Künstliche Intelligenz
Marktforscher: Streaming-Nutzung erreichte im Dezember 2025 neue Rekordzahlen
Im Dezember und insbesondere am ersten Weihnachtstag des vergangenen Jahres haben Streaming-Anbieter in den Vereinigten Staaten neue Rekorde aufgestellt. Die Marktforscher von Nielsen haben am 25.12.2025 55,1 Milliarden Sehminuten bei den Streaming-Diensten gemessen, was den bisherigen Rekord vom selben Tag des Vorjahres um 8 Prozent übertroffen hat. Das lag vor allem an drei Spielen der nordamerikanischen Football-Liga NFL sowie dem an diesem Tag erstmals verfügbaren Finale der TV-Serie „Stranger Things“.
Weiterlesen nach der Anzeige
Gleichzeitig bedeutet dies, dass 54 Prozent aller TV-Geräte in den USA an diesem Tag für Streaming verwendet wurden, ebenfalls ein Rekord für die Streaming-Nutzung eines Tages. Insgesamt erreichte Streaming im Dezember einen Anteil von 47,5 Prozent der Fernsehzeit, während traditionelles Fernsehen (Broadcast) auf 21,4 Prozent und Kabelfernsehen auf 20,2 Prozent kam. Zum Streaming zählt Nielsen aber nicht nur Netflix, Disney+ und Amazons Prime Video, sondern auch YouTube. Googles Videoplattform ist mit 12,7 Prozent der Anbieter mit den meisten Sehminuten.

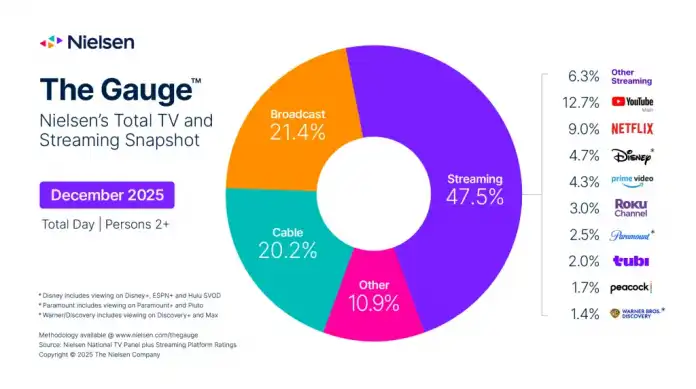
Marktanteile von TV und Streaming im Dezember 2025
(Bild: Nielsen)
Netflix profitierte nicht nur von „Stranger Things“, einer der erfolgreichsten englischsprachigen Serien aller Zeiten, sondern auch von den beiden NFL-Spielen, die der Streaming-Marktführer seit letztem Jahr zu Weihnachten live zeigt. Ende 2024 konnte Netflix wohl auch damit 19 Millionen Kunden Neukunden gewinnen. Im Dezember 2025 konnte Netflix die Zuschauerzahlen gegenüber dem Vormonat um 10 Prozent steigern, wobei „Stranger Things“ in dem Monat der meistgesehene Streaming-Titel war, und 9 Prozent des Fernsehmarkts erreichen.
Sportprogramme als Zuschauermagnet bei allen Anbietern
Auch Amazon setzt für Prime Video auf mehr Live-Sport und hatte sich deshalb die Donnerstagsspiele der NFL gesichert. Da der erste Weihnachtstag 2025 ein Donnerstag war, konnte auch Amazon zum Streaming-Konsum an diesem Tag beitragen und verzeichnete dabei ein Rekordspiel. Im gesamten Dezember erzielte Prime Video 4,3 Prozent der TV-Einschaltquote, im Monatsabstand ein Plus von 12 Prozent, was einen neuen und um 0,3 Prozent höheren Plattformrekord darstellt. Neben den NFL-Donnerstagsspielen profitiert Amazon auch von der neuen Staffel der TV-Serie „Fallout“, schreibt Nielsen.
Auch traditionelles und Kabelfernsehen erzielen mit Live-Sportübertragungen in den USA die höchsten Einschaltquoten. Zwei NFL-Spiele am 28. und 21. Dezember belegen die Spitzenplätze bei den Fernsehprogrammen der Sender CBS und FOX und beim Kabelfernsehen sind fünf NFL-Spiele die meistgesehenen Sendungen des Monats. Diese laufen bei ESPN und NFL Network. Insgesamt konnten Sportprogramme des Kabelfernsehens im Dezember 16 Prozent mehr Zuschauer verzeichnen, so die Marktforscher.
Weiterlesen nach der Anzeige
(fds)












