Künstliche Intelligenz
E-Patientenakte & Co.: Wir brauchen mehr Ehrlichkeit bei Gesundheitsdaten
Für die medizinische Forschung in Deutschland stehen immer mehr Daten zur Verfügung: Allein über das Forschungsdatenportal Gesundheit (FDPG) von der Medizininformatik-Initiative (MII) und der Technologie- und Methodenplattform für die vernetzte medizinische Forschung e.V. (TMF) sind inzwischen mehr als zwei Milliarden Laborwerte und die Basisdaten von über 21 Millionen Patientinnen und Patienten aus 41 Universitätskliniken verfügbar.
Weiterlesen nach der Anzeige
Erst kürzlich feierte die MII über 200 Millionen Vitaldaten aus der Intensivmedizin – darunter Blutdruck, Atemfrequenz, Herzfrequenz und Körpertemperatur –, die dank des Netzwerks Universitätsmedizin im FDPG zur Verfügung stehen. Neben dem FDPG soll das 2025 eröffnete Forschungsdatenzentrum Gesundheit (FDZ Gesundheit) für einen besseren Datenzugang sorgen – mit Daten aus der elektronischen Patientenakte (ePA), medizinischen Registern und weiteren Datenquellen, die der Forschung und Industrie nach erfolgreichem Antrag pseudonymisiert zur Verfügung stehen.


Prof. Sebastian C. Semler ist Arzt und seit 2004 Geschäftsführer der TMF.
(Bild: TMF)
TMF-Geschäftsführer Sebastian Claudius Semler begleitet den Aufbau dieser Strukturen seit über zwei Jahrzehnten. Die TMF koordiniert dabei nicht nur die Begleitstrukturen der Medizininformatik-Initiative, sondern auch weitere Großprojekte wie das zur nationalen Genom-Initiative genomDE. Im Interview erklärt er, warum wir trotz neuer Gesetze und europäischer Visionen wie dem European Health Data Space (EHDS) erst einmal klären müssen, was die neuen Datenquellen wissenschaftlich überhaupt hergeben – und warum Paragrafen allein noch nicht für eine funktionierende Forschungsdateninfrastruktur sorgen.
Sie beschäftigen sich seit vielen Jahren mit der Architektur von Forschungsdateninfrastrukturen. Wenn wir ganz vorne anfangen: Warum braucht es das Forschungsdatenportal Gesundheit (FDPG) überhaupt, wenn es jetzt das Forschungsdatenzentrum Gesundheit (FDZ Gesundheit) gibt?
Um die Zusammenhänge zu verstehen, muss man tatsächlich etwas weiter zurückblicken. Die Wurzeln liegen im Jahr 2003 beim GKV-Modernisierungsgesetz, mit dem die Paragrafen 303a ff. SGB V zur Datentransparenz erstmals eingeführt wurden. Seinerzeit hatte der Gesetzgeber die Spitzenverbände von Krankenkassen und KBV verpflichtet, eine „Arbeitsgemeinschaft für Aufgaben der Datentransparenz“ zu bilden, um Datenzusammenführung und Datennutzung zu Zwecken von Wirtschaftlichkeitsanalysen und für eine bessere Transparenz über die Inanspruchnahme und Kosten von Gesundheitsleistungen zu organisieren.
Nachdem dies nicht vorankam, hat der Gesetzgeber dann 2011 mit dem GKV-Versorgungsstrukturgesetz und mit der Datentransparenzverordnung von 2012 deutlich nachgeschärft. Im Kern ging es darum, die Abrechnungsdaten der Krankenkassen endlich zusammenzuführen und für externe Forschung und für die Bedarfsplanung im Gesundheitswesen nutzbar zu machen, ohne den Sozialdatenschutz aufzugeben. Eine erste Datenherausgabestelle wurde beim seinerzeitigen Deutsche Institut für Medizinische Dokumentation und Information (DIMDI) im Geschäftsbereich des BMG aufgebaut; das DIMDI hat zwischen 2015 und 2018 anonymisierte Krankenkassendaten an externe Forschungsprojekte herausgegeben, wenn auch in einem aufwändigen Verfahren.
Weiterlesen nach der Anzeige
Diese Entwicklung wurde später durch das Digitale-Versorgung-Gesetz 2019 fortgeführt, das DIMDI wurde aufgelöst und die Zuständigkeit ins BfarM verlagert, wo die Entwicklung schließlich in das heutige FDZ Gesundheit mündete, das seit Oktober 2025 nun auch wieder Datenzugang zu Krankenkassendaten ermöglicht. Ab Ende 2026 sollen hier – gemäß Gesundheitsdatennutzungsgesetz (GDNG) von 2024 – auch die pseudonymisierten Daten aus der elektronischen Patientenakte verfügbar gemacht werden.
Parallel dazu gab es aber eine zweite Entwicklung: Das Bundesforschungsministerium startete 2015 die Medizininformatik-Initiative, konzipiert zu einem Zeitpunkt, als die erste E-Health-Gesetzgebung in Deutschland noch nicht verabschiedet war. Dort stand bereits in der Ausschreibung, dass eine verteilte Dateninfrastruktur geschaffen werden soll, in der jede Universitätsklinik ein Datenintegrationszentrum aufbaut. Das Forschungsdatenportal Gesundheit (FDPG) ist im Grunde die direkte Konsequenz aus dieser Förderausschreibung von 2015. Wir hatten es zunächst etwas technokratisch „Zentrale Antrags- und Registerstelle“ genannt, aber die Funktion war klar: Es ging darum, in den forschungsorientierten Standorten, also den Unikliniken, einen deutlich breiteren klinischen Datensatz erschließbar zu machen – und zwar jenseits der reinen Abrechnungsdaten. Und als vernetzende und abfragende Instanz zu diesen verteilt vorliegenden Daten braucht es das zentrale Portal – als Anlaufpunkt für die forschenden Datennutzer.
Die Abkürzungen ähneln sich, die Aufgaben auch – viele verwechseln anscheinend das FDPG mit dem FDZ, das beim Bundesinstitut für Arzneimittel und Medizinprodukte (BfArM) angesiedelt ist. Ist das verwirrend?
Das ist tatsächlich ein Punkt, der oft konfus wirkt und nicht einfach zu verstehen ist. Aber man muss die Unterscheidung machen, denn wir reden hier über völlig unterschiedliche Datenwelten. Es ist schön, dass man das FDZ beim BfArM eingeweiht hat und dort nun endlich Daten für die Forschung bereitstehen. Aber das FDZ arbeitet aktuell eben „nur“ mit den Abrechnungsdaten der gesetzlichen Krankenkassen. Das sind populationsbasierte, sektorenübergreifende Daten. Das ist ein relativ schmaler, aber durchaus aussagekräftiger Datensatz für Versorgungsanalysen.
Der wesentliche Charme dieser Daten war schlicht und ergreifend: Es gab lange Zeit keine anderen. Aber sie haben eben keine klinische Tiefe – es fehlen die Details der Behandlung, die Laborwerte, die Bildgebung. Über das FDPG hingegen erschließen sich primäre klinischen Daten aus den Universitätskliniken. Da gehen wir viel tiefer rein. Dafür sind diese Daten natürlich auf den universitär-stationären Versorgungskontext beschränkt. Man kann also sagen: Keine der beiden Infrastrukturen ersetzt die andere, wir brauchen beide Perspektiven.
Wer darf denn diese Daten beim FDPG eigentlich beantragen? Kann da, wie beim FDZ Gesundheit, jeder kommen?
Grundsätzlich kann jeder einen Antrag stellen, aber wir schauen uns das im Rahmen der Nutzerregistrierung sehr genau an. Es muss ein plausibles, gemeinwohlorientiertes Forschungsinteresse nachgewiesen werden. Wenn jemand mit einer Uni-Adresse ankommt, ist das meist schnell geklärt. Wenn eine Privatadresse oder ein Unternehmen anfragt, prüfen wir tiefer: Gibt es ein substanzielles Forschungsinteresse? Explizit schließen wir die forschende Industrie nicht aus, aber der Zweck muss stimmen.
Außerdem arbeiten wir mit einer breiten Einwilligung der Patienten, dem sogenannten Broad Consent. Das ist ein ganz entscheidender Punkt: Die Patienten müssen aktiv einwilligen, dass ihre Daten für die medizinische Forschung nachgenutzt werden dürfen. Darin ist klar geregelt, dass dies nur für medizinische Zwecke geschehen darf – aber eben nicht für Kosmetikforschung, reinen Datenverkauf oder ähnliches. Die genauen Kriterien stellen wir auch auf unserer Website bereit (https://forschen-fuer-gesundheit.de/daten-und-bioproben/daten-und-bioproben-fur-ein-forschungsprojekt-beantragen/).
Nun sollen noch in diesem Jahr Daten aus der elektronischen Patientenakte (ePA) zu Forschungszwecken ausgeleitet werden. Braucht es das FDPG mit dem Ausbau des FDZ Gesundheit noch?
Generell finde ich die Idee der ePA natürlich super – schon allein zur Behandlungsunterstützung, aber auch mehr strukturierte Daten für die Forschung wären toll. Wir würden uns sogar wünschen, dass wir direkt eine Schnittstelle zur ePA bekommen. Das ist gesetzlich im Paragraf 363 Absatz 8 SGB V tatsächlich auch so vorgesehen: Dort steht, dass Versicherte ihre ePA-Daten mittels einer Einwilligung auch direkt Forschenden für die Forschung freigeben können. Wir könnten die Patienten also – zusätzlich zur automatisierten Ausleitung ans FDZ – auch direkt fragen, ob sie ihre Daten für die Datenintegrationszentren der Universitätsmedizin und deren Nutzungsabfrage via FDPG, verknüpft mit den anderen vorhandenen medizinischen Daten, zur Verfügung stellen. Damit würden auch Fragestellungen zur Vor- und Nachbehandlung rund um einen stationären Aufenthalt beantwortet werden können. Es ist aber noch nicht unklar, wann und wie diese Schnittstelle kommt.
Die Repräsentativität der Daten wurde immer wieder politisch versprochen. Es gibt da aber deutliche Bedenken.
Das ist ein ganz wichtiger Punkt – und der unterscheidet die ePA-Daten von den Kassendaten im FDZ. Selbst wenn wir formal Millionen von ePAs haben, wissen wir ja nicht automatisch, wie sie befüllt sind. Wir wissen nicht, wie vollständig die Daten pro Patient sind oder ob bestimmte Erkrankungen systematisch besser erfasst werden als andere. Wenn beispielsweise chronisch Kranke oder digital affine Menschen überrepräsentiert sind, entstehen Verzerrungen. Aber viel kritischer ist die Frage: Bei wie vielen wird nichts eingestellt? Und das alles müssen Sie wissen, um valide damit forschen zu können.
Dazu kommen ganz praktische Hürden: Viele Inhalte liegen derzeit als PDF vor, was für die Forschungsnachnutzung weitgehend nutzlos ist. Zudem bildet die ePA oft nur Ausschnitte einer Krankengeschichte ab. Und auch der Ruf nach tagesaktuellen Daten klingt zwar attraktiv, bedeutet aber technisch enorme Anforderungen, etwa wenn es um Korrekturen oder Nachmeldungen geht. Das wird noch sehr sportlich. Bis wir in der Fläche mit ePA-Daten im FDZ sinnvoll forschen können, wird es aus meiner Sicht Jahre, wenn nicht gar ein Jahrzehnt dauern. Das soll aber überhaupt nicht dagegen sprechen, sich diesbezüglich auf den Weg zu machen und an der Zielsetzung festzuhalten.
Heißt das im Umkehrschluss, wenn wir genug Daten haben, brauchen wir keine klassischen klinischen Studien mehr?
Nein, das wäre ein Trugschluss. Keine Sekundärnutzung von Versorgungsdaten wird jemals eine kontrollierte klinische Studie ersetzen. In einer Studie schließe ich Störfaktoren aus, um einen Effekt statistisch hart nachzuweisen. Im Versorgungsalltag habe ich aber Patienten, die multimorbid sind, die drei andere Medikamente gleichzeitig nehmen.
Die Versorgungsdaten sind dafür da, den „Realitätscheck“ zu machen: Kommt der Effekt, den wir unter Idealbedingungen in der Studie gesehen haben, im echten Versorgungsalltag überhaupt an? Und bei welchen Gruppen gibt es Nebenwirkungen, die wir in der kleinen Studiengruppe nicht gesehen haben? Beides ergänzt sich, aber eines ersetzt das andere nicht.
Mit verschiedenen Gesetzen wie dem Gesundheitsdatennutzungsgesetz und weiteren geplanten Gesetzen macht die Politik sehr viel Druck. Hilft das?
Es ist gut, dass wir einen Rechtsrahmen haben. Es ist freilich vergleichsweise leicht, ein Gesetz zu schreiben. Aber die technische und medizinische Umsetzung „hinten raus“ bedeutet oft einen Riesenaufwand, der in der Theorie unterschätzt wird. Wenn im Gesetz steht, dass Daten fließen müssen, sind die Schnittstellen noch lange nicht programmiert. Wir müssen aufpassen, dass wir nicht eine Diskrepanz erzeugen zwischen dem, was im Gesetzblatt steht, und dem, was in der IT tatsächlich umgesetzt werden kann.
Ein weiteres ungelöstes Problem ist beispielsweise die Verknüpfbarkeit. Für viele komplexe Forschungsfragen bräuchte man eine Kombination aus vielfältigen, verteilt vorliegenden klinischen Daten und Abrechnungsdaten. Das ist derzeit rechtlich und technisch nur sehr eingeschränkt möglich. Ich vermisse da so ein bisschen den großen Wurf. Man verweist stolz darauf, dass man im FDZ bald Kassendaten und Genomdaten aus dem gesetzlichen Modellvorhaben zur Genomsequenzierung verknüpfen kann, aber für die breite Masse der Forschung fehlt uns ein durchgängiges Konzept, etwa über ein permanentes Forschungspseudonym.
Wenn wir nicht generell sagen wollen, das RKI macht jetzt für alles und für jeden Daten-Pseudonymisierung, dann müssen wir uns eigentlich was Besseres überlegen. Das geht auch aus unserer Stellungnahme zum Medizinregistergesetz (PDF) hervor. Es bräuchte hier dringend ein durchgehendes Fachkonzept, das maßgeblich aus der Perspektive der Forschung und nicht allein aus der ministerialjuristischen Perspektive erarbeitet werden müsste.
Apropos Stellungnahmen. Das Verfahren wird hierzulande immer mal wieder als nicht demokratisch genug bezeichnet: Die vom Bund vorgegebenen Fristen werden beispielsweise des Öfteren als „zu knapp bemessen“ kritisiert, außerdem darf nicht jeder eine Stellungnahme abgeben, beispielsweise beim MRG. Wie sehen Sie den Prozess?
Wir als TMF bemühen uns, die breit gefächerte Expertise in der Community – sei es aus der Mitgliedschaft oder von Partnerorganisationen – einzubeziehen und abgestimmtes Feedback im Rahmen der Kommentierung zu liefern. Gerade für ein solches Vorgehen ist ausreichend Zeit notwendig.
Warum ist die Verknüpfung so schwer?
Man denkt oft: Nehmen wir doch einfach die KV-Nummer. Aber wenn man länger darüber nachdenkt, merkt man, dass das zu kurz springt. Die Rentenversicherung kennt keine KV-Nummer. Die Unfallversicherung kennt keine. Der privatversicherte Bereich zieht erst mühsam nach. Und in primären Forschungserhebungen fragt man erst recht nicht nach einer KV-Nummer des untersuchten bzw. befragten Bürgers – das dürfte man bis dato rechtlich noch nicht einmal.
Wenn wir Daten wirklich über Sektoren hinweg verknüpfen wollen – etwa um zu sehen, wie sich Arbeitslosigkeit oder Reha-Maßnahmen auf die Gesundheit auswirken –, dann ist die KV-Nummer vermutlich eine Sackgasse. Wir bräuchten eigentlich eine übergreifende ID, etwa basierend auf der Steuer-ID, die jeder Bürger hat. Und diese ID müsste erst einmal in alle Datenbestände eingeführt werden, was sehr viel Aufwand und Zeit erfordert. Aber an dieses heiße Eisen traute sich der Gesetzgeber bislang nicht richtig ran; wir sind sehr gespannt, ob sich der jüngste Entwurf zum Forschungsdatengesetz oder das Update zur Digitalstrategie im Gesundheitswesen in diese Richtung entwickeln lassen.
Wer ist beim European Health Data Space (EHDS) in Deutschland eigentlich zuständig?
Im EHDS sind nationale Datenzugangsstellen für den Forschungsbereich vorgesehen. In Deutschland ist dafür das BfArM als zentrale Datenzugangs- und Koordinierungsstelle benannt worden. Daneben gibt es im Versorgungskontext aber noch die nationale Kontaktstelle für die grenzüberschreitende Gesundheitsversorgung, die in Deutschland bei der Gematik angesiedelt ist. Ihre Funktion ist primär koordinierend: Sie bilden die Schnittstelle zwischen den Mitgliedstaaten.
In einem föderalen System wie Deutschland stellt sich zudem die Frage, wie wir die verschiedenen spezialisierten Datenquellen anbinden – also Register, universitäre Daten oder eben Kassendaten. Der EHDS erlaubt glücklicherweise mehrere nationale Zugangspunkte. Das halten wir auch für sehr sinnvoll, denn unterschiedliche Datenarten erfordern unterschiedliche Expertise. Eine rein zentralistische Struktur würde unserer gewachsenen Forschungslandschaft kaum gerecht werden. Gebündelt werden diese dezentralen, domänenspezifischen Datenzugangsstellen allerdings durch die zentrale Stelle beim BfArM.
Es gibt immer wieder Kritik, dass zum Beispiel die Daten aus der elektronischen Patientenakte überhaupt nicht für wissenschaftliche Zwecke geeignet sind. Wie sehen sie das?
Wir diskutieren in Deutschland sehr intensiv über Rechtsrahmen und Technik – aber viel zu wenig über die eigentliche wissenschaftliche Zielsetzung. Es gibt beispielsweise gar keine wissenschaftliche Beschreibung, welche wissenschaftliche Frage der EHDS eigentlich beantworten soll. Das steht nirgendwo im Detail.
Wir müssten uns viel früher fragen: Welche konkreten Forschungsfragen wollen wir mit ePA-Daten eigentlich beantworten? Je nach Fragestellung unterscheiden sich die Anforderungen an Datenqualität und Struktur erheblich. Ohne eine solche Beschreibung und den Blick für die Praxis bauen wir eine Infrastruktur auf, deren wissenschaftliches Potenzial wir am Ende vielleicht gar nicht optimal nutzen können.
Die ePA basiert auf einer Widerspruchslösung. Reicht das für die Akzeptanz?
Die Widerspruchslösung, also das Opt-out, klingt einfacher als eine Einwilligungslösung. Sie erfordert aber einen enormen Aufwand bei der Kommunikation. Vertrauen entsteht ja nicht automatisch durch Gesetzgebung. Gerade wenn Daten künftig auch europäisch nutzbar werden, müssen wir den Bürgerinnen und Bürgern transparent erklären, was passiert.
Spätestens wenn ich keine Einwilligung mehr brauche, ist es viel schwieriger, diese Information an den Mann oder an die Frau zu bekommen. Und die Vorstellung, dass man das auf irgendeine Behördenwebseite packt und sagt „Das war jetzt die Information“, da weiß ich nicht, ob das langfristig akzeptanzfördernd ist.
Wie blicken Sie in die Zukunft?
Ich bin realistisch. Wir haben heute mehr Infrastruktur, mehr Standardisierung und mehr europäische Koordination als je zuvor. Das ist viel, was es an Möglichkeiten gibt.
Aber wir müssen ehrlich bleiben: Daten sind nicht automatisch repräsentativ, Infrastruktur ersetzt keine wissenschaftliche Methodik, und rechtliche Ansprüche ersetzen keine praktikablen Prozesse. Große Visionen brauchen belastbare Umsetzungsstrategien. Die Bottom-Line bei all dem, was wir sagen, ist doch: Keine einzelne Lösung ist eine Lösung für alles. Wir haben unterschiedliche Datentöpfe, unterschiedliche Zugänge, und in der Summe ergänzen sie sich gut. Entscheidend ist, dass wir nicht nur Technik bauen, sondern auch verstehen, was wir damit wissenschaftlich erreichen wollen.
(mack)












Künstliche Intelligenz
Digital Markets Act: Teilerfolg für Meta vor dem EU-Gericht
Meta hat im Ringen um die EU-Regeln für Digitalplattformen einen Teilerfolg erzielt. Das Gericht der Europäischen Union (EuG) hat am Mittwoch einen Beschluss der EU-Kommission teilweise für nichtig erklärt. Die Brüsseler Wettbewerbshüter klassifizierten den Facebook-Mutterkonzern im September 2023 auf Basis des Digital Markets Acts (DMA) als sogenannten Torwächter (Gatekeeper). Diese Einstufung kippte EuG für den hauseigenen Kleinanzeigendienst Marketplace. Für den Kommunikationsdienst Messenger bleibt sie dagegen bestehen.
Weiterlesen nach der Anzeige
Meta hatte gegen beide Benennungen geklagt. Der Plattformbetreiber betrachtet die betroffenen Dienste nicht als eigenständige, kritische Zugangstore für Geschäftskunden.
In seiner Begründung zur Aufhebung des Marketplace-Status sparte das Gericht nicht mit Kritik an der Kommission. Die Luxemburger Richter warfen der ihr einen Rechtsfehler vor. Sie habe sich bei ihrer Bewertung stur auf Daten der letzten drei Jahre vor der Benennung gestützt und dabei wesentliche regulatorische und tatsächliche Änderungen ignoriert, die Meta bereits Ende Juli 2023 eingeführt hatte. Ein Sprecher des US-Konzerns begrüßte das Urteil dementsprechend: Die Entscheidung bestätige, dass der Marketplace von vornherein nicht habe benannt werden dürfen.
Versäumte Analyse und mangelhafte Begründung
Das EuG hebt hervor, dass die Rechtmäßigkeit eines EU-Rechtsakts immer anhand der tatsächlichen Umstände zum Zeitpunkt seines Erlasses beurteilt werden müsse. Genau hier habe die Kommission versagt, da sie weder eine konkrete Analyse der von Meta vorgenommenen Änderungen vorgelegt noch deren Auswirkungen auf die Einstufung als Online-Vermittlungsdienst fundiert erläutert habe. Um als solcher zu gelten, muss ein Dienst es Unternehmen nachweislich ermöglichen, Verbrauchern direkt Produkte oder Dienstleistungen anzubieten. Die Argumente der Kommission in dem Beschluss blieben in diesem Punkt laut der Entscheidung rein hypothetisch und unvollständig.
In der Praxis hat das Urteil in der Rechtssache T-1078/23 für das operative Geschäft des Marketplace aber nur noch symbolische Bedeutung. Die Kommission hob die Gatekeeper-Einstufung für den Kleinanzeigendienst bereits im April 2025 offiziell auf. Meta hatte zuvor zusätzliche Überwachungswerkzeuge implementiert, um die kommerzielle Nutzung durch Firmen einzudämmen. Diese Maßnahmen führten dazu, dass die Zahl der aktiven Geschäftskunden in der EU auf unter 10.000 sank. Das ist weit unter dem Schwellenwert des DMA.
Messenger bleibt im Visier
Weiterlesen nach der Anzeige
Nicht erfolgreich verlief das Verfahren für Meta dagegen mit Blick auf den Messenger. Hier bestätigten die Richter die Auffassung der Kommission in vollem Umfang und wiesen die Argumente des Betreibers ab. Sie stellten fest, dass es sich beim Messenger um einen vom sozialen Netzwerk Facebook getrennten, nummernunabhängigen, interpersonellen Kommunikationsdienst handelt. Meta hatte argumentiert, die Dienste seien tief miteinander integriert. Das EuG verwies indes darauf, dass der Messenger über eigenständige Apps angeboten und unabhängig von Facebook genutzt werden könne. Ferner bewerbe der Konzern gezielt spezifische Werkzeuge, die Unternehmen die direkte Kontaktaufnahme mit Nutzern erlauben.
Auch den Einwand Metas, die Kommission habe die Nutzerzahlen falsch berechnet, ließ das Gericht nicht gelten. Bei der Ermittlung, ob die quantitativen Schwellenwerte des DMA erreicht werden, durften die Brüsseler Beamten korrekterweise alle Endnutzer heranziehen und mussten nicht nur jene zählen, die den Messenger exklusiv ohne Facebook-Konto nutzen. Da Meta keine ausreichenden Argumente vorbringen konnte, um die gesetzlichen Vermutungen des DMA zu entkräften, war die Kommission auch nicht zu einer speziellen Marktuntersuchung verpflichtet.
Meta kündigte an, die Optionen für eine Beschwerde gegen diesen Teil des Urteils beim Europäischen Gerichtshof genau zu prüfen. 2025 verhängte die EU bereits ein Bußgeld von 200 Millionen Euro gegen Meta wegen Wettbewerbsverstößen. Dagegen wehrt sich das Unternehmen ebenfalls vor Gericht.
(mho)
Künstliche Intelligenz
Forscher finden Hinweis auf Protoplaneten in extrem seltenem Meteorit
In der Frühzeit des Sonnensystems umkreiste ein größerer Himmelskörper die Sonne – bis er eines Tages mit einem anderen kollidierte. Forscher der University of Colorado Boulder (CU Boulder) haben einen Überrest dieses Protoplaneten ausgemacht: in Form eines äußerst seltenen Meteoriten.
Weiterlesen nach der Anzeige
Northwest Africa (NWA) 12774 heißt der Meteorit, der 2019 in der Sahara gefunden wurde. Das Team um den Geowissenschaftler Aaron Bell hat ihn untersucht und ist zu dem Schluss gekommen, dass es sich um das Trümmerteil eines Protoplaneten handelt, der wenige Millionen Jahre nach der Entstehung des Sonnensystems entstanden ist. Ein Protoplanet ist der Vorläufer eines Planeten; es ist das zweite Entwicklungsstadium nach den Planetesimalen.

Eine 4 Zentimeter große, 5,6 Gramm schwere Scheibe des Meteoriten NWA 12774
(Bild: John Kashuba)
„Es ist unglaublich zu denken, dass es da einst einen Himmelskörper von dieser Größe gab“, sagte Bell. „Wir wissen von seiner Existenz nur, weil einige Fragmente davon zufällig auf der Erde gelandet sind. Diese Meteoriten sind der Beweis für einen komplett anderen Weg, wie sich frühe Planeten entwickelten.“
Gestein aus der Frühzeit des Sonnensystems
NWA 12774 ist ein Angrit, ein vulkanisches Gestein, das sich in der Frühzeit des Sonnensystems gebildet hat, also vor rund 4,5 Milliarden Jahren. Es ist äußerst selten: Gerade mal 68 der rund 80.000 auf der Erde gefundenen Meteoriten sind Angrite.
Das Besondere an Angriten ist die chemische Zusammensetzung: Sie enthalten kaum Siliziumdioxid, das der Hauptbestandteil der Gesteinsplaneten in unserem Sonnensystem ist. NWA 12774 enthielt zudem Klinopyroxen, einen Mineralkristall, der häufig in der Erdkruste und im Erdmantel vorkommt.
Der Klinopyroxen von NWA 12774 weist jedoch einen außergewöhnlich hohen Gehalt an Aluminium auf. Diese Kombination kann sich nur unter sehr hohem Druck tief unten gebildet haben: Die Forscher rekonstruierten die Bedingungen und fanden heraus, dass es mindestens 17.500 bar gewesen sein müssen. Zum Vergleich: Auf dem Grund des Marianengrabens, der tiefsten Stelle der Erde, herrscht ein Druck von etwa 1000 bar.
Weiterlesen nach der Anzeige
Bisher gingen Forscher davon aus, dass Angrite von Asteroiden stammen. Diese Himmelskörper sind zu klein für die Bedingungen, unter denen dieser Meteorit entstand. Um einen solchen Druck im Innern zu erzeugen, musste der Himmelskörper einen Radius von mindestens 1000 Kilometern gehabt haben.
Kristalle mit scharfen Kanten
Bei ihren Untersuchungen stießen die Forscher auf eine weitere Besonderheit: Die Kristalle im Inneren von NWA 12774 haben immer noch scharfe Kanten sowie feine chemische Strukturen auf, die darauf hindeuten, dass sie in relativ geringer Tiefe entstanden. Wären sie in größerer Tiefe entstanden, wären diese Strukturen nicht mehr vorhanden.
Das Team korrigierte die Größe des Himmelskörpers deshalb noch einmal nach oben: Sein Radius könnte größer als 1800 Kilometer gewesen sein – und damit in etwa so groß wie der Erdmond, vielleicht sogar so groß wie der Mars, dessen Radius 3300 Kilometer beträgt.
Bell hält es für möglich, dass der von ihnen identifizierte Protoplanet nicht der einzige in unserem Sonnensystem war. „In den Archiven liegen noch viele Meteorite, die noch nicht gründlich untersucht wurden, es gab wahrscheinlich noch mehr solcher Protoplaneten, von denen wir nichts wissen.“ ,
Das Team um Bell stellt seine Ergebnisse in der Fachzeitschrift Earth and Planetary Science Letters vor.
(wpl)
Künstliche Intelligenz
Top 10: Die besten Bluetooth-Lautsprecher für Garten, Balkon und WM 2026
Bluetooth-Lautsprecher sind ideal für Garten, Balkon und Public-Viewing zur WM 2026. Wir zeigen die zehn besten aus über 40 Tests.
Ob entspannter Grillabend, Festival oder gemeinsames Fußballschauen im Freien: Ein guter Bluetooth-Lautsprecher sorgt überall für den richtigen Sound. Gerade rund um sportliche Großereignisse wie die Fußball-WM 2026 rücken die mobilen Boxen vermehrt in den Fokus – im Garten, auf der Terrasse oder beim Public-Viewing mit Freunden.
Unsere Analyse zeigt: Besonders gefragt bei unseren Lesern sind kompakte Bluetooth-Lautsprecher mit einem Gewicht von 0,5 kg bis gut 1 kg – handlich genug für den spontanen Einsatz beim Public Viewing, robust genug für den dauerhaften Outdoor-Einsatz. Genau diesen Modellen widmen wir unsere regelmäßig aktualisierte Bestenliste. Wer seine Bluetooth-Box noch leichter wünscht, der sollte bei unserer Bestenliste der kleinen Bluetooth-Lautsprecher vorbeischauen.
Welcher kleine Bluetooth-Lautsprecher ist der beste?
Unser Testsieger ist der JBL Charge 6 für 134 Euro (Amazon). Er vereint kräftigen Klang mit einer langen Akkulaufzeit, der besten App, guter Verarbeitung und kultigem Design.
Zum Technologiesieger küren wir den Marshall Emberton III für 148 Euro (Amazon). Der Vintage-Bluetooth-Lautsprecher besticht nicht nur mit seinem Äußeren, er klingt auch noch verdammt gut und läuft mit einer Akku-Ladung länger als die meisten anderen.
Wer sparen will, greift zu unseren Preis-Leistungs-Sieger Xiaomi Sound Outdoor für schlanke 37 Euro (Alza). Trotz kompakter Maße klingt der Outdoor-Speaker besser als viele deutlich teurere Konkurrenten.
Hier unser vollständiges Ranking:
Der JBL Charge 6 ist der neue Platzhirsch unter den kompakten Bluetooth-Lautsprechern und erobert den Spitzenplatz unserer Bestenliste. Mit verbessertem Klang, längerer Akkulaufzeit und erhöhter Wasserdichtigkeit setzt er die Messlatte etwas höher.
Der Preis von 135 Euro (Amazon) ist angesichts der gebotenen Leistung nachvollziehbar, macht den Charge 6 aber zu einer Investition.
- kraftvoller, präziser Klang mit starkem Bass
- lange Akkulaufzeit
- verbesserte IP68-Wasserdichtigkeit
- hochwertige Verarbeitung
- Auracast und USB-C-Audio
- spürbarer Aufpreis zum Vorgänger
- Schwächen in den mittleren Höhen bei hoher Lautstärke
- kein Mikrofon für Freisprechfunktion
- nur SBC-Codec
Der Marshall Emberton III ist ein kompakter Bluetooth-Lautsprecher, der mit kultiger Optik, hochwertigem Material-Mix und starker Technik aufwartet. Der Klang ist kraftvoll, warm und druckvoll. Die größten Trümpfe des Emberton III sind seine enorme Mobilität dank kompakter Abmessungen und geringem Gewicht sowie die herausragende Akkulaufzeit. Er kostet rund 148 Euro (Amazon).
- kompakt, schick, hochwertig
- kraftvoller, warmer Klang
- enorme Akkulaufzeit & Quick Charge
- Tiefbass nicht so druckvoll wie größere Boxen
- Bedienknopf etwas schwammig
- AUX-Eingang fehlt
Der Xiaomi Outdoor Speaker (2024) beweist: Guter Sound muss nicht teuer sein. Dazu ist der Bluetooth-Lautsprecher schick, wasserdicht und einfach zu bedienen. Für gerade einmal 37 Euro bietet der robuste Klangzylinder eine beeindruckende Performance.
- unschlagbares Preis-Leistungs-Verhältnis
- robustes, wasserdichtes IP67-Design
- kräftiger Bass trotz kompakter Größe
- praktische Trageschlaufe für unterwegs
- unkomplizierte Bedienung
- keine Equalizer
- Höhen könnten präsenter sein
- kein AUX-Eingang
- keine Powerbank-Funktion
- Akkulaufzeit nur Durchschnitt
Ratgeber
Sound: Welche Bluetooth-Lautsprecher haben den besten Klang?
Entscheidend für einen guten Klang ist unter anderem die Treibergröße. Große Treiber ab 50 mm Durchmesser sind besser in der Lage, tiefe Bässe zu reproduzieren. Kleinere Treiber unter 40 mm, wie man sie in kompakten Geräten findet, bieten weniger Druck im Bassbereich. Viele gute kleine Bluetooth-Lautsprecher nutzen zwei Treiber – einen größeren für die tiefen Frequenzen und einen kleineren für die Höhen. So hat etwa der hervorragende JBL Charge 6 einen 53 mm × 93 mm Tief-/Mitteltöner und einen 20 mm Hochtöner.
Gleichzeitig beeinflusst das Material der Treiber den Klang. So setzt etwa der Hochtöner des Edifier ES60 auf Seide.
Die Verstärkerleistung, gemessen in Watt RMS, bestimmt, wie laut und verzerrungsfrei der Lautsprecher spielt. Hier sollte man die Peak-Watt-Angaben ignorieren, da sie wenig über die reale Leistung aussagen. Ein 20-W-RMS-Lautsprecher liefert etwa einen saubereren und verzerrungsfreien Klang als ein Modell, das nur 10 W RMS bei gleicher Lautstärke aufbringen kann. Gute kabellose Lautsprecher bis 1 kg wie der JBL Charge 6 haben bis zu 45 W RMS.
Die Größe und das Gewicht sind entscheidende Faktoren für die Klangqualität, besonders für den Bass. Denn Bass benötigt Platz, um sich voll entfalten zu können. Viele stationäre Lautsprecher verfügen über ein Bassreflexsystem, etwa über Öffnungen im Gehäuse. Das verstärkt den Schalldruck. Bluetooth-Lautsprecher setzen dagegen häufig auf passive Bassradiatoren. Bei ihnen handelt es sich im Grunde um eine oder mehrere geschlossene Membranen. Öffnungen gilt es zu vermeiden, schließlich soll bei der mobilen Outdoor-Nutzung kein Schmutz oder Flüssigkeit eindringen.
Akku: Wie ist die Laufzeit meiner Bluetooth-Box?
Die Akkukapazität eines Bluetooth-Lautsprechers ist ein entscheidender Faktor, wenn es um die Spielzeit geht – aber nicht der Einzige. Viele Hersteller geben die Akkukapazität in Milliamperestunden (mAh) an. Das beschreibt, wie viel Strom der Akku über eine Stunde hinweg liefern kann. Erst zusammen mit der Spannung in Volt ergibt sich die tatsächliche Energiemenge in Wattstunden (Wh), was der tatsächlichen Akkukapazität entspricht. So hat die JBL Charge 6 einen Akku mit 7722 mAh. Multipliziert mit ihrer Spannung von 3,6 V ergibt sich eine Akkukapazität von 27,8 Wh.
Neben der reinen Akkukapazität bestimmen weitere Faktoren wie die Verstärkerklasse und die Stromaufnahme der Treiber die Laufzeit des Bluetooth-Lautsprechers. Ein großer Akku garantiert also nicht automatisch eine lange Laufzeit, ist jedoch ein wichtiges Indiz. Viele moderne Bluetooth-Lautsprecher funktionieren optional auch als Powerbank (Bestenliste). Wer diese Funktion nutzen möchte, sollte zusätzliches Augenmerk auf die Größe des Akkus legen.
Die Laufzeitangabe des Herstellers ist ein weiterer wichtiger Hinweis. Hierbei ist zu beachten, dass diese Werte meist unter wenig transparenten Bedingungen gemessen werden: moderate Lautstärke, kein Einsatz von Bass-Boostern oder anderen stromintensiven Funktionen.

Gerade die Lautstärke ist für die tatsächliche Akkulaufzeit entscheidend. Ein Speaker auf maximaler Lautstärke entleert den Akku viel schneller als ein leise spielendes Gerät. Dabei steigt die Leistungsaufnahme exponentiell an, je lauter der Lautsprecher spielt.
Was die Ladezeit betrifft, so hängt diese sowohl von der Kapazität des Akkus als auch vom verwendeten Ladestrom ab. Moderne Lautsprecher nutzen zunehmend USB-C als Ladestandard. Viele Bluetooth-Boxen kennen kein Quick Charge. Hier kann es selbst bei geringer Akkukapazität einige Stunden dauern, bis der Stromspeicher wieder voll ist. Bei Geräten wie dem Marshall Emberton III mit Quick Charge genügt es, sie 20 Minuten zu laden, um viele Stunden Spielzeit zu erhalten.
Verarbeitung: Wie robust soll eine Bluetooth-Box sein?
Bei der Verarbeitungsqualität eines Bluetooth-Lautsprechers, insbesondere für den Outdoor-Einsatz, spielen Robustheit und Materialwahl eine entscheidende Rolle. Ein Bluetooth-Lautsprecher sollte nicht nur wetterfest sein, sondern auch mechanischen Belastungen wie Stößen, Stürzen und Vibrationen standhalten. Hier sind mehrere Details zu beachten.
Zunächst einmal ist der Schutz gegen Wasser und Staub ein zentrales Kriterium. Die IP-Zertifizierung (Ingress Protection) ist der Industriestandard, um die Widerstandsfähigkeit gegenüber dem Eindringen von festen Partikeln und Flüssigkeiten zu bewerten. Ein Lautsprecher mit einer IP67-Zertifizierung wie der Sony Ult Field 1 ist sowohl staubdicht als auch wasserdicht. Er soll neben einer Unempfindlichkeit gegenüber Staub bis in eine Tiefe von einem Meter unter Wasser für 30 Minuten durchhalten, bevor Flüssigkeit eindringt. Aber Achtung: Diese Werte wurden unter Laborbedingungen gemessen und gelten nicht für Chlorwasser, Wasser mit Seife oder Salzwasser.

Neben der Wasserdichtigkeit spielt die Stoßfestigkeit eine zentrale Rolle. Outdoor-Lautsprecher sollten in der Lage sein, Stürze aus typischen Höhen, etwa 1,5 Meter, ohne Beschädigungen zu überstehen. Hier sind Gehäuse aus Thermoplasten wie TPU (thermoplastisches Polyurethan) oder robuster ABS-Kunststoff besonders vorteilhaft. Diese Materialien kombinieren eine hohe Flexibilität mit einer starken Schlagfestigkeit. Der JBL Charge 6 setzt beispielsweise auf eine Gummierung an den Ecken und Kanten, um Stöße abzufangen, während das Mesh-Gewebe am Gehäuse zusätzlichen Schutz vor Kratzern und Abrieb bietet.
Ein weiterer Aspekt ist die Qualität der Gehäusedichtung. Outdoor-Lautsprecher verwenden oft Gummiabdeckungen, um Anschlüsse wie den USB-Port oder den AUX-Eingang zu schützen. Eine mangelhafte Abdichtung kann dazu führen, dass Feuchtigkeit ins Innere gelangt und Korrosion an den elektronischen Bauteilen verursacht. Hochwertige Lautsprecher setzen daher auf versiegelte, robuste Gummiklappen, die fest sitzen und auch nach häufigem Öffnen und Schließen dicht bleiben.
Design: Wie muss ein guter Bluetooth-Lautsprecher aussehen?
Das Design eines Bluetooth-Lautsprechers geht über ästhetische Aspekte hinaus. Es beeinflusst auch, wie er genutzt werden kann, wie gut er klingt und wie robust er im Alltag ist. Dabei sind vorrangig bei hochmobilen Geräten Formfaktor, Größe und Gewicht zentrale Punkte.
Ein durchdachtes Design vereint Funktionalität mit Ästhetik. Hier geht es nicht nur darum, ob der Lautsprecher gut aussieht, sondern auch darum, wie ergonomisch er ist und welche praktischen Vorteile er im Alltag bietet. Zum Beispiel bieten viele kleine Bluetooth-Lautsprecher kompakte Designs, die auf Portabilität ausgelegt sind. Beispiele dafür sind der Sony Ult Field 1 und der Marshall Emberton III. Diese Geräte können dank mitgelieferter Schlaufen an Rucksäcken, Fahrrädern oder Kleidung befestigt werden, was sich für Outdoor-Aktivitäten anbietet.

Ein weiteres Beispiel für durchdachtes Design sind Lautsprecher mit runden oder zylindrischen Formen wie der LG Xboom 360 DXO2T. Diese Geometrien ermöglichen eine 360-Grad-Soundverteilung, was einen gleichmäßigen Klang in alle Richtungen ermöglicht.
Kleine Bluetooth-Lautsprecher bieten aufgrund ihres kompakten Designs und des geringen Gewichts klare Vorteile für alle, die häufig unterwegs sind. Einige Modelle sind so klein, dass sie sogar in eine Jackentasche passen. Mehr dazu in unserer Bestenliste der kleinen Bluetooth-Lautsprecher.
Freisprecheinrichtung: Telefonieren mit dem Bluetooth-Lautsprecher
Einige Bluetooth-Lautsprecher bieten eine integrierte Freisprecheinrichtung, um Anrufe direkt über den Lautsprecher anzunehmen. Dabei verwenden hochwertige Lautsprecher oft geräuschunterdrückende Mikrofone und Software, um Hintergrundgeräusche auszublenden.
Multipoint: mehrere Geräte gleichzeitig verbinden
Multipoint erlaubt es einem Bluetooth-Lautsprecher, mit mehreren Geräten gleichzeitig verbunden zu sein. Dies ist besonders praktisch, um etwa Notebook und Smartphone gleichzeitig mit dem Gerät zu verbinden. Wenn die Box also Musik vom Laptop spielt und ein Anruf auf dem Smartphone eingeht, schaltet der Lautsprecher automatisch auf den Anruf um. Nach dem Anruf wechselt er selbstständig zurück zur Musik des Laptops.
Verbindungsoptionen (AUX, USB, NFC)
Bluetooth ist die Standardverbindungsmethode für drahtlose Lautsprecher. Doch viele Modelle können mehr.
Ein 3,5-mm-Klinkenanschluss (AUX) ist besonders nützlich, wenn man eine kabelgebundene Verbindung bevorzugt oder wenn das Bluetooth-Signal aus einem Grund nicht verfügbar oder stabil genug ist. Dies gilt vorwiegend in Umgebungen mit vielen Störquellen oder für ältere Geräte ohne Bluetooth. Ein AUX-Anschluss sichert zudem eine verlustfreie, stabile Audioverbindung mit geringer Latenz, was für Audiophile und Gamer wichtig sein kann.
NFC (Near Field Communication): Die NFC-Technologie vereinfacht das Koppeln von Bluetooth-Geräten erheblich. Ein einfacher Kontakt zwischen dem Lautsprecher und einem NFC-fähigen Smartphone reicht aus, um eine Verbindung herzustellen, ohne dass man die Bluetooth-Einstellungen manuell durchlaufen muss.
Hi-Res-Codecs: Einige Bluetooth-Lautsprecher unterstützen neben SBC und in einigen Fällen auch AAC zusätzlich LDAC-, AptX– oder AptX HD-Codecs, die eine höhere Audioqualität über Bluetooth ermöglichen, indem sie Musik mit geringerer Latenz und weniger Komprimierung übertragen.
Fazit
Die richtige Bluetooth-Box zu finden, ist gar nicht so einfach. Einer der wichtigsten Faktoren ist der Klang, der in unserer Bewertung die höchste Priorität hat. Dabei ist wirklich guter Klang erst ab einem gewissen Volumen möglich. Aber auch kleine Bluetooth-Lautsprecher haben ihren Reiz. Hier gilt es, den goldenen Mittelweg zu finden.
Dabei sollte nie das Preis-Leistungs-Verhältnis außer Acht gelassen werden. Auch Design, Verarbeitung und Akkulaufzeit können den ausschlaggebenden Unterschied machen. Dazu kommen noch weitere Funktionen wie Wasserdichtigkeit, ein AUX-Eingang, Freisprecheinrichtung, Multipoint, hochauflösende Codecs, Multiroom und mehr.
Der Testsieger ist die JBL Charge 6, zum Vintage-König küren wir den Marshall Emberton III, und als Preis-Leistungs-Sieger überzeugt der Xiaomi Sound Outdoor.
Weitere passende Artikel:
Testsieger
JBL Charge 6
Der JBL Charge 6 ist mit verbessertem Klang und längerer Akkulaufzeit unser neuer Testsieger. Im Test zeigen wir, warum.
- kraftvoller, präziser Klang mit starkem Bass
- lange Akkulaufzeit
- verbesserte IP68-Wasserdichtigkeit
- hochwertige Verarbeitung
- Auracast und USB-C-Audio
- spürbarer Aufpreis zum Vorgänger
- Schwächen in den mittleren Höhen bei hoher Lautstärke
- kein Mikrofon für Freisprechfunktion
- nur SBC-Codec
Bluetooth-Box JBL Charge 6 im Test
Der JBL Charge 6 ist mit verbessertem Klang und längerer Akkulaufzeit unser neuer Testsieger. Im Test zeigen wir, warum.
JBL hat mit der Charge-Serie einen Bluetooth-Lautsprecher im Portfolio, der regelmäßig die Bestenlisten anführt. Der neue JBL Charge 6 tritt nun in die großen Fußstapfen des beliebten JBL Charge 5. Die Amerikaner versprechen mehr Power, längere Akkulaufzeit und bessere Wasserdichtigkeit. Zeit für einen gründlichen Check: Kann der Newcomer die hohen Erwartungen erfüllen? Wir haben den Lautsprecher auf Herz und Nieren geprüft.
Design und Verarbeitung des JBL Charge 6
Der JBL Charge 6 bleibt dem bewährten Design treu. Das zylindrische Gehäuse mit Mesh-Bezug und Gummipuffern schreit förmlich „Ich bin ein JBL!“. Mit 23 x 10 x 10 cm und 1 kg Gewicht ist er weder winzig noch ein Fliegengewicht, passt aber anstandslos in jeden Rucksack. Man könnte sagen: Er hat die optimale Größe für einen Lautsprecher, der zwar gut klingen, aber trotzdem noch transportabel sein soll.
Die Farbpalette ist groß: Rot, Camouflage, Lila, Blau, Schwarz, Pink und Weiß stehen zur Auswahl. Das klassische JBL-Rot sticht genauso hervor wie das neue Lila, während Schwarz und Weiß zeitlos wirken. Pink und Blau erscheinen etwas blass. Camouflage erweckt den Eindruck, als würde der Lautsprecher zum Wehrdienst eingezogen. Aber Geschmäcker sind verschieden und Auswahl hat noch nie geschadet.
JBL Charge 6 Bilder
JBL Charge 6

JBL Charge 6

JBL Charge 6

JBL Charge 6

JBL Charge 6

JBL Charge 6

JBL Charge 6

JBL Charge 6

JBL Charge 6

Der überarbeitete Gummifuß ist ein echter Fortschritt, der Charge 6 steht im Vergleich zum Vorgänger fest auf dem Boden der Tatsachen. Ebenfalls Lob verdient der breite und griffige Tragegriff. An zwei Befestigungspunkten kann er als Riemen oder Schlaufe angebracht werden. Nur das Einfädeln der Nippel durch die Laschen erfordert Fingerspitzengefühl.
Die Verarbeitung ist wie von JBL gewohnt makellos. Im Härtetest übersteht der Charge 6 sogar Stürze aus einem Meter Höhe auf Asphalt – nichts für schwache Nerven, aber beruhigend für Tollpatsche. Neu ist die Schutzklasse IP68. Der Lautsprecher ist damit nicht nur staubdicht, sondern überlebt auch 30 Minuten in 1,5 Metern Wassertiefe. Der Vorgänger mit IP67 würde bei diesem Tauchgang absaufen.
Wie gut ist der Klang des JBL Charge 6?
Mit 45 Watt Gesamtleistung (30 Watt RMS Woofer, 15 Watt RMS Tweeter) übertrifft der Charge 6 seinen Vorgänger leicht. Der 53 x 93 mm große Tieftöner und der 20 mm Hochtöner decken einen Frequenzbereich von 56 Hz bis 20 kHz ab.
Im Hörtest zeigt der Charge 6, was in ihm steckt. Der Bass ist präziser und druckvoller geworden. Die passiven Bassradiatoren an den Seiten vibrieren wie wild und liefern Tieftöne, die man in dieser Geräteklasse zu schätzen weiß. Bei maximaler Lautstärke – und die ist beachtlich – könnten kleinere Gegenstände auf dem Tisch durchaus ins Tanzen geraten.
Bei hohen Lautstärken offenbart der Lautsprecher allerdings leichte Schwächen in den mittleren Höhen. Bestimmte Stimmen und Instrumente verlieren etwas an Präsenz und werden etwas vom wuchtigen Bass verschluckt. Dennoch gehört der Charge 6 klanglich zur Elite seiner Gewichtsklasse. Der neue „AI Sound Boost“ reduziert Verzerrungen bei hoher Lautstärke etwas.
Bei den Bluetooth-Codecs bleibt JBL konservativ: Nur der Standard-Codec SBC wird unterstützt. Audiophile mögen die Nase rümpfen, doch es gibt einen Lichtblick: Über USB-C ist High-Res-Audio möglich. Im Test führte dies zu einer merklich besseren Klangqualität.
Ein Wermutstropfen bleibt: Auch der Charge 6 verzichtet auf ein integriertes Mikrofon. Als Freisprecheinrichtung taugt er daher nicht – schade.
Bedienung und App des JBL Charge 6
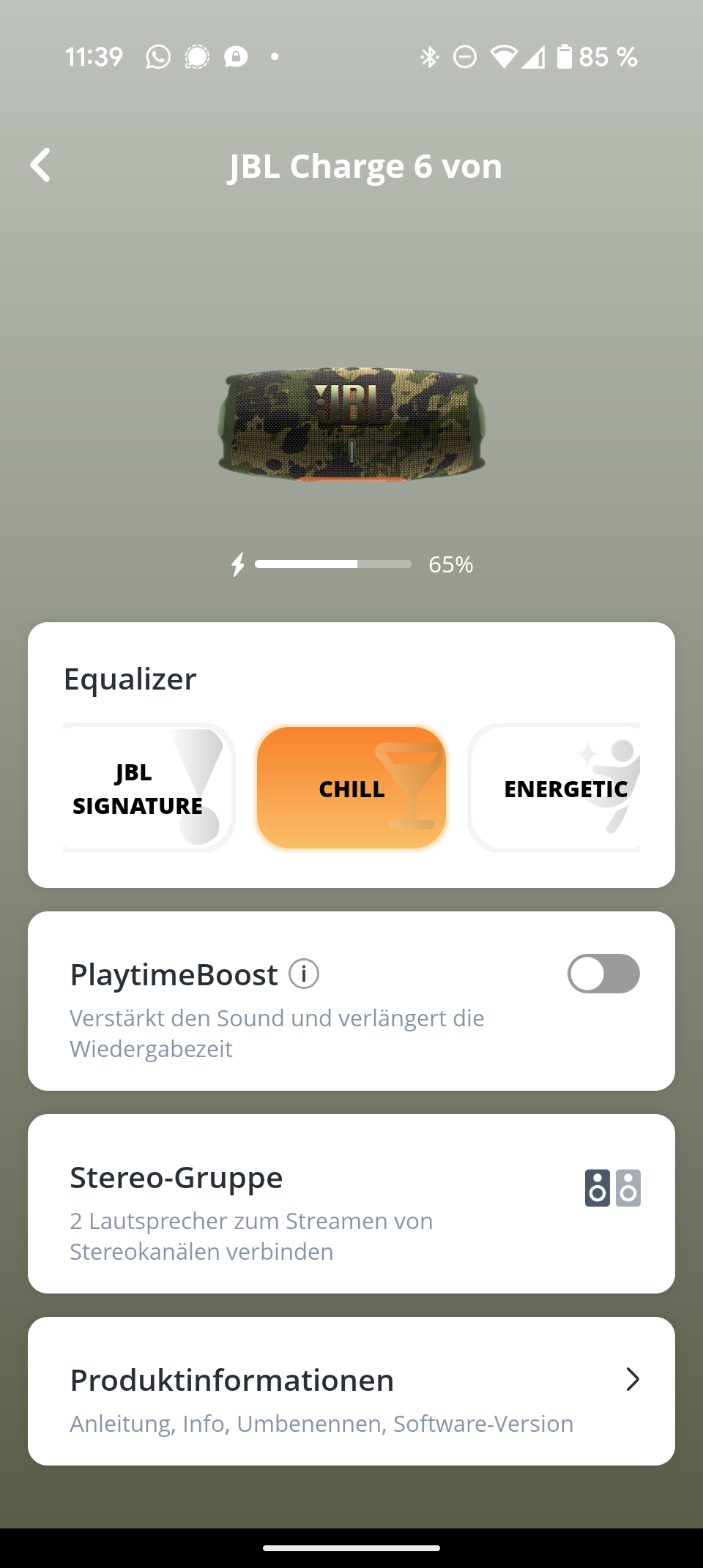
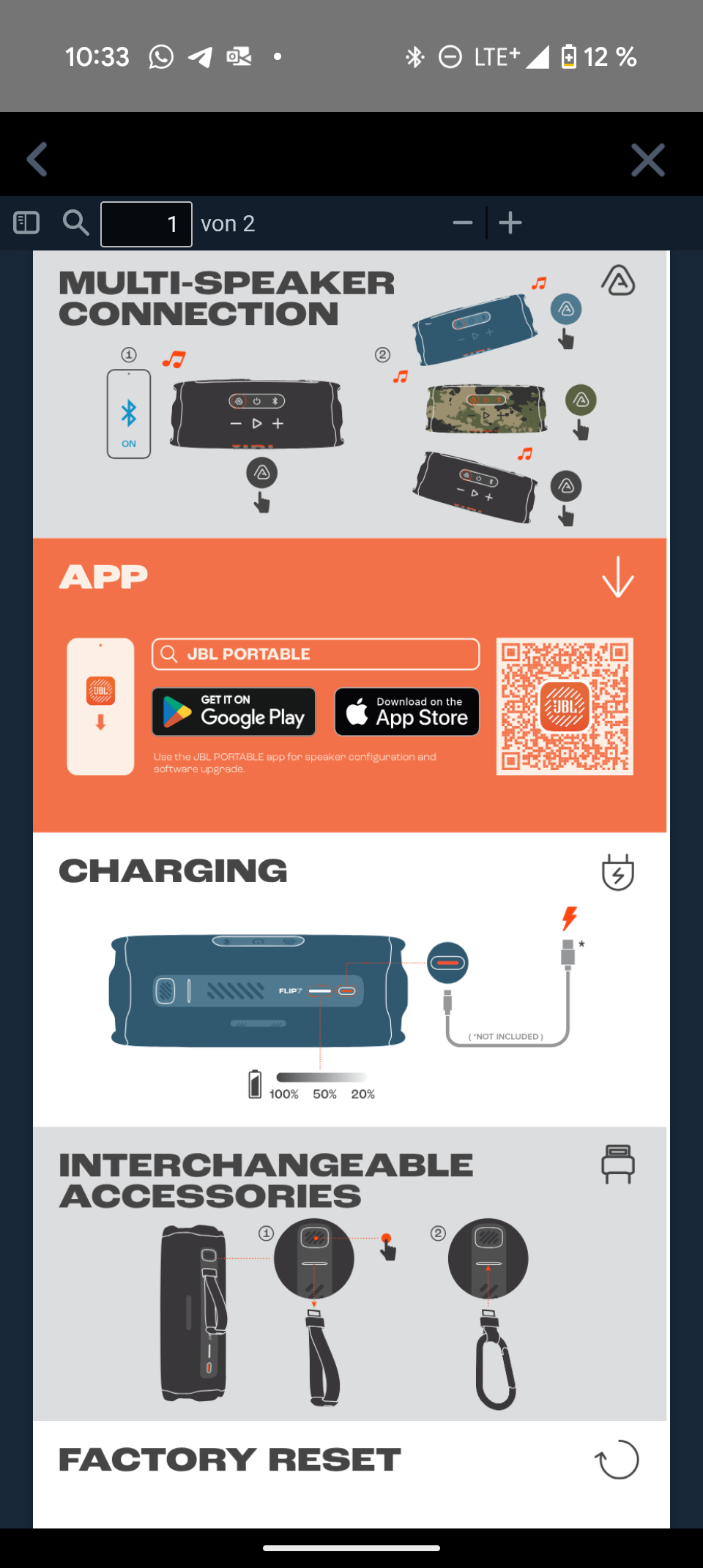
Die Bedienung erfolgt über physische Tasten auf der Oberseite. Diese sind neu angeordnet, bieten einen präzisen Druckpunkt und sind auch im Dunkeln gut zu erfühlen. Neben den üblichen Verdächtigen (Power, Bluetooth, Play/Pause, Lautstärke) gibt es auch eine Auracast-Taste.
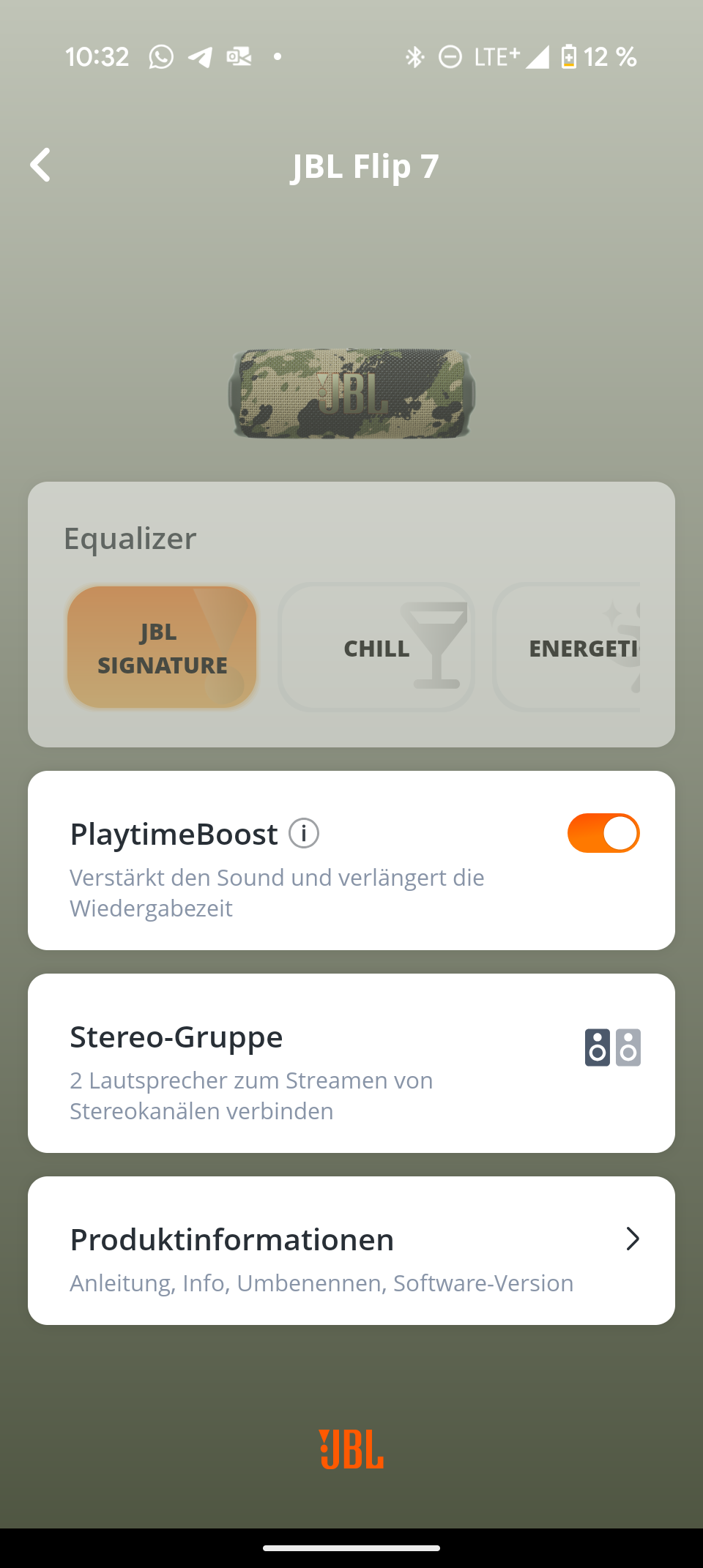
Diese Funktion verbindet mehrere JBL-Lautsprecher mühelos miteinander. Ein Gerät dient als Quelle und überträgt das Signal an die anderen. Die Kopplung ist kinderleicht und gelingt ohne komplizierte Paarungsrituale. Mit zwei Charge 6 lässt sich sogar ein Stereo-Paar bilden – allerdings nur über die App.
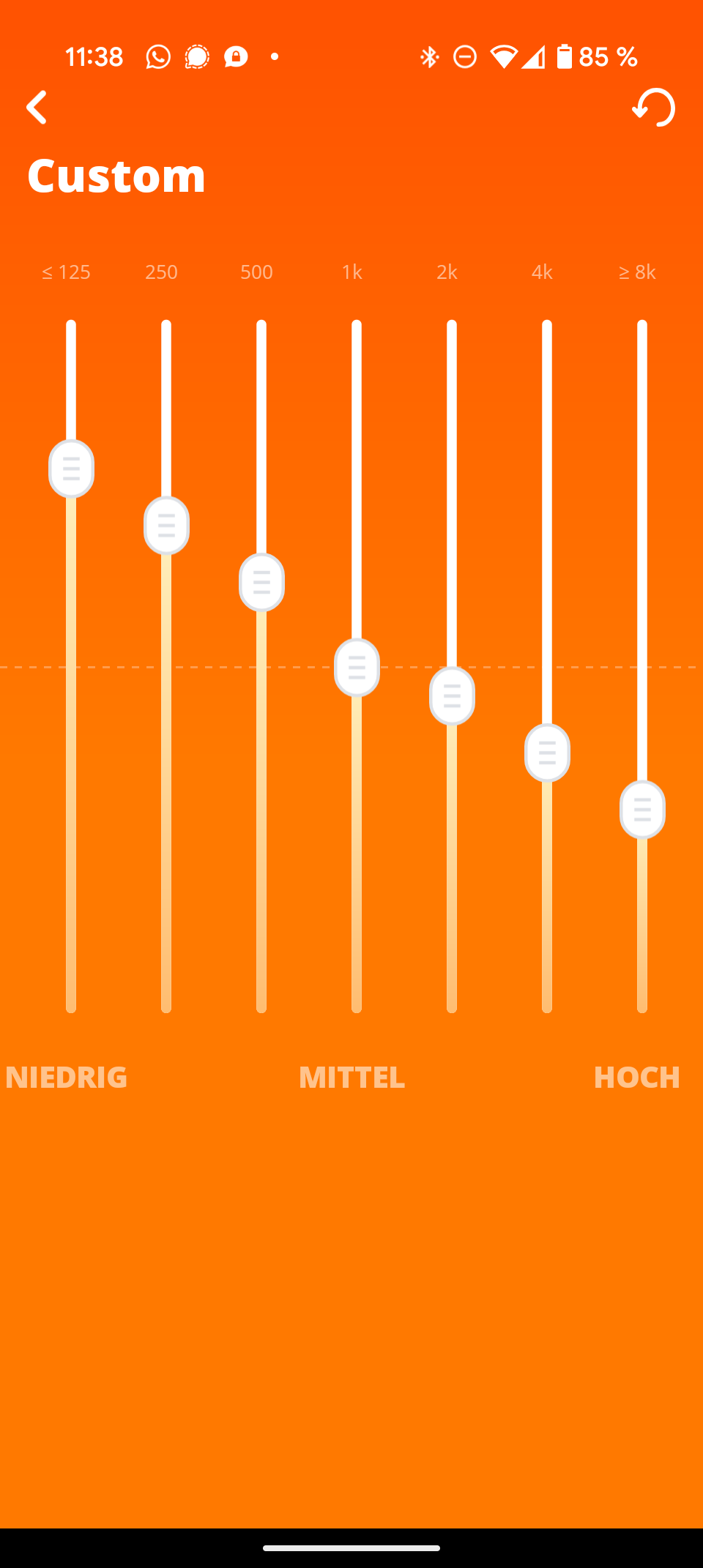
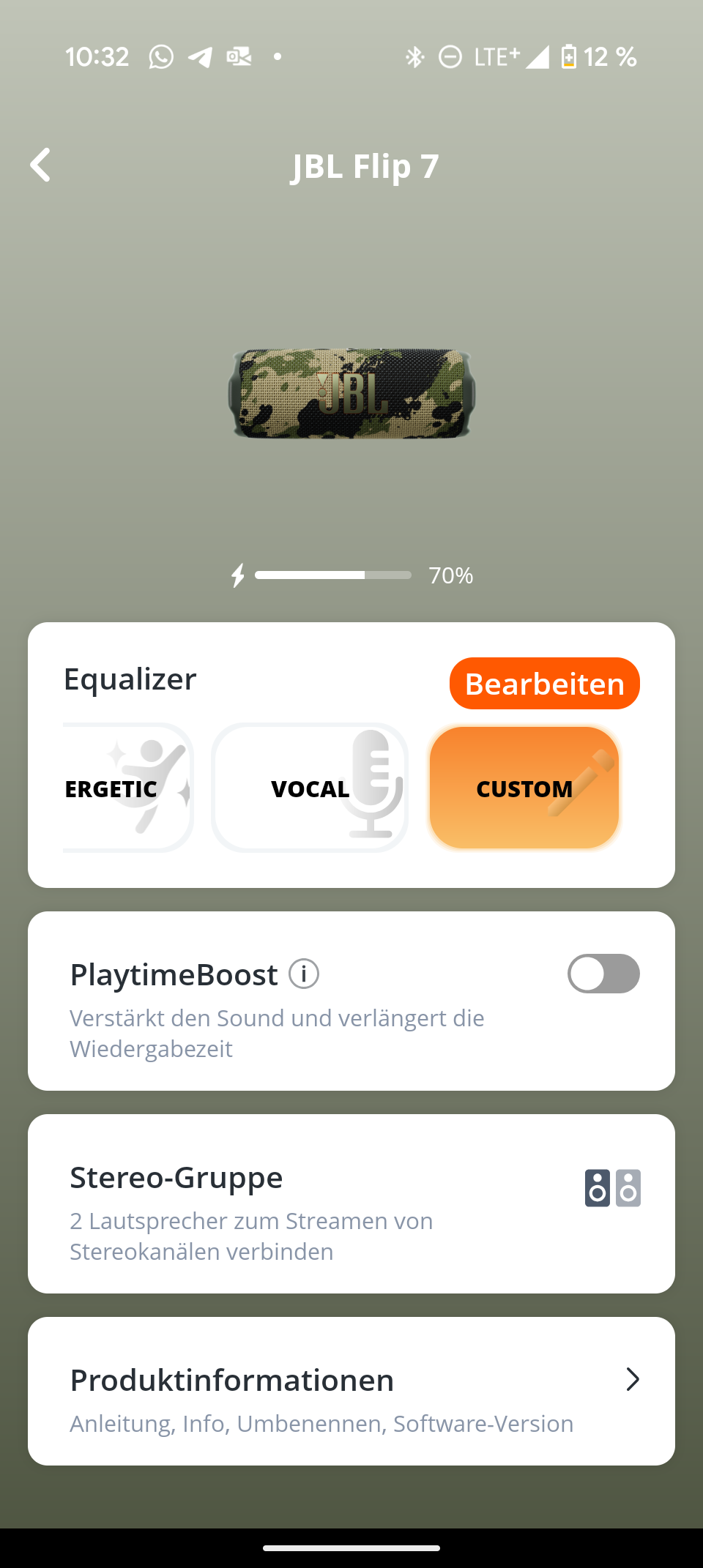
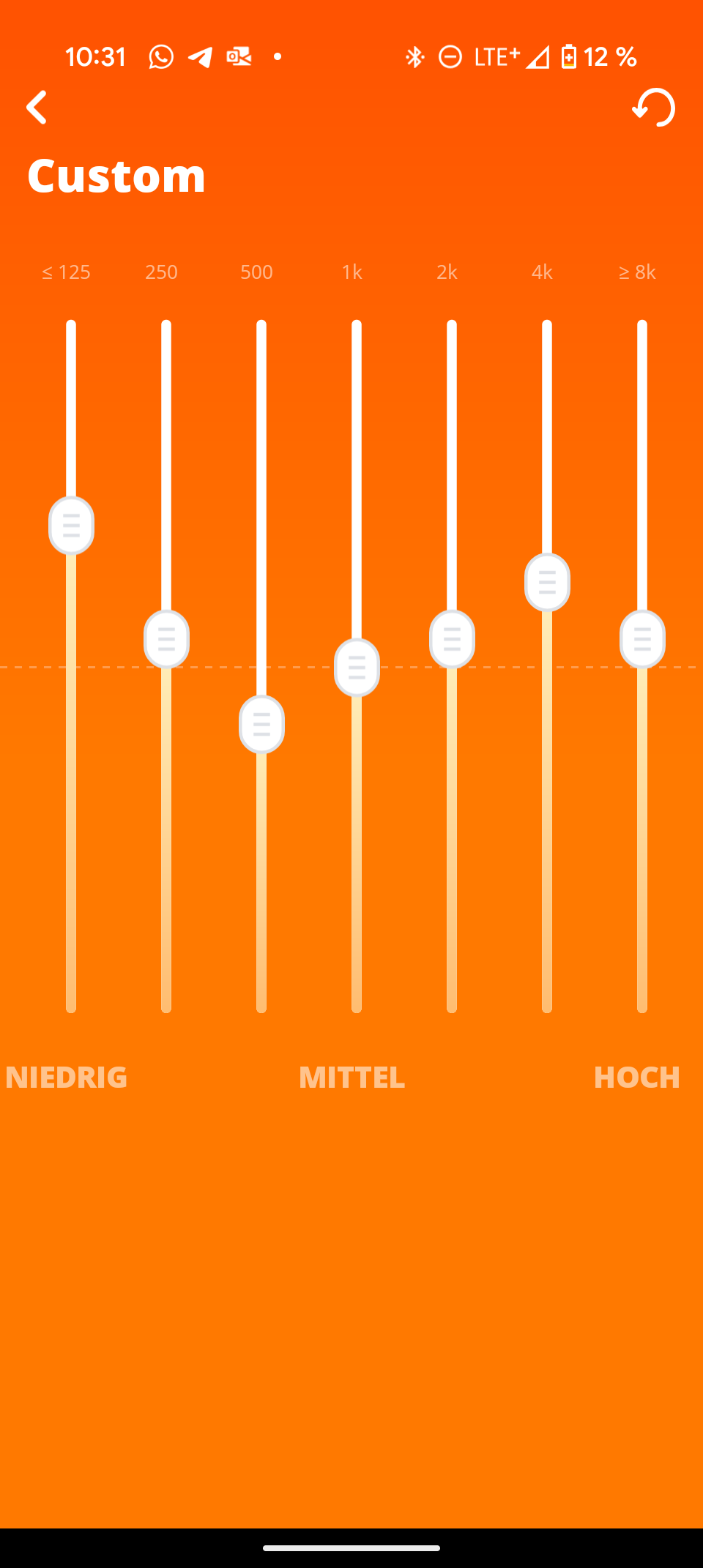
Die JBL Portable App ist übersichtlich und selbsterklärend. Sie zeigt den genauen Batteriestatus und bietet einen neuen 7-Band-Equalizer – ein deutliches Upgrade gegenüber dem 3-Band-Equalizer des Vorgängers. Der neue „Playtime Boost“ optimiert die Akkulaufzeit.
Insgesamt ist die App kein Feature-Monster, aber sie erfüllt ihren Zweck. Wer seinen Lieblingssound einmal eingestellt hat, wird sie vermutlich nur selten öffnen.
JBL Charge 6 Screenshots
JBL Charge 6 Screenshot

