Apps & Mobile Entwicklung
Cores Series 3 „Wildcat Lake“: Intel-CPU mit 6 MB L3 in Benchmark-Datenbank gesichtet

Intels neue Einsteiger-CPU Wildcat Lake wurde bereits gestern von Intel angeteasert, heute gibt es für die neue Intel-Plattform auch Einträge in der Benchmark-Datenbank von Geekbench. Die CPU ist explizit nicht als Nachfolger der N-Serie gedacht, vielmehr wird sie die Lücke von dieser zur regulären Panther-Lake-Familie füllen.
Schon zur CES 2026 war die CPU ein mehr oder weniger offenes Geheimnis. Denn Intel drückte vor Ort US-Analysten sogar den Chip in die Hand. Der regulären Presse wollte man hingegen überhaupt nichts verraten – die rechte Hand wusste dabei zudem nicht so richtig, was die linke eigentlich macht. Nun ist die CPU immer noch nicht offiziell gestartet, aber zumindest schon einmal offiziell angeteasert worden.

Intels Panther-Lake-Prozessoren sind bereits ziemlich breit aufgestellt, bedeutet, sie gibt es auch extrem reduziert, wie beispielsweise in Form des Core Ultra 5 332. „PTL 204“ heißt im Klartext, dass es sich um einen Panther-Lake-Prozessor mit 2 Performance-Kernen, 0 E-Cores und 4 LPE-Cores handelt. Und auch die Grafikstufe ist klar definiert, lediglich 2 Xe-Cores bietet diese Lösung maximal.
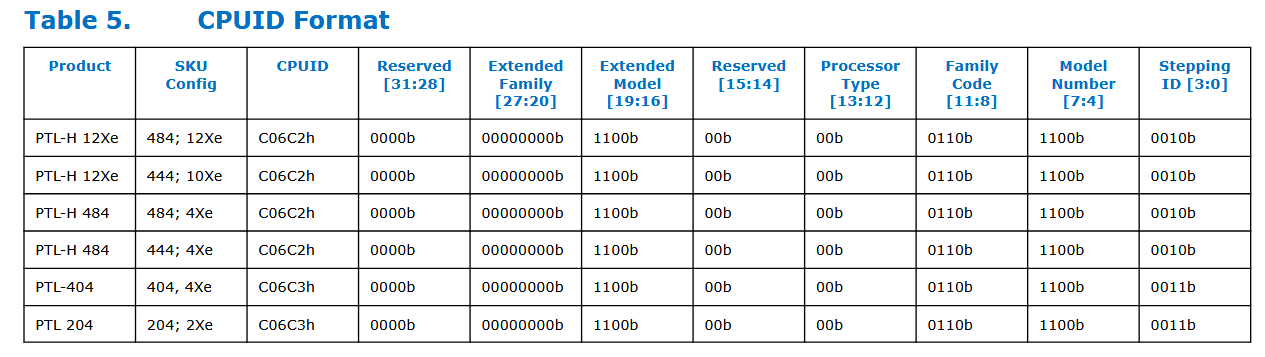
Wildcat Lake setzt auf 204+2Xe
Genau an diesem Modell setzt Wildcat Lake letztlich an und rundet das Portfolio nach unten ab. Auch bei Wildcat Lake alias Core Series 3 (ohne Ultra) wird es die Konfiguration 204+2Xe geben. Verzichten muss das Modell dabei aber wohl auf einen größeren L3-Cache, der Core Ultra 5 332 bietet hier immerhin