Apps & Mobile Entwicklung
Benchmarks zu MacBook Pro M5 Max und MacBook Air M5
In der vergangenen Woche hatte Apple das MacBook Air mit M5 sowie das MacBook Pro mit M5 und M5 Max vorgestellt. ComputerBase hat beide Serien von Apple zum Testen erhalten, zum Fall des Test-Embargos gibt es erste Einblicke in die Testergebnisse bezüglich einer Leistung und Akkulaufzeiten mit M5 und M5 Max.
Die Testmuster
Das MacBook Pro 16“ mit M5 Max (18/40)
Das neue MacBook Pro in 14“ und 16“ Zoll (2026) steht ab sofort mit M5, M5 Pro und M5 Max zur Wahl, wobei es jeweils auch noch verschiedene Ausbaustufen des SoC gibt.

Apple hat ComputerBase ein MacBook Pro 16“ mit M5 Max mit 18 CPU-Kernen und 40 GPU-Clustern zur Verfügung gestellt – das entspricht der größten Ausbaustufe des SoC (mit 128 GB + 4 TB, Space Schwarz, Nanotextur; UVP: 7.179 Euro). Wer noch mehr Geld ausgeben möchte, kann im Konfigurator lediglich noch 8 statt 4 TB SSD-Speicherplatz wählen, der Rest ist schon „maxed out“.


- MacBook Pro M5, M5 Pro & M5 Max: Von 1.899 bis 8.679 Euro hat Apple alles im Angebot

Das MacBook Air 15“ mit M5 (10/10)
Das neue MacBook Air (2026) gibt es nur mit M5, in der Version in 15 Zoll ist immer der ganze Chip mit 10 CPU-Kernen und 10 GPU-Shader-Clustern aktiv. Dieses Modell hat Apple der Redaktion zum Testen gestellt (mit 32 GB + 2 TB in Himmelblau; UVP: 2.749 Euro).


Im parallel aktualisierten 13-Zoll-Modell haben Käufer die Wahl zwischen der 10/10-Kern-Variante und einem Modell mit 10 CPU-Kernen und 8 GPU-Shader-Clustern. Eine Besonderheit bleibt dem Air dabei auch in der Generation mit Apple Silicon M5 erhalten: das lüfterlose Kühlsystem.
- Neues MacBook Air mit M5: Schneller, mit mehr Speicher, aber auch 100 Euro teurer

Erste Benchmarks
Alle von Apple in der vergangenen Woche vorgestellten neuen Produkte (MacBook Pro M5 Pro/M5 Max, MacBook Air M5 & MacBook Neo sowie iPhone 17e und iPad Air M4) kommen am 11. März auf den Markt, vorbestellbar sind sie schon seit dem 4. März. Die Test-Embargos fielen hingegen schon heute.
Krankheitsbedingt (und weil die Geräte erst Donnerstagnachmittag zugestellt wurden), gibt es heute noch keine umfassenden Tests, aber einen ersten Eindruck der Leistungsfähigkeit des neuen M5 Max und des Tempos des M5 im passiv gekühlten MacBook Air 15“ – denn den M5 hatte ComputerBase schon im MacBook Pro 14“ mit M5 im Test.
Ein Überblick zur Einordnung
Die nachfolgende Tabelle stellt alle M-SoCs neben dem M3 noch einmal kompakt gegenüber, abgebildet ist immer nur die größte Ausbaustufe – in den nachfolgenden Benchmarks kamen aber auch nur diese Varianten zum Einsatz.
M5, M5 Pro und M5 Max setzen erstmals auf „Super Cores“, die noch oberhalb der Performance-Cores angesiedelt sind. „Super Cores“ lautet Apples neue (und beim M5 jetzt im Nachgang eingeführte) Bezeichnung für die schnellsten Kerne. Darunter gibt es beim M5 die bekannten Efficiency-Kerne, bei M5 Pro und M5 Max hingegen „neue Performance Kerne“; E-Cores bieten die beiden offiziell keine mehr.
- Apple Silicon: M5 Pro und M5 Max sind Dual-Die-CPUs in 3 nm ohne E-Cores
CPU-Leistung (Single/Multi)
Alle M5-Derivate haben dieselben schnellsten Kerne: die neuen „Super Cores“. M5 im MacBook Pro 14“, M5 Max im MacBook Pro 16“ und M5 im MacBook Air 15“ setzen sich auf dieser Basis auch geschlossen an die Spitze. Dem M5 im MacBook Air 15“ gelingt das allerdings vorrangig dank Cinebench, denn im Geekbench liegt das Air leicht zurück und in WebXPRT (nicht zu 100 %, aber überwiegend ein Single-Core-Test) ziehen auch ein paar M4 vorbei. Im Durchschnitt liegt M5 aber geschlossen in Front.
In Multi-Core-Lasten setzt sich der neue M5 Max mit 18 CPU-Kernen, darunter 6 „Super Cores“ und 12 Performance-Cores, von der hausinternen Konkurrenz ab. Der M4 Pro im Mac Mini wird im Durchschnitt um 28 Prozent geschlagen. In Affinity Foto sind es sogar 52 Prozent, doch in Cinebench 2024 gibt es sogar nur einen Gleichstand. Und nicht zu vergessen: Über dem M4 Pro gibt es auch noch einen M4 Max mit zwei zusätzlichen Performance-Kernen. Doch auch gegenüber diesem Modell dürften deutlich über zehn Prozent Zuwachs in der Leistung möglich sein – bei gleichem Fertigungsprozess, was nicht vergessen werden darf.
Mit Blick auf das neue und das alte MacBook Air sowie das MacBook Pro mit M5-SoC zeigt sich ein Leistungszuwachs von M4 zu M5 im Air, aber der erwartete Leistungsnachteil des M5 im Air gegenüber dem aktiv gekühlten M5 im MacBook Pro. Je länger die Last, desto deutlich kann dieser ausfallen: 30 Prozent Rückstand für das Air sind bei Dauerlast realistisch.
GPU-Leistung (Compute)
In den GPU-Compute-Benchmarks sieht die Leistung des M5 Max mit 40 Shader-Clustern beeindruckend aus und sie ist es auch. Der Vorsprung gegenüber dem M4 Pro erzählt in diesem Fall aber wirklich nur die halbe Geschichte, denn es gab auch einen M4 Max mit doppelt so starker GPU und in neuer Generation gibt es auch einen M5 Pro mit 20-Shader-Cluster-GPU. Aber auch ohne die beiden im Benchmark zu haben, wird deutlich: 40 Shader-Cluster auf basis der M5-GPU-Architektur sind sehr schnell.
Noch deutlicher als bei den CPU-Benchmarks wird bei den GPU-Compute-Ergebnissen am Ende aber klar, warum man mit Blick auf GPU Compute zu einem MacBook Pro mit M5 Pro oder M5 Max schielen könnte statt zum M5 zu greifen, dessen CPU für Alltagsaufgaben mit den schnellen Super Cores und zehn Kernen in Summe auch mehr als schnell genug ist.
Akkulaufzeit
Über das Wochenende schon abgeschlossen wurden die ersten Tests zur Akkulaufzeit: Das neue MacBook Air mit M5 erreicht dabei das Niveau des Vorgängers mit M4. Das MacBook Pro 16“ mit M5 Max hat keine direkten Vorgänger in der Testdatenbank der Redaktion, liegt mit sechzehneinhalb Stunden Laufzeit im Streaming-Test trotz großem 16-Zoll-Display aber weit vorne im Vergleich. Ein Nachteil durch den Wechsel der größeren und/oder leistungsfähigeren SoCs ist trotz gleicher Fertigung nicht zu erkennen.
Fazit
Ab sofort setzen auch MacBook Air und MacBook Pro in den Leistungsklassen Pro und Max auf die aktuellen M5-SoCs, während Chassis, Display, Anschlüsse, Tastatur und Kühlsystem gegenüber den Vorgängern der Generation M4 unangetastet bleiben.
Mit dem Wechsel setzen sich beide Serien jetzt geschlossen an die Spitze der Single-Core-Leistungs-Charts, denn der neue schnellste Kern von Apple – der „Super Core“ – ist am Ende genau das: Der derzeit schnellste CPU-Kern. M5 Pro und M5 Max wechseln gegenüber den Vorgängern zudem von E-Cores auf „neue Performance-Kerne“, was die Leistung auch in Multi-Core-Lasten weiter ansteigen lässt. 10+ Prozent im direkten Vergleich sind möglich, was aber auch zeigt, dass die neuen „Performance Cores“ den alten E-Cores näher stehen als den neuen Super Cores – andernfalls müsste die Leistung noch stärker steigen.

