Künstliche Intelligenz
Model-Schau 2: Neue Architekturansätze bei den Sprachmodellen
Das neue Jahr ist noch jung, aber die Sprachmodell-Community hat sich keine Pause gegönnt. So geht es munter mit neuen Modellen, aber auch mit neuen Architekturansätzen ins Jahr 2026, auch wenn einige der vorgestellten Neuerungen noch aus den letzten Wochen von 2025 stammen.
Weiterlesen nach der Anzeige


Prof. Dr. Christian Winkler beschäftigt sich speziell mit der automatisierten Analyse natürlichsprachiger Texte (NLP). Als Professor an der TH Nürnberg konzentriert er sich bei seiner Forschung auf die Optimierung der User Experience.
Gedächtnis-Titan von Google
Bisher kämpfen fast alle Sprachmodelle mit Amnesie. Sobald sie lange Texte verarbeiten sollen, vergessen sie entscheidende Details. Diese Tendenz verstärkt sich mit längerem Kontext. Besonders die Teile in der Mitte gehen dann verloren (lost in the middle). Es gibt zahlreiche Ansätze, Modelle in dieser Hinsicht zu verbessern. Einige Modelle setzen beispielsweise alternierend sogenannte Mamba-Layer (oder State Space Models) ein, die besonders bei langen Sequenzen besser skalieren und weniger Speicherplatz benötigen, dafür aber nicht so präzise arbeiten wie Transformer. Andere Modelle setzen auf rekurrente neuronale Netze (RNNs), die man nach der Erfindung der Transformer eigentlich schon fast abgeschrieben hatte.
(Bild: Golden Sikorka/Shutterstock)

Die Online-Konferenz LLMs im Unternehmen zeigt am 19. März, wie KI-Agenten Arbeitsprozesse übernehmen können, wie LLMs beim Extrahieren der Daten helfen und wie man Modelle effizient im eigenen Rechenzentrum betreibt.
Google hat nun zwei neue Forschungsartikel dazu veröffentlicht. Der erste nennt sich „Titans“ und führt eine Architektur ein, die nach ihren eigenen Worten „die Geschwindigkeit von RNNs mit der Genauigkeit von Transformern zusammenbringt“. Google erreicht das durch den Einsatz von Transformern und dem Attention-Mechanismus für das Kurzzeitgedächtnis, für das Langzeitgedächtnis verwendet der Ansatz tiefe neuronale Netze (und nicht etwa RNNs). Eine sogenannte Überraschungs-Metrik soll sich besonders auf die Textteile konzentrieren, die nicht erwartete Wörter enthalten. Mit einem adaptiven Verfallmechanismus vergisst das Modell dann die Informationen, die es nicht mehr benötigt.
Google stellt mit „MIRAS“ auch gleich einen Blueprint zur Implementierung vor. Das dahinterliegende KI-Modell fokussiert sich auf eine Memory-Architektur, den Attention-Bias (mit dem es wichtige von unwichtigen Informationen unterscheidet) und die Mechanismen zum Vergessen beziehungsweise zum Aktualisieren des Gedächtnisses. Statt des mittleren quadratischen Fehlers oder des Skalarprodukts optimiert Google nichteuklidische Metriken und nennt dafür drei Beispielmodelle, die auf dem Huber-Loss, generalisierten Normen oder einer Wahrscheinlichkeitsabbildung basieren.
Das klingt äußerst mathematisch, aber Google kann damit in ersten Demos bessere Ergebnisse als mit einer reinen Mamba-Architektur erzielen. Den am Schluss erklärten Extrem Long-Context Recall vergleicht der Artikel allerdings nur mit Modellen wie GPT-4 oder Qwen2.5-72B, die schon mindestens ein Jahr alt sind. Diese Ergebnisse sollte man also mit Vorsicht genießen. Spannend wird es, wenn Google damit richtig große Modelle trainiert und zur Verfügung stellt.
Weiterlesen nach der Anzeige
Liquid Foundation Models
Eine ganz andere Architektur setzen die Liquid Foundation Models ein. Lange waren die Liquid Models schon mit Demos präsent, in denen sie mit kleinen Modellen erstaunliche Fähigkeiten entwickeln konnten. Der Durchbruch kam dann mit LFM2. Teile der Modelle setzen die Transformer-Architektur mit Attention ein, andere nutzen Multiplikations-Gates und Konvolutionen mit kurzen Sequenzen. Allerdings war bisher die Performance der darauf aufbauenden Modelle noch nicht gut genug.
Geändert hat sich das mit LFM2.5, einer ganzen Serie von kleinen Modellen mit nur gut einer Milliarde Parametern. Vorerst sind die Modelle für Edge-Devices gedacht, sie lassen sich aber auch mit hoher Geschwindigkeit auf üblicher Hardware ausführen. Die in Abbildung 1 dargestellten Ergebnisse sind mit Vorsicht zu genießen, da sie vom Anbieter stammen. Unabhängig davon machen die Modelle für ihre Größe einen hervorragenden Eindruck. Für viele Anwendungen wie Retrieval-Augmented Generation (RAG) könnten diese gut zum Einsatz kommen, weil das Wissen dafür nicht in den Modellen selbst stecken muss, die hier nur zum Feinabgleich und für Formulierungen eingesetzt werden. Mit einer kleinen GPU lassen sich die Modelle extrem schnell ausführen. Auf einer performanten CPU arbeiten sie immer noch schnell.

