Apps & Mobile Entwicklung
Nvidias Vera CPU im Detail
Vera ist Nvidias neue Datacenter-CPU für den Einsatz mit Rubin-GPU (als Vera Rubin) oder als eigenständige Lösung im Rack mit bis zu 256 Prozessoren. Im Rahmen der GTC 2026 hat Nvidia weitere technische Details zu Vera verraten: Vera hat mehr Kerne, unterstützt SMT, bietet größere Caches und nutzt schnelleren Speicher.
Nvidia Vera folgt auf die aktuelle Grace-CPU, die von Nvidia unter anderem als Single-Socket-Umsetzung Grace CPU C1, im Doppelpack als Grace CPU Superchip, oder im Zusammenspiel mit Blackwell-GPUs als Grace Blackwell (Ultra) angeboten wird.
Vera kommt auch im CPU-only-Rack
Vera soll im Laufe des zweiten Halbjahres 2026 an den Start gehen. Vorgesehen sind erneut unterschiedliche Konfigurationen, etwa in Kombination mit Rubin-GPUs, oder aber als reines CPU-Rack, das sich in Nvidias Referenz-Lösung mit bis zu 256 Prozessoren bestücken lässt. Partner wie HPE gehen sogar noch weiter und verbauen bis zu 640 Vera-CPUs in einem Server-Schrank.
88 Olympus-Kerne mit SMT
Vera macht einiges anders als Grace, wie eine technische Session zur GTC verdeutlichte. Zunächst einmal bietet Vera schlichtweg mehr Kerne als Grace: 88 statt 72. Es handelt es sich zudem nicht mehr um Neoverse-V2-Kerne von Arm, sondern um ein Custom-Design namens Olympus, dem die Architektur Arm v9.2 zugrunde liegt, auf der auch Neoverse-V3-Kerne basieren. Vera sei vollständig Arm-kompatibel, erklärt Nvidia.
Es sind in Vera aber nicht nur 16 Kerne mehr verbaut, das Design bringt erstmals auch „Spatial Multi-Threading“ (SMT) ins Spiel, sodass 176 Threads verarbeitet werden können. Im Gegensatz zu anderen SMT-Verfahren wird aber nicht auf ein Time-Slicing gesetzt, sodass „A“ und „B“ im Wechsel ausgeführt werden, sondern Vera kann bei SMT tatsächlich zwei Threads parallel über die Pipelines des Kerns verteilen.

