Künstliche Intelligenz
Claude Code geleakt: Milliarden für KI-Sicherheit, null für Softwarehygiene
Es klingt nach dem nächsten großen Skandal: Über 500.000 Zeilen Quellcode von Anthropics CLI-Tool Claude Code tauchen öffentlich auf. Die Security-Community horcht auf, Wettbewerber reiben sich die Hände, Kommentatoren wittern den nächsten Beweis, dass KI eh an allem schuld ist. Doch wer genauer hinschaut, findet keine ausgeklügelte Attacke, keinen Zero-Day-Exploit, nicht einmal Social Engineering. Sondern schlicht eine Source Map im npm-Paket, die da nicht hingehörte. Also bloß ein vergessener Schalter in der Build-Pipeline. System scheint hier nur die Schludrigkeit zu haben.
Weiterlesen nach der Anzeige


Moritz Förster schreibt seit 2012 für die iX und heise online. Er betreut neben dem iX-Channel den Bereich Arbeitsplatz.
Debug-Artefakte im Produktions-Build – ein Klassiker
Source Maps sind nützliche Helfer in der Entwicklung. Sie bilden kompilierten Code zurück auf den lesbaren Quelltext – unverzichtbar beim Debuggen, fatal in der Produktion. Dass sie im fertigen Paket landen, passiert nicht durch einen raffinierten Angriff oder eine ausgerastete KI. Es passiert, weil niemand den Build-Prozess sauber konfiguriert hat. Oder weil die Konfiguration irgendwann still und leise überschrieben wurde. Oder weil schlicht niemand nachgeschaut hat.
Entwickler kennen das Muster. Es ist die vergessene .env-Datei im Git-Repository. Das Docker-Image mit eingebetteten Credentials. Die Debug-API, die seit Monaten offensteht, weil sie ja „nur intern“ ist. Genau das ist Prozessversagen.
Niemand fühlt sich zuständig
Moderne Build-Pipelines sind überaus komplex. Bundler, Transpiler, Minifier, Packager – jeder Schritt erzeugt Artefakte, jeder Schritt kann Dinge durchreichen, die nicht nach draußen gehören. Die Verantwortung dafür verteilt sich auf ein Tohuwabohu an Tools, Konfigurationsdateien und Teams. Am Ende fühlt sich niemand zuständig. „Die Pipeline macht das schon“ ist aktuell einer der gefährlichsten Sätze in der Softwareentwicklung.
Weiterlesen nach der Anzeige
Bei klassischen Projekten geht das meistens noch gut. Die Artefakte sind langweilig, der Schaden überschaubar. Bei einem KI-Tool wie Claude Code sieht das anders aus. Hier stecken im Code nicht nur Implementierungsdetails, sondern Architekturentscheidungen, Feature-Flags für unveröffentlichte Funktionen und die komplette Orchestrierungslogik eines agentischen Systems. Wer das lesen kann – und das kann jeder mit npm und etwas Geduld –, bekommt eine Blaupause frei Haus.
Tempo schlägt Sorgfalt
KI-Unternehmen stehen unter enormem Innovationsdruck. Releases folgen in kurzen Zyklen, Features müssen raus, bevor der Wettbewerber sie zeigt. In diesem Tempo bleiben Sicherheits-Gates auf der Strecke. Nicht aus Schlampigkeit oder gar Böswilligkeit, sondern aus Pragmatismus. Die nächste Demo zählt mehr als das nächste Audit.
Das Ergebnis: Tools, die tief in lokale Entwicklungsumgebungen eingreifen, Code lesen, schreiben und ausführen, werden mit derselben Release-Disziplin behandelt wie ein Frontend-Widget. Dass das schiefgeht, ist keine Überraschung. Es ist nur eine Frage der Zeit.
Bekannte Fehler, neue Dimension
Der aktuelle Vorfall wirkt nicht wie ein völlig isolierter Ausrutscher: Medienberichten zufolge ist es bereits die zweite unbeabsichtigte Offenlegung rund um Claude Code in etwas mehr als einem Jahr. Ganz allgemein kennt die Branche das Problem schon lange. OWASP listet „Cryptographic Failures“ (vormals Sensitive Data Exposure) seit Ewigkeiten in den Top Ten. Trotzdem passiert es immer wieder – nur dass die Konsequenzen wachsen.
Denn ein geleakter Quellcode ist hier mehr als ein PR-Problem. Er zeigt Wettbewerbern, wie Anthropic agentische Workflows orchestriert. Er zeigt Angreifern, wo die Logik Annahmen macht, die man ausnutzen kann. Er zeigt der Öffentlichkeit, dass ein Unternehmen, das Milliarden für KI-Sicherheit einwirbt, bei grundlegender Softwarehygiene patzt.
Firewalls helfen nicht gegen Schlamperei
Der Reflex nach solchen Vorfällen ist vorhersehbar: mehr Security-Tools, mehr Monitoring, mehr Abwehr nach außen. Aber gegen was genau? Hier gab es keinen Angreifer, den man hätte aufhalten können. Keine Firewall der Welt schützt vor einem falsch konfigurierten Build-Skript.
Was helfen würde, ist weniger spektakulär: automatisierte Prüfungen, die vor jedem Release den Paketinhalt scannen. Klare Verantwortlichkeiten im Build-Prozess. Vier-Augen-Prinzip bei Releases sensibler Tools. Alles Dinge, die in der klassischen Softwareentwicklung längst Standard sein sollten – und die offenbar auch bei einem der bestfinanzierten KI-Unternehmen der Welt nicht zuverlässig greifen.
Der eigentliche Weckruf
Und genau weil der eigentlich etablierte Prozess das Problem ist, sollte dieser Vorfall mehr beunruhigen als ein aufsehenerregender KI-Hack. Gegen die in der IT-Branche an vielen Stellen vorherrschende Nachlässigkeit hilft nur Disziplin – und die lässt sich bekanntlich schlecht skalieren.
(fo)










