Apps & Mobile Entwicklung
Nvidia-Roadmap: Feynman nutzt GPU-Die-Stacking, Custom HBM und Rosa-CPU
Nvidia hat sich zur GTC 2026 mittels Roadmap erneut freiwillig in die Karten blicken lassen. Die öffentliche Pläne reichen abermals bis Feynman, dort hat Nvidia jetzt GPU-Die-Stacking, Custom HBM und die Rosa-CPU bestätigt. Und für den Scale-up bei Rubin und Feynman können neben Kupfer auch optische Verbindungen genutzt werden.
Die Nvidia-Datacenter-Roadmap mit dem Ausblick auf Rubin Ultra und Feynman hat ihren Ursprung in der GTC 2025. Seitdem hat Nvidia die Roadmap immer wieder in stetig aktualisierter Form auf Konferenzen gezeigt, zuletzt auf der GTC Washington im Oktober 2025. Zur GTC 2026 folgten nun weitere Einblicke in die bevorstehenden Plattformen.
Rubin Ultra geht auf vier Dies pro GPU-Package
Bekannt war bereits, dass auf Rubin erst einmal Rubin Ultra folgen wird, bevor Feynman an der Reihe ist. Rubin Ultra verdoppelt Rubin, indem Nvidia von zwei auf vier GPU-Dies für jedes Chip-Package wechselt. 16 Stapel HBM4e mit insgesamt 1 TB pro Package sieht Nvidia für Rubin Ultra vor. Nvidia gibt die Rechenleistung eines GPU-Packages mit 100 PetaFLOPS (FP4) an. Mit Rubin Ultra geht zudem eine neue LPU aus der Groq-Partnerschaft einher. Die LP35 soll die aktuelle LP30 ablösen und dabei neben FP8 erstmals auch Support für NVFP4 mitbringen.

Kyber steigert den Scale-up, Oberon bleibt aber verfügbar
Rubin Ultra ist die Generation, mit der Nvidia vom derzeitigen Oberon- zum neuen Kyber-Rack wechseln will – zumindest optional, wenn ein noch dichter gepacktes Rack mit vertikaler Ausrichtung der Blades gefragt ist. Oberon bleibt aber auch künftig eine Option, wie die Platzierung auf der Roadmap auch noch in Richtung Feynman zeigt.
Scale-up mit Kupfer oder optischer Verbindung
Oberon ist das aktuell von Nvidia genutzte Rack-Design. Bereits diese Variante ermöglicht einen dicht gepackten Scale-up von derzeit bis zu 72 GPUs und 36 GPUs – daher auch der Name NVL72. Gezählt werden seit Anfang des Jahres wieder die GPU-Packages, nicht die GPU-Dies. Nvidia hatte hier abgeleitet von den Dies nämlich auch schon mal den Namen NVL144 vorgesehen, da ein GPU-Package bei Blackwell und Rubin aus zwei GPU-Dies besteht. Die neue (eigentlich alte) Namensgebung gilt auch für Kyber.
Oberon skaliert bei Rubin Ultra auf NVL576
Bei Oberon verbindet eine „Kupfer-Wirbelsäule“ rückseitig die Compute-Hardware mit den NVLink-Switches. Zur GTC nannte Jensen Huang aber auch optische Verbindungen als Option für den Scale-up. Statt von NVL72 ist dann von NVL576 die Rede, weil sich 576 GPUs zu einer Domain zusammenschließen lassen, die wie eine einzelne, massive GPU agiert. Von einem Scale-up im Rack kann dann allerdings nicht mehr die Rede sein, weil keine 576 GPUs in ein Oberon-Rack passen. Das zeigt mit „Polyphe“ ein Prototyp von Nvidia, mit dem der optische Scale-up getestet wird. Über den Serverschrank hinaus war bei Nvidia bislang eigentlich immer vom Scale-out statt Scale-up die Rede.