Einen größeren Schritt nach vorne macht auch die GPU, die in M5 Pro und M5 Max 1:1 die bereits vom M5 bekannte Architektur übernommen hat. Gegenüber M4 Pro und M4 Max sind trotz gleicher Anzahl an Shader-Clustern damit teils deutliche Zuwächse zu erzielen.
Auch das passiv gekühlte MacBook Air profitiert dabei vom Einsatz des M5: Trotz mutmaßlich – aber noch nicht per Messung bestätigt – gleichem TDP-Korsett und gleicher Fertigung sind Leistungszuwächse von M4 zu M5 zu verzeichnen, bei GPU Compute sind sie sogar sehr deutlich – das war von M4 zu M5 im MacBook Pro auch schon der Fall. Und die höhere Leistung gibt es im Air immer noch geräuschlos.
Die Leistung des M5 Max im MacBook Pro 16“ es im Leistungs-Modus hingegen nicht, aber das Kühlsystem dreht sehr konstant und es ist im Ende „nur“ Luftrauschen zu hören. Auch dauert es gut 40 Sekunden, bevor die Lüfter überhaupt anfangen hoch zu drehen, kurze Lastspitzen bringen auch das neue MacBook Pro mit M5 Max nicht aus der Ruhe.
Display, Chassis, Touchpad und Tastatur wurden in diesem Artikel nicht erneut gesondert beachtet, dann diese Aspekte sind gegenüber den Vorgängern unangetastet geblieben und liegen weiterhin auf einem extrem hohen Niveau. Das gilt auch für die Verarbeitung.
ComputerBase wurden das MacBook Air 15“ M5 und das MacBook Pro 16“ M5 Max leihweise von Apple unter NDA zum Testen zur Verfügung gestellt. Eine Einflussnahme des Herstellers auf den Test fand nicht statt, eine Verpflichtung zur Veröffentlichung bestand nicht. Die einzige Vorgabe war der frühestmögliche Veröffentlichungszeitpunkt.
Dieser Artikel war interessant, hilfreich oder beides? Die Redaktion freut sich über jede Unterstützung durch ComputerBase Pro und deaktivierte Werbeblocker. Mehr zum Thema Anzeigen auf ComputerBase.











Apps & Mobile Entwicklung
Ugreen DXP4800 GT & DXP2800 GT im Test
Die neuen Ugreen NAS der GT-Serie, DXP2800 GT und DXP4800 GT, treten mit AMD Ryzen, 10 Gigabit LAN und U.2 an. So sollen sie sich stärker als Home-Server positionieren, der zahlreiche Aufgaben parallel erledigen kann. Im ComputerBase-Test profitieren sie allein vom schnelleren LAN im Vergleich zu DXP2800 und DXP4800 schon enorm.
Mit der GT-Serie, bestehend aus dem 4-Bay DXP4800 GT und 2-Bay DXP2800 GT, stellt Ugreen zwei neue Mittelklasse-NAS der DXP-Serie vor, mit der der Hersteller vor zwei Jahren auf dem deutschen Markt gestartet ist und das NAS-Geschäft mit aktueller Technik aufgewühlt hat. Die neuen GT-Modelle sind zwischen den für Einsteiger gedachten DH-Modellen und der neuen, maximal ausgestatteten iDX-Serie mit den AI-NAS iDX6011 und iDX6011 Pro (Test) platziert. Im Vergleich zu der ursprünglichen DXP-Serie mit dem DXP2800 (Test) und DXP4800 (Test) sollen die beiden GT-NAS einige signifikante Upgrades bieten. Unter anderem setzen die neuen GT-NAS auf eine stärkere CPU, nämlich den AMD Ryzen Embedded R2514 mit 4 Kernen, 8 Threads und bis zu 3,7 GHz.
Ugreen zielt mit den neuen Systemen insbesondere auf Nutzer ab, die als Content Creator immer schnellen Zugriff auf ihre Daten benötigen, ohne diese zwischen verschiedenen Systemen zu verschieben, oder die Systeme beispielsweise als Smart-Home-Zentrale zusätzlich 24/7 im Dauereinsatz betreiben möchten.