Künstliche Intelligenz
Irankrieg: Langfristig potenzielle Gefahr für die Chip- und Speicherproduktion
Der Irankrieg könnte die weltweite Chipproduktion beeinflussen, wenn er lange anhält. Insbesondere in Südkorea bereitet die Situation Sorgen, weil dort die zwei weltweit größten Speicherhersteller Samsung und SK Hynix ansässig sind. Aufgrund der hohen Nachfrage bei KI-Rechenzentren herrscht bereits eine Speicherkrise, die insbesondere Endkunden trifft. Kurzfristig soll es jedoch keine signifikanten Auswirkungen geben.
Weiterlesen nach der Anzeige
Ein längerer Konflikt könnte sich auf die Lieferketten für die Speicherproduktion auswirken. Aus dem Nahen Osten stammen etwa große Mengen Helium und Brom. Vor allem Helium ist in der Chipfertigung wichtig. Hersteller verwenden es etwa zur Kühlung von Silizium-Wafern in der Produktion, da Helium eine hohe Wärmeleitfähigkeit und weitere geeignete Eigenschaften aufweist. Brom ist für manche Ätzvorgänge wichtig.
Katar ist laut einer Untersuchung des United States Geological Survey der nach den USA zweitgrößte Lieferant von Helium weltweit. Auf beide Länder entfielen 2025 demnach 76 Prozent der weltweiten Produktion. Katar hat nach iranischen Angriffen und der Bedrohung der Schifffahrtswege durch die Straße von Hormuz Produktion und Export von Helium eingestellt.
Alarmiert, aber nicht kritisch
Die Nachrichtenagentur Reuters gibt Politikeraussagen aus Südkorea wieder, die vor langwierigen Lieferstopps warnen: „Funktionäre wiesen auf die Möglichkeit hin, dass die Halbleiterproduktion gestört werden könnte, wenn einige dieser wichtigen Materialien nicht aus dem Nahen Osten bezogen werden können“, sagt Kim Young-bae, Mitglied der südkoreanischen Nationalversammlung, nach Treffen unter anderem mit Samsungs Führungsriege. Insgesamt sollen Südkoreas Chip- und Speicherhersteller von über einem Dutzend Produkten aus dem Nahen Osten abhängig sein.
SK Hynix gibt zumindest kurzfristig Entwarnung: Der Speicherhersteller verfüge „seit Langem über vielfältige Lieferketten und ausreichende Vorräte“ an Helium. „Daher [ist] kaum mit Auswirkungen auf das Unternehmen zu rechnen.“
Auch der weltweit größte Chipauftragsfertiger TSMC zeigt sich entspannt: Derzeit seien keine wesentlichen Auswirkungen zu erwarten. Die Firma will die Situation aber weiterhin genau beobachten.
Weiterlesen nach der Anzeige
In Südkorea sackten die Aktien von Samsung und SK Hynix zum Wochenbeginn um beinahe zehn Prozent ab. Bei den im Westen gehandelten Hinterlegungszertifikaten (Global Depositary Receipt, GDR) ist das Minus bislang nicht ganz so drastisch. Der gesamte Aktienmarkt ist derzeit volatil.
(mma)
Künstliche Intelligenz
Intel-Prozessor mit zwölf Performance-Kernen startet als „Core 2 with P-Cores“
Weiterlesen nach der Anzeige
Intel bringt einen nagelneuen Prozessor für die mehr als vier Jahre alte Fassung LGA1700: den „Core 2 Series 200 with P-Cores“ alias Bartlett Lake. Die Besonderheit dieser CPU-Baureihe ist, dass sie acht, zehn oder zwölf Performance-Kerne (P-Cores) hat, aber keine Effizienzkerne. Es gibt zwar längst schon LGA1700-Prozessoren mit viel mehr CPU-Kernen, davon waren bisher aber maximal acht P-Kerne.
