecke

Roborock Qrevo Curv 2 Flow – Bilderstrecke

Die Station fällt sofort ins Auge. Roborock setzt erneut auf das kubische Design mit stark abgerundeten Kanten, das schon beim Vorgänger polarisierte. Manche Kollegen in der Redaktion bezeichnen sie als hässliche Tonne, andere finden das Design zumindest ungewöhnlich. Ästhetik ist immer individuell – in jedem Fall kein gewöhnlicher Anblick. Die Station misst 450 × 450 × 450 mm und beherbergt unter dem Deckel den Frischwassertank (4 Liter), den Schmutzwassertank (3 Liter) sowie den Staubbeutel (2,5 Liter) mit einer kleinen Abdeckhaube.
Die Verarbeitungsqualität geht in Ordnung, liegt aber unter dem Niveau des teureren Saros 20. Der Deckel oben an der Station lässt sich bei etwas Gegendruck leicht verwinden und senkt sich nicht sanft, sondern klatscht etwas unsanft nach unten. Das hätte man eleganter lösen können, ist aber nicht weiter tragisch – das Produkt fällt nicht auseinander. Es sind Kleinigkeiten, die im Alltag kaum stören.
Einrichtung: Wie schnell ist der Roborock Qrevo Curv 2 Flow betriebsbereit?
