Apps & Mobile Entwicklung
Benchmarks Linux vs. Windows 11 auf Radeon & GeForce
Wie steht es um die Gaming-Performance von Linux auf GeForce und Radeon (Mesa 26) im Vergleich zu Windows 11? ComputerBase hat in 19 Spielen den Benchmark-Test gemacht. Dabei kamen die neuesten Treiber inklusive Mesa-26-Update für AMD-Grafikkarten zum Einsatz, das die Raytracing-Performance deutlich beschleunigt haben soll.
Linux vs. Windows 11 in der Gaming-Performance mit CachyOS
Linux mausert sich immer mehr zu einer ernsten Gaming-Alternative zu Windows. Entsprechend wird das Interesse der Leser an diesem Thema immer größer und so hatte sich ComputerBase vor etwas mehr als einem halben Jahr erstmals die Spiele-Performance von Linux angesehen und diese mit Windows 11 verglichen. Seitdem ist einige Zeit verstrichen und Treiber- sowie Linux-Updates sind erschienen. Es ist also wieder Zeit für einen neuen Vergleich.
Diesmal gibt es dabei eine neue Linux-Distribution: Anstatt EndeavourOS wie beim letzten Mal setzt die Redaktion auf den Community-Liebling CachyOS, das zwar ebenso Arch Linux als Basis nutzt, aber potenziell mit weiteren Optimierungen ausgestattet ist. Die aktuelle Version nutzt den Linux-Kernel „6.19.5-3-cachyos“ Die Linux-Version basiert auf dem aktuellen Open-Source-Paket Mesa 26.0.1, das weitreichende Raytracing-Optimierungen für Radeon-Grafikkarten erhalten hat. Die Treiberversion hört auf die Bezeichnung „26.0.1-arch2.3“. Nvidia-Grafikkarten setzen auf den aktuellen 590.48.01-Treiber. Unter Windows werden der GeForce 591.86 und der Adrenalin 26.2.1 genutzt.
Als Grafikkarten kommen eine GeForce RTX 5070 Ti und eine Radeon RX 9070 XT zum Einsatz. In 19 verschiedenen Spielen müssen diese in WQHD und in Ultra HD, meistens in Kombination mit DLSS 4 beziehungsweise FSR Upscaling AI, zeigen, wie viele Bilder pro Sekunde unter Linux erreicht werden können. Verglichen werden die Ergebnisse mit einem klassisch konfigurierten Windows 11 25H2 inklusive sämtlicher Updates. Die genauen Spieleinstellungen sind weiter unten detaillierter aufgeführt.
Es gibt Beschränkungen und Unterschiede
ComputerBase nutzt für diesen Test ausschließlich Proton für Steam, entsprechend werden auch nur auf Steam verfügbare Spiele getestet. Zwar lassen sich auch Spiele auf anderen Launchern oder native Titel einbinden, doch ist dies teils komplexer, was für den Test vermieden werden sollte. Die meisten Steam-Spiele laufen hingegen unter Linux mit nicht mehr als einem Doppelklick auf „Starten“. Wie gut welche Spiele laufen, darüber klärt Steam selbst, aber auch die ProtonDB auf. Handfeste Aussagen zur Performance Windows vs. Linux gibt es dort aber nicht.
Was darüber hinaus ebenso nicht getestet werden kann, sind Spiele mit gewissen Anti-Cheat-Mechanismen. EA-Spiele wie zum Beispiel F1 25 laufen generell nicht unter Linux, da diese nicht mit dem Betriebssystem kompatibel sind. Diese Spiele können entsprechend ebenso nicht getestet werden.
Keine „Windows-Benchmark-Tools“
Was die klassischen Hardware- sowie Benchmark-Tools angeht, herrscht unter Linux Flaute. Das, was man unter Windows gewohnt ist, funktioniert unter Linux nicht, so zum Beispiel MSI Afterburner oder CapFrameX – auch wenn von letzterem eine angepasste Linux-Version demnächst erscheinen soll. Bei einer Radeon fehlt sogar das gesamte Treibermenü. Das hat zur Folge, dass potenziell eine ganze Menge Dritt-Software installiert werden muss.
Als Benchmark-Software dient MangoHUD mit Goverlay als grafische Oberfläche, in der sich durchaus einiges einstellen lässt. Wichtig zu erwähnen ist, dass die Zählweise der Frames völlig anders als unter Windows funktioniert und mit MangoHUD deutlich ungenauer ist.
Denn während die Benchmark-Tools unter Windows zum Beispiel durchweg jeden einzelnen Frame erfassen, macht dies zumindest MangoHUD nicht. Stattdessen wird nur alle x Millisekunden (konfigurierbar) die Informationen abgefragt, was weniger genau ist und auch mehr Hardware-Ressourcen fordert. Das framegenaue Protokollieren unter Windows kostet weniger CPU-Zeit als das Protokollieren alle 10 Millisekunden unter Linux, obwohl ersteres genauer ist. Die Performancekosten sind zwar gering, aber auch mit einer schnellen CPU messbar. Das gilt auch für diesen Artikel: Je nach Spiel gehen zwischen 0 bis 2 Prozent an FPS durch die Benchmark-Protokollierung unter Linux verloren.
Es werden viele (ganz viele) Shader kompiliert
Shader vorab zu kompilieren, ist in Spielen mittlerweile ganz normal. Auch über Steam für Linux wird dies gemacht, in diesem Fall aber initiiert auch über Proton. Das von Windows bekannte Kompilieren in Spielen fällt dann weg oder kürzer aus, das Prozedere vor dem Start zieht sich aber. Auf einer Radeon-Grafikkarte ist die Wartezeit meistens ziemlich kurz, ganz anders dagegen schaut es auf einer GeForce aus. Auch hier kann die Sache nach wenigen Sekunden erledigt sein. Immer mal wieder – und das gar nicht so selten – dauert es aber mehrere Minuten. Und da können auch auf einem Ryzen 7 9800X3D schnell einmal 15 bis 20 Minuten bis zum Spielstart vergehen. Das ist eine ziemlich nervige Angelegenheit.