noch 12 MB auf. Listungen für den bisher größten Core Series 3 zeigen aber immerhin 6 MByte L3-Cache, wie Einträge in der Benchmark-Datenbank von Geekbench zeigen. Wildcat Lake wird zudem auch in einer Version mit nur einem P-Core angeboten, lediglich die vier LPE-Kerne sind stets gesetzt. Neue Einträge in Benchmarks der letzten Tage untermauern diese Konfigurationen. Die Besonderheit bei Wildcat Lake ist, dass auch die Xe-Cores in dem CPU-Tile aus Intel-18A-Fertigung sitzen, nur der IO-Die ist separat in TSMC N6 gefertigt. Bei Panther Lake gibt es einen separaten GPU-Tile.
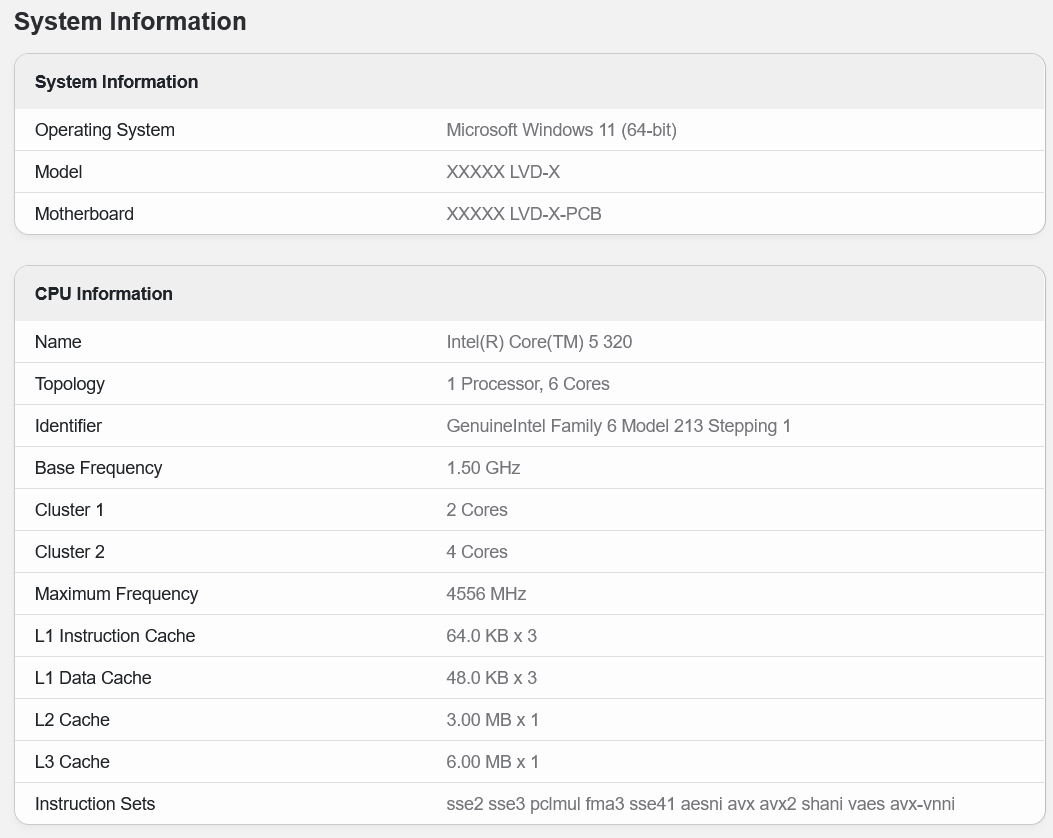
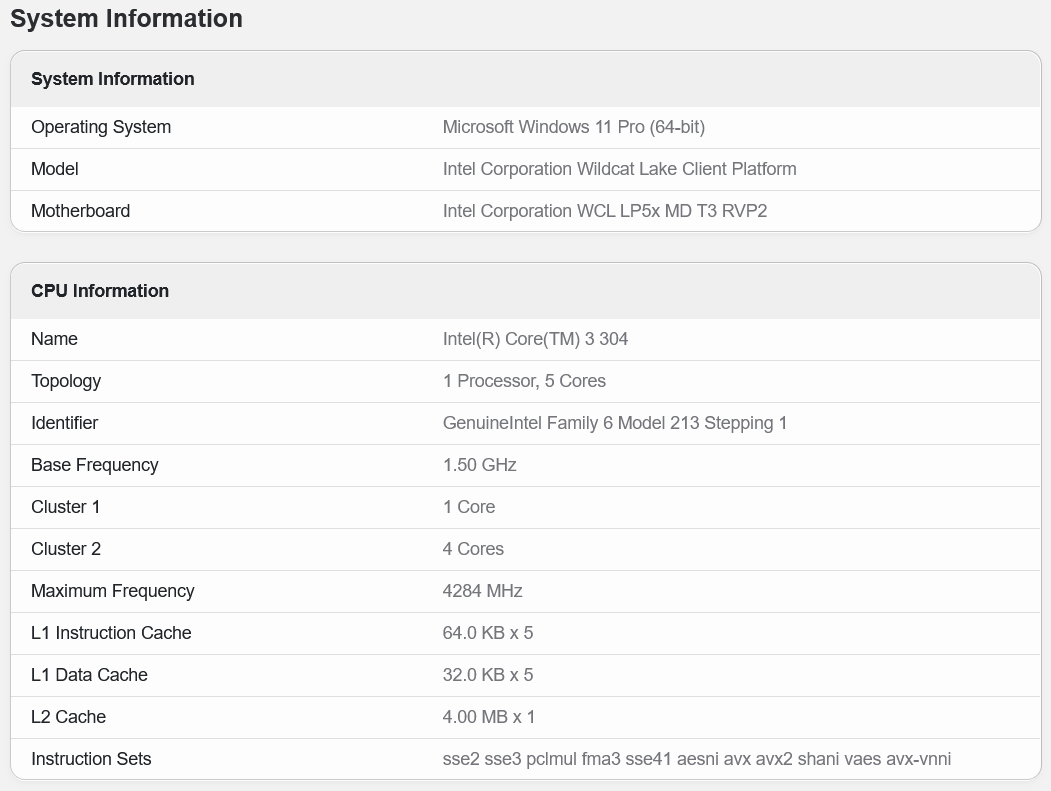
Konter auf das MacBook Neo?
Hinter vorgehaltener Hand hatten Intel-Mitarbeiter schon zur CES klargemacht, dass Wildcat Lake so keinesfalls ein Nachfolger der bekannten N-Serie für beispielsweise Mini-PCs und sehr günstige Notebooks ist. Die Serie wird vielmehr die bisher noch ziemlich teuren Notebooks mit Panther Lake nach unten abrunden und so die Lücke zu N-Modellen wie etwa Intel Twin Lake (Test) füllen. Angesichts des MacBook Neo bekommt diese Preisklasse in diesem Frühjahr so viel Aufmerksamkeit wie noch nie, passende Notebooks mit Wildcat Lake könnten gegen die neue Apple-Lösung antreten.
Die ersten Notebooks hatte vor einer Woche MSI in Japan gezeigt. Auch andere Hersteller bereiten aktuell Geräte vor. Als Startschuss dürfte sich aber wohl die nächste größere Consumer-Messe anbieten: die Computex 2026, die am 2. Juni in Taiwan die Tore öffnet und auf der auch Intel-CEO Lip-Bu Tan exakt an diesem Tag eine Keynote halten wird.