Die Einrichtung folgt dem üblichen Schema für Saugroboter. Zunächst meldet man sich in der Roborock-App an und scannt den QR-Code am Roboter. Danach gewährt man der App die benötigten Berechtigungen für Standort und Umgebungssuche und versetzt den Roboter durch gleichzeitiges Drücken der Home- und Power-Taste in den Pairing-Modus. Anschließend richtet man das WLAN ein – unterstützt wird ausschließlich das 2,4-GHz-Band.
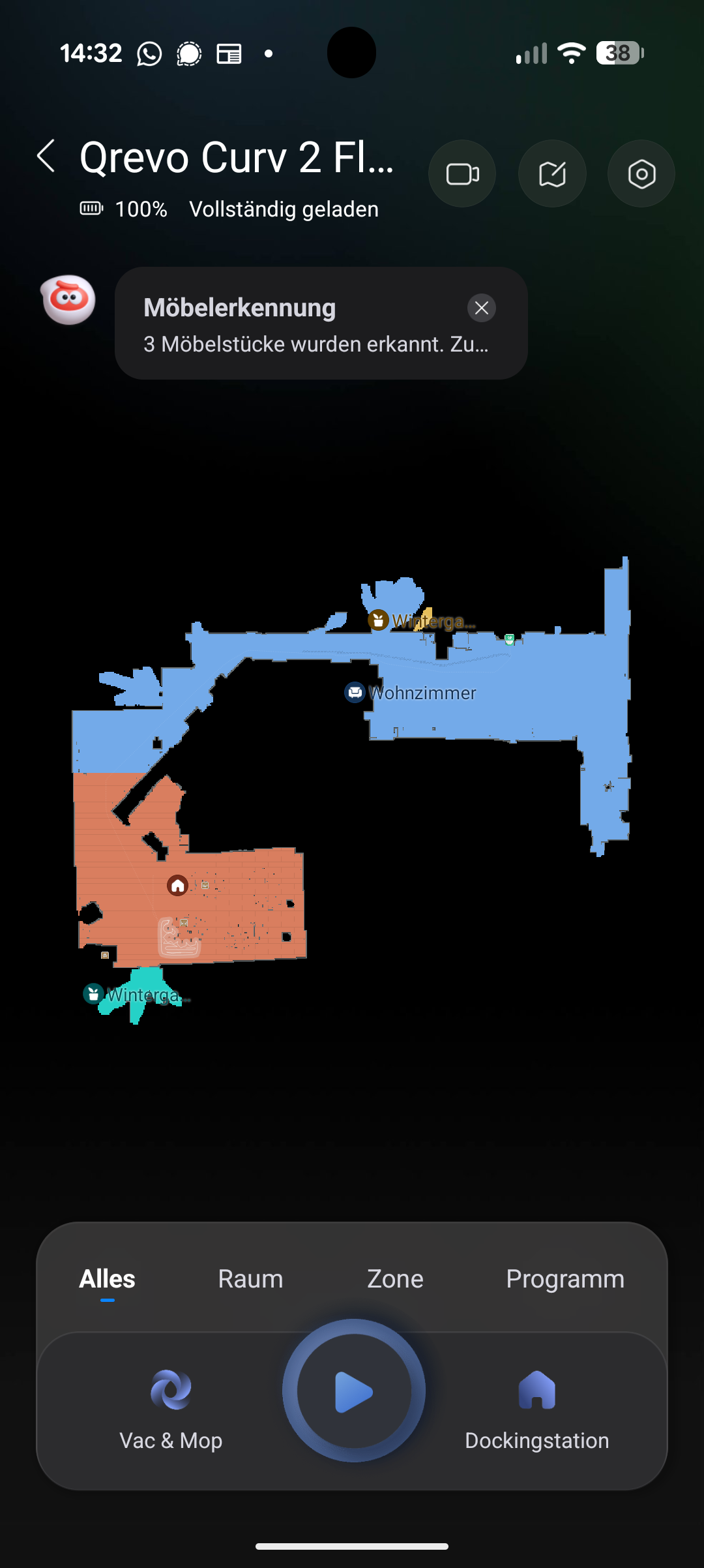
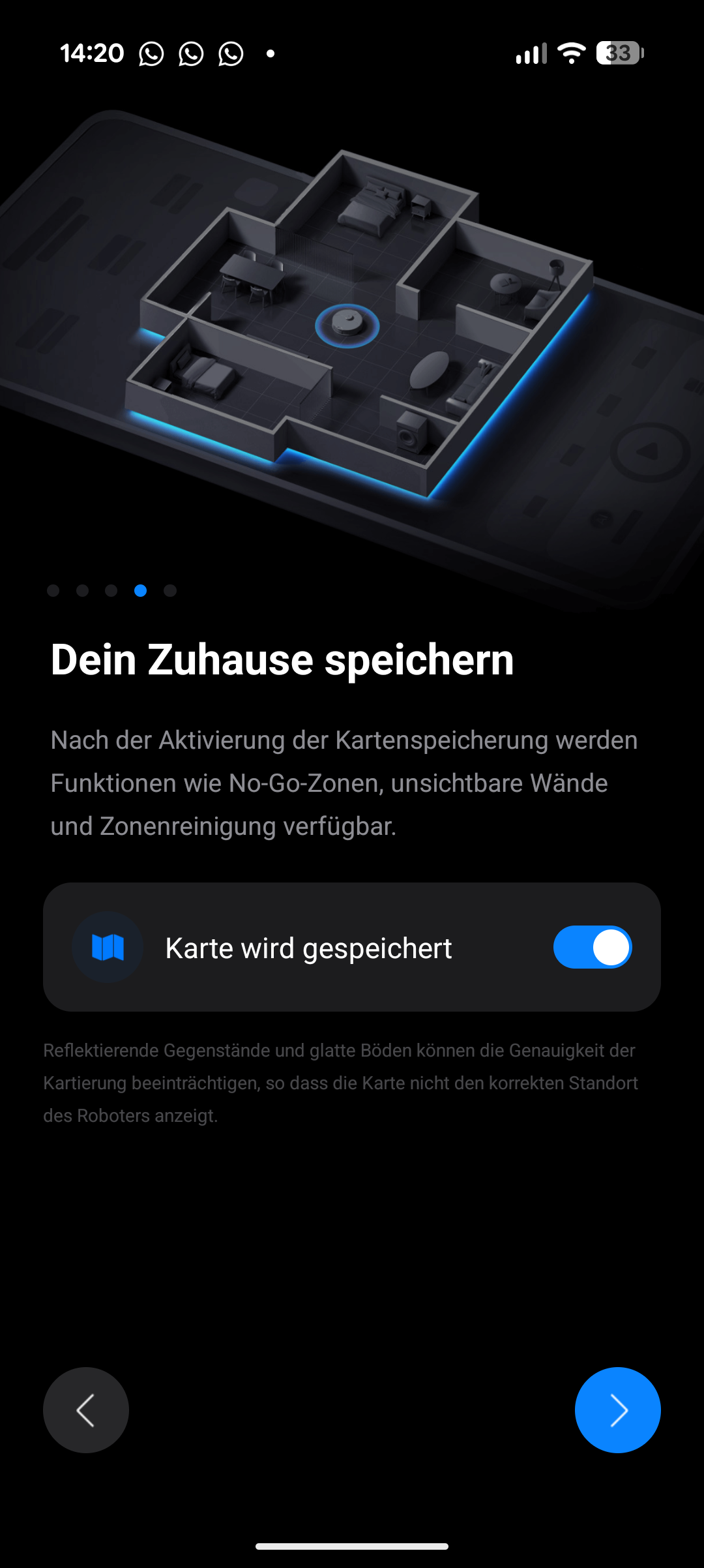
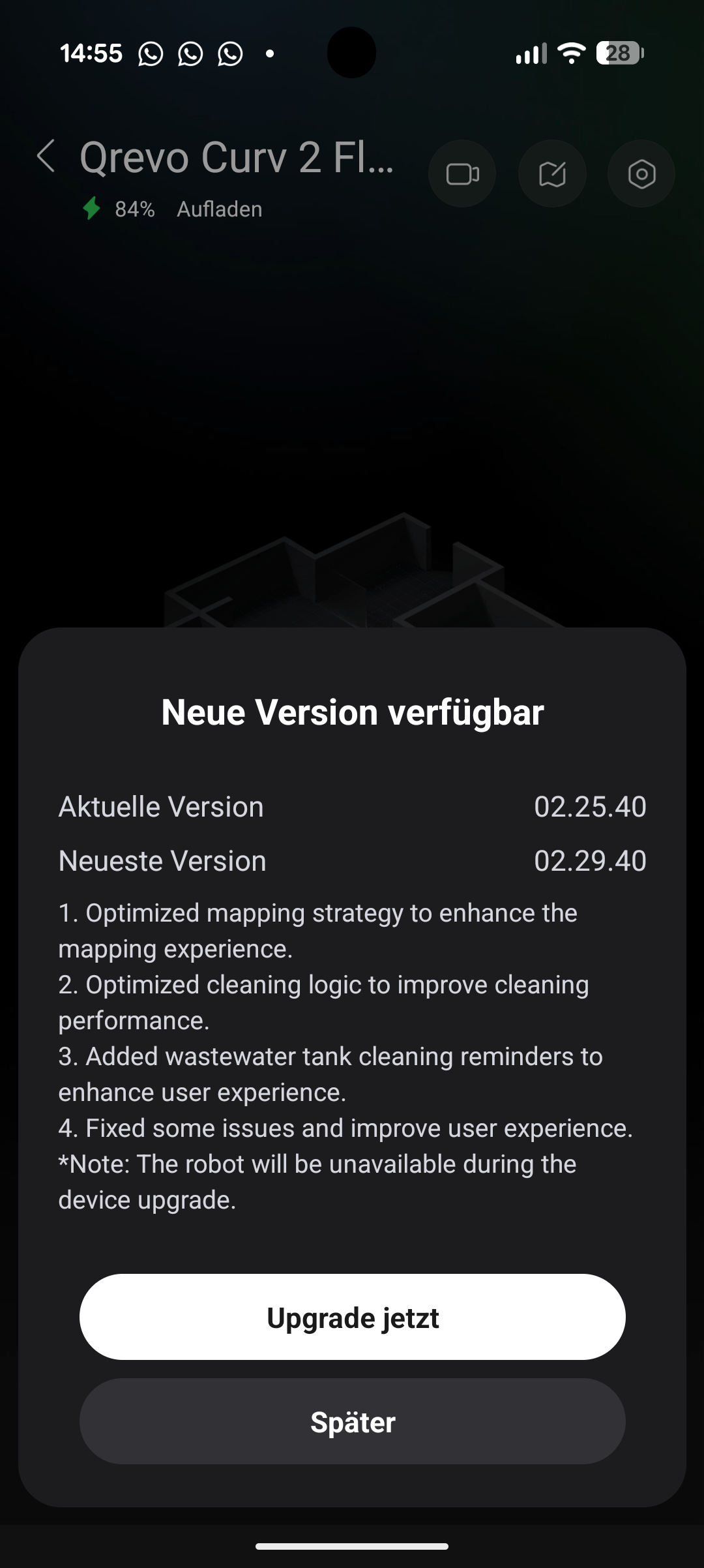
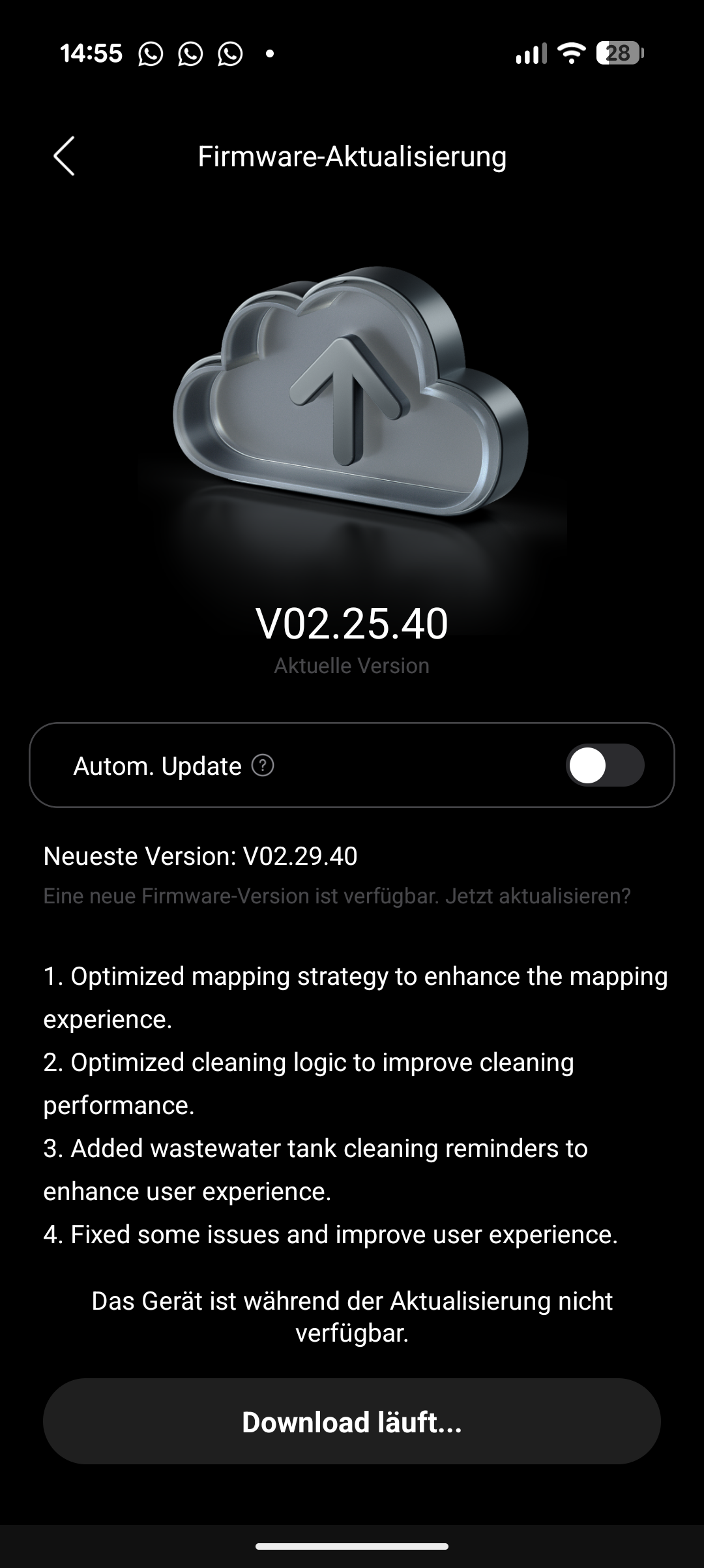
Direkt nach der Einrichtung steht ein größeres Softwareupdate an, das etwa zehn Minuten dauert. Danach startet die Kartierung der Wohnung, die je nach Größe 15 bis 20 Minuten in Anspruch nimmt. Die erstellte Karte fällt dabei etwas ausgefranster aus als etwa beim Saros 20 – die Kanten wirken nicht ganz so klar gezogen, sondern leicht huckelig. Auf die Reinigungsleistung hat das keine Auswirkung, die Räume werden dennoch klar voneinander abgetrennt.
Roborock Qrevo Curv 2 Flow – App & Einrichtung
Roborock Qrevo Curv 2 Flow – App & Einrichtung
Roborock Qrevo Curv 2 Flow – App & Einrichtung
Roborock Qrevo Curv 2 Flow – App & Einrichtung
Roborock Qrevo Curv 2 Flow – App & Einrichtung

