Online Marketing & SEO
Connected TV: Die neue Ära des Wohnzimmers: Wie Teads mit Homescreen und CTV Performance-Kompetenz den Werbemarkt neu definiert
Lange Zeit galt TV-Werbung primär als Instrument für den oberen Funnel (Markenbekanntheit). Teads bricht mit diesem Dogma und bringt Performance-Metriken auf den großen Bildschirm. Möglich macht das unter anderem der Teads Universal Pixel, der Kampagnen mit messbaren Ergebnissen wie Website-Besuchen, Leads oder Käufen verknüpft.
Der Fokus verschiebt sich von reinen Impressionen hin zu konkreten Handlungen („Outcomes“). Werbetreibende können über die Teads-Plattform messen, ob ein Kontakt auf dem Fernseher zu einem Website-Besuch, einem „Add-to-Cart“ oder sogar einem Ladenbesuch geführt hat.
Ein Beispiel aus der Praxis verdeutlicht die Leistungsfähigkeit der Teads CTV Performance-Lösungen: Die US-Marke Men’s Wearhouse nutzte interaktive CTV-Formate, um nicht nur Aufmerksamkeit, sondern Traffic zu generieren. Das Ergebnis waren über 41.000 Website-Besuche und 50.000 Store-Visits, die direkt auf die Kampagne zurückzuführen waren – bei einer Click-Through-Rate (CTR), die 170 Prozent über den Benchmarks lag. Mit Teads wird CTV damit endgültig zum Performance-Kanal im „Lower Funnel“.










Online Marketing & SEO
WARC-Prognose: Krise am Golf könnte Werbemarkt fast 100 Milliarden US-Dollar kosten
Wegen bewaffneter Konflikte sitzt auch das Werbegeld nicht mehr locker
Der Krieg zwischen den USA, Israel und dem Iran belastet nicht nur die Weltwirtschaft, sondern auch den Werbemarkt. Eine Analyse von WARC zeigt, was der Konflikt im schlimmsten Fall bedeuten würde – auch für den deutschen Markt.
Die gute Nachricht vorweg: WARC hat in seiner jüngsten Analyse die Prognose für den globalen Werbemarkt nicht etwa nach unten korrigiert, so
Jetzt Angebot wählen und weiterlesen!
HORIZONT Digital
- Vollzugriff auf HORIZONT Online mit allen Artikeln
- E-Paper der Zeitung und Magazine
- Online-Printarchiv
HORIZONT Digital-Mehrplatzlizenz für Ihr Team
Online Marketing & SEO
Office EU: Die europäische Antwort auf Microsoft 365
Die erste stabile Version von Euro-Office ist da. Zu den Partner:innen des Open-Source-Projekts gehört auch Office EU, das sich als europäische Alternative zu Microsoft 365 und Google Workspace positioniert.
Ob Cloud-Infrastruktur, Büro-Software oder KI: Europas digitale Wirtschaft läuft noch immer größtenteils auf Technologie aus den USA. Das soll sich ändern. Mit dem Technological Sovereignty Plan will die EU europäische Alternativen stärken und die Abhängigkeit von amerikanischen Tech-Konzernen verringern.
Mit der Veröffentlichung der ersten stabilen Version von Euro-Office erhält der Plan nun Rückenwind. Das geht aus einer Ankündigung der Projektpartner Nextcloud und Ionos hervor, über die unter anderem heise online berichtete. Zu den Partner:innen von Euro-Office gehört auch Office EU, eine Suite, die sich als europäische Alternative zu Microsoft 365 und Google Workspace positioniert. Wie die etablierten Lösungen aus den USA bündelt Office EU Anwendungen für Dokumente, Tabellen, Präsentationen, E-Mail, Kalender, Cloud-Speicher und Videokonferenzen in einer Suite. Weitere partizipierende Unternehmen sind unter anderem XWiki, OpenProject und Open-Xchange. Gemeinsam wollen sie europäische Alternativen zu proprietären Office-Lösungen stärken und die digitale Souveränität Europas voranbringen.
Auch wenn Projekte wie Office EU den etablierten US-Unternehmen wohl nicht kurzfristig relevante Marktanteile abnehmen werden, machen sie vielen Verfechter:innen digitaler Souveränität Hoffnung. Wie dringend Europa eigene Alternativen bei Cloud, KI und Software braucht, wurde auch auf der re:publica 2026 deutlich. Dort warnten zahlreiche Speaker, darunter auch re:publica-Gründer Markus Beckedahl, vor der wachsenden Macht großer Tech-Konzerne und der starken Abhängigkeit Europas von digitaler Infrastruktur aus den USA. Beckedahl sprach dabei von einer Monopolbildung „auf Steroiden“, bei der wenige Konzerne durch Daten, Rechenleistung und Kapital ihre Macht kontinuierlich ausbauen.
„Your digital future is made in Europe“:
Europas Plan gegen Tech-Abhängigkeit