Die Baureihe Core 2 200PE ist nicht für gängige Desktop-PCs gedacht, sondern vor allem für Industriecomputer und Embedded Systems – daher auch der Buchstabe „E“ in den Typenbezeichungen. Auf den meisten LGA1700-Mainboards funktioniert ein Core 2 200PE erst gar nicht. Doch es gibt bereits eine große Auswahl an kompatiblen LGA1700-Boards mit den Chipsätzen R680E, Q670E oder H610E. Mehrere Hersteller stellen schon die nötigen BIOS-Updates für Bartlett Lake bereit.
Reife Technik
Die Fassung LGA1700 debütierte Ende 2021 gemeinsam mit dem Core i-12000 Alder Lake, also dem Core i der 12. Generation aus der Fertigungstechnik „Intel 7“, die Intel davor noch 10-Nanometer-Technik nannte. Der entstammen auch die nachfolgenden (und letzten), bis heute gefertigten Core-i-Generationen 13 (Raptor Lake) und 14 (Raptor Lake Refresh).
Lesen Sie auch
Schon seit Anfang 2025 liefert Intel Embedded-Versionen der Raptor-Lake-CPUs für LGA1700-Boards wie Core 3 201E, Core 5 211E und Core 7 251E, die den Codenamen Bartlett Lake tragen. Einige enthalten aber auch E-Cores, zusätzlich zu P-Cores. Diese hybride Mischung eignet sich für manche Anwendungen schlecht, wenn es dabei auf vorhersagbare Latenzen ankommt. In Serverprozessoren (Xeons) kommen daher stets nur Kerne gleicher Bauart zum Einsatz, übrigens auch bei AMD (Epyc) und bei ARM-Serverprozessoren.
Auf Mainboards mit dem Chipsatz R680E steuern die neuen Bartlett-Lake-Prozessoren auch ungepufferte DDR5-Speichermodule mit zusätzlichen DRAM-Chips für Error Correction Code (ECC) an.
Weiterlesen nach der Anzeige
Klarer Gegener: AMD Ryzen Embedded
Viele Embedded Systems mit x86-Technik nutzen Embedded-Versionen von sparsameren und kompakteren Mobilprozessoren. Dafür bieten sowohl AMD als auch Intel jeweils mehrere Serien von lange lieferbaren Chips an.
Die gesockelten Embedded-Prozessoren bieten höhere Rechenleistungen und mehr PCIe-5.0-Lanes für Erweiterungskarten. Sie kommen beispielsweise in Industrierobotern, bildgebenden Medizingeräten, Netzwerkkomponenten wie Firewalls und auch in manchen kompakten (Storage-)Servern zum Einsatz.
AMD verkauft schon länger Ryzen-Embedded-Versionen mit deutlich mehr starken Kernen als Intel, etwa den Ryzen Embedded 7000 mit bis zu 12 Zen-4-Kernen und den Ryzen Embedded 9000 mit bis zu 16 Zen-5-Kernen. Eng verwandt sind die Serverversionen Epyc 4004 (Zen 4/AM4/DDR4-RAM) und Epyc 4005 (Zen 5/AM5/DDR5-RAM) mit jeweils bis zu 16 CPU-Kernen.
Intel kann nun immerhin bei der Anzahl der P-Kerne dichter an die AMD-Konkurrenz für diese Geräte- und Preisklassen mit zwei DDR5-RAM-Kanälen heranrücken. Als Vorteile im Vergleich zum AMD Ryzen Embedded 9700X verspricht Intel für den Core 9 273PE eine niedrigere PCIe-Latenz. Außerdem erwähnt Intel Time Coordinated Computing (TCC) und Ethernet-Adapter mit Time-Sensitive Networking (TSN). Die Bartlett-Lake-Chips will Intel zehn Jahre lang liefern.
Embedded-Versionen von Panther Lake
Auf der Fachmesse Embedded World in Nürnberg will Intel auch Embedded-Versionen der zu Jahresbeginn vorgestellten Mobilprozessorfamilie Core Ultra 300 (Panther Lake) zeigen. Sie findet vom 10. bis 12. März statt.