Roborock Qrevo Curv 2 Flow – App & Einrichtung
Roborock Qrevo Curv 2 Flow – App & Einrichtung

Roborock Qrevo Curv 2 Flow – App & Einrichtung
Roborock Qrevo Curv 2 Flow – App & Einrichtung

Roborock Qrevo Curv 2 Flow – App & Einrichtung

Roborock Qrevo Curv 2 Flow – App & Einrichtung
Roborock Qrevo Curv 2 Flow – App & Einrichtung
Roborock Qrevo Curv 2 Flow – App & Einrichtung
Roborock Qrevo Curv 2 Flow – App & Einrichtung
Roborock Qrevo Curv 2 Flow – App & Einrichtung
Roborock Qrevo Curv 2 Flow – App & Einrichtung
Roborock Qrevo Curv 2 Flow – App & Einrichtung
Roborock Qrevo Curv 2 Flow – App & Einrichtung
Roborock Qrevo Curv 2 Flow – App & Einrichtung
Roborock Qrevo Curv 2 Flow – App & Einrichtung

Roborock Qrevo Curv 2 Flow – App & Einrichtung

Roborock Qrevo Curv 2 Flow – App & Einrichtung

Roborock Qrevo Curv 2 Flow – App & Einrichtung

Roborock Qrevo Curv 2 Flow – App & Einrichtung

Roborock Qrevo Curv 2 Flow – App & Einrichtung
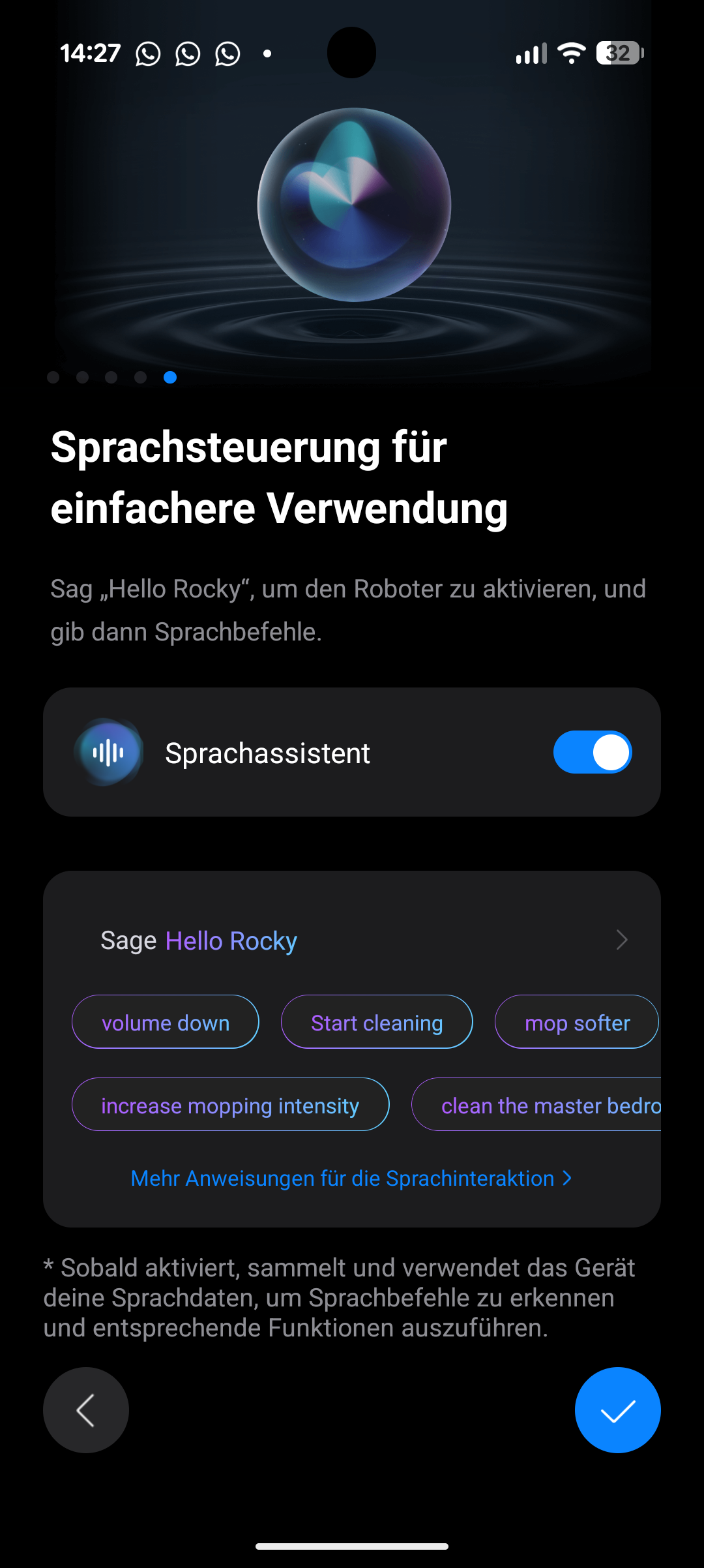
Die Roborock-App gehört zu den ausgewogensten am Markt. Sie ist intuitiv aufgebaut, bietet viele Funktionen und arbeitet zuverlässig ohne Fehler oder Grafik-Glitches. Reinigungszonen, Sperrzonen, Zeitpläne und Reinigungsintensitäten lassen sich komfortabel einstellen. Der Roboter unterstützt zudem Matter, Amazon Alexa, Apple Siri und Google Assistant.
Eine Offline-Karte lässt sich aktivieren, allerdings funktionieren viele Einstellungen, Benachrichtigungen und die Videofunktion – bei der man sich auf die Kamera des Roboters schalten und ihn fernsteuern kann – nur mit Internetverbindung. Für Datenschutz-bewusste Nutzer lässt sich die reaktive KI-Hinderniserkennung deaktivieren. Roborock wirbt zudem mit einer TÜV-Zertifizierung der Software (basierend auf dem Standard ETSI EN 303 645). Generell gilt aber für alle Cloud-abhängigen Produkte, dass diese immer ein Risiko für Schwachstellen und Ausnutzung durch Kriminelle haben, solange sie im Internet hängen und auf das Wohlwollen des Herstellers angewiesen sind, wie lange die Dienste funktionieren.
Die Sprachausgabe des Roboters ist angenehm zurückhaltend. Sie stört nicht mit zu vielen Bemerkungen und hält sich kurz – definitiv eine der angenehmeren unter den Saugrobotern.
Navigation: Wie gut erkennt der Roborock Qrevo Curv 2 Flow Hindernisse?
Der Roborock Qrevo Curv 2 Flow navigiert per LiDAR-Laser und Kamera mit KI-gestützter Hinderniserkennung. Absturzsensoren und Wandlaufsensoren ergänzen die Navigation. Teppiche erkennt der Roboter automatisch und hebt die Wischwalze um bis zu 15 mm an.
Im Test schlägt sich der Curv 2 Flow grundsätzlich gut und schreckt auch vor kniffligen Situationen nicht zurück. Mehrere Stuhlbeine, die unter dem Küchentisch eng beieinander stehen, meistert er problemlos – er fährt hinein und findet den Weg selbst wieder zurück. Rabiat wird er dabei nicht, Hindernisse hat er im Test nicht zusammengefahren.
Die Empfindlichkeit der Hinderniserkennung lässt sich in der App individuell anpassen. Bei der Standard-Einstellung hat sich der Roboter an besonders engen Stellen teilweise nicht getraut und den Reinigungsvorgang vorzeitig beendet. Wer das nicht möchte, dreht die Empfindlichkeit etwas herunter – dann fährt der Curv 2 Flow auch engere Passagen ab.
Reinigung: Wie gut saugt und wischt der Roborock Qrevo Curv 2 Flow?
Der Roborock Qrevo Curv 2 Flow saugt mit bis zu 20.000 Pa Saugleistung. Im Roboter sitzen ein 324-ml-Staubbehälter sowie je 100 ml Frisch- und Schmutzwasser. Die Duo-Divide-Hauptbürste mit Anti-Tangle-Funktion soll verhindern, dass sich Haare um die Bürste wickeln. Zwei gegenläufig rotierende Seitenbürsten befördern Schmutz zur Absaugöffnung in der Mitte des Roboters.
Auf Hartboden überzeugt der Curv 2 Flow. Grobe Partikel nimmt er zuverlässig auf, feiner Staub wird dank der Wischwalze ebenfalls schnell und restlos beseitigt. Die beiden Seitenbürsten arbeiten dabei effektiver als die Einzelbürste des teureren Saros 20, da sie Partikel gegenläufig zur Mitte hin kehren. Allerdings rotieren sie zum Teil zu schnell und schleudern – wie quasi alle Saugroboter – einzelne Partikel durch den Raum.
Auf Teppich entfernt der Roboter grobe Partikel wie Vogelfutter nahezu vollständig. Bei feinem Staub, simuliert durch Mehl, schafft er allerdings nur etwa 75 Prozent. Auf unseren Teppich kommt er dabei nicht ganz so mühelos wie der Saros 20. Zwar kann auch der Qrevo Curv 2 Flow sein Chassis aufkippen und Schwellen bis 2 cm überwinden, im Test faltet er den Teppich aber dennoch teils auf.
Roborock Qrevo Curv 2 Flow – Reinigung
Roborock Qrevo Curv 2 Flow – Reinigung