Apps & Mobile Entwicklung
„Chat is dead“: OpenAI plant größte Umgestaltung von ChatGPT seit 2022

OpenAI bereitet Berichten zufolge die größte Neuausrichtung von ChatGPT seit dessen Einführung 2022 vor. Der Chatbot soll schrittweise von einer reinen Frage-und-Antwort-Plattform zu einer umfassenden KI-Anwendung weiterentwickelt werden. Mit diesem Kurswechsel reagiert das Unternehmen auf den zunehmenden Wettbewerb im KI-Markt.
KI-Agenten sind die Zukunft
Laut einem Bericht der Financial Times sieht OpenAI die Zukunft künstlicher Intelligenz nicht länger in klassischen Chatbots, sondern in KI-Agenten. Diese sollen künftig zunehmend eigenständig auch komplexe Aufgaben übernehmen, anstatt lediglich wie bisher nur Antworten auf Fragen zu liefern. Darin sieht das Unternehmen das deutlich größere Potenzial, auch mit Blick auf die wirtschaftlichen Aspekt. Ein ranghoher Mitarbeiter brachte diese Entwicklung intern mit den Worten „Chat is dead“ auf den Punkt und verdeutlichte damit den Strategiewechsel innerhalb des Unternehmens.
Eine zentrale Rolle bei dieser Transformation soll Codex, OpenAIs Plattform für Programmierung und Softwareentwicklung, einnehmen. Obwohl OpenAI beim Start im Februar deutlich hinter anderen Anbietern zurückgelegen hatte, verzeichnete der KI-Agent im weiteren Verlauf ein hohes Wachstum und kann mittlerweile mehr als fünf Millionen wöchentlich aktive Nutzer auf sich verbuchen. Intern gilt Codex als eine der wichtigsten Einnahmequellen des Unternehmens, da Programmierwerkzeuge und produktive KI-Anwendungen deutlich höhere Erlösmöglichkeiten versprechen als die kostenlose Nutzung von ChatGPT. Entsprechend sollen Codex und verwandte Funktionen künftig deutlich stärker in den Mittelpunkt der Plattform rücken.
Erste Auswirkungen stehen bevor
Erste Folgen der neuen Strategie sollen bereits in den kommenden Wochen sichtbar werden. Geplant sind Anpassungen an der Website sowie an den mobilen ChatGPT-Anwendungen. Darüber hinaus soll OpenAI offenbar an einer engeren Einbindung von Partnerdiensten arbeiten. Langfristig soll die KI selbstständig erkennen, welche Aufgabe ein Nutzer erledigen möchte, und automatisch die passenden Werkzeuge oder Dienste bereitstellen, ohne dass zwischen verschiedenen Anwendungen gewechselt werden muss.
Damit nähert OpenAI das eigene Geschäftsmodell zunehmend der Strategie des direkten Konkurrenten Anthropic an, der sich bereits früh auf Geschäftskunden konzentriert hatte – ein Ansatz, der sich als erfolgreich erwiesen hat. Nach Einschätzung von Jenny Xiao, Partnerin bei Leonis Capital und ehemalige Forscherin bei OpenAI, verfolgen dem Bericht zufolge inzwischen sowohl OpenAI als auch Anthropic das Ziel, ihre Geschäftsmodelle stärker auf Profitabilität auszurichten und sich für mögliche Börsengänge attraktiv zu positionieren.
- ChatGPT-Superapp und Agenten: Wie sich OpenAI aus der (öffentlichen) Misere befreien will
- ChatGPT, Codex und Browser verbinden: OpenAI will ChatGPT zur Super-App umbauen
