Entwicklung & Code
Schlank statt aufgebläht: Was Aggregate und Read Models wirklich sind
Wenn Entwicklerinnen und Entwickler zum ersten Mal mit Domain-Driven Design (DDD), CQRS und Event Sourcing in Berührung kommen, bringen sie bereits mentale Modelle mit. Jahre der Arbeit mit Objekten und Tabellen haben geprägt, wie sie über Daten denken.
Weiterlesen nach der Anzeige


Golo Roden ist Gründer und CTO von the native web GmbH. Er beschäftigt sich mit der Konzeption und Entwicklung von Web- und Cloud-Anwendungen sowie -APIs, mit einem Schwerpunkt auf Event-getriebenen und Service-basierten verteilten Architekturen. Sein Leitsatz lautet, dass Softwareentwicklung kein Selbstzweck ist, sondern immer einer zugrundeliegenden Fachlichkeit folgen muss.
Und so haben sie sofort ein vertrautes Bild im Sinn, wenn sie das Wort „Aggregat“ hören: Ein Aggregat muss wie ein Objekt sein, und Objekte werden auf Tabellen abgebildet. Diese Intuition fühlt sich richtig an. Aber: Sie ist es nicht, und sie führt zu einem System, das verdächtig nach CRUD mit zusätzlichen Schritten aussieht.
Ich habe dieses Muster unzählige Male gesehen. Teams bauen etwas, das sie ein Event-getriebenes System nennen, und landen bei einer einzelnen books-Tabelle, die jedes Feld enthält, das ihr Book-Aggregat hat. Sie haben im Grunde eine relationale Datenbank nachgebaut, nur mit Events als Transportmechanismus. Die Stärken von DDD, CQRS und Event Sourcing, also die Flexibilität, die diese Konzepte versprechen – all das bleibt ungenutzt.
Das Aggregat-Missverständnis
Das Problem ist das, was Entwicklerinnen und Entwickler typischerweise für ein Aggregat halten: einen Container für alle Daten über eine Sache. Sie stellen sich ein Book-Aggregat vor und beginnen, Eigenschaften aufzulisten:
BookAggregate {
id: string
title: string
author: string
isbn: string
currentBorrower: string | null
dueDate: Date | null
location: string
condition: string
purchasePrice: number
acquisitionDate: Date
lastInspectionDate: Date
popularityScore: number
}
Das sieht aus wie ein Objekt. Es hat alle Felder. Es lässt sich sauber auf eine Datenbanktabelle abbilden. Und genau darin liegt der Fehler: das Aggregat als Daten-Container zu behandeln.
Weiterlesen nach der Anzeige
Wenn Sie so denken, wird Ihr Aggregat zu einer aufgeblähten Repräsentation von allem, was Sie jemals über ein Buch wissen wollen könnten. Es spiegelt die Struktur Ihres Read Model wider, weil Sie noch nicht erkannt haben, dass es grundlegend verschiedene Konzepte sind, die grundlegend verschiedene Zwecke erfüllen.
Was ein Aggregat tatsächlich ist
Gemäß DDD ist ein Aggregat eine Konsistenzgrenze für die Entscheidungsfindung. Das ist alles. Sein Zweck ist sicherzustellen, dass Geschäftsregeln eingehalten werden, wenn Commands verarbeitet werden. Es benötigt nur die Informationen, die erforderlich sind, um zu entscheiden, ob ein Command gültig ist.
Betrachten Sie das BorrowBook-Command. Um zu entscheiden, ob ein Buch ausgeliehen werden kann, müssen Sie nur eins wissen: Ist das Buch derzeit verfügbar? Sie brauchen nicht den Titel, die Autorin oder den Autor, die ISBN, den Kaufpreis, den Standort oder das letzte Inspektionsdatum. Keine dieser Informationen hilft Ihnen zu entscheiden, ob dieses spezifische Command erfolgreich sein sollte oder nicht. Das heißt, das Aggregat kann sehr schlank sein, denn es enthält nur den entscheidungsrelevanten Zustand.
Für unser Bibliotheksbeispiel könnte ein richtig entworfenes Book-Aggregat daher folgendermaßen aussehen:
BookAggregate {
isAvailable: boolean
currentBorrower: string | null
}