JBL Charge 6 Screenshot
JBL Charge 6 Screenshot
JBL Charge 6 Screenshot
JBL Charge 6 Screenshot
JBL Charge 6 Screenshot
JBL Charge 6 Screenshot
JBL Charge 6 Screenshot
JBL Charge 6 Screenshot

JBL Charge 6 Screenshot

JBL Charge 6 Screenshot

JBL Charge 6 Screenshot
Der Akku des JBL Charge 6
Die Akkulaufzeit ist beeindruckend: Bis zu 24 Stunden hält der Charge 6 durch – vier Stunden länger als sein Vorgänger. Mit aktiviertem „Playtime Boost“ sind sogar 28 Stunden möglich, allerdings bei reduzierter Lautstärke. Perfekt für Camping-Trips oder Strandtage, die kein Ende nehmen wollen.
Der 34 Wh Akku (7,2 V bei 4722 mAh) lädt in etwa drei Stunden komplett auf. Ein LED-Balken am Gerät zeigt die Restkapazität an – nicht so präzise wie eine Prozentanzeige, aber ausreichend für eine grobe Einschätzung. Die Powerbank-Funktion über USB-C ist ein praktisches Extra für Notfälle.
Was kostet der JBL Charge 6?
Mit 135 Euro (Amazon) ist der JBL Charge 6 kein Schnäppchen.
Fazit
Der JBL Charge 6 ist der neue Platzhirsch unter den kompakten Bluetooth-Lautsprechern und erobert den Spitzenplatz unserer Bestenliste. Mit verbessertem Klang, längerer Akkulaufzeit und erhöhter Wasserdichtigkeit setzt er die Messlatte etwas höher.
Besonders beeindruckend sind der kraftvolle Bass, die hohe Maximallautstärke und die makellose Verarbeitung. Die Auracast-Funktion und der verbesserte Equalizer sind willkommene Ergänzungen. Kleinere Schwächen wie das fehlende Mikrofon und die Beschränkung auf den SBC-Codec trüben das Gesamtbild nur leicht.
Der Preis von 135 Euro (Amazon) ist angesichts der gebotenen Leistung nachvollziehbar, macht den Charge 6 aber zu einer Investition. Wer einen vielseitigen, robusten und klangstarken Bluetooth-Lautsprecher sucht, der auch mal ein unfreiwilliges Bad überstehen kann, wird mit dem JBL Charge 6 glücklich werden.
Wer mehr Wumms braucht, findet in der JBL-Xtreme-Serie größere, lautere Modelle – allerdings zum Preis von mehr Gewicht und Volumen. Für Minimalisten könnte die kompaktere JBL-Flip-Serie interessant sein, die trotz geringerer Größe erstaunlich gut klingt.
Vintage-König
Marshall Emberton III
Der Marshall Emberton III ist ein stylischer und kompakter Bluetooth-Lautsprecher, der das typische Rock-’n‘-Roll-Feeling der kultigen Verstärker-Marke versprüht. Mit seinem robusten Design, dem kraftvollen Klang und der langen Akkulaufzeit will er vor allem unterwegs überzeugen. Ob ihm das gelingt, zeigt unser Test.
- kompakt, schick, hochwertig
- kraftvoller, warmer Klang
- enorme Akkulaufzeit & Quick Charge
- Tiefbass nicht so druckvoll wie größere Boxen
- Bedienknopf etwas schwammig
- AUX-Eingang fehlt
Bluetooth-Lautsprecher Marshall Emberton III im Test
Der Marshall Emberton III ist ein stylischer und kompakter Bluetooth-Lautsprecher, der das typische Rock-’n‘-Roll-Feeling der kultigen Verstärker-Marke versprüht. Mit seinem robusten Design, dem kraftvollen Klang und der langen Akkulaufzeit will er vor allem unterwegs überzeugen. Ob ihm das gelingt, zeigt unser Test.
Kompakte Bluetooth-Lautsprecher erfreuen sich großer Beliebtheit. Sie sind die perfekten Begleiter für unterwegs und sorgen fast überall für den passenden Soundtrack. Mit dem Emberton III bringt Marshall einen mobilen Speaker, der nicht nur mit kultiger Optik im Verstärker-Look, sondern auch mit kraftvollem Klang überzeugen will.
Design und Verarbeitung
Der Marshall Emberton III versprüht mit seinem Design sofort das typische Rock-’n‘-Roll-Feeling der kultigen Verstärker-Marke. Mit Abmessungen von etwa 16 × 7 × 8 cm (B × H × T) und einem Gewicht von lediglich 670 Gramm ist er äußerst kompakt und mobil. Im Vergleich wirken Konkurrenten wie die JBL Charge 5 (Testbericht) mit knapp einem Kilogramm oder der LG Xboom Go DXGQ7 (Testbericht) mit 1,1 kg geradezu wuchtig.
Das Gehäuse des Emberton III ist größtenteils mit einem weichen, gummiert wirkenden Kunstleder überzogen, das sich fantastisch anfühlt. Vorder- und Rückseite zieren hingegen Metallgitter, auf der Front prangt zudem das typische goldene Marshall-Logo. Liebhaber der berühmten Marshall-Verstärker werden hier sofort ein wohliges Retro-Gefühl bekommen.
Auf der Oberseite sitzt ein großer, goldener Knopf. Per mittigem Druck wird die Wiedergabe gestartet oder gestoppt, durch Drücken nach links, rechts, oben oder unten lässt sich die Lautstärke regeln und Titel überspringen. So schick der Knopf aussieht, in der Praxis erweist er sich leider als etwas schwammig und unpräzise. Neben dem goldenen Knopf finden sich ein dezenter Power-Button und eine Bluetooth-Taste. Die andere Seite ziert eine schicke und detaillierte Akku-Anzeige im Marshall-Look. Ganz rechts sitzt ein USB-C-Port zum Laden und eine Befestigungsmöglichkeit für die mitgelieferte Trageschlaufe.
Einen AUX-Eingang sucht man vergebens, auch lässt sich der Speaker nicht als Powerbank nutzen. Auf der gummierten Unterseite sorgen Standfüße für festen Halt.
Verarbeitung und Material wirken rundum hochwertig. Nichts knarzt oder wackelt, die Metallgitter sitzen fest und auch an Übergängen und Nähten gibt es keinerlei Kritikpunkte. Mit IP67-Zertifizierung ist der Marshall zudem komplett staub- und wasserdicht. Selbst ein 30-minütiges Tauchbad in einem Meter Tiefe übersteht er problemlos.
Marshall Emberton III Bilder
Marshall Emberton III

Marshall Emberton III

Marshall Emberton III

Marshall Emberton III

Marshall Emberton III

Marshall Emberton III
Marshall Emberton III

Marshall Emberton III

Marshall Emberton III

Marshall Emberton III

Marshall Emberton III

Marshall Emberton III

Sound: Wie gut ist der Klang des Marshall Emberton III?
Im kompakten Gehäuse des Emberton III stecken 20 Watt Leistung, die den Klang nicht nur nach vorn, sondern dank Fullrange-Treiber auch nach hinten abstrahlen. Das erzeugt eine gewisse Räumlichkeit, wenn auch nicht so ausgeprägt wie beim LG Xboom 360 DXO2T (Testbericht).
Insgesamt gefällt uns der Klang richtig gut. Vor allem im Marshall-Modus umhüllen uns warme, satte Klänge. Verzerrte E-Gitarren bekommen durch den Speaker den klassischen Marshall-Sound verpasst. Die maximale Lautstärke ist ordentlich, in den oberen Pegelbereichen setzen jedoch spürbar Verzerrungen ein.
Auch in puncto Tiefbass muss sich der Winzling so mancher größeren Box geschlagen geben. Mit gerade einmal 670 Gramm Gewicht stößt der Emberton III hier an die physikalischen Grenzen des klanglich Machbaren. Zwar klingt er für sich genommen sehr gut, gegen eine JBL Charge 5 (Testbericht) oder eine LG Xboom Go DXGQ7 (Testbericht) kommt er bassmäßig aber nicht an.
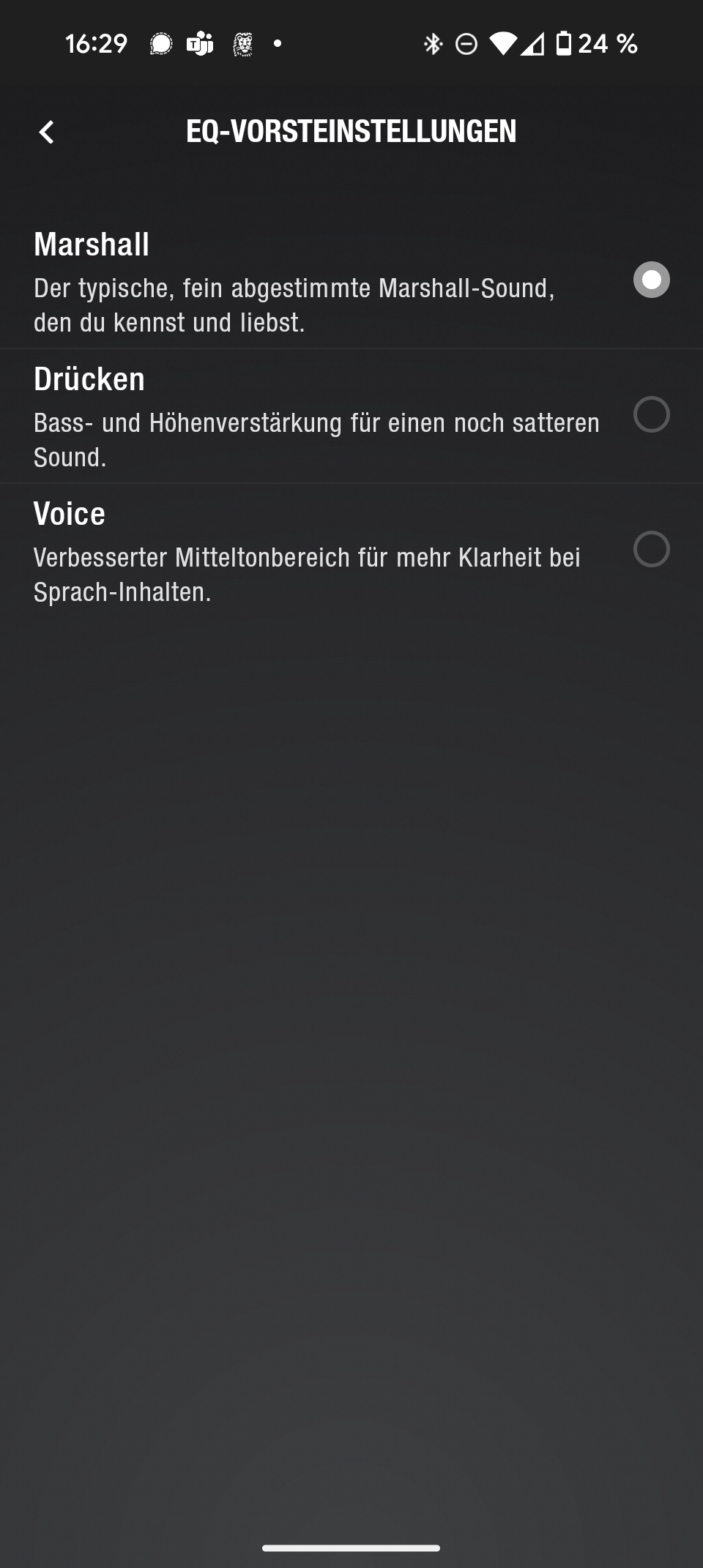
Die Marshall Bluetooth App bietet zwar keinen vollwertigen EQ, aber immerhin drei Presets. Standardmäßig ist der Marshall-Sound mit warmer, recht ausgeglichener Abstimmung aktiviert. Preset 2 hebt Höhen und Bässe an, Preset 3 betont die Mitten und eignet sich gut für Podcasts oder Hörbücher. Fürs reine Musikhören bevorzugen wir den ausgewogenen Marshall-Klang.
Technisch ist der Emberton III auf der Höhe der Zeit. Er verbindet sich per Bluetooth 5.3 und unterstützt neben dem SBC- auch den AAC-Codec. Praktisch: Per Multipoint lassen sich mehrere Zuspieler gleichzeitig koppeln. Dank des eingebauten Mikrofons kann der Marshall auch als Freisprecheinrichtung dienen. Solange man sich nahe am Speaker befindet, ist die Sprachqualität sehr gut. Mit zunehmender Entfernung schleicht sich jedoch ein störender Halleffekt ein.
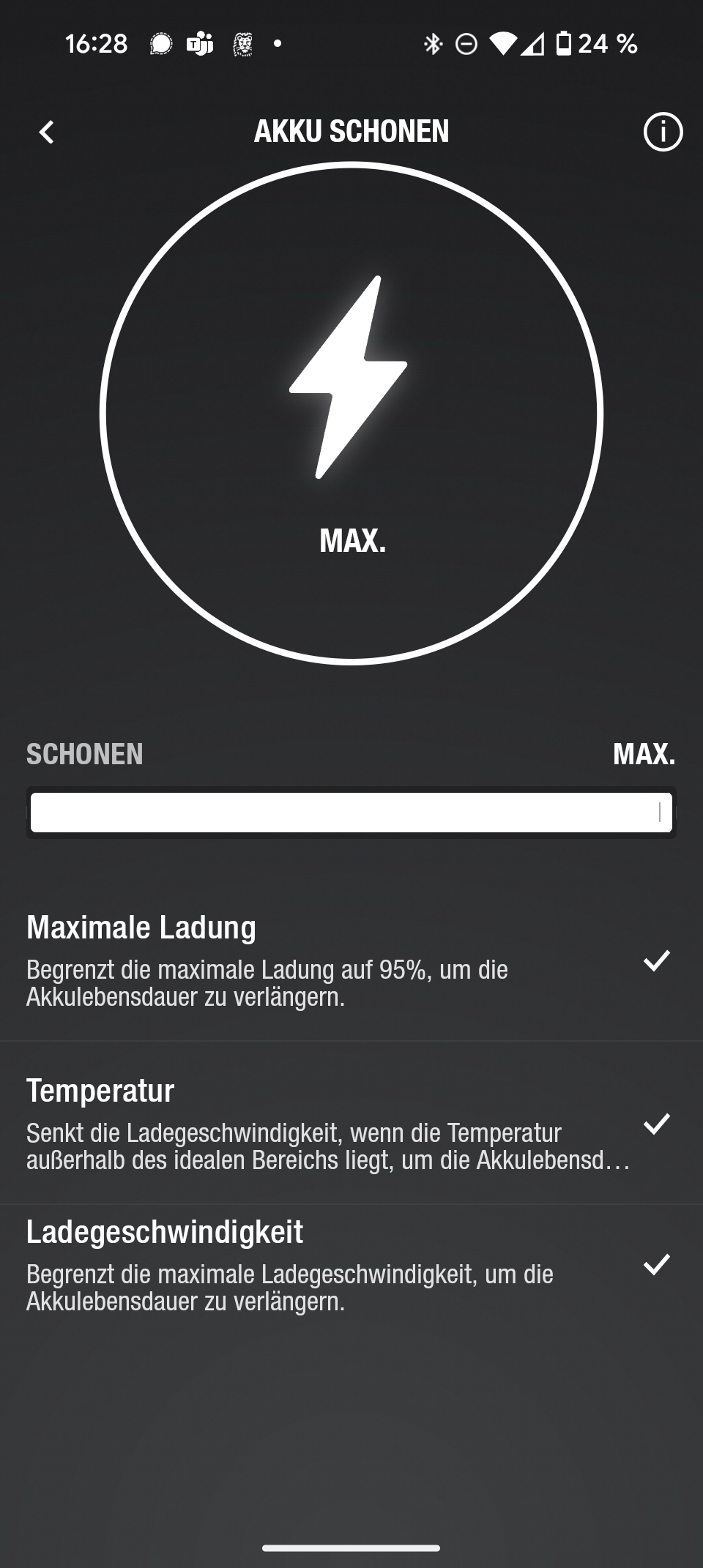
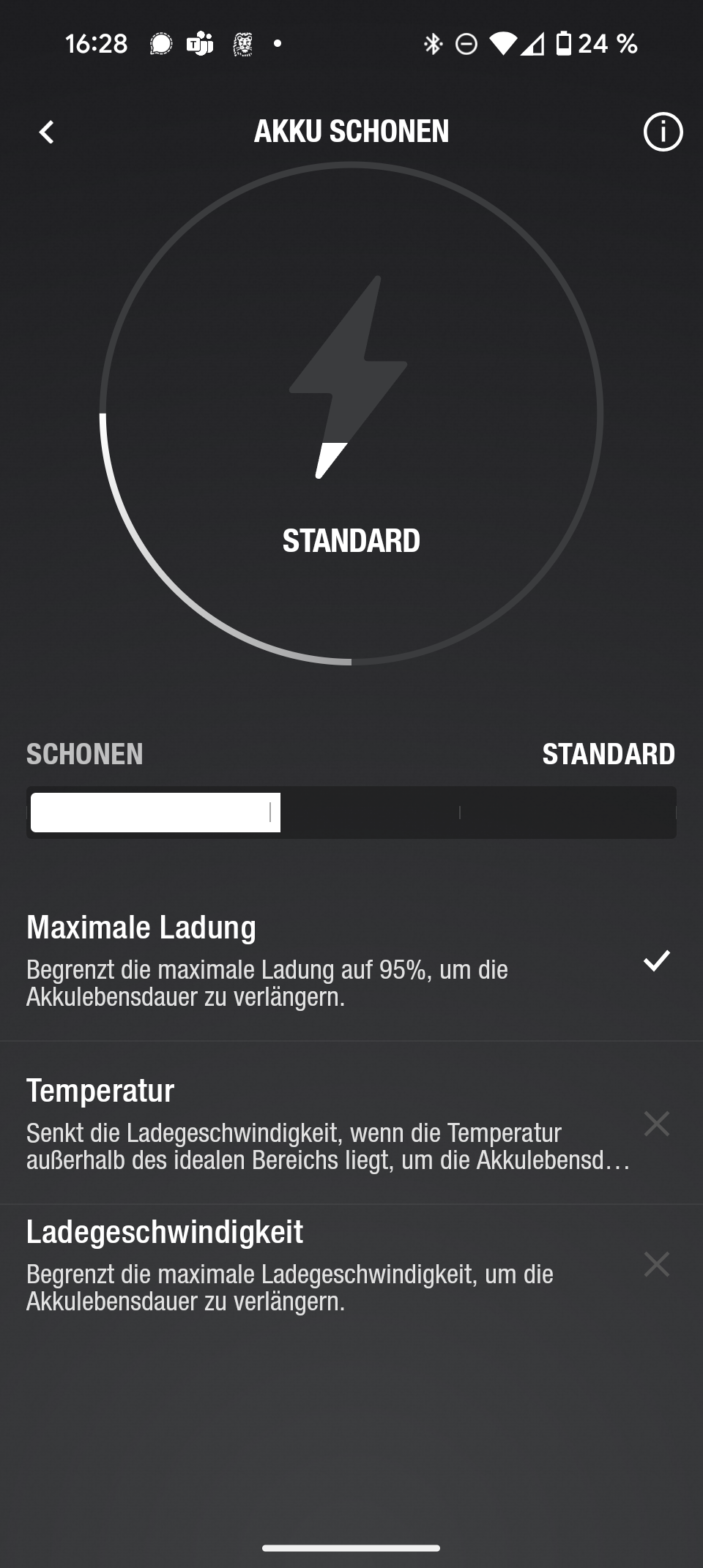
App
Die Marshall-Smartphone-App bietet nicht allzu viele Funktionen. Immerhin lassen sich neben der Wahl dreier Sound-Presets auch Software-Updates einspielen. Es gibt ferner eine Option, den Akku zu schonen. Für den alltäglichen Gebrauch greift man jedoch eher selten zur App, die meisten Funktionen werden direkt am Speaker gesteuert.
Marshall Emberton III Screenshots
Marshall Emberton III Screenshot

Marshall Emberton III Screenshot
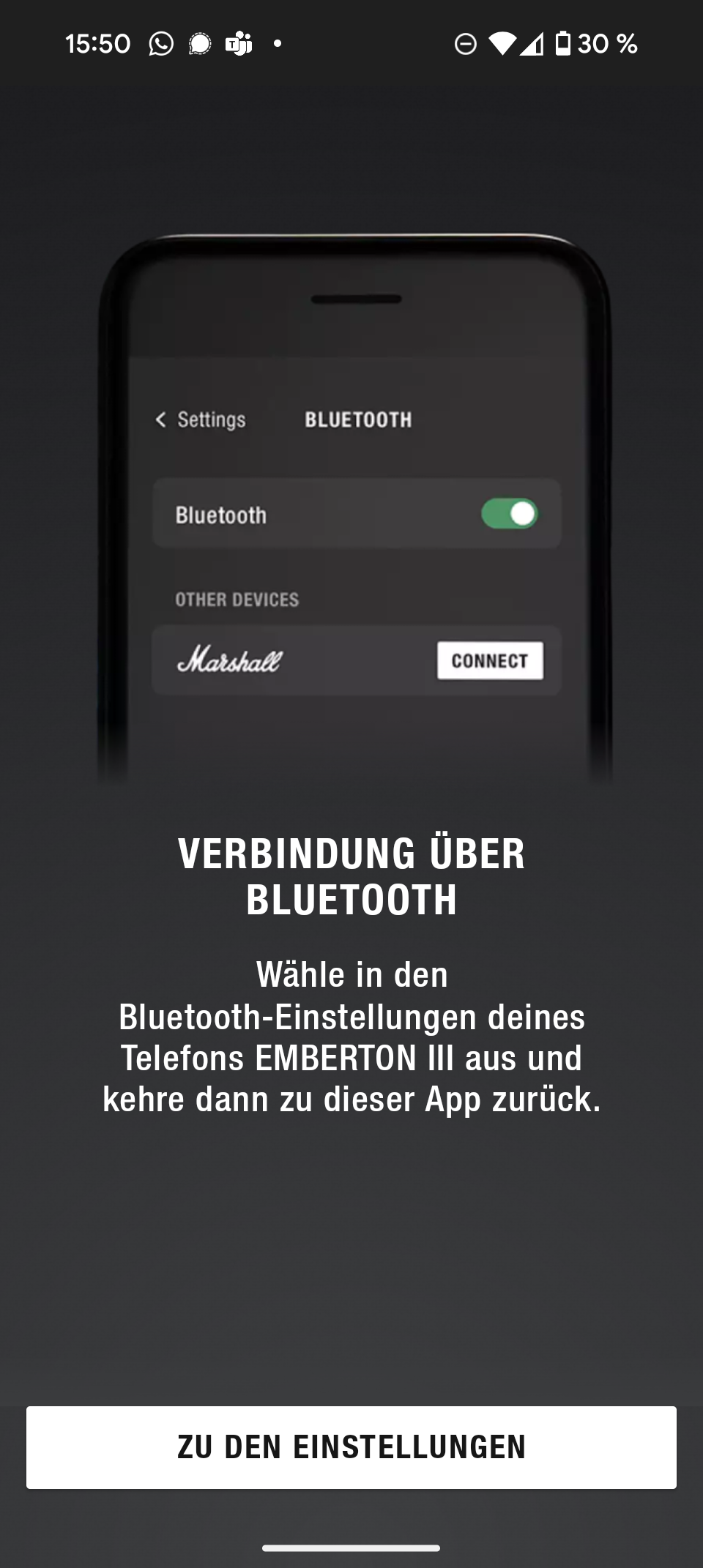
Marshall Emberton III Screenshot
Marshall Emberton III Screenshot
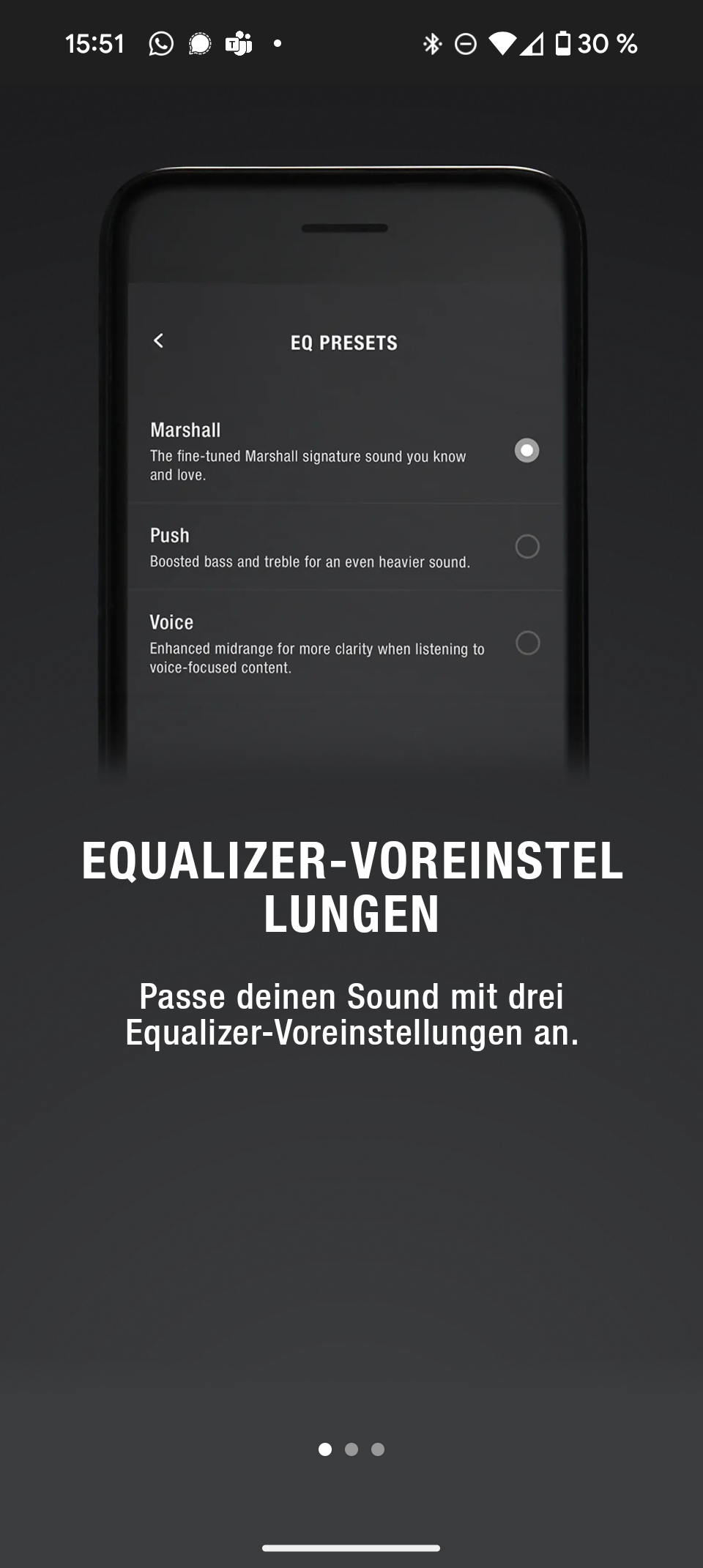
Marshall Emberton III Screenshot
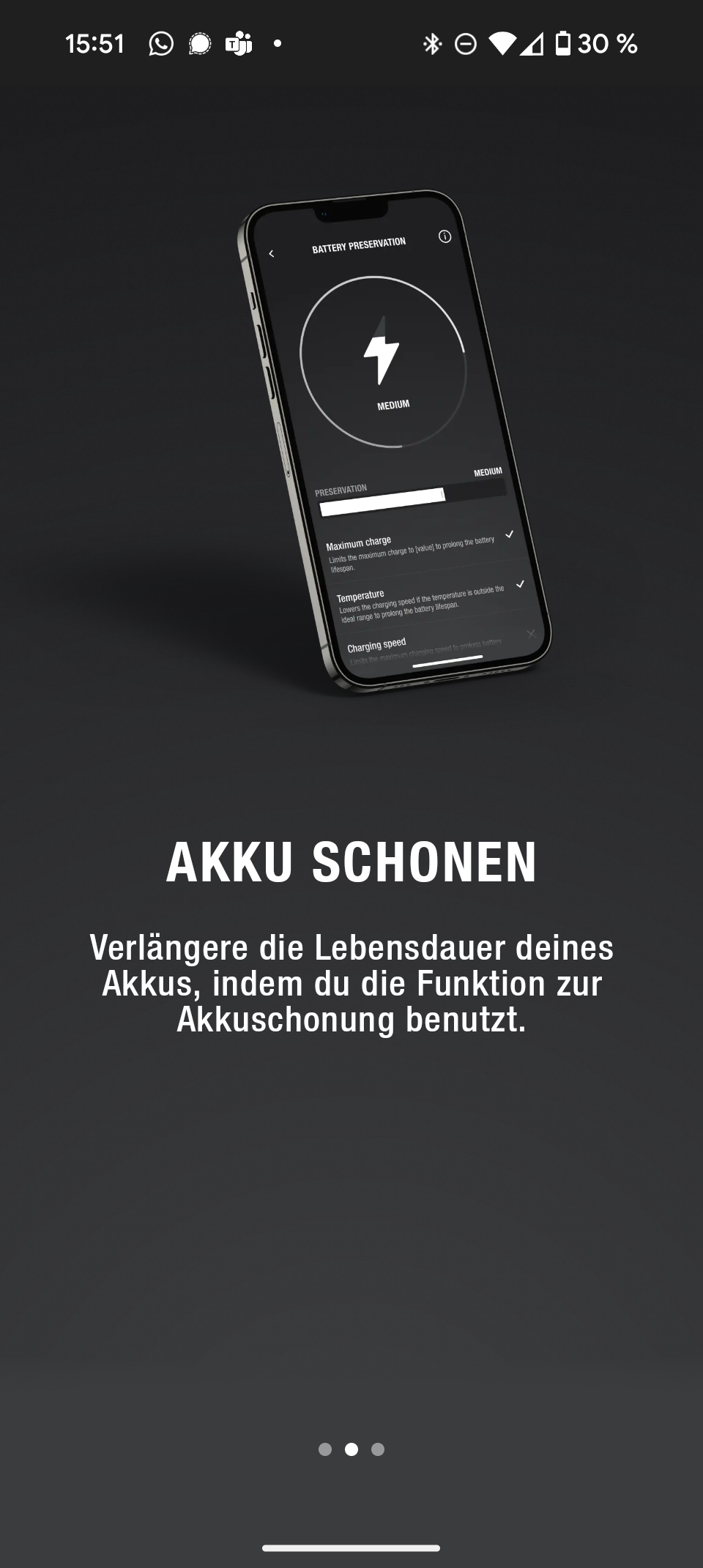
Marshall Emberton III Screenshot

Marshall Emberton III Screenshot

Marshall Emberton III Screenshot

Marshall Emberton III Screenshot
Marshall Emberton III Screenshot
Marshall Emberton III Screenshot
Marshall Emberton III Screenshot
Akku
Einer der großen Überraschungen des Emberton III ist der potente Akku. Laut Marshall soll er eine Wiedergabedauer von bis zu 32 Stunden ermöglichen – allerdings nur bei geringer bis mittlerer Lautstärke. Spielt man überwiegend mit hohem Pegel, schrumpft die Laufzeit deutlich. Trotzdem gehört der Marshall-Speaker zu den ausdauerndsten Mobil-Boxen, die wir bislang im Test hatten.
Ein Lob verdient auch die präzise Akkustandanzeige, die jederzeit über die verbleibende Laufzeit informiert. Geladen wird der Marshall per USB-C, ein passendes Kabel liegt bei. Dank Quick Charge reichen 20 Minuten an der Steckdose, damit der Bluetooth-Speaker wieder sechs Stunden lang Musik spielen kann.
Preis: Was kostet der Marshall Emberton III?
Mit einem Preis von rund 148 Euro (Amazon) ist der Marshall Emberton III im gehobenen Preissegment kompakter Bluetooth-Lautsprecher angesiedelt.
Fazit
Der Marshall Emberton III ist ein kompakter Bluetooth-Lautsprecher, der mit kultiger Optik, hochwertigem Material-Mix und starker Technik aufwartet. Der Klang ist kraftvoll, warm und druckvoll, auch wenn größere Boxen im Hinblick auf Tiefbass und Maximallautstärke die Nase vorn haben. Die größten Trümpfe des Emberton III sind seine enorme Mobilität dank kompakter Abmessungen und geringem Gewicht sowie die herausragende Akkulaufzeit.
Wer den legendären Marshall-Look mag und eine kleine, robuste Box für unterwegs sucht, liegt mit dem Emberton III goldrichtig. Deutlich mehr Wumms bietet die JBL Charge 5 (Testbericht). Unter dem Strich ist Marshall mit dem Emberton III ein rundum gelungener mobiler Spaßmacher mit hohem Lifestyle-Faktor gelungen.
Preis-Leistungs-Sieger
Xiaomi Sound Outdoor
Der Xiaomi Outdoor Speaker (2024) liefert robusten Sound im wasserdichten Gehäuse – und das zum Schnäppchenpreis von unter 40 Euro. Wir testen den kleinen Klangriesen.
- unschlagbares Preis-Leistungs-Verhältnis
- robustes, wasserdichtes IP67-Design
- kräftiger Bass trotz kompakter Größe
- praktische Trageschlaufe für unterwegs
- unkomplizierte Bedienung
- keine Equalizer
- Höhen könnten präsenter sein
- kein AUX-Eingang
- keine Powerbank-Funktion
- Akkulaufzeit nur Durchschnitt
Bluetooth-Lautsprecher Xiaomi Sound Outdoor 2024 im Test
Der Xiaomi Outdoor Speaker (2024) liefert robusten Sound im wasserdichten Gehäuse – und das zum Schnäppchenpreis von unter 40 Euro. Wir testen den kleinen Klangriesen.
Bluetooth-Lautsprecher sind wie Smartphones – gefühlt hat jeder einen, aber nicht jeder einen guten. Xiaomi mischt nun mit dem Outdoor Speaker (2024) den Markt der günstigen Soundboxen auf. Für schlanke 37 Euro verspricht der chinesische Hersteller Features, die man sonst nur bei deutlich teureren Modellen findet: 30 Watt Leistung, IP67-Schutz und Bluetooth 5.4.
Kann der kleine Klangzylinder tatsächlich mit den etablierten Audio-Platzhirschen mithalten oder ist er nur ein weiterer günstiger Plastikbomber mit Bluetooth? Wir haben dem Xiaomi-Speaker auf die Membran geklopft.
Design und Verarbeitung
Der Xiaomi Outdoor Speaker zeigt sich im zylindrischen Gewand mit kompakten Maßen von 196,6 × 68 × 66 mm. Mit etwa 600 g ist er leicht genug für jede Rucksacktour, aber schwer genug, um nicht bei jedem Basswumms vom Tisch zu hüpfen.
Erhältlich in Schwarz, Blau oder Rot, punktet unser schwarzes Testmodell mit einer 2 cm breiten Silikon-Trageschlaufe in der Farbe Orange. Diese dient nicht nur als optischer Akzent, sondern lässt sich auch praktisch an Rucksäcken oder Haken befestigen – ein Feature, das selbst mancher 100-Euro-Box fehlt.
Die Materialkomposition aus Stoff und Gummi fühlt sich hochwertig an und macht einen robusten Eindruck. Das dezente Xiaomi-Logo auf der Vorderseite schreit nicht nach Aufmerksamkeit, sondern fügt sich harmonisch ins Gesamtbild ein.
Mit seiner IP67-Zertifizierung trotzt der Speaker Staub und Wasser gleichermaßen. Die gummierten Elemente schützen zusätzlich vor Stößen.
Xiaomi Sound Outdoor 2024 Bilder
Xiaomi Sound Outdoor 2024

Xiaomi Sound Outdoor 2024

Xiaomi Sound Outdoor 2024

Xiaomi Sound Outdoor 2024

Xiaomi Sound Outdoor 2024

Xiaomi Sound Outdoor 2024

Xiaomi Sound Outdoor 2024

Xiaomi Sound Outdoor 2024

Xiaomi Sound Outdoor 2024

Xiaomi Sound Outdoor 2024

Wie gut ist der Klang des Xiaomi Outdoor Speaker?
Für eine Box dieser Preisklasse liefert der Xiaomi Outdoor Speaker (2024) erstaunlich erwachsenen Sound. Die 30 Watt Gesamtleistung (20-Watt-Woofer + 10-Watt-Tweeter) sorgen für ordentlich Druck.
Der Frequenzbereich von 60 Hz bis 20 kHz deckt das Wesentliche ab, wobei der Bass dank zweier passiver Radiatoren überraschend satt ausfällt. Die Mitten klingen ausgewogen und lassen Stimmen natürlich erscheinen. Bei den Höhen zeigt sich der Speaker etwas zurückhaltender.
Im Vergleich zum viermal teureren JBL Charge 5 (Testbericht) muss sich der Xiaomi in puncto Feinauflösung zwar geschlagen geben, bleibt aber auch bei hoher Lautstärke erstaunlich verzerrungsarm.
Die Möglichkeit, zwei Speaker zum Stereopaar zu verbinden oder theoretisch bis zu 100 Geräte zu koppeln, macht den kleinen Xiaomi zum potenziellen Party-Beschaller – vorausgesetzt, man hat genügend Freunde mit dem gleichen Lautsprecher. Das eingebaute Mikrofon für die Freisprechfunktion überrascht mit klarer Stimmübertragung und minimalen Echos.
Bedienung und App
Die Bedienung erfolgt ausschließlich über sechs physische Tasten am Gerät: drei oben (Lautstärke hoch/runter, Multifunktionstaster) und drei hinten (Ein/Aus, Bluetooth-Pairing, Link-Taste für Multi-Speaker-Modus).
Kaum versetzen wir den Speaker in den Pairing-Modus verbindet er sich auf Anhieb mit dem Smartphone, ohne Zickereien oder komplizierte Prozeduren. Der Verzicht auf eine App bedeutet natürlich auch: kein Equalizer, keine Firmware-Updates, keine Zusatzfunktionen.
Akku
Mit seinem 2600-mAh-Akku hält der Xiaomi Outdoor Speaker bis zu 12 Stunden bei halber Lautstärke durch. Im Mittelfeld der Bluetooth-Speaker ist das ein solider Wert, auch wenn manche Konkurrenten wie der Marshall Emberton III (Testbericht) mit bis zu 32 Stunden deutlich länger durchhalten – aber auch viel mehr kosten.
Das Aufladen erfolgt über USB-C mit maximal 15 Watt. Nach 2,5 Stunden an der Steckdose ist der Akku vollständig geladen. Eine Powerbank-Funktion zum Laden des Smartphones gibt es nicht.
Konnektivität und technische Eigenschaften
Bluetooth 5.4 bildet das Kommunikationsrückgrat des Xiaomi Outdoor Speaker (2024). Die Unterstützung der Codecs SBC und AAC sorgt für problemlose Verbindungen mit praktisch allen Smartphones. High-Res-Codecs wie aptX oder LDAC fehlen. Nicht schlimm – bei einer 40-Euro-Box würde man sie ohnehin nicht hören.
Der USB-C-Anschluss dient ausschließlich zum Laden und versteckt sich hinter einer wasserdichten Gummiklappe. Ein AUX-Eingang fehlt.
Was kostet der Xiaomi Outdoor Speaker?
Schon ab 37 Euro geht der Outdoor Speaker von Xiaomi über die virtuelle Ladentheke. Für diesen Preis bekommt man normalerweise einen Bluetooth-Lautsprecher mit Spielzeugklang. Der Xiaomi Outdoor Speaker (2024) bietet stattdessen 30 Watt Leistung, IP67-Schutz und ordentlichen Sound – ein Preis-Leistungs-Verhältnis, das seinesgleichen sucht.
Fazit
Der Xiaomi Outdoor Speaker (2024) ist der Beweis, dass ordentlicher Sound nicht unbedingt teuer sein muss. Für läppische 37 Euro bietet der robuste Klangzylinder eine beeindruckende Performance.
Seine Stärken liegen im kraftvollen Bass, der soliden, wasserdichten Verarbeitung und dem ansehnlichen Design. Die Bedienung ohne App ist unkompliziert – Auspacken, Einschalten, Musik hören. Die Schwächen: kein AUX-Eingang, keine Klangeinstellungen und Höhen, die präsenter sein dürften. Bei diesem Preis sind das verzeihbare Kompromisse.
Der Xiaomi Outdoor Speaker ist der perfekte Begleiter für preisbewusste Musikfans, die einen robusten Outdoor-Lautsprecher suchen, ohne tief in die Tasche greifen zu müssen. Er macht am Strand genauso eine gute Figur wie unter der Dusche oder auf dem Balkon – und auch wenn er mal ins Wasser fällt, überlebt er das mit stoischer Gelassenheit.
JBL Flip 7
Der JBL Flip 7 überzeugt mit verbessertem Sound, robuster Bauweise, Auracast und praktischem Karabinerhaken. Wir haben den kompakten Bluetooth-Lautsprecher getestet.
- toller Klang für seine Größe
- robuste Bauweise mit IP68
- abnehmbarer Karabiner
- selbsterklärende Bedienung
- Auracast
- keine Freisprechfunktion
- Nur SBC-Codec
- keine Abwärtskompatibilität
- durchschnittliche Akkulaufzeit
Bluetooth-Lautsprecher JBL Flip 7 im Test
Der JBL Flip 7 überzeugt mit verbessertem Sound, robuster Bauweise, Auracast und praktischem Karabinerhaken. Wir haben den kompakten Bluetooth-Lautsprecher getestet.
JBL hat mit der beliebten Flip-Serie seit Jahren einen festen Platz in der Welt der portablen Bluetooth-Lautsprecher. Der neue JBL Flip 7 verspricht gegenüber dem Vorgänger zahlreiche Verbesserungen. Mit einem Preis von 111 Euro bei Amazon positioniert sich der Lautsprecher im mittleren bis gehobenen Preissegment. Wir testen, ob sich der Aufpreis zum mittlerweile deutlich günstigeren Vorgängermodell lohnt und zeigen, welche weiteren Alternativen es gibt.
Design und Verarbeitung des JBL Flip 7
Der JBL Flip 7 bleibt dem charakteristischen zylindrischen Design der Flip-Serie treu. Mit Abmessungen von 183 × 70 × 72 cm und einem Gewicht von nur 560 g ist er etwa halb so schwer wie der JBL Charge 6. Diese Leichtigkeit macht ihn zum perfekten Begleiter für unterwegs.
Das Gehäuse besteht überwiegend aus einem stabilen Stoffbezug, ergänzt durch verstärkte Gummipuffer an den Enden. Die auffälligste Neuerung ist der abnehmbare Tragegriff aus Stoff oder wahlweise ein praktischer Karabiner. Dieses Befestigungssystem ist besser gelöst als beim Charge 6. Besonders der Karabiner erweist sich bei Outdoor-Aktivitäten als Trumpf – ein Klick, und der Lautsprecher hängt sicher am Rucksack.
In sieben Farben erhältlich – Weiß, Blau, Rot, Schwarz, Camouflage, Lila und Pink – bietet JBL eine breite Auswahl. Das matte, metallische JBL-Logo auf der Vorderseite wirkt hochwertig, dahinter schimmert das typische JBL-Rot hervor. Die kompakte Form passt problemlos in Rucksacktaschen oder sogar in Getränkehalter.
Die Verarbeitung ist erstklassig. Dank IP68-Zertifizierung bietet der Flip 7 vollständigen Schutz vor Staub und übersteht 30 Minuten in 1,5 Metern Wassertiefe – eine Verbesserung gegenüber der IP67-Zertifizierung des Flip 6. Stürze aus einem Meter Höhe auf Beton? Dank verstärkter Gummipuffer kein Problem für den robusten Klangzylinder.
JBL Flip 7 Bilder
JBL Flip 7

JBL Flip 7

JBL Flip 7

JBL Flip 7

JBL Flip 7

JBL Flip 7

JBL Flip 7

JBL Flip 7

JBL Flip 7

JBL Flip 7

JBL Flip 7

JBL Flip 7

Wie gut ist der Klang des JBL Flip 7?
Der JBL Flip 7 setzt Maßstäbe für die Klangqualität in seiner Gewichtsklasse. Mit einem 45 × 80 mm großen Tieftöner und einem 16 mm Hochtöner deckt er einen Frequenzbereich von 60 Hz bis 20 kHz ab. Die Ausgangsleistung beträgt 25 Watt RMS für den Tieftöner und 10 Watt RMS für den Hochtöner – beachtliche Werte für einen so kompakten Lautsprecher.
Im Hörtest liefert der Flip 7 einen klaren, kräftigen Klang mit verbesserter Detailgenauigkeit und tieferem Bass. Er ist der beste Lautsprecher seiner Gewichtsklasse. Bei maximaler Lautstärke lässt der Bass allerdings etwas nach – physikalische Grenzen lassen sich eben nicht überlisten. Für unterwegs liefert er jedoch einen Sound, der die meisten Konkurrenten in den Schatten stellt.
Als Mono-Lautsprecher konzipiert, kann der Flip 7 mit einem zweiten Exemplar für echten Stereoklang gekoppelt werden. Die Auracast-Verbindung gestaltet sich erfreulich unkompliziert: Knöpfe auf beiden Geräten drücken, und schon kommunizieren die Lautsprecher miteinander. Der Sound wird nahtlos gespiegelt. Allerdings ist er nicht abwärtskompatibel, mit dem Flip 6 will er sich entsprechend nicht paaren.
Die 5.4-Bluetooth-Übertragung unterstützt nur den SBC-Codec. High-Res-Codecs sucht man vergebens. Auch auf einen AUX-Eingang und ein Mikrofon für Freisprechfunktionen verzichtet JBL komplett.
Bedienung und App des JBL Flip 7
Die Bedienung des Flip 7 ist erfreulich unkompliziert. Die physischen Tasten auf der Oberseite umfassen Power, Bluetooth, Auracast, Play/Pause und Lautstärkeregelung. Diese neue Anordnung ist übersichtlich, logisch aufgebaut und auch im Dunkeln gut zu ertasten.
Die JBL Portable App bietet einen neuen 7-Band-Equalizer – eine klare Verbesserung gegenüber dem Vorgänger. Vier EQ-Voreinstellungen und die „Playtime Boost“-Funktion zur Verlängerung der Akkulaufzeit runden das App-Angebot ab. Insgesamt ist die App eher schlank, deckt aber alle wesentlichen Funktionen ab.
JBL Flip 7 Screenshots
JBL Flip 7 Screenshot
JBL Flip 7 Screenshot
JBL Flip 7 Screenshot
JBL Flip 7 Screenshot
JBL Flip 7 Screenshot
JBL Flip 7 Screenshot
JBL Flip 7 Screenshot
JBL Flip 7 Screenshot

JBL Flip 7 Screenshot
JBL Flip 7 Screenshot
JBL Flip 7 Screenshot
Der Akku des JBL Flip 7
Die Akkulaufzeit beträgt bis zu 14 Stunden bei normaler Nutzung. Mit aktiviertem „Playtime Boost“ verlängert sich die Wiedergabezeit laut JBL auf 16 Stunden, allerdings auf Kosten des Bassumfangs. In 2,5 Stunden ist der Lithium-Ionen-Polymer-Akku mit 17,28 Wh (3,6 V / 4800 mAh) über USB-C wieder vollständig geladen.
Im Vergleich zu anderen Bluetooth-Lautsprechern liegt der Flip 7 im Mittelfeld. Der JBL Charge 6 bietet mit bis zu 24 Stunden (oder sogar 28 Stunden im Boost-Modus) deutlich mehr Ausdauer. Für einen Tagesausflug reicht die Akkulaufzeit des Flip 7 dennoch.
Was kostet der JBL Flip 7?
Der JBL Flip 7 ist aktuell für 111 Euro bei Amazon erhältlich. Angesichts der verbesserten Funktionen, der robusten Bauweise und der hervorragenden Klangqualität ist dieser Preis fair. Der Vorgänger JBL Flip 5 ist mit 93 Euro deutlich günstiger zu haben, bietet jedoch weniger Leistung, geringere Wasserdichtigkeit und kennt kein Auracast.
Fazit
Der JBL Flip 7 setzt neue Maßstäbe für kompakte Bluetooth-Lautsprecher. Mit seinem verbesserten Klang, der robusten IP68-Zertifizierung und dem durchdachten Design überzeugt er auf ganzer Linie. Dazu kommt die einfache Bedienung, der praktische Karabiner und die solide Akkulaufzeit.
Beeindruckend ist die Klangqualität, die trotz der kompakten Abmessungen überraschend kraftvoll und detailreich ausfällt. Die zukunftssichere Auracast-Funktion ist ein weiterer Pluspunkt.
Der Preis ist angesichts der gebotenen Leistung und Qualität angemessen. Wer einen kompakten, robusten und exzellent klingenden Bluetooth-Lautsprecher sucht, der auch bei widrigen Bedingungen zuverlässig funktioniert, macht mit dem JBL Flip 7 nichts falsch.
Sony Ult Field 1
Der Sony Ult Field 1 ist ein kompakter Bluetooth-Lautsprecher für unterwegs mit robustem Gehäuse und Ult-Klang-Boost. Unser Testbericht zeigt, ob sich der Kauf lohnt.
- robustes Design mit IP67-Schutz
- guter Klang mit aktivierter ULT-Funktion
- einfache Bedienung
- Klang ohne ULT-Funktion weniger überzeugend
- App mit wenigen Funktionen
Bluetooth-Lautsprecher Sony Ult Field 1 im Test
Der Sony Ult Field 1 ist ein kompakter Bluetooth-Lautsprecher für unterwegs mit robustem Gehäuse und Ult-Klang-Boost. Unser Testbericht zeigt, ob sich der Kauf lohnt.
Kompakte Bluetooth-Lautsprecher für den mobilen Einsatz gibt es wie Sand am Meer. Sony versucht mit dem Ult Field 1 dennoch, sich von der Masse abzuheben. Der Speaker soll nicht nur robust sein, sondern auch mit besonders gutem Klang punkten. Ob das Konzept aufgeht, klären wir in diesem Test.
Design
Der Sony Ult Field 1 präsentiert sich in einem kompakten Gehäuse, das mit Abmessungen von 206 × 77 × 76 mm und einem Gewicht von 650 g angenehm handlich ausfällt. Erhältlich ist der Lautsprecher in den Farben Weiß, Schwarz, Grün und Orange.
Die Verarbeitungsqualität macht einen hochwertigen Eindruck. Das Gehäuse ist mit einem schmutzabweisenden Stoffbezug überzogen, während die Kanten durch Gummi geschützt sind. Der zusätzliche Schutz verleiht dem Lautsprecher nicht nur ein wertiges Aussehen, sondern wappnet ihn auch für den Outdoor-Einsatz. Die seitlichen Passivradiatoren sind leicht nach innen versetzt und somit vor Beschädigungen geschützt.
Dazu passt die IP67-Zertifizierung des Ult Field 1. Damit ist der Lautsprecher sowohl staubdicht als auch wasserdicht und übersteht ein Untertauchen in bis zu einem Meter tiefem Wasser für 30 Minuten. So ist der Sony Ult Field 1 für Strand, Camping und Poolparty gerüstet.