Beim Erdbeertest kann LFM 2.5 ebenso wenig überzeugen (Abb. 1) …
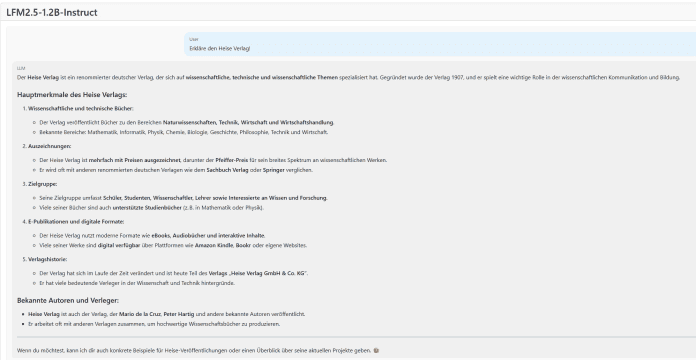
wie mit der Erklärung von heise (Abb. 2).
Neben den Modellen zur Textgenerierung gibt es auch ein hybrides Modell, das gesprochenen Text sowohl verstehen, als auch erzeugen kann. Gerade für mobile Endgeräte kann die Funktion sinnvoll sein, damit man auch ohne Internet- und Cloud-Zugriff Sprache in Text und umgekehrt umwandeln kann.

Performance von LFM2.5-1.2B-Instruct im Vergleich zu ähnlich großen Modellen (Abb.3)
(Bild: Hugging Face)
Schlanke Coding-Modelle erobern Benchmarks
Bei IQuest-Coder handelt es sich um ein neues Modell mit 40 Milliarden Parametern, das insbesondere in der Loop-Variante interessante Ideen mit einbringt. Der Transformer arbeitet rekurrent, verarbeitet also die Tokens mehrfach – zunächst doppelt in zwei Iterationen. IQuestLab verspricht damit deutlich höhere Performance. Seine Entwickler behaupten, in den einschlägigen Benchmarks wesentlich bessere Ergebnisse erzielen zu können als vergleichbar große Modelle. Trotz anfänglicher Euphorie scheint das Modell aber nicht besonders populär zu sein.
Einen anderen Weg geht NousResearch. Es nutzt Qwen-14B als Basismodell, um mit modernen Methoden daraus ein Coding-Modell zu erzeugen. Auch wenn es nicht mit den deutlich größeren Modellen konkurrieren kann, erzielt es für seine Größe gute Ergebnisse und zeigt einen möglichen weiteren Weg für Coding-Modelle auf.
Chinesische Modelle mit offenen Gewichten
Die seit Kurzem an der Börse in Hong Kong notierte Firma Z.ai hat mit GLM-4.7 ein lang erwartetes Modell veröffentlicht, das sich in vielen Benchmarks an die Spitze der Modelle mit offenen Gewichten gesetzt hat. Mit 355 Milliarden Parametern verfügt es zwar über eine stattliche Größe, ist aber immer noch viel kleiner als die Modelle von DeepSeek oder Kimi. Laut Benchmarks ist GLM 4.7 besonders gut bei Coding-Aufgaben und bei komplexen Denkaufgaben.
Im Vergleich zum Vorgänger GLM 4.6 ist es praktisch in allen Dimensionen besser, außerdem hat Z.ai die Kontextlänge auf 200.000 Token erhöht. Das führt zu einem sehr großen Modell mit 335 Milliarden Parametern. Das Modell verfügt dazu über 160 Experten, von denen immer acht (und ein geteilter) aktiv sind. Zusammen mit den ersten dichten Layern ergeben sich damit 32 Milliarden Parameter, die bei jedem Aufruf aktiv sind. Um den RAM-Bedarf der (quantisierten) Modelle etwas zu verkleinern, haben einige User versucht, die Experten zu eliminieren, die häufig schlechte Antworten erzeugen. Das Verfahren dazu nennt sich REAP (Reflection, Explicit Problem Deconstruction, and Advanced Prompting) und produziert schlankere Modelle, deren Ausgabe sich kaum von der des vollen Modells unterscheiden lässt.