Roborock Qrevo Curv 2 Flow – Reinigung

Roborock Qrevo Curv 2 Flow – Reinigung

Roborock Qrevo Curv 2 Flow – Reinigung

Roborock Qrevo Curv 2 Flow – Reinigung

Roborock Qrevo Curv 2 Flow – Reinigung

Roborock Qrevo Curv 2 Flow – Reinigung

Roborock Qrevo Curv 2 Flow – Reinigung

Die Spira-Flow-Wischwalze ist das zentrale Feature des Flow-Modells. Sie rotiert mit 220 Umdrehungen pro Minute und drückt mit 15 Newton auf den Boden. Acht präzise Düsen – sogenannte Hydratationspunkte – versorgen die Walze gleichmäßig mit Frischwasser. Ein integrierter Abstreifer entfernt dabei laufend überschüssige Feuchtigkeit und leitet das Schmutzwasser direkt in den 100-ml-Schmutzwassertank im Roboter. Dieser Prozess findet permanent während der Fahrt statt, nicht erst in der Station. So bleibt die Walze stets optimal feucht, ohne zu tropfen, und die Reinigungsleistung konstant hoch. Herkömmliche Mopps neigen bei zunehmender Sättigung mit Schmutz dazu, gröbere Verschmutzungen eher zu verschmieren als zu entfernen – die Wischwalze schafft das deutlich besser.
Allerdings bringen Wischwalzen auch einen erhöhten Wartungsaufwand mit sich, da mehr Teile zur vollständigen Reinigung des Roboters ausgebaut werden müssen. Den Schmutzwassertank an der Rückseite des Roboters sollte man mindestens wöchentlich von hängengebliebenen Partikeln und Schmutz befreien – er lässt sich einfach entnehmen. Gleiches gilt für die Walze und den Abstreifer: Beide sollte man regelmäßig von Rückständen wie Staub befreien. Bei Roborock lassen sich diese Teile recht angenehm erreichen.
Für Parkettböden kann die Wischwalze allerdings die falsche Wahl sein: Mopps arbeiten hier schonender und verteilen weniger Wasser auf den Boden. Eine Walze kann bei zu viel nachgeträufeltem Wasser das Parkett auf Dauer zum Aufquellen bringen.
Der Roboter wischt mit Frischwasser ohne spezifische Heißwassertemperatur während der Bodenreinigung. In der Station wird die Wischwalze mit bis zu 75 °C heißem Wasser gewaschen und mit bis zu 55 °C warmer Luft getrocknet. Das reicht für den Alltag, gehört aber nicht zu den Spitzenwerten – der Saros 20 arbeitet hier mit 100 Grad. Die Station saugt den Staubbehälter automatisch in den 2,5-Liter-Staubbeutel ab.
Die Lautstärke hält sich im normalen Modus mit 56 dB(A) in Grenzen. Unter Maximalstufe steigt sie auf etwa 65 dB(A).
Akkulaufzeit: Wie lange arbeitet der Roborock Qrevo Curv 2 Flow?
Der Roborock Qrevo Curv 2 Flow wird von einem 14,4-V-Akku mit 5,2 Ah (Li-Ionen) angetrieben. Roborock gibt eine Betriebsdauer von bis zu 242 Minuten an, die wir im Test bestätigen können. Das ist ein starker Wert, der auch größere Wohnungen in einem Durchgang abdecken sollte. Die vollständige Ladung dauert etwa drei Stunden.
Preis: Was kostet der Roborock Qrevo Curv 2 Flow?
Der Roborock Qrevo Curv 2 Flow startet mit einer UVP von 899 Euro.
Fazit
Der Roborock Qrevo Curv 2 Flow ist ein rundum zufriedenstellender Oberklasse-Saugroboter, der mit seiner Spira-Flow-Wischwalze einen spürbaren Vorteil gegenüber klassischen Wischmopps bietet. Acht Düsen versorgen die Walze gleichmäßig mit Wasser, der Abstreifer hält sie sauber – und das alles permanent während der Fahrt. Grobe Verschmutzungen werden nicht verschmiert, sondern tatsächlich aufgenommen.
Die Reinigungsleistung auf Hartboden überzeugt, auf Teppich gibt es bei feinem Staub leichte Abstriche. Die zwei gegenläufigen Seitenbürsten arbeiten gründlich, schleudern aber vereinzelt Partikel weg. Die Station erledigt Reinigung, Trocknung und Absaugung zuverlässig, erreicht bei der Wassertemperatur aber nicht die Spitzenwerte des teureren Saros 20. Die App gehört zu den besten am Markt.
Der erhöhte Wartungsaufwand durch Walze, Abstreifer und Schmutzwassertank ist der Preis für das moderne Wischkonzept. Das Stationsdesign ist sicherlich Geschmackssache. Die Verarbeitung am Deckel zeigt kleine Schwächen. Für 899 Euro bekommt man aber einen mehr als soliden Allrounder.












Künstliche Intelligenz
Social Media: Offenbar weitreichende Störungen bei Meta
Die Plattformen von Meta sind offenbar von einer großflächigen Störung betroffen. Nutzer in aller Welt berichten über Ausfälle und Verbindungsprobleme. Betroffen sind demnach vor allem Instagram und Facebook, darüber hinaus gibt es Berichte über Probleme mit Threads und dem Messenger.
Weiterlesen nach der Anzeige
Auch auf verschiedenen Störungsseiten melden Nutzer seit etwa 15:30 Uhr am Freitagnachmittag Probleme. Sie können Instagram und Facebook nicht erreichen, Inhalte werden nicht geladen. Auch berichten Nutzer, dass sie von ihren Accounts abgemeldet wurden und sich nicht wieder anmelden können.
Weitere Informationen zu Ausmaß und Ursache der Störung gibt es derzeit noch nicht. Für einige Nutzer scheint sich die Lage teilweise wieder zu stabilisieren.