Single Thread Mode oder SMT Mode
Dabei lässt sich Vera in zwei Modi betreiben:
- Im Single Thread Mode gibt es maximal einen aktiven Thread pro Core. Dieser Thread kann auf alle Ressourcen des Cores zugreifen, zum Beispiel auf die sechs SVE2-Pipelines.
- Im SMT Mode können hingegen bis zu zwei Threads pro Core aktiv sein. Jeder Olympus-Kern wird gegenüber dem Betriebssystem als zwei virtuelle Kerne exponiert. Die Ressourcen des Cores werden in dieser Konfiguration physisch partitioniert und stehen beiden Threads in gleicher Anzahl zur Verfügung, also etwa drei SVE2-Pipelines pro Thread. Ist im SMT Mode allerdings nur ein Thread aktiv, kann dieser wieder auf alle Ressourcen zugreifen.
Olympus ist ein 10-wide Design mit FP8-Support
Der Olympus genannte Custom-Arm-Core von Nvidia ist ein „10-wide“ Decode-Design und ist damit deutlich breiter als Grace aufgebaut. Beim Decode werden die geladenen Maschinenbefehle in interne Steuer- und Mikrooperationen übersetzt, damit die Recheneinheiten verstehen, was konkret ausgeführt werden soll.
Nvidia hat zudem den L2-Cache verdoppelt, den L1D-Cache vergrößert, mehr Vector Pipelines integriert, FP8-Support hinzugefügt und das zuvor erläuterte SMT integriert. Die Vera-CPU ist die weltweit erste Arm-CPU, die FP8-Operationen unterstützt, also denselben Datentyp, wie ihn auch Nvidias GPUs unterstützen.
Arm MPAM hält Einzug
Das Design führt zudem Arm MPAM ein. MPAM ist eine Hardware-Erweiterung in modernen Arm-Prozessoren, die eine feingranulare Kontrolle über gemeinsam genutzte Ressourcen wie Cache und Speicherbandbreite ermöglicht. Sie erlaubt es, diese Ressourcen bestimmten Anwendungen, Prozessen oder virtuellen Maschinen gezielt zuzuweisen, zu begrenzen oder zu priorisieren.
Gleichzeitig kann MPAM überwachen, wie stark einzelne Workloads diese Ressourcen tatsächlich nutzen. Das ist besonders wichtig in Systemen mit vielen parallel laufenden Aufgaben (z. B. Cloud, Server oder AI), da so verhindert wird, dass einzelne Anwendungen den Speicher „überlasten“ und andere ausbremsen. Insgesamt verbessert MPAM also Isolation, Vorhersagbarkeit und Quality of Service im System.
Darf es von allem deutlich mehr sein?
Vera ist auch über den Olympus-Kern hinaus ein mächtigerer Chip mit mehr und schnellerem Speicher. Dessen Maximum steigt von 480 GB LPDDR5X bei Grace auf jetzt 1,5 TB SOCAMM2-LPDDR5X. SOCAMM2 ist modular, sodass bei Speicher-Defekten nicht direkt ein Vera-Board ausgetauscht respektive aufwendig repariert werden muss. Auch bei der Speicherbandbreite, der NVLink-C2C-Bandbreite beim Einsatz von zwei CPUs, dem SLC sowie dem Scalable Coherency Fabric (SCF) und weiteren Aspekten legt Vera nach.
Fabric verbindet Nodes mit Cores, Caches und mehr
Über das Scalable Coherency Fabric werden die Cores, der SLC, der Speicher, NVLink und I/O mit 3,4 TB/s Bisektionsbandbreite angebunden. Das Fabric gliedert sich in die Cache Switch Nodes (CSN), von denen jeder Node mit bis zu vier weitere Nodes verbunden ist. Jeder CSN verbindet bis zu zwei Olympus-Kerne und zwei Slices des SLC mit dem Mesh. Angebunden wird an den CSN auch jeweils ein Memory Switch Node (MSN), der wiederum die Verbindung zum LPDDR5X-Speichersubsystem herstellt.