Den Erdbertest besteht GLM-4.7 (Abb. 4).
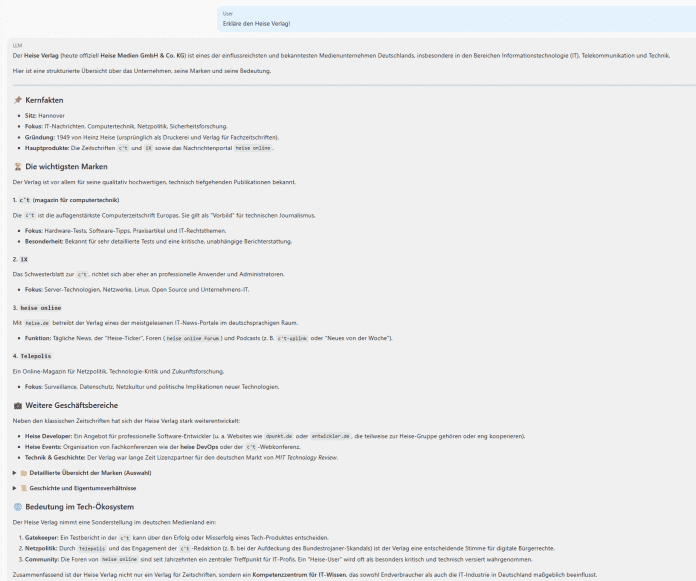
Die heise-Erklärung ist im Vergleich zu vielen anderen Modellen auffällig stimmig, auch wenn sie ausgerechnet bei Heise Developer etwas dazu erfindet. (Abb. 5)

Bei Taiwan gibt sich GLM-4.7 recht offen (Abb. 6).

Auch zu Tiananmen hält sich das Modell kaum zurück (Abb. 7).

Und erklärt sogar die Unterdrückung durch die chinesische Parteiführung (Abb. 8).
Bei MiniMax 2.1 handelt es sich um ein weiteres Modell aus China, das sich ebenso wie GLM 4.7 auf Coding, Nutzung von Werkzeugen und agentische Workflows fokussiert. Der Anbieter veröffentlicht wesentlich weniger Informationen als Z.ai, aber in den entsprechenden Dateien lässt sich einiges finden. Wenig überraschend handelt es sich auch bei MiniMax 2.1 um ein MoE-Modell, allerdings mit 256 Experten, von denen immer acht befragt werden. Von den insgesamt 230 Milliarden Parametern sind dann jeweils immer 10 Milliarden aktiv. Auch MiniMax kann wie GLM 4.7 mit knapp 200.000K Token umgehen.
Die Community ist sich nicht einig, ob GLM 4.7 oder MiniMax 2.1 sich besser für Programmieraufgaben eignet. Zweifellos sind beides sehr starke Modelle, die dank (relativ) weniger aktiver Parameter auch noch verhältnismäßig schnell ausgeführt werden können.

Auch Minimax-M2.1 zählt beim Erdbeertest richtig (Abb. 9).

Bei der heise-Erklärung gibt es eine Mischung aus korrekten und erfundenen Informationen (Abb. 10).

Bei der Taiwan-Frage gibt es eine differenzierte, aber recht knappe Antwort (Abb. 11).

Die Tiananmen-Ereignisse verharmlost das Modell (Abb. 12).