Preis und Verfügbarkeit
Das neue DXP4800 GT und DXP2800 GT sind ab sofort verfügbar. Die unverbindliche Preisempfehlung des DXP2800 GT beträgt 509,99 Euro. Das DXP4800 GT kostet 659,99 Euro. Bis 22. Juni ist das DXP2800 GT für 459,99 Euro und das DXP4800 GT für 589,99 Euro erhältlich. Noch günstiger wird es mit dem 20-Prozent-ComputerBase-Rabatt. Denn Ugreen hat speziell für die Leser von ComputerBase einen Rabattcode bereitgestellt. Mit diesem erhalten ComputerBase-Leser 20 Prozent Rabatt auf die neuen NAS-Systeme der GT-Serie. Der Code ist nicht mit Launch-Rabatten kombinierbar, reduziert die Preise aber auf 399,99 Euro (DXP2800 GT) beziehungsweise 527,99 Euro (DXP4800 GT).
Die Rabatt-Codes lauten:
- 20 % Rabatt auf DXP2800 GT mit dem Code: 2800GTCBAS
- 20 % Rabatt auf DXP4800 GT mit dem Code: 4800GTCBAS
Auch im Ugreen-Store auf Amazon sind die neuen Systeme verfügbar:
Zunächst werden die neuen NAS-Systeme ihrem jeweiligen Pendant ohne GT-Zusatz aus der DXP-Serie gegenübergestellt, um die Unterschiede und Gemeinsamkeiten in der Technik aufzuzeigen.
DXP2800 GT im Vergleich zur DXP2800


DXP4800 GT im Vergleich zum DXP4800 und DXP4800 Plus und DXP4800 Pro


Die direkte Gegenüberstellung der technischen Daten zeigt vor allem in zwei Bereichen Upgrades der GT-Serie: Prozessor und Netzwerk.
AMD Ryzen statt Intel-CPU
Ugreen setzt bei beiden neuen NAS-Systemen auf den AMD Ryzen Embedded R2514 mit 4 Kerne, 8 Threads, 2,1 GHz Basistakt und bis zu 3,7 GHz Turbotakt. Als Embedded-Prozessor verkauft AMD diesen noch bis ins Jahr 2032, obwohl er bereits 2022 vorgestellt wurde. Die Architektur ist nicht mehr die neueste, denn die R2000-Serie setzt noch auf Zen+, während die V2000-Serie von AMD darüber angesiedelt ist und schon Zen 2 nutzt. Dafür bietet der R2514 vier Kerne und acht Threads und unterstützt maximal DDR4-2667 mit ECC. Zudem verfügen die CPUs über die integrierte Grafikeinheit Vega8 mit 512 Shadern. Die TDP des in 12 nm im FP5-Package hergestellten Prozessors beträgt 15 Watt. PCIe liefert er nach Gen 3 über 16 Lanes.

Durch den neuen Ryzen-Embedded-Prozessor sollen sich vor allem dann Verbesserungen ergeben, wenn mehrere Aufgaben parallel erfüllt werden müssen, also beispielsweise Docker, Backups und Dateitransfers parallel laufen.
Aktive Kühlung notwendig
Zudem sind die Embedded-Prozessoren für einen stabilen Dauerbetrieb ausgelegt, bei dem sie nicht heruntertakten und nicht überhitzen. Dafür kühlt Ugreen die CPUs in der neuen GT-Serie allerdings auch mit einem weiteren Lüfter direkt auf dem CPU-Kühler. Dies ist beim DXP2800 und DXP4800 nicht nötig, hier nutzt Ugreen einen passiven Kühlkörper und den Luftstrom des großen Lüfters an der Rückseite des NAS.

Optional mit ECC-RAM
Darüber hinaus unterstützt der Ryzen-Prozessor auch ECC-Arbeitsspeicher, also Speicher mit automatischer Fehlerkorrektur, um die langfristige Datenintegrität zu gewährleisten. Ab Werk sind die NAS-Systeme allerdings mit RAM ohne ECC ausgestattet. Möchte man ECC nutzen, muss man den verbauten RAM also ersetzen. Die Option hat man aber.



Der Wechsel von Intel auf AMD bedeutet zudem wieder einen Wechsel von DDR5 auf DDR4. Ugreen verbaut zwei SODIMM-Steckplätze, von denen ab Werk einer mit einem 8-GB-Modul belegt ist, das Ugreen mit 3.200 MHz ansteuert, also schneller als AMDs offizielle Spezifikationen, an die sich NAS-Hersteller sonst eigentlich halten. RAM lässt sich also auch bei den neuen NAS einfach upgraden, indem die Abdeckung an der Unterseite geöffnet wird. Maximal lassen sich offiziell 64 GB in den NAS nutzen.

Immer 10 Gigabit Ethernet
Das zweite wichtige Upgrade liegt im Bereich der Netzwerkanschlüsse. Denn die GT-Serie bietet immer 10-Gigabit-LAN. Auch das DXP2800 GT bietet einen einzelnen LAN-Anschluss mit 10 GbE. Das DXP4800 GT verfügt sogar über zwei LAN-Anschlüsse mit 10 GbE.