Ein Bücherregal für AI-Hardware
Rubin Ultra bringt aber auch die Option für das neue Kyber-Rack mit. Kyber bringt die Hardware nicht mehr in untereinander liegenden Compute- und NVLink-Trays unter, die rückseitig über Kupferkabel miteinander verbunden werden, sondern in vertikal nebeneinander positionierten Blades, fast so wie bei einem Bücherregal, das Bücher nebeneinander unterbringt. Neu ist dabei, dass Compute vorne in den Blades stattfindet, während NVLink mit den Switches über eine Mid-Plane von hinten angedockt wird. Ein NVLink-Blade erstreckt sich über die Höhe von zwei Compute-Blades. Im 90-Grad-Winkel dazu sitzt die Mid-Plane.

Das schafft Platz für noch mehr Komponenten im Rack, sodass hier die Bezeichnung NVL144 genutzt wird. Gemein sind 144 GPU-Packages mit dann bis zu 576 GPU-Dies für Rubin Ultra. Für das Kyber-Rack will Nvidia zur Einführung der neuen Rack-Architektur mit Rubin Ultra zunächst auf den Scale-up mit Kupfer setzen. Optische Verbindungen sind testweise erst einmal nur für Oberon vorgesehen, bevor sich das mit Feynman dann jedoch auch für Kyber ändern wird. Oberon ist hierfür zunächst der Testballon.
Feynman setzt auf GPU-Die-Stacking
Feynman ist die für 2028 angesetzte GPU-Architektur, bei der Nvidia nicht mehr wie bei Rubin oder Rubin Ultra auf zwei respektive vier nebeneinander gelegte GPU-Dies setzen wird, sondern zum „Die Stacking“ wechselt, um mehrere GPU-Dies übereinander zu stapeln. Wie genau das technisch umgesetzt wird und was sich dafür bei Fertigung und Packaging ändern muss, hat Nvidia zur Konferenz noch nicht verraten. Bekannt ist außerdem, dass nach HBM4 bei Rubin und HBM4e bei Rubin Ultra mit Feynman dann ein Wechsel zu „Custom HBM“ erfolgen soll.

Oberon bleibt, dann aber nicht mehr mit optischem Scale-up
Auch Feynman wird weiterhin eine Oberon-Option bieten. Das ging aus den letzten Roadmap-Veröffentlichungen noch nicht hervor, dort sah bislang alles nach Kyber ab Rubin Ultra aus. Nvidia wird die aktuelle, ältere Rack-Architektur somit fortführen, aber mit neuer Compute-Hardware anbieten, sodass auch Upgrades möglich sind. Die Option auf den Scale-up mit optischen Verbindungen fällt dann aber weg. Diese hebt sich Nvidia bei Feynman exklusiv für Kyber auf. Dort lässt sich ein optischer statt Kupfer-Scale-up von NVL144 auf NVL1152 vollziehen, also 1.152 GPUs innerhalb einer Domain.
Eine neue CPU benannt nach Rosalind Franklin
Nvidia hat zur GTC zudem erstmals eine neue CPU für Feynman bestätigt: Rosa. Bislang war für Feynman noch die aktuelle Vera-CPU auf der Roadmap zu finden. Vermutlich handelte es sich bei Vera um einen Platzhalter, bis Nvidia öffentlich über Rosa reden kann. Der Name leitet sich von der britischen Biochemikerin Rosalind Franklin ab. Technische Details waren zur GTC noch kein Thema. Es dürften erneut Custom-Arm-Kerne mit SMT zum Einsatz kommen, so wie es bei Grace mit Olympus-Kernen der Fall ist.
ComputerBase hat Informationen zu diesem Artikel von Nvidia unter NDA im Vorfeld und im Rahmen einer Veranstaltung des Herstellers in San Jose, Kalifornien erhalten. Die Kosten für An-, Abreise und fünf Hotelübernachtungen wurden vom Unternehmen getragen. Eine Einflussnahme des Herstellers oder eine Verpflichtung zur Berichterstattung bestand nicht. Die einzige Vorgabe aus dem NDA war der frühestmögliche Veröffentlichungszeitpunkt.