Und es äußerst sich zur Zensur, auch wenn es hier den Bezug zu dem zuvor als Referenz genannten Tiananmen auslässt (Abb. 13).
Modelle von LG aus Südkorea
Aus Südkorea hat man bisher wenige Modelle gesehen. Das hat sich nun geändert, mit K-EXAONE stellt LG ein entsprechendes Modell zur Verfügung. Wie nicht anders zu erwarten, ist es vor allem auf englische und koreanische Texte trainiert, spricht aber auch Spanisch, Deutsch, Japanisch und Vietnamesisch. Mit 236 Milliarden Parametern ist es sehr groß, auch wenn nur jeweils immer 23 Milliarden Parameter aktiv sind. Es nutzt Sliding Window Attention und kann damit lange Kontexte von bis zu 256K Token verarbeiten. In den Benchmarks performt das Modell ähnlich gut wie das (deutlich kleinere) gpt-oss-120b oder das (ebenso große) Qwen-235B-A22B-Thinking.
Spannende Zeiten
Es hat sich in den letzten Wochen einiges getan – in ganz unterschiedlichen Richtungen. Ob sich Googles Ideen umsetzen lassen und durchsetzen können, wird sich erst in einer ganzen Weile zeigen. Unstrittig dürfte hingegen sein, dass die Liquid Foundation Models für ihre Größe wirklich Beachtliches leisten. Das trifft auch für die (scheinbar wenig zensierten) großen chinesischen Modelle zu, die sich sehr gut für agentische Aufgaben eignen. Schließlich taucht auch erstmals ein großes koreanisches Modell auf, das konkurrenzfähig ist. Das lässt auf eine weitere Diversifizierung in der Zukunft hoffen.
(rme)