Auch intern hat das Unternehmen mit der Neuorganisation bestehender Strukturen die Voraussetzungen geschaffen, neue Wege einzuschlagen. So wurden unter anderem Codex und weitere Anwendungen unter einer gemeinsamen Führung gebündelt, während gleichzeitig mehrere hochrangige Führungskräfte das Unternehmen verlassen haben. Auch diese Veränderungen verdeutlichen, dass OpenAI den Bereich der Unternehmenskunden als wichtigen Faktor für das weitere Wachstum erkannt zu haben scheint.
Eine App für alles
Hinter all diesen Maßnahmen dürfte die langfristige Vision stehen, ChatGPT von einem einzelnen Produkt zu einer universellen KI-Plattform weiterzuentwickeln. OpenAI geht davon aus, dass die Grenzen zwischen Chatbots, Suchmaschinen, Programmierwerkzeugen, Produktivitätssoftware und digitalen Assistenten künftig zunehmend verschwimmen werden. Statt zahlreiche unterschiedliche Anwendungen zu nutzen, könnten Anwender künftig mit einer einzigen KI interagieren, die sämtliche Aufgaben koordiniert und ausführt. OpenAI-Manager Alex Embiricos geht sogar davon aus, dass in einer Zukunft mit sehr leistungsfähiger künstlicher Intelligenz die Vielzahl eigenständiger Software-Marken weitgehend verschwinden könnte, weil Nutzer ihre Anforderungen direkt an einen zentralen digitalen Assistenten richten.
Apps & Mobile Entwicklung
Jahrelange Partnerschaft vereinbart: SK Hynix und Nvidia arbeiten vereint an Next-Gen-Speicher
SK Hynix und Nvidia haben heute ein Abkommen über mehrere Jahre abgeschlossen, welches primär auf Speicherentwicklung und -lieferungen zielt. Aber auch SK Hynix wird im Gegenzug etwas mehr von Nvidia-Technologie nutzen, um beispielsweise in Simulationen und bei der Optimierung von Arbeitsabläufen schneller zu werden.
Die enge Zusammenarbeit ist ein Novum. Denn bisher hat sich Nvidia noch nie zu einem Speicherhersteller so explizit bekannt wie nun zu SK Hynix, wenngleich es als offenes Geheimnis gilt, dass die Partnerschaft in den letzten beiden Jahren durch die Marktführerschaft von SK Hynix insbesondere bei HBM als verlässlicher Lieferant gewachsen ist. Wie südkoreanische Medien vom Besuch des Nvidia-CEO Jesen Huang in Südkorea berichten, erklärte dieser beim Treffen mit dem Chef von SK Hynix, dass SK Hynix auch in Zukunft der größte Lieferant von HBM für Nvidia bleiben wird.
Genau diese Zukunftspläne legten beide dann in einer offiziellen Vereinbarung offen, die eine jahrelange Partnerschaft und Zusammenarbeit vorsieht. Dabei geht es natürlich in erster Linie um Speicher für alle kommenden Nvidia-Lösungen, denn zu aller erst ist SK Hynix schlicht auch in Zukunft weiterhin erst mal ein Verkäufer von Flash und RAM. Kommende Produkte können nun aber noch mehr auf Nvidia zugeschnitten sein, denn sie sollen gemeinsam entwickelt werden.
Together, we will co-develop the next generation of memory for AI factories and support the accelerating global expansion of AI infrastructure — from frontier model training to agentic and physical AI.
Chey Tae-won, Chairman der SK Group
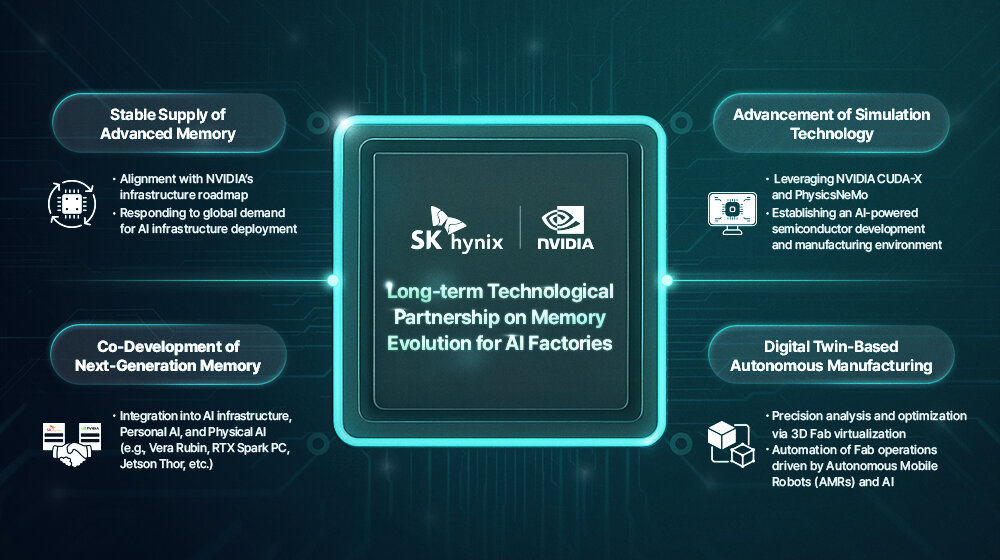