Apps & Mobile Entwicklung
DRAM besser ausnutzen: AMD kauft KI-Startup MEXT für sein Data-Center-Portfolio

AMD übernimmt mit MEXT ein KI-Startup, das sich einer effizienteren Speichernutzung im Server verschrieben hat. Indem inaktive Daten aus dem DRAM auf NAND-Flash ausgelagert und per KI-Vorhersage wieder bereitgestellt werden, soll der DRAM-Bedarf deutlich gesenkt werden. Virtuell wird der Arbeitsspeicher verdoppelt.
Die Branche befindet sich derzeit in einer Zwickmühle: Einerseits verlangen moderne Anwendungen wie KI-Modelle, HPC-Workloads, Datenanalysen und Virtualisierung nach immer mehr Arbeitsspeicher. Andererseits ist dieser durch die extrem hohe Nachfrage knapp und teuer geworden, sodass Speicher inzwischen als größter Kostenfaktor im Rechenzentrum gilt.
Was steckt hinter MEXT?
Mit MEXT übernimmt AMD ein Entwicklerteam mitsamt seiner KI-gestützten „Predictive-Memory-Technologie“. Mit dieser wird primär erreicht, dass sich im System der NAND-Flash wie DRAM verhält. Dadurch wird das Vorhandensein von mehr DRAM simuliert. Im Grunde handelt es sich also um eine Form von virtuellem Arbeitsspeicher.

In einem Beispiel wird gezeigt, wie sich per Software der Arbeitsspeicher im Server verdoppeln lässt. Auf seiner Webseite wirbt MEXT aber auch damit, dass sich die Speichermenge vervierfachen lasse. Im Gegenzug könne dieselbe Speichermenge mit nur der halben Menge (oder einem Viertel) an physischem RAM erreicht werden. Das senkt wiederum die Kosten, denn NAND-Flash ist erheblich günstiger als DRAM.
Allerdings ist NAND-Flash auch wesentlich langsamer als DRAM und eignet sich daher von allein nicht dazu, diesen zu ersetzen.
KI verwaltet Daten in RAM und NAND
Hierbei kommt die KI-Technik von MEXT ins Spiel: Die Software erkennt, welche Daten inaktiv („kalt“) sind und lagert diese vom DRAM auf den NAND-Flash aus. Zugleich liefert sie eine Prognose dafür, welche Daten eine Anwendung demnächst benötigen könnte, um diese schnellstmöglich wieder in den DRAM zu befördern. Damit wird der Geschwindigkeitsnachteil des NAND-Flash kaschiert. Zumindest ist es das, was hier versprochen wird. Inwieweit sich der Einsatz von MEXT auf die Performance im Server auswirkt, ist der Redaktion nicht bekannt.

Das Ziel ist es die steigenden Kosten für Serversysteme im Zaum zu halten und vorhandene Ressourcen effektiver zu nutzen. AMD will die Technik von MEXT fortan im eigenen Data-Center-Portfolio einsetzen. Was genau das bedeutet, bleibt abzuwarten.
Apps & Mobile Entwicklung
Integration von „Tasks“: xAI soll an Automatisierungsfunktion für Grok arbeiten

Auch wenn xAI-Mutterkonzern SpaceX einen beträchtlichen Teil seiner Rechenleistungen mittlerweile für andere Unternehmen wie Google oder Anthropic vermietet, bedeutet das nicht, dass die Entwicklung des eigenen KI-Systems Grok auf Eis gelegt wurde. So soll dieser nun eine Automatisierungsfunktion erhalten.
Tasks sollen in neuer Funktion aufgehen
Mit der neuen Lösung soll unter anderem die bisherige „Tasks“-Funktion ersetzt und erweitert werden. Darüber hinaus sollen laut einem Bericht von TestingCatalog weitere Neuerungen geplant sein, zu denen unter anderem die Auswahl spezieller Grok-Skills sowie die freie Wahl des verwendeten KI-Modells für automatisierte Abläufe gehören sollen.
Entsprechende Hinweise haben die Experten in der aktuellen Grok-Version entdeckt. Diese deuten darauf hin, dass xAI die bestehende Task-Funktion in ein neues Automatisierungssystem überführen möchte. Die bisherigen Möglichkeiten zur zeitgesteuerten Ausführung von Aufgaben sollen dabei erhalten bleiben, Anwender könnten somit weiterhin Prompts zu individuell festgelegten Zeitpunkten automatisch ausführen lassen.