Künstliche Intelligenz
Microsofts nächste Kündigungswelle hat offenbar geringeres Ausmaß
Microsoft bereitet die mittlerweile gewohnte Entlassungswelle zur Mitte eines Jahres vor, um die Kosten einzudämmen. Jetzt wird berichtet, dass diese Runde erneut tausende Mitarbeiter betrifft. Neben der Xbox-Abteilung werden auch die Bereiche Vertrieb und Beratung genannt. Allerdings dürfte dieser Personalabbau weniger Menschen erfassen als zuvor. Diesmal wird demnach weniger als 2,5 Prozent der Belegschaft von 220.000 Beschäftigten gekündigt. Das läuft auf höchstens 5500 Kollegen hinaus.
Weiterlesen nach der Anzeige
Schon letzte Woche gab es Berichte, dass Microsoft eine weitere Kündigungswelle plant. Hintergrund ist, dass Microsoft viel Geld für Künstliche Intelligenz (KI) ausgibt. Daher sucht das Management nach Einsparpotenzial an anderer Stelle. So setzt der Konzern auch im Spielebereich den Rotstift an. Im Rahmen der umfassenden Restrukturierung unter der neuen Xbox-Chefin Asha Sharma, die die Gaming-Sparte seit Februar leitet, stehen mehrere namhafte Xbox-Studios vor dem Aus.
Weiterer Stellenbau nach Abfindungsangeboten
Microsoft plant die neue Entlassungswelle für nächste Woche, schreibt Business Insider unter Berufung auf mit der Angelegenheit vertraute Personen. Diese Pläne könnten sich kurzfristig allerdings noch ändern. Einigen der von dem Stellenabbau betroffenen Mitarbeiter sollen umgehend neue Aufgaben angeboten werden, heißt es.
Diese Pläne reihen sich als nächste Stufe des Personalabbaus bei Microsoft ein. Im April wollte Microsoft wegen der KI-Kosten mit Abfindungen fast 9000 Stellen abbauen. Rund 7 Prozent der 125.000 US-Mitarbeiter konnten davon Gebrauch machen. Etwa ein Drittel der Angestellten hat das Angebot angenommen, heißt es jetzt. Das entspricht den Erwartungen des Konzerns, sodass die für die Jahresmitte inzwischen üblichen Entlassungen entsprechend weniger umfangreich ausfallen.
Sinkender Aktienkurs als Druck auf Microsoft
Vor genau einem Jahr, Anfang Juli 2025, hatte Microsoft bis zu 9000 Mitarbeiter entlassen. Die gestrichenen Stellen entsprachen 4 Prozent der Gesamtbelegschaft. Damals war es die größte Kündigungswelle seit 2023 und sie betraf auch Stellen bei Spielestudios in Europa. Allerdings hatte Microsoft schon zwei Monate zuvor im Rahmen „organisatorischer Veränderungen“ tausende Mitarbeiter entlassen. Mit rund 6000 Angestellten waren 3 Prozent des Personals betroffen – „auf allen Ebenen, in allen Teams und in allen Regionen“.
Weiterlesen nach der Anzeige
Im Vergleich zum Vorjahr fallen die jetzt geplanten Stellenkürzungen von weniger als 2,5 Prozent also relativ moderat aus. Allerdings sieht sich Microsoft offenbar unter Druck, Sparmaßnahmen umzusetzen. Der Aktienkurs war in den letzten vier Wochen zeitweise um 20 Prozent gesunken und hat sich erst in den letzten Tagen wieder etwas erholt. Allein am gestrigen Börsentag machte das Papier einen Sprung von 3 Prozent, was möglicherweise auf den Bericht über die neue Kündigungswelle zurückzuführen ist.
Lesen Sie auch
(fds)
Künstliche Intelligenz
Arduino erweitert Modulino-Serie um drei neue Module
Arduino erweitert seine Modulino-Serie um drei neue Bausteine. Neu hinzu kommen der Modulino Hub, der Modulino Extender und das Modulino-Motors-Modul. Statt Schaltungen händisch zu verdrahten, lassen sich diese Modulino-Komponenten über Qwiic-Kabel einbauen.
Weiterlesen nach der Anzeige
Der Modulino Hub gibt einem Arduino ordentlich I2C-Ports an die Hand. Zwar lassen sich theoretisch bis zu 127 Geräte an einem Bus betreiben, in der Praxis sorgen jedoch identische I2C-Adressen vieler Sensoren und Aktoren für Schwierigkeiten. Wer schon einmal zwei gleiche Sensoren angeschlossen hat, kennt das Spiel. Der Hub erweitert ein bestehendes System um acht zusätzliche I2C-Kanäle, die jeweils einen eigenen Adressraum besitzen. Dadurch können auch mehrere identische Module parallel betrieben werden, ohne dass der bestehende Programmcode angepasst werden muss. Das Modul ist für 8,84 Euro im Arduino-Shop erhältlich.