Über Brücken am Nord- und Südende des Chips erfolgt die Verbindung einerseits zum NVLink-C2C (Norden), um eine Vera-CPU mit einer weiteren zu verbinden. Zum anderen wird darüber die Verbindung zum I/O-Subsystem für PCIe (Süden) hergestellt.
Vera im Benchmark gegenüber Grace
Um die Leistung von Vera gegenüber Grace zu verdeutlichen, hat Nvidia die Leistung im DCPerf Benchmark von Meta demonstriert. Dabei erfolgt das SVT-AV1-Encoding auf Multi-Core-CPUs mittels FFmpeg. DCPerf ahmt die Encoding-Pipeline von Instagram, Reels, Facebook Short Videos etc. nach. Als Datensatz wird der Open-Source-Film El Fuente von Netflix verwendet.
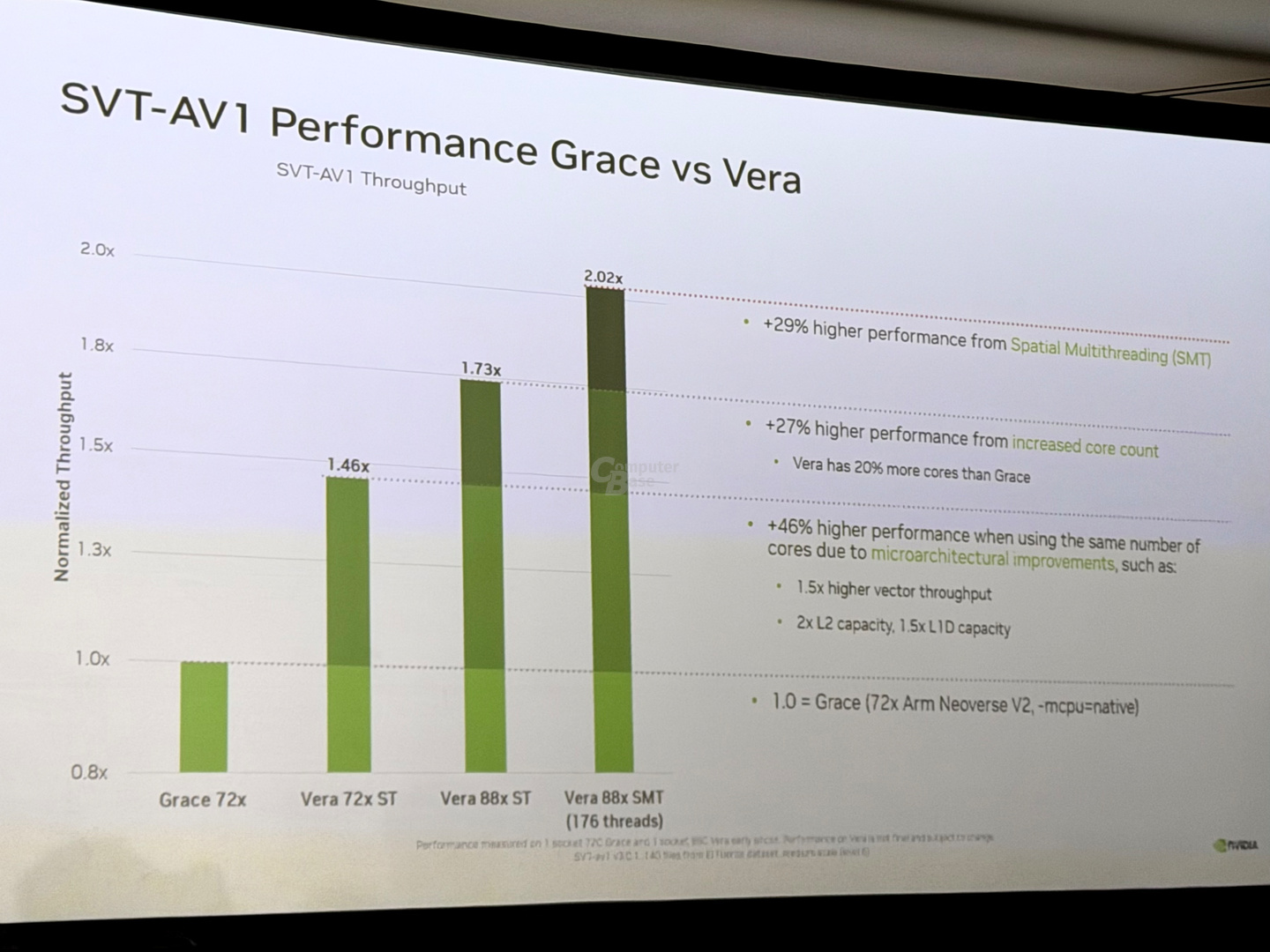
In diesem Benchmark erreicht Vera eine bis zu 2,02-fache Leistung gegenüber Grace. Das lässt sich folgendermaßen erklären: 46 Prozent mehr Leistung Im Vergleich zu Grace kommen zunächst einmal über die Verbesserungen der Mikroarchitektur von Olympus. Der höhere Vektor-Durchsatz und die größeren Caches tragen ihren Teil dazu bei. Weitere 27 Prozent kommen über die 27 Prozent mehr Kerne von Vera hinzu. Weitere 29 Prozent lassen sich mit SMT hinzufügen.
Taktraten waren kein Thema
Nvidia vergleicht dabei nach dem Ansatz „ISO Core“, also mit gleicher Anzahl von Kernen, obwohl Grace 72 Kerne und Vera eigentlich 88 Kerne bietet. Ob der Vergleich auch nach „ISO Clock“ erfolgt ist, wollten die Moderatoren der Session nicht offenlegen. Taktraten blieben ebenfalls unter Verschluss, sie sollen sich aber nicht stark voneinander unterscheiden. Bis zu 3,44 GHz sind es bei Grace.
TDP liegt bei 450 Watt
Zum Abschluss der Session folgte im Raum noch eine letzte Frage zum Verbrauch von Vera. Nvidia gibt bis zu 450 Watt pro Sockel an. Bei Grace sollen es inklusive Speicher 500 Watt sein. Vera könne mit einer TDP von minimal 250 Watt konfiguriert werden.
ComputerBase hat Informationen zu diesem Artikel von Nvidia unter NDA im Vorfeld und im Rahmen einer Veranstaltung des Herstellers in San Jose, Kalifornien erhalten. Die Kosten für An-, Abreise und fünf Hotelübernachtungen wurden vom Unternehmen getragen. Eine Einflussnahme des Herstellers oder eine Verpflichtung zur Berichterstattung bestand nicht. Die einzige Vorgabe aus dem NDA war der frühestmögliche Veröffentlichungszeitpunkt.
Dieser Artikel war interessant, hilfreich oder beides? Die Redaktion freut sich über jede Unterstützung durch ComputerBase Pro und deaktivierte Werbeblocker. Mehr zum Thema Anzeigen auf ComputerBase.