Das reicht aus, um zu entscheiden:
- Kann dieses Buch ausgeliehen werden? (
isAvailable === true) - Kann diese Person es zurückgeben? (
currentBorrower === personId)
Alles andere, jede andere Information über das Buch, gehört woanders hin – und zwar in Read Models, nicht in das Aggregat.
Das Read-Model-Missverständnis
Sobald Entwicklerinnen und Entwickler akzeptieren, dass ein Aggregat bestimmte Felder hat, folgt der nächste Fehler: „Wenn mein Aggregat diese Felder hat, sollte meine Read-Model-Tabelle diese Felder auch haben.“
Das Ergebnis ist vorhersehbar. Sie erstellen eine books-Tabelle mit Spalten für id, title, author, isbn, borrower, dueDate, location, condition, purchasePrice und jedes andere Feld, das Ihnen einfällt. Abfragen werden zu komplexen Joins über diese monolithische Struktur. Die Performance leidet. Die Flexibilität verschwindet.
Das ist CRUD-Denken, angewandt auf Event Sourcing. Die Events existieren, aber sie sind nur eine Transportschicht. Das System dreht sich immer noch um eine einzelne kanonische Repräsentation der Daten, genau wie eine traditionelle relationale Datenbank.
Was Read Models tatsächlich sind
Read Models sind Projektionen, die für spezifische Abfragen optimiert sind. Sie dienen Anwendungsfällen, nicht Datenstrukturen. Und hier ist die entscheidende Erkenntnis: Read Models werden aus Events abgeleitet, nicht aus Aggregaten:
- Ihr Aggregat entscheidet, was passiert.
- Events zeichnen auf, was passiert ist.
- Read Models werden aus diesen Events gebaut, um spezifische Fragen effizient zu beantworten.
Es gibt keine Anforderung, keine Regel, kein architektonisches Prinzip, das besagt, dass Read Models die Struktur von Aggregaten spiegeln müssen.
Tatsächlich ist das Gegenteil wahr. Aus einem Event-Stream können Sie viele verschiedene Read Models bauen. Das ist die Stärke von CQRS, die verloren geht, wenn Sie in Tabellen denken.
Das Bibliotheksbeispiel: Ein Write Model, viele Read Models
Machen wir das konkret mit unserer Bibliothek. Wir haben ein Book-Aggregat, das Entscheidungen handhabt:
BookAggregate {
isAvailable: boolean
currentBorrower: string | null
}
Events fließen durch das System: BookAcquired, BookBorrowed, BookReturned, BookRemoved und so weiter. Diese Events enthalten reichhaltige Informationen darüber, was passiert ist.
Betrachten Sie nun die verschiedenen Fragen, die Menschen beantwortet bekommen möchten:
- Die Katalogsuche muss verfügbare Bücher mit ihren Titeln, Autorinnen und Autoren sowie ISBNs zeigen. Sie interessiert sich nicht für die Ausleihhistorie oder den physischen Standort.
- Das Mitglieder-Dashboard (die „Meine Bücher“-Seite) muss zeigen, welche Bücher das Mitglied ausgeliehen hat, wann sie fällig sind und ob welche überfällig sind. Es braucht keine ISBNs oder physische Standorte.
- Das Statistik-Panel für Bibliothekarinnen und Bibliothekare muss wissen, welche Bücher am beliebtesten sind, durchschnittliche Ausleihdauern und Trends über die Zeit. Es braucht nicht die aktuelle Verfügbarkeit.
- Der Überfällig-Bericht benötigt Namen der Ausleihenden, Kontaktinformationen, Buchtitel und wie viele Tage überfällig. Er benötigt keine Kaufpreise oder Zustandsbewertungen.
- Das Bestandsverwaltungssystem benötigt physische Standorte, Zustandsbewertungen und letzte Inspektionsdaten. Es braucht keine Informationen über Ausleihende.
Jedes davon ist ein separates Read Model, gebaut aus denselben Events, optimiert für seinen spezifischen Anwendungsfall.
Viele kleine Read Models statt einer großen Tabelle
So könnten diese Read Models aussehen:
Katalogsuche-Read-Model:
{
bookId: string
title: string