Für größere Installationen ist der Modulino Extender gedacht. I2C eignet sich normalerweise nur für kurze Leitungen auf einer Platine oder innerhalb eines Gehäuses. Müssen Sensoren oder Aktoren dagegen über mehrere Meter verteilt werden, stößt das Bussystem schnell an seine Grenzen. Der Extender verstärkt das Signal hardwareseitig und ermöglicht laut Arduino Kabellängen von bis zu 30 Metern bei einer Busgeschwindigkeit von 100 kHz. Zusätzliche Bibliotheken oder Änderungen an der Software sind dafür nicht erforderlich. Für 12,33 Euro kann man dieses Modul im Arduino-Shop kaufen.
Ebenfalls neu ist das Modulino-Motors-Modul. Das Modul übernimmt die Ansteuerung von zwei Gleichstrommotoren oder alternativ eines Schrittmotors. Geschwindigkeit, Drehrichtung und Position lassen sich direkt über das Modul regeln. Gerade bei Robotik-Projekten oder automatisierten Mechanismen kann das den Verkabelungsaufwand reduzieren. Im Arduino-Shop ist dieses Modul für 12,82 Euro bestellbar.
Die neuen Bausteine arbeiten unter anderem mit dem Arduino UNO Q, Nesso N1, UNO R4 WiFi sowie verschiedenen Nano-Boards zusammen und sind auf die Nutzung innerhalb des Arduino-Ökosystems ausgelegt. Für Maker bedeutet das vor allem einen schnelleren Weg vom Prototyp zur funktionierenden Anwendung. Wer häufig Sensoren austauscht, neue Ideen ausprobiert oder Projekte schrittweise erweitert, dürfte von dem modularen Konzept profitieren. Statt jedes Mal die komplette Hardware neu aufzubauen, reicht künftig oft ein weiteres Modul in der Kette. Manchmal ist Plug-and-Play eben doch angenehmer als eine Stunde Fehlersuche mit dem Multimeter.
Wer mehr über die aktuelle Arduino-Generation wissen will, findet alles in unserem Test zum Arduino UNO Q.
(das)
Künstliche Intelligenz
Fiido Nomads Pro im Test: Top-Ausgestattetes City-E-Bike mit 100-Nm-Mittelmotor
Das City-E-Bike Fiido Nomads Pro will mit 100-Nm-Mittelmotor, 29-Zoll-Laufrädern und integriertem Bügelschloss überzeugen. Wir haben es getestet.
Fiido kennen wir bislang für leichte, schicke Urban-E-Bikes mit Heckmotor. Das federleichte Fiido Air aus Carbon wog in unserem Test unter 14 kg und begeisterte mit cleanem Design. Auch das Fiido C21 überzeugte als eines der besten China-E-Bikes unserer Tests. Nun geht die Marke einen neuen Weg: Das Fiido Nomads Pro ist das erste Modell des Herstellers mit Mittelmotor – und der schiebt gleich mit satten 100 Nm an.
Damit positioniert sich das Nomads Pro robuster als seine Geschwister. Statt Leichtbau steht hier Kraft im Vordergrund. Große 29-Zoll-Laufräder, eine 120-mm-Luftfederung, Vierkolben-Scheibenbremsen und ein serienmäßig integrierter Gepäckträger sowie ein Bügelschloss zeigen, wohin die Reise geht.
Der Preis liegt bei 1999 Euro und damit im gehobenen Segment. Ob der erste Mittelmotor-Aufschlag von Fiido gelingt, klärt unser Test.
Aufbau, Optik & Verarbeitung
Das Fiido Nomads Pro kommt teilmontiert per Post. Die Endmontage bleibt am Nutzer hängen. Selbst erledigen muss man das Einsetzen des Vorderrads, die Montage des vorderen Schutzblechs, das Einsetzen und Verkabeln der Displayeinheit, das Einstecken der Sattelstange sowie das Anschrauben der Pedale. Werkzeug liegt bei. Die Verkabelung der Displayeinheit gestaltet sich zunächst schwierig, denn die Abbildungen in der Anleitung sind zu klein geraten. Reifen aufpumpen, Kette ölen oder Bremsen justieren entfällt hingegen. Nach rund 45 Minuten ist das E-Bike startklar.
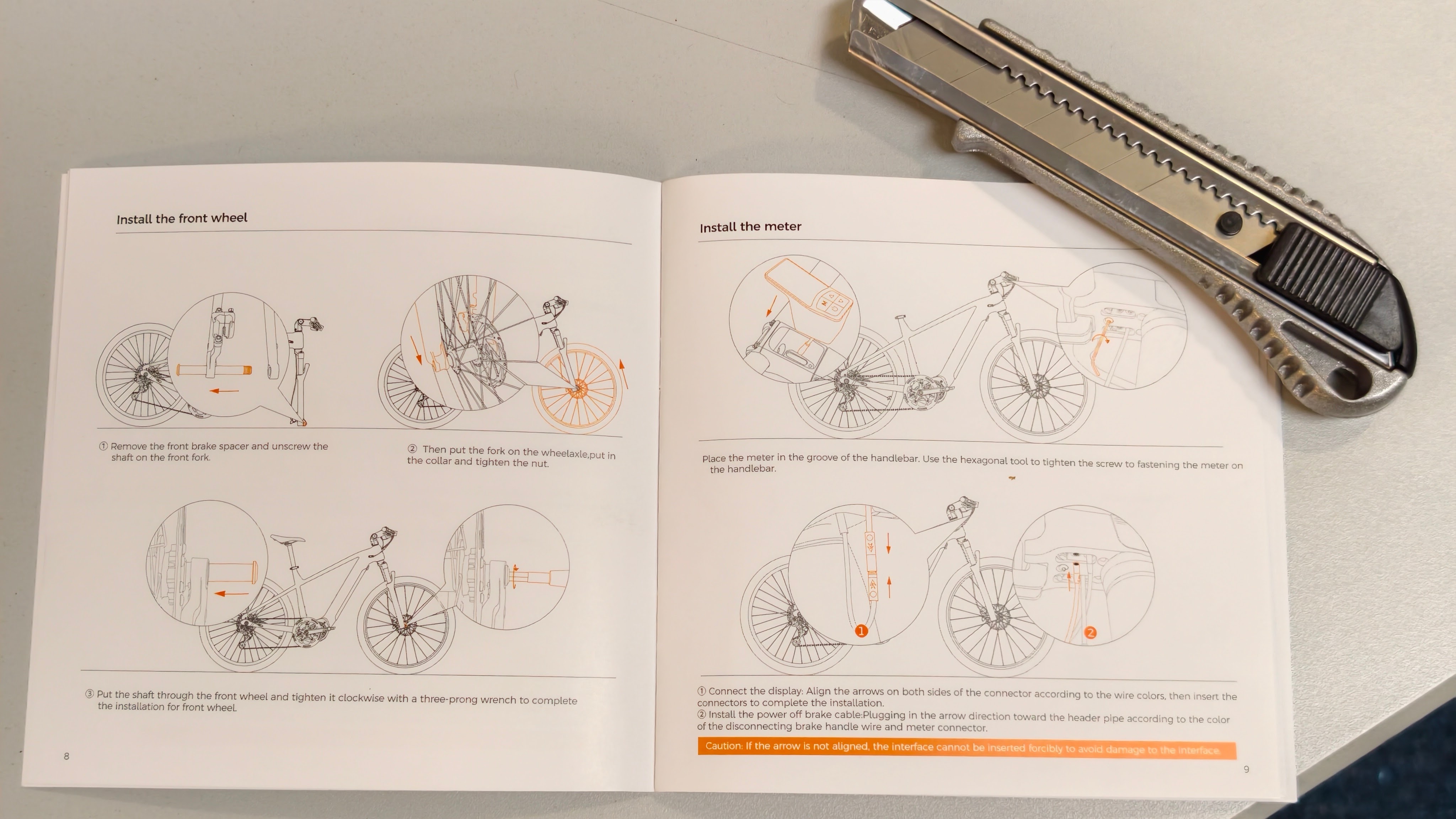
Optisch macht das Nomads Pro eine gute Figur. Der Aluminiumrahmen trägt den Akku sauber integriert, die großen Laufräder verleihen dem Rad eine stattliche Erscheinung. Die Maße bewegen sich im typischen Rahmen dieser Klasse: rund 194 bis 198 cm Gesamtlänge, 74 cm Lenkerbreite und 112 cm Lenkerhöhe. Mit etwa 26 kg wiegt es etwas mehr als der Vorgänger mit 24,7 kg – der Mittelmotor fordert seinen Tribut. Eine Farbwahl gibt es bislang nicht, das Rad kommt nur in Silbergrau.
Die Verarbeitung überzeugt. Schweißnähte, Lack und Kabelführung wissen zu gefallen. Nichts wackelt, nichts quietscht – das Rad wirkt wie aus einem Guss. Ein kleines Highlight ist das serienmäßig in den Rahmen integrierte Bügelschloss. Fiido gewährt zwei Jahre Garantie und verspricht unbegrenzten technischen Support.
Lenker & Display
Der Aluminiumlenker lässt sich in der Höhe anpassen und ermöglicht dadurch eine bequeme Sitzposition. Die Griffe bestehen aus rutschhemmendem TPR. Ergonomisch geformt sind sie aber leider nicht. Wer viel und lange fährt, wünscht sich hier eine Auflagefläche für die Handballen.
Fiido Nomads Pro Bilder
Fiido Nomads Pro