 RTX 5060 Ti 16GB")
 RTX 5060 Ti 16GB")


Apps & Mobile Entwicklung
Intel 18A-P im Detail: Intels HPC-Prozess ist schneller, effizienter, kühler und einfacher

Der neue Fertigungsprozess Intel 18A-P ist in sogenannter „risk production“. Mit vielen Optimierungen im Gepäck wird er 2027 erwartet, da er viele Gemeinsamkeiten mit Intel 18A bietet, soll der Umstieg ganz einfach sein. Und er wird dann wohl der erste, den auch externe Kunden nehmen könnten – die nennt Intel aber noch nicht.
Auf Intel 18A als Basisprozess folgt nun das „Superset“, Intel 18A-P genannt. Und das hat schonmal einen großen Vorteil: Alles was für 18A entwickelt wurde, funktioniert auch mit A-P. Und das Endergebnis vieler Optimierungen und auch Korrekturen in gewissen Bereichen des Basisprozesses bedeutet bei gleicher Leistung einen 18 Prozent geringeren Energieverbrauch oder alternativ bei gleichem Energiebedarf neun Prozent mehr Leistung.

Die Lernkurve setzt dabei an vielen Punkten an und bietet so mehr Entfaltungsspielraum beim Prozess. Designs können aus einem breiteren Spektrum zwischen Power und/oder Leistung wählen. Intel 18A und A-P sind aber explizit für das HPC-Segment ausgelegt, stellte Intel auf Nachfrage klar. Es sind keine Prozesse beispielsweise für einen Smartphone-Chip. Deshalb scheut Intel auch direkte Vergleiche zu TSMC. Power Boost als zusätzliche Lösung für noch mehr Takt und Leistung auf Kosten von Energie, spielt in diese Kategorie mit hinein. Das überrascht nicht, Intel Diamond Rapids als Next-Gen-Xeon mit nur P-Cores wurde für Intel 18A-P bereits offiziell für 2027 bestätigt.