Skills werden mächtiger
Ein zentraler Bestandteil der Weiterentwicklung soll zudem die Integration der sogenannten Skills sein, die xAI erst Mitte Mai eingeführt hatte. Dabei handelt es sich um wiederverwendbare Pakete aus Anweisungen, Skripten und Ressourcen, die Grok ausführen kann. In Verbindung mit den offenbar ebenfalls geplanten erweiterten Steuerungsmöglichkeiten sollen Anwender künftig festlegen können, dass bestimmte Aufgaben stets auf einen definierten Skill zurückgreifen. Die wiederholte Erstellung neuer Prompts wäre damit nicht mehr erforderlich.
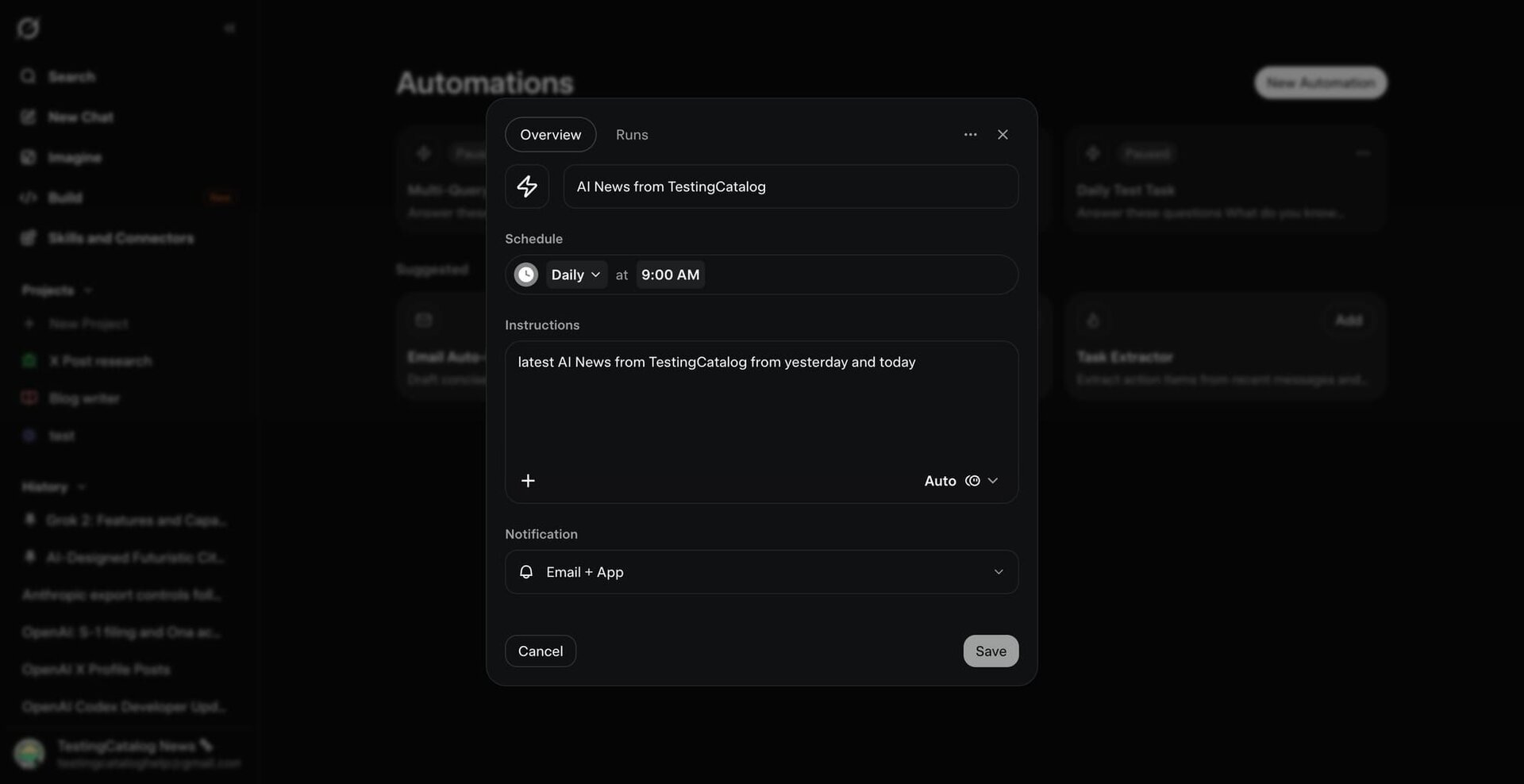
In diesem Zusammenhang soll auch eine direkte Auswahl des verwendeten KI-Modells vorgesehen sein. Bislang bietet die Tasks-Funktion lediglich einen Expert-Modus, der auf ein leistungsfähigeres Modell zurückgreift. Mit dem neuen Ansatz könnten Nutzer künftig abhängig vom jeweiligen Einsatzzweck zwischen verschiedenen KI-Modellen wählen und damit direkten Einfluss auf Kosten, Geschwindigkeit und Ergebnisqualität nehmen.
Das Wie und Wann ist noch unklar
Offen bleibt bislang allerdings, wie die neuen Funktionen umgesetzt werden sollen. Derzeit ist die Tasks-Funktion über das Uhrsymbol in den Grok-Webanwendungen sowie in den mobilen Apps erreichbar. Unklar ist daher, ob die künftigen Automationen ausschließlich dort integriert werden oder zusätzlich in die kürzlich aufgetauchte Desktop-Anwendung „Grok Build“ Einzug halten.
Wann die neuen Funktionen verfügbar sein werden, ist derzeit ebenfalls noch nicht bekannt. Da xAI in den vergangenen Monaten zahlreiche neue Funktionen in kurzer Zeit eingeführt hat, erscheint eine zeitnahe Veröffentlichung durchaus möglich.
Apps & Mobile Entwicklung
Steam Next Fest: Virtuelle Indie-Messe liefert hunderte Spieledemos