(Bild: Screenshot)
Inzwischen meldet Meta selbst Störungen in seinem Werbenetzwerk, die offenbar auf die Verbindungsprobleme zurückgehen. Demnach konnten Anzeigenkunden keine Kampagnen mehr erstellen und ausspielen. Auch der Zugriff auf Anzeigen-Berichte sowie die Geschäftskunden-API von Whatsapp sind demnach betroffen.
Update
12.06.2026,
16:37
Uhr
Angaben zu Störungen in Metas Werbenetzwerk ergänzt.
(vbr)
Künstliche Intelligenz
Bundesnetzagentur vs. Steam: Ermittlungen wegen „Plantagen-Simulator“
Die Gaming-Plattform Steam steht im Fokus der deutschen Behörden. Der bei der Bundesnetzagentur angesiedelte Digital Services Coordinator (DSC) hat Ermittlungen gegen den Betreiber Valve eingeleitet. Anlass für das Verfahren ist das Videospiel „Plantation Simulator“, das vor wenigen Wochen bereits für internationale Proteste sorgte.
Weiterlesen nach der Anzeige
Im Fokus der Untersuchung steht weniger das Spiel selbst als die Frage, ob Steam den strengen Sorgfaltspflichten des Digital Services Act (DSA) nachgekommen ist. Die Behörde prüft, ob die Plattform möglicherweise rechtswidrige Inhalte adäquat filtert und auf Beschwerden von Nutzern rechtzeitig und gesetzeskonform reagiert.
„Plantation Simulator“ ist ein simples Videospiel, in dem es um den Betrieb einer historischen Plantage geht. Vom Entwickler als historische Simulation deklariert, simuliert das Spiel vor allem eine rassistische Vergangenheit: Das spielerische Kernelement bestand darin, die Produktivität des Betriebs durch Auspeitschen der als Arbeitskräfte eingesetzten dunkelhäutigen Spielfiguren zu steigern.
Die Veröffentlichung löste im Netz Entrüstung aus. Auf Plattformen wie Reddit oder X sorgte das „Spiel“ für Debatten. Während einige Beobachter den Entwickler für einen Troll mit geschmacklosem Humor halten, werfen ihm andere die Normalisierung von Sklaverei und rassistischer Gewalt vor. Die Plattform soll zahlreiche Beschwerden über die Veröffentlichung erhalten haben.
Die Rolle des Digital Services Act
Auf Steam findet im Vorfeld von Veröffentlichungen keine Qualitätskontrolle statt. Jeder registrierte Entwickler kann Software einreichen und auf den Servern platzieren, ohne dass der Betreiber Valve die Inhalte vorab aktiv absegnet. Umso wichtiger sind die nachgelagerten Beschwerdemechanismen. Der DSA verpflichtet Plattformen dazu, ein leicht zugängliches, gut auffindbares und benutzerfreundliches Verfahren bereitzustellen, über das Nutzer mutmaßlich rechtswidrige Inhalte unkompliziert melden können.
Solche Hinweise müssen von den Betreibern unverzüglich, sorgfältig und unparteiisch geprüft werden. Zudem steht Steam in der Pflicht, die Nutzer über das Ergebnis dieser Begutachtung transparent zu informieren. An diesem Punkt setzen die Ermittlungen des deutschen DSC an. Bislang äußerte sich Valve nicht dazu, ob der Titel intern überhaupt geprüft wurde oder ob Beschwerdeführer eine Rückmeldung erhielten. Letztlich reagierte nicht Valve, sondern der Entwickler selbst auf den Druck der Öffentlichkeit: Er modifizierte das Spiel zunächst und zog es schließlich vollständig von der Plattform zurück.
Weiterlesen nach der Anzeige
Für die Bundesnetzagentur ist der Fall damit aber nicht ad acta gelegt. Das primäre Ziel des DSA-Verfahrens ist nicht die Entfernung eines einzelnen Titels, sondern zu prüfen, ob eine Plattform die Regeln eingehalten hat. Bei dem Ermittlungsverfahren geht laut einer Mitteilung der Behörde darum, strukturelle Defizite im Meldesystem von Steam aufzudecken und nachhaltig zu korrigieren.
Kooperation und drohende Konsequenzen
Da Steam seinen rechtlichen Vertreter innerhalb der EU in Deutschland benannt hat, fällt die Durchsetzung der Plattformregeln in die direkte Zuständigkeit des hiesigen DSC. Die Ermittler sind dabei international vernetzt: Die französische Medienaufsichtsbehörde Arcom, die als dortiger DSC fungiert, hatte im Vorfeld eigene Erkenntnisse gesammelt und diese gezielt an die Bundesnetzagentur übermittelt.
Steam hat nun Gelegenheit, zu den Vorwürfen Stellung zu nehmen. Sollte die Bundesnetzagentur am Ende des Verfahrens feststellen, dass die Plattform die Vorgaben des DSA missachtet oder unzureichend umgesetzt hat, stehen ihr umfangreiche Sanktionsmittel zur Verfügung. Das Spektrum reicht von Anordnungen zur Mängelbeseitigung über operative Auflagen bis hin zu Bußgeldern, die sich am globalen Umsatz des Unternehmens orientieren.
(dahe)
Künstliche Intelligenz
Medizinregistergesetz: Viele offene Fragen bei Forschungskennziffer und Co.
Mehrere Gesetzgebungsvorhaben sollen die Art und Weise, wie medizinische Daten gesammelt, genutzt und verknüpft werden, grundlegend verändern: unter anderem das Forschungsdatengesetz aus dem Bundesforschungsministerium sowie das Gesetz für Daten und Digitale Innovation im Gesundheitswesen (GeDIG) und das Medizinregistergesetz (MRG) aus dem Bundesgesundheitsministerium (BMG). Ziel ist eine bessere Nutzung von Gesundheitsdaten für die Forschung, die Versorgung und die Politik. Eine Forschungskennziffer soll dafür sorgen, dass Daten aus verschiedenen Quellen verknüpfbar gemacht werden. Kürzlich gab es dazu auch eine Anhörung im Gesundheitsausschuss.
Weiterlesen nach der Anzeige
Wofür es eine Kennziffer benötigt
„In Deutschland haben wir mehr als in anderen Ländern verteilte Datenbestände. Nicht nur aus Krankenhäusern und Praxen, sondern auch Daten aus Rehakliniken bei den Rentenversicherungsträgern oder von der Unfallversicherung. Mangels durchgängiger standardisierter medizinischer Dokumentation, gerade im ambulanten Bereich, erhalten wir bestimmte Informationen eben zum Beispiel nur aus den Daten der Krankenkassen. Wer forschen will, kämpft gegen eine strukturelle Zersplitterung, die historisch gewachsen und politisch kaum aufzubrechen ist“, so Sebastian C. Semler, Arzt und seit 2004 Geschäftsführer der Technologie- und Methodenplattform für die vernetzte medizinische Forschung e. V. (TMF).
Daher ist eine seit Jahren diskutierte Lösung eine eindeutige Kennziffer, die Datensätze verschiedener Herkunft einem gemeinsamen Fall zuordnet. Nicht um den Menschen dahinter zu identifizieren, sondern um zu wissen, dass dieser Datensatz aus dem Krankenhaus und jener aus der Rehaklinik zur selben Person gehören, betont Semler: „Es ist gar nicht wichtig, dass ich den Bürger dahinter erkenne. Es ist wichtig, dass ich weiß: Der Datensatz von Bürger X beim Niedergelassenen gehört zum gleichen Bürger wie der entsprechende Datensatz im Krankenhaus oder eben in der Rehaklinik. Dabei ist im Kern völlig unerheblich, ob das jetzt der Bürger Müller, Meier oder Schulze ist – es ist dabei entscheidend, dass ich die richtigen Daten zusammenführe.“
Uneinigkeit bei KVNR
Mittels Record-Linkage werden Datensätze über Kombinationen von Wohnort, Alter, Geschlecht und ähnlichen Merkmalen verknüpft, was bis zu einem gewissen Grad gut funktioniert. Auf Basis anonymisierter Daten lassen sich durchaus Daten zusammenführen. Laut Semler sei Record-Linkage mit manuellen Prüfungen sehr aufwendig und skaliere nicht. Massendaten ließen sich in dieser Form nicht analysieren. Mit 30 Patienten ginge das noch, aber bei 300.000 Datensätzen nicht.
Nur relativ wenige Identifikatoren sind Semler zufolge in der Fläche verfügbar und geeignet. Dazu gehören die Krankenversichertennummer (KVNR), die Steuer-ID und die Sozialversicherungsnummer. Zwar sei die KVNR in vielen Bereichen des Gesundheitswesens geeignet, aber nicht überall. Die Kassenärztliche Bundesvereinigung begrüßt in ihrer Stellungnahme den Einsatz der KVNR. Anders sieht es jedoch der IT-Sicherheitsrechtler Prof. Dennis-Kenji Kipker, der die Einführung einer Forschungskennziffer grundsätzlich begrüßenswert findet: Das greife aus seiner Sicht allerdings zu kurz, „solange sie nicht wirklich sektorübergreifend angelegt ist und Datenverknüpfungen etwa für Präventions- oder Pandemieforschung ermöglicht“. Zukünftig wird es immer relevanter, wie sich die Arbeitsfähigkeit der Bevölkerung entwickelt, ob Reha-Maßnahmen und Präventionsmaßnahmen wirken. „Dann sind Sie ganz schnell bei Datenbeständen, die Sie dringend brauchen, die aber keine KVNR halten“, so Semler.
Technische Umsetzung
Weiterlesen nach der Anzeige
Wie eine Forschungskennziffer technisch umgesetzt werden könnte, ist nicht trivial zu beantworten. Im Medizinregistergesetz (§ 20 Abs. 1 MRG) dürfen qualifizierte Register „den unveränderbaren Teil der Krankenversicherungsnummer nach § 290 Absatz 1 Satz 2 des Fünften Buches Sozialgesetzbuch zur Erzeugung eines Pseudonyms für die Verknüpfung mit anderen Datenquellen verarbeiten“. Das GeDIG regelt in § 3 GDNG die Forschungskennziffer ebenfalls auf Basis der KVNR. Das Forschungsdatengesetz des BMFTR hingegen setzt auf die Steuer-ID.