Eine europäische Office-Suite für digitale Unabhängigkeit
Während Microsoft, Google und OpenAI derzeit vor allem mit neuen KI-Funktionen um Aufmerksamkeit konkurrieren, setzt Office EU einen anderen Schwerpunkt. Die Office-Suite wirbt vor allem mit europäischer Infrastruktur, Open Source und dem Versprechen, Daten außerhalb außereuropäischer Rechtsräume zu halten.

Sämtliche Dienste werden auf europäischer Infrastruktur betrieben. Office EU setzt auf Open Source, DSGVO-Konformität und verspricht, Daten vor potenziellen Zugriffen durch außereuropäische Behörden zu schützen. Hintergrund ist unter anderem der US CLOUD Act, der US-Behörden unter bestimmten Voraussetzungen Zugriff auf Daten amerikanischer Unternehmen ermöglichen kann. Funktional orientiert sich Office EU an den etablierten Office-Lösungen aus den USA. Zum Angebot gehören:
- Dokumente (EU Docs)
- Tabellen (EU Spreadsheet)
- Präsentationen (EU Presentation)
- Cloud-Speicher (EU Drive)
- E-Mail (EU Email)
- Kalender (EU Calendar)
- Videokonferenzen (EU Talk)
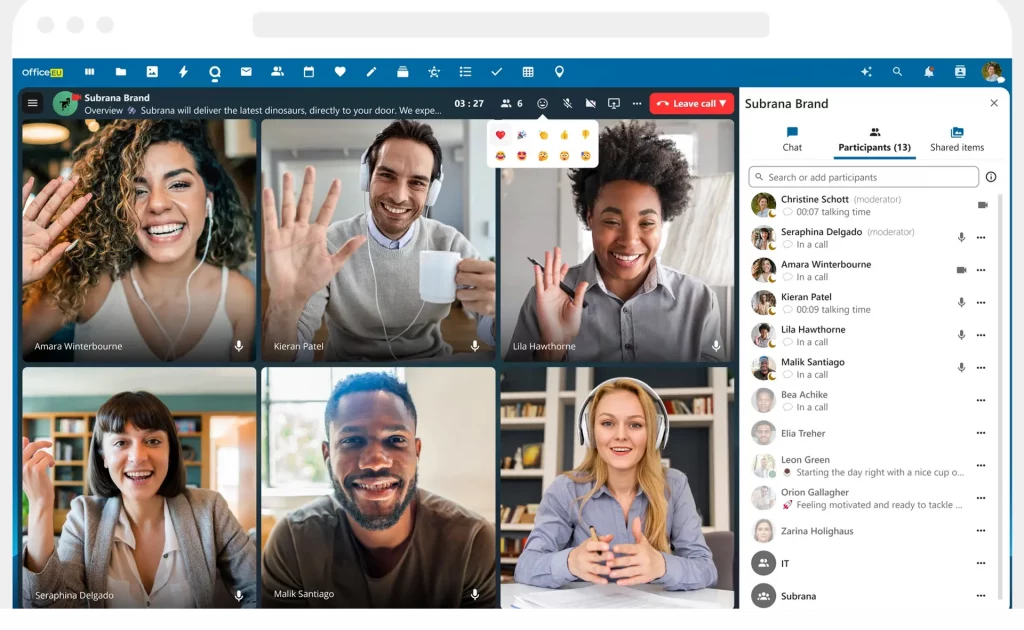
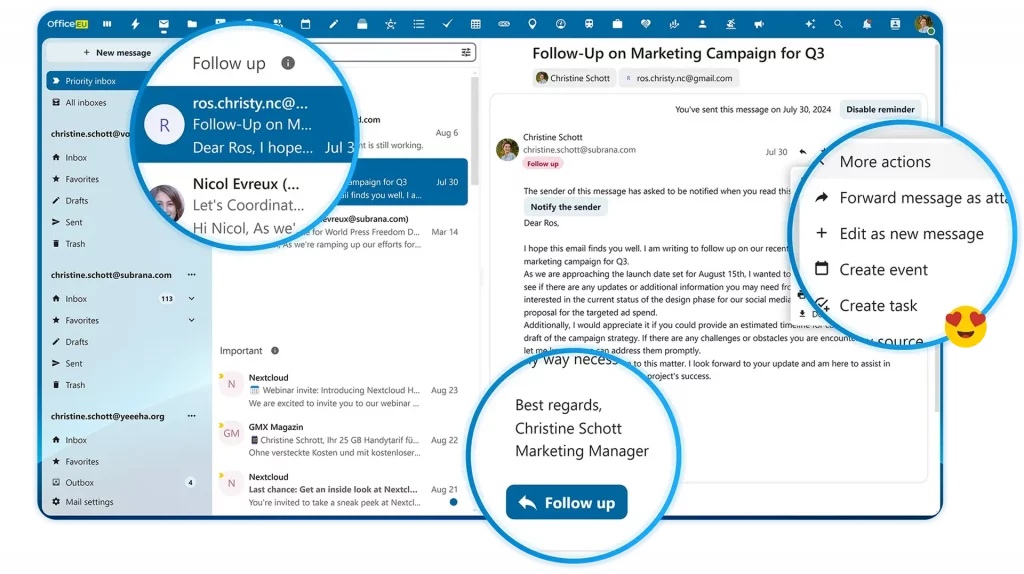
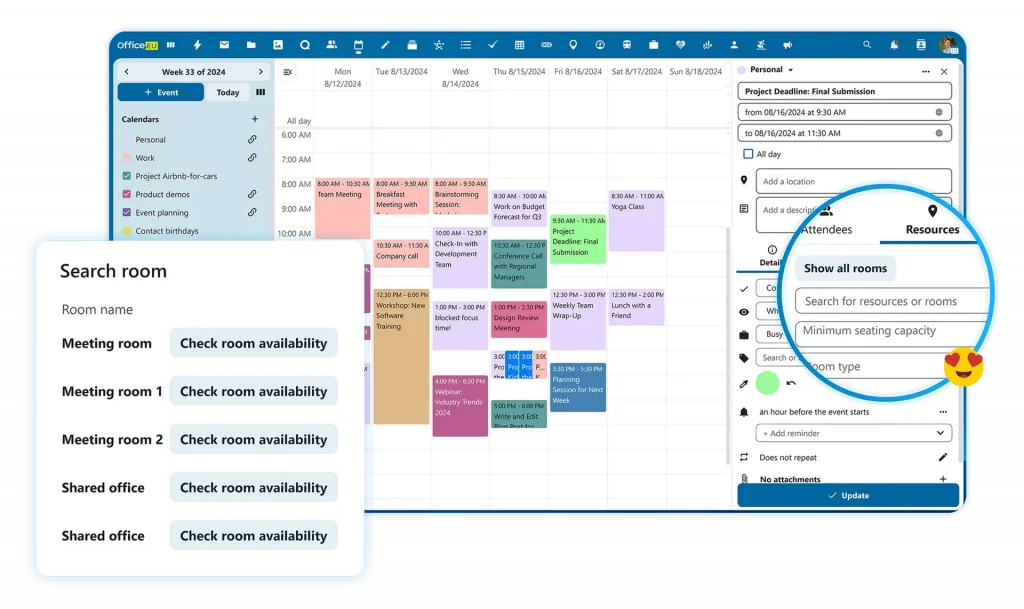