SK Hnyix wird nun auch Nvidia-Bereiche stärker adressieren, die bisher nicht so im Fokus standen oder anderen Zulieferern überlassen wurden. Die Firmen nennen nun explizit „NVIDIA Vera Rubin AI supercomputers, NVIDIA Vera CPUs, NVIDIA RTX Spark powered PCs, and NVIDIA Jetson Thor robotic computing platforms“, die Basis für diese Lösungen ist in der Regel aber aktuell entweder HBM oder LPDDR.
Nvidia wiederum wird seine Entwicklungen aus dem AI-Umfeld die auch explizit auf die Produktion in der Chipfertigung zielen an SK Hynix liefern. Vor allem das Thema „Advancing Fab Digital Twins for Autonomous Manufacturing“ rückt hierbei in den Fokus für die optimierte Fertigung der Zukunft, SK Hynix wird zudem verstärkt CUDA-X und PhysicsNeMo nutzen, um Simulationen in vielen Bereichen von Design bis zur Fertigung schneller zu erledigen.
Apps & Mobile Entwicklung
1666: Amsterdam: Demo zum mystischen Action-Adventure auf Steam verfügbar
Mit 1666: Amsterdam haben ehemalige Assassin’s-Creed-Entwickler ein neues Action-Adventure vorgestellt und zum Summer Game Fest einen ersten Trailer veröffentlicht. Parallel dazu ist bereits eine Demo-Version auf Steam verfügbar. Das in der Unreal Engine 5 entwickelte Spiel soll später in diesem Jahr in den Early Access starten.
Action-Adventure im historischen Amsterdam
Bei 1666: Amsterdam handelt es sich laut den kanadischen Entwicklern von
Panache Digital Games um ein storygetriebenes Action-Adventure in Third-Person-Perspektive, das im Amsterdam des 17. Jahrhunderts spielt. Ergänzt wird das historische Setting mit übernatürlichen Elementen und Hexerei. Spieler übernehmen die Rolle von Noa Brooklyn, einer sogenannten „Eintreiberin“, die mit magischen Fähigkeiten ausgestattet ist und damit gegen verborgene Wesen – sogenannte „Ursprüngliche“ – in der niederländischen Stadt vorgeht. Es handelt sich um übernatürliche Wesen, die sich unter der Bevölkerung verstecken und über archaische Kräfte verfügen.
Die Geschichte von 1666: Amsterdam ist über mehrere Zeiträume hinweg angelegt. So sind neben dem zentralen Schauplatz auch moderne und zeitlich verschobene Kapitel Teil der Erzählstruktur. Abseits des Amsterdams des Jahres 1666 spielen auch ein Abschnitt in den späten 1990er-Jahren sowie eine moderne Zeitebene eine Rolle. Die Handlung soll dabei mehrere Figuren verknüpfen, deren Verbindung sich schrittweise entfalten soll. Im Mittelpunkt steht ein heidnischer Kreislauf, der sich alle 333 Jahre wiederhole.
Bei der Erzählung setzt das Spiel insofern weniger auf eine klassische lineare Struktur, sondern auf das allmähliche Zusammensetzen von Informationen aus verschiedenen Perspektiven. Dabei stehen Themen wie Macht, verborgene Strukturen und rituelle Elemente im Vordergrund, eingebettet in eine düstere Atmosphäre. Die Beschreibung auf Steam weist explizit auf erwachsene Inhalte hin, darunter intensive Gewalt sowie Gore-Elemente, sexuelle Inhalte und Nacktheit.
Gameplay erinnert an alte Assassin’s-Creed-Spiele
Gameplayseitig kombiniert das Spiel Erkundung, die ermittlerische Untersuchung von Umgebungen und ebenso kämpferische Auseinandersetzungen. Tagsüber sollen Spieler Hinweise sammeln, Personen beobachten und Zusammenhänge rekonstruieren. Nachts verlagert sich der Fokus stärker auf direkte Konfrontationen mit den Ursprünglichen.
-