Intel 18A-P packt dabei auch an Problemstellen an, die Intel so bisher kaum öffentlich ausgebreitet hat. Die sogenannten Skew Corner werden deutlich verringert und man nähert sich hier nun langsam dem industriellen Standard an, erklärte Intel, was aber auch heißt, dass man hier bisher noch ziemlich weit darüber lag. Als Skew Corner versteht die Industrie und damit auch Intel die Grenzen des Designs, wie groß die Abweichung von gewissen Werten einschließlich Spannung und auch Temperatur sowohl nach oben als auch unten sein darf und wie viele Grenzen ein Designer auf diesem Prozess beachten muss. Weniger Variationen im Prozess brauchen so nun auch weniger Grenzfälle, am Ende kann auch das letztlich zu gesteigerter Leistung führen.
Weitere Optimierungen betreffen auch die Produktion an sich. Der Thermal Handler Wafer besteht aus neuem Material und ist dünner, hier gab es einigen Spielraum für Optimierungen. Das wirkt sich positiv auf die Wärmeentwicklung unter Last aus. Hintergrund: In der Fertigung mit der Stromversorgung über die Rückseite, wird der Wafer in der Produktion einmal um 180 Grad gedreht und auf den Kopf gestellt. Dafür kommt ein Carrier Wafer zum Einsatz.
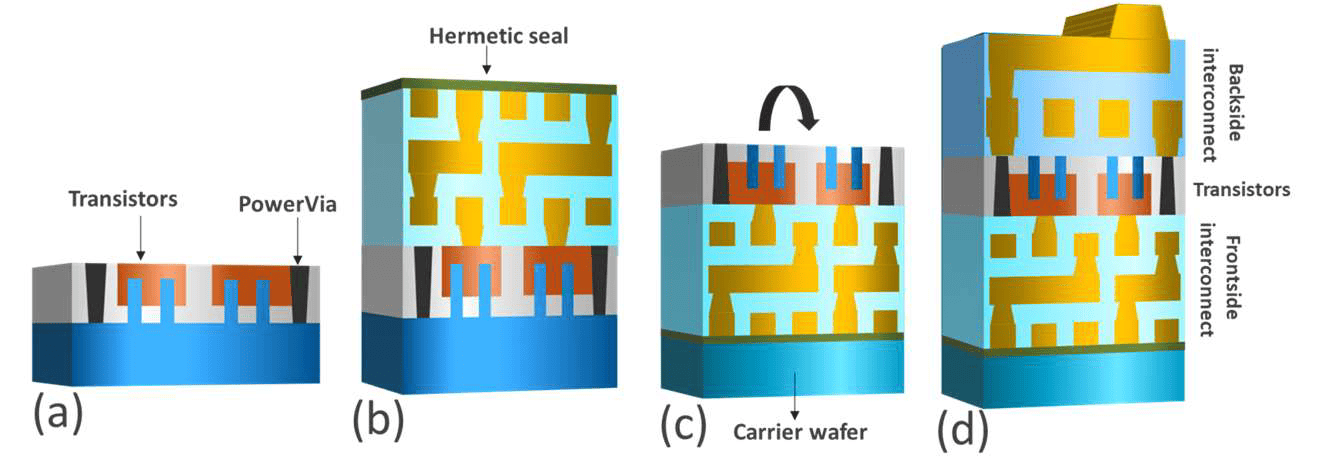
Intels neu bereitgestellte Folie zeigt den Zustand mit den Anpassungen deshalb bereits im gedrehten Zustand: Die Backside Power Delivery ist hier schon oben dargestellt. Dass es letztlich bei der Aufteilung in eine Vorderseite und der rückseitigen Stromversorgung schnell zu Anpassungen kommen würde, war vorab aber bereits erwartet worden. Schließlich ist so etwas vor dem Serienprodukt in Panther Lake noch nie in Großserie gefertigt worden, gewisse Dinge werden erst dann im Zeitverlauf klarer sichtbar und entsprechend in nächster Generation angepasst.

Partner wollen jedoch zuverlässige Vorhersagen, Prognosen und Roadmaps, die so umgesetzt werden, wie sie geplant wurde. Genau hier lagen in den letzten Jahren Intels Probleme, an denen das Unternehmen arbeitet. Intel fasst es nun unter „Trust“ zusammen (Vertrauen). Intel 18A-P soll der erste dieser Meilensteine sein. Partner wurden aber auch heute auf Nachfrage keine genannt, die Gerüchte jonglieren seit Monaten mit großen Namen wie Apple, Nvidia und anderen.

