UX/UI & Webdesign
Mit dem neuen ChatGPT 2 Image Update können nicht nur Bilder generiert, sondern auch Texte geschrieben werden › PAGE online
Das Modell kann komplexe visuelle Aufgaben lösen und deutlich präziser auf detaillierte Anweisungen reagieren. Und kann mittlerweile auch menschliche Handschrift generieren.















UX/UI & Webdesign
Nächster Schritt der Markenevolution – Chelsea FC modifiziert Clublogo – Design Tagebuch
Der Chelsea FC hat sein Clublogo modifiziert. Eine offizielle Ankündigung oder Erläuterung zum Redesign gab es bislang nicht. Die dezent veränderte Bildmarke erschien zunächst auf den Social-Media-Kanälen des Clubs und weist eine Reihe subtiler gestalterischer Anpassungen auf. Auch am zentralen Symbol des Clublogos, dem Löwe, wurde Hand angelegt.
Der Chelsea Football Club, kurz Chelsea FC, wurde 1905 in London gegründet und gehört zu den traditionsreichsten englischen Fußballvereinen. Zu den größten Erfolgen zählen sechs englische Meistertitel, zwei Champions-League-Siege (2012, 2021), zwei Europa-League-Titel sowie zahlreiche FA-Cup- und Ligapokal-Gewinne. Für die Saison 2026/27 wurde der Spanier Xabi Alonso als Trainer verpflichtet.
In einem vor wenigen Tagen vom Chelsea FC veröffentlichten Statement geht die Clubführung auf die Hintergründe zum Rücktritt seines ehemaligen Cheftrainers, Enzo Maresca, im Januar 2026 ein. Maresca tritt bei Manchester City die Nachfolge von Pep Guardiola an. Gleichzeitig blickt der Club mit seinem neuen Manager Xabi Alonso auf die kommende Saison.
Auf die Anpassung des Clublogos wird weder in dem Statement eingegangen, noch wurde im Rahmen der Vorstellung der Spielertrikots für die Saison 2026/2027 näher darauf eingegangen. Anfang Juni hatte der Club neue Trikots präsentiert. Die Einführungs-Kampagne wurde durch die Agentur TILL DAWN begleitet, mit strategischer Unterstützung durch die Markenberatung ICONIC.
Als Flock bzw. Stickerei auf der Brust der Trikots dient einzig der aus dem kreisrunden Clublogo herausgelöste Löwe. Hier fungiert der Löwe im Sinne eines Sekundärlogos. Beim offiziellen Clublogo, dem Primärlogo, wurden verschiedene grafische Änderungen vorgenommen.
Die Einführung des bisherigen Clublogos erfolgte 2005 unter dem früheren Eigentümer Roman Abramovich. Die letzte Anpassung liegt also bereits 21 Jahre zurück. Im Zuge des nun vorgenommenen Redesigns wurde die Darstellung vereinfacht. Der Schattenwurf beim Löwen wurde entfernt, ebenso der gelbe Binnenring und die weiße Outline der Ball- und Blumen-Symbole. Bei genauer Betrachtung wird auch eine veränderte Linienführung beim aufbäumenden Löwen (Rampant Lion) deutlich: Die Hinterbeine des Löwen stehen näher beieinander; die Öffnung des Mauls ist rund statt oval. Die Clubfarbe Blau wurde ebenfalls verändert: der Farbton ist gesättigter und einen Tick heller.
Auch die Typo wurde verändert. Die umlaufende Schrift „Chelsea Football Club“ ist statt in serifenlosen Lettern nun in der Serifenschrift CFC Flared gesetzt. Die CFC Flared ist Teil einer aus insgesamt vier Schriften bestehenden Schriftfamilie, die eigens für den Club entwickelt wurde: CFC Sans, CFC Flared, CFC Serif und CFC X-Sharp. Für die Kreation der Schrift verantwortlich zeichnet die Typefoundry F37.