Fiido Nomads Pro

Fiido Nomads Pro

Fiido Nomads Pro

Fiido Nomads Pro

Fiido Nomads Pro

Fiido Nomads Pro

Fiido Nomads Pro

Fiido Nomads Pro

Fiido Nomads Pro

Fiido Nomads Pro

Fiido Nomads Pro

Fiido Nomads Pro

Fiido Nomads Pro

Fiido Nomads Pro

Fiido Nomads Pro

Fiido Nomads Pro

Fiido Nomads Pro

Fiido Nomads Pro

Fiido Nomads Pro

Fiido Nomads Pro

Fiido Nomads Pro

Fiido Nomads Pro

Fiido Nomads Pro

Fiido Nomads Pro
Fiido Nomads Pro
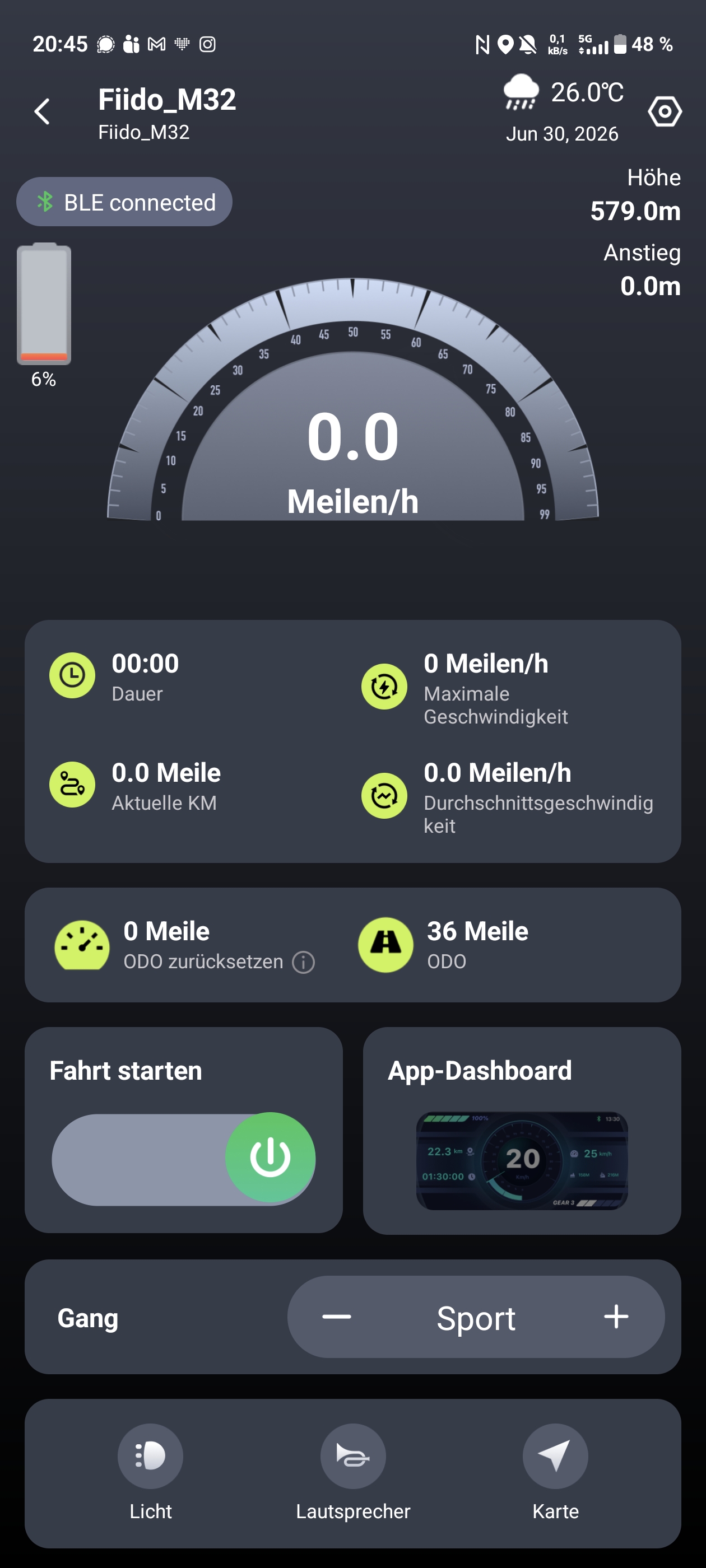
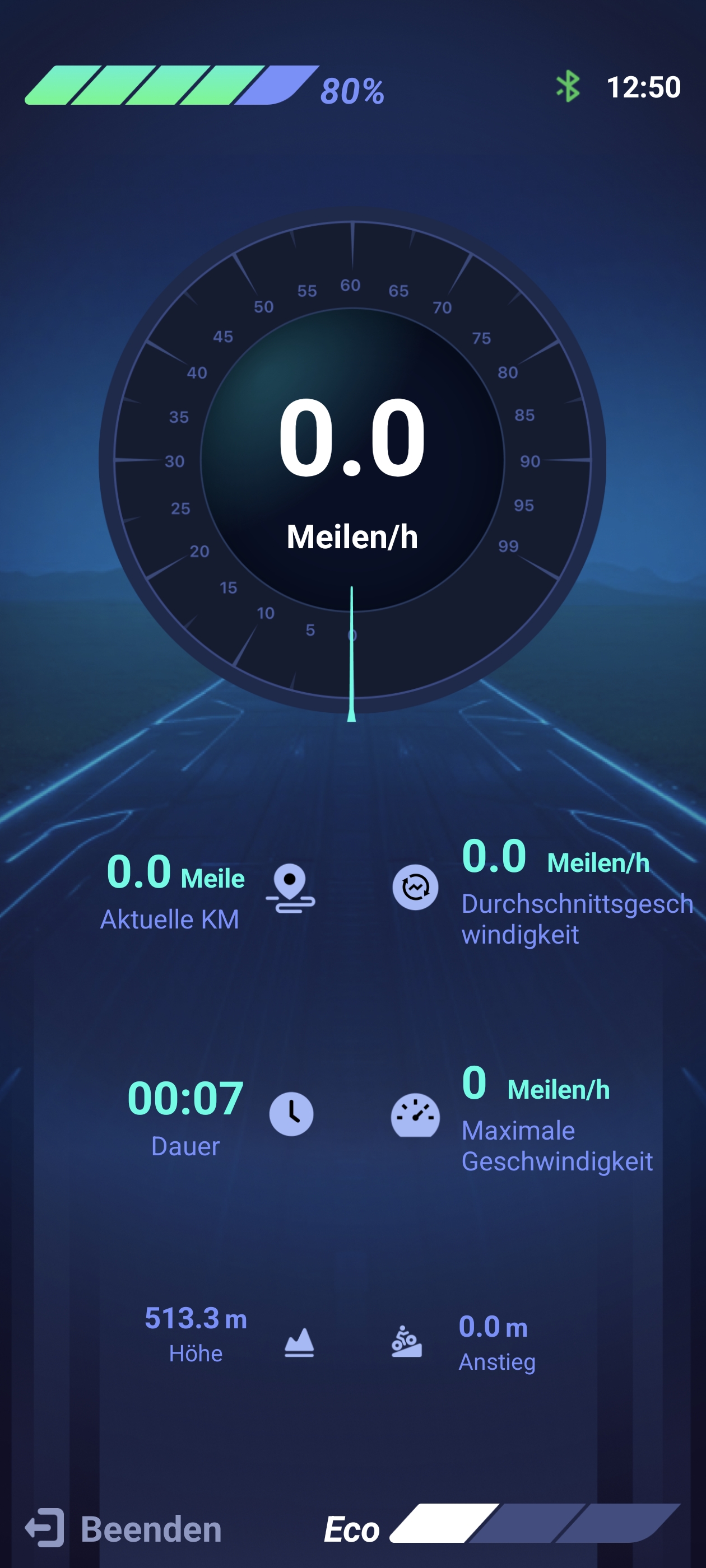
Das Display sitzt schick integriert im Vorbau und bleibt selbst bei Sonne gut ablesbar. Das ist keine Selbstverständlichkeit, denn günstige Farbdisplays schwächeln hier oft. Die farbige Anzeige liefert unter anderem folgende wichtige Werte: Geschwindigkeit, Restkapazität in Prozent, Gesamtkilometer (ODO) und Fahrtdauer. Per Druck auf die M-Taste schaltet man die Anzeigen durch.
Zur Bedienung gibt es gleich zwei Schaltereinheiten. Eine sitzt mittig direkt unter dem Display, die zweite liegt links und lässt sich gut per Daumen erreichen. Einige Tasten sind dabei redundant belegt. Für die Beleuchtung gibt es einen eigenen Knopf auf der linken Seite. Insgesamt geht die Bedienung leicht von der Hand, auch wenn die doppelte Tastenbelegung etwas überflüssig wirkt.
Fahren
Das Herzstück des Fiido Nomads Pro ist sein Mittelmotor mit satten 100 Nm Drehmoment – für Fiido eine Premiere. Zum Vergleich: Das Heybike Galaxy C bietet 80 Nm, das preiswerte Touroll MA2 kommt auf 70 Nm. Mit 100 Nm spielt das Nomads Pro also in einer kräftigeren Liga. Die Steuerung erfolgt über einen Drehmomentsensor. Dadurch wirkt die Kraftentfaltung natürlich und setzt kaum verzögert ein. Am Berg zeigt der Antrieb, was in ihm steckt, und schiebt hier kraftvoll an.