Ein praktisches Detail ist die integrierte Trageschlaufe. Der Lautsprecher kann sowohl waagerecht als auch senkrecht platziert werden. Auf der Rückseite befindet sich hinter einer Klappe ein USB-C-Port zum Aufladen des Geräts.
Sound: Wie gut ist der Klang des Sony Ult Field 1?
Der Sony Ult Field 1 kommt mit einem 16 mm Hochtöner und einem 83 × 42 mm Tieftöner. Auf den ersten Eindruck präsentiert sich der Klang zunächst etwas enttäuschend. Hier kommt jedoch die namensgebende Ult-Taste ins Spiel: Nach deren Aktivierung entfaltet der Lautsprecher sein wahres Potenzial mit deutlich verbessertem Klangeffekt.
Mit aktivierter Ult-Funktion liefert der Ult Field 1 einen spritzigen Sound. Die Höhen sind deutlich ausgeprägt, die Mitten passabel. Der Bass ist für die kompakte Größe des Lautsprechers ordentlich. Insgesamt ergibt sich ein lebendiges Klangbild, das für die meisten Musikgenres geeignet ist.
Sony Ult Field 1
Sony Ult Field 1

Sony Ult Field 1

Sony Ult Field 1

Sony Ult Field 1

Sony Ult Field 1

Sony Ult Field 1

Sony Ult Field 1
Sony Ult Field 1
Komplexe Musikstücke mit vielen gleichzeitig spielenden Instrumenten zeigen allerdings die Grenzen des kompakten Lautsprechers auf. Hier neigt der Klang dazu, zu verschmieren und an Präzision zu verlieren. Auch bei maximaler Lautstärke treten Verzerrungen auf. Positiv: Der Ult Field 1 erreicht insgesamt eine für seine Größenklasse beachtlich hohe maximale Lautstärke.
Neben der Musikwiedergabe macht der Sony Ult Field 1 auch bei der Wiedergabe von Podcasts eine gute Figur. Die Sprachverständlichkeit ist hervorragend. Zudem verfügt der Lautsprecher über eine Telefoniefunktion, die im Test überzeugte. Im Test gibt es auf der Gegenseite zwar einen leichten Halleffekt, ein Echo oder merkliche Verzögerungen bei Gesprächen bleiben aus.
Insgesamt bietet der Sony Ult Field 1 einen für seine Größe überraschend guten Klang, der besonders mit aktivierter Ult-Funktion überzeugt. Für Hörer, die Wert auf einen detaillierten und lebendigen Sound legen, ist er eine interessante Option in der Preisklasse um 100 Euro.
Bedienung und App
Die Bedienung des Sony Ult Field 1 gestaltet sich dank der gut platzierten Tasten auf der Oberseite unkompliziert. Die Buttons für Lautstärke, Ein/Aus, Bluetooth und die Ult-Funktion haben einen guten Druckpunkt und sind selbsterklärend angeordnet und beschriftet.
Erfreulich minimalistisch und übersichtlich ist die zugehörige Sony-App. Sie erfordert keine Registrierung per E-Mail. Nach einem initial nötigen Firmware-Update des Lautsprechers stehen verschiedene Einstellungsmöglichkeiten zur Verfügung.
Sony Ult Field 1 Screenshot
Sony Ult Field 1 Screenshot
Sony Ult Field 1 Screenshot
Sony Ult Field 1 Screenshot
Sony Ult Field 1 Screenshot
Sony Ult Field 1 Screenshot
Sony Ult Field 1 Screenshot
Sony Ult Field 1 Screenshot
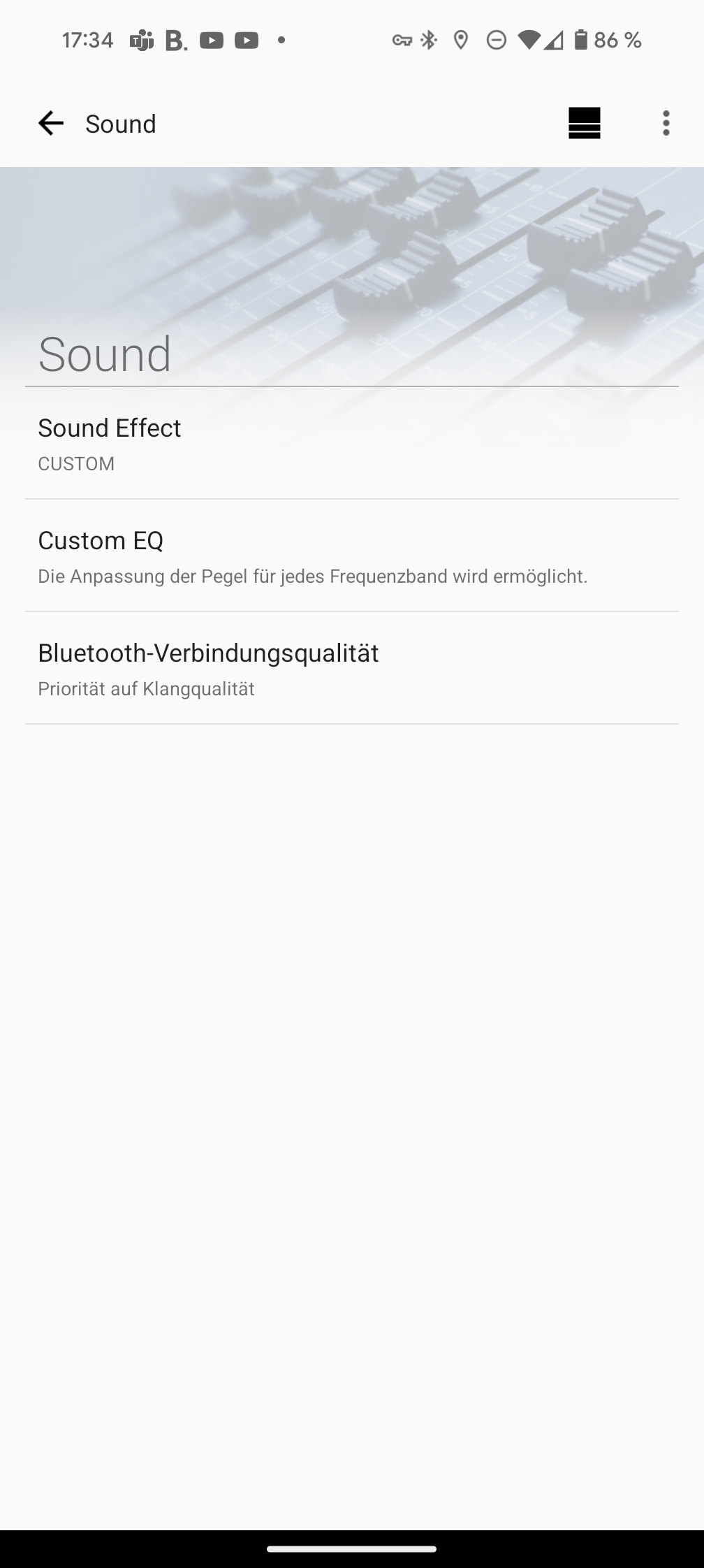
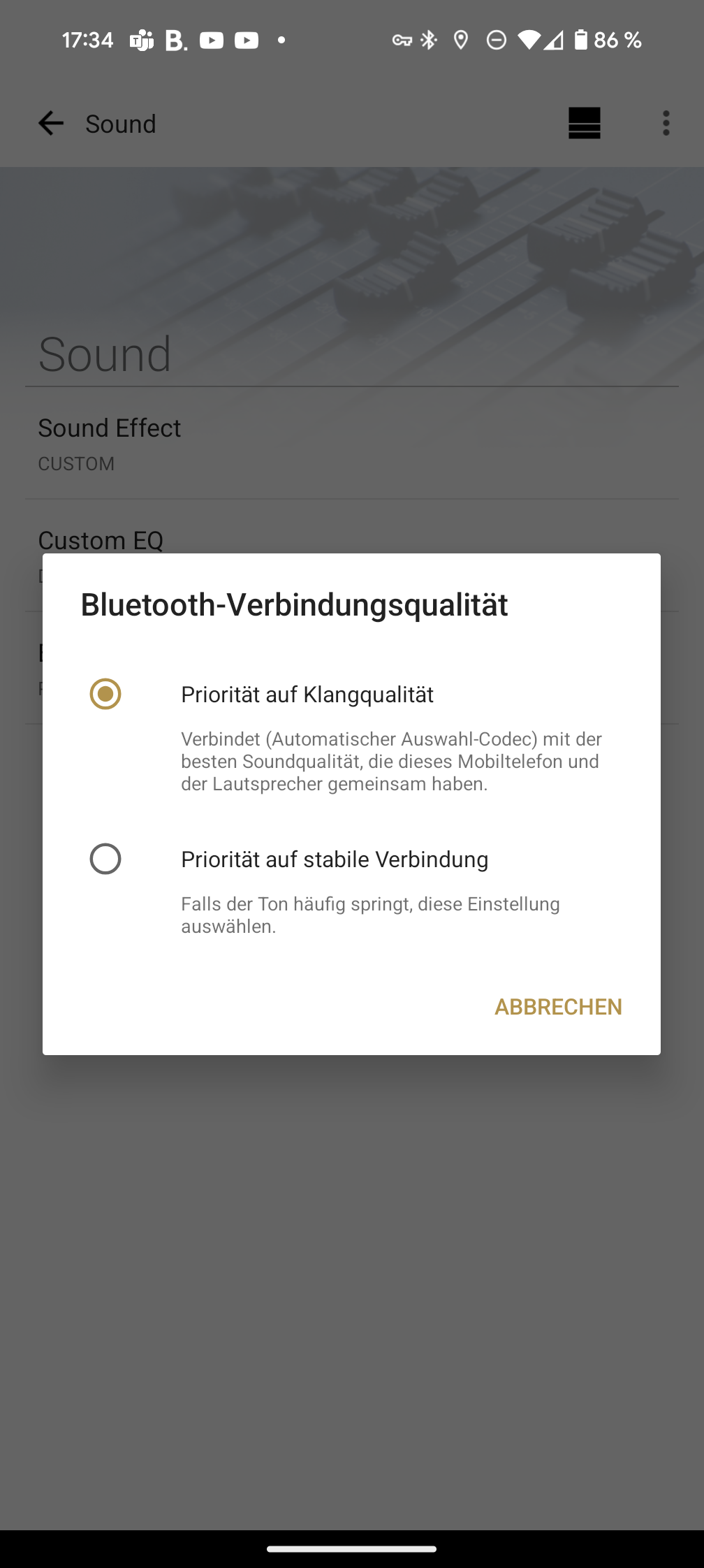
Der integrierte Equalizer ist allerdings nur nutzbar, wenn der Klangmodus auf „Custom“ gestellt ist. In diesem Fall können Höhen, Mitten und Bass individuell angepasst werden. Interessant ist die Option, bei der Bluetooth-Verbindung zwischen Priorität auf Klangqualität oder auf stabile Verbindung zu wählen. Außerdem gibt es eine Art Stromsparmodus.
Insgesamt fällt die App-Funktionalität jedoch eher sparsam aus. Im Vergleich zu manchen Konkurrenzprodukten hätten wir uns hier mehr Einstellungsmöglichkeiten und Features gewünscht.
Akku
Sony verspricht für den Ult Field 1 eine Akkulaufzeit von 12 Stunden. Diese Angabe konnten wir im Test bei mittlerer Lautstärke bestätigen. Damit liegt der Lautsprecher im guten Mittelfeld seiner Klasse und sollte für die meisten Einsatzszenarien ausreichend Ausdauer bieten.
Konnektivität
Der Sony Ult Field 1 setzt auf Bluetooth 5.3 als Übertragungsstandard. Dies gewährleistet eine stabile und energieeffiziente Verbindung zu kompatiblen Geräten. Unterstützt werden die Codecs SBC und AAC für Android- als auch für iOS-Nutzer.
Es ist möglich, zwei Ult Field 1 Lautsprecher zu einem Stereo-Paar zu verbinden. Dies erlaubt eine deutlich breitere Klangbühne und ist besonders für größere Räume oder Outdoor-Bereiche interessant. Ausprobieren konnten wir das jedoch nicht.
Preis: Was kostet der Sony Ult Field 1?
Mit einem Preis von 65 Euro auf Amazon positioniert sich der Sony Ult Field 1 im mittleren Preissegment für kompakte Bluetooth-Lautsprecher. Er konkurriert damit direkt mit beliebten Modellen wie dem JBL Flip 6 oder dem LG Xboom Go. Angesichts der gebotenen Leistung und Funktionen ist der Preis angemessen.
Fazit
Der Sony Ult Field 1 ist ein solider Allrounder unter den kompakten Bluetooth-Lautsprechern. Sein robustes Design mit IP67-Schutz macht ihn zu einem verlässlichen Begleiter für Outdoor-Aktivitäten. Klanglich überzeugt er besonders mit aktivierter Ult-Funktion, die dem Sound deutlich mehr Leben einhaucht. Doch hätte man sich Taste im Grunde sparen können. Niemand will den Sony Ult Field 1 mit ausgeschalteter Ult-Funktion hören.
Die Bedienung gestaltet sich einfach, während die App zwar übersichtlich, aber etwas funktionsarm ausfällt. Die Akkulaufzeit von zwölf Stunden bewegt sich im Mittelfeld. Es gibt zusätzlich die Möglichkeit, zwei Geräte zu einem Stereo-Paar zu verbinden.
Für einen Preis von 65 Euro auf Amazon erhält man mit dem Sony Ult Field 1 einen vielseitigen und gut klingenden Bluetooth-Lautsprecher.
Sonos Play
Der Lautsprecher Sonos Play mit WLAN, Bluetooth und AirPlay 2 tritt gegen die hauseigene Konkurrenz und etablierte Bluetooth-Lautsprecher an.
- kräftiger, voller Klang
- WLAN 6, AirPlay 2, Spotify Connect
- hochwertige Verarbeitung
- lange Akkulaufzeit
- Trueplay-Einmessung
- relativ groß
- Equalizer nur zwei Bänder
- teuer
Bluetooth-Lautsprecher Sonos Play im Test: WLAN, Akku, IP67 & warmer Klang
Der Lautsprecher Sonos Play mit WLAN, Bluetooth und AirPlay 2 tritt gegen die hauseigene Konkurrenz und etablierte Bluetooth-Lautsprecher an.
Sonos hat sich mit smarten Multiroom-Lautsprechern einen Namen gemacht. Mit dem Sonos Play schiebt der Hersteller einen mobilen Bluetooth-Lautsprecher ins Portfolio. Er positioniert sich zwischen dem handlichen Sonos Roam 2 (Testbericht) und dem deutlich größeren Sonos Move (Testbericht). Er kombiniert Bluetooth mit WLAN, AirPlay 2 und Multiroom – ein Paket, das klassische Bluetooth-Lautsprecher so nicht bieten.
Im Vergleich zum Sonos Move fällt der Play mit 1,3 kg deutlich leichter aus. Der Move wiegt stolze 3 kg und eignet sich eher für die Terrasse als für den Rucksack. Dafür bleibt der Play bei Bassfülle und maximaler Lautstärke hinter dem großen Bruder zurück. Gegenüber dem Roam 2 spielt der Neue spürbar erwachsener auf, mit kräftigerem Bass und mehr Lautstärkereserven. Kompakter und leichter als der Roam 2 ist er allerdings nicht.
Design und Verarbeitung des Sonos Play
Hochwertig. Modern. Edel. Der Sonos Play hebt sich optisch klar von typischen Bluetooth-Lautsprechern mit ihren Stoffbespannung ab. Für einen mobilen Lautsprecher fällt er allerdings vergleichsweise groß und schwer aus. Die Abmessungen liegen bei 192 × 113 × 77 cm, das Gewicht bei 1,3 kg. Im Rucksack macht sich das bemerkbar.
Zur Wahl stehen die Farben Schwarz und Weiß. Eine integrierte Schlaufe dient zum Tragen und Aufhängen, durch die allerdings nur zwei Finger passen. Praktisch: Sie lässt sich nach unten drehen und verschwindet dann optisch fast vollständig. Beim weißen Modell setzt die Schlaufe als pastellgrüner Akzent einen dezenten Farbtupfer. Die schwarze Variante kommt mit grauer Schlaufe daher.
Sonos Play Bilder
Sonos Play

Sonos Play

Sonos Play

Sonos Play

Sonos Play

Sonos Play

Sonos Play

Sonos Play

Sonos Play

Sonos Play

Sonos Play

Sonos Play

Sonos Play

Sicher steht der Lautsprecher dank gummierter Unterfläche nur aufrecht. Hinlegen ist keine gute Idee – durch die ovale Form rollt der Play auf schiefer Fläche gerne weg. Die Verarbeitung ist erstklassig. Das stabile Gehäuse eignet sich gut für Terrasse, Garten und Reisen. Dank IP67-Zertifizierung trotzt er Staub und übersteht 30 Minuten in einem Meter Wassertiefe.
Wie gut ist der Klang des Sonos Play?
Für seine Größe spielt der Sonos Play überraschend kräftig und voll auf. Der Bass drückt spürbar, ohne dass das Gehäuse mitvibriert oder das Klangbild in Verzerrungen abrutscht. Stimmen klingen natürlich und gut verständlich – ideal für Podcasts und Hörbücher. Auch die Klangbühne wirkt für einen mobilen Lautsprecher angenehm breit.
Bei der Lautstärke macht der Bluetooth-Lautsprecher ebenfalls eine gute Figur. Er erreicht hohe Pegel, ohne sofort ins Verzerren zu kippen. An den Sonos Move 2 reicht er klanglich aber nicht heran. Der spielt sowohl basswuchtiger als auch lauter auf.
Ein Kritikpunkt: Die Bassabstimmung wirkt je nach Musikrichtung etwas zu dominant. Bei elektronischen Tracks oder Hip-Hop kann der Tiefton andere Frequenzen leicht überdecken. Hier hilft der Equalizer in der App. Allerdings beschränkt sich Sonos auf einen schlichten Zwei-Band-EQ mit Reglern für Bass und Höhen. Mehr Bänder wären wünschenswert gewesen.
Eine echte Aufwertung ist die Trueplay-Einmessung. Sie passt den Klang automatisch an die Raumakustik an. Steht der Play in einem Regal mit Echo-Effekten oder direkt an der Wand, gleicht Trueplay die akustischen Eigenheiten aus. Auf Wunsch misst das System bei jedem Anheben des Lautsprechers automatisch neu ein – ein cleveres Detail für mobile Nutzung.
Wer noch mehr will, koppelt zwei Sonos Play per App zu einem Stereopaar. Das steigert die Klangqualität massiv. Räumlichkeit, Detailauflösung und Lautstärke profitieren spürbar.
Bedienung und App des Sonos Play
Die wichtigsten Funktionen lassen sich direkt am Gerät steuern. Auf der Oberseite sitzen physische Tasten für Lautstärke und Wiedergabe/Pause. Zweimaliges Drücken springt einen Song vor, dreimaliges einen zurück. Eine eigene Taste aktiviert die Sprachsteuerung. Auf der Rückseite finden sich Bluetooth-Taste, Mikrofon-Stummschalter und Ein-/Aus-Knopf.
Die Haptik der Tasten ist etwas fest, was sich in der Praxis aber als Vorteil erweist – Fehleingaben gibt es kaum. Im Dunkeln lassen sich die unbeleuchteten Knöpfe gut ertasten. Eine fummelige Touchbedienung wäre hier die schlechtere Wahl gewesen.
Sonos Play Screenshot
Sonos Play Screenshot
Sonos Play Screenshot
Sonos Play Screenshot
Sonos Play Screenshot
Sonos Play Screenshot
Sonos Play Screenshot
Sonos Play Screenshot
Sonos Play Screenshot
Sonos Play Screenshot
Sonos Play Screenshot
Sonos Play Screenshot
Sonos Play Screenshot
Sonos Play Screenshot
Sonos Play Screenshot

Sonos Play Screenshot
Sonos Play Screenshot

Sonos Play Screenshot
Sonos Play Screenshot
Sonos Play Screenshot
Sonos Play Screenshot
Sonos Play Screenshot
Sonos Play Screenshot
Sonos Play Screenshot
Sonos Play Screenshot
Sonos Play Screenshot
Sonos Play Screenshot
Sonos Play Screenshot
Sonos Play Screenshot
Sonos Play Screenshot
Sonos Play Screenshot
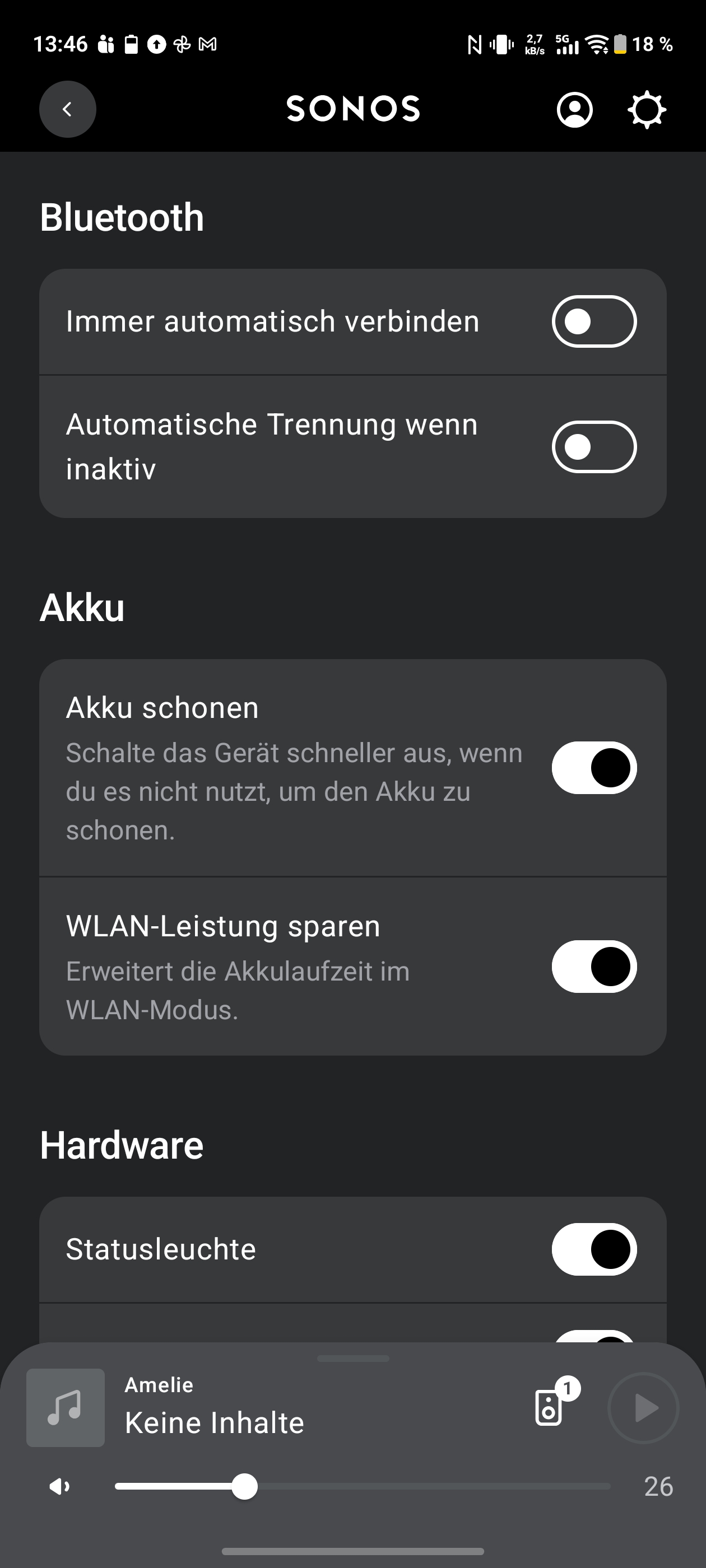
Die Sonos-App bietet eine umfangreiche Funktionsvielfalt. Sie gruppiert Lautsprecher in Räumen, erstellt Stereopaare, regelt den Equalizer und weckt auf Wunsch mit Lieblingsmusik. Auch die Trueplay-Einmessung läuft komplett über die App. Leider zeigt sich diese seit dem großen Update vor einiger Zeit weiterhin instabil und wenig selbsterklärend. Wer Sonos nicht gewohnt ist, sucht manche Einstellung länger als nötig.
Der Akku des Sonos Play
Bis zu 24 Stunden verspricht Sonos bei moderater Lautstärke. Im Test bestätigt sich der Wert weitgehend. Für einen Tag am See oder eine längere Gartenparty reicht der Akku problemlos.
Praktisch: Der Play lädt über USB-C auch externe Geräte wie das Smartphone. Aufgeladen wird er entweder per USB-C-Kabel oder mit der beiliegenden Ladestation. Besonders erfreulich ist der wechselbare Akku. Der Tausch erfordert allerdings Werkzeug – ein schneller Akkuwechsel unterwegs ist nicht vorgesehen. Sonos zielt damit auf bessere Reparierbarkeit und längere Produktlebensdauer.
Konnektivität und technische Eigenschaften des Sonos Play
Hier spielt der Sonos Play seine größte Stärke aus. Statt sich auf Bluetooth zu beschränken, kombiniert er WLAN 6, Bluetooth 5.3, Apple AirPlay 2 und Spotify Connect in einem Gehäuse. Damit bietet er deutlich mehr Möglichkeiten als die meisten klassischen Bluetooth-Lautsprecher.
Über WLAN integriert sich der Play nahtlos ins Sonos-Multiroom-System. Wer bereits andere Sonos-Lautsprecher besitzt, kann den Play in einzelne Räume gruppieren oder im ganzen Haus synchron Musik abspielen. AirPlay 2 erlaubt Apple-Nutzern das direkte Streaming vom iPhone, iPad oder Mac. Spotify Connect funktioniert ebenfalls ohne Umweg über Bluetooth – das spart Akku am Smartphone und erhöht die Klangqualität.
Unterwegs übernimmt Bluetooth 5.3. Der Wechsel zwischen WLAN und Bluetooth läuft nahtlos. Über Amazon Alexa lässt sich der Lautsprecher zudem per Sprache steuern. Auf der Rückseite sitzt ein USB-C-Anschluss, der primär zum Laden dient.
Ein Stereopaar mit zwei Sonos Play ist möglich, ebenso die Einbindung in Multiroom-Setups. Einige dieser Funktionen entfalten ihren Nutzen allerdings erst innerhalb des Sonos-Systems. Wer nur einen einzelnen Bluetooth-Lautsprecher sucht und kein Multiroom plant, lässt einen Teil des Potenzials brachliegen.
Was kostet der Sonos Play?
Der Sonos Play ist für 345 Euro bei Amazon erhältlich. Das ist sportlich. Klassische Bluetooth-Lautsprecher wie der JBL Charge 6 sind deutlich günstiger zu haben, bieten aber auch nicht den vollen Funktionsumfang mit WLAN, AirPlay 2 und Multiroom-Anbindung.
Fazit
Der Sonos Play ist ein gelungener Hybrid aus Smart Speaker und mobilem Bluetooth-Lautsprecher. Er kombiniert hochwertige Optik, robuste IP67-Verarbeitung und kräftigen Klang mit einer Konnektivität, die klassischen Bluetooth-Boxen klar überlegen ist. WLAN 6, AirPlay 2, Spotify Connect und Multiroom heben ihn deutlich aus der Masse heraus.
Klanglich liefert er einen vollen, basskräftigen Sound mit guter Stimmwiedergabe und breiter Bühne. Als Stereopaar wird er richtig stark. Die Trueplay-Einmessung holt zusätzlich Klangqualität aus schwierigen Aufstellorten. Auch der wechselbare Akku und die lange Laufzeit von bis zu 24 Stunden sind klare Pluspunkte.
Wermutstropfen sind die teils instabile App, der knappe Zwei-Band-Equalizer und das vergleichsweise hohe Gewicht. Auch der Preis von 345 Euro will erst einmal verdaut werden. Wer bereits im Sonos-Kosmos unterwegs ist oder die Flexibilität zwischen WLAN und Bluetooth braucht, bekommt mit dem Play einen spannenden mobilen Smart Speaker.
Edifier ES60
Der Edifier ES60 ist ein stylisher Bluetooth-Lautsprecher im Retro-Look. Er bietet kräftigen Klang und Ambientebeleuchtung.
- Retro-Design mit hochwertiger Anmutung
- kräftiger, warmer Bass
- Multipoint
- Ambientebeleuchtung
- Preis-Leistungs-Verhältnis
- Akkulaufzeit nur 9 h
- App ohne echten Equalizer
- keine Farboptionen der Beleuchtung
Edifier ES60 im Test: Retro-Bluetooth-Lautsprecher mit mächtig Bass
Der Edifier ES60 ist ein stylisher Bluetooth-Lautsprecher im Retro-Look. Er bietet kräftigen Klang und Ambientebeleuchtung.
Wer einen Bluetooth-Lautsprecher mit klassischem Verstärker-Charme sucht, denkt häufig an den Marshall Emberton III (Testbericht). Doch auch der Edifier ES60 versprüht Retro-Charme. Optisch sind sich beide Speaker ähnlich – sie kokettieren mit dem rockigen, kultigen Look klassischer Gitarrenverstärker. Preislich liegen die beiden Modelle jedoch weit auseinander: Der ES60 kostet regulär rund 90 Euro, aktuell im Angebot bei Joybuy gar nur unschlagbare 53 Euro. Der Marshall kostet bei Amazon fast dreimal so viel, nämlich 145 Euro.
Beim Akku hängt der Marshall den Edifier deutlich ab – über 32 h Laufzeit beim Emberton III stehen rund 9 h beim ES60 gegenüber. Auch in Sachen Mobilität punktet der Marshall. Er wiegt mit etwa 670 g rund ein Drittel weniger als der ES60 mit knapp einem kg. Beim Schutz vor Wasser liegt der Marshall mit IP67 ebenfalls leicht vorn, während der ES60 mit IP66 zwar gegen starke Wasserstrahlen, nicht aber gegen Untertauchen geschützt ist. Trotzdem kann auch der Edifier überzeugen. Wir haben getestet, ob er dem Marshall Emberton III gefährlich werden kann.
Design und Verarbeitung des Edifier ES60
Der Edifier ES60 ist ein echtes Schmuckstück. Sein Retro-Design erinnert an klassische Gitarrenverstärker und greift damit in die gleiche Stil-Kiste wie der Marshall Emberton III. Erhältlich ist der Lautsprecher in Schwarz oder Elfenbein. Unser vom Hersteller zur Verfügung gestelltes Testmodell kommt in der hellen Elfenbein-Variante daher.
Die Kunstleder-Optik in Verbindung mit dem Metallgitter vorne und hinten sorgt für einen edlen Auftritt. Silberfarbene Bedienelemente setzen einen schicken Akzent und unterstreichen den Vintage-Charakter. Mit Abmessungen von etwa 19 × 9 × 10 cm und einem Gewicht von rund 1 kg ist der ES60 jedoch weder besonders klein noch leicht. Eine Trageschlaufe erleichtert den Transport.
Edifier ES60 Bilder
Edifier ES60

Edifier ES60

Edifier ES60

Edifier ES60

Edifier ES60

Edifier ES60

Edifier ES60

Edifier ES60

Edifier ES60

Edifier ES60

Edifier ES60

Die Verarbeitung ist für die Preisklasse top. Spaltmaße sitzen sauber, das Gehäuse wirkt robust. Die Schutzklasse IP66 schützt vor Staub und starken Wasserstrahlen, ein Tauchgang ist allerdings tabu. Ein nettes Extra ist die integrierte Ambientebeleuchtung mit mehreren Effekten.
Die Taster auf der Oberseite sehen schick aus und bieten einen guten Druckpunkt. Sie sind aber leider unbeleuchtet. Im Dunkeln muss man sich dadurch blind durchtasten, was die Bedienung erschwert.
Wie gut ist der Klang des Edifier ES60?
Im Inneren des ES60 werkelt ein durchdachtes Treiberkonzept. Zwei 19-mm-Seidenkalotten-Hochtöner – einer nach vorn, der zweite nach hinten gerichtet – sorgen für eine breite Klangausbreitung. Den Tiefmittenbereich übernimmt ein ovaler Tiefmitteltöner mit Langhub-Auslegung, unterstützt von einer Passivmembran. Die Gesamtleistung liegt bei 34 W RMS, aufgeteilt in 18 W für den Tiefmitteltöner und 2 × 8 W für die Hochtöner.
Im Hörtest gefällt der ES60 mit kräftigem, warmem Bass. Die Passivmembran erzeugt einen deutlich hörbaren Tiefbasszuwachs. Vor allem Pop, Rock und elektronische Musik machen damit richtig Spaß. Die Abstimmung ist bassbetont.
Dank des zweiten nach hinten gerichteten Hochtöners strahlt der Klang nach vorn und nach hinten ab. Das verleiht dem Sound eine angenehme Räumlichkeit. Die Herstellerangabe eines „360°-Klangs“ ist allerdings nur eingeschränkt nachvollziehbar – der Klang verteilt sich zwar breit, einen wirklich gleichmäßigen Rundumklang erzeugt der Edifier aber nicht.
Die maximale Lautstärke ist hoch und bleibt erfreulich verzerrungsarm. Stimmen werden klar wiedergegeben. Im Hochtonbereich agiert der ES60 jedoch etwas zurückhaltend. Die Detailauflösung erreicht nicht ganz das Niveau höherwertiger Premium-Modelle. Bei komplexen Musikstücken mit vielen gleichzeitig spielenden Instrumenten verliert der Lautsprecher etwas an Feinzeichnung.
Wer noch mehr Klangbreite möchte, kann zwei ES60 zu einem Stereopaar koppeln. Insgesamt gehört der kompakte Bluetooth-Lautsprecher klanglich zu den stärkeren Vertretern seiner Preisklasse – vor allem dank des satten Tieftons.
Bedienung und App des Edifier ES60
Die Bedienung erfolgt direkt am Gerät über separate Tasten für Lautstärke, Ein/Aus, Bluetooth, Wiedergabe/Pause und Titelsteuerung. Auch die Lichtsteuerung lässt sich direkt am Speaker regeln. Eine Batteriestandsanzeige über fünf LEDs gibt einen groben Überblick. Insgesamt ist die Bedienung logisch aufgebaut und unkompliziert.
Die zugehörige App Edifier Connex ist solide, lässt aber Wünsche offen. Sie bietet vier Equalizer-Presets: Music, Game, Movie und Outdoor. Eine Custom-Einstellung fehlt – ein echter Equalizer mit individuellen Bandanpassungen ist also nicht an Bord. Schade, denn so kann man die etwas zurückhaltenden Höhen nicht selbst aufpolieren.
Auch bei der Beleuchtungssteuerung wäre mehr drin gewesen. Die App erlaubt die Anpassung der Beleuchtung, allerdings nur in der Helligkeit und zwischen warmweiß und kaltweiß. Andere Farben sind nicht wählbar, obwohl die Hardware Multi-Color scheinbar unterstützen würde. Es fehlt schlichtweg die Software-Option. Immerhin gibt es einen Alarmmodus, der den Leuchtstreifen an der Unterseite rot blinken lässt. Firmware-Updates und die generelle Gerätekonfiguration laufen ebenfalls über die App.
Edifier ES60 Screenshot
Edifier ES60 Screenshot
Edifier ES60 Screenshot

Edifier ES60 Screenshot
Edifier ES60 Screenshot

Edifier ES60 Screenshot
Edifier ES60 Screenshot
Edifier ES60 Screenshot

Edifier ES60 Screenshot
Edifier ES60 Screenshot
Der Akku des Edifier ES60
Beim Akku zeigt sich die größte Schwäche des ES60. Edifier gibt eine Laufzeit von bis zu 9 h an. Die tatsächliche Laufzeit hängt stark von der Lautstärke und der Nutzung der Ambientebeleuchtung ab.
Im Marktvergleich ist das eher unterdurchschnittlich. Angesichts der Größe und des Gewichts von rund 1 kg hätten wir hier mehr erwartet – im Gehäuse böte sich Platz für einen größeren Akku. Geladen wird der ES60 via USB-C. Eine Powerbank-Funktion zum Laden des Smartphones gibt es nicht.
Konnektivität und technische Eigenschaften des Edifier ES60
Beim Bluetooth-Standard ist der ES60 auf der Höhe der Zeit. Bluetooth 5.4 sorgt für eine stabile und energieeffiziente Verbindung. Dank Multipoint-Funktion lassen sich zwei Geräte gleichzeitig koppeln.
Bei den Codecs hält sich Edifier dagegen zurück. Nur der Standard-Codec SBC wird unterstützt. Höherwertige Codecs wie aptX oder LDAC fehlen. Immerhin gibt es einen USB-C-Audioeingang. Über diesen lassen sich Zuspielgeräte kabelgebunden anschließen, was qualitativ einen Vorteil gegenüber dem SBC-Streaming bringt. WLAN-Konnektivität oder ein integrierter Sprachassistent fehlen.
Was kostet der Edifier ES60?
Der reguläre Preis des Edifier ES60 liegt bei rund 90 Euro. Aktuell gibt es ihn im Rahmen einer Aktion bei Joybuy für nur 53 Euro für Kunden, die über die App kaufen. Das ist ein außergewöhnlich gutes Angebot, üblicherweise fallen etwa 90 Euro an.
Fazit
Der Edifier ES60 ist ein optisch hervorragend gelungener Bluetooth-Lautsprecher. Sein Retro-Look erinnert an klassische Gitarrenverstärker und kann mit dem deutlich teureren Marshall Emberton III konkurrieren. Die Verarbeitung ist für die Preisklasse top. Das weiße Kunstleder, die silbernen Bedienelemente und das Metallgitter wirken edel, die integrierte Ambientebeleuchtung setzt einen dezenten Akzent.
Klanglich liefert der ES60 einen kräftigen, bassbetonten Sound mit guter Räumlichkeit. Pop, Rock und elektronische Musik machen besonders viel Spaß. Schwächen zeigt der Lautsprecher in den Höhen und bei der Detailauflösung anspruchsvoller Musik.
Größter Kritikpunkt bleibt der Akku. Mit 9 h Laufzeit liegt der ES60 deutlich unter dem heutigen Durchschnitt. Auch die Beschränkung auf den SBC-Codec und das Fehlen eines echten Equalizers in der App sind Wermutstropfen. Wer aber einen stylishen Lautsprecher mit kräftigem Klang sucht und mit der überschaubaren Akkulaufzeit leben kann, bekommt – besonders zum aktuellen Aktionspreis von 53 Euro bei Joybuy – einen echten Preis-Leistungs-Tipp.
Bose Soundlink Flex 2
Der Bluetooth-Lautsprecher Bose Soundlink Flex 2 bringt einen verbesserten Klang mit neuem Codec und endlich einen Equalizer.
- warmer Klang mit gutem Bass
- IP67-Schutz
- Equalizer
- Bluetooth 5.3 & aptX Adaptive
- gute Freisprechfunktion
- Akkulaufzeit nur 12 Stunden
- keine großen Hardware-Upgrades
- keine alternativen Anschlüsse
- Bass verliert bei hoher Lautstärke an Präzision
Bluetooth-Lautsprecher Bose Soundlink Flex 2 im Test: warmer Klang, starker Bass
Der Bluetooth-Lautsprecher Bose Soundlink Flex 2 bringt einen verbesserten Klang mit neuem Codec und endlich einen Equalizer.
Bose gehört zu den etablierten Größen im Bluetooth-Lautsprecher-Markt. Mit dem Soundlink Flex 2 zeigt der Hersteller die zweite Generation seines kompakten Outdoor-Speakers. Für 110 Euro (Amazon) verspricht Bose hohe Klangqualität im robusten Gehäuse – allerdings mit nur minimalen Verbesserungen gegenüber dem Vorgänger.
Es gibt unter anderem eine neue Shortcut-Taste, App-Unterstützung mit Equalizer und Bluetooth 5.3 statt des veralteten 4.2-Standards. Hardware-seitig bleibt fast alles beim Alten – was nicht zwangsläufig schlecht ist, schließlich war der Vorgänger bereits ein solider Lautsprecher.
Doch die Konkurrenz schläft nicht: Der JBL Flip 6 kostet ähnlich viel und bietet vergleichbare Features. Der Marshall Emberton III ist etwas teurer, punktet aber mit deutlich längerer Akkulaufzeit von bis zu 32 Stunden. Der Sony Ult Field 1 lockt mit kräftigem Bass zum günstigeren Preis. Kann sich der Soundlink Flex 2 in diesem hart umkämpften Segment behaupten? Wir machen den Test.
Design und Verarbeitung des Bose Soundlink Flex 2
Mit Abmessungen von 20 × 9 × 5,2 cm und einem Gewicht von 600 Gramm bleibt der Soundlink Flex 2 angenehm kompakt. Er passt problemlos in jeden Rucksack, für die Hosentasche ist er allerdings zu groß. Das silikonummantelte Gehäuse fühlt sich weich und rutschfest an, während das pulverbeschichtete Metallgitter auf der Vorderseite für Stabilität sorgt.
Bose bietet den Lautsprecher in vielen Farben an: Schwarz, Dunkelblau, Hellblau, Grau, Rosa, helles Türkis, Gelb und Blütenrosa. Die Farbvielfalt übertrifft viele Konkurrenten. Optisch gibt sich der Speaker elegant, aber wenig spektakulär – er fügt sich unauffällig in verschiedene Umgebungen ein.
Die IP67-Zertifizierung macht den Flex 2 staubdicht und wasserdicht bis zu einem Meter Tiefe für 30 Minuten. Praktisch: Der Lautsprecher schwimmt auf dem Wasser. Die Silikonrückseite schützt vor Stößen und Kratzern. Gummifüße sorgen für stabilen Stand auf verschiedenen Oberflächen. Eine kleine Trageschlaufe ermöglicht das Aufhängen oder Befestigen des Speakers.
Im direkten Vergleich zum Vorgänger fällt auf: Optisch sind beide Generationen fast identisch. Der Flex 2 ist minimal schmaler, ansonsten gibt es weder optisch noch haptisch große Unterschiede. Die Verarbeitungsqualität bleibt auf hohem Niveau – der Lautsprecher fühlt sich durchweg stabil und wertig an.
Bose Soundlink Flex 2 Bilder
Bose Soundlink Flex 2

Bose Soundlink Flex 2

Bose Soundlink Flex 2

Bose Soundlink Flex 2

Bose Soundlink Flex 2

Bose Soundlink Flex 2

Bose Soundlink Flex 2

Bose Soundlink Flex 2

Bose Soundlink Flex 2

Bose Soundlink Flex 2

Bose Soundlink Flex 2

Bose Soundlink Flex 2

Bose Soundlink Flex 2

Bose Soundlink Flex 2

Bose Soundlink Flex 2

Bose Soundlink Flex 2

Wie gut ist der Klang des Bose Soundlink Flex 2?
Der Soundlink Flex 2 liefert einen warmen, bassstarken Klang mit klaren Mitten und nuancierten Höhen. Für seine kompakte Größe bietet er eine beeindruckende Klangqualität. Bose passt den Sound automatisch an die Ausrichtung an: Liegend klingt er runder, stehend direkter und fokussierter.
Bei moderater Lautstärke spielt der Flex 2 seine Stärken aus. Podcasts und Hörbücher profitieren von der klaren Stimmwiedergabe. Bei Musik überzeugt der ausgewogene Klang, wobei der Bass angenehm präsent ist, ohne die Mitten zu überdecken. Die maximale Lautstärke fällt erfreulich hoch aus und reicht für mittelgroße Räume oder Outdoor-Aktivitäten.
Schwächen zeigen sich bei hohen Pegeln: Der Bass verliert merklich an Druck und Definition. Die Separation einzelner Instrumente lässt nach, wodurch komplexe Musikstücke – besonders klassische Musik – an Präzision verlieren. Hier stoßen die kompakten Treiber an ihre physikalischen Grenzen.
Das integrierte Mikrofon mit Echo-Reduktion ermöglicht Freisprechtelefonate in guter Qualität. Gesprächspartner verstehen uns laut und deutlich, selbst aus zwei Metern Entfernung vom Gerät. Im Vergleich zum Vorgänger klingt der Flex 2 minimal besser – der Bass reicht tiefer, die Gesamtabstimmung wirkt ausgewogener. Der neue Equalizer in der App erlaubt erstmals Klanganpassungen.
Mit einem zweiten Soundlink Flex 2 lässt sich ein Stereopaar bilden oder der Party-Modus aktivieren. Diese Funktion konnten wir nicht testen. Unterstützt werden die Codecs SBC, AAC und aptX Adaptive – letzterer ist besonders für Android-Nutzer interessant und bietet bessere Audioqualität. Ein AUX-Eingang oder weitere Audio-Anschlüsse fehlen. Der USB-C-Port dient ausschließlich zum Laden, nicht zur Audioübertragung.
Bedienung und App des Bose Soundlink Flex 2
Die Bedienung erfolgt über sechs Tasten auf der Oberseite: Ein/Aus, Bluetooth-Pairing, eine neue programmierbare Shortcut-Taste, Lautstärke hoch/runter und Play/Pause. Die Druckpunkte haben sich gegenüber dem Vorgänger verbessert, bleiben aber suboptimal – die unter Silikon liegenden Tasten erfordern deutlichen Druck.
Die Tastenreihenfolge ist leicht erlernbar und auch im Dunkeln gut erfühlbar, obwohl eine Tastenbeleuchtung fehlt. Drei kleine LEDs zeigen den Betriebsstatus an. Sprachansagen informieren über Batteriestand, Verbindungsstatus und Anrufer-ID, klingen aber mechanisch und hölzern. Glücklicherweise lassen sie sich abschalten.
Die Bose-App erweitert die Funktionalität erheblich. Ein 3-Band-Equalizer mit Presets für Bass und Höhen ermöglicht Klanganpassungen – allerdings hätten wir uns mehr Bänder gewünscht. Die Shortcut-Taste lässt sich mit verschiedenen Funktionen belegen: Stereo/Party-Modus, Sprachassistent oder Spotify Tap.
Bose Soundlink Flex 2 Screenshots
Bose Soundlink Flex 2 Screenshot
Bose Soundlink Flex 2 Screenshot
Bose Soundlink Flex 2 Screenshot
Bose Soundlink Flex 2 Screenshot
Bose Soundlink Flex 2 Screenshot
Bose Soundlink Flex 2 Screenshot
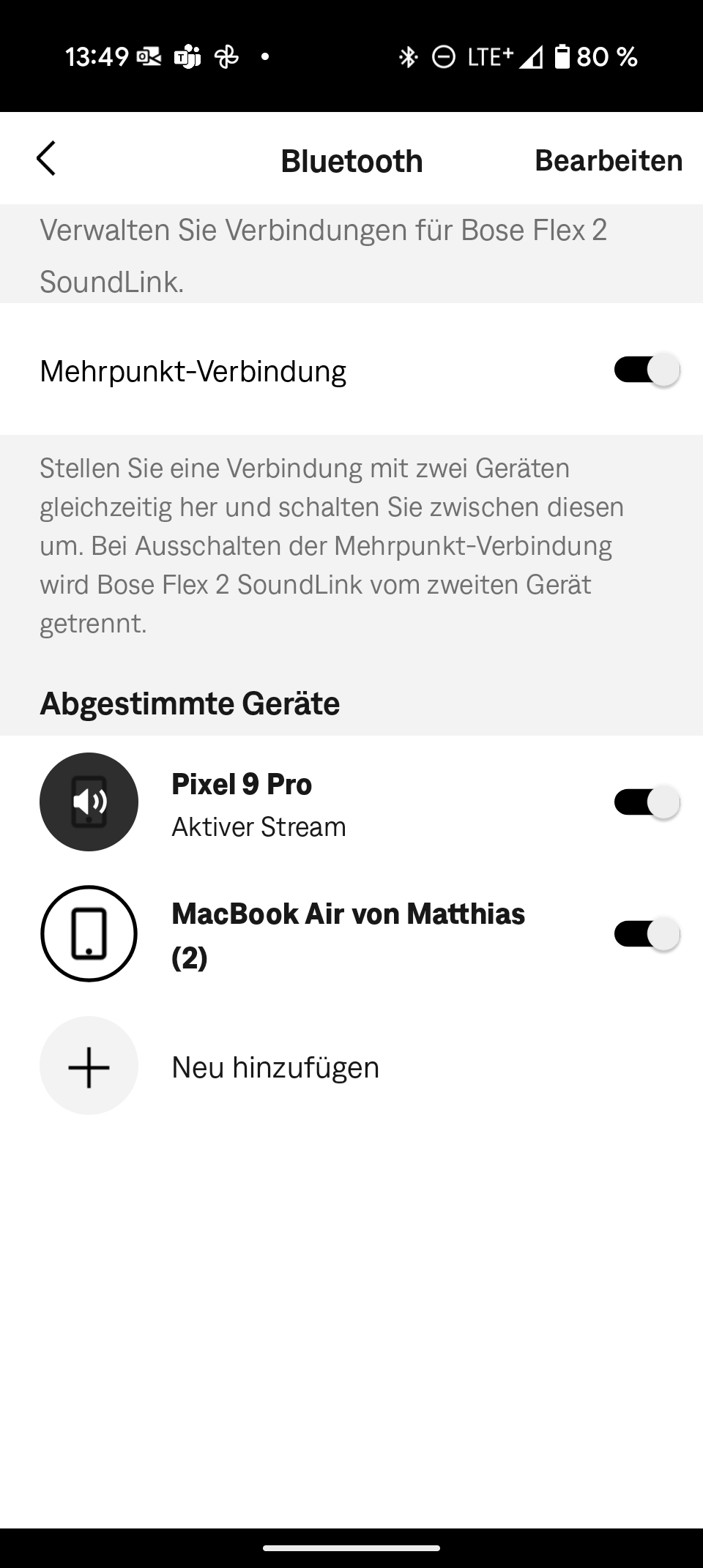
Bose Soundlink Flex 2 Screenshot
Bose Soundlink Flex 2 Screenshot
Weitere App-Features umfassen die Verwaltung von Bluetooth-Quellen, Firmware-Updates, individuelle Benennung, Abschalttimer und Akkustandsansage. Simplesync soll die Kopplung mit Bose-Soundbars oder anderen Speakern ermöglichen. Die Einrichtung gelingt schnell. Multipoint-Bluetooth verbindet bis zu zwei Geräte gleichzeitig.
Der Akku des Bose Soundlink Flex 2
Die Akkulaufzeit beträgt bis zu 12 Stunden bei 50 Prozent Lautstärke, bei maximaler Lautstärke sind es nur noch drei Stunden. Das vollständige Aufladen dauert vier Stunden über USB-C mit 5V/1,5A. Ein USB-C-zu-USB-A-Kabel liegt bei.
Im Vergleich zum Vorgänger hat sich nichts verändert – die Akkuleistung bleibt identisch. Das ist enttäuschend, besonders angesichts der laufstarken Konkurrenz: Der Marshall Emberton III hält mit 30 Stunden mehr als doppelt so lange durch. Eine Powerbank-Funktion zum Laden anderer Geräte fehlt ebenfalls. Für die Preisklasse ist die Akkulaufzeit zu kurz.
Was kostet der Bose Soundlink Flex 2?
Mit einem Straßenpreis von 110 Euro (Amazon) befindet sich der Soundlink Flex 2 deutlich unter der UVP von 179,95 Euro. Damit liegt er preislich beinahe auf Augenhöhe mit dem JBL Flip 6. Der Marshall Emberton III kostet mit etwa 140 Euro mehr, bietet dafür aber die längere Akkulaufzeit.
Fazit
Der Bose Soundlink Flex 2 ist ein solider Bluetooth-Lautsprecher mit bewährten Qualitäten und minimalen Verbesserungen. Die Klangqualität überzeugt angesichts der kompakten Größe, besonders bei moderater Lautstärke. Eine robuste Verarbeitung mit IP67-Schutz macht ihn zum zuverlässigen Outdoor-Begleiter. Die neue App-Unterstützung mit Equalizer und die verbesserte Bluetooth-Verbindung sind willkommene Upgrades. Toll finden wir seine sehr guten Telefonieeigenschaften.
Enttäuschend bleibt die unverändert kurze Akkulaufzeit von maximal 12 Stunden. Die Konkurrenz zeigt, dass deutlich mehr möglich ist. Auch die fehlenden Anschlussmöglichkeiten abseits von Bluetooth schränken die Flexibilität ein. Wer bereits den Vorgänger besitzt, findet kaum Gründe für ein Upgrade. Neueinsteiger erhalten einen guten Bluetooth-Lautsprecher zum fairen Preis.
Teufel Rockster Go 2 Fender Edition
Der Fender x Teufel Rockster Go 2 kombiniert soliden Klang mit markanter Optik. Ob der Aufpreis für die Fender-Edition gerechtfertigt ist, zeigt unser Test.
- robustes, wasserdichtes Gehäuse (IP67)
- lange Akkulaufzeit
- ausgewogener, kraftvoller Klang für die Größe
- markantes Fender-Design
- Stereo-Pairing und Multipoint-Bluetooth
- keine App für Klanganpassungen
- Verzerrungen bei maximaler Lautstärke
- relativ hoher Aufpreis für rein optische Verbesserungen
Bluetooth Speaker Fender x Teufel Rockster Go 2 im Test
Der Fender x Teufel Rockster Go 2 kombiniert soliden Klang mit markanter Optik. Ob der Aufpreis für die Fender-Edition gerechtfertigt ist, zeigt unser Test.
Bluetooth-Lautsprecher sind längst mehr als nur mobile Klangquellen – sie sind Lifestyle-Produkte, die sowohl durch Funktionalität als auch durch Design überzeugen müssen. Mit dem Rockster Go 2 in der Fender-Edition präsentiert Teufel eine Kooperation mit dem legendären Gitarrenhersteller, die Musikfans begeistern soll. Während die Standardversion des Rockster Go 2 bereits für soliden Klang in kompaktem Format bekannt ist, setzt die Fender-Edition mit ihrem markanten Design noch einen drauf. Doch rechtfertigt das den Aufpreis von etwa 30 Euro? Im Vergleich zu ähnlich großen Modellen wie dem JBL Flip 6 oder dem Marshall Emberton III positioniert sich der Teufel Rockster Go 2 im mittleren Preissegment.
Design und Verarbeitung
Die Fender-Edition des Teufel Rockster Go 2 präsentiert sich in einem Steel-Black-Design, das von der Ästhetik der berühmten Fender-Gitarren inspiriert ist. Mit seinen kompakten Abmessungen von 21 × 11 × 6 cm und einem Gewicht von 734 Gramm bleibt der Lautsprecher angenehm transportabel. Das verchromte Fender-Logo auf der Vorderseite verleiht dem Gerät einen unverwechselbaren Look und hebt es optisch von der Standardversion ab.
Das Gehäuse besteht aus robustem Kunststoff mit einer umlaufenden Gummierung, die nicht nur vor Stößen schützt, sondern auch für einen sicheren Griff sorgt. Die Verarbeitung macht einen soliden Eindruck – alle Elemente sind sauber verarbeitet, wobei die Druckpunkte der Bedientasten etwas präziser hätten ausfallen können. Dank der IP67-Zertifizierung ist der Rockster Go 2 sowohl staub- als auch wasserdicht.
Praktisch ist der mitgelieferte flexible Tragegurt, der das Transportieren erleichtert und das Befestigen an Rucksäcken oder Fahrrädern erlaubt. Ein nettes Extra der Fender-Edition ist das beiliegende Plektrum, das eine schöne Reminiszenz an die Gitarrenwelt darstellt. Das Gewinde an der Unterseite erlaubt die Befestigung an einem Stativ.
Teufel Rockster Go 2 Fender Edition Bilder
Teufel Rockster Go 2 Fender Edition

Teufel Rockster Go 2 Fender Edition

Teufel Rockster Go 2 Fender Edition

Teufel Rockster Go 2 Fender Edition

Teufel Rockster Go 2 Fender Edition

Teufel Rockster Go 2 Fender Edition

Teufel Rockster Go 2 Fender Edition

Teufel Rockster Go 2 Fender Edition

Teufel Rockster Go 2 Fender Edition

Teufel Rockster Go 2 Fender Edition

Teufel Rockster Go 2 Fender Edition

Teufel Rockster Go 2 Fender Edition

Teufel Rockster Go 2 Fender Edition

Wie gut ist der Klang des Fender x Teufel Rockster Go 2?
Klanglich setzt der Teufel Rockster Go 2 auf zwei 50-mm-Vollbereichstreiber aus Aluminium und eine 64-mm-Passivmembran. Der abgedeckte Frequenzbereich von 60 Hz bis 20.000 Hz ist für einen Lautsprecher dieser Größenklasse respektabel.
Im Hörtest zeigt sich der Rockster Go 2 kräftig und ausgewogen. Die mittleren Frequenzen werden besonders gut wiedergegeben. Die passive Bassmembran sorgt für eine ansprechende Tieftonwiedergabe, die zwar nicht mit größeren Lautsprechern mithalten kann, aber für die kompakte Bauform überzeugt.
Bei maximaler Lautstärke zeigen sich allerdings die physikalischen Grenzen des kompakten Gehäuses – hier kommt es zu hörbaren Verzerrungen. Im mittleren Lautstärkebereich spielt der Rockster Go 2 jedoch sehr angenehm und detailtreu. Die Höhen könnten etwas präsenter sein, um mehr Brillanz zu erzeugen, aber insgesamt bietet der Lautsprecher einen für seine Größe erstaunlich ausgewogenen Klang.
Es besteht die Möglichkeit, zwei Rockster Go 2 zu einem Stereopaar zu koppeln oder sogar bis zu 100 kompatible Lautsprecher zu einer Party-Kette zu verbinden. Ausprobieren konnten wir das nicht.
Bedienung
Die Bedienung des Teufel Rockster Go 2 erfolgt über die Tasten auf der Oberseite des Gehäuses. Hier finden sich Knöpfe für Ein/Aus, Bluetooth-Pairing, Lautstärkeregelung und Wiedergabe/Pause. Zusätzliche Funktionen wie der Titelwechsel sind über Mehrfachbelegungen möglich. Die Tasten reagieren zuverlässig, wenn auch mit einer leichten Verzögerung.
Die Bedienung ist insgesamt unkompliziert und auch für Technik-Neulinge leicht zu verstehen. Allerdings verzichtet Teufel sowohl bei der Standard- als auch bei der Fender-Version auf eine begleitende App. So fehlen Möglichkeiten zur individuellen Klanganpassung über einen Equalizer oder zur Installation von Firmware-Updates.
Akku
Der Lithium-Ionen-Akku des Teufel Rockster Go 2 bietet eine beeindruckende Laufzeit von bis zu 15 Stunden bei mittlerer Lautstärke. Bei geringer Lautstärke sind laut Teufel sogar bis zu 28 Stunden möglich. Im Test können wir das bestätigen.
Das Aufladen erfolgt über USB-C und dauert etwa 2,5 Stunden bis zur vollständigen Ladung. Ein Ladegerät ist wie mittlerweile üblich nicht im Lieferumfang enthalten. Die LED-Anzeige gibt einen groben Überblick über den verbleibenden Akkustand.
Konnektivität und technische Eigenschaften
Der Teufel Rockster Go 2 setzt auf Bluetooth 5.2 für die kabellose Verbindung mit Audioquellen und unterstützt Multipoint-Verbindungen für zwei Geräte gleichzeitig. Bei den unterstützten Codecs beschränkt sich der Lautsprecher auf SBC und AAC, während fortschrittlichere Codecs wie aptX oder LDAC fehlen.
Interessant ist die Doppelfunktion des USB-C-Anschlusses, der nicht nur zum Laden, sondern auch als Audioeingang dient. Eine separate analoge AUX-Buchse gibt es nicht.
Preis: Was kostet der Fender x Teufel Rockster Go 2?
Fazit
Der Teufel Rockster Go 2 in der Fender-Edition ist ein gelungener Bluetooth-Lautsprecher, der soliden Klang mit robuster Bauweise und einem markanten Design verbindet. Die lange Akkulaufzeit von bis zu 28 Stunden und die IP67-Zertifizierung sprechen für ihn. Der ausgewogene Klang mit ansprechender Basswiedergabe überzeugt in den meisten Situationen, auch wenn bei maximaler Lautstärke Verzerrungen auftreten. Als Kritikpunkte sind das Fehlen einer begleitenden App für Equalizer-Einstellungen zu nennen.
Ob der Aufpreis für die Fender-Edition gerechtfertigt ist, hängt letztlich vom persönlichen Geschmack und der Größe des eigenen Geldbeutels ab. Wer Wert auf das markante Aussehen legt, für den kann sich die Fender-Edition lohnen. Wer hingegen rein auf die Funktionalität und ein möglichst gutes Preis-Leistungs-Verhältnis schaut, ist mit der Standardversion des Rockster Go 2 besser bedient.
Beats Pill (2024)
Der Beats Pill (2024) zeigt, dass auch kleine Pillen große Wirkung haben können. Wir testen, ob der kompakte Bluetooth-Lautsprecher die Konkurrenz schluckt.
- kräftiger Sound mit gutem Bass
- 24 Stunden Laufzeit
- wasser- und staubdicht (IP67)
- schickes Design mit Schlaufe
- Schnellladefunktion
- kein Equalizer
- AUX-Eingang fehlt
- Tastenbedienung im Dunkeln schwierig
- Höhen manchmal etwas scharf
Bluetooth-Lautsprecher Beats Pill (2024) im Test
Der Beats Pill (2024) zeigt, dass auch kleine Pillen große Wirkung haben können. Wir testen, ob der kompakte Bluetooth-Lautsprecher die Konkurrenz schluckt.
Der Beats Pill feiert 2024 ein lautstarkes Comeback. Kann die Apple-Tochter mit ihrem 120-Euro-Speaker gegen etablierte Konkurrenten von JBL, Marshall, Bose und Sony bestehen? Wir haben die Musikpille getestet.
Design und Verarbeitung
Die Pillenform bleibt, alles andere wurde modernisiert. In den Farben Mattschwarz, Gold und Rot erhältlich, macht besonders unser rotes Testgerät eine auffällige Figur und gefällt uns richtig gut.
Die abnehmbare Schlaufe und die ergonomische Silikonunterseite machen den 680 Gramm schweren Speaker zum angenehmen Begleiter. Clever: Die 20-Grad-Aufwärtsneigung sorgt für bessere Klangprojektion auf flachen Oberflächen – der Sound landet im Ohr, nicht in der Tischplatte.
Mit IP67-Zertifizierung ist der Pill staubdicht und wasserfest. Strandbesuche oder Poolpartys sind also kein Problem – solange er nicht länger als 30 Minuten auf Tauchstation geht.
Beats Pill 2024 Bilder
Beats PIll 2024