Schon vor geraumer Zeit hatte der Club damit begonnen, Medienanwendungen mit den neuen Schriften und dem kräftigen Blauton auszustatten, analog wie digital. Der Onlineshop des Clubs unter store.chelseafc.com wurde im letzten Sommer relauncht und auf die neue visuelle Markenidentität umgestellt. Dabei wurde auch die überarbeitete Version des Löwen integriert. Allerdings blieb die Anpassung damals weitestgehend unbemerkt.
Die vor wenigen Tagen erfolgte Umstellung des Clublogos ist also bei weitem nicht die einzige Veränderung, die der Chelsea FC in letzter Zeit in Bezug auf sein visuelles Erscheinungsbild vorgenommen hat. Ein grundlegend verändertes Schriftbild, ein dezent angepasstes Farbschema und das vereinfachte Clublogo geben der Markenidentität eine neue Richtung. Der Wechsel erfolgt nicht abrupt, sondern über einen längeren Zeitraum.
Es ist davon auszugehen, dass der Designprozess bereits Anfang 2025 begonnen hat, wenn nicht schon Mitte/Ende 2024. Die jüngere Entwicklung rund um den neuen Trainer/Manager Xabi Alonso steht mit dem Redesign also nur insofern in Zusammenhang, als im Vorfeld zur Saison 2026/2027 auch das Clublogo auf jene Designsprache umgestellt wird, welche vom Chelsea FC bereits seit gut einem Jahr propagiert wird.
Englische Medien berichten, die Überarbeitung des Clublogos sei in Abstimmung mit Fangruppen vorgenommen worden. Seitens des Clubs wird diese Angabe jedoch nicht bestätigt.
Kommentar
Die neue Designsprache des Chelsea FC ist maßgeblich von der herausragenden CFC-Schriftfamilie geprägt. Dem Club ermöglicht die neue Schriftfamilie eine enorme Bandbreite an Ausdrucksmöglichkeiten – je nach Anwendungsfall und -kontext von sachlich, über nobel bis extravagant. In CFC Serif und CFC Sharp gesetzte Überschriften und Bezeichnungen artikulieren weniger spießige Noblesse, als vielmehr traditionsbewusste Eleganz. 36 gewonnene Titel finden hier einen visuellen Ausdruck. Ein Erscheinungsbild, das Selbstbewusstsein und Souveränität kommuniziert.
Den Löwen aus dem Club-Badge herauszulösen und als Sekundärlogo zu nutzen (Trikots, Merchandising u.a.), ist eine kluge Entscheidung. Denn die Variabilität wird so verbessert, dennoch bleibt das Markendesign konsistent.
Eine Clubmarke ist heutzutage auch eine Fashionmarke. Die veränderte Markenidentität trägt diesem Umstand Rechnung. Die Anpassung des Clublogos sollte nicht einzeln betrachtet werden – es ist der nächste (logische) Schritt der Evolution der Markenidentität des Chelsea FC.
Mediengalerie
Weiterführende Links
UX/UI & Webdesign
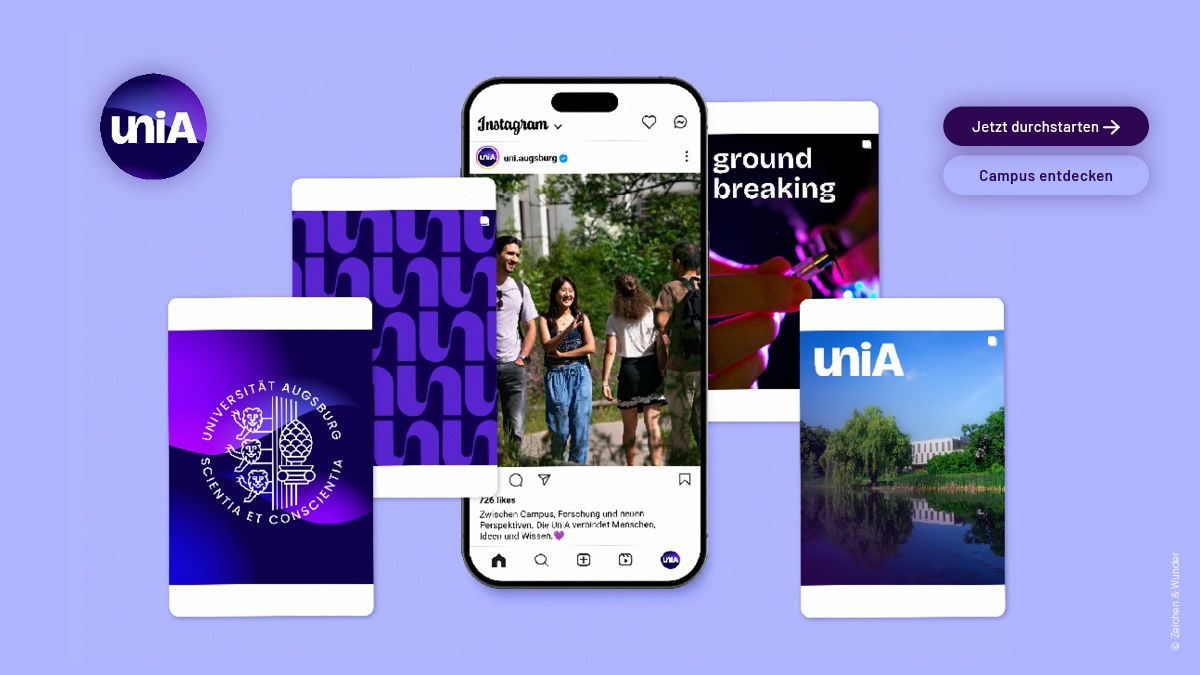
Ressorcenschonend & mit tollem Twist: Redesign der Universität Augsburg › PAGE online
Zeichen & Wunder hat die Universität Augsburg mit einem neuen Auftritt versehen, der ordnet und gleichzeitig Raum für Vielfalt bietet – und ganz auf eine flexible Anwendung ausgerichtet ist.