Ganz geräuschlos geht das nicht vonstatten. Der Motor arbeitet etwas lauter als viele andere Antriebe. Beim Anfahren gibt er zudem ein leichtes „Klack“-Geräusch von sich. Störend ist das nicht, hörbar aber allemal.
Nicht ganz perfekt gerät die Abregelung. Wie es sich gehört, endet die Unterstützung bei 25 km/h (per GPS-App bestätigt) – das hält das Nomads Pro schön legal. Allerdings pendelt die Geschwindigkeit bei konstanter Fahrt leicht. Fällt das Tempo unter einen gewissen Wert, setzt der Motor spürbar wieder ein. Das Rad macht dabei einen winzigen Satz nach vorn. Gewöhnungsbedürftig, aber kein Beinbruch. Wir haben festgestellt, dass dieses Problem besonders im Turbo-Modus auftritt. Wer auf Eco wechselt, spürt es kaum noch.
Für Fahrkomfort sorgt die Luftfederung mit 12 cm Federweg an der Vordergabel. Sie lässt sich bequem vom Lenker aus per Lockout sperren und arbeitet im Test einwandfrei. Damit filtert das Nomads Pro Bordsteinkanten und Unebenheiten deutlich besser als das Ado Air 30 Ultra, dem eine Federgabel gänzlich fehlt. Nur der Sattel dürfte für ein E-City-Bike etwas weicher ausfallen.
Für die Verzögerung sorgen Karasawa-Vierkolben-Scheibenbremsen. Sie bieten eine hervorragende Bremswirkung und einen sauberen Druckpunkt. Vier Kolben statt zwei sind bei City-E-Bikes keine Selbstverständlichkeit. Die montierten CST-Patrol-Reifen in 29 × 2,1 Zoll überzeugen mit gutem Profil und bleiben auch bei Nässe sicher. Geschaltet wird über eine 9-Gang-Schaltung mit klassischem Kettenantrieb.
Bei der Ergonomie fühlt sich unser 1,86 m großer Testfahrer auf Rahmengröße L sehr wohl. Das Nomads Pro gibt es in zwei Größen: M für Körpergrößen von 165 bis 190 cm und L für 175 bis 205 cm. Die Sattelhöhe reicht bei Größe M von 85 bis 102 cm, bei Größe L von 90 bis 108 cm. Die maximale Zuladung liegt laut Hersteller bei 120 kg.