Das beschleunigt nicht nur die maximal mögliche Datentransferrate, sondern Ugreen hat es auch hier vor allem auf Nutzer abgesehen, die verschiedene Dienste gleichzeitig auf dem NAS nutzen möchten. Wenn Home Assistant, Plex, Smart-Home-Kameras und Dateitransfers gleichzeitig auf die Bandbreite der Netzwerkschnittstelle zurückgreifen, bietet diese mit 10 Gigabit/s nun mehr Spielraum, um parallele Anwendungen gleichzeitig zu versorgen.

U.2-NVMe-SSDs in den SATA-Bays
Eine weitere Neuerung, die in den technischen Daten nicht sofort ersichtlich ist, betrifft den Hauptspeicher, der unterstützt wird. Denn die GT-Serie unterstützt auch U.2-NVMe-SSDs über zwei Bays. U.2 ist eine Hardware-Schnittstelle, die primär in Datenzentren genutzt wird und sowohl SAS, SATA als auch PCI Express elektrisch unterstützt. So können in den gleichen Steckplätzen Massenspeicher mit allen drei Protokollen genutzt werden. Gedacht ist U.2 für Workstations, Server- oder Storagesysteme – entsprechend teuer sind diese Laufwerke im Handel.
Doch warum unterstützt Ugreen U.2-NVMe-SSDs? Das Unternehmen möchte hiermit insbesondere eine schnellere Alternative zu SATA abseits der beiden M.2-Steckplätze bieten, sofern schnell auf große Dateien auf den Speichervolumes zugegriffen werden soll. Zudem sind U.2-Laufwerke wie der Embedded-Prozessor auf einen Dauerbetrieb ausgelegt und verfügen meist über eine längere Lebensdauer als Consumer-SSDs unter Dauerlast. Mit SATA, U.2 und M.2 bietet Ugreen nun für verschiedene Workloads unterschiedlich abgestufte Optionen, etwa SATA für die Datenarchivierung, U.2 SSDs für häufig frequentierte Workloads und M.2 SSDs für Docker-Container.

Einschränkend muss beachtet werden, dass das DXP4800 GT U.2 nur in den SATA-Bays 1 und 2 unterstützt. Dies liegt an den begrenzten, aber notwendigen PCIe-Lanes. In den SATA-Bays 3 und 4 können ausschließlich normale SATA-Laufwerke genutzt werden.
10 Gbit/s über USB-A und USB-C
Bei den neuen GT-NAS bieten die USB-A-Schnittstellen nun immer 10 Gbit/s, während je nach Modell vorher nur einer dieser Anschlüsse die volle Geschwindigkeit geboten hat. So lassen sich externe Speichermedien über alle USB-A-Schnittstellen mit maximaler Geschwindigkeit ansprechen. Zudem sind ein USB-C-Anschluss mit 10 Gbit/s und zwei langsamere USB-2.0-Ports verbaut. An der Vorderseite sind der USB-C-Port und ein USB-A-3.2-Anschluss platziert, die beiden USB-2.0-Schnittstellen und die zweite USB-3.2-Buchse sind an der Rückseite verbaut.


Bekannte Qualitäten der Ugreen-NAS bleiben erhalten
HDMI-Ausgang für Videostreaming
Dank der Radeon Vega 8 können auch das DXP2800 GT und DXP4800 GT wieder einen HDMI-Ausgang bieten, der 4K und 8K unterstützt. Schließt man ein Display am NAS an, kann man Videoinhalte vom Smartphone über die Ugreen-App an das NAS streamen. Lokale Inhalte lassen sich ebenso wenig über HDMI abspielen wie das Bild virtueller Maschinen darauf ausgeben.
HDDs und M.2-SSDs als Volume und Cache
Abseits von der Unterstützung für U.2-Laufwerke bietet das DXP2800 GT erneut Platz für zwei SATA-HDDs oder -SSDs und zusätzlich zwei M.2-SSDs. Beim DXP4800 GT können vier SATA-HDDs oder -SSDs und ebenfalls zwei M.2-SSDs eingesetzt werden. Die M.2-Laufwerke lassen sich wahlweise als Cache oder aber auch als normale Laufwerke für Speicherpools nutzen. Hier gibt es seitens Ugreen keinerlei Beschränkungen. Theoretisch lassen sich die NAS so auch nur mit einer oder mehreren M.2-SSDs betreiben.


Beim DXP2800 GT sind die M.2-Steckplätze über die Innenseite der Bays erreichbar. Nimmt man die beiden Laufwerksrahmen heraus, sind seitlich die beiden M.2-Steckplätze mit Wärmeleitpads zu sehen – deren Folie muss bei der Montage der Laufwerke noch entfernt werden. Bei der größeren DXP4800 GT hat Ugreen die beiden M.2-Ports hingegen wieder an der Unterseite unter der Abdeckung platziert, über die auch der RAM zugänglich ist. Entsprechend passende, dicke Wärmeleitpads liegen dem NAS bei, um auch hier die Laufwerke mit dem Gehäuse des NAS thermisch zu verbinden.


3,5-Zoll-Laufwerke lassen sich auf den Laufwerksrahmen erneut schrauben- und werkzeuglos montieren. Die Installation ist so mit wenigen Handgriffen erledigt und das NAS einsatzbereit. Für die Montage von 2,5-Zoll-SSDs liegen Schrauben und ein kleiner Schraubendreher bei.
Die Laufwerksrahmen sind durchnummeriert, wodurch die Reihenfolge der Laufwerke beim gleichzeitigen Herausnehmen der Einschübe nicht durcheinandergerät. Um die Rahmen herauszunehmen, muss lediglich der untere Bereich am Rahmen gedrückt werden und die Arretierung wird gelöst. Die Laufwerksrahmen können im NAS gesichert werden, was aber nur verhindert, dass sie ohne Werkzeug gelöst werden können – ein Diebstahlschutz ist dies nicht.
Kein Upgrade über PCIe-Slot
Einen PCIe-Slot, um eine weitere Netzwerk- oder andere Erweiterungskarte in das NAS einzusetzen, weisen beide Modelle nicht auf.
Hervorragende Verarbeitung
Abgesehen von den goldenen Akzenten weisen beide neuen GT-NAS-Modelle das bekannte Ugreen-Design auf. An der Vorderseite sind die LEDs für das System und die Laufwerke sowie der Power-Button untergebracht. LAN-Ports, der Anschluss für das Netzteil und der HDMI-Ausgang sind hingegen an der Rückseite zu finden. Das externe Netzteil mit Hohlstecker liefert bis zu 72 Watt beim DXP2800 GT und bis zu 150 Watt beim DXP4800 GT.