Dreimal im Jahr rückt Valve mit der Steam-Spielevorschau eine Woche lang Demos zu neuen Indie-Games und Entwickler-Livestreams in den Mittelpunkt – und jetzt ist es wieder soweit. Noch bis zum 22. Juni um 19:00 Uhr stehen auf Steam „hunderte“ noch nicht erschienene Spiele im Rahmen kostenloser Demo-Versionen zur Verfügung.
Eine Woche voller Indie-Demos
Dabei handelt es sich überwiegend um bevorstehende Indie-Projekte und Spiele kleinerer Entwicklerteams. Triple-A-Produktionen nehmen in der Regel nicht an der Aktion teil. Bei den Genres wiederum deckt die Steam-Spielevorschau eine weite Bandbreite ab: Von Action-Rollenspielen über Aufbauspiele bis hin zu Ego-Shootern ist alles dabei. Valve bewirbt das Event als Online-Alternative zu Spielemessen, auf denen Besucher noch lange nicht verfügbare Titel anspielen können, und betont: Im Gegensatz zum hektischen Ausprobieren im Messetrubel lassen sich Spiele beim Next Fest in aller Ruhe und ohne Wartezeit antesten. Das Versprechen ist dementsprechend das Erlebnis der Indie Area in Halle 10 auf der Gamescom – nur eben in virtuell.