Und nochmal zur Einordnungs des Zeitplans: Im April 2025 hatte Intel bekannt gegeben, dass Intel 18A in risk production gegangen ist. Von da an hat es ungefähr acht, neun Monate gedauert, bis die Produktion hochlief, so richtig große Volumen kamen dann letztlich rund ein Jahr später seit diesem Frühjahr heraus. Auch wenn einige Dinge nun eventuell etwas zügiger gehen könnten, Ende 2026/Anfang 2027 ist und bleibt das realistische Ziel für den Start der Massenproduktion von Intel 18A-P. Denn bei 18A hatte Intel wohl im Nachgang betrachtet – und kürzlich bereits berichtet – die Balken noch ziemlich gebogen, so wirklich gut war die Ausbeute seinerzeit nämlich noch nicht. Intels eigene Yield-Kurve untermauert das heute auch.

ComputerBase hat Informationen zu diesem Artikel von Intel unter NDA erhalten. Die einzige Vorgabe war der frühestmögliche Veröffentlichungszeitpunkt.

Apps & Mobile Entwicklung
Snapdragon Reality Elite: Qualcomm bringt VR/MR-Topmodell und gibt STARThilfe
Qualcomm setzt den neuen Snapdragon Reality Elite an die Spitze der SoC-Plattformen für MR/VR-Headsets und liefert damit vor allem mehr CPU-, GPU- und NPU-Leistung bei gleichzeitig geringerem Verbrauch und reduzierter Wärmeentwicklung. Anbietern von XR-Produkten will Qualcomm zudem mit dem START-Programm Unterstützung geben.
Auch bei den Chipsätzen für MR/VR-Headsets zieht bei Qualcomm jetzt die Bezeichnung „Elite“ ein. Anders als bei den Smartphone- und PC-Lösungen des Unternehmens steht der Name aber nicht für den Einsatz der eigens entwickelten Oryon-CPU-Kerne, sondern soll vielmehr das Topmodell in einer Produktkategorie markieren. Der Snapdragon Reality Elite folgt auf den vorherigen Snapdragon XR2+ Gen 2 von 2024.
Xreal Project Aura setzt auf neuen Snapdragon
Der Snapdragon Reality Elite ist für den Einsatz in offenen und geschlossenen Mixed-Reality- und Virtual-Reality-Headsets vorgesehen, demnach nicht für leichtere Brillen wie die Ray-Ban Meta, wo stattdessen auf Lösungen wie den Snapdragon AR1 Gen 1 gesetzt wird. Headsets wie Meta Quest 3(S) oder Apple Vision Pro lassen sich beispielhaft als designierte Produktkategorie des Snapdragon Reality Elite nennen, auch wenn Apple auf eigene Chips setzt. Der Ersteinsatz des Snapdragon Reality Elite soll im Xreal Project Aura mit Android XR erfolgen, einer halboffenen, „tethered“ XR-Brille mit Displays. Qualcomm bezeichnet sie auch als Headset mit „video-see-through“ (VST) und „optical-see-through“ (OST).