An der Verarbeitung beider NAS-Systeme gibt es erneut nichts auszusetzen. Die Laufwerksrahmen sind stabil und fassen gut im Gehäuse, die Metallgehäuse selbst sind erneut ohne große Spaltmaße perfekt gefertigt.



Auch der Blick ins Innere zeigt den durchdachten Aufbau, wobei man als Nutzer keinen Grund hat, das Gehäuse zu öffnen, möchte man nicht beispielsweise den rückseitigen Lüfter austauschen, was dank gestecktem 4-Pin-Anschluss problemlos möglich ist. Eine interne SSD wie bei den größeren Modellen von Ugreen findet sich in den neuen GT-Modellen aber nicht, der Speicher für das System ist fest verlötet.
Mit etwas Geduld lassen sich die NAS-Systeme der GT-Serie also wieder vollständig zerlegen, falls man die Wärmeleitpads gegen Wärmeleitpaste austauschen, Lüfter wechseln oder andere Modifizierungen vornehmen möchte.
-

DXP2800 GT zerlegt
Bild 1 von 10
Inbetriebnahme des Ugreen-NAS
Die GT-Modelle von Ugreen ändern an der Inbetriebnahme und der Software zunächst nichts. Laufwerke einbauen, Strom und LAN anschließen, einschalten und entweder per IP, find.ugnas.com oder Ugreen-NAS-Software auf das NAS im Netzwerk zugreifen. Beim Zugriff wird man direkt durch die ersten Schritte wie die Vergabe eines Netzwerknamens und eines Administratorkontos sowie die Konfiguration der Laufwerke und das Einrichten eines Volumes und erster Ordner geführt.
Innerhalb weniger Minuten ist das erste Setup erledigt und man kann während der Synchronisation eines etwaigen RAID-Verbunds mit der weiteren Konfiguration und Installation von Apps fortfahren. Je nach Anzahl der Laufwerke kann man bei ihrer Konfiguration aus einem Einzellaufwerk, JBOD, RAID 0, RAID 1, RAID 5, RAID 5 + Hot Spare, RAID 6 und RAID 10 wählen. Neben ext4 wird auch btrfs als Dateisystem bei der Formatierung der Laufwerke unterstützt. Neben der Erstellung von Snapshots wird auch eine Dateiversionierung geboten, so dass die wichtigsten Funktionen gegen unbeabsichtigtes Löschen von Dateien abgedeckt sind.
-
Ersteinrichtung des Ugreen NASync DXP4800 GT
Bild 1 von 8
Im Test kommt Version 1.15.20.0004 von UGOS Pro zum Einsatz. Das NAS-Betriebssystem von Ugreen hat seit der ersten Version viele Fortschritte gemacht und viele neue Funktionen erhalten, eine Verschlüsselung auf Laufwerks- oder Ordner-Basis fehlt aber weiterhin. In der Tresor-App lässt sich zwar ein geschützter Bereich erstellen und in diesem Dateien gesondert speichern, dieser lässt sich aber gerade nicht als Freigabeordner anlegen, um leicht auf ihn zuzugreifen. Dateien können nur über den Dateimanager des NAS in den Tresor verschoben werden. Automatisierte Backups in den verschlüsselten Bereich sind ebenso wenig möglich wie der Zugriff über SMB oder andere Standards. Ein Ersatz für eine Ordnerverschlüsselung ist er nicht und diese bleibt Ugreen auch weiterhin schuldig.
Wer selbst sehen möchte, welche Updates Ugreen kürzlich vorgenommen hat oder in naher Zukunft plant, für den hält Ugreen eine eigene Website bereit.
Für weitere Details zu virtuellen Maschinen auf dem NAS, dem Videozentrum und anderen Apps wird an dieser Stelle auf die bisherigen Tests der Ugreen-NAS verwiesen.
An dieser Stelle wird im Folgenden lediglich eine Neuerung des Betriebssystems vorgestellt, das Surveillance Center.