Beats PIll 2024

Beats PIll 2024

Beats PIll 2024

Beats PIll 2024

Beats PIll 2024

Beats PIll 2024

Beats PIll 2024

Wie gut klingt der Beats Pill (2024)?
Der Racetrack-Neodym-Woofer liefert überraschend kräftigen Sound aus dem kompakten Gehäuse. Der Frequenzbereich von 56,6 Hz bis 19,6 kHz ist für diese Größenklasse beachtlich.
Das Klangbild zeigt sich hell, mit sattem Bass und warmen Mitten. Bei manchen Tracks können die Höhen allerdings etwas zu scharf ausfallen.
Mit einer ordentlich hohen maximalen Lautstärke bei erstaunlich geringer Klangverzerrung beschallt der Pill problemlos mittelgroße Räume. Wer es noch lauter mag, kann zwei Pills im Stereo- oder Amplify-Modus koppeln. Ein Bassmonster, etwa für Hip-Hop-Partys, braucht man aber nicht zu erwarten.
Dank integriertem Mikrofon kann man mit der Pille auch telefonieren, auch wenn uns das Gegenüber nur mit etwas Hall versteht.
Bedienung und App
Die Bedienung erfolgt über vier Tasten auf der Oberseite: Ein/Aus (mit Bluetooth-Pairing), eine Multifunktionstaste für Wiedergabe/Pause/Titel-Navigation und zwei Lautstärketasten. Im Dunkeln werden diese allerdings zum Tastratespiel – eine Beleuchtung fehlt.
Apple-typisch gibt es keine separate iOS-App – der Pill integriert sich in die Systemeinstellungen. Dort lassen sich der Name, Anrufsteuerung und Find-My-Funktion anpassen. Android-Nutzer bekommen eine eigene Beats-App mit ähnlichen Funktionen. Ein echter Wermutstropfen: Es fehlt ein einstellbarer Equalizer.
Beats Pill 2024 Screenhsot
Beats PIll 2024 Screenhsot
Beats PIll 2024 Screenhsot
Beats PIll 2024 Screenhsot
Beats PIll 2024 Screenhsot
Beats PIll 2024 Screenhsot
Beats PIll 2024 Screenhsot
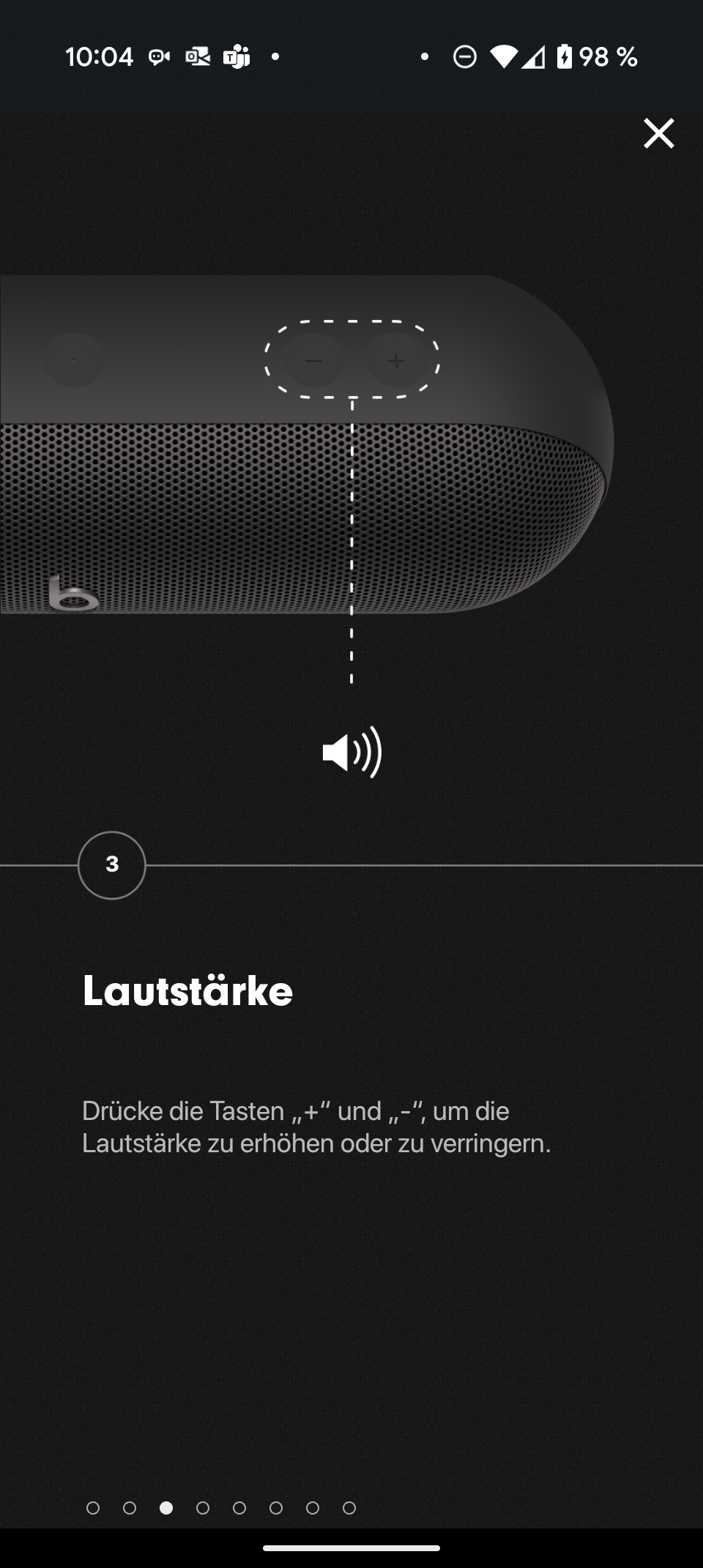
Beats PIll 2024 Screenhsot
Beats PIll 2024 Screenhsot
Beats PIll 2024 Screenhsot

Beats PIll 2024 Screenhsot
Beats PIll 2024 Screenhsot

Beats PIll 2024 Screenhsot

Beats PIll 2024 Screenhsot
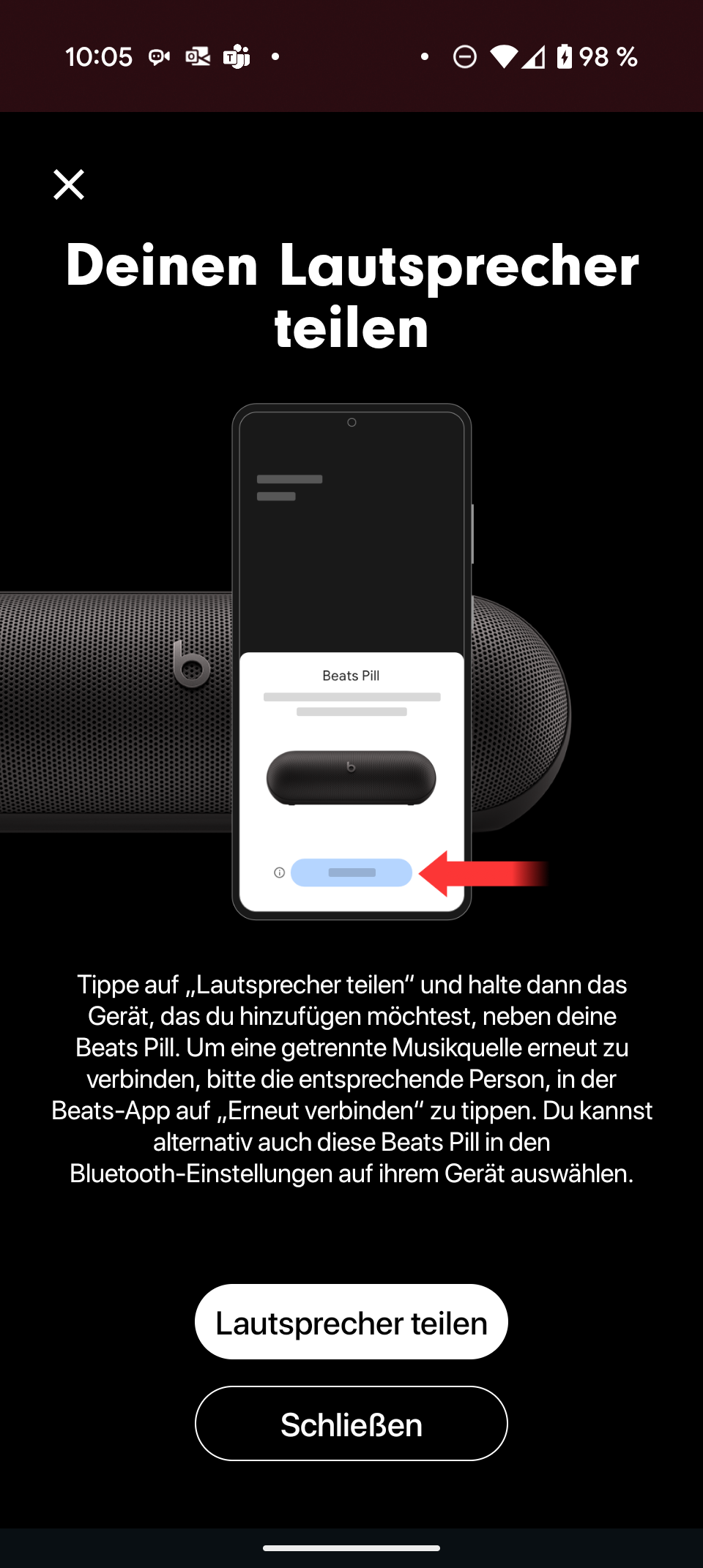
Akku
Mit 24 Stunden Laufzeit bei mittlerer Lautstärke hängt der Pill viele Konkurrenten ab. Eine Schnellladeoption liefert nach 10 Minuten Ladezeit bereits 2 Stunden Musik.
Praktisch: Der USB-C-Anschluss dient nicht nur zum Laden, sondern kann auch als Powerbank für andere Geräte fungieren. Das beiliegende USB-C-Kabel muss allerdings ohne Netzadapter auskommen.
Konnektivität und technische Eigenschaften
Bluetooth 5.3 sorgt für stabile Verbindungen. Der USB-C-Port unterstützt neben dem Laden auch verlustfreies Audio bis 48 kHz/24-Bit. Einen AUX-Eingang sucht man vergeblich.
Bei den Codecs beschränkt sich Beats auf SBC und AAC. aptX oder LDAC bleiben außen vor, was die meisten Nutzer aber kaum bemerken werden.
Preis: Was kostet der Beats Pill (2024)?
Mit einem Straßenpreis von aktuell 111 Euro positioniert sich der Pill im mittleren Preissegment.
Alternativen
Fazit
Der Beats Pill (2024) ist die gelungene Wiedergeburt eines Klassikers. Er vereint kraftvollen Sound, marathonfähigen Akku und robustes Design in einem schicken Paket. Die fehlenden Equalizer-Optionen und der vermisste AUX-Eingang sind kleine Bitterpillen in einer ansonsten runden Medizin. Wer eine Musikpille gegen akute Stille sucht und auf lange Akkulaufzeit Wert legt, ist hier bestens versorgt.
ZUSÄTZLICH GETESTET
Bose Soundlink Micro
Bose Soundlink Micro
Er ist nicht viel größer als zwei Zigarettenschachteln, hat es klanglich aber faustdick unter dem Kunststoff-Deckel: Der ultrakompakte Bose Soundlink Micro verblüfft im Test.
- Guter Klang bei kompakten Maßen
- Sehr gute Verarbeitung
- Hohe Funktionalität
Bose Soundlink Micro im Test
Er ist nicht viel größer als zwei Zigarettenschachteln, hat es klanglich aber faustdick unter dem Kunststoff-Deckel: Der ultrakompakte Bose Soundlink Micro verblüfft im Test.
Vor einigen Jahren setzte Bose mit dem inzwischen in zweiter Generation erschienenen Soundlink Mini Maßstäbe für ein ganzes Marktsegment von mobilen Bluetooth-Boxen. Bei der Größe unterbot man damals sogar den kleinen Bose Sounlink Color 2 (Testbericht) .
Der volle Sound des Sounlink Micro aus kleinem Gehäuse verblüffte seinerzeit selbst Experten. Heute hat man sich dank massivem DSP-Einsatz längst daran gewöhnt, dass man auch Lautsprechern im Bierdosenformat selbst mit einem gewissen Anspruch ohne Ohrenschützer lauschen kann. Grund genug für Bose, mit dem winzigen Soundlink Micro mal wieder für Staunen zu sorgen.
Design und Verarbeitung
Es gab vor dem Bose Soundlink Micro schon einige Lautsprecher in dem relativ jungen Segment, die aber nur halb so viel wie der Bose kosten und entsprechend einfacher gestaltet sind. Doch billig war Bose nie, dafür aber häufig praxisgerecht und von der Performance angemessen. Der 290 Gramm schwere Bluetooth-Lautspecher mit dem Maßen von 9,8 × 9,8 × 3,5 Zentimetern (HxBxT) verfügt über einen Gummi-Strap auf der Rückseite, mit dem er sich am Gürtel oder einer Lenkstange eines Fahrrads oder E-Scooters (Bestenliste) befestigen lässt. Gleichzeitig fungiert der Riemen als Gummipuffer zur Entkopplung des Lautsprechers von der Unterlage und sorgt dafür, dass er bei hohem Pegel nicht gleich herumrutscht.

Das Gehäuse besteht komplett aus Kunststoff und ist wasserdicht nach IPX7. Der Soundlink Micro hingegen hält Wasser nicht nur von außen ab. Bose will sich nicht auf das wasserdichte Gehäuse als einzige Nässeschutz verlassen. Deshalb setzen die Amerikaner auf Materialien wie Silikon, um das Innenleben zusätzlich abzudichten.
Damit der kompakte Mobil-Lautsprecher auch für den bei Bose üblichen guten Klang sorgt, haben ihm seine Entwickler nicht nur einen für die Marke typischen Breitband-Lautsprecher für den gesamten Frequenzbereich unter den Lochgrill gepackt. Ein daneben untergebrachter rechteckiger Passiv-Radiator sorgt zusätzlich für einen Bass-Boost.
Klang

Der Bose Soundlink Micro lieferte trotz seiner sehr kompakten Abmessungen einen satten und natürlichen Klang. Auch was der Micro-Speaker an Dynamik und Klarheit bietet, überrascht uns positiv. Der Bluetooth-Micro-Lautsprecher kann sich klanglich mit mancher Box messen, die in der nächst höheren Größenklasse spielt.
Üblicherweise haben es kleine Lautsprecher bezüglich ihrer maximalen Lautstärke besonders schwer, denn in ihren winzigen Gehäusen lassen sich weniger Treiber unterbringen, die dann auch noch kleiner ausfallen. Doch Boses Breitbänder macht mit ihrem passiven Bass-Radiator einen richtig guten Job, was Stimmvolumen und Dynamik betrifft.

Gerade die Mitten stehen beim Bose nicht auffallend hinter zahlreichen größeren mobilen Bluetooth-Lautsprechern zurück. Hier verfärben andere kleine Bluetooth-Boxen zum Teil deutlich stärker. Der Bass taugte sogar zu einer gewissen Freude an Drums, wobei der Speaker bei genauer Betrachtung nicht wirklich tief in den Keller kommt, was er allerdings mit seiner gelungenen, Abstimmung sehr geschickt überspielt.
Der Klang löst sich auch sehr gut vom Gehäuse und lässt den Bose damit um einiges größer klingen. Dennoch darf man keine Wunder erwarten. Selbst wenn man zwei Soundlink Micro über die Bose Connect App koppelt, wird man damit keine Hip-Hop-Party feiern können. Aber um seinen Sound auf Reisen mitzunehmen, ist Boses Kleinster perfekt geeignet.
Bedienung und Funktionalität

Auf der Schallwandseite des Bose Soundlink Micro gibt es drei Tasten für Lautstärke und Play/Pause. Mit dem Play-Pause-Button in der Mitte lassen sich die Sprach-Assistenten Siri oder Google Assistant aufwecken. Das zu diesem Zweck integrierte Mikrofon ermöglicht obendrein die Annahme von Anrufen über den Lautsprecher.
Der Bose Soundlink Micro spricht mit dem Nutzer und gibt so Feedback zur Bedienung. Das Gerät sagt an, wenn es sich mit einem bestimmten Smartphone verbunden hat oder der Akku fast leer ist. Die fest integrierte Lithium-Ionen-Batterie soll laut Hersteller sechs Stunden durchhalten. Nach unserer Erfahrung ist das nicht übertrieben. Eine seitliche angebrachte Akkuanzeige informiert über den Ladestand. Daneben befindet sich der Ein-/Ausschalter. Der kleine Bluetooth-Speaker bietet damit alles, was man braucht.
Konnektivität

Der Bose Soundlink Micro verfügt über einen Stereo- und einen Party-Modus. Damit lassen sich zwei Bose Soundlink Micro koppeln. Das geht nur mit der kostenlos angebotenen Bose Connect App für Android oder iOS.
Verzichten müssen Bose-Besitzer allerdings auf einen analogen AUX-Eingang. Der einzige mechanische Anschluss ist ein Micro-USB-Port, um das Soundlink Micro über das mitgelieferte Kabel aufzuladen. Dazu muss man sich allerdings ein im Unterhaltungs-Elektronik-Handel separat erhältliches USB-Netzteil zulegen. Schade, dass Bose hier nicht auf dem neuen Standard USB-C setzt.
Preis
Den Bose Soundlink Micro gibt es in den Farben Schwarz, Orange oder Dunkelblau schon ab 80 Euro. Wie die Preisverlaufskurve zeigt, wurde er während des Black Fridays 2020 auch schon für 65 Euro verkauft. Wer ein Schnäppchen machen, der sollte etwas warten.
Fazit
Der Bose Soundlink Micro ist verglichen mit seinen winzigen Abmessungen kein günstiges Angebot. Insofern ergibt seine Anschaffung nur Sinn, wenn Kompaktheit und höchste Mobilität bei der Auswahl im Vordergrund stehen – etwa, wenn man den Bluetooth-Speaker am Fahrradlenker oder am Rucksack befestigen möchte. Zwar kann er es klanglich mit einigen größeren Bluetooth-Lautsprechern aufnehmen, doch so ausgewogen, satt und differenziert wie ein preislich vergleichbarer JBL Flip 5 oder Flip 4 (Testbericht) klingt der Soundlink Micro dann doch nicht, weil ihm hier die Physik Grenzen setzt.
Teufel Motiv Go (Testbericht) ergänzt sehr gut die bestehende Rockster-Serie mit dem Rockster Go als Alternative für Outdoor-Aktive. Klanglich wirkt der kompakte Bluetooth-Speaker für Stubenhocker sehr gelungen. Die Anfassqualität, die sehr stark vom Aluminium-Rahmen des Gehäuses geprägt wird, stimmt ebenfalls. Das serienmäßige Netzteil ist zudem ein nützliches Extra, das man bei vielen Mitbewerbern vergeblich sucht. Dafür gilt es, gewisse Einschränkungen in der Mobilität in Kauf zu nehmen. Der Teufel Motiv Go zielt eher auf heimische Anwendung und lässt sich auch mal in der Reisetasche mitnehmen.
Teufel Motiv Go
Teufel Motiv Go
Der Bluetooth-Lautsprecher Teufel Motiv Go sieht edel aus und verspricht starken Sound im Handtaschenformat. TechStage hat ihn im Testbericht angehört.
- Ausgewogener Klang mit satten Bässen
- Serienmäßiges Netzteil
- Hohe Design- und Verarbeitungsqualität
Teufel Motiv Go im Test
Der Bluetooth-Lautsprecher Teufel Motiv Go sieht edel aus und verspricht starken Sound im Handtaschenformat. TechStage hat ihn im Testbericht angehört.
Teufel ist bekannt dafür, viel Klang zu einem angemessenen Preis zu bieten. Der Teufel Motiv Go will noch mehr: Nämlich richtig gut aussehen. Ob das Konzept aufgeht, zeigt dieser Testbericht. Wem der Motiv Go zu teuer ist, dem empfehlen wir unseren Ratgeber Die besten Bluetooth-Speaker bis 100 Euro . Dort sticht besonders der günstige und kompakte Outdoor-Lautsprecher Tronsmart Element Force (Testbericht) positiv heraus.
Design und Verarbeitung
Während die Bluetooth-Boxen der Rockster-Reihe eher „rustikal“ und poppig wirken, hat Teufel dem Motiv Go einen eleganten, edlen Look mit hochwertigen Metall- und Stoff-Oberflächen gegeben. Dabei sieht zumindest in der silbernen Variante sogar der Stoffgrill auf den ersten Blick nach Metallgitter aus. Der solide Aluminium-Rahmen gibt dem 20 x 11 x 6 Zentimeter großen Lautsprecher Stabilität und sorgt für gute Haptik. Dagegen ist die aus Kunststoff gefertigte Rückseite eher funktionell gestaltet. Das stattliche Gewicht von 900 Gramm spricht allerdings für ordentliche Robustheit.
Die Bedientasten auf der Oberseite des Gehäuses schützt ein Gummiüberzug. Die Anschlüsse sind durch eine Gummi-Klappe geschützt. Durch diese Maßnahmen erfüllt der Teufel Motiv Go die Norm IPX5, ist also gegen Spritzwasser gewappnet. Zwei Dinge dürften einige vermissen: Eine Trageschlaufe und eine bessere Kennzeichnung der Tasten, die gerade bei der schwarzen Gehäusevariante nicht gut zu erkennen sind.

Positiv hervorzuheben ist dagegen das serienmäßige Netzteil. Andere legen in dieser Klasse meist nur USB-Kabel bei. In der Summe ist der Teufel Motiv Go eher für häuslichen Einsatz konzipiert. Wer sich viel draußen aufhält und dabei nicht auf seine Songs verzichten mag, ist mit der Rockster-Serie, zum Beispiel mit dem Rockster Go besser bedient. Auch den Dockin D Fine (Testbericht) können wir dafür empfehlen.
Der Teil des Teufel Motiv Go, den man nicht sieht, ist ebenfalls eine Betrachtung wert. Teufel setzt auf ein Stereo-Konzept mit je einem 5-Zentimeter-Breitband-Lautsprecher mit steifer, leichter Aluminium-Membran für den linken und den rechten Kanal. Dazu kommt je ein nach vorne und nach hinten gerichteter Passiv-Radiator für mehr Druck im Bass. Hinter dem Begriff Dynamore versteckt sich ein Raumklang-Verfahren der Boxen-Bauer, die dem kleinen Motiv Go zu einer bemerkenswerten Räumlichkeit verhilft.
Hier im Preisvergleich zeigen wir die aktuell beliebtesten Teufel-Lautsprecher mit Akku:
Klang
Es sind die Bässe, die im Hörtest des Teufel Motiv Go besonders herausstechen. Im Angesicht des relativ kleinen Gehäuses wachsen sie stark über sich hinaus. Der Bluetooth-Speaker klingt nicht nur satt am unteren Ende des Frequenzspektrums, sondern auch sauber und differenziert. Das bedeutet allerdings keineswegs, dass der Teufel nur Bass kann, doch die natürlich abgestimmten Mitten und Höhen traut man einem solchen Gerät eher zu als die satten, konturierten Bässe. So macht Rockmusik richtig Freude und auch die Freunde von Hip-Hop dürften in dieser Klasse kaum etwas Eindrucksvolleres finden. Daran haben auch die frischen, aber keinesfalls scharfen Höhen einen Anteil.
Das Konzept des Motiv Go setzt zwar auf zwei Kanäle. Jedoch sollte man prinzipbedingt von zwei nur wenige Zentimeter auseinanderliegenden Lautsprecher-Chassis keine richtige Stereo-Wiedergabe erwarten. Gewöhnlich jedenfalls. Wenn die Dynamore-Funktion aktiviert ist, kommt man – die richtige Musik vorausgesetzt – nicht aus dem Staunen heraus.
Sorgt die Funktion mit normalen Pop-Songs lediglich für eine etwas breitere Klangwolke und die Illusion eines etwas größeren Lautsprechers, gelingt ihr mit „Money 2001 Remastered“ von Pink Floyd ein verblüffendes Stereo-Spektakel: Das Geld-Geklimper und Slot-Maschinen-Geräusche scheinen stabil ortbar links und rechts neben dem Gehäuse zu stehen.
Was ebenfalls positiv auffällt: Trotz des erweiterten Klangpanoramas wirkt das Klangbild nicht zu verwaschen und diffus. Ein hohes Maß an Präzision bleibt bewahrt. Deshalb würden wir den Dynamore-Effekt bei den meisten Aufnahmen eingeschaltet lassen.
Unabhängig von der Räumlichkeit überzeugt der Bluetooth-Speaker durch einen weiten Übertragungsbereich und eine hohe Homogenität. Die beflügelt wie sein Auflösungsvermögen gerade die Stimmwiedergabe, auf deren Natürlichkeit man in dieser Gerätegattung noch weniger verzichten mag als auf satte Bässe. Die hohen Dynamik-Reserven lassen den Teufel Motiv Go ohne Zeichen von Anstrengung verblüffend laut spielen. In der Summe ergibt sich daraus das Bild eines in seinem Umfeld fast schon konkurrenzlos gut abgestimmten Lautsprechers, der zumindest als Hintergrundbeschallung in kleinen und mittelgroßen Räumen eine ganze Stereo-Anlage ersetzen kann.

Bedienung und Funktionalität
Das Tastenfeld auf der Oberseite ist zwar nicht gut gekennzeichnet, aber grundsätzlich praktisch. Die zentrale Taste startet und stoppt die Wiedergabe des via Bluetooth gekoppelten Geräts. Links und rechts daneben sitzen die Tasten für Titelsprung rückwärts und vorwärts. Auch die Lautstärke lässt sich auf der Oberseite regeln und es gibt eine Taste zum Einschalten der Dynamore-Raumklang-Funktion. Den Button zum Bluetooth-Pairing hat Teufel auf der rechten Seite versteckt, doch braucht man die Funktion nur beim ersten Verbindungsaufbau. Danach klappt das Ganze schließlich automatisch.
Das integrierte Freisprechmikrofon ermöglicht freihändige Telefongespräche. Die Nutzung von Apple Siri oder Google Assistant ist damit ebenfalls möglich. Durch einen langen Druck auf die Play/Pause-Taste tritt der Sprachassistent in Aktion.
Der eingebaute Lithium-Ionen-Akku hält in der Praxis je nach Lautstärke mehr als zehn Stunden und ist mit dem beigelegten Netzteil nach drei bis vier Stunden wieder aufgeladen. Zur Verlängerung der Akkulaufzeit, schaltet sich der Teufel Motiv Go nach 20 Minuten Inaktivität automatisch ab.
Konnektivität

Der Teufel Motiv Go nutzt Bluetooth 5.0 mit dem AptX-Codec. Zwei Smartphones können sich im Party-Modus gleichzeitig mit dem Smart Speaker verbinden, um zwei „DJ“ die Musik auswählen zu lassen. Dank niedriger Latenzzeit wird Videoton auch im Wireless-Betrieb von Youtube oder von Smartphone-Games Lippen-synchron übertragen. Wer den seitlich unter einer Klappe verborgenen AUX-Eingang mit 3,5-mm-Mini-Klinke nutzt, kennt dieses Problem aber ohnehin nicht. Unter der Gummiabdeckung findet sich auch der Netzteil-Anschluss. Eine USB-Lademöglichkeit ist nicht vorgesehen.
Preis
Der Teufel Motiv Go kostet in den Farben Schwarz und Weiß gut 240 Euro. Da der Lautsprecher noch recht neu ist, gab es ihn bisher noch nicht günstiger. Überhaupt sind Teufel-Lautsprecher vergleichsweise preisstabil, da sie nur direkt vertrieben werden, Teufel hier also die volle Preiskontrolle hat.
Fazit
Der Teufel Motiv Go ergänzt sehr gut die bestehende Rockster-Serie mit dem Rockster Go als Alternative für Outdoor-Aktive. Klanglich wirkt der kompakte Bluetooth-Speaker für Stubenhocker sehr gelungen. Die Anfassqualität, die sehr stark vom Aluminium-Rahmen des Gehäuses geprägt wird, stimmt ebenfalls. Das serienmäßige Netzteil ist zudem ein nützliches Extra, das man bei vielen Mitbewerbern vergeblich sucht. Dafür gilt es, gewisse Einschränkungen in der Mobilität in Kauf zu nehmen. Der Teufel Motiv Go zielt eher auf heimische Anwendung und lässt sich auch mal in der Reisetasche mitnehmen.
JBL Flip 5
JBL Flip 5
Der JBL Flip 5 ist die aktuellste Auflage des Serien-Bestsellers unter den Bluetooth-Lautsprechern. Wir zeigen im Test, ob sch der Kauf des JBL Flip 5 lohnt.
- Ausgewogener Klang mit sattem Bass
- Trageriemen
- IPX7 Wasserdichtigkeit
JBL Flip 5 im Test
Der JBL Flip 5 ist die aktuellste Auflage des Serien-Bestsellers unter den Bluetooth-Lautsprechern. Wir zeigen im Test, ob sch der Kauf des JBL Flip 5 lohnt.
Der Vorgänger JBL Flip 4 hat sich zehn Millionen mal verkauft. Das macht die Bluetooth-Boxen-Serie der zum Harman-Konzern gehörenden Kult-Marke JBL zum Platzhirsch im ganzen Segment. In der fünften Auflage lassen sich die Amerikaner etwas „Neues“ einfallen: Sie wechseln von Stereo auf Mono. Auch wenn es verwundert: Das ist smarter, als es scheint. Warum das so ist und vieles mehr zum Klang des JBL Flip 5 zeigen wir in unserem Testbericht.
Design und Verarbeitung
In den Abmessungen wächst der Flip 5 gegenüber dem Vorgänger Flip 4 (Testbericht) von 7 × 17,5 × 6,8 Zentimeter auf 7,4 × 18,1 × 6,9 Zentimeter (H × B × T). Das Gewicht liegt bei 540 Gramm, was kaum einen Unterschied macht. Die Gehäusegestaltung und die Materialien bleiben beim Modellwechsel erhalten. Stoßgefährdete Stellen werden durch gummiartigen Polymerkunststoff geschützt, der Mittelteil hüllt sich in ein robustes Mesh-Gewebe.
Die größte Neuerung betrifft die Treiber-Konfiguration: Arbeitete der JBL Flip 4 noch mit zwei nach vorne gerichteten Breitband-Lautsprechern, die Unterstützung durch zwei passive Bass-Radiatoren auf beiden Seiten seines runden Gehäuses erhalten, vertrauen die Entwickler im Flip 5 auf einen einzelnen, nach vorne gerichteten ovalen Racetrack-Treiber. Auf den ersten Blick ist der Wechsel von Stereo auf Mono zumindest auf dem Papier ein Nachteil. Dabei besteht bei zwei dicht in dem an eine Coladose erinnernden Gehäuse nebeneinander sitzende Treibern die Gefahr von gegenseitigen Schallauslöschungen. Richtiges Stereo durfte man von dem kleinen Zylinder ohnehin nie erwarten, dazu ist der Abstand der beiden Kanäle einfach viel zu gering.
Obwohl die Akkukapazität beim Modellwechsel von 3000 auf 4800 mAh steigt, liegt die Akkulaufzeit beim Flip 5 wie bisher bei bei zehn bis zwölf Stunden. Hier fordert die auf 20 Watt gesteigerte Ausgangsleistung mit dem entsprechend höheren Strombedarf ihren Tribut. Wasserdichtigkeit nach IPX7 bedeutet, dass man den Lautsprecher sogar ins Wasser werfen kann. Man soll den JBL Flip 5 sogar zwei Meter tief im Pool eintauchen dürfen.
Das Design des in elf Farben lieferbaren Bluetooth-Speakers lässt sich kaum vom Vorgänger unterscheiden. Allerdings gibt es jetzt gegen einen Aufpreis die JBL Flip 5 Eco Edition aus bis zu 90 Prozent recyceltem Kunststoff in den bezeichnenden Farben Ocean Blue und Forest Green.
Ungeachtet äußerlicher Ähnlichkeiten gibt es über die Mono-Masche hinaus Änderungen. Die Freisprechfunktion des Flip 4 fiel dem Modellwechsel zum Opfer. Mit dem Flip 5 lassen sich keine Anrufe mehr entgegennehmen. Damit hat sich auch das Aufrufen der Sprach-Assistenten Siri oder Google Assistant auf dem Smartphone erübrigt. Der analoge AUX-Eingang wurde ebenfalls gestrichen.
Was das mitgelieferte Zubehör betrifft, gibt es nur das Nötigste: Ein USB-C-Ladekabel – allerdings wie mittlerweile üblich ohne Netzteil – liegt bei, den praktischen Trageriemen hat JBL vormontiert. Pfiffig: Die aufklappbare Innenverpackung bestehend aus schwarzem Styropor lässt sich als Transportbox verwenden – eine kreative Maßnahme zur Abfallvermeidung.
Bedienung und Funktionalität
Die gummierten Tasten zur Lautstärkeregelung, Start/Stop/Skip Forward und zum Verbinden von beliebig vielen Flips über Party-Boost sind leider bei unserem Testmuster in Tarnfarbe noch schlechter als bisher zu erkennen. Sie sitzen direkt auf dem umlaufenden Mesh-Gewebe der Schallwand. Auf der Oberseite des für liegenden und stehenden Betrieb konzipierten Gehäuses gibt es ein Tastenfeld mit dem Einschaltknopf und dem Button fürs Pairing mit dem Smart-Device. Grundsätzlich kann man die Bedienung als „narrensicher“ bezeichnen.
Konnektivität
Connect+ ist beim JBL Flip 5 Geschichte. Das bedeutet vom Funktionsumfang aber keinen Rückschritt. Mit der neuen Party-Boost-Funktion können User mehrere hundert JBL Flip per Bluetooth miteinander synchronisieren. Damit lässt sich eine richtige kleine PA-Anlage für große Feiern aufbauen. Einen Haken hat der Fortschritt aber: Mit dem neuen Verfahren kann man alte und neue Flips nicht gemeinsam betreiben. Party-Boost funktioniert nur mit aktuellen Bluetooth-Lautsprechern von JBL. Mit der kostenlosen JBL App für iOS oder Android kann man immerhin der Mono-Tonie des neuen JBL-Konzepts entkommen. Mit ihr lassen sich zwei Flip 5 zum Stereo-Paar verbinden. Das funktioniert nur mit Bluetooth.
Klang
Im Klang macht die vierte Generation des Bluetooth-Bestsellers noch mal einen Schritt nach vorn. Ihr vergrößertes Gehäusevolumen sorgt gemeinsam mit der neuen Treiber-Technik und einer optimierten Abstimmung für eine noch ausgewogenere und sattere Performance. Da wirkt der JBL Flip 4 im direkten Vergleich fast schon dünn und spitz.
Der Treiber-Wechsel bringt allerdings auch einen kleinen Nachteil mit sich. Er richtet durch seine breitere, ovale Membran die Wiedergabe stärker nach vorne aus. Den früheren Flip konnte man auch von der Seite und selbst von hinten ohne wesentliche Klangnachteile hören. Dagegen klingt der Flip 5 direkt von vorne merklich besser als aus allen anderen Richtungen. Der JBL Flip 5 folgt also nicht dem Trend zu omnidirektionaler Abstrahlung wie beispielsweise der Bose Portable Home Speaker (Testbericht) .
Bei der Aufstellung sollte man daher auf die Ausrichtung achten. Dann liefert der JBL Flip 5 die bessere Klangwiedergabe. Der 5er musiziert relaxter und voluminöser mit einem besserem Fundament im Bass.
Damit macht Rockmusik mit akustischem Schlagzeug genauso viel Freude wie elektronische Beats. Der gesamte Bassbereich wirkt souveräner und gehaltvoller als mit dem Vorgänger. Die Bassgewalt drängt erfreulicherweise Gesangsstimmen nicht in den Hintergrund. Dazu kommen frische, aber keinesfalls scharfe Höhen. All das lässt den JBL Flip 5 souveräner als je zuvor erscheinen. Die Bestseller-Story kann also ungebremst weitergehen.
Preis
Der JBL Flip 5 kostet in elf bunten Farben unter 100 Euro. Da der Bestseller schon länger im Programm ist, kostet er nicht viel mehr als mancher No-Name. Durch die große Verbreitung entsteht ein Wettbewerb, der die Preise drückt.
Fazit
Der nun etwas teurere JBL Flip 5 profitiert von der langen Erfahrung, die ihn zum Bestseller machte. Das gilt nicht nur für den Klang, sondern auch für die Funktionalität. Vom Trageriemen über die gute Bedienung und Wasserdichtigkeit bis zur Möglichkeit, ganze Hundertschaften drahtlos als Party-Beschallung zusammenzuschließen, hat JBL den Flip 5 perfekt auf seine junge, aktive Zielgruppe zugeschnitten.
Anker Soundcore Boom 3i
Anker Soundcore Boom 3i
Die Anker Soundcore Boom 3i schwimmt im Salzwasser, bietet einen kräftigen Bass, eine tolle App und eine schicke RGB-Beleuchtung. Wir machen den Test.
- schwimmt im Salzwasser
- kräftiger Bass
- Gute App mit Equalizer
- Preis-Leistungs-Verhältnis
- Bass teilweise zu heftig
- keine Tastenbeleuchtung
- Kein AUX-Eingang
Soundcore Boom 3i im Test: Bluetooth-Lautsprecher schwimmt auch in Salzwasser
Die Anker Soundcore Boom 3i schwimmt im Salzwasser, bietet einen kräftigen Bass, eine tolle App und eine schicke RGB-Beleuchtung. Wir machen den Test.
Anker hat mit der Soundcore-Serie bereits mehrfach bewiesen, dass gute Bluetooth-Lautsprecher nicht teuer sein müssen. Der neue Soundcore Boom 3i tritt nun mit einem Preis von 90 Euro gegen etablierte Outdoor-Speaker wie den JBL Flip 6 oder den Sony Ult Field 1 an. Das Besondere: Der Lautsprecher schwimmt nicht nur, sondern ist sogar salzwasserresistent. Mit 50 Watt Leistung, RGB-Beleuchtung und IP68-Zertifizierung verspricht der Boom 3i ein echter Allrounder für Strand, Pool und Festival zu sein. Was der Speaker kann, zeigt dieser Testbericht.
Design und Verarbeitung des Anker Soundcore Boom 3i
Der Soundcore Boom 3i fällt auf. Erhältlich in Schwarz, Blau, Rose und Grün, sticht besonders unsere giftgrüne Testvariante aus der Masse der schwarzen Speaker heraus. Die blauen Elemente an den Seiten, die blaue Aufhängung für die Trageschlaufe und das blaue Soundcore-Logo an der Front verleihen dem Speaker einen hohen Wiedererkennungswert und eine moderne, Lifestyle-orientierte Optik.
Mit Abmessungen von 21 × 8,5 × 7,85 cm passt der Lautsprecher problemlos in jeden Rucksack. Das Rugged-Design mit robuster Gitterabdeckung signalisiert sofort: Dieser Speaker ist für den Outdoor-Einsatz konzipiert. Die Verarbeitung überzeugt – nichts klappert oder wackelt, alles sitzt fest und stabil.
Soundcore Boom 3i Bilder
Soundcore Boom 3i

Soundcore Boom 3i

Soundcore Boom 3i

Soundcore Boom 3i

Soundcore Boom 3i

Soundcore Boom 3i

Soundcore Boom 3i

Soundcore Boom 3i

Soundcore Boom 3i

Soundcore Boom 3i

Soundcore Boom 3i

Der Boom 3i schwimmt. Fällt er in den Pool oder See, geht er nicht unter und spielt sogar weiter. Die IP68-Zertifizierung schützt ihn gegen das Eindringen von Staub und Wasser. Eine Besonderheit ist die Salzwasserresistenz – eine Eigenschaft, die selbst teurere Konkurrenten oft vermissen lassen. Der Speaker soll zudem Stürze überstehen und sich so für Outdoor-Aktivitäten wie Kajakfahren, Strandausflüge oder Camping eignen.
An den Seiten sitzen die mit RGB-LEDs beleuchteten Passivradiatoren, die synchron zur Musik pulsieren. Sechs dynamische und vier statische Effekte stehen zur Auswahl, die Helligkeit ist anpassbar. Die mitgelieferte Trageschlaufe ermöglicht das bequeme Tragen über der Schulter. Allerdings ist sie recht lang, wir hätten uns zusätzlich eine kurze Trageschlaufe gewünscht.
Wie gut ist der Klang des Anker Soundcore Boom 3i?
Mit 50 Watt Ausgangsleistung, aufgeteilt auf einen kräftigen Woofer und einen separaten Tweeter, liefert der Boom 3i einen beeindruckenden Sound für seine Preisklasse. Der Frequenzbereich reicht tief hinab und sorgt für satten Bass, während die Höhen klar und präzise wiedergegeben werden.
Die Bassup-Funktion verstärkt die tiefen Frequenzen zusätzlich und sorgt für mächtig Druck. Bei manchen Tracks kann der Bass allerdings zu dominant werden und bei maximaler Lautstärke leicht verzerren. Ohne Bassup zeigt sich ein ausgewogeneres Klangbild, das sich über den 9-Band-Equalizer in der App an persönliche Vorlieben anpassen lässt.
Der Mono-Sound des einzelnen Lautsprechers reicht für die meisten Anwendungen aus. Bei basslastiger Musik entfaltet der Boom 3i sein volles Potenzial, während Podcasts eine Anpassung per Equalizer erfordern, um Stimmen optimal zu verstehen.
Zwei Boom 3i lassen sich per TWS (True Wireless Stereo) zu einem Stereopaar koppeln – dafür muss man die entsprechende Taste zwei Sekunden gedrückt halten. Die Partycast-Funktion synchronisiert bis zu 100 kompatible Soundcore-Lautsprecher, inklusive der Lichteffekte. Die Custom-Equalizer-Einstellungen sind per QR-Code an gekoppelte Boxen übertragbar.
Der Boom 3i setzt auf Bluetooth 5.3 mit einer Reichweite von bis zu 30 Metern. Einen AUX-Eingang oder andere kabelgebundene Anschlüsse sucht man vergebens. High-Res-Codecs wie aptX oder LDAC fehlen.
Hält man die Bassup-Taste fünf Sekunden gedrückt, ertönt ein lauter, durchdringender Notfallalarm – wirklich nur für echte Notfälle gedacht.
Bedienung und App des Anker Soundcore Boom 3i
Die Bedienung erfolgt über acht Tasten auf der Oberseite: Power, Bluetooth-Pairing, Lautstärke, Play/Pause, Lightshow, Partycast und Bassup. Eine Tastenbeleuchtung fehlt, die Tasten sind aber auch im Dunkeln gut zu ertasten.
Die Soundcore-App für iOS und Android ist übersichtlich gestaltet und überraschend umfangreich. Vier voreingestellte EQ-Profile (Soundcore Signature, Höhenverstärkung, Stimme, Ausgewogen) stehen zur Verfügung, eigene Profile lassen sich über den 9-Band-Equalizer erstellen.
Soundcore Boom 3i Screenshot
Soundcore Boom 3i Screenshot
Soundcore Boom 3i Screenshot
Soundcore Boom 3i Screenshot
Soundcore Boom 3i Screenshot

Soundcore Boom 3i Screenshot
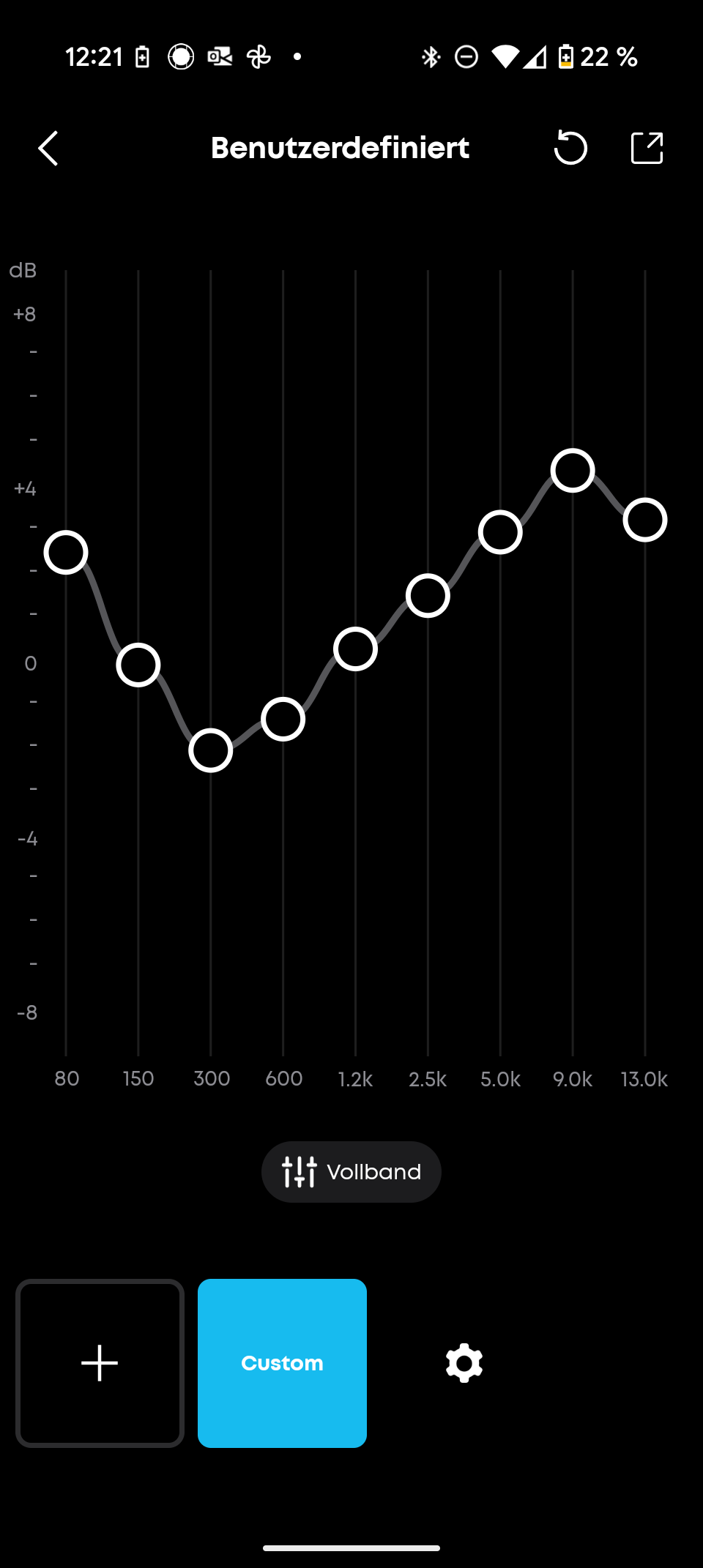
Soundcore Boom 3i Screenshot
Soundcore Boom 3i Screenshot
Soundcore Boom 3i Screenshot
Soundcore Boom 3i Screenshot
Soundcore Boom 3i Screenshot
Soundcore Boom 3i Screenshot
Soundcore Boom 3i Screenshot
Soundcore Boom 3i Screenshot
Kuriose Features wie die „Buzz Clean“-Funktion, die durch eine Bassschleife Schmutz entfernen soll (funktioniert in der Praxis kaum), die White-Noise-Funktion mit großer Soundauswahl oder der Voice Amplifier, der Stimmen über den Lautsprecher wiedergibt, sind eher Spielerei.
Die App zeigt außerdem den Batteriestatus an, ermöglicht Firmware-Updates und erlaubt die Feineinstellung von Auto-Off (standardmäßig nach 20 Minuten Inaktivität), Partycast und Lichtshow. Insgesamt eine sehr gelungene App, die kaum Wünsche offen lässt.
Der Akku des Anker Soundcore Boom 3i
Der 2400-mAh-Akku hält bis zu 16 Stunden bei 50 Prozent Lautstärke – allerdings nur ohne Bassup und Lichteffekte. Mit aktivierter Beleuchtung und höherer Lautstärke reduziert sich die Laufzeit merklich. Das Laden dauert etwa vier Stunden über USB-C (5V/3A). Der Ladestatus wird durch LEDs angezeigt: rot blinkend bei niedrigem Akkustand, rot beim Laden, weiß bei voller Ladung. Ein Ladekabel liegt bei, ein Netzteil jedoch nicht.
Was kostet der Anker Soundcore Boom 3i?
Mit einem Preis von 90 Euro bei Amazon positioniert sich der Soundcore Boom 3i im unteren Preissegment für Outdoor-Bluetooth-Lautsprecher. Der JBL Flip 6 kostet nur minimal mehr, bietet aber weniger Features. Der Sony Ult Field 1 liegt preislich ähnlich, schwimmt aber nicht und hat keine RGB-Beleuchtung. Für die gebotene Ausstattung mit IP68-Schutz, Salzwasserresistenz, 50 Watt Leistung und umfangreicher App ist der Preis äußerst attraktiv.
Fazit
Der Anker Soundcore Boom 3i ist eine Preis-Leistungs-Empfehlung im hart umkämpften Markt der Outdoor-Bluetooth-Lautsprecher. Für 90 Euro erhält man einen robusten, schwimmfähigen Speaker mit kräftigem 50-Watt-Sound und schicker RGB-Beleuchtung. Die Salzwasserresistenz und IP68-Zertifizierung bieten ihn für Strand und Pool an.
Klanglich spielt der Boom 3i in seiner Preisklasse recht weit vorn mit. Der kräftige Bass und die klaren Höhen überzeugen, auch wenn die Bassup-Funktion manchmal zu viel des Guten ist. Die umfangreiche App mit 9-Band-Equalizer bietet viele Spielereien.
Wer einen vielseitigen, robusten Outdoor-Lautsprecher zum fairen Preis sucht, macht mit dem Soundcore Boom 3i definitiv nichts falsch.
Sonos Roam 2
Sonos Roam 2
Der kompakte Lautsprecher Sonos Roam 2 vereint Bluetooth-Mobilität mit Sonos-Box, muss sich aber starker Konkurrenz stellen.
- Sonos-Ökosystem
- Trueplay
- Bluetooth-Button
- IP67-zertifiziert
- Alexa und Sonos Voice
- Akkulaufzeit
- kein Equalizer
- teuer
Sonos Roam 2 im Test: Kleiner Bluetooth-Lautsprecher mit Multiroom überzeugt
Der kompakte Lautsprecher Sonos Roam 2 vereint Bluetooth-Mobilität mit Sonos-Box, muss sich aber starker Konkurrenz stellen.
Sonos steht für hochwertige Multiroom-Systeme und guten Klang. Mit dem Roam 2 zeigt der Hersteller die zweite Generation seines kompaktesten Smart-Speakers. Für 159 Euro verspricht der dreieckige Klangzylinder eine Symbiose aus mobilem Bluetooth-Lautsprecher und vollwertigem Sonos-Speaker fürs Heimnetzwerk.
Die wichtigste Neuerung gegenüber dem Vorgänger Sonos Roam 1 (Testbericht): Ein eigener Bluetooth-Button ermöglicht ein einfaches Pairing mit beliebigen mobilen Geräten. Damit reagiert Sonos auf Kritik am umständlichen Setup des ersten Roam. Wir testen, ob das reicht, um gegen die etablierte Konkurrenz zu bestehen. Der Bluetooth-Lautsprecher wurde uns von Sonos zur Verfügung gestellt.
Design und Verarbeitung des Sonos Roam 2
Mit seinen Maßen von 168 × 62 × 60 mm bleibt der Roam 2 ein Winzling im Sonos-Portfolio. Das dreieckige Zylinderdesign mit abgerundeten Kanten wirkt modern und zeitlos zugleich. Unser mattrotes Testmodell macht optisch richtig was her. Insgesamt stehen fünf Farbvarianten zur Auswahl: Schwarz, Weiß, Grün, Rot und Blau. Das einfarbige Finish mit farblich passendem Logo wirkt im Vergleich zum Vorgänger moderner, bleibt aber optisch sehr ähnlich.
Die perforierte Front besteht aus Metall und verleiht dem 430 Gramm schweren Speaker Stabilität. Die Seiten sind mit weichem Kunststoff überzogen, der sich hochwertig anfühlt. Kleine Gummifüßchen sorgen für sicheren Stand, egal ob der Lautsprecher senkrecht oder flach positioniert wird. Diese Flexibilität ermöglicht die Anpassung an verschiedene Umgebungen – vom Badezimmerregal bis zum Campingplatz.
Die IP67-Zertifizierung macht den Roam 2 staubdicht und wasserfest. Er übersteht damit 30 Minuten in einem Meter Wassertiefe. Kombiniert mit der robusten Bauweise eignet er sich so für Outdoor-Aktivitäten wie Strandbesuche oder Wanderungen. Im Vergleich zum ersten Roam gibt es bei der Materialqualität keine Verbesserungen – die war bereits beim Vorgänger tadellos.
Sonos Roam 2 Bilder
Sonos Roam 2

Sonos Roam 2

Sonos Roam 2

Sonos Roam 2

Sonos Roam 2

Sonos Roam 2

Sonos Roam 2

Sonos Roam 2

Sonos Roam 2

Sonos Roam 2

Sonos Roam 2

Wie gut ist der Klang des Sonos Roam 2?
Im kompakten Gehäuse des Roam 2 arbeiten ein Hochtöner und ein Mitteltöner, welche für die Größe einen erstaunlich ausgewogenen Sound liefern. Der Mono-Lautsprecher lässt sich mit einem zweiten Roam zu einem Stereopaar koppeln. Der Frequenzbereich wird von Sonos nicht spezifiziert, in der Praxis liefert der Speaker aber klare Höhen und für seine Gewichtsklasse satten Bass.
Das automatische oder manuelle Trueplay passt den Klang an die Umgebung an. Steht die Box im Regal, ist der Unterschied spürbar – die Software kompensiert Reflexionen und Resonanzen. Bei freier Aufstellung im Raum fällt der Effekt marginal aus. Diese Funktion unterscheidet Sonos von der Konkurrenz: Während andere Hersteller auf statische Klangprofile setzen, optimiert sich der Roam 2 selbstständig.
Für kleine Räume reicht die Lautstärke aus. Bei maximaler Lautstärke zeigen sich allerdings Verzerrungen – hier stößt die Physik an ihre Grenzen. Der Bass wirkt in großen Räumen schwach, was angesichts des geringen Gewichts nicht überrascht. Im direkten Vergleich mit dem JBL Flip 6 liefern beide ähnliche Klangqualität, wobei der JBL etwas mehr Bass bietet.
Die Klarheit übertrifft die Erwartungen: Podcasts und Hörbücher profitieren von der präzisen Stimmwiedergabe. Bei Musik zeigt sich der Roam 2 vielseitig – von Jazz über Pop bis Elektro meistert er alle Genres souverän. Im Vergleich zum ersten Roam hat sich klanglich nichts verändert. Die identische Audio-Hardware liefert denselben Sound.
Bedienung und App des Sonos Roam 2
Die größte Verbesserung gegenüber dem Vorgänger: Der neue Bluetooth-Button ermöglicht Out-of-the-Box-Pairing ohne App-Zwang. Diese scheinbar kleine Änderung verbessert die Nutzung als mobiler Bluetooth-Lautsprecher erheblich. Die mit weichem Kunststoff überzogenen, aber unbeleuchteten Tasten für Play/Pause, Lautstärke und Track-Skip lassen sich auch im Dunkeln gut ertasten. Eine separate Mikrofon-Taste aktiviert die Sprachsteuerung via Amazon Alexa oder Sonos Voice – beide Assistenten funktionieren zuverlässig.
Die Sonos-App für iOS und Android bietet umfangreiche Funktionen: Das automatische Trueplay kalibriert den Klang, ein manuelles Trueplay steht auch Android-Nutzern zur Verfügung. Sleep-Timer, Alarme und die Integration von Streaming-Diensten wie Spotify, Apple Music und Sonos Radio runden das Angebot ab. Die nahtlose Integration ins Sonos-Ökosystem, auch als Surround-Lautsprecher, funktioniert bei stabilem Netzwerk tadellos. Der Roam 2 wechselt automatisch zwischen Bluetooth und WLAN – verlässt man mit ihm das Haus, schaltet er selbstständig auf Bluetooth um.
Ein Equalizer fehlt. Apple-Nutzer freuen sich über Airplay-2-Unterstützung für direktes Streaming vom iPhone oder iPad.
Sonos Roam 2 Screenshot
Sonos Roam 2 Screenshot
Sonos Roam 2 Screenshot
Sonos Roam 2 Screenshot
Sonos Roam 2 Screenshot
Sonos Roam 2 Screenshot
Sonos Roam 2 Screenshot
Sonos Roam 2 Screenshot
Sonos Roam 2 Screenshot
Sonos Roam 2 Screenshot
Sonos Roam 2 Screenshot
Sonos Roam 2 Screenshot