Einen ersten Anhaltspunkt zu interessanten Spielen liefert neben einem Trailer eine von Valve algorithmisch zusammengestellte „Entdeckungsliste“ an teilnehmenden Spielen mit verfügbarer Demo-Version auf der Startseite der Aktion im Steam-Shop, die unter Berücksichtigung der bisher gespielten Titel eines Steam-Accounts ausgewählt wurden.
Entwickler dürfen mit einem Spiel nur ein Mal an Valves Spielevorschauen teilnehmen. Das bedeutet im Umkehrschluss, dass die allermeisten der diesmal teilnehmenden Titel erstmals im Rahmen einer Demo spielbar sind.
Wer konkrete Spiele empfehlen möchte, kann das in den Kommentaren tun. Auch Anmerkungen oder Erfahrungen zu teilnehmenden Titeln sind gerne gesehen – welche Games kommen bei euch gut an und welche Demo sollte man nicht verpassen?
Entwickler-Livestreams beantworten Fragen
Was während der Teilnahme an einer Vor-Ort-Messe aber auch gegeben ist: Der kommunikative Austausch mit den Entwicklern. Diesbezüglich verweist Valve auf die zahlreichen Livestreams im Rahmen des Steam Next Fests, in denen Spielentwickler ihre eigenen Titel spielen sowie erklären, Einblicke in die Entwicklung geben und auf die Fragen des Publikums eingehen.
Dreimal im Jahr
Das Steam Next Fest findet dreimal im Jahr statt, üblicherweise im Februar, im Juni und im Oktober. Bis zur nächsten Ausgabe mit gänzlich neuen Demos dauert es also noch vier Monate. Bis dahin stehen einige klassische Steam-Sales an, beginnend mit dem großen Summer Sale am 25. Juni. Die nachfolgende Tabelle bietet eine Übersicht über alle Steam-Events bis zum Ende des Jahres 2026.

Milliardendeal: Salesforce übernimmt KI-Kundenservice-Plattform Fin

DRAM besser ausnutzen: AMD kauft KI-Startup MEXT für sein Data-Center-Portfolio

Das sind die Schönsten Deutschen Bücher 2026! › PAGE online

JBL Bar 1300MK2 im Test: Soundbar mit Dolby Atmos, starkem Bass und Akku‑Rears

Oscars 2026: Was die heise‑Leser anders entschieden hätten

Empfehlungsalgorithmen bei TikTok erklärt: Die Maschine hinter dem Endlos‑Feed
-
Künstliche Intelligenzvor 3 Monaten
JBL Bar 1300MK2 im Test: Soundbar mit Dolby Atmos, starkem Bass und Akku‑Rears
-
 Künstliche Intelligenzvor 3 Monaten
Künstliche Intelligenzvor 3 MonatenOscars 2026: Was die heise‑Leser anders entschieden hätten
-
 Künstliche Intelligenzvor 3 Monaten
Künstliche Intelligenzvor 3 MonatenEmpfehlungsalgorithmen bei TikTok erklärt: Die Maschine hinter dem Endlos‑Feed
-

 Social Mediavor 3 Monaten
Social Mediavor 3 MonatenVon Kennzeichnung bis Plattformpflichten: Was die EU-Regeln für Influencer Marketing bedeuten – Katy Link im AllSocial Interview
-

 Künstliche Intelligenzvor 2 Monaten
Künstliche Intelligenzvor 2 Monaten„Don’t Starve Elsewhere“: Survival‑Hit kehrt nach zehn Jahren zurück
-

 Künstliche Intelligenzvor 2 Monaten
Künstliche Intelligenzvor 2 MonatenWeitere Entlassungswelle bei Disney: Bis zu 1000 Mitarbeiter betroffen
-

 Künstliche Intelligenzvor 2 Monaten
Künstliche Intelligenzvor 2 MonateniX-Workshop Angriffsziel lokales AD − Schwachstellen finden und beheben
-

 Künstliche Intelligenzvor 2 Monaten
Künstliche Intelligenzvor 2 MonatenKine‑Exakta: Die erste Spiegelreflexkamera fürs Kleinbild