Auch Ugreen hat jetzt ein Surveillance Center
Außerdem hat Ugreen mit dem Surveillance Center ein neues Feature in der Software freigeschaltet. Dabei handelt es sich derzeit noch um eine Beta-Version, die nicht den finalen Stand darstellt und im Laufe der Zeit weiter verbessert werden soll.
Das Surveillance Center ist wie bei der Konkurrenz etwa von Synology und QNAP eine Anwendung zur Sicherheitsüberwachung, die das NAS zusätzlich als einen Netzwerk-Videorekorder (NVR) nutzen lässt. Nutzer können IP-Kameras hinzufügen und deren Videos aufzeichnen sowie vergangene Aufnahmen wiedergeben. Dies lässt sich auch an Zugriffsrechte koppeln. So kann eingestellt werden, dass Nutzer zwar Livestreams und Aufnahmen ansehen können, aber keinerlei Einstellungen verändern dürfen. Auf Wunsch lassen sich Nutzer auch vollständig vom Zugriff auf das Surveillance Center ausschließen.
Das Surveillance Center ist als eigene App im App Center von UGOS umgesetzt und muss wie die anderen Apps zunächst installiert werden, wenn man es nutzen möchte. Indem jede App nur bei Bedarf installiert wird, wird unnötige Hintergrundaktivität vermieden.
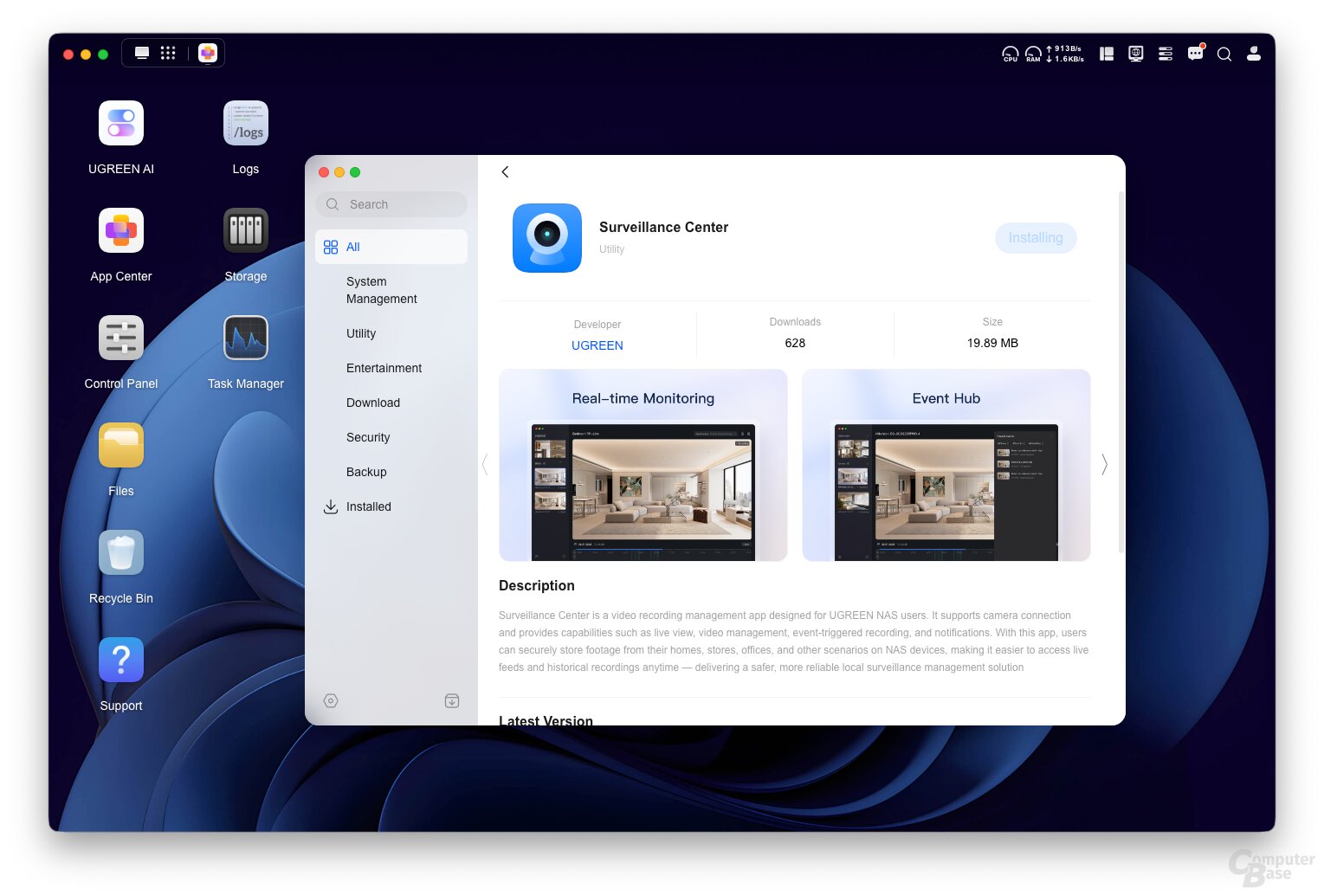
Ugreens Surveillance Center ist vollständig kompatibel mit den gängigen Kamera-Kommunikationsprotokollen ONVIF und RTSP. Ob eine Kamera auf das NAS aufnehmen kann, hängt also in erster Linie von der IP-Kamera ab, nicht vom NAS. Während viele Modelle mit proprietärer Cloud wie die Ring-Kameras von Amazon eine solche Aufnahme auf einem NAS nicht ermöglichen, erlauben es beispielsweise kabelgebundene Kameras von Reolink.
Wählt man in der App „Add camera“ aus, kann die Software zunächst versuchen das Subnetz automatisch nach Kameras zu durchsuchen, bei denen das ONVIF-Protokoll aktiviert ist. Wird eine Kamera gefunden, kann man den Benutzernamen sowie das Passwort für die Authentifizierung eingeben. Kameras lassen sich aber auch manuell anhand der IP-Adresse hinzufügen, wenn sie nicht automatisch erkannt werden.
Bis zu acht Kameras lassen sich dem Surveillance Center derzeit hinzufügen. Für jede Kamera lässt sich der Speicherort, die Aufbewahrungsdauer, die Speicherkapazität, der Aufnahmemodus und ein Kameraname konfigurieren, um die Nutzung des NAS-Speichers zu optimieren. So lässt sich beispielsweise einstellen, dass die älteste Aufnahme immer automatisch überschrieben wird, sobald 500 GB Speicher belegt sind.
Auf der Startseite des Surveillance Center kann man daraufhin einen Livestream aller Kameras einsehen. Auf Wunsch kann man mehrere Kameras gleichzeitig abspielen oder sich eine Kamera größer anzeigen lassen. Wird ein Livestream per Doppelklick ausgewählt, kann man auf die Aufnahmen zugreifen und gezielt Zeitpunkte auswählen. Das System erstellt automatisch alle 10 Minuten eine neue Videodatei.
Unterstützt eine Kamera PTZ, werden unten rechts Bedienelemente angezeigt, um sie zu bewegen.
(*) Bei den mit Sternchen markierten Links handelt es sich um Affiliate-Links. Im Fall einer Bestellung über einen solchen Link wird ComputerBase am Verkaufserlös beteiligt, ohne dass der Preis für den Kunden steigt.
Apps & Mobile Entwicklung
„Chat is dead“: OpenAI plant größte Umgestaltung von ChatGPT seit 2022