Congatec conga-HPC/cPTL: Rechenmodul in der Bauform COM-HPC mit Intel Core Ultra 300 und LPCAMM2-Speichermodul.
(Bild: Congatec)
Unter anderem Congatec hat bereits ein Modul in der Bauform COM-HPC Client Size A angekündigt, das conga-HPC/cPTL. Es bietet eine LPCAMM2-Fassung für ein LPDDR5X-Speichermodul mit bis zu 32 GByte Kapazität.
|
Embedded-Prozessoren Intel Core 2 with P-Cores (Bartlett Lake, Intel 7, LGA1700) |
||||
| Prozessor | P-Kerne |
Takt (Basis / Turbo) |
Cache | TDP |
| Core 9 273PQE | 12 | 3,4 / 5,9 GHz | 36 MByte | 125 W |
| Core 9 273PE | 12 | 2,3 / 5,7 GHz | 36 MByte | 65 W |
| Core 9 273PTE | 12 | 1,4 / 5,5 GHz | 36 MByte | 45 W |
| Core 7 253PQE | 10 | 3,5 / 5,7 GHz | 33 MByte | 125 W |
| Core 7 253PE | 10 | 2,5 / 5,5 GHz | 33 MByte | 65 W |
| Core 7 253PTE | 10 | 1,8 / 5,4 GHz | 33 MByte | 45 W |
| Core 5 223PQE | 8 | 4,0 / 5,5 GHz | 24 MByte | 125 W |
| Core 5 223PE | 8 | 2,9 / 5,4 GHz | 24 MByte | 65 W |
| Core 5 223PTE | 8 | 2,3 / 5,4 GHz | 24 MByte | 45 W |
| Core 5 213PE | 8 | 2,7 / 5,2 GHz | 24 MByte | 65 W |
| Core 5 213PTE | 8 | 2,1 / 5,2 GHz | 24 MByte | 45 W |
| ebenfalls verfügbar | ||||
| Core 3 201E | 4 | 3,6 / 4,8 GHz | 12 MByte | 60 W |
| Core 3 201TE | 4 | 2,9 / 4,6 GHz | 12 MByte | 45 W |
(ciw)
Künstliche Intelligenz
Elektromobilität: Fast 200.000 öffentliche Ladepunkte in Deutschland
Die Ladeinfrastruktur in Deutschland ist hinsichtlich der Zahlen schon längere Zeit besser als ihr Ruf. Laut Bundesnetzagentur gab es zum Stichtag 1. Februar 2026 deutschlandweit 196.353 öffentliche Ladepunkte. 146.449 davon bieten eine maximale Ladeleistung von 22 kW und werden als Normalladepunkte bezeichnet. 49.904 Ladepunkte bieten mehr als 22 kW. In der Regel sind das DC-Ladepunkte, doch es gibt noch ein paar AC-Ladepunkte mit 43 kW, die ebenfalls zu diesen Schnellladepunkten zählen.
Weiterlesen nach der Anzeige
Wechselstrom führt
Innerhalb eines Jahres stieg die Zahl der AC-Ladepunkte um 13 Prozent; am 1. Februar 2025 waren es nur 130.123. Ladepunkte mit bis zu 22 kW sind weitverbreitet, weil für sie ein Anschluss an das dicht geknüpfte Niederspannungsnetz genügt. Das ist günstiger als der Anschluss an das Mittelspannungsnetz, der für die schnelleren DC-Ladepunkte notwendig ist. Allein die Zahl der Ladeeinrichtungen mit 15 bis 22 kW stieg innerhalb eines Jahres um rund 13.000 auf nun 109.077. Schade ist, dass noch immer viele Neuwagen diese 22 kW nicht komplett abgreifen können. Modelle beispielsweise aus dem Volkswagen-Konzern oder von Stellantis können an Wechselstrom meist nur mit 11 kW laden.
Schnelle DC-Lader bevorzugt
Bei den DC-Ladepunkten stieg die Anzahl von 37.350 im Februar vergangenen Jahres um 34 Prozent. Dabei dominieren die Ladepunkte mit mindestens 150 kW das Geschehen inzwischen deutlich. Die Bundesnetzagentur nennt für die Ladeleistung zwischen 150 und 299 kW 19.230 (plus 33 Prozent) und für Punkte mit mindestens 300 kW inzwischen 17.049 (plus 44 Prozent) Lademöglichkeiten in Deutschland. Letzteres ist nötig, denn im vergangenen Jahr sind eine Reihe von Modellen auf den Markt gekommen, die in der Spitze mit mehr als 300 kW laden können. In der Redaktion hält bislang ein Xpeng G9 den Rekord, der eine Säule mit 400 kW komplett auslasten konnte – ohne seine maximale Ladeleistung zu erreichen.
EnBW ist mit weitem Abstand Marktführer
Weiterlesen nach der Anzeige
Unter den Anbietern gibt es ein Rennen um den dritten Platz zwischen BP (2990 Ladepunkte), EWE Go (3362) und Tesla (3665). E.ON ist mit 4715 auf dem zweiten Platz schon etwas voraus, liegt seinerseits allerdings weit hinter dem Marktführer EnBW, der 11.608 Ladepunkte in Deutschland bietet. Nicht überall geht es bei der Ladeinfrastruktur in Deutschland übrigens vorwärts. Die Zahl der öffentlichen AC-Ladepunkte mit Schukostecker sank innerhalb von zwölf Monaten von 4110 auf 3989. Auch wer ein E-Auto mit CHAdeMO-Anschluss öffentlich laden möchte, hat weniger Möglichkeiten als vor einem Jahr. Statt 3567 waren es zuletzt noch 3372.
(mfz)