Sonos Roam 2 Screenshot
Sonos Roam 2 Screenshot
Sonos Roam 2 Screenshot
Sonos Roam 2 Screenshot
Sonos Roam 2 Screenshot
Sonos Roam 2 Screenshot
Sonos Roam 2 Screenshot
Sonos Roam 2 Screenshot
Sonos Roam 2 Screenshot
Sonos Roam 2 Screenshot
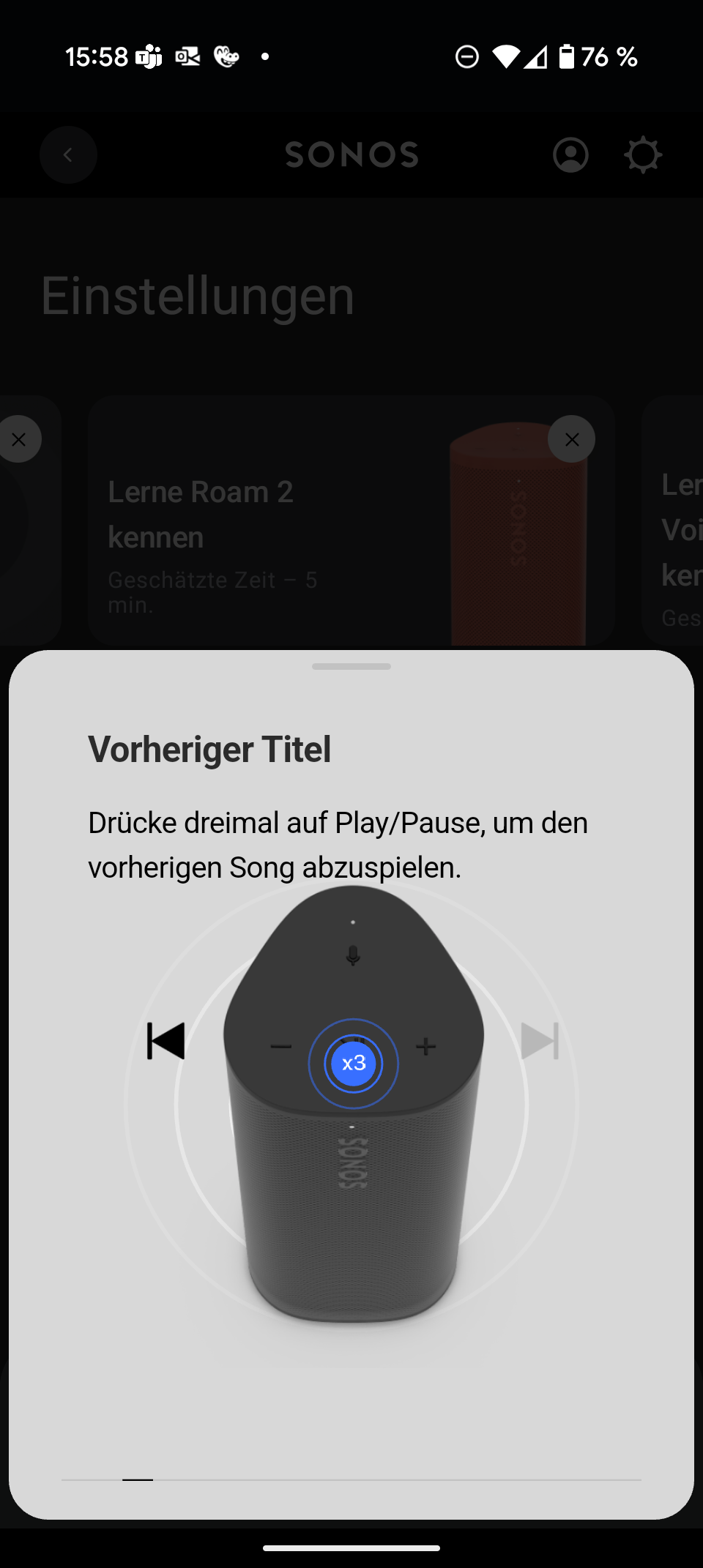
Sonos Roam 2 Screenshot
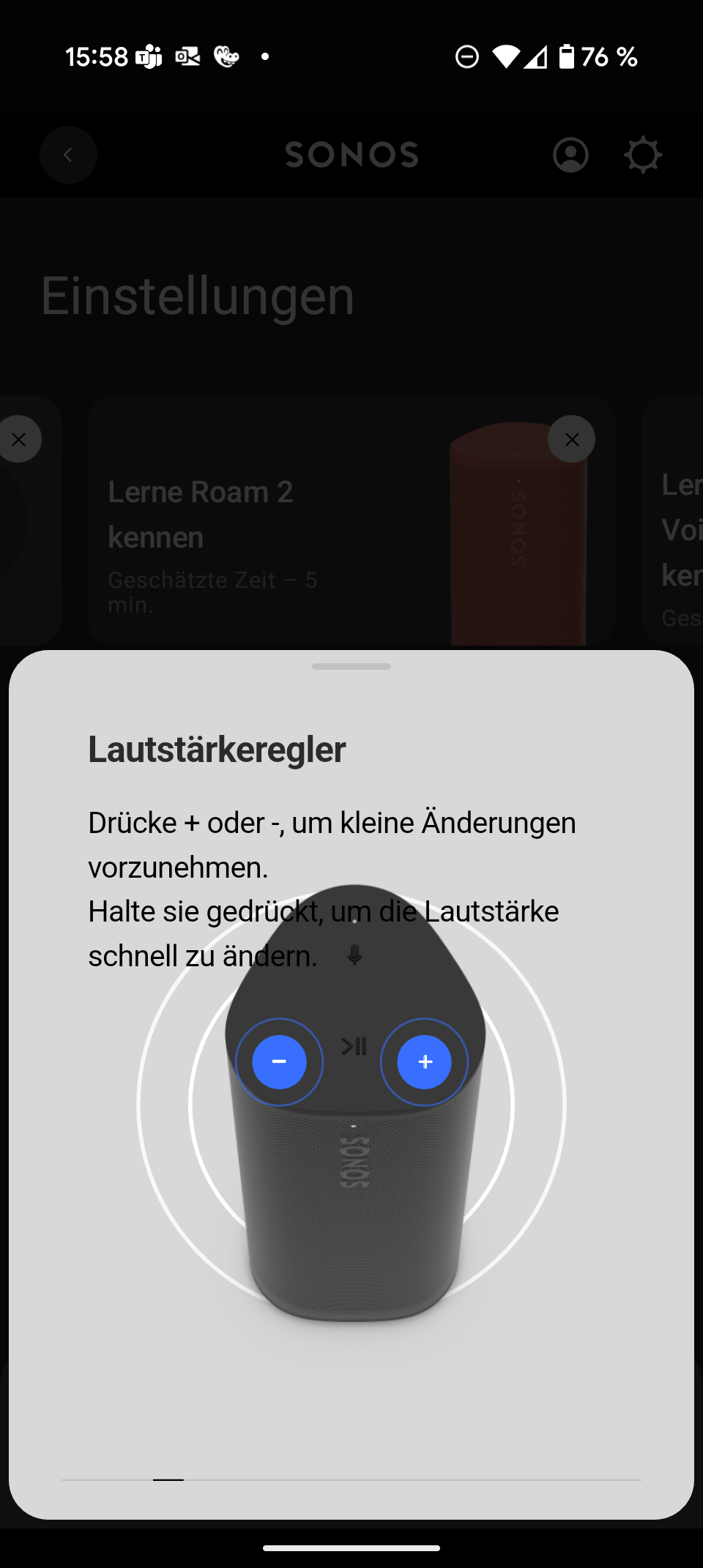
Sonos Roam 2 Screenshot
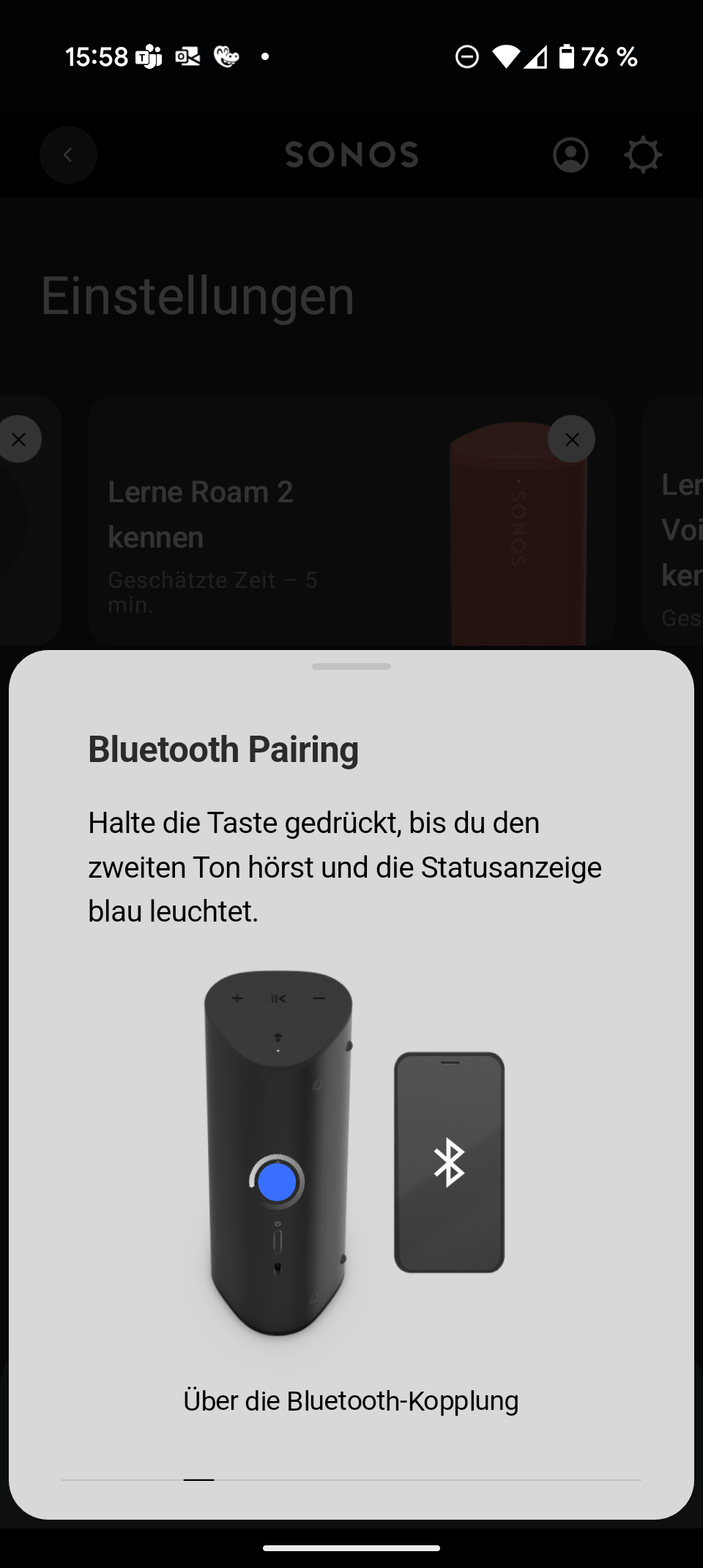
Sonos Roam 2 Screenshot
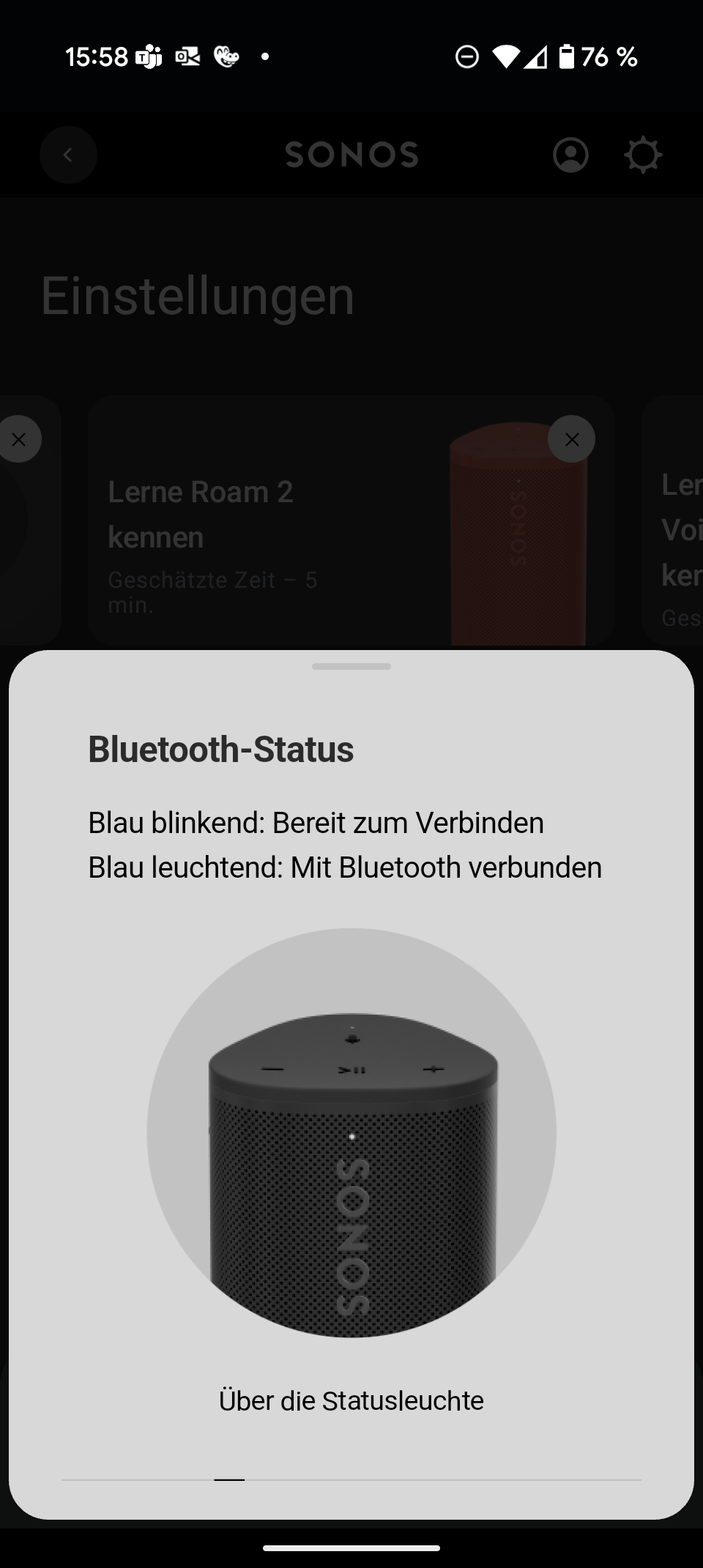
Sonos Roam 2 Screenshot
Sonos Roam 2 Screenshot
Sonos Roam 2 Screenshot
Sonos Roam 2 Screenshot
Sonos Roam 2 Screenshot
Sonos Roam 2 Screenshot
Sonos Roam 2 Screenshot
Sonos Roam 2 Screenshot
Sonos Roam 2 Screenshot
Sonos Roam 2 Screenshot
Sonos Roam 2 Screenshot
Sonos Roam 2 Screenshot
Der Akku des Sonos Roam 2
Mit 18 Wh Kapazität hält der Akku bis zu 10 Stunden bei moderater Lautstärke durch. Das entspricht der Laufzeit des Vorgängers. Die Ladezeit beträgt etwa zwei Stunden über USB-C mit maximal 11 Watt. Im Standby hält der Speaker etwa 10 Tage durch.
Die Akkulaufzeit enttäuscht im Vergleich zur Konkurrenz: Der Marshall Emberton III schafft 32 Stunden, selbst der günstigere JBL Flip 6 hält länger durch. Optional bietet Sonos ein kabelloses Qi-Ladegerät für 49 Euro an – praktisch, aber teuer.
Konnektivität und technische Eigenschaften des Sonos Roam 2
Der Roam 2 kommuniziert via Bluetooth 5.0 und WLAN (802.11b/g/n/ac) auf 2,4 und 5 GHz. Der USB-C-Port dient ausschließlich zum Laden – eine Audio-Übertragung per Kabel ist nicht möglich. Ein USB-C-zu-USB-C-Kabel liegt bei. Ein AUX-Eingang oder andere physische Anschlüsse fehlen.
Die Bluetooth-Reichweite entspricht dem Standard von etwa 10 Metern. Die WLAN-Integration ermöglicht Multiroom-Audio. Apple Airplay 2 erweitert die Streaming-Möglichkeiten für iOS-Nutzer. Die automatische Umschaltung zwischen Bluetooth und WLAN funktioniert nahtlos – der Speaker erkennt selbstständig, welche Verbindung verfügbar ist.
Bei den Codecs beschränkt sich Sonos auf SBC und AAC. High-Resolution-Codecs wie aptX oder LDAC sucht man vergebens. Die Integration von Sprachassistenten funktioniert nur im WLAN – unterwegs bleibt die Sprachsteuerung deaktiviert.
Was kostet der Sonos Roam 2?
Mit einem Angebotspreis von 159 Euro liegt der Roam 2 unter der UVP von 199 Euro. Für einen reinen Bluetooth-Lautsprecher ist das teuer. Als Einstieg oder Ergänzung für das Sonos-Ökosystem relativiert sich der Preis.
Fazit
Der Sonos Roam 2 ist ein guter Bluetooth-Lautsprecher, der seine Stärken vor allem im Sonos-Ökosystem ausspielt. Die nahtlose Integration von Bluetooth und WLAN, automatisches Trueplay und die Multiroom-Fähigkeit heben ihn von reinen Bluetooth-Lautsprechern ab. Der dedizierte Bluetooth-Button verbessert die mobile Nutzung erheblich.
Enttäuschend sind die fehlenden Verbesserungen bei Klang und Akku gegenüber dem Vorgänger. Zehn Stunden Laufzeit sind nicht mehr zeitgemäß. Der fehlende Equalizer und die etwas schwache Bassleistung in großen Räumen trüben das Bild zusätzlich. Für 159 Euro erhält man einen kompetenten Speaker, der aber nur für Sonos-Fans erste Wahl ist. Alle anderen finden bei der Konkurrenz bessere Preis-Leistungs-Verhältnisse.
Marshall Kilburn II
Marshall Kilburn II
Der Marshall Kilburn II verbindet Retro-Charme mit toller Verarbeitung und einem warmen, nostalgisch angehauchten Klang. Wir haben den detailverliebten Rock-Opa getestet.
- Kann sehr laut und lange spielen
- Trageriemen, Klangregelung, hochwertiger Aufbau
- Integriertes Netzteil
- Wenig für echten Outdoor-Einsatz geeignet
Marshall Kilburn II im Test
Der Marshall Kilburn II verbindet Retro-Charme mit toller Verarbeitung und einem warmen, nostalgisch angehauchten Klang. Wir haben den detailverliebten Rock-Opa getestet.
Die Babyboomer kennen die Marke Marshall noch aus den Hochzeiten des Gitarrenrocks. Die legendären Bühnenverstärker prägten mit Bands wie Deep Purple den Sound einer Ära. Bis auf das markante Retro-Design haben die modernen Bluetooth-Speaker der traditionsreichen Marke damit nur wenig gemeinsam. Jedoch orientiert sich auch die warme, volle Klangabstimmung des Kilburn II einen Hauch an den historischen Vorbildern. Wir haben den Bluetooth-Lautsprecher auf zehn gedreht.
Design und Verarbeitung
Wer kennt noch die fetten Gitarrenverstärker mit eingebautem Lautsprecher, mit denen Rockbands der 60er und 70er-Jahre auf der Bühne standen? Der Marshall Kilburn II schaut mit seinem Kunst-Leder-Look, dem Metallgrill und gegen Kratzer geschützten Ecken aus wie eine maßstabsgetreue Verkleinerung seiner Vorbilder. Das kultige Design schlägt sich in vergleichsweise hochwertigen Materialien und dem stattlichen Gewicht von 2,5 Kilogramm nieder. Der nostalgisch angehauchte Bluetooth-Speaker wirkt für diese sonst vor Kunststoff strotzende Gattung geradezu hervorragend verarbeitet.
Drei Drehregler auf der Oberseite des mit einem fetten Trageriemen bestückten Bassreflex-Gehäuses sind für Lautstärke, Bass und Höhen zuständig – eine Reminiszenz an Rock-Giganten vom Schlage Deep Purple . Damit es auch zünftig zur Sache geht, spendierten die Entwickler dem Kilburn II zwei 20-Watt-Class-D-Verstärker für den Tieftonbereich plus zwei weitere mit je sechs Watt für die Hochtöner.
Damit sollen sich, so verspricht Marshall, sagenhafte 100 Dezibel Schalldruckpegel in einem Meter Abstand erzielen lassen. Zur besseren Einordnung: So viel schafft nicht mal so manche ausgewachsene HiFi-Box. Eine Besonderheit ist die vom Aufnahme-Pionier Alan Blumlein inspirierte 360-Grad-Klangabstrahlung, die den relativ kompakten Lautsprecher größer wirken lassen soll.
Klang
Klangpuristen kommen schnell auf die Idee, die Bass- und Höhenregler des Marshall Kilburn II bis zum Anschlag aufdrehen. In Neutralstellung fehlt es dem Schwergewicht unter den Bluetooth-Boxen an Pep. Doch auch bei Rechtsanschlag beider Regler spielt der Nostalgiker weder besonders luftig noch bietet er überzeugenden Tiefgang.
Der Bass-Potentiometer betont lediglich den Oberbass und ist nicht frei von Nebenwirkungen. Exzessiver Einsatz lässt den für natürliche Stimmwiedergabe entscheidenden Mitteltonbereich gegenüber den dann etwas aufgeblähten Bässen verblassen.
Der Effekt lässt Stimmen leicht bedeckt klingen, als stünden die Sängerinnen und Sänger hinter einem Vorhang. Schließlich sind auch die Höhen nicht sonderlich brillant. Der Speaker ist eher etwas für jene, die es laut, satt, aber nicht schrill mögen. Wenn man den Bassregler mit Augenmaß verwendet, verwöhnt er jedoch mit angenehmer, stimmiger Tonalität.
Der Kilburn II klingt mit seiner Blumlein-Stereophonie mit einer gewissen rückseitigen Schallabstrahlung nicht so sehr nach kleinem Kasten wie manch anderer Lautsprecher in dieser Größe. Allerdings sollte man davon keine Raumklang-Wunder erwarten.
Vor allem aber laut spielen, das liegt dem Marshall wirklich ausgesprochen gut. Dabei fällt zusätzlich positiv auf, dass ihm das von den meisten anderen Bluetooth-Speakern bekannte „Pumpen“ DSP-gesteuerter Limiter auch bei hohen Abhörpegeln fremd ist. Insgesamt ergibt das einen durchwachsenen Höreindruck. Verglichen mit seinem Vorgänger, erzielt der Kilburn II aber einen spürbaren Klangfortschritt.

Bedienung und Funktionalität
Die bereits erwähnten Drehregler nützen der Haptik und ermöglichen zudem eine Klangregelung, die Bluetooth-Boxen gewöhnlich abgeht. Die Hommage an gute alte Zeiten birgt aber einen Nachteil: Die Lautstärke zwischen dem Marshall Kilburn II und dem über Bluetooth gekoppelten Smart Device geht nicht synchron. Eine Abstimmung zwischen dem mechanischen Drehpotentiometer – er dient übrigens auch zum Ein- und Ausschalten – und dem Smartphone findet nicht statt. Das ist ausgesprochen unpraktisch und inzwischen auch ungewöhnlich. Wer voll aufdrehen will, muss dazu die Lautstärkeregelung an beiden Geräten separat auf Maximum stellen.
Abgesehen davon gibt es keine Möglichkeit, die Wiedergabe über die Box zu starten und stoppen. Dafür lässt sich das Bedienfeld auf der Oberseite an Übersichtlichkeit kaum toppen und hält sogar eine Batterieanzeige mit vielen kleinen LED-Segmenten bereit. Auch der Pairing-Button sitzt oben, während man ihn etwa beim Teufel Motiv Go kaum sichtbar an der Seite versteckt hat. Der Marshall Kilburn II verfügt über eine Multi-Host-Funktion, um rasch zwischen zwei Bluetooth-Geräten zu wechseln.
Die Schnellladefunktion versprüht einen Hauch Tesla. Mit nur 20 Minuten Ladezeit lässt sich der Lithium-Ionen-Akku für ganze drei Stunden tragbarer Spieldauer befüllen. Das vollständige Aufladen für über 20 Stunden Spielzeit dauert nur gut zweieinhalb Stunden. Dank integriertem Netzteil kann man den Kilburn II direkt an der Steckdose betreiben.

Konnektivität
Dieses Extra ist inzwischen vom Aussterben bedroht: Immer weniger Bluetooth-Lautsprecher bieten einen Analog-Eingang. Der AUX-Anschluss mit 3,5-mm-Klinkenbuchse ermöglicht den Anschluss von Stereo-Quellen, die nicht über eine Bluetooth-Konnektivität verfügen. Allerdings unterstützt der Kilburn II für den gemeinhin gebräuchlicheren Wireless-Betrieb weder AptX- noch AAC-Codecs. Auf der Rückseite des 24,3 × 16,2 × 14 Zentimeter großen Gehäuses findet sich ein Netzanschluss – eine sehr praktische Sache.
Preis
Den Marshall Kilburn II gibt es in den Farben Schwarz, Grau, Burgundy und Indigo. Er kostet aktuell etwa 200 Euro. Allerdings zeigt der Preisverlauf, dass er in der Vergangenheit schon häufig deutlich günstiger den Eigentümer wechselte. Sein Tiefstpreis liegt bei 155 Euro. Wer warten und im besten Fall etwa bei Geizhals einen Preisalarm setzt, kann im Vergleich zum derzeitigen Preis viel Geld sparen.
Fazit
Wer einen Outdoor-Lautsprecher für die nächste Beach Party sucht, findet leicht günstigere Alternativen wie den Dockin D-Fine (Testbericht) , muss dann aber bezüglich der Lautstärke und der Akkulaufzeit Einbußen in Kauf nehmen.
Mit seiner Bassreflex-Öffnung und dem Schallaustrittsgitter auf der Rückseite ist der Marshall Kilburn II trotz IPX“-Zertifizierung am Sandstrand etwa so fehl am Platz wie umgekehrt Flip-Flops in der Oper. Wer bereit ist, für Style, Verarbeitung und Pegelfestigkeit etwas tiefer in die Tasche zu greifen, der bekommt ein lebendes Fossil mit einem nicht zu unterschätzenden Charme und kompletter Ausstattung. Denn ein integriertes Netzteil gibt es nur selten in diesem Bereich.
Teufel Rockster Cross
Teufel Rockster Cross
Der Teufel Rockster Cross gibt den harten Macho unter den Bluetooth-Speakern. Mit einem wasserdichten Gehäuse, großem Akku und gutem Klang will er die Käufer locken. Überlebt der Outdoor-Lautsprecher unseren Hörtest?
- Spielt lange und laut
- Robustes, outdoor-taugliches Gehäuse
- Trageriemen mit Karabinerhaken und Netzteil liegen bei
- Tasten zum Teil auf der Rückseite und nicht optimal gekennzeichnet
Teufel Rockster Cross im Test
Der Teufel Rockster Cross gibt den harten Macho unter den Bluetooth-Speakern. Mit einem wasserdichten Gehäuse, großem Akku und gutem Klang will er die Käufer locken. Überlebt der Outdoor-Lautsprecher unseren Hörtest?
Der Teufel Rockster Cross versprüht einen Hauch von Adrenalin und Abenteuer. Mit seinem knapp 40 Zentimeter breiten Gehäuse wirkt er martialisch und bereit für Outdoor-Partys. Während der Hersteller beim kleinen, feinen Teufel Motiv Go (Testbericht) auf edles Metall setzt, sorgt hier schlagfester, gummierter Kunststoff für ein schroffes, funktionales Aussehen.
Design und Verarbeitung
Bezüglich Abmessungen und Material – das Gehäuse besteht aus dickem, gummiertem Kunststoff – ist der Teufel Rockster Cross gegen Stöße oder Feuchtigkeit gewappnet. Das führt in der Summe zu einem relativ hohen Gewicht von 2,4 Kilogramm. Der demonstrativ robust gestaltete Outdoor Speaker verträgt Strahlwasser nach IPX5-Norm. Doch die Teufel verspricht darüber hinaus eine Wintertauglichkeit für extrem niedrige Temperaturen bis zu -10 °C. Jeder, der beim Après-Ski zum Jagertee unter freiem Himmel gerne etwas musikalische Untermalung möchte, wird hier bestens bedient. Wer sich zutraut, mit der immerhin zwei Liter großen Box ohne Crash die Piste herunterzubrausen, kann sich den Teufel Rockster Cross mit dem beiliegenden Trageriemen mit soliden Karabinerhaken umhängen.
Neben diesem nützlichen Zubehör spendiert Teufel weitere keinesfalls selbstverständliche Beigaben. Anstelle des allgemein üblichen USB-Ladekabels gibt es zu diesem Lautsprecher ein Netzteil. Abseits der Steckdose lässt sich der Teufel Rockster Cross bis zu 16 Stunden mit seinem eingebauten Akku betreiben.
Das Gehäuse des Teufel Rockster Cross besteht aus schlagfestem Kunststoff und bietet einer Batterie von Treibern eine sichere Unterbringung. Der Zwölf-Zentimeter-Tief-Mitteltöner wurde in der Mitte der 16 Zentimeter hohen Schallwand positioniert. Für satten Bass unterstützen ihn zwei auf der Rückseite positionierte Passiv-Radiatoren. Dem Mono-Tief-Mitteltöner stehen für einen gewissen Stereo-Effekt zwei insgesamt zwei Zentimeter durchmessende Gewebe-Hochtöner zur Seite. Mit dem Teufel-eigenen Raumklangverfahren Dynamore soll diese eigenwillige Chassis-Konfiguration ein für diese Klasse weiträumiges Klangfeld erzeugen. Durch ihre vorgeschalteten Hörner erzielen die Hochtöner zudem einen hohen Wirkungsgrad.
Teufel Rockster Cross
Teufel Rockster Cross

Teufel Rockster Cross

Teufel Rockster Cross

Teufel Rockster Cross

Teufel Rockster Cross

Teufel Rockster Cross

Bedienung und Funktionalität
Wer Wert auf eine richtige Stereo-Abbildung mit breitem Staging legt, kommt allerdings auch mit einem zweiten Teufel Rockster Cross nicht weiter. Wem der Rockster Cross trotz seiner leistungsfähigen Treiber nicht laut genug spielt, der kann zwei dieser Lautsprecher via Bluetooth koppeln – allerdings nicht als Stereo-Paar. Die Paarbildung dient allein der Steigerung des maximalen Abhörpegels, um für Partys im Freien gerüstet zu sein.
Der von einer Klappe gegen Spritzwasser geschützte USB-Anschluss für Smartphone und Tablets ermöglicht es, den Teufel Rockster Cross als Powerbank zur Entlastung derer Akkus zu verwenden, was sich zu solchen Anlässen fernab der Steckdose als nützlich erweisen kann.
Die gegen Wasser und Staub geschützten Tasten bestehen wie das Gehäuse aus gummiertem Kunststoff. Sie sitzen auf der Oberseite und der Rückwand und lassen sich bei schwachem Licht mit ihren geprägten Funktionsbezeichnungen nicht gut auseinanderhalten. Das gilt vor allem für die hinteren Buttons, die aber zum Glück nicht so oft benötigt werden wie die obere Reihe.
Dazu zählt etwa die Outdoor-Taste zur Anpassung des Klangs an das Musikhören unter freiem Himmel. Die akustische Wirkung der Funktion fällt allerdings sehr subtil aus.
Die vier größeren Tasten auf der Oberseite dienen der Wiedergabesteuerung des über Bluetooth verbundenen Smartphones oder dem Aufruf der Sprachassistenten von iPhone oder Android-Smartphones. Wer die Mikrofon-Taste länger drückt, weckt Siri oder den Google Assistant, während ein kurzer Druck zum Annehmen eines Anrufs über die Freisprecheinrichtung dient. Da die LEDs zur Anzeige der Batterieladung auch auf die Rückseite verbannt wurden, kann es im Eifer der Party zu unliebsamen Überraschungen kommen.
Der Blick in die Anleitung sei empfohlen. Teufel setzt beim Rockster Cross auf Tricks, auf die man von allein kaum kommen dürfte – etwa den Sprung zum nächsten Titel durch gleichzeitiges Drücken der Start-Stopp sowie der Lautstärke „+“ Taste.
Konnektivität
Der Party-Modus bietet den gleichzeitigen Verbindungsaufbau mit zwei Smartphones, um Songs abwechselnd von beiden Bluetooth-Geräten abzuspielen abspielen. Der AptX-Codec wird für hohe Klangqualität unterstützt. Durch kurze Latenzzeit soll sich beim Schauen von Youtube-Videos kein spürbarer Zeitversatz zwischen Ton und Lippenbewegung ergeben. Darüber hinaus gibt es einen 3,5-Millimeter-Klinkenbuchsen-Eingang für analoge Zuspielung.
Klang
Die Kombination aus zwei Liter großem Gehäuse und großem Tief-Mitteltöner mit Passiv-Radiatoren kommt im Hörtest zur Geltung. Der Teufel Rockster Cross erzielt einen tiefen, konturierten Bass. Große Lautstärken meistert er lässig. Auch wenn sein martialisches Aussehen andere Erwartungen weckt, bringt der Speaker gar Kesselpauken und Kontrabässe für seine Gewichtsklasse sehr ordentlich zu Gehör. Seine neutrale Stimmwiedergabe lässt sich mit Singer-Songwritern genießen. Das Klangniveau liegt noch über dem des vom Preis vergleichbaren Marshall Kilburn (Testbericht). Diese Retro Box klingt insgesamt wärmer und weicher als der neutral und eher trocken im Bass abgestimmte Teufel. Den besten Bluetooth-Speaker im Retro-Design küren wir im Beitrag Wer rockt härter? Bluetooth-Speaker Fender Monterey, Fender Newport und Marshall Kilburn II im Vergleichstest.
Wer auf elektronische Beats steht, wird mit dem breitbandigen, satten und sauberen Klang richtig gut bedient. Der Rockster Cross macht zünftig Druck, geht tief in den Bass-Keller und dürfte sich damit in die Herzen von Rock- und Pop-Fans spielen.
Allerdings gibt es bei aller Raffinesse physikalische Grenzen. Trotz Dynamore und zwei Hochtönern auf beiden Seiten der Schallwand liefert der Rockster Cross keine echte Stereo-Abbildung wie man sie von separaten Boxen kennt. Immerhin erzeugt er damit ein bereiteres Staging als üblich. Auch die Outdoor-Taste wirkte wie bereits erwähnt eher dezent auf die Klangwiedergabe ein.
Preis
Der Teufel Rockster Cross kostet 280 Euro. Aber er war in der Vergangenheit häufiger günstiger. Schnäppchenjäger konnten ihn bereits für 250 Euro erwerben. Wer sich beim Kauf ein paar Euro sparen will, der sollte etwa bei Geizhals einen Preisalarm setzen. Alternativ empfehlen wir aus dem gleichen Haus den vergleichbar teuren aber deutlich eleganteren Teufel Motiv Go (Testbericht).
Fazit
Der Teufel Rockster Cross gehört zu den besten mittelgroßen Bluetooth-Boxen. Das liegt am satten, dynamischen Klang, aber auch an seiner durchdachten Outdoor-Funktionalität. Dank seiner Form und dem Tragegurt trägt er sich sehr gut am Körper. Dazu kommen eine beachtliche Robustheit, ein zum Lieferumfang gehörendes Netzteil und ein großer Funktionsumfang, etwa die Dynamore-Klangverbesserung für weiträumigen Sound oder die Freisprecheinrichtung.
LG Xboom Go DXGQ7
LG Xboom Go DXGQ7
Der LG Xboom Go DXG7Q ist ein kompakter Bluetooth-Lautsprecher, der mit seiner robusten Bauweise, kräftigem Klang und langer Akkulaufzeit überzeugt. Im Test offenbart er viele Stärken, aber auch ein paar Schwächen.
- kraftvoller Klang mit sattem Bass
- lange Akkulaufzeit von 24 Stunden
- robustes, wasserdichtes Gehäuse (IP67)
- sehr gutes Preis-Leistungs-Verhältnis
- Höhen und Mitten könnten etwas präziser sein
- langweiliges Design
- Bluetooth 5.1, keine HighRes-Codecs
Bluetooth-Lautsprecher LG Xboom Go DXGQ7 im Test
Der LG Xboom Go DXG7Q ist ein kompakter Bluetooth-Lautsprecher, der mit seiner robusten Bauweise, kräftigem Klang und langer Akkulaufzeit überzeugt. Im Test offenbart er viele Stärken, aber auch ein paar Schwächen.
Nachdem wir bereits den außergewöhnlichen LG Xboom 360 DXO2T (Testbericht) mit seinem 360-Grad-Klang und den vielen Zusatzfunktionen der App testen konnten, haben wir uns nun den kleineren Bruder, den LG Xboom Go DXG7Q, genauer angeschaut. Der kompakte Bluetooth-Lautsprecher soll mit seiner robusten Bauweise, dem kraftvollen Sound und der langen Akkulaufzeit punkten. Ob er hält, was er verspricht, zeigt unser Test.
Design und Verarbeitung
Der LG Xboom Go DXG7Q präsentiert sich im klassischen Riegel-Format. Mit Abmessungen von etwa 26 x 10 x 10 cm und einem Gewicht von 1,1 kg ist er noch kompakt und leicht genug, um bequem in einen Rucksack zu passen – perfekt also für den mobilen Einsatz draußen.
Das Gehäuse ist größtenteils mit robustem schwarzem Mesh-Stoff bezogen. Die Kanten werden von einem stabilen Kunststoffrahmen geschützt. Dieser ist in Schwarz oder Grau erhältlich und verleiht dem Speaker einen wertigen Look. Auf den Seiten befinden sich zwei große passive Radiatoren, die von farbigen LED-Streifen eingefasst sind. Diese sorgen für ein stimmungsvolles Ambiente und lassen sich über die App individuell anpassen.

Die Bedienelemente sitzen auf einem grauen Kunststoffstreifen auf der Oberseite. Hier kommen erfreulicherweise physische Tasten mit deutlichem Druckpunkt zum Einsatz – keine kapazitiven Touch-Flächen. Neben den üblichen Tasten für Lautstärke, Play/Pause und Bluetooth gibt es noch eine Taste für den „Sound Boost“-Modus. Eine Hintergrundbeleuchtung sucht man jedoch vergeblich.
Auf der Rückseite schützt eine massive Gummiabdeckung die Anschlüsse vor Feuchtigkeit und Schmutz. Hier finden sich ein USB-C-Port zum Laden, ein 3,5-mm-Klinkenanschluss für kabelgebundene Zuspieler sowie ein USB-A-Port, über den man Smartphones und Co. mit Strom versorgen kann – praktisch! Gummifüße auf der Unterseite sorgen für einen sicheren Stand.
Insgesamt macht der LG Xboom Go DXG7Q einen sehr soliden und hochwertigen Eindruck. Mit IP67 ist er komplett staubdicht und kann auch mal unbeabsichtigt ins Wasser fallen, ohne Schaden zu nehmen. Für den Outdoor-Einsatz ist er damit bestens gerüstet.
LG XBoom Go DXGQ7 Bilder
LG XBoom Go DXGQ7

LG XBoom Go DXGQ7

LG XBoom Go DXGQ7

LG XBoom Go DXGQ7

LG XBoom Go DXGQ7

LG XBoom Go DXGQ7

LG XBoom Go DXGQ7

LG XBoom Go DXGQ7
LG XBoom Go DXGQ7

LG XBoom Go DXGQ7

Sound: Wie gut ist der Klang des LG Xboom Go DXG7Q?
Für den Sound zeigt sich im LG Xboom Go DXG7Q ein Mitteltöner, ein Track Woofer und ein Dome Tweet unterstützt von zwei passiven Radiatoren verantwortlich. Mit einer Gesamtleistung von 40 Watt verspricht der koreanische Hersteller kraftvollen Klang.
Und tatsächlich: Der kompakte Bluetooth-Lautsprecher überrascht im Test mit erstaunlich kräftigem und bassbetontem Sound. Gerade in Anbetracht der geringen Größe wummert der Bass enorm druckvoll und präzise. Auch die maximale Lautstärke kann sich hören lassen – der DXG7Q beschallt problemlos ganze Räume oder Grillpartys im Garten. Dabei bleibt der Klang auch bei hohen Pegeln noch relativ verzerrungsarm.
In den Mitten und Höhen offenbart der LG-Speaker dafür einige Schwächen. Hier fehlt es etwas an Klarheit und Brillanz, bei komplexen Stücken mit vielen Instrumenten klingen die Höhen teils etwas verwaschen und blechern. Auch neigen Stimmen gelegentlich zum Zischeln.
Mit der „Sound Boost“-Funktion und dem Equalizer in der App lässt sich der Klang aber effektiv an den eigenen Geschmack und die Musikrichtung anpassen. Vor allem für basslastige Genres wie Elektro, Hip-Hop und Dancehall eignet sich der Speaker gut. Wer hauptsächlich klassische Musik oder Jazz hört, sollte dagegen besser zu neutraler klingenden Alternativen greifen.
Auch Podcasts und Hörbücher gibt der LG Xboom Go DXG7Q dank der präsenten Mitten klar und verständlich wieder. Die eingebauten Mikrofone ermöglichen zudem eine brauchbare Freisprechfunktion, wenngleich das Gegenüber im Test eine leichte Halligkeit bemängelte.
Unter dem Strich liefert der LG Xboom Go DXG7Q ein gutes Klangbild für einen so kompakten und günstigen Bluetooth-Lautsprecher. An Tiefgang und Power übertreffen ihn nur wenige Konkurrenten. Für audiophile Hörer ist er aufgrund der etwas schwächeren Höhen aber eher weniger geeignet.
Der LG Xboom Go DXG7Q lässt sich einfach über Bluetooth 5.1 mit Smartphone, Tablet und Co. koppeln. Die Reichweite liegt bei den üblichen 10 bis 12 Metern, innerhalb derer die Verbindung stabil bleibt. Andere aktuelle Speaker setzen inzwischen schon auf Bluetooth 5.2 oder gar 5.3, hier hinkt LG etwas hinterher.
App
Die Xboom-App ist übersichtlich aufgebaut und bietet zahlreiche nützliche Funktionen. Zentral ist der 6-Band-Equalizer, mit dem man den Klang an die eigenen Präferenzen anpassen kann. Für eilige Nutzer gibt es voreingestellte EQ-Profile.
Die LED-Beleuchtung der beiden passiven Radiatoren lässt sich ebenfalls über die App steuern. Neben ein paar vorgefertigten Licht-Animationen kann man auch eigene Farbkombinationen und Effekte einstellen.
LG XBoom Go DXGQ7 Screenshot
LG XBoom Go DXGQ7 Screenshot
LG XBoom Go DXGQ7 Screenshot
LG XBoom Go DXGQ7 Screenshot
LG XBoom Go DXGQ7 Screenshot
LG XBoom Go DXGQ7 Screenshot
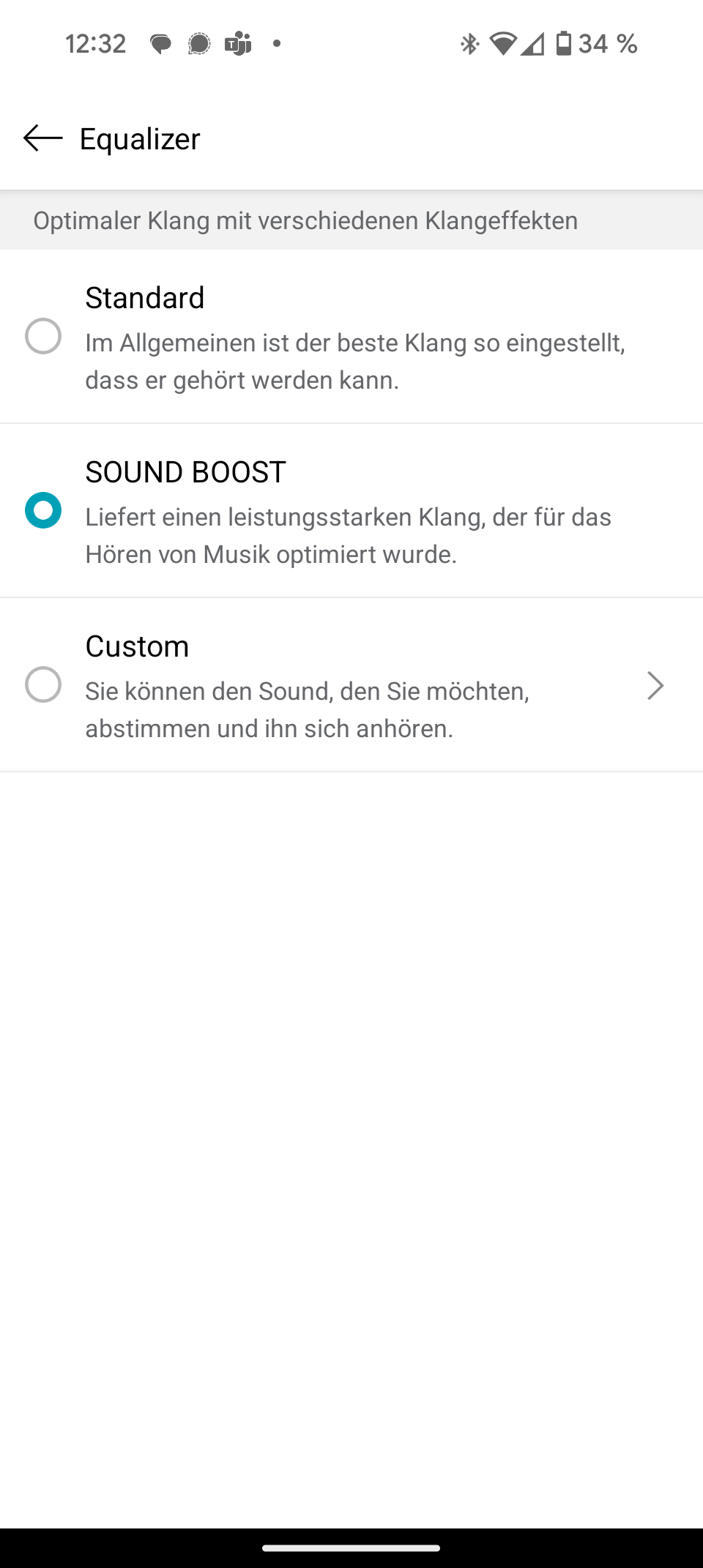
LG XBoom Go DXGQ7 Screenshot
LG XBoom Go DXGQ7 Screenshot
LG XBoom Go DXGQ7 Screenshot
LG XBoom Go DXGQ7 Screenshot
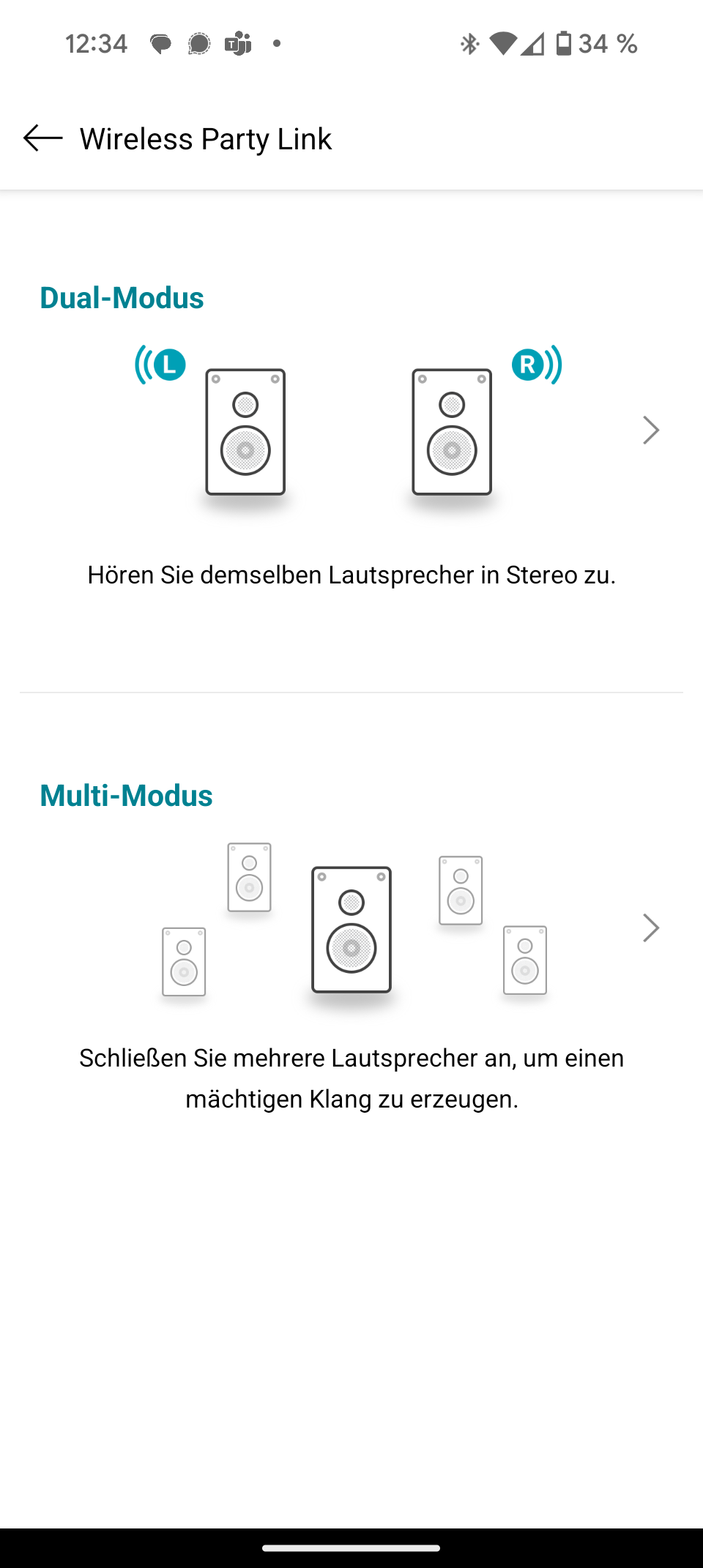
LG XBoom Go DXGQ7 Screenshot

LG XBoom Go DXGQ7 Screenshot
LG XBoom Go DXGQ7 Screenshot
Über die App kann man zwei DXG7Q Lautsprecher für echten Stereo-Sound koppeln. Andere Modelle von LG lassen sich leider nicht verbinden.
Ein nettes Extra ist die integrierte Sleep-Timer-Funktion. Hier kann man eine Zeit einstellen, nach der sich der Lautsprecher automatisch abschaltet. Praktisch, wenn man beim Einschlafen noch etwas Musik oder einen Podcast hören möchte. Sehr nett: Die Beleuchtung dimmt sich dabei langsam immer weiter, sodass man sanft in den Schlaf gleitet.
Bezüglich Bedienung und Funktionsumfang haben wir am LG Xboom Go DXG7Q wenig auszusetzen. Die App bietet viele sinnvolle Zusatzfeatures, ohne dabei überladen zu wirken.
Akku
Mit einem Akku von 3900 mAh ist der mobile Bluetooth-Speaker für lange Hörvergnügen gerüstet. LG verspricht eine Wiedergabedauer von bis zu 24 Stunden – ein Wert, den kaum ein anderer Lautsprecher in dieser Größen- und Preisklasse erreicht.
Über den USB-A Port kann man bei Bedarf auch Smartphones und Tablets mit neuer Energie versorgen. So lässt sich ein leerer iPhone-Akku etwa einmal komplett aufladen. Praktisch, wenn unterwegs mal kein Netzteil zur Hand ist.
Geladen wird der Speaker selbst über den USB-C-Anschluss. Ein passendes Netzteil liegt allerdings nicht bei. Eine komplette Aufladung dauert leider recht lang, gut fünf Stunden muss man einplanen. Eine Schnellladefunktion gibt es nicht. Schade, hier hätten wir uns etwas mehr Tempo gewünscht.
Preis: Was kostet der LG Xboom Go DXG7Q?
Mit einer unverbindlichen Preisempfehlung von 179 Euro ist der LG Xboom Go DXG7Q in einem hart umkämpften Preissegment angesiedelt. Inzwischen bekommt man ihn aber schon für deutlich günstigere 69 Euro (Amazon) – ein neuer Bestpreis für den kompakten Bluetooth-Lautsprecher. Zu diesem Preis ist der DXG7Q eine klare Empfehlung.
Fazit
Der LG Xboom Go DXG7Q gefällt uns im Test. Er vereint einen kraftvollen Klang, lange Akkulaufzeit, robuste Verarbeitung und Zusatzfeatures in einem kompakten Gehäuse. Die dezente LED-Beleuchtung macht ihn zum Hingucker. Kleinere Schwächen wie die langen Ladezeiten, das biedere Design, nur Bluetooth 5.1 oder die nicht ganz perfekte Detailauflösung im Hoch- und Mitteltonbereich lassen sich angesichts des günstigen Preises leicht verschmerzen.
Für aktuell 69 Euro (Amazon) bekommt man hier ein echtes Klangwunder, das in Sachen Preis-Leistungs-Verhältnis kaum zu schlagen ist. Wer einen vielseitigen, robusten und klangstarken Bluetooth-Lautsprecher für unterwegs sucht, sollte den LG Xboom Go DXG7Q definitiv in Betracht ziehen.
JBL Charge 5
JBL Charge 5
Die JBL Charge 5 ist eine kompakte, schicke Bluetooth-Box mit kraftvollem Klang. Sie überzeugt mit langer Akkulaufzeit und ist dank IP67-Zertifizierung auch für Outdoor-Einsätze geeignet. Wir testen den beliebten Lautsprecher.
- Robustes, kompaktes und schickes Design
- Kraftvoller, ausgewogener Klang
- Lange Akkulaufzeit
- Keine Schnellladefunktion
- Kein AUX-Eingang
Bluetooth-Lautsprecher JBL Charge 5 im Test
Die JBL Charge 5 ist eine kompakte, schicke Bluetooth-Box mit kraftvollem Klang. Sie überzeugt mit langer Akkulaufzeit und ist dank IP67-Zertifizierung auch für Outdoor-Einsätze geeignet. Wir testen den beliebten Lautsprecher.
JBL gehört zu den bekanntesten Herstellern von Bluetooth-Lautsprechern. Besonders die Charge-Serie erfreut sich seit Jahren großer Beliebtheit. Mit der JBL Charge 5 zeigt der Hersteller den Nachfolger des erfolgreichen Vorgängers Charge 4. Wie sich die in vielen Farben erhältliche Box im Alltag schlägt und ob sie klanglich überzeugt, klären wir im Test.
Design und Verarbeitung
Die zylindrische JBL Charge 5 ist perfekt durchdesignt und ein echter Hingucker. Mit einer Länge von etwa 22 cm und einem Durchmesser von knapp 10 cm ist sie sehr kompakt, bringt aber mit fast einem Kilogramm ordentlich Gewicht auf die Waage. Man merkt der Box an jeder Ecke die langjährige Erfahrung von JBL bei Bluetooth-Lautsprechern an.
Der hochwertig wirkende Stoffbezug, der den Großteil des Gehäuses umhüllt, ist in neun (!) verschiedenen Farben erhältlich. In unserem Test tritt die Box in knalligem Rot auf. An der Vorderseite prangt mittig das JBL-Logo in mattem Metallic-Look. Direkt darunter sitzt ein LED-Streifen, der den Akkustand anzeigt – eine neue und sehr schicke Lösung.