OpenAI bereitet Berichten zufolge die größte Neuausrichtung von ChatGPT seit dessen Einführung 2022 vor. Der Chatbot soll schrittweise von einer reinen Frage-und-Antwort-Plattform zu einer umfassenden KI-Anwendung weiterentwickelt werden. Mit diesem Kurswechsel reagiert das Unternehmen auf den zunehmenden Wettbewerb im KI-Markt.
KI-Agenten sind die Zukunft
Laut einem Bericht der Financial Times sieht OpenAI die Zukunft künstlicher Intelligenz nicht länger in klassischen Chatbots, sondern in KI-Agenten. Diese sollen künftig zunehmend eigenständig auch komplexe Aufgaben übernehmen, anstatt lediglich wie bisher nur Antworten auf Fragen zu liefern. Darin sieht das Unternehmen das deutlich größere Potenzial, auch mit Blick auf die wirtschaftlichen Aspekt. Ein ranghoher Mitarbeiter brachte diese Entwicklung intern mit den Worten „Chat is dead“ auf den Punkt und verdeutlichte damit den Strategiewechsel innerhalb des Unternehmens.
Eine zentrale Rolle bei dieser Transformation soll Codex, OpenAIs Plattform für Programmierung und Softwareentwicklung, einnehmen. Obwohl OpenAI beim Start im Februar deutlich hinter anderen Anbietern zurückgelegen hatte, verzeichnete der KI-Agent im weiteren Verlauf ein hohes Wachstum und kann mittlerweile mehr als fünf Millionen wöchentlich aktive Nutzer auf sich verbuchen. Intern gilt Codex als eine der wichtigsten Einnahmequellen des Unternehmens, da Programmierwerkzeuge und produktive KI-Anwendungen deutlich höhere Erlösmöglichkeiten versprechen als die kostenlose Nutzung von ChatGPT. Entsprechend sollen Codex und verwandte Funktionen künftig deutlich stärker in den Mittelpunkt der Plattform rücken.
Erste Auswirkungen stehen bevor
Erste Folgen der neuen Strategie sollen bereits in den kommenden Wochen sichtbar werden. Geplant sind Anpassungen an der Website sowie an den mobilen ChatGPT-Anwendungen. Darüber hinaus soll OpenAI offenbar an einer engeren Einbindung von Partnerdiensten arbeiten. Langfristig soll die KI selbstständig erkennen, welche Aufgabe ein Nutzer erledigen möchte, und automatisch die passenden Werkzeuge oder Dienste bereitstellen, ohne dass zwischen verschiedenen Anwendungen gewechselt werden muss.
Damit nähert OpenAI das eigene Geschäftsmodell zunehmend der Strategie des direkten Konkurrenten Anthropic an, der sich bereits früh auf Geschäftskunden konzentriert hatte – ein Ansatz, der sich als erfolgreich erwiesen hat. Nach Einschätzung von Jenny Xiao, Partnerin bei Leonis Capital und ehemalige Forscherin bei OpenAI, verfolgen dem Bericht zufolge inzwischen sowohl OpenAI als auch Anthropic das Ziel, ihre Geschäftsmodelle stärker auf Profitabilität auszurichten und sich für mögliche Börsengänge attraktiv zu positionieren.
- ChatGPT-Superapp und Agenten: Wie sich OpenAI aus der (öffentlichen) Misere befreien will
- ChatGPT, Codex und Browser verbinden: OpenAI will ChatGPT zur Super-App umbauen
Auch intern hat das Unternehmen mit der Neuorganisation bestehender Strukturen die Voraussetzungen geschaffen, neue Wege einzuschlagen. So wurden unter anderem Codex und weitere Anwendungen unter einer gemeinsamen Führung gebündelt, während gleichzeitig mehrere hochrangige Führungskräfte das Unternehmen verlassen haben. Auch diese Veränderungen verdeutlichen, dass OpenAI den Bereich der Unternehmenskunden als wichtigen Faktor für das weitere Wachstum erkannt zu haben scheint.
Eine App für alles
Hinter all diesen Maßnahmen dürfte die langfristige Vision stehen, ChatGPT von einem einzelnen Produkt zu einer universellen KI-Plattform weiterzuentwickeln. OpenAI geht davon aus, dass die Grenzen zwischen Chatbots, Suchmaschinen, Programmierwerkzeugen, Produktivitätssoftware und digitalen Assistenten künftig zunehmend verschwimmen werden. Statt zahlreiche unterschiedliche Anwendungen zu nutzen, könnten Anwender künftig mit einer einzigen KI interagieren, die sämtliche Aufgaben koordiniert und ausführt. OpenAI-Manager Alex Embiricos geht sogar davon aus, dass in einer Zukunft mit sehr leistungsfähiger künstlicher Intelligenz die Vielzahl eigenständiger Software-Marken weitgehend verschwinden könnte, weil Nutzer ihre Anforderungen direkt an einen zentralen digitalen Assistenten richten.
Apps & Mobile Entwicklung
Jahrelange Partnerschaft vereinbart: SK Hynix und Nvidia arbeiten vereint an Next-Gen-Speicher
SK Hynix und Nvidia haben heute ein Abkommen über mehrere Jahre abgeschlossen, welches primär auf Speicherentwicklung und -lieferungen zielt. Aber auch SK Hynix wird im Gegenzug etwas mehr von Nvidia-Technologie nutzen, um beispielsweise in Simulationen und bei der Optimierung von Arbeitsabläufen schneller zu werden.
Die enge Zusammenarbeit ist ein Novum. Denn bisher hat sich Nvidia noch nie zu einem Speicherhersteller so explizit bekannt wie nun zu SK Hynix, wenngleich es als offenes Geheimnis gilt, dass die Partnerschaft in den letzten beiden Jahren durch die Marktführerschaft von SK Hynix insbesondere bei HBM als verlässlicher Lieferant gewachsen ist. Wie südkoreanische Medien vom Besuch des Nvidia-CEO Jesen Huang in Südkorea berichten, erklärte dieser beim Treffen mit dem Chef von SK Hynix, dass SK Hynix auch in Zukunft der größte Lieferant von HBM für Nvidia bleiben wird.
Genau diese Zukunftspläne legten beide dann in einer offiziellen Vereinbarung offen, die eine jahrelange Partnerschaft und Zusammenarbeit vorsieht. Dabei geht es natürlich in erster Linie um Speicher für alle kommenden Nvidia-Lösungen, denn zu aller erst ist SK Hynix schlicht auch in Zukunft weiterhin erst mal ein Verkäufer von Flash und RAM. Kommende Produkte können nun aber noch mehr auf Nvidia zugeschnitten sein, denn sie sollen gemeinsam entwickelt werden.
Together, we will co-develop the next generation of memory for AI factories and support the accelerating global expansion of AI infrastructure — from frontier model training to agentic and physical AI.
Chey Tae-won, Chairman der SK Group
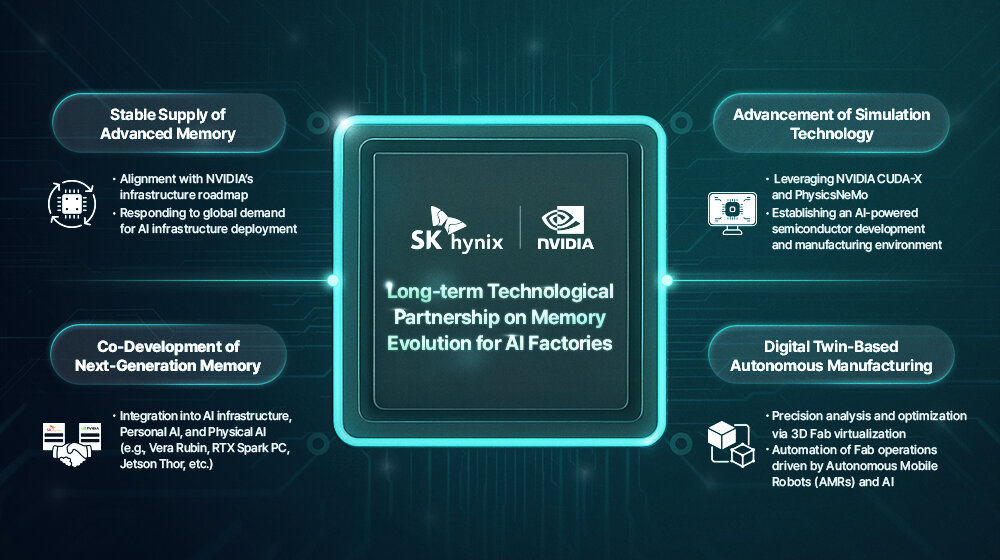
SK Hnyix wird nun auch Nvidia-Bereiche stärker adressieren, die bisher nicht so im Fokus standen oder anderen Zulieferern überlassen wurden. Die Firmen nennen nun explizit „NVIDIA Vera Rubin AI supercomputers, NVIDIA Vera CPUs, NVIDIA RTX Spark powered PCs, and NVIDIA Jetson Thor robotic computing platforms“, die Basis für diese Lösungen ist in der Regel aber aktuell entweder HBM oder LPDDR.
Nvidia wiederum wird seine Entwicklungen aus dem AI-Umfeld die auch explizit auf die Produktion in der Chipfertigung zielen an SK Hynix liefern. Vor allem das Thema „Advancing Fab Digital Twins for Autonomous Manufacturing“ rückt hierbei in den Fokus für die optimierte Fertigung der Zukunft, SK Hynix wird zudem verstärkt CUDA-X und PhysicsNeMo nutzen, um Simulationen in vielen Bereichen von Design bis zur Fertigung schneller zu erledigen.