Künstliche Intelligenz
Always-on-Display unter iOS 26: So wird man das unscharfe Bild los
Aktuelle iPhones kommen mit einem Bildschirm, der stets aktiv bleibt – zumindest, solange die Vorderfront des Gerätes nicht abgedeckt ist. Das seit dem iPhone 14 Pro verbaute Always-on-Display ermöglicht es dann, aktuelle Informationen anzuzeigen, insbesondere die Uhrzeit. Zudem ist das gewählte Hintergrundbild sichtbar, man kann sein iPhone also auch als Fotorahmen nutzen. Mit iOS 26 hat Apple allerdings im letzten Herbst eine Veränderung vorgenommen: Seither ist das Wallpaper nicht mehr nur abgedunkelt, wie bislang, sondern wird auch noch verschwommen dargestellt. Sinn der Sache scheint zu sein, dass sich die Uhrzeit besser ablesen lässt, was aber auch früher eigentlich selten ein Problem darstellte. Glücklicherweise hat Apple aber eine Option in sein Betriebssystem eingebaut, die das „Blurring“ umgehen lässt.
Weiterlesen nach der Anzeige
Einstellung vorhanden
Die Funktion ist allerdings nicht ganz einfach zu finden: Sie lässt sich nicht etwa bei der Erstellung eines Hintergrundbildes setzen, sondern ist in den allgemeinen Bildschirm-Einstellungen unter „Anzeige & Helligkeit“ in den Systemeinstellungen versteckt. Es ist auch nicht möglich, die verschwommene Anzeige je nach Wallpaper einzustellen, sondern nur über einen Hauptschalter.
Dieser befindet unter „Anzeige & Helligkeit“ im Untermenü „Immer eingeschaltet“, das man erreicht, wenn man etwas scrollt. Neben „Hintergrundbild anzeigen“, „Benachrichtigungen anzeigen“ und der Nutzung des Always-on-Display an sich ist nun auch eine Unschärfeoption hinzugekommen.
Uhr auch so gut ablesbar
Ist diese abgedreht, bleibt das Wallpaper künftig auch im Always-on-Modus schön scharf. Die Ablesbarkeit der Uhrzeit tangiert das übrigens kaum, denn diese wird auch dann noch deutlich hervorgehoben, ein eventuell vorhandener Glaseffekt beispielsweise reduziert. Offenbar fand man den Unschärfe-Look in Apples User-Interface-Team besonders attraktiv. Über Usability-Gründe lässt sich streiten.
Denkbar wäre nur, dass Apple das Blurring aus Privatsphärengründen umsetzt – so kann man nicht direkt scharf sehen, was der Nutzer als Wallpaper gewählt hat. Allerdings reicht ein Tipper auf den Bildschirm, um das Bild wieder scharf zu machen, ein Entsperren des iPhone ist nicht notwendig. Apple experimentiert nach wie vor mit dem umstrittenen Liquid-Glass-Look. Ob das unscharfe Always-on-Hintergrundbild auch in iOS 27 erhalten bleibt, das im Herbst erwartet wird, ist also offen.
Weiterlesen nach der Anzeige
(bsc)
Künstliche Intelligenz
LibreOffice kritisiert EU-Kommission wegen proprietärer XLSX-Formate
Die Document Foundation hat in einem offenen Brief die Europäische Kommission aufgefordert, bei der laufenden Konsultation zum Cyber Resilience Act (CRA) nicht ausschließlich auf Microsofts proprietäres XLSX-Format zu setzen. Die EU-Kommission hatte am 3. März 2026 eine Aufforderung zur Rückmeldung zu den CRA-Leitlinien veröffentlicht. Feedback kann bis zum 31. März 2026 ausschließlich über ein XLSX-Template eingereicht werden.
Weiterlesen nach der Anzeige
Die Foundation sieht darin einen Widerspruch zu den eigenen Interoperabilitätszielen der EU. XLSX sei zwar als OOXML nach ISO/IEC 29500 standardisiert, allerdings würden die Implementierungen von Microsoft häufig von den Spezifikationen abweichen. Zudem änderten sich Features oft undokumentiert, was die Kompatibilität mit Open-Source-Software wie LibreOffice erschwere.
In ihrem am 5. März 2026 veröffentlichten Blogpost verweist die Document Foundation auf mehrere EU-Strategien, die eigentlich offene Standards fördern sollten. Dazu zählen das European Interoperability Framework (EIF), die EU Open Source Software Strategy 2020–2023 und deren Nachfolger sowie der Cyber Resilience Act selbst, der systemische Risiken durch Abhängigkeiten von intransparenten Technologien reduzieren soll.
ODF als gleichwertige Alternative gefordert
Die Document Foundation fordert konkret, dass das Template vor Ablauf der Frist am 31. März 2026 zusätzlich im Open Document Format (ODF) bereitgestellt wird. Das .ods-Format ist ein vollständig anbieterneutraler ISO-Standard. Ideal wäre zusätzlich ein webbasiertes Formular oder ein Plain-Text-Format, um die Mitwirkung aller Bürger, Organisationen und Institutionen zu ermöglichen.
Die ausschließliche Verwendung von XLSX schaffe eine strukturelle Voreingenommenheit, argumentiert die Foundation. Nutzer von Open-Source-Software würden benachteiligt, da es beim Öffnen und Bearbeiten des XLSX-Templates in LibreOffice zu Kompatibilitätsproblemen bei fortgeschrittenen Formatierungen oder Makros kommen könne. Betroffen seien auch kleine Organisationen und Behörden, die ODF-basierte Workflows einsetzen.
CRA tritt schrittweise in Kraft
Weiterlesen nach der Anzeige
Der Cyber Resilience Act wurde am 20. November 2024 im EU-Amtsblatt veröffentlicht und trat am 10. Dezember 2024 in Kraft. Die Hauptpflichten gelten ab dem 11. Dezember 2027, Meldepflichten bereits ab dem 11. September 2026. Die Verordnung regelt die Cybersicherheit für Produkte mit digitalen Elementen und richtet sich an Hersteller, Importeure und Distributoren.
Die Document Foundation ruft andere FOSS-Foundations, Projekte und Befürworter dazu auf, den offenen Brief zu unterzeichnen. Eine Reaktion der EU-Kommission auf die Kritik liegt bislang nicht vor. Technisch wäre die geforderte Erweiterung des Templates problemlos umsetzbar.
Kritik an der Verwendung proprietärer Formate durch EU-Institutionen ist nicht neu. Erst kürzlich hat sogar das EU-Parlament einen Bericht verabschiedet, der die EU-Kommission zu Reformen auffordert. Das Ziel müsse Unabhängigkeit von US-Infrastrukturen und mehr heimische KI und Open Source sein. Mit ihrer mangelnden Format-Offenheit in der Konsultation steht die EU-Kommission ohnehin im Widerspruch zu den EU-Zielen der digitalen Souveränität.
Weitere Informationen und der offene Brief selbst finden sich im Blogpost der Document Foundation.
(fo)
Künstliche Intelligenz
Linux From Scratch 13.0 mit systemd erschienen
Das Linux-From-Scratch-Projekt hat Version 13.0 veröffentlicht. Die neue Ausgabe des Build-Systems zum Linux-Selbstbau bringt 36 aktualisierte Pakete mit und setzt künftig ausschließlich auf systemd als Init-System. Die traditionelle System-V-Variante wird nicht mehr weiterentwickelt und bleibt bei Version 12.4 stehen.
Weiterlesen nach der Anzeige
Zu den wichtigsten Neuerungen gehört ein Toolchain-Update: LFS 13.0 nutzt binutils 2.46 (zuvor 2.45), glibc blieb bei Version 2.42 (bereits in 12.4 enthalten). Bei binutils wurden Fehlerkorrekturen für das Strip-Tool integriert und die Unterstützung für die LoongArch-Architektur verbessert.
Der mitgelieferte Linux-Kernel wurde auf Version 6.18.10 aktualisiert. Die Hauptversion 6.18 brachte erweiterte Hardware-Unterstützung für x86_64, ARM, RISC-V und MIPS-Systeme. Neu hinzugekommen sind unter anderem Treiber für MediaTek-SoCs wie den Dimensity 9400 und Kompanio Ultra. Zudem enthält der Kernel experimentelle Rust-Treiber für ARM-Mali-GPUs.
Sicherheitsupdates enthalten
Die Version 13.0 schließt mehrere Sicherheitslücken in den enthaltenen Komponenten. Expat erhielt Korrekturen für Heap-Buffer-Overflows, OpenSSL für einen Timing-Seitenkanalangriff auf ECDSA-Signaturen, der private Schlüssel gefährden könnte. Bei Python wurden Schwachstellen behoben, die unbefugte Codeausführung im venv-Modul ermöglichten. Die LFS-Entwickler empfehlen Nutzern älterer Versionen, die Security Advisories auf der Projektwebsite zu beachten.
Seit der letzten stabilen Version 12.4 vom September 2025 sind 100 Commits in das Projekt eingeflossen. Die Entwicklung durchlief zunächst eine Release-Candidate-Phase, bevor Bruce Dubbs die finale Version am 5. März 2026 freigab.
System-V-Ära endet
Weiterlesen nach der Anzeige
Mit der Fokussierung auf systemd vollzieht das Projekt eine bedeutende Richtungsänderung. Schon länger bot LFS parallel eine systemd-Variante an, die nun zum alleinigen Standard wird. Die Entscheidung dürfte die Wartung vereinfachen, bricht aber mit der Tradition des Projekts, verschiedene Init-Systeme zu unterstützen. Die LFS-Community plant, systemd auch für künftige Versionen als Standard beizubehalten.
Linux From Scratch 13.0 kann von der Projektwebsite heruntergeladen werden: Dort steht das vollständige Handbuch als PDF bereit.
Siehe auch:
(fo)