Wer von Microsoft 365 oder Google Workspace wechseln möchte, kann bestehende Konten anbinden und E-Mails, Kalender sowie Dateien importieren. Die Suite lässt sich zunächst parallel zu bestehenden Lösungen nutzen, sodass kein sofortiger Komplettumstieg notwendig ist. Office EU richtet sich vor allem an kleine und mittelständische Unternehmen, NGOs sowie Privatpersonen und Familien, die nach einer europäischen Alternative zu Microsoft 365 oder Google Workspace suchen.
Vollständig ausgereift sind viele europäische Office-Lösungen allerdings noch nicht. So fehlen teilweise noch native Desktop- und Mobilanwendungen. Auch die Unterstützung offener Standards wie ODF wird in einigen Projekten noch erweitert.
Stelle OnlineMarketing.de als bevorzugte Quelle auf Google ein
Wenn du OnlineMarketing.de auf Google als bevorzugte Quelle einstellen möchtest, um auch in den Schlagzeilen auf Google immer aktuelle News und Tipps aus der Welt des Marketing und der Tech-Entwicklungen zu finden, kannst du einfach die Google-Quelleneinstellungen aufrufen und die Seite anwählen. Über das Stern-Icon neben den Top Stories kannst du ebenfalls bevorzugte Quellen für die spätere Suche speichern.