author: string
isbn: string
isAvailable: boolean
}
Ausleihenden-Dashboard-Read-Model:
{
memberId: string
books: [
{
bookId: string
title: string
dueDate: Date
daysOverdue: number
}
]
}
Bibliotheksstatistik-Read-Model:
{
bookId: string
title: string
totalBorrows: number
averageDuration: number
popularityRank: number
}
Überfällige-Bücher-Read-Model:
{
bookId: string
title: string
borrowerId: string
borrowerName: string
contactEmail: string
daysOverdue: number
}
Bestands-Read-Model:
{
bookId: string
location: string
condition: string
lastInspectionDate: Date
}
Jedes Read Model
- hat nur die Felder, die für seinen Anwendungsfall benötigt werden,
- kann bei Bedarf in einer anderen Datenbank gespeichert werden (PostgreSQL für Transaktionen, Elasticsearch für Suche, Redis für schnelle Lookups),
- kann jederzeit aus Events neu aufgebaut werden und
- entwickelt sich unabhängig von anderen Read Models weiter.
Der Multiplikationseffekt
Hier zeigt Event Sourcing seine wahre Stärke. Aus einem Stream von Events leiten Sie viele spezialisierte Read Models ab. Jedes ist klein, fokussiert und schnell. Das Hinzufügen eines neuen Read Model erfordert keine Änderung des Write Model oder bestehender Read Models. Sie bauen einfach eine weitere Projektion aus denselben Events.
Brauchen Sie einen neuen Bericht? Erstellen Sie ein neues Read Model. Müssen Sie eine langsame Abfrage optimieren? Strukturieren Sie dieses spezifische Read Model um, ohne irgendetwas anderes anzufassen. Müssen Sie einen neuen Anwendungsfall unterstützen? Fügen Sie eine weitere Projektion hinzu.
Diese Flexibilität ist das Versprechen von CQRS. Aber sie materialisiert sich nur, wenn Sie aufhören, Read Models als Spiegel Ihrer Aggregate zu betrachten.
Warum das wichtig ist
Die praktischen Vorteile sind erheblich:
- Die Performance verbessert sich, weil jedes Read Model klein und spezialisiert ist. Abfragen treffen genau die Daten, die sie brauchen, nicht mehr. Indizes können für spezifische Zugriffsmuster optimiert werden.
- Die Flexibilität steigt, weil Sie Read Models hinzufügen, modifizieren oder entfernen können, ohne das Write Model oder andere Read Models zu beeinflussen. Teams können ihre Read Models unabhängig besitzen.
- Klarheit entsteht, weil jedes Read Model einen klaren Zweck hat. Es gibt keine Mehrdeutigkeit darüber, welche Daten für welchen Anwendungsfall sind. Die Struktur jedes Read Model reflektiert die Fragen, die es beantwortet.
- Unabhängigkeit folgt, weil verschiedene Teams an verschiedenen Read Models arbeiten können, ohne Schemaänderungen koordinieren zu müssen. Die Events sind der Vertrag, nicht die Datenbanktabellen.
Die Tabelle verlernen
Der schwierigste Teil von Event Sourcing ist das Verlernen der mentalen Modelle, die Ihnen in CRUD-Systemen gute Dienste geleistet haben. Objekte und Tabellen sind nützliche Konzepte, aber sie sind nicht die richtige Linse, um Aggregate und Read Models zu verstehen.
Hören Sie auf zu fragen: „Welche Felder hat mein Aggregat?“ Beginnen Sie zu fragen: „Was muss ich wissen, um diese Entscheidung zu treffen?“
Hören Sie auf zu fragen: „Welche Tabelle brauche ich für dieses Aggregat?“ Beginnen Sie zu fragen: „Welche Fragen müssen meine Nutzerinnen und Nutzer beantwortet bekommen?“
Das Aggregat ist Ihre Entscheidungsgrenze, schlank und fokussiert. Events sind Ihre historische Aufzeichnung dessen, was passiert ist. Read Models sind Ihre optimierten Sichten für spezifische Abfragen.
Das sind drei verschiedene Konzepte. Sie müssen nicht dieselbe Struktur haben. Tatsächlich sollten sie es wahrscheinlich nicht.
(rme)