Alle datenführenden Stellen erhalten einen Algorithmus, der aus einem vorhandenen „Primäridentifikator“, etwa der KV-Nummer, ein Pseudonym generiert. Semler beschreibt das Modell als technisch grundsätzlich gangbar – mit Schwächen vor allem bei Skalierbarkeit und Updatefähigkeit. „Es ist durchaus denkbar, das so zu machen, wie es im GeDIG steht: Dass ich einen Identifikator habe, aus dem heraus ich eine solche ID generiere.“ Dann werde die ID an alle datenhaltenden Stellen verteilt. Dabei sei jedoch problematisch, dass das Verfahren überholt werden könne und dann nicht mehr sicher sei und dann in Abstimmung aller datenhaltenden Stellen ein neues Verfahren eingeführt werden müsse.
Bei einer weiteren Möglichkeit empfange eine Einrichtung auf Anfrage verschiedene Identifikatoren, generiere daraus ein anlassbezogenes Pseudonym und gebe dieses an den Forscher heraus, ohne dauerhaft personenbezogene Daten zu speichern: „Vielleicht muss ich gar nicht alle IDs irgendwo einführen“, erklärt Semler, „sondern ich schaffe eine Zentralstelle, die zum Bürger gehörige Identifikatoren zusammenführen kann, selbst auf Anfrage ein Pseudonym generiert und herausgibt, und die vor jeder Datenanfrage eine solche ID an den Forscher herausgibt, mit der er eben unterschiedliche Datenbestände abfragen kann. Wie auch immer man es macht: wichtig ist, einmal ein durchgängiges Fachkonzept zu entwickeln – gemeinsam mit Datennutzenden, die Daten zu Auswertungszwecken verknüpfen wollen, und mit Datenhaltenden, die die entsprechenden IDs in ihren Datenbeständen einführen müssen.“
Welcher Unique Identifier?
Die Koordinierungsgruppe Gesundheitsforschungsdateninfrastrukturen (GFDI), ein breites Bündnis wissenschaftlicher Organisationen unter Koordination von TMF, Medizininformatik-Initiative, dem Netzwerk Universitätsmedizin und weiteren, hat dazu in einer gemeinsamen Stellungnahme zum GeDIG unmissverständlich Stellung bezogen: „Zu vermeiden wäre ein Zustand, in dem unterschiedliche Gesetze die Einführung unterschiedlicher Unique Identifier (hier KVNR, dort Steuer-ID, sowie digitale Identität der gematik und EU-ID für die Versorgung) und mehrere Pseudonymisierungsverfahren erfordern, was allen Akteuren unnötige Doppelaufwände abverlangen würde.“ Erfahrungen aus der Verwaltungsdigitalisierung würden bereits zeigen, dass „die Einführung einer Forschungskennziffer in Datenbestände für die datenhaltenden Stellen ohnehin mit einem erheblichen Aufwand verbunden […]“. Dieser müsse in „Zeit- und Ressourcenplänen der Umsetzung berücksichtigt werden“.
KVNR für Obduktionsregister ohne Bezug zu Lebenden
Die GFDI benennt weitere konkrete Grenzen der KVNR: So sei die Verpflichtung, die KVNR aufzunehmen, für manche Register schlicht nicht sinnvoll. Ein Obduktionsregister etwa hat keinen Bezug zu lebenden Versicherten. Ein Lebendspenderegister hält die KVNR des Empfängers, nicht des Spenders. Und schließlich widerspreche sich die Pflicht zur KVNR-Aufnahme mit der im Gesetz vorgesehenen Widerspruchsmöglichkeit gegen eben diese Verarbeitung. Außerdem fehle der Bezug zu einem Unique Identifier, der nach der KVNR kommt – also eine langfristig tragfähige Lösung, die auch über den GKV-Bereich hinaus funktioniert.
Ebenso kritisiert die GFDI, dass die bisherigen Regelungen zur Datenverknüpfung – basierend auf der KVNR und dem staatlichen Pseudonymisierungs- und Vertrauensstellenverfahren beim RKI – „für die Bedarfe der medizinischen Forschung in toto […] viel zu kurz“ greifen. Was es stattdessen brauche, sei ein einheitlicher Identifikator, „der es möglich macht, Datenverknüpfungen über unterschiedliche Datenbestände und über unterschiedliche Geltungsbereiche gesetzlicher Grundlagen (FDG, GDNG, SGB) und deren staatlich-behördlicher Instanzen (FDZ, RKI, DZM etc.) und Verfahren hinweg für die medizinische Forschung datenschutzkonform herbeizuführen.
Thilo Weichert, ehemaliger Landesdatenschutzbeauftragter Schleswig-Holsteins und heute Co-Vorsitzender von Digitalcourage, stellt in seiner Stellungnahme fest, dass das MRG nicht mit dem Forschungsdatengesetz des BMFTR abgestimmt sei, das ebenfalls die Nutzung von Medizinregistern regeln solle. „Diese Diskrepanz führt zwangsläufig zu Rechtsunsicherheit“, schreibt er. Ein weiterer Kritikpunkt ist, dass der Gesetzentwurf Weichert zufolge vollständig ignoriere, dass es sich bei Medizinregistern weitgehend um Datenvermittlungsdienste im Sinne des europäischen Data Governance Acts (DGA) handele. Der DGA mache verbindliche Vorgaben zur Transparenz, Unabhängigkeit und zum Schutz der Betroffenen, die der Entwurf schlicht nicht berücksichtigt würden.
Pseudonymisierung
Kritikern zufolge ist die Forschungskennziffer zwar aus Forschungssicht notwendig, aber bei falscher Umsetzung hochproblematisch. Die Gesetzentwürfe sehen vor, dass Daten nicht mit Klarnamen, sondern pseudonymisiert zusammengeführt werden – auf Basis des unveränderlichen Teils der Krankenversicherungsnummer. „Pseudonymisierung bedeutet nicht Anonymisierung. Auch pseudonymisierte Gesundheitsdaten sind de facto personenbezogene Daten im Sinne der DSGVO, weil sie grundsätzlich wieder einer Person zugeordnet werden können – insbesondere wenn große Datensätze miteinander verknüpft werden,“ kritisiert Stella Merendino von den Linken.
„Das Gesundheitsministerium plant, das Gesundheitsdatennutzungsgesetz umfassend zu überarbeiten und dabei eine Forschungskennziffer einzuführen, mit der Gesundheitsdaten aus verschiedenen Datenquellen für Sekundärzwecke und damit auch für die wissenschaftliche medizinische Forschung zusammengeführt werden können“, sagt Weichert. Dabei werde, um möglichst viele Daten zu nutzen, „allen Gesundheitsdateninhabern erlaubt, die dort vorhandenen Patientendaten mit dieser Forschungskennziffer zu verbinden. Zweck der Kennziffer ist die Pseudonymisierung im Rahmen der Sekundärnutzung, also das Ersetzen der Klarnamen der Patienten durch diese Kennziffer“.
Merendino kritisiert: „Auch wenn Name und Adresse entfernt werden, können Daten über diese Nummer oder daraus erzeugte Kennzeichen langfristig immer wieder derselben Person zugeordnet werden – besonders bei raren Krankheitsbildern. Wenn aus dieser oder daraus abgeleiteten Identifikatoren stabile Forschungspseudonyme erzeugt werden, entsteht eben kein wirklich flüchtiger Datensatz, sondern eine dauerhaft verknüpfbare Datenbiografie.“
Das Zusammenführen der Daten werde so gelingen, so Weichert, „der Schutz der Daten aber nicht: Die Forschungskennziffer wird bei vielen Gesundheitseinrichtungen verfügbar sein. Alle diese Einrichtungen können so fremde über die Datenzusammenführung erlangte Daten den Betroffenen namentlich zuordnen. Bei der Ziffer handelt es sich um eine ‚nationale Kennziffer‘ gemäß Art. 87 DSGVO. Eine solche Ziffer ist nur zulässig, wenn sie ‚unter Wahrung geeigneter Rechte und Freiheiten der betroffenen Person‘ verwendet wird“, erklärt Weichert. Allerdings enthalte der Entwurf diese Garantien nicht.
„Garantien für Rechte und Freiheiten der Betroffenen erforderlich“
Weichert benennt in seiner Stellungnahme zum MRG (PDF) das Re-Identifikationsrisiko explizit als „gewaltig“. Explizite Kritik äußert er auch an der vorgesehenen Speicherdauer von 100 Jahren, die mit Forschungsinteressen begründet werden: „Derartige Forschungsinteressen können aber nicht in Bezug auf sämtliche in Medizinregistern gespeicherten Daten für diese lange Zeit für angemessen angesehen werden. Angesichts der ungenügenden Schutzvorkehrungen hinsichtlich der zumeist mit Klarnamen arbeitenden Register wird mit der Speicherdauer ein lebenslanges unverhältnismäßiges Risiko für die Betroffenen begründet“.
„Damit entsteht faktisch die technische Grundlage für jahrzehntelang nachvollziehbare Gesundheitsdatenbiografien. Während weiter empfohlen wird, Daten möglichst nur begrenzt und zweckgebunden vorzuhalten, öffnet der Gesetzentwurf die Datenverarbeitung sehr breit auch für Training, Validierung und Testung von KI-Systemen“, gibt Merendino zu bedenken. „Geschichte und internationale Beispiele zeigen leider, dass einmal geschaffene Dateninfrastrukturen fast immer ausgeweitet werden,“ mahnt Merendino. Als konkretes Beispiel verweist sie auf Großbritannien. Dort erhielt Palantir 2023 den Zuschlag für die sogenannte „Federated Data Platform“ des NHS – ein riesiges Projekt zur Zusammenführung von Gesundheits- und Verwaltungsdaten. Es folgte massive Kritik, nachdem bekannt wurde, dass externe Vertragspartner teilweise Zugriff auf identifizierbare Patientendaten erhalten hatten. Laut Guardian prüft NHS England inzwischen, ob Ausstiegsmöglichkeiten aus dem 330-Millionen-Pfund-Vertrag genutzt werden können.