Online Marketing & SEO
Bis zu 4 Euro mehr: YouTube erhöht die Premium-Preise
YouTube Premium wird in Deutschland teurer. Einige Abonnements kosten künftig bis zu vier Euro mehr pro Monat. Zudem bringt die Plattform ihre Direktnachrichten in weitere Märkte weltweit.
YouTube Premium wird in Deutschland teurer. Wie heise online berichtet, erhöht Google die Preise für sämtliche Premiumtarife. Besonders Familien müssen künftig tiefer in die Tasche greifen. Ganz überraschend kommt die Entwicklung allerdings nicht. Bereits im April erhöhte Google die Preise für YouTube-Abos zunächst in den USA.
Darüber hinaus bringt YouTube Direktnachrichten für mehr Nutzer:innen weltweit. Wie 9to5Google berichtet, rollt die Streaming-Plattform die Chats zum Teilen und Diskutieren von Videos aktuell in den USA, Großbritannien, Brasilien und Singapur aus. Über den Deutschland-Start der YouTube DMs hatten wir bereits im März berichtet.
YouTube DMs kommen in Deutschland zurück

Mehr Werbung oder mehr zahlen? YouTube erhöht die Preise
Nach Netflix, Disney+ und Spotify erhöht nun auch YouTube die Preise für die Premiumtarife in Deutschland. Vor allem Familien und Nutzer:innen von Premium Lite zahlen deutlich mehr. Künftig gelten folgende Preise:
- YouTube Premium: 14,99 statt 12,99 Euro pro Monat
- YouTube Premium Familienabo: 27,99 statt 23,99 Euro pro Monat
- YouTube Premium Student:innenabo: 8,99 statt 7,49 Euro pro Monat
- YouTube Premium Lite: 7,99 statt 5,99 Euro pro Monat
Besonders Premium Lite verliert damit einen Teil des bisherigen Preisvorteils. Der günstigste Tarif bietet zwar keine Musikextras, dafür aber weniger Werbung bei vielen Videos.
Die höheren Preise gelten offenbar sowohl für Neu- als auch für Bestandskund:innen. Wie Caschys Blog berichtet, informiert YouTube derzeit auch bestehende Abonnent:innen per E-Mail über die Anpassungen.
Nach dem Aus 2019: YouTube bringt Direktnachrichten zurück
2017 führte YouTube Direktnachrichten in der App ein, damit Nutzer:innen Videos teilen und darüber chatten konnten. 2019 stellte die Streaming-Plattform die Funktion jedoch wieder ein, um öffentliche Konversationen stärker in den Fokus zu rücken. Da Direktnachrichten auf vielen Social-Media-Plattformen zu den meistgenutzten Kommunikationskanälen gehören, entschied sich YouTube dazu, die Funktion zurückzubringen.
Im Herbst 2025 startete die Plattform einen ersten, noch stark eingeschränkten Test. Im März weitete YouTube diesen auf mehrere europäische Länder aus und brachte die Chat-Funktion auch nach Deutschland. Jetzt folgt der Roll-out in weitere Märkte weltweit. Aktuell erhalten Nutzer:innen in den USA, Großbritannien, Brasilien und Singapur Zugriff auf die Chats.
Mit den neuen YouTube DMs können Nutzer:innen Videos, Shorts und Livestreams direkt in der App teilen und darüber in privaten 1:1-Chats diskutieren. Auch nicht gelistete Videos lassen sich per Nachricht verschicken. Kontakte können direkt über das Teilenmenü eines Videos angeschrieben werden. Zudem informiert YouTube per Benachrichtigung über neue Nachrichten. Wer möchte, kann Nachrichten zurückziehen, Nutzer:innen blockieren oder Gespräche melden. Die Funktion bringt allerdings auch einige Einschränkungen mit sich:
- Nur 1:1-Chats, keine Gruppenunterhaltungen
- Einladungen erfolgen über einen sieben Tage gültigen Link
- Der Link muss zunächst über einen anderen Messenger verschickt werden
- Verfügbar nur für Nutzer:innen ab 18 Jahren
- Private Videos lassen sich nicht teilen
YouTube will offenbar keine vollwertigen Messaging-Dienst aufbauen. Die zahlreichen Einschränkungen zeigen vielmehr, dass die Streaming-Plattform Chats vor allem als Werkzeug zum Teilen und Diskutieren von Videos versteht. Denn Nutzer:innen sollen ein Video nicht erst auf YouTube entdecken, um die Konversation anschließend auf WhatsApp, Instagram oder Telegram fortzusetzen. Stattdessen möchte YouTube dafür sorgen, dass Nutzer:innen Inhalte entdecken, teilen und diskutieren, ohne die Plattform verlassen zu müssen.
Stelle OnlineMarketing.de als bevorzugte Quelle auf Google ein
Wenn du OnlineMarketing.de auf Google als bevorzugte Quelle einstellen möchtest, um auch in den Schlagzeilen auf Google immer aktuelle News und Tipps aus der Welt des Marketing und der Tech-Entwicklungen zu finden, kannst du einfach die Google-Quelleneinstellungen aufrufen und die Seite anwählen. Über das Stern-Icon neben den Top Stories kannst du ebenfalls bevorzugte Quellen für die spätere Suche speichern.