Apps & Mobile Entwicklung
Vodafone: Gigabit-Internet jetzt für mehr als 30 Mio. Haushalte

Mit dem „Gigabit-Update Mai 2026“ kann Vodafone nun mehr als 30 Millionen Haushalte vermelden, die man in Deutschland auf verschiedenen Wegen mit Gigabit-Internet versorgen kann. Drei Viertel aller Menschen in Deutschland können laut Unternehmensangaben demnach Gigabit-Internet von Vodafone nutzen.
Zuletzt hat die Kooperation mit Deutsche Glasfaser die Glasfaser-Reichweite deutlich erhöht und 70.000 Haushalte haben im Mai von Segmentierungen im Kabelnetz profitiert.
Mehr Haushalte – zumindest auf dem Papier in der Vermarktung
Konkret spricht das Unternehmen nun von 30,9 Millionen Haushalten, denen über Kabel-Glasfaser (HFC) oder Glasfaser (FTTH) eine Geschwindigkeit von mindestens einem Gigabit pro Sekunde angeboten werden kann. Ende März waren es noch 29,7 Millionen Haushalte. Grund für diesen Anstieg ist vor allem die Wiederaufnahme der Vermarktungskooperation mit der Deutschen Glasfaser und der weitere Ausbau durch die OXG – dem Joint Venture von Vodafone.
In Bielefeld startete das Unternehmen demnach den Tiefbau für mehr als 30.000 Haushalte. In Hamburg wurde das Projekt zudem ausgeweitet, so dass insgesamt mehr als 161.000 Haushalte nun Glasfaser aus dem Projekt bekommen sollen. Danke der neuen Partnerschaft mit Deutsche Giganetz und der wiederaufgenommenen Zusammenarbeit mit der Deutschen Glasfaser konnte Vodafone die Glasfaser-Reichweite von 12,4 Millionen im April auf 14,6 Millionen FTTH-Anschlüsse im Mai vergrößern.
Mehr Geschwindigkeit durch stärkere Segmentierung
Und auch bei der Modernisierung seines Kabel-Glasfasernetzes vermeldet Vodafone erneut Fortschritte: Im Mai haben Techniker in ganz Deutschland 200 Segmentierungen
und Fiber-Deep-Maßnahmen in 69 Städten und Gemeinden beendet. Von diesem Maßnahmen sollen 70.000 Haushalte profitieren, indem sie mehr Kapazität und mehr Stabilität an ihren Kabel-Glasfaser-Anschlüssen erhalten, so Vodafone. Verhältnismäßig besonders viele Maßnahmen hat Vodafone nach eigenen Angaben in Ascheberg (10 Maßnahmen), Berlin (8), Hamburg (8), Essen (7) und Mönchengladbach (7) abgeschlossen.
Bei der Netz-Segmentierung teilt Vodafone sein Kabel-Glasfasernetz in kleinere Abschnitte. Da Kabel ein sogenanntes „Shared Medium“ ist, bei dem sich alle Nutzer in einem Bereich die Bandbreite teilen, dient das Verfahren der Kapazitätserweiterung. Durch das Verkleinern der Segmente greifen weniger Haushalte auf dieselben Frequenzen zu, wodurch jedem Kunden mehr Bandbreite zur Verfügung steht. Weniger Nutzer als vorher teilen sich somit die zur Verfügung stehende Bandbreite.
ComputerBase hat Informationen zu diesem Artikel von Vodafone unter NDA erhalten. Die einzige Vorgabe war der frühestmögliche Veröffentlichungszeitpunkt.
Apps & Mobile Entwicklung
OpenAIs erster eigener Chip: Jalapeño soll KI-Abfragen effizienter beschleunigen
OpenAI und Broadcom haben mit Jalapeño den ersten von OpenAI entworfenen KI-Beschleuniger vorgestellt. Der Chip ist nicht für das Training neuer Modelle gedacht, sondern für die Inferenz: Er soll also Anfragen an große Sprachmodelle wie ChatGPT, Codex oder API-Dienste effizienter verarbeiten. Konkrete Leistungsdaten fehlen noch.