Merendino betont auf Anfrage ausdrücklich: Es geht ihr nicht darum, Forschung pauschal abzulehnen. Ihr Palantir-Vergleich beziehe sich „auf die grundsätzliche Infrastruktur-Logik großer verknüpfbarer Datenräume. Demokratische und datenschutzpolitische Fragen werden nicht beantwortet: Wer kontrolliert diese Systeme? Welche privaten Akteure erhalten künftig Zugriff? Wie wird verhindert, dass aus Forschungsinfrastrukturen später Steuerungs- oder Bewertungsinstrumente werden?“
Weitgehende Verarbeitungsbefugnis
Auch Weichert kritisiert in seiner Stellungnahme an den Bundestag, die erlaubten Zwecke gingen weit über Forschung hinaus und erstreckten sich, selbst mit identifizierenden Daten, auf operative Zwecke wie Qualitätssicherung, Unterstützung politischer Entscheidungsprozesse und Entwicklung von KI-Systemen. „Eine derartig weitgehende Verarbeitungsbefugnis ist unverhältnismäßig und daher verfassungswidrig“, schreibt er. Besonders problematisch: Der Einsatz von KI sei sogar bei identifizierenden Daten ausdrücklich erlaubt – ohne verpflichtende Pseudonymisierung.
Transparenz und Betroffenenrechte?
Es fehle an der nötigen Transparenz für die Betroffenen. „Während jeder Forschende die Patientendaten für sein Projekt erhalten kann, wird den Betroffenen die Auskunft über ihre Daten verweigert; selbst ein Überblick, bei wem die Daten landen, wird ihnen vorenthalten“, kritisiert Weichert gegenüber heise online. Das Risiko für Datenmissbrauch sei hoch, weshalb eine „umfassende Kontrolle“ und „wirksam vollziehbarer Sanktionsregelungen“ notwendig seien. Doch werde die Datenschutzkontrolle nicht verbessert, „sondern nur konzentriert. Und jede Strafverfolgung wird von einem Strafantrag abhängig gemacht. Da Betroffene von sie betreffenden Datenmissbräuchen keine Kenntnis erlangen werden, können sie auch keinen Strafantrag stellen“.
„Weitere Vorkehrungen, wie sie der europäische Gesundheitsdatenraum vorsieht, fehlen. Der Entwurf muss umfassend nachgebessert werden. Anderenfalls sind Verstöße gegen das Grundrecht auf Datenschutz und das Patientengeheimnis vorprogrammiert“, schlussfolgert Weichert.
Was das BMG sagt
Auf Anfrage sagt das BMG, die Forschungskennziffer stelle „ein einheitliches Konzept für eine sektorspezifische Kennziffer im Gesundheitsbereich dar, deren Einführung im MRG vorbereitet und im GeDIG-E vollendet werden soll.“ Die KVNR biete sich an, weil sie bei Gesundheitsdateninhabern weit verbreitet sei. „Auch die Rentenversicherung und die Unfallversicherung verfügen bereits über KVNR,“ heißt es von einer BMG-Sprecherin. Die Konzeptionierung sei zudem gemeinsam mit Vertreterinnen und Vertretern der GFDI in einer Workshop-Reihe zur EHDS-Durchführung erfolgt, an der auch das BMFTR beteiligt gewesen sei. Zudem betont das BMG, die Forschungskennziffer sei für die Durchführung des EHDS „zwingend erforderlich“, da „nur so nachgehalten werden kann, wer bestimmten Datennutzungszwecken widersprochen hat.“
„Die technische Ausgestaltung der Forschungskennziffer obliegt dabei der koordinierenden Zugangsstelle für Gesundheitsdaten. Diese Aufgabe soll gemäß GeDIG-Entwurf von der Datenzugangs- und Koordinierungsstelle beim BfArM (dem Bundesinstitut für Arzneimittel und Medizinprodukte) übernommen werden“. Das technische Verfahren werde im Benehmen mit dem Bundesamt für Sicherheit in der Informationstechnik und dem Bundesdatenschutzbeauftragten festgelegt. „Damit ist eine spätere Anpassung des Algorithmus an den Stand der Technik möglich“, so das BMG auf Anfrage.
Uneinigkeit bei Widerspruchslösung
Uneinigkeit herrscht auch bei den Widerspruchsregelungen. Das GeDIG differenziert den Widerspruch nach Nutzungszwecken, beim Medizinregistergesetz ist etwa ein Widerspruch gegen die Datenerhebung und die Verarbeitung der KVNR möglich. Die GFDI empfiehlt in ihrer Stellungnahme zum GeDIG ausdrücklich, „zu prüfen, ob die gestufte Widerspruchsmöglichkeit wirklich erforderlich ist, zumal sie der EHDS nicht verbindlich vorsieht. Eine Widerspruchsmöglichkeit zu einzelnen Nutzungszwecken verkomplizieren das Widerspruchsverfahren für alle Beteiligten erheblich und werden einer notwendigen Automatisierung von Datennutzungsanfragen empfindlich im Wege stehen. Den Betroffenenrechten ist mit der Möglichkeit, grundsätzlich der Nutzung zu widersprechen, Genüge getan.“
Semler spricht sich für ein grundsätzliches Widerspruchsrecht aus. Wer nicht möchte, dass seine Daten für Forschung genutzt werden, soll das klar erklären können: „Wenn ich als Bürger grundsätzlich sagen kann, ich habe keine Lust, dass meine Daten für Forschung genutzt werden, dann ist meiner Autonomie als Bürger Genüge getan.“
Merendino zufolge müsse das Widerspruchsrecht nicht nur formal existieren, sondern technisch vollständig und maschinell umgesetzt werden. Ein erklärter Widerspruch muss zuverlässig umgesetzt werden, was aktuell nicht der Fall ist. Das Widerspruchsrecht ist in seiner jetzigen Form weder praktisch handhabbar noch datenschutzrechtlich belastbar. Aktuell gibt es immer mal wieder Schwierigkeiten bei der Umsetzung des Widerspruchsrechts.
Weichert kritisiert, dass Betroffene mangels individueller Information gar nicht in der Lage sind, informierte Widersprüche zu erklären. Wer nicht weiß, wer seine Daten wie nutzt, kann nicht sinnvoll widersprechen. Die Widerspruchsmöglichkeit ist beispielsweise gegen die Nutzung des unveränderbaren Teils der KVNR formal vorhanden, praktisch aber entwertet. Es fehle unter anderem eine individuelle Information über das Widerspruchsrecht, die „lediglich öffentlich und allgemein“ vorgesehen ist. Da sich die Widerspruchsmöglichkeit auf die Abwehr einer „eher abstrakten Gefahr eines Datenmissbrauchs in äußerst komplexen Verarbeitungszusammenhängen“ beziehe, sei es für Betroffene kaum möglich, insofern eine rationale Entscheidung zu treffen.
Finanzierungsfrage
Was ebenfalls fehle, sei eine tragfähige Finanzierung. Der Gesetzentwurf schaffe erhebliche neue Anforderungen an Qualitätsentwicklung, Dokumentation, Interoperabilität und regulatorische Anpassung. Bei den Vorhaben mangelt es jedoch – wie so oft – an der Finanzierung, wie zahlreiche Verbände in ihren Stellungnahmen bemängeln. Dr. Anne Regierer, Sprecherin der TMF-Arbeitsgruppe Register, sagt dazu: „Nach heutigem Stand würde kaum ein Register eine Qualifizierung nach dem vorgesehenen Verfahren anstreben, weil der Aufwand hoch, der konkrete Nutzen gering und die Risiken schwer einzuschätzen sind.“
Das BMG sieht das anders: Das MRG schaffe „erhebliche Erleichterungen für die Betreiber qualifizierter Medizinregister“ – etwa durch erleichterte Datenverarbeitung per Opt-out und durch Kooperationsmöglichkeiten mit anderen Registern. „Schon jetzt finanzieren sich Medizinregister u.a. durch nutzungsabhängige Bereitstellung ihrer Daten. Inwieweit sich für Medizinregister darüber hinaus andere Finanzierungsmodelle anbieten, geht mit der Frage einher, in welcher Form und durch welche Akteure qualifizierte Medizinregister zukünftig genutzt werden,“ so eine Sprecherin. Weitere Finanzierungsmodelle seien eine nachgelagerte Frage: „Das Medizinregistergesetz geht mit seinen Lösungen also nur einen ersten Schritt, an den sich weitere Fragestellungen anschließen.“
Ausreichende Schutzvorkehrungen notwendig
Weicherts Minimalforderungen für einen solchen Rahmen sind klar, es braucht ausreichende Schutzvorkehrungen: Die Information der Betroffenen muss konkret im Einzelfall erfolgen, nicht nur allgemein. In seiner Stellungnahme an den Bundestag fordert er zahlreiche weitere Regelungen. Dazu zählen beispielsweise eine zweckgebundene differenzierte Speicherfrist, keine pauschalen Freigaben und ein Beschlagnahmeverbot. Zudem müsse das Zentrum für Medizinregister unabhängig genug sein, um tatsächliche Kontrollfunktionen wahrzunehmen.
Zwar begrüßt Weichert eine Ordnung der unübersichtlichen Registerlandschaft, jedoch verstoße der Entwurf „in vieler Hinsicht gegen die DSGVO sowie, grundsätzlicher, gegen das europarechtlich und verfassungsrechtlich garantierte Grundrecht auf Datenschutz“.
Auch Merendino geht es nicht darum, die Forschung pauschal abzulehnen. „Gute Forschung kann Versorgung verbessern. Aber je zentraler, dauerhafter und verknüpfbarer Gesundheitsdaten organisiert werden, desto höher müssen Datenschutz, demokratische Kontrolle und Transparenz sein.“ Nun ist es Aufgabe der Politik, sich um die Regelungen zum Datenschutz, Konzepte und die Finanzierung zu kümmern. „Das schönste Gesetz nutzt nichts, wenn es hinterher keine Anbindung findet,“ so Semler.
(mack)