An den Seiten der Box sorgen zwei passive Bassradiatoren für zusätzlichen Wumms im Tieftonbereich. Sie sind mit einem glänzenden Metallgitter geschützt, auf dem jeweils ein JBL-Logo auf der Membran sitzt. Sehr schick!
Das Bedienfeld mit Tasten für Power, Bluetooth-Kopplung, Lautstärke und Wiedergabe befindet sich auf der Oberseite des Lautsprechers. Der Druckpunkt der Taster könnte etwas definierter sein – gerade beim Play-Button muss man recht fest drücken.
Auf der Rückseite findet man einen USB-C-Port zum Aufladen des integrierten Akkus. Daneben sitzt hinter einer Gummiabdeckung ein zusätzlicher USB-A-Anschluss, über den sich bei Bedarf Smartphones oder andere Geräte laden lassen – die namensgebende Charge-Funktion. Ein AUX-Eingang für kabelgebundene Zuspielung fehlt leider.
JBL Charge 5 Bilder
JBL Charge 5

JBL Charge 5

JBL Charge 5

JBL Charge 5

JBL Charge 5

JBL Charge 5

JBL Charge 5

JBL Charge 5

JBL Charge 5

JBL Charge 5

JBL Charge 5

JBL Charge 5
JBL Charge 5

Die Seiten des Lautsprechers sind durch weiches Gummi geschützt. Auf der Unterseite sorgen Gummistreifen für stabilen Stand auf glatten Oberflächen. Eine Trageschlaufe sucht man vergebens.
Insgesamt hinterlässt die JBL Charge 5 einen sehr robusten Eindruck. Mit der IP67-Zertifizierung ist sie komplett vor Staub und zeitweiligem Untertauchen geschützt. Die Box scheint also bestens für den Outdoor-Einsatz am Strand oder Pool gerüstet zu sein.
Sound: Wie gut ist der Klang der JBL Charge 5?
Für den Klang sorgen ein 52 mm x 90 mm großer Tief-/Mitteltöner und ein 20 mm Hochtöner. Die beiden passiven Bassradiatoren an den Seiten unterstützen die Basswiedergabe effektiv. Schon beim ersten Hören beeindruckt der satte, kräftige Sound der kompakten Bluetooth-Box. Die hohe Ausgangsleistung von 40 Watt macht sich positiv bemerkbar und verleiht der Charge 5 ordentlich Punch im Bass.
Im Hörtest brilliert die Box bei Podcasts und Hörbücher. Stimmen werden klar und deutlich wiedergegeben, ohne zu aufdringlich zu wirken. Auch bei Musikwiedergabe weiß die Charge 5 zu gefallen – egal ob bei rockigen Gitarrenriffs, elektronischen Beats oder klassischen Orchesterstücken.
Die maximale Lautstärke ist für die kompakten Abmessungen beeindruckend hoch. Selbst bei voller Lautstärke bleibt der Klang weitgehend verzerrungsfrei. Lediglich in den Höhen ist dann ein leichtes Klirren wahrnehmbar. Insgesamt wirkt der Sound der JBL Charge 5 ausgewogen und natürlich. Im Gegensatz zu vielen anderen kleinen Bluetooth-Boxen werden alle Frequenzbereiche gleichmäßig abgedeckt, ohne dass einzelne Bereiche zu dominant wirken. So macht das Musikhören einfach Spaß.
Ein Manko gibt es allerdings: Bei manchen Songs fällt auf, dass die Bühnenabbildung etwas eingeengt und der Klang nicht ganz so luftig wirken wie bei größeren Lautsprechern. Das ist aber auf die kompakten Abmessungen zurückzuführen und kein spezielles Problem der Charge 5. Hier stößt die Physik an ihre Grenzen.
Verglichen mit dem Vorgängermodell Charge 4 hat JBL noch eine Schippe draufgelegt. Die neue Box klingt sauberer und definierter. Insgesamt gehört die JBL Charge 5 klanglich zu den besten Bluetooth-Lautsprechern ihrer Größenklasse. Besonders für den mobilen Einsatz liefert sie einen tollen Sound!
Zur kabellosen Musikübertragung setzt JBL auf Bluetooth 5.1. Das neueste Bluetooth 5.3 fehlt zwar, im Test gab es aber keinerlei Verbindungsabbrüche oder Störungen. Im Gegenteil: Die Reichweite fiel sogar etwas höher aus als bei vielen Konkurrenzprodukten. Hier scheint JBL hochwertige Antennen zu nutzen.
Wer zwei JBL Charge 5 besitzt, kann diese per App zu einem echten Stereo-Paar koppeln. Noch spannender ist aber der Partymodus: Hat man mehrere, nicht allzu alte JBL-Boxen in der Nähe, reicht ein Druck auf den Connect-Knopf und die Lautsprecher finden sich automatisch. Das funktioniert mit bis zu 100 Boxen! So lässt sich im Handumdrehen ein riesiger Klangteppich für die nächste Gartenparty zaubern. Ein cooles Feature, da JBL-Speaker sehr verbreitet sind und die Chance hoch ist, dass Freunde ebenfalls eine kompatible Box mitbringen.
JBL Portable App
Die zugehörige JBL Portable App zeigt sich aufgeräumt und einfach zu bedienen. Ihre wichtigste Funktion ist der 3-Band-Equalizer. Dieser hätte ruhig noch etwas feiner unterteilt sein können, erfüllt aber seinen Zweck und ermöglicht eine Anpassung des Klangs an persönliche Vorlieben und Musikstil.
Daneben lassen sich in der App Software-Updates einspielen und mehrere JBL-Lautsprecher zu Gruppen zusammenfassen.
JBL Charge 5 Screenshot
JBL Charge 5 Screenshot
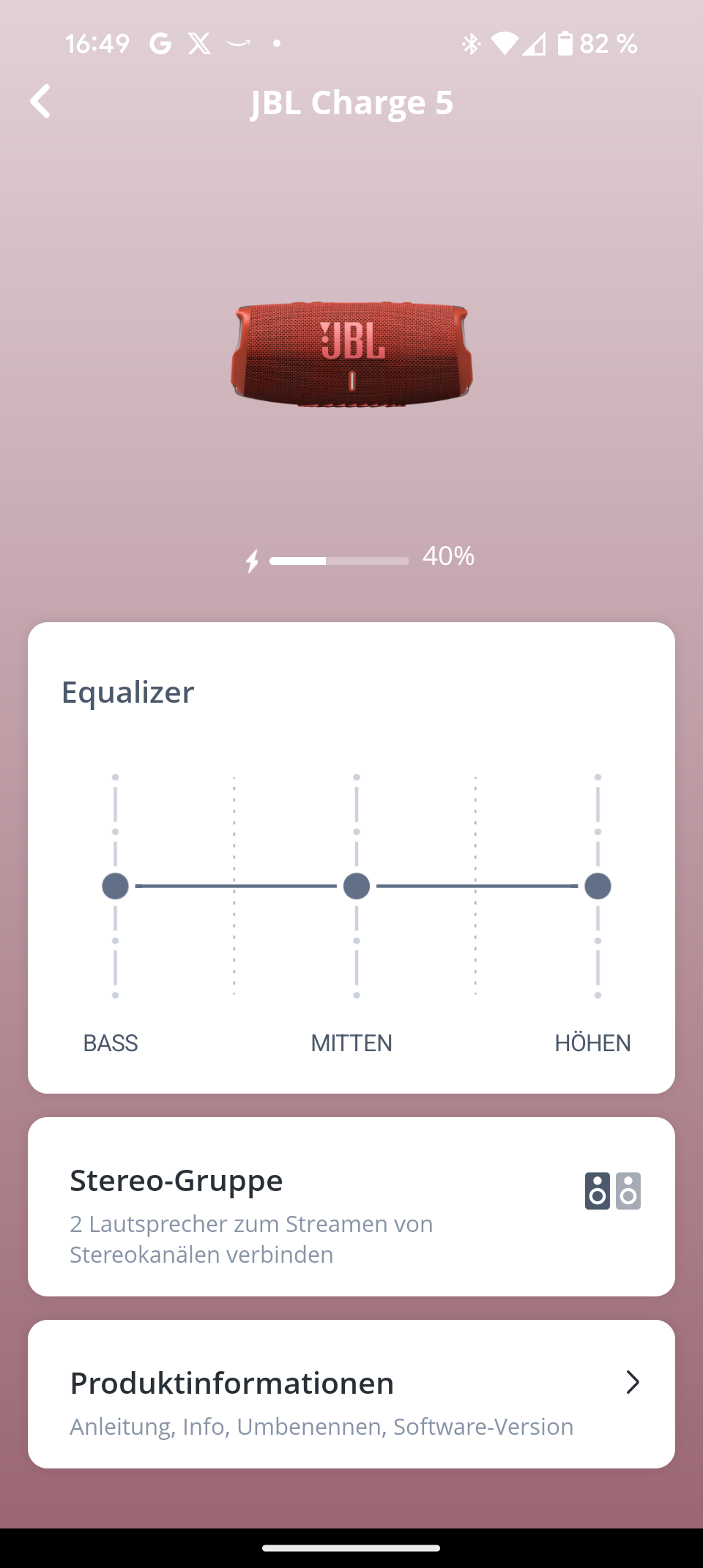
JBL Charge 5 Screenshot
JBL Charge 5 Screenshot

JBL Charge 5 Screenshot

JBL Charge 5 Screenshot
JBL Charge 5 Screenshot
JBL Charge 5 Screenshot
JBL Charge 5 Screenshot
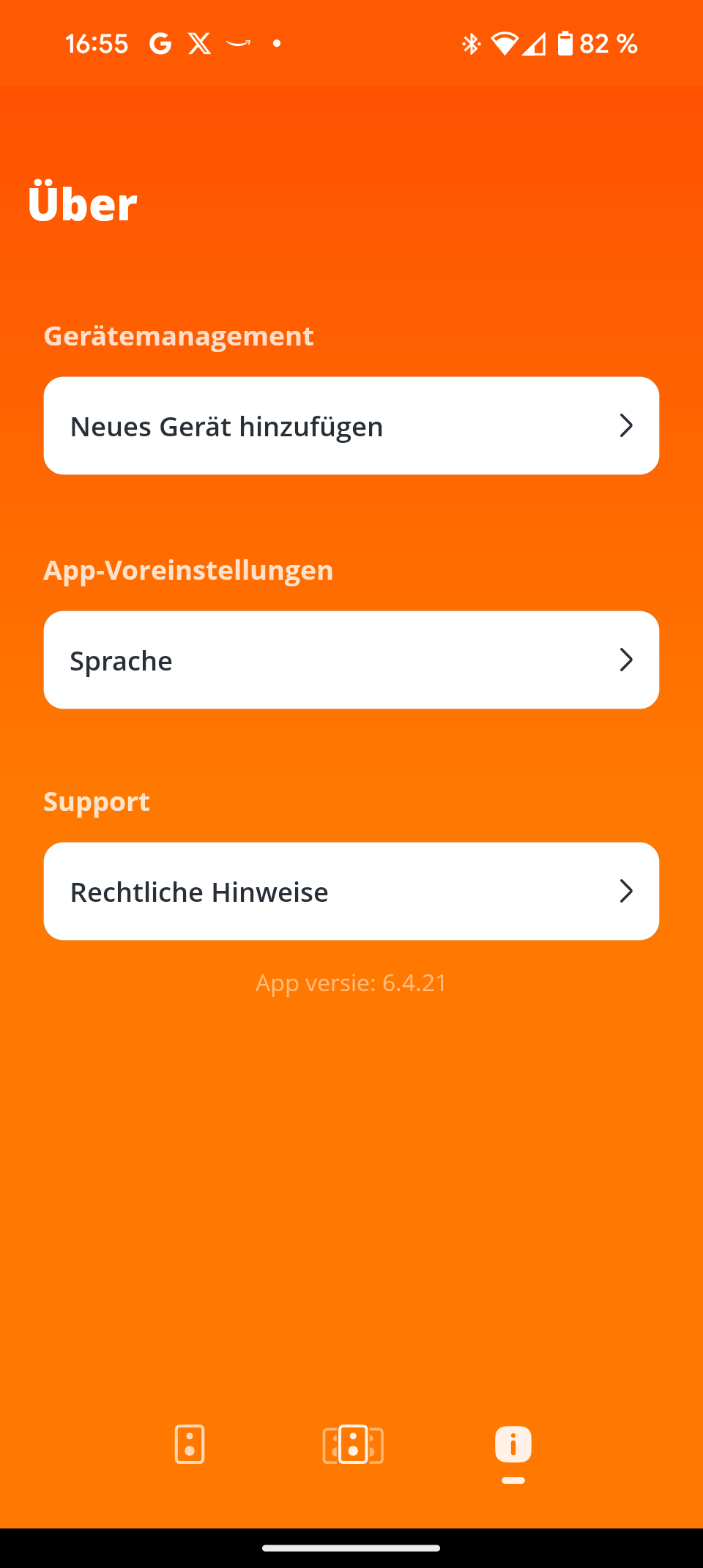
JBL Charge 5 Screenshot
JBL Charge 5 Screenshot
JBL Charge 5 Screenshot
JBL Charge 5 Screenshot

JBL Charge 5 Screenshot

JBL Charge 5 Screenshot

Akku
Im Inneren der Box steckt ein Lithium-Ionen-Akku mit einer Kapazität von 7500 mAh bei 3,6 Watt bzw. 27 Wh. Damit verspricht JBL eine Laufzeit von bis zu 20 Stunden. Dieser Wert ist stark von der Lautstärke abhängig. In unserem Praxistest mit etwa 60 Prozent Lautstärke waren eher 15 Stunden realistisch – immer noch ein sehr guter Wert. Für den Tag am See reicht der Akku also aus.
Wie bereits erwähnt, lässt sich die JBL Charge 5 auch als Powerbank nutzen, um unterwegs Smartphone & Co. aufzuladen. Das geht natürlich auf Kosten der Akkulaufzeit. Eine Schnellladefunktion gibt es nicht. Für eine Vollladung des Akkus sollte man mindestens 4 Stunden Zeit einplanen.
Was kostet die JBL Charge 5?
Der Preis der JBL Charge 5 liegt seit ihrer Einführung sehr stabil bei rund 123 Euro (Amazon). Für einen hochwertigen, vielseitigen Bluetooth-Lautsprecher mit Top-Klang geht dieser Preis absolut in Ordnung.
Fazit
Mit der JBL Charge 5 bekommt man einen richtig guten Bluetooth-Lautsprecher, der kaum Wünsche offen lässt. Das robuste, kompakte Design, die hohe Klangqualität und die lange Akkulaufzeit prädestinieren die Box als perfekten Begleiter für alle Aktivitäten drinnen und draußen.
Die vielseitige Bluetooth-Box spielt ihre Stärken besonders beim Outdoor-Einsatz voll aus. Dank des voll wasserdichten Gehäuses muss man auch keine Angst vor einem Regenguss oder Spritzern am Pool haben. Auch wenn man schon eine Charge 4 besitzt, kann sich das Upgrade lohnen. Der Klang wurde merklich verfeinert und die neue Akku-Anzeige ist ein nettes Extra. Zudem klingen mehrere gekoppelte JBL-Boxen besonders beeindruckend.
Natürlich gibt es bei den kleinen Abmessungen physikalische Grenzen, die auch JBL nicht überwinden kann. Wer absolut high-endigen HiFi-Sound erwartet, wird enttäuscht sein. Für die Größe klingt die Charge 5 aber wirklich beeindruckend gut.
Alternativen gibt es viele, keine sind aber in Summe ihrer Eigenschaften eindeutig besser – die JBL Charge 5 behauptet sich in ihrer Klasse ganz vorne. Das durchdachte Gesamtpaket und die breite Verfügbarkeit sprechen klar für den Kauf.
Wer einen top Bluetooth-Lautsprecher für drinnen und draußen sucht und rund 123 Euro (Amazon) investieren kann, macht mit der JBL Charge 5 garantiert nichts falsch. Eine klare Empfehlung!
Edifier MP230
Edifier MP230
Der Edifier MP230 kombiniert ein nostalgisches MDF-Holzgehäuse mit überraschend kräftigem Klang – allerdings ohne Outdoor-Ambitionen. Wir testen den 50-Euro-Bluetooth-Lautsprecher.
- stilvolles Retro-Design mit Holzgehäuse
- überraschend kräftiger Bass für die Größe
- viele Anschlüsse (Bluetooth, AUX, USB-C, MicroSD)
- leichte Bedienung
- kompakte Maße
- keine Wasserdichtigkeit (keine IP-Zertifizierung)
- mittelmäßige Akkulaufzeit (9 Stunden)
- Verzerrungen bei hoher Lautstärke
- kein eingebautes Mikrofon für Freisprechfunktion
- keine App – kein Equalizer
Bluetooth-Lautsprecher Edifier MP230
Der Edifier MP230 kombiniert ein nostalgisches MDF-Holzgehäuse mit überraschend kräftigem Klang – allerdings ohne Outdoor-Ambitionen. Wir testen den 50-Euro-Bluetooth-Lautsprecher.
Während viele Bluetooth-Lautsprecher aussehen, als wären sie direkt vom Raumschiff Enterprise gebeamt, schlägt der Edifier MP230 einen entgegengesetzten Weg ein. Mit seinem Retro-Design erinnert er an Zeiten, als Radio noch ein Möbelstück war und nicht bloß eine App auf dem Smartphone. Er ist ein Bluetooth-Lautsprecher für Leute, die ihre Musik lieber mit Stil als am Strand hören. Wir haben den Edifier MP230 getestet.
Design und Verarbeitung
Der MP230 ist ein echter Hingucker. Mit seinem rechteckigen MDF-Holzgehäuse und dem Stoffgitter an der Front wirkt er wie ein Miniatur-Radio aus den 1960er Jahren. Erhältlich ist er in Braun mit Walnuss-Furnier, Schwarz, Weiß und Schwarz-Grün – wobei die braune und die weiße Version am meisten Vintage-Flair versprüht.
Die klaviertastenähnlichen Bedienelemente auf der Oberseite verstärken den Retro-Charakter. Leider sind sie aus Kunststoff statt Metall – ein kleiner Authentizitätsbruch. Mit Abmessungen von 164 × 84,3 × 108,8 mm und 850 g Gewicht passt der Lautsprecher problemlos auf jeden Schreibtisch oder ins Regal.
Vier Gummifüße verhindern ungewollte Tanzeinlagen auf glatten Oberflächen. Diese Füße lösen sich recht leicht – ein Tropfen Klebstoff hilft. Anders als viele seiner modernen Kollegen trägt der MP230 keine IP-Zertifizierung. Regen und Sand sind also seine natürlichen Feinde – dieser Lautsprecher fühlt sich in der freien Wildbahn deutlich unwohler als im behüteten Wohnzimmer.
Edifier MP230 Bilder
Edifier MP230

Edifier MP230

Edifier MP230

Edifier MP230

Edifier MP230

Edifier MP230

Edifier MP230

Edifier MP230

Edifier MP230

Edifier MP230

Wie gut ist der Klang des Edifier MP230?
Unter der Holzhaube arbeiten zwei 48-mm-Vollbereichstreiber mit insgesamt 20 Watt RMS. Unterstützt werden sie von dualen passiven Radiatoren für mehr Tiefgang. Der Frequenzbereich reicht von 70 Hz bis 13 kHz.
Für seine kompakte Größe liefert der MP230 einen überraschend kräftigen Klang. Besonders bei Pop und elektronischer Musik überzeugt der Bass – hier spielt der kleine Holzkasten seine Resonanzeigenschaften voll aus. Die Mitten kommen klar und präzise, was Gesang und Gitarren zugutekommt.
Bei den Höhen zeigt der MP230 Schwächen. Komplexe Tracks können dünn klingen, und bei rockiger Musik verschwimmen die Instrumente gelegentlich zu einem undifferenzierten Klangbrei. Bei hoher Lautstärke kommen zudem deutliche Verzerrungen ins Spiel – hier stößt die kleine Box an physikalische Grenzen.
Ein eingebautes Mikrofon sucht man vergebens – Telefonate müssen also weiterhin am Smartphone geführt werden.
Bedienung
Die Bedienung erfolgt über fünf Tasten: Ein/Aus, Bluetooth-Pairing, Wiedergabe/Pause und Lautstärkeregelung. Simpel, intuitiv und ohne Schnickschnack.
Eine begleitende App gibt es nicht. So fehlen Anpassungsmöglichkeiten wie ein Equalizer. Auch Firmware-Updates sind ohne App nicht möglich. Dieser Verzicht passt immerhin zur altmodischen Optik. Die Bluetooth-Kopplung (Version 5.0) funktioniert problemlos und bietet eine stabile Verbindung.
Akku
Mit seinem 2500-mAh-Akku hält der MP230 bis zu 9 Stunden bei mittlerer Lautstärke durch. Das ist okay, aber nichts Besonderes – moderne Konkurrenten schaffen im Schnitt 12 Stunden, der ebenfalls in Retro-Optik gehaltene Marshall Emberton III (Testbericht) gar rekordverdächtige 32 Stunden. Für einen Grillabend reicht es, für ein Festival ohne Steckdose wird es knapp.
Das Laden erfolgt über USB-C, ein Kabel liegt bei. Das Netzteil muss separat erworben werden. Die Ladezeit beträgt etwa drei bis vier Stunden.
Konnektivität und technische Eigenschaften
Der MP230 bietet erstaunlich vielseitige Anschlussmöglichkeiten. Neben Bluetooth 5.0 verfügt er über einen 3,5-mm-Klinkenanschluss (AUX) für kabelgebundene Quellen. Das passende Kabel liegt sogar bei.
Der USB-C-Anschluss dient nicht nur zum Laden, sondern kann auch als Audioeingang genutzt werden. Eine echte Überraschung ist der microSD-Kartensteckplatz – ein Feature, das bei modernen Bluetooth-Lautsprechern fast ausgestorben ist. Der MP230 kann damit eigenständig Musik abspielen, ohne mit einem Smartphone gekoppelt zu sein.
Was kostet der Edifier MP230?
Der Preis variiert je nach Farbvariante zwischen 50 Euro und 80 Euro. Die grüne Version ist am günstigsten, sieht aber auch gewöhnungsbedürftig aus. Die edle Walnuss-Version kostet entsprechend mehr – hier zahlt man auch für den Möbelstück-Charakter.
Welche Alternativen gibt es?
Fazit
Der Edifier MP230 ist der Gentleman unter den Bluetooth-Lautsprechern – stilvoller Auftritt, solide Performance, aber kein Outdoor-Abenteurer. Sein Retro-Design macht ihn zum Hingucker in jedem Wohnzimmer oder Büro.
Klanglich überzeugt er bei mittlerer Lautstärke mit warmem, basslastigem Sound. Die vielseitigen Anschlussmöglichkeiten inklusive MicroSD-Slot bieten Flexibilität, die viele moderne Lautsprecher vermissen lassen. Schwächen zeigt er bei der Akkulaufzeit und fehlendem Wasser- und Staubschutz. Auch bei hoher Lautstärke gerät er an seine Grenzen.
Der MP230 ist der ideale Lautsprecher für alle, die Wert auf Stil legen und ihre Musik lieber im Wohnzimmer als am Strand genießen. Ein charmanter Anachronismus in einer Welt aus wasserdichten Plastikzylindern.
Teufel Rockster Cross
Teufel Rockster Cross
Teufel Rockster Cross
Sonos Roam
Sonos Roam
Der Sonos Roam ist klein, schick, laut und teuer. Er ist ein Outdoor-Speaker mit Bluetooth, integriert sich dank WLAN auch in bestehende Sonos-Systeme. TechStage macht den Test.
- Verblüffender Bass aus sehr kleinem Gehäuse
- Mit WLAN lässt er sich in Sonos-Systeme integrieren
- Wirksame automatische Trueplay Einmessung
- Unterstützt Amazon Alexa und Google Assistant
- Tastenfeld nicht optimal gelöst
- Hoher Preis
Bluetooth/WLAN-Lautsprecher Sonos Roam im Test
Der Sonos Roam ist klein, schick, laut und teuer. Er ist ein Outdoor-Speaker mit Bluetooth, integriert sich dank WLAN auch in bestehende Sonos-Systeme. TechStage macht den Test.
Sonos setzt seit Jahren die Maßstäbe für Multiroom-Audio-Systeme (Ratgeber) mit Lautsprechern, die sich via WLAN oder Ethernet vernetzen lassen. Bluetooth standen die Amerikaner immer skeptisch gegenüber. In der Werbung machten sie sich gar darüber lustig. Viele Nutzer sahen das offenbar trotzdem anders. Mit dem Move brachte Sonos einen mobilen Lautsprecher, der neben WLAN auch Bluetooth unterstützt. Mobil war bei dem Schwergewicht allerdings trotz Akku relativ zu sehen. Trotzdem schneidet der Sonos Move in unserem Testbericht vor allem wegen seines guten Klangs und der sehr guten Verarbeitung mit der Note sehr gut ab.
Design und Verarbeitung
Sonos setzt auf schlichte, aber robuste Gehäuse mit sauberer Verarbeitung. Beim Roam spricht zwar das für die geringen Abmessungen von 6,2 x 16,8 x 6 Zentimetern mit 430 Gramm recht schwer geratene Gehäuse für einen gewissen Materialaufwand, aber die Oberflächen wirken nicht besonders wertig. In der Anmutung hebt sich der teure Roam kaum von günstigen No-Names für einen Bruchteil des Preises ab. Immerhin erfüllt er die IP67-Norm, ist also theoretisch im Stande, eine halbe Stunde in einem Meter Tiefe im Swimmingpool zu überstehen. Das sollte man aber besser nur im Planschbecken ausprobieren, weil der kleine Sonos nicht schwimmen kann und diese Tauchtiefe sonst schneller überschreitet als einem lieb ist. Auch gilt die Wasserdichtigkeit nicht für Salz- oder Seifenwasser. Zudem wäre eine solche Wassermusik klanglich nicht die Offenbarung.

Apropos Klang: Sonos hat in dieser Disziplin einen guten Ruf zu wahren. Deshalb vertrauen die Entwickler auf ein richtiges 2-Wege-System mit großem ovalem Tief-Mittel-Töner und einer auf hohe Töne spezialisierten Kalotte. Dieses Prinzip ist den in dieser Klasse verbreiteten Breitband-Chassis mit einem Treiber für alle Frequenzbereiche gerade bei der Obertonwiedergabe und im Bass überlegen, weil die Chassis auf eine bestimmte Aufgabe optimiert werden können.
Update: Sonos hat im Mai 2022 neue Farbvarianten des Sonos Roam angekündigt. Neben einem schwarzen oder grauen Gehäuse bekommt man den Sonos Roam demnächst in den Versionen „Sunset“, „Wave“ und „Olive“. Technisch hat sich nichts verändert.
Bedienung und Funktionalität
Der An-/Aus-Schalter sitzt auf der Rückseite neben der USB-C-Buchse. Die restlichen Tasten hat Sonos auf der linken Seite untergebracht. Sie sind als winzige Erhöhungen in die Gummioberfläche der Seitenwand eingearbeitet und farblich nicht abgehoben. Daher lassen sie sich sehr schlecht erkennen. Mit den Tasten am Roam lässt sich unter anderem die Wiedergabe starten und stoppen, die Lautstärke regeln, Titel überspringen oder die Mikrofone zum Schutz der Privatsphäre ausschalten. Auch der erstmalige Verbindungsaufbau mit einem Bluetooth-Gerät läuft über das seitliche Tastenfeld. Dabei kommt es auf die Nutzung an, ob sich die Tasten wirklich auf der linken Seite befinden. Wird der Roam nicht liegend, sondern aufrecht stehend betrieben, ist das Bedienfeld leicht zugänglich auf der Oberseite.

Man muss den Sonos Roam wie seine großen Brüder mit der Sonos App einrichten. Dazu will er neben WLAN-Verbindung auch noch Bluetooth aktiviert haben, um den Lautsprecher in der Nähe des Benutzers zu orten. Trotzdem fordert er noch eine Freigabe für die Ortungsdienste. Das ist verglichen mit gewöhnlichen Bluetooth-Boxen nicht nur um einiges Zeitraubender, sondern auch mit der Preisgabe persönlicher Daten verbunden. Denn die Nutzung setzt eine Registrierung bei Sonos voraus, mit der man sich dann in seinem Account einloggen muss.
Was Sonos wie immer toll gelöst hat, ist die Nutzerführung in der App. Ein besonderes Schmankerl ist allerdings die Trueplay-Einmessung. Mit seinem Mikrofon-Array erkennt der Roam den Raum, an den er sich nach einem Standortwechsel mit der Trueplay-Einmessung automatisch anpasst und den Klang für den jeweiligen Ort merkbar optimiert.
Die Mikrofone lassen sich auch zur Kommunikation mit den integrierten Sprach-Assistenten Amazon Alexa und Google Assistant nutzen. Dazu muss der Sonos Roam allerdings über ein WLAN-Netzwerk mit dem Internet verbunden sein. Im Gegensatz zu den Heimlautsprechern der Marke verzichtet der Sonos Roam auf einen Ethernet-Anschluss.

Was Zubehör betrifft, liegt wie bei kleinen Bluetooth-Lautsprechern üblich nur ein USB-C-Ladekabel bei. Wegen der Möglichkeit zur Netzwerk-Einbindung über WLAN wäre aber speziell bei diesem Lautsprecher eigentlich ein eigenes Netzteil wünschenswert. Es gibt allerdings die Möglichkeit, den Sonos Roam gegen einen Aufpreis von rund 50 Euro im Set mit einem kabellosen Ladegerät zu kaufen. Dieses haftet magnetisch an seiner Unterseite.
Die Akkulaufzeit liegt bei maximal zehn Stunden. Durch die Abschalt-Automatik, die den Roam nach kurzer Inaktivität in den Ruhemodus versetzt sind bis zu zehn Tage Standby möglich. Im Standby reagieren allerdings die Sprachassistenten nicht auf Zuruf.
Konnektivität
Man kann nach erfolgter Einrichtung seinen Sonos Roam sowohl über WLAN als auch über Bluetooth benutzen. Letzteres ist überall sinnvoll, wo kein Netzwerk zur Verfügung steht und auch Stromsparen angesagt ist. Also im Grunde überall draußen, wo man nur den Roam alleine direkt von seinem Smartphone aus ansteuern möchte.
Wie bei Sonos üblich, fehlt dem Roam ein analoger AUX-Eingang – ein Trend, der inzwischen auch viele andere Anbieter erreicht hat. So kassierte etwa JBL im Zuge der Modellpflege den Analog-Eingang am Bestseller JBL Flip 5 (Testbericht) ebenfalls ein.

Apple-User können mit AirPlay 2 direkt von ihrem iPhone, iPad oder Mac Musik auf den Roam streamen. Und sie können über Siri die Lautstärke anpassen oder zum nächsten Song skippen. Zusätzlich unterstützt der Lautsprecher Spotify Connect im WLAN.
Stereo-Wiedergabe mit zwei Sonos Roam ist möglich, wenn diese mit dem WLAN verbunden sind. Dann kann der User mit der Sonos App ein Stereo-Paar bilden und eine räumliche Wiedergabe erleben. Es klappt aber nicht, diese beiden Roam als Surround-Effekt-Kanal-Lautsprecher für ein Sonos Heimkino-System zu verwenden.
Klang
Klanglich überzeugt der Sonos Roam an allen möglichen Plätzen mit einem eindrucksvoll starken Bass, der trotz der geringen Abmessungen auch reichlich Tiefgang aufweist. In dieser Klasse macht ihm das keiner nach – zumindest, wenn man nur die Größe, nicht den Preis berücksichtigt.
Die Trueplay-Einmessung arbeitet unauffällig im Hintergrund, man staunt nur, wie viel Bass an jedem Platz im Raum aus dem Mini-Speaker kommt. Wer mal nicht aufpasst und den Sonos auf die falsche Seite legt – weil sich der Schriftzug auch auf dem Kopf stehend lesen lässt und man die winzigen Gummifüße leicht übersehen kann – bekommt einen Eindruck, welche Energie das 2-Wege-System in das kleine dreieckige Gehäuse pumpt. Dann wandert er im Takt der Beats über die Tischplatte.

Die Stimmen muten dafür etwas künstlich an, wenn man ihn mit dem JBL Flip 5 vergleicht, liefert der Sonos hier eine eher durchschnittliche Leistung. Auch wenn der Roam sein Bestes gibt, um Pegel zu erreichen, die man ihm rein äußerlich nicht zutraut, kann er bezüglich der Sauberkeit und Transparenz nicht verbergen, dass es sich um einen sehr kleinen Lautsprecher handelt. Wenn man ihn mit dem Sonos One vergleicht, der mit seinem integrierten Netzteil ebenso viel kostet wie ein Sonos Roam im Set mit dem Ladegerät, dann kann der Knirps klanglich keinen Stich landen. Denn der hat dann wirklich nur noch seine Mobilität und den Betrieb jenseits der Steckdose entgegenzusetzen.
Wenn man den Roam mit normalen Bluetooth-Boxen vergleicht, zieht er in seiner Preisklasse im Klang ebenfalls den Kürzeren. Doch auch hier entzieht er sich letztlich geschickt dem direkten Vergleich, weil er sich zu Hause ins Multiroom-Netzwerk mit unzähligen Streaming-Diensten einbinden lässt und mit Sprach-Assistenten kooperiert. So dürfte er seine spezifischen Anhänger im Sonos-Lager finden, denen er durch seine Vielseitigkeit gute Dienste leistet. Ein Klangwunder für den Preis ist er aber auf keinen Fall, eher schon für die geringe Größe.
Preis
Der in Schwarz oder Weiß erhältliche Sonos Roam kostet 179 Euro, der kabellose Charger zusätzlich 49 Euro. Auf Sonos-Produkte gibt es nur selten Nachlässe.
Fazit
So richtig billig war Sonos nie. Die Marke, die im Design auf Schnörkel verzichtet, besetzt das Premium-Segment der jeweiligen Wireless-Lautsprecher-Klassen. Entsprechend bietet der Roam eine einzigartige Mischung nützlicher Features, die ihn aus dem restlichen Angebot hervorhebt. Ein mobiler, ultrakompakter Bluetooth-Lautsprecher, der sich zu Hause auch via WLAN in das Multiroom-System des Platzhirschs einbinden lässt, ist genauso einzigartig wie die äußerst wirksame und praktische Trueplay-Einmessung zur Klanganpassung an den Aufstellungsort. Allerdings wirkt sein Finish nicht nur im Vergleich zu den großen Brüdern etwas einfach. Auch im Vergleich zu anderen kleinen Bluetooth-Lautsprechern zu einem Premium-Preis kann er zumindest äußerlich kaum punkten.
Um es klar zu sagen: Der Roam macht nur Sinn, wenn man ein Sonos-System zu Hause hat. Dann geht auch rein von der Funktionalität der Preis in Ordnung. Alternativ empfehlen wir aus dem gleichen Haus den teureren, aber deutlich hochwertiger verarbeiteten, klanggewaltigeren Sonos Move (Testbericht), sofern es primär darum geht, den Lautsprecher auch mal auf der Terrasse oder im Garten zu verwenden. Das Beste vom Besten sammeln wir im Beitrag Testsieger Soundbars, Lautsprecher und Multiroom.
Tribit Stormbox Mini+
Tribit Stormbox Mini+
Die Tribit Stormbox Mini+ kommt mit einigen Extras wie Freisprecheinrichtung und Beleuchtung daher und lockt mit einem günstigen Preis von unter 40 Euro.
- gute Verarbeitung
- Stereo-Sound
- RGB-Beleuchtung
- beleuchtete Tasten
- Klang bestenfalls mittelmäßg
- nur Standard-Codec
- relativ groß und schwer
Bluetooth-Lautsprecher Tribit Stormbox Mini+ im Test: viel Leistung, wenig Klang
Die Tribit Stormbox Mini+ kommt mit einigen Extras wie Freisprecheinrichtung und Beleuchtung daher und lockt mit einem günstigen Preis von unter 40 Euro.
Mit dem Stormbox Mini+ setzt Tribit auf eine großzügige Ausstattung zum kleinen Preis: Wer die aufgerufenen 36 Euro (Amazon) zahlt, bekommt einen kompakten Speaker mit 360-Grad-Sound, 12-Watt-Leistung, RGB-Beleuchtung und Freisprechfunktion. Inwiefern die Stormbox Mini+ ihr Geld wert ist und was der Lautsprecher klanglich draufhat, finden wir in unserem Test heraus.
Design und Verarbeitung des Tronsmart Mirtune H1
Der Tribit Stormbox Mini+ hat mit 11,9 x 9,1 x 9,1 cm etwa die Maße einer Kaffeetasse und wiegt 545 g. Das Design des Speakers an sich gefällt uns mit einer Mischung aus Schlichtheit und eigenem Style. Tribit hat sichtlich darauf Wert gelegt, die Stormbox Mini+ nicht wie ein billiges China-Produkt aussehen zu lassen.
Das Gehäuse ist rundum mit einem Stoff-Mesh überzogen, während es auf der Ober- und Unterseite mit Silikon verkleidet ist. Außerdem befindet sich oben noch eine kleine Trageschlaufe aus Stoff, mit der sich der Bluetooth-Lautsprecher flexibel befestigen lässt. Gummifüße an der Unterseite sorgen für zusätzliche Standfestigkeit.
Tribit Stormbox Mini+ Bilder
Tribit Stormbox Mini+

Tribit Stormbox Mini+

Tribit Stormbox Mini+

Tribit Stormbox Mini+

Tribit Stormbox Mini+

Tribit Stormbox Mini+

Tribit verkauft die Stormbox Mini+ in den Farben Schwarz, Grün und Blau, wobei die Grün- und Blautöne jeweils etwas ins Cremefarbene abgleiten. Die Auswahl ist zwar nicht so riesig wie bei JBL, aber alle gebotenen Varianten wirken stimmig und dürften eine große Bandbreite an Geschmäckern abdecken.
Wie es sich für einen Tribit-Lautsprecher gehört, ist auch die Stormbox Mini+ nach IPX7 staub- und wasserdicht. Der Speaker übersteht also ein Eintauchen in einer Wassertiefe von einem Meter für bis zu 30 Minuten.
Wie gut ist der Klang der Tribit Stormbox Mini+?
Der Tribit hat im Inneren des 360°-Stereo-Speakers zwei 48mm-Treiber mit einer Leistung von 12 Watt. Das ist für ein Gerät dieser Kategorie außergewöhnlich, denn vergleichbare Modelle bringen es nur auf Mono-Klang mit unter 10 Watt. Beim abgedeckten Frequenzbereich bietet die Stormbox Mini+ den Standard von 80 Hz bis 20 kHz.
Wir haben den Speaker mit verschiedenen Inhalten auf Herz und Nieren geprüft, darunter sowohl Podcasts und Hörbücher als auch Musik verschiedener Stilrichtungen. Phil Collins’ “In The Air Tonight” klingt relativ ausgeglichen, aber auch ohne große Highlights. Insgesamt wirken sowohl der Bass als auch die Höhen etwas flach und lassen an Volumen missen. Der Equalizer schafft hier etwas Abhilfe, auch wenn man aufpassen muss, einen guten Mittelweg zu finden, damit der Bass nicht matschig wird.
Klassische Musik profitiert ebenfalls von den Einstellungen des Equalizers. Edward Elgars Enigma Variation Nr. 9 (“Nimrod”) lebt von seiner Dynamik, die mit der Tribit Stormbox Mini+ nicht zur Geltung kommt. Derweil lässt Elgars “Pomp and Circumstance” deutlich an Bombast vermissen. Der Speaker hat gerade auf höherer Lautstärke Probleme mit den Tiefen, aber auch mit den Höhen. Bässe wirken matschig und unsauber, während die Höhen unangenehm knirschen und fast kratzig klingen. Insgesamt wirkt der Sound, als käme er aus einem in die Jahre gekommenen Plattenspieler mit integriertem Lautsprecher.
Auch bei gesprochenen Inhalten kann die Stormbox Mini+ nicht komplett überzeugen. Der etwas matschige, gedämpfte Grundklang zieht sich auch bei Podcasts durch das Hörerlebnis. Allerdings fallen die Defizite beim Sound weniger auf, weshalb wir den Speaker für derartigen Content durchaus empfehlen können. Nur bei maximaler Lautstärke wird der Sound unangenehm schrill.
Als zusätzliche Features bietet die Stormbox Mini+ eine Freisprechfunktion. Die Sprachqualität geht absolut in Ordnung. Darüber hinaus besitzt der Speaker einen AUX-Klinke-Eingang, der die Soundqualität ein wenig verbessert. Das entschädigt auch dafür, dass der Bluetooth-Lautsprecher nur den Standard-SBC-Codec unterstützt.
Bedienung und App der Tribit Stormbox Mini+
Tribit orientiert sich bei der Bedienung der Stormbox Mini+ am Platzhirsch JBL und entscheidet sich für eine Kombination aus einem großen Tastenpanel an der Front sowie drei kleinere Tasten auf der Rückseite. Die drei großen Tasten vorne steuern die Wiedergabe und die Freisprechfunktion sowie die Lautstärke des Bluetooth-Lautsprechers. Die hinteren Buttons dienen zum Ein- und Ausschalten des Speakers selbst wie der Bluetooth-Funktion und der Beleuchtung.
Alle Tasten verfügen über einen angenehmen Druckwiderstand. Während die drei Frontbuttons sehr groß sind und sich aufgrund ihrer Haptik gut ertasten lassen, sind die drei kleinen Knöpfe hinten erfreulicherweise beleuchtet, sodass wir sie auch bei geringem Umgebungslicht gut identifizieren können.
Tribit Stormbox Mini+ Screenshot
Tribit Stormbox Mini+ Screenshot
Tribit Stormbox Mini+ Screenshot
Tribit Stormbox Mini+ Screenshot
Tribit Stormbox Mini+ Screenshot
Tribit Stormbox Mini+ Screenshot
Tribit Stormbox Mini+ Screenshot
Tribit Stormbox Mini+ Screenshot
Tribit Stormbox Mini+ Screenshot
Die Tribit Stormbox Mini+ unterstützt die Tribit-App, die kostenlos im App Store von Apple und im Google Play Store zur Verfügung steht. Wer möchte, kann ein Nutzerkonto erstellen, um Einstellungen zu übertragen. Die App funktioniert aber auch ohne eigenen Account. Die Kopplung der Stormbox Mini+ funktioniert im Test problemlos und dauert nur wenige Sekunden. Auf Wunsch können wir direkt die aktuelle Firmware aufspielen, wobei die Aktualisierung etwa fünf Minuten dauert. Die App selbst erlaubt uns dann die Steuerung des Speakers und zeigt den Ladestand des Akkus an. Zudem können wir zwischen bei Modi für die Beleuchtung wechseln.
Das Herzstück der App ist aber der integrierte Equalizer mit fünf Voreinstellungen (Hörbuch, Klassisch, Rock, Jazz und Musik) sowie benutzerdefinierten Profilen, deren Anzahl offenbar nicht begrenzt wird (im Test haben wir probeweise 10 Profile erstellt). Der Equalizer bietet dabei insgesamt neun verschiedene Kanäle zwischen 80 Hz und 13 kHz. Dieser Umfang an Einstellungsmöglichkeiten ist groß für einen Bluetooth-Lautsprecher – einige Konkurrenzmodelle bieten zwar einen Equalizer, allerdings nur mit bis zu fünf Kanälen oder komplett ohne Option für benutzerdefinierte Einstellungen. Weil sich Änderungen am Equalizer auch deutlich auf den Klang auswirken, ist diese Funktion definitiv ein lohnenswertes Extra der App.
Was uns bei der Software aber minimal negativ auffällt, ist die Übersetzung. Hier finden sich teilweise komische Formulierungen wie “Verlassen Sie die aktuelle Schnittstelle während der Aktualisierung nicht” (beim Firmware-Update). Der Bedienbarkeit der Software tut das aber keinen großen Abbruch, weil die Aussagen jederzeit noch verständlich sind und Fehler sich in Grenzen halten.
Der Akku des Tribit Stormbox Mini+
Tribit gibt die Akkulaufzeit der Stormbox Mini+ mit bis zu 12 Stunden an. Dieser Wert gilt bei mittlerer Lautstärke und deaktivierter Beleuchtung und deckt sich mit unseren Erfahrungen im Test. Gemessen an Größe und Gewicht des Bluetooth-Lautsprechers hätte man vielleicht einen etwas leistungsstärkeren Akku erwartet, aber immerhin bewegt sich die Stormbox Mini+ noch im Mittelfeld vergleichbarer Hardware. Ein Ladevorgang mit dem beiliegenden USB-C-Kabel dauert übrigens 2,5 Stunden.
Was kostet die Tribit Stormbox Mini+?
Mit einem Preis von 36 Euro (Amazon) zum Testzeitpunkt bewegt sich die Tribit Stormbox Mini+ im unteren Segment der Bluetooth-Lautsprecher.
Fazit
Die Tribit Stormbox Mini+ ist für einen Bluetooth-Lautsprecher gleich in mehrfacher Hinsicht ungewöhnlich. Erstens ist sie relativ groß und schwer, zweitens bietet sie echten Stereo-Sound und eine recht hohe Leistung von 12 Watt. Trotzdem kann sie in unserem Test nicht vollumfänglich überzeugen.
Zuerst das Positive: Der Speaker ist gut verarbeitet, die integrierte Beleuchtung ist ein nettes Extra und die Bedienung funktioniert reibungslos. Der Equalizer der App wirkt sich tatsächlich auf den Klang aus und die Akkulaufzeit geht mit 12 Stunden noch in Ordnung.
Deutliche Schwächen zeigt die Stormbox Mini+ dann aber beim Klang und beweist, dass hohe Leistung noch lange kein Garant für guten Sound ist. Insgesamt fehlt es dem Speaker einfach an Druck und Volumen, wobei insbesondere der Bass ziemlich verwaschen wirkt. Bei hoher Lautstärke kommen dann auch die Höhen an ihre Grenzen.
Alles in allem können wir eine eingeschränkte Kaufempfehlung für die Stormbox Mini+ von Tribit abgeben. Wer mit den Schwächen beim Klang leben kann, bekommt nämlich eine solide, günstige und stylische Bluetooth-Box geboten.
Blitzwolf WA3
Blitzwolf WA3
Mit einer angeblichen Leistung von 100 Watt will der Bluetooth-Speaker Blitzwolf BW-WA3 die Konkurrenz von JBL, Tronsmart und Co. vom Tisch blasen. Ob er das schafft, zeigt unser Test.
- RGB-Beleuchtung
- keine App erforderlich
- TWS-Pairing möglich
- Klang enttäuscht
- keine Beleuchtung am Bedienpanel
- nur IPX5-Zertifizierung
Bluetooth-Lautsprecher Blitzwolf WA3 im Test
Mit einer angeblichen Leistung von 100 Watt will der Bluetooth-Speaker Blitzwolf BW-WA3 die Konkurrenz von JBL, Tronsmart und Co. vom Tisch blasen. Ob er das schafft, zeigt unser Test.
Outdoor-Lautsprecher für den Urlaub oder die nächste Beachparty gibt es wie Sand am Meer. Blitzwolf sticht aus der Masse mit einer besonders hohen Leistung hervor und zeigt mit dem WA3 Bluetooth-Speaker ein Gerät, das mit 100 Watt die Konkurrenz deutlich übertrumpft. Wir klären in unserem Test, was der Lautsprecher taugt und ob er in der Praxis mit Platzhirschen wie dem JBL Flip 5 (Testbericht) oder dem günstigen Tronsmart Bang (Testbericht) mithalten kann.
Design und Verarbeitung
Schon beim Design hebt sich der WA3 von klassischen Bluetooth-Boxen ab, da er einen eher groben Eindruck hinterlässt. Für seine geringe Größe bringt der Lautsprecher ein hohes Gewicht auf die Waage und überrascht mit seiner kantigen Optik. Dass Blitzwolf den Speaker, der immerhin 1561 Gramm wiegt, als „light weight“ bewirbt, erscheint uns dann doch etwas weit hergeholt.
Trotzdem gefällt uns der WA3: Das graue Kunststoffgehäuse ergänzt sich mit dem Metall-Mesh über den Speakern. Die anpassbare RGB-Beleuchtung der seitlichen Lautsprecher sorgt für Lichtstimmung zur Musik. Der gesamte Lautsprecher lässt sich gut reinigen und macht einen ordentlich verarbeiteten Eindruck. Was uns allerdings negativ aufgefallen ist, war der Geruch des Geräts beim Auspacken: Uns stieg direkt ein beißender Plastikgestank in die Nase – wir empfehlen das Auslüften vor dem ersten Gebrauch.
Obwohl es sich beim WA3 explizit um einen Lautsprecher für den Outdoor-Gebrauch handelt, verfügt das Gehäuse über keinerlei Stoßschutz. Außerdem ist der Speaker nur nach IPX5-Standard zertifiziert, was bedeutet, dass er gegen Spritz- und Strahlwasser geschützt ist, ein Untertauchen in Wasser aber nicht übersteht. Fällt der Speaker also doch mal in den Pool, kann man ihn vermutlich direkt wegschmeißen.

Bedienung und Betrieb
Auch in Bezug auf die Bedienung liegen beim WA3 von Blitzwolf Licht und Schatten nahe beieinander. Zunächst einmal das Positive: Wir können den Speaker ganz einfach per Bluetooth mit unserem Smartphone oder einem anderen mobilen Wiedergabe-Gerät verbinden. Eine App ist nicht erforderlich, die Koppelung dauert nur wenige Sekunden. Alternativ können wir aber auch andere Geräte mit dem beiliegenden AUX-Kabel verbinden oder Musik von einem USB-Stick sowie einer SD-Karte direkt abspielen. Wer möchte, kann die TWS-Pairing-Funktion nutzen, um zwei gleiche Lautsprecher für echten Stereoklang zu verbinden.
Die Bedienung funktioniert über ein gummiertes Bedienpanel, das wir im Test aber ziemlich unübersichtlich empfunden haben. Das Problem: Nur einige der Tasten sind selbsterklärend und es gibt nur kleine LEDs, die anzeigen, ob ein bestimmtes Feature gerade aktiviert ist oder nicht. Nutzer müssen sich also vor allem im Dunkeln genau merken, welche Taste sich wo befindet und welche Leuchte zu welchem Feature gehört. Das hätte man auch geschickter lösen können.
Ein weiteres Problem sind die Tasten selbst, die nicht nur doppelt belegt sind, sondern auch verzögert reagieren. Betätigen wir etwa die Play/Pause-Taste, dauert es mitunter bis zu drei Sekunden, bis die Musik gestartet beziehungsweise pausiert wird. Die Tasten zur Steuerung der Lautstärke reagieren glücklicherweise zügiger, aber den Input-Lag des Play-Buttons empfanden wir im Test als störend.
Eine App für den Blitzwolf WA3 gibt es nicht, dafür verfügt der Speaker über einen integrierten Equalizer. Hier können wir auf Tastendruck am Speaker zwischen drei EQ-Modi wechseln, während eine kleine LED anzeigt, welcher Modus gerade aktiv ist. Die Beleuchtung können wir ebenfalls per Tastendruck ein- oder ausschalten, verschiedene Modi gibt es hier allerdings keine.
Klang
Wir haben den Klang des WA3 in allen drei EQ-Modi mit verschiedenen Songs getestet – und ein ernüchterndes Ergebnis festgestellt. Im normalen Modus klingt etwa Ain’t No Rest For The Wicked von Cage the Elephant seltsam unrund und verzerrt, gleichzeitig aber auch irgendwie dumpf. Bei Adeles Rolling in the Deep verfestigt sich dieser Eindruck, die Gitarrenklänge vibrieren hier sogar und klirren stark. Die kratzigen Töne bleiben im Hochton-Modus erhalten, während der Gesang schon fast unerträglich schrill wird und die Bässe mit dem Schlagzeug wie eine Rappeldose vor sich hinscheppern – bereits bei moderater Lautstärke.

Besonders extrem wird das Klangbild dann bei aktiviertem Bassmodus. Wir haben den Speaker in diesem Fall mit dem Song Under the Influence von The Chemical Brothers laufen lassen. Dabei verstärkten sich alle Probleme, die wir in den anderen Modi bereits festgestellt hatten: Der Sound kam teils dumpf, sogar mit Hall aus den Speakern, während die tiefen Töne kratzig und scheppernd erklangen. Insgesamt wirkte es auf uns so, als hätte jemand eine Band in einem leeren U-Bahn-Tunnel spielen lassen und Teile des Schlagzeugs mit Dosen ersetzt.
Insgesamt konnten wir also in keiner Einstellung und bei keiner Lautstärke einen ansatzweise zufriedenstellenden Sound aus dem WA3 herauskitzeln. Selbst diejenigen unter euch, die keinen großen Wert auf den Klang eines Bluetooth-Speakers für den Outdoor-Gebrauch legen, sind mit Konkurrenzmodellen zum gleichen Preis wie dem Anker Soundcore Motion Boom (Testbericht) deutlich besser bedient.
Akku und Extras
Blitzwolf gibt die Akkulaufzeit des WA3 je nach Modus mit 12 bis 20 Stunden an. Im normalen Musikgebrauch bei mittlerer Lautstärke hielt der Speaker in unserem Test rund zehn Stunden durch, die 20 Stunden beziehen sich auf die Nutzung des Lautsprechers als Freisprechanlage für das eigene Smartphone. In Anbetracht der Leistung von 100 Watt und der Akkukapazität von 5000 mAh ist das ein passabler Wert. Die Ladedauer für ein vollständiges Aufladen des WA3 liegt bei fünf Stunden und bewegt sich damit auf einem vergleichbaren Niveau mit anderen Bluetooth-Boxen wie dem Sony XB33 (Testbericht) oder dem Tronsmart Bang (Testbericht).
Besondere Extras bietet der WA3 von Blitzwolf gegenüber der Konkurrenz nicht. Der Speaker unterstützt zwar Sprachsteuerung via Google Assistant oder Siri, eine integrierte Powerbank oder andere Zusatzfeatures gibt es aber nicht. Dafür können Nutzer das Gerät auch zum Telefonieren nutzen, wenn der WA3 mit einem Smartphone gekoppelt wird.
Preis
Im folgenden Preisvergleich zeigen wir die günstigsten wasserfesten Bluetooth-Lautsprecher ab 15 Watt.
Fazit
Dass viel Leistung nicht ausreicht, um am hart umkämpften Markt für Bluetooth-Speaker zu bestehen, beweist Blitzwolf mit dem WA3 auf eindrucksvolle Weise. Der Lautsprecher ist verhältnismäßig schwer, kommt mit einer IPX5-Zertifizierung schlechter mit Outdoor-Bedingungen zurecht, als die Modelle anderer Hersteller und klingt maximal mittelmäßig.
Hama Twin 3.0
Hama Twin 3.0
Der Hama Twin 3.0 ist ein Bluetooth-Lautsprecher mit Identitätskrise: Ein Gerät, das sich in zwei Hälften teilen lässt. Für aktuell nur 34 Euro (regulär 60 Euro) verspricht er wasserfeste Outdoor-Tauglichkeit und echten Stereo-Sound. Wir machen den Test.
- teilbares Design für echten Stereoklang
- IP67-zertifiziert: staubdicht und wasserfest
- sehr gutes Preis-Leistungs-Verhältnis
- schwacher Bass
- keine App, kein Equalizer
- ungenaue Akkustandsanzeige
- leichte Verzerrungen bei Maximallautstärke
Bluetooth-Lautsprecher Hama Twin 3.0 im Test
Der Hama Twin 3.0 ist ein Bluetooth-Lautsprecher mit Identitätskrise: Ein Gerät, das sich in zwei Hälften teilen lässt. Für aktuell nur 34 Euro (regulär 60 Euro) verspricht er wasserfeste Outdoor-Tauglichkeit und echten Stereo-Sound. Wir machen den Test.
Der Hama Twin 3.0 wagt einen ungewöhnlichen Ansatz: Er lässt sich in zwei separate Lautsprecher teilen. Während andere Hersteller zwei Geräte verkaufen wollen, bietet Hama die Stereo-Lösung in einem Paket.
Für den aktuellen Schnäppchenpreis von 34 Euro (Amazon) ist der Twin 3.0 einer der günstigsten Bluetooth-Speaker mit echter Stereo-Funktion auf dem Markt. Das klingt fast zu gut, um wahr zu sein. Wir haben ihn getestet.
Design und Verarbeitung
Der Twin 3.0 sieht auf den ersten Blick wie ein gewöhnlicher zylindrischer Bluetooth-Lautsprecher aus – bis man ihn in zwei identische Hälften zieht. Eine elastische Silikonhülle umschließt beide Teile im zusammengesetzten Zustand und dient gleichzeitig als Tragegriff.
Mit 865 Gramm Gewicht und kompakten 8,4 x 8,4 x 21 cm ist er leicht zu transportieren. Die Gummifüße verhindern, dass er bei Bass-Attacken über den Tisch tanzt.
Die IP67-Zertifizierung macht den Twin 3.0 zum robusten Outdoor-Begleiter. Er überlebt Sandburgen-Unfälle am Strand und kann sogar auf Wasser schwimmen.
Das Teilungskonzept funktioniert erstaunlich gut: Die Hälften rasten sauber ineinander und koppeln sich beim Trennen automatisch als Stereo-Paar. Wer hätte gedacht, dass eine Trennung so reibungslos verlaufen kann?
Hama Twin 3.0 Bilder
Hama Twin 3.0

Hama Twin 3.0

Hama Twin 3.0

Hama Twin 3.0

Hama Twin 3.0

Hama Twin 3.0

Hama Twin 3.0

Wie gut ist der Klang des Hama Twin 3.0?
Der Klang des Twin 3.0 ist wie ein Film mit Plot-Twist: Als zusammengesteckter Zylinder enttäuscht er zunächst. Höhen und Mitten sind okay, aber der Bass fehlt.
Doch dann kommt die Überraschung: Trennt man die Hälften, entfaltet sich plötzlich ein beeindruckendes Stereo-Panorama. Der Bass bleibt zwar zurückhaltend, aber die räumliche Darstellung macht vieles wett.
Mit 30 Watt Gesamtleistung (2x 15 Watt) wird der Twin 3.0 angenehm laut. Bei Maximallautstärke verzerrt er allerdings – hier zeigt sich dann doch sein Budget-Charakter.
Im Vergleich zu JBL, Soundcore und Co. fehlt es an Bassfundament und Feindetails. Dafür bietet kaum ein anderer Lautsprecher dieser Preisklasse echten Stereoklang ohne Zweitgerät.
Bedienung
Die Bedienung erfolgt über physische Tasten für Ein/Aus, Lautstärke, Wiedergabe/Pause und Bluetooth-Pairing.
Das automatische Pairing der getrennten Hälften funktioniert so zuverlässig, dass sich manches Bluetooth-Headset eine Scheibe abschneiden könnte. Das integrierte Mikrofon ermöglicht Freisprechfunktion mit überraschend klarer Sprachübertragung.
Eine App sucht man vergeblich – kein Equalizer, keine Firmware-Updates, keine Datensammelei. Für Puristen ein Segen, für Klangfeintuner ein Ärgernis. Die Bluetooth 5.0-Verbindung erweist sich als stabil.
Akku
Der 4000-mAh-Akku hält bis zu 10 Stunden bei mittlerer Lautstärke durch. Die Ladezeit von 3 Stunden über USB-C ist akzeptabel.
Die Akkustandsanzeige ist denkbar unpräzise: Eine LED leuchtet rot, wenn der Akku zur Neige geht – mehr Informationen gibt es nicht. Viele Konkurrenten bieten hier deutlich genauere LED-Leisten.
Konnektivität
Der Twin 3.0 setzt ausschließlich auf Bluetooth 5.0. Weitere Anschlussmöglichkeiten? Fehlanzeige. Kein AUX-Eingang, kein MicroSD-Slot. Der einzige Anschluss ist USB-C zum Laden.
Was kostet der Hama Twin 3.0?
Regulär kostet der Hama Twin 3.0 etwa 60 Euro. Aktuell ist er für sehr günstige 34 Euro (Amazon) zu haben.
Fazit
Der Hama Twin 3.0 ist das Schweizer Taschenmesser unter den Bluetooth-Lautsprechern: vielseitig, kompakt und erstaunlich praktisch. Das teilbare Design bietet eine Flexibilität, die in dieser Preisklasse einzigartig ist.
Klanglich überzeugt er vor allem im Stereo-Modus, während ihm als Einzelgerät der fehlende Bass zum Verhängnis wird. Die robuste Bauweise mit IP67-Schutz und Schwimmfähigkeit macht ihn zum idealen Outdoor-Begleiter.
Für 34 Euro (Amazon) ist der Twin 3.0 ein echtes Schnäppchen. Wer einen flexiblen, wasserdichten Bluetooth-Lautsprecher mit Stereo-Funktion sucht und beim Bass Kompromisse eingehen kann, sollte zugreifen.
JBL Flip 6
JBL Flip 6
Der JBL Flip 6 gefällt uns im Test dank seines schicken und robusten Designs, der kompakten Bauweise und des trotzdem starken Sounds.
- kraftvoller, ausgewogener Klang
- robustes, wasserdichtes Design (IP67)
- kompakte Größe und geringes Gewicht
- kein AUX-Eingang für kabelgebundene Geräte
- keine Powerbank-Funktion
- keine Freisprechfunktion
Bluetooth-Lautsprecher JBL Flip 6 im Test
Der JBL Flip 6 gefällt uns im Test dank seines schicken und robusten Designs, der kompakten Bauweise und des trotzdem starken Sounds.
Mit dem Flip 6 hat JBL einen der beliebtesten Bluetooth-Lautsprecher am Markt, der vorwiegend wegen seines guten Klangs bei trotzdem kompakter Bauweise gefällt. Wir haben ihn getestet.
Design und Verarbeitung
Der JBL Flip 6 bleibt dem bewährten zylindrischen Design seiner Vorgänger treu. Das markanteste Merkmal ist das gewebte Stoffgitter, das den Großteil des Lautsprechers umhüllt und in sehr vielen verschiedenen Farbvarianten erhältlich ist. Zur Auswahl stehen unter anderem Schwarz, Weiß, Blau, Grün, Rot, Grau, Türkis und eine spezielle Camouflage-Ausführung. Auffällig ist das überarbeitete JBL-Logo, das nun deutlich größer auf der Front prangt und dem Lautsprecher einen markanten Look verleiht.
Mit Abmessungen von etwa 18 × 7 × 7 cm und einem Gewicht von rund 550 g ist der Flip 6 angenehm kompakt und lässt sich problemlos in einer Tasche oder einem Rucksack transportieren. Die Bauweise ermöglicht sowohl eine horizontale als auch vertikale Aufstellung. An den Seiten befinden sich die passiven Bassradiatoren, die bei tiefen Tönen sichtbar vibrieren.
Die Verarbeitung des JBL Flip 6 ist hervorragend. Alle Materialien fühlen sich hochwertig an und machen einen robusten Eindruck. Die Gummierungen an den Seiten schützen die Bassradiatoren und verleihen dem Lautsprecher zusätzliche Stabilität. Mit der IP67-Zertifizierung ist der Flip 6 nicht nur staub-, sondern auch vollständig wasserdicht – er übersteht damit unter Laborbedingungen ein Untertauchen in bis zu einem Meter Tiefe für 30 Minuten.
JBL Flip 6 Bilder
JBL Flip 6

JBL Flip 6

JBL Flip 6

JBL Flip 6

JBL Flip 6

JBL Flip 6

JBL Flip 6

JBL Flip 6

JBL Flip 6

Wie gut ist der Klang des JBL Flip 6?
Im Gegensatz zum Vorgänger setzt der Flip 6 auf ein Zwei-Wege-System mit einem separaten Hochtöner (16 mm) und einem ovalen Rennbahn-Tiefmitteltöner (45 × 80 mm). Dieses Setup wird durch zwei passive Bassradiatoren an den Seiten unterstützt.
Mit einer Gesamtleistung von 30 Watt (20 Watt für den Woofer und 10 Watt für den Tweeter) bietet der Flip 6 mehr Power als sein Vorgänger. Der Frequenzbereich reicht von 63 Hz bis 20 kHz – für einen Lautsprecher dieser Größe bemerkenswert.
Im Hörtest gefällt der JBL Flip 6 mit einem kraftvollen, dynamischen Klangbild. Die Basswiedergabe ist für einen Lautsprecher dieser Größe überraschend tief und präzise. Die passiven Radiatoren sorgen für ein sattes Fundament.
Mitten werden klar und detailliert wiedergegeben, was besonders Vocals zugutekommt. Stimmen klingen natürlich und präsent, ohne aufdringlich zu wirken. Die separate Hochtoneinheit sorgt für eine verbesserte Wiedergabe der hohen Frequenzen.
Bei höheren Lautstärken bleibt der Klang recht stabil und verzerrungsfrei. Erst bei maximaler Lautstärke zeigen sich negative Effekte. Dabei ist die Maximallautstärke hoch. Sie reicht aus, um einen mittelgroßen Raum oder eine kleine Gartenparty zu beschallen. Ein Mikrofon, um den Lautsprecher als Freisprecheinrichtung zu nutzen, gibt es nicht.
Bedienung und App
Auf der Oberseite befinden sich gut erreichbare Tasten für die wichtigsten Funktionen: Ein-/Ausschalter, Bluetooth-Pairing, Lautstärkeregelung sowie eine Multifunktionstaste für Play/Pause und Titelsprung. Die Tasten haben einen angenehmen Druckpunkt und sind auch im Dunkeln gut zu ertasten.
Die App JBL Portable wirkt aufgeräumt, hat aber (neben der Update-Option) nur zwei relevante Funktionen. Der Equalizer erlaubt das Anpassen von drei Bändern (Bässe, Mitten, Höhen), während die Party-Boost-Option mehrere kompatible JBL-Lautsprecher miteinander verbindet. Dabei gibt es zwei Modi: Im Stereo-Modus funktionieren zwei gleiche Lautsprecher als linker und rechter Kanal, während im Party-Modus bis zu 100 kompatible Lautsprecher synchron denselben Inhalt wiedergeben.
JBL Flip 6 Screenshot
JBL Flip 6 Screenshot
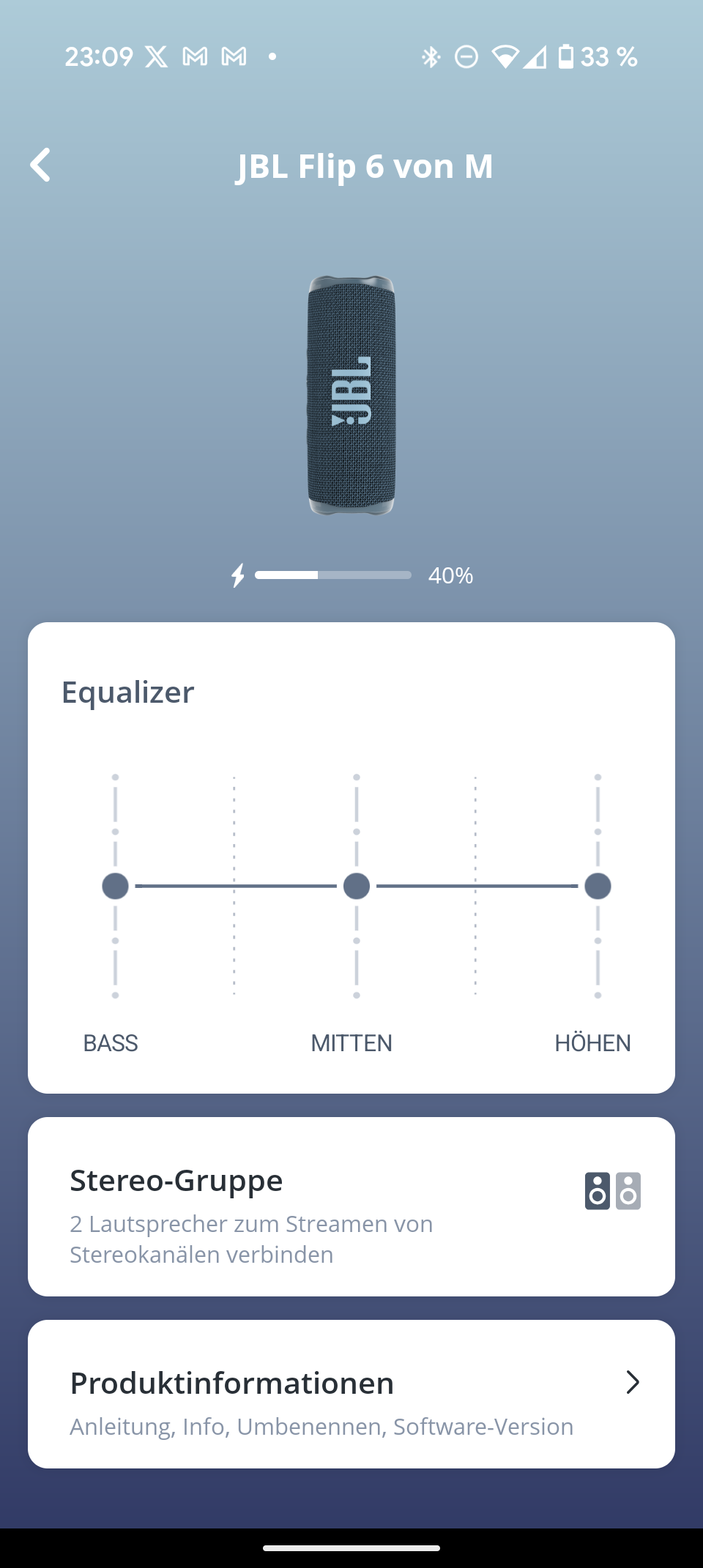
JBL Flip 6 Screenshot
JBL Flip 6 Screenshot
JBL Flip 6 Screenshot
JBL Flip 6 Screenshot