Für Industrie und Autos: AMD bringt Ryzen AI Embedded P100 mit Zen 5 und RDNA 3.5

Zum Geburtstag viele gute Ideen oder eine Dinnerparty? › PAGE online

Irankrieg: Langfristig potenzielle Gefahr für die Chip- und Speicherproduktion

Schnelles Boot statt Bus und Bahn: Was sich von London und New York lernen lässt

Community Management zwischen Reichweite und Verantwortung

Community Management und Zielgruppen-Analyse: Die besten Insights aus Blog und Podcast
-
 Künstliche Intelligenzvor 2 Monaten
Künstliche Intelligenzvor 2 MonatenSchnelles Boot statt Bus und Bahn: Was sich von London und New York lernen lässt
-
 Social Mediavor 4 Wochen
Social Mediavor 4 WochenCommunity Management zwischen Reichweite und Verantwortung
-
 Social Mediavor 1 Woche
Social Mediavor 1 WocheCommunity Management und Zielgruppen-Analyse: Die besten Insights aus Blog und Podcast
-
Künstliche Intelligenzvor 3 Wochen
Top 10: Die beste kabellose Überwachungskamera im Test – Akku, WLAN, LTE & Solar
-

 Entwicklung & Codevor 3 Monaten
Entwicklung & Codevor 3 MonatenKommentar: Anthropic verschenkt MCP – mit fragwürdigen Hintertüren
-

 Künstliche Intelligenzvor 3 Monaten
Künstliche Intelligenzvor 3 MonatenGame Over: JetBrains beendet Fleet und startet mit KI‑Plattform neu
-

 Künstliche Intelligenzvor 3 Monaten
Künstliche Intelligenzvor 3 MonatenDigital Health: „Den meisten ist nicht klar, wie existenziell IT‑Sicherheit ist“
-

 Social Mediavor 3 Monaten
Social Mediavor 3 MonatenDie meistgehörten Gastfolgen 2025 im Feed & Fudder Podcast – Social Media, Recruiting und Karriere-Insights