UX/UI & Webdesign
New York City Opera erneuert Corporate Design – Design Tagebuch
Die New York City Opera präsentiert sich mit einer neuen visuellen Identität samt überarbeitetem Webauftritt. Das Rebranding soll laut Eigenaussage Innovation, Zugänglichkeit und künstlerische Exzellenz verkörpern.
Die New York City Opera (NYCO) wurde 1943 von Bürgermeister Fiorello LaGuardia als „The People’s Opera” gegründet – mit dem Ziel, Oper durch günstige Eintrittspreise einer breiten Öffentlichkeit zugänglich zu machen. Das Opernhaus war das erste, das afroamerikanische Sänger in Hauptrollen besetzte (1945/46) und einen afroamerikanischen Dirigenten einsetzte (1955). Nach einer Insolvenz 2013 wiederauferstanden, präsentiert die NYCO seitdem wieder Produktionen in New York. Seit 2021 ist Constantine Orbelian Music Director und Principal Conductor der New York City Opera.
Innovation, Zugänglichkeit und künstlerische Exzellenz seien seit je her im Selbstverständnis der „The People’s Opera” verankert, wie es in einer Meldung des Hauses anlässlich der Einführung des neuen Erscheinungsbildes heißt. Der neue Markenauftritt soll historische Verwurzelung und globale Ausrichtung verbinden. Angaben zur beauftragten Agentur oder zu konkreten gestalterischen Entscheidungen wurden bislang nicht öffentlich.
In der jüngeren Vergangenheit wurde das Logo des Opernhauses bereits mehrfach verändert (dt-berichtete 2009 und 2016). Das neue Logo greift die bisher verwendete Hochhaussilhouette als Grundidee auf, interpretiert diese, indem sie mit Musiknoten kombiniert werden, jedoch völlig neu. Auch das Farbschema – dunkelrot statt blau-orange – und die Typo – Serifenschrift (PT Serif) statt Groteske (Brandon Grotesque) – unterscheiden sich stark vom bisherigen Auftritt.
Während die Website bereits im Herbst letzten Jahres relauncht wurde, hat das Opernhaus das Logo im Umfeld von Social Media erst vor Kurzem ausgetauscht.
Mediengalerie
-

- New York City Opera Logo – vorher und nachher, Bildquelle: New York City Opera, Bildmontage: dt
-

- New York City Opera Logo, Quelle: New York City Opera
-

- New York City Opera Logo, Quelle: New York City Opera

Reader’s Choice Awards: Bester Monitor-Hersteller 2026

KI-Agenten: Bis zu 234 Milliarden US-Dollar Softwareumsatz in Gefahr

Samsung Foundry: SF1.4+ startet ab 2030, SF2X als HPC-Node bestätigt

iX-Workshop Angriffsziel lokales AD − Schwachstellen finden und beheben

„Don’t Starve Elsewhere“: Survival‑Hit kehrt nach zehn Jahren zurück

Kine‑Exakta: Die erste Spiegelreflexkamera fürs Kleinbild
-
 Künstliche Intelligenzvor 3 Monaten
Künstliche Intelligenzvor 3 MonateniX-Workshop Angriffsziel lokales AD − Schwachstellen finden und beheben
-
 Künstliche Intelligenzvor 3 Monaten
Künstliche Intelligenzvor 3 Monaten„Don’t Starve Elsewhere“: Survival‑Hit kehrt nach zehn Jahren zurück
-
 Künstliche Intelligenzvor 3 Monaten
Künstliche Intelligenzvor 3 MonatenKine‑Exakta: Die erste Spiegelreflexkamera fürs Kleinbild
-

 Künstliche Intelligenzvor 2 Monaten
Künstliche Intelligenzvor 2 MonatenWeitere Entlassungswelle bei Disney: Bis zu 1000 Mitarbeiter betroffen
-
Künstliche Intelligenzvor 3 Monaten
xTool P3 im Test: CO₂-Laser mit 80 Watt schneidet und graviert auch Acryl
-

 Social Mediavor 2 Monaten
Social Mediavor 2 MonatenMetas neuer Creative Setup Workflow: Was sich wirklich ändert – und warum das nicht nur eine UI-Frage ist!
-

 Apps & Mobile Entwicklungvor 2 Monaten
Apps & Mobile Entwicklungvor 2 MonatenMega-GPUs für Nvidia, AMD & Co: TSMC zeigt CoWoS-Package mit >11.600 mm² & 24 × HBM5E
-

 Künstliche Intelligenzvor 2 Monaten
Künstliche Intelligenzvor 2 MonatenApple‑Geräte mit Microsoft Intune verwalten – zweiteiliges Live-Webinar