JBL Flip 6 Screenshot

Akku
Der Akku des JBL Flip 6 ermöglicht laut Hersteller eine Spielzeit von bis zu 12 Stunden. In der Praxis hängt die tatsächliche Akkulaufzeit stark von der gewählten Lautstärke ab. Bei moderater Lautstärke erreicht der Lautsprecher im Test die angegebene Laufzeit. Bei höherer Lautstärke reduziert sich die Spielzeit.
Das Aufladen erfolgt über den USB-C-Anschluss auf der Rückseite und dauert etwa 2,5 Stunden für eine vollständige Ladung. Der Lautsprecher spielt auch während des Ladevorgangs auf Wunsch weiter Musik. Am Gerät zeigt eine LED-Anzeige die Restkapazität. Eine Schnellladefunktion gibt es genauso wenig wie eine Powerbank-Funktion zum Aufladen von Smartphones.
Konnektivität und technische Eigenschaften
Der JBL Flip 6 setzt bei der Verbindung auf Bluetooth 5.1. Die Reichweite beträgt etwa 10 Meter. Die Verbindung bleibt im Test auch dann stabil, wenn sich eine Wand oder andere Hindernisse zwischen Smartphone und Lautsprecher befinden.
Bei der Bluetooth-Verbindung unterstützt die Box die Codecs SBC und AAC. High-Res-Codecs wie aptX oder LDAC werden jedoch nicht unterstützt. Dafür kennt der Flip 6 Multipoint.
Was kostet der JBL Flip 6?
Der JBL Flip 6 kostet etwa bei Mediamarkt 99 Euro. Andere Händler sind teilweise etwas günstiger, hier kommen dann aber Versandkosten hinzu.
Fazit
Der JBL Flip 6 ist ein rundum gelungener Bluetooth-Lautsprecher, der in fast allen Belangen überzeugt. Uns gefällt besonders das schicke, robuste und wasserdichte Design sowie das Zwei-Wege-Soundsystem, welches einen beeindruckenden Klang aus dem kleinen Formfaktor herauskitzelt. Die Partyboost-Funktion ermöglicht zudem, weitere Lautsprecher hinzuzufügen. Die App ist minimalistisch gehalten, bietet aber immerhin einen einfachen Equalizer.
Das Fehlen eines AUX-Eingangs könnte für manche Nutzer ein Nachteil sein, und auch eine Powerbank- und eine Freisprechfunktion wären eine willkommene Ergänzung gewesen.
Zum aktuellen Preis von runter 100 Euro bietet der JBL Flip 6 ein angemessenes Preis-Leistungs-Verhältnis.
JBL Boombox 3 Wi-Fi
JBL Boombox 3 Wi-Fi
Die JBL Boombox 3 Wi-Fi gehört zur Elite der tragbaren Bluetooth-Speaker – zumindest beim Blick aufs Datenblatt. Ob die massive Musikbox auch in der Praxis überzeugen kann, zeigen wir im Test.
- als Bluetooth- und drahtloser Multiroom-Stereolautsprecher einsetzbar
- guter Klang, hohe Leistung
- robust, wasserfest
- Kein aptX und AAC bei Bluetooth
- Preis
JBL Boombox 3 Wi-Fi im Test
Die JBL Boombox 3 Wi-Fi gehört zur Elite der tragbaren Bluetooth-Speaker – zumindest beim Blick aufs Datenblatt. Ob die massive Musikbox auch in der Praxis überzeugen kann, zeigen wir im Test.
Bluetooth-Lautsprecher sind praktische Begleiter für Badesee, Picknick im Stadtpark oder etwa die Geburtstagsfeier im Garten. Besonders praktisch ist es, wenn die mehr oder weniger kleinen Begleiter handlich tragbar und wasserdicht sind. Die JBL Boombox 3 Wi-Fi bietet in dieser Hinsicht eine High-End-Ausstattung.
Schon die optische Erscheinung ist bullig, das lässt auch auf kraftvollen Sound hoffen. Neben Bluetooth kann man Medieninhalte auch per integriertem WLAN auf die Box streamen. Die integrierte Powerbank-Funktion ist ein nützliches Extra. Wasserdicht ist sie ebenfalls, wie fast alle JBL-Boxen. Elitär ist neben der Ausstattung allerdings auch der Preis von momentan 472 Euro bei Amazon. Wie die genannten Features und die Box insgesamt überzeugen, zeigt unser Testbericht.
Weitere empfehlenswerte Artikel sind unter anderem:
Ausstattung & Design
Die JBL Boombox 3 Wi-Fi darf sich schon zu den ganz großen, tragbaren Bluetooth-Boxen zählen. Mit Maßen von 48,2 x 25,7 x 20,0 cm ist sie ganz schön massiv – und stolze 6,79 kg schwer. Zum Transport gibt es einen integrierten, praktischen Tragegriff auf der Oberseite. Ansonsten ist das Design recht standardmäßig für einen JBL-Bluetooth-Speaker, wie wir es bereits von den Modellen der JBL-Extreme-Reihe kennen.
Die Box läuft im Akkubetrieb stolze 24 Stunden bei gemäßigter Lautstärke. Das ist auf der einen Seite lobenswert, der 9.000 mAh große Stromspeicher erklärt aber auch das hohe Gewicht. Ebenso kann die Lautsprecherbox mit Powerbank-Funktion auch das Smartphone oder andere mitgebrachte Geräte mit USB-Ladeanschluss mit 5 V und bis zu 2 A laden. In 4,5 Stunden ist der mächtige Akku wieder vollgeladen, wozu ein zwei Meter langes Netzkabel beiliegt – das Netzteil ist in der Boombox integriert. Damit die Boombox nicht unnötig eingeschaltet bleibt, schaltet sie sich wahlweise nach 15, 30, 45 oder 60 Minuten ohne Signal ab.
Für die Soundqualität entscheidend sind die verbauten Lautsprecher: ein 189 x 114 mm großer Subwoofer, zwei 80,9-mm-Mitteltöner und zwei 20-mm-Hochtöner. Bei Netzbetrieb werden diese mit maximal 1 x 80 W, 2 x 40 W und 2 x 20 W beschickt, am Akku sind es noch 1 x 60, 2 x 30 und 2 x 10 W. Die JBL Boombox 3 Wi-Fi deckt einen Frequenzbereich von 40 Hz bis zu 20 kHz ab. Damit ist der wichtigste Bereich abgedeckt und für eine portable Lautsprecherbox klingen auch die tiefen Töne schön satt.
Um Medieninhalte mit der Box wiedergeben zu können, verfügt sie natürlich über Bluetooth – leider ohne AAC oder aptX. So steht nur der verlustreiche Uralt-Standard SBC bereit. Gerade bei einer so teuren Box hätten wir Hochqualitäts-Standards zur Medienübertragung unbedingt erwartet. Immehin verbindet sich die Boombox dafür mit dem neuesten Bluetooth-Standard 5.3 und Multipoint zur Verbindung von mehreren Endgeräten gleichzeitig wird ebenso unterstützt.
Wie der Name es bereits verrät, verfügt die Box außerdem über WLAN auf 2,4 und 5 GHz. Doch wozu das? Damit lässt sich die JBL Boombox 3 Wi-Fi wie eine Soundbar ansteuern. Unterstützt sind die Dienste Apple Airplay, Google Chromecast, Spotify Connect und Alexa-Multi-Room. Die Auswahl eines dieser Streaming-Standards erfolgt über das Smartphone oder ein anderes kompatibles Endgerät. Analoge Ein- oder Ausgänge oder ein Ethernet-Anschluss sind nicht vorhanden.
Auch die Bedienelemente sind minimiert: Ein/Aus, Start/Stop/Pause, Leiser, Lauter und eine Preset-Taste, die in Zusammenhang mit der „JBL One“-App funktioniert. Für Updates wird diese ebenso genutzt, im Normalbetrieb ist sie nicht erforderlich.
Eine Taste, um die Mikrofone zur Sprachbedienung auszuschalten, gibt es nicht: Es sind zwar zwei Mikrofone verbaut, doch nur, um den Klang einzumessen, nicht aber zur Sprachsteuerung. Die Google-Home-Sprachsteuerung oder Alexa sind dennoch über andere Smart Speaker mit Mikrofon oder ein Android-Smartphone oder -Tablet erreichbar.
Das Gerät ist staub- und wassergeschützt nach IP67: Es soll bis zu 30 Minuten 1 Meter tief untergetaucht werden können, ohne auszufallen. Das gilt allerdings nur in neutralem Süßwasser, nicht in der Badewanne mit Schaumbad und auch nicht in Meerwasser. Zudem kann die Dichtung altern. Und natürlich spielt das Gerät nicht wirklich unter Wasser: Einerseits reißt dann der WLAN- oder Bluetooth-Empfang ab, andererseits geht auch der Schall wortwörtlich baden. Wir konnten es uns trotzdem nicht verkneifen, aus der Boombox ein U-Boot zu machen, sie spielte danach einwandfrei weiter.
Praxiseinsatz: Klang & Betrieb
Die JBL-App ist unkompliziert zu installieren, ebenso klappt die Einrichtung in Google Home ohne Probleme. Mehrere Lautsprecher können dabei in Multiroom-Konfigurationen in unterschiedlichen Gruppen eingebunden werden.
Das Abspielen von Musik aus dem Internet ist unkompliziert möglich, ob Radiosender über Tune-In oder Musik über Spotify, Tidal, Apple Music und andere Streamingdienste. Lokale Dateien lassen sich über Chromecast über WLAN abspielen, oder via Bluetooth.
Der veraltete Verbindungsstandard ist unverständlich, denn die Box spielt in bester Tonqualität und kann sogar HD-Sound und 3D Dolby Atmos wiedergeben. Bei ihrem Preis sollte auch eine Lizenz für hochauflösende Bluetooth-Codecs drin sein. So ist eine Wiedergabe über Bluetooth klar nur 2. Wahl – unterwegs wird man nicht darum herumkommen.
JBL Boombox 3 Wi-Fi – Bilderstrecke
JBL Boombox 3 Wi-Fi – Bilderstrecke

JBL Boombox 3 Wi-Fi – Bilderstrecke

JBL Boombox 3 Wi-Fi – Bilderstrecke

JBL Boombox 3 Wi-Fi – Bilderstrecke

JBL Boombox 3 Wi-Fi – Bilderstrecke

JBL Boombox 3 Wi-Fi – Bilderstrecke

JBL Boombox 3 Wi-Fi – Bilderstrecke
JBL Boombox 3 Wi-Fi – Bilderstrecke
JBL Boombox 3 Wi-Fi – Bilderstrecke
Die JBL Boombox 3 weist ein ausgewogenes Klangbild auf und kommt ohne Scheppern aus. Sie liefert laut und leise einen angenehmen, ausgeglichenen und hochwertigen Klang. Für einen tragbaren Lautsprecher liefert sie trotz der kompakteren Bauform eine vergleichsweise breite Stereobasis.
Die Qualität steigt von selbst digitalisierten LPs über Spotify an, über Bluetooth fällt sie wegen der fehlenden Codecs deutlich ab. Auch hohe Lautstärken werden verzerrungsfrei wiedergegeben. Der Klang strengt auch bei längerem Hören nicht an, der Lautsprecher ist für alle Musikrichtungen und selbstverständlich auch Sprachwiedergabe gut geeignet. Damit ist die Box universell nutzbar und nicht auf etwa Hip-Hop beschränkt.
Preis
Mit knapp 530 € Listenpreis ist die JBL Boombox 3 Wi-Fi kein Schnäppchen, doch für die gebotene Leistung bei solch leistungsfähiger Akkuversorgung die Investition wert. Aktuell bekommt man die Box bei Amazon für 472 Euro.
Fazit
Die JBL Boombox 3 Wi-Fi bietet eigentlich alles außer eingebauten Mikrofonen für Google Home/Alexa, die beim mobilen Betrieb aber ohnehin funktionslos wären. Sie kann dafür locker die halbe Siedlung oder den ganzen Baggersee beschallen und übersteht auch Rasensprenger und Gewitter.
Per WLAN kann man direkt auf die Box streamen über alle mittlerweile üblichen Anwendungen, ob Streaming lokaler Dateien, von Spotify/Tidal/Quboz oder Internetradio. Einzig schmerzt uns das Fehlen von Bluetooth-Übertragungsstandards mit hoher Qualität, da AAC oder aptX fehlen. Bei einer über 400 Euro teuren High-End-Box ist uns das unverständlich. JBL bietet so leider nur den alten, verlustreichen SBC-Standard. Das Design ist ein Hingucker, erscheint uns aber sehr durchdacht & praxisnah. Die Box fügt sich so problemlos an verschiedenen Orten ins Gesamtbild ein.
Insgesamt ein feines Stück Technik mit klar differenziertem Klangbild, schickem Design, tollen WLAN-Feature und einem mittelgroßen Bluetooth-Manko. Für letzteres ziehen wir einen Stern ab, da wir mindestens AAC für so viel Geld als erwartet hätten.
Anker Soundcore Motion Boom
Anker Soundcore Motion Boom
Anker hat mit dem Soundcore Motion Boom einen tragbaren Outdoor-Lautsprecher auf den Markt gebracht, der dem JBL Charge 3 Konkurrenz machen soll. Ob das gelingt und was der Lautsprecher taugt, klären wir in unserem Test.
- Preis-Leistungs-Verhältnis
- IPX7-Zertifizierung
- Akkulaufzeit
- kein Stoßschutz
- mehrfache Belegung des Anker-Buttons
- Kunststoffgehäuse
Anker Soundcore Motion Boom im Test
Anker hat mit dem Soundcore Motion Boom einen tragbaren Outdoor-Lautsprecher auf den Markt gebracht, der dem JBL Charge 3 Konkurrenz machen soll. Ob das gelingt und was der Lautsprecher taugt, klären wir in unserem Test.
Sommer, Sonne, Strand – und die passende Musik? Wer den Urlaub an heißen Tagen richtig genießen will oder eine feuchtfröhliche Poolparty plant, braucht eine passende Musikbox, die eine gewisse Robustheit gegenüber äußeren Einflüssen mit einem guten Klang und einem kompakten Design kombiniert. Genau das will Anker mit dem Soundcore Motion Boom bieten, der in Konkurrenz zum JBL Charge 3 (Testbericht) oder dem Sonos Roam SL (Testbericht) tritt.
Weil der Speaker über eine IPX7-Zertifizierung verfügt, eignet er sich besonders gut für den Outdoor-Bereich. Eine Akkulaufzeit von bis zu 24 Stunden und die integrierte Powerbank sollen den Soundcore Motion Boom von anderen Modellen abheben. Wir haben uns den Bluetooth-Lautsprecher im Test genauer angeschaut und klären, ob die Box ihre bestenfalls 70 Euro wert ist.
Design und Verarbeitung
Beim ersten Hands-On mit dem Soundcore Motion Boom fällt der eher billige Look des Geräts auf: Das Gehäuse besteht ebenso wie der teilweise gummierte Griff aus schwarzem Kunststoff, der einen wenig wertigen Eindruck hinterlässt. Die mattierte Oberfläche lässt sich dafür aber immerhin leicht reinigen, ebenso wie das Metallmesh, das die eigentlichen Frontspeaker bedeckt. Zwei Gummifüße am Boden des Lautsprechers sorgen für eine gute Standfestigkeit, sodass der Soundcore Motion Boom auch bei höherer Lautstärke auf glattem Untergrund nicht verrutscht. Ähnlich wie der Xiaomi Mi Portable (Testbericht) bietet der Soundcore Motion Boom aber keinen Stoßschutz, was wir bei einem Outdoor-Lautsprecher eigentlich erwartet hätten.

Ein großer Pluspunkt ist das Bedienpanel, das Soundcore-typisch mit beleuchteten Tasten daherkommt. Leider hat Anker darauf verzichtet, auch die Laut- und Leise-Buttons mit einer Beleuchtung auszustatten, aber die übrigen Knöpfe lassen sich auch im Dunkeln oder bei geringem Umgebungslicht gut erkennen. Der Soundcore Motion Boom ist nach dem IPX7-Standard zertifiziert, was bedeutet, dass er ein Eintauchen in einem Meter Wassertiefe für 30 Minuten problemlos überstehen soll. Außerdem geht der Speaker nicht unter, sondern treibt an der Oberfläche. Fällt der Lautsprecher also versehentlich in den Pool, überlebt er den unfreiwilligen Badegang problemlos. Salzwasserfest ist der Lautsprecher im Gegensatz zum Sony XB33 (Testbericht) allerdings nicht, deshalb ist am Meer entsprechend Vorsicht geboten.
Bedienung und Betrieb
Wie von den meisten Bluetooth-Boxen gewohnt, koppeln wir auch den Soundcore Motion Boom via Bluetooth 5.0 an ein Smartphone oder ein anderes Bluetooth-fähiges Wiedergabegerät. Dazu reicht ein Druck auf die Bluetooth-Taste am Speaker aus, damit sich die Box mit dem Gerät verbindet. Ein kurzer Sound bestätigt die Koppelung, leuchtet das Bluetooth-Symbol durchgängig blau, steht die Verbindung. Wer möchte, kann über die TWS-Taste einen identischen Soundcore Motion Boom mit dem vorhandenen Speaker verbinden, um Stereo-Sound zu erzeugen.
Soundcore Motion Boom Bilder
Soundcore Motion Boom

Soundcore Motion Boom
Soundcore Motion Boom

Soundcore Motion Boom

Soundcore Motion Boom

Soundcore Motion Boom
Soundcore Motion Boom
Soundcore Motion Boom
Soundcore Motion Boom
Die Bedienung des Soundcore Motion Boom funktioniert ansonsten selbsterklärend und ohne größere Schwierigkeiten. Zwar hat Anker ähnlich wie Xiaomi beim Mi Portable und Sony beim XB33 eine Taste mehrfach belegt. Die Anker-Soundcore-Taste dient sowohl als Play/Pause-Button als auch zum Wechseln der Tracks, zum Annehmen und Ablehnen von Telefonanrufen und zum Aktivieren von Sprachassistenzsoftware. Weil die Anker-Taste aber nicht beleuchtet ist, kann es im Eifer des Gefechts in ziemliche Fummelei ausarten, die einzelnen Funktionen korrekt zu bedienen. Hier wäre eine separate Taste oder wenigstens eine Beleuchtung hilfreich gewesen.
Die Soundcore-App von Anker unterstützt auch den Soundcore Motion Boom und bietet ergänzende Funktionen wie einen Equalizer. Die App ist zum Betrieb der Bluetooth-Box nicht erforderlich, beinhaltet aber eine Reihe nützlicher Features. Wir können über die App die Firmware des Speakers aktualisieren, den Ladestand des Akkus abfragen und eine automatische Abschaltung der Box nach verschiedenen Zeitintervallen festlegen. Der Equalizer beinhaltet vier voreingestellte Settings, mit denen wir den Klang der Box nach unseren individuellen Bedürfnissen anpassen können: ein ausgeglichener Modus, ein Modus für Stimmen, ein Modus mit besonderer Betonung auf Höhen und ein Balance-Modus ohne besonders betonte Höhen und Tiefen. Die App lässt sich einfach bedienen und überzeugt dank guter Übersicht.
Klang
Das Preissegment der Bluetooth-Lautsprecher für den Outdoor-Gebrauch um die 100 Euro ist hart umkämpft. Platzhirsch JBL behauptet sich unter anderem mit dem Flip 5 (Testbericht), während Sony mit dem XB33 (Testbericht) und Sonos mit dem Roam SL (Testbericht) ebenfalls ein Stück vom Klangkuchen abhaben wollen. Wie schlägt sich also der Soundcore Motion Boom im Vergleich? Auf dem Papier kann der Speaker zumindest bei der Leistung überzeugen, denn die liegt bei 30 Watt und damit zehn Watt über der Leistung von JBLs Flip 5. Zum Frequenzbereich macht Anker leider keine Angaben – hier muss der Praxischeck herhalten.
Dass der Soundcore Motion Boom ein ganzes Stück größer ausfällt als der JBL Flip 5 oder der Sony XB33 macht sich beim Klang direkt bemerkbar. Denn der ist überraschend gut. Der Sound kommt sehr satt aus den Speakern, der integrierte Bassboost tut genau das, was er soll und bringt ordentlich Wumms in den Sound, ohne verzerrend zu wirken, während Gesang und hohe Tonlagen weiter klar ertönen. Wir haben den Sound unter anderem mit Adeles Rolling in the Deep getestet, wo die Drums sehr gut mit der Stimme der Künstlerin harmonierten.
Ebenso überzeugt uns der Soundcore Motion Boom bei Steven Wilsons Hand Cannot Erase und Peggy Lees Fever. In beiden Fällen kommen sowohl Beats als auch Gesang und hochtonige Instrumente sehr gut zur Geltung. Eine hohe Lautstärke kann dem Klang kaum etwas anhaben, auch wenn der Speaker ganz vereinzelt anfing zu klirren. Sprache meistert der Lautsprecher übrigens ebenfalls ohne Schwierigkeiten. Unserer Meinung nach stimmt das Preis-Leistungs-Verhältnis insgesamt – für den Preis von deutlich unter 100 Euro, den Anker für den Soundcore Motion Boom aufruft, hätten wir einen derartig klaren Klang nicht erwartet.
Akku und Extras
Anker gibt die Akkulaufzeit des Soundcore Motion Boom mit bis zu 24 Stunden an. Die Akkuleistung liegt bei 10.000 mAh und damit für vergleichbare Bluetooth-Boxen im oberen Bereich. Außerdem fungiert der Motion Boom auch als Powerbank, sodass wir beispielsweise unser Smartphone während der Wiedergabe von Musik laden können. Je nachdem, mit welcher Lautstärke man den Speaker betreibt, variiert die Laufzeit, aber in unserem Test hielt der Motion Boom bei 50 Prozent Lautstärke tatsächlich die angegebenen 24 Stunden durch.
Extras abseits der Powerbank-Funktion bietet der Soundcore Motion Boom kaum, allerdings unterstützt er Sprachassistenten wie Siri oder Google Assistent. Auch das Annehmen von Anrufen per Druck auf die Anker-Taste ist möglich.
Preis
Anker bietet den Soundcore Motion Boom zur UVP von 110 Euro an. Aktuell kostet er etwa 100 Euro. Allerdings zeigt der Preisverlauf, dass er auch schon für 70 Euro den Eigentümer wechselte. Es kann sich also lohnen, auf ein gutes Angebot zu warten. Wir empfehlen das Setzen eines Preisalarms in unserem Preisvergleich.
Fazit
Der Anker Soundcore Motion Boom ist ein echtes Kraftpaket – und das liegt nicht nur an der Leistung von 30 Watt und der Größe des Lautsprechers, sondern auch an dem starken Akku, den der Hersteller eingebaut hat. Man kann diesen Outdoor-Speaker als Rundum-Sorglos-Paket bezeichnen, wenn man bereit ist, das etwas billig anmutende Design und den fehlenden Stoßschutz zu akzeptieren.
Wer den Soundcore Motion Boom im Angebot für gut 70 Euro kaufen kann, macht mit dem Speaker nichts falsch. Aber auch zum Originalpreis schnürt Anker hier ein mehr als faires Gesamtpaket, das sich mit der teureren Konkurrenz von JBL und Co. messen kann.
Loewe We Hear 1
Loewe We Hear 1
Der Loewe We Hear 1 ist ein kompakter Bluetooth-Lautsprecher, der im Test mit modernem Design, hoher Audioqualität und einem günstigen Preis gefällt. Er bietet bis zu 14 Stunden Akkulaufzeit und ist dank IPX6-Schutz gegen Spritzwasser geschützt.
- im Abverkauf nur 59 Euro
- modernes, kompaktes Design
- guter Klang
- lange Akkulaufzeit
- Spritzwasserschutz IPX6
- keine App für Klanganpassung
- kein Mikrofon für Anrufe
- keine Powerbank-Funktion
- Ständer wirkt etwas fragil
Bluetooth-Box Loewe We Hear 1 im Test
Der Loewe We Hear 1 ist ein kompakter Bluetooth-Lautsprecher, der im Test mit modernem Design, hoher Audioqualität und einem günstigen Preis gefällt. Er bietet bis zu 14 Stunden Akkulaufzeit und ist dank IPX6-Schutz gegen Spritzwasser geschützt.
Bluetooth-Lautsprecher sind aus vielen Haushalten nicht mehr wegzudenken. Sie liefern meist ordentlichen Klang und kommen in handlichen Designs daher. Trotz seines sehr günstigen Preises von nur 59 Euro im Abverkauf bietet er einen modernen Look sowie ordentlichen Sound. Wir haben ihn getestet.
Design und Verarbeitung des Loewe We Hear 1
Der Loewe We Hear 1 kommt in einem zylindrischen Gehäuse mit Maßen von 8,3 × 9 × 22 cm daher. Mit 740 g ist er leicht genug, um ihn ohne Mühe mitzunehmen – sei es auf einen Ausflug oder ins nächste Zimmer. Er ist in vier Farben erhältlich: Storm Grey, Coral Red, Cool Grey und Aqua Blue.
Das robuste Gehäuse besteht aus robustem Kunststoff und Mesh. Es trägt die IPX6-Zertifizierung gegen das Eindringen von Spritzwasser. Damit hält es den Einsatz am Pool oder Strand aus, solange es nicht länger untergetaucht wird. Ein etwas seltsam anmutendes Merkmal ist der ausklappbare 18-cm-Ständer. Dieser stabilisiert den liegenden Lautsprecher auf unebenen Flächen wie Gras oder Tischdecken. Aufgrund seiner zylindrischen Form würde er sonst wegrollen. Der Ständer erlaubt zudem eine leichte Neigung, was den Klang je nach Positionierung etwas gerichteter wirken lässt. Allerdings fühlt sich das Scharnier des Ständers etwas zerbrechlich an.
Wer etwa an die Tasten für Lautstärke, Wiedergabe/Pause und Bluetooth-Kopplung will, muss zunächst den Ständer zur Seite schieben. Das ist etwas unpraktisch. Die Tasten sind klar angeordnet und reagieren zuverlässig. Unter einer Abdeckung finden sich der USB-C-Ladeanschluss und ein 3,5-mm-Audioeingang. Abgesehen vom filigranen Ständer hinterlässt der We Hear 1 einen hochwertigen Eindruck.
Loewe We Hear 1 Bilder
Loewe We Hear 1

Loewe We Hear 1

Loewe We Hear 1

Loewe We Hear 1

Loewe We Hear 1

Loewe We Hear 1

Loewe We Hear 1

Loewe We Hear 1

Loewe We Hear 1

Loewe We Hear 1

Wie gut ist der Klang des Loewe We Hear 1?
Der Loewe We Hear 1 bringt eine Audioleistung von 40 W und deckt eine Frequenzbandbreite von 80 Hz bis 17.000 Hz ab. Das ist für ein Gerät dieser Größe beachtlich.
Beim Test mit verschiedenen Musikgenres zeigt sich eine ausgewogene Tonqualität. Die Höhen wirken klar und detailliert – etwa bei akustischen Gitarren oder hohen Stimmen. Die Mitten sind präzise, was Dialoge in Podcasts oder die Gesangsstimmen in Pop-Songs verständlicher macht. Auch der Bass überrascht uns positiv: Für seine Größe liefert er eine tiefe, kräftige Grundlage. Verglichen mit größeren Modellen fehlt es zwar an wuchtiger Tiefe, aber in seiner Klasse schlägt er sich gut.
Das 180-Grad-Sound-Design verteilt den Ton gleichmäßig im Raum. Egal, ob der Lautsprecher mittig oder seitlich steht, der Klang bleibt konsistent. Die Maximallautstärke reicht für kleine bis mittelgroße Räume aus. Voll aufgedreht treten leichte Verzerrungen auf, doch das bleibt im Rahmen dessen, was man von einem kleinen Lautsprecher erwartet.
Bei Podcasts und Hörbüchern bleibt die Stimmwiedergabe klar, ohne dass Höhen scharf oder Mitten matschig klingen. Insgesamt liefert er eine starke Audioleistung, die für den Alltag und gelegentliche Outdoor-Nutzung ausreicht, aber keine Hi-Fi-Qualität ersetzt.
Bedienung und App des Loewe We Hear 1
Die Bedienung des Loewe We Hear 1 ist simpel gehalten. Die Tasten steuern Lautstärke, Wiedergabe und Bluetooth-Kopplung. Sie sind leicht erreichbar und reagieren prompt. Ein kurzer Druck startet oder pausiert die Musik, längeres Halten aktiviert die Kopplung.
Eine App gibt es nicht. Loewe setzt hier auf pure Hardware-Steuerung, was die Bedienung unkompliziert macht, aber auch Einschränkungen mit sich bringt. Wer etwa einen Equalizer zur Klanganpassung erwartet, wird enttäuscht.
Ein Mikrofon für Freisprechfunktionen fehlt ebenfalls. Wer den Lautsprecher nur für Musik und Podcasts nutzt, wird das kaum vermissen. Insgesamt ist die Bedienung zweckmäßig gelöst, aber ohne App oder Zusatzfunktionen bleibt sie technisch schlicht.
Der Akku des Loewe We Hear 1
Der Loewe We Hear 1 hat einen Lithium-Ion-Akku, der bei mittlerer Lautstärke bis zu 14 Stunden durchhält. Das ist überdurchschnittlich lang. Die Ladezeit beträgt etwa 2 bis 3 Stunden über das mitgelieferte USB-C-Kabel, was im Vergleich zu ähnlichen Geräten üblich ist.
Bei hoher Lautstärke sinkt die Laufzeit etwas, bleibt aber im zweistelligen Bereich. Eine Ladestandsanzeige am Gerät gibt es nicht. Sie ist lediglich über das per Bluetooth verbundene Smartphone sichtbar. Der Akku kann keine anderen Geräte laden – eine Powerbank-Funktion fehlt.
Konnektivität und technische Eigenschaften des Loewe We Hear 1
Der Loewe We Hear 1 bietet zwei Anschlussmöglichkeiten: Bluetooth 5.0 und einen 3,5-mm-Audioeingang. Die Bluetooth-Verbindung koppelt schnell und bleibt stabil.
Der Audioeingang erlaubt die kabelgebundene Nutzung, etwa mit Geräten ohne Bluetooth. Das ist praktisch, wenn der Akku leer ist oder drahtlose Verbindungen stören. Eine Besonderheit ist die Möglichkeit, zwei We Hear 1 zu einem Stereopaar zu verbinden.
Was kostet der Loewe We Hear 1?
Der Loewe We Hear 1 kostet im Abverkauf nur 59 Euro bei Amazon.
Fazit
Der Loewe We Hear 1 ist vorrangig für seinen günstigen Abverkaufspreis ein richtig guter Bluetooth-Lautsprecher, der mit seinem kompakten Design und ordentlicher Klangqualität überzeugt. Der ausklappbare Ständer irritiert zunächst, sorgt aber für besseren Halt auf unebenem Untergrund. Ausgewogen ist der Sound und bietet klare Höhen, präzise Mitten und einen für diese Größe erstaunlich starken Bass. Die Bedienung bleibt einfach, auch wenn eine App fehlt. Die Akkulaufzeit ist überdurchschnittlich lang.
Schwächen gibt es bei der fehlenden Mikrofonfunktion und der nicht vorhandenen Powerbank-Option. Auch der Ständer könnte robuster sein. Für seinen niedrigen Preis bietet der We Hear 1 ein gutes Gesamtpaket, das sich sowohl für den Alltag als auch für unterwegs eignet.
Pure Woodland
Pure Woodland
Der Bluetooth-Lautsprecher Pure Woodland bietet neben Bluetooth auch DAB+ und FM. Wie gut das zusammen funktioniert, zeigt unser Test.
- robustes, wasserdichtes Design (IP67)
- integrierte DAB+- und FM-Radiofunktion
- guter Klang für Sprache und leichte Musik
- programmierbaren Sendertasten
- schwacher Bass
- Verzerrungen bei hoher Lautstärke
- keine App-Steuerung, kein Equalizer
- gummierte Stoßfänger ziehen Schmutz an
Bluetooth-Lautsprecher Pure Woodland im Test
Der Bluetooth-Lautsprecher Pure Woodland bietet neben Bluetooth auch DAB+ und FM. Wie gut das zusammen funktioniert, zeigt unser Test.
Anders als viele Konkurrenten in der Preisklasse um die 100 Euro setzt Pure nicht auf grelle Farben und futuristisches Design, sondern auf einen zeitlosen Look mit praktischen Funktionen. Während die meisten Bluetooth-Lautsprecher heute komplett auf Radiofunktionen verzichten, bietet der Woodland zudem sowohl FM als auch DAB+ – eine Kombination, die besonders für Camping und Outdoor-Freunde interessant sein könnte. Ob uns der Pure Woodland überzeugt, zeigt der Test.
Design und Verarbeitung
Der Pure Woodland kommt in einem retro-inspirierten Design. Der Lautsprecher wirkt durch seine Stoffbespannung und die Gummierungen wertig und robust zugleich. Praktisch ist der weiche, etwa zwei Zentimeter breite Tragegriff aus Stoff.
Die Verarbeitung des Pure Woodland macht einen soliden Eindruck. Mit einer IP67-Zertifizierung ist der Lautsprecher sowohl staubdicht als auch wasserdicht. Die Ober- und Unterseite sind zusätzlich verstärkt, sodass der Lautsprecher auch Stürze problemlos übersteht. Mit einem Gewicht von etwa 700 Gramm bleibt er ausreichend mobil.
Die elf Tasten sind mit einer Gummierung überzogen und haben einen guten Druckpunkt. Allerdings ziehen die gummierten Stoßfänger Schmutz geradezu magisch an und sind nur schwer zu reinigen. Das 128 x 32 Pixel große Punktmatrix-Display mit Hintergrundbeleuchtung sorgt für gute Ablesbarkeit bei unterschiedlichen Lichtverhältnissen.
Eine Besonderheit ist die ausziehbare Teleskopantenne für den Radioempfang. Sie verbessert die Empfangsqualität deutlich, könnte aber bei einem Sturz abbrechen und stellt somit einen potenziellen Schwachpunkt dar.
Pure Woodland Bilder
Pure Woodland

Pure Woodland

Pure Woodland

Pure Woodland

Pure Woodland

Pure Woodland

Pure Woodland

Pure Woodland

Pure Woodland

Pure Woodland

Pure Woodland

Pure Woodland

Pure Woodland

Wie gut ist der Klang des Pure Woodland?
Der Pure Woodland nutzt ein 10-Watt-Lautsprechersystem. Der Klang ist warm und satt. Bei der Wiedergabe von Radiosendungen, Podcasts oder Hörbüchern spielt der Pure Woodland seine Stärken aus. Stimmen kommen klar und verständlich, das Klangbild wirkt ausgewogen und natürlich. Auch bei leichteren Musikstilen wie Akustik, Folk oder klassischer Musik gefällt uns der Lautsprecher.
Seine Grenzen erreicht er bei basslastiger Musik. Tiefe Frequenzen wirken eher dünn und zurückhaltend. Er wird recht laut, beginnt jedoch bei hohen Lautstärken zu verzerren. Für den Einsatz im Freien, etwa beim Camping oder Picknick, reicht die Lautstärke völlig aus.
Insgesamt bietet er für ein Gerät dieser Größe eine beachtliche Klangqualität, wobei die Stärken bei der Wiedergabe von Sprache und leichterer Musik liegen.
Bedienung
Die Bedienung des Pure Woodland erfolgt ausschließlich über die elf wasserdichten Tasten am Gerät. Diese erlauben unter anderem grundlegende Funktionen wie Ein-/Ausschalten, Lautstärkeregelung und Quellenwahl zwischen Bluetooth, DAB+ und FM. Praktisch sind die drei programmierbaren Tasten für einen schnellen Zugriff auf Lieblingssender.
Das Display zeigt unter anderem den Sendernamen, den Batteriestatus und die Empfangsqualität. Bei FM-Sendern unterstützt der Pure Woodland RDS für die Anzeige von Senderinformationen. Die Radiofunktion gefällt mit einer komfortablen, digitalen Suchfunktion und bietet sowohl bei DAB+ als auch bei FM einen guten Empfang.
Der Pure Woodland verzichtet auf eine App-Steuerung. Alle Funktionen werden ausschließlich über die physischen Tasten am Gerät gesteuert. Dadurch fehlen ihm Funktionen wie ein Equalizer zur Klanganpassung oder erweiterte Preset-Optionen.
Die Bluetooth-Verbindung (Version 5.1) funktioniert zuverlässig. Der Kopplungsprozess ist unkompliziert und schnell durchgeführt.
Akku
Der Pure Woodland ist mit einem 4000-mAh-Lithium-Akku (3,7V, 14,8Wh) ausgestattet, der eine Laufzeit von bis zu 14 Stunden ermöglicht. Bei maximaler Lautstärke verkürzt sich die Laufzeit. Das Aufladen erfolgt über USB-C. Ein Netzstecker ist nicht dabei.
Preis
Der Pure Woodland ist aktuell für 96 Euro (eleonto.com) erhältlich, was deutlich unter der unverbindlichen Preisempfehlung von 150 Euro liegt.
Fazit
Der Pure Woodland ist ein gelungener Hybrid aus klassischem Radio und Bluetooth-Lautsprecher. Mit seinem retro-inspirierten Design, der robusten Verarbeitung und der IP67-Zertifizierung eignet er sich gut für den Einsatz im Freien.
Klanglich gefällt uns der Pure Woodland vor allem bei der Wiedergabe von Sprache und leichterer Musik, während er bei basslastigen Genres an seine Grenzen stößt. Die Bedienung ist selbsterklärend, eine App gibt es genauso wenig wie einen Equalizer.
Der Pure Woodland bietet ein gutes Preis-Leistungs-Verhältnis für alle, die einen robusten Outdoor-Lautsprecher mit Radiofunktion suchen. Wer hingegen primär auf Klangqualität und Basswiedergabe Wert legt, sollte auf die Radiofunktion verzichten und sich in unserer Top 10 der besten Bluetooth-Lautsprecher nach Alternativen umsehen.
Fender Newport
Fender Newport
Der Fender Newport bringt viel Leistung in einen kleinen Bluetooth-Speaker. Der Test soll zeigen, ob sich der Kauf für 90 Euro lohnt.
- Toller Klang mit 30 Watt Leistung und AptX
- Zwei-Band-Equalizer
- Stufenloser Lautstärkeregler
- Proprietäres Netzteil
- Baubedingt wenig Stereoklang
Fender Newport im Test
Der Fender Newport bringt viel Leistung in einen kleinen Bluetooth-Speaker. Der Test soll zeigen, ob sich der Kauf für 90 Euro lohnt.
Mit dem Fender Newport startet der Instrumenten- und Verstärkerhersteller einen Gegenangriff auf einen alten Rivalen. Denn der Verstärkerhersteller Marshall hat sich in den letzten Jahren mit Bluetooth-Lautsprechern und Kopfhörern einen echten Namen in der HiFi-Branche gemacht. Spannend ist daher, was Fender bei seinen Modellen anders oder gar besser macht. Grund genug, den Fender Newport einem ausführlichen Test zu unterziehen.
Design und Verarbeitung
Der Fender Newport gefällt uns sehr gut. Zwar liegt der Bluetooth-Speaker nur im vergleichsweise langweiligen Schwarzton vor, dennoch weiß die Mischung aus mattem Kunststoff und silbernem Metallgitter zu gefallen. Richtig gut sieht der Newport aber in seinen bunten Farbvarianten aus. Die Farbe Sonic Blue erinnert dabei an den blaugrünen Surfrock-Look Fenders ikonischer Gitarren. Auch Dacota Red findet sich als Farbton bei einigen Instrumenten des Herstellers.
Einen ähnlich großen Wiedererkennungswert haben die drei Drehregler an der Oberseite des Bluetooth-Speakers. Auch diese hat Fender von seinen Gitarrenverstärkern übernommen und überträgt zugleich deren Equalizer-Funktion auf den Bluetooth-Speaker. Doch zu deren Faszination später mehr. Auf der Oberseite findet sich sonst ein schicker An- und Ausschalter sowie Knöpfe zur Annahme von Telefonaten und zum Pairing mit Bluetooth-Geräten.
Die Verarbeitung des Bluetooth-Lautsprechers ist makellos. Zwar setzt Fender beim Newport recht viel Plastik ein, zusammen mit dem hohen Gewicht von 1,5 Kilogramm und dem prominenten Metallgitter auf der Vorderseite wirkt der Lautsprecher aber dennoch hochwertig. Ähnliches gilt für die Knöpfe auf der Oberseite. Die Drehknöpfe bieten einen angenehmen Widerstand und der Kippschalter knallt mit deutlichem Klang von einer Position zur anderen. Lediglich beim Netzteil schwindet Fenders Finesse und der Hersteller legt ein eher mittelmäßiges Fremdherstellerprodukt bei. Auch das Klinkenkabel ist keiner Rede Wert. Hier legt Marshall Produkten wie den Bluetooth-Kopfhörern Marshall Major III deutlich charmantere, eigene Kabel bei.
Klang
Mit unserer Test-Playlist für Bluetooth-Speaker auf Spotify haben wir Musik unterschiedlichster Genres und einen Podcast über den Lautsprecher Probe gehört. Aufgrund seiner AptX-Zertifizierung ist der Fender Newport auch für Filme und Spiele interessant.
AptX ist eine Sammlung an Audio-Codecs, die bei der Übertragung von Musikdateien per Bluetooth die Komprimierung und Dekomprimierung gewährleisten. In der Praxis bedeutet das einen Zugewinn an Audioqualität und besonders geringe Latenzen. Bei Filmen im Originalton passen Stimmen perfekt zu den Lippenbewegungen der Schauspieler, Schüsse oder Explosionen in Videospielen sind ebenfalls synchron zum Bild auf dem jeweiligen Ausgabegerät. Hier zeigen wir die besten Bluetooth-Kopfhörer mit aptX bis 60 Euro .
Das Klangbild des Fender Newport ist insgesamt sehr kraftvoll und äußerst fein abgestimmt. Dabei sind es vor allem komplexe Stücke wie Frank Zappas Inca Roads oder Do It Again von Steely Dan, die beim Zuhören ein Lächeln auf die Lippen zaubern. Feine Geräusche im Hintergrund oder leichte Schmatzer beim Singen sind klar identifizierbar. Unterschiedliche Instrumente lösen sich fein voneinander ab, der Fender Newport hat sein eigenes Ensemble sehr gut im Griff. Diesen schönen Klangteppich untermalt der Lautsprecher mit sehr klaren Bässen.

Diese sind trotz der kompakten Größe des Fender Newport zwar kräftig, aber nicht aufdringlich. Mit wenig Dröhnen bringt der Lautsprecher nicht gleich bei jedem dezenten Basston den ganzen Tisch zum Vibrieren. Denn auch Töne im Bassbereich teilen sich noch einmal in Höhen und Tiefen und genau das ignorieren viele konkurrierende Modelle. Diffizile Bassläufe wie in Marcus Millers Higher Ground oder Thundercats Them Changes klingen sehr gut und auch kurze Bassschläge wie im Elektro-Klassiker Blue Monday von New Order stehen für einen kurzen Moment schön abgelöst von der übrigen Musik im Raum.
In höheren Lautstärkenbereichen beginnt der Bass langsam aber sicher in den Körper zu dringen. Erinnerungen an den letzten Club-Besuch kommen verwaschen ins Gedächtnis, doch so ganz können sie sich aufgrund der kleinen Größe des 30-Watt-Speakers nicht durchsetzen. Eher ist der Bluetooth-Speaker bei Maximallautstärke als kleine, sehr pointierte, Musikquelle zu laut, als dass er den gesamten Raum mit Musik füllt. Erstaunlich ist dennoch, wie wenig der Lautsprecher unter Volllast zum Übersteuern oder Kratzen neigt.
So machen auch kraftvolle Rocksongs in höheren Lautstärken Spaß. Love is only a feeling von The Darkness oder Devin Townsends Borderlands performt der Fender Newport mit viel Selbstbewusstsein. Dennoch stellt der Lautsprecher seine Interpreten immer auf eine sehr enge Bühne. Die zwei Treiber und der einzelne Hochtöner sitzen für eine breite Klangwiedergabe schlichtweg zu nah aneinander. Hier ist der teurere Fender Monterey eine interessante Alternative. Das größere Modell bietet laut Herstellerangaben eine Ausgangsleistung von 120 Watt und verteilt seine insgesamt vier Treiber Lautsprecher im Vergleich zum Newport auf mehr Fläche. Dafür ist der sieben Kilogramm schwere Lautsprecher aber auch deutlich weniger portabel.
Am unteren Ende des Lautstärkespektrums bietet der Newport mit seinem stufenlosen Regler für alle Podcast- und Hörbuchfans noch einen echten Vorteil. Denn häufig liegt die perfekte Lautstärke zum Einschlafen genau zwischen zwei Lautstärkenstufen. Mit dem stufenlosen Regler des Newport findet man hier genau die Mitte.
Bedienung

Die Hauptfunktionen des Fender Newport steuern sich über die Bedienelemente sehr komfortabel und zielsicher. Jeden Befehl kommentiert der Lautsprecher dabei mit individuellen Soundschnipseln. Diese bestehen aus kurzen Gitarren-Riffs und sind auch beim mehrfachen Hören nicht aufdringlich oder zu lang. Über den “Pair”-Knopf ganz links im Bedienfeld verbindet man neue Bluetooth-Geräte. Auf die komfortable Verbindungsmöglichkeit per NFC muss man beim Fender Newport verzichten.
Das ist jedoch nicht weiter schlimm, denn dank Bluetooth 4.2 geht die kabellose Verbindung mit dem Handy ebenfalls flott und reibungslos. Mit seinen drei Drehreglern und dem Kippschalter finden sich auf dem Fender Newport Bedienelemente, an die man sich ein wenig gewöhnen muss. Denn der Lautstärkeregler arbeitet unabhängig von der Lautstärkesteuerung am Bluetooth-Gerät. Somit muss man häufig zum Lautsprecher hingehen, um die Lautstärke hochzudrehen. Das ist ein wenig umständlich, kommt bei Bluetooth-Speakern aber immer mal wieder vor.
Den Kippschalter hat der Hersteller mit einem automatischen Abschaltmechanismus kombiniert, sodass der Bluetooth-Speaker sich nach einigen Minuten der Nicht-Benutzung selbst abschaltet. Ob der Fender Newport angeschaltet ist, deutet eine blaue Leuchte direkt neben dem Kippschalter an. Zur Reaktivierung muss der Schalter einmal auf die Aus-Stellung und zurück auf Ein geschaltet werden.
Akku

Sehr praktisch ist der vollwertige USB-Anschluss an der Rückseite des Fender Newport. Dieser lädt Geräte wie Smartphone, Tablet. Interessanterweise sollte er auch genügend Leistung haben, um Audio-Hardware wie den Google Chromecast Audio (Testbericht) oder den Amazon Echo Input (Testbericht) zu betreiben. So ließe sich der Newport für einen geringen Aufpreis in einen WLAN-Lautsprecher und in einen Smart Speaker verwandeln. Als Audio-Eingang dient in diesem Falle der 3,5-Millimeter-Klinkenanschluss, der sich ebenfalls an der Hinterseite befindet.
Herstellerangaben zufolge reicht die Akkuleistung für das zweimalige Aufladen von Smartphones. Ohne externe Stromfresser soll der Fender Newport zwölf Stunden lang durchhalten. Im Praxistest lag die Akkulaufzeit jedoch eher bei acht bis zehn Stunden. Da der Lautsprecher hier stets auf Zimmerlautstärke arbeitete, ist dieser Wert womöglich der realistischere.
Extras
Das spannendste Extra des Fender Newport ist der Zwei-Wege-Equalizer. Diese regeln die Präsenz von Bässen und Tiefen genauso präzise, wie die Gesamtlautstärke. Dabei sind die Regler effektiv genug, um den Klang genau den eigenen Vorlieben nach anzupassen. Die Steuerung ist dabei derart intuitiv, dass man am liebsten jeden Titel im Klang anpassen möchte. Findet man nach erster Begeisterung die Mitte, wird der Equalizer erst anderer Stelle erneut sehr praktisch. Wer in den Abendstunden gerne Musik hört oder mit dem Fender Newport den Klang seines Fernsehers (Kaufberatung) aufbessert, der kann Bässe ohne Umwege aus dem Klang herausdrehen. Gerade in Mehrfamilienhäusern beugt man so vor, dass der Bass durch die Wände bis ins Schlafzimmer der Nachbarn dringt.
Eher herkömmlich ist die eingebaute Freisprechfunktion im Fender Newport. Leider fehlt dem Fender Newport ein integrierter Sprachassistent (Alexa und Google im Vergleich) , über den sich Anrufe direkt vom Lautsprecher absetzen ließen. Stattdessen erfolgen Anrufe über das Smartphone und die Gesprächsqualität ist anschließend überraschend klar. Vor allem die Ausgabe von Stimmen über den Fender Newport ist sehr natürlich und erfolgt mit ausreichender Lautstärke. Die Gegenseite lobte im Sprachtest die Mikrofone des Fender Newport. Die Lautstärke könnte in unseren Ohren aber ein wenig höher sein. Gerade die Mikrofone fallen bei günstigen Bluetooth-Speakern (Ratgeber) negativ auf.
Lieferumfang

Eine Besonderheit des Fender Newport offenbart sich beim Auspacken des Bluetooth-Speakers. Denn neben dem Lautsprecher selbst und einem 3,5-Millimeter-Klinkenkabel findet sich ein proprietäres Netzteil im schlichten Karton. Fender setzt somit nicht auf einen Ladeanschluss, der über standardisierte Anschlüsse wie Micro-USB oder USB-C funktioniert. Im Bereich der Bluetooth-Speaker ist das inzwischen recht selten geworden.
Das ist auch gut so, denn hier zeigt der Fender Newport seinen ersten Makel. Der Einsatz spezieller Ladekabel ist schlichtweg unpraktisch und bringt keinen wirklichen Vorteil mit sich. Denn besonders schnell wird der Bluetooth-Lautsprecher durch das Netzteil auch nicht aufgeladen. Das im Vergleich zu Handyladekabeln recht klobige Netzteil beim Reisen mit dem Fender Newport zu vergessen, ist eine Gefahr, die sich durchaus vermeiden ließe.
Fazit
Insgesamt ist der Fender Newport ein sehr empfehlenswerter Bluetooth-Speaker. Mit seiner tollen Abmischung hebt ihr sich klanglich von anderen Lautsprechern ab und passt sich dank des Zwei-Band-Equalizers an die Vorlieben des Nutzers an. Zusammen mit der hochwertigen Verarbeitung und dem schicken Design ist es schade, dass der Newport in Deutschland ein Nischenprodukt ist.
Lediglich das proprietäre Netzteil und der baulich bedingt sehr zielgerichtete Klang fallen in der Gesamtwertung negativ auf. Da der Fender Newport inzwischen aber schon für 90 Euro im Internet zu haben ist, sind die beiden Kritikpunkte verkraftbar. In dieser Preisklasse schlägt er viele Alternativen klanglich um Längen. Die unverbindliche Preisempfehlung von 219,99 Euro ist dennoch viel zu hoch angesetzt.
Pure Classic Aura
Pure Classic Aura
Der Bluetooth-Lautsprecher Pure Classic Aura im nostalgischen Holzdesign und mit schicken LED-Effekten kommt ganz ohne App aus – alle Funktionen sind am Gerät wählbar. Doch überzeugt die Retro-Box auch klanglich?
- Retro-Design mit Holzoptik
- LED-Beleuchtung mit 10 Modi
- Lange Akkulaufzeit
- ohne App vollständig zu bedienen
- nur IPX2-Schutz, kaum Outdoor-geeignet
- mit 1,9 kg recht schwer
- keine App für Updates oder Mehrband-Equalizer
- Verzerrungen bei hoher Lautstärke
Bluetooth-Lautsprecher Pure Classic Aura im Test: Volle Kontrolle, ohne App
Der Bluetooth-Lautsprecher Pure Classic Aura im nostalgischen Holzdesign und mit schicken LED-Effekten kommt ganz ohne App aus – alle Funktionen sind am Gerät wählbar. Doch überzeugt die Retro-Box auch klanglich?
Während Konkurrenten wie der Bluetooth-Lautsprecher JBL Charge 6 auf Outdoor-Tauglichkeit setzen, zielt Pure auf den Indoor-Einsatz. Denn der Pure Classic Aura für 129 Euro strahlt die warme Ästhetik klassischer Holzradios aus und kombiniert sie mit einem Ambient-LED-Streifen auf dessen Rückseite. Mit 40 Watt RMS, einem 2-Wege-Stereosystem und bis zu 30 Stunden Akkulaufzeit positioniert sich der Classic Aura im gehobenen Mittelfeld. Die LED-Beleuchtung mit acht RGB-LEDs und zehn Modi – von Aurora-Effekten bis zum Party-Modus – soll das gewisse Extra liefern.
Design und Verarbeitung des Pure Classic Aura
Der Classic Aura wirkt wie eine Hommage an klassische Küchenradios. Erhältlich ist er in Weiß/Eiche oder Schwarz/Walnuss. Wir haben das Modell in warmem Cremefarben mit Eichenholz-Imitation vorliegen. Der metallene Frontgrill schützt die Membranen zuverlässig. Das Kunststoffgehäuse mit Holzimitat-Oberfläche wirkt hochwertig, nur der Plastik-Drehknopf auf der Oberseite passt optisch nicht ins Bild.
Mit 25 cm x 15 cm x 11 cm und 1,9 kg ist er einer der schwersten Bluetooth-Lautsprecher unserer Testreihe. Der Tragegurt befestigt sich über Schlüsselloch-Pins und verschwindet nach hinten geklappt optisch fast vollständig. Acht RGB-LEDs auf der Rückseite projizieren zehn verschiedene Lichtmodi an die Wand – von sanften Verläufen über Sonnenaufgang, Blüten, Blätter, Korallen bis zu pulsierenden Party-Effekten. Besonders vor hellen Wänden entfaltet sich eine beachtliche Effekt-Show. Die IPX2-Zertifizierung schützt nur vor tropfendem Wasser von oben – für Outdoor-Einsätze bei stärkerem Regen ist der Lautsprecher damit ungeeignet.
Pure Classic Aura Bilder
Pure Classic Aura

Pure Classic Aura

Pure Classic Aura

Pure Classic Aura

Pure Classic Aura

Pure Classic Aura

Pure Classic Aura

Pure Classic Aura

Pure Classic Aura

Pure Classic Aura

Pure Classic Aura

Pure Classic Aura

Pure Classic Aura

Pure Classic Aura

Pure Classic Aura

Pure Classic Aura

Pure Classic Aura

So gut ist der Klang des Pure Classic Aura
Das 2-Wege-System kombiniert zwei Full-Range-Treiber vorne mit einem rückwärtigen passiven Bassradiator (ABR). Die 40 Watt RMS decken laut Pure 60 Hz bis 20 kHz ab. Im Test zeigt sich ein ausgewogener Sound mit natürlichen Stimmen und solidem, kräftigem Bass. Die Bühne entpuppt sich für die Größe als beeindruckend breit. Pop und Rock profitieren davon, während sich die Mitten gerade bei Jazz oder Klassik etwas zu sehr zurückhalten.
Drei EQ-Modi sind per dedizierte Tasten direkt anwählbar: Dynamic betont Höhen und Bässe und bietet für unsere Ohren den besten Klang. Comfort zeigt sich insgesamt ausgeglichener und eignet sich für entspanntes Dauerhören. Eco priorisiert Akkulaufzeit mit reduziertem Bass.
Die maximale Lautstärke ist hoch und reicht für mittelgroße Räume, ab 80 Prozent setzen jedoch Verzerrungen ein. Bluetooth 5.3 mit AAC/SBC-Codecs sorgt für stabile Verbindungen mit niedriger Latenz. High-Res-Codecs fehlen, dafür gibt es einen 3,5-mm-AUX-Eingang.
Bedienung des Pure Classic Aura
Pure verzichtet auf eine App – das ist Fluch und Segen zugleich. Keine lästigen Downloads oder Registrierungen, aber auch keine Firmware-Updates oder Mehrband-Equalizer. Die Bedienung erfolgt vollständig über Tasten auf der Oberseite: Power, Bluetooth-Pairing, AUX-Wechsel, Play/Pause, Titelsprung und Lautstärke. Jeder der drei EQ-Modus hat eine eigene Taste.
Die Eco-Taste zeigt bei langem Halten den Akkustand über vier LEDs. Die LED-Steuerung gelingt über drei Taster. Ein kurzer Tastendruck wechselt zwischen den zehn Modi, zwei Sekunden Halten reguliert die Helligkeit (hoch/mittel/niedrig). Die Tasten sind haptisch gut unterscheidbar und teilweise beleuchtet. Für Nutzer ohne App-Affinität ist diese direkte Bedienung ein Segen.
Der Akku des Pure Classic Aura
Der 5000-mAh-Akku verspricht eine Laufzeit von bis zu 30 Stunden – allerdings nur im Eco-Modus bei mittlerer Lautstärke und ohne Beleuchtung. Im Comfort-Modus sind bei mittlerer Lautstärke mit Licht 20 bis 25 Stunden realistisch. Bei Maximal-Lautstärke entlädt sich der Akku deutlich schneller.
Das Laden erfolgt über USB-C mit 5 bis 30 Watt, eine Vollladung dauert 3 bis 4 Stunden. Ein Netzteil liegt nicht bei. Die Powerbank-Funktion liefert maximal 5 Watt – für Notfälle ausreichend, für schnelles Smartphone-Laden ungeeignet. Lobenswert: Der Akku versteckt sich hinter sechs Schrauben und lässt sich selbst wechseln.
Was kostet der Pure Classic Aura?
Mit 129 Euro positioniert sich der Classic Aura im Mittelfeld.
Fazit
Der Pure Classic Aura bietet eine stilvolle Wohnzimmer-Beschallung mit schicken visuellen Highlights. Die Verbindung aus Retro-Design und LED-Technologie macht ihn zum gern gesehenen Indoor-Companion. Klanglich gefällt er uns dank ausgewogenem Sound, natürlichen Vocals und solidem Bass. Die direkte Bedienung ohne App ist erfrischend unkompliziert. Die LED-Effekte schaffen vor allem vor einer weißen Wand zusätzliches Flair. Allerdings ist er für Draußen weniger geeignet, so sollte er nicht im Regen stehen. Auch das hohe Gewicht und die klanglichen Verzerrungen bei hoher Lautstärke sind Negativpunkte.
Sony XB33
Sony XB33
Mit dem XB33 Bluetooth-Speaker will Sony dank vieler Funktionen, langer Akkulaufzeit, Salzwasserfestigkeit und einem fairen Preis punkten. Der Testbericht zeigt, ob diese Rechnung aufgeht.
- wasserfest (auch gegen Salzwasser)
- sehr gute Akkulaufzeit
- fairer Preis & viele Funktionen
- Klang bei hohen Lautstärken ausbaufähig
- doppelte Belegung des Play-Buttons
Sony XB33 im Test
Mit dem XB33 Bluetooth-Speaker will Sony dank vieler Funktionen, langer Akkulaufzeit, Salzwasserfestigkeit und einem fairen Preis punkten. Der Testbericht zeigt, ob diese Rechnung aufgeht.
Der Sommer steht vor der Tür, gutes Wetter und hohe Temperaturen locken an den Strand – und bei einer zünftigen Party am See oder Meer darf der passende Outdoor-Bluetooth-Speaker nicht fehlen. Während Platzhirsch Sonos aktuell drei verschiedene Modelle mit Bluetooth-Support und Wasserdichtigkeit nach IP67 anbieten, etwa den Sonos Roam SL (Testbericht), hat Sony mit dem XB33 einen kabellosen Lautsprecher im Programm, der mit Langlebigkeit und intensivem Bassklang punkten will.
Sony verspricht einen kraftvollen Sound dank doppelter Breitbandlautsprecher und eine hohe Akkulaufzeit von bis zu 24 Stunden. Der Speaker soll Einsätze am Pool und in Salzwasserwassernähe problemlos überstehen und sogar abwaschbar sein. Wir haben uns den XB33 einmal genauer angeschaut und getestet, ob Sony abliefert – oder ob der Fokus auf Outdoor und Robustheit zulasten der Klangqualität geht.
Sollte der Sony XB33 nicht zusagen, empfehlen wir weitere Outdoor-Bluetooth-Lautsprecher, die wir im Rahmen dieser Themenwelt bereits getestet haben:
Design und Verarbeitung
Sony bewirbt den XB33 mit einem „markanten“ Design – das können wir bestätigen. Der Bluetooth-Speaker ist in den Farben Schwarz, Rot, Blau und Taupe (Cremeweiß) erhältlich und besitzt an den Seiten jeweils einen Beleuchtungsring, der um das Gehäuse führt. Die Lichtleisten erstrahlen in verschiedenen, anpassbaren Farben und pulsieren im Takt der Musik. Optisch erinnert der XB33 ansonsten ein wenig an die beliebten JBL-Speaker Flip 4 (Testbericht) und Flip 5 (Testbericht), allerdings setzt Sony auf abgerundete Ecken. Dennoch steht der Lautsprecher angenehm und hält auch bei leichteren Erschütterungen die Position.
Das Bedienpanel befindet sich auf der Oberseite des Lautsprechers und überzeugt mit einer guten Übersicht und leicht zu betätigenden Buttons. Sony verzichtet zwar auf eine farbliche Abgrenzung oder eine separate Beleuchtung der Knöpfe, aber der XB33 lässt sich trotzdem leicht und selbsterklärend steuern. Lediglich bei schwachem Licht könnte das Betätigen der Tasten in Fummelei ausarten.
Die gummierte Oberfläche des Speakers an den beiden Seitenteilen schützt das Gerät bei Stürzen, die der XB33 dann auch problemlos übersteht: Wir haben den Lautsprecher aus einer Höhe von einem Meter sowohl auf Vinylfußboden als auch auf Kies fallen lassen und konnten keine Schäden feststellen. Das Textil-Mesh an der Oberseite ließ sich außerdem problemlos von Schmutz und Staub befreien – ein feuchtes Tuch reichte in unserem Test dafür aus.
Weil der XB33 aber auch über eine IP67-Zertifizierung verfügt, können Nutzer den Speaker direkt unter laufendem Wasser abspülen. Auch das Eintauchen in einem Meter Wassertiefe übersteht das Gerät für eine halbe Stunde. Weiterer Clou: Der XB33 ist zudem gegen Salzwasser geschützt und eignet sich deshalb nicht nur für Poolpartys, sondern gleichzeitig für laue Sommerabende am Meer.