Always-on-Display unter iOS 26: So wird man das unscharfe Bild los

LibreOffice kritisiert EU-Kommission wegen proprietärer XLSX-Formate

Linux From Scratch 13.0 mit systemd erschienen

Schnelles Boot statt Bus und Bahn: Was sich von London und New York lernen lässt

Community Management zwischen Reichweite und Verantwortung

Community Management und Zielgruppen-Analyse: Die besten Insights aus Blog und Podcast
-
 Künstliche Intelligenzvor 2 Monaten
Künstliche Intelligenzvor 2 MonatenSchnelles Boot statt Bus und Bahn: Was sich von London und New York lernen lässt
-
 Social Mediavor 4 Wochen
Social Mediavor 4 WochenCommunity Management zwischen Reichweite und Verantwortung
-
 Social Mediavor 6 Tagen
Social Mediavor 6 TagenCommunity Management und Zielgruppen-Analyse: Die besten Insights aus Blog und Podcast
-
Künstliche Intelligenzvor 2 Wochen
Top 10: Die beste kabellose Überwachungskamera im Test – Akku, WLAN, LTE & Solar
-

 Datenschutz & Sicherheitvor 3 Monaten
Datenschutz & Sicherheitvor 3 MonatenSyncthing‑Fork unter fremder Kontrolle? Community schluckt das nicht
-

 Entwicklung & Codevor 3 Monaten
Entwicklung & Codevor 3 MonatenKommentar: Anthropic verschenkt MCP – mit fragwürdigen Hintertüren
-

 Künstliche Intelligenzvor 3 Monaten
Künstliche Intelligenzvor 3 MonatenGame Over: JetBrains beendet Fleet und startet mit KI‑Plattform neu
-

 Social Mediavor 3 Monaten
Social Mediavor 3 MonatenDie meistgehörten Gastfolgen 2025 im Feed & Fudder Podcast – Social Media, Recruiting und Karriere-Insights