Deutliche Upgrades für CPU, GPU und NPU
Qualcomm gibt für die neue Plattform eine bis zu 30 Prozent höhere CPU-Leistung bei gleichem Verbrauch oder einen 45 Prozent niedrigeren Verbrauch bei gleicher Leistung im Vergleich zum direkten Vorgänger an. Aufseiten der Adreno-GPU liegt der Leistungs- respektive Effizienzzuwachs bei 60 Prozent bei gleichem Verbrauch oder 64 Prozent geringerem Verbrauch bei gleicher Leistung. Qualcomm konnte der Redaktion auf Nachfrage nicht erläutern, auf welche CPU-Kerne von Arm, welche eigene Adreno-GPU oder welchen effizienteren Fertigungsprozess für die Zugewinne gewechselt wurde. Bekannt ist aber, dass der Arbeitsspeicher einen 30 Prozent höheren Durchsatz bietet.
Bei den bisherigen MR/VR-Plattformen von Qualcomm stand eine leistungsfähige NPU für generative KI-Anwendungen noch nicht derart im Fokus der Entwicklung, wie es aktuell der Fall ist. Deshalb erfährt die NPU des Snapdragon Reality Elite mit 48 TOPS (INT8) einen Schub von 160 Prozent zum Vorgänger, was sie laut Qualcomm für Einsatzgebiete wie fotorealistische Avatare, Gaussian Splatting, LLM-basierte Agenten oder Echtzeit-Large-Vision-Models qualifiziere. Das ist vergleichbar zum Snapdragon X1 Elite. Alternativ könne auch hier der Verbrauch um 84 Prozent bei dann gleicher Leistung des Vorgängers reduziert werden.

Der Snapdragon Reality Elite kann Displays mit einer Auflösung von bis zu 4,4K bei 90 FPS pro Auge bespielen. Alternativ sind geringere Auflösungen bei höheren FPS und umgekehrt möglich. Ein optimierter EVA-Block (Engine for Visual Analytics) soll zudem weiter in den Raum sehen und bei geringerem Verbrauch eine 3D-Rekonstruktion erstellen können. Die Plattform ermögliche bis zu 20 Prozent längere Batterielaufzeiten bei gleichzeitig bis zu 12 °C geringerer Oberflächentemperatur unter Last.
Qualcomm gibt STARThilfe für neue XR-Produkte
Die Augmented World Expo in Long Beach, Kalifornien nutzt Qualcomm auch für die Vorstellung des „Snapdragon Scalable Turnkey AI-Ready Toolkit“, kurz START. Im Zentrum des Starthilfe-Programms stehen Hardware-Module, Software-Stacks und White-Label-Skalierungsoptionen von Qualcomm und Partnern, die kleinere Unternehmen dabei unterstützen sollen, einfacher und schneller eigene Wearables wie smarte Brillen auf den Markt zu bringen. Dazu gehören unter anderem vorgefertigte PCBs mit Qualcomms SoCs und weiteren für den Betrieb benötigten Chips. Zum Beispiel wird Qualcomm ein Hardware-Modul mit Snapdragon AR1+ Gen 1 anbieten, das 42,5 mm lang, 8,9 mm breit und 3,08 mm hoch baut und damit kleiner als das PCB eines führenden Anbieters von AR-Brillen ausfalle.

Das START-Programm umfasst aber auch die Software-Stacks von Qualcomm und Unterstützung bei der Skalierung mit White-Label-Produkten. Für Audio und Kameras ist Thundercomm an Bord, für die Integration von Displays ist Applied Materials der Partner. Beim Skalieren der Produktion unterstützen die Fertiger Jorjin und Pegatron.
ComputerBase hat Informationen zu diesem Artikel von Qualcomm unter NDA erhalten. Die einzige Vorgabe war der frühestmögliche Veröffentlichungszeitpunkt.
Apps & Mobile Entwicklung
Steam Machine: Geekbench-Ergebnisse deuten auf zeitigen Marktstart hin