Akku
Der im Rahmen integrierte Akku bietet 36 Volt und 417,6 Wh Kapazität. Zum Laden lässt er sich per Schlüssel gesichert entnehmen. Etwas umständlich ist die Positionierung des Ladeports. Er sitzt an der Unterseite des Rahmens und ist dadurch nur schwer zu treffen. Hier ist Fummelei angesagt.
Fiido gibt eine Reichweite von rund 75 km mit einem Akku an. Solche Werte gelten üblicherweise nur unter optimalen Bedingungen, also Eco-Modus, wenig Steigung und Zuladung sowie mildem Wetter. Doch in diesem Fall bestätigt die Praxis diesen Wert annähernd. Bei durchgehend voller Unterstützung, viel Stop-and-Go in der Stadt, 85 kg Zuladung und gutem Wetter kamen wir auf etwa 60 km. Wer mehr braucht, montiert gegen 700 Euro Aufpreis zwei Zusatzakkus am Gepäckträger. Damit soll das Nomads Pro unter Idealbedingungen bis zu 225 km schaffen.
Fiido Nomads Pro Screenshot
Fiido Nomads Pro Screenshot
Fiido Nomads Pro Screenshot
Fiido Nomads Pro Screenshot
Fiido Nomads Pro Screenshot
Fiido Nomads Pro Screenshot
Fiido Nomads Pro Screenshot
Fiido Nomads Pro Screenshot
Fiido Nomads Pro Screenshot
App
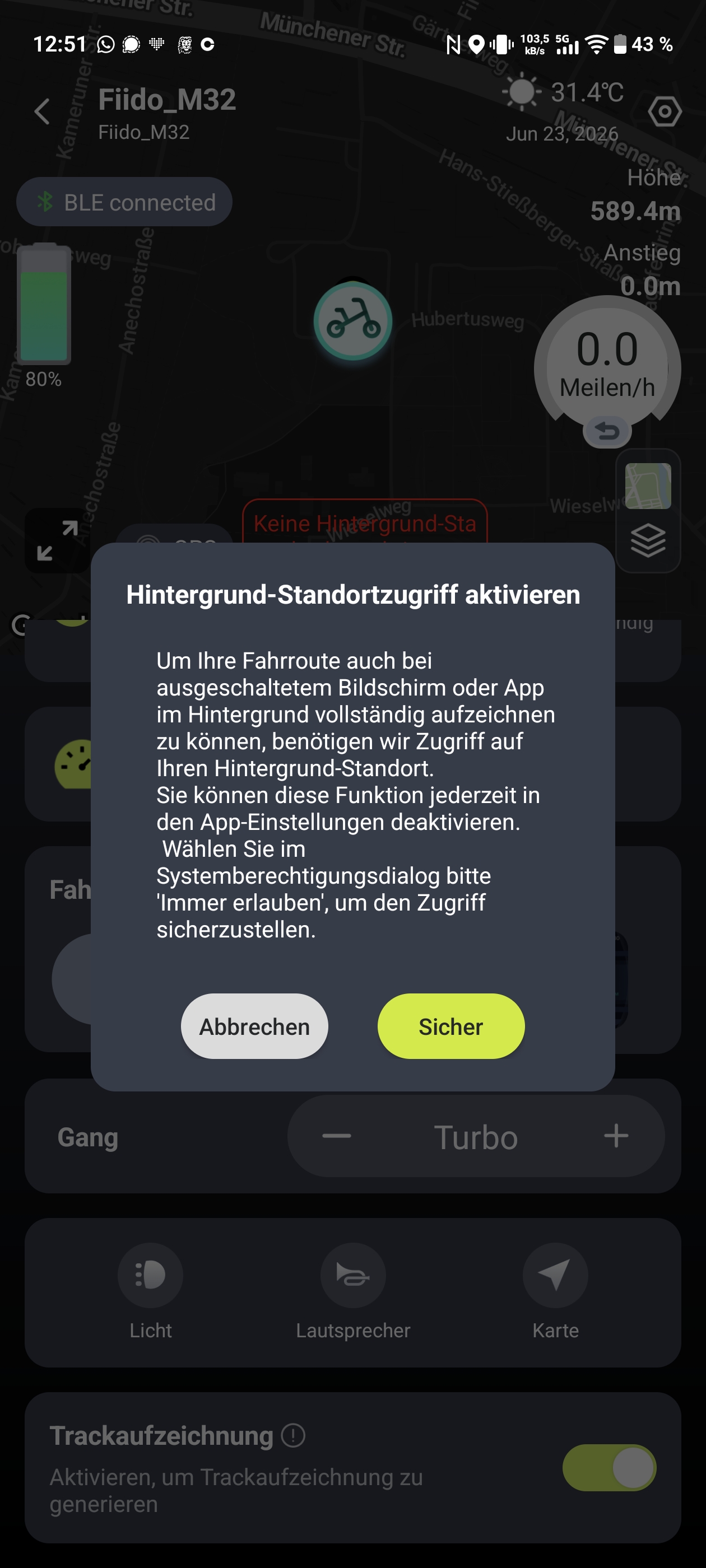
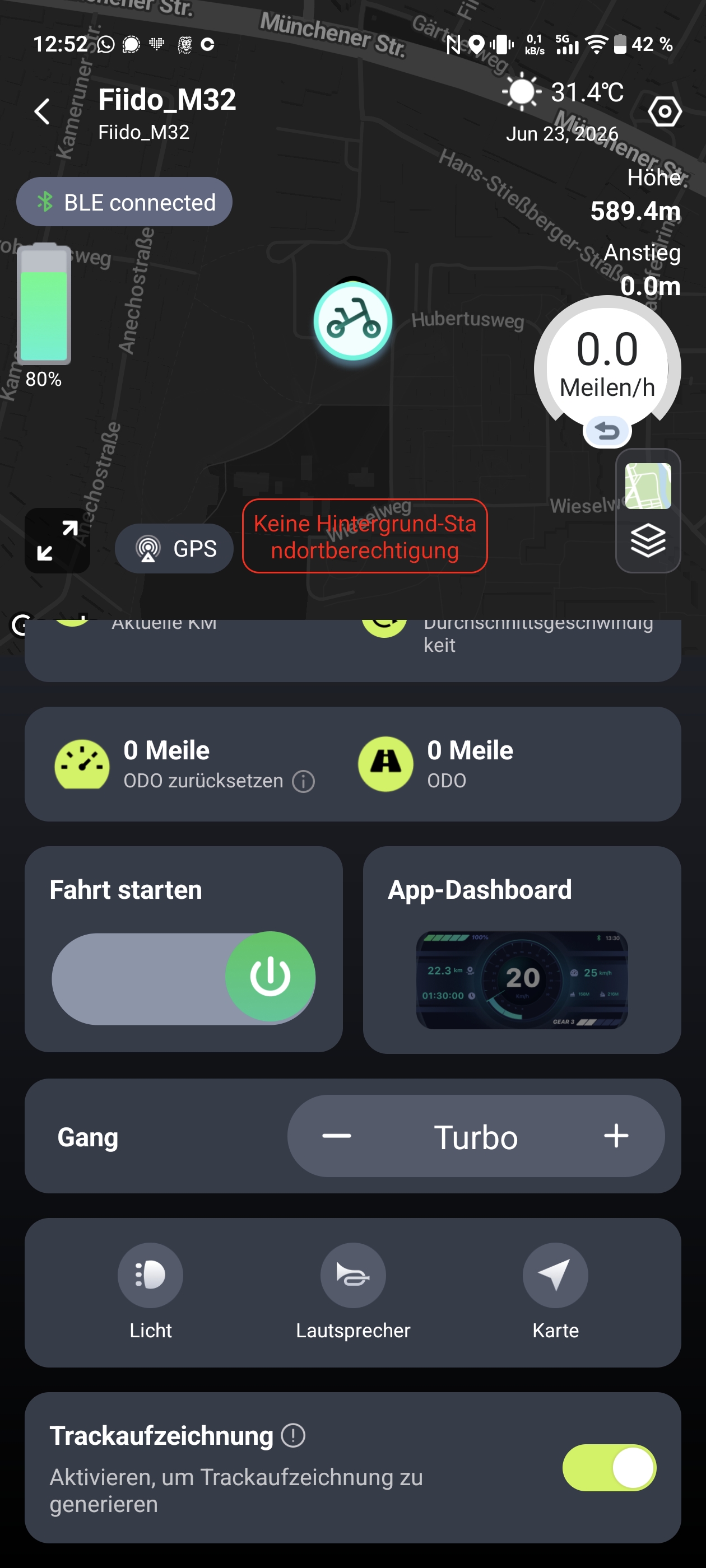
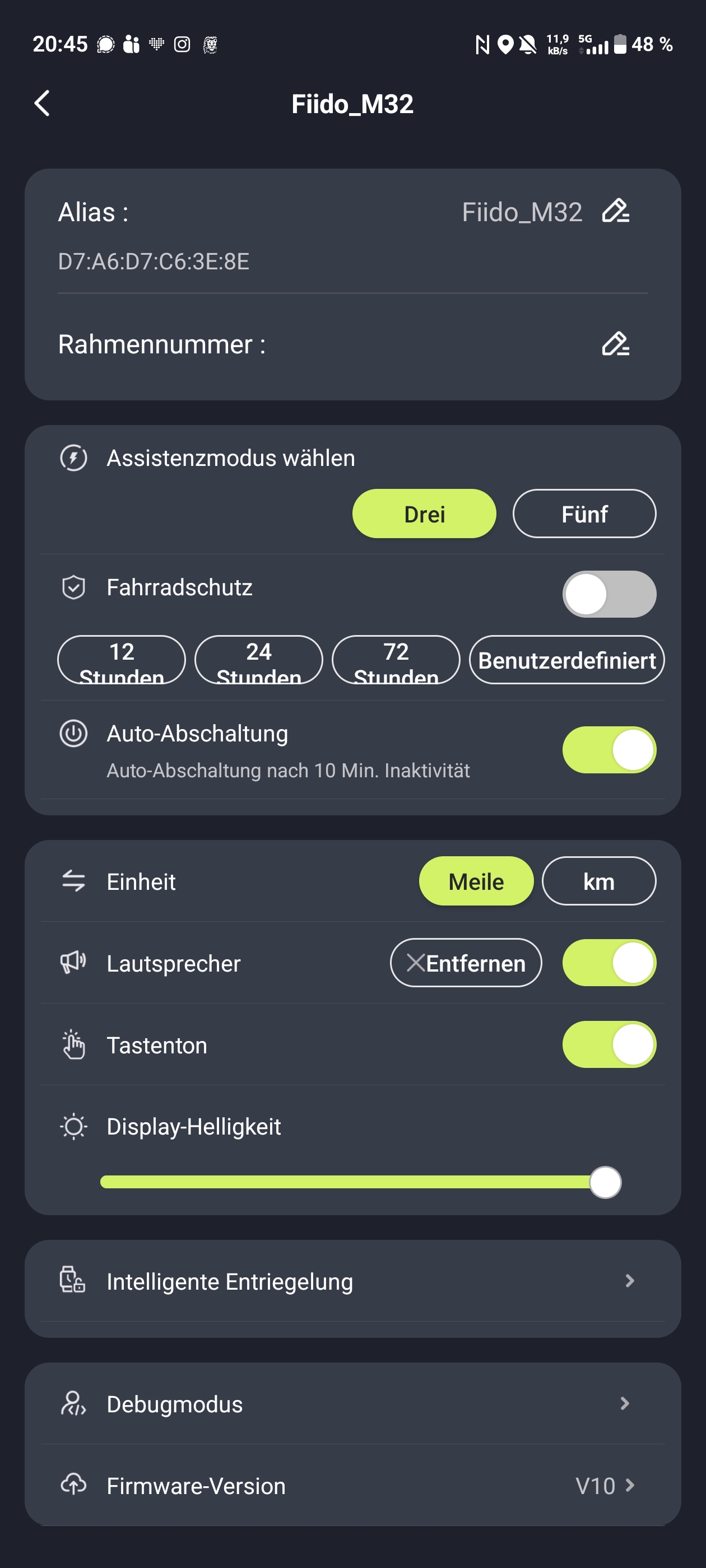
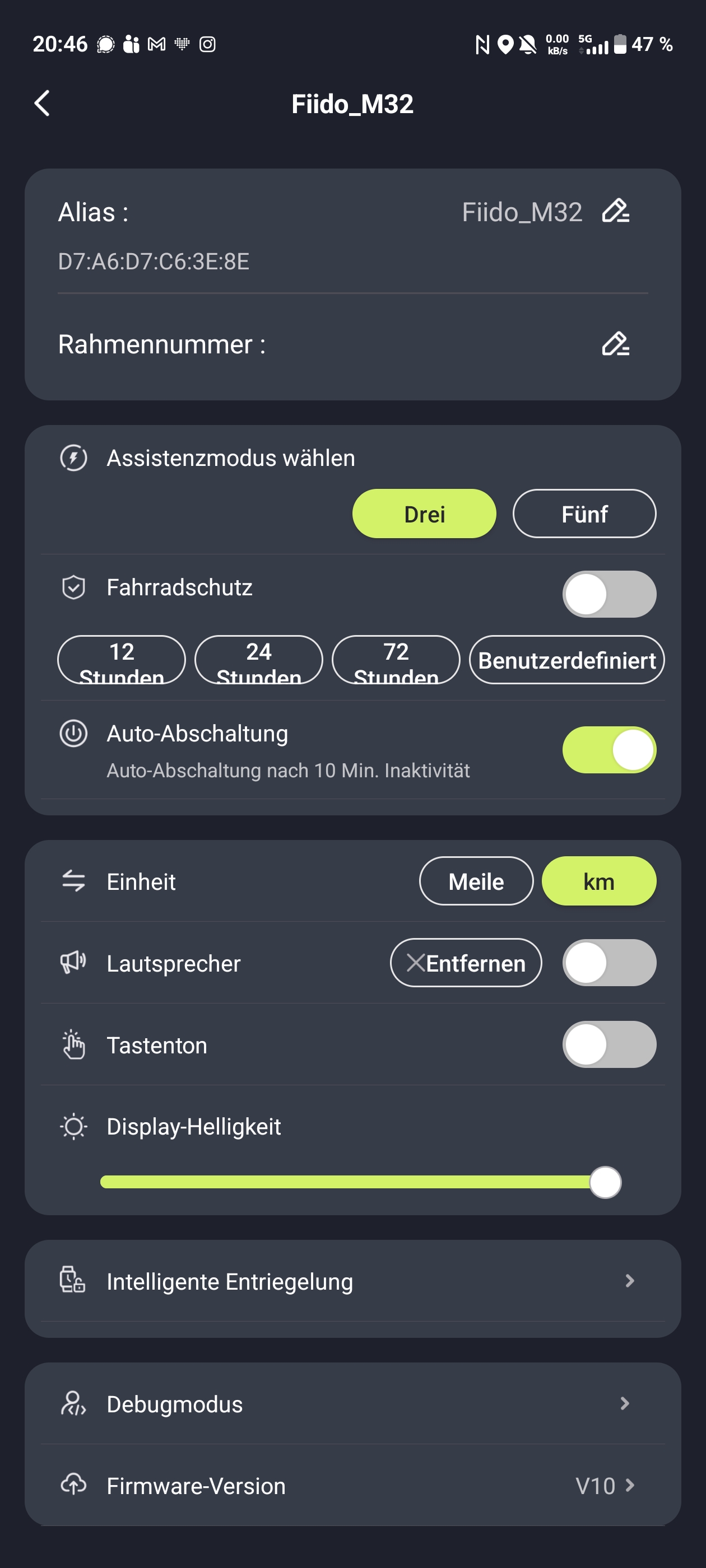
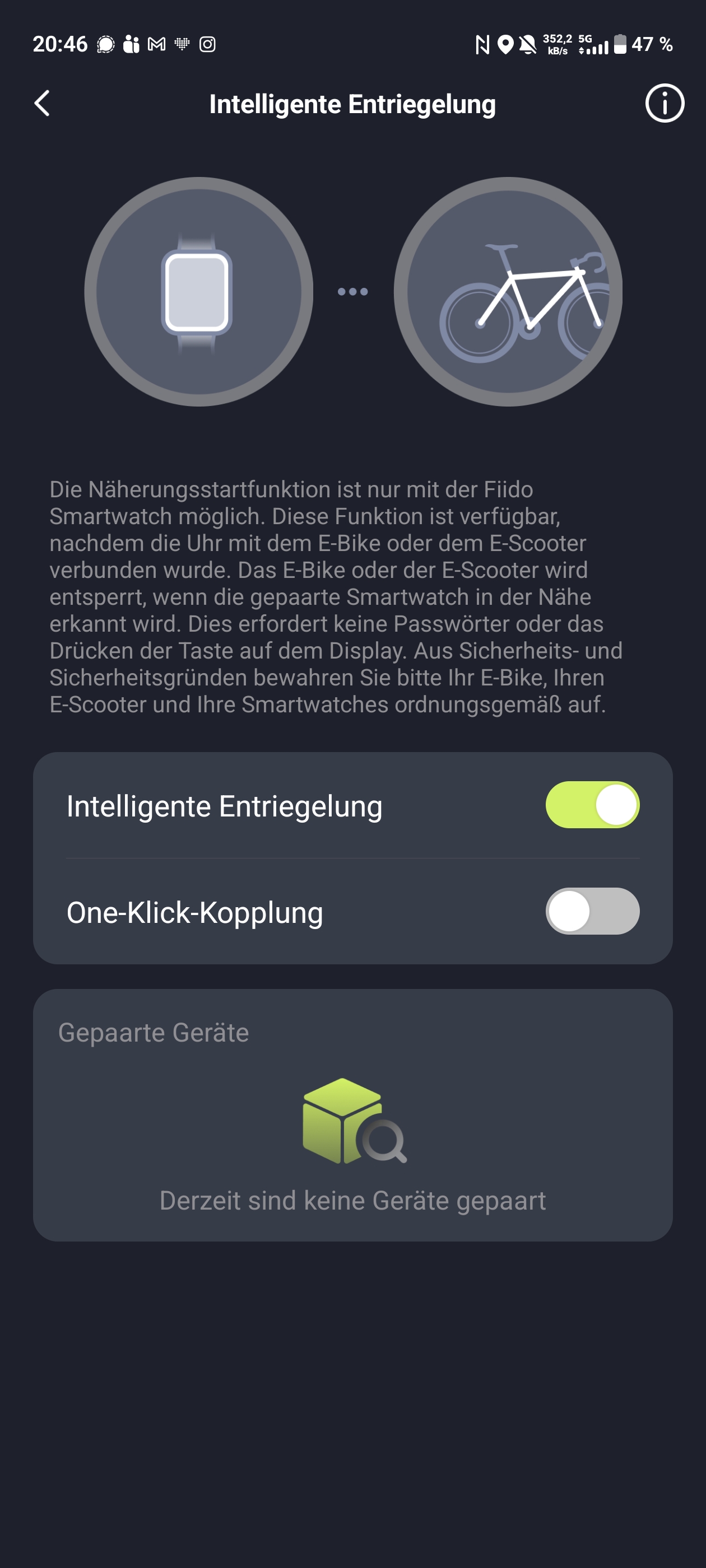
Die Fiido-App verbindet sich per Bluetooth mit dem E-Bike. Direkt nach der Auslieferung sollte man von Meilen auf Kilometer umstellen, denn die Anzeige startet standardmäßig im imperialen Einheitssystem. Danach bietet die App einige nützliche Funktionen. Eine Wegfahrsperre