Ugreen DXP4800 GT & DXP2800 GT im Test
Stadt Offenbach erweitert Corporate Design um eigene Schrift – Design Tagebuch

LinkedIn führt In-Network und Out-of-Network Reach ein

Community-Protest erfolgreich: Galera bleibt Open Source in MariaDB

Blade‑Battery 2.0 und Flash-Charger: BYD beschleunigt Laden weiter

Mähroboter ohne Begrenzungsdraht für Gärten mit bis zu 300 m²
-
 Entwicklung & Codevor 3 Monaten
Entwicklung & Codevor 3 MonatenCommunity-Protest erfolgreich: Galera bleibt Open Source in MariaDB
-
 Künstliche Intelligenzvor 3 Monaten
Künstliche Intelligenzvor 3 MonatenBlade‑Battery 2.0 und Flash-Charger: BYD beschleunigt Laden weiter
-
 Apps & Mobile Entwicklungvor 3 Monaten
Apps & Mobile Entwicklungvor 3 MonatenMähroboter ohne Begrenzungsdraht für Gärten mit bis zu 300 m²
-

 Künstliche Intelligenzvor 3 Monaten
Künstliche Intelligenzvor 3 MonateniPhone Fold Leak: Apple spart sich wohl iPad‑Multitasking
-
Künstliche Intelligenzvor 3 Monaten
JBL Bar 1300MK2 im Test: Soundbar mit Dolby Atmos, starkem Bass und Akku‑Rears
-

 Künstliche Intelligenzvor 3 Monaten
Künstliche Intelligenzvor 3 MonatenPetra‑AI: KI soll Frauen in der Perimenopause unterstützen
-

 Social Mediavor 3 Monaten
Social Mediavor 3 MonatenVon Kennzeichnung bis Plattformpflichten: Was die EU-Regeln für Influencer Marketing bedeuten – Katy Link im AllSocial Interview
-

 Künstliche Intelligenzvor 3 Monaten
Künstliche Intelligenzvor 3 MonateniX-Workshop KRITIS: Zusätzliche Prüfverfahrenskompetenz für § 8a BSIG