1666: Amsterdam (Bild: : Panache Digital Games)
Bild 1 von 9
Noa nutzt dabei magische Fähigkeiten, unter anderem zur Manipulation der Umgebung und im Kampf. Ergänzt wird das Gameplay durch einen ungewöhnlichen Begleiter: einen spielbaren Katzencharakter, der eigene Bewegungsmöglichkeiten wie Klettern oder das Erkunden enger Bereiche bietet und offenbar auch narrativ eingebunden wird. Die Struktur erinnert in Teilen an frühere Assassin’s-Creed-Spiele, insbesondere durch das Beobachten, Identifizieren und Verfolgen von Zielpersonen in einer historischen Großstadt. Der Vergleich liegt nahe, ist jedoch explizit nicht zentraler Bestandteil der Spielbeschreibung.
Kanadische Entwickler mit Ubisoft-Wurzeln
Hinter dem Projekt steht Panache Digital Games aus Montreal. Gegründet wurde das Studio von Patrice Désilets, der zuvor als Creative Director an Prince of Persia: The Sands of Time sowie den ersten Assassin’s Creed-Teilen beteiligt war. 1666: Amsterdam geht auf eine frühere Projektphase bei THQ Montreal zurück und wurde nach der Insolvenz des Publishers sowie rechtlichen Auseinandersetzungen über mehrere Jahre hinweg neu aufgebaut.
Prolog heute, Early Access später 2026
1666: Amsterdam soll im Laufe des Jahres 2026 auf dem PC in den Early Access starten. Ein konkretes Veröffentlichungsdatum liegt noch nicht vor, erfahrungsgemäß wird es aber wahrscheinlich nicht der November. Überraschend haben die Entwickler aber schon mit dem ersten Trailer eine Demo-Version in Form eines Prologs zum Spiel veröffentlicht, die ab sofort auf Steam gespielt werden kann.
Raytracing-Pflicht in der Unreal Engine 5
Technisch basiert das Spiel auf der Unreal Engine 5. Erwähnenswert ist zudem, dass die Entwickler gänzlich auf ein Legacy-Beleuchtungssystem verzichten: 1666: Amsterdam setzt verpflichtend Hardware-Raytracing und damit eine entsprechende Grafikkarte voraus. Bei Nvidia wird Raytracing von allen RTX-Grafikkarten unterstützt; die Systemanforderungen veranschlagen aber minimal eine GeForce RTX 2060 Super. Bei AMD soll es mindestens eine Radeon RX 6600 sein. 8 GB Grafikspeicher sind das absolute Minimum, empfohlen werden aber 12 GB VRAM oder mehr. Ebenso wird zwingend eine SSD vorausgesetzt.