lässt sich aktivieren, die Assistenzstufen erweitert man von drei auf fünf und die Tastentöne kann man abschalten. Ebenfalls möglich ist eine intelligente Entriegelung, die allerdings nur mit einer Fiido-Smartwatch funktioniert – diese haben wir nicht getestet. Zusätzlich lassen sich Touren speichern und weitere Dokumentationen abrufen.
Preis
Das Fiido Nomads Pro kostet in der Grundversion mit einem Akku 1999 Euro. Damit bewegt es sich im leicht gehobenen Preissegment. Zwei zusätzliche Akkus am Gepäckträger schlagen mit 700 Euro Aufpreis zu Buche. Optional gibt es reichlich Zubehör: einen Akkuträger, einen Haustier-Anhänger, einen Kinderanhänger, einen Lasten-Anhänger, eine Packtasche sowie eine Gepäckträgertasche fürs Heck.
Fazit
Mit dem Nomads Pro beweist Fiido, dass sie auch Mittelmotor können. Der Antrieb mit satten 100 Nm gefällt dank natürlicher, kaum verzögerter Kraftentfaltung via des Drehmomentsensors und schiebt am Berg kräftig an. Die Verarbeitung ist tadellos, das Rad wirkt wie aus einem Guss. Besonders löblich sind das serienmäßig integrierte Bügelschloss, die gut funktionierende Luftfederung mit Lockout und die bissigen Karasawa-Vierkolben-Bremsen.
Perfekt ist aber nicht alles. Der Motor arbeitet etwas lauter als die Konkurrenz, und die Abregelung bei 25 km/h könnte konstanter geraten. Kleinere Schwächen sind der fummelige Ladeport, die nicht ergonomischen Griffe, der etwas zu harte Sattel sowie fehlende Extras wie Blinker, Bremslicht und Dämmerungssensor. Immerhin leuchtet das serienmäßige Frontlicht hell genug, um nachts etwas zu sehen.
Trotzdem: Wer ein robustes, kräftig motorisiertes City-E-Bike mit exzellenter Verarbeitung sucht, macht mit dem Fiido Nomads Pro nichts falsch.