Eigener Chip für die Modell-Ausführung
Mit Jalapeño rückt OpenAI tiefer in die (eigene) Hardware-Entwicklung vor. Der Chip wird von den Unternehmen als „Intelligence Processor“ bezeichnet und ist laut Ankündigung von Grund auf für die Inferenz großer Sprachmodelle entworfen worden. Anders als universell einsetzbare Beschleuniger soll Jalapeño stärker auf die Arbeitslasten zugeschnitten sein, die bei interaktiven KI-Diensten entstehen.
Dazu zählen nicht nur reine Rechenleistung, sondern auch Speicherzugriffe, Netzwerk-Anbindung und möglichst geringe Latenzen. Gerade bei Chatbots, Code-Assistenten oder künftigen Agenten-Anwendungen ist nicht nur entscheidend, wie viele Tokens pro Sekunde ein System berechnen kann. Die Antwort soll auch mit möglichst wenig Verzögerung geliefert werden und bei hoher Nachfrage zuverlässig verfügbar bleiben.
OpenAI spricht von besseren Werten pro Watt
Belastbare Benchmarks nennt OpenAI noch nicht. Die Unternehmen erklären lediglich, frühe Tests würden eine deutlich bessere Leistung pro Watt als aktuelle Systeme erwarten lassen. Ein technischer Bericht mit näheren Daten soll erst in den kommenden Monaten folgen. Bis dahin bleibt offen, wie Jalapeño im direkten Vergleich zu Nvidias Beschleunigern, Googles TPUs oder anderen spezialisierten ASICs abschneidet.
Engineering-Samples laufen laut OpenAI bereits im Labor mit Fokus auf Takt und Leistungsaufnahme. Der Tape-out soll in nur neun Monaten erfolgt sein. OpenAI verweist darauf, dass eigene Modelle bei Teilen des Entwicklungs- und Optimierungsprozesses geholfen hätten.
Broadcom liefert Umsetzung und Netzwerk-Technik
OpenAI entwirft den Beschleuniger nicht allein. Broadcom übernimmt zentrale Aufgaben bei Netzwerk- und Verbindungstechnik. Auch Celestica wird als Partner für Platinen, Racks und Systemintegration genannt. Damit geht es nicht nur um einen einzelnen Chip, sondern um komplette KI-Systeme für Rechenzentren.
Der erste Einsatz ist für Ende 2026 vorgesehen. OpenAI und Broadcom stellen Jalapeño nicht als Einzelchip, sondern als Grundlage für eine über mehrere Jahre angelegte Infrastruktur-Basis dar. Bereits im Oktober 2025 hatten beide Unternehmen eine Zusammenarbeit über 10 Gigawatt an OpenAI-entworfenen KI-Beschleunigern angekündigt, deren Bereitstellung in der zweiten Jahreshälfte 2026 beginnen und bis Ende 2029 abgeschlossen werden soll.
Nicht automatisch ein Nvidia-Ersatz
Jalapeño dürfte vorerst vor allem OpenAIs eigene Infrastruktur ergänzen. Der Chip ist auf Inferenz zugeschnitten und damit nicht automatisch ein Ersatz für GPUs, die weiterhin beim Training großer Modelle und für flexible Rechenlasten wichtig bleiben. Für OpenAI kann ein eigener ASIC dennoch strategisch wichtig sein: Je besser Hardware, Software, Modelle und Dienste aufeinander abgestimmt sind, desto stärker lassen sich Kosten, Energiebedarf und Verfügbarkeit beeinflussen.
Die Zusammenarbeit ist zugleich ein weiterer Beleg dafür, dass große KI-Anbieter zunehmend eigene Beschleuniger entwickeln lassen. Nvidia bleibt zwar der dominierende Anbieter im Markt für KI-Beschleuniger, doch OpenAI folgt mit Jalapeño einem Trend, den auch Google, Amazon, Microsoft und Meta mit eigenen oder speziell angepassten Chips verfolgen.