Bedienung und Betrieb
Wer den XB33 in Betrieb nehmen möchte, muss ihn – wie bei dieser Art von Lautsprechern üblich – per Bluetooth mit einem entsprechenden Wiedergabegerät koppeln. Dazu schalten wir den Lautsprecher ein, betätigen die Bluetooth-Taste und wählen beispielsweise auf dem Smartphone den SRS-XB33 als koppelbares Gerät aus. Sobald die Kopplung ausgeführt wurde, ertönt ein Signal und eine Computerstimme informiert uns aus dem Lautsprecher, dass eine Verbindung besteht. Das funktioniert in unserem Test problemlos und innerhalb weniger Sekunden.
Ebenso bequem fällt die restliche Bedienung des XB33 aus: Neben dem Einschaltknopf und der Bluetooth-Taste gibt es einen Playbutton sowie Regler für die Lautstärke. Der LIVE-Button ermöglicht zusätzlich noch den Wechsel der drei Klangmodi für einen stromsparenden, realistischen und besonders basslastigen Klang (dazu später mehr).
Leider hat Sony sich dafür entschieden, den Wechsel zwischen den Songs mit auf die Play-Taste zu legen, sodass dieser Button drei Funktionen hat. Wer mal schnell zwischen einzelnen Musikstücken wechseln möchte, muss also genau darauf achten, wie die Taste gedrückt wird. Wir finden: Eine oder zwei Tasten zusätzlich hätten den Bedienkomfort deutlich erhöht.
Sony XB33 Screenshots
Sony XB33 Screenshots

Sony XB33 Screenshots
Sony XB33 Screenshots

Sony XB33 Screenshots

Sony XB33 Screenshots

Sony XB33 Screenshots
Sony XB33 Screenshots
Sony XB33 Screenshots
Sony XB33 Screenshots
Der XB33 lässt sich direkt nach der Kopplung mit einem Wiedergabegerät nutzen. Der volle Funktionsumfang erfordert aber die Installation der Sonic-Music-Center- und der Fiestable-App. Darauf verweist auch die sehr spartanische Anleitung, die alle wichtigen Funktionen des Lautsprechers in Bildern verständlich erklärt. Die beiden Apps lassen sich über den Google Playstore oder Apples App Store herunterladen und installieren. Fiestable erlaubt anschließend eine spezielle „DJ-Steuerung“ mit Klang-Effekten und Samplings (Trommeln, Jubel etc.) sowie das Aktiveren der Bewegungssteuerung und die Regulierung der Beleuchtung.
Das Sony Music Center verfügt ergänzend über eine Wiedergabe-Funktion für Sounddateien, verschiedene Energieeinstellungen und einen Equalizer. Außerdem können Nutzer mit dieser App den XB33 mit anderen Geräten gruppieren, um etwa zwei Lautsprecher als Stereo-Paar zu verwenden oder mindestens drei Lautsprecher zu einer Party-Verbindung zu koppeln. Beide Apps funktionierten in unserem Test problemlos und erweitern den Lautsprecher um eine Reihe nützlicher Features, ohne zum Must-Have zu mutieren.
Klang
Was Käufer einer Bluetooth-Box wie der XB33 neben der Robustheit für den Outdoor-Gebrauch am meisten interessieren dürfte, ist wohl der Klang. Sony verspricht „kraftvollen Festivalsound“ mit einem besonders tiefen, satten Klang, der durch das Extra-Bass-Feature zustande kommen soll. Um das zu ermöglichen, hat Sony die hauseigene X-Balanced-Speaker-Unit verbaut, die aus zwei ovalen, zu den Seiten leicht schmaler werdenden MRC-Koni besteht. Zwei passive Radiatoren an den Seiten des Lautsprechers ergänzen die Gesamtkomposition.

Der Übertragungsbereich der Speaker liegt im Bereich zwischen 20 Hz und 20.000 Hz, zur Leistung des XB33 macht Sony allerdings keine Angaben. Trotzdem braucht sich das Sony-Modell nicht vor der Konkurrenz wie dem JBL Flip 4 zu verstecken: Denn der handliche Speaker bringt für seine Größe einen durchaus beachtlichen Klang hervor, der auch bei höherer Lautstärke punkten kann. Lediglich bei voll aufgedrehter Lautstärke wird der Sound teils etwas unsauber. Basslastige Stücke wie Hysteria von Muse oder Radioactive von Imagine Dragons fangen hier leicht an zu klirren – auch ohne aktivierten Extra-Bass.
Die hohen Töne gaben ein ähnliches Bild ab: Für diese Preisklasse ist der Sound durchaus gut, man sollte aber keine Höhenflüge erwarten. Das Intro des Songs Brothers In Arms von Dire Straits klang teilweise etwas dumpf, dem Gesang fehlte es an Tiefe – ebenso bei Adeles Rolling in the Deep. Wer sich auskennt, kann mithilfe des Equalizers noch etwas nachregeln und ein leicht besseres Klangbild herausholen.
Akku und Extras
Sony gibt die Akkulaufzeit des XB33 mit bis zu 24 Stunden an, bei aktiviertem Extra-Bass soll der Speaker bis zu 14 Stunden durchhalten. Diese Werte gelten bei 50 Prozent Lautstärke. Wir haben die verschiedenen Modi des Lautsprechers in unserem Test mehrere Stunden laufen lassen und können die Angaben von Sony bestätigen. Die Akkulaufzeit des XB33 kann also durchaus überzeugen – 14 Stunden bei aktiviertem Bass sollten für jede Strandparty ausreichen.
Daneben bietet der Lautsprecher von Sony noch ein paar Zusatzfunktionen: Nutzer können den Speaker auch zum Telefonieren nutzen oder an einen Sprachassistenten (Siri, Google Assistant) koppeln. Telefonanrufe lassen sich über die Bluetooth-Profile HFP und HSP tätigen, während der Sprachassistent ebenfalls über Bluetooth funktioniert. Haben wir die entsprechende Software aktiviert, reicht ein Druck auf den Play-Button des XB33, damit wir einen Befehl an den Sprachassistenten in das Lautsprechermikrofon sprechen können. Unser Android-Smartphone lässt sich dadurch im Test einwandfrei bedienen und auch die Telefoniefunktion arbeitet problemlos.
Preis
Sony bietet den XB33 Extra Bass Lautsprecher zum Listenpreis von 119 Euro an. Damit liegt er preislich auf einer Höhe mit dem JBL Flip 6 und dem Ultimate Ears Boom 3, wobei letzterer laut UVP zwar teurer ist, aber in diversen Online-Shops für rund 100 Euro angeboten wird. Der XB33 ist derweil – je nach gewählter Farbvariante – bereits zu einem Straßenpreis von unter 100 Euro zu haben. Im Angebot kann man ihn auch mal für gut 80 Euro schießen.
Fazit
Mit dem XB33 liefert Sony ein gelungenes Gesamtpaket zu einem fairen Preis. Die Akkulaufzeit kann sich ebenso sehen lassen wie das robuste Äußere und die nützlichen Zusatzfunktionen. Dass man beim Klang auf hohen Lautstärken ein paar Abstriche machen muss, sollte jedem klar sein, der für unter 100 Euro einen Bluetooth-Lautsprecher kaufen möchte.
Im Vergleich zur Konkurrenz muss sich der XB33 jedenfalls keineswegs verstecken. Der Sound ist ordentlich und für eine entspannte Strand- oder Poolparty vollkommen ausreichend. Wer eine gute Alternative zum JBL-Platzhirsch und den teureren Sonos-Modellen sucht, sollte diesem Sony-Lautsprecher unbedingt eine Chance geben.
Tronsmart Bang
Tronsmart Bang
Der Tronsmart Bang will mit kraftvollem Stereo-Sound, coolen Lichteffekten und einem guten Preis-Leistungs-Verhältnis überzeugen. Wir klären im Test, ob der Bluetooth-Lautsprecher mit JBL, Sony und Xiaomi mithalten kann.
- gutes Preis-Leistungs-Verhältnis
- Beleuchtung & integrierte Powerbank
- Pairing von 100 Speakern möglich
- kein Stoßschutz, nur IPX6-Zertifizierung
- Klang enttäuscht bei hoher Lautstärke
- Kunststoffgehäuse wirkt billig
Bluetooth-Lautsprecher Tronsmart Bang im Test
Der Tronsmart Bang will mit kraftvollem Stereo-Sound, coolen Lichteffekten und einem guten Preis-Leistungs-Verhältnis überzeugen. Wir klären im Test, ob der Bluetooth-Lautsprecher mit JBL, Sony und Xiaomi mithalten kann.
Der Sommer lockt nach draußen vor die Tür. Die passende Musik darf dabei nicht fehlen, weshalb sich der Kauf eines passenden Outdoor-Lautsprechers anbietet. Tronsmart hat mit dem Bang einen portablen Bluetooth-Speaker im Angebot, der den Ansprüchen an eine Nutzung im Freien genügen soll. Wir haben uns den Tronsmart Bang genauer angeschaut und verraten im Test, was die Box mit integrierter Powerbank und LED-Beleuchtung im Vergleich zu Konkurrenten wie dem JBL Flip 5 (Testbericht) oder Sony XB33 (Testbericht) taugt.
Design und Verarbeitung
Der Tronsmart bietet beim Design vorrangig eins: Er ist groß. Im Vergleich zum JBL Flip 5 oder dem Ultimate Ears Boom 3 (Testbericht) nimmt er das doppelte Volumen ein und übertrifft bei der Größe sogar den Soundcore Motion Boom (Testbericht). Der Speaker macht dadurch einen ziemlich wuchtigen Eindruck, was sich auch bei dem breiten Haltegriff bemerkbar macht.
Der Griff selbst besteht, ebenso wie das Gehäuse, aus Kunststoff. Weil die Ummantelung aber nicht aus einem, sondern aus zwei Teilen gefertigt ist, zieht sich eine Naht an beiden Seiten über das Gehäuse. Dadurch erweckt es einen eher billigen Eindruck. Dafür lässt sich der Speaker gut reinigen, was an dem pflegeleichten Stoff aus Mesh auf der Oberfläche der Box liegt. Einen Stoßschutz gibt es – ähnlich wie beim Sony XB33 (Testbericht) und dem Xiaomi Mi Portable (Testbericht) – leider nicht.
Dafür verfügt der Tronsmart Bang über eine IPX6-Zertifizierung. Ihr könnt den Speaker also kurzzeitig ins Wasser tauchen oder etwa in der Dusche benutzen. Einen längeren Tauchgang im Pool oder in der heimischen Badewanne, geschweige denn in Salzwasser, übersteht der Bang allerdings nicht. Weil Tronsmart den Lautsprecher explizit als Outdoor Party Speaker bewirbt, hätten wir uns etwas mehr Schutz vor äußeren Einflüssen gewünscht. Aber der Hersteller versteht Outdoor wohl eher im Sinne von Strand- als von Pool-Party.

Bedienung und Betrieb
Wer den Tronsmart Bang in Betrieb nehmen möchte, braucht ein Smartphone. Wir laden die zugehörige App herunter und verknüpfen sie mit dem Speaker – einfach den Lautsprecher einschalten und den Anweisungen in der App folgen. Das dauert nur wenige Sekunden und funktioniert ohne Probleme. Der Bang verfügt über einen sogenannten TuneConn-Button, der es uns erlaubt, bis zu 100 baugleiche Bang-Speaker miteinander zu koppeln. Dadurch können wir nicht nur Stereo-Sound erzeugen, sondern auch große Außenbereiche problemlos beschallen.
Bei der Bedienung erleben wir ansonsten keine Überraschungen: Ein gummiertes Bedien-Panel an der Oberseite ermöglicht das Steuern der einzelnen Klangmodi. Außerdem können wir den sogenannten Soundpulse EQ Button aktivieren, der für besonders klaren Klang sorgen soll. Ob das funktioniert, klären wir später. Wie die meisten Bluetooth-Boxen am Markt belegt auch der Tronsmart Bang die Lautstärke-Tasten doppelt, sodass wir für ein Wechseln der Musikstücke auf gesonderte Buttons verzichten müssen. Eine Tastenbeleuchtung suchen wir vergebens. Immerhin gibt es aber eine Ladestandsanzeige, die uns informiert, wie viel Akkulaufzeit noch verbleibt.
Die Tronsmart-App, die für viele Funktionen des Bang-Speakers erforderlich ist, beinhaltet einen eigenen Equalizer mit verschiedenen Klangmodi, einen Regler für den Abspiel-Modus, die Steuerung für den Broadcast-Modus mit bis zu 100 Speakern und eine Beleuchtungssteuerung. Wir haben die App als übersichtlich und funktional empfunden. Die EQ-Modi reichen für den Durchschnittsnutzer absolut aus, auch wenn ein individuell einstellbarer Modus wünschenswert gewesen wäre. Wer möchte, kann Musik auf dem Bang nicht nur per Bluetooth, sondern auch von einer TF-Karte, einem via Klinke-Kabel angeschlossenen Abspielgerät oder einer externen Festplatte (via USB) wiedergeben. Das alles funktionierte in unserem Test problemlos, ebenso wie die Beleuchtung. Letztere stellen wir entweder auf eine feste Farbe ein oder lassen sie zu den Beats der Musik variabel pulsieren.
Tronsmart Bang Bilder und Screenshots
Tronsmart Bang

Tronsmart Bang

Tronsmart Bang

Tronsmart Bang

Tronsmart Bang
Tronsmart Bang
Tronsmart Bang
Tronsmart Bang

Tronsmart Bang
Klang
Mit seinem Preis von rund 100 Euro muss sich der Tronsmart Bang gegen knallharte Konkurrenz wie dem Sony XB33 (Testbericht), Sonos Roam SL (Testbericht) oder JBL Flip 5 (Testbericht) behaupten. In Bezug auf Ausstattung und Extras auch gegen den Soundcore Motion Boom (Testbericht). Theoretisch sollte der Bang hier eine gute Figur abgeben, denn mit einer Leistung von 60 Watt liegt er deutlich über der Konkurrenz von JBLs Flip 5 (20 Watt) und dem Soundcore Motion Boom (30 Watt). Als Frequenzbereich gibt Tronsmart 20 Hz bis 20.000 Hz an, wodurch der Bang einen größeren Bereich abdeckt als der JBL Flip 5.
Allerdings stellt sich der Klang in der Praxis dann doch eher als enttäuschend heraus. Denn irgendwie kommen trotz der Größe des Speakers weder die Leistung noch der Klangbereich richtig zur Geltung. Adeles Rolling in the Deep bleibt blass, die Gitarren kratzig und bei aktiviertem Bass kommen die tiefen Töne unangenehm dumpf aus der Box. Erhöhen wir die Lautstärke, klirren die hohen Töne in den Ohren.
Auch unser Test mit Brothers in Arms von den Dire Straits gab ein trauriges Bild ab: Der Gesang klang matschig und dumpf, die Gitarren ebenfalls wieder kratzig. Andere Klangmodi wie Hi-Fi brachten hier keine Besserung, weil der Sound insgesamt zu breiig und undifferenziert aus den Speakern kommt. Zwar unterscheiden sich alle Klangmodi des Equalizers deutlich voneinander, aber ein wirklich zufriedenstellendes Ergebnis bekamen wir nicht zustande. Da zeigt Soundcore mit dem Motion Boom (Testbericht), wie es besser geht.
Insgesamt bleibt zum Klang zu sagen: Der Tronsmart Bang ist kein Totalausfall und für den Preis von rund 100 Euro (je nach Angebotslage) ein brauchbarer Outdoor-Lautsprecher für entspannte Partys. Allzu viel sollte man allerdings hier nicht erwarten – und die Soundcore-Konkurrenz hat hier einfach die Nase vorn.
Akku und Extras
Die Akkulaufzeit des Tronsmart Bang liegt laut Herstellerangaben je nach Klangprofil und Lautstärke bei bis zu 15 Stunden. Damit liegt der Bluetooth-Speaker im Mittelfeld vergleichbarer Lautsprecher und auf einem ähnlichen Niveau wie der Sony XB33 (Testbericht). Wir können die Herstellerangaben zur Laufzeit im Test ebenso bestätigen wie die mit 4,5 Stunden angegebene und verhältnismäßig hohe Ladedauer. Angaben zur Kapazität des Akkus macht Tronsmart nicht.
Der Tronsmart Bang bietet ebenso wie das Konkurrenzmodell eine integrierte Powerbank. Nutzer können also unterwegs auch das eigene Smartphone oder vergleichbare Hardware aufladen, auch wenn das freilich zulasten der Wiedergabedauer geht. Ergänzend dazu unterstützt der Bang die Nutzung von Sprachassistenten wie Siri oder Google Assistent, verfügt ansonsten aber über keine weiteren Extras.
Preis
Fazit
Der Tronsmart Bang ist beileibe kein schlechter Lautsprecher – aber er überrascht auch nicht mit besonderen Alleinstellungsmerkmalen. Der Klang ist solide und geht für den aufgerufenen Preis in Ordnung. Die Akkulaufzeit liegt ebenso im Mittelfeld, wie der Preis und die Ausstattung.
Aber genau das ist der Haken bei diesem Lautsprecher: Die mittelprächtige IPX6-Zertifizierung, der mittelmäßige Akku und die eher billige Optik lassen echte Highlights vermissen. Der Bang taugt deshalb zwar durchaus als Outdoor-Lautsprecher für Nutzer, die nicht viel mehr als 100 Euro ausgeben möchten. Aber im direkten Vergleich muss er sich dann doch der Konkurrenz, besonders dem deutlich besseren Soundcore Motion Boom (Testbericht) geschlagen geben.
Harman Kardon Luna
Harman Kardon Luna
Der Harman Kardon Luna vereint edles Design mit robuster Verarbeitung und kräftigem Klang. Aber ist er wirklich 120 Euro wert? Wir machen den Test.
- minimalistisches Design mit hochwertigen Materialien
- hohe Verarbeitungsqualität mit IP67-Zertifizierung
- kraftvoller, ausgewogener Klang
- Multipoint-Verbindung für zwei Geräte gleichzeitig
- keine App für Equalizer-Einstellungen
- kein analoger AUX-Eingang für kabelgebundene Verbindungen
- keine Powerbank-Funktion zum Laden externer Geräte
- Fehlen von HiRes-Codecs wie aptX oder LDAC
Bluetooth-Lautsprecher Harman Kardon Luna im Test
Der Harman Kardon Luna vereint edles Design mit robuster Verarbeitung und kräftigem Klang. Aber ist er wirklich 120 Euro wert? Wir machen den Test.
Anders als viele Mitbewerber wie der JBL Charge 5 oder der Sony Ult Field 1 verzichtet Harman Kardon beim Luna auf auffällige Designelemente und setzt stattdessen auf ein schlichtes, zeitloses Erscheinungsbild. Ob der Luna mit seiner Mischung aus Ästhetik und Leistung überzeugt und für wen er sich eignet, zeigt unser Test.
Design & Verarbeitung
Am Harman Kardon Luna gefällt uns das schlanke und minimalistische Design. Mit Abmessungen von 21 x 7,8 x 8 cm (Breite x Höhe x Tiefe) und einem Gewicht von 700 Gramm ist der Lautsprecher kompakt genug, um problemlos in viele Taschen zu passen.
Das Gehäuse ist mit einem hochwertigen Stoffbezug umhüllt, der in den Farbvarianten Schwarz und Grau erhältlich ist. Er sorgt für eine warme, fast schon wohnliche Anmutung. Die Oberseite besteht aus einer eloxierten Aluminiumplatte.
Die Verarbeitungsqualität des Luna ist hoch. Alle Übergänge sind präzise gefertigt, die Materialien fühlen sich gut an, und das Gerät macht insgesamt einen soliden Eindruck. Dank seiner IP67-Zertifizierung ist er sowohl staub- als auch wasserdicht.
Harman Kardon Luna Bilder
Harman Kardon Luna

Harman Kardon Luna

Harman Kardon Luna

Harman Kardon Luna

Harman Kardon Luna

Harman Kardon Luna

Harman Kardon Luna

Harman Kardon Luna

Harman Kardon Luna

Wie gut ist der Klang des Harman Kardon Luna?
Ausgestattet mit einem 2-Wege-Soundsystem, bestehend aus einem 25 W RMS Woofer und einem 15 W RMS Tweeter, liefert der Luna eine beeindruckende Gesamtleistung von 40 W RMS. Diese Leistung ist für einen Lautsprecher dieser Größenklasse beachtlich.
Der Frequenzbereich des Luna liegt bei 60 Hz bis 20 kHz (-6 dB). Der Tieftonbereich ist für einen kompakten Lautsprecher erstaunlich präsent, ohne dabei zu dominant zu wirken. Die Mitten sind klar und detailreich, der Hochtonbereich gefällt durch seine Klarheit und Detailtreue.
Anders als viele Bluetooth-Lautsprecher, die oft einen übermäßig betonten Bass oder überspitzte Höhen aufweisen, bietet der Luna ein harmonisches Klangbild, das sich für nahezu alle Musikgenres eignet.
Es besteht die Möglichkeit, zwei Luna-Lautsprecher kabellos zu einem Stereopaar zu koppeln. Ausprobieren konnten wir das nicht.
Bedienung
Die Bedienung des Harman Kardon Luna erfolgt ausschließlich über physische Tasten auf der Oberseite. Zu den Bedienelementen gehören eine Ein-/Aus-Taste, Lautstärketasten, eine Wiedergabe/Pause-Taste sowie eine Bluetooth-Pairing-Taste. Die Tasten haben einen angenehmen Druckpunkt und reagieren zuverlässig auf Eingaben.
Der Luna hat keine App und verzichtet damit auf zusätzliche Funktionen wie Equalizer-Einstellungen oder Firmware-Updates. Schade. Eine App hätte den ohnehin schon guten Klang des Luna durch individuelle Anpassungen weiter verbessern können.
Akku
Der Harman Kardon Luna bietet laut dem Hersteller eine Laufzeit von bis zu 12 Stunden. Diese Akkulaufzeit ist für einen Bluetooth-Lautsprecher dieser Leistungsklasse in Ordnung.
Wie bei allen Bluetooth-Lautsprechern ist die tatsächliche Akkulaufzeit stark von der gewählten Lautstärke abhängig. Bei maximaler Lautstärke reduziert sich die Spielzeit deutlich, während bei moderater Lautstärke die angegebenen 12 Stunden erreicht werden können. Fünf LED-Anzeigen auf der Oberseite geben Auskunft über den aktuellen Akkustand.
Die Ladezeit beträgt etwa 2,5 Stunden über USB-C. Eine Schnellladefunktion gibt es nicht. Auch eine Powerbank-Funktion zum Laden externer Geräte vermissen wir.
Konnektivität
In Sachen Konnektivität setzt der Harman Kardon Luna auf Bluetooth 5.3. Zudem unterstützt er Multipoint, um zwei mobile Geräte gleichzeitig zu verbinden.
Der Luna hat keinen analogen Eingangsanschluss (Aux-In). Auch auf Audio-Codecs wie aptX oder LDAC muss man beim Luna verzichten.
Was kostet der Harman Kardon Luna?
Der Harman Kardon Luna kostet bei Jacob.de aktuell 115 Euro.
Fazit
Der Bluetooth-Lautsprecher Harman Kardon Luna bietet eine gelungene Kombination aus elegantem Design, robuster Verarbeitung und richtig gutem Klang. Das minimalistische Erscheinungsbild mit dem hochwertigen Stoffbezug und der eloxierten Aluminiumplatte verleiht ihm eine edle Optik. Gleichzeitig sorgt die IP67-Zertifizierung dafür, dass der Luna auch bei Outdoor-Aktivitäten eine gute Figur macht.
Klanglich kann der Luna mit seinem 2-Wege-Soundsystem und einer Gesamtleistung von 40 W RMS überzeugen. Er liefert einen ausgewogenen, kraftvollen Sound mit spürbaren Bässen, klaren Mitten und detailreichen Höhen. Auch seine maximale Lautstärke kann sich hören lassen.
Die Akkulaufzeit von bis zu 12 Stunden ist ausreichend. Die Multipoint-Verbindung sowie die Möglichkeit, zwei Luna-Lautsprecher zu einem Stereopaar zu koppeln, bieten zusätzliche Flexibilität.
Was fehlt, ist eine dedizierte App für Equalizer-Einstellungen. Auch gibt es keinen analogen AUX-Eingang für kabelgebundene Verbindungen.
Tronsmart Mirtune S100
Tronsmart Mirtune S100
Der Tronsmart Mirtune S100 überrascht im Test mit beeindruckendem Sound zum Bruchteil des Preises etablierter Bluetooth-Lautsprecher wie dem JBL Charge 6.
- tiefer Bass
- Preis-Leistungs-Verhältnis
- IPX7-wasserdicht
- Akkulaufzeit bis zu 20 Stunden
- viele Anschlüsse
- etwas matte Höhen (per EQ korrigierbar)
- lange Ladezeit von 4,5
- recht groß
- optisch wenig inspirierend
Bluetooth-Lautsprecher Tronsmart Mirtune S100 im Test
Der Tronsmart Mirtune S100 überrascht im Test mit beeindruckendem Sound zum Bruchteil des Preises etablierter Bluetooth-Lautsprecher wie dem JBL Charge 6.
Häufig klingen Bluetooth-Lautsprecher fantastisch und kosten ein Vermögen, oder sie sind erschwinglich und klingen wie ein Radio aus den 1950er Jahren. Der Tronsmart Mirtune S100 verspricht, dieses Dilemma zu lösen. Mit einem Preis ab 55 Euro bei Otto und technischen Daten, die selbstbewusst in Richtung der Premium-Liga schielen, will er beweisen, dass guter Sound nicht zwangsläufig viel kosten muss.
Der röhrenförmige Bluetooth-Lautsprecher tritt gegen etablierte Größen wie den JBL Charge 5 (124 Euro, playox.de) oder dessen Nachfolger JBL Charge 6 (179 Euro, amazon.de) an. Auf dem Papier bringt er ähnliche Eigenschaften mit: 50 Watt Gesamtleistung, IPX7-Zertifizierung und ein 2.1-Soundsystem. Doch kann ein Lautsprecher zum halben Preis wirklich mithalten, oder ist er nur ein weiterer Fall von „zu schön, um wahr zu sein“?
Design und Verarbeitung des Tronsmart Mirtune S100
Der Mirtune S100 kommt in einem röhrenförmigen Design, das unverkennbar Anleihen bei der JBL Charge-Serie nimmt – Nachahmung ist bekanntlich die aufrichtigste Form der Anerkennung. Mit 23 x 9 x 10 cm ist er kompakt genug für den Rucksack, wiegt aber trotzdem 1,17 kg (nicht 1,36 kg, wie der Hersteller behauptet).
Unser Testmodell kommt in Schwarz daher und wirkt etwas eintönig. Nur das silberne Logo und die grauen Bedientasten durchbrechen die Monotonie, bringen aber auch keine Farbe ins Spiel. Die blaue Variante macht optisch mehr her. Das Gehäuse besteht aus mattem Kunststoff und Textilgewebe, wobei der Kunststoff nicht gerade Premium-Gefühle weckt. Die Verarbeitung ist dennoch solide und verspricht Langlebigkeit.
An den Seiten sitzen passive Radiatoren, die bei bassintensiver Musik sichtbar mitvibrieren. Ein cleveres Detail ist der einziehbare Gummigriff, der den Transport erleichtert. Kleine LEDs an der Front zeigen den Akkustand an.
Die RGB-LED-Ringe an den Seiten pulsieren im Takt der Musik. Auf Werbebildern sieht das spektakulär aus, in der Realität ist der Effekt jedoch subtil. Die unbeleuchteten Bedientasten lassen sich auch im Dunkeln problemlos ertasten.
Mit seiner IPX7-Zertifizierung übersteht der Lautsprecher problemlos Wasserspritzer oder sogar einen Sturz ins Planschbecken. Laut Hersteller überlebt der S100 auch Stürze aus einem Meter Höhe unbeschadet – eine Behauptung, die wir im Test geprüft haben. Und ja, er hat den Sturz unbeschadet überstanden und spielt stoisch weiter.
Tronsmart Mirtune S100 Bilder
Tronsmart Mirtune S100

Tronsmart Mirtune S100

Tronsmart Mirtune S100

Tronsmart Mirtune S100

Tronsmart Mirtune S100

Tronsmart Mirtune S100

Tronsmart Mirtune S100

Tronsmart Mirtune S100

Tronsmart Mirtune S100

Tronsmart Mirtune S100

Wie gut ist der Klang des Tronsmart Mirtune S100?
Der Mirtune S100 überrascht mit einem Klangbild, das seinen niedrigen Preis Lügen straft. Im Inneren werkelt ein 2.1-Kanal-System mit einem 30-Watt-Racetrack-Subwoofer (85 x 65 mm) und zwei 10-Watt-Hochtönern (25 mm). Diese Kombination liefert eine Gesamtleistung von 50 Watt und deckt einen Frequenzbereich von 50 Hz bis 20 kHz ab.
Der Bass ist die unbestrittene Stärke dieses Lautsprechers – er wummert mit einer Autorität, die man in dieser Preisklasse selten findet. Bei elektronischer Musik lässt der S100 die Luft vibrieren. Für manche Hörer könnte der Bass sogar zu dominant sein.
Die Höhen wirken dagegen ab Werk etwas matt, als würden sie sich hinter dem dominanten Bass verstecken. Glücklicherweise lässt sich dieses Ungleichgewicht über den Equalizer in der App korrigieren. Mit angehobenen Höhen und leicht reduziertem Bass entfaltet der Lautsprecher sein Potenzial und liefert ein ausgewogeneres Klangbild. Der JBL Charge 6 klingt zwar noch immer besser, kostet aber auch 100 Euro mehr.
Besonders spannend ist die Möglichkeit, zwei S100 zu einem Stereopaar zu koppeln. Obwohl wir diese Funktion nicht testen konnten, lehrt die Erfahrung, dass zwei gekoppelte Lautsprecher oft einen überproportional besseren Klang liefern. Mit einem Gesamtpreis ab 140 Euro für zwei Boxen könnte diese Kombination selbst kleinere Partys beschallen und wäre immer noch günstiger als ein einzelner JBL Charge 6.
Der Lautsprecher unterstützt Bluetooth 5.3 mit einer Reichweite von bis zu 15 Metern. Neben Bluetooth bietet der S100 auch einen AUX-Eingang, einen USB-A-Anschluss und einen Micro-SD-Kartenslot für MP3-Dateien. Eine Anschlussvielfalt, die ihresgleichen sucht.
Bedienung und App des Tronsmart Mirtune S100
Die Bedienung des S100 ist erfrischend unkompliziert. Auf der Oberseite finden sich großzügig dimensionierte Tasten für alle wichtigen Funktionen: Ein/Aus, Bluetooth-Kopplung, SoundPulse (Bassverstärkung), Play/Pause und Lautstärkeregelung. Durch langes Drücken der Lautstärketasten lassen sich Tracks überspringen.
Die Tronsmart-App bietet fünf EQ-Voreinstellungen für verschiedene Musikgenres sowie einen anpassbaren 5-Band-Equalizer. Letzterer ist wichtig, um die oben erwähnten matten Höhen anzuheben und den dominanten Bass zu zähmen. Die App bietet zudem drei verschiedene Presets für die RGB-Beleuchtung oder deren akkuschonende Deaktivierung.
Ein eingebautes Mikrofon ermöglicht Freisprechtelefonie und die Nutzung von Sprachassistenten. Im Test klangen wir für unsere Gesprächspartner allerdings recht weit entfernt. Trotzdem ein nützliches Feature, welches selbst teurere Konkurrenten häufig nicht bieten.
Tronsmart Mirtune S100 Screenshots
Tronsmart Mirtune S100 Screenshot
Tronsmart Mirtune S100 Screenshot
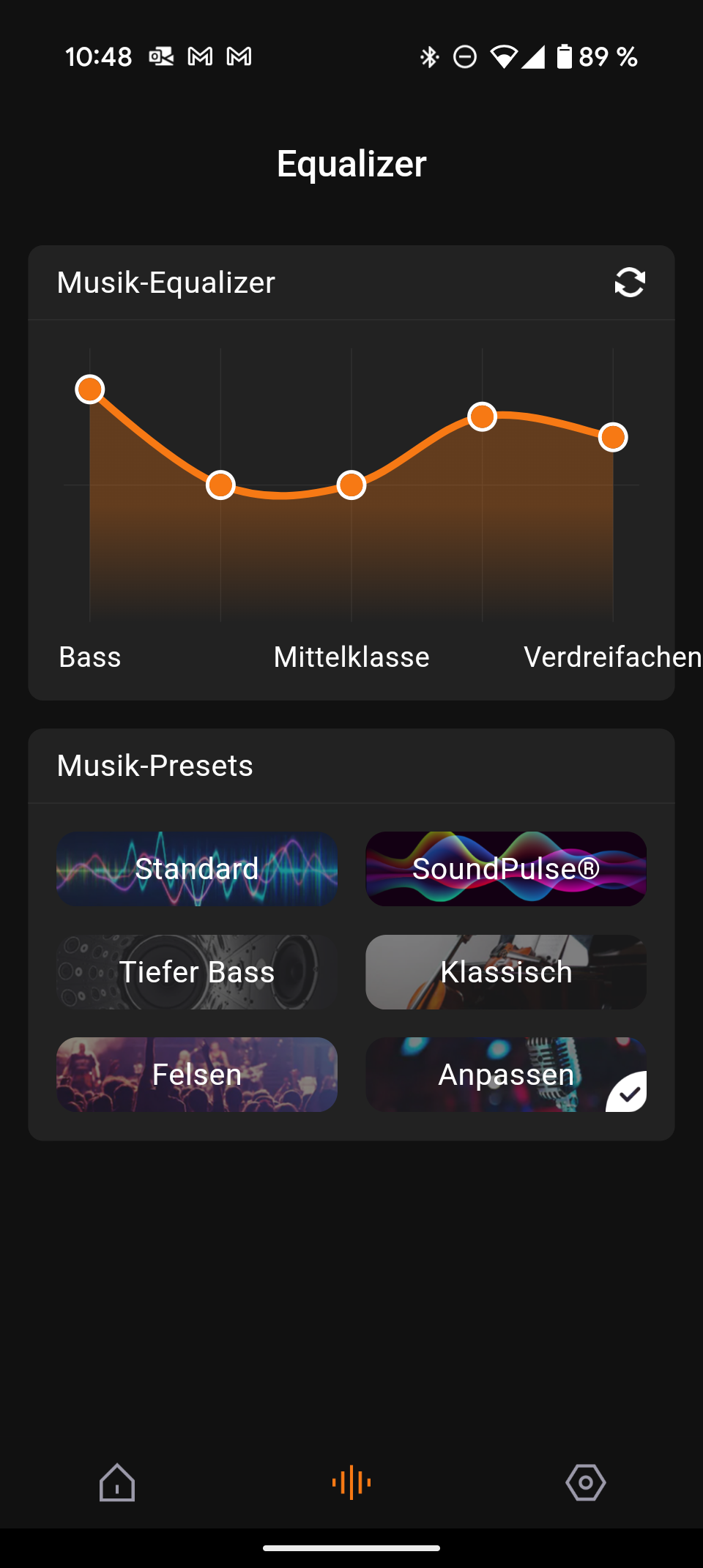
Tronsmart Mirtune S100 Screenshot
Tronsmart Mirtune S100 Screenshot
Tronsmart Mirtune S100 Screenshot
Tronsmart Mirtune S100 Screenshot
Tronsmart Mirtune S100 Screenshot
Der Akku des Tronsmart Mirtune S100
Der 8000-mAh-Akku hält bis zu 20 Stunden bei mittlerer Lautstärke durch – vorausgesetzt, die RGB-Beleuchtung ist deaktiviert. Die Ladezeit von 4,5 Stunden über USB-C ist allerdings ein Geduldsspiel. Hier sind viele Konkurrenten flotter unterwegs. Dafür bietet der S100 eine Powerbank-Funktion und lädt Smartphones über den USB-A-Anschluss.
Was kostet der Tronsmart Mirtune S100?
Der Tronsmart Mirtune S100 ist für 55 Euro bei Otto erhältlich. Damit ist er deutlich günstiger als vergleichbare Modelle etablierter Marken. Der JBL Charge 5 kostet mit etwa 124 Euro (playox.de) gut 50 Prozent mehr, der JBL Charge 6 mit 179 Euro (amazon.de) sogar mehr als das Doppelte.
Angesichts der gebotenen Leistung und Ausstattung bietet der Mirtune S100 ein herausragendes Preis-Leistungs-Verhältnis. Er beweist, dass guter Sound nicht zwangsläufig teuer sein muss.
Fazit
Der Tronsmart Mirtune S100 entpuppt sich als erfreuliche Überraschung in der Welt der Bluetooth-Lautsprecher. Sein kraftvoller, tiefer Bass sucht in dieser Preisklasse seinesgleichen. Die etwas zurückhaltenden Höhen lassen sich glücklicherweise per App-Equalizer aufpeppen, was dem Klang insgesamt sehr zugutekommt.
Die Verarbeitung ist solide, wenn auch nicht luxuriös – irgendwo musste wohl gespart werden. Mit IPX7-Zertifizierung, 20 Stunden Akkulaufzeit, vielen Anschlüssen und Powerbank-Funktion bietet der S100 eine beeindruckende Ausstattung. Die RGB-Beleuchtung ist zwar nett, aber eher ein schmückendes Beiwerk als ein entscheidendes Feature.
Im direkten Vergleich mit Premium-Lautsprechern wie dem JBL Charge 6 muss sich der Tronsmart zwar in einigen Punkten geschlagen geben, doch angesichts des Preisunterschieds ist das kaum verwunderlich. Tipp: Zwei gekoppelte Tronsmart Mirtune S100 kosten noch immer weniger als ein JBL Charge 6, hat aber deutlich mehr Power.
Xiaomi Mi Portable Bluetooth-Speaker
Xiaomi Mi Portable Bluetooth-Speaker
Der 30-Euro-Bluetooth-Lautsprecher Xiaomi Mi Portable will der teuren Marken-Konkurrenz von Sony, JBL und Co. gehörig einheizen. Das Konzept geht auf, wie unser Test zeigt.
- Preis-Leistungs-Verhältnis
- IPX7-Zertifizierung
- Akkulaufzeit und Stereo-Pairing
- kein Stoßschutz
- doppelte Belegung des Play-Buttons
Xiaomi Mi Portable Bluetooth-Speaker im Test
Der 30-Euro-Bluetooth-Lautsprecher Xiaomi Mi Portable will der teuren Marken-Konkurrenz von Sony, JBL und Co. gehörig einheizen. Das Konzept geht auf, wie unser Test zeigt.
Wer für den anstehenden Strandurlaub oder die nächste Poolparty noch nach einem passenden Bluetooth-Lautsprecher sucht, hat die Qual der Wahl: Soll es ein hochwertiges Markengerät wie der Sonos Roam SL oder der JBL Flip 5 sein? Oder lieber eine günstige Alternative aus China? Zu letzterer Kategorie gehört der Xiaomi Mi Portable Bluetooth-Speaker von Xiaomi, der guten Klang für wenig Geld bieten will.
Xiaomi bewirbt den Speaker mit hochwertigem Sound und IPX7 Zertifizierung. Eine Akkulaufzeit von bis zu 13 Stunden soll das Gerät alltagstauglich machen. Wir haben den Xiaomi Mi Portable einem ausführlichen Test unterzogen und geprüft, ob das Preis-Leistungs-Verhältnis des Lautsprechers überzeugen kann.
Design und Verarbeitung
Beim Design kommt der Xiaomi Mi Portable eher unspektakulär daher. Eine schlichte Stoff-Mesh-Oberfläche umhüllt fast das komplette, rechteckige Gehäuse mit abgerundeten Kanten. Zwei Gummifüße sorgen dafür, dass der Lautsprecher nicht verrutschen oder wegrollen kann. Ein Bedienpanel in derselben Farbe wie das Mesh befindet sich oben auf dem Speaker. Das Panel kommt übersichtlich daher, die Buttons lassen sich leicht betätigen. Die Steuerung funktioniert einfach und selbsterklärend. Eine Beleuchtung besitzt der Mi Portable übrigens nicht, was das Ablesen der Buttons bei schlechtem Licht erschwert, in dieser Preisklasse aber verschmerzbar ist.
Anders als Marken-Outdoor-Lautsprecher namhafter Hersteller, wie der Sony XB33 oder der JBL Flip 5 besitzt der Xiaomi Mi Portable keine gesonderte Gummierung oder einen Stoßschutz. Fällt der Speaker also auf harten Boden oder stürzt aus größerer Höhe, kann es zu Schäden an dem Gerät kommen.
Immerhin besitzt der Speaker eine IPX7-Zertifizierung und ist dementsprechend spritzwassergeschützt. Damit überlebt er einen heftigen Regenguss, einen Gang unter die Dusche oder kurzzeitiges Eintauchen in geringe Wassertiefe. Allerdings kann eindringendes Salzwasser den Speaker beschädigen – am Meer solltet ihr also entsprechend auf das Gerät achtgeben.
Bedienung und Betrieb
Die Koppelung des Xiaomi Mi Portable an das Smartphone oder ein vergleichbares Wiedergabe-Gerät funktioniert per Bluetooth 5.0. Das Ganze ist eine Sache von wenigen Sekunden – ein Druck auf die Bluetooth-Taste reicht aus, um die Kopplung einzuleiten. Eine Computerstimme informiert uns, wenn die Verbindung steht.
Die übrigen Tasten auf dem Bedienpanel des Xiaomi Mi Portable sind übersichtlich angeordnet und intuitiv nutzbar. Neben Ein- und Ausschaltknopf sowie Bluetooth-Button gibt es eine Play-Taste, Lautstärke-Regler und einen Button für das Stereo-Pairing mit einem zweiten Xiaomi Mi Portable. Weil es keine separaten Tasten für den Wechsel einzelner Musikstücke gibt, müssen Nutzer hierfür die Lautstärke-Tasten in Doppelbelegung verwenden. Das funktioniert zwar recht gut, ein zusätzlicher Button hätte allerdings nicht geschadet.
Mi Portable Bluetooth-Speaker
Mi Portable Bluetooth-Speaker

Mi Portable Bluetooth-Speaker

Mi Portable Bluetooth-Speaker

Mi Portable Bluetooth-Speaker

Mi Portable Bluetooth-Speaker

Mi Portable Bluetooth-Speaker

Eine eigene App für den Betrieb des Xiaomi Mi Portable gibt es übrigens nicht. Während Premium-Hersteller wie Sony oder JBL entsprechende Software zur Steuerung ihrer Hardware anbieten, läuft das Xiaomi-Gerät ohne entsprechende Zusatzprogramme. Eine Kopplung per Bluetooth reicht aber auch vollkommen aus, weil der Xiaomi Mi Portable auf Zusatzfunktionen wie eine Beleuchtung oder zusätzliche Sound-Effekte verzichtet. Wer möchte, kann aber Drittanbieter-Apps mit integriertem Equalizer nutzen, um in den Genuss entsprechender Features zu kommen.
Klang
Wer sich eine Bluetooth-Box wie die Xiaomi Mi Portable zu einem Preis von unter 50 Euro kauft, erwartet normalerweise kein Klangwunder. Trotzdem bietet der Lautsprecher von Xiaomi für seine Größe und die aufgerufene UVP einen erstaunlich guten Sound. Der Mi Portable verfügt über zwei Lautsprecher mit 8 Watt Nennleistung und einem Frequenzbereich zwischen 80 Hz und 20.000 Hz. Damit liegt er in einem ähnlichen Spektrum wie der JBL Flip 5 mit 65 Hz bis 20.000 Hz, der dafür aber bei der Leistung mit 20 Watt vorne liegt.
Klanglich kann der Xiaomi Mi Portable allerdings mit dem JBL Flip 5 mithalten. Der Sound kommt angenehm satt und klar aus dem kleinen Brüllwürfel und bleibt dabei durchweg ausgeglichen. Liebhaber ausgeglichener Höhen und Tiefen kommen voll auf ihre Kosten. Weder der Bass noch die hohen Lagen dominieren. Das macht sich zum Beispiel bei Adeles Rolling in the Deep bemerkbar, wo der Sound auch bei hoher Lautstärke noch angemessen sauber aus der Box kommt.
Wie gut das Zusammenspiel von Höhen und Tiefen funktioniert, zeigt sich auch bei dem Song Love/Hate Thing von Wale. Sowohl die hohen Background-Vocals als auch der Beat und der eigentliche Sprechgesang kommen mit dem Xiaomi Mi Portable gut zur Geltung. Doch es gibt Klangbereiche, in denen der Speaker Federn lassen muss, etwa bei klassischer Musik oder bei sehr hoher Lautstärke, wo einzelne Passagen in extremen Frequenzen unsauber klingen. Aber das ist bei einem günstigen Modell wie dem Mi Portable unserer Meinung nach absolut verschmerzbar.
Akku und Extras
Die Akkulaufzeit des Xiaomi Mi Portable liegt laut Xiaomi bei 13 Stunden. Je nachdem, wie stark wir die Lautstärke aufdrehen, variiert die Laufzeit, aber wir konnten im Test bei 50 bis 70 Prozent Volumen die 13 Stunden locker ausreizen. Zwar kann der Mi Portable mit seinem 2.600-mAh-Akku nicht mit der teureren Konkurrenz wie dem Sony XB33 mithalten, allerdings empfinden wir die Leistung im Test als ausreichend und besser, als es der geringe Preis des Speakers vermuten lässt.
Viele Extras hat der Xiaomi Mi Portable im Übrigen nicht zu bieten, das haben wir in dieser Preiskategorie aber auch nicht erwartet. Immerhin können Nutzer mit einem Druck auf den Play-Button eingehende Anrufe auf dem Smartphone annehmen.
Preis
Xiaomi verkauft den Xiaomi Mi Portable in den Farben Blau und Schwarz zum Listenpreis von 49,99 Euro. Das entspricht in etwa dem Preis vergleichbarer chinesischer Modelle wie dem Earfun Uboom oder günstigen Alternativen wie dem Tronsmart Element Force (Testbericht). Allerdings verkaufen einige Shops den Speaker bereits ab etwa 30 Euro, was ihn zu einem echten Schnäppchen macht.
Fazit
Wer mit dem Kauf des Xiaomi Mi Portable liebäugelt, darf keine klanglichen Höchstleistungen erwarten. Auch die Outdoor-Festigkeit des Lautsprechers ist ausbaufähig. Allerdings ist dieser Speaker auch unschlagbar günstig, insbesondere, wenn ihr ihn für knapp über 30 Euro kauft.
Der Sound des Xiaomi Mi Portable kann in dieser Preisklasse punkten. Wer darauf achtet, dass der Lautsprecher bei einer Pool- oder Strandparty nicht mit größeren Wassermengen oder Schmutz in Berührung kommt, macht mit dem Kauf des Geräts nichts falsch. Sucht man hingegen ein hochwertigeres Modell mit besserem Schutz gegen äußere Einflüsse, schaut man am besten den Ultimate Ears Boom 3 (Testbericht), den JBL Flip 5 (Testbericht) oder den Sonos Roam SL (Testbericht) an.
Nubert Nugo One
Nubert Nugo One
Der Nubert Nugo One ist ein kompakter Bluetooth-Lautsprecher mit DAB+-Radiofunktion. Wir haben die BT-Box getestet und zeigen, wie gut sie ist.
- mit DAB+ und UKW-Empfang
- Stereo, apt-X HD
- gute Bässe
- teils umständliche Bedienung
- bei ungünstiger Positionierung wenig Höhen
- Display nicht tageslicht-tauglich
Bluetooth-Lautsprecher Nubert Nugo One im Test
Der Nubert Nugo One ist ein kompakter Bluetooth-Lautsprecher mit DAB+-Radiofunktion. Wir haben die BT-Box getestet und zeigen, wie gut sie ist.
Nubert will der Spezialist für gute und günstige (Eigenbezeichnung: ehrliche) Lautsprecher zu Hause sein – ob im Wohnzimmer oder am PC. Nun kann man mit dem Nugo One einen Nubert-Lautsprecher auch mobil nutzen, beispielsweise ins Freibad. Bis 55 Hz hinab soll der tragbare Nubert dann spielen, und das bis zu 24 Stunden am Stück. Nichts für japanische Wohnungen mit Papierwänden, das dürfte zur sofortigen unwiderruflichen Ausweisung führen. Allerdings würde dort auch der Radioempfang versagen, mit einem anderen UKW-Band und ohne DAB+.
Radioempfang? Ja, der Nugo One ist ein tragbarer Stereo-Aktivlautsprecher mit Akkubetrieb, einem Analog-Eingang, Bluetooth sowie einem analogen und digitalen Radioempfänger. Er ist also eine Mischung aus hochwertiger Bluetooth-Box und mobilem Batterieradio. Nur WLAN und Multiroom sind nicht geboten.
Design: Schwarzer Minimalismus
Von der Form her erinnert der Nugo One fast an eine Leica-Kleinbildkamera, nur er ist deutlich größer und das Objektiv fehlt. Dafür ist hinten unten eine Teleskopantenne angebracht, daneben eine 3,5-mm-Stereo-Klinkenbuchse und die USB-Ladebuchse.
Schaltet man das Gerät ein, erwacht zwischen dem Einschalter und einem Drehknopf ein zuvor unsichtbares Display und kurz danach auch der Lautsprecher selbst. Weitere Anschlüsse oder Bedienelemente gibt es nicht. Zum Test lag das Modell in Schwarz vor, was bislang auch die einzige lieferbare Farbe ist. Der Nugo One misst samt Antenne und Drehknopf etwa 250 × 90 × 141 mm und wiegt 1,6 kg.
Der Lautsprecher wird via USB-C-Port geladen. Ein zweiseitiges USB-C-Kabel wird ebenso mitgeliefert wie ein USB-Netzteil. Dieses liefert 15 Watt (5 V mit 3 A), 19,98 Watt (9 V mit 2,22 A) oder 20,04 Watt (12 V mit 1,67 A). An einem normalen 5 V / 2 A-Netzteil lud der Lautsprecher im Test ebenso, nur etwas langsamer; am mitgelieferten Netzteil soll der Akku mit 7,25 V und 4,9 Ah in 2,5 Stunden wieder voll sein.
Ein Drucktaster und ein Drehknopf sind die einzigen Bedienelemente. Auch wenn man den Drehknopf zusätzlich drücken kann, auch mehrfach, ist dies sehr minimalistisch. Selbst die „Programmtasten“ für gespeicherte Rundfunksender befinden sich rein virtuell auf dem Display und müssen zudem über Drehen und Drücken des Lautstärkereglers angesteuert werden – das IPS-LCD ist kein Touch-Display. Zudem wird es nicht sehr hell und befindet sich auch noch im „Dark Mode“ mit heller Schrift auf dunklem Hintergrund.
Der Lautsprecher ist mit IPX5 spritzwassergeschützt und darf damit mit ins Freibad, sollte aber nicht ins Becken fallen. Auch leichten Regen übersteht er. Die Wasserdichtigkeit ist übrigens auch der Grund für die unkomfortable Bedienung: Ursprünglich waren sechs echte mechanische Programmtasten angedacht, doch diese sind nicht so leicht wasserdicht zu bekommen. Einschalter und Dreh-/Druckknopf sind dagegen wasserdicht.
Die Nugo One fungiert als Bluetooth-Box, DAB+- und als UKW-Empfänger. Für den Analog-Eingang gibt es eine 3,5-mm-Klinkenbuchse. Diese funktioniert auch umgekehrt als Ausgang, dann aber optisch-digital (SPDIF). So kann ein größerer Verstärker verlustarm angeschlossen werden, der Nugo One dient dann als UKW- bzw. DAB+-Tuner oder Bluetooth-Empfänger. Das Gerät kann sogar das amerikanische HD-Radio-Verfahren bei FM-Stationen decodieren.
Ausstattung und Installation
Die Einrichtung des Nugo One ist schnell erledigt: Es ist keine App notwendig, es muss auch nichts installiert werden. Für den Bluetooth-Betrieb ist die Box wie üblich mit dem Smartphone oder Tablet zu paaren, für DAB+ ein Sendersuchlauf durchzuführen und dann die gewünschte Station zu wählen. Die Teleskopantenne muss man für guten Empfang mit DAB+ nur teilweise ausfahren, für UKW sollte man sie voll ausziehen. Für den Bluetooth-Betrieb kann sie hinter dem Gerät eingefahren bleiben.
Die Bluetooth-Verbindung zum Smartphone oder anderen Quellen findet dank aptX-HD mit hoher Qualität statt. Für Apple-Geräte ist AAC vorhanden. Bei DAB+ und UKW ist man auf ausreichende Bitrate bzw. Signalstärke angewiesen.
Auch eine Weckfunktion mit Alarmton, DAB+ oder UKW ist vorgesehen. Der Lieblingssong von Spotify ist dagegen zum Aufwecken nicht möglich, weil dieser ja erst am Smartphone gewählt werden müsste.
Praktischer Betrieb
So gut die „inneren Werte“ auch sind, ist die Bedienung manchmal etwas holperig, wobei aber viel bereits per Software-Update verbessert wurde. Die Lautstärkeregelung ist sehr fein gegliedert, von 0 bis -60 dB in 0,5-dB-Schritten. Hier muss man sich nicht wie bei Android mit nur 16 Stufen zufriedengeben. Der Nachteil: Will man im Radiobetrieb die Lautstärke reduzieren, beginnt das große Kurbeln. Andererseits ist die Werbung in Minimalstellung (-60 dB) immer noch deutlich hörbar; einen Schritt weiter ist dann komplett Stille, sodass man nicht mitbekommt, wenn die Werbung vorbei ist. Grund für die lahme Lautstärke-Einstellung ist übrigens die dynamische Loudness-Klangverbesserung, die verzögert reagiert und die Umstellung so ausbremst.
Zum Ein- und Ausschalten drückt man den anderen Knopf drei Sekunden; falls sich das Gerät einmal aufgehängt haben sollte, muss man keinen separaten Reset-Knopf suchen, sondern nur hier 20 Sekunden lang drücken. Kurz drücken hat die Funktion des Rücksprungs aus Menüs. Diese Mehrfachbelegung ist kein Problem.
Kniffliger ist die Mehrfachbelegung des großen Dreh-/Druckknopfs. Schon, um das Hauptmenü aufzurufen, muss man diesen drei Sekunden drücken. Dann kann man zwischen Analog-Eingang, Bluetooth, DAB+, UKW und Grundeinstellungen wählen. Dass der Nugo One relativ langsam einschaltet, fällt nicht so auf; wechselt man aber zu DAB+, stört die Wartezeit bis zum Einsetzen des Empfangs.
Umständlich ist die Senderwahl beim Radiobetrieb (DAB+ sowie UKW), die man per Einknopf-Bedienung mit Drehen und (teils 3x) lang oder kurz drücken ansteuert. Hier wären einige Tasten mehr sehr vorteilhaft gewesen – ein schneller Programmwechsel ist so auch unter den gespeicherten Favoriten nicht möglich. Zudem ist auch das Einschalten und der Senderwechsel bei DAB+ langsam, ein ARM7 statt ARM4 wäre hier besser gewesen. Der Empfang selbst ist aber mit einem Automotive-Chipsatz von Silicon Labs statt des gängigen Frontier Silicon Chipsets hervorragend.
Die Uhrzeit kann sich der Nugo One vom Radiosignal holen und so selbsttätig stellen, was allerdings zunächst eingeschaltet werden muss – ab Werk ist es aus.
Ungeschickt ist, dass die 3,5-mm-Klinkenbuchse nur als analoger Eingang und digitaler Ausgang dienen kann. Ein analoger Ausgang für einen Kopfhörer ist nicht vorhanden und ein Bluetooth-Kopfhörer kann ebenso wenig angeschlossen werden, weil Bluetooth nur als Eingang vom Smartphone zum Nugo One vorgesehen ist. Grund ist, dass ein analoger und elektrischer Anschluss am Verstärker oft zu Störungen durch Masseschleifen und Störungen aus Stromnetz oder Netzteil führt und man deshalb optisch-digital (SPDIF) für vorteilhafter ansah. Doch Kopfhörer mit einem solchen Anschluss gibt es nicht.
Nubert NuGo One – Bilderstrecke
Nubert NuGo One – Bilderstrecke

Nubert NuGo One – Bilderstrecke

Nubert NuGo One – Bilderstrecke

Nubert NuGo One – Bilderstrecke

Nubert NuGo One – Bilderstrecke

Nubert NuGo One – Bilderstrecke

Klang
Der Klang ist bei Nubert eigentlich über jeden Zweifel erhaben. Man baut dort einfach gute Lautsprecher und holt auch hier aus dem recht kompakten Gehäuse saubere Bässe heraus. Stellt man sich den Nugo auf der Gartenliege auf die Brust, ist der Klang dann auch mit guter Stereobasis fantastisch. Praktisch ist dies allerdings nicht, so kann man nicht einmal lesen. Auf dem Schreibtisch in Kopfhöhe, also auf einem Monitor oder einem Buchstapel dahinter, passt auch alles, solange der Stapel nicht umkippt. Steht der Nugo dagegen neben dem Hörer auf der Balkonliege am Boden, so erreichen ihn die Höhen nur noch teilweise und das Ganze wird basslastig und höhenarm. Doch das kann man in der aktuellen Softwareversion nachregeln.
Wo Sonos die Höhen forciert und die Bässe vernachlässigt, ist Nubert hier genau den entgegengesetzten Weg gegangen: Zwei Breitbandlautsprecher mit 6,6 cm Durchmesser plus Passivradiatoren sorgen für guten Klang bis in den Basskeller, doch zusätzliche breiter strahlende Tweeter für die Höhen fehlen. Hier hat sich Nubert zu sehr an die sonst so üblichen Bluetooth-Boxen gehalten, die mit röhrenden Bässen verblüffen wollen. Im Gegensatz zu diesen sind es allerdings neutrale, saubere Bässe. Von Nubert erwartet man keinen Bose- oder Teufel-Klang.
Preis
Mit aktuell 265 Euro ist der Nugo One eines der günstigsten Nubert-Produkte und liefert dafür eine beachtliche Leistung, die in dieser Kombination (Mobilbetrieb, Stereowiedergabe, Radioempfang digital und analog) einmalig ist. Für einen Bluetooth-Lautsprecher mit Radiofunktion ist der Preis allerdings schon recht hoch.
Fazit
Insgesamt ist der Nugo One mit vielen außergewöhnlichen Eigenschaften ausgestattet wie einer Betriebsdauer von bis zu 24 Stunden mit einer Akkuladung, aptX für Bluetooth, einem zumindest im Werk austauschbaren Akku und stolzen 2 × 21 Watt Dauerleistung pro Kanal.
Damit hat Nubert ein einmaliges Produkt kreiert, das im Gegensatz zum Versprechen selbst so mancher Multiroom-Lautsprecher auf kleinem Platz große Anlagen ersetzen kann und ein hervorragendes Preis-Leistungs-Verhältnis bietet. Die Software und manche Konstruktionsdetails können je nach persönlichem Geschmack stören, doch da man Nubert-Produkte ins Haus geschickt bekommt und 30 Tage ausprobieren darf, ist das Risiko eines Fehlkaufs gering.
 im Regen stehen")
Kein FSR 4.1 auf RDNA 3.5?: AMD lässt Millionen APU-Nutzer (vielleicht doch nicht?) im Regen stehen

Digital Markets Act: Teilerfolg für Meta vor dem EU-Gericht

TSMC, Samsung und Intel: Chipfertiger können Nachfrage für AI auf Jahre nicht stillen

Community-Protest erfolgreich: Galera bleibt Open Source in MariaDB

Blade‑Battery 2.0 und Flash-Charger: BYD beschleunigt Laden weiter

Top 10: Der beste Luftgütesensor im Test – CO₂, Schadstoffe & Schimmel im Blick
-
 Entwicklung & Codevor 3 Monaten
Entwicklung & Codevor 3 MonatenCommunity-Protest erfolgreich: Galera bleibt Open Source in MariaDB
-
 Künstliche Intelligenzvor 3 Monaten
Künstliche Intelligenzvor 3 MonatenBlade‑Battery 2.0 und Flash-Charger: BYD beschleunigt Laden weiter
-
Künstliche Intelligenzvor 3 Monaten
Top 10: Der beste Luftgütesensor im Test – CO₂, Schadstoffe & Schimmel im Blick
-

 Künstliche Intelligenzvor 3 Monaten
Künstliche Intelligenzvor 3 MonateniPhone Fold Leak: Apple spart sich wohl iPad‑Multitasking
-

 Apps & Mobile Entwicklungvor 3 Monaten
Apps & Mobile Entwicklungvor 3 MonatenMähroboter ohne Begrenzungsdraht für Gärten mit bis zu 300 m²
-
Künstliche Intelligenzvor 3 Monaten
JBL Bar 1300MK2 im Test: Soundbar mit Dolby Atmos, starkem Bass und Akku‑Rears
-

 Künstliche Intelligenzvor 3 Monaten
Künstliche Intelligenzvor 3 MonatenPetra‑AI: KI soll Frauen in der Perimenopause unterstützen
-

 Social Mediavor 2 Monaten
Social Mediavor 2 MonatenVon Kennzeichnung bis Plattformpflichten: Was die EU-Regeln für Influencer Marketing bedeuten – Katy Link im AllSocial Interview