Mindestzoll für China-Importe: Was Verbraucher jetzt wissen müssen

Digitalminister Wildberger ließ Reden und Gastbeiträge von KI schreiben

Game-Streaming: Schaut ihr anderen beim Spielen zu? Falls ja, wobei und wieso?

JBL Bar 1300MK2 im Test: Soundbar mit Dolby Atmos, starkem Bass und Akku‑Rears

Oscars 2026: Was die heise‑Leser anders entschieden hätten

Empfehlungsalgorithmen bei TikTok erklärt: Die Maschine hinter dem Endlos‑Feed
-
Künstliche Intelligenzvor 3 Monaten
JBL Bar 1300MK2 im Test: Soundbar mit Dolby Atmos, starkem Bass und Akku‑Rears
-
 Künstliche Intelligenzvor 3 Monaten
Künstliche Intelligenzvor 3 MonatenOscars 2026: Was die heise‑Leser anders entschieden hätten
-
 Künstliche Intelligenzvor 3 Monaten
Künstliche Intelligenzvor 3 MonatenEmpfehlungsalgorithmen bei TikTok erklärt: Die Maschine hinter dem Endlos‑Feed
-

 Social Mediavor 3 Monaten
Social Mediavor 3 MonatenVon Kennzeichnung bis Plattformpflichten: Was die EU-Regeln für Influencer Marketing bedeuten – Katy Link im AllSocial Interview
-

 Künstliche Intelligenzvor 2 Monaten
Künstliche Intelligenzvor 2 Monaten„Don’t Starve Elsewhere“: Survival‑Hit kehrt nach zehn Jahren zurück
-

 Künstliche Intelligenzvor 2 Monaten
Künstliche Intelligenzvor 2 MonatenWeitere Entlassungswelle bei Disney: Bis zu 1000 Mitarbeiter betroffen
-

 Künstliche Intelligenzvor 2 Monaten
Künstliche Intelligenzvor 2 MonateniX-Workshop Angriffsziel lokales AD − Schwachstellen finden und beheben
-

 Künstliche Intelligenzvor 2 Monaten
Künstliche Intelligenzvor 2 MonatenKine‑Exakta: Die erste Spiegelreflexkamera fürs Kleinbild