Apps & Mobile Entwicklung
Bundesnetzagentur: Messwoche soll Funklöcher per App sichtbar machen
Die Bundesnetzagentur ruft erneut zur bundesweiten Mobilfunk-Messwoche auf. Bis zum 1. Juli sollen Nutzer mit der App „Mobilfunk-Check“ erfassen, wie gut ihr Netz vor Ort tatsächlich funktioniert – und wo Funklöcher weiterhin den Alltag stören.
Nutzer sollen reale Netzqualität melden
Unter dem Motto „Check Dein Netz“ sollen möglichst viele Messungen aus dem Alltag zusammenkommen. Im Mittelpunkt steht dabei nicht die rechnerische Netzabdeckung der Mobilfunkanbieter, sondern das tatsächliche Nutzungserlebnis dort, wo Nutzer leben, arbeiten oder unterwegs sind. Die Aktion läuft vom 24. Juni bis zum 1. Juli 2026 und findet bundesweit statt.
Für die Teilnahme genügt ein Smartphone mit aktueller Betriebssoftware, eine aktive SIM-Karte oder eSIM sowie die kostenlose App „Mobilfunk-Check“ der Bundesnetzagentur. Eine Anmeldung ist nicht erforderlich. Die App erfasst standortbasiert, ob und mit welcher Mobilfunktechnologie das Gerät verbunden ist. Dadurch sollen auch Gebiete besser sichtbar werden, für die bislang nur wenig Daten vorliegen.
Ergänzung zu den Angaben der Netzbetreiber
Die Bundesnetzagentur erhebt regelmäßig Daten zur Flächenabdeckung mit 2G, 4G und 5G. Diese Werte basieren jedoch auf Berechnungen der Netzbetreiber nach einheitlichen Vorgaben der Behörde. Die Ergebnisse können deshalb von der tatsächlich Empfangsqualität abweichen, die Nutzer im Alltag wahrnehmen. Genau diese Lücke soll die Messwoche schließen.
Die Daten aus der ersten bundesweiten Mobilfunkmesswoche zeigen, welchen Umfang eine solche Mitmach-Aktion erreichen kann. Nach Angaben der Bundesnetzagentur kamen damals knapp 200 Millionen Messpunkte von mehr als 100.000 Teilnehmern zusammen. Die Daten wurden den Mobilfunkunternehmen sowie Ländern und Kommunen zur Verfügung gestellt, damit Ausbauvorhaben besser priorisiert und Hindernisse vor Ort gezielter angegangen werden können.
Ausbauplanung mit Nutzerperspektive
Auch die neuen Messdaten sollen nach der zweiten Messwoche aufbereitet, analysiert und an die beteiligten Stellen weitergegeben werden. Die Bundesnetzagentur sieht die Daten als Ergänzung zu bestehenden Versorgungsmeldungen und als Grundlage für weitere Auswertungen und Vergleiche.
Besonders relevant ist die Aktion für ländliche Regionen, in denen die Mobilfunkversorgung trotz Fortschritten weiterhin nicht überall zuverlässig ist. Während Städte häufig gut versorgt sind, können einzelne Funklöcher oder schwache Verbindungen außerhalb dichter besiedelter Gebiete weiterhin unangenehme Auswirkungen haben – etwa beim Arbeiten, auf Pendelstrecken oder bei digitalen Anwendungen in der Landwirtschaft.
Messungen auch nach der Aktionswoche möglich
Messungen sind nicht nur während des Aktionszeitraums möglich. Auch außerhalb der Woche werden Daten über die App erfasst und können zur besseren Transparenz der Netzqualität beitragen. Ob dann vor Ort tatsächlich schneller ausgebaut wird, hängt allerdings davon ab, wie die gewonnenen Daten anschließend von Netzbetreibern, Behörden und Kommunen genutzt werden.