Keine GPUs, aber CPUs?: Nvidia gibt bei Vera für China Gas, solange es noch geht

OpenAI übernimmt Ona – deutsche-startups.de

Social Media: Offenbar weitreichende Störungen bei Meta

Mähroboter ohne Begrenzungsdraht für Gärten mit bis zu 300 m²

iPhone Fold Leak: Apple spart sich wohl iPad‑Multitasking

JBL Bar 1300MK2 im Test: Soundbar mit Dolby Atmos, starkem Bass und Akku‑Rears
-
 Apps & Mobile Entwicklungvor 3 Monaten
Apps & Mobile Entwicklungvor 3 MonatenMähroboter ohne Begrenzungsdraht für Gärten mit bis zu 300 m²
-
 Künstliche Intelligenzvor 3 Monaten
Künstliche Intelligenzvor 3 MonateniPhone Fold Leak: Apple spart sich wohl iPad‑Multitasking
-
Künstliche Intelligenzvor 3 Monaten
JBL Bar 1300MK2 im Test: Soundbar mit Dolby Atmos, starkem Bass und Akku‑Rears
-

 Künstliche Intelligenzvor 3 Monaten
Künstliche Intelligenzvor 3 MonatenOscars 2026: Was die heise‑Leser anders entschieden hätten
-

 Künstliche Intelligenzvor 3 Monaten
Künstliche Intelligenzvor 3 MonatenEmpfehlungsalgorithmen bei TikTok erklärt: Die Maschine hinter dem Endlos‑Feed
-

 Social Mediavor 3 Monaten
Social Mediavor 3 MonatenVon Kennzeichnung bis Plattformpflichten: Was die EU-Regeln für Influencer Marketing bedeuten – Katy Link im AllSocial Interview
-
Künstliche Intelligenzvor 3 Monaten
Top 10: Die besten Wireless‑Adapter für Carplay im Test – iPhone kabellos nutzen
-

 Künstliche Intelligenzvor 2 Monaten
Künstliche Intelligenzvor 2 MonatenWeitere Entlassungswelle bei Disney: Bis zu 1000 Mitarbeiter betroffen