Valve will wieder in den Markt für stationäre Konsolen einsteigen; die Steam Machine soll dieses Jahr erscheinen, vorzugsweise im Sommer. Neu aufgetauchte Geekbench-Einträge deuten nun darauf hin, dass bereits erste Geräte bei externen Testern angekommen sein könnten. Der Marktstart rückt damit potenziell näher.
Geekbench-Ergebnise kündigen bevorstehende Reviews an
Angekündigt hat Valve die neue Steam Machine im Herbst 2025 ursprünglich für „Anfang 2026“, hatte die Rechnung da aber noch nicht mit der anhaltenden Speicher- und Komponentenkrise gemacht. Nach mehreren Verschiebungen war die stationäre Steam-Konsole zwischenzeitlich für das 2. Quartal erwartet worden, wenngleich Valve bloß noch von diesem Jahr spricht. Jetzt könnte es aber doch noch der Sommer werden.
Darauf deuten frische Geekbench-Ergebnisse hin, die am 15. Juni 2026 aufgetaucht sind. Insgesamt wurden zwei neue Benchmark-Durchläufe veröffentlicht. Zwar ist die Steam Machine sogar schon im August 2025 erstmals auf Geekbench aufgetaucht; damals aber mit Windows und mutmaßlich bei internen Tests. Die jetzt veröffentlichten Ergebnisse basieren erstmals auf SteamOS, also dem Zielsystem der Konsole. Vor dem Hintergrund weiterer Gerüchte, die der Redaktion vorliegen, festigt sich das Bild einer bereits laufenden Review-Phase bei externen Testern und Gaming-Publikationen. Und erfahrungsgemäß ist es von entsprechenden Reviews, die in den kommenden Wochen erscheinen könnten, nicht mehr weit bis zum Marktstart.


An der Hardware selbst hat sich laut Geekbench-Einträgen nichts verändert. Weiterhin kommt unter dem Codenamen „Valve Fremont“ eine AMD-CPU mit sechs Kernen und zwölf Threads sowie 16 MB L3-Cache zum Einsatz. Die gemessenen Werte liegen bei rund 2.280 bis 2.330 Punkten im Single-Core- und etwa 7.300 Punkten im Multi-Core-Test und entsprechen damit weitgehend den früheren Windows-Ergebnissen. Allerdings sind Geekbench-Werte nur bedingt aussagekräftig für die tatsächliche Gaming-Leistung, da es sich ausschließlich um CPU-Benchmarks handelt. Sie sollten entsprechend vorsichtig interpretiert werden.

Intel 18A-P im Detail: Intels HPC-Prozess ist schneller, effizienter, kühler und einfacher

Snap Specs: Erste echte AR-Brille für Konsumenten kostet 2195 Dollar

Snapdragon Reality Elite: Qualcomm bringt VR/MR-Topmodell und gibt STARThilfe

JBL Bar 1300MK2 im Test: Soundbar mit Dolby Atmos, starkem Bass und Akku‑Rears

Oscars 2026: Was die heise‑Leser anders entschieden hätten

Empfehlungsalgorithmen bei TikTok erklärt: Die Maschine hinter dem Endlos‑Feed
-
Künstliche Intelligenzvor 3 Monaten
JBL Bar 1300MK2 im Test: Soundbar mit Dolby Atmos, starkem Bass und Akku‑Rears
-
 Künstliche Intelligenzvor 3 Monaten
Künstliche Intelligenzvor 3 MonatenOscars 2026: Was die heise‑Leser anders entschieden hätten
-
 Künstliche Intelligenzvor 3 Monaten
Künstliche Intelligenzvor 3 MonatenEmpfehlungsalgorithmen bei TikTok erklärt: Die Maschine hinter dem Endlos‑Feed
-

 Social Mediavor 3 Monaten
Social Mediavor 3 MonatenVon Kennzeichnung bis Plattformpflichten: Was die EU-Regeln für Influencer Marketing bedeuten – Katy Link im AllSocial Interview
-

 Künstliche Intelligenzvor 2 Monaten
Künstliche Intelligenzvor 2 Monaten„Don’t Starve Elsewhere“: Survival‑Hit kehrt nach zehn Jahren zurück
-

 Künstliche Intelligenzvor 2 Monaten
Künstliche Intelligenzvor 2 MonateniX-Workshop Angriffsziel lokales AD − Schwachstellen finden und beheben
-

 Künstliche Intelligenzvor 2 Monaten
Künstliche Intelligenzvor 2 MonatenWeitere Entlassungswelle bei Disney: Bis zu 1000 Mitarbeiter betroffen
-

 Künstliche Intelligenzvor 2 Monaten
Künstliche Intelligenzvor 2 MonatenKine‑Exakta: Die erste Spiegelreflexkamera fürs Kleinbild