Entwicklung & Code
Next.js 16.2 bringt Updates für die Nutzung von KI-Agenten
Das Next.js-Team beim Hersteller Vercel hat Version 16.2 des React-Frameworks fertiggestellt. Next.js soll nun deutlich schneller sein, was die Time-to-URL während der Entwicklung und das Rendering in Anwendungen betrifft. Auch an der Performance des Bundlers Turbopack wurde geschraubt und für die KI-gestützte Softwareentwicklung hat Next.js ebenfalls Updates zu bieten.
Weiterlesen nach der Anzeige
(Bild: Stone Story / stock.adobe.com)

Webanwendungen mit KI anreichern, sodass sie wirklich besser werden? Der Online-Thementag enterJS Integrate AI am 28. April 2026 zeigt, wie das geht. Frühbuchertickets und Gruppenrabatte sind im Online-Ticketshop verfügbar.
Support für die KI-gestützte Entwicklung
In Next.js 16.2 ist in create-next-app standardmäßig eine AGENTS.md-Datei enthalten. Durch diese erhalten KI-Agenten Zugriff auf die Next.js-Dokumentation für die genutzte Version bereits zu Beginn eines Projekts. Das soll das Problem umgehen, dass KI-Agenten mit veralteten Daten trainiert werden und aktuelle APIs nicht kennen, woraus inkorrekter Code resultieren kann.
Als experimentelles CLI steht next-browser bereit. Es erlaubt KI-Agenten, eine laufende Next.js-Anwendung zu inspizieren. Zu den Daten, die next-browser den Agenten zugänglich macht, zählen solche auf dem Browser-Level wie Screenshots oder Netzwerkanfragen, ebenso wie Framework-spezifische Insights aus den React DevTools und dem Next.js Dev Overlay, darunter Props, Hooks, Partial Prerendering (PPR) Shells und Fehlermeldungen.
Um next-browser zu verwenden, installieren Entwicklerinnen und Entwickler es als Skill:
npx skills add vercel-labs/next-browser
Dann geben sie /next-browser in ihrem KI-Agenten ein, der mit Skills umgehen kann, beispielsweise Claude Code oder Cursor.
Weiterlesen nach der Anzeige
Weiterführende Hinweise zum Einsatz von next-browser sind im GitHub-Repository zu finden.
Turbopack-Updates für Performance und Security
Seit Version 16 nutzt Next.js den Bundler Turbopack als Standard. Das aktuelle Release bringt für Turbopack zahlreiche Performanceverbesserungen, Bugfixes und Kompatibilitäts-Updates – insgesamt sind über 200 Änderungen eingeflossen.
Eines der neuen Performance-Features betrifft das Neuladen von serverseitigem Code während der Entwicklung. Bisher wurde require.cache für ein geändertes Modul geleert, ebenso wie für alle anderen Module in seiner Import-Kette. Dadurch wurde oft mehr Code als notwendig neu geladen, beispielsweise unveränderte node_modules. In Next.js 16.2 wird nur noch der tatsächlich geänderte Code erneut geladen, was durch Turbopacks Kenntnis über den Module Graph ermöglicht wird. Das soll die Effizienz des serverseitigen Hot Reloading deutlich verbessern.
Das Next.js-Entwicklungsteam untermauert das mit Zahlen, die es in Echtzeitanwendungen beobachtet hat: 67 bis 100 Prozent schnelleres Anwendungs-Refresh und 400 bis 900 Prozent schnellere Kompilierungszeit in Next.js seien möglich.
Ein weiteres Update dreht sich um Security. Der Sicherheitsstandard Content Security Policy (CSP) dient dazu, Angriffe auf Webseiten wie das Cross-Site Scripting (XSS) zu verhindern. Die gängige nonce-basierte Methode erfordert, dass alle Webseiten dynamisch gerendert werden. Da dies die Performance einschränken kann, setzt das Next.js-Team auf die Alternative Subresource Integrity (SRI). Diese berechnet im Vorfeld einen Hash für jedes Skript und erlaubt dem Browser nur das Ausführen von Skripten mit genehmigten Hashes. In Next.js 16.2 besitzt Turbopack experimentellen Support für SRI.
Weitere Informationen zu den Updates in Next.js 16.2 sowie speziell in den Bereichen künstliche Intelligenz und Turbopack lassen sich dem Next.js-Blog entnehmen.
(mai)
Entwicklung & Code
Neu in .NET 10.0 [15]: Klasse Program und Main()-Methode in File-based Apps
Eine File-based App kann die in C# 9.0 (im Rahmen von .NET 5.0) eingeführten Top-Level Statements verwenden. Das wird der Regelfall sein, bei dem die Ausführung der Datei bei der ersten Zeile beginnt:
Weiterlesen nach der Anzeige
Console.WriteLine(System.Runtime.InteropServices.RuntimeInformation.FrameworkDescription);
Console.WriteLine($"Kompilierungsmodus: {(System.Runtime.CompilerServices.RuntimeFeature.IsDynamicCodeSupported ? "JIT" : "AOT")}");