Autos sind zu vernetzt: Polestar gibt den US-Markt auf

Vodafone: Gigabit-Internet jetzt für mehr als 30 Mio. Haushalte

Bundestag wählt Juraprofessor Moritz Hennemann neuen Datenschutzbeauftragten

Empfehlungsalgorithmen bei TikTok erklärt: Die Maschine hinter dem Endlos‑Feed

iX-Workshop Angriffsziel lokales AD − Schwachstellen finden und beheben

„Don’t Starve Elsewhere“: Survival‑Hit kehrt nach zehn Jahren zurück
-
 Künstliche Intelligenzvor 3 Monaten
Künstliche Intelligenzvor 3 MonatenEmpfehlungsalgorithmen bei TikTok erklärt: Die Maschine hinter dem Endlos‑Feed
-
 Künstliche Intelligenzvor 3 Monaten
Künstliche Intelligenzvor 3 MonateniX-Workshop Angriffsziel lokales AD − Schwachstellen finden und beheben
-
 Künstliche Intelligenzvor 3 Monaten
Künstliche Intelligenzvor 3 Monaten„Don’t Starve Elsewhere“: Survival‑Hit kehrt nach zehn Jahren zurück
-

 Künstliche Intelligenzvor 3 Monaten
Künstliche Intelligenzvor 3 MonatenKine‑Exakta: Die erste Spiegelreflexkamera fürs Kleinbild
-

 Künstliche Intelligenzvor 2 Monaten
Künstliche Intelligenzvor 2 MonatenWeitere Entlassungswelle bei Disney: Bis zu 1000 Mitarbeiter betroffen
-
Künstliche Intelligenzvor 2 Monaten
xTool P3 im Test: CO₂-Laser mit 80 Watt schneidet und graviert auch Acryl
-

 Social Mediavor 2 Monaten
Social Mediavor 2 MonatenMetas neuer Creative Setup Workflow: Was sich wirklich ändert – und warum das nicht nur eine UI-Frage ist!
-

 Apps & Mobile Entwicklungvor 2 Monaten
Apps & Mobile Entwicklungvor 2 MonatenMega-GPUs für Nvidia, AMD & Co: TSMC zeigt CoWoS-Package mit >11.600 mm² & 24 × HBM5E