„Chat is dead“: OpenAI plant größte Umgestaltung von ChatGPT seit 2022

Google: Neues KI-Modell läuft auch auf Laptops mit nur 16GB RAM

Globale WM-Kampagne: McDonald’s setzt auf Stars, Sammelbecher und Erlebnislogik

Community-Protest erfolgreich: Galera bleibt Open Source in MariaDB

Blade‑Battery 2.0 und Flash-Charger: BYD beschleunigt Laden weiter

Mähroboter ohne Begrenzungsdraht für Gärten mit bis zu 300 m²
-
 Entwicklung & Codevor 3 Monaten
Entwicklung & Codevor 3 MonatenCommunity-Protest erfolgreich: Galera bleibt Open Source in MariaDB
-
 Künstliche Intelligenzvor 3 Monaten
Künstliche Intelligenzvor 3 MonatenBlade‑Battery 2.0 und Flash-Charger: BYD beschleunigt Laden weiter
-
 Apps & Mobile Entwicklungvor 3 Monaten
Apps & Mobile Entwicklungvor 3 MonatenMähroboter ohne Begrenzungsdraht für Gärten mit bis zu 300 m²
-

 Künstliche Intelligenzvor 3 Monaten
Künstliche Intelligenzvor 3 MonateniPhone Fold Leak: Apple spart sich wohl iPad‑Multitasking
-
Künstliche Intelligenzvor 3 Monaten
JBL Bar 1300MK2 im Test: Soundbar mit Dolby Atmos, starkem Bass und Akku‑Rears
-

 Künstliche Intelligenzvor 3 Monaten
Künstliche Intelligenzvor 3 MonatenPetra‑AI: KI soll Frauen in der Perimenopause unterstützen
-

 Social Mediavor 3 Monaten
Social Mediavor 3 MonatenVon Kennzeichnung bis Plattformpflichten: Was die EU-Regeln für Influencer Marketing bedeuten – Katy Link im AllSocial Interview
-

 Künstliche Intelligenzvor 3 Monaten
Künstliche Intelligenzvor 3 MonateniX-Workshop KRITIS: Zusätzliche Prüfverfahrenskompetenz für § 8a BSIG