Start der File-based App mit Top-Level Statement (Abb. 1)
Neben der Verwendung von Top-Level Statements ist auch der klassische Stil mit class Program und Main()-Methode in den File-based Apps möglich:
class Program
{
static void Main(string[] args)
{
Console.WriteLine(System.Runtime.InteropServices.RuntimeInformation.FrameworkDescription);
Console.WriteLine($"Kompilierungsmodus: {(System.Runtime.CompilerServices.RuntimeFeature.IsDynamicCodeSupported ? "JIT" : "AOT")}");
}
}
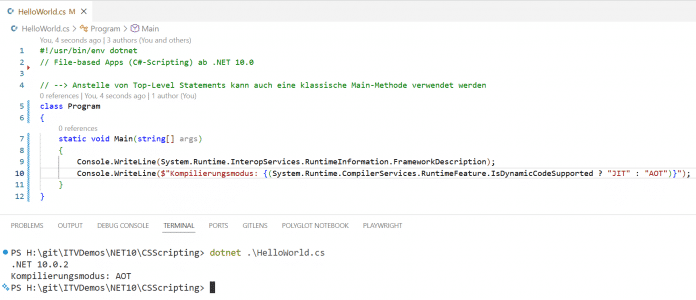
Die File-based App lässt sich auch mit der Main()-Methode in der Klasse Program starten (Abb. 2).
(rme)
Entwicklung & Code
Apple blockiert Updates für Vibe-Coding-Apps
Gegen Vibe-Coding fürs iPhone hat Apple erklärtermaßen keine Einwände. Wer aber auf diese Weise Web-Apps am App Store vorbei entwickeln lässt, geht dem iPhone-Hersteller offenbar zu weit: Dies haben jetzt zwei Anbieter von Vibe-Coding-Apps zu spüren bekommen, deren geplante Updates von Apples App-Store-Kontrolle abgelehnt wurden. Das Unternehmen selbst verweist auf Verstöße gegen die Regeln und zeigt einen möglichen Lösungsweg auf.
Weiterlesen nach der Anzeige
Erst vor kurzem hat Apple selbst einen großen Vorstoß in Richtung Vibe-Coding unternommen. Mit der Einführung von agentischer KI in Apples Entwicklungsumgebung Xcode ist es seit Version 26.3 so einfach wie noch nie, ohne Kenntnis von Programmiersprachen ganze Apps entwickeln zu lassen. Dennoch nimmt die Entwicklung dort ihren klassischen Weg, wie Apple ihn seit Anbeginn des App Stores einfordert: Die Entwicklung findet am Mac statt und die fertige App kann der Entwickler sich wahlweise lokal zum Testen installieren, per TestFlight an größere Testerkreise verteilen oder dem App Review zur Prüfung vorlegen, um sie im App Store zu veröffentlichen.
Maßgeschneiderte Apps im Browser
Die beiden Vibe-Coding-Apps Replit und Vibecode gehen einen anderen Weg. Sie dienen weniger dazu, Apps zu erstellen, die auch andere nutzen. Stattdessen werben die Anbieter damit, dass Nutzer sich ohne Programmierkenntnisse maßgeschneiderte Web-Apps erstellen lassen können. Gibt es also keine passende App im App Store, die den Wünschen gerecht wird, können sich Nutzer per Vibe-Coding einfach eine eigene erstellen lassen. Allerdings besteht dadurch je nach Funktionsumfang auch die Möglichkeit, Alternativen zu Kauf- oder Abo-Apps erschaffen zu lassen. Und dann gehen nicht nur deren Entwickler leer aus, sondern auch Apple als Ladenbetreiber, der pro Verkauf eine Provision bekommt.
Aus Apples Sicht sei der Grund für das Blockieren der Updates allerdings ein ganz anderer, berichtet das Apple-Blog 9to5Mac. So gehe es dem Hüter des App Stores in Wirklichkeit darum, dass es Apps untersagt sei, Code nachzuladen oder auszuführen, der ihre Funktionalität verändere. Dies ist eigentlich eine Vorschrift, die Fake-Apps verhindern soll, die etwa im Gewand einer harmlosen App im App Store erscheinen, dann jedoch in Wirklichkeit Inhalte nachladen, die gegen die Regeln verstoßen. Apple wendet die entsprechenden Paragrafen der Nutzungsbedingungen des Entwicklerprogramms nunmehr auch auf Vibe-Coding-Apps an. Konkret beruft sich Apple dabei auf App Store Guideline 2.5.2 sowie Abschnitt 3.3.1(B) des Developer Program License. Dies berichtete zuvor bereits The Information.
Unversöhnlich gibt sich Apple allerdings nicht. In drei Telefongesprächen in zwei Monaten habe man den betroffenen Entwicklern mögliche Lösungswege aufgezeigt. Einer soll sein, dass App-Vorschauen im Browser angezeigt werden, anstatt sie innerhalb der App zu generieren. Diesen Umstand dürften die Anbieter der Vibe-Coding-Apps aber eher als unnötige Mühsal für ihre Nutzer ansehen, weil diese dann ständig zwischen zwei verschiedenen Apps – Browser und Vibe-Coding-App – wechseln müssten.
Lesen Sie auch
(mki)
Xiaomi Tag im Test: Günstig aber einfach gehalten