Microsofts nächste Kündigungswelle hat offenbar geringeres Ausmaß

Arduino erweitert Modulino-Serie um drei neue Module

Gaming-Benchmarks mit der Intel Pro B70

iX-Workshop Angriffsziel lokales AD − Schwachstellen finden und beheben

„Don’t Starve Elsewhere“: Survival‑Hit kehrt nach zehn Jahren zurück

Kine‑Exakta: Die erste Spiegelreflexkamera fürs Kleinbild
-
 Künstliche Intelligenzvor 3 Monaten
Künstliche Intelligenzvor 3 MonateniX-Workshop Angriffsziel lokales AD − Schwachstellen finden und beheben
-
 Künstliche Intelligenzvor 3 Monaten
Künstliche Intelligenzvor 3 Monaten„Don’t Starve Elsewhere“: Survival‑Hit kehrt nach zehn Jahren zurück
-
 Künstliche Intelligenzvor 3 Monaten
Künstliche Intelligenzvor 3 MonatenKine‑Exakta: Die erste Spiegelreflexkamera fürs Kleinbild
-

 Künstliche Intelligenzvor 2 Monaten
Künstliche Intelligenzvor 2 MonatenWeitere Entlassungswelle bei Disney: Bis zu 1000 Mitarbeiter betroffen
-
Künstliche Intelligenzvor 3 Monaten
xTool P3 im Test: CO₂-Laser mit 80 Watt schneidet und graviert auch Acryl
-

 Social Mediavor 2 Monaten
Social Mediavor 2 MonatenMetas neuer Creative Setup Workflow: Was sich wirklich ändert – und warum das nicht nur eine UI-Frage ist!
-

 Apps & Mobile Entwicklungvor 2 Monaten
Apps & Mobile Entwicklungvor 2 MonatenMega-GPUs für Nvidia, AMD & Co: TSMC zeigt CoWoS-Package mit >11.600 mm² & 24 × HBM5E
-

 Künstliche Intelligenzvor 2 Monaten
Künstliche Intelligenzvor 2 MonatenApple‑Geräte mit Microsoft Intune verwalten – zweiteiliges Live-Webinar