Make Football My Only Job › PAGE online

Schluchten und Horizonte: Die Bilder der Woche 12

Schnelles Boot statt Bus und Bahn: Was sich von London und New York lernen lässt

Community Management und Zielgruppen-Analyse: Die besten Insights aus Blog und Podcast

Community Management zwischen Reichweite und Verantwortung
-
 Künstliche Intelligenzvor 3 Monaten
Künstliche Intelligenzvor 3 MonatenSchnelles Boot statt Bus und Bahn: Was sich von London und New York lernen lässt
-
 Social Mediavor 3 Wochen
Social Mediavor 3 WochenCommunity Management und Zielgruppen-Analyse: Die besten Insights aus Blog und Podcast
-
 Social Mediavor 1 Monat
Social Mediavor 1 MonatCommunity Management zwischen Reichweite und Verantwortung
-
Künstliche Intelligenzvor 1 Monat
Top 10: Die beste kabellose Überwachungskamera im Test – Akku, WLAN, LTE & Solar
-

 UX/UI & Webdesignvor 2 Monaten
UX/UI & Webdesignvor 2 MonatenEindrucksvolle neue Identity für White Ribbon › PAGE online
-

 Künstliche Intelligenzvor 2 Monaten
Künstliche Intelligenzvor 2 MonatenAumovio: neue Displaykonzepte und Zentralrechner mit NXP‑Prozessor
-

 Künstliche Intelligenzvor 3 Monaten
Künstliche Intelligenzvor 3 MonatenÜber 220 m³ Fläche: Neuer Satellit von AST SpaceMobile ist noch größer
-

 Künstliche Intelligenzvor 2 Monaten
Künstliche Intelligenzvor 2 MonateneHealth: iOS‑App zeigt Störungen in der Telematikinfrastruktur

